
Abstract
This paper presents an algorithm for syllable segmentation of speech signals based on the calculation of the singularity exponents in each point of the signal combined with Rényi entropy calculation. Rényi entropy, generalization of Shannon entropy, quantifies the degree of signal organization. We then hypothesize that this degree of organization differs which we view a segment containing a phoneme or syllable unit (obtained with singularity exponents). The proposed algorithm has three steps. Firstly, we extracted silence in the speech signal to obtain segments containing only speech. Secondly, relevant information from segments is obtained by examining the local distribution of calculated singularity exponents. Finally, Rényi entropy helps to exploit the voicing degree contained in each candidate syllable segment allowing the enhancement of the syllable boundary detection. Once evaluated, our algorithm produced a good performance with efficient results on two languages, i.e., the Fongbe (an African tonal language spoken especially in Benin, Togo, and Nigeria) and an American English. The overall accuracy of syllable boundaries was obtained on Fongbe dataset and validated subsequently on TIMIT dataset with a margin of error <5m s.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
For an efficient speech recognition system, the step of speech segmentation into smaller units must be properly performed to facilitate the recognition of phonemes, syllables or words in the spoken phrase. Syllable segmentation involves syllable segment identification. It is used to detect the proper start and end points of syllable boundaries. Most of recent techniques in speech segmentation strongly relied on corpus-based methodologies require the availability of the precisely time-aligned labels of speech units [1]. In the field of speech segmentation, there is a common agreement that a manual segmentation is more precise than automatic segmentation even though manual speech segmentation requires a lot of time and money to segment very large corpora.
Many methods exist for speech segmentation into syllable units and are based on time domain and frequency domain features such as wavelet transform, autocorrelation, short-time energy or spectral energy, zero crossing rate, fundamental frequency, Mel frequency, spectral centroid and spectral flux.
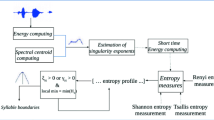
This paper proposes a new approach for automatic syllable segmentation which focuses on the use of time domain features to achieve a speech segmentation into syllable units. This unsupervised approach utilizes only acoustical information and does not require prior knowledge such as the correct phonetic transcription of utterance. It consists of three steps. Firstly, we separate speech segments, noise, and silence segments by using energy and spectral centroid. Secondly, we compute the local singularity exponents in the time domain for a short time analysis of extracted speech segments. Thirdly, to exploit the issued results from singularity exponents, we defined through the third step, a measure based on Rényi entropy to improve the automatic boundaries detection between units which are phonemes or monosyllabic units. After this step, the overlapped candidate segments are rejected leading to new boundaries defined by the voicing degree in these segments. We assume that the short-term energy which is commonly used for syllable boundary detection can not be used directly to perform segmentation due to significant local variations that could often provide the misidentified boundaries. The high energy variations across the signal affect erroneously the techniques using an adaptive threshold computed over the different regions of the signal. Too large regions miss boundaries while too short regions generate spurious boundaries [2]. The basic idea in this work for addressing this problem is to perform a first segmentation from only local maxima of the singularity exponents which contain instructive information about region local dynamics. At this stage, the syllable boundaries also called candidate boundaries are at the lowest local minimum of these exponents between two nuclei. The errors are misidentified boundaries and missed recognition of short syllables that we have subsequently corrected with the entropy measure defined from the short-term energy. The final objective of this work was to achieve a new method for segmentation of a speech signal into syllables. The purpose of such work would be to clearly identify the syllables that make up the speech signal. Figure 1 summarizes the three steps that make up our algorithm. Indeed, syllable is the basic unit of prosody. Its identification would change some prosodic features of the voice (the fundamental frequency, for example) to an appropriate scale, or to integrate these features in speech synthesis systems.
We evaluated the performance of our algorithm on two datasets, i.e., the Fongbe datasetFootnote 1 (an African tonal language spoken especially in Benin, Togo, and Nigeria) and the TIMIT dataset (an American English). The remaining sections of the paper are organized as follows. In Section 2, we briefly present the related works in syllable segmentation and compare our approach with the mentioned works. In Section 3, we describe our syllable segmentation algorithm. Experimental results and performance analysis are reported in Section 3. We conclude in Section 4.
