
Abstract
Plant recognition is closely related to people’s life. The operation of the traditional plant identification method is complicated, and is unfavorable for popularization. The rapid development of computer image processing and pattern recognition technology makes it possible for computer’s automatic recognition of plant species based on image processing. There are more and more researchers drawing their attention on the computer’s automatic identification technology based on plant images in recent years. Based on this, we have carried on a wide range of research and analysis on the plant identification method based on image processing in recent years. First of all, the research significance and history of plant recognition technologies are introduced in this paper; secondly, the main technologies and steps of plant recognition are reviewed; thirdly, more than 30 leaf features (including 16 shape features, 11 texture features, four color features), and then SVM was used to evaluate these features and their fusion features, and 8 commonly used classifiers are introduced in detail. Finally, the paper is ended with a conclusion of the insufficient of plant identification technologies and a prediction of future development.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Plant can be seen everywhere around us. There are a wide variety of plants on earth, for instance, more than 250,000 species of plants have been named and recorded according to statistics. Plant plays an important role e.g. it can conserve soil and water, improve the climate. Especially for humans, plant provides us with the various foods. In fact, each kind of plant has unique characteristics e.g. morphology, habits, economic values. In order to study the plant effectively, plant classification and identification are of great importance.
At present, there are many methods of plant classification, such as plant genetics method, plant chemotaxonomy method, and plant cytotaxonomy method. Plant classification is not only the basis of Botany, but also is the foundation of plant ecology, plant genetics, plant medicine and life science. It makes a very important role in plant resources protection, development and utilization.
However, only researchers can use these methods of classification or identification. And these methods mainly depend on people’s subjective judgment, which affects the accuracy of classification. Therefore, it is hard to meet the needs that people want to quickly identify plant anywhere.
With the development of digital image processing and pattern recognition, the technology of target recognition based on image processing has already entered people’s life, such as face recognition, fingerprint recognition, etc. These techniques provide enough theoretical basis and technical preparation for plant recognition based on image processing.
Therefore, in recent years, study on plant recognition based on image processing has been quietly rising, and more and more popular in the international researchers. This method is rapid and is not dependent on the person’s subjective judgment. It can effectively make up the insufficiency of artificial recognition method, improves work efficiency and the accuracy of plant recognition. This fast and simple method can help people to get to know the plant more quickly and better.
And it is found that the distribution of the articles published in these years of the plant identification from Fig. 1. More and more researchers are concerned about the field of plant identification.

Distribution of the existed papers
In the paper, our topic focuses on leaf feature extraction and classifier in plant recognition based on image processing. We list most of the existed features and provide a simple test for performance evaluation and summarize main classifiers rather than contemplate to go into details of particular algorithms or describe results of comparative experiments.
The rest of paper is organized as follows. The framework of plant recognition is introduced in Sect. 2. Section 3 reviews existed image features including shape, texture and color features; commonly used classifiers are introduced in Sect. 4. In Sect. 5, we propose the existing problems needed to be resolved later and point out some potential research areas in future. Finally, we make a conclusion for the paper.
2 Framework of Plant Recognition Based on Image Processing
First of all, we would like to explain the feasibility or rationality of plant recognition based on image processing. The characteristics of plant leaf, flower, fruit, stem, branches, and other organs are usually employed for plant classification. In fact, plant recognition based on image processing also employs these characteristics.
However, compared with the flower, fruit, stem, branches, and other organs, plant leaves exist in most of the year and can be easily collected. Plant leaves contain a lot of essential feature information, such as the leaf blade, margin, texture and other information. Meanwhile, these features can be directly observed, and also can be captured efficiently and accurately by digital equipment to obtain the corresponding digitized images. Leaf is an ideal organ for image-based plant recognition.
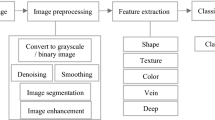
Image-based plant recognition is similar with existing biometric-based image recognition. In this section, plant recognition based on leaf images is taken for example to describe the entire framework of plant recognition based on image processing, as shown in Fig. 2.

Framework of plant recognition based on image processing
Its framework is mainly composed of three steps: image preprocessing, feature extraction, and pattern classification. The image, obtained by camera or other devices, usually has some restrictions or interference with noises. Before feature extraction, it is necessary to carry on image preprocessing including image denoising, image segmentation, image enhancement, etc.
Figure 3 is the typical processes of plant leaf image preprocessing. If color information is not considered, color images are also transformed into gray image because gray images are processed more easily and quickly than color images. Because the captured image usually has random noises, image filtering (e.g. median filter) is necessary. After image filtering, the gray image is segmented by binary segmentation. The outline of plant image can be generated as a result of retaining the maximum connected region and removing leafstalk and holes.

Typical processes of plant leaf image preprocessing
After image preprocessing, we will extract the feature of leaf images. Generally speaking, leaf feature consists of shape information, texture information, and color information. Shape information can be extracted by computing various shape descriptors (e.g. Fourier descriptor, invariant moments, and other shape parameters). Texture information is extracted by computing some statistical features (e.g. co-occurrence matrix, histogram, entropy, consistency, smoothness, etc.). Color information is usually extracted from such color spaces as RGB or HIS.
In the stage of image classification, all extracted features are taken as the feature vector. And then these vectors are classified by the classifier. Finally, the recognition results are obtained.
Seen from above framework, it is found that feature extraction and classifier are key techniques, which have a major impact on the recognition result. Hence, 31 kinds of leaf features (including 16 kinds of shape feature, 11 texture features, 4 color features), and 8 commonly used classifiers will be reviewed in detail.
3 Image Features
The feature is a kind of object that is different from other objects’ corresponding characteristic, or a collection of these characteristics and features. And it is the data that can be extracted after measurement or processing. For the image, each image has its own features that can be distinguished from other types of images, some are natural features that can be intuitively felt, such as edge, brightness, color and texture etc.; some can be obtained after transforming or processing, such as variable moments, the histogram and others. In terms of plant leaf recognition, mainly from the leaf shape, texture and color of the three characteristics are studied.
Here, we first list some of the commonly used variables that appear in the following formula in Table 1.
3.1 Shape Feature
Shape is an important feature of the image description. The accurate extraction of shape features is based on the image segmentation. After the object is segmented from the image, it consists of the boundary and the region pixels surrounded by the boundary. Therefore, the shape feature description can be roughly divided into two categories: the boundary based features and features based on regions. The following will be a detailed introduction.
3.1.1 Aspect Ratio
Aspect ratio denotes the ratio of width to length of the external rectangle of leaf contour. It is defined by
References [1–9] employed this feature when proposing advanced leaf recognition based on leaf contour and centroid for plant classification. And in the process of plant identification, this feature was also used as one of the feature vectors for classification in Refs. [10–26].
3.1.2 Circularity
Circularity is defined by
where A is the area which represents the number of pixels in the target image, P is the perimeter by counting the number of pixels consisting the target image boundary. They are respectively defined by
where I(i, j) is the pixel of the image. Perimeter is to view each pixel as a point, the up, down, left and right side of the each point’s neighbour point distance is 1, the diagonal direction distance is \(\sqrt 2\), the even-numbered chain code number is N e and the odd-numbered chain code number is N 0 according to the eight-direction chain code calculation.
