
Abstract
Wireless Sensor Network (WSN) is the one of the hot area of research in which energy stability and network lifetime are considered to be the twin challenges during its application. Clustering is the optimum energy efficiency strategy that organizes the sensor nodes into potential groups for the objective of attaining energy stability and network lifetime. In this energy potent clustering process, cluster head selection is determined to be highly significant in order to balance energy among the nodes sensor nodes. Moreover, two-tier cluster head selection that includes temporary and final cluster head is identified to be challenging in WSNs. In this paper, Hybrid Fuzzy Logic and Artificial Flora Optimization Algorithm (FL-AFA)-based Two Tier Cluster Head Selection is proposed for improving energy efficiency and prolog network lifetime. This FL-AFA scheme achieved the cluster head selection in two stages, such as, i) Temporary Cluster Head (TCH) selection using FL and, ii) Final Cluster Head (FCH) selection using AFA. In the first stage, the concept of fuzzy logic applied over the input parameters of residual energy (RE), distance to BS (DTBS), and node degree (NDE). In the second stage, the benefits of AFA is employed for computing the fitness function through distance to nearby nodes (DNN), cluster compactness estimation factor (CCEF), and position estimation (PE). Simulation experiments of the proposed FL-AFA scheme and the benchmarked schemes are conducted based on the evaluation metrics of energy efficiency, network lifetime, average delay, and packet delivery ratio (PDR) under the impact of different sensor nodes. .
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
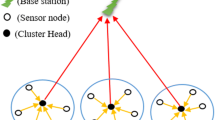
Wireless Sensor Networks (WSNs) comprise of a massive number of sensor nodes (SN) that are deployed in an intended atmosphere for the purpose of sensing, estimating and collecting the data in order to attain make decisions. WSN is applied in numerous applications such as climatic prediction, military force, hospital science, and different types of commercial and industrial sectors in which action is essentially based on the decision derived from the collected data [1]. These deployed SNs are determined to be cost-effective and compact with its inherent potentialities of prediction, computation, and data transmission. SNs are small in size with constraints imposed with respect to restricted energy source. The sensor nodes are responsible for gathering data through Analogue to Digital Converter (ADC) in order to transmit data to the Base Station (BS) or sink node. In BS, the received data is examined for potential decision making for the purpose of initiating required actions needed in the environment. Moreover, the sensor nodes operate as a repeater for transmitting data to alternate SN and BS. Unfortunately, the batteries cannot be replaced or recharged as it is placed in harsh regions or unattended environment for the objective of mitigating issues that hurdles the performance of the given power source in an appropriate manner [2]. In addition, the performance of WSN is influenced by a diverse number of attributes like scalability, fault tolerance, energy efficiency, and so forth. In this context, the sensor nodes drain its power in two different ways, namely sensing the ecological attributes and sending data to BS via intermittent nodes. Transmission of data in WSN consumes massive energy when compared with sensing and computation of data. In WSN, the major challenging issues are inadequate energy sources of SN. As a result, network failure or error exists and leads to node failure. Most often, the SN is draining its energy quickly as the direct data transmission takes place from SN to BS. Additionally, effective power application in WSN is essential to accomplish extended lifetime and enhance the WSN’s performance. The organization of sensor nodes into potential groups is termed as clusters are applied for the purpose of limiting energy utilization and to enhance the system reliability. Every cluster is comprised of a leader termed as Cluster Head (CH) which connects with alternate CH of a system [3]. A sample clustering architecture in WSN is shown in Fig. 1. Since a massive quantity of energy is essential in direct data transmission, a routing protocol has been employed in the grouped WSN to find optimal routes among CH and sink to mitigate energy utilization. The attributes of routing protocols have fault tolerance, scalability, data accumulation, reliability, and so on.

Architecture of clustering in WSN
The main goal of this work is to limit the energy utilization of nodes while transmitting the data directly. It guides to enhance the overall packet transmission to BS by reducing energy utilization by SN. The selection of CH is considered as an optimization problem, and swarm intelligence (SI) techniques can be used to solve it. SI techniques are significantly employed in this study as it is capable of searching, processing, and self-adaptability. Additionally, different studies were introduced for optimizing the performance metrics of WSN like energy cost, network lifespan, and so on [4]. The reduction of SN’s energy application is one of the significant attributes of WSN. Hence, the clustering model was applied widely as it is capable of resolving the issues involved in SN. The traditional routing protocol is inferior because of its difference in energy supply.
