
Abstract
Image style transfer is a remarkable research hotspot in computer image processing. However, state-of-the-art models have some drawbacks, such as low efficiency of transfer time, distorted image structure and loss of detail information. To address these key issues, this paper proposes an innovative fast style transfer model using optimized self-attention mechanism, called FST-OAM, which mainly consists of four modules: Transformer, image edge detection, fusion and postprocessing. Transformer module extracts the features of content images and style images by encoding and gets the resultant image sequence by decoding. In the Transformer, we present an improved self-attention mechanism to reduce the computational overhead. The image edge detection module is used to extract the edge features of the content and style images. The outputs of the Transformer encoder and the image edge information are input to the fusion module to generate multidimensional image features. Finally, the transferred image is generated with a three-layer convolutional neural network in the postprocessing module. Some different scenes of the content and style images were taken to evaluate our FST-OAM model. The experimental results show that our FST-OAM model outperforms state-of-the-art models. Compared with StyTr\(^{2}\), ArtFlow and SCAIST, the training time of FST-OAM is reduced by 78%, 75%, and 81%, respectively. Compared with StyTr\(^{2}\), ArtFlow, DFP, and SCAIST, the average transfer time of FST-OAM is reduced by 37%, 10%, 56%, and 88%, respectively. Compared with StyTr\(^{2}\), ArtFlow, DFP, and SCAIST, FST-OAM has the highest average PSNR, the lowest average \(L_{c}\), and lower average Gram Loss, which best preserves the content features of the content image and better transfers the style of the stylized image. Besides, in terms of user preference, FST-OAM gets more votes than the other four methods and is more suitable for users.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image style transfer has been a hot research topic in recent years, which aims to transfer image styles from one domain to another. For a given content image and a style image, the image style transfer generates an image containing object boundaries of the content image and texture information of the style image. In order to generate high-quality images, object contours and position relationships in the content image should be preserved to the maximum extent, and the texture information should be aligned with the style image to the maximum extent.
In recent years, convolutional neural network-based image style transfer methods [1,2,3,4,5] are proposed to extract the features in the content image and style image by each hidden layer and then fuse the two to obtain the complete transferred image. However, the common CNN methods extract the features of the whole image without considering the semantic correspondence in the content image and the style image. When the semantic correspondence does not match, the transferred images often fail to match human visual perception, such as transferring the style of a tree to a car. To solve this problem, semantic-based image style transfer methods [6,7,8,9,10,11] have been proposed. These methods usually use image matching to transfer regions in the style image to the corresponding content image regions. However, image matching or too much semantics in the image can greatly reduce the efficiency of image style transfer. In addition, the transferred images may be unsatisfactory when the semantic categories contained in the content image and the style image do not correspond exactly.
To solve these problems, some style transfer methods [12,13,14,15] incorporate Transformer into them. The self-attention mechanism in the Transformer is free to learn the global information of the content and style images and obtain a comprehensive understanding in each layer to better extract image features. In addition, the Transformer models the internal relationships in the image such that the features extracted from different layers have similar structures. However, this method only targets the global information of the image and does not consider the semantic local features in the image, which can lose the local detailed information. Besides, due to the large amount of information in the image, Transformer generates a large number of sequences and the computational overhead increases greatly, which leads to a significant decrease in time efficiency.
In this paper, we propose a fast style transfer model based on optimized self-attention mechanism, called FST-OAM, which includes four modules: Transformer, image edge detection, fusion, and postprocessing. First, the content image is encoded and edge information is extracted using the Transformer module and the edge detection module, and then the two are combined by the fusion module to obtain the intermediate result of the content image. Similarly, the style image is encoded and its edge information is extracted to obtain the intermediate result of the style image. Then, the two intermediate results are added and decoded using the Transformer module. Finally, the decoded results are convolved using the postprocessing module to obtain the result image. To keep the encoding of the desired position of the content image constant, we use the content-aware position encoding scheme (CAPE) [12], which adapts to the scaling of the image by dynamically scaling the encoding of the fixed position in the image.
In summary, the contribution of this work is threefold:
-
1.
A fast style transfer model based on optimized self-attention mechanism is proposed to extract the global and local features of the content and style images using edge detection technique, which uses Canny operator to avoids detail loss and structural distortion of the image.
-
2.
The self-attention module in the Transformer is optimized, which sparse the self-attention matrix to greatly reduce the computational overhead and improve the efficiency of overall image style transfer by reducing the size of the encoded and decoded images as well as the self-attention matrix.
-
3.
Compared to the state-of-the-art models, the images generated by the FST-OAM model achieved outstanding results in terms of detail, structure, information integrity, and time efficiency.
The rest of this paper is organized as follows. Section 2 introduces and analyzes related work. In Sect. 3, the FST-OAM model is described in detail. In Sect. 4, we taken some experiments to evaluate the effectiveness of our model. Section 5 summarizes and draws conclusions.
2 Related work
2.1 Image style transfer
Image style transfer is to transfer texture features from a style image to a content image and retain the semantics contained in the content image. Early image style transfer methods [16,17,18] perform style transfer between content images and specific style images based on textures. However, these methods consume a lot of time, and the quality of the transferred images cannot meet the needs of users.
