
Abstract
Prospect theory emerged as one of the leading descriptive decision theories that can rationalize a large body of behavioral regularities. The methods for eliciting prospect theory parameters, such as its value function and probability weighting, are invaluable tools in decision analysis. This paper presents a new simple method for eliciting prospect theory’s value function without any auxiliary/simplifying parametric assumptions. The method is applicable both to choice under ambiguity (Knightian uncertainty) and risk (when events are characterized by objective probabilities). Our new elicitation method is implemented in a simple paper-and-pencil experiment (via an iterative multiple price list format). This is one of the first experiments that elicits non-parametric prospect theory’s value function with salient rewards. The collected data generally confirm findings in the existing literature: the value function is S-shaped (concave in the gain domain and convex in the loss domain) though there is a weaker loss aversion on the aggregate level and a substantial heterogeneity in loss aversion on the individual level (41% loss averse, 6% loss neutral and 53% gain seeking).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
First proposed by Bernoulli (1738/1954) to solve the St. Petersburg paradox, expected utility theory became one of the most well-known decision theories. The descriptive validity of expected utility theory was challenged inter alia by the Allais (1953) paradox and the common ratio effect (Kahneman & Tversky, 1979). Several generalizations of expected utility theory, known as non-expected utility theories, were proposed in the literature (cf. Starmer, 2000). Among these generalizations, prospect theory (Kahneman & Tversky, 1979; Tversky & Kahneman, 1992) raised to prominence for its ability to accommodate a large set of behavioral regularities falsifying expected utility theory. Prospect theory is closely related to rank-dependent utility proposed by Quiggin (1981) and to Yaari’s (1987) dual model. By prospect theory, this paper refers to Tversky and Kahneman (1992) version, also known as the cumulative prospect theory. Kahneman and Tversky (1979) version, also known as the original prospect theory, is its special case (when probability weighting is the same for gains and losses) if prospects (acts, lotteries) have (at most) one gain and (at most) one loss, as it is the case in this paper. Tversky and Kahneman (1992) version is also more general in the sense that it applies to ambiguity (Knightian uncertainty) whereas Kahneman and Tversky (1979) version only applies to risk (when events are characterized by objective probabilities).
In prospect theory, the desirability of various outcomes is captured by its value function. The latter is traditionally normalized to zero at a reference point where it is assumed to have a kink reflecting loss aversion. Prospect theory’s value function is a ratio scale—it can be normalized for one outcome other than the reference point. Methods for eliciting prospect theory’s value function are invaluable tools in decision analysis but it has long been a challenging task so that empirical studies often make simplifying assumptions (e.g., Pennings & Smidts, 2003). A major breakthrough is a non-parametric tradeoff method of Wakker and Deneffe (1996) for eliciting prospect theory’s value function either for gains or for losses under ambiguity. Abdellaoui (2000), Bleichrodt and Pinto (2000) and van de Kuilen and Wakker (2011) extend this method to measuring probability weighting in choice under risk and Abdellaoui et al. (2005)—under ambiguity.
Abdellaoui et al. (2007) propose the first non-parametric method for eliciting prospect theory’s value function both for gains and losses in choice under risk. Their method is a four-step procedure. First, the method of Abdellaoui (2000) is used for eliciting two probabilities with decision weights one half (in gain and loss domains). Second, prospect theory’s value function for losses is elicited by the midpoint method. Third, one gain is elicited that has the same utility (in absolute value) as one of the losses with a known utility (elicited in the previous step). Fourth, the value function for gains is elicited by the midpoint method.
Abdellaoui et al. (2016) propose the first non-parametric method for eliciting prospect theory’s value function both for gains and losses in choice under ambiguity. Their method is a three-step procedure. First, similar to the third step in the elicitation method of Abdellaoui et al. (2007), a decision analyst elicits one gain and one loss that have the same utility in absolute value. Second, the value function for gains is elicited by the tradeoff method of Wakker and Deneffe (1996). Third, the value function for losses is elicited by the same method.
This paper presents a simpler method for eliciting prospect theory’s value function under ambiguity. We simplify elicitation questions, which has practical advantages for a decision analyst and it might reduce the propagation of errors (cf. Blavatskyy, 2006).
