
Abstract
Smart services are a concept that provides services to the citizens in an efficient manner. The online shopping and recommender system can play an important role for smart cities in providing relevant item recommendations to the users. One of the famous Recommendation System strategies is known as Collaborative Filtering and provides popular suggestions to the users. The recommendation is generated by identifying a set of similar users from a user-item rating matrix using a similarity measure. The problem with the majority of the recommender systems is whether the generated recommendations are good enough because users usually find recommendations from their circle more appealing. It is important to use only those similar users that have some kind of trust among them. The accuracy of the recommendations also gets affected due to the sparsity of the user-item matrix. To handle these problems, a trust-based technique TrustASVD++ is proposed, which combines a user’s trust data in the Matrix Factorization context. The proposed method combines trust values with user ratings for improved recommendations using Pearson Correlation Coefficient (PCC). PCC is compared with other state-of-the-art similarity measures, and the results obtained show that PCC outperforms all the other relevant measures. To assess the efficiency of the offered strategy, testing on numerous datasets has been carried out including Epinions, FilmTrust, and Ciao. The results illustrate the considerable improvement of the proposed method over numerous contemporary techniques.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recommendation systems have been widely used to provide customized suggestions to users from a large catalog of items. RS is still considered an emerging research field because of the fundamental necessity of useful applications to enable clients to locate their required items from huge sets of accessible items or products. Recommender systems have been effectively applied in numerous applications in providing useful suggestions, such as books [1], music [2], Business to business products [3], media transmission items [4], the travel industry administration [5], and commentator/master [6]. The primary motivation behind an RS is to plan productive methods for increasing consumer satisfaction. CF has always been considered a compelling and suitable technique in contrast with the other techniques used in RS. Collaborative filtering employs both clear and implied criticism specified by the users to a set of items to produce recommendations. This strategy investigates a measure of client inclinations to anticipate their preferences. One of the noteworthy factors for utilizing CF is its adequacy in recommending the related things without taking into consideration the real consequences. The current CF strategies, for the most part, experience the issues of sparse information and new users/items, which affects their performance. The sparse data issue arises due to the non-availability of the available ratings set by the users. On the other hand, the cold-start issue is faced when limited ratings are available for items. The corresponding issues arise when a user has given a rating to very few items, and the rating matrix is sparse with many of the missing values. Hence, the principle undertaking of a CF-based recommender system is to productively assess, omitted rating values by utilizing accessible ratings. CF filtering strategies are sorted into memory-based and model-based techniques.
The objective of memory-dependent techniques is to utilize the accessible ratings of comparative clients as a clear response in the recommendation process. Then again, model-based techniques try to acquire a propagative paradigm from the rating matrix. On the other hand, model-dependent techniques can also yield dependable outcomes contrasted with memory-based techniques and are considered progressively prevalent [7]. Nevertheless, model-based techniques have an extraordinary ability to depict the attributes of the user-item information, which is fairly simple to accomplish. To handle the cold-start issue, numerous researchers have utilized social trust data in the recommendation procedure [8,9,10]. These techniques depend on the supposition that when two clients trust one another, they, for the most part, have comparable tastes. Also, taking into consideration the trust data in the recommendation process enhances the reliability of outcomes [11, 12]. RS helps the user when there is a state where a user interacts with a large number of the set of items which can be movies on Netflix, music on Pandora, products at Amazon and can be news items on google news. Users can either search a specific item from the catalog but is unaware of many items which may be related and can be useful to the user. The RS takes into consideration the information shared by the user, and then recommends certain related items which are most relevant to the user's interest. Facebook, Twitter, Netflix, LinkedIn, and many other social applications are using RS to provide a more personalized environment to the users. More specifically, RS provides considerable recommendations to the users for the items/things that may be liked by them in future.
CF-based approach recommends items based on a community or a group of people. CF finds a couple of people having more similarities with the target user and then suggests things based on the similarity values. CF-based techniques are considered better than content-based filtering, in which the things/movies that are recommended to the active user do not acquire information from the whole user database. One of the earlier CF-based techniques which rely on nearest neighbors provides reliable recommendations to some extent but still has drawbacks due to cold-start users/items and sparse data issues. The recommendations provided by the CF-based filtering provide recommendations to active users based on similar users and which are taken from the dataset. However, the recommendations provided by the CF may be accurate but not necessarily reliable. This means active users prefer recommendations that consider similar users from their circle, and they trust them. To counter this, a trust-based recommender system uses trust data for giving recommendations and is emerging as a new and enhanced way of suggesting items to users. The trust-based recommender systems have better performance than the CB-based approach that depends only on user and item similarity. In this research work, a trust-based recommendation method TrustASVD++ is proposed. This method considers both the trust and rating data to effectively provide recommendations to users. In the first stage, matrix factorization is used to handle the problems of sparse data and cold-start users. In the second stage, trust data and rating data are used to find similar users. PCC is used as a similarity metric. Lastly, based on similar users, recommendations are made to the target user. The proposed work has the following contributions:
-
We propose an efficient trust-based recommender system to provide more accurate and reliable recommendations
-
We propose a matrix factorization-based approach to handle sparsity issue in the recommender system
The rest of the sections are organized as follows: related work is explained in Sect. 2, methodology is presented in Sect. 3 while results are explained in Sect. 4 followed by the conclusion.
