
Abstract
Groundwater is one of the fundamental sources for the people in Chennai Region; also, determination of groundwater depth will be utilized for prior planning on excavation and construction purposes. This research article determines the depth of groundwater table by adopting various soft computing techniques like support vector machine (SVM), adaptive neuro-fuzzy inference system (ANFIS), and backpropagation (BP). The dataset was collected from the Tamil Nadu Water Supply and Drainage Board (TWAD), Chennai. It consists of input latitude (Lx), longitude (Ly), and the depth of groundwater (dw). The data were processed, and it was incorporated in the above-stated predicting models. The color map was the yield from the developed models. The performance of the developed model was assessed by various statistical parameters, and it was found that all the adopted models yield better performance for predicting the groundwater table. The comparison between the models depicted that support vector machine gave the promising result in determining the groundwater table with an equation for the futuristic purposes. Multifarious statistical analysis was computed in order to justify the attainment of the adopted models. The Taylor diagram and William’s plot were also included in order to substantiate the capability of the developed soft computing models to foretell the groundwater depth for the Chennai City.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Groundwater plays various vital parts in our surroundings and in our economies. Groundwater is the best choice of water supply with limited surface water sources. One of the principal characters is that the quality of the groundwater does not change much throughout the year, which is a benefit. Since the groundwater responds slowly to changes in precipitation, it is feasible in summer. Towards engineering, the groundwater consideration is significant for tunnel and basement excavations and constructions (Khan et al. 2020). When the groundwater level is deep, it requires a lot of energy to pump it, which leads to more expenditure. Furthermore, the deep groundwater may be affected by salt. When the groundwater level is shallow, it may be acidic. In the field of constructions, the determination of groundwater table can be done only by performing bore holes as it is not economical. Therefore, the groundwater table consideration is very mandatory for most civil engineering applications. Hence, the determination of groundwater level is critical and this article paves the economical solution to attain the target. Various researchers have utilized machine learning techniques for estimating the groundwater fluctuations and developed some empirical relations (Nayak et al. 2006; Jalalkamali et al. 2011; Chang et al. 2016; Takafuji et al. 2019; Adiat et al. 2020; Alotaibi 2020).
Soft computing can be interpreted as the computation intelligence which reduces the complexity in conventional computing and provides the effortless yield. Soft computing ideology was inspired from human brain; likely, it is permissive of uncertainty, ingenious algorithms, and approximation (Pratihar 2014). The fuzzy computing, neural networks, swarm intelligence, evolutionary computing, etc. fall under the general category of soft computing techniques (Sharma and Chandra 2019). There are various methods branched under mentioned different soft computing techniques which were adopted for solving numerous complex issues from a wide range of applications (Zhang et al. 2020; Nguyen et al. 2020; Asteris et al. 2021; Band et al. n.d.; Ray et al. 2021; Harirchian et al. 2021; Shahrour and Zhang 2021; Yu et al. 2021).
With support vector machine, the statistical theory imitates the refined tool of prediction (Vapnik 1998). SVM method includes a preparation stage in which a progression of the source of input and target yield esteems is nourished into the model. A trained algorithm is then utilized to assess a different arrangement of training data Suryanarayana et al. 2021). The application of SVM has been escalated because of its capability in solving the quandary. Seismic liquefaction is one of the major effects of earthquake, and it successfully predicted the liquefaction susceptibility of soil by adopting a support vector machine model (Samui 2014; Khan et al. 2021; Li et al. 2021). The researchers had utilized support vector machine for predicting the occurrence times of a few occasions that could occur amid a serious mishap in nuclear power plants with tolerable errors (Seung et al. 2015). Concrete, the most widely utilized building material, has its own uncertainty in its engineering property, i.e., autogenous shrinkage. The research scientists employed the support vector machine model for estimating the autogenously diminution of concrete, and hence, it proved its phenomenal potential (Jun et al. 2016). In addition, the compression strength of light weight foamed concrete was predicted with an encouraging accuracy. The cement content and density matter much in designing foamed concrete mixes (Abbas and Suhad 2017; Alsufyani et al. 2021).
Backpropagation, a family of artificial neural network whose structure consists of interconnected layers which were based on deepest descent method (Buscema 1998). Stimulated annealing-ANN (SA-ANN) was used to extract an unequivocal formula for the peak ground acceleration (PGA) for the tectonic regions of Iran (Gandomi et al. 2016). This SA-ANN model solved the non-linearity and yields the optimized equation for PGA. Moreover, when compared with other 10 models, it exposed its potential by outperforming other models. With the data of electrocardiogram, the investigators estimated the blood pressure with high accuracy with the help of backpropagation (Xu et al. 2017). The critical and paramount parameter of reservoir evaluation is capillary pressure. Backpropagation predicts the capillary pressure curve for both identical and non-identical reservoir with high precision and efficiency (Lijun et al. 2018). The analysts utilized the BP model for the wind speed forecasting in China with better performance (Wei and Yuwei 2018).
Adaptive neuro-fuzzy inference system implements a dynamic machine learning technique to govern changeableness rely upon Zadeh’s fuzzy set theory. This technique has been applied in various fields and yields some impressive outputs. The tunnel diameter convergence and convergence velocity are the most primitive issue for tunneling construction, and it was successfully estimated (Adoko and Li 2012; Jha et al. 2021). Teleconnection patterns were used as the data for modeling the minimum temperature in the northeast of Iran, and adaptive neuro-fuzzy inference system was adopted to model it for the short- and long-term periods (Hojatollah et al. 2015; Khalaf et al. 2021). The investigators had predicted the durability of recycled aggregate from concrete with much better performance compared with multilinear regression (Faezehossadat et al. 2016). The river water data from Surma River of Bangladesh has been incorporated in adaptive neuro-fuzzy inference system for foreseeing the biochemical oxygen demand (BOD). The adaptive neuro-fuzzy inference system model predicted with high coefficient of correlation value and justified its potential in determining the water quality (Ahmed and Shah 2017; Alotaibi et al. 2021). Apart from the abovementioned applications, various researchers had utilized the machine learning techniques in great scale to attain the best solutions to the numerous problems (Wan and Si 2017; Zhang et al. 2017; Miskony and Wang 2018; Mathew et al. 2018; Mallqui and Fernandes 2019 Tang et al. 2019; Rahul et al. 2021; Mosbeh et al. 2021; Guo et al. 2021).
These article coequals the compatible of the envy provided during the identical experimental expounds of the veteran unchangeable techniques flourished. The latitude and longitude of Chennai are 13.08°Ν and 90.27°E, respectively. The dataset was collected from Tamil Nadu Water Supply and Drainage Board (TWAD), Chennai. The compiled dataset has been utilized for estimating the groundwater table depth (dw) by incorporating the data into the abovementioned adopted models. The comparative studies between the developed models were carried out in order to expose the effective model to accomplish the target.
The paper is organized as following: The “Related worksS7” section conveys the related works. The “MethodologyS6” section presents the detailed methodology and adopted model. The “Results and discussions” section composes of the output obtained by the adopted models, where the performance of the adopted models will be compared statistically. Finally, the “Conclusion” section explains the conclusions and possible improvements.
Related works
The traditional models and the field measurements are inadequate for the arid regions due to uncertain hydrological cycle. In order to overcome this, Yang et al. (2019) utilized the maximum height of tree and the volume as the index for the classical measurement error model for determining the groundwater depth in the parched regions. They have generated the mathematical equation with the precision value of R2 = 0.82. In the event of planning the mitigation measures at large scale, tangled hydro-biogeochemical models are required. However, the limitations reach due to inferior data and spatial discretization. The spatial dissemination of nitrate level present in the groundwater was calculated using a parsimonious GIS-based statistical approach (Knoll et al. 2019).
Multiple machine learning techniques such as boosted regression tree, random forest, classification and regression trees, and multiple linear regression were adopted to predict the nitrate concentrations in large scale. The groundwater quality index is the primitive parameter for the drinking purposes, and this was determined by different geostatistical methods for a location in Algeria (Lazhar et al. 2020). The ordinary kriging and co-kriging were utilized to forecast the groundwater quality index based on diversified hydrochemical parameters for 35 wells.
The groundwater level prediction with greater precision and reliability in reclaimed coastal region is one of the strenuous tasks. Zhang et al. (2019) utilized some of the soft computing technique such as nonlinear input-output network (NIO), nonlinear autoregressive network with exogenous inputs (NARX), and wavelet-NARX (WA-NARX). The high-water demand paved the path to exorbitant utilization of the water resource in the Mediterranean region which in turn ultimately leads to seawater intrusion. NARX neural network was utilized to forecast the daily groundwater level for 76 wells (Fabio and Francesco 2020).
In order to make sure the safe water for the drinking purposes, the knowledge on quality of water is highly essential. Therefore, Sudhakar et al. (2021) have utilized various soft computing techniques to determine the entropy weight–based groundwater quality index (EWQI) with different physicochemical parameters as inputs. One of the major environmental issues in the coastal region was groundwater salinization. Dang et al. (2021) had developed distinct machine learning techniques for the prediction of precise salinity concentration of groundwater by using 216 geodatabase and 14 factors. Among the adopted regression models, the CatBoost regression model gave accurate prediction with less error.
Similarly, Tao et al. (2021) had utilized Gaussian processes and kriging model for computing the groundwater salinity in the regions of Australia. The evolution of hybrid models has provided more solutions for the serious complex issues. As an instance, Sami et al. (2021) have utilized a hybrid model, adaptive neuro-fuzzy inference system-evolutionary algorithms (ANFIS-EA) for the determining the optimal groundwater exploitation in the aquifers located in Iran. Along with the ANFIS, particle swarm optimization (PSO), gray wolf optimization (GWO), and Harris hawk optimization (HHO) models were utilized for the higher accuracy.
Similarly, many researchers have utilized many other intelligence techniques in monitoring the quality and the level of water (Moghaddam et al. 2019; Wei et al. 2019; Varouchakis et al. 2019; Sharafati et al. 2020; Panahi et al. 2020; Wei et al. 2020; Mohapatra et al. 2021). Apart from solving groundwater issues, the soft computing intelligent techniques were utilized for resolving many other engineering issues (Bharti et al. 2021; Panagiotis et al. 2021; Kardani et al. 2021; Deepak et al. 2021; Nhu et al. 2020)
Methodology
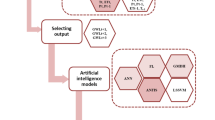
Soft computing technique is a rising technique to deal with registering that gives the noteworthy capacity of the human brain to contend and learn in the environment of vulnerability and doubt. Besides, soft computing might be seen as an establishment part for the developing field of conceptual intelligence. It manages inaccuracy, vulnerability, fractional truth, and closeness to accomplish tractability, robustness, and solution at least amount. As mentioned earlier, the data has been complied, which is then incorporated in the soft computing models like support vector machine, backpropagation, and adaptive neuro-fuzzy inference systems for forecasting the groundwater table for Chennai Region.
Details of support vector machine
Generally, the support vector machine is composed into two cleaves as support vector classification (SVC) and support vector regression (SVR). It is an elegant and evolved method of suspension (Xiang et al. 2012; Alotaibi 2021).
SVM adopts structural risk minimization (SRM) principle, which is admirable than the classical empirical risk minimization (ERM) principle. The SRM principle has been utilized in many other modeling techniques (Mukherjee et al. 1997; Gunn 1998). SRM minimizes the risk, which reduces the error.
Alternate loss function has been introduced and modified to incorporate the distance measure. Furthermore, the cost function has to insert in order to count risk on a hypothesis that leads to measure the regression error. Minimizing the errors could lead to achieving generalized performance. Figure 1 conveys the typical architecture of support vector machine.