The rest of the paper is organized as follows. Section 2 presents our mathematical notation. Section 3 presents our elicitation method. Section 4 describes an experimental design for this elicitation method. Section 5 summarizes how this experiment was implemented. Section 6 presents experimental results. Section 7 concludes.
2 Mathematical notation
Let x0 denote an outcome that is a reference point. The value function of prospect theory is traditionally normalized to zero at the reference point, i.e., v(x0) = 0. Outcomes more desirable than x0 are gains numbered with positive integers: x1, x2, and so on. Outcomes less desirable than x0 are losses numbered with negative integers: x−1, x−2, and so on.
Let E denote any non-null event that can be measured with objective probability (e.g., heads come up on a toss of a fair coin) or not (e.g., a stock market closes in the red). This paper considers only binary prospects that have (at most) one gain and (at most) one loss. Gains (losses) are always conditional on event E being true (false). Notation aEb denotes a binary prospect that yields a (which can be a gain or a reference point x0) if event E is true and b (which can be a loss or a reference point x0) otherwise. For simplicity, a degenerate prospect that yields x0 with certainty is denoted as x0 rather than x0Ex0.
A decision-maker has a preference relation ≽ over binary prospects. As usual, the symmetric part of ≽ is denoted by ∼ and the asymmetric part of ≽ is denoted by ≻. The preference relation ≽ is represented by prospect theory’s utility function that has an additively-separable form: U(aEb) = v(a)*w+ + v(b)*w-, where v(.) is the value function and w+ and w- are weights for gains conditional on E being true and losses conditional on E being false correspondingly. The aim of the paper is to elicit value function v(.) from observed decisions.
For binary prospects that are considered in this paper, the special case when w- = 1 − w+ is known as biseparable preferences (Ghirardato and Marinacci, 2001)—a broad class of preferences that includes inter alia subjective expected utility theory (Savage, 1954), Choquet expected utility (Schmeidler, 1989), multiple priors or maxmin expected utility (Gilboa & Schmeidler, 1989) and α-maxmin theory (Ghirardato et al., 2004). In addition, if event E is measurable with objective probabilities, this class of preferences also includes many theories of decision-making under risk: expected utility theory, disappointment aversion theory (Gul, 1991), rank-dependent utility (Quiggin, 1981) and expected utility—mean absolute semideviation approach (Blavatskyy, 2010). Thus, our elicitation method can be used equally well when preferences are captured by one of the above-mentioned theories.
3 Elicitation method
A decision analyst first chooses one non-null event E and one gain x1 that serves as the unit of measurement. This is the only degree of freedom available to the decision analyst (all other outcomes are elicited from a decision-maker). The decision analyst could alternatively start by picking one loss x−1 as the unit of measurement. In this case, the method described below remains the same except that it is a gain x1 rather than a loss x−1 which is elicited in the first step.
Step 1 The decision analyst elicits a loss x−1 such that a decision-maker is indifferent between accepting and rejecting a mixed prospect x1Ex−1, i.e., the certainty equivalent of x1Ex−1 is x0. According to prospect theory, indifference x1Ex−1 ∼ x0 implies Eq. (1).
Step 2 The decision analyst elicits a gain x2 such that the decision-maker is indifferent between an ambiguous gain x1Ex0 and a mixed prospect x2Ex−1. According to prospect theory, indifference x1Ex0 ∼ x2Ex−1 implies Eq. (2).
Adding Eqs. (1) and (2) together immediately yields v(x2) = 2v(x1).Footnote 1
Step 3 The decision analyst elicits a loss x−2 such that the decision-maker is indifferent between an ambiguous loss x0Ex−1 and a mixed prospect x1Ex−2. According to prospect theory, indifference x0Ex−1 ∼ x1Ex−2 implies Eq. (3).
Adding Eqs. (1) and (3) together immediately yields v(x−2) = 2v(x−1).Footnote 2 Steps 2 and 3 can be also interchanged—a decision analyst can first elicit a loss x−2 and then—a gain x2.
