
Abstract
Many practical problems require the solution of large-scale constrained optimization problems for which preserving feasibility is a key issue, and the evaluation of the objective function is very expensive. In these cases it is mandatory to start with a feasible approximation of the solution, the obtention of which should not require objective function evaluations. The necessity of solving this type of problems motivated us to revisit the classical barrier approach for nonlinear optimization, providing a careful implementation of a modern version of this method. This is the main objective of the present paper. For completeness, we provide global convergence results and comparative numerical experiments with one of the state-of-the-art interior-point solvers for continuous optimization.
Similar content being viewed by others


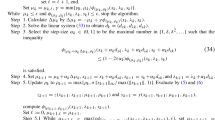
Avoid common mistakes on your manuscript.
1 Introduction
Algorithms for solving continuous constrained optimization problems are iterative. Very frequently a feasible initial point is not available so that we must start with an approximation \(x^0\) that is neither feasible nor optimal. Most algorithms compute successive iterations trying to achieve feasibility and optimality more or less simultaneously or, at least, without giving priority for one feature over another. Moreover, optimization algorithms usually compute both the objective function and the constraints (almost) at every iteration. When the objective function is very expensive and the evaluation of constraints is cheap, this may be a poor strategy. On the one hand, many times, what users really need is a feasible point with a reasonable objective function value. On the other hand, finding a feasible point may demand a non-negligible number of iterations that could become very expensive if we are forced to evaluate the objective function simultaneously with the constraints.
These observations lead us to prefer algorithms that start at a feasible point and preserve feasibility at every iteration. Classical barrier methods, introduced by Frisch (1955) and Fiacco and McCormick (1968), are among the most attractive alternatives for solving constrained optimization problems with those characteristics.
In this paper, we address the case in which the constraints are linear. Namely, the problem considered here will be:
where \(x \in {\mathbb {R}}^n\), \(f:{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) is twice continuously differentiable, \(A \in {\mathbb {R}}^{m \times n}\) \(\ell , u \in ({\mathbb {R}} \cup \{-\infty , +\infty \})^n\), and \(m < n\). Let \({\mathcal {F}} = \{ x \in {\mathbb {R}}^n \mid Ax=b \hbox { and } \ell \le x \le u \}\) be the feasible set for problem (1) and
be the set of points that strictly satisfy the box constraints of (1), called the relative interior of \({\mathcal {F}}\). If an initial feasible approximation is not available, we assume that such approximation may be obtained at low cost by a suitable Linear Programming solver or an specific method for solving affine feasibility problems. Moreover, we assume that, by means of an appropriate pre-processing scheme, we purify the matrix A in order to have linear independent rows.
Pioneered by Frisch (1955) for convex problems, and further analyzed by Fiacco and McCormick (1968) for general nonlinear programming problems, interior-point methods had a revival with the work of Karmarkar (1984) within the linear programming context, specially after the equivalence with logarithmic barrier methods has been established by Gill et al. (1986). The renewed interest in logarithm barrier methods for the general nonlinear programming problem led to the development of the Ipopt algorithm, proposed by Wächter and Biegler (2006). This is one of the state-of-the-art solvers used nowadays in theoretical and practical problems.
The barrier method described in this work starts with an interior approximation such that \(\ell< x^0 < u\) and \(A x^0 = b\). Given an interior feasible \(x^k\), the new iterate \(x^{k+1}\) is computed using matrix decompositions and manipulations by means of which instability due to extreme barrier parameters is avoided as much as possible and, additionally, possible sparsity is preserved. At each iteration, a linear system of equations is solved by means of which one computes new primal and dual approximate solutions. This system approximates KKT conditions for the minimization of a quadratic approximation of the function subject to the linear constraints, except for the fact that the primal \(n \times n\) matrix, which represents the Hessian of the Lagrangian, might need to be modified in order to preserve positive definiteness onto the null-space of A. In other implementations of primal–dual methods (see, for example Wächter and Biegler 2006), an additional (primal) modification may be demanded to ensure that a solution of the KKT system exists. This modification is not needed at all in our approach due to the pre-processing scheme that guarantees full-rank of the matrix A. In linear constrained optimization, the primal modification may cause a temporary loss of feasibility of the next iterate, a feature that we want to avoid completely due to the characteristics of the problems that we have in mind, as stated above. We will show that the resulting method is globally convergent under mild assumptions, preserving feasibility of constraints along the iterations, therefore guaranteeing a feasible solution at the end of the optimization process. The proposed method has been implemented, and a comparative numerical study with Ipopt is provided.
Ipopt is a method for solving optimization problems with constraints of the form \(h(x) = 0\), \(\ell \le x \le u\), where the function h is, in general, nonlinear. In the case in which \(h(x) \equiv A x - b\), assuming that the iterate \(x^k\) is feasible and interior (that is, \(A x^k = b\) and \(\ell< x^k < u\)), the Ipopt basic iteration may be described as follows. Assume that \(\mu > 0\) is a barrier parameter and that \(B(x,\mu )\) is the corresponding logarithmic barrier function, which is well defined whenever \(\ell< x < u\) and goes to infinity when x tends to the boundary. Consider the Newton iteration corresponding to the nonlinear system defined by the optimality conditions for the minimization of \(f(x) + B(x,\mu )\) subject to \(A x = b\). This leads to a linear system of equations whose matrix may not satisfy desired inertia conditions. In order to correct this inertia, the whole diagonal of the matrix may be modified. The solution of the corrected linear system leads to a trial point that may violate both the (interiority with respect to the) bound constraints \(\ell \le x \le u\) and the linear constraints \(A x = b\). This is because, after correction, the search direction may not belong to the null-space ofA. The lack of interiority with respect to the bound constraints is fixed by means of a restriction of the step size. This is not the case of the infeasibility with respect to \(A x = b\), which is fixed using the same restoration procedure that is used in the nonlinear case. The acceptance of the trial point obeys to a filter criterion that combines a measure of infeasibility and the objective function value. The main differences with respect to the method presented in this paper are: (i) the inertia correction does not involve the modification of whole matrix’s diagonal, as we assume that A is full-row rank, a feature that is guaranteed by a pre-processing scheme. As a consequence, feasibility is always preserved and restoration is never necessary; (ii) the acceptance of the trial point is related to sufficient descent for the merit function \(f(x) + B(x,\mu )\).
The rest of this work is organized as follows. Section 2 introduces the proposed barrier method. Section 3 presents its theoretical convergence results. Section 4 shows implementation details and exhibits numerical experiments. Conclusions are given in the last section.
