
Abstract
Moving object detection and extraction are widely used in video surveillance and image processing. In this paper, we present a fast method for moving object detection. We use weights of the Gaussian distribution as decision factors, update parameters of the Gaussian mixture model if its values are smaller than that of those not belonging to the background; otherwise, no updates are done. It improves the existing methods by updating the Gaussian mixture model selectively. Experimental results on various scenes of video surveillance show that computation time of the proposed method is reduced.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Moving object detection is made through foreground detection by comparing the background image and the current frame. It is a fundamental research topic in the field of computer vision and plays an important role in target classification, tracking, recognition and understanding [1,2,3,4]. Typical detection methods include optical flow, frame differentials and background subtraction [5, 6].
Optical flow method detects objects using optical flow field of an image and features of moving objects [7,8,9,10]. It is an approximation of the 2-D motion field in image intensity. It is the projection of 3-D object velocity onto the 2-D imaging surface and is also known as image velocity. Image velocity can be used for many tasks including passive scene interpretation and computation of moving objects. The field vectors of optical flow are smooth over the image area if there are not any moving objects in the image. Moving objects consist of different velocity vectors from the background image when the objects move over the background scene, so we can detect the moving objects.
Frame differential method is to take consecutive video frames and calculate the absolute differences [11,12,13]. A threshold function is then used to determine eligible changes. Frame differential can be realized by using the differences of adjacent frames, and the goal is to identify certain points in an image as moving or static. Classical frame differential methods, used in many approaches proposed in the literature [14], have the problem of producing images that can be easily corrupted by spot noises if the threshold value is not optimal. Some researchers suggest the use of a filtering process to delete these spots and to obtain more meaningful images. The frame differential method has been used for initial moving object detection. Also adjacent moving object pixels can be detected through adaptive threshold and adjacent video frame subtracting technique. With these considerations, if the values of pixel distribution in two frames are known, we can estimate the similarity between the values of two consecutive frames using the radiometric similarity of their close neighborhoods.
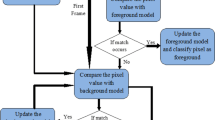
Background subtraction method separates moving object from the static background and is the first step in many applications such as analysis and understanding of video sequences [15,16,17,18]. This method builds a background model according to previous knowledge of the image scenes or statistical information of the pixel features of recent frames. In the frame sequence, image pixels consist of two components. Component one with the largest variance contains the background pixels whose values match the background models. Component two contains the foreground pixels which do not belong to the background. After the matching process, we need to update the background models properly. Background subtraction method consists of four steps [19]. The flow chart of moving objects detection using background subtraction is showed in Fig. 1.

Moving object detection using background subtraction
We will first describe the background subtraction method which extracts moving objects from their background. This method can adapt to multi-modal backgrounds and targets can be detected more accurately; therefore, it has a wider application. Stauffer and Grimson [17] use Gaussian mixture model to solve two key issues of background modeling and background updating. Its disadvantage includes computationally intensive, but failure is easily detected at early stages. Under the number of model matches, Kaewtrakulpong and Bowden [20] use two adjustment approaches, learning rate and update parameters, to solve the problem of early stage detection failure. But the computation is still relatively large. Chen et al. [21], Kolawole and Tavakkoli [22] and Sha and Saul [23] use adaptive color histogram threshold as the match parameters to simplify variance calculation of background pixel, while Gaussian mixture model continues to be updated, However, this approach is not suitable for real-time. Benedek and Sziranyi [24], Chan et al. [25], Sheikh and Shah [26], Junejo [27] and Porikli and Tuzel [28] propose a Bayesian update mechanism. It can estimate the number of required models and achieve accurate adaptation for them. It is flexible to handle illumination variations and other arbitrary changes in the scene. A shortcoming is that it neglects temporal correlations of color values. Berclaz et al. [29], Chen and Lei [30], Li et al. [31] and Magee [32] apply the method to a certain number of frames in a Gaussian distribution where the weights are large enough. The weights are no longer be updated for every frame. In order to remove the continuous update of the model of the background points, update is done only when needed. But it cannot detect background changes within interval frames. The background is easily mistaken for moving objects. When a new Gaussian distribution appears to be not effective, Zivkoviv and Heijden [33] adjust the Gaussian distribution based on the number of adaptation to simplify the calculation and allocation of storage space. Learning rate is a key problem in background update. Bouttefroy et al. [34], Lee [35] and Lin et al. [36] study on the problem of how to choose the learning rate and propose some techniques. These techniques improve the efficiency of background subtraction and object detection. But they have complex computation requirements and are not suitable for real-time processing. The advantages and drawbacks of current methods are shown in Table 1.
