
Abstract
A multi-objective differential evolution-chaos shuffled frog leaping algorithm (MODE-CSFLA) is proposed for water resources system optimization to overcome the shortcomings of easily falling into local minima and premature convergence in SFLA. The performance of MODE-CSFLA in solving benchmark problems is compared with that of non-dominated sorting genetic algorithm II (NSGA-II) and multi-objective particle swarm optimization (MOPSO). At last, the proposed MODE-CSFLA is used to optimize the water resources allocation plan of the East Route of the South-to-North Water Transfer Project in the normal, dry, and extremely dry years. The results reveal that MODE-CSFLA performs better than NSGA-II and MOPSO under all conditions. Compared with shuffled frog leaping algorithm (SFLA), MODE-CSFLA can result in a 29.39, 27.47 and 22.55% increase in water supply when the single objective is to minimize the water pumpage; and a 41.01, 39.63 and 30.94% decrease in total pumpage when the single objective is to maximize the water supply in the normal, dry, and extremely dry conditions, respectively. Thus, MODE-CSFLA has the potential to be used for solving complex optimization problems of water resources systems.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Water resources optimization is increasingly being recognized as a strategic issue (Hossain and El-Shafie 2013; Wen et al. 2018). The water resources optimization model can produce an optimal solution to the decision-making problems in water resources system management. Methods previously implemented into single-objective optimization of water resources systems include linear (Ding et al. 2018) or nonlinear programing (Ahmad et al. 2014), dynamic programming (Zhang et al. 2017) and artificial neural networks (Yu et al. 2015). Recently, evolutionary algorithms (EAs), such as genetic algorithm, particle swarm optimization algorithm, differential evolution (DE) algorithm have been successfully used for solving various water resources optimization problems because of their population-based nature, non-continuous and non-convex objective space, and ease of implementation (Maier et al. 2014; Tayfur 2017).
However, water resources optimization problems have become more complex than ever before, especially when it comes to the water resources systems designed for multi-purposes, such as water supply, flood control, power generation, and irrigation (Wen et al. 2016). A multi-objective optimization model was proposed to improve the operational effectiveness of water resources systems for trade-offing the benefits of their usage (Scola et al. 2014). Traditional multi-objective optimization techniques (weighting and E-constraint) generally transform a multi-objective problem into a single-objective one and then solve with classical optimization algorithms (Guo et al. 2018; Karamouz et al. 2007). However, these methods can only generate one solution, and can become difficult to satisfy inputting reasonable bounds for all objectives. To overcome these problems, EAs based on Pareto theory, better known as multi-objective evolutionary algorithms (MOEAs) (Arshi et al. 2014) have been developed, e.g., non-dominated sorting genetic algorithm (NSGA-II) and multi-objective particle swarm optimization algorithm (MOPSO). These algorithms have been successfully applied to optimize water resource systems (Fallah-Mehdipour et al. 2011; Li et al. 2010; Lopez-Ibanez et al. 2005), which can find a set of non-dominated solutions without the need to convert the multi-objective problem into the single-objective one. In recent years, researchers have attempted to develop novel multi-objective algorithms in the field of water resource management, and achieved various degrees of success (Liu et al. 2012; Makaremi et al. 2017; Siew et al. 2016). Results indicate the modified multi-objective algorithm is a one of crucial methods to optimize the water resources systems. There are still some serious challenges in the operation and management of water resources systems (Sun et al. 2016), therefore it is necessary to develop new multi-objective algorithms for complex water resource management.
Shuffled frog leaping algorithm (SFLA) is a new meta-heuristic population-based EAs inspired by natural memetics (Eusuff et al. 2006), which has only a few parameters, but fast calculation speed and excellent global search capability. SFLA has been successfully applied to solve many optimization problems, such as production scheduling (Yenisey and Yagmahan 2014), water resource distribution (Pazoki et al. 2016), and vehicle routing (Luo and Liu 2014). However, SFLA can easily fall into local minima and has slow convergence in later stage of the evolution and poor calculation accuracy (Sun et al. 2016). Thus, through combination with other optimization algorithms, SFLA has been developed as new algorithms to overcome its shortcomings such as chaos-based SFLA (Li et al. 2008) and hybrid PSO-SFLA (Orouji et al. 2013). Meanwhile, researchers began to extend SFLA to multi-objective problems and proposed the multi-objective SFLA (MOSFLA) based on Pareto theory. Li et al. (2010) presented a MOSFLA incorporating an archiving strategy based on self-adaptive niche method. Rahimi-Vahed et al. (2009) established a hybrid MOSFLA based on SFLA and Bacteria Optimization for solving the Mixed-Model Assembly Line sequencing problem. Gao and Cao (2012) applied the theory of membrane computing and quantum computing to MOSFLA. The above MOSFLA have been tested on several benchmark functions that present their better performance to many optimization problems than some multi-objective algorithms like NSGA-II.
