
Abstract
The demand of cloud-based services is growing rapidly due to the high scalability and cost-effective nature of cloud infrastructure. As a result, the size of the data center is increasing drastically, so is the cost of maintenance in terms of resource management and energy consumption. Hence, it is important to develop a proper resource management plan to maximize the profit by reducing the overhead of operational cost. In this paper, we propose a multi-step-ahead workload prediction approach using Machine learning techniques and allocate the resources based on this prediction in a way that allows the resources to be utilized more efficiently and thereby, reducing the data center’s overall energy consumption. We evaluate the effectiveness of our framework based on real workload trace of Bitbrains. Experimental results show that our framework outperforms other state-of-the-art approaches for predicting workload over a long-run and significantly improves resource utilization while enabling substantial energy savings.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Cloud computing [10, 43] has emerged as a consolidated paradigm for delivery of services through on-demand provisioning of virtualized resources. These services come mainly in the form of infrastructure, platform and software (applications) that can be acquired by the users from anywhere in the world as a pay-as-you-go basis. The rate of cloud computing adaptation in the industry has grown considerably in recent years. Cloud-based solutions have dramatically changed the way business processes are outsourced.
To perform specific tasks, users request resources to Cloud providers in the form of Virtual Machines (VMs) and the providers allocate Physical Machine (PM) to them. Thus, the success of the cloud environment depends primarily on the management of its resources. Cloud infrastructures depend on large scale centralized or distributed data centers, where each data center consists of a large number of physical machines (PMs), and a set of VMs are created on top of them. Virtualization is the key technology that enables the Cloud provider with a set of techniques and tools to facilitate the provision and management of the resources by creating multiple VM instances on a single PM.
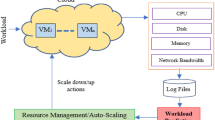
Due to these virtualization technologies, data centers are serving a growing demand for computing resources, such as CPU, memory and storage resources. Along with this growth, energy consumption is getting increased and is expected to grow further as the data centers are expanding both in size and in numbers. A recent study conducted by Green Peace [15] in 2017 showed that the IT sector was already estimated to consume over 7% of global electricity demand in 2012, potentially approaching 12% by 2017 and continues to rise at least 7% annually through 2030. Moreover, virtualization has several drawbacks. One of the essential requirement of a cloud computing environment is to provide reliable Quality of Service (QoS) in terms of Service Level Agreement (SLA). Workloads of many modern applications often experience resource usage patterns that are dynamic in nature. An unexpected rise in resource usage can lead to performance degradation, which may cause the violation of SLA. Over-provisioning may guarantee SLA, but it leads to inefficiency when the load is reduced. Also, the capacity of a PM should be sufficient to satisfy the resource needs of all VMs running on it. Otherwise, the PM will be overloaded and results in performance degradation of its VMs and SLA violations. Thus, each PM must be checked periodically for being overloaded. On the other hand, the utilization of PMs should be kept reasonably high in order to use the resources efficiently. Therefore, efficient resource management is a major challenge for such workloads, and Cloud providers need to find a way that maximizes their profit by reducing the data centre’s energy consumption and resource usage cost.
The optimal strategy for this problem is to timely provide the resources according to the actual demands of the application by accurately predicting the VM’s future resource usage. This will reduce the need for allocating more PMs and at the same time increasing their resource utilization. Machine learning (ML) algorithms are becoming popular to use in this field in recent times. Their ability to find complex patterns in the data makes them more appropriate in the area of forecasting.
Toward the goal of maximizing the profit in cloud, we propose a resource provisioning framework that can be applied in any virtualized data center offering infrastructure as a service (IaaS). The main contribution of this paper is as following:
-
1.
A re-train-based prediction approach that combines machine learning clustering and forecasting techniques to predict the VM’s future resource consumption efficiently.
-
2.
A modified version of Best Fit Decreasing (BFD) algorithm for placing the VMs based on their predicted resource consumption values.
-
3.
Using a real trace of a data center, the accuracy of the predictive model is compared with two state-of-the-art approaches [31, 38]. Extensive experiments demonstrate the efficiency of the proposed model in retaining the accuracy over a long-run.
-
4.
Finally, the effectiveness of the proposed placement algorithm is evaluated using the same trace by comparing it with the conventional placement scheme. The result shows a significant improvement in terms of energy efficiency and resource utilization.
The rest of this paper is organized as follows: Sect. 2 reviews related works. This is followed by the problem description in Sect. 3. Section 4 describes briefly the overall picture of the entire framework. For evaluating the proposed techniques, the setup description is given in Sect. 5. Experimental results have been provided in Sect. 6. Finally, Sect. 7 concludes the paper along with some future direction.
2 Related work
Early work on power management for a virtualized data center [9, 30] shown that randomized and non-deterministic online algorithms normally improve the quality at a higher rate compared to deterministic algorithms. Determining resource usage by application is not easy to be modeled using plain statistical distributions due to the real-world settings complexity; this is observed in several studies [3, 19, 25].
For energy-efficient cloud computing, energy management policies should be done at the architectural level. In [11], the authors have considered the problem of energy-efficient management of resources in hosting centers and propose a new operating system called Muse, which can be used in a hosting center. Muse is an adaptive resource management system and plays a vital role to integrate energy and power resources. It can reduce the energy usage while meeting a specified level of service by determining the resource demand of each application at its current request load level. Similarly, the system proposed in [5] presents a resource management systems that can increase the virtualized data center’s energy efficiency without affecting the QoS. [18, 33] proposed a method to review the progress of energy-saving technologies in high-performance computing in virtualized data center environment. Power management approaches that save energy by adjusting CPU’s operating frequency and voltage of PMs based on their workload within the cluster have also been proposed [20, 36]. The strategies proposed in [22, 37] leverage historical data analysis for identifying the changes in workload and use machine learning-based resource management methods for maximizing resource utilization as well as reducing the consumed power in the cloud data centers.
Energy efficiency is inherently linked with resource management. Migration and dynamic consolidation techniques have been proposed as key solution approaches for improving data center resource utilization. For example, dynamic consolidation approaches proposed in [4, 6, 29] allow VMs to migrate from the under-utilized PMs so that the workload can be consolidated on a smaller subset of PMs. The authors in [4, 6] considered the performance degradation associated with the migration process and proposed a dynamic consolidation framework that guarantees certain SLA level.
Resource provisioning and resource management are vivid elds of research in Cloud computing. Resource provisioning involves dynamic allocation by scaling resources up and down depending on the current and future demand. Several approaches exist to estimate the usage of resources for tasks to be provisioned. Dynamic resource demand of various applications has led the cloud resources, such as CPU, to a constant state of fluctuation, thus on a short time scale they are difficult to predict. In [7], the authors have shown that workload prediction on a short time scale is more difficult to produce accurate results than for long-term forecasting. Since resource usage pattern changes over time, for predicting it traditional time-series models like moving average (MA), autoregressive (AR), autoregressive moving average (ARMA), autoregressive integrated moving average (ARIMA) and fractional ARIMA have been used for a long time [17, 26, 39, 42]. In [17], the authors designed a toolkit to predict future CPU load of servers based on their CPU usage histories and presented AR model as the best prediction model due to its low overhead and its prediction accuracy. In [39], an ensemble prediction algorithm is proposed for predicting future status of energy efficiency in cloud computing environment. The proposed predictor includes base prediction models such as moving average, exponential smoothing and double exponential smoothing. But these approaches are not suitable when there is a significant amount of random variation in the data, since they are based on a linear basis function which is not effective in capturing complex relationship in the data.
Machine learning algorithms are used to overcome this limitation and have been used extensively in the field of forecasting [1, 13, 23, 24, 31, 34, 38]. In [23], using the ANN models and linear regression the authors proposed empirical prediction of resource usages in Cloud. The technique proposed in [13] is a self-adaptive prediction method that uses ensemble model and subtractive-fuzzy clustering-based fuzzy neural network (ESFCFNN). In [24], the authors developed a new model to predict the number of future VM requests in a cloud center, which combines k-means clustering techniques and Extreme Learning Machines (ELMs). A variant of RNN, known as long-short-term-memory(LSTM), has been proposed in [38] to predict the host-load in data center. It is effective in predicting patterns in non-linear data. LSTMs contain special blocks that determine when to retain older information and when to output it into the network. This allows the network to automatically learn the periodicity and repeating trends in a time-series. A multi-step-ahead host load prediction is presented in [31]. The authors have adopted a novel GRU-based Encoder–Decoder (GRUED) network in order to acquire the long-term temporal dependencies in the workload. Their proposed model contains two gated RNNs (GRUs) that act as a pair of GRU encoder and GRU decoder. The former maps a variable-length prior host workload sequence to a fixed-length vector, and the later maps the vector representation back to a variable-length future host workload series. The GRUED adaptively selects the most relevant input features by training jointly both the encoder and decoder module.
An adaptive, effective and simple framework is proposed in [16] for precise workloads prediction and for saving energy in cloud centers. It is a combination of machine learning clustering and stochastic theory, which predicts VM’s demands and cloud resources related to every demand. In [8], several different models are used for time series prediction and an adaptive network is proposed to estimate the future value of CPU load for distributed computing.
However, most of the hybrid predictors mentioned above were designed to perform one-step-ahead prediction, which give very little time for the data centre to re-adjust the resource configuration when the traffic is high. Whereas, our proposed prediction approach can predict resource usages accurately multiple time steps into the future, which could inform the data centre management system well ahead to perform suitable actions to deal with the future demands. Moreover, all the mentioned dynamic consolidation techniques are complementary to our work as they can be added on top of our framework to pack the VMs more tightly over time.