To alleviate these problems, we propose an improved method for moving object detection based on the Gaussian mixture model. Its contribution can be described as follow: In the moving object detection, we dynamically adjust the weights of Gaussian distribution, update parameters of the Gaussian mixture model in the scene pixels selectively. The parameters of Gaussian mixture model related to stationary pixels, which may be a large portion of the image, are not updated. Computation complexity can therefore be reduced and object detecting speed can be increased.
The organization of the rest paper is as follows. Section 2 provides the basic principle of moving object detection method which is directly related to our work. Then in Sect. 3, we present a novel method based on Gaussian mixture model, which addresses the update principle. In Sect. 4, we discuss the proposed method and compare it with existing methods. Finally, we conclude in Sect. 5.
2 Basic method for moving object detection
Gaussian mixture model suggested by Stauffer and Grimson [17] is a typical background subtraction method, which is the mainstream for object detection and, at the same time, it is also the foundation for many other methods.
The background of video image often shows multimodality distribution and generally is not stable in moving object detection. Using the mixture of multiple Gaussian distributions to describe the distribution of each pixel value in the background scene, Gaussian mixture model is suitable for nonstationary background images and can be used to describe the real situation. Its samples can be described by the following equation
where \(X_t\) represents the pixel value of a video frame at time t; \((x_0, y_0)\) represent the pixels coordinate in the picture; \(X_t\) obeys the mixture Gaussian distribution. In the multidimensional case, the probability of the current pixel value is:
where K is the number of Gaussian distributions that every Gaussian mixture model has, which is set based on the backgrounds complexity. The fundamental principle for selecting K is based on the changes of background as the result of composition of multi-Gaussian distributions and K is generally set between 3 and 5. \(\omega _{i,t}, \mu _{i,t}\) and \({\varSigma }_{i,t}\) are the weight, the mean, and the covariance of the ith Gaussian distribution at time t, respectively. \(\eta (X_t,\mu _{i,t},{\varSigma }_{i,t})\) is the normal distribution of the ith Gaussian component and the corresponding probability density function can be represented as:
Here, n is the dimension number of variable \(X_t\); \({\varSigma }\) is the covariance of the gray value, when \(X_t\) is gray scale value; \({\varSigma }\) is the covariance matrix of various dimensions of \(X_t\), when \(X_t\) is RGB value, then the components of RGB are seen as independent with each other and having same variances to simplify the computation. The covariance matrix \({\varSigma }\) can be expressed as:
\(\sigma _R^2,\sigma _G^2\) and \(\sigma _B^2\) are the variances of R, G and B respectively. We assume that red, green, and blue pixel values are independent and have the same variances in the RGB color space, and \(\sigma _R^2=\sigma _G^2=\sigma _B^2=\sigma ^2\) , where \(\sigma \) is the standard deviation of R, G and B pixel values.
From Eq. (2), Gaussian mixture model individual pixels can be built using parameters \(K,\omega _{i,t}, \mu _{i,t}\), and \(\sigma \) , according to the complexity of the background image and computation complexity of the algorithm. After the initialization of the Gaussian mixture model, parameters of every Gaussian distribution can be updated in the following ways:
where, \({\hat{\omega }}_{i,t}, {\hat{\mu }}_{i,t}\) and \({\hat{\sigma }}_{i,t}^2\) are the evaluations of \(\omega _{i,t}, \mu _{i,t}\) and \(\sigma _{i,t}\) at time t respectively. They will be used as the corresponding values at time \(t+1\). \(\alpha \) is the learning ratio, which defines the update speed and can be expressed in the following equation
Generally, \(X_t\) and the kth Gaussian distribution can be used to check whether \(X_t\) and \(\mu _{k,t}\) match according to the below equation [34] :
If the equation is true then they match, i.e., \(P(k|X_t, \mu _{i,t},\sigma _{i,t})=1\) , otherwise \(P(k|X_t,\mu _{i,t},\sigma _{i,t})=0; D\) usually is set to 2.5. After the mixture Gaussian distribution has been updated, the weights are unified based on \(\sum _{i=1}^K \omega _{i,t}=1\) and are ranked according to the fitness value of \(\omega /\sigma \). Then we select the B Gaussian distributions as the representation of the background based on the following equation:
where, T is the minimum proportion of the weights that can represent the background. If the model does not match the current pixel value, the mean and the variance do not change and only the weight is updated. If all of the models do not match the current pixel value, then use a new model to replace the old model with the minimum ratio of the weight and the standard deviation \((\omega /\sigma )\). The current pixel value can be the mean of the new model, while the new model is given less weight and larger initial variance. From the above analysis, it can be seen that the update rate and standard deviation of the model should be calculated once for individual pixels in every frame. These algorithms increase the computation complexity greatly and make the Gaussian mixture model difficult for real-time background subtraction. Compared with other complex background subtraction algorithms, classical Gaussian mixture model has certain advantages, but the large amount of computation cost limits the application of this model.