Architecture of support vector machine
Figure 1 is the modest representation of the SVM model in which the adopted inputs were utilized for framing the scope and kernel functions which in turn transfer to prefer the Lagrange multipliers. Then, with the combination of Lagrange multipliers and kernel functions, the model did the better prediction.
Let as considers the following sample (y)
where “.” illustrates the product, w and b are the developed and diplomatic criterion, respectively, and x is simplified design of the normalized form. The structural anomaly to emirate the valued pentacle provided for risk management established Remp defined the Eq. (2), and the hypothesized peril factor can be epitomized by the flaw (ε)-unresponsive deficit function Lε(y, f(xi, w)) defined as the Eq. (3) (Stitson et al. 1996).
L ε is the ε-insensitive unstable function, sensitivity hung up with determination (yi) and the predicted outcome values(f(xi, w))in affordable prediction, and xi is attempted design. The conundrum of describing a and c to cultivate the tantamount of aforesaid ε-unresponsive deficit function is parallel to the convex upsurge obstacles that taper the margin (w) and slack variables(ξi, ξi) as
where the initial figure \(\left(\frac{1}{2}w.w\right)\) is the materialize to medicate befall the amplify explicate dilation. For resolving the above mentioned optimization problem (equation 4), enrich lengthen the peculiarity of advanced general contrary of developed and depicted as follows
The Lagrange function has magnified to elaborate the parameter \(w,b,{\xi}_i^{\ast }\) and \({\xi}_i\). Such intensified equation develops the variation of Eq. (5) can be obtained to progress the conditions Karush-Kuhn-Tucker (KKT)
where the equation matured into Eq. (6), the variety of accomplishment of Eq. (1), and C is the capacity factor. Now, substituting Eqs. (6) to (9) to the acquired knowledge (Eq. (5)), the bifold pattern of the enhanced multipliers to the Lagrange for the substitution of equation\({\alpha}_i^{\ast}\ge 0,{\alpha}_i\ge 0,{\gamma}_i^{\ast}\ge 0,{\gamma}_i\ge 0,\) and C∗ ≥ 0 becomes Eq. (10)
where \({\alpha}_i^{\ast }\) and αi are Lagrange quadratic method of adopting the variance to expose the methodology adequately and xi. xj is the internal multiplication of dual teaching design. Decisively, Eq. (6) has to be surrogated into Eq. (1); the linear deliverable similarity exemplifies the dataset.
where Lagrange supplies the constant density \(0\le {\alpha}_i^{\ast },{\alpha}_i\le C\); the criterion of the density function that involved w and b is computed as
where xr and xs are any support vectors.
Various dynamic modules of the management of the dataset are to be indulged in prediction.
This study utilizes the radial basis function.
where xi represents the training pattern, x is the testing pattern, d is a measure of the input vector, and σ is the universal base function width respectively.
The dataset consists of latitude (Lx), longitude (Ly), and dw at 27 different points of Chennai. Table 1 reveals the compiled database, and Table 2 conveys the summary of the collected dataset.
In order to construct the support vector machine model, the datasets have been branched into training and testing dataset. Training dataset develops the support vector machine model, and for that, 19 datasets out of 27 were employed for training, whereas the remaining 8 datasets were considered for the testing dataset as it will be used to evaluate the developed training dataset. In order to avoid the complexity for the support vector machine model, the values in the dataset have been normalized within the range of 0 and 1 through the following Eq. (14).
where d is any data, dmin is the lower limit in the respective data, and dmax is the upper limit in the respective data.
Details of backpropagation neural network
Backpropagation was originated during the period 1970s, but it was appreciated in the year 1986. Backpropagation endeavors at high speed to solve the former insoluble problems. Recently, BP is a drudge of learning in neural networks. BP is feed forward. In order to attain the generalized performance, backpropagation filters the errors and confirm the weights which lead to the increase of performance (Haque and Sudhakar 2002; Alotaibi et al. 2021).
Basic BP’s design composes of different layers of input in the beginning, hidden layer in the intermediate, and finally output layer. The simple architecture of backpropagation was delivered in Fig. 2.