In this paper, A Hybrid Fuzzy Logic and Artificial Flora Optimization Algorithm-based Two Tier Cluster Head Selection is proposed for improving energy efficiency in WSNs. This FL-AFA model achieved CH selection through two stages, such as i) Fuzic logic-based tentative CH selection and ii) AFA-based final CH selection. In the first stage, fuzzy logic was applied to three input parameters, namely Node Degree (NDE), Residual Energy (RE) and Distance to Base Station (DTBS). The potential of fuzzy logic is mainly included to handle the uncertainty characteristics of sensor nodes that changes dynamically in the network. Moreover, AFA attained the final process of CH selection based on the computation of fitness function that integrated the factors of distance to nearby nodes (DNN), cluster compactness estimation factor (CCEF) and position estimation (PE). The simulation experiments of the proposed FL-AFA scheme are conducted using the evaluation metrics of energy efficiency, network duration, Packet Delivery Ratio (PDR), and average delays under the influence of different number of sensor nodes in the network.
The major contributions of the paper are listed as follows.
-
i)
The proposed FL-AFA scheme reliably handled the issue of temporary cluster head selection and final cluster head selection based on the merits of the fuzzy logic and the characteristics of AFA.
-
ii)
It is proposed with the capability of balancing the degree of exploitation and exploration in order to prevent the problem of delayed convergence and escape from the local point of optimality.
-
iii)
It is proposed with the potential that prevents frequent cluster head selection by selecting only energy potent sensor nodes as the cluster head in order to reduce delay and at the same time improved the packet delivery rate and throughput.
The remaining sections of the paper are organized as follows. Section 2 presents the comprehensive review of the most recent existing meta-heuristic cluster head selection schemes of the literature with their pros and cons. Section 3 depicts the step-by-step details included during implementation of the proposed FL-AFA scheme that concentrated towards energy efficient cluster head selection. Section 4 demonstrates the experimental evaluation and the results of the proposed FL-AFA scheme compared with the benchmarked schemes considered for investigation, Section 5 concludes the paper with major contributions and possible scope of future enhancement.
2 Related works
In this section, the comprehensive review of the most significant cluster head selection schemes propounded in the literature in the recent years is presented with merits and limitations.
Gravitational Search Algorithm (GSA)-based cluster head selection (GSA-CHS) scheme was proposed for identifying the best CH among a numerous number of CH nodes [5]. This GSA-CHS scheme utilized the residual energy of sensor node during the process of cluster head selection. It also considered the parameters of energy efficiency, intra-cluster distance, and Distance to BS (DBS) during the cluster head selection process. It derived the merits of single hop mechanism for sending data among SN and CH. It adopted the multi-hop model for selecting the next-hop sensor node based on the calculation of the cost function during the process of data propagation and delivery. The performances of this GSA-CHS were determined to be better in terms of energy stability and network lifetime compared to the existing approaches. However, the network lifetime and energy stability of this GSA-CHS is determined to still possess a room in improvement. A Harmony Search Algorithm (HSA)-based Cluster head selection (HSACHS) scheme was proposed for clustering the network and develops an optimal route in WSN for establishing reliable data delivery [6]. This HSACHS also calculated fitness functions based on the factor of Node Degree (ND), energy, intra-cluster distance, and distance among CH and sink. It prevented unnecessary energy utilization by preventing the sensor node with a lower distance from the process of transmitting data. However, the network operations are determined to be highly influenced when the clusters are composed of massive non-CH members.
Further, an Optics Inspired Optimization (OIO)-based cluster head selection scheme (OIOCHS) was proposed for establishing clustering and routing in WSN [7]. This OIOCHS handled the issues of clustering and routing with the help of three significant attributes like ND, energy, and distance for accomplishing remarkable clusters and transmission path, correspondingly. In particular, CH selection was carried out using OIO and a fitness function utilized in allocating nodes to required CH. It always selected the next-hop node with maximum energy in eliminating the data loss is WSN. It was determined to inherit reduced processing complexity by relying on clustering and routing that enhances progressively with respect to the network size. Then, a Biogeography Based Optimization (BBO)-based Cluster Head Selection (BBOCHS) was proposed with the help of factors such as distance between CH and sink, distance between nodes of cluster and RE [8]. This BBOCHS was developed for generating the best shortest route from CH and the sink, and conserving RE of the sensor nodes. In addition, the residual energy of the network was considered to be significantly balanced on par with the compared Genetic Algorithm (GA). Both, OIOCHS and BBOCHS schemes were not capable enough in handling the issues of balancing the trade-offs between exploitation and exploration. A Chemical Reaction Optimization-based unequal clustering scheme was proposed for facilitating a reliable transmission path in WSN [9]. This unequal clustering scheme included a sufficient energy function and molecular structure encoding for selecting CH according to the average BS distance, energy ratio, and node distance. Them, it assigned sensor nodes to each desired CH based on the derivation of the cost function. This clustering scheme handled the problem of imbalanced energy utilization by choosing best CH from a system. However, fault tolerance capability of this unequal clustering scheme was considered to require significant improvement. Simulated Annealing (SA) and Particle Swarm Optimization (PSO)-based cluster scheme was proposed based on the phases of Setup and Steady-state phases [10]. In the setup phase, the CH election and cluster development are operated, and in the second phase, the modes of better nodes are allocated as sleep mode, until computing data transmission. It enabled the normal nodes to forward data to the corresponding CH with Time Division Multiple Access (TDMA) time slot. In addition, it facilitates the CH clusters data packets from corresponding nodes and forward them to the sink.