3 Our proposed method for moving object detection
Using Gaussian mixture model as background modeling, huge amount of computation is a key obstacle that prevents this method from being used extensively. One reason is that the method needs to build 3 to 5 Gaussian distributions for each pixel point or for each component of the RGB value. This is necessary for adapting to dynamic scene. The other reason is the update mechanism of the Gaussian mixture model. For the region that moving objects passing through the model needs to update quickly. But for the other regions which occupy a bigger proportion of the image and the moving objects do not pass through, after certain time of learning, its model needs not update all the time. In [17] and [20] the Gaussian mixture models of current pixels in recent video sequence frame are all updated. They do not consider whether the models match or not. This results in huge amount of computation and is difficult to use in real-time scenes. In fact, parameter \(\alpha \) is the learning rate in Eq. (6). It is used to control the update speed of other parameters in the Gaussian mixture model. Parameter \(\rho \) can be expressed as:
The value of \(\eta (X_t|\mu _{i,t},\sigma _{i,t})\) is very small, so it leads to slow update speed of parameters \(\mu _{i,t}\) and \(\sigma _{i,t}\) . Generally, we use the following expression from [8],
Here, \(P(k|X_t,\mu _{i,t},\sigma _{i,t})\) is the post probability of the kth Gaussian distribution component of current pixel at time t. According to Bayesian Theorem, we have the following:
where p(k) is the prior probability of the kth Gaussian distribution component of the current pixel and \(\sum _{i=1}^K p(k) = 1\). To reduce time consumption, we use Eq. (7) as our matching judgment. If it is true, the value of the post probability \( P(k|X_t,\mu _{i,t},\sigma _{i,t}) = 1 \), otherwise, the value of the post probability \( P(k|X_t,\mu _{i,t}, \sigma _{i,t}) =0 \), just like the following expression:
So we can rewrite Eq. (10) as :
Based on the expression, if the current pixel value is not matched with the kth Gaussian distribution component of the Gaussian mixture model, the values of \(\mu _{i,t}\) and \(\sigma _{i,t}\) remain unchanged and only \(\omega _{i,t}\) is updated according to Eq. (5).
Motivated by this issue, we can do some improvements to the following problems. During the process of pixel value, we need to first judge if the current pixel matches the corresponding Gaussian mixture model. If it successfully matches with a certain Gaussian distribution, then we check the Gaussian distributions weight to see whether it satisfies the following condition:
If the weight satisfies the condition, the Gaussian distribution should be judged as one of the first B Gaussian distributions in background evaluation based on the condition acquired from Eq. (8):
In this case, the pixel can be classified as the background. The Gaussian distribution needs not to be updated at the present time and this would not affect the segmentation result of moving objects. Contrarily, if it does not satisfy Formula (14), then update parameters of the Gaussian mixture model. This way, the continuous updating of the Gaussian mixture model of the background pixels can be retrained and the amount of computation can be reduced.
4 Experiment results and analysis
In order to test the performance of the proposed method, experiments have been done based on video Walking View_007 in the video storage PETS2009, video Highway II and video Laboratory of Shadow Detection Data-Raw at http://cvrr.ucsd.edu/aton/testbed/. The results are then compared to the results presented by Stauffer and Grimson in [17] (named SG method in following discussions) and Kaewtrakulpong and Bowden in [20] (its moving object detecting method is named KB method, its shadow elimination method is named KBSE method). The methods using our proposed update schemes in SG and KB are named ISG(Improved SG) and IKB(Improved KB) separately. The image resolutions of video sequences are all \(360\times 280\). The computation platform is a PC with Intel Core i3 M350, 2.27GHz, and the software is MATLAB.
