
Abstract
Worldwide Interoperability for Microwave Access (Wimax) is power station through which mobile network, commonly known as A Mobile Ad-hoc Network (MANET) is used by the people. A MANET can be described as an infrastructure-less and self-configure network with autonomous nodes. Participated nodes in MANETs move through the network constantly causing frequent topology changes. Designing suitable routing protocols to handle the dynamic topology changes in MANETs can enhance the performance of the network. In this regard, this paper proposes four algorithms for the routing problem in MANETs. First, we propose a new method called Classical Logic-based Routing Algorithm for the routing problem in MANETs. Second is a routing algorithm named Fuzzy Logic-based Routing Algorithm (FLRA). Third, a Reinforcement Learning-based Routing Algorithm is proposed to construct optimal paths in MANETs. Finally, a fuzzy logic-based method is accompanied with reinforcement learning to mitigate existing problems in FLRA. This algorithm is called Reinforcement Learning and Fuzzy Logic-based (RLFLRA) Routing Algorithm. Our proposed approaches can be deployed in dynamic environments and take four important fuzzy variables such as available bandwidth, residual energy, mobility speed, and hop-count into consideration. Simulation results depict that learning process has a great impact on network performance and RLFLRA outperforms other proposed algorithms in terms of throughput, route discovery time, packet delivery ratio, network access delay, and hop-count.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Mobile Ad hoc Network (MANET) is an emerging technology primarily aimed at provisioning communication among self-organized and self-configure devices. MANETs consist of autonomous nodes that collaborate to transport information. Nodes in MANETs can move arbitrarily; besides, there is no pre-defined infrastructure. Therefore, the multi-hop network topology of MANETs can change frequently and unpredictably. Due to the high mobility of nodes, link failure occurs very often. The performance of MANETs is highly related to the routing protocol strategy [4]. Designing a suitable routing protocol which handles the dynamic topology changes in MANETs can enhance the performance of the network. The efficiency of a routing protocol depends on several factors chief among them being convergence time, available bandwidth, energy consumption, and so on [16].
Generally, the routing protocols for MANETs are classified into two basic categories: (a) Topology-based methods which use information about links to perform packet forwarding. Dynamic Source Routing (DSR) protocol [6], Ad hoc On-demand Distance Vector (AODV) routing protocol [15], Temporally Ordered Routing Algorithm (TORA) [13], Optimized Link State Routing (OLSR) [1] protocol are examples of routing protocols to name a few. DSR is a well-known on-demand routing protocol which is simple to implement, even though it does not always select the optimal route for packet transmission. This algorithm especially is designed for routing in MANETs. It allows the network to be completely self-organizing and self-configuring and does not need any prior network infrastructures or administrations. Unlike AODV, DSR algorithm does not utilize periodic routing message transmission; thereby reduces network bandwidth usage, conserves battery power, and avoids large routing updates [2]. AODV is another algorithm which employs a broadcast route discovery mechanism and relies on dynamically-established routing table entries at intermediate nodes. It shares DSR’s on-demand characteristics; hence, discovers routes whenever needed via a similar route discovery process. However, unlike DSR that maintains multiple route cache entries for each destination, AODV adopts traditional routing tables in which one entry per destination is maintained [15]. TORA is a highly adaptive, efficient and scalable distributed routing algorithm. TORA is based on the concept of link reversal and it is proposed for highly dynamic mobile, multi-hop wireless networks. TORA is a source-initiated on-demand routing protocol. It finds multiple routes from a source node to a destination node. The main feature of TORA is that the control messages are localized to a very small set of nodes near the occurrence of a topological change [14]. OLSR is a proactive routing protocol where the routes are always immediately available when necessary. It is often called table driven protocol as it maintains and updates its routing table frequently. In this algorithm, each node intermittently broadcasts its routing table, allowing each node to build an abstract view of the network topology. The process of this protocol creates a large amount of overhead. To reduce it, however, it limits the number of mobile nodes which can forward network-wide traffic. (b) Position-based routing protocols in which the routing decisions are made on the basis of the current position of the source and the destination nodes. Each node in position-based routing protocols determines its own position via GPS or some other types of positioning services [9]. Geographic Routing Protocol (GRP) also known as the position-based routing protocol, is a well-researched approach for ad-hoc routing where each node is aware of its own geographical locations and its immediate neighbors. Moreover, the source node is aware of the destination’s position. The data packets are routed through the network using the geographical location of the destination but the network address is not employed. GRP operates without routing tables and the routing process depends upon the information each node has about its own neighbors [5].
Our contributions can be listed as follows:
-
Designing a routing protocol for MANETs, which applies reinforcement learning and fuzzy logic to update routing tables of the nodes and stability rate of the paths.
-
Using Route-freshness as one of the metrics applied in the proposed approach. This algorithm uses a numerical string to evaluate the freshness of a path.
-
Suggesting four algorithms to represent our proposed ideas in MANETs.
-
Conducting extensive experiments for a number of scenarios to prove the high performance of our proposed approaches.
The rest of the paper is organized as follows: Sect. 2 surveys the previous studies that consider the problem of routing in MANETs. The detailed information about the proposed methods is described in Sect. 3. Section 4 evaluates the performance of our proposed algorithms. Section 5 illustrates the experimental results. And the concluding part is dealt with in Sect. 6.
2 Related Studies
Proposed approach in [7] introduces an energy accuracy scheme to reduce unnecessary energy consumption, increase data transmission, and prolong network lifetime.