The decision analyst then repeats step 2 as many times as necessary by replacing gain x1 with gains x2, x3, etc. and by replacing gain x2 with gains x3, x4, etc. Similarly, the analyst repeats step 3 as many times as necessary by replacing loss x−1 with losses x−2, x−3 etc. and by replacing loss x−2 with losses x−3, x-4 etc. It follows by induction that v(xn) = n*v(x1) and \(v\left( {x_{ - n} } \right) \, = n*v\left( {x_{{ - 1}} } \right)\quad {\text{for}}\quad n \in \left\{ {{3},{ 4}, \, \ldots } \right\}\).
Before-last step The decision analyst elicits the certainty equivalents y1, y2, etc. of ambiguous gains x1Ex0, x2Ex0, etc. According to prospect theory, indifference xnEx0 ∼ yn implies Eq. (4) for n ∊ {1, 2, …}.
Last step The decision analyst elicits the certainty equivalents y−1, y−2, etc. of ambiguous losses x0Ex−1, x0Ex−2, etc. According to prospect theory, indifference x0Ex−n ∼ y−n implies Eq. (5) for n ∊ {1, 2, …}.
Since the value function of prospect theory is a ratio scale, without the loss of generality, we can divide all values by non-zero constant v(x1)*w+ to obtain a normalized value function: v(yn) = n and v(y−n) = − n for all n ∊ {1, 2, …}.
Notice that the before-last step and the last step are not required if event E happens to be such that w+ = w-.Footnote 3 This can be verified by eliciting only two certainty equivalents y1 and y−1 and subsequently checking whether a decision-maker is indifferent between accepting and rejecting a mixed prospect y1Ey−1, i.e., whether the certainty equivalent of y1Ey−1 is x0. If this happens to be the case, then the sequence {… x−2, x−1, 0, x1, x2, …} is already a standard sequence of outcomes equally spaced in utils v(x1). As before, a normalized value function can be subsequently obtained by dividing all values by v(x1).
4 Experimental design
The elicitation method detailed in the previous Sect. 2 can be designed as a simple paper-and-pencil experiment. In each step of the elicitation method, a decision-maker is asked to answer several binary choice questions in a format that is similar to the multiple price list task of Holt and Laury (2002). After completing all steps, one question number is drawn at random and the corresponding binary choice question is played out with real monetary rewards—the decision-maker is rewarded with his chosen option (known as the random lottery incentive scheme). Figure 1 shows an example for the first step (common to all subjects) with x0 = €0, x1 = €10 and event E being “heads come up on a toss of a coin”.

The first step of elicitation procedure as the multiple price list task
In each binary choice question, a decision-maker can choose one of the two choice options or declare indifference (similar as in Hey & Orme, 1994). If the question where the decision-maker reveals indifference is randomly selected for payment at the end of the experiment, an experimenter can choose any of the two choice options for payment.
A decision-maker can reveal several possible choice patterns in binary choice questions belonging to the same elicitation step. In the conventional case, a decision-maker chooses option A in the top questions, reveals indifference in one of the middle questions and chooses option B in the remaining bottom questions. In this simplest case, the elicited outcome is inferred from the question where the decision-maker declares indifference. Another classic case is when a decision-maker chooses option A in the top questions and chooses option B in the remaining bottom questions (without revealing indifference in any of the middle questions). In this case, the elicited outcome is taken as the average of the two outcomes in questions where the decision-maker switches from A to B. For example, if a decision-maker chooses A in the first six questions presented on Fig. 1 and B—in the remaining five questions then the elicited outcome is x−1 = − €4.5.
If a decision-maker chooses option A in the top questions, reveals indifference in several of the middle questions and chooses option B in the remaining bottom questions, then the elicited outcome is taken as the average of the outcomes in questions where the decision-maker reveals indifference (possibly reflecting imprecision and/or noisy preferences cf. Butler & Loomes, 2007, 2011). A decision-maker who switches several times between A and B within the same list of questions violates either the state-wise dominance or transitivity. Such preferences do not admit prospect theory representation and the elicitation procedure stops (is not implementable for decision-theoretical reasons). The last possibility is that a decision-maker never switches from A to B, i.e., chooses either A or B in all questions. In this case, an elicited outcome is outside the range of losses/gains that are feasible in an experiment and elicitation procedure stops as well (is not implementable due to moral/budgetary constraints).