2 Related work
A detailed overview of recommender systems is given in [13] and [14]. Generally, Recommender Systems are classified into three broad categories which are Content Based (CB), Collaborative filtering (CF) based, deep learning-based methods [15,16,17,18], and hybrid methods. CB recommenders look to prescribe things like recently acquired ones. Chaney et al. [19] proposed an SPF (Social Poisson Factorization) method. The proposed technique is based on the POISSON factorization model that considers the implicit user data. User preferences and influences are deduced from the surveyed data containing click history by the users. Moradi et al. [20] designed a novel-graph-based clustering that is comprised of three stages. In the first one, the problem is shown using a diagram, then similar items are grouped into several clusters. Thirdly, a rating is predicted for an unseen item, and top items are being recommended to the active user. Wu et al. [21] proposed a method focusing on incorporating information from multiple sources i.e., item contents, user feedback, etc., to improve the recommendation process and to predict ratings of items. Salah et al. [22] came up with a CF-based technique that aims at reducing the computational cost while providing high-quality recommendations. To handle repeated changes in data, stepwise updates are built that effectively handle the new user’s appearance and the updates of existing ratings. Gohari et al. [23] suggested a technique that is based on confidence, that only focuses on the opinions of a certain user but it also takes into consideration the certainty of the opinions. Four confidence models were taken into account that calculates user's and item's confidence values. Recommender framework was proposed as an approach to find answers for the issue of data overload in communal life and an RS calculation to deliver a customized suggestion for clients dependent on their practices [24]. By taking into consideration the personal interests of the user and their preference, the system proposed in [25] maps the news articles concerning the user’s location and provides recommendations. The collaborative filtering techniques are combined with demographic filtering to overcome issues of sparse information, cold-start, and over adaptation [26]. Movies are recommended to the user based on the type of genre while also considering user preferences. Through analyzing rules of decision paths, the proposed approach allows for deciding whether certain items should be recommended to the user or not [27].
Conventional recommender systems take into consideration only the rating values, and thus, it is difficult to give an accurate recommendation. One basic and viable solution to deal with this issue is to put extra data sources into consideration, for example, user’s profiles and data of user’s friends on communal networks. Clients may have their IDs, skills, personal history, level of information, and convictions. Despite that, data from the trusted friends of users are also acquired for the recommendation process. Consequently, utilizing the trust data in the recommendation procedure appears to enhance the reliability of output [28]. Besides this, numerous scholars have utilized trust data in the recommendation procedure. In [29], a proficient MF method known as RSTE is proposed which considers trust data to suggest items/movies. SocialRec is a method proposed in [29] which utilized a latent factor space to relate rating values and trust data. TrustMF is another technique that uses both the trustor and trustee data in its procedure. A similar approach TrustSVD is suggested in [11] that incorporates the implicit and explicit trusts to diminish the sparse data issue. In [30], the social context data of users were merged into an integrated MF model. In [31], two communal normalization terms are illustrated to feasibly combine friendship information in the simulation.