Authors in [23] present a dynamic trust prediction model to evaluate the trustworthiness of nodes, which is based on the historical behavior of nodes, as well as the future behaviors via extended fuzzy logic rules prediction. Authors integrated the proposed trust prediction model into the source routing mechanism. They call the on-demand trust-based unicast routing protocol for MANETs as Trust-based Source Routing (TSR) protocol, which provides a flexible and feasible approach for choosing the shortest route that meets the security requirement of data packet transmission.
Authors [24] propose a new routing protocol for mobile ad-hoc networks which can tolerate network delay. This algorithm utilizes information carried by packets in the network to choose the best routes. They employ a sliding window mechanism to update the average hop-count matrix dynamically. Too they have defined a heuristic function to estimate the prospective required hop-count between the current node and the destination node.
Reported work in [21] tries to decrease location errors for routing; therefore, it proposes an on-demand routing protocol which takes location errors into consideration. In order to estimate accurate routes and route confidence in route discovery process, Kalman filter [22] is employed. Since Kalman filter provides the root-mean-square error between the actual location and estimated location of a node, and considering the confidence level of links, this algorithm excludes unreliable links.
Proposed work in [18] suggests a machine learning based hybrid power-aware approach for handling critical nodes via load balancing. Applying machine learning to the region of critical nodes for load balancing would serve as a profitable measure to prevent the critical nodes from energy depletion and improves the performance of the MANET. In this algorithm, the fundamental packet delivery is done via standard OSPF algorithm. Mobile nodes are clustered by learning their frequency and direction of packet exchange. Nodes that handle the same pattern of traffic are clustered together. This technique is known as self-similarity based clustering.
The presented work in [10] proposes a new mechanism to establish stable and sustainable paths between all pairs of nodes in a Mobile Ad hoc Network. In this mechanism, a stability function is utilized as the main path selection criterion which relies on the calculating mobility degree of a node corresponding to its neighbors. Authors applied this mechanism to the OLSR protocol in order to select stable and sustainable MultiPoint Relay (MPR) nodes. This mechanism significantly minimizes the recalculation of MPR and recalculation process for routing tables. Moreover, other QoS metrics such as packet loss and response time are guaranteed.
Authors [8] propose an energy management model and a power consumption control flowchart to control power consumption by reducing data transmission time.
The proposed work by [20] applies a Reward-Based Routing Protocol (RBRP) for MANETs. This protocol employs a route strategy based on the Q-learning method to select a stable route in order to enhance system performance. The reward of a route is decided by four factors: hop-count, bandwidth, battery level, and node speed. Route discovery process usually finds multiple routes from the source to the destination node. Then, a path with the greatest reward value is selected for routing.
Another work by [19] suggests a fuzzy logic-based on-demand routing protocol for mobile ad-hoc networks. The proposed algorithm exploits battery level and node speed as two criteria for route selection.
3 Proposed Approaches: Network Model and Assumptions
We use four different scenarios to describe our proposed protocols for routing in MANETs. The first scenario employs a classical logic approach for training all nodes in the network so that nodes will be capable of determining the link stability and finally determine the path stability rate by use of several factors such as available bandwidth, residual energy, mobility speed, and hop-count. In the second scenario, fuzzy logic is employed to train network nodes aiming at recognizing optimal paths. The third scenario, applies reinforcement learning to learn network nodes how to estimate path stability rate. In the fourth scenario, the fuzzy logic method is accompanied with reinforcement learning method to train nodes in order to estimate optimal paths.
Our network is composed of autonomous agents and employs the aforementioned metrics to achieve an optimal solution for the node connectivity table updates. A network topology containing 25 nodes is assumed. The network topology is same for all approaches and node failure scenario analyzed for all approaches.
Definition 1
Route-freshness is another metric that is employed in the proposed approaches. A numerical string is used to evaluate the freshness of a route. It is worth noting that the proposed algorithms do not need to have a model of environment dynamicity, and it is assumed that intelligent agents do not have complete information about network topology.
Definition 2
Reward value is another metric which is computed in the network setup phase and it is initialized to zero for all states. After training, intelligent agents are capable of selecting best possible actions for each possible state of the environment. Also, it is assumed that each node is equipped with a GPS device; therefore, node mobility speed can be computed using acquired information from GPS device. What follows describes the proposed approaches in detail.
3.1 CLRA Algorithm
This section provides a classical fuzzy control algorithm for solving routing problem in MANETs called Classical Logic-based Routing Algorithm (CLRA). In this algorithm, intelligent agents are expected to receive Route REQuest (RREQ) packets and then update visited nodes routing table along the path to the destination using fuzzy control system. The routing table of each visited node is updated using a fuzzy control mechanism in which four fuzzy input variables such as available bandwidth, residual energy, mobility speed, and hop-counts are taken into consideration.
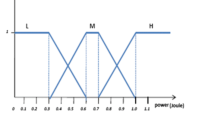
In classical set theory, each element either fully belongs to the set or is completely excluded from the set. This type of sets is called crisp sets. CLRA algorithm works in a way that when an RREQ packet is received by an intermediate node, the parameters of the RREQ packet will be extracted by the intermediate node and then it computes the membership function for all parameters. The evaluation chart shown in Fig. 1 is used to determine the range of stability parameters. If a metric belongs to “Low” range its value equals to zero; otherwise, it is equal to one. The important factor is that a threshold value is chosen for all fuzzy input variables. If the parameter’s value is greater than the threshold then it belongs to “High” range; otherwise, it belongs to “Low” range. As stated before fuzzy input variables include available bandwidth, residual energy, node mobility speed, and hop-counts. Link stability rate is the output variable of the fuzzy system.

