
Abstract
Seismic facies analysis which is aimed at identifying subsurface geological features from seismic data, has evolved due to the time-consuming and labor-intensive nature of its traditional approach. To address these challenges, numerical frameworks such as machine learning have been applied, yet attribute selection still comes with some challenges, particularly for inexperienced interpreters. Additionally, validating results in regions with limited well data poses significant challenges. This paper addresses these challenges through a comprehensive review of seismic facies workflows and a proposed workflow for a case study in the Gulf of Guinea. In this case study, seismic attribute selection is significantly based on the contribution (weights) of the individual attributes in a larger set of attributes. Also, we have introduced spectral decomposition for interpretation and initial validation of the workflow due to its independence on well data. Here, we applied an unsupervised vector quantizer to seismic attribute selection and facies analysis. Using a backward feature selection (BFS) approach for attribute selection based on computed weights assigned by our unsupervised vector quantizer (UVQ) network, we selected six seismic attributes for our facies analysis and tested five different attribute combinations of the attributes for facies analysis. This was followed by spectral decomposition colorblend of 5 Hz, 10 Hz, and 15 Hz frequencies. The facies generated using our seismic attributes varied with each combination due to the variations in the individual attributes. Correlating our seismic attributes and spectral decomposition to our facies, it was possible to identify lithological variations without solely relying on well data. Insights from this paper show the suitability of the automatic approach to seismic facies analysis in aiding the identification of new reserves which can bolster the economies of developing countries.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Seismic facies analysis relates to the ability to characterize enough variation in seismic data to discover relevant information about subsurface geological features. The ability to distinguish between the variations in seismic data is very instrumental in gaining valuable insights into subsurface lithology and reservoirs to enable de-risking during exploration and production (Bagheri and Riahi 2014; Fashagba et al. 2020; Xie et al. 2017). The basic principle of seismic facies analysis is the fusion of geology with seismic data and this relates to the characterization of reservoir properties and heterogeneity in seismic data (Song et al. 2017; Xu and Haq 2022).
Seismic facies analysis has evolved significantly over the past few decades. In the past, the process involved manual interpretation of seismic sections by an interpreter whose work would involve marking the transition between seismic reflection patterns (Kaur et al. 2022; Lima et al. 2020). Some of the main limitations of this approach is its labor intensiveness, the associated time cost, and the interpreter’s subjectivity (Chen et al. 2022; Kaur et al. 2022; Song et al. 2017; Zheng et al. 2019). Other researchers have also associated the limitations to the increased complexity of seismic data (Song et al. 2017; Zhang et al. 2020), and the requirements of modern exploration (Xu and Haq 2022; Zhang et al. 2020).
With increasing technology over the past decades, there has been a need for a more automated approach emphasizing the use of numerical frameworks and pattern recognition in seismic facies analysis. These improvements in technology and computational power have made it possible for seismic facies analysis to become more quantitative and automated to alleviate time consumption and labor intensity (Kim et al. 2019; Su-Mei et al. 2022; Wrona et al. 2018). According to Zhao et al. (2015), there is an increasing trend in the application of machine learning in automated seismic facies analysis. Also, according to Zhang et al. (2020), developing an automatic approach has served as an important means to improve efficiency and reduce ambiguity in seismic facies analysis.
One of the main inputs for many seismic interpretation tasks is seismic attributes. Chopra and Marfurt (2005) have defined seismic attributes as a quantitative measure of any seismic characteristic of interest and an important aspect of seismic interpretation. Over the years, seismic attributes have been used in fault analysis (Ashraf et al. 2020; El-Qalamoshy et al. 2023; Hussein et al. 2021; Ismail et al. 2023; Laudon et al. 2021), facies analysis (la Marca-Molina et al. 2019; La Marca et al. 2022; Lubo-Robles et al. 2023), gas reservoir identification (Chenin and Bedle 2022), gas chimneys (Dixit and Mandal 2020; Ismail et al. 2020a; Ismail et al. 2022; Ramya et al. 2020), gas hydrates (Chenin and Bedle 2020; Kunath et al. 2020; Lubo-Robles et al. 2023; Neves et al. 2022), and direct hydrocarbon indicators (Gadelkarim et al. 2022; Hashem et al. 2022; Srisutthiyakorn et al. 2022; Zhong et al. 2021).
Seismic attributes in feature-based facies analysis improves the efficiency of facies analysis as compared to the manual interpretation (John et al. 2008). As such, selecting seismic attributes for feature-based facies analysis is an important aspect of any attribute-based facies analysis. This involves the evaluation of seismic attributes under consideration to determine an appropriate set of attributes. According to Zhao et al. (2018), the attribute-selection system in use today is simply a weighting system. Instead of simply choosing a set of attributes and assuming each contributes equally to a facies map, the selection of input attributes can be guided by weights calculated using a machine learning algorithm and the interpreter’s experience. This highlights a potential challenge in carrying out seismic facies analysis in the absence of seismic attributes. In such a situation, another approach which is the feature-less facies analysis approach may be used for seismic facies analysis. Bagheri et al. (2013) and Bagheri and Riahi (2017) have noted that defining seismic attributes strongly related to class differences in feature-based facies analysis can be challenging and seismic datasets could also contain missing attributes. As such, justifying the need for an alternate approach using a dissimilarity based classification.
Despite the increasing application of machine learning in seismic facies analysis around the world, there are limited reviews capturing the utilization of these algorithms for seismic facies analysis and their case studies. Coléou et al. (2003), Zhao et al. (2015), and Chopra and Marfurt (2020) are the only papers which have reviewed the application of machine learning techniques in seismic facies analysis within the past three decades. Coléou et al. (2003) reviewed unsupervised learning techniques in seismic facies analysis. These included k-means clustering, principal component analysis (PCA), vector quantization (QV), and self-organizing maps (SOM). Zhao et al. (2015) reviewed unsupervised techniques such as cross-plotting, k-means clustering, independent principal component analysis (ICA), PCA, SOM, and generative topographic mapping (GTM). They also reviewed supervised techniques such as artificial neural networks (ANN) and support vector machines (SVM). They applied the k-means clustering, SVM, ANN, and GTM techniques to seismic data acquired from the Canterbury basin in offshore New Zealand for seismic facies classification. Chopra and Marfurt (2020) also reviewed unsupervised techniques such as cross-plotting, k-means clustering, PCA, SOM, and GTM. Chopra and Marfurt (2020) applied the PCA, SOM, and GTM techniques to facies classification with seismic data from the western Barents Sea. The applications showcased in their studies focused on some of the widely investigated petroleum provinces in the world. Applications of such tools in petroleum provinces such as Offshore West Africa are virtually non-existent. Therefore, there is a need for a comprehensive review of literature on the application of different machine learning techniques in seismic facies analysis and also, how these techniques can be applied to a case study in less researched petroleum basins.
In this paper, we will review literature on machine learning-based seismic facies analysis and present a case study from the Gulf of Guinea. The first part of the paper will focus on seismic facies analysis, the need for the adoption of machine learning, and the different machine learning techniques that have been applied to seismic facies analysis around the world. The second part of this paper will present a case study that utilizes an unsupervised vector quantizer (UVQ) network for seismic facies analysis to discriminate lithological facies using seismic data acquired in the Gulf of Guinea.
Seismic facies analysis
Seismic facies are three-dimensional seismic units which are made up of different groups of seismic responses which differ from adjoining units (Sulaiman et al. 2020). These features are distinguishable from adjacent sedimentary units as a result of their depositional environments. Seismic facies analysis has been crucial in the description of reservoirs (Xie et al. 2017). Seismic facies analysis is extremely beneficial in seismic interpretation and has been used to extract useful information about lithology variations and the structure of reservoirs to find the best trap location and decrease the risk of drilling (Bagheri and Riahi 2013), making seismic facies analysis an important task in seismic interpretation. The traditional approach to seismic facies analysis relies on seismic geometries which are comparable to those of a sedimentary body, which can offer a more comprehensive detail on the depositional environment. To utilize seismic data to characterize the heterogeneity of the reservoir, seismic facies are grouped based on the characteristics of the seismic response in these regions (Saggaf et al. 2001). Here, the human interpreter has to mark the transition between various seismic wave reflection patterns (Lima et al. 2020). According to Xu and Haq (2022), sedimentary facies inferences in the traditional seismic facies analysis are obtained in two steps. Firstly, by using geometry and suitable geological information to classify key seismic facies. Secondly, the conversion of seismic facies to sedimentary facies using a very comprehensive seismic analysis. Similarly, according to Chopra and Marfurt (2020), seismic facies analysis in the late 1980s was performed using 2D seismic data. This was done by inspecting seismic waveforms which are readily distinguished by their amplitude, frequency, and phase after which facies maps were generated. However, the reliability of traditional seismic facies analysis using this approach has been called into doubt and the validity of sedimentary facies derived using this approach has also been evaluated to be too low (Xu and Haq 2022). For large three-dimensional seismic datasets, seismic facies analysis using this approach becomes costly and labor intensive. These limitations have presented the need for an alternate approach to seismic facies analysis to address shortfalls and increase the efficiency of seismic facies analysis. This has led to the introduction of an automatic seismic facies classification which is made up of waveform clustering and multi-attribute seismic facies analysis and relies on the application of machine learning algorithms (Kaur et al. 2022; Puzyrev and Elders 2020). Figure 1 illustrates the different types of seismic facies analysis.

