
Abstract
With the developing technology and automation, automatic labelling of images is of great importance for automatic mapping. However, the most significant disadvantage of this method is that the classes’ labels cannot be generated automatically. In the current remote sensing literature, understanding and automatically labelling clusters obtained from the clustering process without a training phase is a problem that requires effective solutions. In this study, in order to solve this problem, we present a methodology that creates labels without any training phase. We use the bands in the image and Corine data in this process. The methodology uses a database created by examining the spectral characteristics of land classes from sample images collected from various geographies and time periods. The spectral index values of the unlabelled classes obtained are evaluated using this database, and the relevant label is assigned to each class. This database was created by analyzing Sentinel-2 Level-1 images of the Mediterranean and the Black Sea regions in Turkey. Then, these labels compare with the Corine classes corresponds to each pixel according to the ruleset. This developed approach aims to automatically label land, a green agricultural area, forest, urban area, and uncultivated agricultural area. The reason for choosing these areas is that they are the areas that generally make up the environment and a large part of the ecosystem, which are important areas that many researchers frequently use in their studies. The methodology developed was tested with Sentinel 2 images of Gemlik, Hatay regions from Turkey, and Agioi Apostoli region from Greece. The results of the accuracy analysis are 80%, 83%, and %82 for Gemlik, Hatay, and Agioi Apostoli areas.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Land cover information is used in various applications such as land resource management and ecological, environmental monitoring (Lepers et al. 2005; Deka et al. 2019). Remote sensing technologies are frequently used to obtain land cover information quickly, economically, and reliably (Kavzoğlu and Çölkesen 2010; Gallego 2004; Tong et al. 2020; Cao et al. 2020). However, as the amount of information obtained by remote sensing increases, data analysis extraction and updating have become a separate study area (Appel et al. 2018; Audebert et al. 2018; Sun et al. 2019; Zhang and Ge 2019). In particular, automatic extraction and the labelling of land cover classes from remotely sensed images without user dependency is an important field.
While the results of supervised classification methods create labelled results in line with data determined by the user, unsupervised classification methods divide the data into unlabelled groups based on spectral similarities and differences. The user must interpret and label the classes after classification (Jensen and Lulla 1987). Interpretation and labelling may not be easy, as the classification does not always form meaningful clusters, and it can take a great deal of time (Enderle and Weih Jr 2005).
Automatic classification of remotely detected images and automatic labelling of classes is still challenging. The studies in the literature show that it is possible to label target objects in images (Lin et al. 2017; Yuan et al. 2019; Huang et al. 2019). Studies have also been carried out to create target land classes (Wang et al. 2019; Gupta et al. 2018).
In recent studies, convolutional neural networks (CNNs) and deep learning structures have been used for object identification and labelling (Kaiser et al. 2017). In another study, Lin et al. (2017) propose a method for sea-land segmentation and vessel detection in remotely sensed images (Lin et al. 2017). Using this CNN method, they identify oil tankers and naval vessels.
Wu et al. (2020) use older labelled images of a region to update data on land classes in that region. This method gives successful results when the study area has been previously classified and labelled with auxiliary data. However, the authors state that the threshold value parameters used to update old maps are critical and determined by the user. Incorrect classifications made in the change determination operation can negatively affect the determination of the changed regions (Wu et al. 2020).
In this study, an approach is proposed to label land use classes automatically. The approach has been tested primarily on automatic labelling of land, green farmland, forest, urban area, and uncultivated agricultural land. In the method developed, firstly, the raw band values of pixels assigned to classes and the minimum and maximum values of the data created by spectral indexing and other methods are determined. These values are analyzed along with threshold values found in the database created from examining images of many different geographical regions. Finally, according to the ruleset created for this study, these labels were compared with the Corine classes and determined the label of each pixel.
Materials and methods
Data set and study areas
Sentinel 2 images are the preferred images to test the method developed in the study. These high-medium resolution images, which can be obtained free of charge, are widely used in many studies. The Sentinel-2 program was launched by the European Space Agency (ESA) on 23 June 2015 as part of the Copernicus program. This system consists of two polar orbit satellites with high-resolution multispectral sensors, placed in the same orbit with 180 ° graduation, used for tracking Earth’s surface changes (ESA 2018).
Level-2A images from the Sentinel 2 satellite are used to test the algorithm developed within the scope of the study. In order to use as many spectral indexes as possible, the 20 m bands are sharpened by the intensity-hue-saturation (IHS) method to obtain a 10 m spatial resolution. The specifications of the used images are gicen in Table 1.
The images used in this study are of two geographical regions from Turkey and Agioi Apostoli region from Greece. These regions are chosen due to their different climates, topographical features, and urban distributions.
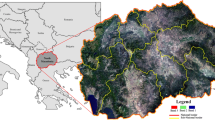
The first image is of the Gemlik region (Fig. 1b). Gemlik is located 19.13 degrees east and 40.12 degrees north. Gemlik is surrounded on three sides by mountains, with the Marmara Sea to the west. The Mediterranean climate generally prevails; however, there is a transition to the Black Sea climate (Gemlik_Belediyesi 2019). The vegetation in the region consists of maquis, forest, and olive trees (URL 2019). The climatic characteristics of the Marmara region of Turkey are used to represent the vegetation, which is chosen as it contains a high density of forest and urban areas.

