
Abstract
Full-image based motion prediction is widely used in video super-resolution (VSR) that results outstanding outputs with arbitrary scenes but costs huge time complexity. In this paper, we propose an edge-based motion and intensity prediction scheme to reduce the computation cost while maintain good enough quality simultaneously. The key point of reducing computation cost is to focus on extracted edges rather than the whole frame when finding motion vectors (optical flow) of the video sequence in accordance with human vision system (HVS). Bi-directional optical flow is usually adopted to increase the prediction accuracy but it also increase the computation time. Here we propose to obtain the backward flow from foregoing forward flow prediction which effectively save the heavy load. We perform a series of experiments and comparisons between existed VSR methods and our proposed edge-based method with different sequences and upscaling factors. The results reveal that our proposed scheme can successfully keep the super-resolved sequence quality and get about 4x speed up in computation time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
High resolution images or videos with reduced computation cost are usually desired for display, processing and analysis. For example, one need is to show low resolution (LR) videos such as standard-definition (SD) video signals on high-definition (HD) displays at high quality. Surveillance videos tend to sacrifice resolution to some degree to guarantee the appropriate frame rate for dynamic scenes. Although imaging or video capturing techniques have been rapidly developed recently, video super resolution (VSR) provides a way to overcome the cost of hardware devices or the limit of low resolution (LR) source signals.
In the passing decades, VSR has been an attractive research topic due to the fast popularization of large size display in consumer markets, such as general-purpose television, medical, and computer vision applications. For maintaining pleasing visual quality of videos captured by low resolution (LR) device after up-scaling, a wide variety of VSR schemes have been studied and proposed to meet the demand of high quality imaging.
The concept of VSR was first claimed by Tsai and Huang[1] and they proposed to obtain super-resolved video by processing in frequency domain. They assume that the input low resolution (LR) sequences are noise-free and it is extended by [2, 3]. Their method is complexity efficient. However, similar to algorithms proposed by Hardie [4] and Bascle [5], those methods mentioned above only focus on sequences with translational motion or with specific motion models, which are too simple to reflect arbitrary scenes in real world.
In earlier researches, classic interpolation-based methods, such as nearest neighbour [6], bilinear [7], bi-cubic [8], Lanczos [9], and multi-level [10] interpolation methods, are proposed. These methods apply filters to upscale every frames in videos independently with high efficiency and fast implementation. However, the high frequency details may be lost and may cause zigzag and ringing effects since the new pixels are generated by merged weighted pixels without using motion information or properties of view content.
A different family of methods is the learning-based VSR approach, which utilizes a certain learning scheme to obtain high frequency details according to characteristic of input LR frames from the corresponding relationship of LR and HR images in a training set [11,12,13,14,15,16]. Most of the methods in this category apply image SR techniques to each frame independently without temporal coherence [17,18,19]. With concern of motion information, Xiong [20] proposed a robust single image SR method for web image/video upscaling. In aspect of video super resolution processing, it divides every frame into primitive (edge, ridge and corners) and nonprimitive fields and upscale all LR frames with bicubic interpolation to initial HR sequence with desired size. After that, it processes learning-based pair matching on primitive fields to enhance initial HR frames with maximum a posterior probability(MAP) by maintaining an off-line trained data set filled with LR and HR patch counterparts and take successive matching pairs of previous frames into concern. This method can be applied to both single image and multi-frame system with good visual quality, but the performance is decided by the training set of the learning procedure and that will influence the video type it can deal with. That is, the incorrect patch will lead to unnatural artifact.
Another kind of VSR approaches is the reconstruction-based algorithms. They utilize the information from a set of successive input LR frames to generate one or several HR frames. Among them, a number of methods use statistical approaches. For instance, Keller [21] presents a frame work of simultaneous motion and intensity calculation on VSR. With maximum a posteriori (MAP) framework and the adoption of prior probability under a variational Bayesian theorem which includes explicit constraint on solutions, the specific characteristics of the input low resolution (LR) sequence is not required and it can process a video sequence with arbitrary scenes. Their method benefits from the dense variational optical flow procedure that utilizes accurate registration of each pixel of adjacent frames, but in return, lengthens the total computational complexity as a bottleneck. Motion compensated iterative back-projection approach was proposed [22]. Similar probabilistic approaches are proposed by Belekos [23], Kim [24] and Farsiu [25].