During moving object detection, SG and KB methods update the matched Gaussian distributions corresponding to background continuously. It needs to do exponential evolution computation and the amount of computation is huge. In this paper, we are able to use the weight value of the matched Gaussian distribution to restrain the continuous updating for backgrounds Gaussian distribution effectively. Figure 2 shows the detection results of moving objects for given frame in three video sequences, using the improved methods, ISG and IKB, and the existing methods, SG and KB. According to the circumstance of video sequences, in Fig. 2 and the following cases, we consider the processing of video Laboratory as indoor non-rigid object experiment. We consider the processing of video Walking View_007 as outdoor non-rigid object experiment and consider the processing of video Highway II as outdoor rigid object experiment.

Detection results using different methods. a Indoor image, b 222th frame, c SG detection, d ISG detection, e KB detection, f IKB detection, g outdoor image, h 727th frame, i SG detection, j ISG detection, k KB detection, l IKB detection, m high-way image, n 370th frame, o SG detection, p ISG detection, q KB detection, r IKB detection
4.1 Time consumption analysis
For the performance of time consumption, we choose 887 frames from video Laboratory for indoor non-rigid object (IndN),794 frames from video Walking View_007 frames for outdoor non-rigid object (OutdN) and 500 frames from video Highway II for outdoor rigid object (OutdR) from every video sequences separately. Table 2 illustrates the comparison results of the average time consumption in processing these different videos, using SG and ISG methods, KB and IKB methods. Figure 3 illustrates the comparison results of the processing time for each frame in various video sequences, using the improved methods, ISG and IKB, and the existing methods, SG and KB.

Comparisons of time consumption in object detection processing (\(K=5\)). a SG and ISG for indoor non-rigid object, b KB and IKB for indoor non-rigid object, c SG and ISG for outdoor non-rigid object, d KB and IKB for outdoor non-rigid object, e SG and ISG for outdoor rigidity object, f KB and IKB for outdoor rigidity object
We can see from Fig. 3 that the processing time in the beginning of the ISG method is bigger. The reason for this phenomenon is that the Gaussian distributions weight of background is not big enough. Through learning and updating for a while, the weight has reached the appropriate threshold level. At this time, the Gaussian distribution that belongs to the background is successfully matched and will not be updated again, so the processing time will remain at a relatively small level. The oscillation of the time curve is due to Gaussian mixture models update responding to the moving objects motion. Through this, the method of this paper only updates parameters for changing regions and is able to maintain detection results effectively.
From the curves of the time consumption of moving object detection in Fig. 3 and the average time consumptions in processing videos presented in Table 2, we can see clearly that the method of this paper is better than SG and KB methods. This is mainly due to the use of Gaussian distribution weights corresponding to the values of successfully matched pixels and parameters update of redundant Gaussian distributions of background pixels. After a certain number of updates, the weight would reach a settling threshold value and the parameters of the Gaussian distribution belonging to the background pixels are not updated. Therefore processing time can be maintained at a low level. We can see also from Fig. 3 that the time consumption of the IKB method in the beginning of detection is bigger than the existing KB method. This is caused by the smaller weight values of Gaussian distributions belonging to the background image pixels. The results in Fig. 3 and Table 2 further verify the proposed method is effectively.
Although K Gaussian distributions have been constructed for each pixel during initialization, the majority of background pixels actually do not need the K Gaussian distributions to describe them. If the number of Gaussian distributions is set between 1 and K, they are enough to describe the current pixel. Each Gaussian mixture model proposed in this paper contains K Gaussian distributions and the number of Gaussian distributions is decided by the complexity of the background points in the video scene. This way, the method is able to select the number of Gaussian distributions dynamically. For example, if the background of a point has two statements, then the weights of the first two Gaussian distributions in the corresponding Gaussian mixture model will be bigger than those that follow. This illustrates that the point whose Gaussian distribution has been successfully matched is certainly a background point and its two Gaussian distributions need not to be updated again. The benefit can be seen clearly.
Our method uses Gaussian mixture model for every one of the pixels in the image. For an image with N pixels, instead of any fixed number of Gaussian distribution K per pixel in traditional methods, a variable number of Gaussians is computed for each pixel in our method. So the computational complexity is O(NK) in the worst case, and O(N) in the best case. We focus our attention on moving object detection in video surveillance. In general, the camera is static and the background scene is static also. Moving objects occupy few area of the whole image in this situation. The number of Gaussian distribution needs to be updated for each pixel is closed to 1, and the time consumption is reduced.