Evaluation chart
For instance, it is assumed that the threshold value for residual energy is 50 J. If the residual energy of a node is equal to 70 J, then this variable belongs to the “High” range and its value equals to one. First, the membership function for each parameter is computed using evaluation chart shown in Fig. 1. Second, the membership functions will be added to the fuzzy inference engine to check the stability of the link between the sender and the receiver of the RREQ packet using fuzzy rule base. If the link stability rate belongs to the “High” range (using Table 1), the neighbor connectivity table will be updated for that node, otherwise, if the link stability rate belongs to the “Low” range, it is expected that link will fail in a short period. This algorithm tries to find links with high stability. Figure 2 shows the block diagram of the classical logic method.

Classical logic block diagram
It can be concluded from Table 1 that stable paths have “High” available bandwidth and residual energy and their hop-count and mobility speed belongs to “Low” range. If the stability of a link is “High” then it should update its own neighbor connectivity table. When RREQ packet arrives at a destination node, parameters will be added to the reply packet at the reverse path, then receiver nodes evaluate the link stability using evaluation chart shown in Fig. 1 in the same way.
The operations of CLRA algorithm are described below. When a source node ‘S’ desires to send data to a destination node ‘D’, it must take the following steps:
-
1.
Source node ‘S’ checks its routing table to find a route to the destination node ‘D’. If a route already exists, then data will be transmitted through this route.
-
2.
If there is no route to the destination in the routing table, the source node ‘S’ creates an RREQ packet (RREQ packet format is shown in Fig. 3a) and starts a rout discovery process by broadcasting the RREQ packet.
Fig. 3 
a RREQ packet format in classical logic approach and b RREP route packet format in classical logic approach
-
3.
The intermediate nodes which receive the RREQ packet extract the needed information from RREQ packet and evaluate the links stability by using the rule-based system. If the link is stable then the intermediate nodes routing table will be updated.
-
4.
Each intermediate node checks whether there is a route to the destination node in its own routing table or not? If the route exists then it creates a Route REPly (RREP) packet and appends its own stability parameters to the packet, then transfers it in reverse path. If the path does not exist, it generates a packet with its own stability parameter and rebroadcasts it.
-
5.
Upon receiving the RREQ packet, the destination node checks the suitability of the link using stability parameters which exist in RREQ packet. If the link is suitable then it will store the route in routing table. Moreover, the link stability rate of each route is computed in the destination node.
-
6.
As depicted in Fig. 3b, destination node generates an RREP packet and copies the source and destination address from RREQ packet. Then sets its own stability parameters into the packet and transmits the RREP packet to the source node.
-
7.
To determine the link suitability, each node in the reverse path extracts and inserts the stability parameters into RREP packet.

3.2 FLRA Algorithm
In this scenario, fuzzy logic is used to solve routing problem in mobile ad-hoc networks. Fuzzy logic was initially introduced by [25] as a means to model the uncertainty of natural language and it has been widely used for supporting intelligent systems. The main idea behind fuzzy systems is that truth values (in fuzzy logic) or membership values are indicated by a value in the range 0–1 with 0 for absolute falsity and 1 for absolute truth. In contrast to the classical set theory according to which each element either fully belongs to the set or is completely excluded from the set; elements in a fuzzy set X possess membership values between 0 and 1. Similar to the first scenario, intelligent agents are required to receive RREQ packet information and update the routing table of visited nodes along the path to the destination using fuzzy logic. The proposed fuzzy logic mechanism for routing in MANETs called Fuzzy Logic-based Routing Algorithm (FLRA) is similar to a controller in the fuzzy system. The controller mechanism is considered as an adaptive fuzzy controller. In fact, to design fuzzy controller we need to discover implicit and explicit relations in the system using intelligent agents then apply fuzzy control rules to estimate the stability of the links. Figure 4 shows the block diagram of the proposed controller system which is comprised of three elements: fuzzifier, fuzzy inference engine, and defuzzifier.

Block diagram of fuzzy logic for fuzzy logic scenario
3.2.1 Fuzzifier
The fuzzifier decides how a crisp input is converted into a fuzzy input to be used by the inference engine. In other words, a fuzzifier maps a crisp value to a fuzzy set. The parameter inputs for the proposed protocol includes available bandwidth, residual energy, mobility speed, and hop-count.
We define two trapezoidal membership functions for each input variable (“H” for upper bound and “L” for lower bound). Figure 5 shows the membership functions of available bandwidth, residual energy, mobility speed, and hop-count. Five triangular fuzzy membership functions are used for output variable (Fig. 5e). The following notations are used to show variable bounds: VL (Very Low), L (Low), M (Medium), H (High), VH (Very High).

