
Abstract
This experimental investigation seeks to confirm and extend previous investigations that resource interdependence vs. independence during problem-solving relatively extends the problem representation phase before convergence on a solution. In this current investigation, ninth-grade Korean native language participants (n = 240) worked online to complete either a well-structured or an ill-structured problem in either independent triads where all of the members were provided with all of the information needed to solve the problem, or in interdependent triads where members were each provided with different portions of the information needed. The discussions were analyzed using a content analysis rubric from Engelmann and Hesse (JAMA 5:299–319, 2010), and knowledge structures were elicited as concept maps and essays and then analyzed using a graph-theoretic psychometric network scaling approach. Analysis of transcripts of the triad interactions showed a similar pattern of divergence and then convergence for the well-structured and the ill-structured problems that confirmed the previous investigations. As anticipated, interdependent triads performed relatively better on the ill-structured problem perhaps due to the extended divergence phase, while independent triads were better on the well-structured problem perhaps due to a rapid transition to the convergence phase. Knowledge structure analysis of group maps shows that the interdependent triad maps resembled the fully explicated problem space, while the independent triad maps most resembled the narrow problem solution space. Suggestions for practice include first increasing students’ awareness of divergent and convergent thinking, allowing enough time for the activity, and also requiring teams to submit a problem space artifact before working on a solution. Such skills are a basis for learning in school, but more importantly, will prepare students for a world where change is a constant and learning never stops.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Jonassen (2010) stressed that “… problem-solving is the most authentic and therefore the most relevant learning activity that students can engage in…” (p 2) and echoes Karl Popper (2013) that “all life is problem-solving.” In school, an emphasis on twenty-first century skills requires an array of problem-solving competencies, including critical-thinking, information literacy, and teamwork (Graesser et al., 2020). While engaging in problem-solving in groups, students can develop their content knowledge, group interaction skills, and problem-solving skills in the targeted domain (Hung et al., 2019).
However, both individual problem solving and teamwork are complex and difficult, and so it is important to explore how these two intertwine when working in a group to solve a problem. This experimental investigation seeks to confirm and extend one aspect of well-structured and of ill-structured problem-solving in groups, the influence of resource interdependence (Buchs et al., 2021; Engelmann & Hesse, 2010; Laal, 2013; Yoo, 2020), which requires that team members must work together because the necessary information is not shared equally.
Divergence and convergence in well-structured and ill-structured problems
Problems and problem-solving are delineated by Jonassen (1997) on a continuum from well-structured to ill-structured; and beyond that the most difficult or impossible problems are referred to as “wicked problems” (Churchman, 1967) because the information and requirements needed to solve these tend to be incomplete or contradictory, and my even be changing dynamically. In the classroom, typically only well-structured problems are used that provide sufficient information to establish the content of the problem space needed to reach a solution. Less frequently used are ill-structured problems that are more difficult to solve because the problem content space is not well defined (i.e., information is incomplete, as in real life), and often, ill-structured problems have equally appropriate alternative solutions and so the rationale for a solution is as critical or even more important that the actual solution.
Guilford (1959) pioneered the constructs of convergent and divergent thinking abilities as traits of creativity. Convergent thinking involves conventional and logical search, recognition, and decision-making strategies applied to describe a problem (Cropley, 2006; Jaarsveld & Lachmann, 2017). Divergent thinking involves forming combinations of available information through semantic flexibility and fluency of association, ideation, and transformation (Guilford, 1959, as cited in Cropley, 2006, p 1). Jaarsveld and Lachmann (2017) note that convergent thinking is mostly about a defined problem space, while divergent thinking is mostly about an ill-defined problem space (p 134).
Jonassen (1997) characterized problem-solving as converging on a solution after “…divergent and creative thinking in order to generate as many alternative representations of the problem as possible.” (p 78). But he then lamented that “students experienced difficulty in fluently generating alternative solutions and representations, and [so] the methods did not transfer to solving ill-structured problems” (p 78), perhaps due to memory disruptions related to common information sharing and collaborative inhibition (Congleton & Rajaram, 2011). He then particularized a somewhat successive, recursive, and perhaps overlapping list of seven activities for solving ill-structured problems including: (a) setting the problem space and contextual constraints; (b) identifying and clarifying alternative opinions, positions, and perspectives of stakeholders; (c) generating multiple possible problem solutions; (d) assessing the viability of alternative solutions by constructing arguments and articulating personal beliefs; (e) monitoring the problem space and solution options; (f) implementing and monitoring the solution; and (g) adapting the solution (Shin et al., 2003). The first three steps in general require adding information to the group collective information space and so by definition are divergent, and these three steps may also require creative thinking that usually depends on divergent thinking; while the final four steps require selection from the collective information and so by definition are convergent thinking towards an acceptable solution. This investigation supports the position that divergence (expanding) then convergence (narrowing) are two broad and natural stages or phases in problem-solving.
Divergence has been shown to relate to openness and creativity that may be a personality style, characteristic, or even trait (Jaarsveld & Lachmann, 2017), since divergent thinking is innate or natural for some people but not for others. Diversity of divergence and convergence styles in a group is likely to benefit problem-solving processes because peers may provide differing perspectives and evidence during problem-solving (Maker, 2020). But all group work has both costs and advantages (Tutty & Klein, 2008).
Problem-solving in groups: benefits and challenges
There are complex processes, features, and outcomes of group work during problem-solving, as well as complexity of group cognition and regulation (Biasutti et al., 2018). In the learning sciences literature, group work is usually categorized based on team members interactions as cooperative or collaborative (Matthews et al., 1995; O’Donnell & Hmelo-Silver, 2013). Nokes-Malach et al. (2015) defines collaboration broadly to mean active engagement and interaction among group members to achieve a common goal (p 646). Cukurova et al. (2018) describe cooperative problem-solving as participants agreeing to work together and contribute to the interaction, while collaborative problem-solving adds social coordination, with sensitivity and awareness of the contributions of the others. “But collaboration is more than this, it also involves participants working in unison as equals and oriented to a jointly agreed goal and often generating ideas that can form the basis for a possible solution or decision” while participants engage “in a coordinated shared endeavor to solve a problem through a coordinated joint commitment to a shared goal, reciprocity, mutuality, the continual (re-)negotiation of meaning” (Cukurova et al., 2018, p 94). So cooperative and collaborative group work can be viewed on a continuum based on the amount of interactive engagement, although a teacher may aspire to true collaboration, this is very difficult to achieve in the classroom every time in every group because individuals may be more or less inclined to engage with others for many reasons (e.g., cognitive, social, practical, style, personal preference).
In the real world, a main advantage of group work is quite simple, because individuals have different backgrounds, information, and perspectives, then a group usually has more ideas than any one individual in the group (Barber et al., 2015); but a group actually produces fewer total ideas than if the members work individually in isolation and then pool their work (refreered to as a nominal group, Nokes-Malach et al., 2015); this phenomenon is a well-established robust effect called collaborative inhibition. A meta-analysis by Marion and Thorley (2016) analyzed 75 effect sizes in 64 studies and as previously reported, found that group recall was considerably less than that of the pooled recall of the same number of individuals, especially for transient groups and for larger groups. However, the same study also reported a main learning benefit for group work, that “collaborative remembering tends to benefit later individual retrieval” (p 1141).