To improve the quality of the transferred images, image style transfer methods based on CNN have been proposed for extracting more comprehensive image features. Jing et al. [19] divide these methods into two categories: image-optimization-based online neural methods and model-optimization-based offline neural methods. For the first category, Gatys et al. [1] use the hierarchical structure in VGG [20] network to extract features at different layers of the content and style images and combine them to generate the output image by iteration. Luan et al. [21] and Mechrez et al. [22] implement photorealistic style transfer using pre-trained VGG19 [20] and gradient processing of the images. These methods mainly generate images by modeling the content and style images and extracting texture features and then performing constant iterations. However, the constant iteration leads to a large amount of computational overhead, resulting in inefficiencies that do not meet the user’s need for real-time performance. For the second category, Chen et al. [23] and Zhang et al. [24] implement a single style of image style transfer using feedforward networks. In addition, methods such as [25,26,27,28] use some lightweight networks to achieve multi-style image style transfer tasks. However, these methods are only for some styles, which is difficult to meet the diversified needs of users, so the arbitrary style image style transfer method is proposed. Chen et al. [29] propose a fast patch-based style transfer method using convolutional and inverse networks to generate images. Gu et al. [30] implement arbitrary style of image style transfer by reshuffling deep features of style image. Xu et al. [31] and Park et al. [32] use encoding-decoding networks to generate stylized images. An et al. [4] use reversible neural flows and an unbiased feature transfer module to avoid content leakage. Wang et al. [3] use deep feature perturbation to achieve diversity and scalability. Other methods [2, 5, 33, 34] are based on adaptive instance normalization (AdaIN), which changes the mean and variance to achieve arbitrary style transfer. Although these methods improve transfer efficiency, they target the whole image without considering the semantic matching problem between the content image and the style image, leading to problems such as loss of details, coarse textures, and incompatibility with human visual perception.
To solve this problem, semantic-based style transfer methods have been proposed. Park et al. [9] perform semantic segmentation of the content and style images to transfer between semantic pairs. Zhao et al. [35] slice the image to extract individual semantics in the image and transfer each semantics separately, and then stitch the transfer results of individual semantics. Liao et al. [7] use both local context networks and global context networks to fully extract and fuse image features based on semantic segmentation. However, mismatches between semantics and too much semantics in the image can lead to degradation in the quality of the transferred images and an increase in transfer time.
To solve the above problems, the Transformer-based style transfer method is proposed. Transformer is a deep learning model based on self-attention mechanism, which completely abandons convolution and recursion and is suitable for parallelized computation and improved computational efficiency. Ashish et al. [15] first propose the transformer architecture, which connects the encoder and decoder based on the self-attention mechanism, greatly reducing the training time. Li et al. [13] learn the transformation matrix in a data-driven manner and encode and decode it using a linear Transformer to generate stylized images. Kotovenko et al. [14] change the content details by finding content similarities using the Transformer for feature extraction of content images. Deng et al. [12] better preserve the content features of the image and improve the efficiency by preserving the positional encoding of the content image. Yao et al. [36] propose a multiple-stroke style transfer model based on self-attention mechanism to generate comparable stylized images with multiple-stroke patterns. Yoo et al. [37] propose a Wavelet Transforms model that can preserve the structural information and statistical properties of the feature space during the transfer process. However, these methods do not consider the edge information of the local semantics of the image, so some details and texture features are lost. Also, due to the relatively large amount of information in the image, Transformer generates numerous sequences and increases the computational overhead.
To solve these problems, we propose a fast style transfer model based on optimized self-attention mechanism called FST-OAM. Our model improves the Transformer by reducing the number of image sequences and the size of the self-attention matrix, which greatly reduces the computational overhead. In addition, our model performs edge detection on the content and style images to obtain the semantic edge features in the images and enhance the extraction of local features.
2.2 Image edge detection operator
Edge detection [38] refers to a process for the outline of a picture in digital image processing. For the boundary, the gray value is more variable and it is defined as an edge. The purpose of edge detection is to point out the differences and identify the physical phenomena that produce them [39]. And its common methods is to use operators to highlight the edges in the image, which are then segmented by thresholding. In order to better extract the edge features of the content and style images, it is essential to choose an excellent operator.
The Roberts operator [40] uses local differences to find edges with high accuracy for edge localization, but is sensitive to noise and cannot suppress the effect of noise. The Sobel operator [41] uses a convolution kernel to convolve the image and then extracts edges according to a threshold, which is fast in processing and the extracted edges are smooth, but is insensitive to grayscale changes. The Kirsch operator [42] uses eight templates to convolve and derive the image and selects the maximum value as the output, which has a good anti-noise effect, but depends on the size of the object. The Prewitt operator [43] convolves the image in two directions of neighborhood to extract the edges in horizontal and vertical directions, which has a smoothing effect on noise, but the accuracy of edge localization is not very high. The Laplacian operator [44] extracts edges by differentiating twice and has rotational invariance but is very sensitive to noise. The LoG operator [45] reduces the effect of noise by smoothing the image and then extracting edges with the Laplacian operator. The Canny operator [46] performs edge by filtering, calculating gradients, non-maximal suppression, and hysteresis techniques to edge detection, which can identify as many actual edges in the image as possible.
In practical applications, the Canny operator [46] can eliminate the effect of noise well and obtain clear and accurate edge images, which is the most widely used operator. Therefore, our model uses the Canny operator [46] to obtain high-precision edge images for better extraction of local features of the content and style images.
