
Abstract
Smart cities development is an ambitious project launched in India in 2015 with around 14 billion USD. Smart city mission program primarily aimed at reducing the carbon footprint and encouraging green and sustainable practices. Under this context, clean energy usage for demand fulfillment became the prime focus. India’s geographic location gifts the nation with diverse clean energy sources (CES). Owing to the multiple sustainable criteria that are both conflicting and correlated, there is an urge for a multi-criteria decision approach. Previously, literatures on CES selection have not been able to grab the hesitation properly and handle uncertainty effectively. Since the human mind is dynamic, hesitation is an integral part of choice making. Hesitant fuzzy set (HFS) is a generic set that captures hesitation better. Driven by these claims, in this work, a new framework for CES selection is developed. Attitude-driven entropy measure is proposed for criteria weight assessment, and a mathematical model is formulated for ranking CESs. Together, these methods constitute a decision framework that (i) considers the attitude of experts and captures hesitation during rating process and (ii) acquires partial personal choices from experts before ranking CESs. To testify the framework, a case study from a smart city within Tamil Nadu (a state in India) is explained. Sensitivity analysis reveals the robustness of the framework, and comparison with other works showcases the novel innovations of the proposal.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
India started focusing rigorously on sustainable green practices with the core aim to reduce the carbon footprint. As per the resolution in Paris Accord (Ourbak and Magnan 2018), India is determined to reduce the emission intensity by 30–35% within 2030. One crucial way to do this is to transform the nation’s focus towards clean energy sources (CESs). Due to the advent of Industry 4.0 and the National Smart City Mission (NSCM) project, the need for energy is abundant in India. Indragandhi et al. (2017) prepared an interesting survey on India’s CESs. They claimed that by 2050, the transformation would aid the country to global sustainable development and retain environmental well-being by satisfying the energy demand with reduced greenhouse gas emissions. Due to the geographic location of India, CESs such as biomass, geothermal, wind, solar, and hydro are dominant (Reddy and Painuly 2004).
CESs are the non-conventional energy options that are clean, renewable, and focus on preserving the ecosystem (Rani et al. 2020a, b). The main theme of the NSCM project is to make use of the technological advancement to promote the lifestyle of people towards healthy and better standards with eco-balance and eco-friendliness. During the process, cities that tend to grow smart need energy for various socio-economic activities (Eremia et al. 2017). As a reliable option, India focused on CESs. Literatures on CES assessment have clarified that there are various criteria associated with each CES and the selection of an apt source is a typical multi-criteria decision problem (MCDP) (Cavallaro and Ciraolo 2013; Cavallaro et al. 2016). Also, it is inferred that uncertainty is an integral part of the process.
Driven by these claims, in this work, a framework is put forward for CES selection by adopting hesitant fuzzy set (HFS) (Torra 2010) information. HFS is a generalization of a fuzzy set that allows experts to provide multiple grades for a specific alternative over a criterion. For example, an interviewer rates a candidate based on her communication ability and the grades provided as 0.45, 0.55, and 0.70. This clarifies that the interviewer can flexibly offer grades, and the sense of hesitation and uncertainty can be better modeled by using HFS. Rodríguez et al. (2014) recently offered a survey presenting the extant decision models in HFS, variants of HFS, and applications where HFS was popularly used. This survey provides certain inferences such as (i) HFS is an elegant and flexible style for decision-making, and (ii) there is high scope for solving problems with uncertainty like the CES selection problem.
Furthermore, in terms of the application, Mardani et al. (2017a, b) prepared an interesting review of the usage of decision approaches for CES selection and assessment. They inferred that (i) CES selection involves a diverse set of competing factors under the perspectives of social, economic, and environment; (ii) uncertainty is implicit in the selection process; and (iii) integrated methods are more suitable and popular for such selection problems. Based on the systematic review, certain challenges are also encountered, such as (i) capturing uncertainty/hesitation in preferences is an ordeal and subjective biases in rating causes inaccuracies in decision-making; (ii) interaction among sustainable criteria for CES selection is not captured adequately; (iii) partial information from experts on each CES may be unutilized, and there is information loss/ignorance in the system.
These challenges motivate the authors to set up the following contributions in this work, and they are as follows:
-
HFS is adopted as the preferred style that not only is flexible but also mitigates subjectivity. Experts gain the freedom to rate CESs by using multiple grades.
-
Furthermore, interactions among criteria are captured by proposing an attitude-based entropy measure that measures uncertainty with weighted information gain factor and considers the behavior of experts who share her/his views on the sustainable criteria.
-
Generally, experts have their preference value or choice in their mind pertaining to each alternative (here CES), which must be gathered and utilized as it serves as potential information in ranking. Such partial information is not modeled properly in previous works related to HFS-based energy source selection (Mardani et al. 2017a, b).
-
Finally, a fusion rule is adopted to obtain a holistic ranking of CESs, and a case example of the smart city within Tamil Nadu state in India is demonstrated to realize the practicality.
The organization of the rest of the paper is as follows. Review of literatures relating to clean energy selection and HFS-based decision models are presented in “Literature review.” Proposed methodology is depicted in detail in “A new methodology for CES selection.” A case example of clean energy source selection is put forward in “Case sample — energy source selection for a smart city” to demonstrate the usefulness of the developed integrated framework. In “Investigation with other methods,” comparative study is conducted to demonstrate the strengths and weaknesses of the framework. Finally, in “Conclusion,” conclusions with future directions are presented.
Literature review
In this section, existing models are reviewed to clearly understand the work done previously that lays the foundation for identifying the research challenges and presenting contributions to circumvent the challenges. Recent and relevant literatures from CES selection models and HFS-decision models are reviewed.
CES selection
CES selection is actively performed with the help of decision-making methods. Mardani et al. (2017a, b) and Kumar et al. (2017) prepared reviews on diverse decision methods used for CES selection.
Xu et al. (2019) to select the most efficient CES for hydrogen production developed a combined fuzzy MCDM approach based on fuzzy analytical hierarchy process (AHP) and data envelopment analysis (DEA).
From the reviews, it is inferred that decision models are appropriate for energy evaluation, and CES selection is an interesting problem in the sustainability domain. With the notion of extending the review on CES selection further, we present the recent and relevant works. Ozorhon et al. (2018) came up with an analytical network process to grab the relationship among technical, environmental, and economic criteria for proper investment in CESs. Cavallaro et al. (2018) gave a new decision approach with entropy measure and intuitionistic fuzzy number to evaluate solar hybrid power plant. Zhang et al. (2019) put forward a hybrid method under a 2D-linguistic context with a mathematical model and TODIM approach for CES evaluation in China. Lee and Chang (2018) came up with a comparative study of decision models for CES assessment in Taiwan to recommend the nation towards apt CES. Entropy measure was used for weight calculation of factors such as cost, job creation, and operations, and diverse ranking methods were applied for ranking CESs. Cavallaro et al. (2018) made an assessment of concentrated solar power technology by integrating TOPSIS with trigonometric entropy measure under intuitionistic fuzzy context. Krishankumar et al. (2019) developed an integrated framework with generalized fuzzy data for CES selection. Mathematical models along with the Maclaurin operator and COPRAS approach were proposed to evaluate energy sources.