There are a variety of ways to increase true collaboration during group work, each with advantages but also drawbacks (see the review by Nokes-Malach et al., 2015). Much of the recent collaborative research involves scaffolds to direct activity that are unfamiliar to students and thus require substantial training and support to be sustained during and beyond the investigation. “The nature of the scaffolding is that it may act to provoke or catalyze, but of course the software tools cannot require that learners mindfully engage with these opportunities” (Reiser, 2015, p 298). Various ways for instituting positive interdependence include establishing common goals, providing group-level rewards, sharing resources, taking roles, and even establishing identity markers such as self-elected team names (Yoo, 2020). But task interdependence mainly benefits project teams when individual autonomy is low (Yoo, 2020) and so externally controlling needed information provided to students in order to establish resource interdependence is one relatively easy and natural strategy for teachers that is worth further investigation.
This investigation utilized common resource sharing as hidden profiles (Lu et al., 2012; Stasser & Titus, 1985) to engender group member resource interdependence. It is fairly easy to provide individual group members with some specific common information but then distribute among members some critical pieces of the information needed to solve the problem, then the group members must depend on each other since no one individual has all of the information. This approach matches ordinary life where individuals also bring different information to group tasks, but in that case the prior information differences are idiosyncratic and unknown to the researcher ahead of time. With hidden profiles, it is possible to know to some degree what relevant information each group member holds during the task, and then to measure whether they share it or not, and also whether members ‘take up’ the new pieces of information provided by the others. Thus measuring the flow of information pieces in the group interactions and in the group’s and the individuals’ artifacts allow researchers to better understand what is occurring.
Asino et al. (2012) considered resource interdependence versus independence using hidden profiles. Undergraduate students in a communications course (n = 40) in 10 groups of 4 were randomly assigned to homework tasks that consisted of reading and mapping all of an assigned textbook chapter (Independent Groups) or reading and mapping the first half, middle half, or last half of that chapter (Interdependent Groups). During class time, groups met and mapped the chapter content together using yellow stickies and magic markers on large sheets of newsprint. Then immediately after group mapping, students individually drew a post concept map from memory. The Independent Groups’ group maps were larger on average than those of the Interdependent Group and their individual post concept maps were more like their own homework pre maps and less like their group map (i.e., the collaboration had relatively less influence on Independent Group members post concept maps). In contrast, the Interdependent Groups’ post concept maps were considerably more like their group’s map, were relatively more like the expert’s map (62% vs. 52%), and their post maps were relatively more like the post maps of others in their group (team member convergence, 38% overlap for interdependent vs. only 30% for Independent Groups). Although that investigation did not involve problem-solving, resource interdependence during group work led to more expert-like post maps (e.g., improved knowledge structure) and so the findings align with Shin et al. (2003) investigation of problem-solving by 9th grade students that reported that ill-structured problem-solving scores were significantly predicted by knowledge structure scores, better knowledge structure lead to better solutions.
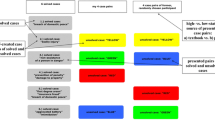
Engelmann and Hesse (2010) consider positive resource interdependence as hidden profiles during group problem-solving in an online setting. German undergraduate students (n = 120) were randomly assigned to 40 triads that were allocated to one of two treatments: an independent treatment where every member had access to all of the information and an interdependent treatment (i.e., hidden profiles) where each member had access to partial information as well as some common shared information. They were all asked to create a group concept map in order to help solve a difficult but well-structured problem about pesticides in a forest. Triad members worked on the problem together online using CmapTools for collaborative concept mapping with Skype for synchronous audio and video communications. Analysis of the video tapes of the triad interactions showed, on average, that the independent triads almost immediately began to discuss solutions while mapping, while the interdependent triads worked on the group map for quite a while before discussing possible solutions (see Fig. 1). Note that the interdependent triads required about 5 min longer to reach a solution to this well-structured problem. From an efficiency view, the independent triads were relatively more efficient.

Clariana et al. (2013) applied Graph Theory centrality measures to reanalyze the triad maps from Engelmann and Hesse (2010). They converted the triad maps to node degree vectors and then compared these vectors to two referents, a fully explicated problem representation that contained all of the information given to the triad members (i.e., the full Expert map) and a solution sub-set of that map that contained only the information needed to solve the problem. The interdependent triad maps resembled the fully explicated problem space with both solution relevant and irrelevant information (see top panel of Fig. 2), while the independent triad maps resembled the problem solution subset with solution relevant information but not much irrelevant information (see bottom panel of Fig. 2).

Time chart from Fig. 1 suggesting how extending divergence for the interdependent triads relates to a more fully explicated group map; while the independent triads almost immediately move to convergence towards a solution subset
So resource interdependence probably extends the problem elaboration stage of problem-solving and delays convergence on a solution. Clariana et al. (2013) proposed that:
A fuller problem representation can be used to solve multiple different problems, while a focused problem representation most efficiently solves the problem that it represents, but not other problems; inadequate formation of the problem space most likely leads to brittle solutions. Further research is suggested to consider this possible role of information adequacy as the distinguishing difference between well-structured and ill-structured problem solving. (p 439)
Information adequacy includes both extent of knowledge (quantity) and form (quality, as structure specificity; Trumpower et al., 2010). Trumpower and Sarwar (2010) note that “knowledge structures … play a more direct causal role in enabling good performance” (p 427).
In this present investigation, knowledge structure (KS) is elicited as concept maps and as essays (Kim & McCarthy, 2021). Will the previous findings from Engelmann and Hesse (2010) and Clariana et al (2013) that positive resource interdependence delays solution convergence replicate with this different population and different content? Also, those investigations used well-structured problems, and so extending these investigations we ask: What is the influence of positive resource interdependence on both well-structured and ill-structured problem-solving?
Purpose of this investigation
This investigation uses age-appropriate well-structured and ill-structured problems in astronomy from Shin et al. (2003) that were validated for this investigation by review and consensus of the three course instructors. As proposed above, will well-structured problems benefit in efficiency from quickly moving to the solution phase (i.e., from divergent to convergent activities) and ill-structured problems benefit from extending divergent activity before transitioning to the solution phase? Specifically, is there a disordinal interaction of interdependence with type of problem-solving? Also this investigation seeks to further validate the graph theoretic measures from Clariana et al. (2013) as a complement to the video content analysis of group process, individual and group maps, and the posttest essay scores.
Method
Participants
Participants were 240 students from Grade 9–10 science courses from the Korea-based local high school. All the participants are native Korean speakers (age distribution from 15 to 17 years old; sex distribution 53% males and 47% females). The participants were briefed on the study and were asked to sign the consent form and also to assent to the consent form signed by their parents. They received course credits for their participation. The participants were randomly assigned to triads with 20 triads assigned to each of four treatments (i.e., a triad × 20 triads × 4 treatments = 240). In this investigation, the four treatment conditions consisted of triads of students working either interdependently (inT) or independently (inD) while solving well-structured (well) or ill-structured (ill) problems (e.g., the four conditions are inT|well, inD|well, inT|ill, inD|ill). This experiment took place in Korea in Korean, thus all materials and communications in this manuscript have been translated to English.