Membership functions for a available bandwidth, b residual energy, c mobility speed, d hop-count, and e output of the fuzzy logic system
3.2.2 Fuzzy Inference Engine
The knowledge base is made up of fuzzy rules in the form of IF–THEN statements. This is the main part of the fuzzy system since the other components of the system are there to implement the rules in an appropriate manner. The inference engine decides how to process the rules in the knowledge base using the fuzzy inputs from the fuzzifier. Inference engine uses fuzzy rules to compute the stability of the links. For example, if the available bandwidth is “Low”, residual energy is “Low”, hop-counts is “High”, and link stability is “Low” then the outcome variable will be “low”. We have used the most commonly used fuzzy inference technique called Mamdani Method [12] due to its simplicity. Two variables are defined for each input parameter which results in 16 fuzzy rules. Table 2 shows the fuzzy logic rule base for second scenario.
3.2.3 Defuzzifier
The defuzzifier decides how to convert fuzzy results from the inference engine back into a crisp value. In other words, a defuzzifier maps a fuzzy set to a crisp value. The method utilized for the defuzzification is the mean of centers. In the proposed algorithm when a source node ‘S’ wants to send data packets to a destination ‘D’, it should follow this steps:
-
(a)
Source node ‘S’ checks its routing table to find a route to the destination ‘D’. If a route already exists, then data will be transmitted through this route.
-
(b)
If there is no route to the destination in the routing table, the source node ‘S’ creates an RREQ packet (RREQ packet format is shown in Fig. 3a) and starts a route discovery process by broadcasting the RREQ packet.
-
(c)
The intermediate nodes which receive the RREQ packet extracts the needed information from RREQ packet and evaluates the links stability by using the rule-based system. If the link is stable then the intermediate nodes routing table will be updated.
Upon receiving an RREQ packet the destination node uses the fuzzy system to compute the link stability. The fuzzy logic system works as follows: extracts four input variables from the RREQ packet and deliver them to the fuzzy controller system. Then fuzzy controller system normalizes each variable into [0.01, 1] range. A range like [α, β] is considered for each variable. Assume that in RREQ packet the value of one variable equals to θ, then Eq. (1) is used to normalize the value.
For example, we assume that residual energy could be in [0.0.1, 100] range. If an RREQ packet arrives at a node and its residual energy is 70 J, then its normalized value is equal to \(N = \frac{70 - 0.01}{100 - 0.01} = 0.69\). In the next step, fuzzifier represents the input values in the form of membership functions. Then this evaluation will be added to the fuzzy inference engine which computes the fuzzy output using fuzzy rule base (shown in Table 2) and Mamdani implication. Also, the means of centers are used as defuzzifier. Route stability is the fuzzy inference system’s output which specifies the stability and suitability of a route. Route stability rate can be computed using Eq. (2).
where i is the route index, m the number of fuzzy rules, and n is the number of input variable membership functions. \(\mu A_{i}^{l} (X_{i} )\) is the fuzzy value of membership functions and \(y^{ - l}\) is the center of outputs.
3.3 RLRA Algorithm
This scenario presents a new method called Reinforcement Learning-based Routing Algorithm (RLRA) to solve routing problem in MANETs. Reinforcement learning method for routing in MANETs can be described as follows:
-
States: Representing the nodes in the network.
-
Actions: Choosing another node for data transmission.
-
Reward for transmission between states: A reflective set of node quality.
Also we use the evaluation chart shown in Fig. 1 to evaluate the reward value for each node. The parameter values in the specified ranges determine the reward value for that parameter. Equation (3) is used for reward calculation in reinforcement learning process. Where \(r_{t}\) is the reward in time t. \(\gamma\) in the above equation is the discount rate which is set to 0.9 in our algorithm. The designated value can be −1 or +1 for penalty and reward, respectively. For example, we assumed that the threshold for residual energy is 50 J. If a node has a value of 20 J then the residual energy of that node belongs to “Low” range and its designated reward will be equal to −1. In general, unstable routes are the routes with “Low” bandwidth, “High” mobility nodes, “Low” energy nodes, “High” hop-count between source and destination. So an optimal method should eliminate this kind of routes and try to opt routes with more cumulative rewards.
The RLRA protocol is inspired by distance vector Bellman-Ford algorithm and it is adopted to work in mobile environments. Aiming at recognizing the suitable links to update routing table of a node, we use a reinforcement learning based system. If a node is recognized as a suitable link, then it will be added to the routing table and the link stability will be increased. The main difference between the proposed algorithm and the well-known Bellman-Ford Algorithm is that nodes do not broadcast their routing table frequently; rather, they transmit a small part of the routing table on-demand. This feature increases the node’s residual energy and decreases bandwidth consumption in the network. This algorithm is on-demand and discovers a route when it is requested by a node. This process perform in two phases: route discovery and route maintenance. What follows describe details of the proposed algorithm using an illustrative example.
3.3.1 Route Discovery
A mobile ad-hoc network could be modeled by an undirected graph \({\text{G}}({\text{V}},{\text{E}})\), where V represents a set of routers or clients and E is the set of undirected edges. An edge connecting two nodes implies that the nodes are in transmission range of each other and a direct connection can be established between them. There are scenarios in which the transmission power of the nodes is not equal and some nodes have higher transmission range, so it is possible for a node such as ‘A’ to transmit data to ‘B’; but maybe it is not possible for ‘B’ to transmit data to ‘A’. To describe the operations of the proposed approach we assume that a process in source node ‘A’ in Fig. 6a transmits a packet to destination node ‘I’. Each node in the network has a routing table which includes two entries: destination address and next hop. Assuming that source node ‘A’ going to send data to destination node ‘I’, then it checks the routing table to see if there is a route to the destination. If there is no entry to destination ‘I’ then a route to ‘I’ should be discovered. As we mentioned before, our proposed algorithm is an on-demand routing algorithm and discovers a route when it is requested by a node.