2 Related Works
This section presents some related works on unsupervised syllable segmentation. Unsupervised syllable segmentation consists in cutting a speech signal with parametric methods in small syllabic segments. There has been a wide range of methods suggested for the unsupervised segmentation of natural speech. These are most of the stationarity measurements, measurements based on the zero crossing rate, on short-term energy or on spectral energy to estimate unit boundaries. There are also the estimation methods of the fundamental frequency to show the difference between voiced and unvoiced segments and spectral features which are extracted from automatically detected syllable nuclei only [3]. Speech segmentation into syllabic units can be approached using three different features: time domain features, frequency domain features and a combination of both.
Automatic syllable segmentation was first approached by Mermelstein through its algorithm based on the convex hull measured on acoustic intensity in formant regions to evaluate the shape of the loudness pattern [4]. Zhao et al. in [5] associated spectral variation detection with convex hull analysis on signal energy to build a hybrid method for automatic syllable segmentation. They used short-time energy to divide a whole utterance to several parts on which they subsequently applied convex hull and zero crossing rate methods. So, they used the last two methods to correct the rejection errors.
Other time domain algorithms for a syllable segmentation were developed by Pfitzinger et al. [6] and by Jittiwarangkul et al. [7]. In [6], Pfitzinger et al. processed the speech signal using a bandpass filter, computed the energy pattern using a short-term window and finally they low-pass filtered this energy function. They used the local maxima of energy contour to find syllable nuclei and compared nuclei positions with manual syllabic segmentation. Various kinds of temporal energy functions and smoothing methods for syllable boundary detection are presented by the authors in [7]. In [8], Wu et al. used syllabic processing to improve the accuracy of speech recognition. By using two-dimensional filtering techniques, they computed smoothed speech spectra to enhance energy changes of the order of 150 ms. Thus, they obtained the features which were combined with log-RASTA and used as input to a neural network classifier for estimating syllable onsets. Along the same lines, Massimo et al. proposed the use of two different energy calculations such as original energy and the low-pass filtered signal energy to detect the most relevant energy maxima [9]. Their syllable segmentation algorithm was based on the analysis of the temporal pattern of the energy of the speech signal and was tested on English and Italian. In [10], Sheikhi et al. used the fuzzy smoothing to propose an algorithm for connected speech segmentation into syllable units. They applied fuzzy smoothing on short-term energy function to smooth any local fluctuation as well as preserve segment information. They tested their method on 200 utterances from Farsi speech dataset and syllable boundaries were detected as energy minima. All syllable segmentation algorithms mentioned above are methods using time domain features. Time domain approaches for syllable segmentation mostly use the short-term energy (STE) contour smoothed by a smoothing algorithm which is not the case with frequency domain approaches that exploit among other cepstrum features.
Recently, frequency domain methods through fractal theory and time-frequency representation have been used in syllable segmentation. The Fractal theory was used by Pan et al. in [11] to determine beginning-ending points of each syllable in continuous speech. They proposed an algorithm which is based on fractal dimension trajectory to carry out syllable segmentation. To improve syllable segmentation, they combined fractal dimension with wavelet transform by using dynamic threshold algorithm to denoise the speech signal. Their simulation results showed that, in the case of low SNR, the syllable segmentation algorithm based on fractal dimension theory remains relative high accuracy (88%) which the other segmentation algorithms can not be matched. In [12], the authors used a time-frequency representation to exploit the speech characteristics depending on the frequency region and the fusion of intensity and voicing measures through various frequency regions for the automatic segmentation of speech into syllables. They assumed that their proposed method tested on TIMIT database of American-English provided a promising paradigm for the segmentation of speech into syllables. In [13], Villing et al. proposed a syllable segmentation algorithm which used the envelope in three frequency bands to identify syllable boundaries. In [14], Mel Frequency Cepstral Coefficients (MFCC) was used as feature extraction method to construct the feature vector of each syllable from birdsongs(Fig 1).

Flow diagram of the method.