DE algorithm (Storn and Price 1997) is a population-based stochastic search technique with applications in many fields, such as pattern recognition (Ilonen et al. 2003), dynamic systems (Angira and Santosh 2007), and folded laminated composite plates (Le-Anh et al. 2015). Chaos is a general phenomenon in nonlinear systems with some special characteristics (Cheng et al. 2008). It has such a high sensitivity that even a tiny change of the initial condition can lead to a dramatic change of the system.
Based on the efficiency of SFLA, DE algorithm and Chaos, considering few published work to deal with multi-objective optimization problems by using MOSFLA in the field of water resource systems, we propose a novel algorithm named as multi-objective differential evolution-chaos shuffled frog leaping algorithm (MODE-CSFLA). The novel MOSFLA initializes a population by Chaos and replaces the local update of SFLA with stochastic search technique of DE algorithm. Moreover, an external archive with dynamic updating mechanism is implemented to improve the diversity of Pareto solutions in MODE-CSFLA. Then, the proposed algorithm is verified using five mathematical benchmark problems compared with that of NSGA-II and MOPSO. At last, MODE-CSFLA is used to solve the multi-objective optimal water resources allocation model of the East Route of the South-to-North Water Transfer (E-SNWT) Project in the normal, dry, and extremely dry conditions.
2 Methodology
2.1 Chaos
The chaotic sequence (Zhu et al. 2017) can usually be produced by the following one-dimensional logistic map:
where xi is the range of the random chaotic variable, xi ∈ (0, 1), i = 0, 1, 2…; and μ is a control parameter,μ ∈ (0, 4]. In this paper,x0 ∉ {0.25, 0.5, 0.75}andμ = 4.
2.2 Shuffled Frog Leaping Algorithm
SFLA is a meta-heuristic optimization method that mimics the memetic evolution of a group of frogs while seeking for the location that has the maximum amount of available food (Khosroshahi et al. 2015). It consists of a set of interacting population of virtual frogs partitioned into different groups referred to as memeplexes. The different memeplexes are considered as different cultures of frogs, each frog performing a local search. Within each memeplex, the individual frog holds ideas that can be influenced by the ideas of other frogs, and these ideas can evolve through a process of memetic evolution. After a defined number of memetic evolution iterations, ideas are passed among memeplexes in a shuffling process.
2.3 Novel Differential Evolution Algorithm
DE algorithm uses mutation, crossover, and selection operators at each generation to move its population toward the global optimum (Zhao et al. 2016). Here, some novelties on each operator were proposed to improve the searching ability of DE algorithm.
-
(1)
Mutation
For each target vector xi, the traditional mutation operation is used to generate a mutant vector vi using Eq.2:
where xi1(t), xi2(t) and xi3(t) are the three vectors selected randomly from sub-population, i1 ≠ i2 ≠ i3,i = 1, 2, …, M,M is the number of each sub-population; t is the current time of sub-population iterations; F is the mutation scale factor, which is a positive constant, F ∈ (0, 2).
Some measures were proposed on Eq.2 to improve the local searching ability of DE algorithm, as shown in Eq.3.
where xbest(t) is the best individual of sub-population.
As the mutant vector vi(t) varies significantly with F, a dynamic change strategy of Fwas proposed to reduce the variance of F with increasing global iteration times, as shown in Eq.4:
where Fmax = 0.75, Fmin = 0.37and Ngen is the times of global iteration, i = 1, 2, ⋯, Ngen.
-
(2)
Crossover
Following the mutation operation, a trial vector uij is generated from the mutant vector vij(t) and its target vector xij(t) using a crossover operation. In this study, the binomial crossover was used, as shown in Eq.5:
where rand1 is a uniform random number, rand1 ∈ [0, 1].CR is the crossover rate, CR ∈ [0, 1]. D is the dimension of the optimization problem, j = 1, 2, …, D.rand2 is a integer randomly selected from {1, 2, 3, …, D}. rand2 is used to ensure the difference between the trial vector and the target vector so as to increase the efficiency of evolution.