In [12], a method called socialMF is brought forward combining trust reproduction in a communal network to build the inclination of a user which was near to the inclination of his/her communal network. The authors ponder this belief by providing the meaning of normalization terms and the writers consider this supposition by giving the meaning of regularization terms and regarded them in a matrix factorization framework. In [9] authors came up with an RS strategy that creates a diagram from implicit and explicit trust data and assembles the users into comparable sets by utilizing a network recognition technique. Yang et al. [11] proposed a methodology that contains a TrustMF model (a combination of the trustor and trustee model). After performing a couple of validations on four datasets, results reveal that the TrustMF model has better performance than existing collaborative filtering methods. It performed well for especially the cold-start users having few ratings. Gou et al. [12] came up with a trust-based MF technique to overcome the problems of cold-start users and data sparsity. This technique takes into account the trust and rating values of users. Social trust information analysis is done on four datasets that elaborate on the fact that both the rating and trust values are compatible with each other and equally important for getting accuracy in the recommendation process. Experimental results revealed that the technique outperforms existing methods. Mei et al. came up with a method in which the association and irregularity between liveliness and dependability are studied to survey the rating and trust behavior in terms of RS. Particularly, association and irregularity are considered as types of impact in a trusted environment where each link represents a trust affiliation. Cui et al. [32] proposed a trust-based technique for videos that provided recommendations using a combination of two models i.e., user finding model and video finding model. In the former model, the value of trust [33] is calculated for the targeted user. In the latter model, trust for the videos was calculated consisting of video activity and video rating. Wang et al. [34] proposed a recommendation technique that is created based on a trust-based recommender paradigm for communal networks. The product ratings were used to find the similarity among users. Existing similarity among users was used to find transition probability. Besides, the cold-start problem was reduced using the user’s latent factor. Moardi et al. [34] proposed a Reliability-Based Trust Aware Collaborative Filtering (RTCF) approach. For an unrated item, the rate value was predicted using a specific trust network. Lee et al. [35] proposed a hybrid approach that merged social trust and user preferences to enhance collaborative-based recommendations. Social trust means implicit and explicit trust relationships among users. Faridani et al. [36] proposed a technique named Effective Trust where active users directly or explicitly specified the trusted neighbors, to enhance recommendations and to overcome problems of new users and sparse data. Ma et al. [37] proposed a technique named ARMOR, which incorporates users to trust relationships and social features to design a friend recommendation mechanism. Tian et al. [38] came up with a method to provide customized web recommendations. The proposed algorithm created the trust relationship that was based on the user’s experience and typifies it by the trust’s level. By considering, the features such as the background of a user’s interest, recommendation outcome, assessment inclination of the user, the validation of trust connection were recognized. Based on trust connections, a customized recommendation method known as PSRTR was suggested.
3 Proposed method
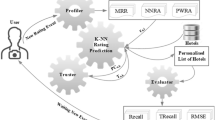
In this section, we have proposed a new technique, called TrustASVD++ which effectively performs recommendations by integrating trust data in its procedure. The proposed algorithm is based on the ASVD++ algorithm that uses matrix factorization to remove sparsity to improve accuracy. The flow diagram of the offered method is elaborated in Fig. 1. In step 1, sparse data and cold-start users or items issues are handled using the ASVD++ algorithm. In further steps, the similarity is calculated, and the trusted network is created based on trust data. After that, top N similar users are selected, and recommendations are made for the target user based on the similarity values.

Flow diagram of proposed method
3.1 Similarity calculation
Usually, a similarity metric is utilized to give ranking to users which are based on the similarity values to the target user. After that, similar users are selected to be utilized in the recommendation process. Many similarity measurements are used in literature but most of them face limitations while dealing with missing data. This is because they just rely on rating data without utilizing any of the extra information means, for example, trust data or rating perspective. Given a user U and an item I, a rank-f calculation is processed with components \(A = (a_{u,i} )\) ϵ \(C^{\left| U \right| \times f}\) and \(B = (b_{u,i} )\) ϵ \(C^{\left| U \right| \times f}\) with the end goal that \(C \approx AB^{T}\), and \(||C \approx AB^{T} ||_{f}^{2}\) is limited. Here, \(C = (c_{u,i} )\) is the rating matrix, entry \(c_{u,i}\) indicates user u's an inclination on item I, and \(f \ll \min \left( {\left| U \right|,\left| I \right|} \right)\) is the number of latent variables. The reason for the calculation is to appraise \(\hat{c}_{u,i}\) given by \(\hat{c}_{u,i} = \sum_{k = 1}^{f} A_{u,k } B_{i,k}\), in which the summation of mistakes between the calculation matrix Ĉ = (\(\hat{c}_{u,i}\)), and C is to be least. The definition regularly utilized for the calculation is given by the following optimization issue:
here Ω shows the identified entries of C, \(\rho_{\Omega }\) speaks to the projection onto the list set Ω. The proposed method looks to split a large-scale enhancement task into a few smaller parts to increase junction speed. To this end, two assistant factors X = (xu, i) ϵ R|U|× f and Y = (yu, i) ϵ R|I|× f are acquainted to disperse the limitations just as, and the accompanying proportional detailing is acquired. The similarity between clients can be acquired by considering rating data or some other relevant data. The famous metrics are Pearson correlation coefficient (PCC) and vector space similarity (VSS). Several users can have distinctive styles of rating, which is not reflected by the similarity measure in the VSS measure. In the proposed method, PCC is utilized to calculate similarity among users and is characterized by:
where \(r_{u}\) signifies the average ratings of user U and the summary of j the summations over j affect the set of regular things that user’s a and b have rated. A little estimation of similarity of a and b shows that the distance \(\left\| {{\varvec{P}}_{{{\varvec{a}}{ }}} - {\varvec{P}}_{{{\varvec{b}}{ }}} } \right\|_{2}\) becomes bigger, and the other way around. In a different context, when two users are more comparable, their underlying attribute vector is closer.