Further, several authors adopted the approaches based on Hidden Markov Models (HMM), Artificial Neural Networks (ANN) and Correlation Intensive Fuzzy C-means (CIFCM) which are widely used in automatic speech recognition for the syllable segmentation [15–18]. In [15], Shastri et al. used the temporal flow network to compute a function having local peaks at syllabic nuclei. Their goal was also to use a different kind of ANN to find syllabic nuclei. Ching et al. in [16] proposed the use of a neural network to segment an utterance into a sequence of silence consonants. For this purpose, they used a concatenating-syllable rule to detect syllable boundaries. They tested their method based on a hierarchical neuro-fuzzy network on Mandarin dataset. Authors in [17] proposed the use of HMM-based approaches which need the support of a language model for automatic segmentation in speech synthesis. Three different methods based on HMM framework were used in [19] to recognize the tonal syllables in continuous speech. In this work, the base syllables (syllables ignoring their tones) are initially recognized by using ans HMM of connected base syllables only; the estimated syllable boundaries are then used for subsequent tone recognition in a separate HMM of tones.
Compared to the methods described in previous works, the one we propose uses time domain approaches to generate the features to detect syllabic units and thus is not dependent on the frequency regions of the signal and the envelope in frequency bands as in works [11–13]. Compared to the approaches based on artificial neural networks and on Hidden Markov Models, our segmentation method does not need a training step and learning parameters. Compared to the method in [17], our method does not need a language model for segmenting speech into syllables units. Unlike the methods using the time domain approaches described in [6, 7, 9, 10], we investigated the use of Rényi entropy based on the short-term energy of the signal to improve the detection of boundaries between syllable units. Compared with the mentioned works regarding time domain approaches which were tested on English, Italian, and Mandarin, in addition to the TIMIT database of American-English, our segmentation method was tested on the Fongbe dataset to confirm its performance. The authors in [20–22] proposed methods close to our automatic syllable segmentation method for the use of microcanonical multiscale formalism for only visually distinguishable phonemes in a speech signal without establishing an automatic segmentation algorithm. In [21], the authors proposed an approach based on fractality using envelop transitions of the local fractal dimension to determine the boundaries between words and phonemes. Authors in [22] proposed also an approach based on the variance fractal dimension trajectory algorithm that is used to detect the external boundaries of an utterance and also its internal pauses representing the unvoiced speech.
3 Algorithm Description
In this section, we present the different steps of our syllable segmentation performed on English and Fongbe speech and a description about boundary detection algorithm using singularity exponents and Rényi entropy. The proposed algorithm steps are the following:
-
a
- Removing silence from the speech signal. We used a method based on signal energy, the spectral centroid, and a simple thresholding criterion is applied in order to remove silence areas in the audio signal.
-
b
- Computing singularity exponents in order to exploit their local distribution to analyze the temporal dynamics of speech segments obtained previously. This leads to the segment candidates.
-
c
- Calculation of the short-time energy in each candidate segment generated by the local analysis of singularity exponents.
-
d
- Finally, we introduced a measure based on Rényi entropy calculated on the matrix for short-term energy that better used singularity exponents to improve the accuracy in the detection of syllable boundaries. This leads to the rejection of certain candidate segments.
3.1 A Syllabic Unit
Syllable is a smaller phonological unit contained in a speech which has long been regarded as robust units of speech processing. It is typically composed of a nucleus (generally, a vowel) optionally surrounded by clusters of consonants (left and right margins) [23]. A syllable - pronounced “with a breath”-, is acoustically defined by the principle of sonority which is assumed to be maximal within the nucleus and minimal at the syllable boundaries [12]. Syllabic units at the output of our algorithm are phonetic units or a simple concatenation of consonants and vowels, leading to a monosyllabic form.
3.2 The Singularity Exponents
The accurate estimation of singularity exponents in multi-scale systems allows characterizing their relevant features and identify their information content [24]. We used these exponents to extract temporal features from the speech signal which is considered as an acquisition of a complex dynamic system. The singularity exponents allow predictability and accurate analysis of the speech signal and are estimated with the methods derived from principles in statistical Physics. In this section, we present the computational approach of singularity exponents using Microcanonical Multi-scale Formalism (MMF) proposed in [20]. Rather than use it for phonetic segmentation as some authors did, we based on the distribution analysis of these exponents to select units containing monosyllabic information. For this purpose, we modified time instance t used in their work to take account of larger segments than phonetic units (> 32m s). Thus, we computed the singularity exponents on a window of 100 ms length around the time t.