3 Proposed method
3.1 Model structure
The overall model of this paper is to add the information extracted by the edge detection algorithm in the process of generating the transferred image to ensure the detail problem of the transferred image, so as to prevent problems such as image distortion and loss of details. In addition, the efficiency of the model is improved by sparsifying the self-attentive matrix in the Transformer to reduce memory consumption and computational overhead. The FST-OAM model has two main tasks: One is to perform edge detection on images to obtain detailed information about the images, and the other is to perform style transfer of images.
To incorporate Transformer’s long-term dependencies into unbiased image style transfer, this paper formulates the image style transfer task as a sequence image generation problem. Then for the entire style transfer model, the input of the model usually needs to be serialized. Here, an content image \( I_{c} \in R^{H\times W\times 3} \) and a style image \( I_{s} \in R^{H\times W\times 3} \) are given, where H is the height of the image and W is the width of the image. The image is divided into blocks (similar to NLP tasks), and a linear projection layer is used to convert the blocks, which are projected onto sequence features and encoded as \(\varepsilon \), with shape \(L\times C\), where L is the length of \(\varepsilon \), C is the \(\varepsilon \) dimension. L is calculated as:
where m is the number of split blocks.
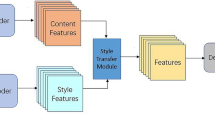
The overall structure of our FST-OAM model is shown in Fig. 1, which consists of four main functional modules: Transformer, image edge detection, fusion and postprocessing. Our model first uses CAPE [12] to encode the position of the content and style images and then uses the Transformer encoder module and the image edge detection module to obtain the encoded information and edge features of the content images and the style images. Then the fusion module is used to combine the encoding information and edge features to get the intermediate results. Finally, the intermediate results are decoded and postprocessed to obtain the transferred image.

FST-OAM model structure
3.1.1 Self-attention mechanism optimization
In order to improve the performance of the network structure and reduce the training time and transfer time, the attention matrix in the Transformer module is sparse in FST-OAM model and it is achieved to reduce memory consumption and computing power by using the idea of Sparse Transformer method [47]. The Sparse Transformer can focus more than the ordinary Transformer because it only focuses on the k most contributing states.
The difference between the self-attention route of Sparse Transformer and the standard self-attention route is an additional process of explicitly selected sparsification. That is to say, the selection is made before the calculation of the score. In order to simplify the complexity of the calculation, the most important elements can be selected and the less important elements can be discarded. Figure 2 is a schematic diagram of Sparse Transformer self-attention execution.

Sparse Transformer self-attention execution
Through sparsifying the matrix, explicit selection is used to improve the attention concentration of the Transformer. Therefore, the attention matrix in the Transformer model is sparse to achieve a model with reduced memory consumption and computational power. The overall idea is to divide the attention operation into selection and softmax normalization to reduce the computational complexity of time. Compared with traditional attention models, the model in this paper does not grant any scores for those values that are not highly relevant to the query.
In this way, the model will understand and retain the features that need the most attention, and eliminate the areas where the correlation coefficient is not strong. This selective method not only retains the most critical pieces of information, but is also very useful in reducing noise and allowing more attention to the most critical factors.
In the Sparse Transformer, the attention score function and softmax normalization are used to calculate the query Q and key K, so as to obtain the expected of the value V and finally generate the output C. Among them, the key \(K\in R^{n\times d}\) and the value \(V\in R^{n\times d}\) are the sequence of output states from the encoder, the query \(Q\in R^{m\times d}\) is the sequence of output states from the decoder, where n is the length of K and V, m is the length of Q, and d is the dimension of the states.
In the implementation, the query Q, key K, and value V are the transfer of the source content x, so that \(Q=W_{q}x, K=W_{k}x\), and \(V=W_{v}x\), where \(W_{q}, W_{k}\), and \(W_{v}\) are learnable parameters. The attention score P is generated by Sparse Transformer as:
The level of score indicates the strength of correlation. Based on this, the model evaluates the score P. Here a mask operation \(M(\cdot )\) is implemented on the basis of the score P to select the previous largest k contributing element. So, it will select the largest k element of each row in P and record the position at the position (i, j) of the position matrix, where k is a hyperparameter. Here, the largest k value of the row i will be recorded as \(t_{i}\); if the value of the jth component is greater than \(t_{i}\), choose to record the position (i, j). In this way, threshold value of each row is connected to form a vector \(t=[t_{1},t_{2},\ldots ,t_{l}]\), where l is the total number of rows. The mask function \(M(\cdot ,\cdot )\) is defined as:
where \(t_{i}\) is the largest k value of row i.
The model in this paper is different from the random abandonment score. Here, the former k item is selected in an explicit way, which can ensure the relevant information of important components. The next step is normalization processing, as in:
where A represents the normalized score. Scores smaller than the former k are assigned to infinity under the action of the mask function \(M(\cdot ,\cdot )\), and the normalized score is approximately 0. Then the output of self-attention C is calculated as:
The output C is the expected value of the value after sparse distribution A. According to the distribution of the selected components, the attention in the Sparse Transformer model can obtain more concentrated attention.
3.1.2 Image edge detection operator
The image edge detection technology in FST-OAM adopts Canny operator [46], which has an outstanding effect and is suitable for the scenes of this paper. The flowchart of the image edge detection algorithm is shown in Figure 3. When performing edge detection on an image, we extract edge information from the content image and style image respectively. For an image, the following five steps are used for edge detection. In the first step, Gaussian filter is used to eliminate the noise in the image, so as to reduce the influence of noise. In the next step, the gradient amplitude and direction are measured to determine the image edge. The third step is to find the edge of the image and reduce the stray response caused by the boundary detection through the non-maximum suppression algorithm. In the fourth step, the double threshold algorithm is used to connect the edges. The last step deals with isolated low threshold points.