3.2 Trust data
Social network RS has attracted much consideration because of the quick expansion of social network services like Facebook and Twitter, give trust cooperation to depict connections between their users. As there is a strong connection between trust data and social networks, researchers start to concentrate on extracting trust data to enhance recommendations. The trust-based recommender systems use certain explicit and implicit-based RS. Explicit RSs allude to the connections that are created directly by the users, while the others are assessed by extracting the rating examples given by the users. Another problem in collaborative filtering techniques is developed due to the large number of users generating big data. The performance of most conventional recommendation techniques has decreased by dealing with such enormous scale frameworks. Most RSs utilize profoundly sparse information because the users give a rating to just scarcely rare items. To handle this problem, extra data means are utilized to enhance the performance of the recommendations. In the suggested method, trust data are used as a normalization strategy. The point of utilizing the social normalization factor is to limit the difference of taste between users and their close friends. The recommendations for an active user are considered to be near to its trusted neighbors and can be defined as:
where \(\alpha\) > 0 handles the impact rate of trust values, f+ (u) indicates arrangement user u’s friends, and \(P_{u}\) is defined as uth row of P. It must be considered that, as \(P_{u}\) and \(P_{v}\) are row’s vectors, \(\left| {\left| {P_{{a{ }}} - P_{{b{ }}} } \right|} \right|{ }_{2} { }\) is equivalent to the typical Euclidean norms. Equation (4) reflects just the outer links of the friends of users, while one ought to likewise consider the inner links of friends of users now and again. In some social networks like Facebook, outer-linked friends are equivalent to inner-linked friends, while the inverse is valid in some SSs (Social Systems) like Epinions. Accordingly:
Likewise, Eq. 5, a communal normalization factor to force requirements among a user and his/her friends is following:
3.3 TrustASVD++
In the proposed method, trust statements are integrated with the ASVD++ algorithm to generate useful results and to improve the eminence of the recommendation procedure. ASVD++ algorithm is a multifaceted collaborative filtering framework that uses matrix factorization to handle cold-start users and to reduce sparsity. Several tests have been performed on datasets including Epinions, FilmTrust, and Ciao. Outputs have depicted that the proposed method surpasses contemporary techniques in terms of precision and accuracy.
3.4 Matrix factorization
Matrix factorization is a technique through which a matrix can be decomposed into its constituent parts. It has been demonstrated to be a powerful method for the origination of an effective RS. Matrix factorization deals with the cold-start and data sparsity problem by using additional sources of information. Matrix factorization takes inference from item rating pattern and both the users and items are characterized by vectors of factors which means that a recommendation is made with a high rating if there is a high correspondence between user factor and item factor. The beauty of matrix factorization is that it can infer the user preference if explicit feedback from the user is not provided. For this inference, user’s history (such as browser history, search patterns) can be used. The idea is to exploit latent associations which exist between the users and items. Mathematically speaking, Matrix Factorization factorize the user-item rating matrix UI into latent feature matrices \(P \in UI^{K \times M}\) and \(Q \in UI^{K \times M}\), where \(K \ll \min \left\{ {N,M} \right\}\) which uses the product P × Q for approximation of the rating matrix.
in the matrix factorization framework is to plot clients and things into a comparable underlying trait period [39,40,41].
3.5 Sensitive analysis
The proposed TrustASVD++ strategy comprises three factors that include the knowledge degree (η), expansion impact controller (λ), and interpersonal organization data impact controller (β). It is a fact that a factor can be evaluated through maximum probability approximation (MPA) if the information arrives in a specific circulation. Sadly, the information does not pursue a particular circulation. The alteration procedure of factors is a tough task to do, there is not a single hypothetical/ideal path for characterizing the ideal qualities of the factors that have been defined yet. The typical route to tune a parameter is by doing experiments by playing out the strategy on various estimations of the element and choosing the one that has produced the best values. It ought to be noticed that the procedure to tune the parameters is done by doing offline experiments. Accordingly, several experiments have been done in this regard to adjusting the factors that are tunable in the suggested method. Considering a reasonable correlation, the procedure of training of every parameter consists of 1000 training contains 1000 training eras on every dataset. For all the three datasets, outputs show that \(\lambda = 1.5\) is a justified setting. The acquired results elaborate that the offered method attains the finest outcomes when alpha’s value is in the range of [1.6,2]. When the best value is in the range of [0.05,3], the suggested method illustrates the best performance.
4 Experiments and results
In this corresponding section, numerous experimentations are performed to assess the excellence of TrustASVD++ results on three datasets and also compared with contemporary techniques. To evaluate the functioning of a method, four segments (80% of the existing ratings are used as the training information and the residual part. i.e., 20% of the available ratings are utilized as testing information). For the assessment of the strategies, four sections (80% of the existing rating data) are utilized in the training information, and the remaining part (20% of the recognized rating data) is utilized in the test set. The experimentation was done on a personal computer with a 2 GHz i5 CPU and 4 GB Ram.
