
Abstract
This paper proposes an opportunistic routing with data fusion (ORDF) protocol for the widely used multi-source wireless sensor networks in which the spatial-temporal correlation among sensory data is ubiquitous. In the ORDF protocol, a new routing metric, which considers the data fusion and expected any-path transmissions, is presented to select a next-hop forwarding node that could save the maximal amount of energy. A candidate set selection algorithm is proposed to find the optimal candidate set of each node. An ACK-based coordination method among candidates is also given for the design of the ORDF protocol. Simulation results show that the ORDF protocol can greatly improve the network lifetime and reduce the network delay compared to general opportunistic routing protocol, such as ExOR, EEOR and OAPF. With increase of the number of source nodes, the ORDF protocol has more significant advantages in prolonging the network lifetime and reducing the network delay.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Due to the complication of wireless channels, the link quality between any two nodes is always influenced by signal transmission attenuation, node moving and environment noise interference. It is a great obstacle for the traditional unipath routing to be applied in a real wireless environment because of the instability of the links [1]. Unlike the traditional routing that pre-selects a node as the next-hop forwarding node, opportunistic routing, which is proposed for the first time as ExOR protocol in [2], pre-selects a set of candidates to forward data packets by making full use of the diversity of the radio. As a result of the diversity of the forwarding node selection, opportunistic routing can be more suitable for application to the network scenario with instable links. In addition, opportunistic routing can improve the reliability of data transmission and reduce the energy consumption caused by data retransmission [3].
Earlier researches about opportunistic routing extend the thought of traditional unipath routing, and design their own candidate set selection algorithm by using deterministic routing metric, such as transmission distance, transmission delay and expected transmission count (ETX) [4]. However, due to the randomicity of data forwarding in opportunistic routing protocol, deterministic routing metric cannot better reflect the whole process of data transmission [5]. The OAPF protocol proposed in [6] uses expected any-path transmission (EAX) as its routing metric. EAX metric can be effectively used in opportunistic routing protocol to improve the reliability of data transmission because it considers potential multi-path for data forwarding. Besides that, the design of routing protocol should not only ensure the reliability of data transmission but also consider the balance of energy consumption so as to prolong network lifetime. In [7], an energy-efficient opportunistic routing (EEOR) protocol is proposed, which focus on selecting and prioritizing forwarder list to minimize energy consumption by all nodes. Expected total cost used as a routing metric in EEOR protocol consists of the cost of data transmission, the cost of data forwarding and the cost of coordination. To provide better QoS for data flows, the opportunistic routing ORAC proposed in [8] considers the admission control of nodes for the different types of flows, which is based on bandwidth, backlog traffic and residual energy of nodes to select forwarding candidates. And the simulation results show that the ORAC scheme can reduce the network congestion and achieve better network performance.
Most of existing research works about opportunistic routing mainly focus on the design of routing protocol for networks with single source node. However, these routing protocols may not be suitable for multi-source wireless sensor networks (MSWSNs). In MSWSNs, sensory data are usually spatial-temporal correlated, thus data fusion is usually considered in the design of routing protocol. It is well known that data fusion can effectively reduce the in-network data flows, for which energy consumption caused by data forwarding and the network delay caused by data congestion can also be reduced. Based on data fusion and transmission reliability, some optimal transmission schemes are proposed in [9] under different network topologies. A data transmission mechanism using information fusion is presented in [10], which uses information granularity as a measurement of data fusion degree. Certainly, most of works about data fusion mainly focus on the design and practical application of fusion algorithms [11, 12].
However, to the best of our knowledge, there are few works about the design of opportunistic routing protocol take into account data fusion. The authors in [13] illustrate the importance of coupling between opportunistic forwarding and data fusion. For mobile opportunistic networks, two cooperative forwarding schemes are proposed in [14] by leveraging data fusion, namely Epidemic Routing with Fusion and Binary Spray-and-Wait with Fusion, which can achieve better tradeoff between delivery delay and transmission overhead. In [15], an opportunistic routing with in-network aggregation is proposed, which saves the cost of data transmission by using sleeping scheme and data fusion. Although those literatures have considered the data fusion under the opportunistic routing framework, there are little research focus on the design of routing metric in this situation. Thus, in this paper, an opportunistic routing with data fusion (ORDF) is proposed for MSWSNs, which not only takes advantage of the radio diversity to improve the reliability of transmission, but also decreases the amount the data flow to alleviate the energy consumption and data congestion.