4.2 Detection effect analysis
For further information about the performance of ISG and IKB methods, we choose different video sequences of the baseline category in the change detection dataset [37], evaluate ISG and IKB performances using 7 measure metrics: Recall, Specificity, False Positive Rate (FPR), False Negative Rate (FNR), Percentage of Wrong Classifications (PWC), F-Measure and Precision [38], compare them with SG and KB. The comparison results are shown in Tables 3 and 4. Some metric values of ISG and IKB are better or worse than that of SG and KB in Office, Pedestrian and Highway video sequences. Overall, their average values are better, as indicated in the last two lines of Tables 3 and 4.
5 Conclusions
Existing methods for moving object detection have a lower speed in processing video images. We analyze the causes of this phenomenon and propose an improved method that uses the weight of Gaussian distribution as the decision factor. As a result, the number of pixel match calculating could be reduced, the detecting efficiency is improved. We do some experiments on indoor and outdoor images of various video sequences using different datasets. The experiment results show that the proposed method increases the efficiency of moving object detection.
References
Bouwmans, T., El-Baf, F., Vachon, B.: Background modeling using mixture of Gaussians for foreground detection: a survey. Recent Pat. Comput. Sci. 1(3), 219–237 (2008)
Tian, Y., Senior, A., Lu, M.: Robust and efficient foregroundanalysis in complex surveillance videos. Mach. Vis. Appl. 23(5), 967–983 (2012)
Xiao, Q., Luo, Y., Wang, H.: Motion retrieval based on switching Kalman filters model. Multimedia Tools Appl. 72(1), 951–966 (2014)
Chandrashekar, G., Sahin, F.: A survey on feature selection methods. Comput. Electr. Eng. 40(1), 1628 (2014)
Huang, M., Yen, S.: A real-time and color-based computer vision for traffic monitoring system. In: IEEE International Conference on Multimedia and Expo (ICME 2004), vol. 3, pp. 2119–2122. (2004)
Peng, S.: Flow detection based on traffic video image processing. J. Multimedia 8(5), 519–526 (2013)
Barron, J., Fleet, D., Beauchemin, S.: Performance of optical flow techniques. Int. J. Comput. Vis. 12(1), 42–77 (1994)
Meyer, D., Denzler, J., Niemann, H.: Model based extraction of articulated objects in image sequences for gait analysis. In: Proceedings of IEEE International Conference on Image Processing, pp. 78–81 (1997)
Stein, F.: Efficient computation of optical flow using the census transform. Lect. Notes Comput. Sci. 3175(1), 79–86 (2004)
Tsai, D.M., Chiu, W.Y., Lee, M.H.: Optical flow-motion history image (OF-MHI) for action recognition. Signal Image Video Process. 9(8), 1897–1906 (2015)
Lipton, A., Fuiyoshi, H., Patil, R.: Moving target classification and tracking from real-time video. In: Proceedings of IEEE Work shop on Applications of Computer Vision, pp. 8–14 (1998)
Zhang, R., Yang, L., Liu, K., Liu, X.: Moving objective detection and its contours extraction using level set method. In: International Conference on Control Engineering and Communication Technology, pp. 778–781 (2012)
Frost, D., Tapamo, J.R.: Detection and tracking of moving objects in a maritime environment using level set with shape priors. EURASIP J. Image Video Process. 2013(1), 1–16 (2013)
Spagnolo, P., Dorazio, T., Leo, M., Distante, A.: Moving object segmentation by background subtraction and temporal analysis. Image Vis. Comput. 24(5), 411–423 (2006)
Haritaoglu, I., Harwood, D., Davis, L.W.: Real-time surveillance of people and their activities. IEEE Trans. Pattern Anal. Mach. Intell. 22(8), 809–830 (2000)
Mandellos, N.A., Keramitsoglou, I., Kiranoudis, C.T.: A background subtraction algorithm for detecting and tracking vehicles. Expert Syst. Appl. 38(3), 1619–1631 (2011)
Stauffer, C., Grimson, W.E.L.: Adaptive background mixture models for real-time tracking. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2, 246–252 (1999)
Mao, S., Ye, M., Li, X., Pang, F., Zhou, J.: Rapid vehicle logo region detection based on information theory. Comput. Electr. Eng. 39(3), 863872 (2013)