CR determines the effect of mutant vector. If CR is large, uij mainly obtained from vij(t) can reduce the convergence speed; on the contrary, uij mostly from the xij(t) can led to the prematurity of the algorithm. A dynamic change strategy of CRwas proposed to overcome this drawback, as shown in Eq.6.
where CRmax = 0.3 and CRmin = 0.1.
-
(3)
Selection
In this part, there is a competition between each target vector xij(t) and its trial vector uij. For maximization problems, the selection operation can be expressed as Eq.7:
where f is the fitness value, and xi(t + 1)is used as a parent vector in the next generation.
2.4 External Archive with Dynamic Updating Mechanism
Here, an external archive with dynamic updating mechanism (Modiri-Delshad and Rahim 2016) is used to save and update the non-dominated solutions. The dynamic updating mechanism consists of two basic operations: the analog binary crossover method and the dynamic crowding distance calculation.
-
(1)
Analog binary crossover
The analog binary crossover method can increase the number of individuals who meet the defined requirements if there are not enough individuals in EA. It is based on the principle of the binary string of single-point crossover, in which chromosome is expressed in real number string and two parent individuals cross to generate new individuals, as shown in Eq.8:
where xi, k is the kth variable of the ith individual; pi, k is the kth variable of parent individuals; βk is a random variable of the kth variable, βk ≥ 0specifically, and βk can be presented in Eq.9:
where u is a random number, u ∈ (0, 1); and ηc is the cross distribution index, ηc ≥ 0.
-
(2)
Crowding distance
The crowding distance is a quality measure for the Pareto front distribution. A solution with a larger crowding distance is located in a less crowded region, and thus it has more potential to be exploited in terms of the population diversity. Solutions with a short crowding distance could be removed, while solutions with a larger crowding distance are preferred (Xiang and Zhou 2015). The crowding distance for the ith solution of the Pareto front can be calculated from Eq.10:
where P[i]dis is the crowding distance of the ith solution with its two neighbors; fk(i + 1) and fk(i − 1) are the i + 1thand i − 1th solution of the kth objective function, respectively; and M is the number of objective functions, k = 1, 2, …, M;
2.5 Multi-Objective Differential Evolution-Chaos Shuffled Frog Leaping Algorithm
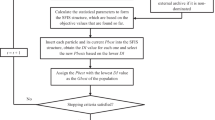
Initializing a population by Chaos can overcome the shortcoming of uneven distributed initial population in optimization problem. Meanwhile, replacing the local update of SFLA with stochastic search technique of NDE algorithm can improve the search ability of SFLA. Meanwhile, EA with dynamic updating mechanism can improve the diversity of Pareto solutions in multi-objective algorithm. Thus, MODE-CSFLA was proposed here by coupling SFLA, NDE algorithm and Chaos together based on the EA theory, aiming to improve multi-objective optimization performance. The detailed process of MODE-CSFLA shown in Fig.1 is summarized as follows:
-
Step 1.
Define objective function and specify parameters of the algorithm.

The flowchart of MODE-CSFLA
where F(x) is objective function set; fn(x) is the objective function; n is the number of the objective function; x is the decision variable; G(x) is the constraint set. The parameters involved in MODE-CSFLA include the dimension of the optimization problem D, the size of population Npop, the size of sub-population Nsub, the times of global iterations Ngen, the times of sub-population iterations Nk, the size of external archive NEA, the maximum and minimum crossover probabilities Pcmax and Pcmin, and the maximum and minimum mutation probabilities Pmmax and Pmmin.
-
Step 2.
Initialize a population based on Chaos.
Generate an initial vector x0 at random and the chaotic variables xi can be obtained from Eq.1. Then, apply xi to the variance ranges of optimization variables by Eq.13:
where Wi, max and Wi, min are the ith variance ranges of optimization variables; W'i is the ith value of the optimization variable.
-
Step 3.
Update EA based on dynamic updating mechanism;
-
(1)
Calculate the objective function values of each individual and sort the solutions in EA according to the value of each objective function, and save the non-dominated solutions;
-
(2)
Check the numbers of the non-dominated sets (Nnds) in EA. If Nnds > NEA, perform Step (3), otherwise, increase the number of individuals to meet the defined requirements in EA using the analog binary crossover method.