Moreover, in this category, since the existing dual mode camera can sparsely catch high resolution (HR) pictures while taking low resolution videos, researches are proposed to cooperate with this mechanism and reconstruct HR sequences with sparsely existing high resolution key frames [26,27,28,29]. Nevertheless, operating dual mode camera is not a general case.
On the other hand, in face of optical flow, there are numbers of the above methods in different categories taking motion estimation (optical flow) as a middle step in progress, namely motion-based flow. We apply the optical flow calculated from motion compensation to collect correlative pixel information from several similar scenes in a video sequence for further reconstruction with different schemes, respectively. Therefore, an appropriate motion compensation is significant to performance of motion-based method. Among all the VSR schemes, the interpolation-based methods are easy to implement, but in exchange, the visual quality is not good enough especially for larger size display. Motion-based methods using sequences with translational motions or with specific motion models are too simple to reflect arbitrary scenes in real world.
In general, dense optical flow is a reliable option to obtain accurate registration between adjacent frames which align the same scene in sub-pixel accuracy, such as [21, 23] and so on. However, the optical flow update is burdened with heavy computation cost. Instead of explicit motion estimation, Takeda [30, 31] proposed a VSR method with the 3D steering kernel regression that computes weighted least-squares relationship of spatio-temporal neighbouring pixels. Also, Protter [32] leads the problem to the patch-based matching procedure, while Su [33] solves the problem by matching sets of feature points between LR frames. A Bayesian approach to adaptive VSR via simultaneously estimating underlying motion, blur kernel, and noise level is proposed [34]. Using sparse coding and belief propagation for VSR is presented [35]. However, those methods above still have to estimate motion vectors pixel-wisely at regions with large motion variations and the block matching algorithms may make motion vectors fall into local optimum due to the search pattern limitations and misleads the search direction.
Dense optical flow estimation with variation methods can manage sequences with arbitrary scenes in real world since it doesn’t limit the motion models of input sequences. Aside from the advantages, dense variational optical flow estimation is a complex task due to the time-costing recursive minimizing convergent procedure, especially when the algorithm adopts big scaling factors that accuracy is a demanding requirement. An example of function load analysis of VSR scheme by Keller [21] is shown in Table 1. We can observe that the forward and backward flow prediction procedure (dense variational optical flow estimation) accounts for 91.25 percent, which is simply the bottleneck of the whole VSR processing. Besides, with the advance of display techniques and consumer market command, the video sequence size to be processed has an increasing trend and aggravates the already complex procedure. Therefore, VSR with reduced computation cost is important, especially in fields such as HD displays, video surveillance, and digital camcorders applications.
The paper is organized as follows: In Section 2, the flowchart of our proposed framework of edge-based motion and intensity prediction for video Super-resolution are described. The detail procedure of the two main steps including optical flow prediction and high resolution sequence construction will also be introduced here. Next, in Section 3, experimental results of our proposed method on 2 × 2 and 4 × 4 super-resolved sequences are presented and compared with state-of-art VSR methods in PSNR, MSE and visual results. The conclusion and future work are given in Section 4.
2 Proposed Edge-based Motion and Intensity Prediction for Video Super-resolution
In this section, in order to resolve the computation cost of full-image motion prediction and HR sequence construction in VSR, we present an edge-based motion and intensity prediction framework. There are two key schemes in the proposed framework to accomplish the complexity reduction.
-
1)
Edge-based processing
-
2)
Obtain corresponding backward flow prediction from forward flow one
The algorithm proposed by Keller [21] processes the input sequence pixel-by-pixel in each frame. It results a long computation time especially when the sequence length or frame size are large as they usually are. Generally, according to human vision system (HVS), human eyes are more sensitive to high frequency signals than low frequency ones that people pay more attention to edge or texture areas rather than smooth regions while watching a video or an image. Moreover, we observe that the backward flow is merely the flip-over version of the forward flow along the sequence order in theory, which means the corresponding backward flow can be inferred from the forward one by cross-referencing. This may reduce up to a half of the total time complexity since the flow prediction part accounts for the main amount of the total time.
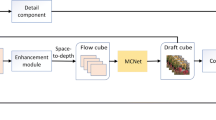
The overall flow diagram of our proposed method is shown in Fig. 1. We first extract the edge of the input LR sequence by canny edge detection and construct LR edge sequence, which is the original LR sequence mainly emphasized on edge. Then, from the LR edge sequence, we predict the forward edge flow in the LR sequence that is further upscaled to initial HR forward edge flow with desired upscale factor. When upscaling the LR edge sequence to initial HR edge sequence, we adopt cubic spline interpolation in [36] to marked edge map, which prevents zigzag artifacts and maintains the contour shape while scaling the edge. Finally, from the HR edge sequence and edge flow prediction, we reconstruct the final HR sequence.

