
Abstract
This paper proposes a deep image analysis–based model for glaucoma diagnosis that uses several features to detect the formation of glaucoma in retinal fundus. These features are combined with most extracted parameters like inferior, superior, nasal, and temporal region area, and cup-to-disc ratio that overall forms a deep image analysis. This proposed model is exercised to investigate the various aspects related to the prediction of glaucoma in retinal fundus images that help the ophthalmologist in making better decisions for the human eye. The proposed model is presented with the combination of four machine learning algorithms that provide the classification accuracy of 98.60% while other existing models like support vector machine (SVM), K-nearest neighbors (KNN), and Naïve Bayes provide individually with accuracies of 97.61%, 90.47%, and 95.23% respectively. These results clearly demonstrate that this proposed model offers the best methodology to an early diagnosis of glaucoma in retinal fundus.
Graphical abstract

Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The human senses are our contact to nature. The human cerebrum consolidates five main senses that are also written in Indian holy books which are the sense of seeing, hearing smelling, tasting, and touching via different organs [1]. The retina is basically an interior lining of layered tissue through which the light comes inside the eye and converted into the neural signal. So, it can be easily observe that it is an extension part of our brain practices, as its function is to enable us to see the outer world [2]. While there are various anatomical structures which contribute to the ability to pursue the vision, this part mainly focuses on retinal image. There are many diseases found in the retina of the eye. All of the examinations of retinal images are done on the basis of fundus images of an eye. To identify the glaucoma, the ophthalmologist can use the optical coherence tomography (OCT) or fundus image; selection of OCT images for evaluation of glaucoma is an expensive option. Hence, nowadays, retinal fundus image plays a vital role in examination and analysis of glaucoma [3]. The range of features is available in retinal fundus images which ophthalmologists can apply for different operation for exact diagnosis of glaucoma [4].
1.1 Types of disease in retinal images
The analysis of retinal images is performed in order to find the different types of retinal diseases [5]. There are several types of retinal diseases which may cause partial or full blindness in an eye. So in order to protect from these diseases, it is necessary to perform regular checkup before it is too late to be diagnosed. So the most important retinal diseases that are common and hazardous are diabetes, diabetic retinopathy, glaucoma, and cardiovascular disease.
The WHO (World Health Organization) releases that every 2nd person in the world has chances of getting diabetes whether it already suffered from diabetes or it tends to be a diabetic patient [6].
Diabetic retinopathy is an eye ailment which is caused due to high sugar or sucrose level in our body and one of the second most causes of loss of sight in America (USA). It is majorly upshot the retinal vessel wall that can lead to ischemia and breakdown of blood-retinal obstruction. In the first stage, diabetic enduring may not be conscious of having tainted by the disease. Therefore, early exposure of diabetic retinopathy is essential to avoid blindness. Cardiovascular diseases made home in the retina counting in various number of ways. Hypertension and atherosclerosis are the two parameters which forcefully change the ratio between the diameter of retinal arteries and veins known as the A/V ratio [7].
1.2 Glaucoma
It is a very common ailment which harms the optic nerve, the component of the eye which carries the descriptions, i.e., image in the form of electric impulse. These electric impulses move to the brain and lead to loss of vision. It is caused due to high pressure, i.e., intraocular pressure on which rate of the colliery body is unbalanced to the rate of drainage in the drainage canal. Glaucoma generally arises when the pressure in the eye elevates above normal pressure and the flow of fluid called aqueous humor is not circulating properly. It is a condition of the eye that start injures to the optic nerve and becomes shoddier over instance. It has a propensity to be acquired and may not exhibit up waiting later in life. The augmented pressure called intraocular pressure of the eye can damage the optic nerve that sends image signals to the brain [8]. If this damage persists for a long time, glaucoma valor brings about never-ending loss of vision. To avoid the loss in vision, glaucoma can only be detected in the prior stage; otherwise, it is difficult to cure later on. Its manual detection is very difficult and sensitive; therefore, diagnosis is highly dependent on the expert ophthalmologist.
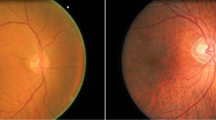
In the last decade, a range of generous efforts has been performed on the automatic detection and prediction of different glaucoma techniques using or without using machine technique. Glaucoma is a neuropathy and it directly attacks on the retina by injuring the ganglion cells and axons. The main acknowledgment mark of glaucoma is cupping of the optic disc, perceptible part of the eye structure [9]. The ratio of the cup to the disc, i.e., CDR, determines the occurrence of glaucoma in the eye but CDR ratio is not the only parameter which surely determines the existence of glaucoma affected in human eye. It needs various features to confirm the existence of glaucoma in the affected eye. The optic disc is imaged as a 2D structure either through the circuitous stereo bio-microscopy or with stereo fundus color photography. The detection of glaucoma can be identified by processing the retinal fundus images to differentiate between glaucoma eye and healthy eye (as shown in Fig. 1) using CDR.