The circularity feature was used in Refs. [1–5, 27–30] when proposing a method which combined some shape features, color moments, and vein features to retrieve leaf images. And in Refs. [15, 20, 25], they used the feature of circularity when investigating the use of a machine-learning algorithm called SVM for the effective classification of leaves in digital images.
3.1.3 Area Convexity
Area convexity is also called convexity, solidity, which is the ratio between the area of the target and the area of its convex hull. And its equation is
where A C is the area of its convex hull (it means the smallest convex set containing all points in an object).
The feature of convexity was used in Refs. [2, 4, 6–8] when they proposed an approach to recognize plant leaves. And a simple and computationally efficient method for plant species recognition using leaf images was presented in Refs. [13, 16–20, 22, 24]. In Refs. [26–28, 30–35], they proposed a new method for leaf recognition system where both local descriptors and this feature were employed.
3.1.4 Perimeter Convexity
Perimeter convexity is also called convex perimeter ratio which is defined as the ratio between the perimeter of the target and the perimeter of its convex hull. And the equation is
where P C is the perimeter of its convex hull.
This feature was used in Refs. [4, 8, 12, 16, 17, 20] when they carried out some related research for leaf recognition. And Refs. [22, 27, 28, 30, 32, 34–36] also employed the feature of convex perimeter ratio when proposing a simple method based on bisection of leaves for recognition.
3.1.5 Rectangularity
Rectangularity describes the similarity between the target region and its rectangle. It’s defined as
where A R is the area of the rectangle (the minimum enclosing rectangle of the target region).
References [3–5, 8, 9] employed this feature when using classifiers with image and data processing techniques to implement a general purpose automatic leaf recognition for plant classification. And this feature was used when Refs. [16, 21–25, 37] investigated an expert system for automatic recognition of different plant species through their leaf images.
3.1.6 Compactness
Compactness is defined as
References [17, 18, 22, 23] employed this feature when describing an optimal approach for feature subset selection to classify the leaves based on leaf images. And the feature of compactness was used when proposing a novel framework for recognizing and identifying plants in Refs. [31, 32, 34, 35, 37].
3.1.7 Hu’s Invariant Moment
Hu’s invariant moment mainly describes the outline of the target region and is defined as Eqs. (9)–(20).
And the normalized central moment is
where the (p + q)th moments of the image f(x, y) is
and γ is
References [4, 15, 25, 27] used this feature when proposing an efficient classification framework for leaf images with complicated background. And the feature of the Hu invariant moment was also employed in Refs. [34, 38–41] when presenting a system for recognizing plant based on leaf images.
3.1.8 Irregularity
Irregularity refers to the ratio of the radius of the inscribed circle and circumcircle radius of the target region. It’s defined as
where r is the target region’s inscribed circle radius, R is the target region’s circumcircle radius.
In Refs. [14, 22, 29, 31, 32, 37], they employed this feature when presenting a measure based on plant leaf images for classifying the different types of plants.
3.1.9 Eccentricity
Eccentricity is defined as
where R max is the maximum distance of the centroid to the target boundary and R min is the minimum distance of the centroid to the target boundary.
This feature was employed by Harish et al. [16] when they used morphological features and Zernike moments to identify and classify plant leaves. Elhariri et al. [20] used this feature when presenting a classification approach based on RF and LDA algorithms for classifying the different types of plants. Zhao et al. [22] used this feature when proposing a measure based on identifying plant blade samples combined with bark recognition. Aakif et al. [26] employed this feature.
3.1.10 Length/Perimeter
Length/perimeter is defined as
This feature was used in Refs. [3, 5, 8, 9] when using some morphological features and vein features to identify and classify the plant leaves. And in Refs. [12, 16, 21, 24, 27], they employed this feature when proposing advanced leaf recognition based on leaf contour and centroid for plant classification.
3.1.11 Narrow Factor
Narrow Factor is defined as
where D is the longest distance between any two points of the target region, and L p is the target region’s long axis length.
Wu et al. [3] employed this feature when using PNN to implement a general purpose automatic leaf recognition for plant classification. Singh et al. [5] used this feature when putting forward three techniques of plants classification for solving multiclass problems. And the feature of narrow factor was used in Refs. [16, 21, 27].
3.1.12 Perimeter Ratio of Physiological Length and Width
Perimeter Ratio of Physiological length and width is defined as
Wu et al. [3] used this feature when employing PNN with image to implement a general purpose automatic leaf recognition. Singh et al. [5] employed this feature when presenting three techniques of plants classification for solving multiclass problems. This feature was employed by Harish et al. [16] when using morphological features and Zernike moments to identify and classify plant leaves. Bijalwan et al. [21] used this feature when conducting some researches for plant recognition.
3.1.13 Zernike Moment
Zernike Moment is defined as
V * is the complex conjugate of V,
where n = 0, 1, 2, …; \(j = \sqrt { - 1}\), p − |q| is the even, r is the radius, θ is the angle between r and the x-axis. And
p is 0 or a positive integer, p − |q| is the odd, |q| ≤ p.
Wang et al. [38] employed this feature when proposing an efficient classification framework for leaf images with complicated background. Kadir et al. [13] used this feature for classification of leaf images. This feature was employed by Wang et al. [25] when they did some researches based on PCNN. When Kulkarni et al. [17, 18] presented a novel framework for recognizing and identifying plants, they used the feature of pseudo Zernike movements, which is defined as
where
3.1.14 Generic Fourier Descriptor
Generic Fourier Descriptor (GFD), also called GFT, is defined as
where PF is
0 < r < R, θ i = i (2π/T) (0 < i<T), 0 < ρ < R, 0 < ϕ < T, R is the radial frequency resolution and T is the angular frequency resolution,
Kadir et al. [29, 31, 32] used this feature when carrying on classification of the leaf image. Aakif et al. [26] employed this feature for plant recognition.
3.1.15 Elliptical Eccentricity
Elliptical eccentricity refers to the eccentricity of the ellipse of which has the same standard second central moment of the target region. And it is defined as
where c is the ellipse half focal length and a is semi-major axis of the ellipse.
Hossain et al. [6] employed this feature when presenting a simple and computationally efficient method for plant species recognition using leaf images.
3.1.16 Center Distance Sequence
Center distance sequence (CDS) is defined as
where D(x, y) is
Wang et al. [42] used this feature when they proposed a novel method for plant recognition based on the leaf image.
3.2 Texture Feature
Texture is comprised of many closely woven elements, and is periodic. Texture of the image is the image gray scale and color change, namely the gray scale and color space in the form of a certain change of figure (model), is a true regional characteristics inherent. The texture of the image describes the features of smooth, sparse, and so on. There are three kinds of commonly used methods for texture description: statistics method, structure method, frequency spectrum method. Here texture features are introduced one by one.
3.2.1 Energy
Energy is also called the second moment that reflects the degree of uniformity of the gray image, and it is defined as
The feature of energy was used in Refs. [7, 13, 15, 17, 18] when they studied the framework for the identification and detection of plant leaf images. And in Refs. [31, 32, 37, 43–49], this feature was employed to build the plant identification system.
