
Abstract
The main objective of this study is to derive a flexible approach based on machine learning techniques, i.e. Support Vector Regression (SVR), for monthly river discharge forecasting with 1-month lead time. The proposed approach has been tested over 300 alpine basins, in order to explore advantages and limits in an operational perspective. The main relevant input features in the forecast performances are the snow cover areas and the discharge behavior of the previous years. Forecasts obtained by training SVR machine on single gauging stations show better performances than the average of the previous 10 years, considered as benchmark, in 94% of the cases, with a mean improvement of about 48% in root mean square error. In case of poorly gauged basins, to increase the number of training sample, multiple basins have been considered to train the SVR machine. In this case, performances are still better than the benchmark, even if worse than those of SVR machine trained on single basins, with a decrease of the performances ranging from 13% to 54%.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Discharge forecast plays a critical role in water resources management. This knowledge influences decision-making process in water demanding activities such as environment protection, drought risk management and hydropower generation (Wang et al., 2009). The role of mountain regions as “water towers”, supplying the most of world’s population with water, is well known ((Messerli & Ives, 1997); (Viviroli & Weingartner, 2004)) despite representing only 27% of the Earth’s continental surface. The balancing effect of snow/glaciers on runoff is detectable in more stable monthly patterns ((Viviroli & Weingartner, 2004), (Beniston, 2006)), redistributing winter precipitation during spring snowmelt thus sustaining the summer base flow (Bartolini et al., 2009). On the opposite, winter rainfalls and rising temperatures patterns could cause more frequent flood peaks detracting base river flows in late spring and early summer (SEPA, 2009).
In this context, an operational forecast system applicable to a wide spectrum of geographically and hydrologically different basins, flexible enough to manage a wide range of variables related to discharge generation, could play a key role in the correct management of water resources.
Hydrologic forecast problems have been addressed in the last decades in different ways, from purely statistical black-box approaches to physical-based and distributed models employing data assimilation techniques (Bauer-Gottwein, 2015).
Satisfactory predictions have been obtained using Machine learning (ML) techniques ((Zealand, 1999), (Bras and Rodriguez-Iturbe 1985) (Salas, 1980), (Wood & Szollosi-Nagy, 1980) (Callegari et al., 2015)). These techniques are frequently compared in performances ((Wang, et al., 2009), (Mohsen, 2009)) showing an improvement in prediction with respect to simpler time series methods (Callegari et al., 2015). The major advantages of discharge prediction methods based on ML with respect to hydrological models are: i) ML methods consider time-varying and stochastic properties of the rainfall–runoff process (Hsu, 1995), ii) ML methods do not need long term meteorological forecast and iii) ML methods keep a relatively low level of complexity during setup phase.
This paper complements a previous research (Callegari et al., 2015), where SVR technique has been applied to monthly discharge forecast in 14 alpine catchments in the South–Tyrol region (Italian Alps).
The main goal of the paper is to test the applicability of SVR forecasting method (with 1-month lead time), at wider scale in an operational perspective, using a large number of cases (over 300 alpine basins) for which observed daily discharge data are available in the years 1990–2012.
In addition to discharge recording, meteorological parameters and other physical variable arguably related to discharge generation, i.e. snow cover area, precipitation, temperature and soil moisture, have been investigated to improve forecast performances.
The innovative points of the paper are: i) the larger study area with respect to previous studies ii) the introduction, in addition to time series of discharges, of meteorological parameters and other parameters such as soil moisture to improve the estimation of the forecast.
After introducing the study area and datasets in section 2, the method of analysis and forecasting experiments are described in section 3; results are shown in section 4 and then discussed in section 5. Finally, conclusions on current applicability and indications for future development are drawn in section 6.
2 Study Area and Datasets
2.1 Study Area
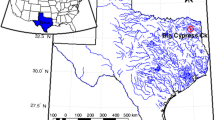
Our study region includes basins located in the European Alps and the contiguous north-west Italian Apennines (geographical area defined by 43.3°–49°N, 2.1°–16.2°E, Fig. 1). The hydrological regimes in the Alpine region vary from nivo-glacial for higher basins to more rainfall driven responses for lower basins.

Study region and basins considered in the study
2.2 Dataset
Used dataset includes basin outlines and recorded discharge time series as basic information for prediction. Further exploration on additional input features has been conducted and a detailed list of them is reported in following paragraphs.
