
Abstract
High concentrations of particulate matter (PM) are frequently associated with serious health problems, underlining the importance of accurate PM prediction. This study aimed to predict PM10 concentrations by analyzing air pollutant data in Korea (Seoul, Incheon, Daejeon, and Busan) using convolutional neural networks (CNNs) and long short-term memory (LSTM) deep learning methods. Real-time data from January 2014 to December 2020 were organized as hourly averages. The SO2, NO2, CO, O3, and PM10 data from 2014 to 2018 were used for training, and data from 2019 to 2020 were used as test data. The highest prediction accuracy was accomplished using all observations. The contribution ratio of each model component to the predictions was verified using SHapley Additive exPlanations (SHAP), and PM10 showed the greatest contribution. The other components, as secondary aerosol precursors, were divided by area. CO and O3 were found to be high in Seoul (Gwanak), which has been highly urbanized. On the other hand, CO and NO2 were found to be high in Incheon (Namdong), Daejeon (Yuseong), and Busan (Sasang), which are relatively suburban areas. The deep learning results indicated that the predicted PM10 concentration was most affected by past and present concentrations of PM10. It is considered that the atmospheric PM10 at the study sites mainly originated from direct emissions. We compared the proposed method with recent prediction methods using algorithms, machine learning, and deep learning. The R2, root mean square error, and mean absolute error evaluation indices supported the suitability of the proposed method for analyses at the study site.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Global warming is contributing to the increase in ocean temperature and causes climate change, as reflected in more severe flooding and droughts (Bernstein et al. 2008). Cai et al. (2017) reported that the wind speed in the Eurasian continent is decreasing, while atmospheric flow in East Asia is becoming stagnant as the polar ice melts and the temperature difference relative to the Eurasian continent decreases. This phenomenon disturbs the vertical mixing of the atmosphere and can increase the concentration of ambient particulate matter (PM) (Lee et al. 2020; Zhao et al. 2021). The emission of air pollutants has significant impacts on the local environment, and their regional transport affects air quality in downwind areas (Yang et al. 2021). PM can originate from natural sources such as crustal weathering, seawater evaporation, volcanic activity, and natural forest fires. Compared to natural sources, the PM emitted from anthropogenic sources is more problematic for air quality maintenance due to its long-term effects. It is emitted during fuel combustion for heating, as well as traffic and industrial activities such as incineration and biomass burning (Muránszky et al. 2011). Atmospheric PM not only reduces visibility but also causes respiratory and skin diseases, which threaten public health (Karagulian et al. 2015; IEA 2020). The International Research Agency on Cancer (IARC), a specialized institution of the World Health Organization (WHO), has designated PM2.5 as a carcinogen of the highest level (IARC 2013; Burnett et al. 2014).
PM is generally classified based on its physical characteristics; fine dust (PM10) includes aerosols with a diameter < 10 μm, and ultra-fine dust (PM2.5) refers to aerosols with a diameter < 2.5 μm. PM can be distinguished by its chemical composition and/or sources, with primary aerosol referring to particles emitted directly into the atmosphere, and secondary aerosol including particles formed by gas-to-particle conversion processes (IARC 2013). PM10 can remain in the air for as long as a few days, and sometimes even for weeks (Pöschl 2005). Health problems arise when PM10 is deposited in the upper respiratory tract of humans (Kampa and Castanas 2008). According to Schwela and Haq (2020), the conversion ratio of PM2.5/ PM10 was ~0.5 in the USA and India, which means that PM2.5 and PM10 are closely related. Thus, this study posited that PM10 could be used to reflect air quality and related pollutants in Korea.
Karagulian et al. (2015) reported on differences in the sources of PM10 emission among Korea, Southern China, and Northern China. The source contributions in Korea were, in order, unspecified sources of human origin, traffic, and industry. In Southern China, the order was unspecified sources of human origin, natural sources including soil dust and sea salt, and industry; and in Northern China, the order was industry, traffic, and domestic fuel burning.