The rest of this paper is organized as follows: In Sect. 2, a MSWSNs model and some assumptions are given as preliminaries to better describe the ORDF protocol. Detailed introductions of the proposed ORDF protocol are given in Sect. 3, which includes a new routing metric, a candidates selection algorithm and a coordination method between candidates. In Sect. 4, simulation results show the advantages of the ORDF protocol in prolonging network lifetime and reducing the network delay. Conclusions are presented in Sect. 5.
2 Network model and assumptions
In this section, a MSWSNs model is given first. And then, some assumptions are given for the description of the ORDF protocol.
2.1 Network model
We consider a multi-source wireless sensor network and assume that all nodes have distinctive ID, i.e. \(i\in [1,N]\). In this paper, we assume that all nodes have a constant communication radius, namely, all nodes have a constant transmission power. MSWSNs can be modeled as a communication graph \(G=(V,E)\), where V is a set of all nodes, i.e. \(|V|=N\),and E is a set of directed links. Each link has an error probability e(u, v), where u and v represent a sensor node on the ends of the link respectively. The data packet transmitted by the node u has a probability \(1-e(u,v)\) to be successfully received by the node v.

A MSWSNs model
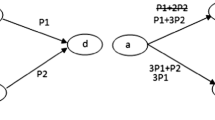
The MSWSNs considered in this paper are consisted of multiple source nodes, one target node and numbers of relay nodes. Source nodes are responsible for data generating and transmitting. Target node needs to collect data from source nodes and relay nodes. Relay nodes are responsible for data collecting, processing and forwarding. A simple model of MSWSNs is shown in Fig. 1, where \(S_1\) and \(S_2\) are two source nodes, \(V_1\sim V_9\) are relay nodes and t represents target node. \(V_1\sim V_3\) are candidate nodes of source \(S_1\), \(V_3\sim V_5\) are candidate nodes of source \(S_2\). The relay node \(V_3\) is the candidate node of both \(S_1\) and \(S_2\) as shown in Fig. 1, in other words, \(V_3\) can receive data from both \(S_1\) and \(S_2\). In this way, the node \(V_3\) should have a higher priority for data forwarding when the node \(V_3\) receives both the data from \(S_1\) and \(S_2\), thereby reducing the network data flows and prolong network lifetime by fusing the received data of the node \(V_3\).
The working process of the MSWSNs considered in this paper is divided into rounds. At the begin of each round, target node broadcasts interesting packets to source nodes in directed diffusion routing. A source node will transmit data packet when it receives the interesting packets.
2.2 Assumptions
Some assumptions are given here to clearly introducing the ORDF protocol.
Assumption 2.1
The acknowledgment (ACK) transmitted by a candidate node can be received by the sender and the other candidate nodes in the same candidate set at a probability of 1.
Remark 2.1
This is a commonly used assumption. In fact, the probability of successful receiving an ACK packet is approximately up to a hundred percent when the ACK packet is repeated a certain number of times [6].
Assumption 2.2
Energy consumption by data calculation can be neglected.
Remark 2.2
Generally, energy consumption caused by calculating is far less than the radio transmitting. In some applications, amounts of computation will be required to fuse some types of data such as audio and video data, which leads to large energy consumption. This occasion is out of the scope of this paper.
3 Opportunistic routing with data fusion (ORDF)
3.1 Date fusion
Integrating opportunistic routing protocol with data fusion can effectively reduce network overhead in MSWSNs where spatial-temporal correlation among sensory data is ubiquitous. Data fusion models can be divided into two categories in [9] according to different fusion ratio, i.e. partial fusion and full fusion. Partial fusion is defined as that the size of the fused data packet is smaller than the total size of all original data packets, but larger than the size of any original data packets. In some application, each node needs to report the average value of its received sensory data, such as reporting the average temperature in a specified area. Thus, the size of the fused data packet is equal to the size of any original data packets. This fusion mode is called as full fusion. Commonly used fusion functions, such as max/min, sum, average and median, belong to this category. In this paper, f(n) is used to represent the size of the fused data packets for all original packets, where n is the total size of all original packets. f(n) satisfies \(f(n)\in {\mathbf {Z}} ^+\).