2.2.1 Basin Extension and River Network
Catchment delineations and river shapes have been derived from CCM2 River and Basin georeferenced vector data set (Vogt et al. 2007) of the European Commission-Joint Research Centre JRC,Footnote 1 with homogeneous coverage all over area of interest, avoiding the need of redefining watersheds starting from topographic data.
2.2.2 Discharge Time Series
Although in principle widely available at EU level, discharge data are far from homogeneous in time, spatial coverage, format and access. In this work, a subset of 1500 gauging station has been analyzed from Italian, Swiss, Slovenian and French Regional hydrological services (Discharge data from websites, 2015). Only a few services provide average meteorological input (such as rainfall and temperature) for the catchment corresponding to discharge data.
Once discharge data have been aggregated on monthly basis, each station has been assigned to the corresponding basin from CCM2 dataset (Catchment Characterization and Modelling dataset by JRC), to get average statistics of variables of interest over the basin area (as rain, temperature and snow).
Stations with less than 10 years of data, having gaps of more than 2 consecutive months in time series, or with discharge series ending before 2011 have been also excluded. The remaining missing data gaps in selected time series have been replaced with a simple 3-parameters multi-regression fitting curve starting from previous and following month discharges.
Above described constrains considerably reduced stations number to 325, still adequate for generalization of results to a broad context. Selected stations have a catchment area range from 3 km 2 to about 42,000 km 2, an average elevation from a few m a.s.l. to over 1500 m a.s.l. and are distributed in 4 countries (Italy France, Slovenia, Switzerland) through the Alps.
2.2.3 Additional Input Features
Several Earth Observation variables have been collected to feed SVR and improve the prediction:
-
Snow Cover Area (SCA), extracted from snow maps obtained with MODIS images. The snow products have been derived with a specific algorithm adapted to mountain areas ((Notarnicola, et al., 2013a), (Notarnicola, et al., 2013b). Raster maps of daily values have been extracted for each basin of interest, producing time series of monthly average SCA from 2003 to current period.
-
Snow water content and Soil water content from Global Land Data Assimilation System-GLDAS (GLDAS, EOBS, 2015). Starting from satellite and ground-based observational data, GLDAS dataset is produced by using land surface modeling and data assimilation techniques, in order to generate fields of land surface states and fluxes (Rodell et al., 2004). Available in multiband raster (NetCDF files) at 0.25-degree resolution, GLDAS Bands, corresponding to snow water equivalent [kg/m2] and soil moisture [kg/m2] down to 200 cm soil depth, have been extracted and converted to time series of average values over each basin, as done for SCA;
-
Daily gridded observational dataset at 0.25-degree resolution for rainfall and temperature called E-OBS ((GLDAS, EOBS, 2015) (Haylock et al., 2008)) interpolated from ground station values are freely available. Dataset goes from year 1950 to current period; daily values have been extracted over each basin, producing time series of average monthly rainfall and temperature. Table 1 resumes collected data.
3 Method
3.1 Short Introduction to Support Vector Regression (SVR) Approach
The relationship between the input data (SCA, precipitation, average river discharge) and the target variable (river discharge forecasted at 1-month lag) has been addressed with a supervised machine learning technique, namely Support Vector Regression (SVR).
Given a set of N training samples, each of which characterized by an input feature vector x i ∈ ℝ m and a target value y i ∈ ℝ, with m equal to the number of input features and i = 1 , 2 , … , N, SVR technique aims at finding the simplest non-linear function y = f(x) that can fit all the training data while minimizing the sum of prediction errors above a predefined threshold.
The main advantage of this approach is the ability to handle complex and not-linear relationships between different kind of inputs and the target variable.
Further details on the SVR method can be found in (Smola & Schölkopf, 2004).
3.2 Training Strategy
Typically, the strategy used in the training phase is to use two datasets, the training set for parameters calibration and the validation set, which allow evaluating performance in the training phase and in case adjusts model parameters. In this paper, we adopted the strategy used by Callegari et al. (2015), by using a t-fold cross-validation procedure. It consists in randomly splitting the original sample into t subsamples having the same size. Then, iteratively, a single subsample is retained as the validation dataset and the remaining t − 1 subsamples are used as training data.