Different branches of seismic facies analysis
Machine learning algorithms
Machine learning algorithms have been widely applied to various problems to build models of well-understood processes, and these algorithms have become very critical in seismic interpretation for exploring hydrocarbons over the past two decades (Dramsch 2020; Troccoli et al. 2022). Machine learning is described as a numerical framework that can learn from available datasets to make accurate predictions (Wrona et al. 2018). This has led to the wide acceptance of machine learning in seismic data analysis and interpretation. This is a result of the large size and availability of numerous seismic datasets which makes a traditional approach very limited and restricted (Hampson et al. 2001). The use of machine learning algorithms has also made it possible to quantify these variations in seismic data giving way to the applicability of statistical analysis using computational resources to analyze reservoir properties (Brown 2011; Zhao et al. 2017). Automatic seismic facies analysis is one process in seismic interpretation that takes advantage of machine learning algorithms in the generation of seismic facies maps to provide information about subsurface geological features (Qian et al. 2017). This is made possible with the improvements in the computing ability of computers and pattern recognition techniques. This makes it possible to analyze huge datasets to produce superior predictions (Qian et al. 2017). There are two main types of machine learning algorithms. These are the supervised machine learning approach which involves the use of labeled datasets and the unsupervised machine learning approach which involves the use of unlabeled datasets. The various algorithms of the two types of machine learning are listed in Table 1. Over the years, numerous studies have been conducted on the application of machine learning in seismic facies analysis (Table 2) and these are discussed in detail in the following sections.
Convolutional neural network
Convolutional neural network (CNN) (LeCun 1989; LeCun et al. 1989) is a machine learning technique used in solving classification problems in seismic interpretation. The simplest CNN architecture is made up of a convolutional layer, a pooling layer, and a fully connected layer (Fig. 2). The convolutional layer extracts distinct features such as object shapes (Waldeland et al. 2018) by kernels which carry out convolutions using the input data. The pooling layer is mostly used in the reduction of training weights while setting aside a majority of the features from the convolutional layer. The fully connected layer which receives information from the pooling layer combines features and maps them into the vector of classification results.
Additionally, several functions are added to the CNN models as such, improving accuracy and efficiency, accelerating training by avoiding vanishing gradient problems, and avoiding overfitting. These functions include activation functions such as rectified linear units (ReLU) (Nair and Hinton 2010), batch normalization (Ioffe and Szegedy 2015), and dropouts (Hinton et al. 2012). Several convolutional neural network-based architectures have been developed and implemented for classifying seismic facies including U-net (Ronneberger et al. 2015), Segnet (Badrinarayanan et al. 2017), Waldeland CNN and Deeplabv3+ (Chen et al. 2018).
Zhao (2018) introduced a CNN model to perform seismic facies analysis. An encoder-decoder CNN model used by Zhao (2018) was found to provide seismic facies results of superior quality when compared with conventional CNN models. However, this CNN model was found to be more tedious when it comes to labeled data picking and a higher computational cost. Wrona et al. (2018) used multiple attributes as input, as well as different classification algorithms to distinguish the facies in terms of their continuity and structural orientation. They found that the convolutional neural network (CNN) enabled them to build a model that captured complex geologic features.
Zhang et al. (2021) built a CNN and a conventional encoder-decoder model and applied an enhanced encoder-decoder (Deeplabv3+) to classify seismic facies using the F3 seismic dataset from offshore Netherlands. The encoder-decoder networks were found to significantly improve the precision and efficiency of the facies interpretation. Zhang et al. (2021) also showed that a small amount of well-labeled data could be used to automatically predict seismic facies. Liu et al. (2019b) also developed a workflow for seismic facies analysis. They built their workflow on the spatial probability classification framework and the CNN. Liu et al. (2019b) demonstrated that CNN was a better classifier in multiattribute seismic classification. The work also demonstrated that they were very efficient for seismic facies analysis in areas with few well logs (Liu et al. 2019b). Kaur et al. (2022) used Deeplabv3 + in a workflow to successfully analyze seismic facies. The Deeplabv3 + predictions had sharper boundaries between the predicted facies as compared to results obtained using GAN.

Schematic diagram of a Convolutional Neural Network (CNN) architecture
Convolutional recurrent neural network
Convolutional Recurrent Neural Network (CRNN) is a hybrid version of the CNN and RNN algorithms (Saikia et al. 2019). This can extract spatial features using CNN and the temporal features using RNN. A CRNN is a modified CNN in which the fully connected layer is replaced with an RNN (Fig. 3). According to Xue et al. (2019), CNN can automatically learn more discriminative feature datasets. However, CNN is unable to depict the interdependencies in features that are related and are apart by some distance.
An analysis of CRNN and other neural network models such as CNN and RNN by Saikia et al. (2019) found the CRNN performed best as compared to the other neural networks; CNN and RNN in terms of precision, accuracy, sensitivity, and specificity as samples increase. A version of a CRNN called the Convolutional-LSTM Network was used by Trinidad et al. (2021) for seismic facies segmentation on the F3 block seismic dataset from offshore Netherlands. They considered images from seismic datasets to have a temporal behavior because they are generated as a function of depth and their CRNN was able to achieve incredible results using few parameters.

Schematic diagram of a Convolutional Recurrent Neural Network (CRNN) architecture
Probabilistic neural network
Probabilistic neural network (PNN) is a Bayes-Parzen classification theory-based neural network (Specht 1990). The architecture of the PNN algorithm consists of four layers; input layer, pattern layer, competitive layer, and finally output layer (Fig. 4). Chaki et al. (2022) developed a PNN based structure for the classification of lithology using seismic and well log data acquired in onshore western India. In their work, lithology maps with four classes (sand, shaly sand, sandy shale, and shale) were generated from five seismic attributes using the PNN. According to Chaki et al. (2022), the PNN is preferred for classification due to PNN’s insensitivity towards outliers or noise and higher computational speed in comparison to other multi-layered perceptron (MLP) networks.

Schematic diagram of a Probabilistic Neural Network (PNN) architecture
Random forest
Random forest (RF) is a tree-based classifier that is used as a suitable option to the much popular neural networks and support vector machine-based algorithms (Kim et al. 2018). RF utilizes decision trees, but since RF integrates separate trees, it reduces bias and overfitting of training data while maintaining excellent prediction accuracy. According to Dramsch (2020), random forests can aid in time series analysis, making RF suitable for use in seismology for seismic facies classification. Kim et al. (2018) applied random forest to seismic facies analysis and determined the sensitivity of each attribute in classifying seismic facies. The predicted facies from a Barnett shale survey in Kim et al. (2018) was able to thoroughly define lime and shale facies.
Support vector machine
Support Vector Machine (SVM) has become very prominent supervised learning technique in pattern classification and regression applications (Zhao et al. 2015). The basic SVM algorithm is made up of an input layer, a hidden layer, and an output layer. Figure 5 shows a schematic diagram of a Support Vector Machine (SVM) architecture. This implies the applicability of the SVM as a classifier or a regression operator. The SVM can predict petrophysical properties when used as a regression operator.
Al-Anazi and Gates (2010) used SVM in lithology facies classification and the modeling of permeability in heterogeneous reservoirs. A non-linear SVM was applied to a sandstone reservoir with significant heterogeneity to aid in the classification of electrofacies and the prediction of the permeability distribution. Results of the SVM predictions in Al-Anazi and Gates (2010) were compared to a probabilistic neural network which showed that the results from the SVM yielded a preferable lithology classification and permeability prediction as compared to a probabilistic neural network. Nazari et al. (2011) also used SVM for permeability prediction from well log and core data. The technique was applied to waveform classification and classification from well data. The results using SVM in Nazari et al. (2011) highlighted a significant correlation with results from structural and stratigraphic analysis. The results obtained from the study also showed that even with few data points, SVM could be used for the estimation of permeability from wells (Nazari et al. 2011). SVM, as a classifier, has been useful in predicting lithology facies. Zhao et al. (2014) classified lithofacies in the Barnett Shale using proximal-SVM. Wrona et al. (2018) implemented support vector machines framework for seismic facies analysis using seismic data. However, comparing the SVM to other machine learning algorithms such as the artificial neural network (ANN) and the convolutional neural networks (CNN) at a comparatively higher computation cost, SVM outperformed ANN in classification (Zhao et al. 2015) but it did not perform well in comparison to CNN since CNN can gain information from adjacent samples (Dramsch 2020).

Schematic diagram of a Support Vector Machine (SVM) architecture
Self-Organizing map
Self-Organizing Map (SOM) (Kohonen 1982) is a network of neurons that classifies datasets based on different geological and geophysical properties (Chenin and Bedle 2022; Kim et al. 2019). It is the most widely used clustering technique (Lubo-Robles and Marfurt 2019). The basic SOM algorithm is made up of an input layer and an output layer as shown in Fig. 6. In exploration seismology, SOMs have been used to help visualize attribute relationships in problems where PCA results are multidimensional (Chenin and Bedle 2020).

Schematic diagram of a Kohonen Self-Organizing map (SOM) architecture
Self-organizing maps were used by de Matos et al. (2007) for unsupervised seismic facies analysis on seismic datasets from the deepwater Namorado oilfield in the Campos Basin, Brazil. The results from their study showed that the relevant number of seismic facies can be estimated using the self-organizing maps (de Matos et al. 2007). Gao (2007) selected gray-level co-occurrence matrix attributes for a one-dimensional SOM to aid in seismic facies mapping in offshore Angola, Africa. Gao (2007) refined clusters using 256 prototype vectors and was able to integrate three-dimensional visualization with information regarding the environment of deposition within offshore Angola to aid in the mapping of clusters. Calibrating the various clusters with available well control resulted in an a priori supervision. Roy et al. (2013) developed a SOM facies analysis workflow using multiple attributes computed from a deepwater system. The mapped clusters were projected onto a two-dimensional non-linear space. Comparing SOM with other unsupervised learning algorithms such as k-means in Zhao et al. (2015), the SOM was found to provide a more interpreter-friendly clustering result. However, it was found to be computationally demanding. In Chenin and Bedle (2020), SOMs were applied to multi-attribute analysis to the identification of bottom simulating reflections (BSRs) in the Pegasus basin, New Zealand. This application showed that SOMs provided a clearer insight into identifying gas hydrates.
Principal component analysis
Principal Component Analysis (PCA) is a popular dimensionality reduction technique used in seismic facies analysis to reduce the redundancy of seismic data which decreases computation time while still generating useful results (Coléou et al. 2003; Roden et al. 2015; Roy et al. 2010). The data is transformed into a dimensionally reduced form using PCA (Deisenroth et al. 2020) and the resulting projections are referred to as principal components (Fig. 7).
Chopra and Marfurt (2014b) applied PCA to assist in seismic attribute selection for multiattribute analysis. In their results, they found out that when PCA is performed on discontinuity attributes, the first principal component (PC1) projects a specific type of geologic feature with the second (PC2) and third principal components (PC3) focusing on artifacts related to computation-related numerical variations rather than geology. PCA has been employed in a framework for multiattribute analysis (Roden et al. 2015). PCA was used by Roden et al. (2015) to evaluate the extent of variation in seismic attributes to the top principal components. The attributes with the most significant contribution were selected for utilization in the subsequent seismic facies analysis (Roden et al. 2015). Lubo-Robles et al. (2023) evaluated different strategies for the selection of seismic attribute using PCA to discriminate seismic facies in the detection of gas hydrates. PCA was applied to select a set of seismic attributes which were used as inputs for the SOM. The results from this work showed that the application of PCA in seismic attribute selection using a balanced training dataset offered a good tradeoff as compared to the exclusive use of samples within the volume and samples related to bottom-simulating reflectors (BSR).