Flow diagram of the proposed edge-based motion and intesity prediction framework.
2.1 Optical Flow Prediction
The detail diagram of forward edge flow prediction is illustrated as Fig. 2. The key idea is to use multi-resolution LR edge sequence to adjust the upscaled forward edge flow iteratively. Figure 3 shows the complete operation of the red box in Fig. 2. We downscale the input LR edge sequence with N intermediate scales into different resolution sequences with frame size no bigger than the input LR edge frame. The multi-resolution level N is also used to decide the intermediate scaling factors. An initial empty forward edge flow is used to cooperate with the first downscaled LR edge sequence and its gradient information to produce update forward edge flow that has the same size as the downscaled LR sequence. Then it is up-scaled to meet the size of the second downscaled LR edge sequence and proceed with the second iteration. The same scheme is iterated for N times to get the forward edge flow of the input LR edge sequence.

Diagram of sequence-based iteration for forward edge flow prediction.

Diagram of the red box in the sequence-based iteration for forward edge flow prediction.
The energy function altered from [21] to be minimized for forward edge flow prediction is as:
where \(\vec {v}_{edge}\) is edge flow(motion) vector. The \(u_{L_{edge}}\) is the LR edge sequence and \(\bigtriangledown u_{L_{edge}}\) represents spatial gradient of edges. t indicates frame number and \(\vec {V_{edge}}=(\vec {v}_{edge}^{t},1)^{T}\) is its spatio-temporal counterpart. \(\mathcal {L}_{\vec {V}_{edge}} \) in Eq. 2 defines the Lie derivative to evaluate changes along the vector field \(\vec {V_{edge}}\) of a function f. The l and t in Eq. 2 are the edge pixel location in an edge frame and the time frame in a video sequence. \(\psi ({s^{2}})=\sqrt {s^{2}+\varepsilon ^{2}}\) is a strictly convex approximation of the L-norm function and it is non-differentiable. ε is a small positive constant; ▽3 denotes the spatio-temporal gradient. p is the edge pixel value.
\(J\vec {v_{edge}}\) denotes the spatio-temporal Jacobian of \(\vec {v_{edge}}(l,t)\) and \(\parallel J\vec {v_{edge}}{\parallel ^{2}_{F}}\) is its Frobenius squared norm |▽3 v 1|2 +|▽3 v 2|2. λ 3,γ are constants. Generally speaking, E 1 acts as the spatio-temporal prior on the intensities and as a data term on the flow that sharpens motion boundaries and lowers sensitivity to changes in brightness. E 2 provides a spatio-temporal diffusion of the edge flow values. Comparison between the updated forward flow from Keller’s [21] full-image based estimation and ours from Eq. 1 are shown in Fig. 4. The color depth of green and red in Fig. 4b and c separately indicate the amplitude of horizontal and vertical component of the motion vector \(\vec {v_{edge}}=(v_{1},v_{2})\). We observe that similar updated forward flow is obtained. Note that this multi-resolution procedure is only for updating forward edge flow and the construction of the backward edge flow is described later.

Comparison of forward optical flow from full-image based method [21] and our proposed edge-based method.
The edge-based optical flow uses multi-resolution LR edge sequences to adjust each upscaled forward edge flow predictions iteratively. The energy functions to be minimized are based on a spatio-temporal prior on the intensities of edges and a spatio-temporal diffusion of the edge flow values. We also infer the corresponding backward flows from the forward ones by cross-referencing since the backward flow is merely the flip-over version of the forward flow.
2.2 High Resolution Sequence Construction
The next step in Fig. 1 is to upscale the LR edge sequence and the forward edge flow we obtained in optical flow prediction, then to construct final high resolution(HR) sequence u H . To get target HR edge sequence \(u_{H_{edge}}\), altered from [21], the intensity energy function \(E_{I_{edge}}\) to be minimized is written as below,
E1 runs the same operation as in Eq. 1 and E3 is a regularization of the spatial total variation measure. The R acts as an uniform distribution as a spatio-temporal moving average filter in Eq. 4, and is the transform matrix to ensure the relation between calculated \(u_{H_{edge}}\) from Eq. 3 and \(u_{L_{edge}}\). \(u_{L_{edge}}\) is the LR edge sequence. The detail diagram is shown in Figs. 5 and 6. In the first part of the first iteration, our main purpose is to use the input initial HR edge sequence, initial HR forward edge flow and the constructed backward edge flow to get an updated HR forward edge flow. To construct backward edge flow, since the backward edge flow is merely a flip-over version of forward edge flow, we follow the steps below to get the backward HR edge flow. We first trace back along the direction of motion vector of every frame in forward edge flow, then we place the corresponding motion vector with opposite horizontal and vertical component in right position of the backward edge flow. The vectors in the forward edge flow are expressed in floating points and assume the existed forward edge flow as:

