
Abstract
Street greening is an important part of urban landscape, and Green view index (GVI) has an important influence on the comfort of street space environment. In this paper, we analyze the GVI of street space based on big data of street view photos and neural network algorithm. By collecting about 25,000 street view photos from Tencent map, we synthesize the panoramic projection photos of equal area. The image segmentation is achieved by training models through DeeplabV3 + network framework, and then the GVI after image recognition is calculated by OpenCV. The spatial distribution of GVI on the street space is analyzed by means of GIS and other means. In this paper, four spatial regression models are applied to analyze the influencing factors of GVI in the context of urbanization development from three perspectives: historical planning, economic and social. A negative correlation between road class and GVI distribution was obtained. When analyzing the influence of different POI distributions on GVI, it was found that the distribution of hospitals and subway stations was significantly correlated with GVI, and the presence of hospitals in neighborhoods would increase the GVI of surrounding streets. The presence of subway stations, on the other hand, decreases the green visibility of the surrounding streets. This study contributes to the development of human-centered planning and design and provides scientific guidance for the construction and renovation of green space in streets by targeting and optimizing the distribution of specific social facilities in the area.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
With the rapid development of modern cities, the population density and building density of cities are increasing, and the conflict between urban construction and green space conservation is becoming more prominent (Wei 2016a). As an important part of urban ecology, urban green space provides residents with a fresh and pleasant environment and a variety of ecological services (Chen and Huang 2020) and is one of the important elements to alleviate "urban diseases" such as increased population concentration, urban pollution, and traffic congestion under urban development (Wang et al. 2014). Meanwhile, the greenness of urban streets has a great impact on people’s mental health. Li and He et al. explored the relationship between Green view index (GVI) and residents’ exposure to green environment in Nanjing city (Li et al. 2020) to analyze the impact of greenness in space on residents’ health. Helbich and Yao et al. used deep learning to identify blue and green spaces in street view photos and combined with questionnaire data to conclude that green and blue spaces in street space can prevent depression among Chinese elderly people (Helbich et al. 2019). Wang and Ruoyu analyzed the relationship between street greenery and well-being index (Wang et al. 2019) and concluded that street greenery and NDVI index were positively associated with mental health.
At present, the indicators for measuring urban green space development in China are mainly traditional indicators, including per capita green area (Luo 2020) and greenery coverage (Shen et al. 2020). The traditional indicators mainly emphasize the quantity of greenery in two-dimensional space, and cannot evaluate the quality of greenery from the human perspective (Yang et al. 2019), ignoring the human spatial perception of greenery quality. The "GVI" was first proposed by Japanese scholar Yo Aoki in 1987, referring to the proportion of green plants in the field of view seen by people’s eyes(Xiao et al. 2018). In 2004, the Japanese government officially made "GVI" one of the regular indicators of the green landscape evaluation system (Matsumoto 2008), which made it possible to evaluate the greening of urban space from a three-dimensional spatial perspective. Some scholars manually took photos in the space and manually selected the plant boundaries in the photo scene through Adobe Photoshop software to estimate the size of GVI in that space (Xu et al. 2018). Some scholars have also measured the 3D green volume of single count trees by 3D laser scanning technology to calculate the 3D green volume of plants more accurately (Li et al. 2017). Since manual photographs can no longer meet the requirements for urban spatial calculations, methods for batch calculations such as machine learning have emerged to enhance the demand for large-scale and efficient GVI measurements. For example, Chen and Zhou et al. implemented the estimation of GVI for cities in the Pearl River Delta by writing an automated program using Matlab software (Chen et al. 2020) and analyzed the correlation with socioeconomic factors. Scholars such as Long analyzed the color composition in street scenes by Matlab(Long and Liu 2017), by converting RGB colors into HSV models to determine the green range in the streetscape. However, this method identifies green objects including cars and other green objects on billboards as green areas when measuring the color range of streetscape. To solve this problem, some scholars later introduced a semantic segmentation method based on convolutional neural networks to semantically classify and classify streetscape images to automatically identify the categories of plants and improve the accuracy of GVI recognition (Helbich et al. 2019).
As a part of the city, urban green space is affected by urban development, therefore some scholars analyze the factors affecting urban green development and explore the mechanism of urbanization development on urban greenery. Li et al. investigated the evolutionary driving mechanism of green space in the central city of Beijing through partial least squares regression (PLSR)-based regression(Li et al. 2019). Wang explored the factors influencing the layout of urban green spaces based on a geographic detector and found that economic, natural factors present different effects on the development of urban green spaces in different regions (Wang et al. 2020b). Ru and Jiang et al. analyzed the drivers of urban green space evolution from three aspects: natural ecology, socio-economic, and policy factors (Ru and Jiang 2015). The above research methods mostly use qualitative or simple regression quantitative research. And such methods tend to ignore the spatial attributes of urban green space. Therefore, some scholars have applied spatial models to urban greening studies by applying them to urban greening. For example, Zhao et al. applied a spatial regression model to explain the inner mechanism of spatial evolution of urban green space from three aspects: economic drive, social growth, and government regulation (Zhao et al. 2020). Guo et al. used a geographically weighted regression model with spatial effects to explain the positive contribution of GDP per capita and fixed asset investment per capita to the optimization of green development(Guo et al. 2020). While GVI, as one of the important indicators of urban green space development nowadays, there are fewer studies related to the driving mechanism and influencing factors of GVI. Meng et al. extracted GVI based on streetscape data using the HSV color model and analyzed the influence of different parameters on GVI identification results (Meng et al. 2020). Wei used SPSS software to analyze the green space rate, the green cover, number of trees and plant type were correlated with GVI, and it was concluded that the combination of plants had the greatest influence on GVI(Wei 2016b). While less on the use of spatial models applied to the influence mechanism of GVI, Wang and Hu et al. studied the relationship between blue and green space with NDVI index and socioeconomic factors in Beijing, but the driving mechanism of GVI could not be fully explained under only a single economic perspective (Wang et al. 2020a). There is a lack of studies combining the spatial distribution patterns and driving mechanisms of GVI under multiple perspectives.
