
Abstract
Interactive features of the hyper-video environment, such as indexing, bookmarks, links to learning materials, multiple-choice questions, and personal and shared annotations, can enhance learning processes. This paper examines integration of the Annoto hyper-video platform in three large undergraduate courses (A, B & C) at a large university. The study combines learning analytics of video-recordings of synchronous lessons (9–15 sessions per course, approximately two hours each), content analysis of the hyper-video annotations written by students and lecturers, and semi-structured interviews with the lecturers and with actively-participating students. The log-analysis was conducted at the user level (n = 880) and at the video level (n = 37). Content analysis was based on the Community of Inquiry framework (Garrison et al. in Internet High Educ 2(2):87–105, 1999, Internet High Educ 13(1):5–9, 2010). The findings revealed that when hyper-video is integrated without academic credit, slightly over 10% of undergraduates chose active participation, beyond watching videos and reading others' annotations. The majority of annotations were shared posts and replies (73–96%), rather than personal notes. Relative to the number of students, the rate of reading annotations was significantly higher in Course C. Accordingly, content analysis revealed significantly more "cognitive presence" and "social presence" codes in Course C, while the amount of "teaching presence" was similar in all courses. However, the three courses used the same interaction pattern of annotations: "student's question—lecturer's answer", without promoting peer feedback. The implications for educational theory and the pedagogical design of hyper-video in academia are discussed.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
One of the technologies that is gaining momentum in higher education and in vocational training is hyper-video. The term "hyper-video" refers to non-linear video, which offers, beyond standard video control options (e.g. play, pause, stop, rewind/fast-forward buttons), includng index, summary, and attachments or links to external resources (Cattaneo et al., 2016). Hyper-video also enables users to receive feedback from the system through answers to multiple-choice questions and writing annotations related to the video content.
Hyper-video annotations are personal notes or interactions with a lecturer and with peers via shared posts and replies (Blau et al., 2018; Sauli et al., 2018). Note that interactions and reflections through hyper-video annotations are essentially different from commenting in discussion groups or pen-and-paper note-taking in asynchronous learning literature, since annotating is conducted during, rather than after studying while watching video-recordings, thus making the learning process active.
This study aims to explore the pedagogical potential of hyper-video for promoting active learning and the actual integration of this innovative technology in academia. The following literature review first discusses the affordances of hyper-video and the realization of its potential for teaching and learning. Following that, we describe a well-established framework in the asynchronous learning literature—the Community of Inquiry Framework—and discuss its appropriateness for the analysis of hyper-video annotations.
Literature review
Empirical findings regarding the impact of hyper-video on learning are still scarce and inconclusive (for review, see: Sauli et al., 2018). For instance, hyper-video annotations were used for developing reflection and teaching practices among in-service teachers in early career stages (McFadden et al., 2014). Despite the potential of the tool, findings showed that the teachers’ annotations were mostly shallow, including explanations and descriptions, and focused on basic levels of thinking and reflection. In contrast, Cattaneo et al. (2016) reported that while integrating hyper-video in vocational training, teachers and students alike expressed their satisfaction with the technology’s affordances, enabling them to make abstract content concrete, to focus their attention, to link theory and practice, to increase learning motivation, and to support their reflection and analysis skills. Based on these promising preliminary findings, the authors emphasized the need for further investigation of the conditions supporting the realization of hyper-video's potential for teaching and learning. Moreover, Mu (2010) found that in a controlled eye-tracking experiment, which compared note-taking behaviors in video-learning with and without hyper-video annotations, participants with hyper-video annotations took fewer notes and focused more on video content. The author argued that the main benefit of hyper-video annotations is that it may decrease non-learning related cognitive load.
Hyper-video is known as "interactive video", as it allows different forms of interactions (Beauchamp & Kennewell, 2008, 2010): (1) interaction with learning materials and (2) a medium through which interactions are conducted with other users. Social constructivism (Vygotsky, 1978) describes the advantages of learning through social interactions beyond personal learning through the term "Zone of Proximal Development" (ZPD). According to this approach, interactions with a teacher or with peers who are more advanced on a learning topic, enables a student to progress to the next level of development within his/her ZPD, beyond the level the student could reach through personal learning. In the context of hyper-video learning, interacting with a lecturer and peers through posts and replies connected to specific video-content, as well as reflecting on the video-content by writing personal notes, can scaffold the learning process and advance learners within their ZPD. Accordingly, previous research (Pardo et al., 2015) has demonstrated positive relationships between writing hyper-video posts/replies and students' mid-term exam scores. However, Pardo et al. examined active versus passive participation as a dichotomous variable, regardless of the amount of written annotations or their quality.
One of the well-established models for analyzing learning interactions in academia is the Community of Inquiry Framework (CoI; Garrison et al., 1999, 2010). This framework analyzes interactions in discussion groups and divides them into three broad categories: cognitive, teaching, and social presence. Cognitive presence (CP) refers to the extent to which the participants in a CoI are able to construct meaning and reach understanding through sustained communication. CP includes a hierarchy of four categories, with learners able to be engaged simultaneously at multiple levels. This begins with a triggering event that allows the learner to understand a problem or ask a question. The exploration category refers to the exchange of information and discussion of unclear issues. The process ends with the integration category, in which ideas are combined and the resolution category, in which a solution to the problem is found. Teaching presence (TP) refers to the design of educational experiences and their facilitation, which are not limited to the lecturer's activities but can be also implemented by students. TP consists of the design, facilitation and direction of the learning process. TP also includes the category of instructional management, referring to the pedagogical design and planning of discussion topics. Building understanding involves sharing personal meaning and values, expressing consensus, or aspiring to reach agreement. Furthermore, TP includes the sub-category of direct instruction, which is expressed in focusing the discussion, providing answers to questions, diagnosing errors and summarizing topics. Finally, social presence (SP) refers to the learners’ ability to project their personal characteristics into the community and present themselves to others as "real people.'' SP consists of the categories such as emotional expression (the use of emoticons, humor and self-disclosure, open communication), interactive answers that include questions, responses to others' messages, and references to the content written by others. A group cohesion category includes sharing emotions, using social expressions (e.g., "hi", "thanks", "hopefully this helps"), referring to others by their name, and using expressions that emphasize a sense of belonging to the group (e.g., "we", "our course"). Beyond the categories described in the CoI model, in the context of hyper-video, emotional responses of appreciating others’ writings can appear by adding "votes" (likes) to comments or replies (Blau et al., 2018).