Study areas a Agioi Apostoli b Gemlik c Hatay
The second study area is the Hatay region (Fig. 1c). Hatay is in southern Turkey, on the shores of the Gulf of Iskenderun. It’s vegetation consists of maquis species.Within Hatay’s boundaries, a Mediterranean climate is seen with hot, dry summers and warm, rainy winters. Hatay has red-brown Mediterranean soil, red Mediterranean soil, brown forest soil, colluvial soils, and alluvial soils (Hatay_Valiliği 2019). This area is used to determine the algorithm’s success in detecting Mediterranean vegetation, different soil types, and dense urban areas.
The third study area is Agiogi Apostoli from Greece (Fig. 1a). Agiogi Apostoli is located in Attica region. Attica, is a triangular peninsula in the Aegean Sea. There is a large basin in the center of the peninsula. This region has a Mediterranean climate.
In order to determine the label of the pixels, the Corine is also used in the proposed algorithm. The Corine project was initiated by the European Union in 1985 to determine the land inventory, monitor the land cover changes, and make environmentally sensitive decisions. Corine Project studies in our country started in 2001. Currently, there are land cover maps for the years 1990, 2000, 2006, 2012, and 2018, which have been added to the European Environment Agency database.
Methods
In current unsupervised classification methods, classification results are generated without labels. This approach increases the dependency on the user, as the results require interpretation. In order to get rid of this disadvantage, a labelling approach is proposed. The study aims to label soil, a green agricultural area, forest, urban area, and uncultivated agricultural area. The flow diagram of the proposed method is given in Fig. 2.

Flowchart of the proposed method
In the first stage of the study, the labels of the clustered data are produced for pre-classified data with the algorithm developed. This algorithm consists of four basic stages. In the first step, the pixels in each class are examined, the spectral indices are calculated using the values of these pixels, and the minimum and maximum values of the calculated spectral indices for each class are determined. In the second step, the spectral index values obtained for each class are compared with previously prepared threshold values for all labels. As a result of this analysis, all classes compatible with the threshold values determined for a label are assigned that label. After repeating this process for all classes, the last stage of the algorithm is to check whether there is more than one suitable label assigned for a class. If only one class is assigned, the labelling process of that class is terminated. If more than one label is assigned to a class, the most repetitive label is assigned to that class. All the assigned labels are presented to the user with probability information according to the repetition rate.
The second phase of the study starts with the acquisition of Corine data belonging to the study area. Corine class corresponding to each pixel in the workspace is determined. Thus, two-class candidates are determined for each pixel. A rule set is developed to decide which tag to choose if the suggested tags are not the same. The final class is determined by choosing the one suitable for this rule set among these two classes. The rule set used in the study is given in Table 2.
The logic in creating this ruleset is that Corine data is prepared every four years, so it cannot reflect the current situation. It is also the use of Corine data to correctly label classes such as soil and fallow land, whose pixel values are very close to each other. For example, if a pixel is assigned to the soil class according to spectral indices, but according to Corine data, this area is seen as an agricultural area, it turns out to be a fallowed agricultural area.
Sentinel 2 images are used to test the proposed algorithm. Sentinel 2 images of the Black Sea and Mediterranean climatic regions are analyzed to determine the threshold values in the algorithm. Accordingly, images from January, April, June, September, and November are used to determine the changes of classes across all seasons.
The spatial resolution of the images is increased to 10 m by the IHS sharpening method. The spectral indices given in Table 3 are calculated from the bands in the images explained in Table 1.
In order to determine the accuracy of the results, the overall accuracy method is used. In this method, 100 points are randomly generated for each study region (Fig. 3). The land cover value corresponding to these points and the classification result are determined and assigned to an error matrix.

