
Abstract
It is crucial yet challenging to estimate the parameters of hydrological distribution for hydrological frequency analysis when small samples are available. This paper proposes an improved Bootstrap and combines it with three commonly used parameter estimation methods, i.e., improved Bootstrap with method of moments (IBMOM), maximum likelihood estimation (IBMLE) and maximum entropy principle (IBMEP). A series of numerical experiments with different small sized (10, 20, and 30) of samples generated from the three commonly used probability distributions, i.e., Pearson Type III, Weibull, and Beta distributions, are conducted to evaluate the performance of the proposed three methods compared with the cases of conventional Bootstrap and without-Bootstrap. The proposed methods are then applied to the estimation of distribution parameters for the average annual precipitations of 8 counties in Qingyang City, China with assumption of Pearson Type III distribution for the average annual precipitations. The resulting absolute deviation (AD) box plots and Root Mean Square Error (RMSE) and bias estimators from both the numerical experiments and the case study show that the estimated parameters obtained by the improved Bootstrap methods have less deviation and are more accurate than those obtained through conventional Bootstrap and without-Bootstrap for the three distributions. It is also interestingly found that the improved Bootstrap provides more relative improvement on the parameter estimation when smaller size of sample is used. The method based on improved Bootstrap paves a new way forward to alleviating the need of large size of sample for quality hydrological frequency analysis.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the field of hydrological frequency analysis, sampling error in small sample cases seriously affects the accuracy of parameter estimation (Liu et al. 2011; Qian et al. 2022; Razmi et al. 2022). Sampling error cannot be avoided, and the smaller the length of the sample series, the greater the impact it causes (Jackson et al. 2019). Internationally, hydrological observations are often sparse or severely deficient, and small samples are common (Aissia et al. 2012; Ma et al. 2013; Wang et al. 2009). For example, long series observations are an important prerequisite for accurate forecasting in meteorological and hydrological extreme hazard risk assessment, yet historical information on extreme hazards are scarce and simulation reproduction is often not possible due to technical and cost factors (Bracken et al. 2016; Liu et al. 2016b; Rahmani and Zarghami 2015). There are still many regions in the world that lack rainfall observations, such as many rural and mountainous regions, where the issue of "lack of meteorological and hydrological observations" cannot be solved in a short time due to economic and technology constraints. Therefore, it is necessary to reduce the error of hydrological frequency analysis under small sample conditions and the past decade has witnessed the rapid research progress in this topic.
Qian et al. (2018) establish the Gumbel extreme value risk prediction model based on maximum entropy estimation, which shows that the model can achieve the parameter estimation effect and stability of the traditional method when the data volume is large by only the maximum and minimum values of the series under the small sample condition. And this method can be extended to the parameter estimation of multivariate hydrological series. In recent years entropy theory has been widely used for parameter estimation of hydrologic frequency distributions (Aghakouchak 2014; Kong et al. 2020; Singh and Asce 2011) with good accuracy and stability in small sample cases (Singh et al. 2017). Liu et al. (2016a) introduce two new information entropy estimators — CS estimator and JSS estimator, and the experimental results show that JSS estimation performs better under small sample conditions and can well characterize the uncertainty of hydrological systems. However, the above methods still have the following problems (De Michele and Salvadori 2005): 1) the scenarios of model application are relatively single and have more restrictions. For example, a part of the algorithm only answers to the estimation of hydrological feature extrema and probability density in small samples; 2) often perform well only for a particular distribution (such as Gumbel distribution), thus demanding more effort to address their generality and robustness. Common hydrological frequency analysis models also include Beta distribution, Weibull distribution, Generalized Extreme Value distribution, Pearson Type III distribution, etc. Therefore, the parameter estimation methods applicable to most distributions under small sample conditions still need to be further developed.
Bootstrap is a better method for dealing with small sample data, and only actual observations are required to develop the corresponding estimation, and the foundational, robustness and applicability of this method have been proven (Zhang et al. 2019). It has wide applications in the processing of small sample data in various fields (Shao et al. 2019). Analytical problems related to small sample sizes are often raised in biomedical research, and Dwivedi et al. (2017) mostly suggest the use of Bootstrap resampling before the testing of relevant randomized experiments, which can lead to more reliable and robust results. In the statistical analysis of small-sample reliability of product performance, several research teams used Bayesian Bootstrap or improved Bootstrap (Bozorg et al. 2020; Jia et al. 2009), and the results all showed that the Bootstrap-based method has significantly improved the performance reliability assessment of small-sample products and has higher estimation accuracy. Zhang et al. (2019) improve the Bootstrap with fatigue life experiments and their simulation experiments demonstrated that the bias fluctuation of the improved estimation was reduced and the reliability was improved, which overcame the limitations of the method itself and made it much more generalizable. The above researches on Bootstrap provide a reference and promising solution to the small sample problem in hydrological calculations.
In fact, the direct use of Bootstrap for estimating distribution parameters of small sample hydrology does not necessarily result in better estimation properties; therefore, Bootstrap are often used in combination with other parameter estimation method, such as method of moment (MOM), maximum likelihood estimation (MLE) and maximum entropy principle (MEP). When they are used to estimate the distribution parameters of small sample data, there is a rather significant drawback (Song et al. 2021; Westhoff et al. 2014; Yang et al. 2020): the excellent property of smaller bias and increase in stability is only shown in some estimation methods with more stable parameter solutions, such as those based entirely on the "sample moment replaces population moment" principle, e.g., MOM, probability-weighted moment estimation and linear moment methods.
For estimation methods like MLE and MEP, the models constructed by them generally have a high degree of nonlinearity. In addition, MLE and MEP require some iterative convergence algorithms to obtain the overall parameter estimates, which can have a problem (Candelario et al. 2022; Rasheed et al. 2021; Xia et al. 2005): It is difficult to converge in the case of small samples. It may be computationally inaccurate or even unsolvable. So, it is not difficult to understand that in the small sample scenario, Bootstrap combined with MLE and MEP (BMLE and BMEP) directly inherits some problems caused by the high nonlinearity of MLE and MEP. Combining the above discussion, Bootstrap combined with MOM (BMOM) is effective but not enough obvious in small samples; BMLE and BMEP do not effectively solve the problem of estimating parameters for small samples in hydrological frequency calculation, and the estimates are often unsolved in practical applications, making the analysis in a difficult situation.
