
Abstract
Yarn strength index is a heavy index of yarn quality, Yarn quality can be well controlled by predicting yarn strength index. Generally, multiple non regression algorithms, support vector machines (SVD) and BP neural network algorithms are generally used to predict yarn strength. This paper presents an algorithm to connect the convolution neural network (CNN) with the BP neural network, which is written as the CNN-BP algorithm. We use 20 sets of data to train CNN-BP algorithm, regression, V-SVD algorithm, and BP neural network. We tested CNN-BP algorithm, regression, V-SVD algorithm, and BP neural network with 5 sets of data. The CNN-BP neural network algorithm is the best in these four algorithms.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The most important step in cotton knitting is the production process from cotton fibre to cotton yarn. The process includes a series of production processes such as cleaning cotton, combing cotton, Thick yarn, Fine yarn, etc. The yarn strength is an important indicator of the quality of the yarn, the yarn is strong, and the end rate is low in the process of processing, and it is beneficial to the process of spinning and weaving, and not only make the product durable. At the same time, it also reduced the intensity of labour, Ti, high production efficiency.
The strength of the yarn is divided into absolute power, which is the force required by the external force directly to the fracture, which is also known as the strength of the fracture and relative strength (such as the length of the yarn, the length of the thread) Class 2. The yarn strength is the maximum load of the unit thickness or the size of the yarn, which is the absolute power and the yarn line. The ratio of density. In the case of machine setting, the strong performance of cotton yarn is mainly determined by the properties of raw materials.
In the analysis of the relationship between fiber performance and yarn quality, the methods of regression analysis and BP neural network are often used in addition to the traditional fracture mechanism model. The two prediction methods are higher, and we use BP neural networks and convolutional neural network (CNN) to predict the results and compare the prediction results with the first two methods.
2 Methodology
2.1 Selection of Input Index and Output Index
Fiber strength (g/tex) and fiber length (inch) and elongation (%), impurity content (Cnl) length irregularity (%), yellow + b, Mike Ronny (MIC), reflectivity (%) factors play a leading role on the strength of yarn, put these 8 indicators as the model input. Yarn strength as output index. 25 groups of data were collected, of which 20 were used for model training, and the 5 groups were used for model testing.
2.2 Structure Design of CNN-BP Neural Network
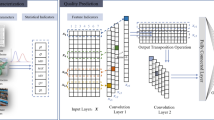
The convolutional neural network is combined with BP neural network to design 5 layers of convolution BP neural network, as shown in Fig. 1, including 1 level input layer, 1 layer volume layer, 1 level sampling layer, 1 level BP training layer, 1 layer fully connected output layer.

CNN-BP neural network
Because there are 8 independent variables, in the input layer, each input sample is constructed in a fixed order into a (3 × 3) matrix \(X = (X_{1} , \ldots , \, X_{m} )^{T}\) and the vacancy is assigned to zero [1,2,3]. The convolutional layer is concretely constructed, as shown in Fig. 2.

Convolutional layer structure
Seven (3 × 3) convolution cores are set up, and two (3 × 3) experts guide the combinatorial structure of the pool core and (1 × 1) convolutional kernel. The number of (3 × 3) convolution kernel and combinatorial structure can vary with specific needs. In the output, the feature graph extracted from the (3 × 3) convolution kernel and the combinatorial structure is arranged in a row [4–6]. Assuming that Mi is the output of the i (3 × 3) convolution kernel, Ni is the output of the i composite structure. The following expression is obtained:
Among them guidpool() instructing the pool core for experts, the effect is to extract a parameter that is considered to have a larger impact on the output. When there are multiple guidpool(), the extracted parameters cannot be the same. Wi, Vi represents the weight vector of the i convolutional kernel and the expert instruction pool core. The operation symbol “\(\otimes\)” represents the convolutional operation of the convolution kernel with the first feature graph or the data matrix, the result of convolution is added to the corresponding offset vector bi or 0i. f() is a specific nonlinear excitation function. Assuming that H is a convolution layer, the production process of H can be described as:
The M, N is (3 × 3) convolution kernel and the characteristic graph of the combined structure extraction respectively. The operation symbol “\(\oplus\)” represents the different feature graphs into one column, and unifies the dimensions of each feature map, and the insufficient part assignment is zero [1,2,3]. The sampling layer here follows the coiling layer and samples the feature graph based on the maximum value of the down sampling rules.
Suppose D is the sampling layer:
The sampling requires a pair of feature graphs Mi or Ni, Only one value is extracted, So the sample core here is extracted from up and down, step by step to extract each feature map or the maximum value within. The output is arranged in a row in the original order.
The \(D = (D_{1} , \ldots ,D_{m} )^{T}\) of the output of the sampling layer is input to the BP training layer as the 1 input vector, and the BP training layer structure is shown in Fig. 3.