Notation If \(v = (v_1,\ldots ,v_n)^\mathrm{T} \in {\mathbb {R}}^n\), \(\mathrm {diag}(v)\) denotes the \(n \times n\) diagonal matrix whose diagonal entries are given by \(v_1,\ldots ,v_n\). If \({\mathcal {K}} = \{ k_1, k_2, \ldots \} \subseteq {\mathbb {N}}\) with \(k_j < k_{j+1}\) for all j then we denote \({\mathcal {K}} \underset{\infty }{\subset }{\mathbb {N}}\).
2 Proposed barrier method
Let us consider the problem
where
\(\mu\) is a positive parameter, \({\mathcal {I}}_\ell {\mathop {=}\limits ^{\hbox {def}}} \{ i : \ell _i \ne -\infty \}\), and \({\mathcal {I}}_u {\mathop {=}\limits ^{\hbox {def}}} \{ i : u_i \ne +\infty \}\). The Lagrange conditions for (3) are given by
e being the n-dimensional vector of all ones, the diagonal matrices L and U defined componentwise by
with pseudo-inverses \(L^\dagger\) and \(U^\dagger\) given by
Defining
we have
where \(Z^\ell = \hbox {diag}(z_\ell )\) and \(Z^u = \hbox {diag}(z_u)\); and, putting all together into (5), we obtain
A natural approach for finding \(x^*\) that approximately solves (3) consists in obtaining \((x^*,\lambda ^*,z_\ell ^*, z_u^*)\) approximately satisfying (8). In practice, we do not use the definition (7) of \(z_\ell\) and \(z_u\), but we indeed find an approximate solution to (8). Since \(\varphi\) in (3) is not defined for \(x \not \in (\ell , u)\) and goes to infinity as any component of x gets closer to \(\ell\) or u, necessarily \(\ell< x^* < u\). This fact, Eqs. (8c) and (8d), and the positivity of \(\mu\) imply that \([z_\ell ^*]_i \ge 0\), for all \(i \in {\mathcal {I}}_\ell\) and \([z_u^*]_i \ge 0\), for all \(i \in {\mathcal {I}}_u\). Therefore, \(z_\ell ^*\) and \(z_u^*\) are \(\mu\)-approximations to the Lagrange multipliers in the KKT conditions of problem (1).
These ideas give support to a method for solving problem (1) that consists in solving a sequence of subproblems of the form (3) by driving to zero the so-called barrier parameter \(\mu _k\), positive for all k. Denoting the outer iterations by the index k, an approximate solution to (8) is computed by an iterative process indexed by j, the inner iterations.
To describe an inner iteration of the method, suppose we have \((x^{k,j},\lambda ^{k,j},z_\ell ^{k,j},z_u^{k,j})\), with \(j \ge 0\), \(x^{k,j} \in {\mathcal {F}}_0\), and positive vectors \(z_\ell ^{k,j}\) and \(z_u^{k,j}\). We consider a line search method to compute \((x^{k,j+1},\lambda ^{k,j+1},z_\ell ^{k,j+1},z_u^{k,j+1})\) such that \(x^{k,j+1} \in {\mathcal {F}}_0\), \([z_\ell ^{k,j+1}]_i>0\) for each \(i \in {\mathcal {I}}_\ell\), and \([z_u^{k,j+1}]_i>0\) for each \(i \in {\mathcal {I}}_u\). For defining the \((j+1)\)th inner approximation, a search direction \((d_x^{k,j}, d_\lambda ^{k,j}, d_{z_\ell }^{k,j}, d_{z_u}^{k,j})\) must be computed, with \(d_x^{k,j}\) a descent direction for \(\varphi _{\mu _k}(\cdot )\) from \(x^{k,j}\), and a step size \(\alpha _{k,j}\) satisfying a sufficient decrease condition.
The Newton’s direction to system (8) from \((x^{k,j}, \lambda ^{k,j}, z_\ell ^{k,j}, z_u^{k,j})\) is the solution to the \((3n+m)\)-dimensional linear system given by
the well-known primal–dual system (Nocedal and Wright 2006). From the last two blocks of (9), we get
Using (10) into the first two blocks of (9), we obtain the \((n+m)\)-dimensional linear system
where \(H_{k,j} = \nabla ^2 f(x^{k,j}) + L_{k,j}^\dagger Z_{k,j}^\ell + U_{k,j}^\dagger Z_{k,j}^u\). From Nocedal and Wright (2006, Thm.16.3), we have that
where \(W \in {\mathbb {R}}^{n \times (n-m)}\) is a matrix whose columns form a basis to the kernel of A and inertia(M) is a triple that denotes the number of positive, negative, and null eigenvalues of the square symmetric matrix M, respectively. Therefore, the matrix of the linear system (11) is nonsingular if \(H_{k,j}\) is nonsingular in the kernel of A. Furthermore, we have the following result.
Lemma 1
Consider the linear system (11). If the matrix \(H_{k,j}\) is positive definite in the kernel of A and the component \(d_x^{k,j}\) of the solution is nonzero, then \(d_x^{k,j}\) is a descent direction for \(\varphi _{\mu _k}(\cdot )\) from \(x^{k,j}\).
Proof
The first block of equations in system (11) implies that
Since \(\nabla \varphi _{\mu _k}(x^{k,j}) = \nabla f(x^{k,j}) - \mu _k L^\dagger _{k,j} e + \mu _k U^\dagger _{k,j} e\), from (13),
The second block of equations in (11) implies that \(d_x^{k,j}\) is in the kernel of A. So, pre-multiplying (14) by \(-(d_x^{k,j})^\mathrm{T}\),
Thus, if \(H_{k,j}\) is positive definite in the kernel of A, then \((d_x^{k,j})^\mathrm{T} H_{k,j} d_x^{k,j}>0\) whenever \(d_x^{k,j} \ne 0\), which, together with (15), imply that \(d_x^{k,j}\) is a descent direction for \(\varphi _{\mu _k}(\cdot )\) from \(x^{k,j}\). \(\square\)
To ensure that (i) the solution of (11) exists and (ii) \(d_x^{k,j}\) is a descent direction for \(\varphi _{\mu _k}(\cdot )\) from \(x^{k,j}\), relation (12) and Lemma 1 indicate that we need
According with (12), this can be accomplished by guaranteeing that \(H_{k,j}\) is positive definite in the kernel of A. For this reason, if the inertia of the matrix of the system (11) is not equal to (n, m, 0), we search for a scalar \(\xi _{k,j}>0\) such that the inertia of the matrix
is (n, m, 0) and then solve the following perturbed version of the system (11)
The subproblem iterates are stated as
in which \(\alpha _{k,j}, \alpha _{k,j}^{z_\ell }, \alpha _{k,j}^{z_u} \in (0, 1]\) determine the step sizes. Since \(\ell<x^{k,j}<u\), \([z_\ell ^{k,j}]_i>0\) for each \(i \in {\mathcal {I}}_\ell\), and \([z_u^{k,j}]_i>0\) for each \(i \in {\mathcal {I}}_u\), we need to preserve these properties in the new iterate. Following Wächter and Biegler (2006), we use a fraction-to-the-boundary parameter \(\tau _k = \max \{ \tau _{\min }, 1 - \mu _k \}\), with \(\tau _{\min } \in (0, 1)\). Moreover, we define the sets \({\mathcal {D}}_-^{k,j} {\mathop {=}\limits ^{\hbox {def}}} \{ i : [d_x^{k,j}]_i < 0 \}\) and \({\mathcal {D}}_+^{k,j} {\mathop {=}\limits ^{\hbox {def}}} \{ i : [d_x^{k,j}]_i > 0 \}\), and compute
Notwithstanding, whenever \(d_x^{k,j}\) is small enough, we take \(\alpha _{k,j}^{z_\ell } = \alpha _{k,j}^{z_u} = 1\), in order to not impair the global convergence of the method. A backtracking must be done to obtain \(\alpha _{k,j} \in (0, \alpha _{k,j}^{\max } ]\), with \(\alpha _{k,j}^{\max } = \min \{ \alpha _{k,j}^\ell , \alpha _{k,j}^u \}\), such that the sufficient decrease condition
is satisfied, for some \(\gamma \in (0,1)\).
