
Abstract
The problem of aggregating large samples of criminal data in visual representations, as often observed in many studies using geographic information systems and optimization tools to perform social assessments and design spatial patterns, is discussed in this work. A compensation bias in the correlation measure of the spatial association can be found in such types of big data aggregations, which may jeopardize the entire analysis and the conclusions from the results. In this work, a big dataset of robbery incidents recorded from the years 2013 through 2016 in Recife, one of the most important Brazilian capitals, is decomposed into nine small sets of specific robberies, namely, larceny, armed robbery, group stealing, motor vehicles thefts, burglary, commercial burglary, saidinha de banco (saucy bank), motor vehicle robbery (carjacking) and arrastão (flash robbery). More accurate measures for the spatial autocorrelation can be derived from the individual incidences as proposed in this work. The visualization of optimized hot spots and cold spots of crime based on these autocorrelation measures besides enable rapid actions where crime concentrates, they have the property to design spatial patterns that can be associated with environmental, social and economic factors to support more efficient decision making on the allocation of public safety resources.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Data Visualization or Visual Analytics refers to the systematic creation and understanding of the visual representation of data. Functional and aesthetic visualizations help users to analyze and abstract evidences from complex big data sets (Kim et al. 2016), and because they are much easier to interpret, better and faster decisions can be obtained compared to numerical-based observations. Statistical graphics, plots, maps, landscapes, dashboards, charts, scatterplots and many other forms of interactive visualizations can accurate the stakeholders’ perception to intuitively identify and explore patterns, trends, make comparisons, determine causality, bias and associations that are hardly detected with eyes on large text-based data (Kim et al. 2016; Thomas and Cook 2005; Tufte 1983; Tukey 1977). Mostly, those image representations are produced by dedicated software packages that despite to provide robust courses of conducting empirical assessments, may include interactive tools to enable users to capture exogenous effects, treat, mine and manipulate data, implement and design polices and analyze patterns and explanatory determinants of the studied behavior.
A substantial number of those representations domains belong to the class of geographic information systems (GIS), defined by Burrough (1986) and Maguire (1991) as computer technologies that can assemble, store, manipulate, display and integrate geo-referenced information, i.e., data that can be extracted and associated through their locations (Nelson et al. 2007). GIS technologies have been widely used in the environment sciences and natural resources management for monitoring river pollution, forest fire, storm runoff, (Arabatzis and Manos 2005; Berry and Sailor 1987; Buccella et al. 2010; Hachikyan et al. 2005; Kaloudis et al. 2005), to diagnose farm’s large-scale energy consumption (Bimonte et al. 2013), in health science to detect and predict epidemic spread and disease outbreaks (Fatima-Zohra et al. 2015; Kirk et al. 2014; Kursah 2017; Rodríguez-González et al. 2013; Schröder et al. 2007) and to mitigate risk and manage crisis (Čerba et al. 2017; Manfré et al. 2012; Power et al. 2013). Many operational problems approaching vehicle routing strategies also are receiving considerable attention by GIS tools and capabilities (Nikolopoulou et al. 2019; Tarantilis and Kiranoudis 2001; Tlili et al. 2013; Zachariadis et al. 2017) and in the field of social sciences, valuable information that combines social, economic, demographic and spatial characteristics can be produced to measure welfare (Andreoni and Galmarini 2016) urban growth and geographic segregation (Hong and Sadahiro 2014; Subasinghe et al. 2016) analyze employment, migration and labor mobility (Boman 2007; Gober-Meyers 1978; Tatsiramos 2009; Webber and Pacheco 2016) among others.
The spatial incidence of crime over urban areas is another embracing subject that has been exhaustively put under discussion in recent technological advances on social evaluations (Bernasco and Elffers 2010; Chainey et al. 2008; Tabangin et al. 2010). The hotspot analysis on the incidence of crime with the support of geographic information systems has been traditionally employed to identify spatial patterns of the criminal behavior that is neither evenly nor randomly distributed along the space (Sherman et al. 1989; Nasar and Fisher 1993; Chainey and Ratcliffe 2013; Maltz et al. 1991). The spatial concentration of felonies and misdemeanors receives particular attention for its property to provide statistical measures that support public policy makers to design strategies based on an empirical understanding of the environmental relations that undergoes in their urban space, and valuable information can be extracted from crime associations with exogenous determinants of criminality among different groups of individuals to support decision making.
Most of traditional and recent studies, however, frame such clustering behavior with feature placing based on an aggregate dataset of property or violent crimes, without a meticulous discrimination of which sort of felony the results are limited to. For instance, Moonen et al. (2008) introduce descriptive models to control police patrol units in the province of West-Vlaanderen, Belgium, considering 16 hotspot locations of violent crime victims aiming to minimize the expected amount of time demanded to arrive in the highest hotspot region. By violent crimes the authors refer to some aggregate statistics on armed robberies, ram raids and similar felonies. Although the prescriptive models provided by the authors may design optimal patterns to deploy the patrol units over the sectors after the identification of most violent hotspots, the empirical judgment that labels the localities based on an overall statistic instead of individual measures of the reported crimes may overestimate (or underestimate) the police allocation of resources. Given the available information, a community where less aggravated armed robberies are concentrated can be considered as bad as another with more severe ram raids, attempted rapes and other forms of violent crimes. This type of assessment reveals that flaws may be found not on the methodological contributions, but in the way the big data has been conditioned.
One of the most important high cited studies on the spatial patterns of criminal behavior is provided by Sherman et al. (1989), which track 323,979 calls to police over 115,000 addresses in Minneapolis, US. The authors aggregates all instances of the analyzed crimes into three categories: Robbery (which includes, among others, simple robbery, armed and aggravated robberies, attempts and alarms for suspicious people), auto theft (also including attempts and alarms) and criminal sexual conduct (rape, molesting and exposing). Despite the valuable information in regards to the criminal incidence and concentration (the authors report that all 4166 robberies, 3908 auto thefts and 1729 sexual abuse calls cluster only on 2.2%, 2.7% and 1.2% of all locations, respectively), the spatial inference to support policing strategies might be compromised by the effect that different determinants have on different criminal conducts aggregated into one metric. Simple streets robberies committed in crowded places to random pedestrians may present different motivations and be associated with different environmental characteristics than armed robberies of which victims are approached closer to their residences. Whereas the first is strictly related to the opportunity granted by the victim’s possible careless behavior or by a set of favorable environmental factors observed in the eyes of the perpetrator, the last might be more consistently associated to a premeditated property crime, less related to the opportunity and more related to strategies adopted by the criminal and prior knowledge of the victim’s routine and response.