a Cover range for broadcast and b Broadcasting from ‘A’ to ‘B’ and ‘D’
To find the location of destination node ‘I’, source node ‘A’ generates an RREQ packet with its own parameters such as hop-counter, the sum of rewards, and initialize them to zero (the RREQ packet format is showed in Fig. 7). Then the packet is broadcasted as shown in Fig. 6b and received by ‘B’ and ‘D’.

RREQ packet format in reinforcement learning scenario
The RREQ packet has several fields as follows:
-
Source Address: an IP address which specifies the address of the source node.
-
Request ID: a unique ID to distinguish requests. In other words, Request ID is a local counter which exists in each node and increases with each RREQ packet transmission. The combination of Source Address and Request ID fields can be used as a key to distinguish duplicated packets.
-
Destinations Address: an IP address which specifies the address of the destination node.
-
Source Sequence Number: a field to count the number of received and transmitted RREQ packets which increases with each received/transmitted packet. The operation of this counter is similar to a clock and it is used to distinguish fresh routes from old routes.
-
Destination Sequence Number: this field specifies the last packet that is received by the source node and contains the same information about destination node. If it does not receive any information about destination yet, then its value equals to zero.
-
Hop-counter: This parameter accounts for the distance (in hops) between the nodes or the number of hops for a feasible path. It equals zero at first and it increases with each passed node.
-
Available Bandwidth: this field stores the link’s available bandwidth for nodes.
-
Residual Energy: shows the remaining battery for a node.
-
Mobility Speed: the node movement speed.
-
Sum of Rewards: sum of all achieved rewards for a link.
When an RREQ packet arrives at an intermediate node, it will be processed as follows:
-
(a)
It will be checked to prevent from generating duplicate packets. If this packet is already processed, then it should be deleted, else the Source Address and Request ID will be stored in a table to prevent from duplicate packets in future, these operations also avoid from loops in the routing process.
-
(b)
Intermediate node (‘B’ and ‘C’ in Fig. 6b) computes the residual energy for the sender of RREQ packet using Eq. (4). When the RREQ packet sender (‘A’ in our example) insert its residual energy in RREQ packet before sending it into media, it loses some amount of energy for packet sending; therefore, intermediate nodes use Eq. (4) to compute residual energy. It is well worth saying that after residual energy computation the reward of this parameter is computed and it will be added to the sum of rewards [17].
$$E_{r} = E_{a} - E_{req - t}$$(4)where \(E_{r}\) is the residual energy of the node and \(E_{a}\) is the available energy of the node which exists in RREQ packet. \(E_{req - t}\) specifies the amount of necessary energy for RREQ packet transmission, which is computed using Eq. (5) [11].
$$E_{req - t} = E_{e} *B + \left( {B_{cfs} *B*D^{2} } \right)$$(5)where \(E_{e}\) is the energy consumption of electrical devices and is equal to \(E_{e} = 50\,{\text{nj}}/{\text{bits}}\). B equals the number of bits in RREQ packet and D is the transmission range of bits. \(B_{cfs}\) is the consumed energy for data transmission at first meter in free space. Intermediate nodes (‘B’ and ‘D’ in our example) check the suitability of a link from received data in RREQ packet. In other words, each intermediate node checks that all stability parameters in RREQ packet are satisfied or not. When an intermediate node recognizes a link as suitable [its reward summation is positive which is computed using Eq. (3)], updates its neighbor connectivity table. Then receiver searches for the destination address in its own routing table. If a new and fresh route is founded, an RREP packet will be sent to the source node to inform it about the founded route. The freshness of a route means that the value of Destination Sequence Number stored in the routing table is greater or equals the value of the similar field in RREQ packet. When the value is smaller, step (c) will be performed.
-
(c)
Since the receiver node does not have any route to the destination, it increases the hop-count value by one, adds its stability parameters to the packet, and then broadcasts the packet. This information is useful since reverse routes can be established through its usage, and replies of the RREQ packet can be sent through this routes (arrows in Fig. 8 shows the process of reverse route construction). When a reverse route is constructed, a timer is set and the route will be deleted if the reply of the RREQ is not received or timer is expired. For instance, neither ‘B’ nor ‘D’ has any route to ‘I’, so they construct a reverse route to ‘A’ aiming at sending reply packets. They set Hop-counter value to 1, add stability parameters to the packet, and rebroadcast the packet (see Fig. 8a). Rebroadcasting packets by ‘B’ will be received by ‘C’ and ‘D’. ‘C’ adds an entity to its own reverse route’s table, adds the earned points to the RREQ packet, and broadcast it again. In contrast, ‘D’ recognizes the packet as duplicated and deletes it (because it is already received by ‘A’). Similarly, the broadcasted packet by ‘B’ and ‘D’ is recognized as duplicated. As Fig. 8b shows the broadcasted packet by ‘D’ accepted in ‘F’ and ‘G’, then it is stored in routing table. After receiving the packet by ‘E’, ‘H’, and ‘I’ the RREQ packet will reach the destination (the packet received by ‘I’ or a node that has a valid route to ‘I’). Similar to intermediate nodes, destination node extracts the stability parameters from the packet and if the link is suitable then it stores the link, computes the cumulative sum of rewards, and multiplies it by γ in Eq. (3) (Fig. 8c shows these processes in detail). Then the best route will be chosen based on the computed cumulative sum of rewards (a route with a maximum cumulative sum of rewards will be chosen). Although we showed the dissemination process as three separate steps, the packet broadcasting in different nodes does not occur simultaneously. Therefore, it is possible for a destination node to receive an RREQ packet at different times and from different nodes. In such a situation destination node wait for a period of time to receive all the RREQ packets from intermediate nodes and prioritize a route that has the maximum cumulative sum of rewards for sending RREQ reply packet.
Fig. 8 
Reverse route construction in reinforcement learning algorithm. a After receiving ‘B’ and ‘D’ broadcast transmission by ‘A’, b ‘C’, ‘F’, and ‘G’ receive broadcast from ‘A’, and c ‘E’, ‘H’, and ‘I’ receive broadcast from ‘A’