3.2.2 Entropy
Entropy reflects the complexity or non-uniformity of the image texture, and it is defined as
sometimes we also calculate the sum of entropy and the entropy difference are described as
and
In Refs. [7, 13, 15, 17, 18, 20, 23, 31, 32], they proposed a texture extraction method combing a non-overlap window local binary pattern (LBP) and Gray Level Co-Occurrence Matrix (GLCM) for plant leaves classification. And in Refs. [37, 43, 44, 47–50], they proposed a new method for a leaf recognition system where both local descriptors and this feature were employed.
3.2.3 Contrast
Contrast is also called the inertia moment and reflects the image clarity, and it is defined by
In Refs. [7, 13, 15, 17, 18, 20, 23, 31, 32], they employed this feature when using texture features and discriminant analysis to identify leaf images. And Refs. [37, 43, 44, 47–50] used the feature of contrast when putting forward a method for plant leaf classification based on the neighborhood rough set.
3.2.4 Correlation
Correlation is used to measure the similarity of the elements of a co-occurrence matrix element to the row or column, and it is defined as
and
This feature was employed when studying for detection and classification of plant leaf images in Refs. [7, 13, 15, 31, 43–46]. And in Refs. [37, 48, 50], this feature was used for plant leaf classification. Sometimes cor1 and cor2 are used that defined as
where Hxy, Hxy1, and Hxy2 are
And in Refs. [17, 18, 20, 23, 47], this feature was used when they investigated an expert system for automatic recognition of different plant species through their leaf images.
3.2.5 Average
Average is a measure of the average luminance of the texture, and it is defined by
The feature of average was used when developing a method to identify and classify medicinal plants from their leaf images using texture analysis of the images as a basis for classification in Refs. [44, 45, 50]. And the feature of sum average was used in Refs. [15, 46] when they proposed a method for the extraction of shape, color and texture features from leaf images and trained an classifier to identify the exact leaf class, and the sum average is
3.2.6 Inverse Difference Moment
Inverse difference moment is also called homogeneity and is defined as
In Refs. [7, 13, 15, 20, 23, 31, 32], they used this feature when developing a method to identify and classify plants from their leaf images using texture analysis. And this feature was employed when presenting a method for plant species identification using images in Refs. [44, 46, 47, 50].
3.2.7 Standard Deviation and Variance
Standard deviation is a measure of average texture contrast and it’s defined as
the n order moments of the mean value μ is
and sometimes variance and sum-variance are calculated as follows,
Bashish et al. [45] used this feature when studying a framework for detection and classification of plant leaves and stem diseases. This feature was employed by Janani and Gopal [15] when they proposed a method for the extraction of shape, color and texture features from leaf images. Elhariri et al. [20] used this feature when presenting a classification approach based on RF and LDA algorithms for classifying different types of plants.
3.2.8 Maximum Probability
Maximum probability is the strongest response to the gray level co-occurrence matrix measure, and it is defined by
Pydipati et al. [50] employed this feature when using color texture features and discriminant analysis to identify the citrus disease. Zhang et al. [44] employed the feature of maximum probability when putting forward a method for plant leaf classification. Shabanzade et al. [7] proposed a new method for leaf recognition system where both local descriptors and this feature were employed.
3.2.9 Uniformity
Uniformity is defined as
Pydipati et al. [50] employed this feature when using color texture features and discriminant analysis to identify the citrus disease.
3.2.10 Entropy Sequence
Entropy sequence (EnS), proposed by Ma [51], is defined by
where p 1[n] and p 0[n] represent the probability when Y ij [n] = 1 and Y ij [n] = 0 in the output Y[n] separately.
Wang et al. [42] employed this feature when they proposed a novel method of plant recognition based on leaf images, and they [25] also used this for plant recognition.
3.2.11 Hog
Histogram of oriented gradient (Hog) feature is object detection feature descriptor in computer vision and image processing. It constitutes the feature of the gradient direction histogram of the local region of the image. Hog feature and SVM classifier have been widely used in image recognition.
Nilsback et al. [52] employed this feature when investigating to what extent combinations of features could improve classification performance on a large dataset of similar classes. Xiao et al. [53] used the feature of this when they studied the recognition of the plant leaf. Qing et al. [54] presented a method to recognize plant leaves employing HOG as the feature descriptor.
3.3 Color Feature
Color features are most stable and reliable of visual features. Compared with geometric features, it has better performance on robustness as it is insensitive to the size and direction of sub objects in images. Color moments are a simple but effective color feature. In the following, some common color features are introduced simply.
3.3.1 Mean of Color
Mean is a most common feature of the data. For color of images, mean can be used for describing the average of color, it is defined as
Kadir et al. [14, 29, 31, 32, 43] used mean of color as an color feature in their leaf retrieval system. In Refs. [15, 37] employed this feature for medicinal plant recognition based on their leaves. Narayan et al. [36] also used it for plant classification. Kulkarni et al. [17, 18] used RBPNN as a classifier and mean of color as the feature for leaf recognition. In 2015, Refs. [23, 35] used this feature for plant classification under complex environments.
3.3.2 Standard Deviation of Color
Standard deviation of color is described as
Kadir et al. [14, 29, 31, 32, 43] employed the feature of standard Deviation of color when they carried out some research on plant recognition. And in Refs. [15, 17, 18, 23, 35–37], this feature was used when proposing a method for the extraction of shape, color and texture features from leaf images and training an classifier to identify the exact leaf class.
3.3.3 Skewness of Color
Skewness of color describes the shape information about the color distribution and it is the measure of the color symmetry. It is defined as
where σ is the standard Deviation of color.
Kadir et al. [14, 29, 31, 32, 43] used the feature of skewness of color when they studied on plant recognition of leaf images. And when reporting the results of experiments in improving performance of leaf identification system, the feature of skewness of color was used in Refs. [15, 17, 18, 23, 35–37].
3.3.4 Kurtosis of Color
Kurtosis of color describes the shape distribution of information about color, and it is a measure of the extent of a normal distribution with respect to sharpen or flat. It is defined as
The feature of kurtosis of color was used by Kadir et al. [14, 31, 43] when they conducted some researches on plant recognition of leaf images. And this feature was employed in Refs. [15, 17, 18, 23, 35–37] when proposing a method for the extraction of shape, color and texture features from leaf images.
3.4 Feature Evaluation
This paper introduces a variety of features (including shape, texture and color, a total of 31), and a list of their applications in much of the literature. In order to make a further understanding of these features, we evaluate them. And the recognition rate of this index is used to measure the effectiveness of the feature. We are following through a series of experiments to evaluate the characteristics.
In experiments, Flavia [55] dataset was used to test our methods. SVM was used as a classifier for this experiment. In order to ensure the reliability of the experiment, we conducted 20 random experiments on each feature. For the sample selection, we made the training samples and test samples as close as possible to the number of 1:1.
As shown in Table 2, the accuracy of each feature was listed, and the recognition rate was expressed by the mean and variance for each one. In order to get a more intuitive understanding, we drew a line chart to display.
As shown in Fig. 4, there are 26 characteristics, and they are all single valued. Their number is shown in Table 1. And the next, multiple value features are shown in Fig. 5. Their numbers 1–6 are corresponding to 27–32 in Table 1.