Despite the importance of felonies disaggregation, this kind of empirical assessment is rare to find since it requires a high level of detailing that is hardly provided by police datasets, statics or reports. This restriction makes contributions aggregating several felonies into one variable usually called ‘property crimes’ or ‘violent crimes’ the common practice. In this work such empirical spatial evaluation is obtained resorting to an online big dataset of property offenses recorded by the victims. The concept of property robbery is decomposed into small sets of nine felonies and misdemeanors. The main goal with this methodology is to provide substantial information that supports the decision making of public safety authorities by i. a rapid visualization on the more appropriate hotspots that indicate not only a higher incidence, but a criminal pattern that might advocate an efficient allocation of sworn officers; and ii. correlating this spatial concentration with environmental determinants to measure the impact of each potential factor in the incidence of crime. For the first consideration, the Optimized Hot Spot Analysis (Getis-Ord Gi*) is employed to visualize the spatial clusters in the desegregate data that present stronger associations with the environment than large aggregate datasets. In regards to the potential environmental determinants, some of the exogenous factors considered are the neighborhood density, public illumination, paving, public spaces (squares, lakes, recreation centers), urban space, income and the proportion of rented houses.
It is expected a higher spatial association from the detailed felonies data compared to the aggregate data. The higher correlation measure must contribute to support the development of practical policing strategies or the construction of useful approaches for specific types of crime in specific geographic regions, instead of considering the region as a whole. Our results indicate that more accurate measures for the spatial concentration to support decision making can be inferred from the disaggregate sets of data. In addition, some of the analyzed crimes, such as arrastão (flash robbery) and saidinha de banco (saucy bank), are very specific for the Brazilian social context, which makes this assessment unique due the difficult to find considerable incidence of those felonies besides Latin American countries. The next section addresses methodological concerns with the autocorrelation measure of concentrated incidents when data are aggregated. This is especially relevant in the criminal behavior design, since most the analyses are made on aggregate incidents. After, the data, city and methodology of analysis will be described, in parallel with the spatial assessment, and some discussion and expectation for future work will be provided in the conclusion.
2 The problem with aggregate visualization
Scholars addressing the social issue of criminality with geographic information data usually regard to micro levels’ concentration of crime in urban zones (mostly census tracts or street segments). In many studies, a common estimative of this concentration is that about 1–5% of the places are responsible for at least 50% of the criminality e.g. Sherman et al. (1989) predatory crimes in Minneapolis; Weisburd et al. (2004) study in Seattle; Braga et al. (2010, 2011) firearms shootings and robberies in Boston; Melo et al. (2015) robberies and thefts in Campinas, Brazil and Weisburd and Amram (2014) study in Tel-Aviv-Jaffa, Israel. Respectively, these authors report proportions around 3%, 5%, 3%, 1% and 4.5% of micro-level places accounting for 50% of the entire number of criminal incidents. Although concentrated, the types of criminal behavior is far from being equally distributed on the urban space. Andresen and Malleson (2011) and similar results in Andresen et al. (2017a) report that, from 5% of street segments which accounted for 50% of felonies in Vancouver, 2.58% corresponded thefts, 7.61% are attributed to burglary, 1.62% assault, 0.84% robberies, about 6% are thefts of vehicles and 2.64% thefts from vehicles.
Andresen et al. (2017b) argues that differences regarding the visualizations of individual spatial concentrations on disaggregate data of crimes present considerable relevance to identify stable patterns, especially when the criminal behavior is dynamic over the time. The authors cite evidences in support of a disaggregate investigation if these patterns are to be understood appropriately. While crimes in Vancouver such as assault barely decreased over the 16 years, other crimes such as burglary and theft of vehicle have decreased more than 50% over the time. When aggregated, the visualization on patterns can be affected creating a scenario where the results for the development of a public safety policy would be compromised. Because the drop of burglary were about six times as much the decrease in assault and about 21 times the decrease in other crimes, potential police strategies failures could be drastically offset by the positive results (decrease) that one specific misdemeanor had over the period. These observations are consistent with Andresen and Linning (2012) which present visual evidences of the differences among aggregate and individual property offenses (assault, burglary and thefts). The authors remark that aggregating different spatial point patterns is not appropriate for polygon-based analyses (census tracts and neighborhoods) because the proportion of incidents may vary considerably at the macro-local levels compared to street segments.
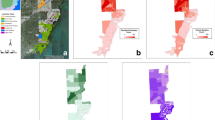
Another important issue in the discussion of aggregate visualization concerns the autocorrelation clustering of feature along the space. Getis and Ord (1992) statistic based on the Moran (1950) spatial correlation is one of the most accepted measure for spatial clustering visualizations (through hot and cold spots with different scales). When localities with high incidence (than the expected value) of the observed phenomena are surrounded by other high incidence localities, a hotspot will represent the spatial association. When localities with low incidence (than the expected value) of the observed phenomena are surrounded by other low incidence localities, a cold spot will represent this spatial pattern. If the polygon representing the locality has high (or low) incidence and is surrounded by low (or high) polygons, a radon-spot will represent this association, i.e., no statistically spatial pattern is observed. Consider the analysis made by Cohen and Gorr (2005) in regards to the property felonies committed in Pittsburgh, Pennsylvania and Rochester, New York. The authors collected 1,643,828 offense reports for Pittsburgh and 538,893 criminal records for Rochester from the years 1990 through 2001 aiming to predict crime in the most concentrated census tracts and support the tactical deployment of police resource. The Figs. 1, 2, 3 and 4 are designed using the shapefiles and dataset provided by the authors.Footnote 1