4.1 Datasets
To assess the efficiency of the suggested method, numerous experimentations are done on datasets including Epinions, FilmTrust, and ciao. The three datasets contain ratings and trust data while the ratings in the Epinions dataset and Ciao dataset are in the range of 1 to 5 whereas in the FilmTrust dataset the values are in the range (0.5,4). Epinions is a website that allows users to rate items between the integer values 1 and 5. The dataset contains 22,166 users and 255,754 social connections. Items are 296,277 in number and ratings are 922,267. Moreover, trust data are categorized into trust and distrust. Trust value is indicated by 1 which illustrates that there is an existence of trust between users whereas distrust is indicated by 0. Filmtrust dataset was obtained from a website that suggests movies to users. On the website, users can deliver feedback on movies and can also create friendship links with other users to give out their feedback.
The ratings in FilmTrust dataset are in the range of [0.5,4]. Filmtrust dataset contains 1508 users, and social connections are 1853. Items are 2071 and ratings 35,497 in number. Moreover, the ciao dataset was collected from the ciao research group. Ciao dataset comprises 7353 users, 99,746 items, 278,483 ratings, and 111,781 social links. The rating values of the FilmTrust dataset are in the range of 1 to 5. Specifications of the datasets used in the offered method are given in Table 1. Epinions dataset is represented by EP, FilmTrust dataset by FT, and ciao dataset by CI.
4.2 Evaluation metrics
For assessment of the results of recommendation techniques, numerous metrics are used [42, 43]. Usually, two famous methods used to assess and evaluate the performance of MF recommenders by computing the actual and predicted rating’s difference. In the proposed strategy, different performance evaluation measures are used including Precision, Recall, MAE, RMSE, Precision, Recall, and F-measure [44,45,46,47,48,49,50,51,52]. MAE calculates the average of the total error and assesses the closeness of actual values of ratings and predicted values of ratings.
Meanwhile, RMSE depicts the robustness and accuracy of the procedure. The basic difference between MAE and RMSE is that MAE assigns equal weightage to every observed error, whereas RMSE assigns additional weightage to the larger errors [45, 48, 53, 54]. MAE and RMSE are used collectively to manage the change in a collection of errors that is forecasted and acquire values that are in the range 0 to ∞. The RMSE and MAE metrics are processed as follows:
Precision is defined as a ratio of TPs to the sum of TPs and FPs. Precision tells how exact/precise your model is out of those predicted positives, what number of them are positive. Precision is a well-known measure to decide when the expenses of False Positive are high. The recall is the ratio of TPs to the sum of TPs and FNs.
Recall calculates the number of TPs captured by the model. The recall is utilized as a model measurement to select the best model when there is a noteworthy rate related to a false negative. F1-measure is defined as the weighted average of precision and recall. In this way, F1-measure considers both FN and FP. F1 Score is utilized to make a balance between precision and recall. Formulas to calculate Precision, Recall, and F1-measure are as under:
where TP is the no. of occurrences that are precisely forecasted, and FN is no. of occurrences that are inaccurately forecasted.
4.3 Results and discussion
The proposed method used a matrix factorization and trust data for Pearson correlation. The results are compared with some of the existing similarity measure methods that include standard PCC, CPCC, PIP, SPCC, and NHSM Sim formula. The mathematical formulas are explained in Table 2. To enhance the performance of the suggested method, when contrasted with contemporary methods. The weights of a and b that are best are determined ranging from 0 to 2, and performance is validated according to these weights. Experimental outcomes related to the performance of the suggested method for different weights of a and b are given in Tables 3 and 4.
The results analysis is performed over three state-of-the-art benchmark datasets—CIAO, Epinions, and FilmTrust. The results are listed in detail in the above-mentioned tables, and different values of A and B are tested to find out the optimum results. Table 3 presents results for the CIAODVD dataset and shows an improvement of results. The highlighted results are the best results achieved during experiments. The best results for the CIAO dataset are achieved when the values for A and B were 2.0 and 0.05, respectively. Then results achieved for CIAO are 0.574, 0.782, 0.647, 0.990, and 0.782 for MAE, RMSE, Precision, Recall, and F1 score, respectively. The results achieved proved the proposed method achieved better performance in terms of top-ranked recommendations, sparsity, and cold-start scenarios. Similarly, Table 4 presents results for the Epinions dataset and shows an improvement of results. The highlighted results are the best results achieved during experiments. The best results for the Epinions dataset are achieved when the values for A and B were also 2.0 and 0.05, respectively. Then results achieved for Epinions are 0.650, 0.888, 0.720, 0.959, and 0.823 for MAE, RMSE, Precision, Recall, and F1 score, respectively. The results achieved also proved the proposed method achieved better performance in terms of top-ranked recommendations, sparsity, and cold-start scenarios. In another experiment, Table 5 presents results for the FILMTRUST dataset and shows an improvement of results. The highlighted results are the best results achieved during experiments for the corresponding evaluation matrix. The best results for the FILMTRUST dataset are achieved for a different set of pairs used for A and B. The best results achieved for different evaluation parameters were different for different values of A and B. Then results achieved for FILMTRUST is 0.574, 0.746, 0.701, 0.965, and 0.812 for MAE, RMSE, Precision, Recall, and F1 score, respectively. The results achieved also proved the proposed method achieved better performance in terms of top-ranked recommendations, sparsity, and cold-start scenarios.