In view of the above problems, this paper applies the DeepLab V3 + algorithm to semantic segmentation of street images for GVI recognition in Jing’an District, Shanghai, and tries to analyze the spatial distribution of GVI in the study area. In addition, this paper tries to construct a spatial regression model from three aspects: planning factors, economic factors, and social factors to analyze the driving mechanism of GVI in Jing’an District, Shanghai. This paper tries to answer the following three questions.
-
1
What is the method and technical route to extract the GVI of street space in this paper?
-
2
What is the spatial distribution of GVI in Jing’an District, Shanghai? What kind of differences exist?
-
3
What is the relationship between street GVI and social, governmental planning, and economic factors?
Study areas, data and methods
Study areas
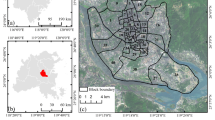
Jing’an District, located in the center of Shanghai(Fig. 1), from the original Zhabei District and the old Jing’an District into one, has a rich historical background with distinct regional characteristics. The district has a total area of 370,000 square kilometers, with a resident population of 1.1 million, and a total of 13 street offices under its jurisdiction. There are 64 roads in the district, with a total length of 63 km. The district has a large number of green spaces, the earliest of which can be traced back to the mid-nineteenth century. The high density of commercial residences and multiple types of street spaces are highly representative of a global city like Shanghai.

The site and sampling points across the street network. Case study area Jing’an district, Shanghai. The white lines in the right subplot are the main roads in the study area obtained from openstreetmap.org
Data acquisition
Streetscape data acquisition
The vector road network data in this study is the road network data provided by OpenStreetMap, which is imported into ArcGIS to simplify the road network, simplifying the complex traffic network, road grades, and multi-way lanes in reality to a one-way road, generating street view sampling points in the study area according to the 50 m distance interval and counting the latitude and longitude of all the collection points. In order to obtain the street view images, we use the API interface provided by Tencent Map Service. The Tencent Street View API service can provide the complete URL address of the street view request and the complete parameters that we need to set in the street view, including location, yaw angle, pitch angle, scene ID, and image size.
As shown in Fig. 2, SIZE indicates the resolution of the photo we need, and the study in this paper synthesizes a panoramic photo by 6 photos with a resolution of 600*400; location indicates the location information of the downloaded street view we need, and we generate the location parameters of each point based on the latitude and longitude of each sampling point generated; heading represents the yaw angle, which is the angle with the due north direction. The range of values is [0,360], and the default value is 0; pitch is the pitch angle, which refers to the head-up or head-down perspective of the street view acquisition camera, 0 for flat view, (0,20] for head-down, and (-90,0] for head-up. In this paper, we define a PYTHON script to call the Tencent Street View API to obtain all the photos of the points in batch and set the horizontal heading parameter to 0°, 60°, 120°, 180°, 240°, 300° in order to more closely match the 360-degree horizontal view of a person, and set the pitch parameter to 0 to simulate the vertical angle when a person is looking at it horizontally, and then download 6 photos with a resolution of 600*400.

Street View Image Acquisition Parameters Description Example
The usual practice is to identify the four angles of the street view photos at the sampling point separately, and then calculate the GVI values in each photo and take the average (Wang et al. 2020a, b), because there are overlapping parts in the four photos, the average calculation will cause errors in the GVI values. In order to more closely match the real scene under the 360-degree view of the human eye, we processed six different angles of street scenes from each sampling point by PTgui software to synthesize one isoparametric cylindrical projection photo. Finally, a total of 25,050 street scene photos were obtained by calling the API. The GVI is the ratio of the vegetation area in the isoprojected image to the total area of the isoprojected image (Zhang et al. 2019).
GVI driving indicators
In urban street space, the magnitude of GVI values can be influenced and constrained by a variety of factors. To investigate the drivers of GVI in urban streets, data were collected from different network data providers. When road construction is planned, different levels of roads assume different needs and therefore different requirements for the construction of road green space. In this paper, road class and road length are selected as planning factors. It has been shown (Liu et al. 2020) that cities with higher economic levels invest more in urban green space construction, which results in better green space construction. The higher the price of the community will be the community green as an important factor to attract people to buy, the better the community its green construction will be better, with the breaking of the wall through the green and other policies make the small area of the landscape spillover, will affect the road around the green view rate to have an impact. In urban construction, the government has different greening construction norms for different types of units, according to the "Urban Greening Planning and Construction Index Regulations" implemented since January 1, 1994 on the requirements to ensure the realization of the urban green space rate index, the green space rate for all types of green space in the city has a minimum requirement. It is stipulated in the unit attached to the green space area of the unit of the total land area ratio of not less than 30%, including industrial enterprises; transportation hubs, warehouses, commercial centers, such as green space rate of not less than 20%, and according to national standards to set up not less than 50 m of protective forest belt; schools, hospitals, rest and recuperation institutions, institutions and groups, public cultural facilities, troops and other units of the green space rate of not less than 35%. Therefore, the greening inside different kinds of building units can have an impact on the GVI of the space. And since 2000, Shanghai has required to break the greenery on both sides of the road. This makes the greenery inside various types of building units increase into the viewpoint of the road, thus affecting the proportion of greenery in the road space. Therefore, parks, neighborhoods, schools, subway stations, hospitals, squares, shopping malls, attractions, etc. were selected according to the different functional categories of buildings required in the implementation of the wall penetration.