3.3 Description of the Proposed Experiments
Three major groups of experiments have been carried out in this research:
-
A SVR machine calibrated for each basin having at least 20 years of recorded discharge data. The experiment is furtherly divided in three different tests that consider respectively the largest numbers of basins (227) with 20 years of recorded data, some basins (45) with different input features and 3 basins investigated for different combinations of input features (test 1 to 3). Hereafter this SVR machine will be called “SVR single”.
-
A SVR machine calibrated using all basins with best performances in first test, in order to assess the overall performance of “SVR multi” and compare it against “SVR single” (test 4, hereafter called “SVR multi”).
-
A single SVR machine calibrated for all basins (including ones with less than 20 years of data), in order to cope with poorly gauged stations (test 5, “SVR all”).
Starting from previous experiments carried out with basins located in South Tyrol (Callegari et al., 2015), we used as base configuration the best result obtained in that area (“base configuration”, BC) that employs the following input feature:
-
Average discharge value of current month (“disch0”);
-
Average SCA value of current month (“SCA0”), of the previous month (“SCA-1”) and of two previous months (“SCA-2”);
-
“Climatology” that is the reference discharge of the month to predict, computed as average of the 10 years before the prediction one (“dischAvg + 1” or “climatology”). This feature is available only for “SVR single” experiments, which involve basin having at least 20 years of discharge data.
To identify input features that better relate to the output variables, a preliminary feature selection phase is needed. For this purpose, the SVR machine is trained with different combinations of features (using data from training set), to find the best performances. During this process, features that do not provide any significant improvement are discarded. After the training phase, SVR machine can be used for estimating the target variables using test dataset in order to assess the forecast performances.
For SVR performances evaluation, percentage root mean square error (RMSE%) has been used:
where T is the “True” value, and P is the “Predicted” value, i.e., the discharge value estimated by SVR machine. Detailed description of experiments setup is illustrated in the following paragraphs.
3.3.1 Test 1 - Basins with at Least 20 Years of Data: “SVR Single”
About 227 basins out of 325 have at least 20 years of discharge data. First 10 years of data are needed to calculate the “climatology” for target month and remaining 10 years to train a SVR machine for each basin. Due to SCA maps availability, usable data range from February 2003 to June 2012 (end of experiment). The dataset has been divided by randomly selecting 3 years for the test set and the remaining data as reference samples (training and validation set). According to Callegari et al. (2015), the selection of full years instead of random months for the test dataset leads to better independence between reference and test samples and to a more realistic interpretation of the performances. For each station, a SVR machine has been calibrated by using the “base configuration”.
3.3.2 Test 2 - Feature Selection on 45 Basins
In this test, 45 basins out of 227 previous ones have been manually selected to have a good geographical and catchment size distribution, with the aim to test other input feature combinations. Stations range from closure of the Po River, the most important Italian river (basin area of over 70′000 km2) to smaller basins (area less than 60 km2).
Experiment proceeded by testing the “base configuration”, combined with other variables arguably related to runoff generation:
-
Air temperature/precipitation
-
Soil Moisture (SM), also used in (Wang & Fu, 2014) and (Dumedah & Coulibaly, 2013) for improving river discharge prediction.
-
Snow Water Equivalent (SWE), related to water content in the snowpack, also used by Mehrkesh & Ahmadi (2014).
Meteorological input features are limited to precipitation and air temperature of current month (“Prec&Temp0”), and, as a proxy of values for the target month, the “climatology” computed in the 10 years before the prediction year (“Prec&TempAvg + 1”).
Soil moisture (SM) has been identified as an important input to improve streamflow estimation by numerous studies ((Berthet et al., 2009), (Legates et al., 2011)). It has been therefore tested as feature input, as well as snow water equivalent (SWE) that is considered an index of the amount of water in the snowpack. Both features have been investigated by considering values ranging from current month to 2 antecedent months (“SM0:-2”, “SWE0: -2”).
Testing all possible combinations where different time frames of input features are considered (over 5000) would have required computational effort beyond purposes of this research. For this reason, we decided to test 19 reasonable feature configurations for 45 selected basins out of 227 well-gauged ones, and document improvements in SVR performances.
3.3.3 Test 3 - Additional Feature Selection on 3 basins
From the 45 basins used in test 2, we selected 3 basins that showed clearly different SVR performances (RMSE% lower than 30%, between 30% and 50% and greater than 50%) and we extended features selection to a wider range of combinations (particularly time frame of input features) up to 384.