Last, but not the least, we have to ensure that \(z_\ell ^{k,j+1}\) and \(z_u^{k,j+1}\) approximately maintain the relationship with \(x^{k,j+1}\) established in (7). These equations guarantee that the northwest matrix in system (11) is an approximation to the Hessian of the log-barrier function (4). Therefore, we consider
and
for \(i = 1, \ldots , n\) and a constant \(\kappa _z \ge 1\). Hence,
which means that (7) will be satisfied with precision \(\kappa _z\) (see Wächter and Biegler 2006).
We consider that a point \((x^{k,j}, \lambda ^{k,j}, z_\ell ^{k,j}, z_u^{k,j})\) is an approximate solution to subproblem (3) whenever
where
and \(\kappa _\varepsilon > 0\). Thus, (18) implies that Eqs. (8a), (8c), and (8d) are approximately satisfied, and by the definition of the method, \(A x^{k,j} = b\), so that (8b) holds. Therefore, \((x^{k,j}, \lambda ^{k,j}, z_\ell ^{k,j}, z_u^{k,j})\) approximately satisfies the optimality conditions (8) of subproblem (3).
After a subproblem is approximately solved, we compute a new barrier parameter
where \(\kappa _{\mu } \in (0, 1)\) and \(\theta _{\mu } \in (1, 2)\). With such an update, the barrier parameter may converge superlinearly to zero.
Algorithms 1, 2, and 3 below summarize the proposed method. Algorithm 1 corresponds to the outer algorithm, while Algorithm 2 corresponds to the inner algorithm, that is used by Algorithm 1 for solving the subproblems. Algorithm 3, taken from Wächter and Biegler (2006, p 36) and reproduced here for completeness, corresponds to the inertia correction procedure.



3 Global convergence
The convergence theory of the proposed method is given in this section. We first present well definiteness results for Algorithm 2.
Lemma 2
In Step 2.2 of Algorithm 2, there exists \(\xi _{k,j} \ge 0\) large enough such that \(\hbox {inertia}(M_{k,j}) = (n,m,0)\), with \(M_{k,j}\) defined in (21).
Proof
Let \({\tilde{H}}_{\xi _{k,j}} = \nabla ^2 f(x^{k,j}) + L_{k,j}^\dagger Z_{k,j}^L + U_{k,j}^\dagger Z_{k,j}^U + \xi _{k,j} I\) and \(W \in {\mathbb {R}}^{n \times n-m}\) a matrix whose columns form a basis to the kernel of A. Notice that, if \({\tilde{H}}_{\xi _{k,j}}\) is positive definite, then \(W^\mathrm{T} {\tilde{H}}_{\xi _{k,j}} W\) is also positive definite. Thus, on the one hand, if \({\tilde{H}}_0\) is positive definite, then \(W^\mathrm{T} {\tilde{H}}_0 W\) is positive definite as well, which together with (12) implies that \(\hbox {inertia}(M_{k,j}) = (n,m,0)\) for \(\xi _{k,j} = 0\). On the other hand, if \({\tilde{H}}_0\) is not positive definite, let \(\lambda _1 \le \lambda _2 \le \cdots \le \lambda _n\) be the eigenvalues of the matrix \({\tilde{H}}_0\), with \(\lambda _1 \le 0\). Therefore, the eigenvalues of \({\tilde{H}}_{|\lambda _1| + \epsilon }\), for \(\epsilon > 0\), are
which implies that \({\tilde{H}}_{|\lambda _1| + \epsilon }\) is positive definite and, consequently, so it is \(W^\mathrm{T} {\tilde{H}}_{|\lambda _1| + \epsilon } W\). Hence, (12) yields \(\hbox {inertia}(M_{k,j}) = (n,m,0)\) for \(\xi _{k,j} \ge |\lambda _1| + \epsilon\). \(\square\)
Next we show that, as long as \(x^{k,j}\) is not stationary for problem (3), it is always possible to compute an adequate search direction in Algorithm 2.
Lemma 3
In Step 2.3 of Algorithm 2, it is possible to compute the search directions \(d_x^{k,j}\) and \(d_\lambda ^{k,j}\). Moreover, if \(d_x^{k,j} \ne 0\), then \(d_x^{k,j}\) is a descent direction for \(\varphi _{\mu _k}(\cdot )\) from \(x^{k,j}\). So, Step 2.6 finishes in a finite number of iterations.