Flow of VM requests in a DataCenter
3 Problem description
3.1 Overview of the environment
The cloud services are hosted in data centers that are composed of a large number of servers also known as Physical Machines (PMs). To perform specific tasks, cloud users request resources (for example, CPU and memory capacity) to service providers and the providers allocate the resources by creating virtual infrastructures on top of the actual hardware, known as Virtual Machines (VMs), which emulates the behavior of a computing system with a specified set of resource characteristics. Virtualization technology enables multiple VMs to share the resources of a PM transparently and in isolation from each other.
The component of virtualization which is responsible for providing the interface of executing many VMs in one PM is known as Hypervisor, which is also known as the Virtual Machine Monitor (VMM).
Cloud users use the services provided by the Cloud Service Providers (CSPs) by issuing requests containing information about the resources (CPU, Memory) they require to run specific applications. The resource requests come in the form of VM requests since every request will be completed by creating a VM that runs on top of a PM. Every data center has multiple physical machines and a Data Center Manager(DC Manager) to control them.

Example of VM allocation
Figure 1 depicts the flow of VMs requests from their creation to their placement on PMs. First, the VM requests from different users appear and are placed in a request queue that the DC Manager receives afterwards. Then, it sends requests to the VMMs to provide the status information of all the PMs. Upon the arrival of the status information from the VMMs, the DC manager places the VM requests to individual physical machines in order to process them and sends back the response to the cloud users.
Figure 2a shows how the VM requests are assigned from the request queue to the PMs. For better illustration, consider 5 VM requests having different resource demands for different applications are there in the queue at a specific time (different colors in the picture indicates different type of applications). DC Manager then selects PMs to distribute these VM requests based on the resources that the PMs currently have and activates the VM instances on them. Here, we assume that all the PMs in the data center are having the same amount of total resources and 3 such PMs are picked by the DC Manager. But, the available resources are not the same for all the 3 PMs, since we assume that PM1 and PM2 are pre-occupied with some running VMs, while PM3 has no VM running on it. It is clear that DC Manager placed 5 VM requests properly on 3 PMs, yet it lets all the PMs in an underutilized state.
After analyzing the VM’s resource consumption pattern over a period of time, it has been observed that most of the time the applications running on VMs do not make full use of their allocated resources. This happens because the users are always requesting for more resources than the actual need of the applications they are running. The DC Manager of every data center assigns the VMs to PMs by considering only their requested resources and end up allocating more PMs than the actual need, which, in turn, increases the data center’s overall energy consumption and most of the time, leaves the majority of PMs in an underutilized state. The solution is to place the VMs on PMs based on the resource requirement of the applications the VMs are running, which eliminates the issue of resource over-provisioning and increases the resource utilization of each PM. Consequently, the number of active PMs decreases resulting in less power to be consumed by the data center and allowing CSPs to make more profit.
Figure 2b explains the scenario discussed above by extending the same example. This time consider that the DC Manager knows for each of the 5 VMs their current resource consumption, which is less than their allocated resources at that time. Now, the DC Manager distributes the VM requests in such a way that there is no need to activate PM3 at all and the requests are served by PM1 and PM2. As a result, the data center’s overall energy consumption is reduced and the resources of active PMs are utilized more efficiently.
3.2 Power model
For the PMs in a data center, CPU consumes more energy compared to other resource such as memory, disk storage and network interfaces. In addition, the CPU utilization is typically proportional to the overall system load. Recent studies [12] have shown that the application of Dynamic Voltage and Frequency Scaling (DVFS) on the CPU results in almost linear power-to-frequency relationship for a PM. Therefore, the power consumption of a PM can be computed using Eq. 1, which is based on the power model proposed in [4].
where Q denotes the fraction of energy consumed by idle PM and \(P_{\max }\) is the maximum power consumed by the fully utilized PM. Due to the variability in workload, the CPU utilization of PM changes with time and hence can be represented as a function of time t. Thus, the total energy consumption, E, can be obtained as:
3.3 Problem statement
The problem of assigning VMs to PMs based on the VM’s predicted future resource(CPU, Memory) usage can be formally stated as follows:
-
Given the VMs resource consumption patterns over the past d days, \((D_1,D_2, \ldots ,D_d)\) in the form of time-series data, it is required to predict the VMs future resource usage at periodic intervals, e.g., next 1 h, and place VMs based on this prediction in such a way that improves the Data center’s resource (CPU, Memory) utilization which in turn maximizes the profit by minimizing the consumption of power.
A typical Datacenter consists of a large number of servers, known as physical machines and a set of virtual machines are created on top of them based on the resources requested by the users to run specific applications. Since the workload of the applications varies over time, the VM’s resource request will also change and hence changes in their resource usage pattern.
At time instant t, we assume that there are M virtual machine requests and the datacenter has N homogeneous physical machines. The problem of assigning VMs based on their resource usage prediction is essentially a mapping from VM to PM which can be described as a \(M \times N\) matrix, where each element \(x_{ij}\) indicates the mapping relationship between \(\mathrm{VM}_i\) and \(\mathrm{PM}_j\), represented as:
Let, \(\mathrm{ru}_i^d\) denotes the resource usage of \(\mathrm{VM}_i\), where d denotes the number of resources associated with each VM, i.e., \(d\in \{\mathrm{CPU}, \mathrm{Memory}\}\). So, the resource utilization of \(\mathrm{PM}_j\) can be calculated as:
where \(C_j^d\) is the resource capacity of \(\mathrm{PM}_j\).
Now, the target is to map these VMs in such a way that it results the PMs to consume less energy and at the same time increasing their resource utilization. We can formulate this problem as a multi-objective VM placement problem as:
The objective is
Subject to the following constraints
Here, \(y_j\) is the VM assignment status of \(\mathrm{PM}_j\), that means, if \(y_j\) is 1, it indicates \(\mathrm{PM}_j\) hosts VMs at time t and if \(y_j\) is 0, then \(\mathrm{PM}_j\) has no VMs assigned at that time. Equation 4 specifies that the resource capacity of active PMs must be equal or greater than the sum of all the VM’s resource capacity, where \(\delta _i^d\) is the resource capacity of \(\mathrm{VM}_i\). Equation 5 indicates that each PM must have equal or higher resource capacity than that of all the VMs mapped on it.
4 The proposed framework