And in order to explore the reasons for the differences in GVI, 12 factors were selected as indicators of the spatial model of GVI from three aspects: historical planning factors, social factors, and economic factors. Since GVI is sampled in the form of points, in order to facilitate the analysis of the correlation between them, the block house price and GVI are averaged into a block for resampling. By defining the area enclosed by multiple roads as a block, the average value of house price within each block was counted. In the research related to urban development, some scholars have conducted related studies by POI (Point of interest) and AOI (Area of interest) data (Cui et al. 2018). The influencing factors of GVI under the calculation of multiple perspectives need data support by multi-sourced big data. Chen and Wang et al. analyzed the travel demand of urban residents by combining traditional data and new Internet big data, using public transportation data, cell phone navigation data, and AOI data (Chen et al. 2020). Cui and He et al. identified various functional areas by POI data density to identify various functional areas in cold cities and overlay GVI for analysis, concluding that the average GVI of work areas is greater than that of residential areas and service areas (Cui et al. 2018). POI refers to all geographic entities that can be abstracted as points, representing a landmark on an electronic map, including all kinds of geographic entities closely related to people’s lives, and AOI refers to area-like geographic entities in map data. In addition to the role of POI data, AOI data also contains area range attributes, which can be used to eliminate duplicate information. In this paper, the impact of different functions of buildings on GVI is calculated by the number of buildings of each type of function within the block area, without considering the floor area of each type of building and the boundary situation. Therefore, this paper selects POI data as the research object. The number of POI in each category and the average GVI within the neighborhood are calculated, and the regression equation of GVI and house price for each neighborhood can be established. In this paper, based on the application program interface (API) provided by the largest online map service provider in China, we define PYTHON scripts to obtain different kinds of POI within each block based on longitude and latitude, and manually de-duplicate and clean the downloaded POI to count the number of POI under each block. Information such as road grade and length is obtained from open data provided by the Shanghai government. Administrative boundaries are obtained from Open Street Map (OSM). We collected the number of neighborhoods from the largest real estate trading platform in China through crawlers, and the average house price of the neighborhoods in Jing’an District, Shanghai. The specific data and sources are shown in Table 1.
Research framework
In this paper, we developed a program to automatically obtain street view photos based on Tencent Street View Map. First, we set sampling points in the study area based on the road network at 50 m intervals according to ArcGIS and obtained the coordinates of all sample points. Based on the coordinate information, 6 photos of each sample point were obtained from Tencent map through a web crawler. The six street photos were synthesized into one high-resolution isoprojected image by panorama synthesis software. After semantic segmentation by DeepLab V3 + neural network algorithm, the vegetation area of each point location is obtained. The GVI of each point location was obtained by calculating the ratio of the vegetation pixel value of each point location to the pixel value of the whole photo. The results were visualized in ArcGis to obtain the GVI spatial distribution map of the study area. The spatial autocorrelation of GVI was also examined, and historical planning factors (road width, road grade), economic factors (housing price), and social factors (metro stations, hospitals, neighborhood distribution) were overlaid to investigate the factors behind the differences in GVI distribution. The technical flow chart is shown in Fig. 3

Technical analysis framework. API Application Programming Interface; POI Point Of Information; GWR Geographically Weighted Regression; SLM Spatial Lag Model; SEM Spatial Error Model
GVI identification and calculation
For thousands of street photos, it is a daunting task to manually identify the GVI of each one accurately. And it is a challenge to extract the area of plant greenery accurately because of the difference of plants and street elements in different scenes across the street, as well as the difference of plant forms in different seasons and weather. To solve this challenge, this paper uses a deep learning model for semantic segmentation of street scenes. Semantic segmentation takes advantage of the spatial invariance of photos in computer recognition to segment the visual information in daily life into each category by computer processing and converts all pixels belonging to each category into a uniform color (Ju et al. 2020), and this technique has higher accuracy compared to extracting with image color features.
DeepLab V3 + model
In this paper, Deeplab V3 + convolutional neural network model is used as the algorithm of semantic segmentation, and the framework is the third generation improvement version of the Deeplab neural network series proposed by Google, and the concept of spatial convolution is proposed in the previous v1, v2 and v3, which effectively solves the problem of excessive resolution of images in semantic segmentation, thus the parameters of network learning are greatly reduced and the network training speed is greatly accelerated (Fig. 4). Compared to the traditional FCN which is not perfect in processing the detailed part of the image and does not take into account the pixel-to-pixel relationship and other problems, Deeplab V3 + maintains the original spatial convolution and ASSP layers and adds the Xception model to improve the accuracy of image feature sampling(Chen et al. 2018).

The input and output of the DeepLab V3 + and the details of the network structure
Model training and computation
The operating system used in this paper is Windows 10, the open source neural network framework TensorFlow is used, and the graphics card used for training is GTX 2080s. The CityScapes dataset is a dataset for understanding urban street scenes, jointly provided by three German units including Daimler, and contains stereo visual data from more than 50 cities, which is the most commonly used dataset to evaluate the performance of vision algorithms for urban neighborhood scenes (Cordts et al. 2016). In this paper, a semantic segmentation model is trained based on the 50-city German autopilot dataset provided by CityScapes, combined with a pre-trained model after 100,000 iterations. The crawled streetscape photos are fed into the network and processed by convolution and pooling operations to achieve image classification and semantic segmentation. Since the data volume of streetscape images is too large and the manual recognition is too time-consuming, in order to realize the automatic recognition of GVI, the semantic map after recognition segmentation is analyzed by using OpenCV to calculate the total number of pixel values occupied by each category in the segmentation result, and the GVI calculation formula is
The pixels of all green parts in the image are denoted as \({N}_{g},N\) is the total number of pixels in the whole panorama.\({R}_{G}\) is the GVI result of each panorama.
Spatial regression model
According to the first law of geography, there is a corresponding connection between points in space. In order to explore the driving factors of GVI, it is first necessary to test the spatial autocorrelation of the spatial distribution of GVI. Moran’s I is used to test the spatial autocorrelation of GVI. Based on the geometric distance between each sampling point, this paper uses the K-nearest neighbor method to establish the spatial weights of the whole area to calculate Moran’s I through the latitude and longitude coordinates of sampling points.
The local Moran’s analysis is used to find the degree of regional association in different geographic locations and is used to test whether the high and low values of local areas with high and low green-visibility rates show clustering in space. In order to understand the relationship between the influencing factors and the green view rate, four different spatial models were selected to fit the regression between the green view rate and the influencing factors in this paper. They are ordinary least squares (OLS), spatial lag model (SLM), spatial error model (SEM), and geographically weighted regression (GWR) (Gao et al. 2020). The optimal model is selected by Log likelihood (LogL), Likelihood ratio (LR), Akaike information criterion (AC), Schwartz criterion (sc). The larger the LogL, the smaller the AC and SC values, the larger the LogL, the smaller the AC and SC values, the better the model fits.