-
(3)
Computer the crowding distance of each solution for the non-dominated sets using Eq.10, and remove solutions with the smallest crowding distance. An infinite distance value is assigned to the boundary solution.
-
Step 4.
Global optimal operation by SFLA and local optimal operation by the NDE algorithm;
-
(1)
Divide the whole population into sub population and search the dominated solutions (WDS) of each sub population.
-
(2)
Update WDS based on NDE algorithm.
-
(3)
Compare the new solutions (WNS) with WDS, and define the updated solutions (WUS).
Decision for \( WUS=\left\{\begin{array}{l} WNS\kern1.5em if\ \mathrm{WNS}\ \mathrm{can}\ \mathrm{dominate}\ WDS\ \\ {} WDS\kern1.25em if\ \mathrm{WNS}\ \mathrm{can}\ \mathrm{not}\ \mathrm{dominate}\ WDS\ \end{array}\right. \).
-
(4)
Save the non-dominated solutions from WUS. And for dominated solutions: Repeat (2) and (3) until the times of sub-population iteration Nk is satisfied and apply the non-dominated solutions in EA to replace WDS in each sub population.
-
(5)
Shuffle the sub population to the whole population.
-
Step 5.
Check the stopping criteria.
Repeat Step2 until the times of population iteration Ngen is reached. Finally, export the optimal Pareto solutions.
The Multi-objective optimization algorithm aims to achieve two objectives: one is that the obtained exact non-dominated solution set (PFkonw) should quickly approach the real non-dominated solution set (PFtrue), and the other one is that PFkonwshould be evenly distributed in PFtrue. In this paper, MODE-CSFLA is firstly applied to solve the five mathematical benchmark problems (ZDT1, ZDT2, ZDT3, ZDT4, and ZDT6) (Zitzler et al. 2000). Meanwhile, generational distance metric (γ) and diversity metric (Δ) are used to evaluate the performance of the algorithm (Fonseca et al. 2003).
3 Case Study
3.1 Study Area and Data
The E-SNWT Project is constructed to mitigate water shortage in Northern China. Water from the Yangtze River is pumped by many pumping stations, and then flows along the Grand Canal in Jiangsu Province, through a tunnel under the Yellow River and down an aqueduct to reservoirs in Shandong Province. In this study, we focus on the project in Jiangsu Province (32°15′-34°30’ N, 117°00′-119°45′ E), as shown in Fig.2. This project involves three lakes (Hongze (HZ) Lake, Luoma (LM) Lake and Nansi (NS) Lake) and twelve pumping stations. The three lakes are presented in Table 1. The twelve pumping stations can be categorized into six cascaded groups, as shown in Table 2. The water is used for agricultural, industrial and domestic purposes through hundreds of sluices along the canal. Water users can be categorized into six groups based on their locations. The schematic diagram of the E-SNWT Project is shown in Fig.2.

The location and schematic diagram of the E-SNWT Project
The other parameters are the same as in the benchmark problems. Based on the cumulative distribution function fitting analysis of the annual runoff data for 60 years, three typical hydrological years with a probability of 50%, 75 and 95% were selected to represent normal (1971.6–1972.5), dry (1958.6–1959.5), and extremely dry (1959.6–1960.5) conditions, respectively.
3.2 Optimal Water Resources Allocation Model for the E-SNWT Project
The optimal water resources allocation model for the E-SNWT Project includes objective functions and constraints. The optimization model is at a monthly time step. The pumpage of each pumping station group is set as the decision variable.
-
(1)
Objective functions
The objective functions here are to minimize the total pumpage and to maximize the water supply rate (defined as the ratio of total supply to total demands), which can be expressed as:
where Obj1 and Obj2 are the total pumpage (m3) and the water supply rate (%), respectively; T is the total number of allocation periods, T = 12. N is the total number of water users, N = 6. M is the total number of pumping station groups, M = 6. WP(m,t) is the pumpage of the mth pumping station group at time stept, m = 1,2,...M.WR(n,t) and WN(n,t) are the water supply and water requirement of the nth water user at time step t, respectively, t = 1,2,...,T, n = 1,2,...,N.
-
(2)
Constraints
There are four main constraints, as follows.