3.3.4 Test 4 - SVR Machine Calibrated on Multiple Basins
The second step of the study involves a SVR machine trained on multiple basins. The first objective is to compare performances of this approach and those of SVR trained on single basins. However, a SVR machine calibrated on several basins could show lower performances with respect to a SVR trained on a single basin. The latter, in fact, is specialized on a single data set and it can learn from a uniform discharge time series of the considered basin.
A SVR machine (“SVR multi”) has been calibrated by using all basins with best performances “SVR single” in “base configuration” (67 basins), excluding in the training phase one basin at a time and using it as a test set (jack knife approach), to assess the overall performances of “SVR multi” and compare it with “SVR single”.
3.3.5 Test 5 - SVR Machine Calibrated on all Basins
In this test, a SVR machine has been trained with all basins (“SVR all”), including those having less than 20 years of discharge data, by using again a jack knife approach.
In both tests (4 and 5), given the high variability of the basin size, the discharge values have been normalized with respect to the catchment area to have comparable quantities.
The use of “SVR all” machine is mainly intended for poorly gauged basins where such regional machine could compensate, in principle, lack of long discharge time series necessary to have “climatology” data. Table 2 summarizes the tests performed.
4 Results
In the following sections, SVR forecast skills will be discussed in comparison to “climatology”, which is considered a simple and frequently used benchmark for seasonal hydrological forecast (Pappenberger et al., 2015).
4.1 Test 1: Results
In this test, a SVR machine is trained for each gauging station (out of 227 basins with more than 20 years of discharge data) using the “base configuration” of input features. The results are summarized in Fig. 2, where stations are divided in tree groups based on SVR performance. The graph shows that ≈ 30% of them has RMSE% lower than 30%, 20% has RMSE ranging between 30% and 50% and the remaining 50% of the basins has an error greater than 50%. Comparison with “climatology” (red line) clearly indicates that 94% of the cases have performances in predicting river discharge higher than the one obtained by using the “climatology” and the mean improvement is in average about 48%.

RMSE % for the 227 basins with at least 20 years of data. The red line represents RMSE% computed by using the “climatology”; the blue line RMSE% using SVR machine for each gauging station
4.2 Test 2: Results
Results show that 21 basins out of 45 shows the best performance with the base configuration. The remaining 24 basins show a mean performance improvement of 8% with the different input feature configurations even if the only new input feature determining an improvement is soil moisture. The effect is particularly evident for the values of current month and previous month. However, only four basins out of 45 decrease the error below 30%.
4.3 Test 3: Results
Three out of 45 basins have been selected to further investigate feature combinations, exploring different time frame (discharge from 1 to 12 antecedent months and SCA/SM from 1 to 4 months before to the target month, with and without “climatology”) for total of 384 combinations. The considered basins are:
-
Inn River basin (area of 1588 km 2 and SVR RMSE% = 29.3% in Test 2)
-
Thur River basin (area of 52 km 2 and SVR RMSE% = 48.6% in Test 2)
-
Bòrmida di Spigno River basin (area of 1518 km 2 and SVR RMSE% = 90.4% in Test 2).
The basin with higher error has very noisy and irregular discharge signal and more pronounced torrential regime. This basin is characterized by high discharge variability from peaks in rainy season to very low values in summer season.
Extreme variability from year to year is particularly evident in the winter/spring seasons: in April discharge peaks ranges from about 9.5 m3/s in 2007 to 152 m3/s in 2009. It is no surprise that in such conditions SVR performances are low, since data-driven models are known to well describe systems if there are no considerable changes in system behavior during the period analyzed (Solomatine et al., 2009). Results show that, again, soil moisture is informative, adding value to forecast, only up to two previous months, while SCA seems to influence the river discharge up to the three antecedent months.
The SVR performances vary from Test 2 results in the following way:
-
Bòrmida di Spigno: from 90.4% to 67.3%
-
Thur: from 48.6% to 64.0%
-
Inn: from 29.3% to 24.6%
The main results from tests on individual basins can be summarized as follows:
-
Test 1: 94% of 227 basins analyzed shows higher performances by using SVR with respect to the ones obtained with the “climatology”.