Unlike discussion groups in academic courses, which contain exclusively shared comments and replies (i.e., everything written there can be seen by others), hyper-video annotations can be expressed as both shared writings and personal notes. These personal notes are parallel to a note-taking strategy in traditional learning. By writing personal notes, students can use hyper-video as a medium for reflection on the learning content or process and externalization of their knowledge or insights. Thus, writing personal notes in hyper-video cannot be attributed to Beauchamp and Kennewell’s (2008) categorization of either interaction with instructional content or a medium for interacting with the lecturer and/or peers through shared writing. It presents an additional type of interactivity, in which technology serves as a medium for personal reflections and externalization of knowledge/thoughts.
In contrast to automatically-generated annotations (Imran et al., 2016), student annotations in a hyper-video environment may transform the learning process from the passive viewing of video content or recorded lessons into an active learning process (Blau et al., 2018; Sauli et al., 2018). Despite the contribution of active participation to the quality of learning, most users in different digital environments are lurkers who regularly log in, but seldom post, and seem to be satisfied with such passive participation (Sun et al., 2014). Passive participation in hyper-video refers to viewing videos or reading the posts and replies of others, without producing videos or writing themselves (Sauli et al., 2018).
Based on the CoI model presented above, previous research (Gorsky & Blau, 2009) has retroactively compared the active and passive participation of graduate students in two discussion groups studying in the same course in the same semester. Incidentally, the lecturer who moderated one group received a very high student rating at the end of the semester, whereas the lecturer who moderated the second group received a very low student rating. Coding the course posts revealed that at the beginning of the semester, no significant differences were found in the number of posts and replies published by the two lecturers, and accordingly, no differences were found in the number of student readings and posts. During the semester, differences developed in the active participation of the two lecturers, and accordingly, the gap in the number of students' readings and posts between the two groups increased. When the lecturers’ messages were coded based on the CoI model, it became clear that the highly rated lecturer posted significantly more teaching and social messages. However, there were no differences between the lecturers in cognitive presence posts, except for the basic category of a triggering event. Namely, the highly rated lecturer encouraged the beginning of the thinking process, but did not conducted the exploration phase instead of the students and did not provide answers containing content integration or solutions.
Note that the data from Gorsky and Blau (2009) relate to interactions in the discussion groups with very high percentages of social presence codes—44.3% in the forum of the lecturer who received negative ratings and 64.3% in the forum of the lecturer who received positive ratings. It is reasonable to assume that, unlike in discussion groups, interactions in hyper-video are mainly content-related and less social by nature. This is despite the potential of hyper-video in allowing interactions, expressing and exchanging views, and receiving feedback, which is similar to forums (Colasante, 2011; Hulsman & van der Vloodt, 2015; Zahn et al., 2010). For instance, in contrast to forums, in hyper-video there is less place for self-disclosure, expression of emotions, and group cohesion, but rather the focus is on asking questions related to a specific point of time in the video. Therefore, we assume that hyper-video will contain mainly CP and TP with a minimum amount of SP that is necessary.
Study goals and questions
As mentioned above, the pedagogical potential of hyper-video is different from that of discussion groups or pen-and-paper note-taking in more traditional asynchronous learning. However, very few studies have investigated how the instructional potential of hyper-video is realized (Cattaneo et al., 2016; Sauli et al., 2018), especially in higher education. Moreover, studies discussed in the literature above that explored learning or training with hyper-video generally used learning analytics or an interview-based methodology. In addition to this, we aimed to triangulate participation data from learning analytics with content analysis of hyper-video annotations. For this purpose, we mapped shared annotations based on various types of presence, as defined by the CoI Framework (Garrison et al., 1999, 2010). Content analysis of the posts in hyper-video environments based on the CoI framework can add to the research literature by providing important theoretically grounded insights regarding the behavioral patterns of active participation through writing annotations, beyond log analysis or self-report data.
Thus, the aim of this study was to explore the patterns of active versus passive participation in hyper-video environments in academia. For active participation, the study compared shared and private hyper-video annotations and explored pedagogical design aimed at promoting active participation. Consequently, the research questions were: (1) What patterns of active and passive participation can be identified among students in hyper-video environments and what role do lecturers play in this process? (2) Are there any differences between active shared (posts-and-replies) and private participation patterns (personal-notes)? (3) What are the characteristics of instructional design aimed to promote annotating (i.e., active participation) in hyper-video environments? (4) What is the nature of shared annotations in terms of cognitive, teaching and social presence (based on the CoI model; Garrison et al., 1999, 2010)?
Method
Participants and context
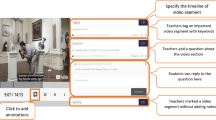
The study included courses participating in a pilot implementation of the integration of Annoto hyper-video technology conducted by a large Israeli university. An illustration of the Annoto interface can be seen in Fig. 1 (the in English text on this figure is an illustration not related to this study, in which the annotations were written in Hebrew). This technology enables students to add bookmarks to video content, as well as writing shared posts/replies and personal notes. An example of annotations (translation from our study data) are: Comment-Student 1: "Is it possible to compare these studies according to the research instruments appropriate for each of them? Or there is no connection between the type of research [quantitative/qualitative] and the tools used [interviews/observations]?”; Reply-Student 2: "Hello! The types of research do not differ in the research tools. In each research paradigm, similar tools can be used (interviews, observations). Different research questions require different methodology."

Illustration of video recording with annotations. The bars under the timeline of the video show the annotations. The high bars are time-points with multiple annotations. Clicking on a bar opens the text window on the right side showing the annotations of that bar, as well as annotations' writers and related icons
The Annoto system was integrated into the university course websites as part of the University's Center for the Integration of Technologies in Distance Learning’s initiative, to encourage active learning in the video environment. Importantly, the hyper-video activity was incorporated in all the courses as a non-accredited option. The researchers were not involved in choosing the courses for the pilot or in the design of hyper-video activities. The lecturers of the courses volunteered to participate in the pilot because of their interest in exploring the potential of this technology to enhance learning.
The pilot was carried out in the spring of 2017 in four courses, including three large undergraduate courses with 800–1500 students each, and one small graduate course with approximately 30 students. This study focuses on the three undergraduate courses—courses A, B and C, including a course in exact sciences (A) and two courses in social sciences (B & C). The courses under investigation belong to different programs and do not share the same undergraduate students. The graduate course was excluded from the analysis due to major differences in both the pedagogical design and the number of students enrolled.