Underlying architecture of backpropagation
The number of layers for input, hidden, and the output is problem-specific (Zhang et al. 1998). According to a researcher (Bishop 1995), an architecture with a single secret layer using a sigmoid activation function can use almost accurate continuous function provided an approved number of hidden neurons. The delta rule relying upon the squared error minimization principle has been adopted by backpropagation (Haykin 1998).
Let w and b as the weight and the bias. The ultimate accomplishment of backpropagation is to calculate the partial derivatives \({\partial C}\left/ {\partial w}\right.\) and \({\partial C}\left/{\partial b}\right.\) of the application C with respect to w and b. The two main assumptions have to make in the event of backpropagation execute. The cost function (C) can be composed as
where x is any training example. Cx is the cost function over C.
The main sense for this assumption is that the BP calculates the partial derivatives for single training data, and then, it can be reclaimed for many datasets. The cost function C can be the function of the outputs.
where aL is the output activation.
Thus, the quadratic cost for single training data can be penned as
where j is the amount of datasets and y is the output.
BP is based the nourished variability of deviation that is weight parallel to the lowered error. Mathematically, it can be expressed as
where w represents procuring match at η epoch. dk is the direction vector.
The positive constants can be preferred by the manipulator, and it is named as learning rate. The dimension of the predicted value dissemination to which “E” which is addressed below.
There are two varieties of learning backpropagation. When the weights are brought updated utilization of the incoming used data and output pairs instantaneously, then it is called online learning. Batch learning is another variety. The network has been modernized with the consideration of all input and output in an array. As a matter of fact, the vector wk includes the weights reckoned in the time of kth iteration. The estimated functional data can be criticized based on the gaps in the output generated (Kamarthi and Pittner 1999).
where p is the input pattern. Ep(wk) is the half sum of the squares error function of the output network.
The training patterns were imparted in every cycle for the efficient usage, and it is referred as an epoch. The sigmoid function has been endrossed in backpropagation to the modification, and it is referred as “back problem to the initiative” (Widrow and Lehr 1990). The upcoming equation delivers the finest.
By endorsing Taylor series expansion, a new approach can be designed that is the Taylor series can be initiated as the function of the weight vector.
where \(g=\frac{\Delta E}{\Delta w}\) is the flash matrix and Hessian matrix, \(H=\frac{\partial^2w}{\partial {w}^2}\).
The unchanged dataset of support vector machine was used for constructing and determining the performance of BP, as it has been divided into training dataset and testing dataset. The dataset which was adopted for constructing the model is training dataset (19 datasets), whereas the pending dataset (8 datasets) was considered for evaluating the developed model which is referred as testing dataset.
Details of adaptive neuro-fuzzy inference system
Adaptive neuro-fuzzy inference system is a type of artificial neural network relies on Takagi–Sugeno fuzzy inference system (Jang 1991). Adaptive neuro-fuzzy inference system is the combo of backpropagation and fuzzy principles. This neuro-adaptive approach paves the way for the fuzzy system to learn the knowledge about the dataset. By using the dataset, adaptive neuro-fuzzy inference system develops a system whose function parameters are modified or adjusted either only by backpropagation or with the integration of least squares type method. This adjustment makes the fuzzy systems to acquire info from the data. The underlying architecture of ANFIS is depicted in Fig. 3.