Proof
From Lemma 2, it is possible to find \(\xi _{k,j}\) such that \(\hbox {inertia}(M_{k,j}) = (n,m,0)\). Therefore, \(M_{k,j}\) is a nonsingular matrix, and the linear system in Step 2.3 has a unique solution. Notice that, if \(d_x^{k,j}=0\) and \(d_\lambda ^{k,j}=0\), the right-hand side of the linear system (22) yields the pair \((x^{k,j}, \lambda ^{k,j})\) to be primal–dual stationary for problem (3). In case \(d_x^{k,j}=0\) but \(d_\lambda ^{k,j}\ne 0\), also from (22) we obtain the primal–dual stationary pair \((x^{k,j}, \lambda ^{k,j}+d_\lambda ^{k,j})=(x^{k,j}, \lambda ^{k+1,j})\) for problem (3). Now, from Lemma 1, since \(\hbox {inertia}(M_{k,j}) = (n,m,0)\), we have that, whenever a direction \(d_x^{k,j} \ne 0\) is computed, it will be of descent for \(\varphi _{\mu _k}(\cdot )\) from \(x^{k,j}\). So, there exists \(\alpha _{k,j}\) such that the sufficient decrease condition at Step 2.6 is verified.\(\square\)
Lemmas 2 and 3 show that Algorithm 2 is well defined. The well definiteness of Algorithm 1 is subject to the global convergence of Algorithm 2, and this is established in the sequel. By global convergence, we mean that we analyze the properties of the infinite sequence generated by the method that emerges when the stopping criterion at Step 2.1 is removed from Algorithm 2. With some abuse of notation, we refer to this sequence as the infinite sequence generated by Algorithm 2. Analyzing the properties of this infinite sequence, we prove that the stopping criterion at Step 2.1 of Algorithm 2 is satisfied in finite time. Based on ideas from Chen and Goldfarb (2006), we present a global convergence analysis for the proposed algorithm, but in a more detailed fashion, and strongly connected with the structure of problem (1). The global convergence results rest upon the following assumptions.
Assumption 1
The set \({\mathcal {F}}_0\), defined in (2), is nonempty.
Assumption 2
The objective function f of problem (1) is continuous and at least twice continuously differentiable.
Assumption 3
The sequence \(\{ x^{k,j} \}\) generated by Algorithm 2 is bounded, for all k.
Assumption 4
The matrices \({\bar{H}}_{k,j} = H_{k,j} + \xi _{k,j} I\) satisfy \(d^\mathrm{T} {\bar{H}}_{k,j} d \ge \sigma \Vert d \Vert ^2\), for all \(d \in {\mathbb {R}}^n\), \(d \ne 0\), such that \(Ad = 0\), for some \(\sigma > 0\) and for all k and j.
Although Assumption 3 is a conjecture about the sequence generated by the method, which we have no control at a first glance, this is implicitly assured when (i) box constraints exist for every variable, i.e., when \(-\infty< \ell _i \le u_i < +\infty\), for \(i = 1, \ldots , n\), or (ii) when the level set \(\{ x \in {\mathcal {F}} \mid f(x) \le f(x^0) \}\) is bounded, where \(x^0 \in {\mathcal {F}}_0\). Assumption 4 establishes that the matrices \(\{ {\bar{H}}_{k,j} \}\) must be uniformly positive definite in the kernel of matrix A. Compared with other requirements, as in the work by Chen and Goldfarb (2006, Condition (C-5)), our hypothesis is slightly weaker, since Lemma 2 guarantees the attainment of a scalar \(\xi _{k,j}\) in Step 2.2 of Algorithm 2 which properly adjusts the inertia of the matrix of the system (22) . Thus, Assumption 4 may be accomplished by the numerical nature of the inertia correction method used.
Lemma 4
Suppose that Assumptions 1, 2and3hold and consider that the sequence generated by Algorithm 2 is \(\{ x^{k,j+1}, \lambda ^{k,j+1}, z_\ell ^{k,j+1}, z_u^{k,j+1} \}\). Then, there exists \(\delta > 0\) such that
-
I.
for all \(j \in \{0, 1, 2, \ldots \}\), it holds
-
(a)
\(\ell _i + \delta \le x^{k,j+1}_i\), for all \(i \in {\mathcal {I}}_\ell\) and
-
(b)
\(x^{k,j+1}_i \le u_i - \delta\), for all \(i \in {\mathcal {I}}_u\);
-
(a)
-
II.
for all \(j \in \{0, 1, 2, \ldots \}\), it holds
-
(a)
\(\displaystyle [ z_\ell ^{k,j+1} ]_i \in \frac{\mu _k}{\delta } \left[ \frac{1}{\kappa _z},\kappa _z \right]\), for all \(i \in {\mathcal {I}}_\ell\) and
-
(b)
\(\displaystyle [ z_u^{k,j+1} ]_i \in \frac{\mu _k}{\delta } \left[ \frac{1}{\kappa _z},\kappa _z \right]\), for all \(i \in {\mathcal {I}}_u\).
-
(a)
Proof
To show (I), suppose, by contradiction, that there exist an infinite set \(\displaystyle {\mathcal {J}} \underset{\infty }{\subset }{\mathbb {N}}\), and \({\hat{\imath }} \in {\mathcal {I}}_\ell\) such that
By Step 2.1 of Algorithm 2, \(E_{\mu _k}(x^{k,j+1}, \lambda ^{k,j+1}, z_\ell ^{k,j+1}, z_u^{k,j+1}) > \kappa _\varepsilon \mu _k\), and by the line search of Step 2.6 of Algorithm 2,
Assumptions 2 and 3 imply that the sequences \(\{ f(x^{k,j+1}) \}\), \(\{ x^{k,j+1}_i - \ell _i \}\), for all \(i \in {\mathcal {I}}_\ell\), and \(\{ u_i - x^{k,j+1}_i \}\), for all \(i \in {\mathcal {I}}_u\), are bounded. Thus, by (25) and by the definition of the function \(\varphi _\mu (\cdot )\) in (4),
which contradicts (26). An analogous reasoning applies in case there exist an infinite set \(\displaystyle {\mathcal {J}} \underset{\infty }{\subset }{\mathbb {N}}\), and \({\hat{\imath }} \in {\mathcal {I}}_u\) such that \(\{ x^{k,j+1}_{{\hat{\imath }}} \}_{j \in {\mathcal {J}}} \rightarrow u_{{\hat{\imath }}}\).
Part (II) follows directly from the computations within Step 2.8 of Algorithm 2. \(\square\)
In the following, auxiliary results ascertain the boundedness of the sequences generated by Algorithm 2, in preparation to the global convergence theorem.
Lemma 5
Suppose Assumptions 2and 3hold. Then, the sequence \(\{ {\bar{H}}_{k,j} \}\) generated by Algorithm 2 is bounded.