Node ‘I’ generates an RREP packet as shown in Fig. 9. The source address and destination address are copied from RREQ packet. Also, the stability parameters of the destination node are added to the RREP packet. Assuming that the Destination Sequence Number is adopted from counter located in the memory of node ‘I’, the Hop-Counter field will be set to zero. The Life Time field determines the time validation of a route. This packet will be sent to the nodes that the RREQ packet is received from that node (node ‘G’ in our example). The packet passes its reverse route from ‘D’ to ‘A’ and the Hop-Counter will be increased by one at each intermediate node. By doing this, each node knows its distance to the destination node (‘I’ in our example) and each node in the reverse path adds its stability parameters to the RREP packet in order to determine the suitability of a link.

RREP packet format in reinforcement learning scenario
Each intermediate node in the reverse path checks the packet, and if one of the following condition is satisfied, then some information about the path to the destination will be stored in the intermediate nodes routing table.
-
If the intermediate node does not has any known route to the destination ‘I’.
-
If the Destination Sequence Number is greater than the stored number in routing table.
-
If the Destination Sequence Number is equal but the newer route hop-count is smaller (recent route is shorter).
In this method, all the intermediate nodes, which located in the reverse path will be informed about the exact route to reach node ‘I’. Intermediate nodes which receive RREQ packet from forwarding path but there are not in the reverse path (‘B’, ‘C’, ‘E’, ‘F’, ‘H’ in our example) will delete the reverse path to ‘A’ after time expiration.
3.3.2 Route Maintenance
Since node mobility in MANETs is high and nodes may shut down completely due to the lack of energy, the topology of the network changes frequently. For example, in Fig. 10 if node ‘G’ get unavailable suddenly, then node ‘A’ does not know the path to reach destination node ‘I’ (means “A → D → G → I”) is no longer available. This protocol should be designed in a way so that nodes will be aware about location of other nodes by using hello messages which include nodes ID and node location. Hello messages are passed to neighbor nodes in time intervals. This information can be used for removing routes no longer available. Each node like ‘N’ stores a list of destinations from which its neighbors send a data packet in time period ∆T. This list is called active neighbors of node N. For this purpose, node ‘N’ has a table containing destination address which is the key to it. For example node ‘D’ in Fig. 10 has a routing table similar to Table 3.

