
Abstract
The concept of well-being has evolved over the last decades and a multidisciplinary literature has acknowledged the multidimensional nature of this phenomenon that encompasses different key dimensions. To give concise measure of well-being, methodologies based on composite indices assume relevance, for their capability to summarize the multidimensional issues, rank the units and provide interesting analysis tools. This paper intends to make a contribution to the efforts of assessing human and ecosystem well-being in the Italian urban areas, by appreciating the spatial dimension of the elementary indicators involved in the building process of the composite indicator. To this end, we derive a set of local weights reflecting the spatial variability of data through the Geographically Weighted PCA. Then, the analysis proceeds by employing a unitary-input DEA model, also known as Benefit of Doubt approach, as a benchmarking tool for constructing a spatial composite indicator to evaluate the well-being in the Italian urban areas. In such way, we can take local peculiarities into account and identify the best performing cities to follow as examples of good administrative practices for promoting urban well-being. The approach followed in this specific study is applied empirically with data from the Urban ‘Equitable and Sustainable Well-Being” (Ur-Bes) project, proposed by ISTAT.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Over the last decades, many studies have been focused on the measurement of well-being and quality of life through theoretical and empirical research in various disciplines (see, for an overview, Eger and Maridal 2015).
The estimation of the well-being that exists within a given society is a rather complex task. Well-being is a multifaceted concept which can be viewed as the outcome of compound interactions among a number of elements (Costanza et al. 2009).
Research into this field has been approached in different ways. For many years the Gross-Domestic Product (GDP) has been used as a proxy measure of well-being and employed as a benchmark in assessing and comparing the development of countries and regions. In spite of its extensive use, numerous scholars have called growing attention about the limitations of GDP as a simple and intuitive measure in guiding the progress of societies (Michalos 2008; Larraz Iribas and Pavia 2010; Costanza et al. 2009; Fleurbaey 2009; Stiglitz et al. 2009; UNDP 2010; OECD 2011). In fact, the GDP does not provide a picture of other people’s dimensions of life, such as health, employment, social interactions and personal safety.
New impulse to the literature aimed at improving data and indicators which integrate the GDP has been added by a multidisciplinary academic debate in rethinking well-being. This has resulted in many projects, and prominent among them are the United Nations Development Programme (2010), the European Commission “GDP and beyond” (European Commission 2009), the OECD “Better Life” Initiatives, launched by the OECD (2011) and the suggestions of the so-called Stiglitz–Sen–Fitoussi report (Stiglitz et al. 2009).
Also, many initiatives around the world have been undertaken to improve the measurement of well-being at sub-national levels, in regions and cities, recognizing that the mix among well-being dimensions is unique to each community where people live. Specifically, over the years, there has been an increasing attention on the value of linking urban environment and well-being (Banai and Rapino 2009; Insch and Florek 2008).
The need of well-being assessment at urban level is relevant for a number of reasons. Firstly, urban environments are multi-faced and change continuously and dynamically. For instance, over half of the world’s population lives in urban areas and this proportion is projected to increase by 2% annually, so that two billion of people are expected to be added to urban populations over the next three decades (United Nations 2014). With this rapid global urbanization, cities are at the center of the sustainability agenda.
On one hand, the main driver of the urban population growth is the promise of better life that cities may ensure for the majority of their citizens. In this respect, Beaupuy (2005) argues that cities are the place where the future is built: universities, research center and so on. Although cities provide residents with a number of advantages, it is possible to enumerate the challenges posed by the rapid urbanization, such as environmental stressors, health hazard, inequalities in opportunities, income and access to services, insecurity, unemployment and social exclusion.
Basically, the root of understanding well-being in regions and cities lies in the intersection of well-being and public policy. Therefore, more fine-grained measures of well-being will help policy-makers to enhance the design and targeting of policies and improve their capacity to respond to the paramount and varied needs of residents. In other terms, in the policy-making process the possibility to rely on local well-being measures becomes essential when one moves from a simple measurement perspective to an action-oriented one.
Accordingly, in literature, it is possible to find several examples of well-being and quality of life evaluation in urban settings (Bai et al. 2012). Although these studies characterized for having different purposes, most of them mainly focus on the construction of composite comprehensive indicators for measuring and evaluating urban well-being.
Following the place-based well-being literature, this paper sheds light on the construction of a multidimensional urban well-being index for the Italian Province capital cities and on assessing inequality among these Italian cities in terms of their performance in promoting human and ecosystem well-being.
In this paper, the conceptual framework, providing grounds for understanding well-being and what the dimensions and components of this concept are, is that adopted by ISTAT within the “Equitable and Sustainable Well-Being” project, whose Italian acronym, used hereafter, is BES (Istat 2015).
This theoretical framework reflects the conceptual complexity of well-being and is based on the model published by OECD (Hall et al. 2010). The BES reference structure highlights the well-being dependence upon attributes specific to each person (e.g. health, education), clustered together as attributes of human well-being, and on attributes shared with other people or revealing the relations between them or how a society is peaceful, resilient, cohesive. All of these factors can be clustered together as “social well-being”.
The BES framework is also predicated on the idea that well-being has to be maintained or improved over space and time, for present and future generations, so that people have the conditions, opportunities and sufficient resources to pursue their well-being goals.