Ordinary least squares (OLS)
OLS is a global regression method used to study the relationship between the dependent and independent variables, which can be shown by the formula
where \({y}_{i}\) is the dependent variable (GVI in this paper), \({x}_{i}\) is the independent variable, \({\varepsilon }_{i}\) is the error term, β is the coefficient of the independent variable and \({\beta }_{0}\) is the intercept. However, OLS as a global regression model, the regression coefficient estimates obtained by it are the average values of the whole study area, which cannot reflect the real geographic characteristics of the regression parameters, and the multicollinearity between variables can affect the results (Han et al. 2020).
Spatial lag model (SLE)
The SLE model is mainly used to study whether a variable is spatially diffuse or not, and its expression is
\(Y\) is the dependent variable, X is the independent variable, \(\rho\) is the spatial lag coefficient, \(Wy\) is the spatial weight matrix, \(\varepsilon\) is the random error, and \(\beta\) is the independent variable coefficient(Han et al. 2020). Reflecting the role of spatial distance on the variables in the region (GVI).
Spatial error model (SEM)
The spatial error model, as the name implies, considers random disturbance terms (error terms) correlated in space, and its expression is
\(\beta\) is the independent variable coefficient, Y is the dependent variable, X is the independent variable, \(W\varepsilon\) denotes the spatial adjacency weight matrix of the residuals (residuals are the difference between the actual observed values and the estimated values (fitted values); \(\lambda\) is the regression coefficient of the spatial residual term; \(u\) denotes the error term that is not spatially correlated, so the spatial correlation effect on the dependent variable (GVI) is not considered (Han et al. 2020).
Geographically weighted regression (GWR)
Geographically weighted regression is an extension of ordinary linear regression in which the regression coefficients for a particular locality in the model are no longer assumed constants obtained using all the information, but variables that vary spatially with local geographic location, estimated by local regression using information from a subsample of neighboring observations.
In the above equation, \(\left({\mu }_{i},{v}_{i}\right)\) is the coordinates of sampling point i,\({\beta }_{0}\) is the intercept, yi is the dependent variable, xi is the independent variable, \({\varepsilon }_{i}\) is the random error. \({\beta }_{k}\left({\mu }_{i},{v}_{i}\right)\) is the k regression parameter on sampling point i, which is a function of geographic location, and is obtained by using the weight function method in the estimation process (Gao et al. 2020).
Analysis of results
Model validation analysis
In this study, we propose to perform semantic segmentation of street photos by DeepLab V3 + algorithm for recognition to calculate GVI. In order to prove the effectiveness of this model, we validate it by comparing with the results of previous studies. We compared four algorithms, PSPnet, DeepLab V3, Fastrcnn, and HSV color thresholding. It is obvious from Fig. 5 that the DeepLab V3 + in this paper has the highest accuracy in terms of segmentation compared with the other four methods. HSV color thresholding is segmented by thresholding the image color, and the selected threshold value causes uncertainty in segmentation. And the green areas in the image that are not vegetation are also segmented, such as garbage cans, store signs, etc. Therefore, the overall accuracy is the lowest, while PSPnet, Fastrcnn, DeepLab V3, and other three algorithms all have some segmentation errors to a certain extent, resulting in some vegetation not being accurately identified. The DeepLab V3 + algorithm used in this paper has the lowest segmentation error and more accurate segmentation boundary for vegetation. It proves that the algorithm of this paper is effective in vegetation segmentation calculation of GVI.

Comparison of different semantic segmentation algorithms
GVI value distribution
Overall analysis
As shown in Fig. 6, the overall GVI of the streets in Jing’an District is good, and after excluding the points where the streetscape does not exist, the GVI results are obtained for a total of 3870 points. According to a study by the Japanese scholar Yoji Aoki, when the GVI is higher than 25%, people have the feeling that the surrounding environment is green; when it is higher than 50%, people have the psychological feeling that the greenery is good, and people are more relaxed and happy mentally (Yoji Aoki, 1987). The overall level of GVI of streets in Jing’an District can basically meet the standard.

Histogram of greenery distribution in Jing’an District. a. Distribution of Average Green Vision Ratio of sampling sites. b. Distribution of Average Green Vision Ratio on Streets
In order to explore the average road GVI level, after distributing all the points into the road network equally, the total number of 424 roads in the whole Jing’an District, the highest GVI of roads is 54.2%. According to the distribution map shown Jing’an District’s overall GVI level at about 0.11% the first peak, at about 30% the second peak, in the overall level is relatively smooth. The distribution shows an approximately normal distribution.
Partition analysis
According to the previous paper, the distribution of GVI values in the southern, central and northern parts of Jing’an District were counted separately, and the results are shown in Table 2 below. 135 total road sections were found in the central area, with a maximum GVI of 38% and a minimum GVI of 0.9%, and an average GVI of 14.6%. The overall variance is 0.006, compared with the variance of 0.019 for the whole Jing’an district, indicating that the GVI distribution in the central part of Jing’an district is more stable. The overall GVI level in the central part shows an approximately normal distribution, but the average GVI is much lower than the normal level of 25%, due to the poor greening of the old roads in the central area, resulting in a low GVI. According to Fig. 7, there is a singular value around 10%-13%, and the number of roads in this interval is the most in the overall roads, which can best represent the average GVI level in the central region. The roads in this GVI range do not have a special distribution pattern or gather in a certain area, but present a partial aggregation in the southeast and southwest corners, and it is estimated that the singular value is due to a factor in these two areas that causes the two areas to present clustering. The GVI in the northern part of Jing’an District is more balanced, with 135 total roads in the north, which is equal to the collected roads. The average GVI is 24.96%, and the overall GVI level is better in the north compared to the central stage, with a maximum GVI value of 46.5% and a minimum value of 3%, with a GVI variance of 0.009, and a more stable overall GVI level than in the central part. Comparing with the histogram of the average GVI distribution of the northern roads, the overall green level in the northern region is better, basically reaching 25% of the normal level. The overall distribution shows a normal distribution, with odd values in 26–30%, and the distribution of road sections reaches 28 road sections, which is just near the overall GVI mean value, and the road sections in this range can best represent the average GVI level in the northern region. Comparison of the southern GVI distribution histogram can be obtained, the southern region GVI distribution is also showing a normal distribution, the overall distribution is relatively smooth, in the 30–36% near the presence of odd values, the number of roads in the range of 63, can basically represent the normal level of the region.