The objectives of this paper are twofold: proposing a Bootstrap method that enhances accuracy and robustness of the conventional Bootstrap method in combination with probability distributions and parameter estimation methods with high degree of nonlinearity, and investigating the specific extent of applicability of the improved Bootstrap to various distribution parameter estimation methods under small sample conditions. Comparative experiments on the parameter estimation effects before and after the expansion of samples by the improved Bootstrap are conducted to study the parameter estimation effects of method of moments estimation, great likelihood estimation and maximum entropy estimation under small sample conditions, taking Pearson Type III, Weibull and Beta distributions as examples.
2 Distribution Functions
The study of the small sample expansion method in this paper involves the following three distributions: the Pearson Type III distribution, the Weibull distribution, and the Beta distribution. Their distribution functions and the associated parameters are given in Appendix A. (Kong et al. 2020; Krit et al. 2021; Ryu and Famiglietti 2005).
3 Parameter Estimation Methods
Three methods are commonly used to estimate the parameters for distribution functions of hydrologic data series, i.e., MOM, MLE, and MEP. The nonlinear equations that need to be solved iteratively to obtain the parameters of the above-mentioned three distributions are presented in Appendix B, respectively.
Estimating the parameters of a distribution using different parameter estimation methods involves solving the corresponding nonlinear equations, which often requires a large sample size to ensure the stability and accuracy of the solution (Chen 2004; Mindham et al. 2018; Zhang et al. 2018). In the small sample case, the higher the degree of nonlinearity, the more often invalid solutions or no solutions are obtained for the system of equations (Benchohra and Lazreg 2015; Dosne et al. 2016). In general, the MOM method has the lowest degree of nonlinearity among the three parameter estimation methods for the system of equations to be solved; MLE and MEP have comparable degrees of nonlinearity and are relatively higher with MOM.
4 Improved Bootstrap
Bootstrap does not require prior knowledge or assumptions about the distribution properties of the observed samples. In the case where only small samples from a certain distribution are available, the overall distribution properties can be inferred by simply resampling the original samples with equal probability several times. The specific modeling procedures are described in the literature (Zhang et al. 2018). Bootstrap is often used in other fields to estimate distribution parameter deviations, standard errors, and confidence intervals.
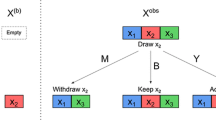
Through a series of comparison experiments, it is found that Bootstrap combined with various parameter estimation methods adopts a "Parallel expansion" model in the process. As shown in Fig. 1, each Bootstrap sample obtained by resampling can be regarded as an expansion, with no direct connection and equal status between them. The estimation \(\hat{\theta }(F_{n}^{(i)} )\) is generated from each Bootstrap sample, and its Bootstrap deviation \(R_{n}^{(i)}\) from the estimation \(\hat{\theta }(F_{n} )\) generated from the original sample is obtained. Then based on the core assumptions of Bootstrap \(T_{n} \approx R_{n}^{(i)}\), the quantified equation of the population parameters, \(\theta (F) = 2\hat{\theta }(F_{n} ) - \hat{\theta }(F_{n}^{(i)} ),i = 1,2, \cdot \cdot \cdot ,N\), can be obtained. Finally, the Bootstrap estimation \(\theta_{B}\) and its function \(g(\hat{\theta }_{B} )\) are obtained. The model is fed with the original sample \(x\) to obtain the parameter estimates for each distribution. Obviously, the sample size of Bootstrap is the same as the original sample size in the "Parallel expansion" model, and Bootstrap cannot be combined with MLE and MEP with high nonlinearity to effectively estimate the parameters in the small sample case.

Schematic diagram of the "Parallel expansion" and "Connection expansion" model
In order to solve the above-mentioned problems of the Bootstrap method in expansion, we propose an improved Bootstrap method by replacing the "Parallel expansion" mode with a so called "Connected expansion" mode. As shown in Fig. 1, the Bootstrap training samples from the original samples are directly connected to form a set of connected samples that are then passed into the "Parameter estimation methods" column instead of the original samples, and the rest of the steps are basically the same as the conventional Bootstrap, but the dimension of the deviation \(R_{n}^{{}}\) is changed from \(N\) to 1. The "Connection expansion" can produce a connected sample \(X^{*}\) with a sample size of generally about 1000 times of the original sample size and can effectively resolve the problem of sample size requirement for the parameter estimation method, thus improving the stability and accuracy of the solution.
The procedure of the improved Bootstrap implementation are as follows.
Step1
With the original sample sequence \(X = (x_{1} ,x_{2} , \cdot \cdot \cdot ,x_{n} )\), an empirical distribution function can be constructed as shown below:
where \(x_{(1)} \le x_{(2)} \le \cdot \cdot \cdot \le x_{(n)}\) is the order statistic of the original sample \(x_{1} ,x_{2} , \cdot \cdot \cdot ,x_{n}\). Similarly, we define the population distribution and the empirical distribution of the Bootstrap training samples as \(F(x)\) and \(F_{n}^{(i)} (x),i = 1,2, \cdot \cdot \cdot ,N\), respectively, and the Bootstrap samples obtained from the next \(N\) training sessions are connected into one connected sample with the empirical distribution denoted as \(F_{n}^{*} (x)\).
Step2
Sample the \(N\) group from \(F_{n}\) by the following steps:
-
1.
In the interval 0 ~ \(M\) (\(M\) is much larger than \(n\)), a random integer \(\eta\) is generated with independence and uniformity.
-
2.
Calculate \(i = \eta \% n\) where \(i\) is the remainder of \(\eta\) divided by \(n\).
-
3.
Find the sample \(x_{i}\) corresponding to the subscript \(i\) in the original sample as the regenerated sample \(x_{1}^{(1)}\).
-
4.
Repeat (1)-(3) until, the number of regenerated samples reaches \(n\). The first set of Bootstrap training sample is formed by far, which is denoted as \(X^{*} (1) = (x_{1}^{(1)} ,x_{2}^{(1)} , \cdot \cdot \cdot ,x_{n}^{(1)} )\).
-
5.