Jha and Singh (2019) came up with data envelopment analysis for ranking states with India in terms of high scope for CESs and inferred that Tamil Nadu is the leading state, followed by Haryana and Uttar Pradesh. Rani et al. (2019) evaluated CESs by using Pythagorean fuzzy data, divergence measure, and VIKOR that aids in understanding a suitable source for meeting the demands of the Indian population. Recently, Siksnelyte-Butkiene et al. (2020) presented an interesting review on decision methods for CES assessment with households. Fossile et al. (2020) gave a new framework with linear programming and a flexible-interactive trade-off method for identifying suitable CES for Brazilian port with the help of 20 sustainable criteria. Rani et al. (2020a, b) gave a fuzzy-based framework with divergence and TOPSIS approach for CES assessment to satisfy Indian demands. Wang and Yang (2020) developed a non-linear framework supported with projection, clustering, and genetic algorithm for assessing sustainability criteria such as economic, energy, environment, and society for CES adoption in the United Nations. Krishankumar et al. (2021a, b) proposed a new framework for CES evaluation in the Indian context for peoples’ energy demand by adopting generic fuzzy data and integrated regret theory with the Maclaurin operator. Alizadeh et al. (2020) provided an improved model for CES decision-making with the help of ANP and BOCR methods that considers criteria such as vulnerability, technology, economy, well-being and determines viable energy option for Iran. Krishankumar et al. (2020) developed a new model under the linguistic context for CES assessment by proposing methods for criteria/expert weight calculation and ranking. Wu et al. (2020) assessed the risk factors in adopting CES in China owing to the Belt and Road initiative and found that out of 34 risk factors, political and economic risks are substantial for CES adoption. ANP-cloud model was adopted to understand the effects of these risk factors in 54 nations. Krishankumar et al. (2021a, b) gave a new model under a q-rung fuzzy context that allows data preprocessing and decision-making for rational CES selection. Meng et al. (2021) put forward DEMATEL method with TOPSIS/VIKOR for evaluating fintech projects to aid investment support for clean energy by adopting Pythagorean fuzzy information. Pandey et al. (2021) gave a review from the bibliometric context for clean energy assessment with MCDM methods and different fuzzy variants. Wood (2021) prepared fuzzy/intuitionistic fuzzy TOPSIS along with subjective/objective weights determination strategies for evaluating the feasibility stage of clean energy alternative. Kokkinos et al. (2021) integrated TOPSIS with cognitive maps under fuzzy context for the selection of suitable biomass feedstock for biofuel generation. Solangi et al. (2021) developed an integrated AHP-TOPSIS with fuzzy data for assessing the barriers associated with clean energy adoption.
Table 1 provides evidence/support from the literature studies on CES selection for the challenges that are identified (presented in Abstract and Introduction). It can be inferred directly that attitude/weight values of experts are not considered during criteria weight determination. Besides, hesitation of experts is not captured during rating of criteria. Finally, the importance value associated with each CES given by an expert cannot be utilized during the ranking process. Though there are some frameworks that attempt to tackle these challenges, all these challenges are not adequately addressed by a framework to the best of authors’ knowledge. Driven by the claim, in this paper, a new framework with HFS data is proposed for CES selection that could circumvent the challenges (mentioned in Abstract and Introduction).
HFS-based decision models
HFS (Torra 2010) is an interesting generalization to the fuzzy set that promotes experts to provide multiple grades to model their hesitation/uncertainty with respect to MCDPs. Some basic operations on HFS are developed in (Torra and Narukawa 2009). Scholars extended popular ranking methods such as VIKOR (Krishankumar et al. 2018), best-worst approach (J. Li et al. 2019), and MOOSRA (Narayanamoorthy et al. 2020), combined compromise solution approach (Mishra et al. 2021), TOPSIS (Senvar et al. 2016), WASPAS (Mishra et al. 2019), AHP (Zhu et al. 2016), and TODIM (Zhang and Xu 2014) under HFS for rational selection of alternatives. Certain entropy (Zhang et al. 2014) and distance measures (Li et al. 2020; Xu and Xia 2011) under the HFS context are developed for decision-making. Preferences from multiple experts in HFS information are aggregated by using operators such as Qin et al. (2015), Xia and Xu (2011), and Qin et al. (2016). Scholars also provided certain variants such as dual-HFS (Zhu et al. 2012), probabilistic HFS (Xu and Zhou 2016), interval-HFS (Darabi and Heydari 2016), and alike for improving decision-making activities. Some scholars proposed some interesting applications of HFS to environmental and sustainable problems. Wang et al. (2020) present a multi-stage gray group decision-making method based on hesitant fuzzy linguistic term sets for water pollution treatment alternatives. Özkan et al. (2020) to identify alternative landfill sites suggest a method by combining hesitant fuzzy linguistic term sets (HFLTS) and GIS. Boyaci et al. (2021) to find out sites for waste vegetable oil and waste battery collection boxes offer a methodology that combines geographic information systems (GIS), hesitant fuzzy linguistic term set (HFLTS), and the full multiplicative form of multi-objective optimization by ratio analysis (MULTIMOORA).
The literature review made above adds motivation to the contributions presented in this research paper used to circumvent the challenges inferred from these literatures. In the next section, the core methodology is explained in detail.
A new methodology for CES selection
The core contribution of this paper is explained in detail in the forthcoming sections. We provide some basic concepts that lay the foundations for the proposed methodology. A stepwise explanation is provided for the proposed methods.
Preliminaries
Let us make a brief review of the HFSs and their operations.
Definition 1
(Torra 2010): \(XT\) is a fixed set. An HFS on \(XT\) is a function \(h\) that yields a subset in the unit interval that is mathematically given by:
where \({h}_{HV}\left(xt\right)=h\) accepts multiple grades for membership in the unit interval.
Remark 1: For brevity, \({h}_{i}={\mu }_{i}^{k}\) is a hesitant fuzzy element (HFE) where \(k\) is the index associated with multiple grades.
Definition 2
(Xia and Xu 2011): \({h}_{1}\) and \({h}_{2}\) are two HFEs as before. Some arithmetic operations with the elements are given by:
where \(\zeta >0\).
Definition 3
(Torra 2010): \({h}_{1}\) is an HFE as defined earlier. The score and deviation measures are given by:
where \({\#h}_{1}\) denotes the instance elements in an HFS, \(S(.)\) is the score measure, and \(D(.)\) is the deviation measure.
It must be noted that Eqs. (6) and (7) are used for comparison of HFEs. Elements with higher score values are preferred more and elements with lower deviation values are preferred more.