Normal eye (left) and glaucoma-infected eye (right)
1.3 Motivation and contribution
Glaucoma is a chronic disease which is also called silent theft of sight; it ultimately results in the irreversible vision loss due to damage in the optical nerve of an eye [10]. Initially, there are no symptoms of the disease as there is no effect on sight, but as the disease progresses and reaches advanced stage, it leads to irretrievable vision loss. The only available alternative is the early and timely diagnosis of the disease; hence, sensing glaucoma during the initial stage is very imperative so that its progression can be stopped or at least minimize and vision can be preserved [11]. This disease is more commonly caused in elderly individuals who have diseases like severe nearsightedness, diabetes, or high blood pressure. However, its progression can be minimized if it can be diagnosed timely and at early stage. Ophthalmologists diagnose this disease using a retinal examination of the dilated pupil. They use diverse widespread retinal examinations such as ophthalmoscopy, tonometry, perimetry, gonioscopy, and pachymetry to detect glaucoma. These approaches are manual, time-consuming, and may be prone to subjective errors.
Potential patients have to seek advice from a proficient ophthalmologist on a periodic basis to aid its early and timely identification. Classically, ophthalmologists follow manual analysis of captured retinal image of the patient for the identification of the symptoms of the disease. Many prior studies prove that this process is extremely time-consuming [12]. Highly experienced and expert ophthalmologists are required for precise confirmation and accurate verification. Reputed organizations like WHO have reported that in the coming years, the number of glaucoma patients will increase at a very fast pace across the world [13,14,15,16]. Thus, the situation gets worst in the under developing countries and undeveloped countries where there is a lack of expert human resources and shortage of diagnosis equipment. Moreover, the situation becomes critical when already overloaded expert ophthalmologists also have to examine those patients’ images, periodically, where there is no disease symptoms. Thus, there is an immense need to develop a robust and highly predictive artificial intelligence–based expert computer-aided diagnosis system. The classical techniques of glaucoma diagnosis have undergone enormous modifications since the invasion of machine learning techniques into the processing of eye fundus images. This motivates us to propose machine learning–based automatic screening system that will advise only patients with detected glaucoma symptoms to seek medical treatment. The presented work is a generic attempt in this direction which will help the human society by correct, early and timely detection of the disease. At the same time, it will also reduce the pressure on already overloaded expert ophthalmologists.
The major contributions of this paper include the following purpose and objective:
-
To experiment and investigate studies done on various extracted features like inferior, superior, nasal, and temporal (ISNT) regions, and cup-to-disc ratio. This involves the practice associated to deep image analysis.
-
To provide a comparative study for different machine learning algorithm-based self-adapting models for sensitivity, specificity, and computation time.
-
To perform the prediction of glaucoma with various machine learning–based classification models like SVM, KNN, Naïve Bayes, and ANN; the achieved accuracies are 97.61%, 90.47%, 95.23%, and 98.60% respectively.
-
It is observed that the ANN model gives the best performance on the basis of the sensitivity and specificity of classifier which is 95.82% and 98.59% respectively.
The organization of this paper is started with the introduction of the type of disease in retinal (eyes) along with the differentiation of normal eye and glaucoma-infected eye. Furthermore, Section 2 discusses the background and related work in the field of glaucoma retinal fundus images. In Section 3, a brief outline is provided for proposed methodology and various feature extraction techniques required for diagnosis of glaucoma in retinal fundus. Section 4 provides the performance and parametric techniques related to classification based on machine learning. Section 5 reports the performance measurement of different machine learning algorithms for the mentioned purpose. Section 6 presented the result discussion followed by conclusion in the last section which is Section 7.
2 Background and related works
Glaucoma is a degenerative disease which produces harm to the optic nerve that results in regenerative and constant vision losses. It is one of the biggest reasons of blindness. It is the situation which causes the incremented pressure between the eyeballs, resulting regenerated, irreversible, and gentle loss of sight. In this proposed work, the main motive is to advise the better technology for automatic diagnosing of glaucoma in retinal images by using different machine learning techniques. Some of the different approaches for solving the problem have been advised in the last decade which is based on various feature extraction from retinal fundus images. In this section, deep discussion is presented on some of the prominent works published in the last 5 years related to glaucoma diagnosis where machine learning classifiers have been employed. The work conducted by various authors has been reported into Table 5 mentioned under Section 6.
Wei Zhou et al. [25] in their novel approach proposed a system for glaucoma detection, namely “AWLCSC: adaptive weighted locality-constrained sparse coding” in which weighted matrix is determined by combining multiple distances for testing and training image for calculation. Fan et al. [26] proposed a methodology for automatic glaucoma identification which identifies the clinical measurement features (extracted through enhanced UNet++) and ImageNet features. The paper is also reported with fully extracted texture features and other hidden image. Researcher Lamiaa [12] reported with wavelet-based glaucoma identification where statistical and textural features were identified from green and blue approximation for optic disc–segmented region. It was also applied to verify the subject retinal image of potential patient for glaucomatous.
Kim et al. [27] implemented a system, having strong prediction power and interpretability, for early glaucoma screening which is based on four machine learning classifiers. Glaucoma is predicted on the basis of retinal nerve fiber layer (RNFL) thickness and visual field (VF). An et al. [28] presented a study in which the authors developed a machine learning–based algorithm for open-angle glaucoma identification from extracted images from optical coherence tomography (OCT) data and color fundus images of potential patients. Lee at al. [29] applied and validated novel four machine learning–based glaucoma diagnosis approaches which utilize SAP data. New composite variables using two visual field clustering schemes, the Garway-Heath map and GHT sector map, were used in addition to TD/PD values as input variables due to which significant improvement in prediction is noticed. Civit-Masot et al. [30] in their experimental study developed a glaucoma diagnosis tool (consisting of two subsystems). With the first subsystem, it implicated with machine learning techniques to segment for optic disc and optic cup. Then, it combines these images with the extracted positional features. And, in the second subsystem, it is implicated with the concept of transfer learning with “pre-trained” convolution neural network model for identifying glaucoma into complete eye fundus images.
David et al. [31] described in their empirical study based on “adaptive histogram equalization” for exchanging the color images with gray-scale one. This work is reported with significant feature selection with 97.55% classification accuracy in adoption of HCSD (hybrid color and structure descriptor). Benzebouchi et al. [32] proposed a study in which multimodal classification method has been used for glaucoma detection. The proposed methodology was based on hybrid approach using convolutional neural networks and support vector machine classifier. Raj et al. [33] attempted for diagnosis and assessment of fundus images with the help of different model based on combination where different features were extracted. This proposed methodology was using extracted green channel image and then converted the image using different EWT-DWT approaches.
In a recent published study by Kanse and Yadav [34], the authors designed HG-SVNN-based glaucoma classifier which makes use of both the harmonic operator and the genetic algorithm (GA) for the neural network training. The public HRF dataset was selected for experimentation process. In a just-published study, the authors (Shehryar et al. [35]) focused on the detection of glaucoma by combining and correlating fundus and SD-OCT image analysis.
In a further study conducted by Ajesh et al. [36], they attempted to increase the accuracy of glaucoma detection by proposing a novel effective optimization-driven classifier. The proposed “Jaya-CSO” was designed using a combination of chicken swarm optimization (CSO) technique and Jaya algorithm using recurrent neural network classifier. The authors worked on HRF dataset of 45 fundus images. The results reach up to 97% in efficiency parameters like accuracy, specificity, and sensitivity. In another prominent work published by Ajesh et al. [37], they also attempted to detect glaucoma in an early stage using many-feature analysis which is enhanced with machine learning algorithm and discrete wavelet transform. The authors achieved the accuracy of 95%. In an effort made by researchers Gour and Khanna [38] for timely identification of glaucoma, from fundus images, they proposed an approach based on PHOG and GIST features. The converted images were ranked and principal component analysis (PCA) was also used for selecting different features using SVM classifier.
The paper proposed by Al-Bander et al. [23] indicates the possibility of achieving an automated method for learning features for glaucoma detection by applying the methods of deep learning. They used CNN architecture for distinguishing glaucomatous and normal images. Unlike old methods in which features of optic disc are handcrafted, here, extraction of features is done automatically by CNN from raw images and is passed to the SVM. The output of SVM is the classification of images into one of the two categories: glaucomatous or normal. Raghavendra et al. [39] proposed a method for glaucoma screening in which they initially performed the optic disc segmentation; after that, the Radon transformation technique is applied. In order to screen the glaucoma, non-parametric and GIST features are extracted from fundus images. The authors obtained the accuracy of 97.00% and 93.00% on private dataset and public dataset respectively. Phan et al. [40] reported with deep convolution neural networks for identification of glaucoma using high-resolution color fundus images. The proposed method was not an adequate and reliable solution. It should be improved with artificial intelligence approach for more accurate results and predictions.
With the support of a hybrid structural and textual feature, Khalil et al. [41] proposed a computer-based glaucoma identification system, which consists of two modules, hybrid structural feature set (HSF) and hybrid texture feature set (HTF), that identify glaucoma from the grouping of fundus and optical coherence tomography (OCT) images. The HSF module helped to segment a particular image using support vector machine classifier and HTF module was used to examine an image on different features based on its intensity and texture. In the work contributed by Salam et al. [42], hybrid structural and non-structural features were analyzed using cup-to-disc ratio to improve glaucoma detection. For analysis, the changes in the structure features were noted with the support of fundus images, with the combined approach of machine learning and structural features for enhancing the model efficiency evaluation metrics. Discriminatory parameters and adaptive thresholding techniques were applied in the study for glaucoma diagnosis which was proposed by Ashish Issac et al. [43] in which extracted features include cup-to-disc ratio, neuroretinal rim, and blood vessels to better segmentation usage.
Acharya et al. [17] reported with the identification of glaucoma using Gabor transformation. The proposed scheme was used to extract the features from the retinal fundus images using PCA techniques. In this system, ranking of the features is taken care of for the classification of retinal images. Vijapur et al. [44] proposed the model for glaucoma identification where neuroretinal rim thickness, neuroretinal rim area, and CDR feature are inputs. The authors presented a significant improvement in sensitivity and specificity in the classification. The authors in their study discussed the method based on multi-disciplinary “HAL” [45]. The main aim of this method was to remove noise added in the image due to several processing techniques it went through. They discussed that in glaucoma detection, noise removal is necessary for best results. In this process, some components like non-uniform illumination, size differences, and blood vessels have been extracted from the fundus image. This method suggests extraction of high dimensional feature vectors followed by compression via PCA and classification via SVM.
Juneja et al. [46] proposed an architecture using deep learning to classify glaucoma eye from non-glaucoma eyes. The technique discussed in the study involves pre-processing of input images to remove the outliers. Initially, the raw image is cropped for the removal of any unnecessary part of the image. Useful information was extracted from the cropped image. The filtered images were passed to the neural network. This stage is utilized in segmenting the optic disc for removal of any part of the image, which is not essential; the optic cup settles inside its disc. CDR value is calculated.
From the above literature survey, it can be deduced that the diagnosis of glaucoma is very essential in determining the cause of retinal disease type which may lead to the damage of the optic nerve that may result into progressive and irreversible vision loss. There is an immense need of a global dynamics feature-based model on retinal image analysis that helps the medical practitioners to diagnose the presence of glaucoma with much accuracy and less computation time. The proposed system is designed and implemented in the same line of expectations.
The motivation of the proposed work is to improve the accuracy by considering various parameters that cause glaucoma. In this sequence, four machine learning approaches like SVM, KNN, Naïve Bayes classifier, and ANN have been suggested to compare for better accuracy and performance based on deep image features as discussed in Section 3.3.1.
3 Proposed methodology
In this paper, the model is proposed which helps to diagnose the glaucoma in retinal fundus image using different machine learning techniques. The retinal fundus images have been used as input for further processing that does deep analysis of such images with 20 features. The results of foresaid glaucoma detection for each input data, i.e., fundus images, have both possibilities: either healthy or glaucoma-infected. The proposed method has been divided into main three stages: preprocessing, deep image feature extraction, and classification as shown in Fig. 2.