Schematic diagram of a Principal Component Analysis (PCA) architecture
Independent component analysis
Independent Component Analysis (ICA) is centered on high-level statistical analysis and divides multi-variable signals into separate subsections to establish logical representations in non-Gaussian datum (Oja and Hyvärinen 2000). It allows for the extraction of fascinating information from multiple variables (Honório et al. 2014). ICA is based on the central limit theorem (Oja and Hyvärinen 2000). The ordering of every independent component is not defined and as a result, it cannot be ranked (Tibaduiza et al. 2012). It can project data from numerous input data sets into an orthogonal structure, separating different geological features in the original input data (Lubo-Robles and Marfurt 2019). The basic architecture of an ICA algorithm is made up of an input layer, mixed signals (X), and individual signals (P) as illustrated in Fig. 8. Where X is a recorded signal and \(X = \{X1, X2\}\), where X1 and X2 are individual mixed signals. Also, P is an original signal, and \(P = \{P1, P2\}\), where P1 and P2 are individual original signals. The recorded signal is represented as
The original signal is represented as
Where A is the mixing matrix and W is the inverse of the mixing matrix.
Independent Component Analysis has been applied in unsupervised seismic facies analysis. Lubo-Robles and Marfurt (2019) applied ICA to reservoir geomorphology and seismic facies analysis on seismic datasets obtained from the Taranaki Basin in New Zealand. In their study, they used spectral magnitude components as inputs into an ICA algorithm. Their results proved that ICA improved the resolution and was useful in separating geological features from noise as compared to other algorithms such as PCA (Lubo-Robles and Marfurt 2019).

Schematic diagram of an Independent Component Analysis (ICA) architecture
K-means clustering
The k-means clustering (MacQueen 1967) is a clustering approach that partitions datasets into K clusters, with the individual clusters allocated to a cluster with the closest center of mass (La Marca et al. 2022). The purpose of k-means clustering is not for dimensionality reduction but to partition data. According to Chopra and Marfurt (2020), k-means clustering divides the unlabeled datapoints into a specific number of clusters (Chopra and Marfurt 2020). Due to its ease of use, it is frequently chosen for analyses involving multiple variables (Arianfar et al. 2007). The application of k-means enables data grouping into geologically relevant groups which will enhance the analysis of seismic facies using highly dimensional data (La Marca et al. 2022).
Studies by La Marca et al. (2022) have found the application of k-means as an ideal clustering technique to aid in the identification of channel facies with lower inaccuracy levels. According to Zhao et al. (2015), a lower number of clusters in the k-means makes it a very easy algorithm to set up for faster interpretation. K-means as an unsupervised algorithm is an excellent alternative for the analysis of 3D seismic data with limited traditional structural interpretation to identify features. However, the technique comes with some drawbacks. The requirement of specifying the number of clusters is one drawback of using the k-means clustering algorithm (Zhao et al. 2015). Also, there is no structure to the clustering, hence there is no relationship between cluster numbers and cluster proximity. This causes similar facies to appear in completely different colors, complicating interpretation, therefore resulting in a reduction in the resolution of the output (Zhao et al. 2015). Ferreira et al. (2019) applied k-means clustering for an unsupervised seismic facies analysis of a presalt carbonate reservoir in the Santos Basin, offshore Brazil. Their results show that k-means enabled the building of a map of a section of the reservoir and sag-phase seismic reflection patterns to predict the best areas for drilling.
Generative topographic map
Generative Topographic Map (GTM) (Bishop et al. 1998) is a machine learning tool for clustering and dimensionality reduction which enables the statistical description of the vectors of data in space (Chopra and Marfurt 2020; La Marca et al. 2022). GTM was developed by Bishop et al. (1998) as an alternative in overcoming the limitations of the self-organizing map. GTM has been very successful in the prediction of the occurrences of specific seismic facies and estimating petrophysical properties. Chopra and Marfurt (2014a) first presented generative topographic mapping for seismic facies analysis. Roy et al. (2014) discussed this approach extensively and showed how it may be used for the classification of seismic facies using seismic data from the Veracruz Basin in Mexico. Roy et al. (2014) applied GTM to determine natural clusters in the datasets and estimate the likelihood of the presence of seismic facies. The method provided a projection of the likelihood of finding facies that correspond to the wells utilized for training if those particular locations were drilled (Roy et al. 2014). GTM has shown promising results in seismic facies analysis and can be applied in modern risk analysis. As compared to SOM, GTM has an advantage compared to the SOM with regard to the comprehensive facies distribution and distinct expressions observed on display (Chopra and Marfurt 2020).
Unsupervised vector quantizer network
Unsupervised Vector Quantizer (UVQ) is an unsupervised machine learning approach similar to artificial neural networks and SOM (Aminzadeh and de Groot 2006). The basic architecture of the UVQ network in Fig. 9 is made up of the input layer, a cluster layer and an output layer (segment and/or match). UVQ is a form of competitive learning. The aim of competitive learning is finding the structure in data to extract relevant features. For UVQ, the goal is the segmentation (clustering) of the input data (El Oul 1998). UVQ finds sections of seismic data with similar input vectors and classifies them into classes. The classes are identified by the network through correlation of the input data. As a result, they are regarded as self-organizing networks. In UVQ, preprocessing involves the use of PCA which dimensionally reduces attributes in seismic volume to fewer principal components (Ross and Cole 2017). According to Ross and Cole (2017), UVQ lacks a priori information to work with and neither compares nor contrasts heavily reliant attributes nor does it lessen the inaccuracy among the unknown output and the input data. As such, PCA is used to reduce non-orthogonal elements in the seismic volume before its use in the learning.
There have been successful applications in facies classification for features such as channels, basin floor fan systems, and the prediction of saturated sands using seismic waveform (Ross and Cole 2017). Ross and Cole (2017) applied UVQ to facies classification along the Gulf Coast of Texas. In their results, the found that UVQ with PCA preprocessing produced superior results as compared with UVQ without PCA preprocessing. Raef et al. (2019) also performed unsupervised seismic facies analysis using UVQ. In their work, Raef et al. (2019) trained and applied the UVQ to classify seismic waveforms into three classes in order to build an understanding of seismic facies related to petrophysics and lithofacies based on previously obtained information from well log facies model. Ismail et al. (2022) used UVQ in an unsupervised learning to predict gas channels in offshore West Nile Delta, Egypt. Using six seismic attributes as inputs, the UVQ network was able to accurately generate four classes that represent gas-saturated sand, gas-saturated zones, shaly sands and shales.

Schematic diagram of an Unsupervised Vector Quantizer (UVQ) Network architecture
Convolutional autoencoder
Convolutional autoencoder (CAE) is an autoencoder which obtain high-level features from data using convolutional layers while keeping the localized relationships using convolutional kernels in the various layers (Puzyrev and Elders 2022). A convolutional autoencoder is made up of the encoder f(x) which compresses data input x to a lower dimension in the hidden feature layer h, and the decoder g(x) which takes the latent features as input and reconstructs them as output r to be as close as possible to the original data (Fig. 10):
In contrast to conventional supervised learning techniques, a larger number of training datasets which is labeled is not needed to automatically discover distinctive characteristics in data. In training, CAE does not insist on labeled datasets and as a result, CAE is mostly implemented using the original input data as the output data. As such,
CAE has been found to be superior to PCA in reducing redundancy and extracting useful information (Qian et al. 2020). CAE has over the years been employed for applications in seismic facies analysis. Qian et al. (2020) proposed a CAE network for seismic facies recognition using prestack seismic data from the LZB region of the Sichuan Basin, China. The results showed that the approach was superior to conventional clustering and classification techniques such as k-mean and SOM (Qian et al. 2020). Puzyrev and Elders (2020) have also applied CAE for unsupervised seismic facies analysis on seismic data obtained in the Northern Carnarvon Basin, Australia. The approach used in their work was successful as it allowed the analysis of geological patterns in real-time (Puzyrev and Elders 2020).

Schematic diagram of a Convolutional Autoencoder (CAE) architecture
Case Study: Lithology characterization of a turbidite system in the Gulf of Guinea using multi-attribute seismic facies analysis and unsupervised vector quantizer network
Geological setting
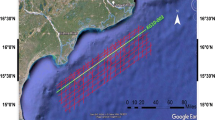
The study area lies around the West African Transform Margin in the Gulf of Guinea (Fig. 11). Sandstone reservoirs are dominant, although some carbonate reservoirs may exist at some levels. The steepness of the continental slope has encouraged the accumulation of separated deepwater sandstones and turbidite sands. Downslope projections of deltas created in the study area are thus potential for turbidite channels and ponded turbidite sandstone reservoirs. The seals within the study area are made of marl, shales, and clays. These seals prevent the migration of hydrocarbons from the reservoir rocks. Seals associated with reservoirs are made up of shales and faults. The integrity of seals is also enhanced by unconformity surfaces. The accumulation of hydrocarbon deposits which are linked with fault-block traps has been discovered throughout the Gulf of Guinea.