Materials
The investigation used a well-structured and an ill-structured problem in the context of astronomy that were devised and studied by Shin et al., (2003; see Table 1). A senior researcher in astronomy and two experts in test development revised and translated this set of problem items into Korean for these students (see Table 1). For the well-structured problem, most students answered the two questions in one solution instead of two separate solutions, so the combined scores were used in the analysis. The ill-structured problem does not have a single correct solution, instead, participants must depend on their reasoning to find a solution based on the content understanding and so the ill-structured problem-solving scores for analysis are based on the qualities of selecting appropriate information, organizing the selected information, choosing a potential solution, and developing justifications of the solution.
Procedure
Pre-collaboration
On the first day of the investigation, the triad members were individually required to watch one of two course-related 30-min video lectures developed by three instructors for this investigation, either “Finding the Distance to a Star” for the well-structured problem or “Controlling an Astronomical Emergency” for the ill-structured problem. Each 30-min video lecture consists of three 10-min subtopics. Participants in the Independent condition were asked to watch and map the entire video lecture that covers all three sub-topics, while participants in the Interdependent condition were asked to watch and map one of three 10 min-subtopic video lectures. All were told to “do your map in order to support your team”. All were provided with the same list of 30 key terms from the lecture that they could use for their individual Premaps with the statement, “Use any appropriate words in your concept map, but here are a few important words that you could use”, i.e., open-ending concept mapping. The provided 30 key terms were evenly selected by three instructors from each subtopic (10 from each subtopic) based on their consensus of the essential terms from each subtopic. All participants were individually required to create a map after watching a video using the browser-based software tool Graphical Interface of Knowledge Structure—Map (GIKS-Map is explained in detail below). The participants accessed GIKS-Map with their assigned individual, ID then they worked alone at their own pace to create their Premaps, but on average they spent about 25 min for the Independent Groups and 10 min for the Interdependent Groups to complete the Premaps.
Collaboration
On the second day of the investigation, triad members worked together online in a synchronous collaboration mode that allows for video communications. The group task was to determine together how to resolve the given problem (e.g., either the well-structure or ill-structured problem; see Table 2) by first creating a group map of the problem content space using GIKS-Map software that allows for collaborative mapping. Each group accessed GIKS-Map with their assigned group ID. The group maps and communications were recorded. Note that compared to the independent condition, the available information in the interdependent condition was evenly divided across the three members in a way that each member had some common and some unique pieces of information but no one individual had the complete solution information. Thus, the interdependent triad members must depend on others in order to solve the problem.
Post-collaboration
On the third day of the investigation, all participants were individually required to write an essay from memory using the browser-based software tool Graphical Interface of Knowledge Structure—Text (GIKS-Text is explained in detail below). Participants accessed GIKS-Text with their assigned individual ID then they were asked to write and submit their problem-solving essays.
Data types
All of participants’ concept maps (Pre maps and Group maps) and essays (Post essays) were converted into Pathfinder Networks (PFnets), a graph-theoretic psychometric network scaling measure (Tossell et al., 2010), in order to compare each PFnet to one another (e.g., participants’ map to map PFnets, map to essay PFnets, etc.) and also to compare all of the participants’ map and essay PFnets to expert-derived content and solution referent PFnets.
Referent PFnets
Following Clariana et al. (2013), three instructors worked together to establish the full Expert referent maps, one for the well-structured problem and one for the ill-structured problem, that contains the full information of the entire lecture (i.e., both solution-relevant and solution-irrelevant) and the Solution maps, subset of the full maps, one for the well-structured problem and one for the ill-structured problem, that contains only the solution-relevant information (see Fig. 3 for an example). For creating the referent maps, the three instructors were provided with a list of all of the terms used by the participants in their maps and essays, arranged in order of frequency of occurrence. While considering this list and the lesson content, the experts collaborated face-to-face to reach a consensus on the essential terms for the full Expert map, 23 terms for well-structured problem and 22 terms for ill-structured problem, and for the subset Solution map, 15 terms for well-structured problem and 12 terms for ill-structured problem; these terms were then used to establish the two full expert PFnets and two solution PFnets. This full and solution PFnets were used as the referent map for comparing to the students’ PFnets.

A full expert referent PFnet with a subset solution referent PFnet in red (top) and students’ problem-solving essay PFnets, one from independent (bottom left) and one from Interdependent Group (bottom right)
Concept maps to PFnets conversion
The software tool GIKS-Map was used to convert concept maps into PFnets. The GIKS-Map was developed by integrating two different computational algorithms, Jrate and Pathfinder KNOT. Jrate software was used to capture the raw proximity data as the distance between the selected key terms in the referents’ (full expert and solution) and participants’ (pre & group) concept maps. Jrate software transformed each concept map into a proximity data array of the pair-wise term distance elements; for example, for the solution map with 15 key terms, 105 pair-wise term distance elements were calculated, (152–15)/2 = 105. Then all of the participants and referents’ map proximity data from the Jrate were converted into PFnets using Pathfinder KNOT software. Briefly put, the Pathfinder algorithm is a psychometric data reduction scaling approach based on graph theory that intends to reveal the underlying organization or structure of the data (see for details, Tossell et al., 2010; for validity of KNOT, see Sarwar (2011). Pathfinder scaling has been applied to capture the strongest associations in sets of associations by removing less important/weak association data across highly diverse domains, including flight training (English & Branaghan, 2012), categorization of satellite images (Barb & Clariana, 2013), language transfer (Kim & Clariana, 2015), reading comprehension (Fesel et al., 2015; Kim, 2017a), and text mining (Patil & Brazdil, 2007). In this investigation, we claim that the resulting PFnet from the GIKS-Map represents the most salient connections between key concepts in the original concept maps.
Essays to PFnets conversion
The software tool GIKS-Text was used to convert essays to PFnets. The GIKS-Text was developed by integrating two different computational algorithms, ALA-Reader and Pathfinder KNOT. The ALA-Reader algorithm was designed to capture the raw proximity data as the sequence of important key terms in a text, adding only “1” or “0” to indicate the sequential occurrence of the key terms in the text. Then the pair-wise term sequence data can be visually represented as PFnets using KNOT as in the process for maps to PFnets (see for details, Clariana et al., 2014; Kim, 2017b; see for validity of ALA-Reader, Kim, 2012). This ALA-Reader + PFnet approach has been employed in diverse domains; for example, to score essays (Clariana et al., 2014), to elicit text structure (Fesel et al., 2015), to compare directed vs. translated writings (Kim & Clariana, 2015), and to provide feedback of online learners’ written assignments (Kim et al., 2019). GIKS-Text is an automatic version of the ALA-Reader + PFnet approach that can automatically convert writings into PFnets. Here the resulting PFnet from the GIKS-Text represents the most salient linkages between key concepts in the essay.