Synchronous lessons were recorded and the video-recordings with hyper-video annotations were later available to all students of these courses– including those who did and did not participate in the lesson. When watching the recorded videos, the participants could add shared annotations or/and private notes, as well as replying to others. Note that hyper-video was not integrated into Massive Open Online Courses (MOOCs), but rather into standard academic courses, which do not contain learning content in video format. All of the lessons in the studied courses were synchronous and conducted through Zoom videoconferencing technology. Zoom enables natural and spontaneous two-way video-and-oral communication between the lecturer and students (Blau et al., 2017, 2020; Weiser et al., 2018). The number of such synchronous lessons in the courses investigated in the study ranged between 9 and 15, with each lesson lasting from two to two and a half hours. The lessons were recorded and fully accessible to students, and were segmented into short topics by hyper-video bookmarks.
Instruments and procedure
The study used a mixed-method methodology, combining the learning analytics of the participants' behavior in the hyper-video environment, content analysis of the video annotations, and semi-structured interviews with the lecturers and active students. Table 1 summarizes the learning analytics of the participants' behavior during the semester. It represents the following three categories of logs: users' activities, active participation through writing of shared posts/replies or personal notes, and passive participation through watching videos or reading posts/replies/notes (Blau & Hameiri, 2012, 2017). Only the parameters of passive participation, offered by the Annoto team towards the end of the semester and were not available earlier to students, are reported in Table 1 for the last month of the semester.
The parameters analyzed in this study were at the individual user level (Table 2) and at the video-recording level (Table 3). "Votes" parameter in Table 2 is a visual feedback, which refers to the number of like-emoticons provided by users in response to others’ annotations. To avoid social pleasing, users could see the number of votes of each annotation, but not the number of votes provided/received by specific users.
All the parameters in Table 2 and most of the parameters in Table 3, except for lecturer's posts and replies, lecturer's replies only, and the number of students who write openly, were not normally distributed. Therefore, the differences between the courses were analyzed in the “Results” section using a-parametric statistics.
Quantitative content analysis of the annotations was conducted based on the CoI framework (Garrison et al., 1999, 2010) according to the sub-categories of cognitive, social and teaching presences described in the literature review above. After the end of the semester, the Annoto team anonymously extracted comments and transferred them to the authors for analysis. Rather than analyzing an average representative lecture in each course, the most interactive lecture of each course representing its best practice in terms of interactivity was chosen for the content analysis. In total, six hours of video-recording were analyzed. All of these lessons were conducted at the same period of time—after mid-semester, and lasted an average of two hours and 24 min. A rater trained by the researchers performed the coding. To assess the inter-rater reliability, 30% of the messages were independently coded by another rater, Cohen's kappa was κ = 0.88 indicating a high level of inter-rater agreement.
In addition, semi-structured interviews were conducted with lecturers from each of the courses investigated in the study and with two of the most active students. The purpose of the interviews was to shed light on the perspectives of the lecturers regarding appropriate pedagogical design for integrating hyper-video in academic courses and the perspectives of students regarding the benefits of active participation in the hyper-video environment. Examples of the interview questions for lecturers are: "Did the integration of the Annoto hyper-video contribute to learning processes in the course, and how? If it did not contribute, why?" "In your opinion, what skills did the system develop among students?" The interview questions particularly emphasized ways of increasing active learning and explored the differences between writing shared posts and personal notes, for example: "Did you reply to students’ comments through Annoto and/or did the students reply to each other? Did you encourage students to reply to each other and if so, how?" "The system allows students to write/share comments and replies, as well as personal-notes. What are the advantages and disadvantages of each type of writing? Do you favor one of the annotation types and why?" Examples of the interview questions for students are: "What made you actively participate in the Annoto environment? Did the use of Annoto contribute to your learning during the course and how? If it did not contribute, why?" Some of the questions explored the effect of collaboration in the hyper-video environment: "How did you react when other students replied to your writings? Why did you reply to other students' comments and what was their reaction, if any?".
The interviews were recorded, transcribed, and analyzed. The thematic analysis was conducted based on the principals of the Grounded Theory approach (Corbin & Strauss, 1990). Because of the small number of the interviewees (n = 9), we did not count interview codes, but rather present the citations related to our quantitative results, in order to deepen understanding and provide additional qualitative insights or alternative explanations.
Results
Active participation vs. lurking and shared posts vs. private notes
Table 4 presents the frequencies of active participation during the semester in the three courses that were examined in the study. All of the percentages in this table are calculated out of the total number of hyper-video users in each course (and not only out of users who wrote annotations).
It can be seen that when the pedagogical design was based on learning activities that were not accredited in the course, slightly more than 10% of students in each course chose to participate actively in the hyper-video environment and write shared posts/replies or personal-notes. Qualitative data from the interviews confirms this finding. As the lecturer from Course C said: "I would very much like them to ask more questions. I love to answer, but I feel that the students’ general approach is to ask less and remain more passive, more dependent on prepared materials". Similarly, student A stated: "Unfortunately there were only a few students with whom I used the tool to further process the content, to reflect on it through an additional channel. It was difficult to conduct a fruitful dialogue, since there were not enough students in Annoto who commented and replied". The interviews also provided a possible reason for the low rate of active participation: "I think that most of the learning is passive. Part of it is because the students do not understand and are ashamed to ask and show it." (Course A lecturer).
On the other hand, both the lecturers and students perceived the potential benefit of hyper-video to students who choose to use it actively. One of the students stated (O): "To me, personally, it contributed a lot. It provided an opportunity for more active learning—I could bookmark important points on the video and process the content and reflect on it in a different way". Similarly, the lecturer from course A said: "It is a tool that requires students to be active: Watching the video, stopping and asking themselves: did I understand? If they did not understand something, then they could ask as much as they could during the lesson. It allows students to communicate about the topic and reach understanding. These reflections and questions are really essential in the learning process, and Annoto can help do this easily."
Table 5 shows additional elements of the pedagogical design: the frequencies of active participation by writing shared posts and replies versus personal notes, as well as passive participation by reading these messages.