Our case study considers the Italian Province capital cities as units of analysis and employs the urban Bes (Ur-BES) report data, which refers to 64 particular indicators, belonging to 11 dimensions, identified within the BES initiative .
In our analysis, a special focus is placed on the importance of surveying the spatial dimension of the local well-being indicators and their related variables. Most of the existing literature on the construction of composite indicators neglects to consider the spatial heterogeneity of the units in the computation of their relative composite indicators scores. As matter of fact, it could happen that the value of a composite indicator may be more dependent on a certain sub-indicator in a given location, and on another sub-indicator in a different location. To ascertain this kind of spatial dependence can reveal useful for policy decision makers in tackling problems in an efficient way, and distinguishing their causes at local level.
With regard to this research issue, we propose a two-step approach. Firstly, for each well-being dimension we employ the Geographically Weighted (GW) Principal Component Analysis (PCA). The GW PCA, introduced by Harris et al. 2011, is deemed a local version of the traditional PCA, in that it takes into account spatial variations across a study region and produces maps of spatial variations of each local principal component and local variance at each place. This variant of global PCA is chosen for its merits in assessing the spatial variability of each Ur-BES pillar data dimensionality and checking how the elementary indicators influence the corresponding spatially-varying component.
In the second stage of our empirical procedure, the synthesis of Ur-Bes elementary indicators, obtained through the GW PCA, is included in a unitary-input Data Envelopment Analysis (DEA) model, also known as Benefit of Doubt (BoD) approach, to derive a spatial composite index. The employment of DEA facilitates the ranking of the Italian Province capital cities according to their efficiency in promoting equitable and sustainable well-being.
After this introduction, in Sect. 2, we focus on some theoretical issues related to composite indicators. Section 3 provides details of the theoretical background of the GW PCA technique, and presents the basic of DEA method, as well as the specific model selected for the case study. In Sect. 4, the proposed aggregation strategy is illustrated by constructing a spatial composite urban well-being index for the Italian Province capital cities. The paper ends with conclusions in Sect. 5.
2 Composite Indicators: Theoretical Issues
In literature, composite indicators (CIs) are largely used to have a comprehensive view on a phenomenon that cannot be captured by one single indicator. The idea behind the CIs is that of combining multidimensional concepts and variables into a single value. CIs provide a big picture of the phenomenon of interest and facilitate the construction of a rank of the units under analysis, usually countries, communicating, in a synthetic way, their performance level (Saltelli 2007). Thus, CIs have been widely advocated as useful tools, in a wide spectrum of fields, for benchmarking purposes and for supporting decision processes.
However, the lack of a standard methodology underlying the construction of CIs has generated a large debate in the scientific community about their use. A critical assessment can be found in Freudenberg (2003), whereas a summary of the pros and cons in using CIs is in Nardo et al. (2008) and in the Organization for Economic Co-operation and Development (OECD) (2008).
In particular, the OECD and the Joint Research Centre of the European Commission (JRC) provide guidelines for the CIs construction.
On conceptual grounds, the construction of CIs poses the challenge of defining a robust theoretical framework, that implies to achieve a clear definition of the multidimensional phenomenon at hand and the individuation of which factors are relevant for it. In fact, the strength of a CI depends largely on the quality and relevance of the elementary selected indicators.
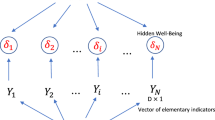
In this stage, depending on if casuality moves from indicators to multidimensional phenomenon (concept to define) or from the multidimensional phenomenon to indicators, it is possible to distinguish a formative model versus a reflective measurement model, respectively (Diamantopoulos et al. 2008). The formative model implies that correlations between indicators are not explained by the model since indicators are not interchangeable; in contrast, the reflective model relies on opposite assumptions.
From the empirical point of view, key issues in the process involved in the construction of a CI are the normalization, weighting and aggregation steps of the elementary indicators.
Through the normalization, the elementary indicators, expressed in their own units, are transformed into pure, dimensionless numbers. The conversion of different indices into the same scale can be done in several ways. Ranking, standardization (or z-score), re-scaling (min–max algorithm) and distance to a reference are, among others, well-known normalization procedures. The different normalization methods imply pros and cons and therefore they will have significant effects on the construction of the composite index. The choice by the analyst depends on data properties and the objectives of the index it has to be constructed (Freudenberg 2003). For instance, for the normalization process, ranking is the simplest method, robust to outliers, albeit it does not allow to make any conclusion about differences in performance since it eliminates information on levels. Another rationale underlying the normalization lies in the fact that this step guarantees a direct reading of values in terms of phenomenon under study, so that an increase in the normalized indicators corresponds to an increase in the composite index. Put in other way, the normalization permits to take into account the sign of the relationship between the indicator and the phenomenon under study (the so-called “polarity”). In this respect, it is worth noting that some indicators may be positively correlated with the phenomenon to be measured (positive “polarity”) whereas others may be negatively correlated with it (negative “polarity”).
In the construction of CIs also the weighting and aggregation steps require a particular attention because they impact on the quality and reliability of the resulting index. The weighting process consists in a meaningful assignment of the weights to the variables involved in the definition of the overall CI.
Facing these issues, researchers have chosen different approaches. A simple method is that of the assignment of equal weight to the different components (Hagerty and Land 2007). This decision is particular appropriate in absence of an underlying theoretical framework, or when there is an insufficient knowledge of the causal relationships between variables (OECD 2008).