Map of the study area showing the Gulf of Guinea located off the African Coast (Google Earth, 2023)
Dataset and methods
The 3D seismic data used in this study was acquired in the Gulf of Guinea. The seismic data has a surface area of about 80km2 with a sampling rate of 2 ms, a record length of 7 binary seconds, a streamer separation of 75 m, a source separation of 37.5 m, a bin size of 12.5 m × 18.75 m, and a dominant frequency of 38 Hz.
The workflow used in this work has been summed up in Fig. 12. It involved the application of a dip-steered median filter (Tingdahl 2003), a filtering mechanism which removes noise to enhance the signal-to-noise ratio of the seismic data. The seismic data was integrated with well data to perform a seismic-to-well tie. Horizons and seismic attributes were extracted from the seismic data. Some useful attributes were then selected to classify seismic facies using an unsupervised vector quantizer (UVQ) network. The results from the seismic attributes, facies, and spectral decomposition were analyzed to help in interpretation.

Workflow of the research covering data filtering, attribute generation and selection, facies analysis and spectral decomposition
Seismic attribute selection and training
Seismic attributes selection
Seismic attributes have been defined by Chopra and Marfurt (2007) as measurements extracted from seismic data which allows geophysicists to quantify and interpret seismic patterns related to reservoir properties, depositional environment, and geomorphology. The attributes which were chosen for the initial training and attribute selection included instantaneous attributes, geometric attributes, and GLCM or textural attributes. Determining attribute importance was necessary and helpful in choosing the input attributes and thus, reducing the computational time. The choice of attributes was set to six seismic attributes in line with Chaki et al. (2015) and Na’imi et al. (2014). The UVQ network was able to help in identifying six seismic attributes with high statistical weight and contribution (Table 3), arriving at the final set through a backward feature selection (BFS) approach.
Training
The UVQ network reorganized and divided the input data into classes with different individual features resulting from information obtained from the input data. The purpose of this UVQ network analysis was the organization of classified vectors from the multiple seismic attributes and to find clusters that represent smoothly defined specific color codes that can represent the different facies in the seismic profile. The average matching between the attributes to the number of vectors trained showed a high matching. The average matching percentage was recorded at 94%. Figure 13 shows that the average match increases when the number of vectors trained also increases. This continues until a stable average match causes a flat line to occur. It is recommended for the average match to be above 90% for good results.

Average matching versus number of vectors trained
Spectral decomposition
Spectral decomposition refers to the transformation of seismic data into individual frequency components within the seismic bandwidth (Guo et al. 2009). First introduced by Partyka et al. (1999), it is one of the fundamental tools used in various techniques related to seismic data processing and interpretation. According to Okiongbo and Ombu (2019), the thin bed tuning effect is the reason for the application of spectral decomposition method on seismic data. It is helpful in identifying gas zones and stratigraphic variations (Ismail et al. 2020a). The decomposition of the full-bandwidth of seismic data into different spectral components can be carried out using decomposition methods such as discrete fourier transform (DFT) and continuous wavelet transforms (CWT). In this paper, we convert the seismic data into the frequency domain via the Fourier transform method which gives the overall frequency behaviour of the seismic dataset at output frequencies of 5 Hz, 10 Hz, and 15 Hz. The Fourier Transform \(F\left(\omega \right)\) of a time-domain seismogram \(f\left(t\right)\) is expressed as (Okiongbo and Ombu 2019):
Where t is time.
Results
Seismic data filtering
We applied a dip-steered median filter to our seismic data before extracting attributes for our facies analysis. It is essential that our dataset is noise-free to ensure that the signal-to-noise ratio of the seismic data is improved. Figure 14 shows the overall effect of the dip-steered median filter. It is easy to compare improvements made from the unfiltered seismic data in Fig 14a to the filtered seismic data in Fig. 14b.

Seismic inline (a) without dip steered median filter (b) with dip steered median filter
Seismic attributes
We extracted six different seismic attributes from the 3D seismic volume. Fig. 15a shows the seismic volume (inline, xline, and horizon) with the original seismic amplitude before attribute extraction. The attributes, background, and interpretations are discussed below.



Seismic attributes extracted from seismic data (a) original seismic amplitude (b) instantaneous amplitude (c) natural log of instantaneous frequency attribute (d) instantaneous bandwidth (e) energy (f) sweetness (g) instantaneous quality factor attributes
Instantaneous amplitude
The instantaneous amplitude attributes represent the instantaneous energy of the signal and is proportional in its magnitude to the reflection coefficient (Koson et al. 2014). The instantaneous amplitude is widely used to accurately determine the location of reservoirs through anomalies such as bright, flat, and dim spots (Oumarou et al. 2021). The attribute is given by the equation (Taner et al. 1979):
The instantaneous amplitude attribute when high, is useful in identifying bright spots, possible gas accumulation, and gas channels as shown in Fig. 15b. Low instantaneous amplitude zones are also indicative of shaly bodies.
Natural logarithm of instantaneous frequency
The attribute is a variation of the instantaneous frequency attribute which is a time derivative of the phase (Rai et al. 2020). It can indicate bed thickness, lithology parameters, and the edges of low impedance thin beds (Subrahmanyam and Rao 2008).This variation of the instantaneous frequency attribute is given by:
Where \(IF\left(t\right)\)is given by (Rai et al. 2020):
Low frequencies are often associated with change in lithology, saturated reservoirs, and gas saturated sand. High frequencies are also associated with non-gas bearing zones with sharp interfaces representing thin laminated shales. In Fig. 15c, the two wells are located in the lower frequency zone which correspond to thicker reservoir zones.
Instantaneous bandwidth
The instantaneous bandwidth attribute is a measure of the rate of change of instantaneous amplitude (Iturrarán-Viveros 2012). The attribute shows the overall absorption pattern and the changes in the seismic character (Rai et al. 2020). The equation of the instantaneous bandwidth attribute is given by Subrahmanyam and Rao (2008) as:
The instantaneous bandwidth attribute is sensitive to gas bearing zones and used to show loss in energy. In Fig. 15d, significant differences can be noted in the bandwidth across the horizon, indicating the absorption pattern with two wells located in the low bandwidth zone.
Energy
The energy attribute is a measure of the reflectivity in a specified time window (Sanguinetti 2006). It is independent of phase and helps to view gas bearning zones often associated with amplitude anomalies (Azeem et al. 2016). It is given by the equation (Ismail et al. 2020a):
High energy zones in Fig. 15e are indicative of strong reflections often associated with sand overlaying shale, whereas low energy zones are also indicative of weaker reflections, suggesting shale overlaying sand.
Sweetness
The sweetness attribute is ratio of the instantaneous amplitude to the square root of the instantaneous frequency (Hart 2008). The sweetness attribute has been found to be very useful in differentiating intervals of sand and shale and detecting channels (Torrado et al. 2020). Also, according to Hart (2008), the sweetness attribute is also useful in the detection of channels. The attribute is given by the equation:
The sweetness attribute is useful for detecting good sand bodies and channels where, high amplitude in seismic data with low frequency represents high sweetness as shown in Fig. 15f. The high sweetness zones are also indicative of bright spots which represent good sand zones, with the low sweetness zones indicating shaly bodies.
Instantaneous quality factor
The instantaneous quality factor is related to the attenuation of a medium. The changes in quality factor is related to the relative acoustic impedance of the seismic trace and the relative absorption characteristics of beds. The instantaneous quality factor is given by the equation below (Barnes 1992):
Where d(t) is the instantaneous decay rate. In Fig. 15g, high quality factor zones correspond with lower absorption characteristic, while low quality factor zones relate to a higher absorption characteristic along the horizon.
Unsupervised seismic facies classification
The output of the segment profiles of the UVQ neural network was used to generate seismic volumes from the attributes listed in Table 3. Five attribute combinations (Table 4) were used to classify seismic facies from the seismic attributes. This allowed for the visualization and analysis of the variation in the multi-attribute response to classify seismic facies.
In Fig. 16a, two attributes (AT1) were used in the facies classification. The resulting facies classification were generated by identifying the similarities between the two attributes, however, the sand facies (red color code) was not defined. The facies map could be indicative of the changes in lithology across the seismic horizon. In Fig. 16b, the three attributes (AT2) were also not able to define the sand facies (red color code). The result was similar to the facies generated in Fig. 16a. In Fig. 16c, four attributes (AT3) were used in the seismic facies classification. Three distinct color codes (red, blue, and green) are observed on the seismic horizon which are related to the lithology variation from the multi-attribute responses. The red color code corresponds to sands observed in Fig. 15b, e, f. In Fig. 16d, five attributes (AT4) are used in generating a seismic facies map, and all three color codes were observed on the seismic horizon which corresponds with various multi-attribute responses. The red color code corresponds to sands observed in Fig. 15b, e, f. This facies map varies slightly from the facies generated in Fig. 16c. In Fig. 16e, it is observed that using the six attributes (AT5), it is also easy to distinguish between the lithology variation on horizons. The zones in red are indicative of possible sand bodies. These interpretations correspond to sand bodies observed in Fig. 15b, e, f and Fig. 17.


Five seismic facies generated from seismic attributes in Table 4 (a) using AT1 (b) using AT2 (c) using AT3 (d) using AT4 (e) using AT5. Facies 1 representing shale, facies 2 representing silty sand, and facies 3 representing sand
Spectral decomposition
Spectral decomposition was introduced after possible sand and channel features were observed in the various attributes and the corresponding facies. Channels are good for the deposition of sand, thus, could serve as potential reservoir zone for migrating hydrocarbons. Spectral decomposition is capable of identifying sands and channels using the frequency content of the seismic data. Using spectral decomposition, it was possible to identify bright areas in the RGB color blend (Fig. 17d) from three frequencies; 5 Hz (Fig. 17a), 10 Hz (Fig. 17b), and 15 Hz (Fig. 17c) on the horizon. The bright areas observed are indicative of stronger reflections due to the high acoustic impedance contrast between lithological units present in those areas. Sand deposits are also characterized by high acoustic impedance contrast when located close to other non-sands and appear as bright areas. In Fig. 17d, channels are clearly distinguished in the RGB color blend.