The primary purpose of this work is to develop a framework for accurate prediction of various workload metrics (CPU and memory usage) of VMs running in a data center and place the VMs wisely based on this predictions. VMs, that consistently have a certain level of workload, implies that their future workload can be predicted based on historical observation. Since resource usage data come in the form of a time-series, we propose a framework that can handle the dynamic nature of time-series data efficiently.
A time-series is basically a finite sequence of observations ordered in time, where time is the independent variable. Each VM’s resource usage, in the form of time-series data, can be represented as a sequence of points \(\mathrm{VM}_i = [v_{i,1},v_{i,2},\ldots ,v_{i,s}]\), where each point \(v_{i,s}\in \mathbb {R}\) is denoting the \(i{\text {th}}\) VM’s resource usage at time instance s. Here, we have N such time-series for N number of VMs.
Since, in a typical data center, various applications run on different types of VMs, the resource consumption pattern of each VM also differs. Now, developing a generic predictive model using the VM’s past resource usage fails to properly capture the heterogeneity of applications running in the data center, thus ending up building a model that could generate less accurate results. Therefore, first we categorize the VMs based on their resource consumption pattern and then build predictive models for each of the categories, which can improve the performance of individual models.
In short, we can say that our framework is basically composed of three components: (1) Workload Characterization, which identifies common workload patterns across multiple VMs and divides them into several categories. (2) Workload prediction, to estimate the workload of VMs in each category and (3) VM Placement, to place VMs in a way that results in less power to be consumed by the data center. In this section, we describe each of the components briefly.
4.1 Workload characterization
This module aims to identify the groups of VMs that have similar resource usage patterns over time. Clustering is a data mining technique which separates homogeneous data into uniform groups (clusters). The goal of a clustering system for multiple time-series is to find a partition P into \(C =\{C_i \mid \textit{i =1 to k}\}\), in such a way that homogeneous time-series are grouped together based on a certain similarity measure. Then, \(C_i\) is called a cluster, where \(P=\bigcup _{i=1}^k C_i\) and \(C_i \cap C_j = \phi , \forall i \ne j\).
Here, we apply the agglomerative hierarchical clustering (AHC) algorithm [32] to form clusters of VMs. It produces a nested hierarchy of similar groups of objects, according to a pairwise distance matrix of the objects. One of the advantages of this method is its generality, since the user does not need to provide any parameters such as the number of clusters. The AHC algorithm starts by treating each data point as an individual cluster and continues to merge similar clusters until one big cluster is formed. The steps involved are written below.
-
Step 1:
Calculate the distance between all objects. Store the results in a distance matrix.
-
Step 2:
Search through the distance matrix and find the two most similar clusters/objects.
-
Step 3:
Join the two clusters/objects to produce a cluster that now has at least two objects.
-
Step 4:
Update the matrix by calculating the distances between this new cluster and all other clusters.
-
Step 5:
Repeat step 2 until all cases are in one cluster.
So, the first step is to select an effective distance/similarity metric. We choose the Dynamic Time Warping (DTW) method [27] for calculating similarity information. The reason behind selecting DTW is due to its ideal shape-based similarity measurement for time-series data. It uses dynamic programming technique to find all possible paths in every pair of VM’s time-series data of resource usage and chooses the one that is minimum using a distance matrix.
Suppose we have two time series with the same length \(a=\{a_i\in \mathbb {R} \mid \textit{i=1 to s}\}\) and \(b=\{b_i\in \mathbb {R} \mid \textit{j=1 to s}\}\). First, we create an \(s*s\) matrix, where every element (i, j) of the matrix is the cumulative sum of the distance at (i, j) and the minimum of the three elements neighboring the (i, j) element. We can define the (i, j) element as:
where \(d_{ij} = \mid a_i+b_j \mid\)
Then, to find an optimal path, we have to choose the path that gives minimum cumulative distance. The distance is defined as:
where P is a set of all possible warping paths, and \(w_k\) is (i, j) at kth element of a warping path and K is the length of the warping path.
Here, we have a set of N time-series data where each element of the set is composed of l number of feature vectors. These set of elements and a symmetric \(N*N\) matrix populated by the values of DTW are given to the AHC algorithm, and a binary tree structure referred to as a dendrogram is formed by successively combining the closest cluster pairs until a single cluster remains. We use the popular Ward method to quantify inter-cluster similarity as it minimizes the variance of the clusters being merged.
4.2 Workload prediction
After the VMs have been classified into different clusters, a multi-step forecasting model, for each cluster, is constructed. The model relies on observing the VM’s past variations in resource usage pattern over a period of time in order to estimate the resource usages for a future time span. A number of well-known ML models have been used for prediction, and an appropriate model for each cluster is chosen based on the ability of producing results with minimal error. The ML models considered here, which fall under the family of Supervised Machine Learning include linear regression( LR), k-nearest neighbor (k-nn), decision tree (DT), support vector machine (SVM) and gradient boosting (GB).
For converting the VM’s time-series data into a supervised learning problem, sliding window method [14, 21] has been used. The VM’s historical resource usage data, for each cluster, are divided into segments of windows of a fixed size interval, referred to as the Observation Window (\(O_\mathrm{w}\)). After selecting the first segment, the window slides by one time step and the next segment is selected. The process is repeated until all the VM’s resource usage data of a particular time period considered for the experimental purpose are segmented. These segments are then used to train the ML models.
The size of the observation window plays an important role in time-series forecasting, since it is the key to capture the local trends in the time-series data and thus it has a direct impact on determining the accuracy of the models. If the model is unable to capture the trends in the training data, then the model is said to be underfitted. Decreasing the size of the observation window allows more flexibility for the model to fit the data and overcome the problem of underfitting but reducing it excessively may overfit the model as well. In both cases, the performance of the model degrades. Therefore, selecting an appropriate observation window is a challenging problem in this context. Moreover, since the predicted resource usage value at each estimation step is used as a feature to predict the resource usage in next step, the accuracy of the prediction decreases gradually as the model attempts to predict further into the future. Hence, a re-train based multi-step ahead forecasting technique has been adopted, enabling the models to predict the resource usage with acceptable accuracy as long as the VMs are running. Where each time after a certain number of estimation step, referred as the Prediction Window (\(P_\mathrm{w}\)), the models are re-trained with the VM’s actual resource usage values during that time.