Attitude entropy for HFS information
The section primarily deals with the idea of criteria weight calculation under the HFS context. Driven by the work of Kao (2010), it is concluded that weights must be methodically determined for reducing subjectivity and inaccuracies. Motivated by this, an attitude entropy measure is put forward for weight calculation using HFEs. In general, weights can be assessed in two ways, viz., (a) without any information over the criterion and (b) with some partial information over the criterion. A common idea in both these themes is that each expert provides a vector of rating over the criteria. Following this, in the former setting, relative importance is fully unavailable, which may be due to a lack of expertise or pressure from diverse sources. The latter part includes certain information about the significance of the criteria.
The latter setting puts an overhead of additional information that is circumvented in the former setting. The popular methods in the former context are the analytical hierarchy process (Beskese et al. 2020), stepwise weighted assessment ratio analysis (Mardani et al. 2017a, b), (Rani et al. 2020a), best-worst method (Pamucar et al. 2021), and so on. But, these methods cannot efficiently quantify uncertainty, and hence, the idea of entropy is extended to HFS for rational weight calculation. Entropy (Namdari and Li 2019) is used to quantify uncertainty by calculating average uncertainty with the help of information gain in the weighted form. Moreover, entropy is integrated with an attitude of experts to understand the interacting choice behavior of criteria. Motivated by these claims, we present the procedure for weight calculation via attitude entropy measure for HFS information.
-
Step 1: Obtain a rating vector from each expert on each criterion in the form of \(ax\) vectors of order \(1\times n\). HFS information is used for rating criteria.
-
Step 2: Obtain the attitude value of experts that forms a vector of order \(1\times ax\), and the value is in the unit interval. Apply Eq. (5) to form weighted rating vectors.
-
Step 3: Score measure is adapted from Eq. (6) to the vectors from Step 2 to form a score matrix of order \(ax\times n\).
-
Step 4: Apply Eq. (8) to determine the entropy values associated with each criterion, and this forms a vector of order \(1\times n\)
$${HE}_{j}=-\frac{1}{ax-1}\left(\sum_{j}\left(\frac{{\mu }_{lj}^{*}}{\sum_{l}{\mu }_{lj}^{*}}ln\left(\frac{{\mu }_{lj}^{*}}{\sum_{l}{\mu }_{lj}^{*}}\right)\right)\right)$$(8)
where \({\mu }_{lj}^{*}\) is the weighted score value from the score matrix and \({HE}_{j}\) is the entropy associated with the \({j}^{th}\) criterion.
A higher entropy value for a criterion signifies that there is potential information quantified for better handling uncertainty.
-
Step 5: Equation (9) is employed to normalize the entropies for obtaining weights of criteria that form to be a \(1\times n\) vector.
$${ctw}_{j}=\frac{{HE}_{j}}{\sum_{j}{HE}_{j}}$$(9)
where \({ctw}_{j}\) is the \({j}^{th}\) criterion weight, and it is in the unit interval with the sum of weights equal to unity.
Some properties of \({HE}_{j}\) are given below:
-
(i)
\({HE}_{j}=0\) when normalized score factors are 0 or 1;
-
(ii)
\({HE}_{j}\) is maximum when the normalized score factor is 0.50;
-
(iii)
\({HE}_{j}\) monotonically increases in the window (0, 0.50) and monotonically decreases in the window (0.50, 1);
-
(iv)
\({HE}_{j}={HE}_{j}^{c}\) for a binary entropic measure.
Proofs:
Whenever the normalized score value gets 0 or 1, the resultant entropy value from Eq. (8) becomes 0. That is, \({HE}_{j}=0\) either from \(1ln1\) or \(0ln0\);
From the binary entropic measure, it is clear that the entropy measure is associated to both the belongingness and non-belongingness grades indicating \({\mu }^{*}\) and \(1-{\mu }^{*}\). Clearly, at 0.50, \({HE}_{j}\) is the maximum;
From Eq. (8), it is clear that the value grows from 0 and reaches a peak at 0.50 (from (ii)). Later, from 0.50, there is a drop in values, and \({HE}_{j}\) becomes 0 at \(1ln1\). This ensures the monotonicity of the measure;
In the binary entropic measure,\(HE_j=zlnz+\left(1-z\right)\ln\left(1-z\right)=1-zln\left(\mathit1\mathit-z\right)\mathit+\left(\mathit1\mathit-z\right))ln\left(\left.\mathit1\mathit-\left(\mathit1\mathit-z\right.\right)\right)\mathit=HE_j^c\) \({HE}_{j}=zlnz+\left(1-z\right)\mathrm{ln}\left(1-z\right)=1-zln\left(1-z\right)+(1-\left(1-z\right))ln(1-\left(1-z\right))={HE}_{j}^{c}\) ■
In order to better understand the working of the method, let us consider an example:
Example 1: Consider two criteria rated by two experts by using HFS as the preference style. C1 is rated by D1 as (0.4, 0.5, 0.6) and D2 as (0.3, 0.4, 0.6); C2 is rated by D1 as (0.3, 0.35, 0.44) and D2 as (0.5, 0.55, 0.65). D1 is 0.35 and D2 is 0.65. Score of C1 and C2 with D1 is 0.22 and 0.15; score of C1 and C2 with D2 is 0.31 and 0.42. These values are obtained by applying Eqs. (5) and (6). By Eqs. (8) and (9), the weights are calculated as 0.49 and 0.51, respectively.
Ranking algorithm with HFS information
The ranking is a crucial step in decision-making that allows the sorting of alternatives based on the preference information from an expert(s). The ordering of alternatives provides a sequence in which the alternatives may select for the process being considered. Commonly, preferences are aggregated, and a method is applied to obtain the rank values of alternatives (Kumar et al. 2017). In this idea, experts cannot share their personal opinion/importance on each alternative, and to circumvent the challenge, a new algorithm is put forward. The main idea of the algorithm is to acquire personal choice along with the preference rating values and use this information for ordering alternatives.
Driven by the idea, a new algorithm is developed in this section. A mathematical model is constructed to acquire personal choices, and finally, a combination rule is presented to obtain the net ordering of alternatives. Some key features of the algorithm are the following: (i) considers personal choices of experts, (ii) considers nature of criteria, and (iii) yields both individual and combined ranking of alternatives.

Weighted matrices are formed by applying the vector of order \(1\times n\) to the \(ax\) matrices of order \(m\times n\) through Eq. (5). Equations (10) and (11) are applied to determine positive and negative points criteria wise.
where \(Z\) denotes the number of benefit type criteria, \({h}_{ij}^{*}\) is the weighted HFE, and \(n-Z\) denotes cost type criteria.
\({h}_{j}^{P}\) and \({h}_{j}^{N}\) are two vectors of order \(1\times n\). Construct Model 1 to formulate an optimization problem with objective function and constrains.
Model 1:
Subject to
\({RC}_{i}\) is in the unit interval
Model 1 is solved for all \(ax\) experts, and each time a vector of order \(1\times m\) is obtained that must be combined to form a holistic ranking of CESs. For this, the combination rule is given in Eq. (12). The attitude of experts is used in the combination rule for the rational fusion of values. It is intuitively inferred that these rank vectors are based on the rating from each expert. Hence, the consideration of their attitude values is essential for obtaining the net rank value.
where \(r=\mathrm{1,2},\dots , ax\).