-
Test 2: addition of new input parameters (precipitation, air temperature, SM and SWE) for 45 basins: 21 out of 45 has the best performances with “Base configuration”
-
Test 3: different time frame of the variables are tested. Soil moisture is informative only in the time lag from two previous months to the prediction month and SCA contributes with values relatives to the current month and to the three antecedent months
-
1.1
Test 4: results
-
1.1
The goal of test 4 is to compare performances of a SVR machine trained over single basins with a SVR trained on multiple basins. Basins belonging to group 1 (highest performances, Fig. 2) and showing one of two following conditions have been used for the comparison:
-
Benchmark error greater than 50% but SVR RMSE% lower than 30%.
-
Benchmark error lower than that of SVR RMSE% although both below 30%.
-
The basin having the absolute best performances
The area of test basins ranges from 16 km 2 to 5356 km 2 and 7 out of 9 are in Switzerland and 2 in France.
Features used for Test 4 training are those of base configuration (disch0, SCA0:-2 and “climatology”), which leads to the best performances in most cases. As shown in Table 3, results of this test generally yield less accurate predictions than “SVR single” in test 1, while retaining better performance than discharge “climatology” in the same cases, with one exception (Swiss basin of Lonza River), although by minimal variations. This result is coherent with previous findings (Callegari et al., 2015).
4.4 Test 5: Results
All 325 stations have been used to train this SVR machine by using as input feature disch0, SCA0:-2, and the antecedent 12 months’ discharge (disch0:-11). In this test, we aim at extending the predictive capabilities of the SVR machine to poorly gauged stations for which a single SVR machine could not be trained due to missing input features such as the “climatology”.
Ten test basins are used and they are randomly selected, considering a wide variability in catchment size and discharge values (Table 4). Performances of Test 5 are generally worse than those obtained in Test 1 with a decrease of the performances ranging from 13% to 54% except in 2 cases (Saane River and Rhône River). With respect to the benchmark (“climatology”), SVR performances are generally better or comparable. In some cases, the comparison cannot be made because on those basins the results of Test 1 or the “climatology” are not available due to the missing input data, i.e. the length of discharge time series.
5 Discussion
Results indicate that in general river discharge based on SVR approach shows better performances when compared with the standard forecasting based on the “climatology”. The SVR performances range from RMSE% values of 400% to 12% but in 94% of the basins these values are lower than the ones obtained with the “climatology”.
Qualitative analysis of results shows that SVR performances depend on river discharge variability: a noisy discharge signal corresponds, in general, to lower performances. For example, for the big basin of Rodano River (area of 5356 km2) that has a very regular discharge trend, SVR commits an error equal to 12.5%, while the small basin of Le Méaudret River (area of 81 km2) having a noisy discharge signal, belongs to the group with the worst performances (group 3).
These results are obtained when the SVR machine is trained for each individual basin; for this training, a long record of input data is available. One dominant feature considered in this analysis is the time series of river discharge values. These values are very useful because allow us to identify the past behavior of the basin on which is based the prediction of the river discharge at 1 month lag. In this case, the mean improvement with respect to the “climatology” benchmark is about 48%. Callegari et al. (2015) obtained similar results in the previous study, where the SVR in most cases outperforms the “climatology” with a mean improvement of the RMSE% of 11%. In the analysis of results no correlation was found with specific basins characteristics such as the size or the mean river discharge, the udometric coefficient or the drainage density.
The predictability seems, instead, to be related to the “memory” of the basin: when it is dominated by snow accumulation with a reduced effect of rainfall, the RMSE% has lower values.
On the other side, stations with strong precipitation signal are less predictable, due to the high randomness of the signal and the poor correlation with precipitation event as input. In this case, as no meteorological forecast has been used, rainfall amount until the previous month to the target one does not bring relevant information nor improves forecast performances.
From the “base configuration”, other features were added as meteorological parameters (temperature and rainfall) and state variables (SM and SWE).
Possible reasons of the limited benefit of new features could be the coarse spatial resolution of the data, particularly for smaller basins. SWE and SM values derive from land-surface models forced with observation, while EOBS gridded dataset is interpolated from ground stations variable in density and position; both variables are provided at spatial resolution of 0.25 degree (around 28 km pixel size). Another reason is that certain meteorological input and state variable plays arguably limited long time storage effect compared to snow, i.e. rainfall up to current month have limited capability to explain next month’s discharge when compared to target month precipitation. Comparing results to “climatology” (benchmark), it emerges that the SVR technique, in most cases, can predict the discharge better than the long-term average does, which works better only in two cases.