There are two advantages in MSWSNs to integrate the opportunistic routing protocol with data fusion:
-
In MSWSNs, data congestion would be easily happened due to a large number of data flows, which may lead to larger network delay. Data fusion can effectively alleviate redundancy and reduce the in-network data flows, and hence it reduces the network delay.
-
In MSWSNs, data fusion can reduce the energy consumption caused by data transmitting and receiving, which can contribute to the prolongation of the network lifetime.
3.2 Routing metric
In this section, a routing metric used in ORDF protocol will be given, which considers the EAX metric and the number of received data packets.
3.2.1 EAX metric
EAX metric represents the expected number of any-path transmissions needed for reliable delivery of a packet from a sending node s to a target node t, mathematical description as follows [6]:
where A is the candidate set of the node s. The nodes in A are sorted based on their EAX metric in increasing order, and numbered from 1 to |A| such that \(EAX(i,t)>EAX(j,t)\), if \(|A|\ge i>j>0\). \(p_j=1-e(s,j)\) is the probability that the node j successful receives a packet transmitted by the node s. S(s, t) is the expected number of transmissions that at least one node in the set A received a packet from s. Z(s, t) is the expected number of transmissions for forwarding the packet from a node in set A to the target node t.
3.2.2 Routing metric
In this section, a routing metric which will be used in ORDF protocol is given. The routing metric of a node is defined as the amount of energy saved by selecting the node as the next-hop forwarding node, in which the sizes of received data packets, the size of fused data packet, the EAX metrics of sending nodes and the EAX metric of the node will be taken into account.
We consider a situation that the candidate node j received k original data packets from k sending nodes \(\{S_i\}, i=1,2,\ldots ,k\), the sizes of the received original data packets are \(\{n_i\},i=1,2,\ldots ,k\). The total size of the received packets of the candidate node j is n, i.e. \(n=n_1+n_2+\cdots +n_k\). The size of the fused data packet of the node j is f(n). If the node j is selected as the next-hop forwarding node, the expected energy consumption will be \(EAX(j,t)\cdot f(n)\cdot E_t\) for transmitting the fused data packet to target node t, where \(E_t\) is the energy consumption of transmitting 1 byte of data. Therefore, the energy conservation by using data fusion is \(EAX(j,t)\cdot (n-f(n))\cdot E_t\). On the other hand, selecting a node with smaller EAX metric as the next-hop forwarding node is also beneficial for energy conservation. Assume that each sending node \(S_i\) has a candidate set \(A_i\), then \(j\in \bigcap _{i=1}^{k}A_i\). For the ith original data packet received from \(S_i\), the maximal energy consumption to forward the ith original data packet among the nodes in set \(A_i\) is \(\max _{l\in A_i}(EAX(l,t))\cdot n_i\cdot E_t\). Thus, We define the energy conservation by selecting the EAX metric of the node j as \(\sum _{i=1}^{k}\max _{l\in A_i}(EAX(l,t))\cdot n_i\cdot E_t-EAX(j,t)\cdot n\cdot E_t\). In this way, the routing metric of the node j can be expressed as the sum of the energy conservation by using data fusion and by selecting the EAX metric of the node j:
In a real environment, it is hard to acquire the maximal EAX metric in each candidate set. From the Candidate Set Selected Algorithm introduced in Sect. 3.3, we know that \(EAX(l,t)<EAX(S_i,t)\), \(\forall l\in A_i\). Thus, replacing \(max_{l\in A_i}(EAX(l,t))\) with \(EAX(S_i,t)\), formula (1) can be rewritten as
Remark 3.1
The target node has the highest priority at any time.
Remark 3.2
The routing metric proposed in this paper can be equivalent transformed into an EAX metric if the number of source nodes is 1.