Table 5 demonstrate that the vast majority of posts throughout the semester in the three courses were shared writings rather than personal notes (p's < .001). The interview quotes are consistent with the quantitative data. The lecturer from course B said: "I think, Annoto is, first of all, another place to post questions. Personal annotations are OK, but they are "nice to have". Similarly, the Course A lecturer stated: "There is a recorded lesson, a student can ask a question about this second of the video. It is a unique and critical affordance of Annoto, which contributes to learning in a very natural way. This is a very important aspect of the platform, which has shown that the university is technologically moving forward, because discussion groups as a learning tool are, in my opinion, a bit outdated." Students also suggested strategies to promote shared writings in hyper-video: "The lecturer can explicitly and continuously encourage comments and peer-feedback in Annoto, by mentioning the names of students who write posts and responding to others, and praising such activities" (Student D).
Table 5 also reflects some differences between the fields of knowledge. While the rate of shared posts in social sciences (courses B and C) was around 75%, in the exact sciences (course A) it was above 95%. It seems that the exact science course is perceived as being more difficult to understand, and consequently, produces more questions that need to be answered rather than self-reflections of students. This explanation is consistent with the interview data: "Our subject is very difficult, i.e., many students find it difficult and many want to ask questions" (course A lecturer).
Despite this difference between the courses in shared versus private writing, Table 5 demonstrates that the total number of writings relative to the number of participants in the hyper-video environment did not depend on the field of knowledge. In course B in social sciences, the ratio of writings was close to 30%, while in course A (in exact sciences) and course C (in social sciences), the ratio of active participation was around 50%. Table 5 also demonstrates differences in the ratio of readings - the total number of readings relative to the number of participants in the hyper-video environment, again regardless of the field of knowledge. Namely, there is a very large gap between the two courses in the social sciences: the ratio of readings in course B was only 20%, while in course C it was 220%.
Table 6 presents findings regarding the differences between the courses in active and passive participation of students at the user level. Since, as presented in the “Methods” section, most of the parameters of participation were not normally distributed, in order to examine the differences between the courses in active and passive participation, instead of ANOVA tests, analyses of variance were conducted using Kruskal–Wallis tests. Mann–Whitney tests were used for paired-comparisons.
As for passive participation, Table 6 shows that while in course B the students were focused on video viewing, students in courses A and C were more interactive in reading posts and replies. On the other hand, there was no difference between the courses in active participation, both in shared and personal writing. As for the votes, the students in the social sciences voted significantly more compared to the exact sciences. We will address the importance of votes for expressing social presence in the content analysis sub-section.
As can be seen in the Methods—“Instruments” section, the analysis on the level of users and on the video level revealed different parameters of participant behavior (see Tables 2, 3). Moreover, since the courses examined in the study differed in the number of students participating, analysis of the variance between the courses at the level of video recordings (Table 7) was conducted in ratios (i.e., absolute numbers presented in Table 5 divided by the number of users in the hyper-video environment). Although most of the ratios were normally distributed, because of the small number of lectures in each course, the analysis of variance and paired-comparisons were again conducted using a parametric statistics - the Kruskal–Wallis and Mann–Whitney tests.
Similar to Table 6, the analysis on the level of video in Table 7 shows that students in course B focused on watching videos rather than on active participation. No differences were found between the courses in the number of personal notes or the number of students who wrote them. With regard to interactivity, course C has a clear advantage over the other courses. While no differences were found between the courses in the posts published by the lecturers, in course C, more students' posts were written and more replies were received from both students and the lecturer. In addition, students in course C wrote more shared messages.
However, qualitative data revealed that the lecturer of course C did not perceive peer replies as valuable: "Look, I think it's impossible to have Annoto annotations without me being involved, I must control it. It is an undergraduate course, some students are novice and can provide incorrect answers. I have to follow the annotations and correct them when needed. It is not something I can leave to peer-feedback, not in my course." The lecturer of course B expressed similar epistemic thinking that each question has a correct answer and students seem not to be knowledgeable enough to provide it. This information ownership resulted in a need to control the annotations and in a reluctance to encourage peer-feedback: "This issue of collaboration and peer-feedback is not my cup of tea… I don't see the point in promoting discussions between students. One says: I think so, the other says: I think so, and then they wait for me to tell them who is right or what the correct answer is". Students also perceived the lecturer as the principal source of knowledge and expressed a similar need for the lecturer's corrections: "Feedback from the lecturer is very important; it will tell you if you have made a mistake. You have a lot of freedom to write whatever you want, but if I write something that is a significant mistake, I would like to receive the lecturer's correction and not the personal opinion of another student" (Student A).
Finally, for active participation only, differences between shared and personal writings were examined in the three courses altogether. These analyzes were performed at the video level and in ratios, in light of the differences between the courses in the number of users of the hyper-video environment. The t-tests showed that the videos contained significantly more shared writings compared to personal notes (M = 0.017 versus 0.001, t(36) = 8.111, p = .000). In addition, more students chose to write openly than those who chose to participate privately (M = 0.012 versus 0.001 respectively, t(36) = 7.217, p = .000).
Characteristics of hyper-video pedagogy and learning processes
Analysis of characteristics of the pedagogical design, as described in the interviews, showed a uniform pattern in the three courses—hyper-video served as a forum and/or as a student notebook. In other words, questions and answers in the hyper-video environment replaced or added to discussions in the course forum. As the lecturer of course B stated in the interview: "Today the students watch videos, the videos raise many questions, and the alternative ways of receiving answers to their questions are not very convenient. So here students have a platform which helps them receive answers". Hyper-video also allows students to write personal notes linked to specific topics in the recorded lessons. The lecturer of course A explains: "If we give students a tool, they should have a convenient option to mark important points and write notes on the video, not in the traditional notebook".
Despite the differences between the fields of knowledge, analysis of the instructional design of hyper-video activities demonstrated that all of the lecturers responded directly to the students' questions and neither encouraged them to answer their peers' questions, nor promoted discussions among the students. Similarly, the lecturer of course A stated: "There was no discussion. I think that Annoto is a platform where concrete questions are answered, such as questions from assignments. There was almost no collaborative learning in the sense that David asks, Rachel answers him and the teacher does not have to intervene."
Moreover, the instructional design analysis revealed that the lecturers asked very few questions and mainly provided answers, and that the interactions were usually in the format of "student’s question—lecturer's answer". This finding regarding students’ and lecturers’ behavior in the hyper-video environment is consistent with the interview statements, for example: "I did not initiate interaction, but rather reacted: A student asks a question and I answer him/her." (Course B lecturer).