In South Korea, the annual average concentrations of PM10 and PM2.5 from 2011 to 2014 decreased from 131,000 to 98,000 and 82,000 to 63,000 ton/yr, respectively. PMs concentrations in 2015 were slightly increased in both countries (Natural Air Pollutants Emission Service, https://airemiss.nier.go.kr). The atmospheric concentration of total suspended particles (TSP) also increased significantly from 2015 to 2018 (from 147,000 to 604,000 ton/yr). TSP accounted for the most air pollutants, followed by nitrogen oxide (NOx), volatile organic carbons (VOCs), and CO. National warnings about particulate material, i.e., PM2.5 concentrations, were issued 173 times in 2015; this warning increased to 316 times in 2018. The number of days of high-concentration fine dust in Korea has increased since 2015 (Korea Environment Corporation, https://www.airkorea.or.kr/). Seoul metropolitan area is one of the most polluted in the world, and in 2017 Korea had the highest concentration of PM10 among OECD member countries (IEA 2020).
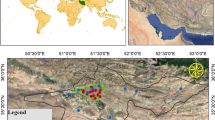
Our study sites included Incheon on the northwestern coast of South Korea, Seoul, which is the biggest city on the northwestern inland, Daejeon on the central inland, and Busan, which is the second largest city on the southeastern coast (Fig. 1). It is important to predict the PM10 concentration in major cities in South Korea. The Gwanak monitoring station in Seoul (Silrim-dong Community Service Center) is located in the urban area and is not surrounded by mountains or hills, so can immediately detect air quality changes. The monitoring stations in Namdong (Incheon) and Sasang (Busan) are located in the urban area next to the coast, so the air quality is influenced in complicated ways by industrial pollutants and ocean sources, such as sea salt. The Annual Report of Air Quality in Korea 2019 issued by the National Institute of Environmental Research (NIER) (2020) reported that the highest concentration of PM10 from 1999 to 2003 occurred in Seoul, although that changed to Incheon from 2004 to 2017. During the monitoring period (1999 to 2017), Daejeon had the lowest PM10 concentration among the big cities in Korea. Busan showed an intermediate concentration between Daejeon and Incheon in this period.

Location of four study sites (Namdong, Gwanak, Yuseong, and Sasang) in Korea. The study sites are marked on the map as gray dots
This study applied deep learning network techniques, especially one-dimensional convolutional neural networks (1D CNN) and recurrent neural networks (RNN), to predict the PM10 concentration after 1 h using time averaged air pollutant data from the preceding 3 h (PM10, O3, NO2, CO, and SO2). Using the deep learning model, we aimed to determine the relative contributions of various factors to predictions of PM10 concentration at each site, and compared the accuracy of the proposed prediction method with other prediction methods. Here, we present preliminary results and discuss the advantages and limitations of the proposed deep learning method.
Related works
A mechanistic or deterministic approach is usually applied for statistical analysis and prediction in PM pollution research. The mechanical method uses computer modeling to predict spatio-temporal PM variation based on emission sources, geographical properties, and transportation. Statistical methods are usually applied to previously collected (measured) data to predict future pollution or pollution levels in an unmeasured region.
Munir and Mayfield (2021) used a linear auto-regressive integrated moving average (ARIMA) with exogenous variables (ARIMAX) model to predict NO2 concentrations. Cross-validation ARIMAX demonstrated strong associations with the measured concentrations, with a correlation coefficient of 0.84 and RMSE of 9.90. Badicu et al. (2020) proposed application of the ARIMA model for PM2.5 and PM10 prediction, and performed statistical analyses to correct mechanical errors resulting from humidity. The results showed that, in 89% of cases, the predicted values were within an acceptable uncertainty range, and the Pearson correlation coefficients were significant.
Xayasouk et al. (2020) used long short-term memory (LSTM) (Hochreiter and Schmidhuber 1997) and deep autoencoder (DAE) methods to predict PM2.5 and PM10 concentrations in Seoul, and compared the model results in terms of the root mean square error (RMSE) values. To predict PM after 10 days, they used PM10 and PM2.5 data, and meteorological data, as input nodes. The LSTM model had minimum RMSE values of 11.113 for PM10 and 12.174 for PM2.5 at a batch size of 32, while the DAE model had minimum RMSE values of 15.038 for PM10 and 15.437 for PM2.5 at a batch size of 64.
Similarly, Chae et al. (2020) performed PM2.5 and PM10 predictions for Seoul. They used 6 kinds of air quality data, including PM10, PM2.5, O3, CO, SO2, and NO2, to predict PM2.5 and PM10 for 24 solar terms. The results of the LSTM model and other deep learning models (RNN, CNN, gated recurrent unit [GRU], DAE, and Q-networks) exhibited high accuracy.