Data analysis
The data were analyzed by two network analytic methods that have been shown to be sensitive to assessing network similarity, including correlation of the raw proximity data (e.g., Kim & Clariana, 2015), and similarity of the pruned proximity data (e.g., Clariana et al., 2014), because the different methods capture different aspects of structural similarity inherent in the maps and essay data.
First, we used the raw proximity data from maps and essays for comparison. We conducted correlation between the raw proximity data (i.e., pair-wise term distance data from concept maps and pair-wise term sequential data from essays); for example, the pairwise term distances in one concept map are compared by Pearson correlation (r) to the same pairwise term distance in another concept map. Such raw proximity data analysis has been effectively used for assessing structural similarity of networks because it has the largest amount of information as both true and error variance (see for applications, Kim & Clariana, 2015; Kim, 2017b, Kim & Tawfik, 2021). Following Kim & Clariana (2015), and Kim et al. 2019), we used the raw proximity data to average together individual raw proximity data within each condition in order to obtain and compare ‘average group raw proximity data’ as it captures the most data points so likely best to have a group average data.
Second, we directly compared PFnets (i.e., pruned proximity data) by configural similarity (also known as neighborhood similarity), calculated by common links divided by the unique links in the two PFnets, i.e., common links/uncommon links, with the value of 0 (no similarity) to 1 (perfect similarity). For example, in Fig. 3 below, the student’s essay network from the Interdependent Group has a stronger similarity with the full expert network of 78% [27/((40 + 29)/2)] but less stronger with the solution network of 47% [11/((18 + 29)/2)] showing extended divergence; whereas the student’s essay network from the Independent Group has a stronger similarity with the solution network of 78% [16/(18 + 23)/2] but less stronger with the full expert network of 57% [18/(40 + 23)/2] showing solution convergence. The PFnet similarity scores have been extensively and empirically used in various studies (see for examples, Clariana et al., 2014; Kim et al., 2019; Coronges et al., 2007; Draper, 2013). Following Kim & Clariana (2015), and Kim et al. (2019), we used the pruned proximity data (represented as PFnets) to compare participants’ PFnets to the referent PFnets to assess the participants’ problem-solving performance as it has the most salient relations.
Results
The data for analysis includes the video records of the online collaborations, human-rater measures of problem-solving essays, and PFnets from individual Pre maps [n = 240, (60 × 4 groups)], Group maps [n = 80, (20 × 4 groups)] and individual Post essays [n = 240, (60 × 4 groups)]. First, the video record analysis (collaboration processes) and the human rater measures of post essays are presented in order, and then PFnet data are described and compared in two ways including (A) Correlation of PFnets (as raw proximity data) for (1) analysis within-students between-tasks and (2) analysis between-students within-tasks, (B) Similarity of PFnets (as pruned proximity data) to consider the (3) similarity to the Expert map and (4) similarity to the Solution map.
Collaboration processes
Following the approach of Engelmann and Hesse (2010), the video and audio files were analyzed in terms of the start and end time (in seconds) of collaborative problem-solving activities by condition; (1) the starting and ending time of mapping for a given problem (i.e., the time in drawing the first or last node/link of the map), (2) the starting and ending time of discussing the solution to a given problem (i.e., the time to start and then end the discussion for solving a given problem), and (3) the first time the correct answer is mentioned (see Fig. 4). Referring back to Fig. 1 above, the data in this investigation exactly aligns with that reported by Engelmann and Hesse (2010). The Independent Groups started significantly earlier in discussing the solution for both the well-structured problem (MinD = 198.1 vs. MinT = 788.6 s., F(1,122) = 15.44, p < .001, partial η2 = .720) and the ill-structured problem (MinD = 232.5 vs. MinT = 964.4 s., F(1,122) = 8.78, p < .001, partial η2 = .957). In addition, the Independent Groups ended significantly faster in drawing the map for both the well-structured problem (MinD = 720.1 vs. MinT = 1260.2 s., F(1,122) = 12.53, p = .002, partial η2 = .749) and the ill-structured problem (MinD = 1025.3 vs. MinT = 1381.9 s., F(1,122) = 22.01, p = .001, partial η2 = .681). Also, the Independent Groups solved significantly faster the well-structured problem (MinD = 810.4 vs. MinT = 1377.1 s., F(1,122) = 9.91, p < .001, partial η2 = .438) and the ill-structured problem (MinD = 1152.4 vs. MinT = 1407.2 s., F(1,122) = 6.88, p < .003, partial η2 = .555).

Average time distribution of problem-solving collaborative processes for the well-structured problem (top) and the ill-structured problem (bottom). Note. start/end M: start/end time of creating the map; start/end S: start/end time of discussion of the solution to a problem; correct: first time the correct answer to a problem is mentioned
When the time period of each activity was taken into consideration, an interesting different interaction pattern emerged from the two groups. The Independent Groups showed the same pattern, short mapping time (738.1 vs. 1245.5 s. of MinT) but long solution-discussion time (1270.4 vs. 984.8 s. of MinT) for both problems, while the Interdependent Groups showed the opposite pattern, long mapping time but short solution-discussion time in both problems. Looking ahead to the results, interdependence (extending divergence) showed better performance for the ill-structured problem while independence (immediate convergence to a solution) showed better performance for the well-structured problem.
Problem-solving performance (as human-rater measures of the essays)
Using the scoring rubrics from Shin et al (2003), three raters scored each post essay for correctness (0 ~ 5 point scale) and then reached a consensus score. A one-way MANOVA was conducted to determine the effect of type of collaboration (interdependent and independent) on problem-solving essay scores (well-structured and ill-structured). Preliminary assumption checking revealed that data was normally distributed, as assessed by Shapiro–Wilk test (p > .05); there were no univariate or multivariate outliers, as assessed by boxplot and Mahalanobis distance (p > .001), respectively; there were linear relationships, as assessed by scatterplot; no multicollinearity (r = .393, p = .002); and there was homogeneity of variance–covariance matrices, as assessed by Box’s M test (p = .003). The descriptive statistics of the scores are presented in Table 3.
The differences between the collaborations on the combined dependent variables were significant, F(3, 112) = 17.675, p < .001; Wilks’ Λ = .376; partial η2 = .387. Follow-up univariate ANOVAs showed that both will-structured problem-solving scores, F(2, 57) = 30.875, p < .001; partial η2 = .620, and ill-structured problem-solving scores, F(2, 57) = 14.295, p = .00; partial η2 = .594, were significantly different between collaborations, using a Bonferroni adjusted conservative α level of .025. Tukey post-hoc tests showed that independent participants had significantly higher mean scores than interdependent participants for the well-structured problem-solving, (d = 1.18, p < .001), while interdependent participants had significantly higher mean scores than independent participants for the ill-structured problem scores, (d = .82, p < .001).