Once a decision-maker completes all questions belonging to the same elicitation step, she hands in her answer page to an experimenter and receives one of the pre-printed pages with questions for the next elicitation step (an experimenter has a set of pages corresponding to each possible outcome that might be elicited in the previous step). Thus, a decision-maker effectively faces an iterative multiple price list format. For example, if a decision-maker chooses A in the first six questions presented on Fig. 1 and B—in the remaining four questions then the elicited outcome is x−1 = − €4.5 and she receives the list of questions presented on Fig. 2 in the second step of the elicitation procedure. A decision-maker who chooses A in the first six questions presented on Fig. 1, reveals indifference in the seventh question and chooses B—in the remaining four questions (so that the elicited outcome is x−1 = − €4) receives the same list of questions as presented on Fig. 2 with €4.5 replaced by €4.

The second step of elicitation procedure as the multiple price list task
5 Experimental implementation
The experiment is implemented as a field paper-and-pencil experiment. We set x0 = €0, x1 = €10 and elicit two losses (x−1 and x−2) and one gain x2 as well as four corresponding certainty equivalents (y−1, y−2, y1 and y2), a total of seven multiple price lists. We limit the standard sequence of outcomes to only five elements (two losses, two gains and the reference point) because a pilot experiment showed that a longer sequence frequently involves losses of €20 or more, which we did not find morally acceptable.
The subject pool consists of 40 farmers from villages around the city of L’viv in western Ukraine (average age 43 years, 32.5% female). In addition to seven multiple price list tasks analyzed in this paper, the subjects were also asked to complete three decision problems framed as farming tasks that are analyzed elsewhere. In these problems, the subjects could earn either €20, or €30 or €40. These gains were used to offset any possible losses from the subsequent elicitation procedure. We used coin flipping for event E because one of the most popular TV shows in Ukraine turns out to be “Heads or Tails” so that all subjects were at ease with outcomes conditional on a toss of a fair coin. At the end of the experiment, the subjects were encouraged to use their own coin and to perform the coin toss if necessary for determining their winnings.
The experiment was conducted in individual sessions. Every subject first received the multiple price list task presented on Fig. 1 (translated into Ukrainian with all outcomes multiplied by 30 and € changed into the local currency UAH). Once this task was completed, the subject received the next multiple price list task corresponding to the outcome inferred from the completed task. This was repeated for all seven multiple price lists. At the end of the experiment, each subject was asked to draw one-numbered ticket from a closed bag. The corresponding binary choice question was then played out for payment. If the subject opted for a sure gain in this question, she just received this gain. If the subject opted for a sure loss in this question, this loss was subtracted from her winnings in the “farming” tasks. If the subject opted for a risky lottery, a coin toss was performed (nearly always by the subject herself with her own coin) and the subject received the corresponding state-dependent outcome.
6 Experimental results
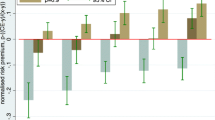
Two subjects revealed multiple switching points within the same multiple price list, i.e. their preferences are not represented by prospect theory. Another four subjects revealed no switching point in one of the multiple price list.Footnote 4 This leaves us with 34 subjects for whom we were able to elicit a standard sequence of five outcomes {y−2, y−1, 0, y1, y2} presented in Table 1 in the Appendix.Footnote 5 The median elicited standard sequence is {− 5.25, − 2.25, 0, 3, 6.5} and the corresponding median value function is presented on Fig. 3. It is slightly concave in the gain domain, slightly convex in the loss domain and slightly steeper at the reference point for losses compared to gains, as described by Kahneman and Tversky (1979).

Median elicited value function
At the individual level, 28 out of 34 subjects (82%) reveal a concave value function in the gain domain (y2 > 2y1), four out of 34 subjects (12%) reveal a linear value function in the gain domain (y2 = 2y1) and two out of 34 subjects (6%) reveal a convex value function in the gain domain (y2 < 2y1). In the loss domain, 32 out of 34 subjects (94%) reveal a convex value function (y−2 < 2y−1), one out of 34 subjects (3%) reveals a linear value function (y−2 = 2y−1) and one out of 34 subjects (3%) reveals a convex value function in the gain domain (y−2 > 2y−1).