Furthermore, Ant Lion Optimization (ALOC)-based clustering scheme was proposed for enhancing the energy efficiency of the network [11]. This ALOC scheme computed fitness function based on the parameters of RE, count of neighboring nodes, distance from nodes, and distance between individual sensor nodes and sink. It selected CH depending on the value of the maximum fitness possessed by each of the sensor nodes of the network. It also established effective route from CHs to BS based on the application of Discrete ALOC. An Evolutionary Multipath Energy-Efficient Routing (EMEER) protocol was proposed with the merits of energy efficiency in order to sustain the rate of alive and dead nodes in the network [12, 20]. In this EMEER protocol, the Cuckoo Search (CS) approach was employed for grouping the network based on similarity and energy level attributes [13] [21, 22]. It facilitated CH selection based on the distance from the base station to a specific node, energy level for estimating the measure of trust. The energy utilization of a system is minimized on par with the LEACH, PEGASIS, and TEEN protocols. However, EMEER fails to examine the active nodes, while computing data transmission. In addition, a PSO related energy-constrained clustering routing for reducing the energy application of WSN. A SN with maximum RE is assumed to be a candidate CH in clustering mechanism. Once the PSO clustering is completed, data transmission has been invoked among nodes to CH and CH to sink. Afterward, data collection, aggregation, and CH scattering were essential in WSN. [14] manufactured Fractional lion (FLION) clustering approach for generating effective routing path in WSN. The FF of the FLION module was inter-and intra-cluster distance, energy of CH, normal nodes, and latency. The adjacent solution was predicted by embedding a fractional-order derivative in FLION model. A rapid CH election by applying FLION scheme has enhanced the network duration. But, FLION clustering does not consider the ND in the clustering process [23,24,25].
2.1 Extract of the literature
-
i)
The network lifetime and energy stability of the existing works of the literature are determined to still possess a room in improvement.
-
ii)
Most of the existing schemes were not capable enough in handling the tradeoff between the rate of exploitation and exploration during the process of cluster head selection.
-
iii)
Majority of the existing schemes were not able to handle fault tolerance and prevent frequent cluster head selection during the process of clustering.
3 The proposed FL-AFA based clustering algorithm
The workflow involved in the FL-AFA algorithm is exhibited in Fig. 2. As shown, the nodes in WSN are arbitrarily placed in the target area and the initialization process is carried out. Afterward, the selection of TCHs using FL technique takes place with three input parameters namely RE, DTBS, and NDE. Once the TCHs are chosen, they compete for becoming final CHs by executing the AFA. The AFA makes use of a fitness function using three different parameters namely DNN, CCEF, and PE to elect FCHs. Next to the selection of FCHs, the nearby nodes join the FCH and become a cluster member (CM); thereby clusters get constructed. Finally, data transmission process begins from CMs to CHs and then to BS via intermediate CHs.

Block diagram of FL-AFA based clustering process
3.1 Energy consumption model
Here, the energy consumption approach of radio frequency free space communication was applied. Eq. (1) to (4) shows the energy consumption model [15]:
Where k means the size of forwarded data, d denotes the distance among transmitter and receiver, d0 defines a threshold of node communication distance, ETx(k, d) signifies the energy application of transmission end, ERx(k, d) implies the energy utilization of reception end, Ec represents the energy consumption of data fusion, Eelec illustrates the energy employment of 1-bit data while transmission and reception, εfs and εmp denotes constant distributions where amplification factors of circuit signal amplifiers are employed, EDA refers energy conservation of 1-bit data fusion, M shows the No. of nodes in a cluster.