Proof
Assumptions 2 and 3 imply that the sequence \(\{ \nabla ^2 f(x^{k,j}) \}\) generated by Algorithm 2 is bounded. Furthermore, Assumption 3 and Lemma 4(I) imply that the sequence \(\{ L_{k,j}^\dagger , U_{k,j}^\dagger \}\) generated by Algorithm 2 is bounded. In addition, Lemma 4(II) implies that the sequence \(\{ Z_{k,j}^L, Z_{k,j}^U \}\) generated by Algorithm 2 is bounded. Finally, according with Lemma 2, \(\xi _{k,j} \ge | \lambda _1 | + \epsilon\) is large enough to correct the inertia of matrix \(M_{k,j}\), which gives an implicit upper bound in \(\xi _{k,j}\). Putting all these facts together, the result follows. \(\square\)
Lemma 6
Suppose that Assumptions 1, 2, and3hold. Then, the sequence \(\{ d_x^{k,j}, \lambda ^{k,j+1}, z_\ell ^{k,j+1}, z_u^{k,j+1} \}\) generated by Algorithm 2 is bounded.
Proof
According with Lemma 4(II), the sequence \(\{ z_\ell ^{k,j+1}, z_u^{k,j+1} \}\) is bounded. In order to get a contradiction, suppose there exists an infinite set \(\displaystyle {\mathcal {J}} \underset{\infty }{\subset }{\mathbb {N}}\) such that
Assumptions 2 and 3 and Lemma 4(I) imply that the sequence
is bounded. This fact, together with Lemmas 4(II) and 5, assure the existence of an infinite set \(\displaystyle \hat{{\mathcal {J}}} \underset{\infty }{\subset }{\mathcal {J}}\) such that
Using (21), we can rewrite the system (16) in order to get
recalling that (29) implies that \(\lim _{j \in \hat{{\mathcal {J}}}} M_{k,j} = M_{k,*}\).
By (28), we have that the right-hand side of the system (30) is bounded for \(j \in \hat{{\mathcal {J}}}\). Besides that, Step 2.2 of Algorithm 2 guarantees that \(M_{k,j}\) will be nonsingular for all j. Thus, from (30), it follows that
contradicting (27). \(\square\)
Lemma 7
Consider that Assumptions 1, 2, 3, and 4hold. Then, the sequence \(\{ d_x^{k,j} \}\) generated by Algorithm 2 goes to zero as j tends to infinity.
Proof
Lemma 6 implies that the sequence \(\{ d_x^{k,j} \}\) is bounded, therefore it admits some convergent subsequence. Let us consider, by contradiction, that there exists an infinite subset \(\displaystyle {\mathcal {J}} \underset{\infty }{\subset }{\mathbb {N}}\) such that
Lemma 5, Assumption 3, and Lemma 6 imply that there exists an infinite set \(\displaystyle \hat{{\mathcal {J}}} \underset{\infty }{\subset }{\mathcal {J}}\) such that
Pre-multiplying the first block of equations from the system (16) by \(d_x^{k,j}\), which, by the second block of equations from the system (16), belongs to the kernel of A, we have that
Thus,
Taking the limit in (32) for \(j \in \hat{{\mathcal {J}}}\), it follows that
By Lemma 4(I), we have that \(\ell _i + \delta \le x^{k,j}_i\), for all \(i \in {\mathcal {I}}_\ell\) and \(x^{k,j}_i \le u_i - \delta\), for all \(i \in {\mathcal {I}}_u\), with \(\delta > 0\). Taking the limit for \(j \in \hat{{\mathcal {J}}}\), it follows that \(\ell _i < x^{k,*}_i\), for all \(i \in {\mathcal {I}}_\ell\) and \(x^{k,*}_i < u_i\), for all \(i \in {\mathcal {I}}_u\). Therefore, there exists \({\hat{\alpha }} \in (0,1]\) such that, for all \(\alpha \in (0, {\hat{\alpha }}]\),
Since \(d_x^{k,*} \ne 0\) and (33) implies that \(\nabla \varphi _{\mu _k}(x^{k,*})^T d_x^{k,*} < 0\), then there exists \({\tilde{\alpha }} \in (0, {\hat{\alpha }}]\) such that, for all \(\alpha \in (0, {\tilde{\alpha }}]\), (34) holds and
is verified, with \({\bar{\gamma }} \in (\gamma , 1)\). Notice that this is a sufficient decrease condition, which ensures the existence of \({\tilde{\alpha }}\). Nonetheless, this is a more rigorous condition than the one required in Step 2.6 of Algorithm 2, given that \({\bar{\gamma }} > \gamma\). Since \(\varphi _{\mu }(\cdot )\) is a continuously differentiable function, from the strict fulfillment of the bound constraints (34), and the fact that \(d_x^{k,*}\) is a descent direction from \(x^{k,*}\), according with (33), we can define
such that
and
for all \(j \in \hat{{\mathcal {J}}}\), j large enough. Then,
which implies that
contradicting Assumptions 2 and 3 . \(\square\)
Theorem 1 establishes the global convergence result for Algorithm 2.
Theorem 1
Suppose that Assumptions 1, 2, 3, and 4hold. Then, any limit point of the sequence \(\{ x^{k,j} + \alpha _{k,j} d_x^{k,j}, \lambda ^{k,j} + d_\lambda ^{k,j}, z_\ell ^{k,j} + \alpha _{k,j}^{z_\ell } d_{z_\ell }^{k,j}, z_u^{k,j} + \alpha _{k,j}^{z_u} d_{z_u}^{k,j} \}\) generated by Algorithm 2 satisfies the first-order optimality conditions (8) for problem (3).
Proof
Let \((x^{k,*}, \lambda ^{k,*}, z_\ell ^{k,*}, z_u^{k,*})\) be any limit point of the sequence
namely the subsequence whose indexes belong to the infinite set \(\displaystyle {\mathcal {J}} \underset{\infty }{\subset }{\mathbb {N}}\). Taking the limit in (16) for \(j \in {\mathcal {J}}\), by Lemma 7 we have that
In other words,
Lemma 7 implies that, for \(j \in {\mathcal {J}}\) large enough, \(d_x^{k,j}\) will be small enough and, for this reason, conditions (23) will be satisfied and \(\alpha ^{z_\ell }_{k,j} = \alpha ^{z_u}_{k,j} = 1\). Therefore, taking limits in (10) for \(j \in {\mathcal {J}}\) and considering (17c) and (17d), we have that
Thus, (36) and (37) together imply that
Therefore, since \(Ax^{k,*} = b\), (38) gives us that (8) holds in \((x^{k,*}, \lambda ^{k,*}, z_\ell ^{k,*}, z_u^{k,*})\). \(\square\)
Now, we are ready to show that Algorithm 1 is well defined. First, by Assumption 1, it is always possible to find an initial point \(x^0 \in {\mathcal {F}}_0\). Thus, to prove the well definiteness of Algorithm 1, it is enough to check that Step 1.2 is well defined, which is closely related to the well definiteness of Algorithm 2. The next result completes the analysis.