Accuracy of each single valued feature

Accuracy of each multiple value feature
We found a single single-value feature recognition rates were generally low from Figs. 4 and 5. In view of this, we tried their pairwise fusion to see whether their recognition rate would be improved when using two single-value features. These eight features were the best eight in the single-valued feature.
In addition to the features of each group only ten random tests, the experiment set is basically the same with the above experiment. Table 3 is some features of their shorthand. The eight features of the best recognition rate in the single valued feature are selected and the experimental results are obtained after pairwise fusion are shown in Table 4.
From Fig. 6, their number is shown in Table 4. It was found that the recognition rate of two features was better than the recognition rate of single valued features. Through the contrast experiment, we found that the recognition rate was increased at the same time as the characteristic value was added. And this led us to select the fusion of multiple features as the input feature in the future.

Comparison of experimental results of single valued and fusion features
4 Classifiers
Classification is a very important method of data mining, which is based on the existing data to learn a classification function or construct a classification model (that is, we usually refer to the classifier). The function or model can make the record data in the database map to a given category one, which can be applied to forecast the data. In a word, the classifier is generally referred to classifying samples in data mining methods, include the decision tree, logistic regression, naive bayes and neural network algorithm and so on. Construction and implementation of a classifier great experience through the following steps:
-
(a)
Select samples (including positive samples and negative samples), all the samples are divided into two parts of training and testing samples;
-
(b)
Perform the classifier algorithm on the training sample, and generate a classification model;
-
(c)
Perform the classification model on the test sample, and generate predictions;
-
(d)
According to forecasts, calculate the necessary assessment and evaluate the performance of the classification model.
Compared with the classification of plants, BP, KNN, RBPNN and SVM are commonly used. In this paper, the application of classifiers in plant classification is introduced one by one.
4.1 SVM Classifier
The main idea of Support Vector Machine (SVM) classifier can be summarized as two points: (1) It is analyzed for the linear separable case, and in the case of linear inseparable, through using a nonlinear mapping algorithm that makes linear inseparable samples in the low dimensional input space transform into a high dimensional feature space, which is in order to make it linearly separable, so as to make the high dimensional feature space by using linear algorithm for linear analysis on the nonlinear characteristics of samples possible; (2) It is based on the theory of structural risk minimization, the optimal segmentation hyperplane is constructed in feature space which makes the learning machine get global optimization.
This classifier was applied by Singhet al. [5] to a database of 1600 leaf shapes from 32 different classes, where most of the classes have 50 leaf samples of similar kind, and obtained 96 % recognition accuracy. Nilsback et al. [52] investigated to what extent combinations of features could improve classification performance on a large dataset of similar classes, and the accuracy reached 88.33 % for the SVM classifier. Watcharabutsarakham et al. [11] proposed a herb leaf classification method for making an automatic categorization, and the experimental results performed 95 % accuracy on ten classes of leaf type with this classifier. This classifier was used by Zhang et al. [56] to discuss the use for recognizing cucumber leaf diseases and got a good accuracy. Tian et al. [57] proposed a new strategy of Multi-Classifier System based on SVM for pattern recognition of wheat leaf diseases and got a higher recognition accuracy of 95.16 %. This classifier was used by Valliammal et al. [37] when they described an optimal approach for feature subset selection to classify the leaves based on GA and KPCA, and the experimental result was up to 92 % accuracy. Prasad et al. [58] used SVM classifier to implement an automated leaf recognition system for plant leaf identification and classification, and 300 leaf features were extracted from a single leaf of 624 leaf dataset to classify 23 different kinds of plant species with an average accuracy of 95 %. Harish et al. [16] used morphological features and Zernike moments to study the classification of plant leaves, and they obtained more than 87.20 % accuracy by using the SVM as a classifier. Narayan et al. [36] got the experiment result of 88 % accuracy when employing the SVM classifier to do some research on the plant recognition. Gang et al. [59] proposed a plant leaf classification technique using shape descriptor by combining Scale Invariant Feature Transform (SIFT) and HOG from the image segmented from the background via Graph cut algorithm, used the SVM classifier and the classification rate was up to 95.16 %. Ahmed et al. [30] conducted some experiments on the plant classification, and the analysis of the results revealed that SVM achieved above 97 % accuracy over a set of 224 test images. Hsiao et al. [60] conducted a comparative study on leaf image recognition and proposed a novel learning-based leaf image recognition technique via sparse representation (or sparse coding) for automatic plant identification, and the experiment result declared that the SVM classifier obtained 95.47 % accuracy. This classifier was used by Le et al. [61] when they proposed a new plant leaf identification based on KDES, and the experiment result was up to 97.5 % accuracy. Ghasab et al. [23] investigated an expert system for automatic recognition of different plant species through their leaf images by employing the ant colony optimization (ACO) as a feature decision-making algorithm, the efficiency of the system was tested on around 2050 leaf images collected from two different plant databases, FCA and Flavia, and the results of the study achieved an average accuracy of 95.53 %. This classifier was employed by Zhao et al. [22] when they presented a measure based on identifying plant blade sample combined with bark recognition, and the experiments based on 4 kinds of plant of the 120 leaf images and 120 bark images, experimental result showed that the average correct recognition rate of only leaves was 97 %, meanwhile the data of combination with bark feature parameters could be up to 98.5 %. Wang et al. [42] proposed a novel method of plant recognition based on leaf images, and the experimental result showed the proposed method got the better accuracy of 97.82 % than other methods. Priyankara et al. [62] described a leaf image based plant identification system using SIFT features combining with Bag Of Word (BOW) model, and the system is trained to classify 20 species and obtained 96.48 % accuracy level. Kazerouni et al. [63] studied a comparison of modern description method for the recognition of 32 plant species, and got the accuracy of 89.35 %. Quadri et al. [64] discussed leaf recognition of different species of plants using multiclass kernel support vector machine, the SVM classifier was tested with flavia dataset and its accuracy was up to 100 %. This classifier was employed by Wang et al. [25] when they did some researches on the leaf recognition based on PCNN, and the experiment result was 96.67 % accuracy.
4.2 KNN Classifier
The adjacent algorithm or k-nearest neighbor (KNN) classification algorithm is one of the simplest methods in the data mining classification technology. K nearest neighbor is that each sample can be represented by its closest K neighbors. The core idea of the KNN algorithm is that if a majority of a sample of the k nearest neighbors in feature space belong to a category, then the sample also belong to this category, and has the characteristics of the samples in this category.