3.2 FL based TCH selection process
For the selection of TCHs, the FL technique utilizes three parameters namely RE, DTBS, and NDE. The fuzzy sets are implied in Eq. (5).
The above-mentioned input fuzzy linguistic variables are incorporated with unique membership degree divisions as mentioned below:
-
RE is composed of “low”, “medium” and “high;
-
DTBS is composed of “close”, “moderate” and “far”;
-
NDE is composed of “low”, “medium” and “high.
The probably applied Membership Functions (MF) for Fuzzy Inference System (FIS) are triangular MF as depicted in Eq. (8) and Trapezoidal Membership Function (TMF) as illustrated in Eq. (9). μTRI(x) and μTRA(x) refers the membership degree in corresponding MF to define the dynamic modification of respective fuzzy linguistic attributes. a1, b1 and c1 means the mapping scores on X axis of 3 vertices of a triangle correspondingly; a2, b2, c2 and d2 implies the mapping scores on X axis of 4 vertices of a trapezoid correspondingly. Typically, TMF is applied for boundary variables whereas triangular MF is employed for middle variables [16]. The general block diagram of FL mechanism is shown in Fig. 3.

The process involved in FL based TCH selection
The main responsibility of FIS changes the actual input variables into parallel fuzzy linguistic variables according to the input MF. In FL application, an extremely applied model is that instantiation of linguistic function like popular IF premise, THEN conclusion, where premise means decision criteria defined by fuzzy linguistic variables while conclusion denotes the fuzzy output variable. Aldo, IF-THEN rule-based knowledge implication depends upon the natural language representations. It refers that fuzzy engine estimates the score of resultant variables on the basis of rules that use professional’s experience of evaluation systems. Therefore, diverse forms of Mamdani approach presented by TSK fuzzy system apply Eq. (10) for estimating the crisp value as final parameter rather than using fuzzy linguistic variable.
The description of TSK method results y as depicted in Eq. (9).
where m signifies the count of fuzzy rules and αj implies the MF of parallel linguistic variable of fuzzy input variable in the jth rule.
To accommodate this estimation, it is defined as βj in Eq. (10). Next, Eq. (11) is used to define the simulation outcome of \( \hat{y}. \)
Integrating the MFs of 3parameters like RE, DTBS, NDE as well as the existing knowledge of database results in upper function as implied in Eq. (12).
Followed by, the least square estimation for P has been accomplished where the resultant attribute in TSK fuzzy model has been obtained. Afterward, possibility of last crisp value yTSK(X) has been estimated using Eq. (13).
where \( {f}^i(X)\equiv {T}_{K=1}^P{\mu}_{F_k^i}\left({x}_k\right) \), it refers the rule’s excitation intensity and T showcases T-norm. Once the crisp output is accomplished, a node turns competes with CH state, and forwards Head-competing message along with a node’s ID to the adjacent nodes with transmission range “R”.
3.3 AFA based FCH selection process
The elected TCHs execute the AFA to determine the chance of becoming FCHs. AFA is an intelligent optimization algorithm [17], which is based on the feature of plant migration for updating the solutions. The task of identifying best survival location has been employed in this study to identify accurate solution set of issues. The 4 components of AFA are actual plant, offspring plant, plant position, and propagation distance. Also, the behavioral patterns are evolution behavior, spreading behavior, and select behavior. Each plant position implies a solution, and fitness of position has been employed to represent the supremacy of s solution. Initially, the method provides actual plants in a random fashion. Followed by, the seeds are dispersed within the spreading scope where the spreading scope is selected by a propagation distance. Then, the fitness of a seed can be measured on the basis of objective functions where fitness shows the quality of solution quality. Lastly, roulette has been employed in deciding the survival seeds. The survival seeds are developed as actual saplings. The frequent iterations are followed till reaching stopping criteria. The different process involved in AFA is defined as follows and the flowchart is depicted in Fig. 4.

Flowchart of AFA
3.3.1 Initialization
The decision variables of test functions applied in this approach are composed of the upper limit \( {\overrightarrow{X}}^{max}={\left[{X}_1^{\mathrm{max}},{X}_2^{\mathrm{max}},\dots, {X}_D^{\mathrm{max}}\right]}^T \) and lower limit \( {\overrightarrow{X}}^{min}={\left[{X}^{\mathrm{min}},{X}^{\mathrm{min}},\dots, {X}_D^{\mathrm{min}}\right]}^T \). Initially, a method provides N actual plants based on the upper and lower limits of decision variables in random fashion. The approach that applies i rows and j columns matrix Pij to show the place of actual plants, in which i = 1, 2, …, D signifies dimensionality, j = 1, 2, …, N denotes the No. of original plants:
Where rand(0, 1) stands for uniformly distributed values from [0, 1].