Repeat (4) \(N\) times and update the regenerated samples obtained to form \(N\) groups of Bootstrap training samples \(X^{*} (j) = (x_{1}^{(j)} ,x_{2}^{(j)} , \cdot \cdot \cdot ,x_{n}^{(j)} )\), \(j = 1,2, \cdot \cdot \cdot ,N\). Then form a connected Bootstrap sample by joining the \(N\) groups, which is denoted as
$$\begin{aligned} X^{*} & = (X^{*} (1),X^{*} (2), \cdot \cdot \cdot ,X^{*} (N)) \\ & = (x_{1}^{(1)} ,x_{2}^{(1)} , \cdot \cdot \cdot ,x_{n}^{(1)} ,x_{1}^{(2)} , \cdot \cdot \cdot ,x_{n}^{(2)} , \cdot \cdot \cdot ,x_{n}^{(N)} ) \\ \end{aligned}$$(2)
Step3
The deviation \(R_{n} = \hat{\theta }(F_{n}^{*} ) - \hat{\theta }(F_{n}^{{}} )\) between the Bootstrap statistic \(\hat{\theta }(F_{n}^{*} )\) and the statistic \(\hat{\theta }(F_{n}^{{}} )\) generated by the empirical distribution of the original sample is calculated, as well as the deviation \(T_{n} = \hat{\theta }(F_{n}^{{}} ) - \theta (F)\) between \(\hat{\theta }(F_{n}^{{}} )\) and the population parameter to be estimated \(\hat{\theta }(F)\), which is further reduced by \(T_{n} \approx R_{n}^{{}}\) to obtain \(\theta (F) = 2\hat{\theta }(F_{n}^{{}} ) - \hat{\theta }(F_{n}^{*} )\), where both \(F(x)\) and \(F_{n}^{*} (x)\) can be derived from the original sample. Because of the specificity of the "Connection expansion", only one estimate of the population parameter to be estimated, \(\theta (F)\), is obtained, which combines the information of \(N\) groups of Bootstrap training samples and also allows the parameter estimation of the distribution by replacing the original sample with the connected sample generated. The number of connected samples is generally 1000 times more than that of the original samples, which can provide rich sample information to meet some distribution parameter estimation models that require large samples.
Step4
The final Bootstrap estimate \(\hat{\theta }_{B}\) and \(g(\hat{\theta }_{B} )\) as a function of \(\hat{\theta }_{B}\) are obtained by averaging or taking the median of \(\theta (F)\). The three parameter estimation methods used in this paper, i.e., MOM, MLE, and MEP, are combined with the improved Bootstrap as IBMOM, IBMLE and IBMEP, respectively. For the MOM method, \(\hat{\theta }_{B}\) and \(g(\hat{\theta }_{B} )\) can be directly input into Eqs. (14)–(16) in Appendix B for the final distribution parameter estimates; whereas, for the MLE and MEP methods that require providing iterative initial values, \(\hat{\theta }_{B}\) and \(g(\hat{\theta }_{B} )\) are first input into the MOM model and use the obtained parameter distribution estimates as the initial values of the iterative algorithm, i.e., the MOM method is nested once. For the Pearson Type III distribution, \(\hat{\theta }_{B}\) (or \(g(\hat{\theta }_{B} )\)) is \(\overline{x},\sigma^{2} (x){\text{ or }}C_{s}\) while for the Weibull and Beta distributions, \(\hat{\theta }_{B}\) (or \(g(\hat{\theta }_{B} )\)) is \(\overline{x}{\text{ or }}\sigma^{2} (x)\). \(\overline{x},\sigma^{2} (x){\text{ and }}C_{s}\) are mean, variance and skewness coefficients in statistics, respectively.
Step5
\(\theta_{B}\), \(g(\theta_{B} )\) and the connected sample \(X^{*}\) are input into the estimation method models of various candidate distributions to estimate their associated parameters using different estimation methods. This procedure applies for beyond the three distribution and three parameter estimation methods presented in this study; it in principle applies to any parameter estimation method for any probability distribution.
Bootstrap is random when expanding the samples; the samples left in training set by expanding are roughly 63.2% of the original dataset (Shao et al. 2019). The training sample has some information different from the original sample which potentially affects performance in terms of accuracy. Moreover, the conventional Bootstrap treats each training sample in parallel and thus estimate the parameters in parallel with each sample, which makes the randomness stronger and more uncontrollable. Unlike the conventional Bootstrap, the improved Bootstrap does not treat each training sample in parallel. Instead, it merges them into a set of combined samples with a larger size and perform estimate using the combine samples. There is only one merged sample in an individual estimation, and it is obtained by the origin sample trained 1000 times, which makes the parameter estimates through the improved Bootstrap based on the same original sample are stable.
5 Simulation Experiments
This section will design 1000 pre- and post-expansion randomized simulation experiments for three distributions commonly used in the field of hydrologic frequency calculation — Pearson Type III distribution, Weibull distribution and Beta distribution, and parameter estimation methods — MOM, MLE and MEP, for different degrees of small sample cases — n = 10, 20 and 30, to compare verify the effectiveness and performance improvement of the methods. As suggested in the paper (Hussain and Ahmad 2021), RMSE and bias are used as accuracy measures for the parameter estimation. The procedure of the randomized simulation experiment is detailed as follows:
-
1.
Generate small size (10, 20, and 30) of random numbers that follow Pearson Type III, Weibull distribution and Beta distributions respectively with parameters associated with each distribution given below and sample size requirements as the original samples. The following ideal parameters are set for the three distributions.
$$P - {\rm I}{\rm I}{\rm I}(\alpha ,\beta ,a_{0} ) \Rightarrow P - {\rm I}{\rm I}{\rm I}(4,1, - 2)$$$$Wbl(a,b) \Rightarrow Wbl(3,4)$$$$Beta(a,b) \Rightarrow Beta(3,4)$$In the above equation, the left side indicates the distribution parameters, and the right side indicates the set ideal values.
-
2.
Three types of processing are performed: conventional Bootstrap expansion, improved Bootstrap expansion, and no expansion. For the expansion experiments, the number of trained samples \(N\) by Bootstrap is set to 1000 to ensure the validity of a particular expansion.
-
3.