Wu et al. [3] employed 12 leaf features and used this classifier, trained 1800 leaves to classify 32 kinds of plants with an accuracy of 93 %(1-NN), 92 %(4-NN). Du et al. [4] used the KNN classifier, the sample of 200 kinds of images of 20 pieces of the blade was tested with the accuracy of 93 %(1-NN), 92 %(4-NN). Stefan et al. [65] proposed a method for an automatic identification of plant species from low quality pictures of their leaves using mobile devices, and obtained a good recognition rate for the SVM classifier. This classifier was used by Wang et al. [66] when they proposed to improve leaf image classification by taking both global features and local features into account and the experiment result was up to 91.3 %. Li et al. [67] used this classifier to do some research on the plant recognition and the accuracy was more than 96.76 %. The result on a database of 500 plant images belonging to 45 different types of plants with different orientations scales, and translations showed that the proposed method by Bama et al. [68] outperformed 97.9 % of retrieval efficiency. This classifier was used by Zhang et al. [44] to do some research on the plant recognition, experimental results on plant leaf image database demonstrated that the proposed method is efficient and feasible for leaf classification, and got the accuracy of 90.67 %. Shabanzade et al. [7] employed this classifier to study the leaf recognition, and the experimental results showed that using the feature vector containing the local features and global characteristics leaded us to obtain 94.3 % recognition rate. Zhang et al. [69] proposed a new method for plant leaf recognition and the experiment result was up to 96.63 % by using of KNN. Tian et al. [57] put forward a new strategy of Multi-Classifier system for pattern recognition of wheat leaf diseases and obtained a higher recognition accuracy of 87.13 % with the KNN classifier. Harish et al. [16] used morphological features and Zernike moments to study classification of plant leaves, and they got more than 65.10 % accuracy by using the KNN as a classifier. This classifier was used by Zhang et al. [70] when they presented a SLPA method for plant leaf classification, and the experimental results was up to 96.33 % (on the Swedish leaf dataset), 90.81 % (on the ICL [71] dataset). Amin et al. [72] put forward a scalable approach for classifying plant leaves using the 2-dimensional shape feature, and got the accuracy of 71.5 % with this classifier. Du et al. [73] used the KNN classifier to do some research on the plant classification and the experimental results demonstrated the recognition rate was 87.14 %. Narayan et al. [36] used 26 characteristics, the KNN classifier is used for the experimental study, and the recognition rate of 85 % is obtained. Arunpriya et al. [19] put forward an ANFIS (Adaptive Neuro-Fuzzy Inference System) for efficient classification, the ANFIS is trained by 50 different leaves to classify them into 5 types and its accuracy was up to 80 % with this classifier. Amlekar et al. [33] employed ANN to study the method of leaf identification, and the recognition rate of 85.54 % is obtained by using kNN classifier. Nidheesh et al. [74] used the geometrical feature to study the recognition method of plant leaves, and the recognition rate of the recognition rate reached 93.17 %(1-NN) by using KNN classifier. Gaber et al. [24] developed a model for plant identification based on their leaf shape, color and texture features, and the accuracy was up to 99.32 %. Wu et al. [75] presented a novel method for leaf recognition and evaluated with extensive experiments on different databases with different sizes by using this classifier. This classifier was used by Zhang et al. [76] when they doing some research on plant leaf recognition based on leaf images. Naresh et al. [77] used this classifier when proposing a symbolic approach for classification of plant leaves based on texture features is proposed. In order to improve the robustness and discriminability of plant leaf recognition further, a fuzzy k-NN classifier is introduced for matching by Wang et al. [78], and its experiment result was up to 98.03 % on ICL dataset.
4.3 PNN Classifier
The main idea of the Probabilistic Neural Network (PNN) is to use the Bayes decision rule to make the expectation risk minimum of the error classification, and separate the decision space in the multi-dimensional input space. It is a kind of artificial neural network based on the statistical principle and a feed-forward network model using the Parzen window function as the activation function. PNN absorbs the advantages of the radial basis neural network and the classical probability density estimation, which has a more remarkable advantage in pattern classification compared with the traditional feed-forward neural network. No matter how complex the classification problem, as long as there is enough training data, it can guarantee the optimal solution of the Bayes criterion.
PNN is trained by 1800 leaves to classify 32 kinds of plants with an accuracy greater than 90 % when Wu et al. [3] conducted some research on the plant recognition. Singh et al. [5] studied the plant identification method. The PNN classifier was used to analyze the sample of 32 kinds of images of 1600 kinds of leaves, and the recognition rate of 91 % was obtained. The method proposed by Hossain et al. [6] had been tested using ten-fold cross-validation technique and the system showed 91.41 % average recognition accuracy with 1200 simple leaves from 30 different plant species. Pednekar et al. [79] implemented general purpose automatic leaf recognition for plant classification and the PNN is trained by 1800 leaves to classify 32 kinds of plants with an accuracy greater than 95 %. Kadir et al. [13] used the PNN classifier for experimental study of the plant classification and the recognition rate was more than 93 %. Uluturk et al. [12] employed PNN that was trained with 1120 leaf images from 32 different plant species which were taken from the flavia dataset, and experiments and comparisons show that method based on half leaf features has reached one of the best results in the literature for PNN with 92.5 % recognition accuracy. Harish et al. [16] employed the shape feature to study the identification method of the plant leaf, the PNN classifier is used for the experiment and the recognition rate is more than 85.6 %. Kadir et al. [14] did the experiment and its result showed that the method for classification gived an average accuracy of 93.75 % when it was tested on Flavia dataset, which contained 32 kinds of plant leaves. Kadir et al. [43] also was in the study of application of neural network in leaf recognition, used PNN classifier for 60 classes leaf samples and obtained the recognition rate of 93.08 %. When Mahdikhanlou et al. [80] using the center distance for leaf identification, they used PNN as a classifier for classification, and recognition rate was about 80 %. When the image recognition method of the leaf was studied by Hsiao et al. [60], the recognition rate was 90 % for the PNN classifier. Nidheesh et al. [74] did some research on the plant recognition and the experiment result was up to 90.31 % with the PNN classifier. This classifier was used by Hasim et al. [81] when they conducted some researches on the plant classification based on plant leaves.
4.4 RBPNN Classifier
Radial basis probabilistic neural network (RBPNN) is a new kind of feed-forward neural networks, which are developed on the basis of the radial basis function neural network (RBFNN) and PNN. RBPNN network structure is also divided into input layer, hidden layer, output layer. But the network with two hidden layers, the first hidden layer is nonlinear processing layer, it implements the nonlinear classification of input or the nonlinear transform of the input samples; the second hidden layer is the selective summation and clustering on the first hidden layer outputs.
Zhang et al. [44] used the RBPNN as a classifier to study the plant recognition, and the experiment result of the recognition rate reached 93.73 %. Husin et al. [82] employed the image processing and neural network classification algorithm to study the plant recognition, and they used the BPNN classifier to obtain the recognition rate of 98.9 %. This classifier was used by Kulkarni et al. [17] to conduct some researches on a system of plant recognition, and the experiment result reached 95.12 % with 1280 leaf images, and the results on the Flavia leaf dataset indicated that the proposed method by Kulkarni et al. [18] for leaf recognition yielded an accuracy rate of 93.82 %. Nidheesh et al. [74] used the geometrical feature to study the recognition method of plant leaves, and the recognition rate of the recognition rate reached 91.18 % by using PNN classifier.
4.5 Hypersphere Classifier
Hypersphere classifier is a kind of classification method to compress the reference samples. By compressing the sample data, effectively reducing the storage space and computing time, and there is no effect on the recognition rate. The basic idea is to use a hypersphere to represent a cluster points (a sample in a high dimensional space is a point, a category corresponds to a set of points in space). We can use a series of hyperspheres to fit the high dimensional space where the point locates. The overall idea is to approximate the number of hyper spheres for each sample, and simultaneously, extends the radius of the hyper sphere to include a number of sample points. Reducing the storage quantity of the hyper sphere so as to eventually contain all the sample points and the multi sample space.