Architecture of adaptive neuro-fuzzy inference system
Figure 3 exposes that the adaptive neuro-fuzzy inference system is analogous to neural network, as it maps the income and the outcomes through their respective member functions and parameters which shall be utilized to construe the input or output map.
Adaptive neuro-fuzzy inference system makes inference by fuzzy logic and shapes fuzzy membership function using neural network (Altrock 1995; Brown and Harris 1994). Like Mamdani and Sugeno, the fuzzy rule–based systems have created various inference skills (Brown and Harris 1994).
As mentioned earlier, Sugeno-type systems were implemented in which a crisp function individualizes the outcome of the fuzzy rule. If (x1, x2, x3, ……xn) = (A1, A2, A3, .……An), then y = f(x) in (A1, A2, A3, .……An) which are fuzzy sets and y is crisp function. In this specified structure, the output of every norm is crisp value and the weighted average has been utilized to determine the outcome of every norms. The customized deliveries are intrigued with framed fFS that can be construed as follows:
where m is the measure of rules, n is considered as the count of data points, and μA is the membership function of fuzzy set A.
This method included various types of membership functions such as square oval and modulated techniques. The membership commitments can be duplicated repeatedly to obtain better output. The Gaussian function was utilized for a jury, and it is in the following form:
where c represents the average of the collected data. σ is the standard deviation of the data.
The unchanged dataset of support vector machine was adopted for developing the adaptive neuro-fuzzy inference system model that means same inputs. Like support vector machine and backpropagation, the adaptive neuro-fuzzy inference system model’s dataset has to be segregated into the two subsets.
Training dataset
As mentioned earlier, it was compiled for framing the adaptive neuro-fuzzy inference system model. The alike 19 datasets out of 27 are considered as the training datasets.
Testing dataset
After the development of the model, the dataset which was utilized for verifying the developed model is the testing dataset. The left-out 8 datasets were utilized as testing datasets.
Both the datasets are scaled to 0 and 1 which is obtained by urging Eq. (14).
MATLAB was the application tool utilized for developing the mentioned support vector machine, backpropagation, and adaptive neuro-fuzzy inference system model.
Results and discussions
In this study, radial basis function (Eq. (13)) has been chosen as a covariance function. There are three different design parameters C, ε, and σ which have to be estimated by cut and try method. The design values are C = 10000, ε=0.007, and σ=0.3.The support vectors are those which are non-zeros. In this study, the amount of support vectors counted is 19. The corresponding tuning parameters performs constantly to not count on the C values. The following equation has been developed based on support vector machine by incorporating\(K\left({x}_i,x\right)=\mathit{\exp}\left\{-\frac{{\left({x}_i-x\right)}^T\left({x}_i-x\right)}{2{\sigma}^2}\right\}\), which are design values in Eq. (11).
The coefficient of correlation (R) computes the competence of the constructed support vector machine model. The optimal value of R is one, and it will not exceed one.
where dai and dpi are the possessions of the innovative techniques to its extent, and \({\overline{d}}_{\mathrm{a}}\) and \({\overline{d}}_{\mathrm{p}}\) are the values determined in the variation of the datasets.
The built support vector machine has the value of R in the vicinity to unity, so it can be concluded that the developed support vector machine has the capability on forecasting the dw value of the Chennai Region. Figure 4 conveys the behavior of the support vector machine model.

Training and testing performance of support vector machine
Figure 4 reveals the performance to the empirical value of judgment. Since the value of R is in the vicinity to one, then it is represented as the better developed model. The succeeding Fig. 5 depicts the effectiveness of the developed SVM model, which is the predicted spatial variability of water depth in Chennai. The output will be exposed in the form of a map as shown in Fig. 5a and b.

a Two-dimensional map of the predicted dw by support vector machine model. b Three-dimensional map of the predicted dw by support vector machine model
The above maps which were delivered by the support vector machine model can be used for determining the groundwater table for the futuristic purposes.
The coefficient of correlation (R) was used to evaluate the potential of BP. As the matter of fact, when the value of R is near to one, then the model is considered to be the better predictive model. The abovementioned Eq. (26) provides the formula for determining the R value. Figure 6 exposes the performance of training and testing dataset of backpropagation.

Training and testing performance of backpropagation model
It is clear from the above figures that the developed backpropagation is a good model. Hence, the output will be appreciable. Figure 7a and b establish the yield of the backpropagation model.

a Two-dimensional spatial variability map of dw by using backpropagation. b Three-dimensional spatial variability map of dw by using backpropagation
The output of backpropagation model can be used for the future and various purposes. For the adaptive neuro-fuzzy inference system model, initial count of membership functions for every input is 21. An appropriate design has to be preferred for the optimal workability and outcome of the network. The final configuration fuzzy inference system (FIS) is detailed below after the work out with 60 epochs.
The count of input and output membership functions is 21 numbers; however, fuzzy rules have the same number of rules. The number of inputs is 2 (Lx and Ly), where Lx and Ly are coordinates of the location of the borewells. The kind of membership functions utilized for each input and output was Gaussian and linear functions. The ANFIS model took 60 numbers of training epochs and hence yield the value of R for the training dataset (R) = 0.827 and testing performance (R) = 0.785.
The capability of the adaptive neuro-fuzzy inference system model can be assessed by coefficient of correlation (R). A known fact, when R is in the vicinity to 1, then the developed model can be considered as better model. Equation (26) provides the formula for the judgment of R value. Figure. 8 delivers the peculiarity of the developed models.

Performance of adaptive neuro-fuzzy inference system model
It is clear from the above figures constructed during the adaptive neuro-fuzzy inference system is a good model. Hence, the output will be valuable. Fig. 9a and b convey the result of adaptive neuro-fuzzy inference system.

a Two-dimensional spatial variability map of dw by using adaptive neuro-fuzzy inference system. b Three-dimensional spatial variability map of dw by using adaptive neuro-fuzzy inference system
The output of the adaptive neuro-fuzzy inference system model can be advantageous for the forthcoming purposes.
The above-developed models provide the best output information of depth (dw) for Chennai Region. The comparison between the developed support vector machine, adaptive neuro-fuzzy inference system, and backpropagation model was carried out. The above three-dimensional surface graphs of Lx, Ly, and dw are presented. The subtlety of the predicted dw to Lx and Ly can be verified (Gandomi and Alavi 2013). Figure 10 illustrates the capability of the verified designs with respect to the determined R value.