3.3 Finding the optimal candidate set
The routing metric described as formula (2) cannot be used to select the candidate set of a node since the size of each received data packet of the node is dynamic. In this paper, the selection of a candidate set is according to the EAX metric. The candidate set of a node s should be a subset of its neighboring nodes N(s) such that the node s has the smallest EAX metric. Suppose that the nodes in N(s) is ordered based on their EAX metric in increasing order such that \(|N(s)|\ge i>j>0=>EAX(i,t)>EAX(j,t)\). A property known as prefix is defined as a set X which is the set of first k elements of an order set Y [7]. Three lemmas are given firstly as follows:
Lemma 1
The optimal candidate set of the nodesis aprefixofN(s).
Lemma 2
Consider a nodes, aprefix\(N^*(s)\)ofN(s) and a node\(v\in N(s)\backslash N^*(s)\), if\(EAX(v,t)<EAX(s,N^*(s))\), then\(EAX(v,t)<EAX(s,N^*(s)\cup v)<EAX(s,N^*(s))\)where\(EAX(s,N^*(s))\)represents the EAX metric of node s with candidate set\(N^*(s)\).
Lemma 3
Consider a nodes, aprefix\(N^*(s)\)ofN(s) and a node\(v\in N(s)\backslash N^*(s)\), \(EAX(s,N^*(s)\cup v)>EAX(s,N^*(s))\)if\(EAX(v,t)>EAX(s,N^*(s))\).
Optimal candidate set can be selected as in Algorithm 1 based on above three lemmas.

As shown in Algorithm 1, for a node s and its candidate set C, the node v that has the smallest EAX metric among the nodes in set \(N(s)\backslash C\) will be add to the set C if it satisfies that \(EAX(v,t)<EAX(s,C)\), because adding the node v into the set C will decrease the EAX metric of the node s according to the Lemma 2. On the other hand, based on Lemma 3, if the node v does not satisfy the condition \(EAX(v,t)<EAX(s,C)\), the node v will not be added in the set C. The EAX metrics of remaining nodes in \(N(s)\backslash C\) are larger than the EAX metric of the node v, thus, the remaining nodes will not be added in the set C.
In Algorithm 1, the known EAX metrics of all nodes in N(s) are needed when calculating the EAX metric of the node s. Thus, how to reasonably use the Algorithm 1 to calculate the EAX metric of each node should be considered carefully. In this paper, an initialization algorithm is given for MSWSNs to determine the optimal candidate set of each node and its EAX metric.

In Algorithm 2, the set of all nodes V is divided into two set \(C_1\) and \(C_2\). Initially, \(C_1 = V\), \(C_2=\emptyset\). \(\forall v\in C_1\), let \(EAX(v,t) =\infty\) and \(EAX(t,t)=0\). Moving a node that has the smallest EAX metric in the set \(C_1\) to the set \(C_2\). The target node will be added to the set \(C_2\) first. Then, for each neighboring node of the newly added node in set \(C_2\), run Algorithm 1 if the neighboring node belongs to \(C_1\). Moving a node that has the smallest EAX metric now in the set \(C_1\) to the set \(C_2\) again. The algorithm continues until the number of nodes in set \(C_1\) is zero.
Lemma 4
The communication graph conducted by the Algorithm 2 is loop free and each node has the optimum EAX metric.
Remark 3.3
The similar proofs of above four lemmas can be found in [7] and omitted here.
3.4 ACK-based coordination
Coordination among candidates has always been a challenging issue in opportunistic routing. In this paper, an ACK-based coordination is used by candidates to clarify which of the received packets should be forwarded.
Some symbols which will be used in the ACK-based coordination are given in Table 1.
In order to clearly describe the ACK-based coordination, some introductions are given first as follows:
-
A node sends a data packet which contains the data it needs to send, its EAX metric, its ID and the IDs of its candidates.
-
A candidate replies ACK packets for each received data packets. Each ACK packet contains the routing metric and the ID of the candidate node and the ID of the sending node.
-
The candidates in a candidate set are sorted based on their EAX metric in increasing order. Candidates will reply ACK packets in order of the priority of their EAX metrics. Namely, the candidate that has the smallest EAX metric will reply an ACK packet first.