In order to understand the characteristics of pedagogical design which encourage participation in hyper-video, recordings of three synchronous lessons held in June 2017 were rated using the Annoto system. These recordings had the highest level of user involvement during the period of time analyzed in this study. Figures 2, 3, and 4 show the popularity of viewing these recordings over time and the level of involvement (the number of posts versus the number of their writers) in shared posts versus in personal notes. As can be seen, in the three recordings, writing, both shared and private, chronologically precedes the increased popularity of viewing the video recordings (measured as the number of video views over time). In addition, the large waves of popularity of viewing the videos occurs during the period of preparation for the final exam. The figures also suggest that preparations for the exam encourages personal rather than shared writing. Namely, for the exam students rely primarily on writing personal notes at the expense of asking others and learning from interpersonal interactions.

The most interactive video patterns—frequencies

The second interactive video patterns—frequencies

The third interactive video patterns—frequencies
Table 8 summarizes activities of the three the most active participants of each video.
Table 8 demonstrates that in all of the most interactive lessons the lecturer was one of the most active writers, but not necessarily the most active one. Moreover, in the most interactive videos, the lecturers not only responded to students, but also initiated new discussions.
Active participation: CoI framework coding
In order to deepen our understanding of interactions in hyper-video, we performed an analysis of shared posts and replies based on the CoI model (for ethical reasons, the content of personal notes could not be examined). As mention in the “Methods” section, the most interactive lesson of each course was chosen for the analysis (Table 9).
Table 9 shows that the lesson in course C was the most interactive (67 types of presence codes versus 35 and 22 in the other courses, both p's < .001). However, in the three lessons we analyzed, almost all of the cognitive presence statements were of the most basic type—a triggering event, for example: "I did not understand the differences between cases A and B. I would be happy to receive a clearer explanation." The exploration category of CP was only found in the Course C lesson, in which there were two relevant statements, for example: "Actually, to me it is still unclear. Why is the computer example a negative reinforcement and not a positive reinforcement? For instance, when the child prepares lessons—a positive behavior—he is allowed to play on the computer. This is a reward, and thus, a positive reinforcement." None of the analyzed lectures contained integration or resolution statements. It seems, therefore, that the students rarely used high-levels of thinking in their use of hyper-video. However, even these basic levels of cognitive presence expressed in writing can be beneficial to students. For example, student A said: "I also read the comments of others, but did not benefit from it as well as when I wrote a comment myself. It pushed me to rethink the issue, further process it, and carefully formulate comments or questions."
Regarding teaching presence, the three lessons that were analyzed contained no "building understanding" codes in the form of focusing discussions, diagnosing errors, and summarizing topics, as characterized by the CoI model (Garrison et al., 1999, 2010). Instead, an absolute majority of TP codes appeared under the category of "direct instruction", for example: "True, the value should be 2." Moreover, both content analysis and interviews suggest that some of the direct instruction was not in the form of writing, but rather conducted by marking correct answers with asterisks: "If a student wrote a correct answer, I gave him/her an asterisk, that is, a recommendation, which means that this answer is very good, worth reading" (course A lecturer).
The most salient type of presence in the lectures analyzed was social presence (71 codes compared to 26 and 27 statements of CP and TP respectively, both p's < .001). However, differences were found between the courses in social presence, with the course C lecture containing 42 SP statements, while in the other courses' lessons only 11 and 18 social codes were found. The superiority of course C was salient in the categories of "open communication" and "group cohesion". In courses A and B the students settled for questions with few "open communication" codes, which refer to their peers' writings and respond to their questions. This finding is consistent with the interview data: "Sometimes students answered their peers’ questions, but this was a really rare thing" (course B lecturer). Regarding emotional expression codes, unlike forums, where this category is conveyed in the form of emoticons and self-disclosure writings, in hyper-video it appeared in all of the lessoned analyzed exclusively as votes and emoticons, for example:  .
.
Discussion
This section first discusses the active and passive participation of students in the hyper-video environment, as well as the role of lecturers in this process. For active participation, we compare shared posts and personal-notes. Following that, we discuss different characteristics of the pedagogical design of hyper-video annotation activities. To conclude, we discuss the nature of shared discussion in the hyper-video environment in terms of cognitive, teaching and social presence (Garrison et al., 1999, 2010).
Regarding active participation versus lurking, the literature claims that hyper-video enables students to interact directly with learning content and overcome passive use of videos in education (for review see: Sauli et al., 2018). Namely, hyper-video is designed to support deeper learning processes, such as reflection, elaboration and annotation. Our interview data demonstrated that both the lecturers and active students showed clear understanding of this potential to promote learning. They spoke about the unique affordance of Annoto, enabling them to write comments about specific moments of the video, which contributes to learning in a very natural way. However, learning analytics of all students' behavior painted a different picture and suggested that the potential benefits of hyper-video remain unfulfilled. When hyper-video learning activities were integrated in courses without academic credit, as in this study, very few students in each course chose to write shared posts/replies or personal-notes (Table 4). The ratio of active undergraduates who annotate videos without credit found in the current study is consistent with the rates of voluntary participation in collaborative writing, e.g., in Wikipedia (Lanamäki, & Lindman, 2018). Previous research (Goldberg et al., 2015) emphasized the importance of active participation for learning, demonstrating that among almost 10,000 enrollments in a MOOC, students who completed the MOOC engaged in significantly more forum discussions than participants who dropped out. Since in academia the number of participants is significantly smaller, the active students interviewed in this study complained about the absence of a "critical mass" of writers in order to conduct a productive dialogue. They suggested that lecturers should explicitly promote active participation and peer-feedback, and praise students who do so. In a model that explains motivation for participation in online communities based on a comprehensive literature review, Sun et al. (2014) presented four reasons for lurking: environmental impact, personal preference, individual-group relationship, and security reasons (which are less relevant to the academic context). The suggestions of our interviewees are consistent with the strategies provided by Sun et al. (2014) for de-lurking in online communities: Increase user friendliness, explicitly encourage active participation, and guide newcomers. In order to realize the pedagogical potential of hyper-video, which seems to be very difficult to conduct without providing academic credit, we also suggest considering external incentives—another strategy for de-lurking offered by Sun et al., by adding annotations to course requirements. All of these strategies seem relevant to promoting active participation in hyper-video in academia. However, the last suggestion of offering external incentives has its disadvantages, in light of a previous study of participation in forum discussions (Dennen, 2008) which demonstrated that students who participated solely to meet course requirements had less positive impressions regarding the impact of discussions on their learning and focused mostly on posting, without reading others’ messages.