3.3.2 Evolution behavior
The original plants generate the offspring within a particular scope of applied propagation distance, where novel propagation distance shows the propagation distance of parent as well as grandparent plant:
where c1 and c2 refers a learning coefficient, dlj and d2j means the propagation distance of grandparent and parent plant correspondingly, and rand (0, 1) showcased the equally distributed values from [0, 1]. A parent propagation distance is considered to be novel grandparent propagation distance as expressed below:
The remarkable AF optimization model applies SD from place of actual and offspring plants as novel parent propagation distance:
To maintain the best solutions, AFA optimization scheme utilized the plants. A novel parent propagation distance is considered as a distance among location of plants \( {P}_{i_d}^{\ast } \) and offspring plants \( {P}_{i_d}^{\prime } \):
3.3.3 Spreading behavior
It produces offspring plants on the basis of actual plant position and propagation distance:
where b = 1, 2, …, B, B denotes the number of offspring plants where an original plant can propagate, \( {P}_{i,j\cdotp b}^{\prime } \) defines the place of offspring plant, Pi, j means the place of original plant, Gi, j · b signifies a random value with Gaussian distribution of mean 0 and variance j. Then, generate novel original plants based on Eq. (14) when no offspring plant exists.
3.3.4 Select behavior
For standard AF approach, the survival probability estimates whether an offspring plant is active or dead which is determined as follows:
Where QX means the selection probability range among 0 and 1. Fmax shows the fitness of offspring plants. \( F\left({P}_{i,j\cdotp b}^{\prime}\right) \) indicates the fitness of (j · b)th solution. Estimation formulas of fitness are assumed to be the objective problem. In AFA model, Pareto dominance functions were employed. Hence, survival probability is described as:
Where domi(j · b) stands for number of solutions dominated by solution (j · b). B denotes the quantity of offspring plants where actual plant might be propagated.
3.3.5 AFA based cluster construction process
Normally, AFA fitness function is capable of resolving the problems involved in the clustering approach. As the clustering scheme is complicated, numerous control packets have to be interchanged among the nodes in CH election, which has resulted in system burden. Hence, this work is completely concentrated on presenting AFA fitness function. In this work, AFA considers the DNN, CCEF, and PE for becoming FCHs. If the CH is selected, then it manages to distribute the CH, eliminate imputed data, combine the closest CH quickly, and energy utilization of CH is higher than member nodes or CM. With no optimal management of energy, the CH node energy is drained simply which results in the premature death of CH. Hence, energy of CH has to be estimated occasionally. Typically, a node with maximum energy is considered as CH node which helps in the effective management of energy conservation. Also, the position of CH has to be organized and to reduce the size of CH placed nearby BS nodes, thus enormous CH sends the data and enhances the practical function.
Consider that there are N nodes in WSN which are developed into K clusters with M(K < < M) candidate CH. Afterward, a network with \( {C}_n^k \) feasible clustering models and deciding the best clustering mechanism is one of the major optimization issues. While applying the AFA fitness function to overcome the optimal clustering model, the outline of the fitness function should be concerned about DNN, DTBS, and PE. Initially, BS estimates the maximum energy of nodes on the basis of energy details from network node [18]. A node with maximum RE is assumed as a candidate CH of recent iteration. Next, the BS implements AFA scheme for computing the best clustering scheme through FF as illustrated in Eq. (22).
The local density ρi of CH is developed from a kernel function as depicted in Eq. (23)
where \( S={\left\{{a}_i\right\}}_{i-1}^k \) implies a CH set in WSN, dc shows a truncation distance, and d(ai, aj) means the distance among CH ai and aj. f1 refers the DNN score. When adjacent distance becomes higher, the CH with and without massive local densities is dispersed to the greater extent. Also, dispersion of CH is accomplished by limiting the adjacent distance of a CH. The norm f1 is described by Eq. (24).
where f2 signifies a cluster compactness estimation factor (CCEF) and lower average distance among the node as well as CH is calculated through Eq. (25).
where d(ni, CHPj, K) shows the distance from node ni and corresponding CH, and ∣CPj, K∣ implies the No. of nodes in a cluster CK.Finally, f3 indicates the CH PE factor, NC means the network center, and CH position is identified by applying Eq. (26).