Comparison of the developed models
Although all the three developed models are effective in determining the dw, a superior model has to sort out. The support vector machine model outweighs the other back propagation and adaptive neuro-fuzzy inference system model in computing the dw for Chennai. The equations generated by the SVM model can be able to predict the groundwater table level in the Chennai Region for the futuristic purposes. Moreover, the maps were generated by the models. The above shown maps represent the predicted groundwater table of Chennai Region which will help in determining the level of groundwater table at any point of location without performing any experimental works. This in turn reduces the cost of any infrastructural projects and the groundwater utilization–related projects.
The sensitivity examination researches the commitment of the input parameters to the yield expectation. In order to perform this sensitivity examination, the following equations were utilized to compute the percentage of sensitivity (Se) of the output to each input parameter (Nash and Sutcliffe 1970).
where fmax(di) and fmin(di) are the upper limit and the lower limit of the foreseen yield over the ith domain, whereas the remaining variables are proportionate to the mean value. The computed sensitivity values of the developed models are tabulated in Table 3.
From the above Table 3, the latitude (Lx) has the maximal effect on determining the depth of groundwater (dw). The following Fig. 11 depicts the sensitivity of the inputs for the developed models.

Sensitivity analysis of inputs for the developed model
The developed SVM, BP, and ANFIS models may require more verification for justifying the capability of the models; hence, the parametric study was carried out. The literature recommended some statistical approaches for justifying the veracity of the predictive models; hence, the same statistical parameters were determined for the adopted SVM, BP, and ANFIS models. Root mean square error (RMSE) correlates the measured and foreseen values, and then, it calculates the square root of the mean leftover miscue. The lessen RMSE value hints the improved capability of the model. Weighted mean absolute percentage error (WMAPE) examines the contrast between the residual error of each data with the measured or target data. Nash-Sutcliffe efficiency (NS) is known as coefficient of efficiency (E) which is the ratio of residual error variance to measured variance in observed data (Nash and Sutcliffe 1970).
Variance account factor (VAF) illustrates the proportion of error deviation to detected data deviation. Adjusted determination coefficient (Adj. R2) was utilized to determine performance index (PI) in the event of computing the accuracy of the model (Yagiz et al. 2012). Normalized mean biased error (NMBE) reckons the potential of the model to foresee the value which is settled away from the mean value. The non-negative value of NMBE describes that the prediction is elevated, whereas negative value exposes that the prediction is held down of the developed model (Srinivasulu and Jain 2006). Root mean square error to observation’s standard deviation ratio (RSR) consolidates the advantages of error index measurements and incorporates a scaling/standardization factor, with the goal that the subsequent measurement and revealed qualities can apply to different constituents. The depressed value of RSR depicts the best efficiency of the model and vice versa, whereas the optimal value that is zero was computed for each model by the following equations and it was tabulated in Table 3 (Gandomi and Alavi 2013; Gokceoglu 2002; Gokceoglu and Zorlu 2004; Nayak et al. 2005; Moriasi et al. 2007; Wang et al. 2009; Chen et al. 2012; Nurichan 2014; Chandwani et al. 2015)),
where n is the count of training and testing dataset; dt is the measured value; dmean is the mean of actual value; and yt is the predicted value
The above equations were adopted to determine various statistical parameters, and Table 4 expresses the value of the various statistical parameters of the developed models.
Figure 12 depicts the statistical performances in the form of chart which justifies the performance of the developed model.

Statistical performances of the developed model
Table 4 clearly represents the computed values of distinct statistical parameters in which for all the three models, the RMSE is less which indicate the appreciable performances of the developed model. Furthermore, RSR values are in the vicinity of the optimal value zero, which exposes the accuracy of the developed model. The coefficient of determination value is more for support vector machine which illustrates the superiority of the model when compared with the other backpropagation and adaptive neuro-fuzzy inference system model. The researchers expressed that the accomplishment indicators were used to evaluate the precision of the developed model; however, not one thing is exceptional (Gokceoglu 2002).
The Taylor diagram is one of the pictorial representations of briefing how adjacently the pattern matched with the observations. This figure assesses the diversified features of convoluted models (Taylor 2001). The models which produce the predicted values which agree with the measured value will lie in the vicinity of x-axis which depicts the high-pitched correlation and low errors.
The following Fig. 13 shows the Taylor diagram which depicted the model performance, in which SVM model plot is near the best correlation than the other two ANFIS and backpropagation neural network (BP) models. The plots which were made between fitted value and residual values show the linearity, the homoscedasticity, and the availability of outliers; moreover, it exposes average residual value for every fitted value close to zero. The Q-Q (quantile-quantile) plot technically conveys the plot between theoretical quantiles and the standardized residuals that shows that the residuals are on the dashed line. A horizontal line having equitably dispersed points indicates the better homoscedasticity of the variance of residues. The leverage against residual plot allows to determine the effective observances in the regression models. The point which falls exterior to the dashed line was considered as the influential point. The following are the charts which depict the William plot for the developed models.

Taylor diagram for the developed soft computing models
In the above Fig. 14a, b, and c, most of the points are in the linear line with less outliers and good homoscedasticity; however, SVM model is doing well compared to the other ANFIS and BPNN model. Marginal histogram analyzes the distribution of each measure by adding it to the boundaries of each axis in the scatter plot. It displays the predicted data on several aggregated levels in single view (Dai et al. 2022)

William’s plot for the developed model. a SVM. b ANFIS. c BPNN
The above Figure 15 depicts the marginal histogram by using the forecasted groundwater depth for the specific Chennai City. In the abovementioned figure, SVM model lies within the range with fairly acceptable errors compared to the other developed ANFIS and BP models.