Randomly created points for accuracy analysis: a Gemlik; b Hatay c Agioi Apostoli
Results and discussion
In this study, threshold values are used in the labelling algorithm. In order to determine these threshold values, Sentinel 2 images of the Black Sea and Mediterranean regions of Turkey are analyzed. The reflections of the land cover classes in the images change depending on the season. Accordingly, images from January, April, June, September, and November are used to determine the classes’ changes. The spatial resolution of these images is increased to 10 m with the IHS sharpening method. The wetness Index, SAWI, REM, SATVI, OSAVI, NGRDI, NDWI, NDVI, NDSI, NBR, TBI, GVI, EGI, BI, and AWEI spectral indices are calculated using the bands in the images. The analysis shows how the values of these indices change seasonally in the regions. The variation of index values by months and regions is given in Figs. 4 and 5.

Spectral index values in Karadeniz Region


Spectral index values in Akdeniz Region
Threshold values were determined from the obtained data. This threshold values are determined by calculating the average values covering all seasonal changes. The values obtained are given in Table 4.
The approach developed for automatic labelling of the classification results is tested with Sentinel 2 images for the geographical regions of Hatay and Gemlik. The spatial resolution of the images is increased to 10 m by the IHS method. The labelling algorithm developed for the study is tested in study areas and aims to label soil, a green agricultural area, forest, urban area, and uncultivated agricultural area.
Gemlik study area
In order to test the proposed approach, the results obtained for Gemlik region are determined by the algorithm and given in Fig. 6.

Gemlik Region: a Satellite image b Corine Classes c Labelling process result
Hatay study area
The result obtained for the classes in the image of the Hatay region is determined by the algorithm and given in Fig. 7.

Hatay Region: a Satellite Image b Labelling process result c Corine Classes
Greece study area
The result obtained for the classes in the image of the Hatay region is determined by the algorithm and Corine Classes and given in Fig. 8.

Agioi Apostoli study area: a Satellite Image b Labelling process result b Corine Classes
The results of the “Overall accuracy” analysis applied to the algorithm and Corine land classes covering the study area are given in Table 5.
The accuracy analysis shows that the overall accuracy rate is 80% for the resulting map obtained by the algorithm for the Gemlik region. While water and urban areas are separated with high accuracy, soil areas and green areas outside the forest area could not be determined. In Gemlik, there are no green agricultural areas such as wheat or barley fields. Agriculture generally consists of fruit trees. Nevertheless, the algorithm labels green pastures and grass areas as green agricultural areas. The accuracy analysis shows that the overall accuracy rate is 71% for the Corine classes. While forest and water areas are separated with high accuracy, land areas and soil areas outside the forest area could not be determined successfully.
The accuracy analysis shows that generally successful results are obtained for water, urban areas, and agricultural areas for the algorithm. When the results are analyzed, it is shown that the overall accuracy rate is 0.65.
Discussion
If class labels are not produced by unsupervised classification methods, users are required to interpret the results. This requires detailed knowledge of the area studied and increases dependence on the user. In this study, an approach is proposed to automatically label data classified with an unsupervised classification method. The aim is to determine green farmland, forest, fallow, city, and water classes from Sentinel 2 images. In the study, temporal and geographical variation of spectral indices for land cover classes are examined. As a result of this analysis, threshold values are determined to separate the classes. The threshold values obtained and the algorithm developed are tested in two study areas. Besides, the Corine labels of the pixels are used. In the last stage of the algorithm, the best label according to the rule set determined by authors is assigned to the pixels.
When the results are examined, the overall accuracy rate of the labelling in the study area, Gemlik, is 80% if the proposed algorithm is used, while the overall accuracy rate is 0.71 for the Corine classes. On the other hand, the overall accuracy is 0.83 for the proposed algorithm, while the overall accuracy rate is 0.62 for the Corine classes in study area results show that the proposed algorithm is capable of labelling with high accuracy. One of the reasons for this is that the resolution of the Corine classes is 100 m, so they cannot show the details found in high-resolution images. Figure 9 shows one of the examples of this. The marked region is labelled as Port in the Corine classes. However, when examined in detail, it is seen that there are details such as water and soil in this area. General evaluation of the results obtained shows that the proposed approach effectively determines the target classes, revealing that spectral indices can be used for labelling land classes. In addition, it is thought that expanding the analysis to changes in spectral indices using a more comprehensive time range would increase the accuracy rates and target class diversity.