Candidate segments’ selection
Given a signal s, Eq. 1 is a relation which must be valid for each time instance t and for small scales r.
where h(t) is the singularity exponent of signal s for time instance t and Γ r is one scale-dependent functional. The smaller h(t) is, the less predictable system is for t. With the Eq. 2, the functional Γ r is defined from the gradient s ′ of the signal.
Γ r can be projected into wavelets to obtain continuous interpolations from discrete sampled data. With a wavelet Ψ, the projection of the functional for the time instance t is given by the equation
If s satisfies the Eq. 1 then the measure s ′ computed with the Eq. 3 satisfies a similar equation with the same singularity exponent h(t) ([25]). This condition leads to a simple estimation of singularity exponents by log-log regression on a projection into wavelets at each point t [26].
For more details on singularity exponents estimation and their computation one may refer to [20]. At this stage, we applied the calculation of singularity exponents on each speech segment. By analyzing the local distribution of exponents and an interpretation of various level changes we got small segments so-called candidate segments that contain a phoneme (e.g., C-V) or a set of consonants and vowels (e.g., CV). We also got raw syllable boundaries but with segments containing overlapping syllables. Results obtained using singularity exponents are shown in Figs. 2 and 3. This stage may produce errors such “misidentified boundaries” and “missed recognition of short syllables”. Section 3.3 describes the used method to correct these errors.

TOP- The original speech signal of Fongbe utterance “A k w ε a ? ”, original transcription plotted in dotted vertical lines, MIDDLE- The same original speech signal with the manual syllabic transcription plotted in dotted vertical lines, BOTTOM- Curve of change levels of singularity exponents h(t) with minima in green and maxima in red, obtained boundaries in the solid vertical lines and manually identified boundaries in dotted vertical lines.

TOP- The speech signal “ She had your dark suit in greasy wash water all year ”, original transcription plotted in dotted vertical lines,MIDDLE- The same original speech signal with the manual syllabic transcription plotted in dotted vertical lines, BOTTOM- Curve of change levels of singularity exponents h(t) with minima in green, maxima in red, obtained boundaries in the solid vertical lines and manually identified boundaries in dotted vertical lines.
3.3 Syllable Boundaries
A simple method is described for the effective detection of the syllable boundaries in each speech candidate segment. This method allows to better exploit the level changes of singularity exponents and consists of two calculation steps: short-term energy and entropy. Rather than calculate entropy from the spectral density or a frequency scale, we performed the calculation of short-term energy in order to know how this energy was varying with time and also to exploit the energy time variation in the candidate segments that showed the distribution of singularity exponents.
Syllabic units - Short time energy is defined as shown by Eq. 4.
where s(n) is a discrete-time audio signal, m represents the frame shift or rate in number of samples, l is the length of frame (samples) and w H is the Hamming window function. Voiced segments have higher energy than unvoiced segments. This has implications on the voicing degree calculated by entropy. The near-zero energy values at the break between two segments allow a boundary beginning which is improved with the linear interpretation of the entropy in segments.
A number of descriptors based on Shannon entropy were proposed for speech segmentation, but not in the context of segmentation into syllables. Because of their advantageous properties, entropy measurements help to give a view on the level of speech distribution and measure the degree of uncertainty in a speech signal. These are measures that are maximum in the vocalic nucleus and minimum at the syllable borders. Rényi entropy [27] is a generalization of Shannon entropy as Tsallis entropy and is defined by the Eq. 5.
where α ≥ 0 and ≠1, p is a probability distribution. Tsallis entropy is stated as useful when the system has distinct microstates with strong correlation amongst them. It may be advisable to consider Rényi entropy with a coefficient α large enough in place of the Shannon entropy, so as to amplify the differences between voiced and unvoiced segments.
Rényi entropy measures the signal complexity when it applies to a time-frequency distribution (TFD) [28]. One of the most popular TFDs introduced by Wigner and extended by Ville to analytic signals [29], was treated as a pseudo-probability density function for a nonstationary signal to which Rényi entropy was applied as a measure of signal complexity.
Boundary detection - The intuitive idea of our work is to obtain a syllable segmentation from time domain features by treating the probability density function as the energy distribution throughout the segment (see Eq. 6).