The weight coefficient of evaluation factor meets ε1 + ε2 + ε3 = 1. Based on the FF, the higher FF value is able to satisfy the following conditions namely, better CH dispersion, CH energy is maximum, and CH is nearby BS. Additionally, cluster developed by FF consumes lower energy and composed of massive CHs; hence, tiny clusters are developed in the vicinity of BS, which manages the energy dissipation from all clusters.
4 Experimental validation
The simulation experiments of the proposed FL-AFA and the benchmarked benchmarked FSNUCP, IPSO, SSO and GWO schemes are conducted using Matlab R2018 tool [19,20,21,22,23,24,25,26,27]. This simulation experiments are conducted based on the parameters and its considered values presented in Table 1. Moreover, the performance estimation of FL-AFA approach is carried out with classical techniques based on the evaluation metrics of energy efficiency, network duration, Packet Delivery Ratio (PDR), and the average delay [28,29,30,31,32].
Initially, Table 2 and Fig. 5 depicts the energy efficiency analysis of the FL-AFA model with respect to average RE. The figure portrays that the GWO method has showcased poor outcomes by accomplishing maximum energy dispersion with lower average RE. At the same time, the SSO and IPSO methodologies have depicted moderate average RE than GWO. Simultaneously, the F5NUCP scheme has managed to imply competing outcomes with considerable average RE. However, the projected FL-AFA framework has depicted supreme energy efficiency when compared with classical approaches. For example, under the execution round of 1000, the FL-AFA model has reached higher average RE of 0.9921 J while the GWO, SSO, IPSO, and F5NUCP methodologies have accomplished lower average RE of 0.9587 J, 0.9654 J, 0.9748 J, and 0.9787 J. Similarly, under the execution round of 2000, the FL-AFA scheme reached a higher average RE of 0.9652 J.

Average residual energy analysis of FL-AFA model
Then, Table 3 and Fig. 6 presents the average delay analysis of the proposed FL-AFA and the benchmarked schemes. The average delay of the proposed FL-AFA scheme is considered to be highly reduced on par with the benchmarked schemes, since it prevents frequent selection of cluster head. This prevention of unnecessary cluster head selection plays a vital role in preventing worst potent sensor nodes from being selected as the cluster head nodes. This predominant selection of cluster heads also facilitates the forwarding of packets through the reliable or trustworthy path in the network. Hence, the proposed FL-AFA is determined to minimize average delay by 8.64%, 10.92%, 12,34% and 13.48%, superior to the benchmarked FSNUCP, IPSO, SSO and GWO schemes used for comparison.

Performance of FL-AFA: Average delay with number of sensor nodes
Further, Table 4 and Fig. 7 exemplars the network lifetime analysis of the FL-AFA method evaluated in terms of first node die (FND), half node die (HND), and last node die (LND). The proposed FL-AFA scheme was visualized to prolong the network lifetime moderately by gaining FND at 321 iterations while the GWO, SSO, IPSO, and F5NUCP methodologies have attained previous FND of 76, 164, 194, and 265 rounds correspondingly. On the other hand, the proposed FL-AFA extended HND at 1489 iterations. However, the benchmarked GWO, SSO, IPSO, and F5NUCP schemes have resulted in HND at the earlier iterations of 521, 987, 1231, and 1345 rounds respectively. This proposed FL-AFA scheme attained higher network lifetime and have accomplished maximum LND of 2680 rounds, which is reasonable superior than the baselines schemes considered for investigation. .

Performance of FL-AFA: Network Lifetime Analysis with respect to first node death, half node death and last node death
Furthermore, Table 5 and Fig. 8 demonstrates the performance of the proposed FL-AFA scheme and the baseline approaches investigated based on number of alive nodes with increasing number of rounds. The number of alive nodes sustained by the proposed FL-AFA scheme is considered to be maximized on par with the benchmarked schemes, since the degree of exploitation is highly maintained through the inclusion of factors such as spreading and selecting factor that attributes to the potential cluster head selection. For instance, the proposed FL-AFA scheme at 1000 rounds of implementation was able to attain an optimal alive node count of 354 nodes while the GWO, SSO, IPSO, and F5NUCP methods have gained least number of alive nodes 98, 243, 259, and 292 respectively. On the other hand, the performance of the proposed FL-AFA at 2000 rounds is able to achieve only an optimality alive node counts of 126 nodes, while the PSO and F5NUCP approaches have obtained minimum alive node count of 65 and 96, respectively.