In our last experiment, the proposed TrustASVD++ is compared with existing similarity measures PCC, CPCC, PIP, SPCC, and NHSM. The results are presented for CIAODVD, Epinions, and FILMTRUST in terms of average MAE and RMSE. All the reported results for methods other than the proposed method are calculated using the KNN approach with 5 neighbors. The results show that the proposed method showed significant improvement in results for both MAE and RMSE across all datasets as presented in Fig. 2a–c. The proposed method is also compared with the two state–of-the-art techniques IPWR [55] and TrustANLF [56]. While using the RMSE error metric over the Epinions dataset the value of IPWR comes as 1.201. TrustANLF performs a little better by providing a value of 1.063. However, the proposed method TrustASVD++ outperforms both by giving a value of only 0.888. Similarly, the results obtained on the CIAO dataset provide values of 0.791, 0.519, and 0.502, respectively, again proving the strength of TrustASVD++. Likewise, Over the Epinions dataset, IPR gives the value of 0.899 when the MAE error metric is adopted, TrustANF gives 0.785, while the proposed approach shows remarkable improvement and gives a value of 0.650. With the CIAO dataset, the value of TrustASVD++ is 0.502 which is a slight improvement on the TrustANLF method a far superior improvement on the IPWR method. These results are presented in Table 6 and show that the performance of the proposed TrustASVD++ is better than the published work.

a–c The comparison between the state-of-the-art similarity methods with proposed TrustASVD++ are presented here for CIAODVD, EPINIONS, and FILMTRUST
5 Conclusion
Traditional recommender systems generate recommendations based on similar users irrespective of the fact whether they trust each other or not. Therefore, the generated ratings may be accurate but lack the reliability factor. The recommendations provided to the users should be accurate and reliable. The users prefer recommendations when similar users are from its trust circle. In this paper, a trust-based MF model known as TrustASVD++ is proposed. The proposed technique utilizes trust data in the MF system to enhance the recommendation process so that the sparse data and cold-start users/items issue can be resolved. Several experiments were done over three datasets. i.e., Ciao, Filmtrust, and Epinions. Results illustrate that the offered method has acquired better precision and accuracy when assessed with a rating and trust-based method. Further, the utilization of trust data has enhanced the performance of the recommendation procedure.
References
Núñez-Valdéz ER, Lovelle JMC, Martínez OS, García-Díaz V, De Pablos PO, Marín CEM (2012) Implicit feedback techniques on recommender systems applied to electronic books. Comput Hum Behav 28(4):1186–1193
Lee SK, Cho YH, Kim SH (2010) Collaborative filtering with ordinal scale-based implicit ratings for mobile music recommendations. Inf Sci 180(11):2142–2155
Shambour Q, Lu J (2015) An effective recommender system by unifying user and item trust information for B2B applications. J Comput Syst Sci 81(7):1110–1126
Zhang Z, Lin H, Liu K, Wu D, Zhang G, Lu J (2013) A hybrid fuzzy-based personalized recommender system for telecom products/services. Inf Sci 235:117–129
Al-Hassan M, Lu H, Lu J (2015) A semantic enhanced hybrid recommendation approach: a case study of e-Government tourism service recommendation system. Decis Support Syst 72:97–109
Protasiewicz J, Pedrycz W, Kozłowski M, Dadas S, Stanisławek T, Kopacz A, Gałężewska M (2016) A recommender system of reviewers and experts in reviewing problems. Knowl-Based Syst 106:164–178
Adomavicius G, Tuzhilin A (2005) Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions. IEEE Trans Knowl Data Eng 17(6):734–749
Azadjalal MM, Moradi P, Abdollahpouri A, Jalili M (2017) A trust-aware recommendation method based on Pareto dominance and confidence concepts. Knowl-Based Syst 116:130–143
Moradi P, Ahmadian S, Akhlaghian F (2015) An effective trust-based recommendation method using a novel graph clustering algorithm. Phys A 436:462–481
Massa P, Avesani P (2007) Trust-aware recommender systems. In: Proceedings of the 2007 ACM Conference on Recommender Systems, pp 17–24