Repeat Steps 1) and 2) 1000 times as an ideal random simulation experiment of the algorithm.
-
4.
The vectors of parameter estimators for each group of distributions obtained from 30 experiments are collated to generate the boxplots. They are grouped for each parameter of each distribution. To visualize the difference between each parameter of each distribution before and after expansion by the improved Bootstrap and the improvement of parameter estimation performance, the vertical axis of the boxplots is quantified by the absolute deviation (AD),
$$AD = |\hat{\theta } - \theta |$$(3)
where \(\hat{\theta }\) is the estimated value of the distribution parameter before or after the expansion obtained from the random simulation experiment; \(\theta\) is the set true value of the distribution parameter.
-
5.
Quantification of specific values of precision and error. The 1000 estimates obtained from each experiment are entered together into Eqs. (4) and (5) to calculate the evaluation estimator. Equation (5) widely used by researchers in related fields is a classical evaluation indicator in mathematical statistics (Hussain and Ahmad 2021). It combines the bias and variance of the estimates and is more convincing than the bias.
$$Bias(\hat{\theta }) = E(\hat{\theta }) - \theta$$(4)$$\overline{RMSE} (\hat{\theta }) = \sqrt {{\text{var}} (\hat{\theta }) + (Bias(\hat{\theta }))^{2} }$$(5)where \(\theta\) is the set true value of the distribution parameter; \(E(\hat{\theta })\) is the expectation of the estimated value of the distribution parameter before or after the expansion. However, in 5.1 and 5.2, for convenience, the value of \(\overline{RMSE} (\hat{\theta })\) is marked with RMSE.
5.1 Performance Testing of Pearson Type III Data Using Improved Bootstrap
When the experiment is carried out to Step 4), we obtained Fig. 2. The horizontal coordinate "MOM:10" in Fig. 2 represents the group of boxplots for the experiment with n = 10 sample size, including estimated parameters by IBMOM(This is recorded in the table as the "After(IB)" column, i.e., the parameter estimates obtained by improved Bootstrap expansion.), estimated parameters by BMOM (Similarly, it is recorded as the "After(B)" column in the table.), and estimated parameters directly by MOM without expanding the data(it is recorded as the "Before" column in the table.). The other horizontal coordinates are labeled using the same manner. BMLE and BMEP have no solution because they cannot meet the sample requirements of nonlinear equations. In Tables 1, 2 and 3, we use "—" to indicate that the experiment cannot be carried out.

AD boxplots of Pearson Type III data after expansion by improved Bootstrap, conventional Bootstrap and without expansion: a, b and c are for the parameters \(\alpha\), \(\beta\) and \(a_{0}\), respectively
The boxplots in Fig. 2 are essentially the distribution of AD. Intuitively, the blue boxplots in all three plots have lower upper, median, and upper and lower quartiles than the red and green boxplots indicating that the AD distribution expanded by the improved Bootstrap possesses the excellent property of being closer to zero and having a smaller degree of divergence than the AD distribution expanded by Bootstrap and the unexpanded one. In addition, IBMOM still maintains a high range of AD before and after the expansion despite the large absolute number of AD decreases after the expansion and the obvious effect. While the absolute number of AD decreases after the expansion of IBMLE and IBMEP is relatively small, its AD before and after the expansion lies within the smaller values, indicating that these two estimation methods perform fairly in themselves when applied to Pearson Type III data, and improved Bootstrap further improves the performance of both estimation methods. The boxplots in Fig. 2 reveal that the parameter estimates obtained by improved Bootstrap for Pearson Type III distribution data have the smallest bias and highest precision for a set sample size.
Further combining the RMSE and bias in Table 1, it shows that the improved Bootstrap is more efficient when the sample size is smaller, and is most efficient when the sample size is 10. From the upper quartile of the boxplots, the upper quartile of the AD boxplots of each parameter estimate after the improved Bootstrap expansion is generally reduced by 50% when the sample size is 10. That is, the smaller the sample size, the more significant the contraction of the boxplots expanded by improved Bootstrap compared to the unexpanded and expanded by Bootstrap boxplots. This is also in line with common sense, as the sample size is gradually increasing, the information contained in it is bound to accumulate to the point of redundancy, and the difference between expansion and non-expansion is very small at this point. However, as shown in Fig. 2 and Table 1, the expansion algorithm maintains a significant difference from the unexpanded algorithm at least in the incremental process of n = 10,20,30.
Finally, a longitudinal comparison of the tables easily reveals that using IBMLE and IBMEP to estimate the distribution parameters at each sample size yields smaller RMSE and bias, the smallest for MEP, followed by MLE, while the two estimators for IBMOM are generally larger. The two estimators for BMOM are slightly lower than the unexpanded data, but significantly larger than IBMOM. Compared to the AD boxplots, RMSE and bias are further convincing. Comprehensive analysis shows that for n = 10,20,30 Pearson Type III data using IBMEP has the best effect, IBMLE is better. And the difference between the effect of IBMOM before and after expansion is obvious, but RMSE and bias are larger, which is the less effective among the three methods.
5.2 Performance Testing of Weibull and Beta Data Using Improved Bootstrap
Figures 3 and 4 clearly show that the improved Bootstrap expansion is also effective for Weibull and Beta data. The AD distribution of each parameter to be estimated in each case expanded by the improved method, i.e., the blue boxplots, are lower than the red and green boxplots, which indicates that the error and dispersion of the expanded parameter estimates are smaller.

AD boxplots of Weibull data after expansion by improved Bootstrap, conventional Bootstrap and without expansion: a and b are for the parameters \(a\) and \(b\), respectively

AD boxplots of Beta data after expansion by improved Bootstrap, conventional Bootstrap and without expansion: a and b are for the parameters \(a\) and \(b\), respectively
Then RMSE and bias estimators of the two distributions in Tables 2 and 3 respectively which intuitively shows that the accuracy of the estimated parameter obtained by the three estimation methods themselves is generally satisfactory. The improvement in estimation after the improved Bootstrap expansion is not obvious at the absolute number level, but the effect is considerable at the level of relative numbers. The average reductions in RMSE and bias for the Weibull data after the IBMOM expansion are about 0.2408 and 0.1184, respectively, for each set sample size, with relatively average reductions of 40.17% and 16.96%. RMSE and bias are reduced by 7.48% and 3.84% on average after expansion by BMOM, which are significantly worse than those of IBMOM; RMSE and bias are reduced by about 0.9689 and 0.8373 on average by expansion by IBMOM for each set sample size, with relatively average reductions of 47.61% and 70.44%, respectively. RMSE and bias are reduced by 7.83% and 8.04% on average by BMOM expansion, which is significantly worse than IBMOM.