Network graph after node “G” gets shutdown
When a neighbor of node ‘D’ gets unavailable, ‘D’ checks its routing table to find nodes which use deleted nodes along their path to the destination. All nodes whose route to destination goes through ‘G’ will be informed. Also, active nodes inform their active neighbors and this process will be repeated until the deactivated node is removed from the routing table of nodes. In Fig. 6a it is assumed that node ‘G’ is shut downed suddenly and network topology changed like Fig. 10. When node ‘D’ knows that ‘G’ is no longer available, checks if ‘G’ is on the path to ‘E’, ‘G’, and ‘I’, then the union of active neighbors of this nodes is ‘A, B’. In other words ‘A’ and ‘B’ relay on ‘G’ in some routes, so these nodes should be informed about the unavailability of node ‘G’. Node ‘D’ informs them by sending failure report packets and they modify their own routing table. Also, node ‘D’ removes the corresponding entry of ‘E’, ‘G’, and ‘I’ from its own routing table.
3.4 RLFLRA Algorithm
The operation of this method is similar to RLRA algorithm described in the previous section. This algorithm differs in a way that value of reward will be computed using fuzzy logic. We call this algorithm Reinforcement Learning and Fuzzy Logic-based Rotting Algorithm (RLFLRA). The reward value must be selected in [−1, +1] range. The value of rewards will be specified using fuzzy logic. For example, if the energy of a node is 43 J, then it belongs to “Low” range and as stated in Sect. 3.3, the assigned reward will be −1, but fuzzy logic assigns −0.28 to this parameter. Also, if the residual energy is 70 or 90 J then its reward will be +1 as described in Sect. 3.3, but in this method their reward value will be +0.70 and +0.90 respectively. This method is more accurate than proposed method in Sect. 3.3.
4 Performance Evaluation
In this section aiming at evaluating the performance of the proposed works, the simulation results will be presented. Our simulations are conducted on OPNET Modeler [3] simulator. We have conducted several experiments to verify the effectiveness of the proposed algorithms. The following metrics are used to measure the performance of the proposed works.
-
Throughput: throughput is defined as the total amount of data a receiver actually receives divided by the time between receiving the first packet and the last packet.
-
Route discovery time: The time necessary for discovering a route to the destination.
-
Average delay: This is the average delay of all packets that are correctly received by the destination. The average over all received packets is then computed.
-
Media access delay: the time from when the data reaches the MAC layer until it is successfully transmitted out on the wireless medium.
-
Packet delivery ratio: The packet delivery ratio (PDR) of a receiver is the number of data packets actually delivered to the receiver versus the number of data packets supposed to be received.
-
Hop-count: The distance in hops to reach destination.
4.1 Simulation Assumption
We randomly distributed 25 nodes in an 1127 m × 1127 m area. Vector trajectory is chosen for node mobility model which has application in heterogeneous networks. Also, nodes can rotate in different degrees from 0° to 359°. Rotation time is about 0–200 s and movement speed for each node equals to 1–10 mps. The node movement speed can be set to zero initially. Node movement speed can be achieved by GPS devices on each node. Figure 11 shows a model for network topology in OPNET Modeler. Also Fig. 12 represents node model structure.

A representation of network editor for simulation model

Node editor for simulation model
Transmission range for each node equals 250 m. Also, the available bandwidth for each node is selected randomly in the range of 1–10 Mbps. We run the simulation process for 600 s. Figure 13 shows the process model for three states including initial, wait, and turn. Also Fig. 14 shows the network model after node movements.

Process model for simulated model

Network model after node movements
5 Experimental Results
We conducted several experiments to evaluate the performance of our proposed algorithms. Figure 15 compares our proposed algorithms in terms of throughput. As results show the RLFLRA algorithm has better performance in comparison to other proposed algorithms. Given that most of routing algorithms for MANETs assume a two-way connection between nodes, there are situations in which it is not possible to have a two-way transmission. Fuzzy logic helps reinforcement learning to opt better routes for data transmission. Therefore, the throughput for RLFLRA is higher than other algorithms.

Network throughput
As obtained results from Fig. 16 shows, we have meaningful improvements in route discovery time for RLFLRA as simulation time increases. RLFLRA uses fuzzy logic after learning process which results in better route selection for data transmission. It can be concluded from the results, as time passes RLFLRA has a better performance because nodes learn to select more stable routes. Since stable routes are available until the transmission process ends, there is no need to run routing algorithm after learning process and it results in decreasing route discovery time.

Route discovery time
Figure 17 represents the obtained result for the average delay in the network. With the passage of simulation time, RLFLRA has a lower delay. RLFLRA is capable of considering stability parameters more accurately. In other words, most reliable routes are chosen for data transmission.

Network delay
Another metric to compare our algorithms is network access delay which is an important parameter for many real-time applications. Figure 18 verifies the performance of our proposed algorithms in terms of network access delay. RLFLRA has lower process time which results in lower MAC layer delay too.

Network media access delay
The objective of this experiment is to compare the performance of our proposed algorithms in terms of packet delivery ratio (PDR). The obtained result from Fig. 19 shows that proposed algorithms have a proximity similar results but as simulation time elapses, it could be seen that RLFLRA and RLRA have better performance comparing to CLRA and FLRA. The superiority of RLFLRA and RLRA is due to the learning process.

Packet delivery ratio
In this experiment, we want to compare the performance of our proposed algorithms in terms of hop-count. It can be concluded from Fig. 20 that FLRA has a lower hop-count. Since proposed algorithms take the hop-count as an input parameter for route selection, proposed approaches try to select the stable routes which have lower hop-count.