Guo G, Zhang J, Yorke-Smith N (2015) Trustsvd: collaborative filtering with both the explicit and implicit influence of user trust and of item ratings. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 1
Jamali M, Ester M (2010) A matrix factorization technique with trust propagation for recommendation in social networks. In: Proceedings of the Fourth ACM Conference on Recommender systems, pp 135–142
Bobadilla J, Ortega F, Hernando A, Gutiérrez A (2013) Recommender systems survey. Knowl Based Syst 46:109–132
Lu J, Wu D, Mao M, Wang W, Zhang G (2015) Recommender system application developments: a survey. Decis Support Syst 74:12–32
Shambour Q (2021) A deep learning based algorithm for multi-criteria recommender systems. Knowl Based Syst 211:106545
Fu Z, Gao H, Guo W, Jha SK, Jia J, Liu X, Long B, Shi J, Wang S, Zhou M (2020) Deep learning for search and recommender systems in practice. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp 3515–3516
Dong M, Yuan F, Yao L, Wang X, Xu X, Zhu L (2020) Trust in recommender systems: a deep learning perspective. arXiv preprint arXiv:2004.03774
Bobadilla J, Alonso S, Hernando A (2020) Deep learning architecture for collaborative filtering recommender systems. Appl Sci 10(7):2441
Chaney AJ, Blei DM, Eliassi-Rad T (2015) A probabilistic model for using social networks in personalized item recommendation. In: Proceedings of the 9th ACM Conference on Recommender Systems, pp 43–50
Moradi P, Ahmadian S (2015) A reliability-based recommendation method to improve trust-aware recommender systems. Expert Syst Appl 42(21):7386–7398
Wu H, Yue K, Pei Y, Li B, Zhao Y, Dong F (2016) Collaborative topic regression with social trust ensemble for recommendation in social media systems. Knowl Based Syst 97:111–122
Salah A, Rogovschi N, Nadif M (2016) A dynamic collaborative filtering system via a weighted clustering approach. Neurocomputing 175:206–215
Gohari FS, Aliee FS, Haghighi H (2018) A new confidence-based recommendation approach: Combining trust and certainty. Inf Sci 422:21–50
Ar Y, Bostanci E (2016) A genetic algorithm solution to the collaborative filtering problem. Expert Syst Appl 61:122–128
More D, Phand A, Komarashetty N, Choudhari S, Vengurlekar PN (2019) News recommendation based on user preferences and location. Int Res J Eng Technol 6(02):5160-5164
Pereira N, Varma SL (2019) Financial planning recommendation system using content-based collaborative and demographic filtering. In: Smart Innovations in Communication and Computational Sciences. Springer, pp 141–151
Rutkowski T, Romanowski J, Woldan P, Staszewski P, Nielek R, Rutkowski L (2018) A content-based recommendation system using neuro-fuzzy approach. In: 2018 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE). IEEE, pp 1–8
Wang J-C, Chiu C-C (2008) Recommending trusted online auction sellers using social network analysis. Expert Syst Appl 34(3):1666–1679
Ma H, King I, Lyu MR (2009) Learning to recommend with social trust ensemble. In: Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. pp 203–210
Lu Y, Tsaparas P, Ntoulas A, Polanyi L (2010) Exploiting social context for review quality prediction. In: Proceedings of the 19th International Conference on World Wide Web, pp 691–700
Lin T-H, Gao C, Li Y (2018) Recommender systems with characterized social regularization. In: Proceedings of the 27th ACM International Conference on Information and Knowledge Management, pp 1767–1770
Cui L, Sun L, Fu X, Lu N, Zhang G (2017) Exploring a trust based recommendation approach for videos in online social network. J Signal Process Syst 86(2–3):207–219
Mei J-P, Yu H, Shen Z, Miao C (2017) A social influence based trust model for recommender systems. Intell Data Anal 21(2):263–277
Wang Y, Yin G, Cai Z, Dong Y, Dong H (2015) A trust-based probabilistic recommendation model for social networks. J Netw Comput Appl 55:59–67
Lee W-P, Ma C-Y (2016) Enhancing collaborative recommendation performance by combining user preference and trust-distrust propagation in social networks. Knowl Based Syst 106:125–134
Faridani V, Jalali M, Jahan MV (2017) Collaborative filtering-based recommender systems by effective trust. Int J Data Sci Anal 3(4):297–307
Ma X, Ma J, Li H, Jiang Q, Gao S (2018) ARMOR: A trust-based privacy-preserving framework for decentralized friend recommendation in online social networks. Futur Gener Comput Syst 79:82–94