Similarly, for IBMLE expansion, the average reductions in the two metrics mentioned above are 0.2394 and 0.0958 for the Weibull data, with relatively average reductions of 37.49% and 51.00%, respectively. For the Beta data, the mean reductions are 0.7792 and 0.5045, with relatively mean reductions of 42.34% and 55.35%.
For IBMEP expansion, the average reductions of Weibull data are 0.2108 and 0.0946, with relatively average reductions of 35.05% and 38.99%. The average reductions of Beta data, on the other hand, are 0.7692 and 0.4887, with relatively average reductions of 41.65% and 49.74%. In summary, in terms of relative numbers, improved Bootstrap has a good contribution to the reduction of bias and improvement of accuracy of the distribution parameter estimates for each set sample size. The experiments also show that for distributed parameter estimation of the Weibull data in small sample cases, IBMLE should be considered as the first choice; while for the Beta data, the difference in effect between IBMLE and IBMEP is not significant, and IBMOM is a better choice.
6 Case Study
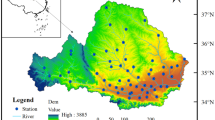
To verify its performance, we applied the improved Bootstrap to annual precipitation frequency analysis using 55-year data (1961–2015) collected from 8 counties in Gansu Province, China, namely Huanxian, Qingcheng, Xifeng, Zhenyuan, Huachi, Heshui, Zhengning and Ningxian, as shown in Fig. 5. Before further proceed, two notes are given as follows:
-
1.
A large amount of literature shows that many hydrological sequences in China fit well with Pearson Type III distribution (Lei et al. 2019, 2018; Sun et al. 2018), such as the annual runoff and annual average precipitation, therefore the annual precipitation sequence is assumed to follow Pearson Type III distribution in this study.
-
2.
There are some missing data in the annual precipitation series of each county, which are eliminated, resulting in a series less than 55 records for each county. 10, 20, and 30 data are selected from the annual precipitation series as small samples to investigate the performance of the improved Bootstrap on different samples size. The three parameters of the Pearson Type III distribution are estimated by MOM, MLE, and MEP using unexpanded and expanded data by improved Bootstrap.

The map of Qingyang City
The empirical frequency is first obtained as the base line for comparison. The empirical frequency curve (EFC) for the annual precipitation of each county can be calculated using Eq. (6) (Qian et al. 2022) based upon all the available measurement data \(X = \left\{ {X_{1} ,X_{2} , \cdot \cdot \cdot ,X_{N} } \right\}\) for the county.
where \(H_{i}\) denotes the empirical frequency value of the observation sample ranked in the \(i\) th position from smallest to largest.
The theoretical frequency curves (TFC) of the annual precipitation following Pearson Type III distribution can be obtained from Eq. (8) in Appendix A with the parameters estimated using MOM, MLE, and MEP with unexpanded sample and expanded sample sequences based on 10, 20, and 30 samples selected from the measurement data. The RMSE is calculated as follows.
where \(G_{i}\) is the theoretical frequency. The P-P plots of the EFC against the TFC for counties of Zhengning, Xifeng, and Heshui generated from distribution functions with parameters estimated by MOM, MLE, and MEP using unexpanded and expanded data are shown in Figs. 6, 7 and 8. And the P-P plots for other counties are shown in Figs. 9, 10, 11, 12 and 13 in Appendix C. The RMSE of the EFC against the TFC are shown in Table 4.

P-P plots of the EFC and TFC using unexpanded and expanded data in the Zhenning County
Observing Figs. 6, 7 and 8, we find that the TFC of expanded data (yellow lines) all fit the EFC (blue lines) well. On the contrary, the TFC of unexpanded data (red lines) deviate from the blue lines more times. And red lines deviate badly from the yellow and blue lines several times, such as "MEP, n = 10" for the frequency curve plot of Zhengning County in Fig. 6, "MOM, n = 10" for the frequency curve plot of Xifeng County in Fig. 7, and "MLE, n = 10" for the frequency curve plot of Heshui County in Fig. 8 and other cases (They are detailed in Appendix C), while the yellow lines fit better with the blue lines. These examples all further verify the conclusion obtained in the simulation experiments that the estimated parameters using the data expanded by the improved Bootstrap are less biased and more accurate than those obtained without the expansion. Moreover, the estimated parameters of Pearson Type III data expanded by the improved Bootstrap show better results for small samples.

P-P plots of the EFC and TFC using unexpanded and expanded data in the Xifeng County

P-P plots of the EFC and TFC using unexpanded and expanded data in the Heshui County
Table 4 shows that RMSE of the parameter after the improved Bootstrap expansion generally decreases by 30% to 50%. The minimum RMSE after expansion of the improved Bootstrap is around 0.240; indicating that the estimated parameters are satisfied using the improved Bootstrap. The average relative improvement of RMSE after expansion for MOM, MLE and MEP are 29.14%, 29.28% and 34.21%, respectively. The improvement of MEP is the best after expansion, followed by MLE and MOM.
Meanwhile, we can collate the average of differences between before and after expansion for RMSE under a given set sample size, i.e., \(\Delta RMSE_{n}\). It shows that the smaller the sample size, the larger the \(\Delta RMSE_{n}\), i.e., the better the effect of the improved Bootstrap expansion for Pearson Type III data.
Among the cases of a variety of sample size, IBMOM, IBMLE, and IBMEP reach the maximum \(\Delta RMSE_{n}\) at n = 10, 0.0268, 0.0283 and 0.0396, respectively, indicating that IBMEP has the most significant improvement in fitting effect in very small samples compared to the unexpanded case. And \(\Delta RMSE_{n}\) of the IBMEP at n = 20, 30 are 0.0187 and 0.0095 respectively, which are also the largest compared to the other two. This indicates that expansion by improved Bootstrap for Pearson Type III data in the small sample case has the most marginal advantage and provides the most efficient distribution parameter estimates with less error and higher accuracy.