The hypersphere was used as a classifier when Du et al. [4] and Wu et al. [3] did some research on plant classification methods, and they obtained the classification rate of 91 and 92 % respectively. Wang et al. [38] was in the research of the classification of plant leaves under complex background, and the accuracy reached 92.6 % by using this classifier with 1200 leaf images from 20 different classes. Zhang et al. [44] used the hypersphere as a classifier to study the plant recognition, and the experiment result of the recognition rate reached 94.46 %. When the image recognition method of the leaf was studied by Hsiao et al. [60], the recognition rate was 90 % for the hypersphere classifier.
4.6 BP Classifier
Back Propagation (BP) neural network is a multi-layer feed-forward networks consisting of the nonlinear conversion units, which is composed of the input layer, the hidden layer and the output layer. Under normal circumstances, a three layer BP networks can complete mapping of arbitrary n-dimensional to m dimension, which needs only one hidden layer. When the BP neural network is used as a classifier, the input of the neural network is n components, and that is the n characteristic of plant leaves.
Saitoh et al. [1] collected 20 pairs of pictures from 16 wild flowers in the fields around their campus and obtained a recognition rate of 96 % for this classifier with four features of flowers and two features of leaves. Bashish et al. [45] did some research on plant classification methods, and they obtained the classification rate of 92.7 %. Abirami et al. [47] was in the research of the classification of plant leaves and the accuracy reached 92.6 % by using this classifier. Amlekar et al. [33] employed ANN to study the method of leaf identification, and the recognition rate of 96.53 % is obtained by using BP classifier.
4.7 RF Classifier
Random forest classifier (RF) builds a forest with a random way, the forest is composed of many decision-making trees, and there is no association between each random decision tree forests. After getting the forest, when there is a new sample enters, make every decision tree of the forest to carry on the next judgment to see the sample should belong to which category, and then to see which category is selected the most, predicts the sample for this class.
When Elhariri et al. [20] using RF as a classifier to study the system of plant classification, they obtained the accuracy of 88.82 %. This classifier was employed by Hall et al. [35] to discuss the plant recognition under the complex background, the accuracy was up to 97.3 %.
4.8 k-Means Classifier
The k-average or k-means algorithm is a widely used clustering algorithm. It is the mean of all data samples within the clustering subset as the representative of the clustering. The main idea of the algorithm is through an iterative process to make the data set divide into different categories, and makes the evaluation of clustering criterion function achieve the optimal performance, so that the generated within each cluster is compact. This algorithm is not suitable for processing discrete data, but it has good clustering effect for continuous data.
When Kruse et al. [83] using this classifier to study on the plant identification method, they did some experiments and the classification rate reached 93 %.
4.9 Other Classifiers
In addition to some commonly used classifiers, with the continuous development of plant identification, there have been some new recognition algorithm or rarely used classification methods, these identification methods are listed below.
When Arunpriya et al. [19] studied a new method for the plant classification, the Radial Basis Function (RBF) neural network was trained with 50 different leaves to classify them into 5 types and its result was about 88.6 % accuracy.
Elhariri et al. [20] presented a classification approach based on RF and Linear Discriminant Analysis (LDA) algorithms for classifying the different types of plants, the experimental results showed that LDA achieved classification accuracy of 92.65 % with combination of shape, texture, and vein features. Kruse et al. [83] used LDA to study on the plant identification method, they did some experiments and the classification rate reached 95 %. Kalyoncu et al. [34] was in the research of the classification of plant leaves and the accuracy was more than 70 % by using Linear Discriminant Classifier (LDC).
Lei et al. [84] proposed orthogonal locally discriminant spline embedding (OLDSE-I) and OLDSE-II methods which were applied to recognize the plant leaf and are examined using the ICL-PlantLeaf and Swedish plant leaf image databases, and numerical results show the proposed method can achieve 94.29 ± 2.25 %.
Aakif et al. [26] used the artificial neural network (ANN) to train with 817 samples of leaves from 14 different fruit trees and gives more than 96 % accuracy, and it has also been tested on Flavia and ICL datasets and it gives 96 % accuracy on both the datasets.
Jassmann et al. [85] utilized a convolutional neural network (CNN) in an android mobile application to classify natural images of leaves and got a good result.
Hidden naive bays (HNB) classifier is employed by Eid et al. [86] and several experiments are conducted and demonstrated on 1907 sample leaves of 32 different plant species taken form Flavia dataset, which shows consistently performances of 97 % average identification accuracy.
5 Existing Problems and Future Work
Although a lot of methods of plant recognition based on leaf image were proposed in the past years and some of them have achieved interesting recognition results, some problems still exist and summarized in the following.
Recently there are several datasets in the world, these datasets are built by researchers according to their target. Hence, the kind of plant collected in these datasets is less and not representative. Because researchers live in different regions, these datasets are vulnerable to geographical restrictions. In addition, because researchers employ their own rules to build the dataset, these datasets do not have a unified rule. Therefore, a fully representative, unified, universally accepted standard database or dataset should be built in the future.
More new features should be explored by numerous techniques. When we propose a novel feature, we should consider whether it is easy to extract, whether it is not sensitive to the noise and whether it has the ability of distinguishing different kinds of plant exactly. In fact, with the change of time and the impact of the environment, the color or shape of the organ maybe change even for the same plant. Therefore, this problem should be taken into consideration in the future.
The existing classifiers are designed from the theory and the application environment of plant recognition is not considered. Then when these classifiers are employed for plant recognition, they do not show their best performance.
For the analysis of experimental results, the researchers use different datasets and the size of data sample is also different in each dataset. This makes it difficult to evaluate the performance of different algorithms or the classifier. Hence, efficient evaluation criteria are necessary for plant recognition. By virtue of the same evaluation criteria, all proposed methods can be evaluated objectively.
6 Conclusion
Plant recognition based on image processing is the result of the development of image processing and pattern recognition. The paper mainly reviews the proposed methods of plant recognition based on image processing in recent years. More than 30 features of plant and 10 kinds of classifier are described in the paper and SVM was used to evaluate the features. Base on the analysis of references, we find out some problems in feature exaction and classification and point out the future work, e.g. building standard dataset, exploring new features, optimizing classifies, etc.