Image edge detection flow chart
3.1.3 Fusion of encoding information and edge information
The fusion of edge detection information is to constrain the transformation representation of the output structure and details of the reconstructed image to prevent image distortion and loss of details. The strategy in this paper is to use the image edge detection operator to extract the edge information features of the image, and then combine edge information features with Transformer decoder input branch. This strategy ensures that the impact of image details is reduced during transfer to match the local and global information of the content image, while preserving important details such as edges.
The fusion process of the content image can be expressed as:
where \(\phi _{c}\) represents the combination result of the content image and its edge map, \(F_{fusion}\) is the fusion block, \(E_{c}\) is the edge feature corresponding to the content image, \(A_{c}\) represents the output sequence information of the content image through the Transformer encoder, \(\otimes \) represents the point multiplication process, and \(\oplus \) represents the addition process.
Similarly, the fusion process of the style image can be represented as:
where \(\phi _{s}\) represents the combination result of the style image and its edge map, \(E_{s}\) is the edge feature corresponding to the style image, and \(A_{s}\) represents the output result of the style image through the Transformer encoder.
The above is the process of fusion of image edge features and style transfer in the FST-OAM model. The structure of this model is mainly to solve the problems of loss of image details and distortion after transfer.
3.1.4 Postprocessing
The postprocess module is used to process the output sequence of the Transformer decoder to obtain the final desired style transfer image. Here, the output of the Transformer decoder and the segmentation mask obtained from the semantic segmentation are combined in the final postprocess, which is achieved by combining the deconvolution layer of the segmentation and the deconvolution layer of the decoder. The output sequence size of the Transformer is \(\frac{HW}{64}\times C\). In this paper, the output sequence of the Transformer is not directly upsampled to construct the result, but the three-layer CNN decoder is used to refine the output of the Transformer decoder. This strategy is better than the image obtained by the direct upsampling operation. For each layer of the output, the scale is enlarged by the operation of \(3\times 3Conv+ReLu+2\times upsampling\), and finally, the output result image of size \(H\times W\times 3\) can be obtained.
3.2 Loss function
The loss function of our model is calculated for the image after extracting features through the VGG19 [20] network. Due to the fact that the fusion process is performed before the Transformer decoder performs decoding and the result image is obtained by the CNN decoder refining the decoding results, the loss of edge detection and transfer branch for fusion is already included in each loss of the final transferred image. Therefore, this model finally only needs to consider the content loss and style loss of the transferred image. So, the loss functions of the FST-OAM model are content loss, style loss, and identity loss.
3.2.1 Content loss and style loss
This model can construct content loss \(L_{c}\) to judge the content difference between the transferred image \(I_{cs}\) and the content image \(I_{c}\) and use the style loss \(L_{s}\) to judge the style difference between the transferred image \(I_{cs}\) and the style image \(I_{s}\).
The content loss is defined as:
where \({N_{l}}\) represents the number of layers involved in the calculation, \(\phi _{i}\) represents the feature extracted from the ith layer in the pre-trained VGG19 [20].
The neural network layer can extract the image features in different domains, such as mean and variance. Therefore, the style loss in our model is defined as:
where \(\mu (\cdot )\) represents the mean of the feature, \(\sigma (\cdot )\) represents the variance of the feature.
3.2.2 Identity loss
This paper draws from the idea of self-supervised learning as a learning paradigm, and the network can be trained using this constructed supervised information to learn useful information. Therefore, this model adopts an auxiliary self-style transfer task to learn richer and more accurate representations of semantic and style. If two identical content images \(I_{c}\) are input into the style transfer model, the transferred content image \(I_{cc}\) should be the same as the content image \(I_{c}\). Similarly, if the input of the style transfer model is two identical style images \(I_{s}\), the transferred style image \(I_{ss}\) should be the same as the style image \(I_{s}\).
Therefore, this model can define the content identity loss, which is used to simulate the difference between \(I_{c}\) and \(I_{cc}\). Also, the difference between \(I_{s}\) and \(I_{ss}\) is defined as the style identity loss. The calculation method is as in:
where \(L_{id1}\) is content identity loss, \(L_{id2}\) is style identity loss. Therefore, the loss function of the overall model is as in:
where L is the total loss, \(\lambda _{c}\) is the weight of the content loss \(L_{c}\), \(\lambda _{s}\) is the weight of the enhanced style loss \(L_{s}\), \(\lambda _{id1}\) is the weight of content identity loss \({L_{id1}}\), and \(\lambda _{id2}\) is the weight of style identity loss \(L_{id2}\).
In order to eliminate the influence of the amplitude difference, the final parameter settings are obtained through experimental comparison.
4 Experimental results and analysis
4.1 Experimental settings
We conduct comparative experiments for three different scenes, which are indoor scenes, outdoor scenes, and single-object scenes. For the comparison of three different scenes, we adopted qualitative comparison at the visual level and quantitative comparison of indicators evaluation, respectively, and analyzed an excellent model suitable for image scenes through a series of comparative analysis.