-
1)
Water balance constraint
where V(i, t) is the water storage of the ith lake at time step t, m3. PI(i, t) + PR(i + 1, t) are the inflow and outflow of the ith lake at time step t, m3, respectively. W(i, t) is the water supply of the ith lake at time step t, m3. WS(i, t) − W(i, t) are the water pumpage from and into the ith lake at time step t, m3, respectively.
-
2)
Pumping capacity constraint
where WSmax(i, t) and WImax(i, t) are the maximum pumping capacity of the pumping station group of the ith lake at time stept, m3.
-
3)
Lake level constraint
where Lmin(i, t) and Lmax(i, t) are the minimum and maximum level boundary of the ith lake at time step t, m, respectively.
-
4)
Minimum lake level for water diversion
Generally, water pumping will be stopped if the lake level is lower than the minimum level for water diversion (shown in Table 1).
4 Results and Discussion
4.1 Results of Mathematical Benchmark Problems
The algorithms were performed in Matlab. MODE-CSFLA was coded in 4 function files (one main function, and three sub-functions) with only 402 lines of code. The decision variables are coded by real values. In this study, MODE-CSFLA, NSGA-II and MOPSO were applied to solve the five mathematical benchmark problems. The simulations times, Npop, Ngen and NEA of the three algorithms are 20, 100, 1000 and 50, respectively. Pcmax and Pcmin of MODE-CSFLA are 1 and 0.75, and Pmmax and Pmmin are 1 and 0.80, respectively. Nsub and Nk of MODE-CSFLA are 5 and 15, respectively.
Fig.3 shows the comparison between the Pareto solutions of MODE-CSFLA and the real Pareto front for benchmark problems. It is evident that the Pareto solutions of MODE-CSFLA are evenly distributed and agree well with the real Pareto front for all ZDT problems.

The Pareto solutions of MODE-CSFLA and the real Pareto front for benchmark problems: (a) ZDT1, (b)ZDT2, (c) ZDT3, (d) ZDT4, and (e) ZDT6
Table 3 lists the mean and variance of the convergence index (λ) and diversity index (Δ) for the five benchmark problems. It shows that MODE-CSFLA performs best in solving ZDT1, ZDT2, ZDT3 and ZDT4, as indicated by the minimum mean and variance value of λ. However, for ZDT6, the mean λ of MODE-CSFLA is slightly higher than that of MOPSO (0.003 vs. 0.000), while the variance of λ is zero. MODE-CSFLA presents the minimum mean and variance value of Δ for the five benchmark problems. The variance of Δ is close to zero except for ZTD4. These results indicate that the EA with dynamic updating mechanism can improve the diversity of Pareto solutions. Compared with NSGA-II and MOPSO, MODE-CSFLA can better handle the convex or non-convex multi-modal optimization problems with discontinuous or non-uniform distribution of the target space However, MODE-CSFLA improves accuracy in solving complex multi-objective optimization problems with sacrificing computational speed. It takes MODE-CSFLA about 92.378 s to perform one test problem, which is 5 and 0.4 times lower than NSGA-II and MOPSO, respectively.
4.2 Multi-Objective Optimal Water Resources Allocation of the E-SNWT Project
The model was solved by MODE-CSFLA, NSGA-II and MOPSO, based on which the optimal water resources allocation strategy was proposed for the E-SNWT Project. Two single-objective optimal allocation models regarding Obj1 and Obj2 were also solved by SFLA and MODE-CSFLA, respectively. Npop, Ngen and NEA of NSGA-II, MOPSO and MODE-CSFLA are 200, 10,000 and 100, respectively. Nsub of MODE-CSFLA is 20. Fig. 4 shows the multi-objective model solved by MODE-CSFLA, NSGA-II and MOPSO, and the single-objective model solved by SFLA and MODE-CSFLA under the three conditions. It can be seen that the solutions space of the three multi-objective algorithms is more extensive than that of SFLA. The results in all multi-objective algorithms can dominate those derived by SFLA for single-objective models.

Pareto solutions of the multi-objective model optimized by MODE-CSFLA, NSGA-II, and MOPSO and single-objective model optimized by SFLA and MODE-CSFLA in (a) normal, (b) dry, and (c) extremely dry years.
