
Abstract
Machine learning approaches can help facilitate the optimization of machining processes. Model performance, including accuracy, stability, and robustness, are major criteria to choose among different methods. Besides, the applicability, ease of implementations, and cost-effectiveness should be considered for industrial applications. In this study, we develop the Gaussian process regression (GPR) models to predict springback radii and angles for air bending of high-strength sheet steel from the sheet geometry, tool design, and metal properties. The models are simple and accurate and stable for the data considered, which might contribute to fast springback radius and angle estimations. By combining the optimization results from the Taguchi method and GPR approach, it might be expected that more quantitative data can be extracted from fewer experimental trials at the same time.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Air bending is one of metal forming processes to produce straight-line bends on metal sheets, by using a die having a pair of shoulders [1]. During the air bending, the sheet metal is placed on the pair of the shoulders that are separated by a certain distance, the die gap. A punch load is applied at the mid-span of the sheet material to render a displacement. At the end of the deformation process, the bend angle is always smaller than the initial load angle after the punch load is removed. This inevitable phenomenon is due to the elastic recovery of the sheet metal, which is called springback.
For materials with high strength, air bending is a preferred method over V-die bending [2,3,4,5]. Also, air bending allows overbending to compensate the springback effect. Generally, the extent of springback radii and the angle of the sheet metal are closely related to the sheet geometry, tool design, and metal properties. It is suggested that the degree of springback increases as a result of an increasing radius of the bend and a decreasing thickness [6, 7]. These parameters are independent from each other and have different impacts on the springback magnitude, which are usually described by the springback radius and angle. The eventual springback magnitude is a synergistic result of these parameters, the understanding of which usually requires a large amount of efforts in experiment design, tests, and measurements. The Taguchi orthogonal array of experiments is commonly used to design experiments with a large number of variables and a relatively small amount of experimental trials [8]. However, parameter optimizations through the Taguchi method are based on minimizing the effects of uncontrollable factors (noise factors), which do not provide numerical correlations between variables and target performance.
Several mathematical methods have been developed to estimate the springback effect. For example, by assuming the workpiece to be a narrow beam, a quantitative method is proposed to predict the residual stress and the springback magnitude [9, 10]. However, this method ignores the presence of the transverse stress during the forming process, which leads to an inaccurate prediction. Another analysis based on the Young’s modulus, yield strength, and thickness of metal sheets presents a chart that provides comparisons between the initial bend radius and final bend radius as a design guidance. Besides, numerical equations are developed to describe the springback magnitude and residual stress distribution as a function of the sheet thickness, punch radius, and mechanical properties of the material, such as stress-strain characteristics [11]. Furthermore, molecular dynamics simulation techniques and finite element modeling (FEM) are utilized to simulate the metal forming process [12,13,14,15,16]. The study shows that the springback is proportional to the bending moment and the bent arc length, which are dependent on the strength, strain hardening, and normal anisotropy. However, these approaches require a lot of data inputs and computational resources due to complexities associated with air bending processes.
Recently, data driven approaches, such as the neural network [17], Gaussian process regression (GPR) [18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38], and simple linear regression [39], have been used to model important physical parameters and materials performance in diverse systems, such as magnetocaloric effects in lanthanum manganites [20,21,22, 26], superconducting transition temperature in high-temperature superconductors [18, 19, 35, 37], lattice constants of cubic, orthorhombic, and monoclinic perovskites and half-Heusler alloys [24, 28, 29, 31, 33, 39], optical and electronic properties of oxides [25, 27], thermal properties of nanofluids, lubricant additives, and polymers [23, 34, 36], glass transitions [30], transformation temperature for shape memory alloys [32], and magnetic performance of superconducting solenoids [39]. Particularly, the GPR technique has been found to generate decent prediction performance for small and medium sample sizes. By combining the Taguchi method with statistical methods, researchers are vable to analyze the relationship between multiple manufacturing process parameters and workpiece characteristics [40, 41]. Statistical regression techniques and other soft computing are often categorized as machine learning approaches, which have reasonable tolerances of uncertainties, approximations, and imprecisions [42,43,44,45,46]. Several machine learning approaches have been taken to predict important metal forming and casting behavior. For example, an optimized method combining the artificial neural network and Taguchi method is used to analyze the radial force and strain inhomogeneity in the radial forging process. The results show good agreements between the optimized method and conventional FEM method [47]. Fuzzy logic and support vector regression techniques are also incorporated with the Taguchi method to predict the cutting tool life [48]. For machine learning approaches, the average percent deviation, generalization capability, and runtime are the main characteristics that are used to compare among the models.