MS-COCO [48] is used as training dataset and test dataset. In the training phase, all images are randomly cropped to \(256\times 256\), while in the testing phase, arbitrary image sizes are supported. Here Adam [49] optimization is used, and the learning rate is set to 0.0005 using a warm-up adjustment strategy [50]. In the experiment, we use \(conv4\_1\) and \(conv5\_1\) to calculate the content loss \(L_{c}\) and set the weights \(\lambda _{c}\), \(\lambda _{s}\), \(\lambda _{id1}\), and \(\lambda _{id2}\) to 10, 7, 50, and 1, respectively. And we use \(conv1\_1\), \(conv2\_1\), \(conv3\_1\), \(conv4\_1\), and \(conv5\_1\) to calculate the gram loss. All the algorithms in this paper are implemented in Python, and they are implemented on a computer equipped with a NVIDIA GeForce RTX 3090 24GB GPU.
4.2 Evaluation indicators
Quantitative comparisons will be made in comparative experiments to prove the effectiveness of the model in this paper. For the style transfer task of images in this paper, five evaluation indicators are selected here, namely content loss \(L_{c}\), PSNR [51], \(Gram\ Loss\) [52], user preference test [53], and time indicators.
PSNR, or peak signal-to-noise ratio, measures the degree of distortion between the transferred image and the content image. The value of this indicator is proportional to the quality of the image, and the larger the value, the better the quality of the image. The calculation method is as in:
where n is the number of bits of the pixel, MSE is the mean square error between the content image \(I_{c}\) and the transferred image \(I_{cs}\). The MSE is calculated as:
where m is the total number of pixels in the image.
\(Gram\ Loss\) is the mean squared error of the Gram matrix of the style image features and the Gram matrix of the final transferred image features. This indicator is used to quantitatively evaluate the ability of the model’s style transfer style for stylized images and style images through the difference of the Gram matrix of the five-layer style features extracted from VGG19 [20]. The \(Gram\ Loss\) indicator is calculated as:
where \(G_{i}(\cdot )\) is the corresponding Gram feature matrix.
This model mainly solves the problem of the efficiency of transfer and the loss of detailed information of the image and the problem of structural distortion. Therefore, the PSNR, content loss, and \(Gram\ loss\) between the content image and the transferred image are used as indicators to measure the quality of the transferred image by the model. The larger the PSNR, the smaller the content loss and \(Gram\ loss\), and the better the image quality.
The user preference test is to invite different users to select images with good visual effects. We measure the quality of the visual effect through the user’s selection preference.
The time indicators mainly include two components: training time and transfer time. In this paper, the training time is compared between FST-OAM model and other models by setting different number of iterations. Also, this paper compares the transfer time between the FST-OAM model and other models by setting different content and style images sizes. The better the time indicators, the higher the efficiency of the model.
4.3 Experimental results
The experimental data selected in this paper are randomly selected images from MS-COCO [48], and they are divided into content image set and style image set. Some comparative experiments will be conducted to verify the effectiveness of the model in this paper. The transferred images of our FST-OAM model are compared with StyTr\(^{2}\) [12], ArtFlow [4], DFP [3], and SCAIST [7] for a series of outdoor scenes, indoor scenes, and single-object scenes.
4.3.1 Evaluation of PSNR and \(L_{c}\)
The first is the experimental comparison of image style transfer for outdoor scenes. As can be seen from the comparison results in Fig. 4, StyTr\(^2\) [12], ArtFlow [4], DFP [3], and SCAIST [7] all produce painting-like distortions, individual objects in the image are distorted, and some details are not transferred. In contrast, the images obtained by our model can prevent these problems from happening through edge feature information fusion, and the results of this model look more visually satisfactory.

Comparison of results of various transfer models for outdoor scenes. a Style image, b Content image, c StyTr\(^2\), d ArtFlow, e DFP, f SCAIST, g FST-OAM
Table 1 shows the detailed values of the comparison indicators between each comparative experimental model and our model for outdoor scenes, mainly the results of the PSNR indicator and content loss. Compared with StyTr\(^2\) [12], ArtFlow [4], and DFP [3], our model outperforms them in terms of PSNR and content loss. Compared with SCAIST [7], our model outperforms it in terms of content loss, and only one set of images is inferior to it in terms of PSNR. The possible reason for this result is that the content image and style image have similar styles. In general, our model has good data indicators, which indicates that for outdoor scenes it can generate images of high quality and the closest in content to the content image.
The second is experimental comparison of image style transfer for indoor scenes. Figure 5 is the comparison result of the style transfer between our FST-OAM model and StyTr\(^2\) [12], ArtFlow [4], DFP [3], and SCAIST [7] four models for indoor scenes. From the qualitative comparison results in Fig. 5, it can be seen that our model has a better style transfer effect for the indoor scenes.

Comparison of results of various transfer models for indoor scenes. a Style image, b Content image, c StyTr\(^2\), d ArtFlow, e DFP, f SCAIST, g FST-OAM
Table 2 shows the results of PSNR indicator and content loss between each comparative experimental model and our model for the indoor scenes. Compared with StyTr\(^2\) [12], ArtFlow [4], and DFP [3], our model outperforms them in terms of PSNR and content loss. Compared with SCAIST [7], our model outperforms it in terms of content loss, and only one set of images is inferior to it in terms of PSNR. Good data indicators show that our model can generate images of high quality and closest in content to the content image.
The following is a comparison of style transfer experiments for single-object images. Figure 6 shows for a single-object scenes the result of style transfer for StyTr\(^2\) [12], ArtFlow [4], DFP [3], SCAIST [7], and our FST-OAM model. It can be seen that our model has excellent visual effects for the single-object scenes.