Complete layout of machine learning–based proposed system for glaucoma detection
3.1 Pre-processing for input image
Pre-processing is one of the techniques which plays an imperative role in image processing for enhancing the quality by removing the undesirable features in the image like blind spots, speckles, etc. After acquisition process, it is also expected to introduce the noise, in between the period of illumination or various levels of contrast [47, 48]. The pre-processing is also used to increase the important features for further processing in this method. In this proposed pre-processing technique, the resizing and the extraction of green channel along with median filter and histogram equalization are investigated. Initially, all the input images have been resized and converted in equal size to make the dataset homogeneous. Furthermore, we have applied the image cropping method to crop the region of interest (ROI). Figure 3 demonstrates the system implemented for data processing required for glaucoma identification.

Working system for processing data for glaucoma detection
3.1.1 Green channel extraction
Figure 4a depicts the red, green, and blue (RGB) colors in fundus images which are generally known for three channels as described in red, blue, and green color format. If such images are found with multiple colors, then it is difficult to perform various operations on it [49, 50]. Therefore, in that condition, it should be extracted over one channel which is highly necessary for the optimization of the result. In Fig. 4b, the green channel image is shown that used to depict the sensitive part of the human eye and it carries most of the information. Initially, input fundus images are converted into gray/green channel component. RGB to gray/green channel conversion is constituted by forming the weighted sum of RGB component using the mentioned Eq. 1

Pre-processing steps. a Sample image. b Green channel. c Median filter. d Histogram equalization
Here, R, G, and B show the red, green, and blue components of fundus images.
3.1.2 Median filter
The median filter is an effective technique which is applied to remove or to reduce various types of noises (Rayleigh, salt and pepper, Gaussian, gamma, and exponential and uniform) in fundus images which results into variety of errors [20]. This filter uses the median value and replaces the pixels by median value; this operation is performed with all pixels of neighborhood w.
Here, w has been used as neighborhood and centered on the location [p, q] in the image. Figure 4c depicts the results after applying the filter of medium on such images. When filtration is applied on an input fundus image, the range of the signal-to-noise (SNR) value lies between 9.2584 and 10.961 which is better than other filtration like averaging filter, order statistic filter, or sharpening filter.
3.1.3 Histogram equalization
In order to adjust the brightness of the input image, the histogram equalization method is very effective. In modifying the input image, intensity is equally distributed in all over the image. The main focus of this technique is equal intensity distribution all over image.
It provides the linear trend to the cumulative probability function (CDF) which is defined as sum of all the probabilities existing in domain and the discrete form of the transformation equation is defined as below:
The expected output image is obtained by relating each pixel with input image as intensity mk to corresponding pixel Yk in the output image. The transformation (mapping) X(mx) can be called a histogram equalization or histogram linearization transformation.
The equalization describes the transformation or conversion function that is completely used to produce an output image which is having uniform histogram. The signals are various features which are extracted to ensure the sum of histogram with features like entropy, kurtosis, variance, mean, skewness, and energy. Figure 4d depicts the equalized given fundus image.
3.2 Image segmentation
The image segmentation is the segment/part of the image which is used to sub-divide a particular image to its component region. The objects intend to determine the particular sub-division within the input image. The segmentation is also performed for deep image analyzing of features like optic disc and optic cup in the retinal fundus images.
For detection of optic cup and optic disc, we first crop the region of interest from the input fundus color images. Color image has basically three important channels (red, green, and blue) in this work which extracted the green channel for further processing. As a next step, we have applied the median filter for removing the unwanted signal from the fundus image. Histogram equalization is used to provide the equal distribution of intensity in fundus image. It also provides better quality of the image. Furthermore, we have applied the multistep closing morphological operation for removing the unwanted blood vessels. Maximally stable external region (MSER) is a method for blob detection in images or thresholding. The entire pixel below is identified as black and all those above or equally identified is identified as white in the fundus image. The concept of MSER is linked to the one component tree of the image. In the proposed method, MSER is applied twice, first for localizing the disc location in the fundus image and second for separating the cup area from the disc area.
3.2.1 Optic disc
The optic nerve head (optic disc) is the position where ganglion cells axons exit the eye to form the optic nerve. The blind spot is present when there are no rods and cones. A coincide point of small blind spot at optic disc is raised due to the dullness of receptor rods and cones in that particular region. In identifying glaucoma, optic disc is normally used for finding its ratio with respect to cup-to-disc. Figure 5a depicts sample image for optic cup and optic disc.