GPRs are probabilistic models, which are simple and require relatively short runtime. To authors’ knowledge, this approach has not been used to predict the springback magnitude in air bending. In the current study, we develop the GPR model to predict springback radii and angles of advanced and ultra-high strength sheet steels based on the sheet geometry, tool design, and metal properties. The model manifests accurate and stable performance for the data considered, and thus might be promising as a fast, robust, and low-cost tool for springback magnitude estimations.
2 Methodology
GPRs are nonparametric probabilistic models.Footnote 1 Let \(\left\{ \left( x_{i}, y_{i}\right) ;i=1,2, \ldots , n\right\} \), where \(x_{i} \in {\mathbb {R}}^{d}\) and \(y_{i} \in {\mathbb {R}}\), be the training dataset from a distribution that is unknown. Provided \(x^{new}\)-the input matrix, constructed GPRs make predictions of \(y^{new}\)-the response variable.
Let \(y=x^{T} \beta +\varepsilon \), where \(\varepsilon \sim N\left( 0, \sigma ^{2}\right) \), be the linear regression model. The GPR tries to explain y through incorporating \(l(x_{i})\)-the latent variable, where \(i=1,2, \ldots , n\), from a GP such that \(l(x_{i})\)’s are jointly Gaussian-distributed, and b-basis functions that project x into a p-dimensional feature space. Note that the smoothness of y is captured by \(l(x_{i})\)’s covariance function.
The covariance and mean characterize the GPR. Let \(k\left( x, x^{\prime }\right) ={\text {Cov}}\left[ l(x), l\left( x^{\prime }\right) \right] \) represent the covariance, \(m(x)=E(l(x))\) the mean, and \(y=b(x)^{T} \beta +l(x)\), where \(l(x) \sim GP\left( 0, k\left( x, x^{\prime }\right) \right) \) and \(b(x) \in {\mathbb {R}}^{p}\), the GPR. The parameterization of \(k\left( x, x^{\prime }\right) \) usually is through \(\theta \)-the hyperparameter and thus one could have \(k\left( x, x^{\prime } | \varvec{\theta }\right) \). Different algorithms generally make estimations of \(\beta \), \(\sigma ^{2}\), and \(\theta \) during the process of model training and allow one to specify b and k, as well as parameters’ initial values.
We investigate five kernels-the exponential, squared exponential, Matern 5/2, rational quadratic, and Matern 3/2-specified in Eqs. (1)–(5), respectively, where \(\sigma _{l}\)-the characteristic length scale-defines how far apart \(x's\) could be so that \(y's\) are uncorrelated, \(\sigma _{f}\) is the signal standard deviation, \(r=\sqrt{\left( x_{i}-x_{j}\right) ^{T}\left( x_{i}-x_{j}\right) }\), and \(\alpha >0\) is the scale-mixture parameter. In addition to these five kernels, we also take into consideration their automatic relevance determination (ARD) versions, specified in Eqs. (6)–(10), that use a separate length scale, \(\sigma _{m}\), for each predictor, where \(m=1,2,...,d\) and d is the number of predictors. \(\theta \) under this circumstance is parameterized as \(\theta _{m}=\log \sigma _{m}\) for \(m=1,2,...,d\) and \(\theta _{d+1}=\log \sigma _{f}\).
We investigate four basis functions-the empty, constant, linear, and pure quadratic-specified in Eqs. (11)–(14), respectively, where \({B}=\left( {{b}\left( {x}_{1}\right) },\,{{b}\left( {x}_{2}\right) },\,{\cdots }\, , {{b}\left( {x}_{n}\right) }\right) ^{T}\), \({X}=\left( {x}_{1}, {x}_{2}, {\cdots } , {x}_{n}\right) ^{T}\), and \(X^{2}=\left( \begin{array}{cccc}{x_{11}^{2}} &{} {x_{12}^{2}} &{} {\cdots } &{} {x_{1 d}^{2}} \\ {x_{21}^{2}} &{} {x_{22}^{2}} &{} {\cdots } &{} {x_{2 d}^{2}} \\ {\vdots } &{} {\vdots } &{} {\vdots } &{} {\vdots } \\ {x_{n 1}^{2}} &{} {x_{n 2}^{2}} &{} {\cdots } &{} {x_{n d}^{2}}\end{array}\right) \).