Comparison of results of various transfer models for the single-object scenes. a Style image. b Content image, c StyTr\(^2\), d ArtFlow, e DFP, f SCAIST, g FST-OAM
Table 3 shows the results of PSNR indicator and content loss for each comparative experimental model and our model for the single-object scenes. Compared with StyTr\(^2\) [12], ArtFlow [4], and DFP [3], our model outperforms them in terms of PSNR and content loss. Compared with SCAIST [7], our model is superior to it in terms of content loss, but two groups of images are inferior to it in terms of PSNR. The possible reason for this result is that the style weight is large and introduces some noise. However, our model retains most of the content features and has good visual effects.
4.3.2 Evaluation of \(Gram\ Loss\)
\(Gram\ Loss\) measures the similarity in style between the final transferred image and the style image. We calculate the average values of the \(Gram\ Loss\) between the transferred images and style images for the outdoor scenes, the indoor scenes, and the single-object scenes. The specific data are shown in Table 4, and the quantitative results can be displayed. Compared with StyTr\(^2\) [12], ArtFlow [4], and DFP [3], our FST-OAM model outperforms them in terms of average \(Gram\ Loss\) for all three scenes. Compared with SCAIST [7], \(Gram\ Loss\) of our FST-OAM model is better for single-object scenes, but not as good as it for indoor and outdoor scenes. The reason for this result is that our model sets smaller style weight for indoor and outdoor scenes to increase the retention of content features. In general, the \(Gram\ Loss\) value of our model is small, so the results of our model are close to the style image in style.
4.3.3 Evaluation of User Preference Test
User preference testing is a way to evaluate the results of an experiment in the most intuitive perspective. In the user preference test, 12 groups of images were selected for the user to choose from. The images in the same group were randomly presented to the users and they could choose the best result image based on their own feelings. In this experiment, a total of 62 users made their choices, and the results are shown in Fig. 7. Among them, 18% chose the images generated by the StyTr\(^2\) [12] model, 12% chose the images generated by the ArtFlow [4] model, 10% chose the images generated by the DFP [3] model, 28% chose the images generated by the SCAIST [7] model, and 32% chose the images generated by our FST-OAM model. Based on the statistical comparison results, it can be seen that the images generated by our model are more in line with the needs of the users.

Comparison results of different models in user preference test
4.3.4 Evaluation of Time Indicators
Time indicators are the most direct way to evaluate the efficiency of a model. In this paper, our FST-OAM model, StyTr\(^2\) [12], ArtFlow [4], DFP [3], and SCAIST [7] are trained and transfer image using the same dataset, and the training time and transfer time are recorded, which will be compared in the following.
First, the training efficiency of different models was compared. The actual training time of each model was obtained by using the same image dataset for training under the same running environment, as shown in Table 5. Due to using a pre-trained VGG [20] network, DFP [3] does not have training time. Compared with StyTr\(^2\) [12], the training time of FST-OAM is reduced by 78%. Compared with ArtFlow [4], the training time of FST-OAM is reduced by 75%. Compared with SCAIST [7], the training time of FST-OAM is reduced by 81%. This shows that our FST-OAM model has the highest training efficiency, which will be more beneficial to apply it to other image domains.
At the same time, this paper compares the transfer time between different models. By using the same dataset for transfer in the same runtime environment, the actual transfer time of each model was obtained for two sizes of images, as shown in Table 6. Compared with StyTr\(^2\) [12], the average transfer time of FST-OAM is reduced by 37%. Compared with ArtFlow [4], the average transfer time of FST-OAM is reduced by 10%. Compared with DFP [3], the average transfer time of FST-OAM is reduced by 56%. Compared with SCAIST [7], the average transfer time of FST-OAM is reduced by 88%. Therefore, our FST-OAM model has the highest transfer efficiency and can be used in practice to transfer images more quickly for use.
5 Conclusion
To address the problem of efficiency and the quality of the transferred images in image style transfer, we propose a fast style transfer model, which uses optimized self-attention mechanism, called FST-OAM. Our model uses the Canny operator to perform edge detection on both content and style images to better extract local features of the image and avoid detail loss and structure destruction. Besides, we have optimized the self-attention module in Transformer. By sparsifying the self-attentive matrix to reduce its size, the computational overhead is greatly reduced, which improves the image generation efficiency of the whole model. We use some images of different scenes to evaluate our FST-OAM model. In terms of time efficiency, our model outperforms state-of-the-art models. Compared with StyTr\(^2\), ArtFlow, and SCAIST, the training time of FST-OAM is reduced by 78%, 75%, and 81%, respectively. And the transfer time of FST-OAM is reduced by 37%, 10%, 56%, and 88% compared to StyTr\(^2\), ArtFlow, DFP, and SCAIST, respectively. In terms of image quality, our model is superior to state-of-the-art models, which preserves the content features of the content image to the maximum extent and better transfers the style features of the style image. Compared with StyTr\(^2\), ArtFlow, DFP, and SCAIST, FST-OAM has the highest average PSNR, the lowest average \(L_{c}\), and lower average \(Gram\ Loss\). Moreover, FST-OAM received the most votes in terms of user preference, which is more in line with the visual perception of users. At present, the \(Gram\ Loss\) of our model is not as low as SCAIST, which shows that our model does not do well enough in preserving the style features. Enhancing the transfer of stylistic features while preserving content features will be an interesting future direction.