a Optic disc. b Optic cup
3.2.2 Optic cup
It is mid-point at optic disc which appears to be white cup kind of shape. The optic curve is responsible for the human eye’s retina motion. The larger distance with the diameter in such optic curve reports with the possibility of glaucoma. Figure 5b depicts optic cup as sampled image [51].
3.3 Different extracted features
The feature is the background information used for solving the task related to the specific application. In the case of the image, features may be points, edges, curves, or objects. Feature extraction method is relevant to extract features holding more and more information from the large set of data of images [52]. It is employed to extract features holding vital information from the large database of images. In this experimentation, we have extracted 20 features from infected retinal fundus image set belonging to well-accepted public database for classification among glaucoma or healthy. This set of features form a feature extraction database. Hence, such feature-based deep image extraction is fruitful for classification techniques. This proposed methodology enhanced the existing models that extract around 20 features in retinal fundus as shown in Table 1 to identify and classify between healthy and glaucoma-infected sample images.
3.3.1 Standard features
It measures the variability, i.e., how much dispersion and variation exists or how much distribution is spreading out for different parameters as listed in Table 1.
3.3.2 Homogeneity
Homogeneity is the state or quality having even structure or similar kind or composition throughout. It can be calculated using the following formula
3.3.3 Contrast
One of the important features is contrast in image which is identified by the change into brightness and color of a particular object for the same region of the human eye. It can be calculated as:
3.3.4 Correlation
Correlation feature demonstrates the linear dependency for gray-scale values with the co-occurrence matrix. This feature measures the correlation of a pixel is to its neighbor over the whole image.
3.3.5 Optic cup-to-disc ratio
It is one of the significant features used for detecting glaucoma. One or many cup-to-disc ratios (CDRs) can be noticeable like horizontally and vertically in the same fundus image. CDR is 0.3 for regular healthy eye, and over this ratio, the eye is expected to be glaucoma-affected [53].
3.3.6 Optic disc mean
It is the mean of segmented optical disc image F0i(l1, l2) with ROI images
where (l1, l2) represents the pixel location in image. Here, S0 shows the total number of pixels in a segmented optical disc.
3.3.7 Optic cup mean
The result provided by the mean is average of the pixel of segmented optic cup area Fi(l1, l2); here, M0 is the mean of optic cup
where (l1, l2) represents the pixel location of the image. Here, T0 represents the total number of pixel in the image.
3.3.8 Optic disc entropy
Entropy features have been extracted for optic disc–segmented image F0i(l1, l2) with the help of the following constituted equation
Histogram probability is represented by qh(a1) for the segmented optic disc image and it is represented by
where T1 is the total number of pixel at the gray level a1.
3.3.9 Optic cup entropy
Entropy features have been extracted for optic disc–segmented image Fi(l1, l2) with the help of the following constituted equation
Histogram probability is represented by q0h(b1) for optic cup region at the gray level b1.
where T11 is the total number of pixel at gray level b1. T00 is the total number of pixel in segmented optic cup region.
3.3.10 Optic disc energy
Energy features are calculated for the segmented optic disc F0i(l1, l2) with the help of the following equation
3.3.11 Optic cup energy
Energy features are calculated for the segmented optic disc Fi(l1, l2) with the help of the following equation
3.3.12 Optic disc standard deviation
The standard deviation for optic disc region is computed with the following equation.
Here, ai represents the pixels in the optic disc image and T0 is the total number of pixels.
3.3.13 Standard deviation for optic cup
For a particular given region for healthy human eye, it is computed by applying the following equation.
Here, bi represents the pixel in the optic cup region and T1 represents the total number of pixels in the optic cup.
3.3.14 Inferior superior nasal temporal regions
Inferior superior nasal temporal (ISNT) stands for different regions specially I (area of inferior region), S (area of superior region), N (area of nasal region), and T (area of temporal region) as shown in Fig. 6. ISNT rule is widely used for differentiating glaucoma-infected eyes and healthy eyes [43]. For the normal eye, the value of these regions is already defined as area of inferior region > area of superior region > area of nasal region > area of temporal region.

Different area in ISNT regions
In the proposed methodology, the role of ISNT regions is very important as there is strict demand to enhance existing model based on image analysis. The extracted features based on the region specifically inferior, superior, nasal, and temporal in retinal fundus images can be considered for detecting the glaucoma [52]. In Fig. 7, after extracting the area of ISNT, the performed calculation of each region is depicted with black and white scale. This action has been performed on both types of dataset, i.e., with/without glaucoma disease images.