The boxplot of the total pumpage and water supply rate optimized by NSGA-II, MOPSO and MODE-CSFLA is shown in Fig.5. Under normal and dry conditions, the total pumpage optimized by MODE-CSFLA is 20.95–33.73% higher than that optimized by NSGA-II and MOPSO; while the water supply rate optimized by MODE-CSFLA is 0.13–39.05% higher. Therefore, MODE-CSFLA can produce more reasonable solutions than NSGA-II and MOPSO. Under extremely dry conditions, NSGA-II and MOPSO can produce a wider range of Pareto solutions than MODE-CSFLA. However, these solutions are dominated by that obtained by MODE-CSFLA. Besides, the solutions obtained from MOPSO appear to be unevenly distributed at the front of the Pareto curve, while that obtained by MODE-CSFLA are more uniformly distributed.

Boxplots of Pareto solutions optimized by the three multi-objective algorithms in normal, dry and extremely dry years: (a) total pumpage and (b) water supply rate
The comparison between the closet solutions of MODE-CSFLA interpolated from the Pareto solutions (a1, a2; b1, b2; c1, c3 in Fig.4) and SFLA for the single-objective optimal allocation models Obj1 and Obj2 is shown in Table 4 and Table 5. Compared with SFLA, MODE-CSFLA can result in a 29.39, 27.47 and 22.55% increase in water supply when the single objective is to minimize the water pumpage (Obj1); and a 41.01, 39.63 and 30.94% decrease in total pumpage when the single objective is to maximize the water supply (Obj2), in the normal, dry, and extremely dry scenarios, respectively.
Table 4 presents the total pumpage and water supply for Obj1 optimized by MODE-CSFLA and SFLA in normal, dry and extremely dry years, respectively. It shows that the total pumpage of BJ and HH group is increased by 8.20–22.78 108m3; while water pumped by HS, PZ, TL and HL group is reduced by 8.60–22.90 108m3 after optimization by MODE-CSFLA. More water supplied for YZ and HZ Users leads to the improvement of the water supply rate for the whole study area. However, there are negative values of water supply for some users, because water is pumped to meet their upstream users.
Table 5 shows the total pumpage and water supply for Obj2 optimized by MODE-CSFLA and SFLA under all scenarios. In this case, MODE-CSFLA results in a decrease in the total pumpage of each pumping station group by 1.29–53.62 108 m3, indicating that MODE-CSFLA can make better use of natural inflow to meet the model requirements. Compared with Obj1, the total pumpage is increased by 38.51–52.90% to meet the needs of water supply, and there are less negative water supply values under all hydrological conditions.
5 Summary and Conclusions
A novel multi-objective algorithm, MODE-CSFLA, was proposed in this study for water resources system optimization. The novel MOSFLA initialized a population by Chaos and replaced the local update of SFLA with stochastic search technique of DE algorithm. Moreover, EA with dynamic updating mechanism was implemented to improve the diversity of Pareto solutions in MODE-CSFLA. The performance of MODE-CSFLA in solving benchmark problems was presented compared with NSGA-II and MOPSO. At last, MODE-CSFLA was used to solve the optimal allocation model of water resources in the E-SNWT Project in the normal, dry, and extremely dry conditions. Experimental results show that MODE-CSFLA can overcome the shortcomings of uneven distributes initial population, easily falling into local minima and early convergence in SFLA, and improve the diversity of Pareto solutions. Thus, it has the potential to be used for solving complex optimization problems of water resources systems.