Twenty-six out of 34 subjects (76%) reveal a concave value function in the gain domain and a convex value function in the loss domain. Thus, both on the individual and the aggregate level the value function exhibits diminishing sensitivity.
Even though the elicited value function is clearly S-shaped for an overwhelming majority of subjects, the observed utility curvature is relatively modest. This can be attributed either to small outcomes used in our experiment or salient rewards (or both). Wakker and Deneffe (1996) also report relatively modest utility curvature over small outcomes. Blavatskyy et al. (2020) in a recent large meta-study of 9152 observations of the classic Allais (1953) paradox find that subjects are more likely to violate expected utility when outcomes are large and hypothetical.
There are several measures of loss aversion proposed in the literature e.g., Kahneman and Tversky (1979), Wakker and Tversky (1993, pp. 164–165), Köbberling and Wakker (2005), Blavatskyy (2011). Unfortunately, none of them are directly applicable to a non-parametric value function defined on a standard sequence of outcomes (as in this paper). Abdellaoui et al. (2016, Sect. 4.3.2) proposed to measure loss aversion with an index − y1/y−1 in such case (loss aversion corresponding to this index values greater than one).
In our data set, 14 out of 34 subjects (41%) reveal loss aversion (− y1/y−1 > 1), two out of 34 subjects (6%) reveal loss neutrality (− y1/y−1 = 1) and 18 out of 34 subjects (53%) reveal gain seeking (− y1/y−1 < 1). The median loss aversion index − y1/y−1 among loss averse subjects is 2.58 and among gain seeking subjects—0.8. Thus, loss averse subjects have a relatively steeper value function for losses than for gains whereas gain seeking subjects have a value function that is nearly as steep for losses as for gains. This explains our finding that while slightly more than one half of all subjects reveal no loss aversion, the median value function depicted on Fig. 3 is nonetheless steeper for losses than for gains (with index − y1/y−1 = 1.34). This finding is also reflected in the fact that the mean loss aversion index − y1/y−1 in the collected data is 1.55 while the median loss aversion index is only 0.90. For comparison, Abdellaoui et al. (2016, Table 4) report a higher median value of − y1/y−1 = 1.88 (for a comparable experiment with drawing a ball from an urn with five red and five black balls).
For all subjects, outcome y1 is the certainty equivalent of a risky lottery that yields €10 with probability 0.5 (since we used a toss of a fair coin). Thus, all subjects can be also classified as risk-averse (y1 < 5), risk-neutral (y1 = 5) or risk seeking/loving (y1 > 5). All, but one subject, (97%) are found to be risk-averse (with one subject being risk-neutral). Under expected utility theory, such risk-aversion is equivalent to the concavity of utility function. Under generalized non-expected utility theories, such as prospect theory, risk-aversion can be driven both by the concavity of a value function in the gain domain and underweighting of probability 0.5 (for gains). Indeed, our elicitation method shows that only 28 out of 34 subjects (82%) reveal a concave value function in the gain domain. Thus, relying on a simple risk-aversion test (via elicitation of certainty equivalents) overestimates the number of subjects with a concave value function when some subjects weight probabilities in a non-linear manner.
7 Conclusion
This paper presents a simple non-parametric method for eliciting prospect theory’s value function under ambiguity or risk. The method is implemented as a simple paper-and-pencil field experiment with a subject pool that is not accustomed to a computerized interface. This is one of the first experiments that elicits non-parametric prospect theory’s value function with salient rewards. The value function elicited with a new method generally confirms the results from the existing literature except for loss aversion (a significant individual heterogeneity in loss aversion and a lower loss aversion on the aggregate level are observed in the data).