Histogram of greenery distribution in Jing’an District. a. Histogram of greenery distribution in central Jing’an District. b. Histogram of greenery distribution in southern Jing’an District. c. Histogram of greenery distribution in northern Jing’an District
GVI spatial distribution
Overall analysis
The GVI spatial visualization is shown in Fig. 8, and the set collection points are recalculated based on the actual roads, and the collection points on the same road are averaged to each road. The average GVI of streets was classified into 5 grades by Nature Breaks method(Chen et al. 2013), with 0–7% as worst, 8%-18% as worse, 19%-28% as mideam, 29%-38% as better, and 39%-54% as best. The distribution map shows that there are obvious regional characteristics in the distribution of GVI in the whole Jing’an District, with the overall GVI distribution in the south of Jing’an District being good, in the central part of the district being largely poor, and in the north being more evenly distributed.

Results of the study of the distribution of green Vision on roads in the region
Spatial autocorrelation analysis
In order to study whether the distribution pattern of GVI within Jing’an District is correlated with the internal area, spatial autocorrelation analysis was conducted for the GVI within the whole Jing’an District. The Moran’s I value of the GVI of the whole Jing’an District was calculated, and the result was 0.551, with an obvious positive spatial correlation. The local spatial autocorrelation analysis shows that the central region of Jing’an District shows a clear clustering of low GVI values, and in the north there is a partial clustering of low and high values. The southern region, on the other hand, mainly shows high value clustering. Consistent with the previous spatial distribution results, Fig. 9 shows that the GVI in Jing’an District shows a significant level of aggregation.

Spatial Autocorrelation(Moran’s I) Analysis. (a) Global Moran Analysis Scatterplot. (b) Partial Moran clustered scatter plot. (c) Partial Moran distinctive scatter plot
The southern part of Jing’an District is mostly secondary roads and bypasses, and the overall GVI distribution is relatively good, with mostly high values clustered. In the central area, there are elevated roads and bypasses, but in contrast to the southern area, most of the bypasses do not have high values, showing a large number of low values clustered. In contrast, in the northern region, the road conditions are more even. In the north, the main elevated road sections show a concentration of low values while high values are distributed with each bypass, and the overall distribution is more balanced.
Analysis of driving factors
Multicollinearity analysis
In order to prevent the presence of multicollinearity in our selected indicators from generating errors in the established regression models, all the indicators for which regression models were established were tested to verify the correlation coefficients between the variables before regression. The results are shown in the Fig. 10, and the Pearson correlation coefficients for all indicators are between 0 and 1. Except for the correlation coefficient between the same variables, which is 1, all of them are less than 0.8. Therefore, there is no significant linear relationship between all independent variables.

Multi-collinearity testing of regression equation metrics. Each cell in the figure indicates a correlation between two factors, and a correlation greater than 0.8 indicates that the factor is significan
Regression model analysis
The results of the OLS regression of the GVI of each sampling point by the road class to which it belongs are shown in Table 3. The P-value of the road class is less than 0.01 at 99% confidence level and the coefficient is -0.048 indicating that there is a significant negative correlation between the road class and the GVI of the road. The regression P-value of road length and GVI is 0.028 less than 0.05. It is significant at 95% confidence level. While the coefficient is smaller proves that there is a weak positive correlation between the length of the road and the GVI of the road.
By running Ordinary Least Squares (OLS) regression of the mean GVI values at the neighborhood level and the average house price at the neighborhood level, an R-Squared of 0.07 can only represent 7% of the sample. But the p-value is highly significant at the 0.01 level. The residuals of the regression were tested for autocorrelation with Moran’s I of 0.6767. Therefore, the residuals are spatially correlated. The residuals of the OLS were then subjected to lagrange Multiplier test and Robust LM test. The results are shown in Table 4. From the table shows that both lag and error of lagrange Multiplier are significant, and continue to analyze Robust LM results, p < 0.01 for Robust LM(lag) and p > 0.01 for Robust LM(error). therefore, the optimal spatial autocorrelation model in this paper is SLM spatial lag model. The spatial heterogeneity model was established by the geographically weighted regression tool of ArcGIS. The SLM results are compared with OLS results and GWR geographically weighted results in the following Table 5 By comparing the results of the four models, Among them, SLM has the smallest AICc value and the highest R2 of 75.4% as the optimal model. According to the regression coefficient 1.88699e-007 in the SLM model proves that the house price in the middle neighborhood of Jing’an district shows a significant positive correlation with the GVI value. While we establish OLS regression for street economic input and GVI with p-value of 0.76 > 0.05 and chi-square test with p-value of 0.77 > 0.05. Therefore, the original hypothesis is rejected and it is proved that there is no significant correlation between street economic input and GVI.
For the social indicators, the number of POIs in each category for each neighborhood range was counted to establish a regression model with the average GVI of the neighborhood. The OLS regression results are shown in Table 6. It can be found through the above table that the GVI has a significant positive correlation with schools, hospitals, and attractions. The regression results of GVI with subway, square, and shopping mall show a significant negative correlation. The rest of the variables are not significant. The non-significant variables were excluded and the OLS regression was continued. The R-squared of the regression was increased from 0.20 to 0.21. There was no significant increase. From the previous section, it is clear that there is significant spatial autocorrelation in the GVI of the study area, so the residuals of the OLS regression results are tested for spatial autocorrelation, as well as the lagrange Multiplier test and Robust LM test. The result Moran’s I is 0.5685 there is significant spatial autocorrelation, while lagrange Multiplier’s lag is significant at the 0.000 level. Thus there is spatial dependence, consistent with the above. The SLM model was continued to be chosen for the fitting. The fitted R-squared is 0.7540. P-value for metro station and hospital is significant at 0.05 level.