Performance of FL-AFA: Alive node analysis with increasing rounds
In addition, the performance of the proposed FL-AFA and the benchmarked schemes with different sensor nodes are compared and the results are portrayed in Table 6 and Fig. 9. The PDR of the proposed FL-AFA is determined to be better than the benchmarked schemes with different sensor nodes, since the inclusion of fuzzy and AFA handled uncertainty during cluster head selection and confirmed only superior sensor nodes being selected as cluster heads. For example, the proposed FL-AFA schemes with the 500 number of nodes have accomplished a higher PDR of 0.9977, while the baseline GWO, SSO, IPSO, and F5NUCP methods were able to attain only a marginal PDR of 0.8770, 0.9005, 0.9174, and 0.9334 correspondingly, respectively. Moreover, the proposed FL-AFA is estimated to improve the packet delivery by 9.21%, 10.84%, 11.24% and 12.82%, better than the benchmarked FSNUCP, IPSO, SSO and GWO schemes used for comparison. It is also confirmed that the proposed FL-AFA method has accomplished effectual performance when compared with previous approaches by gaining higher network lifetime and energy efficiency.

Performance of FL-AFA: Packet delivery Rate with number of sensor nodes
Finally, the cost analysis of the proposed FL-AFA scheme is computed over the convolutional models in terms of best, worst,mean, median and standard deviation. In the best case of the proposed scheme, it exhibited 56.19%and 2.31% better than existing AFA and SSO algorithm, respectively. In the worst case, the computation of the worst case of the proposed scheme depicted 72.38% and 35.72% better than AFA and SSO technique,respectively. While computing the median, the proposed FL-AFA scheme is is 7.84% and 0.96% better than convolutional AFA and SSOA approaches. Moreover, the standard deviation of the proposed method exhibited 89.24% and 95.24%, than the baseline approaches.
5 Conclusion
In this paper, a Hybrid Fuzzy Logic and Artificial Flora Optimization Algorithm (FL-AFA)-based Two Tier Cluster Head Selection was proposed as a reliable attempt to improve the energy efficiency and prolog network lifetime. This proposed FL-AFA scheme facilitates CH selection in two stages, TCH selection using FL and FCH selection using AFA. The nodes in WSN are arbitrarily placed in the target area and the initialization process is carried out. Subsequently, the choice of TCHs using FL technique takes place with the three input parameters, namely RE, DTBS, and NDE. Once the TCHs are elected, they participate to become final CHs by executing the AFA. The AFA makes use of a fitness function using three different parameters, namely DNN, CCEF, and PE to elect FCHs. Finally, the data transmission process begins from CMs to CHs and then to BS via intermediate CHs. A detailed experimental study is done to verify the effective energy efficient performance of the presented model. The obtained results notified the superiority of the FL-AFA over the comparative methods in terms of different aspects. In the future, the network lifetime can be further lengthened using multi-hop routing and data aggregation techniques.
References
Vajdi A, Zhang G, Wang Y, Wang T (2016) A new self-management model for largescale event-driven wireless sensor networks. IEEE Sensors J 16(20):7537–7544
Sabet M, Naji HR (2015) A decentralized energy efficient hierarchical cluster-based routing algorithm for wireless sensor networks. AEU-International Journal of Electronics and Communications 69(5):790–799
Mittal N (2019) Moth flame optimization based energy efficient stable clustered routing approach for wireless sensor networks. Wirel Pers Commun 104(2):677–694
Moh’d Alia O (2018) A dynamic harmony search-based fuzzy clustering protocol for energy-efficient wireless sensor networks. Ann Telecommun 73(5–6):353–365
Morsy NA, AbdelHay EH, Kishk SS (2018) Proposed energy efficient algorithm for clustering and routing in WSN. Wirel Pers Commun 103(3):2575–2598
Lalwani P, Das S, Banka H, Kumar C (2018) CRHS: clustering and routing in wireless sensor networks using harmony search algorithm. Neural Comput & Applic 30(2):639–659
Lalwani P, Banka H, Kumar C (2017) CRWO: clustering and routing in wireless sensor networks using optics inspired optimization. Peer-to-Peer Networking and Applications 10(3):453–471
Lalwani P, Banka H, Kumar C (2018) BERA: a biogeography-based energy saving routing architecture for wireless sensor networks. Soft Comput 22(5):1651–1667