City of Rochester—Robbery patterns. a Charlotte; b, c Maplewood; d 14,621; e 19th Ward, Plymouth Exchange, Corn Hill, South Wedge, Wadesworth Square, Mayor’s Heights; f Josana, Bulls Head, Dutchtown

City of Rochester—Aggregate patterns. a Charlotte; b, c Maplewood; d 14,621; e 19th Ward, Plymouth Exchange, Corn Hill, South Wedge, Wadesworth Square, Mayor’s Heights; f Josana, Bulls Head, Dutchtown

City of Pittsburgh—Robbery patterns. a Lincoln–Lemington–Belmar, Homewood North, Homewood South; b Larimer, Homewood West, Shadyside, Point Breeze North, Squirrel Hill North, Point Breeze; c Squirrel Hill North, Squirrel Hill South

City of Pittsburgh—Aggregate patterns. a Lincoln–Lemington–Belmar, Homewood North, Homewood South; d Larimer, Homewood West, Point Breeze North, Squirrel Hill North, Point Breeze; Regent Square; e Stanton Heights, Garfield, East Liberty, Bloomfield, Friendship, Shadyside, Squirrel Hill North, North Oakland, West Oakland, Central Oakland, South Oakland
The Figs. 1 and 3 represent the spatial relation of robberies over the years in the studied cities. Figures 2 and 4 design the aggregate relation composed by the sum of robbery, burglary, motor vehicle theft and larceny. To exemplify the controversial effects of the aggregation, see the neighborhood of Charlotte [cluster (a) Fig. 1, composed by two census tracts], depicted as a cold spot in this visual representation. Charlotte is defined as cold spot for its property to have a low incidence of robberies surrounded by three census tracts with similar low incidence (b, c and d) that belongs the neighborhoods Maplewood and ‘14,621’. When aggregated, the higher incidence of burglary and larceny in the (d) census tract, which belongs the neighborhood ‘14,621’, and the higher incidence of larceny and vehicle thefts in the (b) tract belonging to Maplewood, increases the overall incidence of property crime above the average expected occurrence, and change the prior spatial relationship maintained for Charlotte from the Fig. 1 to a random pattern in the Fig. 2. While the first visualization deems Charlotte as a safe zone, the second will be inconclusive.
This compensation bias in the autocorrelation measure of spatial patterns derived from Cohen and Gorr (2005) data analysis happens because Charlotte maintains a low incidence of property felonies when robberies are aggregated with other types of crimes, but the similar proportion is not sustained for its neighbors, which turn to have higher concentration of crimes when aggregated. A well-defined pattern (low surrounded by low) designed from micro data becomes a random pattern (low surrounded by low and high) when data are aggregate from larger sets, leading to a lack of statistical significance to support resource allocation and police strategies spatially. Similarly, taking into account the hotspots tracts of robbery from Rochester [clusters (e) and (f), Fig. 1, including the neighborhoods 19th Ward, Plymouth Exchange, Corn Hill, South Wedge, Wadesworth Square, Mayor’s Heights, Josana, Bulls Head and Dutchtown], and Pittsburgh’s [cluster (a), Fig. 3, composed by the neighborhoods Lincoln–Lemington–Belmar, Homewood North and South] when aggregated, the spatial association loses explanatory power. The compensation in Pittsburgh occurs not only forward (spatial correlations turning into random patterns) but backwards (random patterns turning to well-defined spatial correlations), since many neighborhoods which do not take part in the hot spot cluster (b), e.g. Garfield, East Liberty, Bloomfield, North, West, Central and South Oakland, are present in the aggregate visualization [cluster (e)].
The misinterpretation of results can be aggravated when hot spots become directly cold spots, or cold spots turn straight to hot spots. Especially in many studies which regard the spatial association with socio and economic characteristics of the geographic coverage, such as population density, literacy, higher education, proportion of women, young and black people and income, direct compensations in the autocorrelation measures can be more evident. For instance, in the exploration of the unemployment-crime relationships from 1995 to 2000 at Virginia county level by Sridharan and Meyer (2005), the effects of resource deprivation in the individual statistics of burglary, larceny and thefts will be drastically changed if these typifications are aggregated to see the overall impact of the economy in the criminal behavior, e.g. Caroline County is directly remodeled from a robbery cold spot at micro level to a hot spot in the aggregate measure. These concerns reveal the importance of suitable data mining process applied to big data sets of geographic information prior the statistical assessment, in order to identify the most precise units and features of analysis. The next section is reserved for the description of the data mining and method used in this work. The methodology of Getis and Ord (1992) spatial autocorrelation and its extension to the optimized hot spots are put in formal details gather with the description of the property felonies.
3 Data and method
The geo-referenced data concerns the incidents of property robberies in Recife, Brazil, extracted from the Google Maps web service using a Java algorithm for refinement. The data feeding is made by a Brazilian organization that collects reports from property crimes victims or witnesses of the delinquency. Users may access the website http://www.ondefuiroubado.com.br/ and provide relevant information with regard the address where the crime occurred, the type of felony, date and time of the incident, stolen objects, estimated loss in R$ (Brazilian Real) currency, and the victim’s genre. A total of 1199 incidents were obtained by data extraction, which concerns the period from August 2013 to June 2016, distributed along the urban space with particular concentrations in the southeast and center east regions, which also happens to be the wealthier and bustling spots in the city, as presented by the dark-red feature points in the Fig. 5. About 47% the number of incidents occurred during the daylight and about 61% are female victims, being the most stolen items: purses or backpacks, wallets, and cell phones. With the support of Google Maps tools, the environmental conditions and spatial structure where each feature point is traced can be accessed (e.g. paved streets, nearby alleys, public illumination, and street graffiti). This information can be exported as exogenous layers in the GIS technology and be associated with the concentration patterns of each misdemeanors.