Sequence-based iteration for HR sequence reconstruction.

Sequence-based iteration for HR sequence reconstruction.
where \(({x_{i}^{t}},{y_{i}^{t}})\) are the horizontal and vertical coordinate of edge pixels in frame t of forward edge flow and \((v_{1,i}^{t},v_{2,i}^{t})\) are the corresponding motion vectors expressed in floating points. The corresponding position to be placed in the backward edge flow can be obtained by rounding them to the nearest integer coordinate as the equation below.
where \(({x_{j}^{t}},{y_{j}^{t}})\) is the horizontal and vertical coordinate of edge pixels in frame t of the backward edge flow we want to place. Notice that some of them may not be projected successfully at once since the projections might be overlapped or out of boundary from time to time. In this case, these empty holes will be gradually filled in the following one level simple optical flow prediction procedure, which also operates on initial forward edge flow to approach accuracy step by step in forgoing M iterations. The comparison of backward optical flow from full-image based method [21] and our proposed edge-based method is as Fig. 7. We can find that the backward flow by our method is similar to Keller’s [21] full-image based estimation at edge part.

Comparison of backward optical flow from full-image based method [21] and our proposed edge-based method.
After getting the forward and backward motion vectors, we can get the predicted position in the former and the latter frame of the pixel currently processing to solve E 1 and E 3 minimization in Eq. 3 and to obtain a temporary \(u_{H_{edge}}\) as the next part within the same iteration. With Fig. 8, to solve (3) and (4), the intensity updating equation is as Eq. 7 below:
where N e w(x t,y t) will be the updating pixel value at \(u_{H_{edge}}(x, y, t)\) and P t represents the pixel value currently processing while P t− 1, P t+ 1 are pixel values of the corresponding coordinate in previous and next frame through back and forward flow. N e i g h b o r i indicates the pixel value of four neighbour pixels of P t . The new pixel value is the combination of spatio-temporal neighbourhood pixels with different weighting values.