For active participation, the analysis was conducted at the annotation-level and the user-level. The exploration of shared and personal writings revealed that hyper-video annotations contained significantly more shared writings compared to personal-notes. Moreover, at the user level, the findings showed that there were significantly more students who wrote openly, in comparison with students who chose private note-taking. Thus, in terms of the social constructivist principles (Vygotsky, 1978), students seem to take advantage of learning from social interaction through hyper-video to advance their understanding of the learning content within their ZPD.
With that said, there were differences between the courses in the rate of shared posts: While the rate of shared posts in social science courses was around 75%, in the exact sciences course it was above 95%. This difference might reflect the perceived difficulty of the exact science, compared to social science, courses, thus resulting in more students who ask for help.
In addition, the analysis of the most interactive recordings demonstrated (Figs. 2 and 3) that writings, both shared and private, chronologically precede the increased popularity of viewing the videos over time. Interestingly, the wave of second or main popularity of the videos occurs during preparations for the final exam. However, these preparations almost exclusively encouraged personal writing. It appears that during the exam period students rely primarily on personal learning, at the expense of learning from interpersonal interaction (Vygotsky, 1978). An alternative explanation for this pattern might be that most of the questions have already been asked and answered during the semester. Unfortunately, the data regarding the reading of each video's shared and personal writings is not available on the Annoto dashboard. Informed pedagogical decisions require an understanding of patterns of passive participation in general, and during exam preparation in particular. We recommend that developers of hyper-video environments provide this learning-process data to lecturers and researchers.
In addition, the analysis revealed important differences between the courses in the same field of social sciences in both active and passive participation (Table 5). In course C, the ratio of writings (i.e., the number of posts relative to hyper-video users) was close to 50%, compared to only 30% in course B. Moreover, there was a very large gap between these courses in the ratio of reading (i.e., the number of readings out of the number of hyper-video users): approximately 220% in course C compared to only 20% in course B. Further analysis revealed (Table 7) that while course B focused mostly on watching videos, course C had a clear advantage over the other courses in both writing and reading. Despite no difference between the courses in the number of posts published by the lecturers, in course C, more students' posts were written and more replies were received from both students and the lecturer. In addition, students in course C posted more shared messages.
Altogether, these findings highlight the important role of pedagogical design for learning in hyper-video environments. Hyper-video annotations may offload non-learning related cognitive loads (Mu, 2010). Moreover, hyper-video can facilitate reflective skills, particularly if learners have to adopt an active role and negotiate meaning, which leads to a better understanding of the topic and to more extended creative, social, cognitive and metacognitive competencies (Sauli et al, 2018; Stahl et al., 2006).
Despite this potential, our analysis of the characteristics of the pedagogical design characteristics suggested a lack of appropriate pedagogy and showed a uniform pattern of using hyper-video in the three courses: questions and answers in the hyper-video environment replaced or added to discussions in the course forum or served as a student notebook. Moreover, the main pattern of the dialogue was "student's question—lecturer's answer". Although interviews revealed that active students craved more peer interactions, lecturers, including the lecturer of the most interactive course C, did not perceive peer-feedback in hyper-video as important and worthwhile to promote.
Lecturers' interview statements regarding their need for control and for the psychological ownership of information were consistent with their pedagogical design, as well as with previous findings among teachers (Blau et al., 2016) and university students (Blau & Caspi, 2009; Caspi & Blau, 2011). Moreover, a similar perspective was expressed by the students interviewed in our study, who perceived the lecturer as a "knowledge authority" and therefore, wanted their posts' content to be addressed and "approved" of by the lecturer, and not by peers. Such a perspective considers knowledge as isolated facts (Murtonen et al., 2017) and denies the complexity of social learning and peer-teaching processes by rejecting their contingent, emergent and negotiating qualities (Addison, 2014; Blau & Shamir-Inbal, 2017). This perspective reflects personal epistemic thinking, which affects the evaluation of trustworthiness in online environments (Barzilai & Zohar, 2012). Specifically, the perspectives of both lecturers and students, expressed an absolutist epistemology that knowledge is objective, located in the external world, and certain, rather than a multiplist epistemology, according to which the knowledge is individually constructed and therefore multiple, subjective, uncertain, and cannot be adjudicated. Both the lecturers and students in our study seemed to hold traditional behavioristic perspectives on teaching–learning processes and outcomes—that the role of the lecturer is to transmit knowledge and the role of students is to acquire this. Such traditional epistemological perspectives are surprisingly common, not only in educational practice (Hadad et al., 2020), but also in research. For instance, a recent review of educational outcome papers (Murtonen et al., 2017) found that not only was traditional behavioristic epistemology evident in twenty-first century studies, but also that 40% of the papers reviewed addressed this epistemology uncritically.
The analysis of activities in the most interactive video-recordings (Figs. 1, 2, 3) revealed that although in all of them the lecturer was one of the three most active writers, s/he was not necessarily the most active one. Moreover, s/he not only responded to the students, but also initiated new discussions to promote interactivity. This finding suggests that initiating discussions is a prominent pedagogical strategy that lecturers use to realize the potential benefit of shared hyper-video annotations. Our finding is consistent with a previous study (Gorsky & Blau, 2009), in which the interactivity pattern of the highly rated lecturer was not providing answers, but rather initiating discussions and encouraging students to continue negotiating meaning and building understanding.
Regarding the expression of cognitive, social and teacher presence (Garrison et al., 1999, 2010) in annotations, the course C lecture was the most interactive, with 67 presence codes compared to 35 and 22 in other lectures. However, the analysis of the cognitive presence hierarchy revealed that, although the course C lecture contained at least as twice the number of cases of CP as other course lectures, none of the lectures contained higher-level thinking in the form of integration or resolution categories. Moreover, except for two inquiry codes in course C, all other CP codes were of the most basic type—triggering event. It seems, therefore, that, similar to findings regarding the use of hyper-video among teachers in early career stages in McFadden et al.'s (2014) study, our undergraduates very rarely used hyper-video at high-levels of thinking.