Data Availability
The datasets analyzed during the current study are available from the corresponding author on reasonable request.
References
Gatys, L.A., Ecker, A.S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2414–2423 (2016). https://doi.org/10.1109/CVPR.2016.265
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4401–4410 (2019). https://doi.org/10.1109/CVPR.2019.00453
Wang, Z., Zhao, L., Chen, H., et al.: Diversified arbitrary style transfer via deep feature perturbation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7789–7798 (2020). https://doi.org/10.1109/CVPR42600.2020.00781
An, J., Huang, S., Song, Y., et al.: Artflow: unbiased image style transfer via reversible neural flows. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 862–871 (2021). https://doi.org/10.1109/CVPR46437.2021.00092
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1501–1510 (2017). https://doi.org/10.1109/ICCV.2017.167
Shih, Y., Paris, S., Barnes, C., et al.: Style Transfer for Headshot Portraits. Association for Computing Machinery (ACM) (2014). https://doi.org/10.1145/2601097.2601137
Liao, Y.S., Huang, C.R.: Semantic context-aware image style transfer. IEEE Trans. Image Process. 31, 1911–1923 (2022). https://doi.org/10.1109/TIP.2022.3149237
Li, Y., Wang, N., Liu, J., et al.: Demystifying neural style transfer. arXiv preprint arXiv:1701.01036 (2017)
Park, J.H., Park, S., Shim, H.: Semantic-aware neural style transfer. Image Vis. Comput. 87, 13–23 (2019). https://doi.org/10.1016/j.imavis.2019.04.001
Hong, K., Jeon, S., Yang, H., et al.: Domain-aware universal style transfer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14609–14617 (2021). https://doi.org/10.1109/ICCV48922.2021.01434
Kotovenko, D., Sanakoyeu, A., Lang, S., et al.: Content and style disentanglement for artistic style transfer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4422–4431 (2019). https://doi.org/10.1109/ICCV.2019.00452
Deng, Y., Tang, F., Dong, W., et al.: Stytr2: image style transfer with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11326–11336 (2022). https://doi.org/10.1109/CVPR52688.2022.01104
Li, X., Liu, S., Kautz, J., et al.: Learning linear transformations for fast image and video style transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3809–3817 (2019). https://doi.org/10.1109/CVPR.2019.00393
Kotovenko, D., Sanakoyeu, A., Ma, P., et al.: A content transformation block for image style transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10032–10041 (2019). https://doi.org/10.1109/CVPR.2019.01027
Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need. Adv. Neural Inf. Process. Syst. (2017). https://doi.org/10.48550/arXiv.1706.03762
Bruckner, S., Groller, M.E.: Style transfer functions for illustrative volume rendering. In: Computer Graphics Forum, Wiley Online Library, pp. 715–724 (2007). https://doi.org/10.1111/j.1467-8659.2007.01095.x
Debevec, P., Hawkins, T., Tchou, C., et al.: Acquiring the reflectance field of a human face. In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, pp. 145–156 (2000). https://doi.org/10.1145/344779.344855
Efros, A.A., Freeman, W.T.: Image quilting for texture synthesis and transfer. In: Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, pp. 341–346 (2001). https://doi.org/10.1145/383259.383296
Jing, Y., Yang, Y., Feng, Z., et al.: Neural style transfer: a review. IEEE Trans. Vis. Comput. Graph. 26(11), 3365–3385 (2019). https://doi.org/10.1109/TVCG.2019.2921336
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Luan, F., Paris, S., Shechtman, E., et al.: Deep photo style transfer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4990–4998 (2017). https://doi.org/10.1109/CVPR.2017.740
Mechrez, R., Shechtman, E., Zelnik-Manor, L.: Photorealistic style transfer with screened Poisson equation. arXiv preprint arXiv:1709.09828 (2017)
Chen, D., Yuan, L., Liao, J., et al.: Stereoscopic neural style transfer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6654–6663 (2018). https://doi.org/10.1109/CVPR.2018.00696
Zhang, H., Dana, K.: Multi-style generative network for real-time transfer. In: Computer Vision-ECCV 2018 Workshops: Munich, Germany, September 8–14, 2018, Proceedings, Part IV 15, pp. 349–365. Springer, Berlin (2019). https://doi.org/10.1007/978-3-030-11018-5_32
Chen, D., Yuan, L., Liao, J., et al.: Stylebank: an explicit representation for neural image style transfer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1897–1906 (2017). https://doi.org/10.1109/CVPR.2017.296
Li, Y., Fang, C., Yang, J., et al.: Diversified texture synthesis with feed-forward networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3920–3928 (2017). https://doi.org/10.1109/CVPR.2017.36
Zhang, L., Ji, Y., Lin, X., et al.: Style transfer for anime sketches with enhanced residual u-net and auxiliary classifier gan. In: 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), pp. 506–511. IEEE (2017). https://doi.org/10.1109/ACPR.2017.61
Dumoulin, V., Shlens, J., Kudlur, M.: A learned representation for artistic style. arXiv preprint arXiv:1610.07629 (2016)
Chen, T.Q., Schmidt, M.: Fast patch-based style transfer of arbitrary style. arXiv preprint arXiv:1612.04337 (2016)
Gu, S., Chen, C., Liao, J., et al.: Arbitrary style transfer with deep feature reshuffle. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8222–8231 (2018). https://doi.org/10.1109/CVPR.2018.00858