This strengthens the temporal information obtained with singularity exponents and clearly distinguishes the changes of syllables. For major properties of Rényi entropy and what distinguishes it from other entropies, one may refer to [30].
With the computed entropies of all segments, we obtained the entropy profile for each candidate segment c i given by expression (7).
To exploit the changes in the entropy profile evolution, we defined measure ξ H which always takes the negative of entropy. This measure is given by Eq. 8.
A boundary is clearly detected when ξ H >0 and m i n(ξ H ). The candidate boundary is maintained as a boundary when its \( \xi _{H_{i}} > 0\) is the lowest in the entropy profile. Otherwise, c i is removed from the candidate segments. In addition, ξ H does not change its value in overlapping candidate segments. This additional information helps to remove the overlapped segments and new boundaries are to be established by the linear variation of ξ H . Algorithm 1 summarizes the procedure of boundaries detection.

For each iteration (Algorithm 1), we search for ξ i H that minimizes the entropy profile of a given candidate segment. This minimum is located in [ ξ α H ξ β H ] if ξ α H and ξ β H have the same sign or opposite signs and α and β are consecutive iterations. The smallest ξ i H becomes an end segment boundary if its value is greater than 0. The effective location of a boundary in a candidate segment depends strongly on the detection of ξ i H that minimizes its entropy profile. otherwise the candidate segment is removed after all iterations.
4 Experimental Results
4.1 Speech Data
The proposed algorithm was first evaluated on Fongbe speech corpus and then for validation on the American-English TIMIT database. Fongbe is a poorly endowed language which is characterized by a series of vowels (oral and nasal) and consonants (unvoiced, fricatives). By excluding compound words and derived words, the words of Fongbe language can be grouped into monosyllabic (V and CV), into bisyllabic (VCV; CVV; CVCV and VV) and trisyllable (VCVCV and CVCVCV). It has a complex tonal system, with two lexical tones, high and low, which may be modified by means of tonal processes to drive three further phonetic tones: rising low-high, falling high-low and mid. The Fongbe speech corpus is divided into train and test sets which respectively contain 2307 and 810 sentences uttered by 56 speakers whose ages are between 9 and 45 years. It contains for the full database approximately 12 thousand words and 48 thousand syllables.
TIMIT comprises hand labeled and segmented data of quasi-phonetically balanced sentences read by native speakers of American English. The TIMIT database contains 4620 utterances for the train set and 1680 utterances for the test set.
4.2 Results and Performance Measures
The obtained results were compared to those of the simple method using singularity exponents presented in [1]. This performance measure is calculated using others basic metrics required for performance evaluation of speech segmentation whose definitions are as follows.
-
H R (Hit Rate): represents the rate of correctly detected boundaries (N H /N R ). It utilizes the number of correctly detected boundaries (N H ) and the total number of boundaries (N R ).
-
F A (False Alarm Rate): represents the rate of erroneously detected boundaries (N T −N H )/N T which utilizes the total number of detected boundaries N T and the number of correctly detected boundaries N H .
-
O S (Over Segmentation Rate) : shows how much more (or less) is total number of algorithm detections, compared to the total number of reference boundaries taken from the manual transcription (N T −N R )/N R .
In order to describe the overall quality of our algorithm, we computed F-value from precision rate and hit rate whose expression is F 1 = (2 × (1 − F A )×H R )/(1−F A + H R ). F-value is one scalar value usually used for evaluating a segmentation method and which simultaneously takes the hit and false alarm rates into account. Another global measure, referred to as the R-value, decreases as the distance to the target grows, i.e., similarly as the F-value does, but is critical towards over-segmentation. It has been proposed in [31] and is supposed to be more accurate than F-value. It is calculated by R = 1 − (|r1| + |r2|)/2 with \(r1 = \sqrt {(1 - H_{R})^{2} + OS^{2}}\) and \( r2 = (H_{R} - OS -1) / \sqrt {2}\).