Update intensity of HR sequence.
Next, after a little adjusting to ensure the relationship of the temporary \(u_{H_{edge}}\) and the \(u_{L_{edge}}\) as E 0 in Eq. 4, we obtain the updated \(u_{H_{edge}}\) and merge them into the initial HR sequence as updated HR sequence. If the average square error of the updated and non-updated \(u_{H_{edge}}\) is less than a fixed threshold, the procedure will be ended. The updated \(u_{H_{edge}}\) will then update the two HR optical edge flows and proceed with the same scheme in the second and further iterations. After M iterations, we get the final reconstructed HR sequence u H . Note that all of them are size-unchanged during the whole process in M iterations.
The HR edge sequences can be obtained from predicted edge optical flows iteratively by minimizing a spatio-temporal prior on the intensities of edges and the regularization of the spatial total variation measure. Initial HR sequences with a desired size are upscaled from multi-resolution LR frames with bicubic interpolation. From the HR edge sequences, edge flow predictions and initial HR sequences, we reconstruct the final HR sequences iteratively.
3 Experimental Results
The simulations are executed on a standard PC (AMD II X4 Quad-core 3 GHz, 8GB RAM, 64-bit) and the code is written in C++ using the CImg library [37]. The experiments are on subjectively evaluating classic 2 × 2 and 4 × 4 magnification factors.
To obtain a ground truth image, we downscale an input sequence by the magnification factor in the simulation, such that there exists a ground truth to compare with the upscaling results. In the simulations, we downscale with the factor 0.5 × 0.5 for 2 × 2 upscaling. We simply use the downscale projection matrix R in Eq. 4, instead of using a Gaussian blur kernel which may alter image formatting and affect the results. And for 4 × 4 upscaling, we do two times 2 × 2 upscaling.
To experiment on real-world sequence, the test sequences are downloaded from Youtube [38,39,40,41,42], including 720 × 576 × 15 sequence Jesse, Football, Sea, Fight, sWave, sHero, and 720p sequence (720 × 1280 × 15) Wave and Hero.
The parameters we adopt are λ s = λ t = 1,λ 3 = 70,γ = 200,N = 100,M = 10, We compare the HR results of our proposed method with several general state-of-art video super resolution researches, which includes classic bilinear, bicubic, Lanczos [9] interpolation, Farsiu [25] (similar to our motion-based VSR procedure), a recent super resolution enhancer software [43], Zongliang [44], Keller [21] and our primary results [45] respectively. The simulation results of PSNR and MSE are shown in Table 2. The relation of PSNR and time is in Figs. 9 and 10. For visual comparison, the resulting videos in frames at different time are shown in Figs. 11 and 12 for 2 × 2 upscaling. Figures 13 and 14 are for 4 × 4 upscaling. From the results, we can observe that the method proposed by Zongliang [44] has clear visual quality with the sharpest edge. The Zongliang’s method is a fast image/video super resolution framework using edge and onlocal constraint with classical back projection method and self-similarity. However, judge from Table 2, its PSNR and MSE are the worst. Also, from Figs. 11k, 12k, 13k and 14k, we can see that this method ends in over-strengthening the edge volume and gives unnatural look especially when adopting big upscaling factors. Images by bilinear, bicubic and Lanczos [9] are blur at edges while Farsiu’s [25] has zig-zag artifacts. Besides, Farsiu’s method [25] has unstable results specially when encountering sequences with drastic motion changes such as in Fight sequence since it can only process with translational motion that the PSNR will gradually fall along t and get awful results. The super resolution enhancer software [43] uses information from a number of neighbour frames to extract maximum details instead of only using information from one current frame and gives stable PSNR and SSIM that are close to our method, though the edges are not sharp enough and there still exist some slightly block-effect at edges as in Figs. 11p, 12p, 13p and 14p.

PSNR comparison of Fight.

PSNR comparison of Hero.

Comparisons of zoomed Fight at t = 1 between different VSR algorithm with 2 × 2 upscaling.

Comparisons of zoomed Fight at t = 5 between different VSR algorithm with 2 × 2 upscaling.

Comparisons of zoomed Hero at t = 1 between different VSR algorithm with 4 × 4 upscaling.