Extracted image of inferior superior nasal temporal (ISNT) regions
Prior studies, like [54], pointed out that if training is performed on lesser amount of data, the classification accuracy of the model may be reduced. That is why we have collected sufficient number of 20 vital features.
3.4 Dataset description
The proposed work has been investigated and evaluated on the dataset publicly available of color retinal fundus images. The classification accuracy of the algorithms is more sensitive to the training datasets [55]. Real-time scenarios (datasets) must be selected for training. That is why, standard, well-recognized, and public dataset has been selected for this study. The dataset used is DRIONS-DB, which is being provided with the ground truth of optic disc. There are 140 images (70 images are affected with glaucoma and 70 images are from normal eye) of resolution 600 × 400 pixels available for experimentation in which almost 50% are glaucomatous images and remaining healthy images.
Cross-validation is a procedure for analyzing machine learning techniques in which available input dataset is evaluated and analyzed on the complementary subset of the data. This process is implemented in three steps; initially, some fraction of the sample dataset is fixed, then it used the rest of the data to train the model. Finally, the entire test has been modeled using the reserve portion of the dataset [55]. The same scenario has been adopted in this study for two cases. In the first case, 30% of the data is tested of the model and the remaining 70% is trained. In the second case, the model is trained on 50% of the data and the remaining 50% is reserved for testing of the trained model. These cases have been briefed into Table 3 and Table 4 under Section 6.The advantages like faster execution and simpler to examine have been observed with the simulated results.
4 Performance and parametric techniques
The proposed work has be investigated and evaluated on the dataset publicly available of color retinal fundus images [56].
4.1 Considered parameters
The purpose of the said experiments is to help in determining the fundus images as healthy or infected one on the basis of parameters discussed in Section 3.3.1. Additionally, the rate of cross-validation for this experiment setup has been chosen with k = 5, i.e., 5-fold cross-validation. The performance of such parameters has been described with the help of confusion matrix with specified mathematical equations as shown below.
Note: TP abbreviation of true positive, TN abbreviation of true negative, FP abbreviation of false positive, FN abbreviation of false negative, O abbreviation of observed value, T target value.
-
True positive (TP): Prediction is positive and person is glaucomatic, we want that.
-
False positive (FP): Prediction is positive and person is healthy, false alarm that is bad
-
True negative (TN): Prediction is negative and person is healthy, we want that too.
-
False negative (FN): Prediction is negative and person is glaucomatic, the worst.
Or in other words, TP represents the number of glaucomatic images accepted as glaucoma, whereas TN depicts the number of normal retinal images accepted as normal retinal images. Also, FP represents the number of normal images incorrectly accepted as glaucoma while FN presents the number of glaucomatous images misclassified as normal (non-glaucoma) [57].
Sensitivity
TPR stands for true positive rate. It is computed as ratio of the right positive predictions to the overall number of positives. It is also termed as recall (REC). The best value of TPR is 1.0 and the worst value is 0.0. Sensitivity is the ability to obtain a positive result and it measures the number of positive glaucoma images detected by the model.
Specificity
TNR stands for true negative rate. It is computed as the ratio of the right negative predictions to the overall number of negatives. The worst value of specificity is 0.0 and the best value is 1.0. The specificity tells how much similar the negativity of the test comes back in someone who does not have the characteristic. Specificity is concerned with an ability to detect negative results classifying the zeros correctly is more important than classifying the ones.
Accuracy
Accuracy is the ratio of the number of correct prediction to the number of the predictions made or actual value. Usually, it is represented as percentage by multiplying it by 100. It measures the trueness of the classifier model and mathematically computed as
Receiver operating characteristic curve
It is fabricated by mapping the true positive rate (TPR) and the false positive rate (FPR) against each other. TPR is also termed as sensitivity and FPR is termed as fall-out. This curve represents the sensitivity as a function of fall-out. The receiver operating characteristic (ROC) curve is shown in Fig. 8.

Curve of receiver operating characteristic (ROC)
4.2 Classification techniques
The proposed methodology is focused on the following four classification techniques based on machine learning algorithms:
4.2.1 Artificial neural network
Artificial neural network (ANN) is a computation model which is based on function and structure of the neuron system. It is a system which is parallel-distributed and consists of very interlinked neural computing units known as neurons. Neural computing element (or say) neurons have the capability to gain and obtain knowledge. It is of much use to resolve problems. The ANN training is done by applying either unsupervised or supervised algorithm for training. ANN proves to be very much helpful in the field of forecasting, recognition of pattern, and processing of image and optimization, which are hard to solve with the help of rule-based methods [58].
This classification method makes use of MLP (multilayer perceptron) for the purpose of classifying the data. It comprises three layers, i.e., hidden, input, and output layers. In MLP, there is forward flow of information. The training of MLP net was done with the help of supervised learning. The output produced the network for the comparison of training data for error calculation with the target data. In ANN, the amount of change in weight is determined with the help of mean square error (MSE). The neural network training tool is used to define the pictorial representation of the proposed method. It also defines the performance, number of iterations, as well as the histogram of the error.
4.2.2 K-nearest neighbors
K-nearest neighbor (KNN) is a non-complex but quite productive method for classification. It is a lazy learning method that is why it has low efficiency. It makes use of limited resources while training a large dataset. It is based on unsupervised learning. The KNN rule classifies the x by allotting the label regularly in K-nearest samples. Initially, KNN trains the record and thereafter identifies the latest records, which are much similar to the training records. It explores the space for k training points that are nearest to the new points as the new point neighbors. In this method, the nearest distance is found with the help of a distance metric termed as Euclidean distance.
4.2.3 Support vector machine
This methodology is a meticulous machine learning approach in which regression and classification problems are used [59]. It analyzed different features obtained from input data in the coordinate plane. It is very much preferred because it produces high accuracy with little computation. It is used to identify a hyper plane in an N-dimensional space (N-D space) that clearly classifies the data points. For the given test data values, SVM predicts the target values. Support vector machine (SVM) is generally used as a binary linear classifier but it can also be extended for multiclass problems. With the help of SVM, a non-linear classifier can also be transformed into a linear separating hyper plane. It is also used for regression.
4.2.4 Naive Bayes classifier (NBC)
This classifier is based on Bayes’ theorem and is a collection of classification algorithms. It is a family or group of those algorithms which have identical principle, i.e., each pair of features or attributes which is to be classified is non-dependent of one another [25]. The objects in an image are classified by examining their prior probabilities with the help of Bayes classifier.
5 Result and analysis
In the proposed method, standard public database is used for experimental setup which comprises 140 retinal fundus images which have been obtained for the identification of glaucoma using digital database. Preprocessing is performed followed by segmentation (optic cup and optic disc); thereafter, 20 features have been extracted. In this proposed work, four classification techniques based on machine learning, namely Naïve Bayes, SVM, k-nearest neighbors, and ANN, have been incorporated. It has been observed that this proposed model reports with better results as compared to individual implications of existing techniques specifically Naïve Bayes classifier, support vector machine, and k-nearest neighbor.
Confusion matrix is prepared for classifiers and compared with mentioned classification techniques. It is observed that ANN reports better results in terms of accuracy, specificity, and sensitivity when compared with other classification techniques. In the training phase, ANN yields an analog output value in the range from 0 to 1.0.
The proposed model comprises input layer of 20 nodes, hidden layer of 12 nodes, and output layer of 2 nodes. This network has been trained with Bayesian regularization method to modify the weight and bias values as stated in optimization method of Levenberg-Marquardt. The proposed model has trained for 1000 iterations. The weights and bias associated to network have modified conforming to MSE metrics. The performance, gradient, and momentum (Mu) are found to be 0.127, 0.00190, and 0.100, respectively, as per the requirement of the proposed model.
This proposed model used the classifier which obtained the maximum accuracy for 0.127 of 98.60% with sensitivity being 98.52% and specificity 98.59%, whereas SVM reports with accuracy 97.61% with sensitivity 99.12% and specificity 96.15%. The parameters for FPR and FNR in the proposed model are found to be 0.01408 and 0.01471, respectively, whereas FPR and FNR are 0.03846 and 0.0, respectively, for SVM. The coefficient of correlation (R), MSE (mean square error), and RMSE (root mean square error) compute the anticipating power related to the model. The interconnection between target and output is linear if the value of “R” is “1,” and the model then proves to be 100% accurate. The ROC curve for the ANN classification is shown in Fig. 8. The performance plot defines the plotting between the MSE and the number of epochs. The plotting has defined on the MSE of validation data, training data, test data, and the best value of the data corresponding to a particular epoch as defined in Fig. 9. Neural network training tool has been used to measure the performance, error, number of iterations, as well as the time taken for the classification process. The other significant parameter to computethe classifiers’ performance is the area formed by the ROC forclass 1 and class 2 and depicted in Fig. 10.