Previous studies estimated PM2.5 at ground level using Moderate Resolution Imaging Spectroradiometer (MODIS) products combined with the Multi-Angle Implementation of Atmospheric Correction (MAIAC) algorithm (Lyapustin et al. 2018; Represa et al. 2019; Stafoggia et al. 2019). Represa et al. (2019) used hourly PM2.5 data from 2008 to 2018, along with meteorological and land use information, to predict PM2.5 concentrations. The results were about 90% consistent with the observed data on the spatio-temporal variation of PM2.5. A helpful method for predicting PM2.5 and PM10 using a Transformer has been proposed by Kim and Lee (2021). These deep learning and statistical techniques can be applied in early warning systems for predicting potential pollution episodes, to allow proactive adoption of precautionary measures.
Materials and methods
Proposed method
Given that data of natural phenomena have a time series element, the 1D CNN method has been proposed for deep learning applications. This method has various applications, such as weather forecasting and semiconductor yield prediction (Haidar and Verma 2018; Fu et al. 2019). In this method, as the input data pass through the 1D convolution layer, the model is trained using the filter values so that the important features of the data can be extracted. The extracted values are then used as the inputs for the prediction model. In the present study, a residual block (He et al. 2016) was applied during data preprocessing to increase the accuracy of PM10 concentration prediction.
The residual block was constructed for effective transmission of data through the skip connection. The values of the data obtained using the residual block were added to the LSTM cell (Hochreiter and Schmidhuber 1997), and the PM10 was then predicted as the final output (Fig. 2).

Flow chart of the method proposed in this research
The first step in this process involved increasing the data dimensions by passing the input data to the convolution layer, and then to the dimensional layer. The data were then passed through the convolution layer again, and adjusted according to the dimensions of the original data for residual block application. Passage of the input data through the convolution layers enhances the information content. These 1D CNN layers are shared at [tn − 2, tn].
The 1D CNNs are mostly used for one-dimensional signal processing, such as sentence classification, weather prediction, and yield prediction for semi-conductors (Chen 2015; Lee et al. 2017; Haidar and Verma 2018; Fu et al. 2019). We can use the 1D CNN to remove unnecessary noise from the original input. In addition, it is possible to create a more effective input that considers the correlation of each component, which are used as the input to the LSTM cell.
After the 1D CNN process, the data were used as input for the LSTM cell, which can retain information for a prolonged period, although the interaction between the input and output data becomes remote. In this study, the convolution filter kernel size was fixed to 3. Next, batch normalization (Ioffe and Szegedy 2015) and activation functions were applied to the CNN layer, and the feature map outputted from the previous step was then passed through the convolution layer at the same depth one more time; the batch normalization and activation functions were then applied. Finally, the data were passed through the CNN layer with a kernel size of 3; the depth of the feature map was set as 5, which was the same as the original size. The data obtained through these processes were subjected to batch normalization and added to the original data. The schematic outline of these processes is presented in Fig. 2.
Implementation detail
The experimental environment for the model train was adapted from Ubuntu 16.04.7, Anaconda 4.7.12, Python 3.6.12, and PyTorch 1.8.0. We carried out the training and test using an Intel(R) Xeon(R) Gold 5218R CPU @ 2.10 GHz and GPU Quadro RTX 6000.
As hyperparameters applied during training, the input and output data of the residual block were set to a sequence length of 3 and input dimension of 5. The depth of the 1D CNN layer was set to 128, and the size of the hidden layer between the LSTM cells to 256. ADAM was used as the optimizer, and RMSE was used as the loss function. The epoch used for training was set to 1000.
We applied learning rate (lr) scheduling for more sophisticated training. The initial lr was set to 10−2, and was then reduced to 80% in 100-epoch units. Gradient clipping with max norm was set to 5 to ensure that model training proceeded stably toward the convergence region.
Experiment
Comparison with other studies
In this section, the validity of the proposed method was verified through experiments. To train the deep learning model, we collected air pollutant data for sites in Seoul (Gwanak), Incheon (Namdong), Daejeon (Yuseong), and Busan (Sasang) from the Air Korea website (https://www.airkorea.or.kr) operated by the Korea Environment Corporation. The data were organized as hourly average data from January 2014 to December 2020, except for missing values and outliers. The SO2, NO2, CO, O3, and PM10 data from 2014 to 2018 were used for training, and data from 2019 to 2020 were used for the test (Table 1).