Spectral decomposition of seismic data (a) 5 Hz spectral decomposition (b) 10 Hz spectral decomposition (c) 15 Hz spectral decomposition (d) RGB color blend spectral decomposition
Discussion
The need for the application of machine learning (ML) in seismic facies analysis has been necessitated by three main factors; labor intensity, time consumption, and subjectivity. Automatic seismic facies analysis which is based on the application of machine learning has helped in addressing these issues of time consumption, labor intensity, and subjectivity which were associated with the traditional approach to seismic facies analysis. Basically, these algorithms learn the relationship in data to aid in the identification of important geological features.
Twelve (12) widely investigated machine learning algorithms in seismic facies analysis have been listed in Table 1 with relevant literature on their applications in Table 2. These algorithms were applied to seismic data from different sedimentary basins around the world including the Campos and Santos basins in Brazil, Northern Carnarvon basin in Australia, Pegasus and Taranaki basins in New Zealand, Sichuan basin in China, and the Veracruz basin in Mexico. This review has also highlighted that convolutional neural network (CNN), support vector machine (SVM), self-organizing map (SOM), and principal component analysis (PCA) are some of the commonly used machine learning algorithms in seismic facies analysis.
Although studies such as Wrona et al. (2018), Kaur et al. (2022), and Zhang et al. (2021) have shown that applying different ML algorithms or configurations of a ML algorithm to a seismic dataset helps in selecting the best algorithm for improved classification, Zhao et al. (2015) have noted that the classification technique is not an important parameter in comparison to the input data. However, settling on the choice of attribute is quite challenging, especially for an inexperienced interpreter. Also, in areas with limited well data, it is difficult to validate the results. Hence, there is a need to incorporate an alternate validation technique which is independent of well data. As such, we have proposed a new seismic facies workflow which is based on a weight-based attribute selection using an unsupervised learning algorithm with spectral decomposition as a validation technique.
Most of the widely used workflows in automatic seismic facies analysis for multi-attribute applications require a minimum of two algorithms for seismic attribute selection and facies classification. However, algorithms such as SOM and UVQ can handle both attribute selection and facies classification tasks independently, streamlining the process by ranking attributes based on their importance and identifying clusters related to specific subsurface responses. We presented a case study from the Gulf of Guinea using seismic facies and ML to distinguish lithology facies.
We applied a dip-steered median filter (Tingdahl 2003) to enhance the quality of the seismic dataset to ensure that results were not affected by noise. We also carried out seismic-to-well tie as a quality control (QC) tool to match stratigraphic markers obtained from well data to reflectors in our seismic data, achieving a good correlation coefficient of 0.62. The UVQ network was used in ranking our input attributes, thus, selecting six relevant seismic attributes using a backward feature selection (BFS) method and grouped these attributes into five attribute combinations based on their statistical weight from Table 3. These attributes in Table 3 are instantaneous attributes and energy attributes valuable for lithology identification.
The UVQ network was employed in an unsupervised manner, relying solely on input attributes for the facies classification. Clusters in the attributes of the seismic data were mapped, helping to identify lithological variations. Results in Fig. 16 revealed lithology variation within the study area. Five different seismic attribute combinations in Table 4 were further explored to enhance understanding with three combinations highlighting possible sand bodies. The three facies (Facies 1, Facies 2, and Facies 3) which were extracted from the attributes through the unsupervised facies analysis were shale facies, silty sand facies, and sand facies respectively. The study correlated results in Figs. 15 and 16 with spectral decomposition (Fig. 17) which helped to highlight sand zones and features such as channels, confirming areas with sand bodies and channels, which indicates areas with the potential for hydrocarbon exploration.
The workflow used in the case study is suitable for utilization by inexperienced interpreters and individuals with limited geological background since the attribute selection is mainly based on the contribution of the attribute computed using an unsupervised machine learning algorithm. Also, the workflow is suitable for application in regions with limited or non-existing well data, using validation techniques such as spectral decomposition. However, it is necessary to ensure that the initial suite of attributes for the given task has a good relation with the feature of interest as this may lead to challenges in finding clusters in the seismic attributes which define the relevant seismic facies.
The improvements in seismic facies analysis using ML presents significant implications for hydrocarbon exploration not only in the Gulf of Guinea or Africa but also in other parts of the world. This contributes to accelerated seismic interpretation and the identification of more reserves which will contribute significant to the development of growing economies.
Conclusions
This paper offers significant insights into the acceptance and application of machine learning in seismic facies analysis. Seismic facies analysis using machine learning (ML) has gained traction for improving upon the challenges in the traditional approach to seismic facies analysis. These ML algorithms have been used in their supervised and unsupervised forms with remarkable outcomes. In the first part, we evaluated the evolution of seismic facies analysis and the incorporation of ML algorithms. About twelve (12) different supervised and unsupervised ML algorithms were analyzed with regard to their development, basic architecture and relevant applications in seismic facies analysis. ML algorithms such as CNN, SVM, PCA, and SOM have recorded significant application in seismic facies analysis as compared to the other ML algorithms. Also, the application of these ML algorithms were less significant in developing parts of the world such as Africa. This was evidenced by the presence of limited literature and case studies on the incorporation of ML in seismic facies workflows on the continent. In the second part, we presented a case study on machine learning and seismic facies using seismic data acquired in the Gulf of Guinea. Our case study revealed the suitability of the ML-assisted seismic facies analysis in discriminating between lithological units based on information derived from multi-attribute response as compared to the traditional approach cited in this review. The results highlights the importance of attribute selection using ML algorithms to the resulting facies output in seismic facies analysis. The results of the case study suggest that employing ML algorithms like neural networks in seismic facies analysis could significantly aid in discovering more potential hydrocarbon reserves. The advantages of ML using seismic facies analysis such as cost effectiveness, speed, and reduced labor intensiveness underscores its significant impact for potential exploration benefits. The review concludes by emphasizing the potential of ML-assisted seismic facies analysis in expediting the exploration process for new hydrocarbon reserves by advocating for broader application, especially in regions like Africa, to leverage the benefits for resource discovery. Future research endeavors should focus on the optimization of machine learning algorithms to reduce the computational cost associated with automatic seismic facies classification for faster predictions while mitigating risks and uncertainties.
Data availability
Data used in this work is proprietary data which was obtained from a National Oil Company and cannot be shared.
References
Al-Anazi A, Gates ID (2010) A support vector machine algorithm to classify lithofacies and model permeability in heterogeneous reservoirs. Eng Geol 114:267–277. https://doi.org/10.1016/j.enggeo.2010.05.005
Aminzadeh F, de Groot P (2006) An introduction of artificial neural networks. EAGE Publications, Netherlands
Arianfar A, Khedri B, Haghighi M, Golalzadeh A, Poladzadeh M, Mehdipour Z (2007) Case history: Seismic facies analysis based on 3D multiattribute volume classification in Shadegan oilfield - Asmari reservoir, Iran. Society of Petroleum Engineers - SPE/EAGE Reservoir Characterization and Simulation Conference 2007, 1–13. https://doi.org/10.2118/111078-ms
Ashraf U, Zhang H, Anees A, Mangi HN, Ali M, Ullah Z, Zhang X (2020) Application of unconventional seismic attributes and unsupervised machine learning for the identification of fault and fracture network. Appl Sci 10(11):3864. https://doi.org/10.3390/app10113864
Ashraf U, Zhang H, Anees A, Mangi HN, Ali M, Zhang X, Imraz M, Abbasi SS, Abbas A, Ullah Z, Ullah J, Tan S (2021) A core logging, machine learning and geostatistical modeling interactive approach for subsurface imaging of lenticular geobodies in a clastic depositional system, SE Pakistan. Nat Resour Res 30(3):2807–2830. https://doi.org/10.1007/s11053-021-09849-x
Azeem T, Yanchun W, Khalid P, Xueqing L, Yuan F, Lifang C (2016) An application of seismic attributes analysis for mapping of gas bearing sand zones in the sawan gas field, Pakistan. Acta Geod Geoph 51(4):723–744. https://doi.org/10.1007/s40328-015-0155-z