Before providing the case study to testify the usefulness of the model, certain novelties of the proposed methodology are (i) weights of criteria are determined by capturing the hesitation of experts during the rating process along with the attitude/weight value associated with each expert who rated the criteria. Intuitively, this formulation aided in rational weight estimation, which was lacking in the existing models (kindly refer Table 1); (ii) importance of each CES from the perception of an expert was considered as a potential information in the proposed formulation, which led to rational ranking of CES. This parameter was missing in the existing models (kindly refer Table 1); and (iii) personalized ranking of CESs along with net ranking was obtained by using the proposed algorithm that gave the experts a feel of personalization and holistic decision-making, which was also lacking in the existing models (kindly refer Table 1).
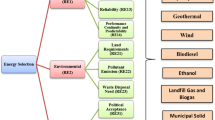
The research model developed (kindly refer Fig. 1A and B) in this paper uses HFS information and attempts to provide mathematical support for the rational selection of CESs to satisfy the demand of smart cities in Tamil Nadu, India. Experts form a panel for solving the problem at hand. Different CESs are prescreened within Tamil Nadu, and suitable sources are shortlisted for the decision process. Based on the literature analysis, followed by a detailed discussion with the panel members, the criteria are finalized. Each expert gives her/his rating on each CES based on a particular criterion. HFS preference style is adopted for rating energy sources.


A Proposed research model for CES selection with HFS information. B Flow diagram of the developed framework with HFS information
Furthermore, each expert gives her/his opinion of each criterion fed as input to the weight calculation procedure. Output from this procedure is a vector in the unit interval with the sum of values equal to unity. These values are considered as weight values of the criteria. Later, the decision matrices from experts are considered for formulating optimization models that are solved using the optimization toolbox to obtain rank values of CESs based on each expert’s preference data and personal choice. Finally, the rank values are fused from each expert to form an aggregated rank value vector that aids in ordering CESs to satisfy the demand in the smart city. Finally, sensitivity analysis and comparison with other methods reveal the superiority of the proposed integrated framework.
Figure 1B shows the working procedure of the developed framework. After data collection from experts on CESs and the criteria used for rating these sources, the model attempts to calculate the weights of criteria to understand its importance. For this, attitudinal entropy measure is adopted, which not only handles hesitation during preference sharing but also considers the reliability factor associated with each expert. This provides rational weight values. Later, personal choices on each CES are obtained from experts and they are formulated as constraints for ranking CESs in a personalized fashion based on the data from each expert. Finally, the rank values from experts are fused to obtain net rank values that help in ordering the CESs.
Case example — energy source selection for a smart city
This section demonstrates a case example of selecting a viable CES for meeting the energy demands in the smart city within Tamil Nadu (TN). The Union Ministry of Housing and Urban Affairs initiated the smart city program within Tamil Nadu by planning to enhance livelihood and health in 11 cities, viz., Chennai, Trichy, Madurai, and Salem. Tamil Nadu has completed 167 projects with a total cost of around 2000 crore INR. Murugaiah et al. (2018) claimed that there are many definitions of smart city, and all these make a partial overlapping with the core idea being the active usage of ICT technologies for improving the competitive advantage through human and technology capital. They also stated that a smart city is an umbrella under which smart health, smart energy, smart environment, smart economy, and so on evolve.
In this context, CESs are the essential form of energy that preserves eco-balance and aid in proper satisfaction of high energy demand. Smart energy programs trigger nations to use non-conventional energy sources driven from nature and are pollution-free. India has taken a brave step towards reducing the carbon footprint by 2030 without compromising on growth and development at the global level. In India, Tamil Nadu is the 11th largest state that spreads out to 130,058 sq. km. Its geographic location allows the state to spread over both the Eastern and Western Ghats. This geographic advantage makes Tamil Nadu a significant contributor to CES, with a net contribution of around 17.20% of the total energy produced in the country. Popular natural sources for Tamil Nadu constitute wind, solar, and water that could be effectively utilized for energy production. The government of Tamil Nadu initiated clean energy production as a people movement to make the contribution significant for the nation. In 1984, the Tamil Nadu energy development agency (TEDA) was constituted that took care of the energy demand within Tamil Nadu. TEDA is primarily involved in enhancing R&D activities in the energy sector and improving clean energy production from Tamil Nadu. It must be noted that around 8000 MW, 4000 MW, and 2000 MW of wind, solar, and hydro energy are produced, respectively, by Tamil Nadu. TEDA looks after projects for clean energy generation such as Raasi green energy, BTN solar, and ReNew solar for solar energy generation worth 100 MW from each project. Later, Gamesa and Muppndal wind projects help wind energy generation of worth 850 KW and 25.5 MW, respectively. Also, certain projects associated with hydropower generation are Kunda and Anamalai hill projects with a capacity for around 500 MW of hydropower. The main theme of these projects is to minimize carbon footprint and enhance sustainability. In 2005, a biogas power project was initiated in Tamil Nadu for 18 MW power generation. In 2014, IIT–Madras investigated that India has a potential for 12.45 MW of power from tidal sources of which the Mannar channel of Tamil Nadu plays a vital part.
With this brief and interesting backdrop, in this section, we demonstrate the usage of the proposed framework by aiding in the rational selection of CES for meeting the energy demand of Chennai (a smart city) in Tamil Nadu. Five potential CESs are considered in this study: solar, wind, tidal, hydro, and biogas. Based on the literature of CES (Mardani et al. 2017a, b) selection, six criteria for assessing the CESs are fixed. They are given as durability, adaption to government norms, pollution control, security, land usage, and total cost. The last two criteria are cost type, and the rest are benefit type. Three experts from the academics and government sectors constitute the decision panel. A senior research scientist from the energy division, legal and finance personnel, and chief energy engineer are the panel members. For the sake of implementation, we refer CESs by \(NC=\left({nc}_{1},{nc}_{2},{nc}_{3},{nc}_{4},{nc}_{5}\right)\); criteria by \(MC=\left({mc}_{1},{nc}_{2},{mc}_{3},{mc}_{4},{mc}_{5},{mc}_{6}\right)\); and experts by \(DP=\left({dp}_{1},{dp}_{2},{dp}_{3}\right)\). The second and third authors of this paper prepared a questionnaire for data collection that was fine-tuned based on detailed discussion with other authors and the experts who agreed to participate in the case example and provided their valuable preferences for effective demonstration of the practicality of the framework. The second and third authors detailed the work and the preference structure via video conferencing, and after a clear understanding, the experts accepted the questionnaires and provided their responses. The response for the questionnaires from each expert was sent via email, and with the ethical understanding between authors and experts, the integrity of the data is maintained. The main reason for collecting data in the HFS form is that the experts gain adequate flexibility to freely share their grades of preferences for CESs based on each sustainable criterion. The data from all three experts were collected. A datasheet was formed that was statistically verified based on Cronbach’s test and chi-squared test at 95% confidence to clarify the data’s sampling consistency and homogeneity.