The weighting of variables can also follow a participatory approach based on expert-driven techniques. In this respect, there are a variety of ways to summarize experts’ judgement, albeit it is becoming increasingly popular to resort to multi-criteria methods (Saaty 1980, 2001). Another methodological stream, in the determination of weights, proceeds by means of statistical techniques, e.g. factor analysis, principal component analysis (Nicoletti et al. 2000). The main purpose of these methods is accounting for the highest variation in the data set, replacing the original variables with the smallest possible number of factors or components that reflect the underlying “statistical” dimension of the data set.
The weights can be also determined endogenously, without using exogenous information or personal preferences, deriving them directly from the data, adopting a data-driven approach. Data Envelopment Analysis (DEA) and Benefit of Doubt (BoD) techniques are conventional ways to endogenously generate weights.
The last step to be followed to develop a CI regards the definition of a proper aggregation function to combine the elementary indicators to form the composite index. Different aggregation methods are possible (OECD 2008) and they differentiate according to the degree of compensability or substitutability of indicators permitted, i.e. the possibility of offsetting a disadvantage on some indicators by a sufficiently large advantage on other indicators. For this reason, data aggregation has always been a controversial topic in composite index construction (Saltelli 2007; Mazziotta and Pareto 2016). The simplest and most widespread additive method, that is the linear summation of weighted and normalized indicators, assumes a full compensability among the different components whereas the geometric aggregation, that implies the product of weighted indicators, is a less compensatory approach since it attenuates the limits tied to substitutability among indicators. As noticed in Munda and Nardo (2009), weights in additive or geometric aggregation have the meaning of substitution rate and do not indicate the importance of the indicator associated. The attempt to interpret weights as importance coefficients is achieved by using a non-compensatory multi-criteria approach. The interested reader can refer to the work of Casini et al. (2019) for a recent contribute for well-being assessment founded on multi-criteria approach.
In reviewing the literature on the CIs construction we found that little attention is paid to the spatial dimension of the variables involved in the building process and to their consequences in the assignment of weights. Environmental, economic and social phenomena rarely take place uniformly in given conventional borders. As a result, the location where data were collected might play a crucial role in creating link among data values, their positions and their values in the nearest location, leading to two important spatial effects: spatial heterogeneity and spatial dependence (Anselin 1990). There are only few works that improve the methodology for the construction of CIs by considering the spatial dimension of information.
Fusco et al. (2018) propose a method to incorporate spatial heterogeneity in the CIs building process relying on the BoD framework. The distinguishing feature of their methodology is to recognize that the underlying observed differences in CI scores may be attributed to a multitude of territorial conditional variables.
Trogu and Campagna (2018) introduce a spatial extension of the methodology recommended by OECD/JRC for constructing CIs, by replacing the traditional multivariate analysis with GW PCA, in order to derive a set of local weights based on the spatial variability of data.
Also in this paper, we propose an approach based on GW PCA to develop a spatial composite index for human and ecosystem well-being and in the next section we will delineate the necessary steps to obtain the resulting index for the Italian Provincial Capitals.
3 The Spatial Based Approach for Urban Well-Being CI Construction
Our study proceeds along the lines of research delineated in Sect. 2 and relies on a combined approach, rooted in GW PCA and DEA to derive a spatial composite index for assessing the well-being in the Italian urban areas. The first step towards the construction of a spatial composite index for urban well-being is to use the GW PCA to reduce the the dimensionality of Ur-Bes elementary indicators. Next, the profiling of Italian Province capital cities well-being efficiencies is achieved by means of a BoD model. In what follows, we introduce both GW PCA and DEA-BoD techniques.
3.1 Geographically Weighted PCA
As discussed before, during the process of construction of a composite index, multivariate statistical methods can be used in the phase of variables weighting. These methods enjoy the benefit of no requiring prior assumptions on the weights of the different dimensions. In the weighting of CIs the most used multivariate techniques are Factor analysis and PCA (Booysen 2002), and Tabachnick and Fidell (2007) recommend to use the latter when the researcher’s goal is to obtain an empirical summary of the data set that explain the maximum variance with a unique mathematical solution.
Here, we propose a parsimonious summarization of well-being sub-indicators within each pillar of Ur-Bes through the GW PCA.
GW PCA is a local spatial form of the PCA, firstly implemented by Harris et al. (2011), able to provide locally derived sets of principal components for each location, to account for spatial heterogeneity. The extension of the basic PCA model to encompass geographic effects requires the supposition that there are regions of the geographic space in which distinct PCA models apply. In our study, dealing with the construction of composite index for each urban well-being dimension for the Italian Province capital cities, this means that despite the employment of the same variables across the Italian peninsula, they may have different local importance because of the probable presence of spatial heterogeneity.
To obtain geographically weighted principal components, the starting point is the admittance that the elementary indicators have an associated location, that may cause spatial effects, that is spatial heterogeneity and spatial autocorrelation (Demšar et al. 2013). Accordingly, we assume that the vector of observed well-being variables at location i has a multivariate normal distribution, with mean vector \({{\varvec{\mu }}}\) and variance-covariance matrix \({{\varvec{\Sigma }}}\) (\(x_{i} \sim \mathcal {N}({{\varvec{\mu }}}, {{\varvec{\Sigma }}})\)). The mean vector \({{\varvec{\mu }}}\) and variance-covariance matrix \({{\varvec{\Sigma }}}\) are now function of location i, with coordinates (u, v). This implies that each element of the mean vector and the variance matrix is, in turn, function of position and are expressed as \({{\varvec{\mu }}}(u,v)\) and \( {{\varvec{\Sigma }}}(u,v)\), respectively.