Badrinarayanan V, Kendall A, Cipolla R (2017) SegNet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell 39(12):2481–2495
Bagheri M, Riahi MA (2013) Support vector machine-based facies classification using seismic attributes in an oil field of Iran. Iran J Oil Gas Sci Technol 2(3):1–10
Bagheri M, Riahi MA (2014) Seismic facies analysis from well logs based on supervised classification scheme with different machine learning techniques. Arab J Geosci 8(9):7153–7161. https://doi.org/10.1007/s12517-014-1691-5
Bagheri M, Riahi MA (2017) Modeling the facies of reservoir using seismic data with missing attributes by dissimilarity based classification. J Earth Sci 28(4):703–708. https://doi.org/10.1007/s12583-017-0797-6
Bagheri M, Riahi MA, Hashemi H (2013) Reservoir lithofacies analysis using 3D seismic data in dissimilarity space. J Geophys Eng 10(035006):1–9. https://doi.org/10.1088/1742-2132/10/3/035006
Barnes AE (1992) Instantaneous bandwidth. 1992 SEG Annual Meeting 57(11):1168–1171. https://doi.org/10.1190/1.1821938
Barnes AE, Laughlin KJ (2002) Investigation of methods for unsupervised classification of seismic data. SEG Technical Program Expanded Abstracts:2221–2224. https://doi.org/10.1190/1.1817152
Bishop CM, Svensén M, Williams CKI (1998) GTM: the generative topographic mapping. Neural Comput 10(1):215–234. https://doi.org/10.1162/089976698300017953
Brown AR (2011) Interpretation of three-dimensional seismic data, 7th edn. Society of exploration geophysicists and American association of petroleum geologists. https://doi.org/10.1190/1.9781560802884
Caf AB, Lubo-Robles D, Pranter MJ, Bedle H, Marfurt KJ, Reza ZA (2022) CO2 injectivity and storage potential of the Arbuckle Group using supervised machine learning and seismic-constrained reservoir modeling and simulation, Wellington Field, Kansas. August 462–466. https://doi.org/10.1190/image2022-3751017.1
Cassel M (2018) Machine learning and the construction of a seismic attribute-seismic facies analysis data base [University of Oklahoma]. https://hdl.handle.net/11244/301652
Chaki S, Routray A, Mohanty WK (2015) A novel preprocessing scheme to improve the prediction of sand fraction from seismic attributes using neural networks. IEEE J Sel Top Appl Earth Obs Remote Sens 8(4):1808–1820. https://doi.org/10.1109/JSTARS.2015.2404808
Chaki S, Routray A, Mohanty WK (2022) A probabilistic neural network (PNN) based framework for lithology classification using seismic attributes. J Appl Geophys 199(October 2021):104578. https://doi.org/10.1016/j.jappgeo.2022.104578
Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2018) DeepLab: semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFs. IEEE Trans Pattern Anal Mach Intell 40:834–848. https://doi.org/10.1109/TPAMI.2017.2699184
Chen X, Zou Q, Xu X, Wang N (2022) A stronger baseline for seismic facies classification with Less Data. IEEE Trans Geosci Remote Sens 60. https://doi.org/10.1109/TGRS.2022.3171694
Chenin J, Bedle H (2020) Multi-attribute machine learning analysis for weak BSR detection in the Pegasus Basin, Offshore New Zealand. Mar Geophys Res 41(4):21. https://doi.org/10.1007/s11001-020-09421-x
Chenin J, Bedle H (2022) Unsupervised machine learning, multi-attribute analysis for identifying low saturation gas reservoirs within the deepwater Gulf of Mexico, and Offshore Australia. Geosci (Switzerland) 12(3). https://doi.org/10.3390/geosciences12030132
Chevitarese DS, Szwarcman D, Gamae Silva RM, Vital Brazil E (2018) Deep learning applied to seismic facies classification: a methodology for training. Saint Petersburg 2018: Innovations in Geosciences - Time for Breakthrough, August. https://doi.org/10.3997/2214-4609.201800237
Chopra S, Marfurt KJ (2005) Seismic attributes - a historical perspective. Geophysics 70(5):3SO. https://doi.org/10.1190/1.2098670
Chopra S, Marfurt KJ (2007a) Seismic attributes for prospect identification and reservoir characterization. Society of Exploration Geophysicists and European Association of Geoscientists and Engineers
Chopra S, Marfurt KJ (2007b) Overview of seismic attributes. In: Seismic attributes for prospect identification and reservoir characterization, pp 1–24. https://doi.org/10.1190/1.9781560801900.ch1
Chopra S, Marfurt K (2014a) Seismic facies analysis using generative topographic mapping. SEG Tech Program Expanded Abstracts. https://doi.org/10.1190/segam2014-0233.1
Chopra S, Marfurt KJ (2014b) Churning seismic attributes with principal component analysis. SEG Denver 2014 Annual Meeting, 2672–2676
Chopra S, Marfurt KJ (2018) Seismic facies classification using some unsupervised machine learning methods. SEG Tech Program Expanded Abstracts 2056–2060. https://doi.org/10.1190/segam2018-2997356.1
Chopra S, Marfurt KJ (2020) Unsupervised machine learning applications for seismic facies classification. SPE/AAPG/SEG Unconventional Resources Technology Conference 2020, URTeC 2020, 1–8. https://doi.org/10.15530/urtec-2019-557
Coléou T, Poupon M, Azbel K (2003) Unsupervised seismic facies classification: a review and comparison of techniques and implementation. Lead Edge (Tulsa OK) 22(10):942–953. https://doi.org/10.1190/1.1623635
de Matos MC, Osorio PLM, Johann PRS (2007) Unsupervised seismic facies analysis using wavelet transform and self-organizing maps. Geophysics 72(1):9–21. https://doi.org/10.1190/1.2392789
Deisenroth MP, Faisal AA, Ong CS (2020) Mathematics for machine learning. Cambridge University Press. https://doi.org/10.1017/9781108679930
Di H, Wang Z, AlRegib G (2018) Why using CNN for seismic interpretation? An investigation. SEG Tech Program Expanded Abstracts 2216–2220. https://doi.org/10.1190/segam2018-2997155.1
Dixit A, Mandal A (2020) Detection of gas chimney and its linkage with deep-seated reservoir in Poseidon, NW shelf, Australia from 3D seismic data using multi-attribute analysis and artificial neural network approach. J Nat Gas Sci Eng 83(September):103586. https://doi.org/10.1016/j.jngse.2020.103586
Dramsch JS (2020) 70 years of machine learning in geoscience in review. Adv Geophys 61:1–55. https://doi.org/10.1016/bs.agph.2020.08.002
Dramsch JS, Lüthje M (2018) Deep learning seismic facies on state-of-the-art CNN architectures. SEG Tech Program Expanded Abstracts 2036–2040. https://doi.org/10.1190/segam2018-2996783.1
El Oul J (1998) Artificial neural networks. Neural Networks Introduction:1–11 https://static.dgbes.com/images/PDF/NN_intro.pdf
El-Qalamoshy TR, Abdelhafeez TH, Shebl S, Reda M, Mossad M (2023) Detecting fault trends using seismic attributes: a case study of the southern part of Meleiha, North. Al-Azhar Bull Sci: 115–138. https://doi.org/10.58675/2636-3305.1661
Farzadi P (2006) Seismic facies Analysis based on 3D multi-attribute volume classification, Dariyan formation, SE Persian Gulf. J Pet Geol 29(2):159–174
Farzadi P, Hesthammer J (2007) Diagnosis of the Upper cretaceous palaeokarst and turbidite systems from the Iranian Persian Gulf using volume-based multiple seismic attribute analysis and pattern recognition. Pet Geosci 13(3):227–240. https://doi.org/10.1144/1354-079306-710
Fashagba I, Enikanselu P, Lanisa A, Matthew O (2020) Seismic reflection pattern and attribute analysis as a tool for defining reservoir architecture in ‘SABALO’ field, deepwater Niger Delta. J Petroleum Explor Prod Technol 10(3):991–1008. https://doi.org/10.1007/s13202-019-00807-1
Feng R, Balling N, Grana D, Dramsch JS, Hansen TM (2021) Bayesian convolutional neural networks for seismic facies classification. IEEE Trans Geosci Remote Sens 59(10):8933–8940. https://doi.org/10.1109/TGRS.2020.3049012
Ferreira DJA, Lupinacci WM, De Andrade Neves I, Zambrini JPR, Ferrari AL, Gamboa LAP, Azul MO (2019) Unsupervised seismic facies classification applied to a presalt carbonate reservoir, Santos Basin, offshore Brazil. AAPG Bull 103(4):997–1012. https://doi.org/10.1306/10261818055
Gadelkarim A, Helal AE-N, El Rawy A (2022) Application of seismic attributes for pliocene turbiditic channel reservoirs delineation, denise field, Offshore Eastern Mediterranean, Egypt. Egypt J Geol 66(1):0–0. https://doi.org/10.21608/egjg.2022.167557.1024
Gao D (2007) Application of three-dimensional seismic texture analysis with special reference to deep-marine facies discrimination and interpretation: Offshore Angola, West Africa. AAPG Bull 91(12):1665–1683. https://doi.org/10.1306/08020706101
Google Earth (2023) Map of gulf of Guinea. https://earth.google.com/. Accessed Dec 2023
Guo H, Marfurt KJ, Liu J (2009) Principal component spectral analysis. Geophysics 74(4):P35. https://doi.org/10.1190/1.3119264
Hadiloo S, Siahkoohi HR, Edalat A (2009) Unsupervised seismic facies analysis using continues wavelet transform and self-organizing maps. 71st Eur Association Geoscientists Eng Conf Exhib 2009: Balancing Global Resour Incorporating SPE EUROPEC 2009 21:893–897. https://doi.org/10.3997/2214-4609.201400182
Hampson DP, Schuelke J, Quirein J (2001) Use of multi-attribute transforms to predict log properties from seismic data. Geophysics 66(1):220–236. https://doi.org/10.1190/1.1444899
Hart B (2008) Channel detection in 3-D seismic data sing sweetness. Am Assoc Pet Geol Bull 92(6):733–742. https://doi.org/10.1306/02050807127
Hashem I, Helal AE-N, Lala AMS (2022) Application of AVO and seismic attributes techniques for characterizing Pliocene Sand reservoirs in Darfeel Field, Eastern Mediterranean, Egypt. Int J Geosci 13(10):973–984. https://doi.org/10.4236/ijg.2022.1310049
Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov RR (2012) Improving neural networks by preventing co-adaptation of feature detectors. In: ArXiv computer science: neural and evolutionary computing, pp 1–18. https://doi.org/10.48550/arXiv.1207.0580
Honório BCZ, Sanchetta AC, Leite EP, Vidal AC (2014) Independent component spectral analysis. Interpretation 2(1):SA21–SA29. https://doi.org/10.1190/INT-2013-0074.1