Stepwise procedure for CES selection is given below:
-
Step 1: Each expert provides his/her preference information in the form of HFS data that yields a matrix of order \(5\times 6\). Each data matrix represents the rating of CESs based on the criteria chosen for assessing the sources.
Table 2 shows the data in the form of HFS information collected from experts in a questionnaire. The experts gained an opportunity to grade CESs based on diverse criteria flexibly. Opinions of all three experts on each CES over a criterion are obtained as preference grades, and it is considered the dataset for the decision process.
-
Step 2: Each expert also provides a preference vector of order \(1\times 6\) that describes his/her choice on each criterion. Top officials of the smart city program give the panel members reliability values that are considered the weight/attitude of each expert. All values are in the unit interval, and they imply the percentage of reliability and the sum of the values equal unity.
Table 3 shows the opinions from each expert on each criterion. All experts provide his/her opinion as vectors in the form of HFS information. Specifically, a matrix of order \(3\times 6\) is presented that is used for weight calculation.
-
Step 3: Use the data from Step 2 and the procedure given in “Attitude entropy for HFS information” to calculate the weights of the criteria. A vector of order \(1\times 6\) is obtained with values in the unit interval and the sum of values equal to unity.
By applying Eqs. (8) and (9) to the values (obtained from Eq. (6)) in Fig. 2, the entropy and weight value of each criterion are calculated and that is given as 1.081, 1.085, 1.097, 1.0788, 1.0797, and 1.098; 0.1659, 0.1664, 0.1683, 0.1654, 0.1656, and 0.1684, respectively.
-
Step 4: Data from Step 1 and the calculated weight values from Step 3 are used to rank CESs in a personalized fashion. A rank vector is calculated for each expert based on their data/preferences, and the final rank order of CESs is determined to help the smart city with their energy demands.

Score values in a matrix of order 3 by 6
Figure 3 depicts the objective function coefficients for all experts. By applying the distance norm under the minimization framework, the objective function is formulated. As constraints, the partial choice information or personal opinion of each expert is considered and its given by \({nc}_{1}\le 0.3\), \({nc}_{2}\le 0.1\), \({nc}_{3}\le 0.35\), \({nc}_{4}={nc}_{5}\le 0.25\), \({nc}_{1}+{nc}_{2}+{nc}_{3}\le 1\), \({nc}_{4}+{nc}_{5}\le 0.5\), \({nc}_{1}+{nc}_{2}\le 0.2\) for the first two objective functions; \({nc}_{2}+{nc}_{3}+{nc}_{4}\le 0.55\) and \({nc}_{2}+{nc}_{4}+{nc}_{5}\le 0.45\) are additional information provided by \({dp}_{3}\). As a result, the rank values of CESs (alternatives) changes based on the set of constraints. With the help of the MATLAB® optimization toolbox, the formulated constrained optimization problem is solved. Table 4 provides the rank values and the ordering of CESs based on each expert’s perception. In general, the final rank values are given by Eq. (12) as \({NR}_{1}=0.118\), \({NR}_{2}=0.092\), \({NR}_{3}=0.350\), \({NR}_{4}=0.232\), and \({NR}_{5}=0.234\), and the net order is given by \({nc}_{3}\prec {nc}_{5}\prec {nc}_{4}\prec {nc}_{1}\prec {nc}_{2}\) with wind energy as viable CES for satisfying the energy demand of Chennai, followed by solar and hydro sources.
-
Step 5: Sensitivity analysis on criteria weights is conducted by creating six weights based on shift operation. Figure 4 shows the rank values for each new weight set, and from the figure, it is clear that the order of CESs does not change, indicating the robustness of the framework.

Coefficients of objective functions of each expert

Rank values for different weight sets
Investigation with other methods
To clearly understand the strengths and the shortcomings of the framework, a comparative investigation is performed in this section. For this purpose, application-oriented and method-oriented frameworks are considered from the literature. Under the application context, frameworks such as Rani et al. (2019), Fossile et al. (2020), Zhang et al. (2019), and Rani et al. (2020a, b) are compared with the proposed work. All these models address the CES selection problem under diverse preference structures. Furthermore, under the method perspective, we consider Mishra et al. model (Mishra et al. 2021), Mishra et al. model (Mishra et al. 2019), and Krishankumar et al. (2018) for comparison with the proposed work. These models use the HFS structure for developing decision models. Table 5 presents the summary of the comparison under application context and based on the pointwise explanation. The proposed framework is novel and substantial for CES selection Table 6.
Some innovations of the proposed framework are listed below:
-
The framework uses an HFS structure for preference information that provides flexibility to experts to share multiple opinions for a particular instance. Specifically, experts gain the freedom to share multiple grades for expressing their preferences that are lacking in the extant frameworks.
-
Interrelationship among criteria is captured along with the experts’ hesitation during grading criteria, which is also lacking in extant models. Besides, each expert’s attitude is considered a parameter in the formulation to calculate weights rationally.
-
Unlike extant models, preference grades are directly obtained from the experts instead of transforming rating data from Likert scale form, which preserves data integrity and provides an open window for experts to share their grades freely.
-
Unlike the extant models, the proposed framework (i) acquires personal choices of experts on each CES as partial information, (ii) determines the personalized ranking of CESs based on the partial information, and (iii) finally, these values are fused to form net ranking of CESs.
-
The proposed work offers a two-way ranking of CESs, one from the experts’ point of view and the other is the holistic rank based on the personalized ranking, which is lacking in earlier CES selection models.
We conduct experiments for uniqueness tests based on correlation values of ranking orders from diverse methods from the method perspective. Furthermore, a simulation setting is adopted with 350 matrices of order \(5\times 6\) generated with HFS information, and all these matrices are fed as input to these methods. Rank values are obtained, and a deviation measure is used to calculate the discrimination factor for each vector. Based on Fig. 5, it is inferred that the proposed work discriminates CESs with acceptable variations among individual experiments and the values are statistically significant at 95% confidence. Apart from this, sensitivity analysis is performed for the reliability test in Step 5 of “Case example — energy source selection for a smart city.”

Boxplot of proposed vs. other methods — rank value variations
In Fig. 6, correlation values are determined between every pair of methods with respect to the proposed framework by adopting Spearman’s correlation. Ideally, it is inferred that the proposed work is highly unique compared to the earlier approaches in terms of the formulation and ranking order. This is true because the proposed work considers the personal choices of experts and embeds them as partial information during model formulation. Furthermore, individual expert ordering of CES is obtained based on the solution to each objective function for an expert data matrix, which is fused to form a net ranking of CESs. Earlier models lack the ability to process personal choices from experts, and hence, the proposed work is unique and novel.