As a result of the above analysis, both from the perspective of the index "the average of the relative improvement between before and after expansion for RMSE", which reflects the performance at each sample size, and from the index \(\Delta RMSE_{n}\), which reflects the performance at a certain sample size, it shows that IBMEP is the best application, which is consistent with the conclusion of the simulation experiment.
7 Summary and Conclusion
This paper proposes an improved Bootstrap using the "Connection expansion" mode and combines the improved Bootstrap with MOM, MLE, and MEP. The data from different distributions and sample sizes are subjected to 30 experiments based on the improved Bootstrap expansion, and the estimated values before and after the expansion are collected and compiled to obtain the corresponding AD boxplots, RMSE and bias. To further verify the conclusions obtained from the simulations, empirical analysis is conducted with the average annual precipitation of 8 counties in Qingyang, China. The main findings of this paper are as follows.
-
1.
According to the simulation experiment, the estimated values of distribution parameters obtained by the improved Bootstrap expansion are less deviation and more accurate than the estimation values without corresponding expansion for Pearson Type III, Weibull distribution, and Beta distribution data. Specifically, for Pearson Type III data, the smaller the sample size is, the better the effect of the improved Bootstrap expansion is. IBMEP model performs the best, which provides the smallest RMSE and bias among the three models, followed by the IBMLE model and IBMOM model. For Weibull data, the IBMLE model should be considered first. The RMSE and bias of Weibull data are reduced by 37.49% and 51.00% on average after expansion in each sample size. For Beta data, the difference in effect between IBMLE and IBMEP is not significant, and IBMOM is a better choice.
-
2.
The fitting experiments demonstrate that the distribution estimates obtained with the improved Bootstrap expansion are significantly better than those obtained without expansion for the small sample cases of n = 10,20,30 for Pearson Type III, Weibull, and Beta data. The effect of the estimates obtained by the improved Bootstrap expansion for Pearson Type III data only becomes better as the sample size decreases. Furthermore, the IBMEP model can have a good estimation for Pearson Type III data at each sample size; for Weibull data, the IBMEP model is also a good estimation choice; while for Beta data, IBMEP and IBMLE models have little difference in estimation effect, and IBMOM is a better choice. In summary, the improved Bootstrap provides a more feasible solution to the small sample problem that widely exists in hydrological frequency analysis.
Future research on the improved Bootstrap can be made to solve the problems of overlapping sample information and "how to reasonably extrapolate sample information" in Bootstrap expansion. The applicability of the method can also be broadened by designing experiments coupled with other estimation methods under different distributions.
Availability of Data and Materials
Available from the corresponding author on request.
References
Aghakouchak A (2014) Entropy–copula in hydrology and climatology. J Hydrometeorol 15(6):2176–2189
Aissia MAB, Chebana F, Ouarda TB, Roy L, Desrochers G, Chartier I, Robichaud É (2012) Multivariate analysis of flood characteristics in a climate change context of the watershed of the Baskatong reservoir, Province of Québec, Canada. Hydrol Process 26(1):130–142
Benchohra M, Lazreg JE (2015) On stability for nonlinear implicit fractional differential equations. Matematiche (catania) 70(2):49–61
Bozorg M, Bracale A, Caramia P, Carpinelli G, Carpita M, De Falco P (2020) Bayesian bootstrap quantile regression for probabilistic photovoltaic power forecasting. J Protect Control Modern Power Syst 5(1):1–12
Bracken C, Rajagopalan B, Cheng L, Kleiber W, Gangopadhyay S (2016) Spatial Bayesian hierarchical modeling of precipitation extremes over a large domain. Water Resour Res 52(8):6643–6655
Candelario G, Cordero A, Torregrosa JR, Vassileva MP (2022) An optimal and low computational cost fractional Newton-type method for solving nonlinear equations. Appl Math Lett 124(1):107650
Chen G (2004) Stability of nonlinear systems. Encyc RF Microw Eng 4881–4896
De Michele C, Salvadori G (2005) Some hydrological applications of small sample estimators of Generalized Pareto and Extreme Value distributions. J Hydrol 301(1–4):37–53
Dosne AGL, Bergstrand M, Harling K, Karlsson MO (2016) Improving the estimation of parameter uncertainty distributions in nonlinear mixed effects models using sampling importance resampling. J Pharmacokinet Pharmacodyn 43(6):583–596
Dwivedi AK, Mallawaarachchi I, Alvarado LA (2017) Analysis of small sample size studies using nonparametric bootstrap test with pooled resampling method. Stat Med 36(14):2187–2205
Hussain Z, Ahmad I (2021) Effects of L-moments, maximum likelihood and maximum product of spacing estimation methods in using pearson type-3 distribution for modeling extreme values. Water Resour Manag 35(5):1415–1431
Jackson EK, Roberts W, Nelsen B, Williams GP, Nelson EJ, Ames DP (2019) Introductory overview: Error metrics for hydrologic modelling–A review of common practices and an open source library to facilitate use and adoption. Environ Model Softw 119:32–48
Jia ZQ, Cai JY, Liang YY (2009) Real-time performance reliability evaluation method of small-sample based on improved Bootstrap and Bayesian Bootstrap. Appl Res Comput 26(8):2851–2854
Kong X, Hao Z, Zhu Y (2020) Entropy theory and pearson type-3 distribution for rainfall frequency analysis in semi-arid region. IOP Conf Ser Earth Environ Sci 495(1):012042
Krit M, Gaudoin O, Remy E (2021) Goodness-of-fit tests for the Weibull and extreme value distributions: A review and comparative study. J Commun Stat-Simul Comput 50(7):1888–1911
Lei G-J, Wang W-C, Yin J-X, Wang H, Xu D-M, Tian J (2019) Improved fuzzy weighted optimum curve-fitting method for estimating the parameters of a Pearson Type-III distribution. Hydrol Sci J 64(16):2115–2128