For parameter estimations, we maximize the marginal log likelihood function in Eq. (15), where \(K({X},{X}|{\theta })\) represents the covariance matrix:
\(\left( \begin{array}{cccc}{k\left( x_{1}, x_{1}\right) } &{} {k\left( x_{1}, x_{2}\right) } &{} {\cdots } &{} {k\left( x_{1}, x_{n}\right) } \\ {k\left( x_{2}, x_{1}\right) } &{} {k\left( x_{2}, x_{2}\right) } &{} {\cdots } &{} {k\left( x_{2}, x_{n}\right) } \\ {\vdots } &{} {\vdots } &{} {\vdots } &{} {\vdots } \\ {k\left( x_{n}, x_{1}\right) } &{} {k\left( x_{n}, x_{2}\right) } &{} {\cdots } &{} {k\left( x_{n}, x_{n}\right) }\end{array}\right) \). The algorithm will first compute \(\hat{{\beta }}\left( {\theta }, \sigma ^{2}\right) \), which maximizes the log likelihood with respect to \(\beta \) provided \(\theta \) and \(\sigma ^{2}\). It then gets the \(\beta \)-profiled likelihood,
\(\log \left\{ P\left( {y} | {X}, \widehat{{\beta }}\left( {\theta }, \sigma ^{2}\right) , {\theta }, \sigma ^{2}\right) \right\} \), which will be maximized over \({\theta }\) and \(\sigma ^{2}\) to arrive at their estimates.

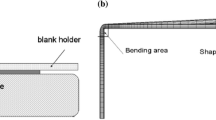
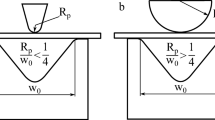
The schematic drawing of the experimental setup
Model performance will be assessed by the correlation coefficient (CC), mean percentage error (MPE), root mean square error (RMSE), and mean absolute error (MAE) in Eqs. (16)–(19), where n is the number of data points, \(y_{i}^{exp}\) and \(y_{i}^{est}\) are the i-th (\(i=1,2, \ldots , n\)) experimental and estimated value of the target variable, and \(\overline{y^{exp}}\) and \(\overline{y^{est}}\) are their averages. Our analysis is carried out through MATLAB.

Predictions and prediction errors calculated as predictions minus experimental values
3 Dataset
Details on the experimental setup, tool use, and measurement setup can be found in [17]. Figure 1 illustrates the schematic drawing of the experimental setup. Air bending tests were performed on five types of advanced and ultra-high strength sheet steels, WELDOX700, WELDOX900 and OPTIM960 with different Young’s modulus (E), yield strength (\(\sigma _{y}\)), strength-hardening exponents (n), Poisson’s ratios, and densities. The factors that have a significant impact on the springback are identified as the sheet thickness (t), tool gap (c), punch radius (r), yield strength (\(\sigma _{y}\)), Young’s modulus (E), and punch displacement (e). For these particular materials, the strain-hardening exponents range from 0.0255 to 0.0431, which are small enough to have neglectable effects on springback. Particularly, the strain–stress characteristic of sheet steels is described by the ratio of the yield strength to Young’s modulus (\(\sigma _{y}/E\)). Therefore, a total of 5 descriptors were used in the Taguchi parameter design for air-bending tests. A URSVIKEN OPTIMA 2200t Press Brake was used for air bending tests. The formed workpieces were measured by the Atos-II three-dimensional laser scanning system with the precision of ± 0.005 mm. A total of 25 experimental trials with orthogonally-designed descriptors were carried out. The data in Table 1 from [17] contain a total of 25 experimental trials acquired from the orthogonal array and are utilized in our study to find the correlation between springback magnitude and influencing factors. With the laser scanning system, a 3D datapoint cloud was obtained. The datapoint cloud data were then transferred into the CAD/CAM software for modeling. The two target variables, springback radii (R) and angles (\(\alpha \)) were thus obtained from the CAD model.