Our evaluation is carried out on the full test set of each database. Table 1 displays the results obtained with different frame step sizes. For the three used metrics and all frame step sizes, ξ H outperforms the singularity exponents for both datasets. The overall performance of our algorithm is obtained at 0.2s considered as the mean duration. We noted a significant improvement in F A . This shows that ξ H identifies correctly a boundary whenever a boundary is detected and effectively removes insertions introduced by SE (see Fig. 6 from Fongbe dataset and Fig. 7 for an example from TIMIT). Figure 4 shows the evolution of H R and F A relative to the frame step sizes plotted in abscissa. An observation is that for F S S<0.11, there are more misidentified boundaries obtained by ξ H for Fongbe utterances but is effective for utterances from TIMIT-Test dataset. Generally, Fig. 4 shows that the smaller frame step size is, the higher rate of erroneously detected boundaries is. For the best performance from ξ H compared to the singularity exponents, we obtained an improvement in H R (24 % from Fongbe and 12 % from TIMIT) and a reduction in F A (26 % from Fongbe and 16 % from TIMIT) for the same frame step size (0.2s)s.

H R and F A curves of each method.
We also evaluated our algorithm by using the global measures F and R. Table 2 presents the performance of each method. We observed a significant improvement in F v a l u e and R v a l u e. For F S S>0.15, F v a l u e and R v a l u e are practically the same when ξ H is applied. This may be observed clearly in Fig. 5. The obtained performance for 0.2s of frame step size shows that in this study, our algorithm is well suited for high precision detection of syllable boundaries.

F-value and R-value curves of each method.
All this leads to confirm that Rényi entropy calculated on short-term energies efficiently improves the syllable boundary detection for utterances from both speech dataset. Indeed, a basic detection with singularity exponents is to determine the change levels in the temporal dynamics of speech signal. Figures 6 and 7 demonstrate the segmentation of the given continuous speech signal at syllable boundaries. In these figures, it is obvious that singularity exponents have a higher variance in points containing silence and breaks in speech. This makes the single use of singularity exponents difficult for automatic boundaries detection because they include these points in delimited segments. Energies, on the other hand, have smaller variance near zero in the endpoints and are more sensitive in speech breaks. Thus, the use of short-term energy based on Rényi entropy enhances the boundary detection. The overall accuracy is determined with the measure ξ H and the obtained scores F-value and R-value in Table 2 show its performance. The error margins allowed while calculating are of <5m s for data from TIMIT corpus and vary between 5 ms and 10 ms for data from Fongbe dataset. The Fongbe speech syllables are affected by the phoneme tone which is added to the pronunciation of a sound during a breath. The pronunciation with tone has an impact on the pause detection between syllables and increases the sound duration in each frame step size, which may not be the same for syllables in English if we want to achieve the same performance with the defined entropy measure. This may justify the performances obtained with the TIMIT dataset compared to Fongbe dataset.

TOP- Original signal and its transcription with syllable boundaries of “A xa k w ε a ?” from Fongbe dataset which in English means “Did you count the money ?”, MIDDLE- Curve of change levels of singularity exponents h(t), BOTTOM- The short-term energy E n plotted in red with the distribution of singularity exponents to show the difference in the variations and the additional information provided by the calculation of entropy on energies. This allows to easily find the syllable boundaries which are plotted in black color.

TOP- Original signal and its transcription with syllable boundaries of “ She had your dark suit in greasy wash water all year ” from TIMIT dataset, MIDDLE- Curve of change levels of singularity exponents h(t), BOTTOM- The short-term energy E n plotted in red with the distribution of singularity exponents to show the difference in the variations and the additional information provided by the calculation of entropy on energies. This allows to easily find the syllable boundaries which are plotted in black color.
Our proposed algorithm was compared with four segmentation methods mentioned in the related works using data from TIMIT-Test corpus. A comparison is done with the basic method of Mermelstein which is included in some works as [32] for syllable segmentation whose performances are similar. We also implemented the method of Villing in [13] and a method based on the computation of MFCC features studied in [14]. With the latter, the original signal is cut into short overlapping frames, and for each frame, we computed a feature vector which consists of Mel Frequency Cepstrum Coefficients. The last implemented method for comparison is not dependent on acoustic models or forced alignment, but operates using deep neural network (DNN) for syllable boundary detection. To do this, we have adopted the same process as described in [18] but on windowing length of a syllable. The detected syllable boundaries obtained by each method were compared with the hand labeled reference syllable boundaries to count the number of correct detections, insertion errors, and deletion errors by using the following equations:
-
\(\text {correct detection} = \frac {\text {number of correct detections}}{\text {number of automatically obtained segments}}\)
-
\(\text {insertion error} = \frac {\text {number of insertions}}{\text {number of automatically obtained segments}}\)
-
\(\text {deletion error} = \frac {\text {number of deletions}}{\text {number of reference segments}}\)
We specify that these parameters were calculated by considering the entire of each dataset. Table 3 displays the score rates of each method. It clearly shows that the overall performance according to three criteria is obtained with our proposed algorithm even if the DNN method presents almost the same performance except for insertion errors.