Recife—distribution of robberies from 2013 to 2016
Recife has a population of 1,537,704 residents and about 218,435 km2 urban and rural area decomposed into 1852 census tracts that put together regions with similar socio-economic characteristics. The problem of urban violence in the city has been addressed by studies on the hooligan behavior (Nepomuceno et al. 2017), homicides (Menezes et al. 2013; Pereira et al. 2015, 2017), drug market (Daudelin and Ratton 2017) and robberies by means of multicriteria decision modeling (Figueiredo and Mota 2016). In this work, from the geospatial dataset, nine types of robberies are considered using geographic information analysis: larceny, armed robbery, group stealing, motor vehicle theft, burglary, commercial burglary, saidinha de banco (saucy bank), motor vehicle robbery and arrastão (flash robbery). In addition, the aggregate data which represents the sum of the described felonies is taken into consideration for comparison purposes. Considering the occurrences, the landscape of the city can be divided into three lots where incidents may concentrate: the north side with a low incidence of robberies, the center region composed by a mix of poor and wealth neighborhoods with higher incidence of crimes, higher population density and good literacy rate measured from the population over 15 years old, and the south side of the city which is a high-income region located at the shores of famous beaches and tourist spots concentrating most of the burglary and motor vehicle thefts.
The Optimized Hot (and Cold) Spots identification based on Getis and Ord (1992) spatial autocorrelation statistics is adopted as the method to recognize criminal patterns along the urban space composed by feature points representing the robberies distribution. The validation of this methodology results a Gi* statistics for each feature point representing a z-score for each robbery in the available layer. An associated p value defines the grade of clustering association (i.e. whether it will represent a hotspot, cold spot, or radon pattern). The Ord and Getis (1995) Gi* statistic is given by the Gi statistic minus its expectation divided by the variance square root:
where \({\text{w}}_{{{\mathrm{i}},{\mathrm{j}}}}\) and \({\text{x}}_{{\mathrm{j}}}\) are the spatial weight between the neighborhoods (census tracts) i and j and the attribute for feature j, respectively. The Gi* statistic provides the information of where neighborhoods with either high (depictured by red hot spots) or low (depictured by blue cold spots) incidents cluster spatially. To be statistically significant, i.e. to present a considerable spatial association, the sum of incidents from each census tract i and its neighboring tract j is compared to what should be an expected value of incidents, taking into consideration the sum of all census sectors (see Eq. 1). When the difference from the sum of incidents of i and j with regard the expected value of the sum of incidents is large enough to reject the hypothesis that both are statistically similar, then a hot spot (a census tract with high occurrences surrounded by other census tract with high incidence) or cold spot (tracts with low incidents surrounded by other low incidence tracts) will be designed. In this methodology, a core hot spot (or core cold spot) is defined to have p value equal or less than 0.01 (i.e. confidence level equal or greater 0.99).
The spatial visualization of property felonies follows both a systematic and a subjective data curation process which has implication over the determination of public safety strategies to investigate the criminal behavior distributed on the urban space. The systematic process is made with the data collection and heuristic to organize and integrate the spatial references provided by the web-site repository of property offenses. The support of Gi* statistical tool makes feasible the construction of optimized clusters, in which significant information regarding the concentration and dispersive tendencies over the analyzed census sector can be extracted and evaluated. It is interesting to observe that to be a statistically significant hotspot the locality, in addition to high number of incidents, must be spatially associated to high incidence neighbors; otherwise it may be distinguished as an outlier. This is the case of the startling number of burglary incidents described by Oliveira (2004) that took place in the Recife’s neighborhood Casa Amarela during the spring 2014. Most the occurrences were recorded for the same street segment. Since this is a one-shot event (i.e. similar number is not observed before or after) and surround tracts do not present similar tendencies, Casa Amarela is a natural outlier (does not appear in the visualization patterns of the next section spatial assessment). Thus, the visualization analytics suggest that permanent allocation of sworn officers for this community would be a waste of resource.
The subjective side of the curation process requires substantial experience from the analyst to understand the grade of discrimination in which each felony might reach in the disaggregation procedure. In the present work, this has been done by a meticulous checking on the motivation and expectations underling each criminal conduct in our data (e.g. the double-disaggregated motor vehicle robberies introduced in the spatial assessment of this work). Certainly, the subjective nature of our assessment undergoes for several barriers when the analyst judgment over the criminal patter causes a misleading perception of the observed reality by an inappropriate discrimination of some types of felonies, or for an inaccurate aggregation of others. This is a field that requires an exceptional expertise by the decision maker (analysts or stakeholders) to provide accurate discriminant measures to perform geo-referenced data divisions in the best way possible to represent the studied local criminal behavior.
The importance of this methodology in the visualization of georeferenced data leads to additional arguments to support better decision making of public resources allocation, once the inference of policing strategies is not exclusive based on the quantity of occurrences. Some assessed regions with a large amount of property crimes incidents might not be enough to be considered as a statistically significant hotspot. For this purpose, beyond the high value of the set of incident, it remains necessary that the locality with higher incidence be surrounded by other high value localities, which in Fig. 1 is represented by the dark-red feature points. The spatial association is corrected for false-positive differences using Caldas de Castro and Singer (2006) False Discovery Rate Control (FDR). The motivation for this proposed methodology aims the identification of significant spatial clusters on dependent big data. As the number of incidents and locations increase, assessing significant measures for spatial concentration becomes complex. Clusters are only partially identified and multiple and dependent comparisons compromised. Thus, controlling the proportion of false significance (when the null hypothesis is true) can result statistically more significant z-score for the spatial evaluation.
4 Spatial assessment
Exploring unrandom spatial patters and relationships with the environment in the disaggregate data allows the police maker to use the spatial dependency measure as a source of precise information instead of an irregularity to be corrected. The environment associations with the distinct patterns of larceny, armed robberies, group stealing, thefts from vehicles, burglary, commercial burglary, saidinha de banco (saucy bank), motor vehicle robbery and arrastões (flash robberies) can mitigate uncertainties in the identification of optimized hotspots of the criminality and provide more robust degrees of correlation among the closest micro level localities compared to the macro level (aggregate) analysis. We separate each of these specific robberies in different layers with all the important geographic information attached to the feature incidents. The results from the Getis and Ord (1992) spatial autocorrelation regards the degree of hot and cold spots concentration along the urban space in the visualizations provided by the Figs. 6 (larceny), 7 (armed robberies), 8 (group stealing), 9 (thefts from vehicles), 10 (burglary), 11 (commercial burglary), 12 (saucy bank), 13 (motor vehicle robbery), 14 (flash robberies) and 15 (aggregate robberies).

Recife—patterns of larceny. Incident polygons: 188; cold spots: 0.90 confidence: 65, 0.95 confidence: 78, 0.99 confidence: 384; hot spots: 0.90 confidence: 24; 0.95 confidence: 29; 0.99 confidence: 289; not significant: 960; average count (ic): 1.46; half degree of concentration: 50–2.78%; overall concentration: 10.28%

Recife—patterns of armed robbery. Incident polygons: 354; cold spots: 0.90 confidence: 26, 0.95 confidence: 57, 0.99 confidence: 539; hot spots: 0.90 confidence: 34; 0.95 confidence: 105; 0.99 confidence: 379; not significant: 689; average count (ic): 1.72; half degree of concentration: 50–4.97%; overall concentration: 19.35%

Recife—patterns of group Stealing. Incident polygons: 101; cold spots: 0.90 confidence: 121, 0.95 confidence: 204, 0.99 confidence: 178; hot spots: 0.90 confidence: 34; 0.95 confidence: 52; 0.99 confidence: 260; not significant: 980; average count (ic): 1.24; half degree of concentration: 50–2.19%; overall concentration: 5.52%

Recife—patterns motor vehicle thefts. Incident polygons: 27; cold spots: 0.90 confidence: 87, 0.95 confidence: 4, 0.99 confidence: null; hot spots: 0.90 confidence: 13; 0.95 confidence: 35; 0.99 confidence: 218; not significant: 1472; average count (ic): 1.22; half degree of concentration: 50–0.60%; overall concentration: 1.48%

Recife—patterns of burglary. Incident polygons: 13; cold spots: 0.90 confidence: 2, 0.95 confidence: null, 0.99 confidence: null; hot spots: 0.90 confidence: 12; 0.95 confidence: 83; 0.99 confidence: 36; not significant: 1696; average count (ic): 1.23; half degree of concentration: 50–0.27%; overall concentration: 0.71%

Recife—patterns of commercial burglary. Incident polygons: 1; cold spots: 0.90 confidence: null, 0.95 confidence: null, 0.99 confidence: null; hot spots: 0.9 confidence: null; 0.95 confidence: null; 0.99 confidence: 188; not significant: 1641; average count (ic): 1.00; half degree of concentration: 50–0.05%; overall concentration: 0.05%

Recife—patterns of saucy bank. Incident polygons: 2; cold spots: 0.90 confidence: null, 0.95 confidence: null, 0.99 confidence: null; hot spots: 0.90 confidence: 192; 0.95 confidence: 57; 0.99 confidence: null; not significant: 1580; average count (ic): 1.00; half degree of concentration: 50–0.05%; overall concentration: 0.11%

Recife—patterns of motor vehicle robbery. Incident polygons: 59; cold spots: 0.90 confidence: 157, 0.95 confidence: 147, 0.99 confidence: 59; hot spots: 0.90 confidence: 68; 0.95 confidence: 129; 0.99 confidence: 226; not significant: 1043; average count (ic): 1.12; half degree of concentration: 50–1.42%; overall concentration: 3.22%

Recife—patterns of flash robbery. Incident polygons: 8; cold spots: 0.90 confidence: null, 0.95 confidence: null, 0.99 confidence: null; hot spots: 0.90 confidence: 41; 0.95 confidence: 41; 0.99 confidence: 72; not significant: 1675; average count (ic): 1.00; half degree of concentration: 50–0.22%; overall concentration: 0.44%