Lei G-J, Yin J-X, Wang W-C, Wang H (2018) The analysis and improvement of the fuzzy weighted optimum curve-fitting method of Pearson–type III distribution. Water Resour Manag 32(14):4511–4526
Liu Y, Brown J, Demargne J, Seo DJ (2011) A wavelet-based approach to assessing timing errors in hydrologic predictions. J Hydrol 397(3–4):210–224
Liu D, Wang D, Wang Y, Wu J, Singh VP, Zeng X, Wang L, Chen Y, Chen X, Zhang L (2016a) Entropy of hydrological systems under small samples: Uncertainty and variability. J Hydrol 532:163–176
Liu Z, Törnros T, Menzel L (2016b) A probabilistic prediction network for hydrological drought identification and environmental flow assessment. Water Resour Res 52(8):6243–6262
Ma M, Song S, Ren L, Jiang S, Song J (2013) Multivariate drought characteristics using trivariate Gaussian and Student t copulas. Hydrol Process 27(8):1175–1190
Mindham DA, Tych W, Chappell NA (2018) Extended state dependent parameter modelling with a data-based mechanistic approach to nonlinear model structure identification. Environ Model Softw 104:81–93
Qian L, Wang H, Dang S, Wang C, Jiao Z, Zhao Y (2018) Modelling bivariate extreme precipitation distribution for data-scarce regions using Gumbel-Hougaard copula with maximum entropy estimation. Hydrol Process 32(2):212–227
Qian L, Zhao Y, Yang J, Li H, Wang H, Bai C (2022) A new estimation method for copula parameters for multivariate hydrological frequency analysis with small sample sizes. Water Resour Manag 36(4):1141–1157
Rahmani MA, Zarghami M (2015) The use of statistical weather generator, hybrid data driven and system dynamics models for water resources management under climate change. J Environ Inf 25(1):23–35
Rasheed M, Shihab S, Rashid T, Enneffati M (2021) Some step iterative method for finding roots of a nonlinear equation. J Al-Qadisiyah Comput Sci Math 13(1):95–102
Razmi A, Mardani-Fard HA, Golian S, Zahmatkesh Z (2022) Time-varying univariate and bivariate frequency analysis of nonstationary extreme sea level for New York City. Environ Process 9(1):1–27
Ryu D, Famiglietti JS (2005) Characterization of footprint-scale surface soil moisture variability using Gaussian and Beta distribution functions during the Southern Great Plains 1997 (SGP97) hydrology experiment. Water Resour Res 41(12):4203–4206
Shao Y, Lu P, Wang B, Xiang Q (2019) Fatigue reliability assessment of small sample excavator working devices based on Bootstrap method. Frattura Ed Integrità Strutturale 13(48):757–767
Singh VP (1998) Entropy-based parameter estimation in hydrology. Springer, Dordrecht
Singh VP, Asce F (2011) Hydrologic synthesis using entropy theory: Review. J Hydrol Eng 16(5):421–433
Singh VP, Sivakumar B, Cui H (2017) Tsallis entropy theory for modeling in water engineering: A review. Entropy 19(12):641
Song S, Kang Y, Song X, Singh VP (2021) MLE-based parameter estimation for four-parameter exponential gamma distribution and asymptotic variance of its quantiles. Water Resour Manag 13(15):2092
Sun P, Wen Q, Zhang Q, Singh VP, Sun Y, Li J (2018) Nonstationarity-based evaluation of flood frequency and flood risk in the Huai River basin, China. J Hydrol 567:393–404
Wang C, Chang NB, Yeh GT (2009) Copula-based flood frequency (COFF) analysis at the confluences of river systems. Hydrol Process Int J 23(10):1471–1486
Westhoff MC, Zehe E, Schymanski SJ (2014) Importance of temporal variability for hydrological predictions based on the maximum entropy production principle. Geophys Res Lett 41(1):67–73
Xia J, Wang G, Tan G, Ye A, Huang G (2005) Development of distributed time-variant gain model for nonlinear hydrological systems. Sci China Ser D Earth Sci 48(6):713–723
Yang X, Li Y, Liu Y, Gao P (2020) A MCMC-based maximum entropy copula method for bivariate drought risk analysis of the Amu Darya River Basin. J Hydrol 590:125502
Zhang J, Lin G, Li W, Wu L, Zeng L (2018) An iterative local updating ensemble smoother for estimation and uncertainty assessment of hydrologic model parameters with multimodal distributions. Water Resour Res 54(3):1716–1733
Zhang M, Liu X, Wang Y, Wang X (2019) Parameter distribution characteristics of material fatigue life using improved bootstrap method. Int J Damage Mech 28(5):772–793
Funding
The study was supported by the National Key Research and Development Program of China (2021YFC3201100), The Belt and Road Special Foundation of the State Key Laboratory of Hydrology-Water Resources and Hydraulic Engineering (Grant No. 2020nkms03), National Natural Science Foundation of China (Grant No 41875061), and NUPTSF (Grant Nos. NY219161 and NY220035).
Author information
Authors and Affiliations
Contributions
The contribution of Hanlin Li is project design, model construction, and simulation experiments. The contribution of Longxia Qian includes project design and result analysis. The contribution of Jianhong Yang is algorithmic programming. The contribution of Suzhen Dang is model validation. The contribution of Mei Hong is model analysis.
Corresponding author
Ethics declarations
Ethics Approval
The authors confirm that this article is original research and has not been published or presented previously in any journal or conference in any language (in whole or in part).
Consent to Participate and Consent to Publish
The authors declare that have consent to participate and consent to publish.
Competing Interests
The authors have no conflict of interest and are completely satisfied with the publication of their article in water resources management journal.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Distribution Functions
1.1 Pearson Type III Distribution
It contains three parameters \(\alpha ,\beta ,a_{0}\) with the following probability density:
where \(\alpha\) is the shape parameter, \(\beta\) is the scale parameter, and \(a_{0}\) is the position parameter; \(x > a_{0}\), \(\beta > 0\); \(\Gamma (\alpha ) = \int_{0}^{\infty } {t^{\alpha - 1} e^{ - t} dt}\).
The distribution function of the Pearson Type III distribution has the following form:
1.2 Weibull Distribution
This paper studies the latter two-parameter estimation problem with the following probability density function.
where \(a\) is the shape parameter and \(b\) is the scale parameter; \(a > 0\), \(b > 0\).