References
Ahmad A, El-Shafie A, Razali SFM, Mohamad ZS (2014) Reservoir optimization in water resources: a review. Water Resour Manag 28:3391–3405. https://doi.org/10.1007/s11269-014-0700-5
Angira R, Santosh A (2007) Optimization of dynamic systems: A trigonometric differential evolution approach. Comput Chem Eng 31:1055–1063
Arshi SS, Zolfaghari A, Mirvakili S (2014) A multi-objective shuffled frog leaping algorithm for in-core fuel management optimization. Comput Phys Commun 185:2622–2628
Cheng C-T, Wang W-C, Xu D-M, Chau KW (2008) Optimizing hydropower reservoir operation using hybrid genetic algorithm and Chaos. Water Resour Manag 22:895–909. https://doi.org/10.1007/s11269-007-9200-1
Ding Z, Fang G, Wen X, Tan Q, Huang X, Lei X, Tian Y, Quan J (2018) A novel operation chart for cascade hydropower system to alleviate ecological degradation in hydrological extremes. Ecol Model 384:10–22
Eusuff M, Lansey K, Pasha F (2006) Shuffled frog-leaping algorithm: a memetic meta-heuristic for discrete optimization. Eng Optimiz 38:129–154. https://doi.org/10.1080/03052150500384759
Fallah-Mehdipour E, Haddad OB, Mariño M (2011) MOPSO algorithm and its application in multipurpose multireservoir operations. J Hydroinf 13:794–811
Fonseca CM, Fleming PJ, Zitzler E, Deb K, Thiele L (2003) Evolutionary multi-criterion Optimization In: Second International Conference, EMO 2003. Springer
Gao H, Cao J (2012) Membrane-inspired quantum shuffled frog leaping algorithm for spectrum allocation. J Syst Eng Electro 23:679–688
Guo Y, Fang G, Wen X, Lei X, Yuan Y, Fu X (2018) Hydrological responses and adaptive potential of cascaded reservoirs under climate change in yuan river basin. Hydrol Res. https://doi.org/10.2166/nh.2018.165 (in press)
Hossain MS, El-Shafie A (2013) Intelligent systems in optimizing reservoir operation policy: a review. Water Resour Manag 27:3387–3407
Ilonen J, Kamarainen J-K, Lampinen J (2003) Differential evolution training algorithm for feed-forward neural networks. Neural Process Lett 17:93–105. https://doi.org/10.1023/a:1022995128597
Karamouz M, Tabari MMR, Kerachian R (2007) Application of genetic algorithms and artificial neural networks in conjunctive use of surface and groundwater resources. Water Int 32:163–176
Khosroshahi MT, Kazemi FM, Oskuee MRJ, Najafi-Ravadanegh S (2015) Coordinated and uncoordinated design of LFO damping controllers with IPFC and PSS using ICA and SFLA. J Cent South Univ 22:3418–3426
Le-Anh L, Nguyen-Thoi T, Ho-Huu V, Dang-Trung H, Bui-Xuan T (2015) Static and frequency optimization of folded laminated composite plates using an adjusted differential evolution algorithm and a smoothed triangular plate element. Compos Struct 127:382–394. https://doi.org/10.1016/j.compstruct.2015.02.069
Li Y, Zhou J, Yang J, Liu L, Qin H, Yang L (2008) The Chaos-based shuffled frog leaping algorithm and its application. In: 2008 fourth international conference on natural computation, 18–20 Oct. 2008 . pp 481–485. doi:https://doi.org/10.1109/ICNC.2008.242
Li Y, Zhou J, Zhang Y, Qin H, Liu L (2010) Novel multiobjective shuffled frog leaping algorithm with application to reservoir flood control operation. J Water Resour Plan Manag 136:217–226
Liu D, Guo S, Chen X, Shao Q, Ran Q, Song X, Wang Z (2012) A macro-evolutionary multi-objective immune algorithm with application to optimal allocation of water resources in Dongjiang River basins, South China. Stoch Env Res Risk A 26:491–507. https://doi.org/10.1007/s00477-011-0505-5
Lopez-Ibanez M, Prasad TD, Paechter B (2005) Multi-objective optimisation of the pump scheduling problem using SPEA2. In: Evol Comput. The 2005 IEEE Congress on, 2005. IEEE, pp 435–442
Luo J, Liu J (2014) An MILP model and clustering heuristics for LED assembly optimisation on high-speed hybrid pick-and-place machines. Int J Prod Res 52:1016–1031. https://doi.org/10.1080/00207543.2013.828173
Maier HR et al. (2014) Evolutionary algorithms and other metaheuristics in water resources: current status, research challenges and future directions Environm Model Software 62:271–299
Makaremi Y, Haghighi A, Ghafouri HR (2017) Optimization of pump scheduling program in water supply systems using a self-adaptive NSGA-II; a review of theory to real application. Water Resour Manag 31:1283–1304. https://doi.org/10.1007/s11269-017-1577-x