Bouwmans, T.: Traditional and recent approachs in background modeling for foreground detection: an overview. Comput. Sci. Rev. I1–I2, 3166 (2014)
Kaewtrakulpong, P., Bowden, R.: An improved adaptive background mixture model for real-time tracking with shadow detection. In: Proceedings of the 2nd European Workshop on Advanced Video-based Surveillance Systems, pp. 149–158 (2001)
Chen, Z., Pears, N., Freeman, M., et al.: Background subtraction in video using recursive mixture models, spatio-temporal filtering and shadow removal. In: International Symposium on Visual Computing (ISVC), pp. 1141–1150 (2009)
Kolawole, A., Tavakkoli, A.: Robust foreground detection in videos using adaptive color histogram thresholding and shadow removal. Int. Symp. Vis. Comput. (ISVC) 2, 496–505 (2011)
Sha, F., Saul, L.K.: Large margin Gaussian mixture modeling for phonetic classification and recognition. Proc. ICASSP 2006, 265–268 (2006)
Benedek, C., Sziranyi, T.: Bayesian foreground and shadow detection in uncertain frame rate surveillance videos. IEEE Trans. Image Process. 17(4), 608–621 (2008)
Chan, A.B., Mahadevan, V., Vasconcelos, N.: Generalized StaufferGrimson background subtraction for dynamic scenes. Mach. Vis. Appl. 22, 751–766 (2011)
Sheikh, Y., Shah, M.: Bayesian modeling of dynamic scenes for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 27(11), 1778–1792 (2005)
Junejo, I.N.: Using dynamic Bayesian network for scene modeling and anomaly detection. Signal Image Video Process. 4(1), 1–10 (2010)
Porikli, F., Tuzel, O.: Bayesian background modeling for foreground detection. In: Proceedings of ACM Visual Surveillance and Sensor, Network, pp. 55–58 (2005)
Berclaz, J., Fleuret, F., Engin, T., Fua, P.: Multiple object tracking using K-shortest paths optimization. IEEE Trans. Pattern Anal. Mach. Intell. 33(9), 1806–1819 (2011)
Chen, B.S., Lei, Y.Q.: Indoor and outdoor people detection and shadow suppression by exploiting HSV colour information. In: IEEE Computer Society, The Fourth International Conference on Computer and Information Technology, pp. 137–142 (2004)
Li, G., Zeng, R., Lin, L.: Moving target detection in video monitoring system. Proc. IEEE World Congr. Intell. Control Autom. 2, 9778–9781 (2006)
Magee, D.R.: Tracking multiple vehicles using foreground, background and motion models. Image Vis. Comput. 22(2), 143155 (2004)
Zivkoviv, Z., Heijden, F.V.: Efficient adaptive density estimation per image pixel for the task of background subtraction. Pattern Recognit. Lett. 27(7), 773–780 (2006)
Bouttefroy, P.L., Bouzerdoum, A., Beghdadi, A., Phung, S.: On the analysis of background subtraction techniques using Gaussian mixture models. In: IEEE International Conference on Acoustics, Speech, and Signal Processing, pp. 4042–4045 (2010)
Lee, D.S.: Effective Gaussian mixture learning for video background subtraction. IEEE Trans. Pattern Anal. Mach. Intell. 27(5), 827–832 (2005)
Lin, H.H., Chuang, J.H., Liu, T.L.: Regularized background adaptation a novel learning rate control scheme for Gaussian mixture modeling. IEEE Trans. Image Process. 20(3), 822–836 (2011)
Change Detection Dataset: http://www.changedetection.net
Wang, Y., Jodoin, P.M., Porikli, F., Konrad, J., Benezeth, Y., Ishwar, P.: CDnet 2014: an expanded change detection benchmark dataset. In: IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 393–400 (2014)
Acknowledgements
The work of this paper is supported by National Natural Science Foundation of China (No. 51375132), Jincheng Science and Technology Foundation, China (No. 201501004-5), Shanxi Provincial Natural Science Foundation, China (No. 2013011017) and Ph.D. Foundation of Taiyuan University of Science and Technology, China (No. 20122025). We also thank Chen’s work for this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhang, R., Liu, X., Hu, J. et al. A fast method for moving object detection in video surveillance image. SIViP 11, 841–848 (2017). https://doi.org/10.1007/s11760-016-1030-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-016-1030-2