Performance plots based on specified epochs

ROC curve of the ANN-based classification
Training state plot, error histogram, and regression plot for the classification process have been defined in Fig. 11. The pictorial representation of neural network, algorithm-used measurement of progress parameters, and the plots for performance, error histogram, training state, and regression has been defined in Fig. 11. Statistical results show that ANN classification is better than other classifiers.

Training tool of neural network
ROC is a plot between the TPR and FPR and its value lies between “0” and “1.” This tool is used to represent the neural network, its structure, algorithms used, progress of the process, and the plot of performance metrics of the model.
The plot of the training state defines (a) the plot between the gradient value and the number of epochs, (b) the plot between the value of mu and the number of epochs, and (c) the plot between the validation check at different epochs as shown in Fig. 12. The training model reports gradient (0.0018961), mu (0.1), and validation checks (6) at epoch 612.

Training state plots at different epochs
The error histogram is defined on instances and error parameters as shown in Fig. 13. This histogram is based on the validation data, training data, and test data that define the point of zero error. It is clear that the maximum error between the target value and the output value is 0.4833 as presented in Fig. 13.

Histogram of error plots
The regression plot has plotted for (a) validation of data, (b) data for training, (c) data for test, and (d) for all the data. This plot has been used to define the fitness line of the data and plotted between the output value and the target value as in Fig. 14. Fitness line is initiated for the different data in the range (0.4, 0.5). Table 2 is also complied to represent computation times (in seconds).

Regression training plots
6 Discussion
This section demonstrates the performance analysis of shortlisted classifiers and compares the performance of our work with prior published studies.
6.1 Comparison performance of different classifiers
Table 3 presents the information regarding the classifiers about their accuracy, sensitivity, and specificity which is calculated with the help of obtained confusion matrix for every classifier. From Table 3(and Fig. 15), it is very much clear that ANN yields the best accuracy, which is found to be 98.60%, whereas other classifiers observe comparatively less accuracy. As far as specificity is concerned, ANN again leads the show in terms of values when compared with other classifiers. When it comes to sensitivity, SVM has more value than other classifiers as well as ANN. It has being observed that SVM produces the accuracy very near to the accuracy produced by ANN.

Performance results obtained using machine learning–based classifiers
The experimental simulation has been chosen in which dataset is divided into two equal halves; 50% for training and 50% for testing; the simulation results are shown into Table 4.
6.2 Success and failure cases
In this sub-section, classification of the given glaucoma images are focused with the help of four scenarios. Figure 16 shows two images from the healthy class. The case represented by Fig. 16a is successful because the image is normal and our proposed system also predicts normal. The case represented by Fig. 16b is a failure case because the image is glaucomatous and our proposed system predicts normal. In the case of Fig. 16b, it can be observed that the optic cup utilizes a bigger segment of optic disc into the given fundus image, i.e., generally, a case for glaucomatous situation. Figure 17 depicts different scenarios with the help of glaucomatic and healthy human eyes. Figure 17apoints out a success case, whereas Fig. 17b presents a failure case. If these figures are compared, it can be recognized that the case of optic disc with Fig. 17bis reported with limited optic cup situation, which is, on behalf of nearly all cases, an attribute of healthy images.