References
Saitoh T, Kaneko T (2000) Automatic recognition of wild flowers. In: Proceedings 15th international conference on pattern recognition, pp 507–510
Wu Q, Zhou C, Wang C (2006) Feature extraction and automatic recognition of plant leaf using artificial neural network. Adv Artif Intell 3–10
Wu SG, Bao FS, Xu EY, Wang Y-X, Chang Y-F, Xiang Q-L (2007) A leaf recognition algorithm for plant classification using probabilistic neural network. In: 2007 IEEE international symposium on signal processing and information technology, pp 11–16
Du J-X, Wang X-F, Zhang G-J (2007) Leaf shape based plant species recognition. Appl Math Comput 185:883–893
Singh K, Gupta I, Gupta S (2010) Svm-bdt pnn and fourier moment technique for classification of leaf shape. Int J Signal Process Image Process Pattern Recognit 3:67–78
Hossain J, Amin MA (2010) Leaf shape identification based plant biometrics. In: 2010 13th international conference on computer and information technology (ICCIT), pp 458–463
Shabanzade M, Zahedi M, Aghvami SA (2011) Combination of local descriptors and global features for leaf recognition. Signal Image Process Int J 2:23–31
Lee K-B, Chung K-W, Hong K-S (2013) An implementation of leaf recognition system. ed: ISA, ASTL Vol 21, pp 152–155
Lee K-B, Hong K-S (2012) Advanced leaf recognition based on leaf contour and centroid for plant classification. In: The 2012 international conference on information science and technology, pp 133–135
Yelin H, Zhengyu C, Junhua Q (2012) Classification of leaf shapes and estimation of leaf mass. In: 2012 international conference on green and ubiquitous technology (GUT), pp 167–171
Watcharabutsarakham S, Sinthupinyo W, Kiratiratanapruk K (2012) Leaf classification using structure features and Support Vector Machines. In: 2012 6th international conference on new trends in information science and service science and data mining (ISSDM), pp 697–700
Uluturk C, Ugur A (2012) Recognition of leaves based on morphological features derived from two half-regions. In: 2012 international symposium on innovations in intelligent systems and applications (INISTA), pp 1–4
Kadir A, Nugroho LE, Santosa PI (2012) Experiments of Zernike moments for leaf identification. J Theor Appl Inf Technol 41(1):82–93
Kadir A, Nugroho LE, Susanto A, Santosa PI (2013) Leaf classification using shape, color, and texture features. arXiv preprint arXiv:1401.4447
Janani R, Gopal A (2013) Identification of selected medicinal plant leaves using image features and ANN. In: 2013 international conference on advanced electronic systems (ICAES), pp 238–242
Harish B, Hedge A, Venkatesh O, Spoorthy D, Sushma D (2013) Classification of plant leaves using Morphological features and Zernike moments. In: 2013 international conference on advances in computing, communications and informatics (ICACCI), pp 1827–1831
Kulkarni A, Rai H, Jahagirdar K, Kadkol R (2013) A leaf recognition system for classifying plants using RBPNN and pseudo Zernike moments. Int J Latest Trends Eng Technol 2:1–11
Kulkarni A, Rai H, Jahagirdar K, Upparamani P (2013) A leaf recognition technique for plant classification using RBPNN and Zernike moments. Int J Adv Res Comput Commun Eng 2:984–988
Arunpriya C, Thanamani AS (2014) A novel leaf recognition technique for plant classification. Int J Comput Eng Appl 4:42–55
Elhariri E, El-Bendary N, Hassanien AE (2014) Plant classification system based on leaf features. In: 2014 9th international conference on computer engineering and systems (ICCES), pp 271–276
Bijalwan P, Mittal R, Choudhary S, Bajaj S, Khanna N (2014) Stability analysis of classifiers for leaf recognition using shape features. In: 2014 international conference on communications and signal processing (ICCSP), pp 657–661
Zhao Z, Huang X, Yang G (2015) Plant recognition based on leaf and bark images⋆. J Comput Inf Syst 11:857–864
Ghasab MAJ, Khamis S, Mohammad F, Fariman HJ (2015) Feature decision-making ant colony optimization system for an automated recognition of plant species. Expert Syst Appl 42:2361–2370
Gaber ATT, Snasel V, Hassanien AE (2015) Plant identification: two dimensional-based vs. one dimensional-based feature extraction methods. In: 10th international conference on soft computing models in industrial and environmental applications, pp 375–385
Wang Z, Sun X, Zhang Y, Ying Z, Ma Y (2015) Leaf recognition based on PCNN. Neural Comput Appl 27(4):899–908
Aakif A, Khan MF (2015) Automatic classification of plants based on their leaves. Biosyst Eng 139:66–75
Lagerwall R, Viriri S (2011) Plant classification using leaf recognition. In: 22nd annual symposium of the Pattern Recognition Association of South Africa, pp 91–95
Mishra PK, Maurya SK, Singh RK, Misra AK (2012) A semi automatic plant identification based on digital leaf and flower images. In: 2012 international conference on advances in engineering, science and management (ICAESM), pp 68–73
Kadir A, Nugroho LE, Susanto A, Santosa PI (2011) Foliage plant retrieval using polar fourier transform, color moments and vein features. arXiv preprint arXiv:1110.1513
Ahmed F, Al-Mamun HA, Bari AH, Hossain E, Kwan P (2012) Classification of crops and weeds from digital images: a support vector machine approach. Crop Prot 40:98–104
Kadir A, Nugroho LE, Susanto A, Santosa PI (2012) Performance improvement of leaf identification system using principal component analysis. Int J Adv Sci Technol 44:113–124
Kadir A, Nugroho LE, Susanto A, Santosa PI (2013) Experiments of distance measurements in a foliage plant retrieval system. arXiv preprint arXiv:1401.3584
Amlekar M, Manza RR, Yannawar P, Gaikwad AT (2014) Leaf features based plant classification using artificial neural network. IBMRD’s J Manag Res 3:224–232
Kalyoncu C, Toygar Ö (2014) Geometric leaf classification. Comput Vis Image Underst 133:102–109
Hall D, McCool C, Dayoub F, Sunderhauf N, Upcroft B (2015) Evaluation of features for leaf classification in challenging conditions In: 2015 IEEE winter conference on applications of computer vision (WACV). IEEE Computer Society, pp 797–804
Narayan V, Subbarayan G (2014) An optimal feature subset selection using GA for leaf classification. Ratio 1388:885.193
Valliammal N, Geethalakshmi S (2012) An optimal feature subset selection for leaf analysis. Int J Comput Commun Eng 6:192–193
Wang X-F, Huang D-S, Du J-X, Xu H, Heutte L (2008) Classification of plant leaf images with complicated background. Appl Math Comput 205:916–926
Chaki J, Parekh R (2011) Plant leaf recognition using shape based features and neural network classifiers. Int J Adv Comput Sci Appl 2
Chaki J, Parekh R (2012) Designing an automated system for plant leaf recognition. Int J Adv Eng Technol 2:149–158
Chaki J, Parekh R, Bhattacharya S (2015) Plant leaf recognition using texture and shape features with neural classifiers. Pattern Recogn Lett 58:61–68
Wang Z, Sun X, Ma Y, Zhang H (2014) Plant recognition based on intersecting cortical model. Int Jt Conf Neural Netw 975–980
Kadir A, Nugroho LE, Susanto A, Santosa PI (2013) Neural network application on foliage plant identification. arXiv preprint arXiv:1311.5829
Zhang S, Feng Y (2010) Plant leaf classification using plant leaves based on rough set. In: 2010 international conference on computer application and system modeling (ICCASM), pp V15-521–V15-525