Recife—patterns of aggregate robberies. Incident polygons: 531; cold spots: 0.90 confidence: 46, 0.95 confidence: 59, 0.99 confidence: 526; hot spots: 0.9 confidence: 61; 0.95 confidence: 79; 0.99 confidence: 327; not significant: 731; average count (ic): 2.26; half degree of concentration: 50–6.014%; overall concentration: 29.03%
The spatial pattern observed by the red-to-blue scale from Figs. 6, 7, 8, 9, 10, 11, 12, 13, 14 and 15 measures the strength of the clustering concentration as high and low incidences of the related felony placed on a given census region. The feature points of property robberies present in the Fig. 5 are aggregated into 1852 polygons that represent the census sectors of Recife for this analysis. Hot and cold clusters bring statistical evidences of an underlying spatial pattern based on the assumed confidence level the z-score information provided to each aggregated feature. Positive z-scores for a p value below its assumed confidence level brings empirical evidences for a significant hotspot (high incidents of the related felony clustering together); negative z-scores for a p value below its assumed confidence level indicates a significant cold spot (low incidents of the analyzed felony clustering together). For the optimized clustering, the Inverse Distance approach is applied which implies closer features weighed more heavily than features that are distant to each other.
The scale of analysis is defined by incremental spatial autocorrelation performed with the support of Moran’ I statistic Moran (1950), measuring the intensity of the spatial clustering in seven dimensions, 0.99, 0.95 and 0.90 confidence levels for both high and low clusters of incidents. A non-significant scale is defined whenever the feature layer does not present enough statistical evidence for an accurate relation of the studied felony with the environment. A short description of the main statistics is provided below each visualization. Incident polygons concerns the number of census tracts in which at least one occurrence of robbery is recorded. This number varies abruptly from common felonies with high incidence distributed over many perimeters, such as armed robberies (Fig. 7, 354 zones have registered at least one incident) to low incident and more concentrate felonies, such as saucy bank (Fig. 12, having only two census zones with incidents). The composition of these regions by the number of hot and cold spots, according their statistical significance, is also present. For instance, from the 188 zones registering at least one incident of larceny (Fig. 6), 65 are cold spots with 90% confidence, 78 with 95% confidence, and 384 tracts are cold spots with 99% confidence; considering hot spots, 24 are framed with 90% confidence; 29 with 95% confidence and 289 have 99% confidence to be considered as violent localities. In addition, information on the number of tracts with no spatial patterns and the average occurrence (taken into consideration only incident polygons) is presented, e.g. larceny 960 and 1.46 occurrence per locality, respectively.
The half degree of concentration (hdf) is defined as the percentage of micro level space where 50% of the crime concentrates. This is a well-established and largely used measure of spatial concentration (Andresen and Malleson 2011; Andresen et al. 2017a; Braga et al. 2011; Melo et al. 2015; Sherman et al. 1989; Weisburd and Amram 2014; Weisburd et al. 2004) for its property to discount the diversity of small incidents of data over many localities. Especially when big data are disaggregated into smaller sets, few localities turns to concentrate most incidents and most localities present 1 or 2 incidents each. This situation makes crime spread widely over the landscape on many micro level localities with few incidents, which do not represent the real concentration. For this reason, 50% proportion of the incidents may be a more accurate measure for the spatial concentration than the entire incidence. A good example can be observed in the aggregate visualization of robberies (Fig. 15). While the half degree of concentration exhibits the proportion 50–6.014%, the overall concentration is about five times as much, with proportion 100–29.03%. Formally, the half degree of concentration is the percentage of the mth number of feature layers (localities) j which the up-down sum of the attributes (crimes) reaches 50%:
The hotspot maps that clusters larcenies, group stealing and thefts from vehicles observed in the center side of Figs. 6, 8 and 9 have basically the same hotspot patterns composed by 406 census tracts (polygons) which belong to 28 mixed-use intensive neighborhoods, i.e. zones that blends residential, commercial, cultural, and industrial uses. These are deemed as the most critical regions having the highest incidence of armed robberies compared to the other types of robbery felonies. This specific type of robbery present similar concentration on mixed-use zoning as larceny and group stealing, plus 208 census tracts that correspond to 16 main street residential/commercial neighborhoods and rural areas. Hot spots patterns on burglary, commercial burglary, saucy bank, vehicle robberies and flash robberies have different drawings to represent the spatial association over the urban perimeter.
5 Discussion
Burglary (Fig. 10) concentrates in low income informal settlements (favelas) surrounded by medium income communities in the neighborhoods Imbiribeira and Ipsep. The percentage of rented houses in these localities is not positive correlated with the incidents, as suggested by many works (Alba et al. 1994; Glaeser and Sacerdotev 1999; Rephann 2009; Spelman 1993; Tseloni and Thompson 2015). The victims’ residence usually looks better than surrounding neighbors with visible cable tv antennas, plaster and ceramics, and streets segments are characterized by paved alleys and a vast number of graffiti. Commercial Burglaries (Fig. 11), on the other hand, occurs in commercial units on the corner of important Boa Viagem avenues (high income neighborhood with important touristic spots and beaches). Having a first glance on these concentration patterns, the visualization suggests the accessibility (in the case of house burglary) and the few number of neighboring units (stores, shops or residences in the case of commercial burglary located on corner houses) as determinants for the decision making by criminals and for the spatial concentration of the specific felonies.
Saucy bank (Fig. 12) is a particular type of urban robbery found in some Latin America countries, especially common in Brazilian cities by the term “saidinha de banco”. It happens when criminals approach customers leaving bank branches immediately after withdrawing money. The spatial analysis on this misdemeanor is limited to two neighborhoods and 249 census tracts with no more than 95% confidence: Boa Viagem in the southeast spot of the visualization, and Derby in the center-east of the city. Derby is characterized as a mix-used neighborhood shared by the service industry, banks, hospitals, restaurants, public spaces, parks and residential buildings. Both the regions are characterized by high income, small population density, increased flow of people (close to shopping mall, supermarket, stores, parking lot and bus stops) and crossroads of easy accessibility. Due the particularity of the felony which can occur only in very specific spots, i.e. nearby banks or financial institutions settled in predefined commercial places, and due the limitation on data, the region is distinguished extremely concentrated in regards to this type of robbery as it is commercial burglary (about 0.05% of census tracts account for 50% saucy bank and commercial burglary crimes), which limits additional statistical evaluations besides visualization inference.
Motor vehicle robberies are the most heterogeneously distributed type of robbery. The incidence correspond 59 census tracts concentrated into nine cores, mostly far from each other which may jeopardize the identification of significant spatial-related clusters and makes difficult the appropriate use of resources. For this reason, this specific type of robbery has been double-desegregated into a smaller set of vehicle robberies according the built characterization, i.e. the adaptation of the criminals’ motivation to the environment. Four types of vehicle robberies can be identified: vehicle robberies upon arrival, on leaving or parked nearby the owner’s residence (28.8%), vehicle robberies while parking at work (7.57%), vehicle robberies while commuting between home and work or home and school (30.3%) and vehicle robberies while parking in other places e.g. shops, gyms, general streets or avenues (33.3%). The first type of vehicle robbery is selected to perform additional analysis and the results depicted in the Fig. 16 exhibit less disperse patterns in the urban segments than the prior assessment (see Fig. 13).