4 Result
Among all kernels and basis functions examined, the GPR model is constructed based on the isotropic exponential kernel (Eq. 1) and constant basis function (Eq. 12), with predictors standardized for R-the springback radius. Its parameter estimates are: \(\sigma =1.3210\), \(\beta =273.1362\) \(\sigma _{l}=28.6942\), and \(\sigma _{f}=294.0364\). For \(\alpha \)-the springback angle, the GPR model is built based on the nonisotropic Matern 3/2 kernel (Eq. 10) and empty basis function (Eq. 11), with predictors nonstandardized. Its parameter estimates are: \(\sigma =0.2641\), \(\sigma _{1}=141.6112\), \(\sigma _{2}=239.9583\), \(\sigma _{3}=165.0488\), \(\sigma _{4}=0.0801\), \(\sigma _{5}=208.5101\), and \(\sigma _{f}=180.8414\), where \(\sigma _{1}\), \(\sigma _{2}\), \(\sigma _{3}\), \(\sigma _{4}\), and \(\sigma _{5}\) are associated with the sheet thickness (t (mm)), tool gap (c (mm)), punch radius (r (mm)), ratio of the yield strength to Young’s modulus (\(\sigma _{y}\) (MPa)/E), and punch displacement (e (mm)), respectively.
Detailed numerical predictions of the two target variables are reported in Table 1. Performance summaries are presented in Table 2 and Fig. 2. It is observed that the GPR models produce stable and accurate predictions. The CCs are 99.99%. The MPEs are 0.0048% and − 0.0020% for the training and validation testing sub-samples for R, and the MPEs are − 0.0001% and 0.0029% for the training and validation testing sub-samples for \(\alpha \). The RMSEs are 0.0095 and 0.0335 for the training and validation testing sub-samples for R, and the RMSEs are 0.0122 and 0.0120 for the training and validation testing sub-samples for \(\alpha \). The MAEs are 0.0074 and 0.0175 for the training and validation testing sub-samples for R, and the MAEs are 0.0098 and 0.0106 for the training and validation testing sub-samples for \(\alpha \).
In [17], a back propagation neural network (BPNN) model and a genetic algorithm (GA) BPNN model are developed for the same dataset studied here. These two models both produce good predictions and the GA-BPNN model produces predictions that are better than the BPNN model. In Table 3, we compare performance of the BPNN, GA-BPNN, and GPR models, and find that the GPR models might have potential to further improve accuracy. But this is only based on the five observations and more out-of-sample applications might be needed to further confirm the usefulness of the GPR models to predict springback radii and angles during the air bending of high strength sheet steels. It also has been found that a smaller springback magnitude might be achieved for materials with a decreased ratio of the yield strength to Young’s modulus, an increased thickness, a decreased tool gap, and an increased punch displacement.
5 Conclusion
We develop the Gaussian process regression models to predict springback radii and angles in air bending of high-strength sheet steel from influencing factors that include the sheet thickness, tool gap, punch radius, yield strength, Young’s modulus, and punch displacement. The models are simple and accurate and stable for the data considered, which might contribute to fast springback magnitude estimations. By combining the optimization results from the Taguchi method and GPR approach, it might be expected that more quantitative data can be extracted from fewer experimental trials at the same time. The approach may apply to a wide variety of metal forming processes to find statistical correlations among process parameters, performance parameters, and final work piece quality. Statistical relationships among materials properties, process parameters, and target properties in rolling, extrusion, die forming, indenting, and forging can be quantitatively interpreted through the GPR and/or other machine learning models.