Modiri-Delshad M, Rahim NA (2016) Multi-objective backtracking search algorithm for economic emission dispatch problem. Appl Soft Comput 40:479–494
Orouji H, Haddad OB, Fallah-Mehdipour E, Mariño M (2013) Extraction of decision alternatives in project management: application of hybrid PSO-SFLA. J Manag Eng 30:50–59
Pazoki M, Orouji H, Fallah-Mehdipour E, Biswas A, Mahmoudi N (2016) Shuffled frog-leaping algorithm for optimal design of open channels doi:https://doi.org/10.1061/(ASCE)IR.1943-4774.0001059
Rahimi-Vahed A, Dangchi M, Rafiei H, Salimi E (2009) A novel hybrid multi-objective shuffled frog-leaping algorithm for a bi-criteria permutation flow shop scheduling problem. Int J Adv Manuf Technol 41:1227–1239
Scola LA, Takahashi RH, Cerqueira SA (2014) Multipurpose water reservoir management: an evolutionary multiobjective optimization approach Mathematical Problems in Engineering 2014
Siew C, Tanyimboh TT, Seyoum AG (2016) Penalty-free multi-objective evolutionary approach to optimization of Anytown water distribution network. Water Resour Manag 30:3671–3688. https://doi.org/10.1007/s11269-016-1371-1
Storn R, Price K (1997) Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J Glob Optim 11:341–359
Sun P, Z-q J, T-t W, Y-k Z (2016) Research and application of parallel normal cloud mutation shuffled frog leaping algorithm in Cascade reservoirs optimal operation. Water Resour Manag 30:1019–1035. https://doi.org/10.1007/s11269-015-1208-3
Tayfur G (2017) Modern optimization methods in water resources planning, engineering and management. Water Resour Manag 31:3205–3233. https://doi.org/10.1007/s11269-017-1694-6
Wen X, Fang G, Guo Y, Zhou L (2016) Adapting the operation of cascaded reservoirs on Yuan River for fish habitat conservation. Ecological Modelling, 337:221-230. http://dx.doi.org/10.1016/j.ecolmodel.2016.06.018
Wen X, Liu Z, Lei X, Lin R, Fang G, Tan Q, Wang C, Tian Y, Quan J (2018) Future changes in Yuan River ecohydrology: Individual and cumulative impacts of climates change and cascade hydropower development on runoff and aquatic habitat quality. Sci Total Environ 633:1403–1417
Xiang Y, Zhou Y (2015) A dynamic multi-colony artificial bee colony algorithm for multi-objective optimization. Appl Soft Comput 35:766–785
Yenisey MM, Yagmahan B (2014) Multi-objective permutation flow shop scheduling problem: literature review, classification and current trends. Omega 45:119–135. https://doi.org/10.1016/j.omega.2013.07.004
Yu R-F, Wang W, Cheng W-P, Chen M-M (2015) Erratum to: on-line evaluating the SS removals for chemical coagulation using digital image analysis and artificial neural networks. Int J Environ Sci Technol 12:421–421. https://doi.org/10.1007/s13762-014-0676-y
Zhang W, Hu Y, He H, Liu Y, Chen A (2017) Linear and dynamic programming algorithms for real-time task scheduling with task duplication. J Supercomput. https://doi.org/10.1007/s11227-017-2076-9
Zhao Z, Yang J, Hu Z, Che H (2016) A differential evolution algorithm with self-adaptive strategy and control parameters based on symmetric Latin hypercube design for unconstrained optimization problems. Eur J Oper Res 250:30–45
Zhu X, Zhang C, Fu G, Li Y, Ding W (2017) Bi-level optimization for determining operating strategies for Inter-Basin water transfer-supply reservoirs. Water Resour Manag 31:4415–4432. https://doi.org/10.1007/s11269-017-1756-9
Zitzler E, Deb K, Thiele L (2000) Comparison of multiobjective evolutionary algorithms: empirical results. Evol Comput 8:173–195
Acknowledgements
This research is funded by the National Natural Science Foundation of China (U1765201, 51609061), the Fundamental Research Funds for the Central Universities (2018B11314), CRSRI Open Research Program (CKWV2016370/KY), Open Fund Research of State Key Laboratory of Hydraulics and Mountain River Engineering (SKHL1621), the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD) and the Postgraduate Education Innovation Project of Jiangsu Province (2016B05327), Water Conservancy Science and Technology Project of Jiangsu Province (2014012).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Fang, G., Guo, Y., Wen, X. et al. Multi-Objective Differential Evolution-Chaos Shuffled Frog Leaping Algorithm for Water Resources System Optimization. Water Resour Manage 32, 3835–3852 (2018). https://doi.org/10.1007/s11269-018-2021-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-018-2021-6