5 Conclusion
In this work, a nonlinear approach for the speech analysis was used for syllable segmentation. We developed an algorithm by using the geometric properties of singularity exponents detailed in [1] to define a measure based on Rényi entropy to improve syllable boundary detection in speech segmentation. Experiments were performed on Fongbe speech dataset and TIMIT dataset. The results showed the improvement in the boundary accuracy with our measure. Based on the performances, it could be concluded that Rényi entropy can be applied to energy distribution and introduced as a measure into speech segmentation using local singularity analysis. We also confirm that our algorithm is simple to implement for automatic speech recognition tasks and is performed with less computational expressions.
Notes
References
Khanagha, V., Daoudi, K., Pont, O., & Yahia, H. (2014). Phonetic segmentation of speech signal using local singularity analysis. Digital Signal Processing, Elsevier, 35, 86–94. doi:10.1016/j.dsp.2014.08.002.
Prasad, V.K., Nagarajan, T., & Murthy, H.A. (2004). Automatic segmentation of continuous speech using minimum phase group delay functions. Speech Communication, 42(34), 429–446. doi:10.1016/j.specom.2003.12.002.
Origlia, A., Cutugno, F., & Galat, V. (2014). Continuous emotion recognition with phonetic syllables. Speech Communication, 57, 155–169. doi:10.1016/j.specom.2013.09.012.
Mermelstein, P. (1957). Automatic segmentation of speech into syllabic units. Journal of the Acoustical Society of America, 58, 880–883.
Zhao, X., & O’Shqughnessy, D. (2008). A new hybrid approach for automatic speech signal segmentation using silence signal detection, energy convex hull, and spectral variation. In Canadian Conference on Electrical and Computer Engineering, IEEE (pp. 145–148).
Pfitzinger, H., Burger, S., & Heid, S. (1996). Syllable detection in read and spontaneous speech. In Proceedings of the Fourth International Conference on Spoken Language (ICSLP), Vol. 2, IEEE (pp. 1261–1264).
Jittiwarangkul, N., Jitapunkul, S., Luksaneeyanavin, S., Ahkuputra, V., & Wutiwiwatchai, C. (1998). Thai syllable segmentation for connected speech based on energy. In The Asia-Pacific Conference on Circuits and Systems, IEEE (pp. 169–172).
Wu, L., Shire, M., Greenberg, S., & Morgan, N. (1997). Integrating syllable boundary information into speech recognition. In Proceedings of International Conference on Acoustics, Speech and Signal Processing, Vol. 2, IEEE (pp. 987–990).
Petrillo, M., & Cutugno, F. (2003). A syllable segmentation algorithm for english and italian. In Proceedings of 8th european conference on speech communication and technology, EUROSPEECH, Geneva (pp. 2913–2916).
Sheikhi, G., & Farshad, A. (2011). Segmentation of speech into syllable units using fuzzy smoothed short term energy contour. In Proceedings of international conference on acoustics, Speech and Signal Processing, IEEE (pp. 195–198).
Pan, F., & Ding, N. (2010). Speech denoising and syllable segmentation based on fractal dimension. In International Conference on Measuring Technology and Mechatronics Automation, IEEE (pp. 433–436).
Obin, N., Lamare, F., & Roebel, A. (2013). Syll-o-matic: an adaptive time-frequency representation for the automatic segmentation of speech into syllables. In International conference on acoustics, Speech and Signal Processing, IEEE (pp. 6699–6703).
Villing, R., Timoney, J., Ward, T., & Costello, J. (2004). Automatic blind syllable segmentation for continuous speech. In Proceedings of the irish signals and systems conference, Belfast, UK (pp. 41–46).