Correlation of PFnet (based on raw proximity data)
Analysis within students, between tasks
To consider the influence of group collaboration on individual KS, we analyzed the correlation between each participant’s Pre map-to-Post essay and Group map-to-Post essay PFnets, a within-student between task analysis. It is expected that we can identify if group members have developed their KS (as posttest essays) due to the collaboration or not by comparing Pre map-to-Post essay PFnets and Group map-to-Post essay PFnets within the same participants. Each participant’s raw proximity data in a Pre map were compared by Pearson correlation (r) to those of the same participant’s Post essay (PreM-to-PostE), and each Group map’s raw proximity data were correlated to those of Group member’s Post essay (GroupM-to-Post essay). Then, these correlation r values were converted into Fisher z values (z) since correlation values are not interval-level data. These Fisher z values were averaged together to get PreM-to-PostE average Fisher z values and GroupM-to-PostE average Fisher z values. This within-student analysis was applied to all four treatments (see Table 4).
This data set shows that the Independent Group members’ Post essays had a strong relationship with their Pre maps (Range of average Fisher z = .65–.77, approximately 32–42% overlap) compared to the interdependent (d = 1.1, p < .001), but the PreM-to-PostE relationship was more pronounced with the ill-structured problem than the well-structured problem (d = .79, p = .01). Interestingly, the Interdependent Group members’ Post maps were more like the Group maps (Range of average Fisher z = .82–1.07, approximately 45–62% overlap) compared to the independent (d = .8, p < .001) but their GroupM-to-PostE relationship was larger in the ill-structured problem relative to the well-structured problem (d = .64, p = .01). This suggests that the Independent Group members paid less attention to their Group maps, their Post essays were more dependent on their Premaps and their initial unique knowledge, especially in the ill-structured problem-solving; whereas the interdependent members paid more attention to the Group map, so their Post essays were more dependent on their Group map and the group’s knowledge, especially for ill-structured problem-solving.
Analysis between students, within tasks (convergence)
Are Group maps more alike in the same condition? Are the post essays of Group members more related to each other? Here, the convergence is defined as the similarity of a group member’s KS to other members’ KS in the same condition, and is measured as average percent overlap in each condition (see Table 5). To obtain the average percent overlap, every students’ raw proximity data were correlated by Pearson correlation (r) to every other students within their condition and then the correlation r values were squared into coefficients of determination (r2).
Only Group map and Post essay convergence results are presented here due to our interest in collaboration and its effect on Post essays as a measure of what is learned during the tasks. This data set shows that the Interdependent Group maps are considerably more alike (i.e., homogenous Group maps) than are the Independent Group maps (d = .89, p < .001), but their higher peer-peer convergence was more pronounced with the ill-structured problem than the well-structured problem situation (d = .61, p < .001). For Post essays, the within-students between-tasks analysis reported above that the Group maps more strongly influenced the interdependent members’ Post essays, especially in the ill-structured problem-solving situation (see Table 4), and this trend was also observed for peer convergence in the Interdependent Groups’ Post essays. The interdependent members’ Post essays substantially overlap with each other (i.e., homogenous Post essays) relative to those of the independent members (d = 1.00, p = .00), and their Post essays’ peer-peer convergence was more evident in the ill-structured problem than the well-structured problem situation (d = .68, p = .00), i.e., the interdependent members had a strong KS convergence with their triad members compared to the independent triad members.
Although the Independent Group maps were less alike relative to the Interdependent Group maps, the Independent Group maps were significantly more like each other in the well-structured problem than in the ill-structured problem situation (d = .64, p = .00) and their Post essays were also more alike for the well-structured problem than for the ill-structured problem (d = .67, p = .01), i.e., the Independent Group members had a relatively strong KS convergence for the well-structured problem-solving than for the ill-structured problem-solving.
Similarity of all PFnets to the expert and the solution referents
Participants’ Premaps, Group maps, and Post essays are separately compared to the full expert map referent and to the solution submap referent. For that, the raw proximity data derived from all maps and essays were converted by KNOT into PFnets that were then compared to the referent PFnets.
Similarity to the expert referent
Analysis of the participants’ similarity to the expert referent was analyzed by a two-between, one-within repeated measures ANOVA with the between-subjects factors collaboration (interdependent and independent) and type of problem (well-structured and ill-structured), and the within subjects factor time (Premap, Group map, and Post essay PFnets). Means are shown in Table 6. There was one outlier assessed as a value greater than 3 box-lengths from the edge of the box. The similarity values were normally distributed (p > .05) except for one group (independent condition in the ill-structured problem at the Premaps), as assessed by Shapiro–Wilk’s test of normality. There was homogeneity of variances, as assessed by Levene's test for equality of variances (p > .05).
There was a significant three-way interaction between collaboration, problem type, and time, F(2, 54) = 6.101, p = .004, partial η2 = .184 (see the left panel of Fig. 5). Statistical significance was set at the p < .025 level for two-way interactions and simple main effects. There was a significant two-way interaction of collaboration and time for well-structured problem, F(2, 54) = 13.408, p < .001, partial η2 = .425, and for ill-structured problem, F(2, 54) = 7.406, p < .001, partial η2 = .598. There was a significant simple main effect of collaboration for well-structured problem at Pre maps, F(2, 54) = 7.406, p = .001, partial η2 = .135, and Group maps, F(2, 54) = 2.868, p = .005, partial η2 = .292, and Post essays, F(2, 54) = 12.94, p = .001, partial η2 = .199. There was a significant simple main effect of collaboration for ill-structured problem at Pre maps, F(2, 54) = 1.138, p = .018, partial η2 = .598, Group maps, F(2, 54) = 28.941, p < .001, partial η2 = .722, and Post essays, F(2, 54) = 15.44, p = .001, partial η2 = .446.

The two-way interaction of similarity to the Expert referent (left panel) and the Solution referent (right panel) over time for well-structured problem (solid lines) and ill-structured problem (dashed lines) for the interdependent and the independent treatments
All pairwise comparisons were examined for significant simple main effects. Bonferroni correction were made (for inflated Type I error) with comparisons within each simple main effect considered a family of comparisons. Adjusted p-values are reported. For Pre maps, as anticipated, the independent condition’s Premaps (whole mapped) were more like the full expert map compared to the interdependent condition’s Premaps (partial mapped) for the well-structured problem-solving [a mean difference of 0.212, 95% CI (.067, 0.417), p = .006, Cohen’s d = .67] and for the ill-structured problem-solving [a mean difference of .256, 95% CI (.131, .261), p < .001, Cohen’s d = .71]. For Group maps, the interdependent condition’s Group maps were more like the full expert map compared to the independent condition’s Group maps for the well-structured problem-solving [a mean difference of .176, 95% CI (.031, .201), p < .001, Cohen’s d = .77] and for the ill-structured problem-solving [a mean difference of .186, 95% CI (.031, .161), p < .001, Cohen’s d = .66]. For Post essays, the interdependent condition’s Post essays were more like the full expert maps than the independent Post essays for the ill-structured problem-solving [a mean difference of .135, 95% CI (.031, .161), p < .001, Cohen’s d = .59] and for the well-structured problem-solving [a mean difference of .131, 95% CI (.009, .255), p = .01, Cohen’s d = .60]. Note that the independent members Post essays were more like the full expert map in the ill-structured problem than in the well-structured problem. This can be explained by their correlate values, reporting the strong relationship between Pre map and Post essays in the ill-structured problem than in the well-structured problem. It could be reasonable to assume that they might bring forward their full expert map-like Pre map knowledge, including both solution relevant and irrelevant information, to their Post essays to address the ill-structured problem.