The reason for this might be related to our findings regarding teaching presence, the absolute majority of which appeared in the category of direct instruction. None of the lectures contained codes of building understanding, which, according to the CoI framework (Garrison et al., 1999, 2010), emphasizes the lecturer's facilitation in the form of focusing discussions, diagnosing errors, and summarizing topics. Thus, our findings suggest that attempts to use an appropriate pedagogy in order to realize the potential benefits of hyper-video annotations for promoting students' thinking processes were lacking (Blau & Shamir-Inbal, 2018).
Regarding social presence, our general assumption that, in contrast to forum discussions, hyper-video annotations would contain minimum, if any, social statements because of associations to specific video-content, was not supported by the data. Actually, SP was the most salient type of presence found in the data, with all of the three SP categories posited by the CoI framework. Similarly, SP was the most salient type of presence in forums (e.g., Gorsky & Blau, 2009). The only difference in hyper-video annotations was conveying the "emotional expression" category of the CoI framework exclusively by emoticons and votes rather than through writings in forums. The high prevalence of SP in hyper-video annotations, similarly to forums, is counter-intuitive and strengthens the argument in the research literature regarding the importance of social processes for active asynchronous learning in academia (Caspi & Blau, 2008; Garrison et al., 1999, 2010).
SP was also found to differ strongly between the lectures analyzed, with the course C lecture containing most of the social codes. Among these, course C had a clear advantage in the "open communication" and "group cohesion" categories. In a study conducted by Gorsky and Blau (2009), significant differences in social presence were found between forums of the instructors who received high and low student feedback. Moreover, SP in an asynchronous environment was found to be positively associated with the cognitive aspect of perceived learning (Caspi & Blau, 2009). In our study, a very high ratio of reading (Table 5) and a relatively large number of CP codes (Table 9) were found in course C. These might be explained by the high level of SP in course C, which is essential for effective asynchronous learning (Caspi & Blau, 2008; Garrison et al., 1999, 2010), apparently regardless of the technology (forum or hyper-video). Our finding suggests that, although counter-intuitive, enhancing social interactions might be an appropriate pedagogical strategy to realize the learning potential of hyper-video for both students who write and benefit in terms of CP and students who only read annotations.
Conclusion and implications
This study reported findings regarding the integration of the innovative hyper-video system Annoto in academic courses. In addition to higher education, the findings of this study are generalizable to structured video-based learning and training courses in general, including MOOCs, since all of them can integrate hyper-video in similar ways.
Unlike previous studies, this work triangulated learning analytics with content analysis based on the CoI model (Garrison et al., 1999, 2010) and interviews with lecturers and active students. As a pioneer study which employs the CoI framework for analyzing hyper-video annotations, this paper contributes to the literature by providing theoretically grounded insights regarding the behavioral patterns of active participation in this environment, beyond log analysis or self-report data.
Importantly, the study contributes to the literature in terms of understanding the lack of alignment between the affordances of hyper-video for teaching and learning, the epistemic thinking of lecturers and students, and the required pedagogy in actual integration of this technology in academia. The findings suggest that hyper-video activities reflected the lecturers’ need for control and for psychological ownership of information and the subsequent desire of students for approval by lecturers as a "knowledge authority".
Based on the findings we recommend, beyond a direct instruction strategy which was frequently used in our data, to promote active pedagogy through strategies, such as asking questions and conducting dialogue between students to reach high-level thinking (Shamir-Inbal & Blau, 2021). It is also important to encourage peer teaching through addressing comments and questions of other students in hyper-video environment in order to contribute to the learning of both parties. Cultivating SP in a hyper-video environment stimulates both the expression of CP through writing, as well as building understanding through passive participation by reading messages. The limitation of this pioneer study, which should be taken into consideration, is that the data were collected in three undergraduate courses in only one university. Although the findings might be to some extent affected by the university's learning culture, the sample was large and covered different knowledge fields and topics. Importantly, the hyper-video activity was incorporated in all of the participating courses as a not accredited option, which, according to the literature (Sun et al., 2014), is characterized by a very-high rate of passive participation. Annotations designed as credited activities and annotations in graduate courses might demonstrate different participation patterns. It is therefore important to continue examining the issue of active participation versus lurking, as well as types of presence, in a larger and more diverse sample of hyper-video environments in academic courses.
References
Addison, N. (2014). Doubting learning outcomes in higher education contexts: From performativity towards emergence and negotiation. International Journal of Art & Design Education, 33(3), 313–325.
Barzilai, S., & Zohar, A. (2012). Epistemic thinking in action: Evaluating and integrating online sources. Cognition and Instruction, 30(1), 39–85.
Beauchamp, G., & Kennewell, S. (2008). The influence of ICT on the interactivity of teaching. Education and Information Technologies, 13, 305–315.
Beauchamp, G., & Kennewell, S. (2010). Interactivity in the classroom and its impact on learning. Computers & Education, 54(3), 759–766.
Blau, I., & Caspi, A. (2009). Sharing and collaborating with Google Docs: The influence of psychological ownership, responsibility, and student's attitudes on outcome quality. In E-Learn: World Conference on E-Learning in Corporate, Government, Healthcare, and Higher Education (pp. 3329–3335). Association for the Advancement of Computing in Education (AACE).
Blau, I., & Hameiri, M. (2012). Teachers-families online interactions and gender differences in parental involvement through school data system: Do mothers want to know more than fathers about their children? Computers & Education, 59, 701–709.
Blau, I., & Hameiri, M. (2017). Ubiquitous mobile educational data management by teachers, students and parents: Does technology change school-family communication and parental involvement?. Education and Information Technologies, 22(3), 1231–247.
Blau, I., Peled, Y., & Nusan, A. (2016). Technological, pedagogical and content knowledge in one-to-one classroom: Teachers developing “digital wisdom.” Interactive Learning Environments, 24(6), 1215–1230.
Blau, I., & Shamir-Inbal, T. (2017). Re-designed flipped learning model in an academic course: The role of co-creation and co-regulation. Computers & Education, 115, 69–81.
Blau, I., & Shamir-Inbal, T. (2018). Digital technologies for promoting “student voice” and co-creating learning experience in an academic course. Instructional Science, 46(2), 315–336.