BP neural network structure
Among them, X = (X1,…, Xm)T is input vector, Y = (Y1,…,Ym)T is output vector, Wij is the weight coefficient of the connection between the input layer and the middle layer, Vjt is the weight coefficient of the connection between the middle layer and the output layer, S = (S1,…,Sm)T input vectors of each element in the middle layer, B = (B1,…,Bm)T is the output vector of each element in the middle layer, T = (T1,…,Tm)T is expected output vector. The concrete steps of the algorithm are as follows:
-
(1)
In the range of the interval (− 1, 1), the weight value, and the initial value of the threshold are set.
-
(2)
A set of randomly selected input Xm and target Ym learning samples are provided to the neural network.
-
(3)
For the middle layer, the input value of each node is Sm, and the output value of each node in the middle layer is Xm with input sample \(\omega_{ij}\), weight θj and threshold Bm, and calculated by input value Sm.
-
(4)
The output function of the weights and biases in the neural network is:
$$F = f\left| {\mathop \sum \limits_{i = 1,\;j = 1}^{n} W_{ij} V_{ij} - B_{ij} } \right|.$$(4)Using the weight matrix set and the bias vector obtained by this function, the output value of each unit of the output layer is calculated Ym.
-
(5)
Using the formula (5) (of which S is the total number of samples, Dk is the dimension of the output vector, and Ym is the network output vector), the unit error dt of the output layer is calculated [4– 6].
$${\text{d}}_{\text{i}} = \frac{1}{\text{S}}\mathop \sum \limits_{i = 1}^{S} \left| {\mathop \sum \limits_{j = 1}^{{B_{k} }} (Y_{m} - T_{m} )^{2} } \right|.$$(5) -
(6)
The weight value Vjt and the threshold value θj of each node of the output layer are constantly corrected until the value reaches a predetermined error dt.
-
(7)
Randomly select the unlearned sample vectors into the neural network from the training sample set, return to step 3, until all the training samples are completed.
-
(8)
Select a set of input and target samples randomly from the selected learning samples and return to step 3, until the global error of the network is less than a set minimum value, that is, the network convergence. If it is in an infinite learning state, the network can not converge [7,8,9].
-
(9)
Finish the training and get the best output value.
After repeated training, the BP neural network constantly adjusts the value of weight and bias vector, which makes the output value of the neural network close to the expected value.
3 Results and Discussion
3.1 Predictive Value of Multiple Regression Method
The principal component analysis method is used to extract three main factors from 8 factors, and the relationship between the three main factors and the influencing factors is the relationship between the main factors and the influencing factors, as shown in Table 1.
Expression by formula:
Among them, Y = (Y1, Y2, Y3) of the main factors were, and x = (x1, x2,…,x8) were the influencing factors.
Based on the above relations, the data matrix corresponding to three principal factors is calculated, and then the yarn strength is taken as the dependent variable and the three principal factors as independent variables [10,11,12]. Logistic multiple regression equation is obtained, as shown in Table 2.
Or for formula:
Among them, the Z is the output value, that is the yarn strength. as shown in Table 3.
3.2 Predictive Value of BP Neural Network Method
The simplest three layer BP neural network is shown in Fig. 4.