Rao PS, Banka H (2017) Novel chemical reaction optimization based unequal clustering and routing algorithms for wireless sensor networks. Wirel Netw 23(3):759–778
Mekonnen MT, Rao KN (2017) Cluster optimization based on metaheuristic algorithms in wireless sensor networks. Wirel Pers Commun 97(2):2633–2647
Yogarajan G, Revathi T (2018) Improved cluster based data gathering using ant lion optimization in wireless sensor networks. Wirel Pers Commun 98(3):2711–2731
Ezhilarasi M, Krishnaveni V (2019) An evolutionary multipath energy-efficient routing protocol (EMEER) for network lifetime enhancement in wireless sensor networks. Soft Comput 23(18):8367–8377
Gao F, Luo W, Ma X (2019) Energy constrained clustering routing method based on particle swarm optimization. Cluster Comput 22(3):7629–7635
Sirdeshpande N, Udupi V (2017) Fractional lion optimization for cluster head-based routing protocol in wireless sensor network. J Frankl Inst 354(11):4457–4480
Xiu-wu YU, Hao YU, Yong L, Ren-rong X (2020) A clustering routing algorithm based on wolf pack algorithm for heterogeneous wireless sensor networks. Comput Netw 167:106994
Zhang Y, Wang J, Han D, Wu H, Zhou R (2017) Fuzzy-logic based distributed energy-efficient clustering algorithm for wireless sensor networks. Sensors 17(7):1554
Cheng L, Wu XH, Wang Y (2018) Artificial flora (AF) optimization algorithm. Applied Sciences 8(3):329
Xiuwu Y, Qin L, Yong L, Mufang H, Ke Z, Renrong X (2019) Uneven clustering routing algorithm based on glowworm swarm optimization. Ad Hoc Netw 93:101923
Chen J, Mao G, Li C, Liang W, Zhang D (2018) "Capacity of cooperative vehicular networks with infrastructure support: multiuser case," in IEEE Transactions on Vehicular Technology, vol. 67, no. 2, pp. 1546–1560
Zhang D, Li G, Zheng K, Ming X and Pan Z (2014) "An energy-balanced routing method based on forward-aware factor for wireless sensor networks," in IEEE Transactions on Industrial Informatics, vol. 10, no. 1, pp. 766–773
Zhang D, Liu S, Zhang T, Liang Z (2017) Novel unequal clustering routing protocol considering energy balancing based on network partition & distance for mobile education. J Netw Comput Appl 88:1–9
Zhang D, Zhang T, Liu X (2018) Novel self-adaptive routing service algorithm for application in VANET. Appl Intell 49(5):1866–1879
Zhang D, Wang X, Song X, Zhao D (2014) "A Novel Approach to Mapped Correlation of ID for RFID Anti-Collision," in IEEE Transactions on Services Computing, vol. 7, no. 4, pp. 741–748
Yang J, Ding M, Mao G, Lin Z, Zhang D, Luan TH (2019) Optimal base station antenna Downtilt in downlink cellular networks. IEEE Trans Wirel Commun 18(3):1779–1791
Zhang D, Zhang T, Dong Y, Liu X, Cui Y, Zhao D (2018) Novel optimized link state routing protocol based on quantum genetic strategy for mobile learning. J Netw Comput Appl 122:37–49
Zhang D, Ge H, Zhang T, Cui Y, Liu X, Mao G (2019) New multi-hop clustering algorithm for vehicular ad hoc networks. IEEE Trans Intell Transp Syst 20(4):1517–1530
Zhang T, Zhang D, Yan H, Qiu J, Gao J (2021) A new method of data missing estimation with FNN-based tensor heterogeneous ensemble learning for internet of vehicle. Neurocomputing 420:98–110
Kardi A, Zagrouba R (2020) Rach: a new radial cluster head selection algorithm for wireless sensor networks. Wirel Pers Commun 113(4):2127–2140
Subramanian P, Sahayaraj JM, Senthilkumar S, Alex DS (2020) A hybrid grey wolf and crow search optimization algorithm-based optimal cluster head selection scheme for wireless sensor networks. Wirel Pers Commun 113(2):905–925
Nagarajan L, Thangavelu S (2020) Hybrid grey wolf sunflower optimisation algorithm for energy-efficient cluster head selection in wireless sensor networks for lifetime enhancement. IET Commun 3(1):45–56
Sharma R, Vashisht V, Singh U (2020) EeTMFO/GA: a secure and energy efficient cluster head selection in wireless sensor networks. Telecommun Syst 74(3):253–268
Kumar MM, Chaparala A (2020) A hybrid BFO-FOA-based energy efficient cluster head selection in energy harvesting wireless sensor network. International Journal of Communication Networks and Distributed Systems 25(2):205
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Anandkumar, R. Hybrid fuzzy logic and artificial Flora optimization algorithm-based two tier cluster head selection for improving energy efficiency in WSNs. Peer-to-Peer Netw. Appl. 14, 2072–2083 (2021). https://doi.org/10.1007/s12083-021-01174-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12083-021-01174-7