The geographically weighted principal components are obtained through the decomposition of the geographically weighted variance-covariance matrix:
where \({\mathbf {W}}(u,v)\) is a diagonal matrix of weights. As for any geographically weighted methods, diverse kernel functions (Gaussian, exponential, bi-square) can be employed to generate the diagonal matrix of weights, under the control of a parameter known as bandwidth.
The local principal component at location \((u_{i},v_{i})\) can be written as:
where \( {\mathbf {L}}(u_{i},v_{i})\) is the matrix of the geographically weighted eigenvectors and \({\mathbf {V}}(u_{i},v_{i})\) is the diagonal matrix of the geographically weighted eigenvalues. For p variables, the GW PCA provides p components, p eigenvalues, p set of component loadings and p set of component scores for each data location in the study area.
For the GW PCA is possible to specify a robust version to compress the artificial effects that outliers may have on local data structure. In the robust framework GW PCA, each local covariance matrix is estimated using the robust minimum covariance determinant (MCD) estimator (Rousseeuw 1985). The GW PCA results can be mapped to identify the spatial variation in multivariate data composition and inform on the complexity and local intrinsic dimensionality of the data.
Before proceeding to interpreting local relationships between original variables at each location, it is essential to ascertain if eigenvalues vary significantly across space and, hence, if there is any spatial non-stationarity present in the data matrix. To this end, a Monte Carlo test (Hope 1968) is performed and a significance level computed from a large number of randomized distributions. Differently from GWR, for the local PCA, until now, there are no available diagnostics to judge whether it provides a significant benefit over its global counterpart. Full technical details underlying GW PCA are described in Harris et al. (2011).
3.2 DEA-CI Model
DEA, which was pioneered by Charnes et al. (1978), has been traditionally employed as a performance evaluation methodology to measure the so-called relative efficiency of organizational homogeneous units, termed Decision Making Units (DMUs), within production contexts, characterized by multiple outputs and inputs. DEA uses linear programming methods to determine how well a DMU converts a set of inputs into a set of outputs. Specifically, this technique compares the resources used (inputs) and the quantities produced (outputs) of a DMU to the levels of other units, and the result is the construction of an efficient frontier. In such way, it is established a dichotomous classification between efficient and inefficient units: the DMUs lying on the frontier, achieving a unitary score, are technically efficient, whilst the others, with scores less than unity, are technically inefficient.
A variety of forms of the DEA model have been proposed in literature. The most common DEA models are the CCR (Charnes et al. 1978), which works with constant return to scale (CRS), and the BCC (Banker et al. 1984), which, instead, presupposes variable returns-to-scale (VRS). In the case of CRS model it is assumed a proportional increase (or decrease) of the outputs compared to an increase (or decrease) in inputs. Instead, DEA models are referred as VRS models when there is a greater increase (or decrease) of the outputs compared to a proportional increase in the inputs (or decrease) or when there is smaller increase (or decrease) of the outputs compared to a proportional increase (or decrease) in the inputs. Besides, the DEA models can be input or output oriented and the choice depends on the context of performance evaluation and the DMUs purposes. With input-oriented DEA, the linear programming model is configured so as to determine how much the input use of a DMU could contract if used efficiently in order to achieve the same output level. In contrast, with output-oriented DEA, the linear optimization is configured to maximize outputs without requiring an expansion of any of the observed input values, to achieve the full efficiency. A taxonomy and a general model framework can be found in Cook and Seiford (2009).
During the last decades the scope of DEA has broadened considerably. In particular, this technique has been used in many decisional situations related, for instance, to education, health, financial institutions, sports. In this regard, Emrouznejad and Yang (2018) provide an extensive listing of DEA-related articles.
In DEA literature, it has been appreciated the conceptual similarity between the original problem, that is the measurement of each DMU relative efficiency, given the observations on inputs and outputs in a sample of peers, and the one of constructing CIs.
Despotis (2005a) highlights that the appealing feature of the DEA of being a data-oriented technique, where weight are endogenously determined, turns out useful in the field of CIs. In fact, DEA guarantees that a poor performance of a DMU cannot be attributable to a given weighting scheme. In other words, each DMU is put in the most favorable light as any other set of weights would yield a lower composite score. Therefore, the lack of consensus on an appropriate weighting scheme in the typical CI-context justifies the adoption of this data-oriented weighting method which represents a deviation from common practices in the CIs construction.
The application of DEA to the field of composite indicators is traditionally named as Benefit of Doubt (BoD) approach. This method was originally used by Melyn and Moesen (1991) in the context of macro-economic performance evaluation. The underlying intuition of BoD method is that a good relative performance of a unit in a particular dimension means that this unit considers that dimension as relatively important. Equally, a poor performance indicates that a unit attaches less relative importance to that dimension. As highlighted by de Witte et al. (2013), unlike standard DEA, BoD exclusively focuses on aggregating outputs. It can be easily verified that the BoD model is like a DEA model with “dummy inputs” equal for all units and the indicators as outputs (Cherchye et al. 2007). Other than the consideration that the weights implemented for each indicator vary from unit to unit and they are the most advantageous for each unit, other valuable remarks arising from the BoD application in the context of CIs are that the aggregation between indicators is done as a linear combination and the index obtained is related to the units analyzed and ranges from 0 to 1.