Chou, C.-H., Liu, P.-H., & Cai, B. (2008). On the studies of syllable segmentation and improving mfccs for automatic birdsong recognition. In Asia-Pacific Services Computing Conference, IEEE (pp. 745–750).
Shastri, L., Chang, S., & Greenberg, S. (1999). Syllable detection and segmentation using temporal flow neural networks. In Proceedings of the Fourteenth International Congress of Phonetic Sciences (pp. 1721–1724).
Ching-Tang, H., Mu-Chun, S., Eugene, L., & Chin, H. (1999). A segmentation method for continuous speech utilizing hybrid neuro-fuzzy network. Journal of Information Science and Engineering, 15(4), 615–628.
Makashay, M., Wightman, C., Syrdal, A., & Conkie, A. (2000). Perceptual evaluation of automatic segmentation in text-to-speech synthesis. In Proceedings of the 6th conference of spoken and language processing, Beijing, China.
Vuuren, V.Z., Bosch, L., & Niesler, T. Unconstrained speech segmentation using deep neural networks. In ICPRAM 2015 - Proceedings of the international conference on pattern recognition applications and methods, lisbon, Portugal, Vol. 1.
Demeechai, T., & Makelainen, K. (2001). Recognition of syllables in a tone language. Speech Communication, Elsevier, 33(3), 241–254. doi:10.1016/S0167-6393(00)00017-0.
Khanagha, V., Daoudi, K., Pont, O., & Yahia, H. (2011). Improving text-independent phonetic segmentation based on the microcanonical multiscale formalism. In IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE (pp. 4484–4487).
Fantinato, P.C., Guido, R.C., Chen, S.H., Santos, B.L.S., Vieira, L.S., J, S.B., Rodrigues, L.C., Sanchez, F., Escola, J., Souza, L.M., Maciel, C.D., Scalassara, P.R., & Pereira, J. (2008). A fractal-based approach for speech segmentation. In Tenth IEEE International Symposium on Multimedia, IEEE Computer Society (pp. 551–555).
Kinsner, W., & Grieder, W. (2008). Speech segmentation using multifractal measures and amplification of signal features. In 7th International Conference on Cognitive Informatics, IEEE Computer Society (pp. 351–357).
Hall, T. Encyclopedia of language and linguistics, Elsevier 12.
Pont, O., Turiel, A., & Yahia, H. (2011). An optimized algorithm for the evaluation of local singularity exponents in digital signals. In Combinatorial Image Analysis, Springer Berlin Heidelberg (pp. 346–357).
Turiel, A., & Parga, N. (2000). The multi-fractal structure of contrast changes in natural images: from sharp edges to textures. Neural Computation, 12, 763–793.
Turiel, A., Prez-Vicente, C., & Grazzini, J. (2006). Numerical methods for the estimation of multifractal singularity spectra on sampled data: A comparative study. Journal of Computational Physics, 216(1), 362–390. doi:10.1016/j.jcp.2005.12.004.
Renyi, A. (1961). On measures of entropy and information. In Proceedings of the fourth berkeley symposium on mathematical statistics and probability Vol. 1, University of California Press, Berkeley, Calif (pp. 547–561).
Baraniuk, R., Flandrin, P., Janssen, A., & Michel, O. (2001). Measuring time-frequency information content using the renyi entropies. In IEEE Transactions on Information Theory, Vol. 47, IEEE (pp. 1391–1409).
Boashash, B. Time frequency signal analysis and processing: A comprehensive reference. In Elsevier, Oxford, Elsevier (p. 2003).
Liuni, M., Robel, A., Romito, M., & Rodet, X. (2011). Rényi information measures for spectral change detection. In IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE (pp. 3824–3827).
Rasanen, O., Laine, U., & Altosaar, T. (2009). An improved speech segmentation quality measure: the r-value. In Proceedings of INTERSPEECH (pp. 1851–1854).
Howitt, A. (2002). Vowel landmark detection. Journal of the Acoustical Society of America, 112(5), 2279. doi:10.1121/1.4779139.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Laleye, F.A.A., Ezin, E.C. & Motamed, C. Automatic Text-Independent Syllable Segmentation Using Singularity Exponents And Rényi Entropy. J Sign Process Syst 88, 439–451 (2017). https://doi.org/10.1007/s11265-016-1183-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-016-1183-9