Spearman’s correlation for uniqueness test
Based on the results from the proposed framework and policy actions within India, certain policy implications can be made, and they are listed below:
-
Tamil Nadu is a gifted state in India because of its geographic location, making it a potential state for CES. As per the report from TEDA, Tamil Nadu contributes 17.20% of total clean/renewable energy (CRE) produced by India. Also, the Ministry of New and Renewable Energy identified that by 2022, India would expand CRE production close to 16%. This would satisfy the demands within the nation and aid in future planning and sustainability.
-
As per the inference from Jha and Singh (2019), states such as Tamil Nadu are a leading
-
contributor for CRE within India, and as mentioned earlier, there are many solar and wind projects that are approved by TEDA for expanding green practices.
-
According to the Paris Accord, in 2015, India committed to reducing greenhouse gas emissions by 33 to 35%. Furthermore, India expanded CRE usage to 40% from 28% that made a notable reduction in carbon footprint, adhering to the prediction of about 50,000 t of CO2 equivalent will reduce yearly.
-
India plans on an ambitious target of 175 GW of CRE to satisfy people’s present and future demands. Under this initiative, Tamil Nadu plays a crucial part by nearly generating 2621 MW of solar power and 1567 MW of wind power (https://www.thehindubusinessline.com article 33991339 dated: 17.04.2021). As of 2016, Tamil Nadu has a potential of about 2212 MW of hydropower as per the report from (https://www.electricalindia.in/hydro-power-scenario-in-tamilnadu/ dated: 17.04.2021).
-
A recent report estimated that Tamil Nadu had a total potential of about 15,876 MW of CRE. A biogas initiative was launched in the Namakkal region of Tamil Nadu that had the potential to fuel 1000 vehicles per day (https://www.thehindu.com article31899752 dated: 17.04.2021). This scheme was under a tie-up from Indian oil and German oil tanking with a cost of around INR 25 crore.
-
The results produced in this research are also in line with the available resources and the contribution from each clean source. Wind power is identified as the most dominant alternative from Tamil Nadu that can satisfy energy needs effectively. Scope for tidal energy in Tamil Nadu is subtle, and biogas is preceding as a clean energy option.
-
Criteria, viz., pollution control and total cost are highly preferred, followed by land usage and durability, which are also in line with the policies in Tamil Nadu. The entire nation focuses on reducing carbon footprint (Shukla and Chaturvedi 2012), which adheres to the present study. Another crucial focus of the nation is on the feasibility of such energy, and its impact on the economy has been prime focus (Muneer et al. 2005).
Conclusion
This work is a value addition to the decision frameworks that are actively used for CES selection. The proposed framework utilizes a flexible data structure that mitigates subjective randomness and allows experts to share multiple preference grades. The present framework calculates weights of criteria rationally by considering the attitude values (weights) of experts and hesitation during the preference elicitation process. Furthermore, the personalized ranking of CESs based on experts’ choice is possible in the proposed framework, along with the net ranking of CESs. Such innovations are lacking in extant frameworks for CES selection.
Moreover, the framework presented in this paper is robust for different criteria weight sets (obtained from shift operation) that are realized through sensitivity analysis. Though the rank values change, the ordering remains intact. Spearman’s correlation is applied to the ranking order to ensure the uniqueness of the method. Finally, the boxplot shows that the proposed framework is able to discriminate alternative CESs with acceptable variations of rank values.
Managerial implications that can be inferred are (i) the framework is a ready-to-use model that aids managers to make rational and methodical decisions, (ii) subjectivity/hesitation involved in the modeling is handled effectively by the framework, (iii) certain level of training via workshops and hands-on must be given to the managers to better understand the data and inference from the framework, and (iv) finally, in the present work, personal choices are given consideration that allows managers to express their choices as partial information on each CES.
To further expand research directions in the future, plans are made to understand the relationship among the number of experts and reliability of results. Furthermore, plans are made to incorporate pre-processing methodologies such as feature reduction and data cleaning and the integration of machine learning methods with decision aiding methods. New decision models with stochastic information can be developed for handling environmental/sustainable issues. Finally, the energy evaluation problems with multiple sub-criteria and non-preference data can be solved by developing new orthopair frameworks.
Availability of data and materials
Not applicable.
References
Alizadeh R, Soltanisehat L, Lund PD, Zamanisabzi H (2020) Improving renewable energy policy planning and decision-making through a hybrid MCDM method. Energy Policy 137:111174. https://doi.org/10.1016/j.enpol.2019.111174
Beskese A, Camci A, Temur GT, Erturk E (2020) Wind turbine evaluation using the hesitant fuzzy AHP-TOPSIS method with a case in Turkey. J Intell Fuzzy Syst 38(1):997–1011. https://doi.org/10.3233/JIFS-179464
Çalış Boyacı A, Şişman A, Sarıcaoğlu AK (2021) Site selection for waste vegetable oil and waste battery collection boxes: a GIS-based hybrid hesitant fuzzy decision-making approach. Environ Sci Pollut Res 28(14):17431–17444. https://doi.org/10.1007/s11356-020-12080-5
Cavallaro F, Ciraolo L (2013) Sustainability assessment of solar technologies based on linguistic information. In: Cavallaro F. (eds) Assessment and Simulation Tools for Sustainable Energy Systems. Green Energy Technol 129. Springer, London. https://doi.org/10.1007/978-1-4471-5143-2_1
Cavallaro Fausto, Zavadskas EK, Raslanas S (2016) Evaluation of combined heat and power (CHP) systems using fuzzy shannon entropy and fuzzy TOPSIS. Sustainability (Switzerland) 8(6):1–25. https://doi.org/10.3390/su8060556
Cavallaro F, Zavadskas EK, Streimikiene D (2018) Concentrated solar power (CSP) hybridized systems. Ranking based on an intuitionistic fuzzy multi-criteria algorithm. J Clean Prod 179:407–416. https://doi.org/10.1016/j.jclepro.2017.12.269
Darabi S, Heydari J (2016) An interval- valued hesitant fuzzy ranking method based on group decision analysis for green supplier selection. IFAC-PapersOnLine 49(2):12–17. https://doi.org/10.1016/j.ifacol.2016.03.003