a Healthy image. b Glaucomatous image

a Glaucomatous image. b Glaucomatous image
6.3 Performance comparison of results with prior studies
According to the data represented in Table 5, it can be easily deduced that the best accuracy (prime factor) is achieved in the proposed work. While keenly observing the values of the parameters generated in the proposed case, it can be concluded that the proposed methodology is reported with effective and signifying aspect.
The work conducted by Acharya et al. [17] reported with sensitivity rates of lesser than that of the proposed scheme in this paper. The sensitivity is an exceptionally significant quantity, preferably, and is supposed to be perhaps in a maximum. The work done by Al-Bander et al. [23] also presented with uneven expected results based on evaluation metrics and observed with lower rates than the proposed method for this paper. In the next study by practitioners, Acharya et al. [24] reported with a model for earlier and accurate glaucoma recognition with 90% accuracy. Such system was built with the combination of texture and higher order spectra (HOS) features. The classifiers like SVM, random forest, Naïve Bayes, and sequential minimal optimization are applied for classification of fundus images. Gajbhiye and Kanthane [18] employed three machine learning–based classifiers (SVM, KNN, and error back-propagation training algorithm (EBPTA)) for early and timely detection of glaucoma. The authors used wavelet for image decomposition; thereafter, these images are employed for further feature extraction.
The experiments were simulated using wavelet and geometric moment features. de Sousa et al. [19] proposed the system for detection of glaucoma in which texture with the optical disc image region was observed using local binary pattern with optic disc region. The obtained texture features were forwarded to SVM classifier with categorization purpose. In the last, selected, comparative study by Maheshwari et al. [22], fractal dimensional feature and entropies such as Yager entropy, Kapur entropy, and Renyi entropy have been extracted from decomposed components of iterative variational mode decomposition (VMD) method. Thereafter, relief method is applied for feature selection and ranking. Private dataset of 488 images was selected for experimentation and simulation presented an accuracy of 95.19%.
6.4 Advantages and limitations of the study
In this paper, the proposed methodology is reported with greater sensitivity than other proposed scheme. It means that the proposed method in this paper is better to detect positive cases, which is the best situation for a medical study. Hence, the conclusion will always help to make the much better result of the glaucoma identification primary for better daily clinical glaucoma care. Moreover, the work is likely to be good enough as maximum generated accuracy is acceptable for the standards of American Academy of Ophthalmology. All these methods for the detection of glaucoma ultimately decrease the ophthalmologist efforts. It would help all the patients worldwide from defending more vision decline during timely medical involvement.
The proposed system should be still experienced on large-sized clinical image dataset for testing in real scenarios, too, so that it becomes the second opinion by the expert ophthalmologists. Efforts are still required to make the proposed model generalized for all fundus images. Moreover, there is still scope of improvement in sensitivity and accuracy, to reach up to 100%.
7 Conclusion
The diagnosis of glaucoma is very essential in determining the cause of retinal disease type which may lead to the impairment of the optic nerve which may result into overall vision loss for the human eye. The proposed model based on deep image features helps the medical practitioners to diagnose the presence of glaucoma with higher accuracy and less computation time. It has been observed that extracted features are inter-dependent and are combined to build for parametric-based investigation for glaucoma in retinal fundus. The various extracted deep image features in the proposed methodology have been used for training and testing to enhance the existing model—support vector machine (SVM), K-nearest neighbor (KNN), Naïve Bayes classifier (NBC), and artificial neural networks (ANN). Thus, the experiment is reported with performance accuracy for SVM, KNN, Naïve Bayes, and proposed neural network–based model with deep image analysis as 97.61%, 90.47%, 95.23%, and 98.60% respectively. It has been observed that the proposed model shows auspicious performance when compared with other existing models in the state-of-art techniques on the basis of sensitivity, specificity, and computation time. As a future direction, we need to work on monitoring of glaucoma progression, its embedding in IoT devices, and availability at cloud environment.
References
Siamak YG, Michael H, Madhusudhanan B, Tzyy-Ping J, Robert WN, Felipe MA, Linda ZM, Jeffrey LM, Christopher GA, Christopher B (2013) Glaucoma progression detection using structural retinal nerve fiber layer measurements and functional visual field points. IEEE Trans Biomed Eng 61(4):1143–1154
Cheng J, Liu J, Xu Y, Yin F, Tan NM, Wong WKD, Lee BH, Cheng X, Gao X, Zhang Z, Wong TY (2017) Methods and systems for automatic location of optic structures in an image of an eye, and for automatic retina cup-to-disc ratio computation. US Patent 9:684,959
Martins J, Cardoso JS, Soares F (2020) Offline computer-aided diagnosis for glaucoma detection using fundus images targeted at mobile devices. Comput Methods Prog Biomed 192:105341
Kourkoutas D, Karanasiou IS, Tsekouras GJ, Moshos M, Iliakis E, Georgopoulos G (2012) Glaucoma risk assessment using a non-linear multivariable regression method. Computer Methods Programs Biomed 108(3):31149–31159
Singh, L. K., & Garg, H. (2019). Detection of glaucoma in retinal fundus images using fast fuzzy C means clustering approach. In 2019 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS) (pp. 397-403). IEEE
Ortíz, D., Cubides, M., Suárez, A., Zequera, M., Quiroga, J., Gómez, J. and Arroyo, N., (2010). Support system for the preventive diagnosis of hypertensive retinopathy. In: Annual International Conference of the IEEE Engineering in Medicine and Biology (pp. 5649-5652). IEEE
Atto AM, Pastor D, Mercier G (2008) Detection threshold for non-parametric estimation. SIViP 2(3):207–223
Deepti Y., Partha MS., Malay K.D., (2014). Classification of glaucoma based on texture features using neural networks. In 7th International Conference on Contemporary Computing (IC3) (pp. 109-112). IEEE
Saleh MD, Eswaran C, Mueen A (2011) An automated blood vessel segmentation algorithm using histogram equalization and automatic threshold selection. J Digit Imaging 24(4):564–572
Roodhooft J (2002) Leading causes of blindness worldwide. Bull Society BelgeOphtalmol 283:19–25
Haleem MS, Han L, Van Hemert J, Li B (2013) Automatic extraction of retinal features from colour retinal images for glaucoma diagnosis: a review. Comput Med Imaging Graph 37(7–8):581–596
Abdel-Hamid L (2020) Glaucoma detection from retinal images using statistical and textural wavelet features. J Digit Imaging 33(1):151–158
Tuck MW, Crick RP (1992) Screening for glaucoma: age and sex of referrals and confirmed cases in England and Wales. Ophthalmic Physiol Opt 12(4):400–404
George R, Ve Ramesh S (2010) Glaucoma in India: estimated burden of disease. J Glaucoma 19(6):391–397
Quigley HA, Broman AT (2006) The number of people with glaucoma worldwide in 2010 and 2020. Br .J .Ophthalmol 90(3):262–267
Vajaranant TS, Wu S, Torres M, Varma R (2012) A 40-year forecast of the demographic shift in primary open-angle glaucoma in the United States. Invest Ophthalmol Vis Sci 53(5):2464–2466
Acharya UR, Ng EYK, Eugene LWJ, Noronha KP, Min LC, Nayak KP, Bhandary SV (2015) Decision support system for the glaucoma using Gabor transformation. Biomedical Signal Processing and Control 15:18–26
Gajbhiye GO, Kamthane AN (2015) Automatic classification of glaucomatous images using wavelet and moment feature. In: annual IEEE India conference (INDICON), pp 1–5
de Sousa JA, de Paiva AC, Sousa de Almeida JD, Silva AC, Junior GB, Gattass M (2017) Texture based on geostatistic for glaucoma diagnosis from fundus eye image. Multimed Tools Appl 76(18):19,173–19,190