References
Wang, J., Verma, S., Alexander, R., Gau, J.T.: Springback control of sheet metal air bending process. J. Manuf. Process. 10(1), 21–27 (2008). https://doi.org/10.1016/j.manpro.2007.09.001
Schwartz, J., Koch, C.C., Zhang, Y., Liu, X.: Formation of bismuth strontium calcium copper oxide superconductors. U.S. Patent US9773962B2, September 26, 2017. https://patentimages.storage.googleapis.com/dd/a0/5d/f73e3aa9c2eae4/US9773962.pdf
Zhang, Y., Johnson, S., Naderi, G., Chaubal, M., Hunt, A., Schwartz, J.: High critical current density Bi\(_{2}\)Sr\(_{2}\)CaCu\(_{2}\)O \(_{x}\)/Ag wire containing oxide precursor synthesized from nano-oxides. Supercond. Sci. Technol. 29(9), 095012 (2016). https://doi.org/10.1088/0953-2048/29/9/095012
Zhang, Y., Koch, C.C., Schwartz, J.: Formation of Bi\(_{2}\)Sr\(_{2}\)CaCu\(_{2}\)O \(_{x}\)/Ag multifilamentary metallic precursor powder-in-tube wires. Supercond. Sci. Technol. 29(12), 125005 (2016). https://doi.org/10.1088/0953-2048/29/12/125005
Zhang, Y., Koch, C.C., Schwartz, J.: Synthesis of Bi\(_{2}\)Sr\(_{2}\)CaCu\(_{2}\)O\(_{x}\) superconductors via direct oxidation of metallic precursors. Supercond. Sci. Technol. 27(5), 055016 (2014). https://doi.org/10.1088/0953-2048/27/5/055016
Botros, B.M.: Springback in sheet metal forming after bending. In: Mechanical Engineering, vol. 90, No. 1, p. 62. ASME-Amer Soc Mechanical Eng, New York (1968)
Davies, R.G.: Springback in high-strength steels. J. Appl. Metalwork. 1(4), 45–52 (1981). https://doi.org/10.1007/BF02834345
Siddiquee, A.N., Khan, Z.A., Goel, P., Kumar, M., Agarwal, G., Khan, N.Z.: Optimization of deep drilling process parameters of AISI 321 steel using Taguchi method. Procedia Mater. Sci. 6, 1217–1225 (2014). https://doi.org/10.1016/j.mspro.2014.07.195
Schroeder, W.: Mechanics of sheet metal bending. Trans. ASME 65, 817–827 (1943)
Gardiner, F.J.: The springback of metals. Trans. ASME 79, 1–9 (1957). https://doi.org/10.1115/1.4012908
Queener, C.A., De Angelis, R.J.: Elastic springback and residual stresses in sheet metal parts formed by bending. Trans. ASM 61, 757–768 (1968)
Hamouda, A.M.S., Khadra, F.A., Hamadan, M.M., Imhemed, R.M., Mahdi, E.: Springback in V-bending: a finite element approach. Int. J. Mater. Prod. Technol. 21(1–3), 124–136 (2004)
Song, H., Hunte, F., Schwartz, J.: On the role of pre-existing defects and magnetic flux avalanches in the degradation of YBa\(_{2}\)Cu\(_{3}\)O\(_{7-x}\) coated conductors by quenching. Acta Mater. 60(20), 6991–7000 (2012). https://doi.org/10.1016/j.actamat.2012.09.003
Thieme, C.L.H., Gagnon, K.J., Coulter, J.Y., Song, H., Schwartz, J.: Stability of second generation HTS pancake coils at 4.2 K for high heat flux applications. IEEE Trans. Appl. Supercond. 19(3), 1626–1632 (2009). https://doi.org/10.1109/TASC.2009.2017914
Xu, W., Wu, Y., Gou, X.: Effective elastic moduli of nonspherical particle-reinforced composites with inhomogeneous interphase considering graded evolutions of elastic modulus and porosity. Comput. Methods Appl. Mech. Eng. 350, 535–553 (2019). https://doi.org/10.1016/j.cma.2019.03.021
Xu, W., Jia, M., Zhu, Z., Liu, M., Lei, D., Gou, X.: \(n\)-Phase micromechanical framework for the conductivity and elastic modulus of particulate composites: design to microencapsulated phase change materials (MPCMs)-cementitious composites. Mater. Des. 145, 108–115 (2018). https://doi.org/10.1016/j.matdes.2018.02.065
Fu, Z., Mo, J.: Springback prediction of high-strength sheet metal under air bending forming and tool design based on GA-BPNN. Int. J. Adv. Manuf. Technol. 53(5–8), 473–483 (2011). https://doi.org/10.1007/s00170-010-2846-5