Comparisons of zoomed Hero at t = 10 between different VSR algorithm with 4 × 4 upscaling.
From the experimental results, our proposed method has better PSNR and MSE than other methods until Keller’s. However, our method has only 0.07-0.4 decrement in PSNR compared with Keller [21]. Note that our goal is to reduce the computation time of full-image estimation of optical flow and HR sequence construction while keeping the output quality. Thus, the function load comparison of our edge-based scheme toward Keller’s method [21] which adopts full-image estimation is shown in Table 3. It shows that our method can successfully release the heavy load of the most time consuming step — forward and backward flow prediction with 3.78x speed up and 2.34x in processing HR sequence reconstruction. Our method has a total 3.59x speed up compared with Keller’s method. The increment of computation time on upscaling HR sequence is caused by the HR edge sequence upscaling, which is not involved in Keller’s steps. In fact, it is endurable since it merely accounts for very small proportion of the whole procedure.
Note that the function load and results of the two evaluations of our proposed method perform slight alterations between different sequences according to the amount of edges we extract at the very first step. When the amount of edges in the video sequences are large, the processing time reduction is large. In other words, the distribution of edges in the input LR sequence will affect the performance.
4 Conclusion
VSR with full-image based motion prediction has advantages of outstanding outputs with arbitrary scenes but costs huge amount of computation complexity. Our proposed edge-based motion and intensity prediction scheme can reduce the huge computation time while maintaining good enough quality. The key idea of our method is based on human visual perception more on edges/textures than smooth regions. We extract edges rather than processing the sequences pixel by pixel when finding optical flows of video sequences. Also, we obtain backward flows from foregoing forward flow predictions instead of going through both sequential processing and effectively save the heavy load. We perform a series of experiments and comparisons between existing VSR methods and our proposed edge-based method with different sequences and upscaling factors. The results reveal that our proposed method has better PSNR than most previous methods and only gets 0.07-0.4 decrement in PSNR compared with Keller’s method [21]. Our method obtains about 4x speed up in dense variational optimal flow estimations and 2x faster in HR sequence reconstructions, and 4x speed up in the total computation time compared with Keller’s method.
References
Tsai, R., & Huang, T. (1984). Multiframe image restoration and registration. Advances in Computer Vision and Image Processing, 317–319.
Kim, S., Bose, N., & Valenzuela, H. (1990). Recursive reconstruction of high resolution image from noisy undersampled multiframes. IEEE Transactions Acoustic Speech and Signal Process, 38(2), 1013–1027.
Bose, N., Kim, H., & Valenzuela, H. (1993). Recursive total least squares algorithm for image reconstruction from noisy, under sampled frames. Multidimensional Systems and Signal Processing, 4(3), 253–268.
Hardie, R., Barnard, K., & Armstrong, E. (1997). Joint map registration and high-resolution image estimation using a sequence of undersampled images. IEEE Transactions on Image Processing, 6(12), 1621–1633.
Bascle, B., Blake, A., & Zisserman, A. (1996). Motion deblurring and super resolution from an image sequence. Proceedings of the fourth European Conference on Computer Vision, 6, 573–582.
Fifman, S. (1973). Digital rectification of ERTS multispectral imagery. In Proceedings of significant results obtained earth resources technology. Satellite-1 (Vol. 1, pp. 1131–1142).
Parker, J., Kenyon, R., & Troxel, D. (1983). Comparison of interpolation methods for image resampling. IEEE Transactions on Medical Imaging, 2(3), 31–39.
Hou, H., & Andrews, H. (1978). Cubic splines for image interpolation and digital ltering. IEEE Transaction on Acoustics, Speech and Signal Processing, ASSP-26(6), 508–517.
Turkowski, K. (1990). Filters for common resampling tasks. In Graphics and game gems database academic press professional (pp. 147–165).
Yu, Z., Li, H., Wang, Z., Hu, Z., & Chen, C. (2013). Multi-level video frame interpolation: exploiting the interaction among different levels. IEEE Transactions on Circuits and System for Video Technology, 23(7), 1235–1248.
Gajjar, P., & Joshi, M. (2010). New learning based super-resolution: use of DWT and IGMRF prior. IEEE Transactions on Image Processing, 19(5), 1201–1213.
Kang, Y., Song, S., & Jeong, B. (2012). Fast super-resolution algorithms using one-dimensional patch-based training and directional interpolation. IET Image Processing, 6(5), 548–557.
Zhang, K., Gao, X., Tao, D., & Li, X. (2013). Single image super-resolution with multiscale similarity learning. IEEE Transactions on Neural Networks and Learning Systems, 24(10), 1648–1659.
Dang, C., Aghagolzadeh, M., & Radha, H. (2014). Image super-resolution via local self-learning manifold approximation. IEEE Signal Processing Letters, 21(10), 1245–1249.