The implementation of DEA methods to constructs CIs can be found in different studies in which DEA-based CIs have inter alia been used to assess environmental performance (Färe et al. 2004), macro-economic performance (Ramanathan 2006), sustainable energy (Zhou et al. 2007), technology achievement (Cherchye et al. 2008) and road safety performance (Hermans et al. 2009; Shen et al. 2010).
Furthermore, DEA has greatly contributed to construct CIs for human development. The properties of DEA as a powerful aggregation tool have been exploited for the first time to evaluate the quality of life by Hashimoto and Ishikawa (1993). After the above-mentioned work, there have been other experiences involving the application of DEA to human and social development.
Among these researches, the prominent papers that rely on DEA-BoD are those of Despotis (2005a, b), Zhou et al. (2010), Murias et al. (2006), Guardiola and Picazo-Tadeo (2014). Anyway, a structured literature review focusing on human development and DEA is provided in Mariano et al. (2015). In our case, to introduce DEA as a tool for constructing urban well-being composite indicator, we consider n entities, the Italian Province capital cities, for each of them m indicators are available. To be in line with the standard DEA jargon, we also refer to indicators as outputs. We denote with \(y_{ij}\) the value of indicator i in the province j. In order to provide an aggregated performance score for each capital Province j in terms of well-being outputs, we consider the following linear programming problem:
From above, it results that all weights are required to be positive. Also, in the objective function the weights, automatically derived, have to guarantee that no capital Province city achieves a value greater than unity. In such way, we obtain an intuitive interpretation of the CI, whose values are in the range [0,1], with higher values indicating better relative performance.
The assumptions underlying this specific analysis are the variable returns-to-scale (VRS) and the output-oriented approach. In this latter regard, as pointed out by Despotis (2005a), it should be noticed that the above linear programming is, indeed, conceptually equivalent to perform an output-oriented DEA model with constant inputs. More exactly, the indicators represent the different outputs and a single “dummy input”, with unitary value, is assigned to each city. Lovell et al. (1995) and Cherchye et al. (2007) emphasize the appropriateness of a DEA model with only outputs and a single unitary input to deal with situations in which one does not have the classic production model but one can only rely on secondary variables, obtained as rates or combinations of primary variables.
4 Urban Well-Being in Italy: The Case of Provincial Capitals
To evaluate the relative efficiency of Italian Province capital cities in promoting human and ecosystem well-being, we refer to the Ur-Bes framework which appraises well-being by a great deal of variables, belonging to eleven different dimensions. It is worth noting that unlike the national BES project, in the urban initiative the subjective well-being is not measured at all.
Owing to the data unavailability and missing values, our analysis is restricted to 103 Province capital cities and takes into account eight out of eleven domains of the original Ur-Bes dataset. In particular, we focus on the following domains: “Health”, “Education and Training”, “Work and Life Balance”, “Economic well-being”, “Social Relationships”, “Security”, “Landscape and Cultural Heritage”, “Environment”. The list of the elementary indicators available at NUTS3 (provincial) level is provided in Table 2, displayed in the “Appendix”.
According to the method described in the previous section, we first compute a spatial composite index for each Ur-Bes dimension, exploiting the weights extracted from GW PCA.
GW PCA analyses were performed in R, utilising the GWmodel package (Gollini et al. 2015; Lu et al. 2014). Before the application of the GW PCA, the original set of indicators have been normalized to a common, comparable, unitless scale using a max–min method. The linear transformation obtained through the normalization of individual variables preserves the ranking and correlation structure of the original data (Tran et al. 2010).
In the analysis, we used a bi-square kernel function with adaptive bandwidths, whose sizes are selected via cross-validation (Farber and Páez 2007). Such specification tends to provide outputs that vary smoothly over space, with the useful property that the weight is zero at a finite distance. Besides, the calibration of GW PCA with adaptive bandwidths is required to suit irregular sample configurations.
The output of GW PCA returns both local change in the structure of multivariate data and how the original well-being indicators influence the local principal components retrieved for each Ur-Bes pillar.
To highlight how the results of analysis are affected by spatial effects, both the conventional PCA and its local version (GW PCA) were separately applied to the selected domains of Ur-Bes framework.
Using the global PCA, it was possible ascertain that for the majority of dimensions the first two components can collectively explain more than 70% of the total variances, as shown in Table 3 provided in the “Appendix”.
Albeit the global PCA has its merit in dealing with comprehensive and complex data sets, the standard version ignores any spatial variation across a study area. In fact, PCA related outputs are whole map statistics which are unable of capturing local characteristics.
By plotting the scores of first component for each Ur-Bes pillar, we observe that their spatial distributions exhibit a certain degree of geographically clustering trend across the Italian peninsula. The correspondent maps are shown in the “Appendix”. Specifically, there is a strong spatial differentiation between the positive and negative principal component scores, recorded in the North and the South part of the country, respectively. As a further analysis, we carried out the Moran I test for the two first global components scores. In general, the results of Moran I test (see Table 4 in the “Appendix”) reveal a statistically positive spatial autocorrelation for both the components we considered, leading to reject the hypothesis that principal components scores express a random spatial pattern.