In the case of poorly gauged basins, there is the necessity to increase the number of input data to have a reliable training of the SVR machine. For this reason, different basins have been considered to train a SVR machine. Results indicate that the performances of this machine, which uses, in addition to SCA and discharge of current month, only the antecedent 12 months’ discharge, are worse than the performances of the SVR trained on the specific basins but they are still better than the “climatology”.
6 Conclusions
In this research, we applied artificial intelligence techniques namely the Support Vector Regression approach to derive monthly river discharge forecast with 1-month lead-time. To explore advantages and limits of this methodology, extensive tests have been performed with more than 300 basins spread around the alpine region in a wide spectrum of size (3 to 41,816 km2 drained area) and hydrological regimes.
Experiments aim at identifying most informative features among those available both from direct ground monitoring and from Earth observation resources, but also at discussing capabilities of SVR to act as regional machine over vast areas, where poorly gauged stations are available. SVR on single basins systematically delivers better results than “climatology” benchmark and, in case of adequately monitored stations (roughly 20 years of recorded discharge), it is certainly worth investing time and resources in accurate feature selection to refine performances. For poorly gauged stations, however, training a SVR on multiple basins is still a viable option to get results comparable to “climatology” benchmark, but further investigation is needed and we argue that a careful selection of basins to train machine, i.e. preliminary identification of homogenous hydrological areas, may lead to better performances.
Concerning input features, most informative resources have proved to be discharge time series itself, “climatology” computed over antecedent 10 years, Snow Cover Area up to 3 antecedent moths, and, marginally, Soil Moisture up to 2 antecedent months. Precipitation, temperature, Snow Water Equivalent did not improve performances. Reasons of such behavior could be found in data limits such as ground resolution. In future works, high resolution input features may be addressed such as soil moisture derived from SAR (Synthetic Aperture Radar) sensors which can deliver SM maps of around 1 km ground resolution every 3–5 days (based on ASAR Envisat). The new generation of SM maps will be based on Sentinel 1A and B images with ground resolution up to 20 m and temporal frequency every 6 days.
References
Bartolini E, Claps P, D’odorico P (2009) Interannual variability of winter precipitation in the European Alps: relations with the North Atlantic Oscillation. Hydrol Earth Syst Sci 13(1):17–25
Bauer-Gottwein PJ-S (2015) Operational river discharge forecasting in poorly gauged basins: the Kavan-go River basin case study. Hydrol Earth Syst Sci 19(3):1469–1485
Beniston M (2006) Mountain weather and climate: a general overview and a focus on climatic change in the Alps. Hydrobiologia 562(1):3–16
Berthet L, Andréassian V, Perrin C, Javelle P (2009) How crucial is it to account for the antecedent moisture conditions in flood forecasting? Comparison of event-based and continuous approaches on 178 basins. Hydrol Earth Syst Sci Discuss 13:819
Bras RL, Rodriguez-Iturbe I (1985) Random functions and hydrology. Dover Publications, New York
Callegari M, Mazzoli P, De Gregorio L, Notarnicola C, Pasolli L, Petitta M, Pistocchi A (2015) Seasonal River Discharge Forecasting Using Support Vector Regression: A Case Study in the Italian Alps. Water 7(5):2494–2515
Dumedah G, Coulibaly P (2013) Evolutionary assimilation of streamflow in distributed hydrologic modeling using in-situ soil moisture data. Adv Water Resour 53:231–241
Haylock M, Hofstra N, Tank AK, Klok E, Jones P, New M (2008) A European daily high-resolution gridded dataset of surface temperature and rainfall J Geophys Res (Atmospheres):113(D20119):1–12
Hsu KG (1995) Artificial neural network modeling of the rainfall-runoff process. Water Resour Res 31(10):2517–2530