With all this in mind, the above algorithm is devised to determine the most appropriate ML model for each cluster to accurately estimate the VM’s future resource usage. The algorithm takes as input for each cluster the VM’s resource usage data, the ML models, observation widows of various sizes and a fixed size prediction window. The resource usage data are divided into training and testing part.
The algorithm first selects the dataset for each cluster from ClusterDataList, and then, for each model in MLModels, it iterates over the list of observation windows(ObsWindow) and tries to find the appropriate window size for which the model yields minimum prediction error on the test data. In line 4, for each observation window \(O_\mathrm{w}\), the ConvertToSupervised() method makes the selected time-series data’s training set into supervised learning problem. In line 5, the selected model is then being trained using the function Train() and finally the Test() method applies the trained model over the testing period (line 6) and the prediction error PredErr is added to the Error list (line 7). After the selected model has been tested for all the observation windows, the one for which it produces the minimum prediction error is chosen using the FindMinPredErr() function and adds it to the MinErrModel list (line 9).
The algorithm ends up returning the list BestModelPerCluster, for each cluster which stores the best ML model by applying the same FindMinPredErr() function on MinErrModel list (line 11, 12).
4.3 Virtual machine placement
The prediction of all VMs future resource consumption is passed next to the placement module, which places the VMs based on this prediction. We have used a modified Best Fit Decreasing (BFD) heuristic to fit the VMs in such a way that less number of PMs are needed. The original algorithm [2, 28] could not be applied directly in our framework as it considers only one dimension. Hence, a modification is added to the algorithm to work with our framework where PMs and VMs have multiple dimensions (i.e., multiple types of resources). It takes as input a list of VM (VMList) and a list of PM (PMList) and generates the allocation of VM to PM as a list (AllocationList). Algorithm 1 shows the step by step approach for VM placement.