Hatay Region a Satellite Image; b Proposed algorithm c Corine Classes
On the other hand, as seen in Fig. 9, some green areas in urban areas such as parks or stadiums are labelled as green agr. Areas or forests. This is because there is no class label in our previously determined pilot labels for this study.
Conclusions
This study aims to produce unsupervised classification labels, and a method is developed for this purpose. Spectral values in various classes obtained by the method developed are compared to a land class threshold value database and assigned to the appropriate class. In order to create the database, images from January, April, June, September, and November of Mediterranean and the Black Sea regions with different climatic and geographical characteristics are examined. The threshold values of the classes are determined by this analysis. The approach developed is tested on images of two regions. High accuracy results are obtained, as shown by the accuracy analysis applied to the labels created. The successful results illustrate the potential of the proposed method for automatic labelling.
This study was carried out using sample data and pilot classes as first steps towards automatic labelling of images classified by unsupervised classification methods. When thresholds are determined, labels can be created for different classes with this method. It is recommended to examine the results by expanding the range of labels at least as much as the Corine classes.
References
Appel M, Lahn F, Buytaert W, Pebesma E (2018) Open and scalable analytics of large earth observation datasets: from scenes to multidimensional arrays using SciDB and GDAL. ISPRS J Photogramm Remote Sens 138:47–56
Audebert N, Le Saux B, Lefèvre S (2018) Beyond RGB: very high resolution urban remote sensing with multimodal deep networks. ISPRS J Photogramm Remote Sens 140:20–32
Cao S, Weng Q, Mingyi D, Li B, Zhong R, Mo Y (2020) Multi-scale three-dimensional detection of urban buildings using aerial LiDAR data. GISci Remote Sens 57(8):1125–1143
Capolupo A, Monterisi C, Tarantino E (2020) Landsat images classification algorithm (LICA) to automatically extract land cover information in Google earth engine environment. Remote Sens 12(7):1201
Deka J, Tripathi OP, Khan ML, Srivastava VK (2019) Study on land-use and land-cover change dynamics in eastern Arunachal Pradesh, NE India using remote sensing and GIS. Trop Ecol 60(2):199–208
Du Y, Zhang Y, Ling F, Wang Q, Li W, Li X (2016) Water bodies’ mapping from Sentinel-2 imagery with modified normalized difference water index at 10-m spatial resolution produced by sharpening the SWIR band. Remote Sens 8(4):354
Enderle DIM, Weih RC Jr (2005) Integrating supervised and unsupervised classification methods to develop a more accurate land cover classification. J Ark Acad Sci 59(1):65–73
ESA (2018) "SENTİNEL-2". https://sentinel.esa.int/web/sentinel/missions/sentinel-2. Accessed 31 Dec 2018
Escadafal R (1989) Remote sensing of arid soil surface color with Landsat thematic mapper. Adv Space Res 9(1):159–163
Feyisa, Gudina L, Henrik Meilby, Rasmus Fensholt, and Simon R Proud. 2014. "Automated water extraction index: a new technique for surface water mapping using Landsat imagery." Remote Sens Environ 140:23–35
Gallego FJ (2004) Remote sensing and land cover area estimation. Int J Remote Sens 25(15):3019–3047
García MJL, Caselles V (1991) Mapping burns and natural reforestation using thematic mapper data. Geocarto Int 6(1):31–37
Gemlik_Belediyesi (2019) "Gemlik". http://gemlik.bel.tr/tr/gemlik. Accessed 1.7.2019
Gupta A, Byrne J, Moloney D, Watson S, Yin H (2018) Automatic tree annotation in LiDAR data. Paper presented at the GISTAM
Hatay_Valiliği TC (2019) "Sosyal ve Coğrafi Durum". http://www.hatay.gov.tr/sosyal-ve-cografi-durum. Accessed 1/7/2019
Henrich V, Götze E, Jung A, Sandow C, Thürkow D, Gläßer C (2009) Development of an online indices database: motivation, concept and implementation. Paper presented at the proceedings of the 6th EARSeL imaging spectroscopy SIG workshop innovative tool for scientific and commercial environment applications, Tel Aviv, Israel