Discussion
Determination of GVI
In previous studies, due to the lack of sufficient data, the sampling locations of street images are mostly chosen as a certain section of a neighborhood, or the spatial photos of streets in some areas are collected manually by cameras and so on. For example, CBD. With the rapid development of web data street view services, street view map services can provide a large number of photos of street space, such as in this study, we obtain the current situation of street space by calling Tencent Street View Map. Previously, some scholars used Street View Map to obtain the GVI values calculated from 4 horizontal 90° pictures and averaged them to calculate the GVI. Some scholars also calculated the average GVI from 6 pictures with a heading angle of 60° or 8 pictures with a horizontal angle of 45°. In this study, we stitched 6 horizontal 60° street view pictures into a horizontal cylindrical projection panorama by PTgui software and directly calculated the GVI. This method avoids the computational overlap error that occurs in the overlapping part of multiple street views. Dong compared the errors of several methods and concluded that the method in this study is the most appropriate.
This study proposes the semantic segmentation by DeepLab V3 + algorithm combined with streetscape maps to achieve the measurement of road space GVI. Unlike previous studies, this study can automatically identify the GVI size of road space in large quantities through a neural network framework, as opposed to manual segmentation and extraction of street scenes through PS software. The DeepLab V3 + applied in this paper has the highest segmentation accuracy compared to the deep learning PSPnet, FCN, and other frameworks applied by previous scholars. The overall distribution of green landscape rate in Jing’an District is obtained through semantic recognition analysis, and it is very obvious that there are obvious regional differences as well as spatial autocorrelation in GVI of road space in Jing’an District, and the reasons for the spatial regression model are explored.
Spatial regression model for the analysis of GVI
In this paper, by studying the relationship between road class and road width and GVI, we get that the average GVI of streets shows a certain negative correlation with road class and a certain positive correlation with road length. The reasons for this result may be: (1) The higher the road grade, for example, in primary roads, there are often more elevated sections, and the presence of elevation will make the GVI range in the field of view significantly lower. (2) Since the study area is Jing’an district, there are only three grades of roads in the study area, and the range of high grade roads exists only for the sections related to the north–south elevated roads, while the others are mostly low grade roads. So it causes the sample of high grade of roads is not enough and there is obvious GVI difference. Usually in our perception, the longer the road length degree, the more open view in the field of view will continue more greenery, so the GVI is higher.
In contrast, when the GVI of the block was regressed with the economic input of the block, the economic level of the block was not significantly correlated with the GVI. The reasons for this are (1) due to the limited access to data and the large scope of the block, the GVI averaged to the block is no longer significantly representative of the region. Therefore, the analysis results are not correlated. (2) Since the greening of blocks in Shanghai is managed by the Shanghai Municipal Bureau of Greening and Urbanism, there is no specific statistical division of the economic investment in greening for each block in the Shanghai Municipal Bureau of Greening and Urbanism. Therefore, it may lead to insignificant regression results between block-wide economic inputs and GVI. In contrast, there is a significant positive correlation between the average house price within the block and GVI, and the R-square of the SLM model proves to explain 75% of the block GVI level. Since the green environment and quality of neighborhoods are directly linked to house prices. The green space construction in and around the neighborhoods with higher house prices is generally better, and the government’s construction specification will also give the developer a certain range of public greenery construction outside the planning red line as an additional condition, and after the construction is completed, it will be transferred to the Greening and Amenities Bureau for unified management and maintenance. Therefore neighborhoods with higher house prices will strengthen the greening of the surrounding streets, therefore further affecting the GVI level of the streets.
The regression of GVI with schools, hospitals, and attractions in the previous section is significant and positive. The GVI showed a significant negative correlation with subways, plazas, shopping malls, etc. In the SLM model, GVI showed a significant negative correlation with subway stations and a significant positive correlation with hospitals. The reasons for this are as follows: (1) Most of the subway stations in Jing’an District are located on major roads and road intersections, and the view near the subway stations is occupied by elevated roads and subway lines, resulting in a lower percentage of greenery in the space. (2) The greening effect in hospitals is generally good, due to the influence of the policy of breaking down the wall and greening in three dimensions so that the good greening inside the hospital increases the greening in the view of the street, and thus the GVI of the road is improved. The significant factors of schools, attractions, plazas, and shopping malls in the OLS return may be due to the functional needs of these places themselves. For example, plazas require sufficient hard paving and open space for evacuation, schools require playgrounds, shopping malls need entrance gathering plazas, etc. These variables are not significant in the SEM model, indicating that their spatial effects are limited.
Discussion of the differences in GVI distribution
Combining the characteristics of the GVI distribution in each part, the study makes a preliminary guess about the variability of the area in which it is located. In order to verify the correctness of the reason for the guess, an example analysis is made based on Moran’s locally significant results for the areas showing very significant high and low values in the whole Jing’an district and the areas where high and low values are clustered within each partition. The minimum values of GVI in the three sub-areas were analyzed as shown in Fig. 11. The minimum value in the whole Jing’an District is the northern area. According to Fig. 11, most of the low levels in the north are constrained by the elevated road sections, which block the view to different degrees due to the elevation causing a significant reduction in the green level in the view, as well as the influence of some road intersections. The low values in the center according to the significance map can be seen mainly gathered in the central northwest, southeast section as well as elevated road sections, through the example map, it can be seen that the extent of the road sections are low greening, mostly for the lack of street trees. Most of the road is in disrepair, construction. So the greenery on both sides of the street is seriously damaged. A few areas are affected by elevation like the north, leading to a lower percentage of green space under the viewpoint. Through the overall comparison, the road width of the whole central region, the form is basically close. The reason for the change in GVI is that the old roads in the central region are in serious disrepair, and the single road form makes the roadside greenery destroy seriously, and thus the GVI decreases. In the south, there are fewer low values from the visualization results, and a small number of them exist in the intersection of the streets and the internal roads of some neighborhoods. Therefore, the reason for the low GVI in the southern area is the poor greening of the internal roads of some subdivisions and the road restrictions of the road intersections that lead to the absence of street trees or single street trees, resulting in the low GVI.