The distribution function of the Weibull distribution has the following form:
The Weibull is a two-parameter distribution that can be considered as an inverse generalized extreme value distribution.
1.3 Beta Distribution
Its probability density function containing two parameters \(a,b\) is shown as follows.
where the range of parameters is \(a > 0\), \(b > 0\) and \(0 < x < 1\), \(a,b\) are called shape parameters.
The distribution function of the Beta distribution has the following form:
Appendix B: Parameter Estimation Methods
2.1 Method of Moments (MOM)
-
1.
MOM for Pearson Type III distribution is as follows:
-
2.
MOM for Weibull distribution is as follows:
$$\left\{ \begin{array}{l} \overline{x} = b\Gamma (1 + \frac{1}{a}) \hfill \\ \sigma^{2} (x) = b^{2} \Gamma (1 + \frac{2}{a}) \hfill \\ \end{array} \right.$$(15)
-
3.
MOM for Beta distribution is as follows:
$$\left\{ \begin{array}{l} \overline{x} = ab \hfill \\ \sigma^{2} (x) = a^{2} b \hfill \\ \end{array} \right.$$(16)where \(x\) is the original sample sequence, \(\alpha ,\beta ,a_{0}\) is the parameters to be estimated for the Pearson Type III distribution, which are shape, scale and location parameters, respectively, and which used the first three orders of sample moments \(\overline{x},\sigma^{2} (x),C_{s}\), i.e., mean, variance and skewness coefficients to build a ternary system of equations; \(a,b\) is the two parameters to be estimated for the Weibull and Beta distributions.
2.2 Maximum Likelihood Estimation (MLE)
-
1.
MLE for Pearson Type III Distribution is as follows:
-
2.
MLE for Weibull distribution is as follows:
$$\ln L(x;a,b) = n\ln (\frac{a}{b}) + (a - 1)\sum\limits_{i = 1}^{n} {\ln (\frac{{x_{i} }}{b})} - \sum\limits_{i = 1}^{n} {(\frac{{x_{i} }}{b})^{a} }$$(19)$$\left\{ \begin{array}{l} \frac{1}{a} = \frac{{\sum\limits_{i = 1}^{n} {x_{i}^{a} \ln x_{i} } }}{{\sum\limits_{i = 1}^{n} {x_{i}^{a} } }} - \frac{1}{n}\sum\limits_{i = 1}^{n} {\ln x_{i} } \hfill \\ b^{a} = \frac{1}{n}\sum\limits_{i = 1}^{n} {x_{i}^{a} } \hfill \\ \end{array} \right.$$(20)
-
3.
MLE for Beta distribution is as follows:
$$\ln L(x;a,b) = n\ln \Gamma (a + b) - n\ln \Gamma (a) - n\Gamma (b) + \sum\limits_{i = 1}^{n} {\ln (x_{i}^{a - 1} (1 - x_{i} )^{b - 1} )}$$(21)$$\left\{ \begin{array}{l} \frac{\partial [\ln \Gamma (a)]}{{\partial (a)}}{ - }\frac{\partial [\ln \Gamma (a + b)]}{{\partial (a)}} = \frac{1}{n}\sum\limits_{i = 1}^{n} {\ln x_{i} } \hfill \\ \frac{\partial [\ln \Gamma (b)]}{{\partial (b)}}{ - }\frac{\partial [\ln \Gamma (a + b)]}{{\partial (b)}} = \frac{1}{n}\sum\limits_{i = 1}^{n} {\ln (1 - x_{i} )} \hfill \\ \end{array} \right.$$(22)where \(\Gamma ( \cdot )\) and \(\psi ( \cdot )\) are the gamma function and the Pusey function, respectively, and the expression of the relationship between them is that,
$$\begin{aligned} \psi (x) & { = }\int_{0}^{\infty } {[\frac{{e^{ - t} }}{t} - \frac{{e^{ - xt} }}{{1 - e^{ - t} }}]} dt \\ & = \frac{d}{dx}\ln \Gamma (x) = \frac{{\Gamma^{\prime}(x)}}{\Gamma (x)} \\ \end{aligned}$$(23)where \(x\) must satisfy \({\text{Re}} (x) > 0\), i.e., the real part of each sample is greater than 0.
2.3 Maximum Entropy Principle (MEP)
Based on the book "Entropy-based Parameter Estimation in hydrology" by Singh of Louisiana State University (1998), the derivation of the maximum entropy estimates for the three distributions involved in this paper is given below.
-
1.
MEP for Pearson Type III distribution is as follows:
-
2.
MEP for Weibull distribution is as follows:
$$\left\{ \begin{array}{l} b^{a} = \frac{1}{n}\sum\limits_{i = 1}^{n} {\ln x_{i}^{a} } \hfill \\ \psi (1) - \ln b = \frac{1}{n}\sum\limits_{i = 1}^{n} {\ln x_{i} } \hfill \\ \end{array} \right.$$(25)
-
3.
MEP for Beta distribution is as follows:
$$\left\{ \begin{array}{l} \frac{1}{n}\sum\limits_{i = 1}^{n} {\ln x_{i} } = \psi (a) - \psi (a + b) \hfill \\ \frac{1}{n}\sum\limits_{i = 1}^{n} {\ln (1 - x_{i} )} = \psi (b) - \psi (a + b) \hfill \\ \end{array} \right.$$(26)
The significance of each parameter in the Eqs. (24) to (26) of this section has been described in detail in the previous two subsections.
Appendix C: Empirical Analysis

P-P plots of the EFC and TFC using unexpanded and expanded data in the Huanxian County

P-P plots of the EFC and TFC using unexpanded and expanded data in the Qingcheng County

P-P plots of the EFC and TFC using unexpanded and expanded data in the Zhenyuan County

P-P plots of the EFC and TFC using unexpanded and expanded data in the Huachi County

P-P plots of the EFC and TFC using unexpanded and expanded data in the Nianxian County
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, H., Qian, L., Yang, J. et al. Parameter Estimation for Univariate Hydrological Distribution Using Improved Bootstrap with Small Samples. Water Resour Manage 37, 1055–1082 (2023). https://doi.org/10.1007/s11269-022-03410-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-022-03410-y