The main methodological contribution of the paper is to extend the toolbox of decision analysis with a new method how to elicit a subjective utility function when event weights of a decision-maker are unknown and possibly sign-dependent (different for gains and losses) without making any parametric assumptions. The method relies on a series of indifferences between an ambiguous gain (or an ambiguous loss) and a mixed binary prospect as well as on the elicitation of certainty equivalents for ambiguous gains and losses. The existing methods, such as Abdellaoui et al. (2016), based on the tradeoff method of Wakker and Deneffe (1996) typically rely on indifferences between two mixed binary prospects. Comparing two mixed prospects is arguably a more cognitively demanding task than comparing one mixed prospect and an ambiguous gain (or an ambiguous loss). When faced with a more cognitively demanding task of comparing two mixed prospects, a decision-maker may adopt some simple heuristics, such as compensating the difference in gains with the same difference in losses, which would bias the elicitation method in the direction of a linear utility [see also a related discussion in Abdellaoui et al. (2016, Sect. 6)]. For eliciting utility function over five points, our proposed method involves seven elicitation questions as does the method of Abdellaoui et al. (2016). For eliciting utility function over more than five points, our proposed method requires more elicitation questions compared to the method of Abdellaoui et al. (2016).
The paper also contributes to the toolbox of experimental economics. It provides a new experimental design for eliciting subjective non-parametric utility function with salient incentives. This, in itself, highlights an important methodological challenge that does not appear to have been previously acknowledged in the literature. A sequence of chained elicitation questions, such as an iterative multiple price list format, used in this paper can quickly confront subjects with substantial losses that cannot be properly incentivized. The experimental design presented in this paper circumnavigates this problem by eliciting a short sequence of only five standard outcomes. This is obviously an unsatisfactory solution which highlights the need for new experimental methods of implementing large losses with salient incentives. Additionally, chained elicitation questions might not be incentive compatible if subjects learn to behave strategically and misreport their true preferences in initial stages.
Last but not least, the paper collects a new data set of non-parametric utility functions that are robust to non-linear weights, possibly different for gains and losses. There are numerous data sets for estimating parametric utility functions but such estimates are difficult to compare across studies because different studies use different functional forms and different econometric models of probabilistic choice. The majority of subjects in our data set have an S-shaped value function (concave for gains and convex for losses) but there is a lot of individual heterogeneity in terms of loss aversion.
Notes
Note that weight w+ cannot be zero because event E is non-null.
Note that weight w− cannot be zero because event E is non-null.
For example, Gaechter et al. (2007) make a simplifying assumption that probability weights are the same for gains and losses.
In all four cases, the second loss x−2 must have been less than − €20 which would have endangered these subjects with the possibility of real losses not offset by earnings in the “farming” part of the experiment.
All outcomes in the paper are reported in Euros, we used a market exchange rate 30:1 between UAH and EUR; the PPP exchange rate for January 2020 is not yet know but it has been close to 10:1 in 2018 (the latest year for which the statistics is currently available).
References
Abdellaoui, M. (2000). Parameter-free elicitation of utility and probability weighting functions. Management Science, 46, 1497–1512.
Abdellaoui, M., Bleichrodt, H., l’Haridon, O., & van Dolder, D. (2016). Measuring loss aversion under ambiguity: a method to make prospect theory completely observable. Journal of Risk and Uncertainty, 52(1), 1–20.
Abdellaoui, M., Bleichrodt, H., & Paraschiv, C. (2007). Measuring loss aversion under prospect theory: a parameter-free approach. Management Science, 53, 1659–1674.
Abdellaoui, M., Vossmann, F., & Weber, M. (2005). Choice-based elicitation and decomposition of decision weights for gains and losses under uncertainty. Management Science, 51, 1384–1399.
Allais, M. (1953). Le Comportement de l’Homme Rationnel devant le Risque: critique des postulates et Axiomes de l’Ecole Américaine. Econometrica, 21, 503–546.
Bernoulli, D. (1738). Specimen theoriae novae de mensura sortis” Commentarii Academiae Scientiarum Imperialis Petropolitanae; translated in Bernoulli, D., (1954) “Exposition of a new theory on the measurement of risk” Econometrica 22, 23–36
Blavatskyy, P. (2006). Error propagation in the elicitation of utility and probability weighting functions. Theory and Decision, 60, 315–334.
Blavatskyy, P. (2010). Modifying the mean-variance approach to avoid violations of stochastic dominance. Management Science, 56(11), 2050–2057.