It starts by sorting the list of VMs in decreasing order of their resource consumption (line 1). The intuition behind this sorting criteria is to consider VMs with larger CPU and memory demands for placing first as they are harder to fit due to their requirement for larger free space. Since each VM has two resources, the product of the CPU and memory consumption is used as a metric of sorting [16]. It is worth mentioning that the product of the CPU and memory consumption is just used as a sorting metric and the CPU and memory consumption associated with each VM are actually checked when it is placed on a PM. The algorithm then iterates on the sorted VMs and starts by picking the first VM in the ordered VMList. Next, it iterates over the list of PMs and tries to fit the picked VM within a PM. Whenever the first PM is found that can fit the picked VM, its power status is checked. The PM can be either in OFF or ON state. If the PM is in OFF state, then its state is changed to ON (line 6), otherwise the line is skipped. Then, in line 8, the PM’s load, if the VM is allocated to it, is calculated and checked to see if it exceeds the capacity threshold set for that particular PM or not (line 9). This is another modification that have been made over the algorithms presented in [2]. The block of codes from line 8 to line 13 is used to check if the PM becomes overloaded after hosting the VM. Here, the load of a PM refers to the product of its consumed CPU and memory capacity. Similarly, a particular percentage of the product of a PM’s total CPU and memory capacity is considered as the threshold for that PM. If the load is below the threshold level, then the VM is allocated to the PM by updating the AllocationList (line 11) as well as the selected PM’s resource utilization (line 12).
If the load exceeds, then the algorithm keeps iterating over the PMs in PMList until the VM fits one PM without violating its capacity threshold. In order to account for service level aspect, the threshold for each PM has been set, i.e., an overloaded PM may cause the violation of SLA in terms of QoS. The algorithm then picks next the following VM in VMList and similarly try to fit it in a PM. It repeats the same procedure until all VMs are placed.
After assigning all the VMs, the algorithm checks whether there are PMs that are ON but have zero utilization. If that is the case, then these PMs are need to be switched to the OFF state (line 20).
The algorithm ends up returning the final AllocationList, which contains the final VM to PM mapping information.
5 Experimental setup
In this section, we conduct the experiments to evaluate the performance of the proposed approach.
5.1 Dataset description
To evaluate our proposed VM placement framework for better utilization of data center resources on a large-scale virtualized data center, a publicly available workload trace, named fastStorage [41], has been used. The trace is collected from a typical data center managed by Bitbrains, which is a service provider that specializes in managed hosting and business computation for enterprises. The trace is representative for business-critical workloads which are comprised of applications that often use the same VMs for long periods of time, typically over several months. The trace accumulates performance metrics of 4 types of resources, i.e., CPU, memory, network and disk for 1250 VMs in one operating month, sampled every 5 min.
Only the metrics for CPU and memory have been selected in our experiment, which includes: the provisioned CPU capacity, the actual CPU usage, the provisioned memory capacity and the actual memory usage. All the values of the metrics are the average over the sampling interval.
We further analyze the trace to capture the difference between the provisioned and the actual usage for both the CPU and memory. Some of the statistics of the metrics is shown in Table 1. A detailed description of the trace is given in [35].
To evaluate our approach and tune the different parameters that are involved in our framework, we take a sequence of VM’s resource usage data of 350 h and break it into two parts, referred as the training and the testing set. The training set consists of the first span of 300 h of data, and the remaining 50 h of data are included in the testing set.
5.2 Server description
In our experiment, the results of the SPECpower benchmark [40], which provide a set of real data on power consumption versus performance of different hosts, have been used. We have selected Dell PowerEdge R6525 server that comprises of 2000 MIPS 64 core processor and 128GB of RAM. All the experiments are performed on a system of 100 such homogeneous servers. The power consumed by this server with different CPU utilization is shown in Table 2 and is calculated using equation 2. The fraction of energy, Q can be determined by performing the following:
So, the idle power consumption for Dell PowerEdge R6525 server is 20.2% of the fully utilized server. Therefore, equation 2 can be rewritten as:
5.3 Performance metrics
For determining the optimal number of clusters and analyzing the performance of the ML methods, we have used several metrics.
Silhouette score has been used as an internal validity measure, which reflects the connectedness and the separation between the cluster partitions. The score is based on silhouette coefficient. It evaluates the quality of clustering by measuring how close an object is to other objects within its own cluster as opposed to those in the adjacent clusters. The calculation is based on the full pairwise distance matrix over all data points. For a single data point \(\mathrm{VM}_i\), its Silhouette value \(\mathrm{sil}(i)\) is calculated as:
where a(i) is the average DTW distance of \(\mathrm{VM}_i\) to all the other VMs in its own cluster and b(i) is the average DTW distance of \(\mathrm{VM}_i\) to all the VMs in its closest neighboring cluster.
The \(\mathrm{sil}(i)\) ranges from − 1 to 1. When a(i) is much smaller than b(i), it indicates the distance of the data point to its own cluster is much smaller than that to other clusters, the \(\mathrm{sil}(i)\) is close to 1 to show this data point is well clustered. In the opposite way, the \(\mathrm{sil}(i)\) is close to − 1 to show it is badly clustered.
Since VM’s resource usage prediction using ML methods is an regression problem, we have used the Root-Mean Square Error (RMSE) and the Mean Absolute Error (MAE) to evaluate the performance of our prediction module. RMSE shows how our module deviates from the actual value, whereas MAE measures the absolute magnitude of the produced error. The formula for calculating the RMSE and MAE is given below:
where \(a_t\) is the actual resource consumption and \(p_t\) is the estimated resource consumption at time interval t, and n is the number of performed estimations.
6 Results
In this section, we demonstrate our findings and assess the performance of our proposed framework.
6.1 Characterization of workload based on resource types
On the basis of the two types of resources, i.e., CPU and memory, the VMs in the training set have been divided into two groups. In each of the group, we have applied the AHC algorithm mentioned in Sect. 4.1 to categorize the VMs that posses similar resource usage pattern over time. The silhouette score is then calculated for different number of clusters, starting from \(C=2\) to 10, shown in Fig. 3.