BP neural network framework
-
(1)
The input layer.
The input variable: X = {xi, i = 1, 2, 3}, the output variable: \(y_{i}^{(1)} = f\left( . \right) = f\left( {net_{i}^{(1)} } \right) = f\left( {x_{i} } \right) = x_{i}\).
-
(2)
Hidden layer.
The input variable: net(2)j = wji(1)yi(1), the output variable: yj(2) = f(net(2)j) = f(wji(1)yi(1)) among them: i = 1, 2, 3; j = 1, 2, 3, 4 [13–15].
-
(3)
The output layer.
The input variable: net(3)k = wkj(2)yj(2), the output variable: yk(3) = f(net(3)k) = f(wkj(2)yj(2)) among them: j = 1, 2, 3, 4; k = 1, 2 [16,17,, 17].
-
(4)
Error.
yk is the output of the neural network, compared with the actual sample data dk, and takes the objective function (this error): E(t) = (dk − yk(t))2/2.
Then the total objective function: J(t) = E(t) < ε, p = 1,2,…The total number of running samples (accumulative error).
-
(5)
Inverse weight correction, gradient.
-
1.
The correction of w(2).
$$\begin{aligned} w_{kj} \left( {t + 1} \right) =\, & \, w_{kj} \left( t \right) + \Delta w_{kj} \left( t \right) \\ =\, & w_{kj} \left( t \right) - \lambda \frac{{\partial E_{k} (t)}}{{\partial w_{kj} (t)}} \\ =\, & w_{kj} \left( t \right) + \lambda (d_{k} - y_{k} ) \cdot f^{\prime } (net^{(3)}_{k} ) \cdot y_{j}^{(2)} \\ \frac{{\partial E_{k} }}{{\partial w^{(2)}_{kj} }} =\, & \frac{{\partial E_{k} }}{{\partial (net^{(3)}_{k} )}} \cdot \frac{{\partial (net^{(3)}_{k} )}}{{\partial w^{(2)}_{kj} }} \\ = \,& \frac{{\partial E_{k} }}{{\partial y^{(3)}_{k} }} \cdot \frac{{\partial y^{(3)}_{k} }}{{\partial (net^{(3)}_{k} )}} \cdot \frac{{\partial (net^{(3)}_{k} )}}{{\partial w^{(2)}_{kj} }} \\ = \,& - \,(d_{k} - y_{k} ) \cdot f^{\prime } (net^{(3)}_{k} ) \cdot y_{j}^{(2)} \\ \end{aligned}.$$(9) -
2.
Correction of W(1).
$$\begin{aligned} \frac{{\partial E_{k} }}{{\partial w^{(1)}_{ji} }} =\, & \frac{{\partial E_{k} }}{{\partial (net^{(2)}_{j} )}} \cdot \frac{{\partial (net^{(2)}_{j} )}}{{\partial w^{(1)}_{ji} }} \\ =\, & \frac{{\partial E_{k} }}{{\partial y_{j}^{(2)} }} \cdot \frac{{\partial y_{j}^{(2)} }}{{\partial (net^{(2)}_{j} )}} \cdot \frac{{\partial (net^{(2)}_{j} )}}{{\partial w^{(1)}_{ji} }} \\ =\, & \frac{{\partial E_{k} }}{{\partial (net_{k}^{(3)} )}} \cdot \frac{{\partial (net_{k}^{(3)} )}}{{\partial y_{j}^{(2)} }} \cdot f^{\prime } (net_{j}^{(2)} ) \cdot y_{i}^{(1)} \\ =\, & - \,(d{}_{k} - y_{k} ) \cdot f^{\prime } (net_{k}^{(3)} ) \cdot \sum\limits_{k} {w_{kj}^{(2)} } \cdot f^{\prime } (net_{j}^{(2)} ) \cdot y_{i}^{(1)} \\ \end{aligned}.$$
-
1.
-
(6)
The y is the output value, that is the yarn strength as shown in Table 4.
Table 4 Comparison between the BP predicted value and the observed value
3.3 Predictive Value of V-SVM Regression Machine Method
Using V-SVM Regression the machine establishes the prediction model of yarn quality, and through genetic algorithm and cross a combinatorial optimization of model parameters, the initial population of genetic algorithm, the number is 20. Predictive value of the yarn strength, as shown in Table 5.
3.4 CNN-BP Prediction Method Comparison with Other Three Forecasting Methods
The absolute error curved surface shows in Fig. 5, absolute error distributed cloud map shows in Fig. 6 by the absolute error surface of the predicted value and the actual value of CNN-BP neural network. It is comparison of 4 kinds of predicted values and observation values in Fig. 7 and absolute error contrast diagram of 4 forecasting methods in Fig. 8. There is comparison of four forecasting methods in Table 6.