Eremia M, Toma L, Sanduleac M (2017) The smart city concept in the 21st century. Procedia Eng 181:12–19. https://doi.org/10.1016/j.proeng.2017.02.357
Fossile DK, Frej EA, Gouvea da Costa SE, Pinheiro de Lima E, Teixeira de Almeida A (2020) Selecting the most viable renewable energy source for Brazilian ports using the FITradeoff method. J Clean Prod 260:121107. https://doi.org/10.1016/j.jclepro.2020.121107
Indragandhi V, Subramaniyaswamy V, Logesh R (2017) Resources, configurations, and soft computing techniques for power management and control of PV/wind hybrid system. Renew Sustain Energy Rev 69(November 2016):129–143 https://doi.org/10.1016/j.rser.2016.11.209
Jha AP, Singh SK (2019) Performance evaluation of Indian states in the renewable energy sector for making investment decisions: a managerial perspective. J Clean Prod 224:325–334. https://doi.org/10.1016/j.jclepro.2019.03.170
Kao C (2010) Weight determination for consistently ranking alternatives in multiple criteria decision analysis. Appl Mathe Model 34(7):1779–1787. https://doi.org/10.1016/j.apm.2009.09.022
Kokkinos K, Karayannis V, Moustakas K (2021) Optimizing microalgal biomass feedstock selection for nanocatalytic conversion into biofuel clean energy, using fuzzy multi-criteria decision making processes. Front Energy Res 8(February):1–20. https://doi.org/10.3389/fenrg.2020.622210
Krishankumar R, Nimmagadda SS, Rani P, Mishra AR, Ravichandran KS, Gandomi AH (2021) Solving renewable energy source selection problems using a q-rung orthopair fuzzy-based integrated decision-making approach. J Clean Prod 279:123329. https://doi.org/10.1016/j.jclepro.2020.123329
Krishankumar R, Ravichandran KS, Kar S, Cavallaro F, Zavadskas EK, Mardani A (2019) Scientific decision framework for evaluation of renewable energy sources under q-rung orthopair fuzzy set with partially known weight information. Sustainability 11(15):1–21. https://doi.org/10.3390/su11154202
Krishankumar R, Ravichandran KS, Murthy KK, Saeid AB (2018) A scientific decision-making framework for supplier outsourcing using hesitant fuzzy information. Soft Comput. https://doi.org/10.1007/s00500-018-3346-z
Krishankumar R, Sangeetha V, Rani P, Ravichandran KS, Gandomi AH (2021) Selection of apt renewable energy source for smart cities using generalized orthopair fuzzy information, IEEE symposium series on computational intelligence, 2861–2868https://doi.org/10.1109/ssci47803.2020.9308365
Krishankumar Raghunathan, Mishra AR, Ravichandran KS, Peng X, Zavadskas EK, Cavallaro F, Mardani A (2020) A group decision framework for renewable energy source selection under interval-valued probabilistic linguistic term set. Energies 13(4):1–19. https://doi.org/10.3390/en13040986
Kumar A, Sah B, Singh AR, Deng Y, He X, Kumar P, Bansal RC (2017) A review of multi criteria decision making (MCDM) towards sustainable renewable energy development. Renew Sustain Energy Rev 69:596–609. https://doi.org/10.1016/j.rser.2016.11.191
Lee HC, Chang CT (2018) Comparative analysis of MCDM methods for ranking renewable energy sources in Taiwan. Renew Sustain Energy Rev 92:883–896. https://doi.org/10.1016/j.rser.2018.05.007
Li C, Zhao H, Xu Z (2020) Hesitant fuzzy psychological distance measure. Int J Mach Learn Cybern 11(9):2089–2100. https://doi.org/10.1007/s13042-020-01102-w
Li J, Wang J Qiang, Hu J Hua (2019) Multi-criteria decision-making method based on dominance degree and BWM with probabilistic hesitant fuzzy information. Int J Mach Learn Cybern 10(7):1671–1685. https://doi.org/10.1007/s13042-018-0845-2
Mardani A, Nilashi M, Zakuan N, Loganathan N, Soheilirad S, Saman MZM, Ibrahim O (2017) A systematic review and meta-analysis of SWARA and WASPAS methods: theory and applications with recent fuzzy developments. Appl Soft Comput J 57:265–292. https://doi.org/10.1016/j.asoc.2017.03.045
Mardani A, Zavadskas EK, Khalifah Z, Zakuan N, Jusoh A, Nor KM, Khoshnoudi M (2017) A review of multi-criteria decision-making applications to solve energy management problems: two decades from 1995 to 2015. Renew Sustain Energy Rev 71:216–256. https://doi.org/10.1016/j.rser.2016.12.053
Meng Y, Wu H, Zhao W, Chen W, Dinçer H, Yüksel S (2021) A hybrid heterogeneous Pythagorean fuzzy group decision modelling for crowdfunding development process pathways of fintech-based clean energy investment projects. Fin Innov 7(1):1–33. https://doi.org/10.1186/s40854-021-00250-4
Mishra AR, Rani P, Krishankumar R, Zavadskas EK, Cavallaro F, Ravichandran KS (2021) A hesitant fuzzy combined compromise solution framework-based on discrimination measure for ranking sustainable third-party reverse logistic providers. Sustainability 13(4):1–25. https://doi.org/10.3390/su13042064
Mishra AR, Rani P, Pardasani KR, Mardani A (2019) A novel hesitant fuzzy WASPAS method for assessment of green supplier problem based on exponential information measures. J Clean Prod 238:117901. https://doi.org/10.1016/j.jclepro.2019.117901
Muneer T, Asif M, Munawwar S (2005) Sustainable production of solar electricity with particular reference to the Indian economy. Renew Sustain Energy Rev 9(5):444–473. https://doi.org/10.1016/j.rser.2004.03.004
Murugaiah V, Shashidhar R, Ramakrishna V (2018) Smart cities mission and AMRUT scheme: analysis in the context of sustainable development. OIDA Int J Sustain Dev 11(10):49–60
Namdari A, Li Z (2019) A review of entropy measures for uncertainty quantification of stochastic processes. Adv Mech Eng 11(6):1–14. https://doi.org/10.1177/1687814019857350
Narayanamoorthy S, Annapoorani V, Kang D, Baleanu D, Jeon J, Kureethara JV, Ramya L (2020) A novel assessment of bio-medical waste disposal methods using integrating weighting approach and hesitant fuzzy MOOSRA. J Clean Prod 275:122587. https://doi.org/10.1016/j.jclepro.2020.122587
Ourbak T, Magnan AK (2018) The Paris agreement and climate change negotiations: small islands, big players. Reg Environ Change 18(8):2201–2207. https://doi.org/10.1007/s10113-017-1247-9
Ozorhon B, Batmaz A, Caglayan S (2018) Generating a framework to facilitate decision making in renewable energy investments. Renew Sustain Energy Rev 95:217–226. https://doi.org/10.1016/j.rser.2018.07.035
Özkan B, Sarıçiçek B, Özceylan E (2020) Evaluation of landfill sites using GIS-based MCDA with hesitant fuzzy linguistic term sets. Environ Sci Pollut Res 27(1):42908–42932. https://doi.org/10.1007/s11356-020-10128-0
Pamucar D, Deveci M, Canıtez F, Paksoy T, Lukovac V (2021) A novel methodology for prioritizing zero-carbon measures for sustainable transport. Sustain Prod Consum 27:1093–1112. https://doi.org/10.1016/j.spc.2021.02.016