Hop-count
6 Conclusion
This paper proposed four approaches four routing problem in mobile ad-hoc networks. We used four different scenarios to represent our proposed protocols. In the first scenario using a classical logic all nodes are trained and they will be capable to determine the stability of each link in the network and finally determine the path stability rate by use of stability input variables such as available bandwidth, residual energy, mobility speed, and hop-count. In the second scenario fuzzy logic is used to train network nodes aiming at recognizing optimal paths using stability metrics. Third scenario uses reinforcement learning and by use of reward and penalty values, network nodes learn how to estimate path stability rate exploiting stated input variables. In the fourth scenario we use fuzzy logic and reinforcement learning jointly to train nodes in order to estimate optimal paths. We conduct several experiments to verify the performance of our algorithms. Simulation results proved the applicability of the proposed algorithms.
References
Clausen, T., & Jacquet, P. (2003). Optimized link state routing protocol (OLSR), RFC 3626, IETF, 2070-1721.
El-Afandi, H. (2006). An intelligent wireless ad hoc routing protocol. Milwaukee: University of Wisconsin at Milwaukee.
Fitzgerald, J., & Dennis, A. (2009). OPNET lab manual. OPNET Technologies.
Garg, N., Aswal, K., & Dobhal, D. C. (2012). A review of routing protocols in mobile ad hoc networks. International Journal of Information Technology, 5(1), 177–180.
Hightower, J., & Borriello, G. (2001). Location systems for ubiquitous computing. Computer, 34(8), 57–66.
Johnson, D., Hu, Y.-c., & Maltz, D. (2007). The dynamic source routing protocol (DSR) for mobile ad hoc networks for IPv4, RFC 4728, 2070-1721.
Kumar Jain, Y., & Kumar Verma, R. (2012). Energy level accuracy and life time increased in mobile ad-hoc networks using OLSR. International Journal of Advanced Research in Computer Science and Software Engineering, 2, 97–103.
Kumar, K., & Singh, V. (2014). Power consumption based simulation model for mobile ad-hoc network. Wireless Personal Communications, 77(2), 1437–1448.
Mauve, M., Widmer, J., & Hartenstein, H. (2001). A survey on position-based routing in mobile ad hoc networks. IEEE Network, 15(6), 30–39.
Moussaoui, A., Semchedine, F., & Boukerram, A. (2014). A link-state QoS routing protocol based on link stability for Mobile Ad hoc Networks. Journal of Network and Computer Applications, 39, 117–125.
Naruephiphat, W., & Usaha, W. (2008). Balanced energy-efficient routing in MANETs using reinforcement learning. Paper presented at the international conference on information networking, 2008. ICOIN 2008.
Negnevitsky, M. (2005). Artificial intelligence: A guide to intelligent systems. Upper Saddle River: Pearson Education.
Park, V., & Corson, M. S. (1997). Temporally-ordered routing algorithm (TORA) functional specification. Internet Draft, July 2001. Available from: http://tools.ietf.org/id/draft-ietf-manet-tora-spec-04.txt.
Park, V. D., & Corson, M. S. (1997). A highly adaptive distributed routing algorithm for mobile wireless networks. Paper presented at the INFOCOM’97. Sixteenth annual joint conference of the IEEE computer and communications societies. Driving the information revolution, proceedings of IEEE.
Perkins, C., Belding-Royer, E., & Das, S. (2003). Ad hoc on-demand distance vector (AODV) routing, RFC 3561, IETF, 2070-1721.
Raich, A., & Vidhate, A. (2013). Best path finding using location aware AODV for MANET. International Journal of Advanced Computer Research, 3(3), 336.
Santhi, G., Nachiappan, A., Ibrahime, M. Z., Raghunadhane, R., & Favas, M. (2011). Q-learning based adaptive QoS routing protocol for MANETs. In 2011 international conference on recent trends in information technology (ICRTIT) (pp. 1233–1238). IEEE.
Sivakumar, B., Bhalaji, N., & Sivakumar, D. (2014). A survey on investigating the need for intelligent power-aware load balanced routing protocols for handling critical links in MANETs. The Scientific World Journal.
Tabatabaei, S., & Hosseini, F. (2016). A fuzzy logic-based fault tolerance new routing protocol in mobile ad hoc networks. International Journal of Fuzzy Systems, 18, 883–893.
Tabatabaei, S., Teshnehlab, M., & Mirabedini, S. J. (2015). A new routing protocol to increase throughput in mobile ad hoc networks. Wireless Personal Communications, 83(3), 1765–1778.
Vu, T. K., & Kwon, S. (2014). Mobility-assisted on-demand routing algorithm for MANETs in the presence of location errors. The Scientific World Journal, 2014. doi:10.1155/2014/790103.
Welch, G., & Bishop, G. (1995). An introduction to the Kalman filter. Technical Report TR 95-041. University of North Carolina at Chapel Hill, Chapel Hill, NC, USA.
Xia, H., Jia, Z., Li, X., Ju, L., & Sha, E. H.-M. (2013). Trust prediction and trust-based source routing in mobile ad hoc networks. Ad Hoc Networks, 11(7), 2096–2114.
You, L., Li, J., Wei, C., Dai, C., Xu, J., & Hu, L. (2014). A hop count based heuristic routing protocol for mobile delay tolerant networks. The Scientific World Journal, 2014. doi:10.1155/2014/603547.
Zadeh, L. A. (1996). Fuzzy logic= computing with words. IEEE Transactions on Fuzzy Systems, 4(2), 103–111.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Tabatabaei, S., Behravesh, R. New Approaches to Routing in Mobile Ad hoc Networks. Wireless Pers Commun 97, 2167–2190 (2017). https://doi.org/10.1007/s11277-017-4602-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-017-4602-8