Recife—patterns of motor vehicle robbery nearby residences. Incident polygons: 17; cold spots: 0.90 confidence: 47, 0.95 confidence: 1, 0.99 confidence: null; hot spots: 0.90 confidence: 42; 0.95 confidence: 92; 0.99 confidence: 92; not significant: 1580; average count (ic): 1.12; half degree of concentration: 50–0.44%; overall concentration: 0.93%
Naturally, smaller number of incidents implies an increase in the half degree and overall concentration power (from 1.42 to 0.44% and 3.22. to 0.93%), with 42 less entries (from 59 to 17 incident localities). The new designed pattern is not similar to any other data visualization. There is only one core hotspot composed by three neighborhoods: San Martin, Mangueira and Jardim São Paulo, and many communities represented by undefined spots in the vehicle robbery aggregate visualization. When double-desegregated, these localities have a considerable number of carjacking nearby home that cannot be discriminated statistically significant in the broader patterns of vehicle robberies, and unnoticed potential exogenous determinants.
With the combined information from the Google maps platform, about 78.95% vehicle robberies nearby residences occur in corner houses or buildings situated in between street intersections. From this percentage, 80% are crossroads of high mobility, and 20% T-junction segments (three-way intersections). Other potential determinants of this type of delinquency, such as public illumination, property value (i.e. victims’ residence in the occurrence), lack of commercial activity (stores, gas stations, pharmacies, supermarkets, restaurants) and whether the residential spot is hidden by trees, buildings or other structures do not seem positively associated with the incidence. Most the victims residences in front of (or close to) the vehicle robberies incidents are wide visible for a passerby (about 84.21%) and only few incidents occurs in regions where other sorts of robberies are concentrated, e.g. larceny, armed robbery, thefts from vehicle and commercial burglary.
Most of the incidents however occurs in poor communities surrounded by medium income neighborhoods (about 58%) and the easy way in and out, defined by the number of intersections, paved streets and divided highways close to the hotspot seems more crucial for the criminals carjacking decision (about 79% of the localities have these characteristics). These findings contradict the common sense that urban criminals avoid motor vehicles parked in front of houses or driveways for being wide open and visible. Some of them are minor age juvenile delinquents (at least 10.52% of the vehicle robberies nearby residences, as far as data descriptions can tell) which reckless and less rational behavior is expected, without considering all the available information.
Flash robberies, popular known as “arrastão” is a type of urban raid committed by three or more individuals together to take hold of personal belongs from one person or a group of people. It is characterized by a rapid action by the perpetrators (usually running to approach the victims) and many forms of vandalism. Excepting few occurrences outside the core hot spot cluster in the east side of the visualization, this felony concentrates in crowded slow-moving neighborhoods with intense pedestrian traffic during weekends such as Recife Antigo, Boa Vista, and Pina. Most of the occurrences are associated with the Recife’s main hooligan fan bases (see the discussion provided by Nepomuceno et al. 2017), which brings a strategic positioning for policing by predicting where the crime takes place (center east spot) when it is ought (likely) to happen (during weekends before or after soccer matches) and who commits them (most of them club supporters).
Blue cold spots determine the safer regions in the city for each individual felony. As for the remaining tracts without coloration, the analysis cannot afford conclusive statistical support on the spatial association, though crime may occur. Similar cold spots from safe regions can be visualized in the north side patterns of larceny (Fig. 6), armed robbery (Fig. 7), group stealing (Fig. 8) and in the aggregate measure of robberies (Fig. 15). These patterns correspond mostly to high population density, high education and income neighborhoods: Graças, Espinheiro, Torre, Madalena, Rosarinho, Parnamirim and Casa Forte; and to some low income, black majority and high populated communities: Peixinhos, Morro da Conceição, Arruda, Santo Amaro, Água Fria, Dois Unidos and Macaxeira. This specific finding brings evidences that more homogenous localities i.e. neighborhoods composed by majority high income families or communities composed by majority low income families, are safer than more heterogeneous income localities, i.e. regions composed by similar rate of high and low income families distributed along the same perimeter.
This important remark is supported by the spatial regression results in the Tables 1 and 2. The tables present results with regard the explanatory power of 14 socio-economic and environmental potential determinants of larceny and armed robberies.Footnote 2 Many different social, economic and environmental factors have different impact on robbery. The role of the income and economic inequality has been investigated by many studies along the past decades (Andresen 2013; Menezes et al. 2013; Fajnzylber et al. 2002; Scorzafave and Soares 2009). Race (Alba et al. 1994) rental occupancy (Rephann 2009; Tseloni and Thompson 2015) and education (Lochner 2004) are some of the common social and environmental characteristics correlated with property misdemeanours. We have selected some of the most discussed potential socio-economic and environmental determinants of the criminality based on the data availability, specialized literature and similar studies (Figueiredo and Mota 2016; Pereira et al. 2015, 2017; Menezes et al. 2013).
The statistical significance of each variable and the proportion of negative or positive association with the designed crime are present. These associations can be interpreted as the mutual relationship between the environment and the felony. For instance, all tracts where high incidents of larceny occur have low regional population density (a negative relation). A region with high levels of education represented by literacy rate is about 70% and 80% significant to explain incidence of armed robberies and larceny, respectively (a positive relation). On the other hand, the proportion of male young people, the population density at street level and the number of residents in given community do not seem to be interesting to explain the behaviour of those robberies types. As it can be observed, poor communities (characterized by the percentage of families with no income or the percentage of families up to 1 minimum wage) have a negative relationship with crime and can be explained by the fact that many criminals live in those poor localities and can be easily recognized, which prevent them to commit unlawful activities.
Lastly, an important representation of the direct compensation effect in the autocorrelation measure of Recife’s robberies can be identified on the south side of visualizations 13 (the spatial patterns for the motor vehicle robberies) and 15 (the spatial patterns for the aggregate robberies). These assessments are dragged out into the Figs. 17 and 18. The neighborhood Ibura has a high incidence of motor vehicle robberies as presented by the Fig. 18. Nevertheless, the low incidence of larceny (Fig. 6) and group stealing (Fig. 8) offsets the high incidence of motor vehicle robberies in the neighborhood, turning it to a cold spot (Fig. 17) when aggregated, i.e. the aggregation makes it appears to be safer than really is. The development of non-compensatory models to aggregate geo-spatial data of the criminal behavior may become an interesting avenue for future advances in the analysis of public security.