Silhouette score for selecting the number of clusters
Since the optimal number of cluster is the one with the highest silhouette score, we have divided the VMs into clusters of 3 based on their CPU usage patterns over time. Out of 1250 VMs, most of the VMs are categorized under cluster 1 (1090 VMs), having average CPU usages per hour ranging from 1.53 to 3.30 GHz, shown in Fig. 4. At the same time, Figs. 5 and 6 depict the hourly average CPU usage of cluster 2 (83 VMs) and cluster 3 (66 VMs), which varies in between 0.5–101 GHz and 13.8–81.33 GHz, respectively.
Similarly, based on the memory usage patterns over time, we have divided the VMs into 2 clusters. The first cluster, shown in Fig. 7, comprises of 1070 VMs with hourly average memory usage varying in between 0.5 and 7.9 GB, whereas in the second cluster, the hourly average memory usage of 180 VMs is ranging from 0.278 to 0.177 GB, which is depicted in Fig. 8.

Average CPU usage of VMs in Cluster 1

Average CPU usage of VMs in Cluster 2

Average CPU usage of VMs in Cluster 3

Average memory usage of VMs in Cluster 1

Average memory usage of VMs in Cluster 2
6.2 Prediction of VM’s resource consumption
After the VMs have been classified into a number of clusters, we have implemented the algorithm described in Sect. 4.2 which identifies the appropriate ML model for each cluster to accurately estimate the future resource usages of the VMs. Algorithm 1 evaluates the performance of each ML model by quantifying their estimation error for different lengths of the observation window, \(O_\mathrm{w}\), the values of which have been considered here, from 5 to 20. We have set a value of 5 for \(P_\mathrm{w}\), the length of the prediction window. Since the resource usage data are accumulated at an interval of 5 min, the prediction window of length 5 is equivalent to a prediction time of 25 min. Likewise, the observation time is ranging from 25 to 100 min. To estimate CPU and memory usages in each of the corresponding clusters, the RMSE and MSE for the ML models on the test data are reported in Tables 3 and 4.
Table 3 shows for each of the clusters, the performance of the ML models to estimate CPU usages, where it is clear that among all the models, GB with \(O _\mathrm{w} = 10\), DT with \(O_\mathrm{w} = 17\) and SVM with \(O_\mathrm{w} = 12\) generates minimum RMSE and MAE value for cluster 1, cluster 2 and cluster 3, respectively. Similarly, it becomes clear from Table 4 that for estimating memory usages, SVM with \(O_\mathrm{w} = 11\) for cluster 1, and for cluster 2, GB with \(O_\mathrm{w} = 9\) produces minimum RMSE and MAE. The corresponding rows in the table have been highlighted. Here, the energy consumption for running Algorithm 1 is assumed to be negligible compare to the energy consumption of the data center in idle setup. In an idle data center, all the PMs are in OFF state, thereby consuming the least energy.
6.3 Evaluation of the prediction approach
To evaluate the effectiveness of our strategy in predicting CPU and memory usages, the models with minimum RMSE and MAE in each cluster have been compared with LSTM [38] and GRUED [31]. The usefulness of these methods in predicting time-varying data is already mentioned in Sect. 2. For both the methods, a grid search has been conducted in order to determine their optimal parameters. The search includes the size of the observation window, \(O_\mathrm{w}\), which ranges from 5 to 40 and the size of the hidden layers \((H_\mathrm{L})\) which ranges over the set \(H \in \{8,16,32,64,128\}\). Since, GRUED comprises of two gated recurrent units, namely GRU encoder and GRU decoder, the hidden layers of both the units has been considered here. For the sake of simplicity, the size of them are kept equal. The number of iterations and learning rate are set to 100 and 0.05, respectively, for both LSTM and GRUED. For each cluster, Table 5 shows the combination of \(O_\mathrm{w}\) and \(H_\mathrm{L}\), for which LSTM and GRUED generate the least RMSE and MAE on the test data. From the results, it is clear that the ML models selected by Algorithm 1 outperform both the methods in all clusters. It can also be noticed that, for predicting the resource consumption, LSTM and GRUED both require a observation window of comparatively bigger size than the selected ML models, specifying the effectiveness of our approach in capturing the trends in the data.
Figures 9 and 10 depict the hourly average change in RMSE over the first 10 h of the testing period for estimating CPU and memory consumption. In all the corresponding clusters, the change is plotted using LSTM, GRUED and the selected ML models. At the initial phases of the testing period, both LSTM and GRUED generate results with more accuracy, but it decreases gradually as they fail to capture the patterns in long-term resource usages. Whereas, Algorithm 1 re-trains the ML models after each prediction window, \(P_\mathrm{w}\), which keeps them updated about the changes in resource usage patterns over time. Thus, enabling the models to retain the accuracy throughout the testing period.

Hourly avg. RMSE of different methods for estimating CPU consumption in each cluster during the first 10 h of testing period

Hourly avg. RMSE of different methods for estimating memory consumption in each cluster during the first 10 h of testing period
6.4 VM placement based on resource usage prediction
According to our aim of managing the resources of the DC efficiently, the VMs are placed based on their predicted amount of resource consumption using the MBFD algorithm described in Sect. 4.3. We have evaluated our framework by comparing it against the two other placement strategies. In the first strategy, the VM’s exact amount of future resource usage is known and based on this, the VMs are placed. It reflects the optimal scenario for DC’s resource utilization that we want to achieve. Whereas, the second strategy places the VMs according to their provisioned resources, representing the conventional way of VM assignment. In both the cases, we have used the same version of our proposed MBFD algorithm for VM placement. The comparison with these two placement schemes demonstrates the accurateness and appropriateness of our proposed method in managing the resources. For all the schemes, we set the value for threshold as 90% of the PM’s capacity.