The predicted PM10 concentration after 1 h can be calculated from the concentrations of SO2, NO2, CO, O3, and PM10 in the previous 3 h. Based on the test results obtained through this process, the predicted distributions for 2019 and 2020 are shown in Fig. 3. The first row shows 2019 data, and the second shows 2020 data. The observations and predictions are presented in the order of Namdong, Gwanak, Yuseong, and Sasang. Observation values are blue and prediction values are orange (Fig. 3).

Distribution of the observation (blue column) and prediction (orange column) values in each region based on PM10 using the proposed method
The methods were compared with the previous studies (Represa et al. 2019; Badicu et al. 2020; Chae et al. 2020; Xayasouk et al. 2020). To compare the prediction accuracy of various methods, we selected recently published and reliable studies on PM prediction. The results of the comparison are presented in Fig. 4. The x axis is the observed PM10 concentration, and the y axis is the predicted concentration. The datasets in each row are presented in the order of Namdong, Gwanak, Yuseong, and Sasang. Columns are ordered according to the data from the comparison group with the order of Badicu et al. (2020), Chae et al. (2020), Xayasouk et al. (2020), and Represa et al. (2019). The data of each study are easily distinguished by the trend line y = x (light-green solid line).

Experimental results for each region. First row: Namdong, second row: Gwanak, third row: Yuseong, and fourth row: Sasang
The evaluation metrics were R2, RMSE, mean absolute percentage error (MAPE), and mean absolute error (MAE). The expressions for each indicator are as follows:
In these equations, ytar is the observed value, ypred is the predicted value, \( \overline{y_{tar}} \) is the average of the observations, and n is the number of data points inytar. The value of R2 is within the range of [0, 1], and numbers closer to 1 indicate greater accuracy. On the other hand, for RMSE, MAPE, and MAE, values closer to 0 indicate greater accuracy.
The results for the three study sites are as follows Table 2 and Fig. 3. The values of evaluation metrics R2, RMSE, and MAE in all regions showed the best concordance with the comparison group. However, according to the MAPE, the proposed method was less accurate only in the Gwanak region.
Differences were found between the evaluation metrics and predicted values for each city. Similar numbers of data were collected in each region: approximately 40,000 for training and 15,000 for testing in Seoul (Gwanak), 39,000 for training and 16,000 for testing in Incheon (Namdong), 41,000 for training and 15,000 for testing in Daejeon (Yuseong), and approximately 40,000 for training and 16,000 for testing in Busan (Sasang), (Table 1). The accuracy of the results for the Yuseong and Sasang was relatively low compared to those for Gwanak and Namdong. This likely reflects the fact that the predictions for Gwanak and Namdong were based on the wide concentration range of the training data. The largest industrial complex in Busan is located in the Sasang region. Moreover, a highway passes through this area, and an airport is located on the left side of this site. The relatively low accuracy of experimental results in the Sasang region was influenced by the variable air quality of coastal downtown areas.
Ablation study
This section describes the ablation study used to assess the validity of the proposed method, and to determine whether model components could be regarded as causal based on the deep learning model. The time sequence of the proposed model for PM10 concentration prediction was set to 3, the number of hidden dimensions to 256, and the number of stack layers to 1. We used 5 components (SO2, NO2, CO, O3, and PM10) to predict PM10 concentration. The validity of the proposed model was examined through experiments wherein the 4 hyperparameter values (time sequence, hidden dimension, stack layer, and prediction components) were changed. The evaluation metric used was the R2 value. The experimental results are shown in the Table 3.
The first ablation factor was the time sequence, obtained by increasing the length of the time sequence from 3 to 5. In general, the more abundant the information about the previous time, the more accurate the data will be. However, the results showed that the highest value was recorded in all regions when the time sequence was fixed to 3.
Next, we changed the number of hidden dimensions. The results confirmed that 256 hidden dimensions gave the best results. In sequence, we evaluated the effect of the number of stack layers in the LSTM cell. In general, performance varies according to the number of stacks in the LSTM, and more favorable results are expected as the number of training parameters increases. However, due to the small input factors used in this experiment, one stack layer obtained the best results.
The last step was to validate the contributions of PM10, SO2, NO2, CO, and O3. The experimental results were obtained using the following values: PM10, CO, O3, NO2, and SO2 (entered in that order). The results showed that including all of the training and prediction factors yielded the best results.