Lemma 8
Consider that Assumptions 1, 2, 3, and 4hold. Then, for all k, it is possible to find \((x^{k+1}, \lambda ^{k+1}, z_\ell ^{k+1}, z_u^{k+1})\) in finite time using Algorithm 2 such that
Proof
First, notice that \(\mu _0 > 0\) and, from Step 1.3, \(\mu _k > 0\) for all k. Thus, we have that \(\kappa _{\varepsilon } \mu _k > 0\) for all k. On the other hand, for each k, Theorem 1 implies that, as j tends to infinity, the sequence generated by Algorithm 2 converges to a point \((x^{k,*}, \lambda ^{k,*}, z_\ell ^{k,*}, z_u^{k,*})\) such that \(E_{\mu _k}(x^{k,*}, \lambda ^{k,*}, z_\ell ^{k,*}, z_u^{k,*}) = 0\) (according with (38)). Therefore, for j large enough, Algorithm 2 can find a point \((x^{k,j}, \lambda ^{k,j}, z_\ell ^{k,j}, z_u^{k,j})\) such that \(E_{\mu _k}(x^{k,j}, \lambda ^{k,j}, z_\ell ^{k,j}, z_u^{k,j}) \le \kappa _\varepsilon \mu _k\). Consequently, it is possible to find \((x^{k+1}, \lambda ^{k+1}, z_\ell ^{k+1}, z_u^{k+1}) = (x^{k,j}, \lambda ^{k,j}, z_\ell ^{k,j}, z_u^{k,j})\) in finite time with Algorithm 2. \(\square\)
With the previous results, we can establish the global convergence of Algorithm 1. Once again, with some abuse of notation, we refer to the infinite sequence generated by the method that emerges when the stopping criterion (Step 1.1) is removed from Algorithm 1 as “the infinite sequence generated by Algorithm 1”.
Theorem 2
Consider that Algorithm 1 generates an infinite sequence of iterates and that Assumptions 1, 2, 3, and 4hold. If the sequence generated by Algorithm 1 admits a limit point \((x^*, \lambda ^*, z_\ell ^*, z_u^*)\), then
with \(E_\mu (x,\lambda ,z_\ell ,z_u)\) defined in (19).
Proof
Let \(\displaystyle {\mathcal {K}} \underset{\infty }{\subset }{\mathbb {N}}\) be an infinite set such that
Suppose that (39) does not hold. Then,
By Step 1.2 of Algorithm 1, we have that
for all k, which means that
for all k. Since \(\displaystyle {\mathcal {K}} \underset{\infty }{\subset }{\mathbb {N}}\), we have, by Step 1.3 of Algorithm 1, that
From (40), (41b), and (42b), for all k large enough, we have that
which yields \(0 < \mu _k (\kappa _\varepsilon + 1)\). It is a contradiction, since (43) holds. Analogously, (40), (41c), and (42c) produce the same contradiction.
On the other hand, from (40), (41a), and (42a), for all k large enough,
which implies that \(0 < \kappa _\varepsilon \mu _k\), being also in contradiction with (43). Therefore, (41) cannot occur, implying that (39) holds. \(\square\)
Theorem 2 assures that, given any sequence generated by Algorithm 1, if such a sequence admits a limit point, then this point satisfies the set of equations in (8) with \(\mu = 0\). Consequently, this limit point also satisfies the KKT conditions for the original problem (1), since \(z_\ell ^*\) and \(z_u^*\) are nonnegative and, by the definition of the method, they satisfy the complementarity relations in (8c) and (8d) with \(\mu = 0\). Therefore, the next result is obtained.
Corollary 1
Suppose Algorithm 1 generates an infinite sequence of iterates and that Assumptions 1, 2, 3, and 4hold. If the sequence generated by Algorithm 1 admits any limit point \((x^*, \lambda ^*, z_\ell ^*, z_u^*)\), then this point satisfies the KKT conditions for problem (1).
Additionally, the convex case yields the following result.
Corollary 2
Suppose Algorithm 1 generates an infinite sequence of iterates, that Assumptions 1, 2, 3, and 4hold, and that, in addition, the objective function f is convex. If the sequence generated by Algorithm 1 admits any limit point \((x^*, \lambda ^*, z_\ell ^*, z_u^*)\), then this point is a global minimizer for problem (1).
Proof
The proof follows from Corollary 1 and the fact that, in the convex case, every KKT point is a global minimizer (see Nocedal and Wright 2006). \(\square\)
4 Implementation and numerical experiments
We now present numerical experiments to evaluate the performance of Algorithms 1 and 2. We consider all the 200 problems from CUTEst collection (Gould et al. 2015) with linear equality and box constraints. Table 1 displays the distribution of the number of variables n and the number of constraints m in the considered set of problems. It should be noted that, in all the problems, a constraint of the form, \(\ell _i \le x_i \le u_i\) with \(-10^{20} \le \ell _i \le u_i \le 10^{20}\) for \(i=1,\dots ,n\) is present; this being a sufficient condition for the satisfaction of Assumption 3.
We implemented Algorithms 1, 2, and 3, referred as Lcmin from now on, in Fortran 2008. The codes are freely available in the web.Footnote 1 Tests were conducted in an Intel Core i7-8700 3.20GHz processor with 32 GB RAM, running Ubuntu 18.04.3 LTS operating system. Codes were compiled using the GNU Compiler Collection version 7.4.0 with -O3 flag enabled.
In practice, we consider a scaled version of the stopping criterion (20) at Step 1.1 of Algorithm 1 given by
where \(s=(s_d,s_\ell ,s_u)\),
\(s_{\max } \ge 1\) is a given constant, and
In theory, all iterates of Lcmin are feasible. However, in practice, numerical errors may lead to some loss of feasibility. For this reason, once the stopping criterion (44) has been satisfied, we check the value of \(\Vert A x^k - b \Vert _\infty\). We consider “the problem has been solved” (stopping criterion SC1) if
where \(\varepsilon _{\hbox {{feas}}} > 0\) is a given constant. If
we say that “an acceptable feasible point was obtained” (stopping criterion SC2). Otherwise, we declare that “convergence to an infeasible point was obtained” (stopping criterion SC3). In addition to (44), Lcmin also stops whenever
- SC4::
-
\(\Vert x^{k,j} \Vert _{\infty } \ge \kappa _x\), where \(\kappa _x\) is a large positive given value;
- SC5::
-
\(k \ge k_{\max }\), where \(k_{\max } > 0\) is given; or
- SC6::
-
\(\mu _k \le \varepsilon _{\hbox {{tol}}}/10\) and \(j \ge j_{\max }\), where \(j_{\max } > 0\) is given.