Hussein M, Stewart RR, Wu J (2021) Which seismic attributes are best for subtle fault detection. Interpretation 9(2):299–314
Ioffe S, Szegedy C (2015) Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. International Conference on Machine Learning, 448–456
Ismail A, Ewida HF, Al-Ibiary MG, Gammaldi S, Zollo A (2020a) Identification of gas zones and chimneys using seismic attributes analysis at the Scarab field, offshore, Nile Delta, Egypt. Petroleum Res 5(1):59–69. https://doi.org/10.1016/j.ptlrs.2019.09.002
Ismail A, Ewida HF, Al-Ibiary MG, Zollo A (2020b) Integrated prediction of deep-water gas channels using seismic coloured inversion and spectral decomposition attribute, West offshore, Nile Delta, Egypt. NRIAG J Astron Geophys 9(1):459–470. https://doi.org/10.1080/20909977.2020.1768324
Ismail A, Ewida HF, Nazeri S, Al-Ibiary MG, Zollo A (2022) Gas channels and chimneys prediction using artificial neural networks and multi-seismic attributes, offshore West Nile Delta, Egypt. J Petrol Sci Eng 208(PA):109349. https://doi.org/10.1016/j.petrol.2021.109349
Ismail A, Radwan AA, Leila M, Abdelmaksoud A, Ali M (2023) Unsupervised machine learning and multi-seismic attributes for fault and fracture network interpretation in the Kerry Field, Taranaki Basin, New Zealand. Geomech Geophys Geo-Energy Geo-Resources 9(1). https://doi.org/10.1007/s40948-023-00646-9
Iturrarán-Viveros U (2012) Smooth regression to estimate effective porosity using seismic attributes. J Appl Geophys 76:1–12. https://doi.org/10.1016/j.jappgeo.2011.10.012
Jin L (2018) Machine learning approaches for seismic facies prediction and reservoir property inversion. SEG Tech Program Expanded Abstracts 2147–2151. https://doi.org/10.1190/segam2018-2996374.1
John AK, Lake LW, Torres-Verdin C, Srinivasan S (2008) Seismic facies identification and classification using simple statistics. SPE Res Eval Eng 11(06):984–990. https://doi.org/10.2118/96577-PA
Kaur H, Pham N, Fomel S, Geng Z, Decker L, Gremillion B, Jervis M, Abma R, Gao S (2022) A deep learning framework for seismic facies classification. Interpretation 11(1):1–47. https://doi.org/10.1190/int-2022-0048.1
Kim Y, Hardisty R, Torres E, Marfurt KJ (2018) Seismic facies classification using random forest algorithm. SEG Tech Program Expanded Abstracts 2018:2161–2165
Kim Y, Hardisty R, Marfurt KJ (2019) Attribute selection in seismic facies classification: application to a Gulf of Mexico 3D seismic survey and the Barnett Shale. Interpretation 7(3):281–297
Kohonen T (1982) Self-Organized formation of topologically correct feature maps. Biol Cybemetics 43:59–69
Koson S, Chenrai P, Choowong M (2014) Seismic attributes and seismic geomorphology. Bull Earth Sci Thail 6(1):1–9
Kunath P, Chi W, Berndt C, Chen L, Liu C, Kläschen D, Muff S (2020) A shallow seabed dynamic gas hydrate system off SW Taiwan: results from 3-D seismic, thermal, and fluid migration analyses. J Geophys Res: Solid Earth 125:1–25. https://doi.org/10.1029/2019JB019245
La Marca K, Bedle H, Stright L, Pires de Lima R, Marfurt KJ (2022) Quantifying uncertainty in unsupervised machine learning methods for seismic facies using outcrop-derived 3D models and synthetic seismic data. In: Second international meeting for applied geoscience and energy. Society of Exploration Geophysicists and the American Association of Petroleum Geologists, pp 1312–1316. https://doi.org/10.1190/image2022-3746992.1
la Marca-Molina K, Silver C, Bedle H, Slatt R (2019) Seismic facies identification in a deepwater channel complex applying seismic attributes and unsupervised machine learning techniques. A case study in the Tarinaki Basin, New Zealand. SEG Tech Program Expanded Abstracts 2059–2063. https://doi.org/10.1190/segam2019-3216705.1
Laudon C, Qi J, Rondon A, Rouis L, Kabazi H (2021) An enhanced fault detection workflow combining machine learning and seismic attributes yields an improved fault model for Caspian Sea asset. First Break 39(10):53–60. https://doi.org/10.3997/1365-2397.fb2021075
LeCun Y (1989) Generalization and network design strategies. Connectionism in Perspective 19:143–155 https://api.semanticscholar.org/CorpusID:59861896
LeCun Y, Boser B, Denker JS, Henderson D, Howard RE, Hubbard W, Jackel LD (1989) Backpropagation applied to digit recognition. In Neural computation (vol 1, Issue 4, pp 541–551). https://www.ics.uci.edu/~welling/teaching/273ASpring09/lecun-89e.pdf
Lima G, Ramos G, Rigo S, Zeiser F, da Silveira A (2020) Binary Segmentation of Seismic Facies Using Encoder-Decoder Neural Networks. 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada, 218(2): 1262–1275
Liu Z, Cao J, Lu Y, Chen S, Liu J (2019b) A seismic facies classification method based on the convolutional neural network and the probabilistic framework for seismic attributes and spatial classification. Interpretation 7(3):SE225–SE236. https://doi.org/10.1190/INT-2018-0238.1
Lubo-Robles D, Marfurt KJ (2019) Independent component analysis for reservoir geomorphology and unsupervised seismic facies classification in the Taranaki Basin, New Zealand. Interpretation 7(3):SE19–SE42. https://doi.org/10.1190/INT-2018-0109.1
Lubo-Robles D, Devegowda D, Jayaram V, Bedle H, Marfurt KJ, Pranter MJ (2020) Machine learning model interpretability using SHAP values: Application to a seismic facies classification task. SEG Technical Program Expanded Abstracts, 2020-Octob, 1460–1464. https://doi.org/10.1190/segam2020-3428275.1
Lubo-Robles D, Bedle H, Marfurt KJ (August 2022) Pranter MJ (2023) Evaluation of principal component analysis for seismic attribute selection and self-organizing maps for seismic facies discrimination in the presence of gas hydrates. Marine and Petroleum Geology 150:106097. https://doi.org/10.1016/j.marpetgeo.2023.106097
MacQueen J (1967) Some methods for classification and analysis of multivariate observations. Proc Fifth Berkeley Symp Math Stat Probab 1(14):281–297. https://digitalassets.lib.berkeley.edu/math/ucb/text/math_s5_v1_article-17.pdf. Accessed on 29 Oct 2023
Na’imi SR, Shadizadeh SR, Riahi MA, Mirzakhanian M (2014) Estimation of reservoir porosity and water saturation based on seismic attributes using support vector regression approach. J Appl Geophys 107:93–101. https://doi.org/10.1016/j.jappgeo.2014.05.011
Nair V, Hinton GE (2010) Rectified Linear Units Improve Restricted Boltzmann Machines. Proceedings of the 27th International Conference on Machine Learning, pp 807–814
Nazari S, Kuzma HA, Rector JW (2011) Predicting permeability from well log data and core measurements using support vector machines. SEG Technical Program Expanded Abstracts:2004–2008. https://doi.org/10.1190/1.3627601
Neves EHP, Silva CG, Matsumoto R, Freire AFM (2022) Analysis of seismic attributes to enhance a bottom simulating reflector (bsr) in the gas hydrate area of Umitaka Spur, Eastern Margin of Japan Sea. Brazilian J Geophys 40(3):1–17. https://doi.org/10.22564/brjg.v40i3.2179
Oja E, Hyvärinen A (2000) Independent component analysis: algorithms and applications. Neural Netw 13(4–5):411–430. https://doi.org/10.1016/S0893-6080(00)00026-5
Okiongbo KS, Ombu R (2019) Application of spectral decomposition and seismic attributes for Channel geometry and Infill Lithology determination: a case study from the Southern North Sea Basin. Int J Earth Sci Geophys 5(1). https://doi.org/10.35840/2631-5033/1823
Oliveira I, Braga I, Puga J, Franco A, Pereira L, Ouverney G (2019) Development of a Multi-attribute Convolutional Neural Network to Seismic Facies Classification. 1–6. https://doi.org/10.22564/16cisbgf2019.210
Oumarou S, Mabrouk D, Tabod TC, Marcel J, Iii SN, Marcel J, Essi A, Kamguia J (2021) Seismic attributes in reservoir characterization : an overview. Arab J Geosci 14(402):1–15. https://doi.org/10.1007/s12517-021-06626-1
Partyka G, Gridley J, Lopez J (1999) Interpretational applications of spectral decomposition in reservoir characterization. Lead Edge 18(3):353. https://doi.org/10.1190/1.1438295
Puzyrev V, Elders C (2020) Deep convolutional autoencoder for unsupervised seismic facies classification. EAGE/AAPG Digital Subsurface for Asia Pacific Conference 2020. https://doi.org/10.3997/2214-4609.202075024
Puzyrev V, Elders C (2022) Unsupervised seismic facies classification using deep convolutional autoencoder. Geophysics 87(4):IM125. https://doi.org/10.1190/geo2021-0016.1
Qi J, Lin T, Zhao T, Li F, Marfurt K (2016) Semisupervised multiattribute seismic facies analysis Special section: Seismic attributes t Semisupervised multiattribute seismic facies analysis. February. https://doi.org/10.1190/INT-2015-0098.1
Qian F, Yin M, Su M-J, Wang Y, Hu G (2017) Seismic facies recognition based on prestack data using deep convolutional autoencoder. 1. http://arxiv.org/abs/1704.02446. Accessed on 23 Nov 2023
Qian F, Yin M, Su M, Wang Y, Hu G (2020) Seismic facies recognition based on prestack data using deep convolutional autoencoder. 60(1): 521–535. https://doi.org/10.1190/geo2019-0627.1
Raef AE, Totten MW, Linares A, Kamari A (2019) Lithofacies Control on Reservoir Quality of the Viola Limestone in Southwest Kansas and Unsupervised Machine Learning Approach of Seismic attributes facies-classification. Pure appl Geophys 176(10):4297–4308. https://doi.org/10.1007/s00024-019-02205-4
Rai N, Singha DK, Shukla PK, Sain K (2020) Delineation of discontinuity using multi-channel seismic attributes: An implication for identifying fractures in gas hydrate sediments in offshore Mahanadi basin. Results in Geophysical Sciences 1–4(November):100007. https://doi.org/10.1016/j.ringps.2020.100007
Ramya J, Somasundareswari D, Vijayalakshmi P (2020) Gas chimney and hydrocarbon detection using combined BBO and artificial neural network with hybrid seismic attributes. Soft Comput 24(3):2341–2354. https://doi.org/10.1007/s00500-019-04064-6
Roden R, Smith T, Sacrey D (2015) Geologic pattern recognition from seismic attributes: principal component analysis and self-organizing maps. Interpretation 3(4):SAE59–SAE83