Zhang, Y., Xu, X.: Yttrium barium copper oxide superconducting transition temperature modeling through Gaussian process regression. Comput. Mater. Sci. 179, 109583 (2020). https://doi.org/10.1016/j.commatsci.2020.109583
Zhang, Y., Xu, X.: Predicting doped MgB\(_{2}\) superconductor critical temperature from lattice parameters using Gaussian process regression. Physica C Supercond. Appl. 573, 1353633 (2020). https://doi.org/10.1016/j.physc.2020.1353633
Zhang, Y., Xu, X.: Curie temperature modeling of magnetocaloric lanthanum manganites using Gaussian process regression. J. Magn. Magn. Mater. 512, 166998 (2020). https://doi.org/10.1016/j.jmmm.2020.166998
Zhang, Y., Xu, X.: Machine learning the magnetocaloric effect in manganites from lattice parameters. Appl. Phys. A 126, 341 (2020). https://doi.org/10.1007/s00339-020-03503-8
Zhang, Y., Xu, X.: Machine learning the magnetocaloric effect in manganites from compositions and structural parameters. AIP Adv. 10(3), 035220 (2020). https://doi.org/10.1063/1.5144241
Zhang, Y., Xu, X.: Predicting the thermal conductivity enhancement of nanofluids using computational intelligence. Phys. Lett. A 384, 126500 (2020). https://doi.org/10.1016/j.physleta.2020.126500
Zhang, Y., Xu, X.: Machine learning modeling of lattice constants for half-Heusler alloys. AIP Adv. 10, 045121 (2020). https://doi.org/10.1063/5.0002448
Zhang, Y., Xu, X.: Machine learning optical band gaps of doped-ZnO films. Optik 217, 164808 (2020). https://doi.org/10.1016/j.ijleo.2020.164808
Zhang, Y., Xu, X.: Relative cooling power modeling of lanthanum manganites using Gaussian process regression. RSC Adv. 10, 20646–20653 (2020). https://doi.org/10.1039/D0RA03031G
Zhang, Y., Xu, X.: Machine learning band gaps of doped-TiO\(_{2}\) photocatalysts from structural and morphological parameters. ACS Omega 5, 15344–15352 (2020). https://doi.org/10.1021/acsomega.0c01438
Zhang, Y., Xu, X.: Machine learning lattice constants for cubic perovskite \(A_{2}^{2+}BB^{\prime }O_{6}\) compounds. CrystEngComm 22, 6385–6397 (2020). https://doi.org/10.1039/D0CE00928H
Zhang, Y., Xu, X.: Machine learning lattice constants for cubic perovskite \(ABX_{3}\) compounds. ChemistrySelect 5, 9999–10009 (2020). https://doi.org/10.1002/slct.202002532
Zhang, Y., Xu, X.: Lattice misfit predictions via the Gaussian process regression for Ni-based single crystal superalloys. Met. Mater. Int. 27, 235–253 (2021). https://doi.org/10.1007/s12540-020-00883-7
Zhang, Y., Xu, X.: Transformation temperature predictions through computational intelligence for NiTi-based shape memory alloys. Shape Mem. Superelast. 6, 374–386 (2020). https://doi.org/10.1007/s40830-020-00303-0
Zhang, Y., Xu, X.: Machine learning lattice parameters of monoclinic double perovskites. Int. J. Quantum Chem. 121, e26480 (2021). https://doi.org/10.1002/QUA.26480
Zhang, Y., Xu, X.: Machine learning decomposition onset temperature of lubricant additives. J. Mater. Eng. Perform. 29, 6605–6616 (2020). https://doi.org/10.1007/s11665-020-05146-5
Zhang, Y., Xu, X.: Predicting doped Fe-based superconductor critical temperature from structural and topological parameters using machine learning. Int. J. Mater. Res. 112, 2–9 (2021). https://doi.org/10.1515/ijmr-2020-7986
Zhang, Y., Xu, X.: Machine learning glass transition temperature of polymers. Heliyon 6, e05055 (2020). https://doi.org/10.1016/j.heliyon.2020.e05055
Zhang, Y., Xu, X.: Machine learning F-doped Bi (Pb)–Sr–Ca–Cu–O superconducting transition temperature. J. Supercond. Novel Magn. 34, 63–73 (2021). https://doi.org/10.1007/s10948-020-05682-0
Zhang, Y., Xu, X.: Machine learning the central magnetic flux density of superconducting solenoids. Mater. Technol. 37, 272–279 (2022). https://doi.org/10.1080/10667857.2020.1830567