Blau, I., Shamir-Inbal, T., & Yarkoni, R. (2018). Private and shared annotations in Annoto: Insights about active participation and lurking from content analysis and learning analytics of hyper-video environment in academia. In Y. Eshet-Alkalai, I. Blau, A. Caspi, N. Geri, Y. Kalman, & V. Silber-Varod (Eds.), Learning in the Technological Era (pp. 22–33). The Open University of Israel. [in Hebrew].
Blau, I., Shamir-Inbal, T., & Avdiel, O. (2020). How does the pedagogical design of a technology-enhanced collaborative academic course promote digital literacies, self-regulation, and perceived learning of students?. The Internet and Higher Education, 45, 100722. https://doi.org/10.1016/j.iheduc.2019.100722.
Blau, I., Weiser, O., & Eshet-Alkalai, Y. (2017). How do medium naturalness and personality traits shape academic achievement and perceived learning? An experimental study of face-to-face and synchronous e-learning. Research in Learning Technology, 25. Retrieved from http://repository.alt.ac.uk/2380/1/1974-9742-1-PB.pdf.
Caspi, A., & Blau, I. (2008). Social presence in online discussion groups: Testing three conceptions and their relations to perceived learning. Social Psychology of Education, 11, 323–346.
Cattaneo, A. A., Nguyen, A. T., & Aprea, C. (2016). Teaching and learning with Hypervideo in vocational education and training. Journal of Educational Multimedia and Hypermedia, 25(1), 5–35.
Caspi, A., & Blau, I. (2011). Collaboration and psychological ownership: How does the tension between the two influence perceived learning? Social Psychology of Education, 14(2), 283–298.
Colasante, M. (2011). Using video annotation to reflect on and evaluate physical education pre-service teaching practice. Australian Journal of Educational Technology, 27(1), 66–88.
Corbin, J. M., & Strauss, A. (1990). Grounded theory research: Procedures, canons, and evaluative criteria. Qualitative Sociology, 13(1), 3–21.
Dennen, V. P. (2008). Pedagogical lurking: Student engagement in non-posting discussion behavior. Computers in Human Behavior, 24(4), 1624–1633.
Garrison, D. R., Anderson, T., & Archer, W. (1999). Critical inquiry in a text-based environment: Computer conferencing in higher education. The Internet and Higher Education, 2(2), 87–105.
Garrison, D. R., Anderson, T., & Archer, W. (2010). The first decade of the community of inquiry framework: A retrospective. The Internet and Higher Education, 13(1), 5–9.
Goldberg, L. R., Bell, E., King, C., O’Mara, C., McInerney, F., Robinson, A., & Vickers, J. (2015). Relationship between participants’ level of education and engagement in their completion of the Understanding Dementia Massive Open Online Course. BMC Medical Education, 15(1), 60–67.
Gorsky, P., & Blau, I. (2009). Online teaching effectiveness: A tale of two instructors. The International Review of Research in Open and Distance Learning, 10, 1–27.
Hadad, S., Shamir-Inbal, T., Blau, I., & Leykin, E. (2020). Professional development of code and robotics teachers through Small Private Online Course (SPOC): Teacher centrality and pedagogical strategies to promote computational thinking of students. Journal of Educational Computing Research. https://doi.org/10.1177/0735633120973432
Hulsman, R. L., & van der Vloodt, J. (2015). Self-evaluation and peer-feedback of medical students’ communication skills using a web-based video annotation system. Exploring content and specificity. Patient Education and Counseling, 98(3), 356–363.
Imran, A. S., Cheikh, F. A., & Kowalski, S. J. (2016). Automatic annotation of lecture videos for multimedia driven pedagogical platforms. Knowledge Management & E-Learning: An International Journal (KM&EL), 8(4), 550–580.
Lanamäki, A., & Lindman, J. (2018). Latent Groups In Online Communities: A longitudinal study in wikipedia. Computer Supported Cooperative Work (CSCW), 27(1), 77–106.
McFadden, J., Ellis, J., Anwar, T., & Roehrig, G. (2014). Beginning science teachers’ use of a digital video annotation tool to promote reflective practices. Journal of Science Education and Technology, 23(3), 458–470.
Mu, X. (2010). Towards effective video annotation: An approach to automatically link notes with video content. Computers & Education, 55(4), 1752–1763.
Murtonen, M., Gruber, H., & Lehtinen, E. (2017). The return of behaviourist epistemology: A review of learning outcomes studies. Educational Research Review, 22, 114–128.
Pardo, A., Mirriahi, N., Dawson, S., Zhao, Y., Zhao, A., & Gašević, D. (2015). Identifying learning strategies associated with active use of video annotation software. In Proceedings of the Fifth International Conference on Learning Analytics and Knowledge (pp. 255–259). ACM.
Shamir-Inbal, T., & Blau, I. (2021). Characteristics of pedagogical change in integrating digital collaborative learning and their sustainability in a school culture: e-CSAMR framework. Journal of Computer Assisted Learning. https://doi.org/10.1111/jcal.12526.
Sun, N., Rau, P. P. L., & Ma, L. (2014). Understanding lurkers in online communities: A literature review. Computers in Human Behavior, 38, 110–117.
Sauli, F., Cattaneo, A., & Van der Meij, H. (2018). Hypervideo for educational purposes: a literature review on a multi-faceted technological tool. Technology, Pedagogy, and Education, 27(1), 115–134.
Stahl, E., Finke, M., & Zahn, C. (2006). Knowledge acquisition by hypervideo design: An instructional program for university courses. Journal of Educational Multimedia and Hypermedia, 15, 285–302.
Vygotsky, L. S. (1978). Mind in Society: The Development of Higher Psychological Processes. Harvard University Press.
Weiser, O., Blau, I., & Eshet-Alkalai, Y. (2018). How do medium naturalness, teaching-learning interactions and students’ personality traits affect participation in synchronous e-learning? The Internet and Higher Education, 37, 40–51.
Zahn, C., Pea, R., Hesse, F. W., & Rosen, J. (2010). Comparing simple and advanced video tools as supports for complex collaborative design processes. The Journal of the Learning Sciences, 19(3), 403–440.
Acknowledgements
This paper was supported by the Research Authority Foundation, The Open University of Israel.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Blau, I., Shamir-Inbal, T. Writing private and shared annotations and lurking in Annoto hyper-video in academia: Insights from learning analytics, content analysis, and interviews with lecturers and students. Education Tech Research Dev 69, 763–786 (2021). https://doi.org/10.1007/s11423-021-09984-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11423-021-09984-5