Legates DR, Mahmood R, Levia DF, DeLiberty TL, Quiring SM, Houser C, Nelson FE (2011) Soil moisture: A central and unifying theme in physical geography. Prog Phys Geogr 35(1):65–86
Mehrkesh, A., & Ahmadi, M. (2014). Forecasting the Colorado River Discharge Using an Artificial Neural Network (ANN) Approach. arXiv preprint arXiv:1411.7508
Messerli B, Ives JD (1997) Mountains of the World: A Global Priority. Parthenon Publishing, New York. doi:10.1002/(SICI)1099-145X(200003/04)11:2<197:AID-LDR390>3.0.CO;2-U
Mohsen BK (2009) Generalization performance of support vector machines and neural networks in runoff modeling. Expert Syst Appl 36(4):7624–7629
Notarnicola C et al (2013a) Snow cover maps from MODIS images at 250 m resolution, Part 1: Algorithm description. Remote Sens 5:110–126
Notarnicola C et al (2013b) Snow Cover Maps from MODIS Images at 250 m Resolution, Part 2: Validation. Remote Sens 5:1568–1587
Pappenberger F, Ramos M, Cloke H, Wetterhall F, Alfieri L, Bogner K et al (2015) How do I know if my forecasts are better? Using benchmarks in hydrological ensemble prediction. J Hydrol 522:697–713
Rodell M, Houser P, Jambor U, Gottschalck J, Mitchell K, Meng C-J et al (2004) The Global Land Data Assimilation System. Bull Amer Meteor Soc 85(3):381–394
Salas JD (1980) Applied Modeling of Hydrologic Time Series. Water Resources Publication, Littleton, Colorado
SEPA, (2009). Change in river flow variability in snow influenced catchments in Scotland. Retrieved from http://www.sepa.org.uk/climate_change/publications.asp
Smola AJ, Schölkopf B (2004) A tutorial on support vector regression. Stat Comput 14(3):199–222
Solomatine D, See LM, Abrahart RJ (2008) Data-driven modelling: concepts, approaches and experiences. In: Abrahart RJ, See LM, Solomatine DP (eds) Practical hydroinformatics: computational intelligence and technological developments in water application. Springer, Berlin, pp 17–30
Viviroli D, Weingartner R (2004) The hydrological significance of mountains: from regional to global scale. Hydrol Earth Syst Sci Discuss 8(6):1017–1030
Vogt JV, Soille P, de Jager AL, Rimaviciute E, Mehl W (2007) A pan-European river and catchment database. EC-JRC Report EUR 22920 EN, Luxembourg, pp 120
Wang WC, Chau KW, Cheng CT, Qiu L (2009) A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J Hydrol 374:294–306
Wang H, Fu X (2014) Utilization of climate information and soil moisture estimates to provide monthly and sub-monthly streamflow forecasts. Int J Climatol 34:3515–3527
Wood EF, Szollosi-Nagy A (1980) Real-Time Forecasting/Control of Water Resource Systems; Selected Papers from an IIASA Workshop, October 18–21, 1976. Pergamon Press
Zealand CM (1999) Short term streamflow forecasting using artificial neural networks. J Hydrol 214:32–48
Websites:
Discharge data from websites. (2015). Retrieved from Piedmont region, Emilia-Romagna Region, France, Slovenia, Swiss: www.arpa.piemonte.it, www.arpa.emr.it, www.eaufrance.fr, www.arso.gov.si/en/water/data, www.hydrodaten.admin.ch
Retrieved from GLDAS (2015), EOBS: http://disc.sci.gsfc.nasa.gov/hydrology/data-holdings, http://www.ecad.eu/download/ensembles/download.php
Acknowledgments
The research was conducted with support awarded to GECOsistema, R&D Unit Sudtirol, by the Province of Bolzano (LP 14/2006, “Bando Innovazione” 2011), in collaboration with EURAC Research.
We acknowledge the E-OBS dataset from the EU-FP6 project ENSEMBLES (http://ensembles-eu.metoffice.com) and the data providers in the ECA&D project (http://www.ecad.eu).
The data used in this study [GLDAS] were acquired as part of the mission of NASA’s Earth Science Division and archived and distributed by the Goddard Earth Sciences (GES) Data and Information Services Center (DISC).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
De Gregorio, L., Callegari, M., Mazzoli, P. et al. Operational River Discharge Forecasting with Support Vector Regression Technique Applied to Alpine Catchments: Results, Advantages, Limits and Lesson Learned. Water Resour Manage 32, 229–242 (2018). https://doi.org/10.1007/s11269-017-1806-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-017-1806-3