Zhang, Y., Xu, X.: Machine learning lattice constants for spinel compounds. Chem. Phys. Lett. 760, 137993 (2020). https://doi.org/10.1016/j.cplett.2020.137993
Zhang, Y., Xu, X.: Predicting As\(_{x}\)Se\(_{1-x}\) glass transition onset temperature. Int. J. Thermophys. 41, 149 (2020). https://doi.org/10.1007/s10765-020-02734-4
Ko, D.C., Kim, D.H., Kim, B.M.: Application of artificial neural network and Taguchi method to preform design in metal forming considering workability. Int. J. Mach. Tools Manuf. 39(5), 771–785 (1999). https://doi.org/10.1016/S0890-6955(98)00055-8
Ko, D.C., Kim, D.H., Kim, B.M., Choi, J.C.: Methodology of preform design considering workability in metal forming by the artificial neural network and Taguchi method. J. Mater. Process. Technol. 80, 487–492 (1998). https://doi.org/10.1016/S0924-0136(98)00152-6
Wang, Y., Zheng, J., Zhu, Z., Zhang, M., Yuan, W.: Quench behavior of high-temperature superconductor (RE) Ba\(_{2}\)Cu\(_{3}\)O \(\times \) CORC cable. J. Phys. D Appl. Phys. 52(34), 345303 (2019). https://doi.org/10.1088/1361-6463/ab1e2c
Qiu, D., Wu, W., Pan, Y., Xu, S., Zhang, Z.M., Li, Z.L., Li, Z.Y., Wang, Y., Wang, L., Zhao, Y., Zhang, Z.W.: Experiment and numerical analysis on magnetic field stability of persistent current mode coil made of HTS-coated conductors. IEEE Trans. Appl. Supercond. 27(4), 1–5 (2017). https://doi.org/10.1109/TASC.2017.2652538
Yang, P., Li, K., Wang, Y., Wang, L., Wu, Q., Huang, A., Hong, Z., Jiang, G., Jin, Z.: Quench protection system of a 1 MW high temperature superconductor DC induction heater. IEEE Trans. Appl. Supercond. 29(5), 1–6 (2019). https://doi.org/10.1109/TASC.2019.2900983
Yang, P., Wang, Y., Qiu, D., Chang, T., Ma, H., Zhu, J., Jin, Z., Hong, Z.: Design and fabrication of a 1-MW high-temperature superconductor DC induction heater. IEEE Trans. Appl. Supercond. 28(4), 1–5 (2018). https://doi.org/10.1109/TASC.2018.2810498
Pan, Y., Sheng, J., Wu, W., Wang, Y., Zeng, W., Zhao, Y., Zhang, Z.W., Li, Z., Hong, Z., Jin, Z.: Numerical study on simplified resistive joints of coated conductors: Is there a lower limit of the joint resistance? IEEE Trans. Appl. Supercond. 27(4), 1–5 (2017). https://doi.org/10.1109/TASC.2017.2653358
Sanjari, M., Taheri, A.K., Movahedi, M.R.: An optimization method for radial forging process using ANN and Taguchi method. Int. J. Adv. Manuf. Technol. 40(7–8), 776–784 (2009). https://doi.org/10.1007/s00170-008-1371-2
Gokulachandran, J., Mohandas, K.: Prediction of cutting tool life based on Taguchi approach with fuzzy logic and support vector regression techniques. Int. J. Qual. Reliab. Manag. 32, 270–290 (2015). https://doi.org/10.1108/IJQRM-06-2012-0084
Koriyama, T., Kobayashi, T.: A comparison of speech synthesis systems based on GPR, HMM, and DNN with a small amount of training data. In: Sixteenth Annual Conference of the International Speech Communication Association (2015). https://www.isca-speech.org/archive_v0/interspeech_2015/papers/i15_3496.pdf
Li, Y., Yang, W., Dong, R., Hu, J.: MLatticeABC: generic lattice constant prediction of crystal materials using machine learning. ACS Omega 6(17), 11585–11594 (2021). https://doi.org/10.1021/acsomega.1c00781
Sheng, H., Liu, X., Bai, L., Dong, H., Cheng, Y.: Small sample state of health estimation based on weighted Gaussian process regression. J. Energy Storage 41, 102816 (2021). https://doi.org/10.1016/j.est.2021.102816
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhang, Y., Xu, X. Predicting springback radii and angles in air bending of high-strength sheet steel through gaussian process regressions. Int J Interact Des Manuf 16, 863–870 (2022). https://doi.org/10.1007/s12008-022-00945-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12008-022-00945-7