Ibura (as cold spot of Robbery)

Ibura (as hot spot of Vehicle Robbery)
6 Conclusions
The research fills a void in the criminology literature which concerns the structure that the spatial relationship of crime versus environment has been constructed from the georeferenced data. It has been shown that environment technical features, socio-economic and demographic characteristics of census tracts may lead to different interpretation of results using autocorrelation measures or spatial regressions to investigate the explanatory power of those potential determinants of criminality. This difference is attributed to a compensation bias, of which disaggregated big data may cope with. In addition, some practical implications of this research methodology can be observed from the table results. For instance high populated localities with low income and considerable number of black people have few number of incidents compered to medium and high income zones composed by unequal levels of educated families and considerable number of rented houses (the last is not significant in the case of residential burglary, as the analysis proposes). These results, besides innovative for the correct understanding of the criminal behavior in regions with similar socio-economic characteristics as Recife has, also might support the better allocation of public resources, technologies and policing strategies.
A limitation that concerns the conceptualization of the spatial relationship made on fixed distance bands and disaggregate data resides on the effect of polygons with no occurrence or very small number of incidents. This data pulls down the “mean incident” and make polygons with few occurrences to become hotspots. This is a crucial issue for this type of spatial assessments and requires caution from the analyst to perceive where the number of incidents is too small to be autocorrelated with surround features. In this case, data should be aggregated somehow. Non-compensatory multicriteria decision models can be helpful on this purpose, and future research is expected considering this line of thought. Another concern is present in the quality of the collected data. Since this analysis regards victimization data, provided by any individual connected to the web network, they are subjected to intentional lies, errors or wrong bias. Nevertheless, this concern does not undermine the importance of geoinformation systems to support the decision making of public policy makers. A tight data mining processes might be able to minimize this concern.
The next steps for future research can rely on additional exploratory regressions to further investigate the interaction that each disaggregated criminal conduct described by the cluster’s feature layers has with the potential spatial, demographic, social and economic determinants of criminality, such as home security systems, income inequality, economic crisis and the influence of environmental characteristics such as placemaking levels, structure of public spaces, churches, and pubs. Some types of property crimes had to be omitted in this research for not present enough empirical evidence for statistical analysis. The collection of those data may add much more for the big picture still under construction and for the good prospects of the public safety decision makers.
Notes
When disaggregated, data on the individual types of the remaining robberies, besides larceny and armed robbery, become insufficient to explore additional spatial regressions.
References
Alba RD, Logan JR, Bellair PE (1994) Living with crime: the implications of racial/ethnic differences in suburban location. Soc Forces 73(2):395–434
Andreoni V, Galmarini S (2016) Mapping socioeconomic well-being across EU regions. Int J Soc Econ 43(3):226–243
Andresen MA (2013) Unemployment, business cycles, crime, and the Canadian provinces. J Crim Justice 41(4):220–227
Andresen MA, Linning SJ (2012) The (in)appropriateness of aggregating across crime types. Appl Geogr 35:275–282
Andresen MA, Malleson N (2011) Testing the stability of crime patterns: implications for theory and policy. J Res Crime Delinq 48:58–82
Andresen MA, Curman AS, Linning SJ (2017a) The trajectories of crime at places: understanding the patterns of disaggregated crime types. J Quant Criminol 33(3):427–449
Andresen MA, Linning SJ, Malleson N (2017b) Crime at places and spatial concentrations: exploring the spatial stability of property crime in Vancouver BC, 2003–2013. J Quant Criminol 33(2):255–275
Arabatzis S, Manos B (2005) An integrated system for water resources monitoring, economic evaluation and management. Oper Res Int J 5(1):193–208
Bernasco W, Elffers H (2010) Statistical analysis of spatial crime data. In: Piquero AR, Weisburd D (eds) Handbook of quantitative criminology. Springer, New York, pp 699–724. https://doi.org/10.1007/978-0-387-77650-7_33
Berry JK, Sailor JK (1987) Use of a geographic information system for storm runoff prediction from small urban watersheds. Environ Manag 11(1):21–27
Bimonte S, Pradel M, Boffety D, Tailleur A, André G, Bzikha R, Chanet JP (2013) A New sensor-based spatial OLAP architecture centered on an agricultural farm energy-use diagnosis tool. Int J Decis Support Syst Technol (IJDSST) 5(4):1–20
Boman A (2007) Does migration pay? Earnings effects from geographic mobility following job displacement. rapport nr.: Working papers in Economics 244
Braga A, Hureau DM, Papachristos AV (2010) The concentration and stability of gun violence at micro places in Boston, 1980–2008. J Quant Criminol 26:33–53
Braga A, Hureau DM, Papachristos AV (2011) The relevance of micro places to citywide robbery trends: a longitudinal analysis of robbery incidents at street corners and block faces in Boston. J Res Crime Delinq 48:7–32
Buccella A, Cechich A, Gendarmi D, Lanubile F, Semeraro G, Colagrossi A (2010) GeoMergeP: geographic information integration through enriched ontology matching. New Generation Computing 28(1):41–71
Burrough PA (1986) Principles of geographical information systems for land resources assessment. Clarendon Press, Oxford
Caldas de Castro M, Singer BH (2006) Controlling the false discovery rate: a new application to account for multiple and dependent test in local statistics of spatial association. Geogr Anal 38:180–208
Čerba O, Jedlička K, Čada V, Charvát K (2017) Centrality as a method for the evaluation of semantic resources for disaster risk reduction. ISPRS Int J Geo-Inf 6(8):237
Chainey S, Ratcliffe J (2013) GIS and crime mapping. Wiley, New York
Chainey S, Tompson L, Uhlig S (2008) The utility of hotspot mapping for predicting spatial patterns of crime. Secur J 21(1–2):4–28
Cohen J, Gorr WL (2005) Development of crime forecasting and mapping systems for use by police in Pittsburgh, Pennsylvania, and Rochester, New York, 1990–2001. ICPSR04545-v1. Ann Arbor, MI: Inter-university Consortium for Political and Social Research [distributor], 2006-08-31. https://doi.org/10.3886/icpsr04545.v1
Daudelin J, Ratton JL (2017) Mercados de drogas, guerra e paz no Recife. Tempo Social 29(2):115–133
Fajnzylber P, Lederman D, Loayza N (2002) What causes violent crime? Eur Econ Rev 46(7):1323–1357
Fatima-Zohra Y, Djamila H, Omar B (2015) A surveillance and spatiotemporal visualization model for infectious diseases using social network. Int J Decis Support Syst Technol (IJDSST) 7(4):1–19