In the experiments, following Wächter and Biegler (2006), we set \(\mu _0 = 0.1\), \(\varepsilon _{\hbox {{tol}}} = 10^{-8}\), \(\kappa _\varepsilon = 10\), \(\kappa _\mu = 0.2\), \(\theta _\mu = 1.5\), \(\gamma = 10^{-4}\), \(\tau _{\min } = 0.99\), \(\kappa _z = 10^{10}\), \(\kappa _\xi ^-\,=\,1/3\), \(\kappa _\xi ^+\,=\,8\) e \({\bar{\kappa }}_\xi ^+\,=\,100\), \(\xi _{\hbox {{ini}}} = 10^{-4}\), \(\xi _{\hbox {{min}}}\,=\,10^{-20}\), \(\xi _{\hbox {{max}}}\,=\,10^{20}\), \(s_{\max }=100\), \(\varepsilon _{\hbox {{feas}}}=10^{-8}\), \(\kappa _x = 10^{20}\), \(k_{\max }=50\), and \(j_{\max }=200\). Three implementation features are in order. Routine HSL MA57Footnote 2 was used to solve the linear systems. Matrix A of the constraints of problem (1) may not have full row rank as required, and may even be such that \(m>n\). Thus, routine HSL MC58Footnote 3 was used to check whether (i) \({{\,\mathrm{rank}\,}}(A) = m\); (ii); \({{\,\mathrm{rank}\,}}(A)<m\) and \({{\,\mathrm{rank}\,}}(A)={{\,\mathrm{rank}\,}}(A|b)\); or (iii) \({{\,\mathrm{rank}\,}}(A)<m\) and \({{\,\mathrm{rank}\,}}(A) \ne {{\,\mathrm{rank}\,}}(A|b)\). In the first case, A satisfies the full row-rank assumption and there is nothing to be done. In the second case, constraints \(Ax=b\) are replaced by an equivalent set of constraints \({{\bar{A}}} x = {{\bar{b}}}\) in which \({{\bar{A}}}\) satisfies the full row-rank assumption (\({{\bar{A}}}\) is given by routine MC58 and \({{\bar{b}}}\) can be easily computed). In the third case, the problem is infeasible and there is nothing to be done. (Infeasibility was detected in 6 out of the 200 problems at this pre-processing stage.) Finally, an interior point \(x^0 \in {\mathcal {F}}_0\) is required to start Algorithm 1. For this reason, we tried to find such a point using a phase 1 procedure, that consists in approximately solving the feasibility problem
with
for \(i = 1, \ldots , n\), \(\kappa _1>0\), and \(\kappa _2 \in (0, \frac{1}{2})\). To approximately solve (45), we apply Algencan (Andreani et al. 2008; Birgin and Martínez (2014)) with the option Ignore-objective-function enabled. The phase 1 procedure starts from the given initial point, making it somehow useful in the computation of the initial interior point. (Infeasibility was detected in phase 1 for only 1 problem out of the remaining \(194 = 200 - 6\) problems.)
We have applied Ipopt (Wächter and Biegler 2006), version 3.12.13, within the same computational environment, also using the HSL MA57 routine for solving the linear systems, taking into account the same time budget for each problem, and considering all its default parameters, except for honor_original_bounds no. Such a parameter, which does not affect the overall performance of Ipopt, inhibits this solver to projectFootnote 4 the final iterate onto the box defined by the bound constraints of problem (1), allowing us to measure the violation of the bounds at the final iterate. Additional experiments with Ipopt considering the default choice honor_original_bounds yes were also carried on; the comparison showed results qualitatively similar to those reported below.
Detailed output of both methods for each one of the 200 problems, as well as tables summarizing the results, with a CPU time budget of 10 minutes per problem, can be viewed at the same repository the code is locatedFootnote 5. Since the methods under analysis have different stopping criteria, we consider that a problem \(p \in \{ 1, 2, \ldots , 200\}\) is solved by a method \(M \in \{ \hbox {Ipopt}, \hbox {Lcmin} \}\) if
where \(f_{\min }^p = \min \{ f_{\text {Ipopt}}^p, f_{\text {Lcmin}}^p \}\), and \(f_{\text {tol}}\in [0,1]\),
with \(\varepsilon _{\text {feas}}\ge 0\), and
with \(\varepsilon _{\text {bnd}}\ge 0\) and \((\cdot )_{+} = \max \{ \cdot , 0\}\).
We first take a close look at the feasibility of the final iterate found by the methods. In Table 2, we show the number of problems in which each method found a point satisfying (47) with \(\varepsilon _{\text {feas}}=10^{-8}\) and (48) with \(\varepsilon _{\text {bnd}}\in \{ 10^{-1}, 10^{-2}, \ldots , 10^{-16}, 0 \}\), no matter the objective function value. Since Lcmin preserves feasibility during all the optimization process, the amount of problems whose bound constraints are satisfied does not depend on \(\varepsilon _{\text {bnd}}\). On the other hand, the number of problems whose bound constraints hold for Ipopt varies according to the tolerance \(\varepsilon _{\text {bnd}}\). The \(26 = 200-174\) failures in Lcmin correspond to (i) 7 problems detected as being infeasible, 6 in the pre-processing of the coefficients’ matrix A and 1 during phase 1; (ii) 7 problems in which Lcmin generated a final iterate whose feasibility does not satisfy (47) with \(\varepsilon _{\text {feas}}=10^{-8}\); and (iii) 12 problems in which Lcmin exceeded the 10 min established as CPU time budget. When \(\varepsilon _{\text {bnd}}= 0.1\), the \(46 = 200 - 154\) failures in Ipopt correspond to (i) 10 problems in which Ipopt generated a final iterate that does not satisfy (47) with \(\varepsilon _{\text {feas}}=10^{-8}\); (ii) 13 problems in which Ipopt exceeded the 10 min established as CPU time budget; and (iii) 23 problems to which Ipopt is not applicable because of the degree of freedom of A in the constraints of the problemFootnote 6. For other values of \(\varepsilon _{\text {bnd}}\), the increasing number of failures is due to the bound constraints violation at the final iterate.
Lcmin detected the problem is infeasible at phase 1 in 7 problems; and it exceeded the CPU time limit of 10 min in 13 problems. In the remaining 180 problems, it stopped satisfying the stopping criteria \(\mathrm {SC1}, \mathrm {SC2}, \dots , \mathrm {SC6}\) in 168, 6, 0, 0, 3, and 3 problems, respectively. As a consequence, it found a feasible point (satisfying (47) with \(\varepsilon _{\text {feas}}=10^{-8}\) and (48) with \(\varepsilon _{\text {bnd}}=0\)) in 174 out of the 200 considered problems. Considering these 174 problems, Lcmin performed, in average, 6.35 outer iterations (being 51 the maximum) and 30.54 inner iterations (being 610 the maximum) per problem. In 132 out of the 174, the inertia of the matrix of coefficients of the linear system (16) was never corrected, meaning that a single matrix factorization per iteration was performed. In the remaining 42 problems, the average number of matrix factorizations per iteration was 1.26.