-
Sending node will retransmit data packet if it does not receive any ACK packets replied by its candidates.
-
Time domain is divided into multiple adjacent waiting time \(T_w\) as shown in Fig. 2. A candidate will receive data packets in a period \(T_w\) and reply ACK packets at next \(T_w\).
-
The coordination time \(T_c\) is far less than the waiting time \(T_w\). In this way, it can be guaranteed that the candidate node can reply ACK packet at next \(T_w\) after it received a data packet.
-
The flag is a Boolean property of a data packet with valid values of true and false. It is used to indicate that a candidate whether has received all ACK packets about the data packet.

The division of time domain
The routing metric of a candidate node cannot be known by sending nodes in advance since the total size of data packets received by the candidate node is unknown for the sending nodes. Thus, all candidates in a candidate set should reply an ACK packet that contains its routing metric. In this way, a candidate can know the information of routing metrics of other candidates by receiving the ACK packets from other candidates, thereby determining its priority. Here, the time when a candidate node should transmit ACK packets and the time when the candidate node can make sure it has received all ACK messages for a received data packet are introduced in Algorithm 3.

The ACK-based coordination is given in the form of an algorithm for a candidate node and bases on running timeline of the candidate node. In this coordination method, a candidate node will begin listening ACK packets when it received a data packet from a sending node and end listening ACK packets when the flags of all received data packets are true. For each data received by a candidate node, if the candidate does not have the largest routing metric among the candidates in corresponding candidate sets, then the data will be discarded from the candidate node.

In the ACK-based coordination shown in Algorithm 4, the candidate node v will first listen the ACK packets from other candidates and discard the data packets that have been received by other candidates in the last waiting time \(T_w\). Then, for each remaining data packet, the node v will run Algorithm 3 to reply ACK packets and to judge that whether the node v has received all ACK packets about the data packet. Finally, the candidate node v will determine whether to forward the received data packets based on its priority in corresponding candidate sets.
Figure 3 shows how ACK-based coordination works, and it is based on the MSWSNs model given in Fig. 1.

ACK-based coordination
The candidate set of the source \(S_1\) can be represented as \(A=\{V_1,V_2,V_3\}\) in which the candidates are given in increasing order according to the EAX metric. And the candidate set of the source \(S_2\) can be represented as \(B=\{V_3,V_4,V_5\}\) in which the candidates are ordered as in set A. The \(S_1\) and \(S_2\) send data in an asynchronous manner (\(S_1\) sends data before \(S_2\) does). \(Data_1\) and \(Data_2\) is the data needed to be sent by \(S_1\) and \(S_2\) respectively. After sending data by \(S_1\) and \(S_2\), \(V_1\), \(V_3\) and \(V_4\) have received data packets during the first \(T_w\). \(V_2\) does not receive the data from \(S_1\). The candidate \(V_5\) receives the data from \(S_2\) during the second \(T_w\), which is denoted with broken lines and an arrow. \(V_1\) replies ACK packets that contain the ID of \(S_1\), and \(V_3\) replies ACK packets that contain the ID of \(S_2\) in the first \(T_c\) after the first \(T_w\) because they have the smallest EAX metric in the candidate set A and B respectively. The other candidates can determine whether the received ACK packet is needed or not based on the contained information of the ACK packet. For example, candidate \(V_1\) will ignore the ACK packet sent by candidate \(V_3\) in the first \(T_c\) since the ACK packet contains the ID of \(S_2\). In set A, candidate \(V_2\) will not transmit and receive any ACK packets because it does not receive any data packets. Candidate \(V_3\) will reply an ACK packet at the third \(T_c\). In set B, candidate \(V_4\) replies an ACK packet at the second \(T_c\). The candidate \(V_5\) will discard the data packet received from \(S_2\) because it receives the ACK packet that contains the ID of \(S_2\) from \(V_3\) and \(V_4\). The flags of all received data packets of \(V_1\), \(V_3\) and \(V_4\) are true when the current time is larger than the end time of the third \(T_c\). Then, the candidates will determine which of received data packets should be forwarded. In Fig.3(a), candidate \(V_3\) has the highest priority both in set A and B. Thus, \(V_3\) will forward the \(Data_3\) which is the fused data of \(Data_1\) and \(Data_2\). \(V_1\) and \(V_4\) will discard received data packets. In Fig.3(b), \(V_1\) has the highest priority in set A and \(V_3\) has the highest priority in set B. Therefore, \(V_1\) forwards the \(Data_1\) and \(V_3\) forwards the \(Data_2\). \(V_3\) discards the \(Data_1\) and \(V_4\) discards the \(Data_2\).