Blavatskyy, P. (2011). Loss aversion. Economic Theory, 46, 127–148.
Blavatskyy, P., Andreas, O., Valentyn, P., (2020) “Now you see it, now you don’t: how to make the Allais paradox appear, disappear, or reverse” American Economic Journal: Microeconomics, forthcoming
Bleichrodt, H., & Pinto, J. L. (2000). A parameter-free elicitation of the probability weighting function in medical decision analysis. Management Science, 46, 1485–1496.
Butler, D., & Loomes, G. (2007). Imprecision as an account of the preference reversal phenomenon. American Economic Review, 97(1), 277–297.
Butler, D., & Loomes, G. (2011). Imprecision as an account of violations of independence and betweenness. Journal of Economic Behavior and Organization, 80, 511–522.
Gaechter, S., Johnson, E. J., Herrmann, A. (2007). Individual-level loss aversion in risky and riskless choice. IZA Discussion Paper No. 2961
Ghirardato, P., Maccheroni, F., & Marinacci, M. (2004). Differentiating ambiguity and ambiguity attitude. Journal of Economic Theory, 118, 133–173.
Ghirardato, P., & Massimo, M. (2001). Risk, ambiguity, and the separation of utility and beliefs. Mathematics of Operations Research, 26(4), 864–890.
Gilboa, I., & Schmeidler, D. (1989). Maxmin expected utility with a non-unique prior. Journal of Mathematical Economics, 18, 141–153.
Gul, F. (1991). A theory of disappointment aversion. Econometrica, 59(3), 667–686.
Hey, J. D., & Orme, C. (1994). Investigating generalizations of expected utility-theory using experimental data. Econometrica, 62(6), 1291–1326.
Holt, C. A., & Laury, S. K. (2002). Risk aversion and incentive effects. American Economic Review, 92(5), 1644–1655.
Kahneman, D., & Tversky, A. (1979). Prospect theory: an analysis of decision under risk. Econometrica, 47(2), 263–292.
Köbberling, V., & Wakker, P. P. (2005). An index of loss aversion. Journal of Economic Theory, 122, 119–131.
Krantz, D.H., Luce, R. D., Suppes, P., Tversky, A. (1971). Foundations of Measurement, Vol. 1 (Additive and Polynomial Representations). Academic Press
Pennings, J. M. E., & Smidts, A. (2003). The shape of utility functions and organizational behavior. Management Science, 49, 1251–1263.
Quiggin, J. (1981). Risk perception and the analysis of risk attitudes. Australian Journal of Agricultural Economics, 25(2), 160–169.
Savage, L. J. (1954). The foundations of statistics. . Wiley.
Schmeidler, D. (1989). Subjective probability and expected utility without additivity. Econometrica, 57(3), 571–587.
Starmer, C. (2000). Developments in non-expected utility theory: the hunt for a descriptive theory of choice under risk. Journal of Economic Literature, 38(2), 332–382.
Tversky, A., & Kahneman, D. (1992). Advances in prospect theory: cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5, 297–323.
Van de Kuilen, G., & Wakker, P. P. (2011). The midweight method to measure attitudes toward risk and ambiguity. Management Science, 57(3), 582–598.
Wakker, P. P., & Deneffe, D. (1996). Eliciting von Neumann-Morgenstern utilities when probabilities are distorted or unknown. Management Science, 42, 1131–1150.
Wakker, P. P., & Tversky, A. (1993). An axiomatization of cumulative prospect theory. Journal of Risk and Uncertainty, 7, 147–176.
Yaari, M. (1987). The dual theory of choice under risk. Econometrica, 55, 95–115.
Funding
Pavlo Blavatskyy is a member of the Entrepreneurship and Innovation Chair, which is part of LabEx Entrepreneurship (University of Montpellier, France) and funded by the French government (Labex Entreprendre, ANR-10-Labex-11-01).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Rights and permissions
About this article

Cite this article
Blavatskyy, P. A simple non-parametric method for eliciting prospect theory's value function and measuring loss aversion under risk and ambiguity. Theory Decis 91, 403–416 (2021). https://doi.org/10.1007/s11238-021-09811-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11238-021-09811-6