Yang, J., Wang, Z., Lin, Z., Cohen, S., & Huang, T. (2012). Coupled dictionary training for image super-resolution. IEEE Transactions on Image Processing, 21(8), 3467–3478.
Dai, S., Baker, S., & Kang, S. (2009). An MRF-based deinterlacing algorithm with exemplar-based refinement. IEEE Transactions on Image Processing, 18(5), 956–968.
Wu, Z., Yu, H., & Chen, C. (2010). A new hybrid DCT-Wiener-based interpolation scheme for video intra frame up-sampling. IEEE Signal Processing Letters, 17(10), 827–830.
Yu, J., Gao, X., Tao, D., Li, X., & Zhang, K. (2014). A unified learning framework for single image super-resolution. IEEE Transactions on Neural networks and Learning systems, 25(4), 780–792.
Guo, K., Yang, X., Lin, W., Zhang, R., & Yu, S. (2012). Learning-based super-resolution method with a combining of both global and local constraints. Institute of Image Communication and Information Processing, 6 (4), 337–344.
Xiong, Z., Sun, X., & Feng, W u. (2010). Robust web image/video super-resolution. IEEE Transactions on Image Processing, 19(8), 2017–2028.
Keller, S., Lauze, F., & Nielsen, M. (2011). Video super-resolution using simultaneous motion and intensity calculations. IEEE Transactions on Image Processing, 20(7), 1870–1884.
Hsieh, C., Huang, Y., Chen, Y., & Fuh, C. (2011). Video super-resolution by motion compensated iterative back-projection approach. Journal of Information Science and Engineering, 27, 1107–1122.
Belekos, S., Galatsanos, N., & Katsaggelos, A. (2010). Maximum a posteriori video super-resolution using a new multichannel image prior, (Vol. 19.
Yap, K., He, Y., Tian, Y., & Chau, L. (2009). A nonlinear L1-norm approach for joint image registration and super-resolution. IEEE Transactions on Signal Processing Letters, 16(11), 981–982.
Farsiu, S., Robinson, D., Elad, M., & Milanfar, P. (2004). Fast and robust multi-frame super-resolution. IEEE Transactions on Image Processing, 13, 1327–1344.
Ge, J., Liu, J., Ge, C., & Yang, X. (2013). A robust video super-resolution based on adaptive overlapped block motion compensation. Signals Systems and Computers (ASILOMAR) Conference, 0, 187–194.
Najafi, S., & Shirani, S. (2012). Regularization function for video superresolution using auxiliary high resolution still images. Signal-Image Technology and Internet-Based Systems, 1713–1717.
Song, B., Jeong, S., & Choi, Y. (2011). Video super-resolution algorithm using bi-directional overlapped block motion compensation and on-the-fly dictionary training. IEEE Transactions on Circuits and Systems for Video Technology, 21, 274–285.
Hung, E., Queiroz, R., Brandi, F., Oliveira, K., & Mukherjee, D. (2012). Video super-resolution using codebooks derived from key-frames. IEEE Transactions on Circuits and System for Video Technology, 22(9), 1321–1331.
Takeda, H., van Beek, P., & Milanfar, P. (2008). Spatio-temporal video interpolation and denoising using motion-assisted steering kernel (MASK) regression. IEEE International Conference on Image Processing, 637–640.
Takeda, H., Milanfar, P., Protter, M., & Elad, M. (2009). Super-resolution without explicit subpixel motion estimation. IEEE Transactions on Image Processing, 18(9), 1958–1975.
Protter, M., Elad, M., Takeda, H., & Milanfar, P. (2009). Generalizing the nonlocal-means to super-resolution reconstruction. IEEE Transactions on Image Processing, 18(1), 36–51.
Su, H., Wu, Y., & Zhou, J. (2012). Super-resolution without dense flow. IEEE Transactions on Image Processing, 21(4), 1782–1795.
Liu, C., & Sun, D. (2014). On Bayesian adaptive video super resolution. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(2), 346–360.
Barzigar, N., Roozgard, A., Cheng, S., & Verma, P. (2012). A robust super resolution method for video. IEEE Asilomar conference on Signals, Systems and Computers, 1679–1683.
Wu, W., Wang, T., & Chiu, C. (2013). Edge curve scaling and smoothing with cubic spline interpolation. In Signal processing systems (SiPS) (pp. 65–70).
Cimg library Available: http://cimg.sourceforge.net/ (2014).
Youtube Available: https://www.youtube.com/watch?v=sK80h2RBMbc https://www.youtube.com/watch?v=sK80h2RBMbc (2014).
Youtube Available: https://www.youtube.com/watch?v=2uUk9K9TQhg (2014).
Youtube Available: https://www.youtube.com/watch?v=cHhYFhs6NcY&list=PLhOCgraOBvQLlsfc933yfDJxJxvWN4x3j (2014).
Youtube Available: https://www.youtube.com/watch?v=MnABZM96AhQ https://www.youtube.com/watch?v=MnABZM96AhQ (2014).
Youtube Available: https://www.youtube.com/watch?v=iKF-AxRvQ4w https://www.youtube.com/watch?v=iKF-AxRvQ4w (2014).
Video Enhencer Version 1.9.10 [Online] Available: http://www.infognition.com/VideoEnhancer/ (2014).
Zongliang, G. (2013). Low complexity image and video super resolution using edge and nonlocal self-similarity constraint. IEICE Transactions on Information and Systems, 96(7), 1569–1572.
Wang, J.-W., & Chiu, C.-T. (2014). Edge-based motion and intensity prediction for video super-resolution. IEEE Global Conference on Signal and Information Processing (GlobalSIP), 1039–1043.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Wang, JW., Chiu, CT. Video Super-resolution using Edge-based Optical Flow and Intensity Prediction. J Sign Process Syst 90, 1699–1711 (2018). https://doi.org/10.1007/s11265-017-1310-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-017-1310-2