Marginal histograms based on the predicted results of SVM, ANFIS, and BP models
Some observations arise from the results generated from the adopted SVM, ANFIS, and BP models. The 2D map and 3D maps were obtained from all the models; however, based on the accuracy, SVM model has more precision than the other models. Based on the statistical hypothesis, SVM model shows appreciable values even though it was under trained. The sensitivity for the input latitude (Lx) is greater than the other input in all the adopted models. The exploration of other regression models is possible, but the advanced level models were utilized here for this specific problem. Based on the Taylor diagram, the William plot, and the marginal histogram, again SVM outperforms the other ANFIS and BP models.
Conclusion
This article describes the efficiency of the regression procedures for foretelling groundwater depth. In this, all the models provide the map as an output, whereas support vector machine produces the equation for determining dw for various datasets. Support vector machine uses three tuning parameters, whereas Adaptive neuro-fuzzy inference system uses six tuning parameters. Even though all the adopted models yield the better output, support vector machine issued the best result among the developed models. Various statistical calculations and graphical representation expose that the SVM model has the better potential in determining the groundwater table depth for the specific Chennai City. Thus, the adopted model provided the better equation for earlier prediction of groundwater table for the respective Chennai City in order to be utilized for the future drinking water and construction projects.
References
Abbas MA, Suhad MA (2017) Modelling the strength of lightweight foamed concrete using support vector machine (SVM). Case Stud Constr Mater 6:8–15
Adiat KAN, Ajayi OF, Akinlalu AA, Tijani IB (2020) Prediction of groundwater level in basement complex terrain using artificial neural network: a case of Ijebu-Jesa, southwestern Nigeria. Appl Water Sci 10:8
Adoko AC, Li W (2012) Estimation of convergence of a high-speed railway tunnel in weak rocks using an adaptive neuro-fuzzy inference system (ANFIS) approach. J Rock Mech Geotech Eng 4(1):11–18
Ahmed AAM, Shah SMA (2017) Application of adaptive neuro-fuzzy inference system (ANFIS) to estimate the biochemical oxygen demand (BOD) of Surma River. J King Saud Univ - Eng Sci 29(3):237–243
Alotaibi Y (2020) Automated business process modelling for analyzing sustainable system requirements engineering. In 2020 6th International Conference on Information Management (ICIM) (pp. 157-161). IEEE.
Alotaibi Y (2021) A new database intrusion detection approach based on hybrid meta-heuristics. CMC-Comp Mater Continua 66(2):1879–1895
Alotaibi Y, Malik MN, Khan HH, Batool A, Islam SU, Alsufyani A, Alghamdi S (2021) Suggestion mining from opinionated text of big social media data. Comp Mater Continua 68(3):3323–3338
Alsufyani A, Alotaibi Y, Almagrabi AO, Alghamdi SA, Alsufyani N (2021) Optimized intelligent data management framework for a cyber-physical system for computational applications. Complex Intell Syst:1–13
Altrock CV (1995) Fuzzy logic and neurofuzzy applications explained. Prentice- Hall, New Jersey
Asteris PG, Skentou AD, Bardhan A, Samui P, Lourenço PB (2021) Soft computing techniques for the prediction of concrete compressive strength using non-destructive tests. Constr Build Mater 303:124450
Band SS, Ardabili S, Mosavi A, Jun C, Khoshkam H, Moslehpour M Feasibility of soft computing techniques for estimating the long-term mean monthly wind speed. Energy Rep 8:638–648
Bharti JP, Mishra P, Sathishkumar VE, Cho Y, Samui P (2021) Slope stability analysis using Rf, Gbm, Cart, Bt and Xgboost. Geotech Geol Eng 39(5):3741–3752
Bishop CM (1995) Neural networks for pattern recognition. Clarendon Press, Oxford
Brown M, Harris C (1994) Neurofuzzy adaptive modeling and control. Prentice-Hall, New Jersey
Buscema M (1998) Back propagation neural networks. Subst Use Misuse 33:233–270
Chandwani V, Agrawal V, Ravindra N (2015) Modeling slump of ready-mix concrete using genetic algorithms assisted training of artificial neural network. Expert Syst Appl 42:885–893
Chang FJ, Chang LC, Huang CW, Kao IF (2016) Prediction of monthly regional groundwater levels through hybrid soft-computing techniques. J Hydrol 541:965–976
Chen H, Xu C, Guo S (2012) Comparison and evaluation of multiple GCMs, statistical downscaling and hydrological models in the study of climate change impacts on runoff. J Hydrol 434–435:36–45
Dai Y, Khandelwal M, Qiu Y, Zhou J, Monjezi M, Yang P (2022) A hybrid metaheuristic approach using random forest and particle swarm optimization to study and evaluate backbreak in open-pit blasting. Neural Comp Appl 1–16.
Dang AT, Maki T, Nam TH, Van TN, Doan VB, Thanh DD, Quang VD, Dieu TB, Trieu AN, Le VP, Pham TBT, Tien DP (2021) Evaluating the predictive power of different machine learning algorithms for groundwater salinity prediction of multi-layer coastal aquifers in the Mekong Delta, Vietnam. Ecol Indic 127:107790
Deepak K, Thendiyath R, Anshuman S, Dar H, Pijush S (2021) A simplified approach for rainfall-runoff modeling using advanced soft-computing methods. Jordan J Civ Eng 15(3)
Fabio DN, Francesco G (2020) Groundwater level prediction in Apulia region (Southern Italy) using NARX neural network. Environ Res 190:110062
Faezehossadat K, Sayed MJ, Neela D, Shreenivas L (2016) Predicting strength of recycled aggregate concrete using artificial neural network, adaptive neuro-fuzzy inference system and multiple linear regression. Int J Sustain Built Environ 5:355–369
Gandomi AH, Alavi AH (2013) Hybridizing genetic programming with orthogonal least squares for modeling of soil liquefaction. Int J Earthquake Eng Hazard Mitig 1:1–8
Gandomi M, Soltanpour M, Zolfaghari MR, Gandomi AH (2016) Prediction of peak ground acceleration of Iran’s tectonic regions using a hybrid soft computing technique. Geosci Front 7(1):75–82
Gokceoglu C (2002) A fuzzy triangular chart to predict the uniaxial compressive strength of the agglomerates from their petrographic composition. Eng Geol 66(1–2):39–51
Gokceoglu C, Zorlu K (2004) A fuzzy model to predict the uniaxial compressive strength and the modulus of elasticity of a problematic rock. Eng Appl Artif Intell 17:61–72