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for for biomedical image segmentation. In: 18th international conference on medical image computing and computer-assisted intervention – MICCAI 2015, pp 234–241. https://doi.org/10.1007/978-3-319-24574-4_28
Ross CP, Cole DM (2017) A comparison of popular neural network facies-classification schemes. Lead Edge 36(4):340–349. https://doi.org/10.1190/tle36040340.1
Roy A, Matos M, Marfurt K (2010) Automatic seismic facies classification with Kohonen Self Organizing maps - A Tutorial. Spgindia Org, December, 6–14. http://spgindia.org/geohorizon/dec2010/automatic.pdf. Accessed on 12 Nov 2023
Roy A, Jayaram V, Marfurt KJ (2013) Active learning algorithms in seismic facies classification. SEG Technical Program Expanded Abstract:1467–1471. https://doi.org/10.1190/segam2013-0769.1
Roy A, Romero-Peláez AS, Kwiatkowski TJ, Marfurt KJ (2014) Generative topographic mapping for seismic facies estimation of a carbonate wash, Veracruz Basin, southern Mexico. Interpretation 2(1):SA31–SA47. https://doi.org/10.1190/INT-2013-0077.1
Roy A, Zhao T, Jayaram V, Devegowda D (2015) Well performance predictions from geologic, petrophysical and completions-related parameters using generative topographic mapping: a field case study. SEG Technical Program Expanded Abstracts:2853–2857. https://doi.org/10.1190/segam2015-5916229.1
Saggaf MM, Marhoon MI, Toksöz MN (2001) Seismic facies mapping by competitive neural networks. SEG Technical Program Expanded Abstracts:1544–1547. https://doi.org/10.1190/1.1816404
Saikia P, Nankani D, Baruah RD (2019) Reservoir Facies Classification using Convolutional Neural Networks. Proceedings of the 2019 IEEE Recent Advances in Geoscience and Remote Sensing: Technologies, Standards and Applications, TENGARSS 2019, 34–38. https://doi.org/10.1109/TENGARSS48957.2019.8976038
Sanguinetti R (2006) Image processing techniques applied to 3-D attribute volumes for lithology distribution. SEG Tech Program Expanded Abstracts 1806–1810. https://doi.org/10.1190/1.2369875
Song C, Liu Z, Wang Y, Li X, Hu G (2017) Multi-waveform classification for seismic facies analysis. Comput Geosci 101(May 2016): 1–9. https://doi.org/10.1016/j.cageo.2016.12.014
Specht DF (1990) Probabilistic neural networks. Neural Netw 3:109–118
Srisutthiyakorn N, Wei K, Aussavy AV, Zamanian A, Rodina O, Gelinsky S (2022) Validation of seismic attributes as hydrocarbon indicators. SEG Technical Program Expanded Abstracts, 2022-Augus, 1820–1824. https://doi.org/10.1190/image2022-3751813.1
Su-Mei H, Zhao-Hui S, Meng-Ke Z, San-Yi Y, Shang-Xu W (2022) Incremental semi-supervised learning for intelligent seismic facies identification. Appl Geophys 19:41–52. https://doi.org/10.1007/s11770-022-0924-8
Subrahmanyam D, Rao PH (2008) Seismic Attributes- A Review. 7th International Conference & Exposition on Petroleum Geophysics, pp 398–405
Sulaiman N, Muhammad Amiruddin MAS, Sulaiman N, Ali Khan MM, Rosmadi NS (2020) Seismic Facies and Geological Structure Interpretation of the A-Field, Malay Basin, Malaysia. IOP Conference Series: Earth and Environmental Science, 549(1). https://doi.org/10.1088/1755-1315/549/1/012019
Taner MT, Koehler F, Sheriff RE (1979) Complex seismic trace analysis. Geophysics 44(6):1041–1063
Tibaduiza DA, Mujica LE, Anaya M, Rodellar J, Güemes A (2012) Principal component analysis vs. independent component analysis for damage detection. Proceedings of the 6th European Workshop - Structural Health Monitoring 1: 632–639
Tingdahl KM (2003) Improving seismic chimney detection using directional attributes. In: Developments in petroleum science, vol 51. Elsevier, pp 157–173. https://doi.org/10.1016/S0376-7361(03)80013-4
Torrado L, Carvajal-Arenas LC, Mann P (July2019) Bhattacharya J (2020) Integrated seismic and well-log analysis for the exploration of stratigraphic traps in the Carbonera Formation, Llanos foreland basin of Colombia. Journal of South American Earth Sciences 104:102607. https://doi.org/10.1016/j.jsames.2020.102607
Trinidad MJC, Canchumuni SWA, Feitosa RQ, Pacheco CMA (2021) Seismic facies segmentation using atrous convolutional-LSTM network. In: XLII Ibero-Latin-American congress on computational methods in engineering and III Pan-American congress on computational mechanics, vol 3. ABMEC-IACM. https://publicacoes.softaliza.com.br/cilamce2021/article/view/6157
Troccoli EB, Cerqueira AG, Lemos JB, Holz M (2022) K-means clustering using principal component analysis to automate label organization in multi-attribute seismic facies analysis. J Appl Geophys 198(January):104555. https://doi.org/10.1016/j.jappgeo.2022.104555
Waldeland AU, Jensen AC, Gelius LJ, Solberg AH (2018) Convolutional neural networks for automated seismic interpretation. Lead Edge 37(7):529–537
Wang Z, Di H, Shafiq MA, Alaudah Y, Alregib G (2018) Successful leveraging of image processing and machine learning in seismic structural interpretation: a review. Lead Edge 37(6):451–461. https://doi.org/10.1190/tle37060451.1
Wong KW, Ong YS, Gedeon TD, Fung CC (2005) Reservoir characterization using support vector machines. Computational Intelligence for Modelling, Control and Automation, International Conference on Intelligent Agents, Web Technologies and Internet Commerce, pp 345–359
Wrona T, Pan I, Gawthorpe RL, Fossen H (2018) Seismic facies analysis using machine learning. Geophysics 83(5):O83–O95. https://doi.org/10.1190/geo2017-0595.1
Xie T, Zheng X, Zhang Y (2017) Seismic facies analysis based on speech recognition feature parameters. Geophysics 82(3):O23–O35. https://doi.org/10.1190/geo2016-0121.1
Xu G, Haq BU (2022) Seismic facies analysis: Past, present and future. Earth-Sci Rev 224(August 2021): 103876. https://doi.org/10.1016/j.earscirev.2021.103876
Xue X, Feng J, Gao Y, Liu M, Zhang W, Sun X, Zhao A, Guo S (2019) Convolutional recurrent neural networks with a self-attention mechanism for personnel performance prediction. Entropy 21(12):1227. https://doi.org/10.3390/e21121227
Zahraa A, Zailani A, Ghosh DP (2017) Characterizing Geological Facies using Seismic Waveform Classification in Sarawak Basin. IOP Conference Series: Earth and Environmental Science 88(1):012001. https://doi.org/10.1088/1755-1315/88/1/012001
Zhang G, Wang Z, Chen Y (2018) Deep learning for seismic lithology prediction. Geophys J Int 215:1368–1387. https://doi.org/10.1093/gji/ggy344
Zhang Y, Liu Y, Zhang H, Xue H (2020) Seismic facies Analysis based on deep learning. IEEE Geosci Remote Sens Lett 17(7):1119–1123. https://doi.org/10.1109/LGRS.2019.2941166
Zhang H, Chen T, Liu Y, Zhang Y, Liu J (2021) Automatic seismic facies interpretation using supervised deep learning. Geophysics 86(1):IM15–IM33. https://doi.org/10.1190/geo2019-0425.1
Zhao T (2018) Seismic facies classification using different deep convolutional neural networks. SEG Tech Program Expand Abstr: 2046–2050. https://doi.org/10.1190/segam2018-2997085.1
Zhao T, Marfurt KJ (2017) Different training sample selection strategies in unsupervised seismic facies analysis. SEG Tech Program Expand Abstr: 2132–2136. https://doi.org/10.1190/segam2017-17739947.1
Zhao T, Jayaram V, Marfurt KJ, Zhou H (2014) Lithofacies classification in Barnett shale using proximal support vector machines. SEG Technical Program Expanded Abstracts:1491–1495. https://doi.org/10.1190/segam2014-1210.1
Zhao T, Jayaram V, Roy A, Marfurt KJ (2015) A comparison of classification techniques for seismic facies recognition. Interpretation 3(4):SAE29–SAE58. https://doi.org/10.1190/INT-2015-0044.1
Zhao T, Li F, Marfurt KJ (2016) Constraining self-organizing map facies analysis with stratigraphy: an approach to increase the credibility in automatic seismic facies classification. Interpretation 5(2):T163–T171. https://doi.org/10.1190/INT-2016-0132.1
Zhao T, Li F, Marfurt KJ (2017) Automated input attribute weighting for unsupervised seismic facies analysis. SEG Tech Program Expand Abstr: 2122–2126. https://doi.org/10.1190/segam2017-17740318.1
Zhao T, Li F, Marfurt KJ (2018) Seismic attribute selection for unsupervised seismic facies analysis using user-guided data-adaptive weights. Geophysics 83(2):O31–O44. https://doi.org/10.1190/GEO2017-0192.1
Zheng Y, Zhang Q, Yusifov A, Shi Y (2019) Applications of supervised deep learning for seismic interpretation and inversion. Lead Edge 38(7):526–533. https://doi.org/10.1190/tle38070526.1
Zhong G, Jiang R, Yi H, Wu J, Castagna J, Feng C, Zhou G, Wang K, Liu L, Sun M (2021) Direct hydrocarbon detection (DHI) techniques for prospective exploration targets in Chaoshan Depression. IOP Conference Series: Earth and Environmental Science 865(1):012017. https://doi.org/10.1088/1755-1315/865/1/012017
Acknowledgements
The authors acknowledge dGB Earth Sciences for the generous donation of OpendTect Seismic Interpretation Software under an academic license to the Department of Physics, Kwame Nkrumah University of Science and Technology, Kumasi which was used in this work.
Funding
The authors received no funding for this study.
Author information
Authors and Affiliations
Contributions
All authors contributed to the preparation and submission of the manuscript. Conceptualization and preparation of draft manuscript was done by B.A.O. and C.D.B. B.A.O. prepared all figures. C.D.B. and V.-D.S.A. provided supervision and review of draft manuscript. S.K.D., C.D.A., and J.A.Q. critically reviewed and improved the manuscript for submission and publication.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Communicated by: Hassan Babaie
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Owusu, B.A., Boateng, C.D., Asare, VD. et al. Seismic facies analysis using machine learning techniques: a review and case study. Earth Sci Inform (2024). https://doi.org/10.1007/s12145-024-01395-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12145-024-01395-3