Now, we are interested in those problems in which both Ipopt and Lcmin converged to a point satisfying (47) with \(\varepsilon _{\text {feas}}= 10^{-8}\) and (48) with \(\varepsilon _{\text {bnd}}= 0\). For this set, composed by 62 problems, Table 3 shows, for each solver, the number of problems in which (46) holds with \(f_{\text {tol}}\in \{10^{-1}, 10^{-2}, \ldots , 10^{-8}, 0\}\).
We now consider, on the one hand, the set of 57 problems in which both Lcmin and Ipopt found a final iterate satisfying (46) with \(f_{\text {tol}}= 0.1\), (47) with \(\varepsilon _{\text {feas}}= 10^{-8}\), and (48) with \(\varepsilon _{\text {bnd}}= 0\). Figure 1 depicts, for these problems, the performance profiles Dolan and Moré (2002) using as performance measure the number of functional evaluations, the number of iterations, and the CPU time consumed by each solver. Considering the remaining \(143 = 200 - 57\) problems, we have that: (i) in 24 problems, none of the methods found a point satisfying (47) with \(\varepsilon _{\text {feas}}=10^{-8}\) and (48) with \(\varepsilon _{\text {bnd}}=0\); (ii) in 2 problems, Ipopt found a point satisfying (47) with \(\varepsilon _{\text {feas}}=10^{-8}\) and (48) with \(\varepsilon _{\text {bnd}}=0\), while Lcmin failed; (iii) in 112 problems, Lcmin found a point satisfying (47) with \(\varepsilon _{\text {feas}}=10^{-8}\) and (48) with \(\varepsilon _{\text {bnd}}=0\), while Ipopt failed; (iv) in 5 problems both found a point satisfying (47) with \(\varepsilon _{\text {feas}}=10^{-8}\) and (48) with \(\varepsilon _{\text {bnd}}=0\), but the objective functional value of one of them does not satisfy (46) with \(f_{\text {tol}}=0.1\); (v) regarding the 5 problems mentioned in (iv), the objective function found by Ipopt was smaller than the objective functional value find by Lcmin in 4 problems, while the opposite situation occurred in 1 problem.

Performance profiles comparing a the number of functional evaluations, b the number of iterations, and c–d the CPU time of Lcmin and Ipopt in the subset of 57 problems in which both solvers found iterates satisfying (46) with \(f_{\text {tol}}= 0.1\), (47) with \(\varepsilon _{\text {feas}}= 10^{-8}\), and (48) with \(\varepsilon _{\text {bnd}}= 0\). In d the CPU time spent by Lcmin to find a feasible initial point has been ignored
5 Final remarks
In this work, a feasible line-search interior-point method for linearly constrained optimization has been described, implemented, and analyzed. The global convergence theory is accompanied with numerical experiments, encompassing a classical test set from the literature. The performance of the proposed algorithm was put into perspective with Ipopt, a current state-of-the-art solver.
No winner emerged from the comparative results, which was somehow expected, since both methods have the interior-point strategy as the main principle. Nevertheless, we point out that feasibility may be an issue: while the general purpose solver Ipopt may relax bounds, Lcmin always guarantees a feasible final iterate, except when numerical difficulties may occur, as in the 7 cases of failure of Lcmin in the numerical experiments, which evidences that the problem is numerically difficult or even numerically infeasible. Therefore, Lcmin is recommended for applications in which feasibility is a desired feature.
Notes
Available at http://www.hsl.rl.ac.uk/catalogue/mc58.html.
The bound constraints might be dynamically relaxed by Ipopt during the optimization process (Wächter and Biegler (2006), §3.5), starting from a relative relaxation factor whose initial value is \(10^{-8}\).
It means that, in problem (1), A has more rows than columns. Lcmin eliminates redundant constraints, which makes A to have full row rank in most cases, except in those in which the feasible set is empty. Ipopt does not start optimization in these cases, stopping with the output Problem has too few degrees of freedom.
References
Andreani R, Birgin EG, Martínez JM, Schuverdt ML (2008) On augmented Lagrangian methods with general lower-level constraints. SIAM J Optim 18(4):1286–1309
Birgin EG, Martínez JM (2014) Practical augmented Lagrangian methods for constrained optimization. Society for Industrial and Applied Mathematics, Philadelphia
Chen L, Goldfarb D (2006) Interior-point \(\ell _2\)-penalty methods for nonlinear programming with strong global convergence properties. Math Progr 108(1):1–36
Dolan ED, Moré JJ (2002) Benchmarking optimization software with performance profiles. Math Progr 91(2):201–213
Fiacco AV, McCormick GP (1968) Nonlinear programming: sequential unconstrained minimization techniques. Wiley, New York (1968, Reprinted by SIAM Publications, 1990)
Frisch KR (1955) The logarithmic potential method of convex programming. Tech. rep., University Institute of Economics, Oslo, Norway
Gill PE, Murray W, Saunders MA, Tomlin JA, Wright MH (1986) On projected Newton barrier methods for linear programming and an equivalence to Karmarkar’s projective method. Math Progr 36(2):183–209
Gould NIM, Orban D, Toint PL (2015) CUTEst: a constrained and unconstrained testing environment with safe threads for mathematical optimization. Comput Optim Appl 60(3):545–557
Karmarkar N (1984) A new polynomial-time algorithm for linear programming. In: Proceedings of the Sixteenth Annual ACM Symposium on theory of computing, STOC ’84, pp. 302–311. ACM, New York, NY, USA
Nocedal J, Wright SJ (2006) Numerical optimization, 2nd edn. Springer, New York
Wächter A, Biegler LT (2006) On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. Math Progr 106(1):25–57
Acknowledgements
The authors are thankful to the anonymous reviewers for providing insightful suggestions which improved the presentation of this work.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work has been partially supported by FAPESP (Grants 2012/05725-0, 2013/07375-0, and 2018/24293-0) and CNPq (Grants 302915/2016-8, 302538/2019-4, and 302682/2019-8).
Rights and permissions
About this article

Cite this article
Birgin, E.G., Gardenghi, J.L., Martínez, J.M. et al. On the solution of linearly constrained optimization problems by means of barrier algorithms. TOP 29, 417–441 (2021). https://doi.org/10.1007/s11750-020-00559-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11750-020-00559-w