Accordingly, it is crucial to extricate the detailed local variations by means of GW PCA. GW PCA has the benefit to distinguish regions in the geographic space in which different and distinct PCA have to be performed. The spatial nature of GW PCA enables to map the spatial variations of each local component. Besides, the use of GW PCA ensures that the percentage of the total variance explained is returned for each spatial unit. Figure 1 shows, for each pillar, the localized proportion of the total variance (PTV) for the robust GW PCA. The PTVs maps reveal that the spatial patterns in the proportion of the explained variance vary significantly across the study region, allowing, in such way to highlight urban differences.


Robust PTV data for the first two local components for each Ur-Bes domain
In general, for the majority of the urban well-being domains the highest PTVs are located in the Province capital cities of the Southern Italy. Some exceptions are recorded for the “Security” pillar, for which the PTVs data are lower in the Province capital cities of Central Italy. The spatial clustering trend for the variance values (Fig. 1) suggests that the interactions among the selected urban well-being indicators converge spatially. In the areas characterized by highest PTVs it is sensible to assume a major correlation (or local collinearity) among well-being data, thereby not all Ur-Bes indicators should be considered.
To extricate how each Ur-Bes elementary indicator influences a given dimension, it is possible to map, the “winning variable”, that is the variable with the highest loading value (Lloyd 2010).
Previous to interpreting the localized PCA, we carried out a significance analysis to diagnose if there is any spatial heterogeneity in the distribution of indicators across the study region. A significance test has been performed for the first principal component of the Ur-Bes dimensions; results of Monte Carlo test confirm the presence of spatial heterogeneity for all dimensions.
In what follows, we present the findings obtained retaining only the first component, accounting for a substantial proportion of the variability in the original data (Fig. 2). It should be noted that, owing to the large number of spatial units involved, the calibration of GW PCA in R environment does not allow to automatically detect the variable with the highest loading value, the so-called “winning variable”. As a feasible compromise, we consider the use of the variable loadings of the first components, which explain a large part of total variance of the data (more than 70% for all urban well-being domains).


Robust GW PCA results for the winning variable on the first component for each Ur-Bes domain
Looking at the robust outputs for the domain “Health”, the thematic maps of the local principal components reveal multifaceted geographical variations in the variables with the largest loadings. From GW PCA robust results, we see that first component is mainly represented by the age-standardised cancer mortality rate (19–64 years old) in the Province capital cities of Piemonte and Trentino Alto Adige; by life expectancy at birth (male) in most cities of central Italian regions and in Sardinia, and by life expectancy at birth (female) and mortality rate for road accidents (15–34 years old) for the Southern Province capital cities.
By mapping the spatial variation of the first local component of the “Education and Training” domain, we find out that it mainly considers the participation to primary school and this elementary indicator dominates in most urban areas, with some exceptions for a number of Province capital cities of Calabria and Sicily, where the leading variable is represented by the early leavers from education and training, aimed to capture the problem of school dropout.
For ‘Work and life balance” pillar we observe a lesser geographic variation in the influence of each variable on the first component: for the majority of cities the dominant variable is the employment rate of women.
Focusing on the “Economic well-being” dimension, the map of robust GW PCA results indicates some geographical differences in the highest absolute loadings. In particular, in the Italian Northern Province capital cities the winning variable on the first local component is households with suffering bank debts, while in the Central area of study region the dominant indicator is related to the per capita adjusted disposable income; finally in the Southern cities the most influential variable is linked to quality of dwellings.
As for the “Social relationships” dimension, we record that in the Northern Italian Province capital cities the first local component is characterized by the disseminations of no-profits institutions and by the number of paid workers in local units of social cooperatives; in the urban areas of the South of Italy determinant for this component is the presence of social cooperatives.
Moving to analyze the results for the “Security” domain, we observe geographical variations in the indicators selected for having a picture of crime. On the basis of the winning variable for first local component, we are able to discriminate the Northern spatial units, where the dominant variable is represented by the number of burglaries, from the Southern provinces, for which the relevant indicator is linked to the homicide rate.
The presence of spatial differences is also confirmed for the “Landscape and cultural heritage” pillar. In the provinces of Northern Italy, the winning variable is related to the conservation of historic urban fabric; conversely, in the Central and Southern urban areas determinant is the influence of the variable associated to the fruition of museums.
Finally, we focus on the “Environment” domain. We see that for the robust GW PCA, the “winning variable” in the Northern cities is the indicator related to the exceeding of the daily limit for the protection of human health for\(PM_{10};\) whereas, in the Central and South part of Italy mostly dominant is the variable describing the drinkable water supplied every day per capita.