4 Numerical simulation
4.1 Performance evaluation index
In this section, network lifetime, delay and average delay will be redefined, which will be used to evaluate the performance of ORDF protocol.
Definition 1
Network lifetime is defined as the number of rounds that the network running until a node is failed.
Definition 2
Delay is defined as a period from the time that one of sources starts to send packet to the time that the target node receives all packets in a round.
Definition 3
Average delay is defined as the average number of delays in a whole network lifetime.
4.2 Numerical simulation
In this paper, a \(200{\mathrm{{m}}}\times 100{\mathrm{{m}}}\) rectangular area is considered as a simulation paradigm as shown in Fig. 4. The target node represented as a black triangle is located at coordinates (200, 50). Some relay nodes are distributed randomly on the rectangular area and denoted as filled circle. A number of sources are distributed randomly on a \(100{\mathrm{{m}}}\times 100{\mathrm{{m}}}\) square area and denoted as hollow circle. For simplicity, full fusion mode is considered in this simulation, namely, each packet has the same packet size. Due to the randomness of the node location, a large amount of simulations have been done. We take the mean of all simulation results to reduce discrepancies.

Simulation paradigm

The comparison results of average delay and network lifetime under different protocols
Figure 5 shows the performance about average delay and network lifetime of ORDF protocol compared with ExOR, EEOR and OAPF. It can be observed in Fig. 5(a) that the average delay of ORDF protocol is larger than the other three protocols when the number of sources is small, which is caused by the complicated coordination method of the ORDF protocol. However, the average delay of ORDF protocol becomes smaller than the other three with the increasing number of source nodes, which is because the data fusion can reduce the in-network data flows and hence effectively reduce the delay caused by data congestion. In Fig. 5(b), the ORDF consistently outperforms the other three protocols in terms of network lifetime, and the gap is more wider with the increasing number of source nodes. Accordingly, we can derive that data fusion used in the ORDF protocol reduces the in-network data flows so as to reduce the energy consumption caused by data transmitting and receiving.

The comparison results of average delay and network lifetime for ORDF protocol under different transmission radius

The comparison results of average delay and network lifetime for ORDF protocol under different number of relays
The performances of the ORDF protocol under different communication radius of 20, 30 and 40 m are described in Fig. 6. In Fig. 6(a), it can be observed that there is a significant negative correlation between the average delay and communication radius, which is because the small communication radius not only increases the number of hops from a source node to the target node but also reduce the opportunities of in-network data meet to fuse data. Figure 6(b) shows that the network lifetime of the ORDF protocol is short when the communication radius is 20 m, which can be explained with the same reason as mentioned for Fig. 6(a). However, because of the added transmitting cost bring by the large transmission radius, the network lifetime of the ORDF protocol with the communication radius of 40 m is larger than that of 30 m. Therefore, it is necessary to select a suitable communication radius when using the ORDF protocol.
The performance of the ORDF protocol under different simulation scenarios with 150 relays, 200 relays and 250 relays are described respectively in Fig. 7. It can be observed from Fig. 7(a) that the average delay is decreased with the increasing number of relays. This is because that the large number of relays can reduce the EAX metrics of source nodes so as to reduce the average delay. Figure 7(b) shows that the network lifetime of the ORDF protocol is lengthened with the increasing number of relays, but its increment is shorted, which can be explained by the fact that with the increase of relay nodes, more and more relay nodes consume energy to receive data packets and need not to transmit them. The increase of the relays usually lead to higher cost, therefore, the number of relays is also should be fully considered.