Gunn S (1998) Support vector machines for classification and regression. In: Image speech and intelligent systems technical report. University of Southampton, Southampton
Guo D, Chen H, Tang L, Chen Z, Samui P (2021) Assessment of rockburst risk using multivariate adaptive regression splines and deep forest model. Acta Geotech 105:1–23
Haque ME, Sudhakar KV (2002) ANN back-propagation prediction model for fracture toughness in microalloy steel. Int J Fatigue 24(9):1003–1010
Harirchian E, Hosseini SE, Jadhav K, Kumari V, Rasulzade S, Işık E, Wasif M, Lahmer T (2021) A review on application of soft computing techniques for the rapid visual safety evaluation and damage classification of existing buildings. J Build Eng 43:102536
Haykin S (1998) Neural networks: a comprehensive foundation, 2nd edn. Macmillan, New York
Hojatollah D, Taghi T, Mahmood K, Saeed T (2015) Modeling minimum temperature using adaptive neuro-fuzzy inference system based on spectral analysis of climate indices: a case study in Iran. J Saudi Soc Agric Sci 14:33–40
Jalalkamali A, Sedghi H, Manshouri M (2011) Monthly groundwater level prediction using ANN and neuro-fuzzy models: a case study on Kerman plain. Iran J Hydroinform 13(4):867–876
Jang JSR (1991) Fuzzy modeling using generalized neural network and Kalman filter algorithm. Proceedings of the 9th National Conference on Artificial Intelligence, Anahem, CA, USA. AAAI 19(2):762–767
Jha N, Prashar D, Khalaf OI, Alotaibi Y, Alsufyani A, Alghamdi S (2021) Blockchain based crop insurance: a decentralized insurance system for modernization of Indian farmers. Sustainability 13(16):8921
Jun L, KeZhen Y, Xiaowen Z, Yue H (2016) Prediction of autogenous shrinkage of concretes by support vector machine. Int J Pavement Res Technol 9:169–177
Kamarthi SV, Pittner S (1999) Accelerating neural network training using weight extrapolation. Neural Netw 12:1285–1299
Kardani N, Bardhan A, Gupta S, Samui P, Nazem M, Zhang Y, Zhou A (2021) Predicting permeability of tight carbonates using a hybrid machine learning approach of modified equilibrium optimizer and extreme learning machine. Acta Geotech 1–17.
Khalaf OI, Sokiyna M, Alotaibi Y, Alsufyani A, Alghamdi S (2021) Web attack detection using the input validation method: DPDA theory. CMC-Comp Mater Continua 68(3):3167–3184
Khan HH, Malik MN, Zafar R, Goni FA, Chofreh AG, Klemeš JJ, Alotaibi Y (2020) Challenges for sustainable smart city development: a conceptual framework. Sustain Dev 28(5):1507–1518
Khan HH, Malik MN, Alotaibi Y, Alsufyani A, Algamedi S (2021) Crowdsourced requirements engineering challenges and solutions: a software industry perspective. Comput Syst Sci Eng 39(2):221–236
Knoll L, Breuer L, Bach M (2019) Large scale prediction of groundwater nitrate concentrations from spatial data using machine learning. Sci Total Environ 668:1317–1327
Lazhar B, Ammar T, Lotfi M (2020) Spatial distribution of the groundwater quality using kriging and co-kriging interpolations. Groundw Sustain Dev 11:100473
Li G, Liu F, Sharma A, Khalaf OI, Alotaibi Y, Alsufyani A, Alghamdi S (2021) Research on the natural language recognition method based on cluster analysis using neural network. Math Probl Eng 2021:13
Lijun Y, Qigui T, Yili K, Chengyuan X, Chong L (2018) Reconstruction and prediction of capillary pressure curve based on particle swarm optimization-back propagation neural network method. Petroleum 4(3):268–280.
Mallqui DCA, Fernandes RAS (2019) Predicting the direction, maximum, minimum and closing prices of daily Bitcoin exchange rate using machine learning techniques. Appl Soft Comput 75:596–606
Mathew J, Griffin J, Alamaniotis M, Kanarachos S, Fitzpatrick ME (2018) Prediction of welding residual stresses using machine learning: comparison between neural networks and neuro-fuzzy systems. Appl Soft Comput 70:131–146
Miskony B, Wang D (2018) Construction of prediction intervals using adaptive neurofuzzy inference systems. Appl Soft Comput 72:579–586
Moghaddam HK, Moghaddam HK, Kivi ZR, Bahreinimotlagh M, Alizadeh MJ (2019) Developing comparative mathematic models, BN and ANN for forecasting of groundwater levels. Groundw Sustain Dev 9:100237
Mohapatra J, Piyush J, Madan J, Biswal S (2021) Efficacy of machine learning techniques in predicting groundwater fluctuations in agro-ecological zones of India. Sci Total Environ 785:147319
Moriasi DN, Arnold JG, Van Liew MW, Bingner RL, Harmel RD, Veith TL (2007) Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans ASABE 50(3):885–900
Mosbeh RK, Abidhan B, Navid K, Samui P, Jong WH, Ahmed R (2021) Novel application of adaptive swarm intelligence techniques coupled with adaptive network-based fuzzy inference system in predicting photovoltaic power. Renew Sust Energ Rev 148:111315
Mukherjee S, Osuna E, Girosi F (1997) Nonlinear prediction of chaotic time series using support vector machine. In: IEEE Workshop on Neural Networks for Signal Processing, 7th edn. Institute of Electrical and Electronic Engineers, New York, pp 511–519
Nash JE, Sutcliffe JV (1970) River flow forecasting through conceptual models part I – a discussion of principles. J Hydrol 10(3):282–290
Nayak PC, Sudheer KP, Rangan DN, Ramasastri KS (2005) Short-term flood forecasting with a neurofuzzy model. Water Resour Res 41:1–16
Nayak PC, Rao YRS, Sudheer KP (2006) Groundwater level forecasting in a shallow aquifer using artificial neural network approach. Water Resour Manag 20:77–90
Nguyen MD, Pham BT, Ho LS, Ly HB, Le TT, Qi C, Le VM, Le LM, Prakash I, Bui DT (2020) Soft-computing techniques for prediction of soils consolidation coefficient. Catena 195:104802
Nurichan C (2014) Application of support vector machines and relevance vector machines in predicting uniaxial compressive strength of volcanic rocks. J Afr Earth Sci 100:634–644
Nhu VH, Samui P, Kumar D, Singh A, Hoang ND, Tien BD (2020) Advanced soft computing techniques for predicting soil compression coefficient in engineering project: a comparative study. Engineering with Computers 36(4):1405–1416
Panagiotis GA, Athanasia DS, Abidhan B, Pijush S, Kypros P (2021) Predicting concrete compressive strength using hybrid ensembling of surrogate machine learning models. Cem Concr Res 145:106449
Panahi M, Sadhasivam N, Reza PH, Rezaie F, Lee S (2020) Spatial prediction of groundwater potential mapping based on convolutional neural network (CNN) and support vector regression (SVR). J Hydrol 588:125033