Analysis of proposed model
SHAP (SHapley Additive exPlanations) has recently been applied to explain the prediction results of black box models (Lundberg and Lee 2017). This theory is based on the concept of the Shapley value, which is an algorithm used in game theory for calculating the contribution of each player in a game. SHAP exhibited local accuracy, missingness, and consistency.
The validity of our proposed method was analyzed using SHAP. The results regarding the prediction tendency of the model, based on the trends in the input and output data, are discussed below.
The SHAP value of each feature in all test data was calculated to determine which input feature impacts the model the most. The following Fig. 5 shows the distribution of SHAP values for the test data on Gwanak, Namdong, Yuseong, and Sasang.

SHAP value distributions in each region obtained using the proposed method
The results of the prediction trend evaluation were as follows. Regardless of the region, the most influential factor for predicting the PM10 at time t + 1 was the PM10 at time [t - 2, t]. CO was the next most influential factor, but its influence was quite small compared to PM10. For Namdong and Yuseong, NO2 was the next most important factor. Compared to that parameter, O3 was more meaningful contributor in Gwanak and SO2 was more meaningful contributor in Sasang. The NO2 and O3 were known to be generated by the photochemical reaction of NOx from transport sources with VOCs (Han et al. 2011). SO2 made smaller contributions than the other air pollutants except the Sasang region. This result is thought to be due to the influence of the thermal power plant, which is located about 7 km from the observation point. Thus, the relative influence of SO2 affects the formation of PM10 (Choi et al. 2021). These results well matched existing algorithm-based results. This process also confirmed that the method proposed in this paper was valid.
The results showed that gas components, such as SO2, NO2, CO, O3, contributed to the secondary formation of ultra-fine particles (PM2.5), which are part of PM10. However, it may be that fine particles emitted from a local source are more important in the formation of P PM10, which remains in the air at steady concentrations for a considerable time. Future studies should employ a sophisticated prediction model considering atmospheric conditions such as relative moisture, amount of rainfall, temperature, wind speed, etc., as input data.
According to the NIER (2020) report, the concentration of PM10 observed at monitoring stations in the seven largest cities in South Korea (Seoul, Incheon, Busan, Daejeon, Daegu, Gwangju, Ulsan) has been steadily decreasing since 1995. The annual average concentration was about 36 ~ 43 μg/m3 in 2020, and has since declined. Although the number of days with high concentrations of PM10 increased in the mid- to late 2010s, the average annual PM10 concentration gradually decreased. Thus, it appears that global efforts to reduce greenhouse gases and air pollutant emissions are reflected in the current atmosphere. Air quality improvement in the future mainly depends on the reduction of PM from local direct emission sources; efforts by individuals to reduce PM emissions are also necessary.
Conclusion
As interest in health increases, along with awareness of the problem of PM, accurate prediction of the PM10 concentration is required. In this study, we proposed a deep learning model to predict the concentration of PM10, based on 1D CNN, LSTM from RNN methods, in the Seoul (Gwanak), Incheon (Namdong), Daejeon (Yuseong), and Busan (Sasang) areas. This method could be used to analyze PM in various areas, including inland urban, coastal urban, and inland rural areas.
Data on air pollutants (i.e., concentrations of SO2, NO2, CO, O3, and PM10) in Gwanak, Namdong, Yuseong, and Sasang from 2014 to 2020 were analyzed, and evaluation metrics included R2, RMSE, MAPE, and MAE. Recently published algorithms, and machine learning and deep learning methods, were applied. The method proposed in this study outperformed four alternative approaches.
The influence of each input (model component) was calculated using SHAP, and the results showed that present concentrations of PM10 and CO play a significant role in future ones. The contribution ratio of direct emissions, as the primary aerosol responsible for PM10 formation, was higher than that of other precursors of secondary aerosols. Thus, the Korean government should endeavor to reduce air pollutants from direct emission sources. This study contributes basic data for short-term PM10 prediction, and could inform air pollution control policies.