Datacenter’s avg. PM requirement per hour to place the VMs by applying different placement strategies

Datacenter’s avg. CPU utilization per hour using different placement strategies

Datacenter’s avg. memory utilization per hour using different placement strategies

Datacenter’s avg. power consumption per hour using different placement strategies
We start by analyzing how effectively the DC’s resources in terms of CPU, memory are utilized. Figure 11 shows the snapshot of PMs needed to place the VMs over the testing period when different placement strategies are applied. Since most of the VMs consume very less of their provisioned resources, assigning VMs in the conventional way without being aware of their actual resource usage results in the allocation of more PMs (on avg. \(\approx\) 80 PMs per hour) and eventually leading to the DC’s resources to be less utilized. On average, 18.7% of CPU and 5.6% of memory have been utilized per hour, and snapshots of which on the testing period are depicted in Figs. 12 and 13. For completeness, in Table 6 we have shown the average CPU and memory utilization and the average PMs needed per hour over the entire duration of the testing period.
On the other hand, it can be clearly seen, that our framework significantly reduces the number of assigned PMs (on avg. \(\approx\) 16 PMs per hour) by increasing the DC’s overall resource utilization, as it accurately estimates the VM’s consumption of resources. An average increase in DC’s CPU utilization of 80% (from 18.7 to 93.7%) and memory utilization of 77% (from 5.6 to 35%) has been observed throughout the testing period, along with an average reduction of 80% (from 80 to 16 PMs) in PM requirement. The performance metrics achieved under our framework is in fact, very close to that of the optimal scheme. One thing to be noticed here that sometimes, the resource utilization level showed improvements over the optimal scenario, for example, at 20th, 21st and 22nd hours, the average CPU and memory utilization exceeded the optimal utilization level. But this did not prove the superiority of our framework over the optimal approach because, the gap is mainly occurred due to prediction errors. It is worth mentioning that the optimal resource management does not achieve 100% resource utilization due to the bin packing nature, where some PMs may have some resources left unused.
Now, we assess the total energy consumed by the DC under each of the placement schemes. The DC’s total energy includes the energy consumed by both the PMs that are in ON and OFF state. We have calculated the total energy using Eq. 10 and plotted the snapshot of the DC’s hourly energy consumption during the testing period for our proposed and other placement methods, shown in Fig. 14. The hourly average consumption of energy for the entire duration of the testing period is shown in Table 6.
It can be clearly observed that our framework consumes less amount of energy compared to the conventional method. Throughout the testing period, an average reduction in energy consumption of 7.7% (from 0.5432 to 0.5018 MW) has been achieved when our framework is applied over the conventional method. However, the avg. energy reduction rate is much lower than the avg. rate of reduction in PM allocation (7.7% \(\ll\) 80%). This is because of our framework has considerably increased the allocated PM’s CPU utilization and the energy consumption of a PM is linearly dependent on its CPU utilization.
7 Conclusion and future work
Due to the excessive operational cost and high consumption of electrical energy, managing resources in a profitable way is challenging in cloud environment. Moreover, PMs in a virtualized data center are always in a constant state of resource fluctuation, which makes it more difficult to allocate the resources properly. In order to address these issues, we have proposed an integrated energy-aware resource provisioning framework toward improving the DC’s resource utilization and energy efficiency. First, the future consumption of VM’s resources are predicted using ML models and then, based on these prediction, VMs are placed on the PMs. The effectiveness of our framework is evaluated using a real workload trace of Bitbrains. Experimental results indicate that our framework predicts the VM’s resource consumption with a high degree of accuracy compared to other state-of-the-art predictive approaches and outperforms the conventional placement scheme in terms of energy saving and resource utilization.
There are several potential routes for future research that have arisen from this work, which include, firstly, adopting a stochastic resource provisioning framework, as the stochasticity is not fully addressed in this paper. Secondly, excessive re-training can be reduced by dynamically adjusting the size of the prediction window. Furthermore, we can apply several dynamic VM consolidation techniques on top of our framework to see the effectiveness of our approach in terms of SLA violation and migration cost.
References
Ahmed NK, Atiya AF, Gayar NE, El-Shishiny H (2010) An empirical comparison of machine learning models for time series forecasting. Econom Rev 29(5–6):594–621
Ajiro Y, Tanaka A (2007) Improving packing algorithms for server consolidation. In: International CMG Conference, vol 253, pp 399–406
Barford P, Crovella M (1998) Generating representative web workloads for network and server performance evaluation. In: Proceedings of the 1998 ACM SIGMETRICS Joint International Conference on Measurement and Modeling of Computer Systems, pp 151–160
Beloglazov A, Abawajy J, Buyya R (2012) Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing. Future Gener Comput Syst 28(5):755–768
Beloglazov A, Buyya R (2010) Energy efficient resource management in virtualized cloud data centers. In: 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing. IEEE, pp 826–831
Beloglazov A, Buyya R (2012) Managing overloaded hosts for dynamic consolidation of virtual machines in cloud data centers under quality of service constraints. IEEE Trans Parallel Distrib Syst 24(7):1366–1379
Benson T, Anand A, Akella A, Zhang M (2011) Microte: fine grained traffic engineering for data centers. In: Proceedings of the Seventh Conference on Emerging Networking Experiments and Technologies, pp 1–12