Pandey AK, Krishankumar R, Pamucar D, Cavallaro F, Mardani A, Kar S, Ravichandran KS (2021) A bibliometric review on decision approaches for clean energy systems under uncertainty. Energies 14(20):6824, 1-25 https://doi.org/10.3390/en14206824
Qin J, Liu X, Pedrycz W (2015) Hesitant fuzzy maclaurin symmetric mean operators and its application to multiple-attribute decision making. Int J Fuzzy Syst 17(4):509–520. https://doi.org/10.1007/s40815-015-0049-9
Qin J, Liu X, Pedrycz W (2016) Frank aggregation operators and their application to hesitant fuzzy multiple attribute decision making. Appl Soft Comput 41:428–452. https://doi.org/10.1016/j.asoc.2015.12.030
Rani P, Mishra AR, Krishankumar R, Mardani A, Cavallaro F, Ravichandran KS, Karthikeyan B (2020) Hesitant fuzzy SWARA-Complex proportional assessment approach for sustainable supplier (HF-SWARA-COPRAS). Symmetry 12(7):1–19 https://doi.org/10.3390/sym12071152
Rani P, Mishra AR, Mardani A, Cavallaro F, Alrasheedi M, Alrashidi A (2020) A novel approach to extended fuzzy TOPSIS based on new divergence measures for renewable energy sources selection. J Clean Prod 257:120352. https://doi.org/10.1016/j.jclepro.2020.120352
Rani P, Mishra AR, Pardasani KR, Mardani A, Liao H, Streimikiene D (2019) A novel VIKOR approach based on entropy and divergence measures of Pythagorean fuzzy sets to evaluate renewable energy technologies in India. J Clean Prod 238:117936. https://doi.org/10.1016/j.jclepro.2019.117936
Reddy S, Painuly JP (2004) Diffusion of renewable energy technologies-barriers and stakeholders’ perspectives. Renew Energy 29(9):1431–1447. https://doi.org/10.1016/j.renene.2003.12.003
Rodríguez RM, Martínez L, Torra V, Xu ZS, Herrera F (2014) Hesitant fuzzy sets: state of the art and future directions. Int J Intell Syst 29(2):495–524. https://doi.org/10.1002/int
Senvar O, Otay I, Bolturk E (2016) Hospital site selection via hesitant fuzzy TOPSIS. IFAC-PapersOnLine 49(12):1140–1145. https://doi.org/10.1016/j.ifacol.2016.07.656
Shukla PR, Chaturvedi V (2012) Low carbon and clean energy scenarios for India: Analysis of targets approach. Energy Econ 34(3):487–495. https://doi.org/10.1016/j.eneco.2012.05.002
Siksnelyte-Butkiene I, Zavadskas EK, Streimikiene D (2020) Multi-criteria decision-making (MCDM) for the assessment of renewable energy technologies in a household: a review. Energies 13(5):1–20. https://doi.org/10.3390/en13051164
Solangi YA, Longsheng C, Shah SAA (2021) Assessing and overcoming the renewable energy barriers for sustainable development in Pakistan: an integrated AHP and fuzzy TOPSIS approach. Renew Energy 173:209–222. https://doi.org/10.1016/j.renene.2021.03.141
Torra V (2010) Hesitant fuzzy sets. Int J Intell Syst 25(2):529–539. https://doi.org/10.1002/int
Torra Vicente, Narukawa Y (2009) On hesitant fuzzy sets and decision. IEEE Int Conf Fuzzy Syst 1378–1382https://doi.org/10.1109/FUZZY.2009.5276884
Wang Q, Yang X (2020) Investigating the sustainability of renewable energy – an empirical analysis of European Union countries using a hybrid of projection pursuit fuzzy clustering model and accelerated genetic algorithm based on real coding. J Clean Prod 121940https://doi.org/10.1016/j.jclepro.2020.121940
Wang J, Qian W, Du J, Yong L (2020) Effective allocation of resources in water pollution treatment alternatives: a multi-stage gray group decision-making method based on hesitant fuzzy linguistic term sets. Environ Sci Pollut Res 27(3):3173–3186. https://doi.org/10.1007/s11356-019-07265-6
Wood DA (2021) Feasibility stage screening for sustainable energy alternatives with a fuzzy multi-criteria decision analysis protocol. Model Earth Syst Environ. https://doi.org/10.1007/s40808-021-01140-5
Wu Y, Wang J, Ji S, Song Z (2020) Renewable energy investment risk assessment for nations along China’s Belt & Road Initiative: an ANP-cloud model method. Energy 190:116381. https://doi.org/10.1016/j.energy.2019.116381
Xia M, Xu Z (2011) Hesitant fuzzy information aggregation in decision making. Int J Approx Reason 52(3):395–407. https://doi.org/10.1016/j.ijar.2010.09.002
Xu Z, Xia M (2011) Distance and similarity measures for hesitant fuzzy sets. Inf Sci 181(11):2128–2138. https://doi.org/10.1016/j.ins.2011.01.028
Xu Z, Zhou W (2016) Consensus building with a group of decision makers under the hesitant probabilistic fuzzy environment. Fuzzy Optim Decis Mak 16(4):1–23. https://doi.org/10.1007/s10700-016-9257-5
Xu L, Shah SAA, Zameer H, Solangi HYA (2019) Evaluating renewable energy sources for implementing the hydrogen economy in Pakistan: a two-stage fuzzy MCDM approach. Environ Sci Pollut Res 26(32):33202–33215. https://doi.org/10.1007/s11356-019-06431-0
Zhang L, Xin H, Yong H, Kan Z (2019) Renewable energy project performance evaluation using a hybrid multi-criteria decision-making approach: case study in Fujian, China. J Clean Prod 206:1123–1137. https://doi.org/10.1016/j.jclepro.2018.09.059
Zhang X, Xu Z (2014) The TODIM analysis approach based on novel measured functions under hesitant fuzzy environment. Knowl-Based Syst 61:48–58. https://doi.org/10.1016/j.knosys.2014.02.006
Zhang Y, Wang Y, Wang J (2014) Objective attributes weights determining based on shannon information entropy in hesitant fuzzy multiple attribute decision making. MatheProbl Eng 463930https://doi.org/10.1155/2014/463930
Zhu B, Xu Z, Xia M (2012) Dual hesitant fuzzy sets. J ApplMathe 879629https://doi.org/10.1155/2012/879629
Zhu B, Xu Z, Zhang R, Hong M (2016) Hesitant analytic hierarchy process. Eur J Oper Res 250(2):602–614. https://doi.org/10.1016/j.ejor.2015.09.063
Author information
Authors and Affiliations
Contributions
The paper has been read by all authors, and they agree for its submission to the journal. RK conceptualized the idea, methods, and the criteria for the assessment of cleaner energy. RK made the draft of the manuscript that was fine-tuned by KSR. DP revised the calculations and finally FC and KSR checked the result and provided valuable suggestions. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Responsible Editor: Philippe Garrigues
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Appendix A
Abbreviations used in the paper are expanded in a tabular form () to add clarity to readers.
Table 7 depicts the symbols used in this paper along with the associated semantics.
Table 8 provides a sample questionnaire for clarity to readers
Rights and permissions
About this article

Cite this article
Krishankumar, R., Pamucar, D., Cavallaro, F. et al. Clean energy selection for sustainable development by using entropy-based decision model with hesitant fuzzy information. Environ Sci Pollut Res 29, 42973–42990 (2022). https://doi.org/10.1007/s11356-022-18673-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-022-18673-6