References
Badicu A, Suciu G, Balanescu M, Dobrea M, Birdici A, Orza O, Pasat A (2020) PMs concentration forecasting using ARIMA algorithm. In 2020 IEEE 91st vehicular technology conference (VTC2020-spring) 1-5
Bernstein L, Bosch P, Canziani O, Chen Z, Christ R, Riahi K (2008) Climate change 2007: synthesis report. Intergovernmental panel on climate change (IPCC). IPCC publication, Geneva
Burnett RT, Pope CA III, Ezzati M, Olives C, Lim SS, Mehta S, Shin HH, Singh G, Hubbell B, Brauer M, Anderson HR, Smith KR, Balmes JR, Bruce NG, Kan H, Laden F, Prüss-Ustün A, Turner MC, Gapstur SM et al (2014) An integrated risk function for estimating the global burden of disease attributable to ambient fine particulate matter exposure. Environ Health Perspect 122(4):397–403. https://doi.org/10.1289/ehp.1307049
Cai W, Li K, Liao H, Wang H, Wu L (2017) Weather conditions conducive to Beijing severe haze more frequent under climate change. Nat Clim Chang 7(4):257–262. https://doi.org/10.1038/nclimate3249
Chae M, Han S, Lee H (2020) Outdoor particulate matter correlation analysis and prediction based deep learning in the Korea. Electronics 9(7):1146. https://doi.org/10.3390/electronics9071146
Chen Y (2015) Convolutional neural network for sentence classification. Master’s thesis, University of Waterloo, Ontario
Choi H, Lee H, Kim DH, Lee KK, Kim Y (2021) Physicochemical and isotopic properties of ambient aerosols and precipitation particles during winter in Seoul. S Korea Environ Sci Poll Res:1–19. https://doi.org/10.1007/s11356-021-16328-6
Fu Q, Niu D, Zang Z, Huang J, Diao L (2019) Multi-stations’ weather prediction based on hybrid model using 1D CNN and BI-LSTM. In 2019 Chinese control conference (CCC)3771–3775https://doi.org/10.23919/ChiCC.2019.8866496
Haidar A, Verma B (2018) Monthly rainfall forecasting using one-dimensional deep convolutional neural network. IEEE Access 6:69053–69063. https://doi.org/10.1109/ACCESS.2018.2880044
Han S, Bian H, Feng Y, Liu A, Li X, Zeng F, Zhang X (2011) Analysis of the relationship between O3, NO and NO2 in Tianjin, China. Aerosol Air Qual Res 11(2):128–139. https://doi.org/10.4209/aaqr.2010.07.0055
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In proceedings of the IEEE conference on computer vision and pattern recognition 770–778
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
International Agency for Research on Cancer (IARC) (2013) Air pollution and cancer. IARC Scientific Publication. IARC publication, Lyon
International Energy Agency (IEA) (2020) Country report Korea 2020 energy policy review. Kluwer Law International BV, Alphen Aan Den Rijn
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. Int Conf Mach Learn 37:448–456
Kampa M, Castanas E (2008) Human health effects of air pollution. Environ Pollut 151(2):362–367. https://doi.org/10.1016/j.envpol.2007.06.012
Karagulian F, Belis CA, Dora CFC, Prüss-Ustün AM, Bonjour S, Adair-Rohani H, Amann M (2015) Contributions to cities' ambient particulate matter (PM): a systematic review of local source contributions at global level. Atmos Environ 120:475–483. https://doi.org/10.1016/j.atmosenv.2015.08.087
Kim J, Lee C (2021) Deep particulate matter forecasting model using correntropy-induced loss. J Mech Sci Technol 35:4045–4063. https://doi.org/10.1007/s12206-021-0817-4
Lee D, Wang SYS, Zhao L, Kim HC, Kim K, Yoon JH (2020) Long-term increase in atmospheric stagnant conditions over Northeast Asia and the role of greenhouse gases-driven warming. Atmos Environ 241:117772. https://doi.org/10.1016/j.atmosenv.2020.117772
Lee KB, Cheon S, Kim CO (2017) A convolutional neural network for fault classification and diagnosis in semiconductor manufacturing processes. IEEE Trans Semicond Manuf 30(2):135–142. https://doi.org/10.1109/TSM.2017.2676245
Lundberg SM, Lee SI (2017) A unified approach to interpreting model predictions. In proceedings of the 31st international conference on neural information processing systems 4768-4777
Lyapustin A, Wang Y, Korkin S, Huang D (2018) MODIS collection 6 MAIAC algorithm. Atmospheric Measurement Techniques 11(10):5741–5765. https://doi.org/10.5194/amt-11-5741-2018