Soltani, A., Badaoui, A., Battikh, T. and Jabri, I., (2018). A novel system for glaucoma diagnosis using artificial neural network classification. In: 5th International Conference on Control, Decision and Information Technologies (CoDIT) (pp. 1128-1133). IEEE
Kim, P.Y. &Iftekharuddin, K.M. (2013). Novel fractal feature-based multiclass glaucoma detection and progression prediction, IEEE J. Biomed. Health. Inf. 17 (2)
Maheshwari S, Pachori RB, Kanhangad V, Bhandary SV, Acharya UR (2017) Iterative variational mode decomposition based automated detection of glaucoma using fundus images. ComputBiolChem 88:142–149
Al-Bander, B., Al-Nuaimy, W., Al-Taee, M. A., &Zheng, Y. (2017). Automated glaucoma diagnosis using a deep learning approach. In 2017 14th International Multi-Conference on Systems, Signals & Devices (SSD) (pp. 207-210). IEEE
Rajendra Acharya U, Dua S, Xian D, VinithaSree S, Chua CK (2011) Automated diagnosis of Glaucoma using texture and higher order spectra features. IEEE Trans InfTechnol Biomed 15(3):449–455
Zhou W, Yi Y, Bao J, Wang W (2019) Adaptive weighted locality-constrained sparse coding for glaucoma diagnosis. Medical & Biological Engineering & Computing 57(9):2055–2067
Guo, F., Li, W., Tang, J., Zou, B., & Fan, Z. (2020). Automated glaucoma screening method based on image segmentation and feature extraction. Medical & Biological Engineering & Computing, 1-20
Kim SJ, Cho KJ, Oh S (2017) Development of machine learning models for diagnosis of glaucoma. PLoS One 12(5):e0177726
An, G., Omodaka, K., Hashimoto, K., Tsuda, S., Shiga, Y., Takada, N.,& Nakazawa, T. (2019). Glaucoma diagnosis with machine learning based on optical coherence tomography and color fundus images. Journal of Healthcare Engineering, 2019
Lee SD, Lee JH, Choi YG, You HC, Kang JH, Jun CH (2019) Machine learning models based on the dimensionality reduction of standard automated perimetry data for glaucoma diagnosis. Artif Intell Med 94:110–116
Civit-Masot J, Domínguez-Morales MJ, Vicente-Díaz S, Civit A (2020) Dual machine-learning system to aid glaucoma diagnosis using disc and cup feature extraction. IEEE Access 8:127519–127529
David DS, Jayachandran A (2020) A new expert system based on hybrid colour and structure descriptor and machine learning algorithms for early glaucoma diagnosis. Multimed Tools Appl 79(7):5213–5224
Benzebouchi NE, Azizi N, Ashour AS, Dey N, Sherratt RS (2019) Multi-modal classifier fusion with feature cooperation for glaucoma diagnosis. Journal of Experimental & Theoretical Artificial Intelligence 31(6):841–874
Raj A, Tiwari AK, Martini MG (2019) Fundus image quality assessment: survey, challenges, and future scope. IET Image Process 13(8):1211–1224
Kanse SS, Yadav DM (2020) HG-SVNN: harmonic genetic-based support vector neural network classifier for the glaucoma detection. Journal of Mechanics in Medicine and Biology 20(01):1950065
Shehryar, T., Akram, M. U., Khalid, S., Nasreen, S., Tariq, A., Perwaiz, A., &Shaukat, A. (2020). Improved automated detection of glaucoma by correlating fundus and SD-OCT image analysis. International Journal of Imaging Systems and Technology. 1–20
Ajesh F, Ravi R (2020) Hybrid features and optimization-driven recurrent neural network for glaucoma detection. Int J Imaging Syst Technol 30:1143–1161
Ajesh, F., Ravi, R., & Rajakumar, G. (2020). Early diagnosis of glaucoma using multi-feature analysis and DBN based classification. Journal of Ambient Intelligence and Humanized Computing, 1-10
Gour, N., & Khanna, P. (2019). Automated glaucoma detection using GIST and pyramid histogram of oriented gradients (PHOG) descriptors. Pattern Recogn Lett
Raghavendra U, Fujita H, Bhandary SV, Gudigar A, Tan JH, Acharya UR (2018) Deep convolution neural network for accurate diagnosis of glaucoma using digital fundus images. Inf Sci 441:41–49
Phan S, Satoh SI, Yoda Y, Kashiwagi K, Oshika T, Japan Ocular Imaging Registry Research Group (2019) Evaluation of deep convolutional neural networks for glaucoma detection. Jpn J Ophthalmol 63(3):276–283
Khalil T, Akram MU, Khalid S, Jameel A (2017) Improved automated detection of glaucoma from fundus image using hybrid structural and textural features. IET Image Process 11(9):693–700
Salam AA, Khalil T, Akram MU, Jameel A, Basit I (2016) Automated detection of glaucoma using structural and non-structural features. Springerplus 5(1):1519
Issac A, Sarathi MP, Dutta MK (2015) An adaptive threshold based image processing technique for improved glaucoma detection and classification. Comput Methods Prog Biomed 122(2):229–244
Vijapur NA, Kunte RSR (2017) Sensitized glaucoma detection using a unique template based correlation filter and undecimated isotropic wavelet transform. Journal of Medical and Biological Engineering 37(3):365–373
Xiong, L., Li, H. and Zheng, Y., (2014). Automatic detection of glaucoma in retinal images. In 2014 9th IEEE Conference on Industrial Electronics and Applications (pp. 1016-1019). IEEE
Juneja, M., Singh, S., Agarwal, N., Bali, S., Gupta, S., Thakur, N., & Jindal, P. (2019). Automated detection of glaucoma using deep learning convolution network (G-net). Multimedia Tools and Applications, 1-23
Hagiwara Y, Koh JEW, Tan JH, Bhandary SV, Laude A, Ciaccio EJ, Tong L, Acharya UR (2018) Computer-aided diagnosis of glaucoma using fundus images: a review. Comput Methods Prog Biomed 165:1–12
Jorge, B., Barrera, D., Caro, MP, Estupinan, AM, Gonzalez-Neira, EM, Perez, N., Carlos, S., Suarez, DR and Torres, MJ, (2018). Dispatch rules in programming of elective surgical procedures: impact on occupation and opportunity indicators. Health Sciences Magazine
Chai Y, Liu H, Xu J (2020) A new convolutional neural network model for peripapillary atrophy area segmentation from retinal fundus images. Appl Soft Comput 86:105890
Noronha K, Acharya UR, Nayak KP, Kamath S, Bhandary SV (2013) Decision support system for diabetic retinopathy using discrete wavelet transform. Proceedings of the Institution of Mechanical Engineers. Part H, Journal of engineering in medicine 227(3):251–261
Singh LK, Garg H (2020) Detection of glaucoma in retinal images based on multiobjective approach. International Journal of Applied Evolutionary Computation (IJAEC) 11(2):15–27
Fink, F., Worle, K., Gruber, P., Tome, A.M., Gorriz-Saez, J.M., Puntonet, C.G. and Lang, E.W., (2008). ICA analysis of retina images for glaucoma classification. In: 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (pp. 4664-4667). IEEE
Orujov, F., Maskeliunas, R., Damaševičius, R., & Wei, W. (2020). Fuzzy based image edge detection algorithm for blood vessel detection in retinal images. Applied Soft Computing, 106452
Zilly J, Buhmann JM, Mahapatra D (2017) Glaucoma detection using entropy sampling and ensemble learning for automatic optic cup and disc segmentation. Comput Med Imaging Graph 55:28–41
Salazar-Gonzalez A, Kaba D, Li Y, Liu X (2014) Segmentation of the blood vessels and optic disk in retinal images. IEEE Journal of Biomedical and Health Informatics 18(6):1874–1886
Yousefi S, Goldbaum MH, Balasubramanian M, Medeiros FA, Zangwill LM, Liebmann JM, Girkin CA, Weinreb RN, Bowd C (2014) Learning from data: recognizing glaucomatous defect patterns and detecting progression from visual field measurements. IEEE Trans Biomed Eng 61(7):2112–2124
Toğaçar M, Özkurt KB, Ergen B, Cömert Z (2020) BreastNet: a novel convolutional neural network model through histopathological images for the diagnosis of breast cancer. Physica A: Statistical Mechanics and its Applications 545:123592
Fathi A, Naghsh-Nilchi AR (2013) Integrating adaptive neuro-fuzzy inference system and local binary pattern operator for robust retinal blood vessels segmentation. Neural Comput & Applic 22(1):163–174
Toğaçar M, Ergen B, Cömert Z (2020) Detection of lung cancer on chest CT images using minimum redundancy maximum relevance feature selection method with convolutional neural networks. Biocybernetics and Biomedical Engineering 40(1):23–39
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Singh, L.K., Pooja, Garg, H. et al. An enhanced deep image model for glaucoma diagnosis using feature-based detection in retinal fundus. Med Biol Eng Comput 59, 333–353 (2021). https://doi.org/10.1007/s11517-020-02307-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11517-020-02307-5