Within each pillar, the set of well-being elementary indicator is combined through the GW PCA, exploiting the advantageous property of accounting for local differences in the spatial scale of variations of the utilized indicators. Through this spatial version of PCA we achieve the loading for each variable in each of 103 locations of the spatial model. Once weights are obtained for each variable in each location, the spatial composite indicator for the urban well-being dimensions, has been computed as the weighted sum (linear combination) of the variables, location by location. For the arising composite indices a data transformation has been undertaken to respect their positive o negative linkages with equitable and sustainable well-being and assure strictly positive data.Footnote 1
In the second stage of the analysis, the overall well-being index is obtained via DEA-BoD, with entities defined only by outputs. DEA is applied to evaluate and compare the relative efficiency of Italian Province capital cities in promoting well-being. Table 1 shows the efficiency scores and ranking levels of the Italian Province capital cities. Efficiencies are between 78.8 and 100% while the mean efficiency is 97.2%. For thirty-four cities we record a well-being efficiency score which is below average. A large number of efficient cities are located in the North and Central part of Italy; among the provinces of South achieve the highest level in the ranking Taranto, Enna, Ragusa, Palermo, Trapani, Caltanisetta and Oristano. In the last positions of the ranking we find Napoli, Salerno, Foggia, Bari, Benevento, Isernia, Caserta, Ascoli Piceno, Chieti, Macerata and Agrigento.
Our results can act as a vehicle for policy makers, spur public support and create a mechanism for prioritizing resources. For instance, the capability of GW-PCA to extract the local importance of a certain indicator by means of the local variable loading, gives insights on local determinants of wellbeing. From a planner’s point of view, knowledge on the spatial structure of data can be used to shape local policy priorities. For this specific study, as previously observed, we found out that some Province capital cities in the South have a clear disadvantage in terms of early leaving from education and training. Accordingly, education authorities should strive to address the underlying factors of this phenomenon which, as known, translates into reduced opportunities in the labour market and an increased likelihood of unemployment, socio-economic inequalities, health problems, as well as reduced participation in political, social and cultural spheres. Abundant research indicates that strategies to tackle and combat early leaving from education and training should include prevention, intervention and compensation policies. On the other hand, it is easy to understand that the characterization and identification of specific well-being drivers and the way they accumulate in a given area would missing using global multivariate analysis. The usage of global PCA for the dimension at hand (the education pillar) would have only revealed the leading role of the elementary indicator associated to early leavers for the whole country, masking the geographic heterogeneity that might exist between variables over space. This, in terms of policies, would mean a less coherent and focused strategies to improve outcomes well-being delivery.
Similarly, another clear example of policy implications arising from our study, can be inferred for the security domain. Taking the spatial characteristics of data into account, we found out that the homicide rate is the driver of that domain in the Southern urban areas. It is well known that crime has direct and huge long-lasting effects on victims as well as economic and social consequences, such as the erosion of human and social capital, a worse business climate. As a result, it is desirable to bring down homicide rates. To this end, potential decision-makers should target interventions backed by sustained engagement and trust between communities and law enforcement. As before, these local peculiarities cannot be captured through the lens of global analysis. In terms of efficiency ranking, one can interpret the overall spatial composite indices for each urban context as useful tools for evaluating areas where human and ecosystem well-being inequalities are accumulating.
5 Conclusions
This study has proposed a spatial composite indicator of urban well-being which can provide objective measures to decision makers and insights on how cities are governed and regulated.
The research we conducted has the merit to evaluate and compare the Italian Province capital cities well-being according to different perspectives. Specifically, to evaluate the relative efficiency of Italian Province capital cities in promoting human and ecosystem conditions, we have gone through two different steps of analysis.
Initially, we looked at each city emphasizing the driving elementary indicators for the Ur-Bes dimensions and taking into account the spatial effects that may occur among the involved variables. To this end, we exploited the advantage of employing the GW PCA to understand the spatial dimension of the data. Our approach has the potential to give proper attention to the spatial dimension of variables which characterize the urban well-being pillars, highlighting in this way the spatial differences in values of a given elementary indicator for the probable presence of spatial heterogeneity.
From GW PCA results, it can be concluded that there is the presence of different spatial relations among indicators, depending on the place, with consequently varying importance in contributing to the overall index.
Our empirical study confirms the presence of heterogeneity between Northern and Southern capital cities. Among the specificities arising from the analysis, it is worth underling the leading role, for the education index, that the rate of early leavers from education and training play in most cities of Sicily and Calabria. Analogously, significant spatial divergences also characterize almost all the dimensions of well-being considered. Overall these results, confirm that the urban well-being divide in Italy is as important as the economic gaps, suggesting to give more attention in public policies to the well-being features of the Italian progress.
In the second stage of analysis, by using a BoD model to construct a composite indicator of urban well-being, we reduce subjectivity in the process involved in the building of this overall measure, because the weights that best support the cities in the analysis are not driven by a prior choice but they are endogenously decided. Results arising from this study provide comparable information on urban areas and interesting opportunities in terms of usefulness to policy makers and local policies aimed at increasing citizens’ well-being. Local managers can rely on synthetic information on urban well-being valuable to understand the strengths and weakness of their cities and to optimize the allocation of territorial resources and, in general, to make more robust and and more effective decisions.
Finally, it should be noted that the results of cities performance assessment here presented is obviously different from that obtained in our previous work on the same data (Nissi and Sarra 2018), where other assumptions, mainly in terms of weighting system and spatial effects, have been adopted. In this respect, we believe that embedding the spatial dimension on the construction of a CI enables to obtain a more robust representation of the area under study and more insightful findings for local policy-making.
Notes
We adopted a min–max transformation in a continuous scale from 70 (minimum) to 130 (maximum), which represents the range of each indicator over the given time period.