Bey KB, Benhammadi F, Mokhtari A, Guessoum Z (2009) CPU load prediction model for distributed computing. In: 2009 Eighth International Symposium on Parallel and Distributed Computing. IEEE, pp 39–45
Borodin A, Karp R, Tardos G (1990) On the power of randomization in online algorithms. In: Proceeding of the Twenty-Second Annual ACM Symposium on Theory of Computing
Buyya R, Yeo CS, Venugopal S, Broberg J, Brandic I (2009) Cloud computing and emerging it platforms: vision, hype, and reality for delivering computing as the 5th utility. Future Gener Comput Syst 25(6):599–616
Chase JS, Anderson DC, Thakar PN, Vahdat AM, Doyle RP (2001) Managing energy and server resources in hosting centers. ACM SIGOPS Oper Syst Rev 35(5):103–116
Chen Y-L, Chang M-F, Chao-Wei Yu, Chen X-Z, Liang W-Y (2018) Learning-directed dynamic voltage and frequency scaling scheme with adjustable performance for single-core and multi-core embedded and mobile systems. Sensors 18(9):3068
Chen Z, Zhu Y, Di Y, Feng S (2015) Self-adaptive prediction of cloud resource demands using ensemble model and subtractive-fuzzy clustering based fuzzy neural network. Comput Intell Neurosci 2015:919805
Chou J-S, Nguyen T-K (2018) Forward forecast of stock price using sliding-window metaheuristic-optimized machine-learning regression. IEEE Trans Ind Inf 14(7):3132–3142
Cook G, Lee J, Tsai T, Kong A, Deans J, Johnson B, Jardim E (2017) Clicking clean: who is winning the race to build a green internet? Greenpeace Inc., Washington, DC
Dabbagh M, Hamdaoui B, Guizani M, Rayes A (2015) Energy-efficient resource allocation and provisioning framework for cloud data centers. IEEE Trans Netw Serv Manag 12(3):377–391
Dinda PA (2006) Design, implementation, and performance of an extensible toolkit for resource prediction in distributed systems. IEEE Trans Parallel Distrib Syst 17(2):160–173
Duan H, Chen C, Min G, Yu W (2017) Energy-aware scheduling of virtual machines in heterogeneous cloud computing systems. Future Gener Comput Syst 74:142–150
Feitelson DG (2002) Workload modeling for performance evaluation. In: IFIP International Symposium on Computer Performance Modeling, Measurement and Evaluation. Springer, pp 114–141
Garg SK, Yeo CS, Anandasivam A, Buyya R (2011) Environment-conscious scheduling of HPC applications on distributed cloud-oriented data centers. J Parallel Distrib Comput 71(6):732–749
Hota HS, Handa R, Shrivas AK (2017) Time series data prediction using sliding window based RBF neural network. Int J Comput Intell Res 13(5):1145–1156
Iranfar A, Zapater M, Atienza D (2018) Machine learning-based quality-aware power and thermal management of multistream HEVC encoding on multicore servers. IEEE Trans Parallel Distrib Syst 29(10):2268–2281
Islam S, Keung J, Lee K, Liu A (2012) Empirical prediction models for adaptive resource provisioning in the cloud. Future Gener Comput Syst 28(1):155–162
Ismaeel S, Miri A (2015) Using ELM techniques to predict data centre VM requests. In: 2015 IEEE 2nd International Conference on Cyber Security and Cloud Computing. IEEE, pp 80–86
Li H (2009) Workload dynamics on clusters and grids. J Supercomput 47(1):1–20
Li M, Ganesan D, Shenoy P (2009) Presto: feedback-driven data management in sensor networks. IEEE/ACM Trans Netw 17(4):1256–1269
Łuczak M (2016) Hierarchical clustering of time series data with parametric derivative dynamic time warping. Expert Syst Appl 62:116–130
man Jr EGC, Garey MR, Johnson DS (1996) Approximation algorithms for bin packing: a survey. In: Approximation algorithms for NP-hard problems, pp 46–93
Mastroianni C, Meo M, Papuzzo G (2013) Probabilistic consolidation of virtual machines in self-organizing cloud data centers. IEEE Trans Cloud Comput 1(2):215–228
Nathuji R, Schwan K (2007) Virtualpower: coordinated power management in virtualized enterprise systems. ACM SIGOPS Oper Syst Rev 41(6):265–278
Peng C, Li Y, Yu Y, Zhou Y, Du S (2018) Multi-step-ahead host load prediction with gru based encoder-decoder in cloud computing. In: 2018 10th International Conference on Knowledge and Smart Technology (KST). IEEE, pp 186–191
Rodrigues PP, Gama J, Pedroso J (2008) Hierarchical clustering of time-series data streams. IEEE Trans Knowl Data Eng 20(5):615–627
Rong H, Zhang H, Xiao S, Li C, Chunhua H (2016) Optimizing energy consumption for data centers. Renew Sustain Energy Rev 58:674–691
Saini LM, Soni MK (2002) Artificial neural network-based peak load forecasting using conjugate gradient methods. IEEE Trans Power Syst 17(3):907–912
Shen S, van Beek V, Iosup A (2015) Statistical characterization of business-critical workloads hosted in cloud datacenters. In 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing. IEEE, pp 465–474
Shojafar M, Cordeschi N, Amendola D, Baccarelli E (2015) Energy-saving adaptive computing and traffic engineering for real-time-service data centers. In: 2015 IEEE International Conference on Communication Workshop (ICCW). IEEE, pp 1800–1806
Son J, Dastjerdi AV, Calheiros RN, Buyya R (2017) SLA-aware and energy-efficient dynamic overbooking in SDN-based cloud data centers. IEEE Trans Sustain Comput 2(2):76–89
Song B, Yao Yu, Zhou Yu, Wang Z, Sidan D (2018) Host load prediction with long short-term memory in cloud computing. J Supercomput 74(12):6554–6568
Subirats J, Guitart J (2015) Assessing and forecasting energy efficiency on cloud computing platforms. Future Gener Comput Syst 45:70–94
The SPECpower Benchmark. https://www.spec.org/power_ssj2008/results/res2020q1/power_ssj2008-20200310-01018.html/
Trace description. http://gwa.ewi.tudelft.nl/datasets/gwa-t-12-bitbrains/
Tran N, Reed DA (2004) Automatic ARIMA time series modeling for adaptive I/O prefetching. IEEE Trans Parallel Distrib Syst 15(4):362–377
Voorsluys W, Broberg J, Buyya R et al (2011) Introduction to cloud computing. In: Cloud computing: principles and paradigms, pp 1–44
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Banerjee, S., Roy, S. & Khatua, S. Efficient resource utilization using multi-step-ahead workload prediction technique in cloud. J Supercomput 77, 10636–10663 (2021). https://doi.org/10.1007/s11227-021-03701-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-021-03701-y