Pratihar DK (2014) Soft computing: fundamentals and applications. Alpha Science International Ltd, Oxford
Rahul R, Deepak D, Samui P, Roy LB, Goh ATC, Wengang Z (2021) Application of soft computing techniques for shallow foundation reliability in geotechnical engineering. Geosci Front 12(1):375–383
Ray R, Kumar D, Samui P, Roy LB, Goh AT, Zhang W (2021) Application of soft computing techniques for shallow foundation reliability in geotechnical engineering. Geosci Front 12(1):375–383
Sami GM, Abbas R, Naser AA, Saman J (2021) Development of adaptive neuro fuzzy inference system – evolutionary algorithms hybrid models (ANFIS-EA) for prediction of optimal groundwater exploitation. J Hydrol 598:126258
Samui P (2014) Vector machine techniques for modeling of seismic liquefaction data. Ain Shams Eng J 5:355–360
Seung GK, Young GN, Poong HS (2015) Prediction of severe accident occurrence time using support vector machines. Nucl Eng Technol 47:74–84
Shahrour I, Zhang W (2021) Use of soft computing techniques for tunneling optimization of tunnel boring machines. Undergr Space 6(3):233–239
Sharafati A, Asadollah SBHS, Neshat A (2020) A new artificial intelligence strategy for predicting the groundwater level over the Rafsanjan aquifer in Iran. J Hydrol 591:2020
Sharma D, Chandra P (2019) A comparative analysis of soft computing techniques in software fault prediction model development. Int J Inf Technol 11(1):37–46
Srinivasulu S, Jain A (2006) A comparative analysis of training methods for artificial neural network rainfall-runoff models. Appl Soft Comput 6:295–306
Stitson MO, Weston JAE, Gammerman AV, Vapnik V (1996) Theory of support vector machines (Report No. CSD-TR-96–17). Royal Holloway University, London
Sudhakar S, Srinivas P, Soumya SS, Rambabu S, Suresh K (2021) Prediction of groundwater quality using efficient machine learning technique. Chemosphere 276:130265
Suryanarayana G, Chandran K, Khalaf OI, Alotaibi Y, Alsufyani A, Alghamdi SA (2021) Accurate magnetic resonance image super-resolution using deep networks and Gaussian filtering in the stationary wavelet domain. IEEE Access 9:71406–71417
Takafuji EHM, Rocha MM, Manzione RL (2019) Groundwater level prediction/forecasting and assessment of uncertainty using SGS and ARIMA models: a case study in the Bauru Aquifer System (Brazil). Nat Resour Res 28:487–503
Tang H, Dong P, Shi Y (2019) A new approach of integrating piecewise linear representation and weighted support vector machine for forecasting stock turning points. Appl Soft Comput 78:685–696
Tao C, Dan P, Mat G (2021) Gaussian process machine learning and kriging for groundwater salinity interpolation. Environ Model Softw 144:105170
Taylor KE (2001) Summarizing multiple aspects of model performance in a single diagram. J Geophys Res-Atmos 106(D7):7183–7192
Vapnik VN (1998) Statistical learning theory. Wiley, New York
Varouchakis EA, Theodoridou PG, Karatzas GP (2019) Spatiotemporal geostatistical modeling of groundwater levels under a Bayesian framework using means of physical background. J Hydrol 575:487–498
Wan Y, Si YW (2017) Adaptive neuro fuzzy inference system for chart pattern matching in financial time series. Appl Soft Comput 57:1–18
Wang CW, Chau KW, Cheng CT, Qiu L (2009) A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J Hydrol 374:294–306
Wei S, Yuwei W (2018) Short-term wind speed forecasting based on fast ensemble empirical mode decomposition, phase space reconstruction, sample entropy and improved back-propagation neural network. Energy Convers Manag 157:1–12
Wei C, Mahdi P, Khabat K, Hamid RP, Fatemeh R, Davoud P (2019) Spatial prediction of groundwater potentiality using ANFIS ensembled with teaching-learning-based and biogeography-based optimization. J Hydrol 572:435–448
Wei Z, Wang D, Sun H, Yan X (2020) Comparison of a physical model and phenomenological model to forecast groundwater levels in a rainfall-induced deep-seated landslide. J Hydrol 586:124894
Widrow B, Lehr MA (1990) 30 years of adaptive neural networks: perceptron, Madaline, and backpropagation. Proc IEEE 78(9):1415–1442
Xiang YW, Xian JZ, Hong YY, Juan B (2012) A pixel-based color image segmentation using support vector machine and fuzzy C-means. J Neural Netw 33:148–159
Xu Z, Liu J, Chen X, Wang Y, Zhao Z (2017) Continuous blood pressure estimation based on multiple parameters from electrocardiogram and photoplethysmogram by back-propagation neural network. Comput Ind 89:50–59
Yagiz S, Sezer EA, Gokceoglu C (2012) Artificial neural networks and nonlinear regression techniques to assess the influence of slake durability cycles on the prediction of uniaxial compressive strength and modulus of elasticity for carbonate rocks. Int J Numer Anal Methods Geomech 36:1636–1650
Yang XD, Qie YD, Teng DX, Ali A, Xu Y, Bolan N, Liu WG, Lv, GH, Ma LG, Yang ST, Zibibula S (2019) Prediction of groundwater depth in an arid region based on maximum tree height. J Hydrol 574:46–52
Yu Y, Nguyen TN, Li J, Sanchez LF, Nguyen A (2021) Predicting elastic modulus degradation of alkali silica reaction affected concrete using soft computing techniques: a comparative study. Constr Build Mater 274:122024
Zhang G, Patuwo BE, Hu MY (1998) Forecasting with artificial neural networks: the state of art. Int J Forecast 14(1):35–62
Zhang ZL, Luo XG, García S, Herrera F (2017) Cost-sensitive back-propagation neural networks with binarization techniques in addressing multi-class problems and non-competent classifiers. Appl Soft Comput 56:357–367
Zhang J, Zhang X, Niu J, Hu B, Soltanian M, Qiu H, Yang L (2019) Prediction of groundwater level in seashore reclaimed land using wavelet and artificial neural network-based hybrid model. J Hydrol 577:123948
Zhang W, Zhang R, Wu C, Goh AT, Lacasse S, Liu Z, Liu H (2020) State-of-the-art review of soft computing applications in underground excavations. Geosci Front 11(4):1095–1106
Acknowledgements
The authors thank the Tamil Nadu Water Supply and Drainage Board (TWAD), Chennai, for providing the data.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Responsible Editor: Broder J. Merkel
Rights and permissions
About this article

Cite this article
Ramasamy, V., Alotaibi, Y., Khalaf, O.I. et al. Prediction of groundwater table for Chennai Region using soft computing techniques. Arab J Geosci 15, 827 (2022). https://doi.org/10.1007/s12517-022-09851-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-022-09851-4