5 Conclusions
In this paper, an opportunistic routing with data fusion (ORDF) is proposed for multi-source wireless sensor networks (MSWSNs). In this protocol, a new routing metric is defined to select next-hop forwarding node that saves the maximal amount of energy. A candidate set selection algorithm and an ACK-based coordination between candidates are also given. Simulation results show that the ORDF protocol can simultaneously achieve shorter network delay and longer network lifetime compared with ExOR, EEOR and OAPF protocols.
In Assumption 2.1, although the probability of successful receiving an ACK packet is approximately up to 1 by repeating the ACK packet a certain number of times, it may introduce lots of traffic in the networks. Thus, in the further work, we will take this factor into consideration.
References
Banu, M. B., & Periyasamy, P. (2013). A survey of unipath routing protocols for mobile ad hoc networks. International Journal of Information Technology and Computer Science (IJITCS), 6(1), 57–67.
Sanjit, B., & Robert, M. (2005). ExOR: opportunistic multi-hop routing for wireless networks. ACM Sigcomm Computer Communication Review, 35(4), 133–144.
Azzedine, B., & Amir, D. (2014). Opportunistic routing in wireless networks: Models, algorithms, and classifications. ACM Computing Surveys, 47(2), 1–36.
Nessrine, C. (2015). A survey on opportunistic routing in wireless communication networks. IEEE Communication Surveys & Tutorials, 17(4), 2214–2241.
Lu, M. & Wu, J. (2009). Opportunistic routing algebra and its applications. In Proceedings of the IEEE conference on computer communications (INFOCOM), pp. 2374C2382.
Zhong, Z. & Nelakuditi, S. (2007). On the efficacy of opportunistic routing, sensor, mesh and ad hoc communications and networks. In Proceeding of IEEE conference on communications society, pp. 441–450.
Mao, X. F., Tang, S. J., Tang, Xu X H, Li, X. Y., & Ma, H. D. (2011). Energy-efficient opportunistic routing in wireless sensor networks. IEEE Transaction on Parallel and Distributed Systems, 22(11), 1934–1942.
Qin, Y., Li, L., Zhong, X. X., Yang, Y. Y., & Ye, Y. B. (2015). Opportunistic routing with admission control in wireless ad hoc networks. Computer Communications, 55, 32–40.
Luo, H., Tao, H. X., Ma, H. D., & Das, S. K. (2011). Data fusion with desired reliability in wireless sensor networks. IEEE Transactions on Parallel and Distributed Systems, 22(3), 501–513.
Zhang, Z. J., Lai, C. F., & Chao, H. C. (2014). A green data transmission mechanism for wireless multimedia sensor networks using information fusion. IEEE Wireless Communication, 21(4), 14–19.
Kreibich, O., Neuzil, J., & Smid, R. (2014). Quality-based multiple-sensor fusion in an industrial wireless sensor network for MCM. IEEE Transactions on Industrial Electronics, 61(9), 4903–4911.
Barnett, J. A. (2008). Computational methods for a mathematical theory of evidence. In Proceeding of international joint conference on artificial intelligence, pp. 868–875.
Ma, H. D., Zhao, D., & Yuan, P. Y. (2014). Opportunities in mobile crowd sensing. IEEE Communications Magazine, 52(8), 29–35.
Zhao, D., Ma, H. D., Tang, S. J., & Li, X. Y. (2015). COUPON: A cooperative framework for building sensing maps in mobile opportunistic networks. IEEE Transactions on Parallel and Distributed Systems, 26(2), 392–402.
So, J., & Byun, H. J. (2014). Opportunistic routing with in-network aggregation for asynchronous duty-cycled wireless sensor networks. Wireless Networks, 20(5), 833–846.
Acknowledgements
This work was supported by National Natural Science Foundation of China under Grant U1334210 and China Academy of Railway Sciences Foundation under Grant 2016YJ109.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Li, J., Jia, X., Lv, X. et al. Opportunistic routing with data fusion for multi-source wireless sensor networks. Wireless Netw 25, 3103–3113 (2019). https://doi.org/10.1007/s11276-018-1705-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11276-018-1705-4