Similarity to the solution referent
Analysis of the participants’ similarity to the solution referent was analyzed by a two-between, one-within repeated measures ANOVA with the between-subjects factors collaboration (interdependent and independent) and type of problem (well-structured and ill-structured), and the within subjects factor time (Premap, Group map, and Post essay PFnets). The similarity values were normally distributed, as assessed by Shapiro–Wilk’s test (p > .05), and there were no outliers in the data, as assessed by inspection of a boxplot. There was homogeneity of variances (p = .05), as assessed by Levene’s test for equality of variances.
There was a statistically significant three-way interaction between collaboration, problem type, and time, F(2, 60) = 7.406, p = .001, partial η2 = .236 (see the right panel of Fig. 5). Statistical significance was accepted at the p < .025 level for two-way interactions and simple main effects. There was a significant two-way interaction of collaboration and time for the well-structured problem-solving, F(2, 60) = 5.252, p = .008, partial η2 = .298, and for the ill-structured problem-solving, F(2, 60) = 2.868, p = .065, partial η2 = .117. There was a statistically significant simple main effect of collaboration for the well-structured problem-solving at Premaps, F(2, 60) = 14.766, p < .001, Group maps, F(2, 60) = 62.96, p < .001, partial η2 = .708, and Post essays, F(2, 60) = .660, p = .521, partial η2 = .220. There was a statistically significant simple main effect of collaboration for the ill-structured problem-solving at Pre map, F(2, 60) = 1.191, p = .013, partial η2 = .518, Group maps, F(2, 60) = 4.128, p = .003, partial η2 = .292, and Post essays, F(2, 60) = 132.493, p < .0005, partial η2 = .836 (see Table 6).
As did in the comparison with the expert referent, all pairwise comparisons were run for significant simple main effects. Bonferroni correction were made (for inflated Type I error) with comparisons within each simple main effect considered a family of comparisons. Adjusted p-values are reported. For Pre maps, as expected, the independent condition’s Premaps (whole mapped) were more like the solution map compared to the interdependent condition’s Premaps (partial mapped) for the well-structured problem-solving [a mean difference of .231, 95% CI (.107, .391), p = .001, Cohen’s d = .66] and for the ill-structured problem-solving [a mean difference of .176, 95% CI (.033, .461), p < .001, Cohen’s d = .61]. For Group maps, the independent condition’s Group maps were far more like the solution map compared to the interdependent condition’s Group maps for the well-structured problem-solving [a mean difference of .155, 95% CI (.011, .463), p < .001, Cohen’s d = .97] and for the ill-structured problem-solving [a mean difference of .099, 95% CI (.008, .303], p < .001, Cohen’s d = .63]. For Post essays, the independent condition’s Post essays were more like the solution maps than the interdependent Post essays for the ill-structured problem-solving [a mean difference of .075, 95% CI (.011, .301), p = .01, Cohen’s d = .68] and for the well-structured problem-solving [a mean difference of 0.055, 95% CI (.019, .425], p = .005, Cohen’s d = .52].
Discussion
This experimental investigation seeks to confirm and extend an aspect of problem-solving in groups, resource interdependence vs. independence, during both well-structured and ill-structured problem-solving. Resource interdependence had a profound influence on individual performance on the post essays rater scores that was mediated by the triad task processes, as measured by the analysis of video recordings and by the pieces of knowledge structure flow at Pre map, to group map, and to Post essay. Specifically, independent triads substantially outscored the interdependent triads on the Posttest-essay rater scores for the well-structured problem, M = 7.2 > 5.5, Cohen d = 1.18, p < .001; while the interdependent triads outscored the independent triads on the Posttest-essay rater scores for the ill-structured problem, M = 6.7 > 6.1, Cohen d = .82, p < .001, this is the disordinal interaction anticipated by Clariana et al. (2013).
Analysis of the process data (video recording) almost exactly matched that reported by Engelmann and Hesse (2010), compare Figs. 1, 2, 3, 4. Specifically, the independent triads on average spent less time adding information to the map but more time establishing the solution (e.g., less divergence, more convergence) for both well- and ill-structured problems, while the interdependent triads on average spent more time adding information to the map but less time establishing the solution (i.e., more divergence, less convergence) for both well- and ill-structured problems. This means that the Independent Group members decided to quickly move to the solution phase, perhaps because each member believed that they had all the information they needed, while the Interdependent Groups extended the time spent in elaborating the problem content space.
As proposed by Clariana et al. (2013), information adequacy that includes both extent of knowledge (quantity) and form (quality, as structure specificity) may be a distinguishing difference for successfully solving well-structured and ill-structured problem. These results provide evidence that resource independence engenders convergence that is relatively better and more efficient for well-structured problem-solving where all members have adequate information, while resource interdependence engenders divergence that is relatively better but less efficient for ill-structured problem-solving.
Analysis of similarity to the Expert and Solution referent maps for both well- and ill-structured problems aligns with the problem-solving process data. It shows that the interdependent triads’ Group maps and Post essays for both well- and ill-structured problems were more like the full expert map, containing both solution relevant and irrelevant information (see Table 6). In contrast, the independent triads’ Group maps and Post essays for both well- and ill-structured problems were similar to the Solution map, containing mostly solution relevant information (see Table 6). Therefore, the interdependent members had an advantage of having both solution-relevant and solution-irrelevant information for solving the ill-structured problem, while the independent members only had an advantage of more quickly focusing on solution-relevant information for solving the well-structured problem.
Knowledge structure analysis comparing Pre map to Group map to Post essays (see Table 4) indicates that the independent triads post essays were more like their Pre maps (Fisher z = .65 and .77, showing little change from pre to post) while the interdependent triads’ post essays were more like their group maps (Fisher z = .82 and 1.07, indicating a strong influence of the group map on the post essay). These results confirm and extend the previous findings of Asino et al. (2012). In addition, the interdependent Post essays were more like their peers’ Post essays, with 61% and 69% overlap compared to 40% and 33% for the Independent Group (see Table 5). Resource interdependence increased peer-peer within group convergence.
On the other hand, the independent Post essays were quite like their own initial Pre maps (see Table 4) but were only moderately like their Group’s map and moderately like their Peer’s post essays, indicating that the group activity did influence their Post essays but it was relatively less than for the interdependent triad members. Overall, when members work together on a problem, their KS within triad and within treatment converges to be more like that of the other participants but convergence is larger under resource interdependence conditions.