absolute error curved surface

Absolute error distributed cloud map

Comparison of 4 kinds of predicted values and observation values

Absolute error contrast diagram of 4 forecasting methods
4 Conclusion
Cotton yarn strength prediction method is proposed combined with a convolutional neural network and BP neural network algorithm. The prediction error of yarn strength of CNN-BP algorithm is 0.9%, and the prediction error of mobile communication user number is 2.46% by number fitting and support vector regression algorithm. The error of BP neural network is 11.25%, the error of regression algorithm is 6.22%, and the error of v-SVM algorithm is 3.15%. It is obvious that the CNN-BP algorithm is superior to the support vector regression algorithm and the regression algorithm. The prediction error of the yarn strength of the CNN-BP algorithm is better than that of the BP neural network. The test results show that the error rate of the CNN-BP neural network algorithm is 2.46%, while the error rates of the other three algorithms are more than 3%.
References
Kim, J. S., Sim, J. Y., & Kim, C. S. (2014). Multiscale saliency detection using random walk with restart. IEEE Transactions on Circuits and Systems for Video Technology, 24(2), 198–210.
Cheng, M. M., Zhang, G. X., Mita, N. J., et al. (2015). Global contrast based salient region detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37(3), 569–582.
Liang, Z., Wang, M., Zhou, X., et al. (2014). Salient object detection based on regions. Multimedia Tools and Applications, 68(3), 517–544.
Shi, J., Yan, Q., Xu, L., et al. (2016). Hierarchical image saliency detection on extended CSSD. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(4), 717–729.
Wang, B., Pan, F., Hu, K. M., et al. (2012). Manifold-ranking based retrieval using k-regular nearest neighbor graph. Pattern Recognition, 45(4), 1569–1577.
Murphy, K. P. (2012). Machine learning: A probabilistic perspective (pp. 82–92). Cambridge, MA: MIT Press.
He, K., Zhang, X., & Ren, S., et al. (2015). Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the 2015 IEEE international conference on computer vision (pp. 1026–1034). Piscataway, NJ: IEEE.
Hinton, G. E., Srivastava, N., & Krizhevsky, A., et al. (2015). Improving neural networks by preventing co-adaption of feature detectors [R/OL]. Accessed on October 26, 2015, from http://arxiv.org/pdf/1207.0580v1.pdf.
Nguyen, A.,Yosinski, J., & Clune, J., et al. (2015) Deep neural networks are easily fooled: High confidence predictions for unrecog-nizable images. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (pp. 427–436). Washington, DC: IEEE Computer Society.
Cheng, M. M., Zhang, G. X., Mitra, N. J., et al. (2015). Global contrast based salient region detection. IEEE Transactions on Patter Analysis and Machine Intelligence, 37(3), 569–582.
Yang C, Zhang L, Lu H, et al. (2013). Saliency detection via graph based manifold ranking. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, CVPR ‘13 (pp. 3166–3173). Washington, DC: IEEE Computer Society.
Zhou, D., Weston, J., & Gretton, A., et al. (2015). Ranking on data manifolds [EB/OL]. Accessed on November 08, 2015 from http://www.kyb.mpg.de/fileadmin/user_upload/files/publications/pdfs/pdf2334.pdf.
Achanta, R., Shaji, A., & Smith, K., et al. (2015). SLIC super pixels [EB/OL]. Accessed on December 11, 2015 from http://islab.ulsan.ac.kr/files/announce-ment/531/SLIC_Superpixels.pdf.
Goodfellow, I. J., Warde-Farley, D., & Mirza, M., et al. (2016). Maxout network [EB/OL]. Accessed on January 12, 2016 from http://www-etud.iro.umontreal.ca/~goodfeli/maxout.pdf.
Lin, M., Chen, Q., & Yan, S. (2016). Network in network [EB/OL]. Accessed on January 12, 2016 from http://arxiv.org/pdf/13124400v3.pdf.
Murphy, K. P. (2012). Machine learning: A probabilistic perspective (pp. 82–92). Cambridge, MA: MIT Press.
Lecun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278–2324.
Hinton, G. E., Osindero, S., & Teh, Y. W. (2006). A fast learning algorithm for deep belief nets. Neural Computation, 18(7), 1527–1554.
Lee, H., Grosse, R., Ranganath, R., et al. (2009). Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. ICML ’09. In Proceedings of the 26th Annual inter-national conference on machine learning. New York: ACM, (pp. 609–616).
Dalal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Conference on computer vision and pattern recognition. Washington, IEEE Computer Society, (pp. 886–893).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zhenlong, H., Qiang, Z. & Jun, W. The Prediction Model of Cotton Yarn Intensity Based on the CNN-BP Neural Network. Wireless Pers Commun 102, 1905–1916 (2018). https://doi.org/10.1007/s11277-018-5245-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-018-5245-0