Xu, Z., Wilber, M., Fang, C., et al.: Learning from multi-domain artistic images for arbitrary style transfer. arXiv preprint arXiv:1805.09987 (2018)
Park, D.Y., Lee, K.H.: Arbitrary style transfer with style-attentional networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5880–5888 (2019). https://doi.org/10.1109/CVPR.2019.00603
Wang, H., Li, Y., Wang, Y., et al.: Collaborative distillation for ultra-resolution universal style transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1860–1869 (2020). https://doi.org/10.1109/CVPR42600.2020.00193
Huang, X., Liu, M.Y., Belongie, S., et al.: Multimodal unsupervised image-to-image translation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 172–189 (2018). https://doi.org/10.1007/978-3-030-01219-9_11
Zhao, H.H., Rosin, P.L., Lai, Y.K., et al.: Automatic semantic style transfer using deep convolutional neural networks and soft masks. Vis. Comput. 36, 1307–1324 (2020). https://doi.org/10.1007/s00371-019-01726-2
Yao, Y., Ren, J., Xie, X., et al.: Attention-aware multi-stroke style transfer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1467–1475 (2019). https://doi.org/10.1109/CVPR.2019.00156
Yoo, J., Uh, Y., Chun, S., et al.: Photorealistic style transfer via wavelet transforms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9036–9045 (2019). https://doi.org/10.1109/ICCV.2019.00913
Elaraby, A., Al-Ameen, Z.: Multi-phase information theory-based algorithm for edge detection of aerial images. J. Inf. Commun. Technol. 21(2), 233–254 (2022). https://doi.org/10.32890/jict2022.21.2.4
Shah, B.K., Kedia, V., Raut, R., et al.: Evaluation and comparative study of edge detection techniques. IOSR J. Comput. Eng. 22(5), 6–15 (2020). https://doi.org/10.9790/0661-2205030615
Albdour, N., Zanoon, N.: A steganographic method based on Roberts operator. Jordan J. Electr. Eng. 6, 266 (2020). https://doi.org/10.5455/jjee.204-1583873433
Ravivarma, G., Gavaskar, K., Malathi, D., et al.: Implementation of Sobel operator based image edge detection on fpga. Mater. Today Proc. 45, 2401–2407 (2021). https://doi.org/10.1016/j.matpr.2020.10.825
Kirsch, R.A.: Computer determination of the constituent structure of biological images. Comput. Biomed. Res. 4(3), 315–328 (1971). https://doi.org/10.1016/0010-4809(71)90034-6
Prewitt, J.M., et al.: Object enhancement and extraction. Pict. Process. Psychopict. 10(1), 15–19 (1970)
Wang, X.: Laplacian operator-based edge detectors. IEEE Trans. Pattern Anal. Mach. Intell. 29(5), 886–890 (2007). https://doi.org/10.1109/TPAMI.2007.1027
Marr, D., Hildreth, E.: Theory of edge detection. Proc. R. Soc. Lond. Ser. B Biol. Sci. 207(1167), 187–217 (1980). https://doi.org/10.1098/rspb.1980.0020
Canny, J.: A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 6, 679–698 (1986). https://doi.org/10.1109/TPAMI.1986.4767851
Child, R., Gray, S., Radford, A., et al.: Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509 (2019)
Lin, T.Y., Maire, M., Belongie, S., et al.: Microsoft coco: common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, Berlin (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Xiong, R., Yang, Y., He, D., et al.: On layer normalization in the transformer architecture. In: International Conference on Machine Learning, PMLR, pp. 10524–10533 (2020). https://doi.org/10.5555/3524938.3525913
Qi, F., Lv, H., Wang, J., et al.: Quantitative evaluation of channel micro-doppler capacity for mimo uwb radar human activity signals based on time-frequency signatures. IEEE Trans. Geosci. Remote Sens. 58(9), 6138–6151 (2020). https://doi.org/10.1109/TGRS.2020.2974749
Li, Y., Fang, C., Yang, J., et al.: Universal style transfer via feature transforms. Adv. Neural Inf. Process. Syst. (2017). https://doi.org/10.48550/arXiv.1705.08086
Li, M., Huang, H., Ma, L., et al.: Unsupervised image-to-image translation with stacked cycle-consistent adversarial networks. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 184–199 (2018). https://doi.org/10.1007/978-3-030-01240-3_12
Acknowledgements
This work was supported in part by the Chinese National Natural Science Foundation under Grant 12275208.
Author information
Authors and Affiliations
Contributions
All authors were involved in the conception, design, and implementation of the study. Xiaozhi Du provided ideas and technical guidance for our work and helped us to check for errors. Material preparation, data collection, and experiments were done by Ning Jia and Hongyuan Du. The first draft of the manuscript was written by Xiaozhi Du and Ning Jia. The writing and review of the final manuscript was done by Hongyuan Du. All authors commented on the previous versions of the manuscript and read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
All authors certify that they have no competing interests as defined by Springer, or other interests that might be perceived to influence the results reported in this manuscript.
Ethical approval
This project has no ethical risk, so there is no further ethical review required.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Du, X., Jia, N. & Du, H. FST-OAM: a fast style transfer model using optimized self-attention mechanism. SIViP 18, 4191–4203 (2024). https://doi.org/10.1007/s11760-024-03064-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-024-03064-w