The self-correlations indicate different strategies in problem-solving between the two conditions, as expected, resource interdependence engenders group knowledge-oriented problem-solving. Most of the content in the interdependent Post essays came exclusively from their fully explicated group map (see Table 4) and thus extended divergence benefited ill-structured problem-solving (see Table 3). However, triad members in the independent condition tended to rely on their own initial understanding and somewhat disregarded “group knowledge”. A tendency to trust your own understanding of a problem and solution over that of your team may be normal for transient group members working together. McLeod (2015) notes that such trust is risky, but can be compelled by contextual constraints such as resource interdependence. This then raises a question, is merely the perception of interdependence important? To consider this, a future investigation could extend this current investigation by assigning participants to small groups and providing everyone with the same information, then to establish the perception of resource interdependence, half of the groups would be falsely told that each individual in the team has unique important information not given to the others in the group. We predict that the perception of resource interdependence would relatively extend the divergence stage of the task in the same way as actual resource interdependence does.
In sum, the results of the current investigation show a disordinal interaction between type of collaboration and type of problem, here interdependence is better for ill-structured problem-solving while independence is better for well-structured problem-solving. Problem-solving skills used for well-structured problems are necessary but not sufficient for ill-structured problem-solving (Jonassen, 1997; Reed, 2016). For example, Reed (2016) stated that the most distinctive cognitive difference between ill-structured and well-structured problem-solving is the ability to justify a solution, because ill-structured problems usually have divergent or multiple alternative solutions. But that presumes that students have established an adequate problem space, and this seems unlikely if divergence is short circuited in a rush to a solution. In order to comprehend the complexity of the ill-structured problem, he suggested that ill-structured problem solvers must perceive and reconcile many various perspectives, views, and interpretations on the problem; which by itself is a daunting task.
Similarly, Jacobson (1991) argued that “It is only through the use of multiple schemata, concepts, and thematic perspectives that the multi-faceted nature of the content area can be represented and appreciated” (p 21). So rather than constructing a single problem space, the construction of a richly complex problem space may benefit ill-structured problem-solving (Reed, 2016).
Implications for practice
Note that transient collaborating groups typical in educational settings are fundamentally different from high performing teams in real-world settings (Engelmann et al., 2014). High performing teams are the basic functional unit of how most projects are organized and managed within organizations worldwide (Daniel, 2015) and these group are fundamentally different than the transient groups formed in school-age formal and informal settings. Thus, although the results observed in this present investigation likely do not apply to high-performing teams, nevertheless, the results should generalize to problem solving group tasks in real school settings.
The results indicate that extending divergence time leads to a fuller problem representation that is better for ill-structured problem-solving, while in contrast, a focused problem–solution representation is ok for well-structured problem-solving. Thus in the classroom, an instructor can explain divergent and convergent thinking and then divide a problem-solving task into two group artifacts, the problem space and the solution space, and then provide an adequate amount of class time for each phase. Further, assigning only well-structured problems in class over time will tend to reward and reinforce convergent thinking but discount divergent thinking, thus, students will practice over and over only one phase of problem solving. So to better develop students’ problem-solving ability, instructors should use a mix of easier and tougher well-structured problems, as well as ill-structured problems. Developing problem-solving skills provides a basis for learning, but more importantly, prepares students for a world where change is a constant and learning never stops.
References
Asino, T., Clariana, R. B., Dong, Y., Groff, B., Ntshalintshali, G., Taricani, E., Techatassanasoontorn, C., & Yu, W. (2012). The effect of Independent and Interdependent Group collaboration on knowledge extent, knowledge form and knowledge convergence. convergence. Proceedings of Selected Research and Development Papers Presented at the National Convention of the Association for Educational Communications and Technology, 35, 20–29 (Louisville, November 2012).
Barb, A. S., & Clariana, R. B. (2013). Applications of PathFinder Network scaling for improving the ranking of satellite images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 6(3), 1092–1099. https://doi.org/10.1109/JSTARS.2013.2242254
Barber, S. J., Harris, C. B., & Rajaram, S. (2015). Why two heads apart are better than two heads together: Multiple mechanisms underlie the collaborative inhibition effect in memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41(2), 559.
Biasutti, M., & Frate, S. (2018). Group metacognition in online collaborative learning: Validity and reliability of the group metacognition scale (GMS). Educational Technology Research and Development, 66(6), 1321–1338.
Buchs, C., Dumesnil, A., Chanal, J., & Butera, F. (2021). Dual effects of partner’s competence: Resource interdependence in cooperative learning at elementary school. Education Sciences, 11, 210–226. https://doi.org/10.3390/educsci11050210
Churchman, C. W. (1967). Wicked problems. Management Science, 14, 141–146.
Clariana, R. B., Engelmann, T., & Yu, W. (2013). Using centrality of concept maps as a measure of problem space states in computer-supported collaborative problem solving. Educational Technology Research and Development, 61(3), 423–442. https://doi.org/10.1007/s11423-013-9293-6
Clariana, R. B., Wolfe, M. B., & Kim, K. (2014). The influence of narrative and expository lesson text structures on knowledge structures: Alternate measures of knowledge structure. Educational Technology Research and Development, 62(5), 601–616. https://doi.org/10.1007/s11423-014-9348-3
Congleton, A. R., & Rajaram, S. (2011). The influence of learning methods on collaboration: Prior repeated retrieval enhances retrieval organization, abolished collaborative inhibition, and promotes post-collaborative memory. Journal of Experimental Psychology: General, 140, 535–551. https://doi.org/10.1037/a0024308
Coronges, K. A., Stacy, A. W., & Valente, T. W. (2007). Structural comparison of cognitive associative networks in two populations. Journal of Applied Social Psychology, 37(9), 2097–2129. https://doi.org/10.1111/j.1559-1816.2007.00253.x
Cropley, A. (2006). In praise of convergent thinking. Creativity Research Journal, 18, 391–404. https://doi.org/10.1207/s15326934crj1803_13
Cukurova, M., Luckin, R., Millán, E., & Mavrikis, M. (2018). The NISPI framework: Analysing collaborative problem-solving from students' physical interactions. Computers & Education, 116, 93-109.
Daniel, T. (2015). Developing and sustaining high-performance work teams. Retrieved November, 30, 2015.
Draper, D. C. (2013). The instructional effects of knowledge-based community of practice learning environment on student achievement and knowledge convergence. Performance Improvement Quarterly, 25(4), 67–89. https://doi.org/10.1002/piq.21132
Engelmann, T., & Hesse, F. W. (2010). How digital concept maps about the collaborators’ knowledge and information influence computer-supported collaborative problem solving. International Journal of Computer-Supported Collaborative Learning, 5(3), 299–319.
Engelmann, T., Kozlov, M. D., Kolodziej, R., & Clariana, R. B. (2014). Computers in Human Behavior Fostering group norm development and orientation while creating awareness contents for improving net-based collaborative problem solving. Computers in Human Behavior, 37, 298–306. https://doi.org/10.1016/j.chb.2014.04.052
English, D., & Branaghan, R. (2012). An empirically derived taxonomy of pilot violation behavior. Safety Science. http://www.sciencedirect.com/science/article/pii/S0925753511001809
Fesel, S. S., Segers, E., Clariana, R. B., & Verhoeven, L. (2015). Quality of children’s knowledge representations in digital text comprehension: Evidence from pathfinder networks. Computers in Human Behavior, 48, 135–146. https://doi.org/10.1016/j.chb.2015.01.014
Graesser, A. C., Greiff, S., Stadler, M., & Shubeck, K. T. (2020). Collaboration in the 21st century: The theory, assessment, and teaching of collaborative problem solving. Computers in Human Behavior.