Huang F, Yu Y, Feng T (2019) Automatic extraction of urban impervious surfaces based on deep learning and multi-source remote sensing data. J Vis Commun Image Represent 60:16–27
Jensen JR, Lulla K (1987) "Introductory digital image processing: a remote sensing perspective"
Kaiser P, Wegner JD, Lucchi A, Jaggi M, Hofmann T, Schindler K (2017) Learning aerial image segmentation from online maps. IEEE Trans Geosci Remote Sens 55(11):6054–6068
Kauth RJ, Thomas GS (1976) The tasselled cap--a graphic description of the spectral-temporal development of agricultural crops as seen by Landsat. Paper presented at the LARS symposia
Kavzoğlu T, Çölkesen İ (2010) Destek vektör makineleri ile uydu görüntülerinin sınıflandırılmasında kernel fonksiyonlarının etkilerinin incelenmesi. Harita Dergisi 144(7):73–82
Lepers E, Lambin EF, Janetos AC, DeFries R, Achard F, Ramankutty N, Scholes RJ (2005) A synthesis of information on rapid land-cover change for the period 1981–2000. BioScience 55(2):115–124
Lin H, Shi Z, Zou Z (2017) Maritime semantic labeling of optical remote sensing images with multi-scale fully convolutional network. Remote Sens 9(5):480
Marsett RC, Qi J, Heilman P, Biedenbender SH, Watson MC, Amer S, Weltz M, Goodrich D, Marsett R (2006) Remote sensing for grassland management in the arid southwest. Rangel Ecol Manag 59(5):530–540
Rondeaux G, Steven M, Baret F (1996) Optimization of soil-adjusted vegetation indices. Remote Sens Environ 55(2):95–107
Rouse Jr JW (1973) "Monitoring the vernal advancement and retrogradation (green wave effect) of natural vegetation"
Salomonson VV, Appel I (2004) Estimating fractional snow cover from MODIS using the normalized difference snow index. Remote Sens Environ 89(3):351–360
Sinergise (2019) "Sentinel 2 EO products". https://www.sentinel-hub.com/develop/documentation/eo_products/Sentinel2EOproducts. Accessed 01 Jan 2019
Sun J, Zhang Y, Wu Z, Zhu Y, Yin X, Ding Z, Wei Z, Plaza J, Plaza A (2019) An efficient and scalable framework for processing remotely sensed big data in cloud computing environments. IEEE Trans Geosci Remote Sens 57(7):4294–4308
Tong X-Y, Xia G-S, Lu Q, Shen H, Li S, You S, Zhang L (2020) Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens Environ 237:111322
Tucker CJ (1979) Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens Environ 8(2):127–150
URL (2019) "T.C. Gemlik Kaymakamlığı". http://www.gemlik.gov.tr/ilcemiz. Accessed 25/7/2019
Wang S, Azzari G, Lobell DB (2019) Crop type mapping without field-level labels: random forest transfer and unsupervised clustering techniques. Remote Sens Environ 222:303–317
Woebbecke DM, Meyer GE, von Bargen K, Mortensen DA (1995) Color indices for weed identification under various soil, residue, and lighting conditions. Trans ASAE 38(1):259–269
Wu T, Luo J, Zhou Y’n, Wang C, Xi J, Fang J (2020) Geo-object-based land cover map update for high-spatial-resolution remote sensing images via change detection and label transfer. Remote Sens 12(1):174
Yuan M, Liu Z, Wang F, Jin F (2019) Rethinking labelling in road segmentation. Int J Remote Sens 40(22):8359–8378
Zhang X, Ge Z (2019) Local parameter optimization of LSSVM for industrial soft sensing with big data and cloud implementation. IEEE Transactions on Industrial Informatics 16(5):2917–2928
Acknowledgements
This study was produced from a DOCTORATE thesis conducted by Dilek Küçük MATCI under the supervision of Assoc. Prof Uğur Avdan.
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
All authors has made equal contribution to the study.
Corresponding author
Ethics declarations
Ethics approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Conflict of interest
No potential conflict of interest was reported by the authors.
Additional information
Communicated by: H. Babaie
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Matcı, D.K., Avdan, U. Data-driven automatic labelling of land cover classes from remotely sensed images. Earth Sci Inform 15, 1059–1071 (2022). https://doi.org/10.1007/s12145-022-00788-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-022-00788-6