Figueiredo CJJD, Mota CMDM (2016). A classification model to evaluate the security level in a city based on GIS-MCDA. Math Problems Eng 2016. https://doi.org/10.1155/2016/3534824
Getis A, Ord JK (1992) The analysis of spatial association by use of distance statistics. Geogr Anal 24(3):189–206
Glaeser EL, Sacerdotev B (1999) Why is there more crime in cities? J Polit Econ 107(S6):S225–S258
Gober-Meyers P (1978) Migration analysis: the role of geographic scale. Ann Reg Sci 12(3):52–61
Hachikyan A, Scherer R, Angelova M, Lazarova M (2005) Decision support system for a river network pollution estimation based on a structural-linguistic data model. Oper Res Int J 5(1):105–113
Hong SY, Sadahiro Y (2014) Measuring geographic segregation: a graph-based approach. J Geogr Syst 16(2):211–231
Kaloudis ST, Lorentzos NA, Sideridis AB, Yialouris CP (2005) A decision support system for forest fire management. Oper Res Int J 5(1):141–152
Kim MC, Zhu Y, Chen C (2016) How are they different? A quantitative domain comparison of information visualization and data visualization (2000–2014). Scientometrics 107(1):123–165
Kirk KE, Haq MZ, Alam MS, Haque U (2014) Geospatial technology: a tool to aid in the elimination of malaria in Bangladesh. ISPRS Int J Geo-Inf 4(1):47–58
Kursah MB (2017) Modelling malaria susceptibility using geographic information system. GeoJournal 82(6):1101–1111. https://doi.org/10.1007/s10708-016-9732-0
Lochner L (2004) Education, work, and crime: a human capital approach. Int Econ Rev 45(3):811–843
Maguire DJ (1991) An overview and definition of GIS. In: Maguire DJ, Goodchild MF, Rhind DW (eds) Geographical information systems: principles and applications, vol 1. Wiley, Hoboken, pp 9–20
Maltz M, Gordon AC, Friedman W (1991) Mapping crime in its community setting: event geography analysis
Manfré LA, Hirata E, Silva JB, Shinohara EJ, Giannotti MA, Larocca APC, Quintanilha JA (2012) An analysis of geospatial technologies for risk and natural disaster management. ISPRS Int J Geo-Inf 1(2):166–185
Melo SN, Matias LF, Andresen MA (2015) Crime concentrations and similarities in spatial crime patterns in a Brazilian context. Appl Geogr 62:314–324
Menezes T, Silveira-Neto R, Monteiro C, Ratton JL (2013) Spatial correlation between homicide rates and inequality: evidence from urban neighborhoods. Econ Lett 120(1):97–99
Moonen M, Cattrysse D, Van Oudheusden D (2008) Organising patrol deployment against violent crimes. Oper Res Int J 7(3):401–418
Moran PAP (1950) Notes on continuous stochastic phenomena. Biometrika 37:17–23
Nasar JL, Fisher B (1993) ‘Hot spots’ of fear and crime: a multi-method investigation. J Environ Psychol 13(3):187–206
Nelson EP, Connors KA, Suárez C (2007) GIS-based slope stability analysis, Chuquicamata open pit copper mine, Chile. Nat Resour Res 16(2):171–190
Nepomuceno TCC, de Moura JA, e Silva LC and Costa APCS (2017) Alcohol and violent behavior among football spectators: AN empirical assessment of Brazilian’s criminalization. Int J Law Crime Justice 51:34–44. ISSN 1756-0616. http://dx.doi.org/10.1016/j.ijlcj.2017.05.001
Nikolopoulou AI, Repoussis PP, Tarantilis CD, Zachariadis EE (2019) Adaptive memory programming for the many-to-many vehicle routing problem with cross-docking. Oper Res Int J 19(1):1–38. https://doi.org/10.1007/s12351-016-0278-1
Oliveira W (2004) Arrombamentos de residências assustam moradores de Casa Amarela. Diário de Pernambuco. http://blogs.diariodepernambuco.com.br/segurancapublica/?p=7585. Accessed 31 Aug 2017
Ord JK, Getis A (1995) Local spatial autocorrelation statistics: distributional issues and an application. Geogr Anal 27:286–306. https://doi.org/10.1111/j.1538-4632.1995.tb00912.x
Pereira DV, Mota CM, Andresen MA (2015) Social disorganization and homicide in Recife, Brazil. Int J Offender Ther Comp Criminol 1:2. https://doi.org/10.1177/0306624X15623282
Pereira DV, Mota CM, Andresen MA (2017) The homicide drop in Recife, Brazil: a study of crime concentrations and spatial patterns. Homicide Studes 21(1):21–38
Power DJ, Roth RM, Karsten R (2013). Decision support for crisis incidents. Engineering effective decision support technologies: New Models and Applications: New Models and Applications, 149
Rephann TJ (2009) Rental housing and crime: the role of property ownership and management. Ann Reg Sci 43(2):435–451
Rodríguez-González A, Alor-Hernandez G, Mayer MA, Cortes-Robles G, Perez-Gallardo Y (2013) Application of probabilistic techniques for the development of a prognosis model of stroke using epidemiological studies. Int J Decis Support Syst Technol (IJDSST) 5(4):34–58
Schröder W, Schmidt G, Bast H, Pesch R, Kiel E (2007) Pilot-study on GIS-based risk modelling of a climate warming induced tertian malaria outbreak in Lower Saxony (Germany). Environ Monit Assess 133(1):483–493
Scorzafave LG, Soares MK (2009) Income inequality and pecuniary crimes. Econ Lett 104(1):40–42
Sherman LW, Gartin P, Buerger ME (1989) Hot spots of predatory crime: routine activities and the criminology of place. Criminology 27:27–55
Spelman W (1993) Abandoned buildings: magnets for crime? J Crim Justice 21(5):481–495
Sridharan S, Meyer J (2005) Exploratory spatial data approach to identify the context of unemployment-crime linkages in Virginia, 1995–2000. ICPSR04546-v1. Inter-university Consortium for Political and Social Research [distributor], Ann Arbor, MI, 2006-08-31. https://doi.org/10.3886/icpsr04546.v1
Subasinghe S, Estoque R, Murayama Y (2016) Spatiotemporal analysis of urban growth using GIS and remote sensing: a case study of the Colombo metropolitan area, Sri Lanka. ISPRS Int J Geo-Inf 5(11):197
Tabangin DR, Flores JC, Emperador NF (2010) Investigating crime hotspot places and their implication to urban environmental design: a geographic visualization and data mining approach. Int J Hum Soc Sci 5(4):210–218
Tarantilis CD, Kiranoudis CT (2001) Using the vehicle routing problem for the transportation of hazardous materials. Oper Res Int J 1(1):67–78
Tatsiramos K (2009) Geographic labour mobility and unemployment insurance in Europe. J Popul Econ 22(2):267–283
Thomas JJ, Cook KA (2005) Illuminating the path: the R&D agenda for visual analytics. Natl Visual Anal Center, USA
Tlili T, Krichen S, Faiz S (2013) Towards a decision making support system for the capacitated vehicle routing problem. Int J Decis Support Syst Technol (IJDSST) 5(4):21–33
Tseloni A, Thompson R (2015) Securing the premises. Significance 12(1):32–35
Tufte E (1983) The visual display of quantitative information. Graphics Press, Cheshire
Tukey J (1977) Exploratory data analysis. Addison-Wesley, Boston
Webber D, Pacheco G (2016) Changes in intra-city employment patterns: a spatial analysis. Int J Soc Econ 43(3):263–283
Weisburd D, Amram S (2014) The law of concentrations of crime at place: the case of Tel Aviv-Jaffa. Police Pract Res 15:101–114
Weisburd D, Bushway S, Lum C, Yang S-M (2004) Trajectories of crime at places: a longitudinal study of street segments in the City of Seattle. Criminology 42:283–321
Zachariadis EE, Tarantilis C, Kiranoudis CT (2017) Vehicle routing strategies for pick-up and delivery service under two dimensional loading constraints. Oper Res Int J 17(1):115–143
Funding
Funding was provided by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Nepomuceno, T.C.C., Costa, A.P.C.S. Spatial visualization on patterns of disaggregate robberies. Oper Res Int J 19, 857–886 (2019). https://doi.org/10.1007/s12351-019-00479-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12351-019-00479-z