Case study on the types of characteristics in the Jing’an district
Meanwhile, according to the significance results, the clustering of high GVI values in the three sub-districts was analyzed by example, and the highest GVI values of roads in the whole Jing’an District were found in the southern area, and a large number of high GVI values were clustered in the south. The GVI maximum road sections in the south are distributed in the northern section of the southern region, and the road sections with high GVI values basically run through the entire southern region, and there is no certain special distribution pattern, so the overall unified analysis. According to Fig. 11, the road width along the river section is smaller and the greening configuration is higher, which leads to the maximum GVI. The highest value of GVI in the central region is located in Baoshan Road section, due to the good growth of roadside greenery and the rich level of greenery configuration leading to the high level of GVI. The maximum values in the northern region are mostly located in the roads around the urban green areas, where the high greening of the green areas leads to a significant increase in the proportion of green in the field of vision, and the overall roads basically show a similar road width, although the greening configuration is relatively single compared to the central region, but the street trees in the range are growing well and the canopy is also relatively complete. Therefore, the overall GVI level is relatively good. The main reason for the regional nature of the entire study area is the difference in the roadside greenery level of the road and street space, while the central area, which has the lowest GVI level, is mostly old internal roads, and a lot of construction has destroyed a lot of street greenery. In contrast, the northern area, compared to the central area, does not have a lot of construction, and the level of greenery is basically at a normal level. In the southern region, the level of road greening is greatly improved, and the greening configuration of some road sections is more abundant in level making the southern region the highest GVI.
Limitations of this study
The following limitations exist in this study. First, this paper conducts research through the streetscape photos provided by Tencent Maps, but some lots lack the corresponding streetscape maps, and the points can only be removed by hand. Second, the street view photos were taken too early, which may not be consistent with the current situation leading to errors in the analysis. Thirdly, the viewpoints of the streetscape map come from the carriageway, and it is impossible to collect the distribution of greening viewpoints under the viewpoints of the sidewalk. In the future, we can consider combining the streetscape map with the field survey to compare the distribution of green landscape rate in streetscape space from multiple perspectives and analyze the evolution of urban green space by combining the current situation and past streetscape.
In addition, this paper uses neural network for streetscape recognition. The accuracy of recognition is affected by the neural network algorithm, and later with the development of research has a more accurate recognition algorithm applied to the extraction of GVI. Finally, due to the limitation of the obtained data, such as the population distribution data at the street block level and the expenditure budget of urban street greening cannot be obtained. In the future, there is a need to combine more indicators and data sets for a more detailed study of urban greening development.
Finally, three indicators of economic, social, and governmental planning are selected for the study, but for different research problems, different indicators may be considered and not limited to economic, social, and governmental planning. Considering of different countries and regions background (e.g., climate factors in extreme cold region), new indicators may be added for new situations.
Conclusion
As an answer to the questions 1 and 2, this paper is based on DeepLab V3 + algorithm for semantic segmentation, combined with the street view provided by the map service provider to study the GVI of the street space. This paper generates equal volume cylindrical projection from six different horizontal angles of the street view through the panoramic synthesis software to simulate the 360° surround effect of a person. The synthesized photos are segmented semantically by a neural network model, and the segmentation category map is output using OPENCV to identify the proportion of greenery, and finally the GVI levels of the streets in the study area are obtained. The study shows that there is an obvious spatial relationship between the distribution of greenery visibility in Jing’an District, and the GVI levels in the central, northern, and southern parts of Jing’an District are more different. Among them, the GVI distribution is better in the southern area, while the overall GVI level in the central and northern areas needs to be improved. Especially in the central area, there is an obvious clustering of low GVI values, and the reason for this difference is mostly the difference in the roadside greening level of road and street space, and the massive destruction of street greening by a large amount of construction.
This paper analyzes the GVI from three perspectives: economic, social, and governmental planning, and uses a spatial model that combines the spatial attributes of the GVI to find that the road class is negatively correlated with the GVI, while the length of the road is positively correlated with the GVI. Distribution of hospitals showed a significant positive correlation and a negative correlation with subway stations. This will provide targeted guidance and help for future street greening planning and design.
Based on research on urban GVI in this paper, targeted renovation strategies can be proposed for specific areas, and the following strategies are proposed for improving the overall urban street GVI. (1) Policies should support to break walls to penetrate greenery. Although Jing’an District has already implemented the practice, but there are still some old neighborhoods with solid walls. In the next urban renewal, such areas should be broken to enhance green permeability. (2) In urban construction, the greening layout of street space should be focused on, and the greening design should be emphasized in elevated sections to avoid the lack of GVI in elevated sections. (3) In the next phase, the greening level should be upgraded while making up for the shortage of GVI in the central and northern section. Accelerate and improve the green infrastructure construction in the area, improve the GVI at the junction of the central, southern and northern areas, enhance the coordination and balance of greening in the city streets, and finally improve the overall greening quality of the city streets. This study provides new ideas for the optimization of urban ecosystem assessment. Limited by current conditions such as data acquisition, a more precise analysis of the influencing factors of GVI combined with new data and frameworks will provide scientific guidance for the construction and renovation of green space in streets.