Tian H, Liang P (2017) Personalized service recommendation based on trust relationship. Sci Program 2017:1–8
Parvin H, Moradi P, Esmaeili S (2018) A collaborative filtering method based on genetic algorithm and trust statements. In: 2018 6th Iranian Joint Congress on Fuzzy and Intelligent Systems (CFIS), IEEE, pp 13–16
Navgaran DZ, Moradi P, Akhlaghian F (2013) Evolutionary based matrix factorization method for collaborative filtering systems. In: 2013 21st Iranian Conference on Electrical Engineering (ICEE). IEEE, pp 1–5
Takács G, Pilászy I, Németh B, Tikk D (2009) Scalable collaborative filtering approaches for large recommender systems. J Mach Learn Res 10:623–656
Jabeen F, Maqsood M, Ghazanfar MA, Aadil F, Khan S, Khan MF, Mehmood I (2019) An IoT based efficient hybrid recommender system for cardiovascular disease. Peer-to-Peer Netw Appl 12(5):1263–1276
Iqbal M, Ghazanfar MA, Sattar A, Maqsood M, Khan S, Mehmood I, Baik SW (2019) Kernel context recommender system (KCR): a scalable context-aware recommender system algorithm. IEEE Access 7:24719–24737
Sampaul Thomas GA, Robinson YH, Julie EG, Shanmuganathan V, Nam Y, Rho S (2020) Diabetic retinopathy diagnostics from retinal images based on deep convolutional networks. https://doi.org/10.20944/preprints202005.0493.v1
Nawaz H, Maqsood M, Afzal S, et al (2020) A deep feature-based real-time system for Alzheimer disease stage detection. Multimed Tools Appl. https://doi.org/10.1007/s11042-020-09087-y
Jung S, Moon J, Park S, Rho S, Baik SW, Hwang E (2020) Bagging ensemble of multilayer perceptrons for missing electricity consumption data imputation. Sensors 20(6):1772
Bukhari M, Bajwa KB, Gillani S, Maqsood M, Durrani MY, Mehmood I, Ugail H, Rho S (2020) An efficient gait recognition method for known and unknown covariate conditions. IEEE Access 9:6465–6477
Yasir M, Durrani MY, Afzal S, Maqsood M, Aadil F, Mehmood I, Rho S (2019) An intelligent event-sentiment-based daily foreign exchange rate forecasting system. Appl Sci 9(15):2980
Jifara W, Jiang F, Rho S, Cheng M, Liu S (2019) Medical image denoising using convolutional neural network: a residual learning approach. J Supercomput 75(2):704–718
Muhammad K, Ahmad J, Mehmood I, Rho S, Baik SW (2018) Convolutional neural networks based fire detection in surveillance videos. IEEE Access 6:18174–18183
Kalsoom A, Maqsood M, Ghazanfar MA, Aadil F, Rho S (2018) A dimensionality reduction-based efficient software fault prediction using Fisher linear discriminant analysis (FLDA). J Supercomput 74(9):4568–4602
Jiang F, Grigorev A, Rho S, Tian Z, Fu Y, Jifara W, Adil K, Liu S (2018) Medical image semantic segmentation based on deep learning. Neural Comput Appl 29(5):1257–1265
Maqsood H, Mehmood I, Maqsood M, Yasir M, Afzal S, Aadil F, Selim MM, Muhammad K (2020) A local and global event sentiment based efficient stock exchange forecasting using deep learning. Int J Inf Manag 50:432–451
Afzal S, Maqsood M, Nazir F, Khan U, Aadil F, Awan KM, Mehmood I, Song O-Y (2019) A data augmentation-based framework to handle class imbalance problem for Alzheimer’s stage detection. IEEE Access 7:115528–115539
Ayub M, Ghazanfar MA, Mehmood Z, Saba T, Alharbey R, Munshi AM, Alrige MA (2019) Modeling user rating preference behavior to improve the performance of the collaborative filtering based recommender systems. PLoS ONE 14(8):e0220129
Parvin H, Moradi P, Esmaeili S, Qader NN (2019) A scalable and robust trust-based nonnegative matrix factorization recommender using the alternating direction method. Knowl Based Syst 166:92–107
Acknowledgements
This research was supported by the National Research Foundation of Korea (NRF) Grant funded by the Korea government (MSIT) (No. 2020R1F1A1076976).
Author information
Authors and Affiliations
Corresponding authors
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This paper is an extended version of our paper published in the Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI’20), Las Vegas, USA, 16–18 Dec 2020.
Rights and permissions
About this article

Cite this article
Rahim, A., Durrani, M.Y., Gillani, S. et al. An efficient recommender system algorithm using trust data. J Supercomput 78, 3184–3204 (2022). https://doi.org/10.1007/s11227-021-03991-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-021-03991-2