Guilford, J. P. (1959). Traits of creativity. In H. H. Anderson (Ed.), Creativity and its Cultivation (pp. 142–161). Harper.
Hung, W., Dolmans, D. H. J. M., & Van Merriënboer, J. J. G. (2019). A review to identify key perspectives in PBL meta-analyses and reviews: Trends, gaps and future research directions. Advances in Health Sciences Education, 24(5), 943–957.
Jaarsveld, S., & Lachmann, T. (2017). Intelligence and creativity in problem solving: The importance of test features in cognition research. Frontiers in Psychology, 8, 134–145.
Jacobson, M. J. (1991). Knowledge acquisition, cognitive flexibility, and the instructional applications of hypertext: A comparison of contrasting designs for computer-enhanced learning environments. University of Illinois at Urbana-Champaign.
Jonassen, D. H. (1997). Instructional design models for well-structured and III-structured problem-solving learning outcomes. Educational Technology Research and Development, 45(1), 65–94.
Jonassen, D. H. (2010). Research issues in problem solving. 11th International Conference on Education Research.
Kim, K., & Clariana, R. B. (2015). Knowledge structure measures of reader’s situation models across languages: Translation engenders richer structure. Technology, Knowledge and Learning, 20(2), 249–268.
Kim, K. (2017a). Visualizing first and second language interactions in science reading: A knowledge structure network approach. Language Assessment Quarterly, 14, 328–345.
Kim, K. (2017b). Graphical interface of knowledge structure: A web-based research tool for representing knowledge structure in text. Technology Knowledge and Learning, 24, 89–95.
Kim, K., Clarianay, R. B., & Kim, Y. (2019). Automatic representation of knowledge structure: Enhancing learning through knowledge structure reflection in an online course. Educational Technology Research and Development, 67, 105–122.
Kim, K., & Tawfik, A. A. (2021). Different approaches to collaborative problem solving between successful versus less successful problem solvers: Tracking changes of knowledge structure. Journal of Research on Technology in Education, https://doi.org/10.1080/15391523.2021.2014374
Kim, M. K. (2012). Cross-validation study of methods and technologies to assess mental models in a complex problem solving situation. Computers in Human Behavior, 28(2), 703–717. https://doi.org/10.1016/j.chb.2011.11.018
Kim, M. K., & McCarthy, K. S. (2021). Using graph centrality as a global index to assess students’ mental model structure development during summary writing. Educational Technology Research and Development, 69(2), 971–1002.
Laal, M. (2013). Positive interdependence in collaborative learning. Procedia-Social and Behavioral Sciences, 93, 1433–1437.
Lu, L., Yuan, Y. C., & McLeod, P. L. (2012). Twenty-five years of hidden profiles in group decision making: A meta-analysis. Personality and Social Psychology Review, 16(1), 54–75.
Maker, C. J. (2020). Identifying exceptional talent in science, technology, engineering, and mathematics: Increasing diversity and assessing creative problem-solving. Journal of Advanced Academics, 31(3), 161–210.
Marion, S. B., & Thorley, C. (2016). A meta-analytic review of collaborative inhibition and postcollaborative memory: Testing the predictions of the retrieval strategy disruption hypothesis. Psychological Bulletin, 142(11), 1141.
Matthews, R. S., Cooper, J. L., Davidson, N., & Hawkes, P. (1995). Building bridges between cooperative and collaborative learning. Change: the Magazine of Higher Learning, 27(4), 35–40. https://doi.org/10.1080/00091383.1995.9936435
McLeod,, C. (2015). Trust. In E. N. Zalta (Ed.). The Stanford encyclopedia of philosophy (Fall 2015 Edition). https://plato.stanford.edu/archives/fall2015/entries/trust/
Nokes-Malach, T. J., Richey, J. E., & Gadgil, S. (2015). When is it better to learn together? Insights from research on collaborative learning. Educational Psychology Review, 27(4), 645–656.
O’Donnell, A. M., & Hmelo-Silver, C. E. (2013). Introduction: What is collaborative learning?: An overview. In The International Handbook of Collaborative Learning (pp. 1–15). Taylor and Francis. https://doi.org/10.4324/9780203837290-6
Patil, K., & Brazdil, P. (2007). Text summarization: Using centrality in the pathfinder network. International Journal of Computer Science & Information Systems, 2, 18–32.
Popper, K. (2013). All life is problem solivng. Routledge.
Reed, S. K. (2016). The structure of ill-structured (and well-structured) problems revisited. Educational Psychology Review, 28(4), 691–716.
Reiser, B. J. (2015). Scaffolding complex learning: The mechanisms of structuring and problematizing student work. The Journal of the Learning Sciences, 13(3), 273–304.
Sarwar, G. (2011). Structural assessment of knowledge for misconceptions: Effectiveness of structural feedback provided by pathfinder networks in the domain of physics. Kolln, Germany: LAP Lambert Academic Publishing. https://scholar.google.com/scholar?q=Structural+assessment+of+knowledge+for+misconceptions%3A+Effectiveness+of+structural+feedback+provided+by+pathfinder+networks+in+the+domain+of+physics&btnG=&hl=en&as_sdt=0%2C39#0
Shin, N., Jonassen, D. H., & McGee, S. (2003). Predictors of well-structured and ill-structured problem solving in an astronomy simulation. Journal of Research in Science Teaching, 40(1), 6–33.
Stasser, G., & Titus, W. (1985). Pooling of unshared information in group decision making: Biased information sampling during discussion. Journal of Personality and Social Psychology, 48(6), 1467.
Tossell, C., Schvaneveldt, R., & Branaghan, R. (2010). RESEARCH ARTICLES-targeting knowledge structures: A new method to elicit the relatedness of concepts. Cognitive Technology, 15(2), 11.
Trumpower, D. L., & Sarwar, G. S. (2010). Effectiveness of structural feedback provided by pathfinder networks. Journal of Educational Computing Research, 43(1), 7–24. https://doi.org/10.2190/EC.43.1.b
Trumpower, D. L., Sharara, H., & Goldsmith, T. E. (2010). Specificity of structural assessment of knowledge. Journal of Technology, Learning, and Assessment, 8(5), n5.
Tutty, J. I., & Klein, J. D. (2008). Computer-mediated instruction: A comparison of online and face-to-face collaboration. Educational Technology Research and Development, 56(2), 101–124.
Yoo, S. (2020). The effects of expertise diversity and task interdependence on project team effectiveness: The moderating role of individual autonomy [Doctoral dissertation, University of Minnesota]. University Digital Conservancy Home persistent link https://hdl.handle.net/11299/216356.
Funding
National Science Foundation Award 2215807, PI: Roy B. Clariana.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kim, K., Clariana, R.B. The influence of resource interdependence during problem solving in groups: tracking changes in knowledge structure. Education Tech Research Dev 71, 833–857 (2023). https://doi.org/10.1007/s11423-023-10206-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11423-023-10206-3