Munir S, Mayfield M (2021) Application of density plots and time series modelling to the analysis of nitrogen dioxides measured by low-cost and reference sensors in urban areas. Nitrogen 2(2):167–195. https://doi.org/10.3390/nitrogen2020012
Muránszky G, Óvári M, Virág I, Csiba P, Dobai R, Záray G (2011) Chemical characterization of PM10 fractions of urban aerosol. Microchem J 98(1):1–10. https://doi.org/10.1016/j.microc.2010.10.002
National Institute of Environmental Research (NIER) (2020) Annual report of air quality in Korea 2019. National Institute of National Research publication, Incheon
Pöschl U (2005) Atmospheric aerosols: composition, transformation, climate and health effects. Angew Chem Int Ed 44(46):7520–7540. https://doi.org/10.1002/anie.200501122
Represa SN, Palomar-Vázquez J, Porta A, Fernández-Sarría A (2019) Daily concentrations of PM2.5 in the Valencian community using random forest for the period 2008–2018. Multidisciplinary Digital Publishing Institute Proceedings 19, 13(1). https://doi.org/10.3390/proceedings2019019013
Schwela DH, Haq G (2020) Strengths and weaknesses of the who global ambient air quality database. Aerosol Air Qual Res 20(5):1026–1037. https://doi.org/10.4209/aaqr.2019.11.0605
Stafoggia M, Bellander T, Bucci S, Davoli M, De Hoogh K, De'Donato F, Gariazzo C, Lyapustin A, Michelozzi P, Renzi M, Scortichini M, Shtein A, Viegi G, Kloog I, Schwartz J (2019) Estimation of daily PM10 and PM2.5 concentrations in Italy, 2013–2015, using a spatiotemporal land-use random-forest model. Environ Int 124:170–179. https://doi.org/10.1016/j.envint.2019.01.016
Xayasouk T, Lee H, Lee G (2020) Air pollution prediction using long short-term memory (LSTM) and deep autoencoder (DAE) models. Sustainability 12(6):2570. https://doi.org/10.3390/su12062570
Yang X, Qian W, Gong D, Zhao C, Chan PW, Zhou W, Huang Y, Zhang F, Li Z (2021) Vertical characteristics of pollution transport in Hong Kong and Beijing, China. Atmosphere 12(4):457. https://doi.org/10.3390/atmos12040457
Zhao S, Feng T, Tie X, Li G, Cao J (2021) Air pollution zone migrates south driven by East Asian winter monsoon and climate change. Geophys Res Lett:e2021GL092672. https://doi.org/10.1016/j.atmosenv.2020.117772
Acknowledgments
The authors wish to thank Chung-Mo Lee of the Korea Institute of Geoscience and Mineral Resources (KIGAM) for help with the mapping of the study area. This research was principally supported by the Basic Science Research Program through a National Research Foundation of Korea grant from the Ministry of Education (NRF-2018R1D1A1B07044596). This research was also supported by a grant from the Basic Research Project (21-3411) of KIGAM (Ministry of Science and ICT). Myungjoo Kang was supported by the NRF grant (2021R1A2C3010887). We thank the journal reviewers for providing thoughtful comments on the manuscript. The comments highly improved this paper.
CRediT authorship contribution statement
Han-Soo Choi: Conceptualization, Methodology, Data curation, Formal analysis, Investigation, Writing - original draft. Kyungmin Song: Methodology, Data curation, Formal analysis, Investigation, Resources. Myungjoo Kang: Writing - review & editing. Yongcheol Kim: Funding acquisition, Writing - review & editing. Kang-Kun Lee: Writing – review & editing. Hanna Choi: Supervision, Writing - review & editing.
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Code availability
Not applicable.
Funding
This research was principally supported by the Basic Science Research Program through a National Research Foundation of Korea grant from the Ministry of Education (NRF-2018R1D1A1B07044596). This research was also supported by a grant from the Basic Research Project (21–3411) of KIGAM (Ministry of Science and ICT).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical approval
Not applicable.
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Communicated by: H. Babaie
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Choi, HS., Song, K., Kang, M. et al. Deep learning algorithms for prediction of PM10 dynamics in urban and rural areas of Korea. Earth Sci Inform 15, 845–853 (2022). https://doi.org/10.1007/s12145-022-00771-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-022-00771-1