Change history
02 December 2021
A Correction to this paper has been published: https://doi.org/10.1007/s12145-021-00726-y
References
Chen J, Yang ST, Li HW et al (2013) Research on Geographical Environment Unit Division Based on the Method of Natural Breaks (Jenks). Int Arch Photogramm Remote Sens Spatial Inf Sci XL-4/W3:47–50. https://doi.org/10.5194/isprsarchives-XL-4-W3-47-2013
Chen L, Papandreou G, Kokkinos I et al (2018) DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans Pattern Anal Machine Intell 40:834–848. https://doi.org/10.1109/TPAMI.2017.2699184
Chen J, Zhou C, Li F (2020) Quantifying the green view indicator for assessing urban greening quality: An analysis based on Internet-crawling street view data. Ecol Ind 113:106192. https://doi.org/10.1016/j.ecolind.2020.106192
Chen X, Wang Y, Dai Z, Ma X (2020) Research on demand identication for customized bus based on multi-source mobility data. Big Data Res 6:105–118
Chen Z, Huang G (2020) Research progress on supply and demand of urban green space: differences and connections. Chin J Appl Ecol 1–11
Cordts M, Omran M, Ramos S, et al (2016) The Cityscapes Dataset for Semantic Urban Scene Understanding
Cui Z, He M, Lu M (2018) An Analysis of Green View Index in Cold Region City: A Case Study of Harbin. J Chin Urban Forestry 16:34–38
Gao C, Feng Y, Tong X et al (2020) Modeling urban growth using spatially heterogeneous cellular automata models: Comparison of spatial lag, spatial error and GWR. Comput Environ Urban Syst 81:101459. https://doi.org/10.1016/j.compenvurbsys.2020.101459
Guo F, Lyu X, Yu W et al (2020) Performance evaluation and driving mechanism of green development in Shandong Province based on panel data of 17 cities. Sci Geogr Sinica 40:200–210
Han Y, Qi X, Yang Y (2020) Analysis of the spillover effect of energy intensity among provinces in China based on space-time lag model. Environ Sci Pollut Res 27:16950–16962. https://doi.org/10.1007/s11356-020-08169-6
Helbich M, Yao Y, Liu Y et al (2019) Using deep learning to examine street view green and blue spaces and their associations with geriatric depression in Beijing, China. Environ Int 126:107–117. https://doi.org/10.1016/j.envint.2019.02.013
Ju H, Wei L, Susan T, et al (2020) CrackU‐net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct Control Health Monitor 27
Li F, Shi H, Sa L et al (2017) 3D green volume measurement of single tree using 3D laser point cloud data and differential method. J xi’an Univ Architect Technol 49:530–535
Li F, Xie S, Li X (2019) Evolutionary driving mechanism of greenspace in central Beijing City based on the PLSR model. J Beijing Forestry Univ 41:116–126
Li Z, He Z, Zhang Y et al (2020) Impact of greenspace exposure on residents’ mental health:A case study of Nanjing City. Progress Geogr 39:779–791. https://doi.org/10.18306/dlkxjz.2020.05.007
Liu Z, Han C, Wang J, Hong G (2020) Influence of socioeconomic factors on the green rate of built districts in China from the perspective of spatial spillover effect. J Suzhou Univ Sci Technol (Engineering and Technology) 33:39-44+80
Long Y, Liu L (2017) How green are the streets? An analysis for central areas of Chinese cities using Tencent Street View. PLoS ONE 12:e0171110. https://doi.org/10.1371/journal.pone.0171110
Luo X (2020) GIS-Based Research on Evaluation and Construction of Ecological Greenland System in Industrial Cities – Taking the Built-up Area of Zibo City, Shandong Province as an Example. PhD Thesis, Shandong Jianzhu University
Matsumoto T (2008) Issues and Future Prospects for Regulatory and Guidance Methods to Create a Good Landscape. J Japan Real Estate Soc 22:104–113. https://doi.org/10/gjt97t
Meng Q, Wang X, Sun Y et al (2020) Construction of green view index model based on street view data and research on its influence factors. Ecol Sci 39:146–155
Ru X, Jiang T (2015) Analysis on Evolution Driving Factors and Landscape Pattern of Urban Green Space -Taking Built-up Area of Ji’nan City as an Example. Res Soil Water Conserv 22:197–203
Shen S, Liu X, Sun X, Ding L (2020) Regional Coupling Differences of Green Coverage Rate and Green Space Rate of the Cities with Districts in China——A Perspective Based on Dry and Wet Climate Zoning. J Northwest Forestry Univ 35:236–241
Wang K, Yan B, Wang F, Gao X (2014) Countermeasures of Urban Planning to Manage“Urban Disease”: The Experiences from Foreign Countries. World Regional Studies 23:65–72
Wang R, Helbich M, Yao Y et al (2019) Urban greenery and mental wellbeing in adults: Cross-sectional mediation analyses on multiple pathways across different greenery measures. Environ Res 176:108535. https://doi.org/10.1016/j.envres.2019.108535
Wang H, Hu Y, Tang L, Zhuo Q (2020a) Distribution of Urban Blue and Green Space in Beijing and Its Influence Factors. Sustainability 12:2252. https://doi.org/10.3390/su12062252
Wang J, Liu Z, Liu L, Hong G (2020b) Study on the Influencing Mechanism of Spatial Differentiation of Green Rate of Built District of Typical Transects in China Based on Geodetector. Ecol Econ 36:104–111
Wei Y (2016a) Research on Visible Green Index Evaluation of High Density Urban Area on Macau Peninsula. PhD Thesis, South China Agricultural University
Wei Y (2016b) Research on Visible Green Index Evaluation of High Density Urban Area on Macau Peninsula. Master’s thesis, South China Agricultural University
Xiao X, Wei Y, Li M (2018) The Method of Measurement and Applications of Visible Green Index in Japan. Urban Plann Int 33:98–103
Xu L, Jiang W, Chen Z (2018) Study on Perceived Safety in Public Spaces: Take Perception of Stree View in Shanghai as an Example. Landsc Architect 25:23–29
Yang W, Li X, Ye C (2019) Evaluation Index System for Urban Green System Planning. Planners 35:71–76
Zhang W, Zhou Y et al (2019) Research on automatic identification and measurement of panoramic visible green index. Landscape Architecture 26:89–94
Zhao H, Wang S, Meng F et al (2020) Green space pattern changes and its driving mechanism:a case study of Nanjing metropolitan area. Acta Ecol Sin 40:7861–7872
Funding
National Natural Science Foundation of China (51978329, 51778364).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by H. Babaie
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised: The Figure 1 contained errors and has been corrected.
Rights and permissions
About this article

Cite this article
Gou, A., Zhang, C. & Wang, J. Study on the identification and dynamics of green vision rate in Jing’an district, Shanghai based on deeplab V3 + model. Earth Sci Inform 15, 163–181 (2022). https://doi.org/10.1007/s12145-021-00691-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12145-021-00691-6