Al Bashish D, Braik M, Bani-Ahmad S (2010) A framework for detection and classification of plant leaf and stem diseases. In: 2010 international conference on signal and image processing, pp 113–118
Sathwik T, Yasaswini R, Venkatesh R, Gopal A (2013) Classification of selected medicinal plant leaves using texture analysis. In: Fourth international conference on computing, communications and networking technologies, pp 1–6
Abirami S, Ramalingam V, Palanivel S (2014) Species classification of aquatic plants using GRNN and BPNN. AI Soc 29:45–52
Song X, Li Y, Chen W (2008) A textural feature-based image retrieval algorithm. In: International conference on natural computation, pp 71–75
Tang Z, Su Y, Meng JE, Qi F, Zhang L, Zhou J (2015) A local binary pattern based texture descriptors for classification of tea leaves. Neurocomputing 168:1011–1023
Pydipati R, Burks T, Lee W (2006) Identification of citrus disease using color texture features and discriminant analysis. Comput Electron Agric 52:49–59
Ma Y, Dai R, Li L, Wei L (2002) Image segmentation of embryonic plant cell using pulse-coupled neural networks. Chin Sci Bull 47:169–173
Nilsback ME, Zisserman A (2008) Automated flower classification over a large number of classes. In: Indian conference on computer vision, pp 722–729
Xiao XY, Hu R, Zhang SW, Wang XF (2010) HOG-based approach for leaf classification. Springer, Berlin, Heidelberg
Xia Q, Zhu HD, Gan Y, Shang L (2014) Plant leaf recognition using histograms of oriented gradients. In: 10th international conference on intelligent computing, ICIC 2014, Taiyuan, China, August 3–6, 2014, pp 369–374
Zhang J, Zhang W (2010) Support vector machine for recognition of cucumber leaf diseases. In: 2010 2nd international conference on advanced computer control (ICACC), pp 264–266
Tian Y, Zhao C, Lu S, Guo X (2011) Multiple classifier combination for recognition of wheat leaf diseases. Intell Autom Soft Comput 17:519–529
Prasad S, Kudiri KM, Tripathi RC (2011) Relative sub-image based features for leaf recognition using support vector machine. In: International conference on communication, computing and security, icccs 2011, Odisha, India, pp 343–346
Gang SM, Yoon SM, Lee JJ (2014) Plant leaf classification using orientation feature descriptions. J Korea Multimed Soc 17(3):300–311
Hsiao J-K, Kang L-W, Chang C-L, Lin C-Y (2014) Comparative study of leaf image recognition with a novel learning-based approach. Sci Inf Conf (SAI) 2014:389–393
Le T-L, Tran D-T, Pham N-H (2014) Kernel descriptor based plant leaf identification. In: 2014 4th international conference on image processing theory, tools and applications (IPTA), pp 1–5
Chathura Priyankara HA, Withanage DK (2015) Computer assisted plant identification system for Android. In: Moratuwa engineering research conference, pp 148–153
Kazerouni MF, Schlemper J, Kuhnert K-D (2015) Comparison of modern description methods for the recognition of 32 plant species. Signal Image Process 6:1
Quadri AT, Sirshar M (2015) Leaf recognition system using multi-class kernel support vector machine. Int J Comput Commun Syst Eng (IJCCSE) 2(2):260–263
Fiel S, Sablatnig R (2010) Leaf classification using local features. In: Workshop of the Austrian Association for Pattern Recognition, pp 69–74
Wang Z, Lu B, Chi Z, Feng D (2011) Leaf image classification with shape context and SIFT descriptors. In: International conference on digital image computing: techniques and applications, pp 650–654
Guan-Lin LI, Zhan-Hong MA, Wang HG (2012) Image recognition of wheat stripe rust and wheat leaf rust based on support vector machine. J China Agric Univ 17:72–79
Bama BS, Valli SM, Raju S, Kumar VA (2011) Content based leaf image retrieval (CBLIR) using shape, color and texture features. Indian J Comput Sci Eng 2:202–211
Zhang S, Lei Y-K (2011) Modified locally linear discriminant embedding for plant leaf recognition. Neurocomputing 74:2284–2290
Zhang S, Lei Y, Dong T, Zhang X-P (2013) Label propagation based supervised locality projection analysis for plant leaf classification. Pattern Recogn 46:1891–1897
Amin AHM, Khan AI (2013) One-shot classification of 2-D leaf shapes using distributed hierarchical graph neuron (DHGN) scheme with k-NN classifier. Proc Comput Sci 24:84–96
Du J-X, Zhai C-M, Wang Q-P (2013) Recognition of plant leaf image based on fractal dimension features. Neurocomputing 116:150–156
Nidheesh P, Rajeev A, Nikesh P (2015) Classification of leaf using geometric features. Int J Eng Res Gen Sci 3(2):1185–1190
Wu H, Wang L, Zhang F, Wen Z (2015) Automatic leaf recognition from a big hierarchical image database. Int J Intell Syst 30:871–886
Zhang C, Zhang S, Fang W (2016) Plant leaf recognition through local discriminative tangent space alignment. J Electr Comput Eng 2016:1–5
Naresh YG, Nagendraswamy HS (2015) Classification of medicinal plants: an approach using modified LBP with symbolic representation. Neurocomputing 173(2016):1789–1797
Wang X, Liang J, Guo F (2014) Feature extraction algorithm based on dual-scale decomposition and local binary descriptors for plant leaf recognition. Digit Signal Proc 34:101–107
Pednekar V, Chavan H (2010) A geometrical feature classified leaf recognition algorithm using probabilistic neural network. In: International conference and workshop on emerging trends in technology, pp 1022–1022
Mahdikhanlou K, Ebrahimnezhad H (2014) Plant leaf classification using centroid distance and axis of least inertia method. In: 2014 22nd Iranian conference on electrical engineering (ICEE), pp 1690–1694
Hasim A, Herdiyeni Y, Douady S (2016) Leaf shape recognition using centroid contour distance. In: IOP conference series: earth and environmental science, p 012002
Husin Z, Shakaff A, Aziz A, Farook R, Jaafar M, Hashim U et al (2012) Embedded portable device for herb leaves recognition using image processing techniques and neural network algorithm. Comput Electron Agric 89:18–29
Kruse OMO, Prats-Montalbán JM, Indahl UG, Kvaal K, Ferrer A, Futsaether CM (2014) Pixel classification methods for identifying and quantifying leaf surface injury from digital images. Comput Electron Agric 108:155–165
Lei YK, Zou JW, Dong T, You ZH, Yuan Y, Hu Y (2014) Orthogonal locally discriminant spline embedding for plant leaf recognition ☆. Comput Vis Image Underst 119:116–126
Jassmann TJ, Tashakkori R, Parry RM (2015) Leaf classification utilizing a convolutional neural network. In: SoutheastCon
Eid HF, Hassanien AE, Kim T-H (2015) Leaf plant identification system based on Hidden Naïve bays classifier. In: International conference on advanced information technology and sensor application, pp 76–79
Acknowledgments
This work is jointly supported by China Postdoctoral Science Foundation (Grant No. 2013M532097), Fundamental Research Funds for the Central Universities (lzujbky-2015-197 and lzujbky-2014-52), National Science Foundation of China (Grant Nos. 61201421).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors of this paper have no potential conflict of interest.
Rights and permissions
About this article

Cite this article
Wang, Z., Li, H., Zhu, Y. et al. Review of Plant Identification Based on Image Processing. Arch Computat Methods Eng 24, 637–654 (2017). https://doi.org/10.1007/s11831-016-9181-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11831-016-9181-4