References
Anselin, L. (1990). What is special about spatial data? Alternatives perspectives on spatial data analysis. In D. A. Griffith (Ed.), Spatial Statistics, Past, Present and Future (1st ed.). Ann Arbor, MI: Institute of Mathematical Geography.
Bai, X., Nath, I., Capon, A., Hasan, N., & Jaron, D. (2012). Health and wellbeing in the changing urban environment: Complex challenges, scientific responses, and the way forward. Current Opinion in Environmental Sustainability, 4(4), 465–472.
Banai, R., & Rapino, M. A. (2009). Urban theory since A Theory of Good City Form (1981): A progress review. Journal of Urbanism: International Research on Placemaking and Urban Sustainability, 2(3), 259–276.
Banker, R. D., Charnes, A., & Cooper, W. W. (1984). Some models for estimating technical and scale inefficiencies in data envelopment analysis. Management Science, 30, 1078–1092.
Beaupuy, J. (2005). Report on the urban dimension in the context of enlargement. Technical report, Committee on Regional Development, Session Document of the European Parliament.
Booysen, F. (2002). An overview and evaluation of composite indices of development. Social Indicators Research, 59(2), 115–151.
Casini, L., Boncinelli, F., Contini, C., & Gerini, F. (2019). A Multicriteria Approach for Well-Being Assessment in Rural Areas. Social Indicators Research, 143, 411–432.
Charnes, A., Cooper, W. W., & Rhodes, E. (1978). Measuring the efficiency of decision making units. European Journal of Operational Research, 2(6), 429–444.
Cherchye, L., Moesen, W., Rogge, N., & Van Puyenbroeck, T. (2007). An introduction to ‘benefit of the doubt’ composite indicators. Social Indicators Research, 82(1), 111–145.
Cherchye, L., Moesen, W., Rogge, N., van Puyenbroeck, T., Saisana, M., Saltelli, A., et al. (2008). Creating composite indicators with DEA and robustness analysis: The case of the Technology Achievement Index. Journal of the Operational Research Society, 59(2), 239–251.
Cook, W. D., & Seiford, L. M. (2009). Data envelopment analysis (DEA)—Thirty years on. European Journal of Operational Research, 192(1), 1–17.
Costanza, R., Hart, M., Posner, S., et al. (2009). Beyond GDP: The need for new measures of progress. Technical report, Boston University Creative Services
de Witte, K., Rogge, N., Cherchye, L., & van Puyenbroeck, T. (2013). Economies of scope in research and teaching: A non-parametric investigation. Omega, 41(2), 385–390.
Demšar, U., Harris, P., Brunsdon, C., Fotheringham, A. S., & McLoone, S. (2013). Principal component analysis on spatial data: An overview. Annals of Association of American Geographers, 103(1), 106–128.
Despotis, D. K. (2005a). A reassessment of the Human Development Index via Data Envelopment Analysis. The Journal of the Operational Research Society, 56(8), 969–980.
Despotis, D. K. (2005b). Measuring human development via data envelopment analysis: The case of Asia and the Pacific. Omega, 33, 385–390.
Diamantopoulos, A., Riefler, P., & Roth, K. P. (2008). Advancing formative measurement models. Journal of Business Research, 61, 1203–1218.
Eger, R. J., & Maridal, J. H. (2015). A statistical meta-analysis of the wellbeing literature. International Journal of Wellbeing, 5(2), 45–74.
Emrouznejad, A., & Yang, G. L. (2018). A survey and analysis of the first 40 years of scholarly literature in DEA: 1978–2016. Socio-Economic Planning Sciences, 61(1), 1–5.
European Commission. (2009). GDP and beyond. Measuring progress in a changing world. Technical report, European Commission Communication
Farber, S., & Páez, A. (2007). A systematic investigation of cross-validation in GWR model estimation: Empirical analysis and Monte Carlo simulations. Journal of Geographical Systems, 9(4), 371–396.
Färe, R., Grosskopf, S., & Hernández-Sancho, F. (2004). Environmental performance: An index number approach. Resource and Energy Economics, 26(4), 343–352.
Fleurbaey, M. (2009). Beyond GDP: The quest for a measure of Social Welfare. Journal of Economic Literature, 47(4), 1029–1075.
Freudenberg, M. (2003). Composite indicators of country performance: A critical assessment. Technical report, OECD Science, Technology and Industry Working Papers. Paris: OECD Publishing
Fusco, E., Vidoli, F., & Sahoo, B. K. (2018). Spatial heterogeneity in composite indicator: A methodological proposal. Omega, 77(C), 1–14.
Gollini, I., Lu, B., Charlton, M., Brunsdon, C., & Harris, P. (2015). An R package for exploring spatial heterogeneity using geographically weighted models. Journal of Statistical Software, 63(17), 1–50.
Guardiola, J., & Picazo-Tadeo, A. J. (2014). Building weighted-domain composite indices of life satisfaction with data envelopment analysis. Social Indicators Research, 117(1), 257–274.
Hagerty, M. R., & Land, K. C. (2007). Constructing summary indices of quality of life: A model for the effect of heterogeneous importance weights. Sociological Methods and Research, 35(40), 455–496.
Hall, J., Giovannini, E., Morrone, A., & Ranuzzi, G. (2010). A framework to measure the progress of societies. Technical report, OECD statistics working papers, 2010/5, OECD Publishing
Harris, P., Brunsdon, C., & Charlton, M. (2011). Geographically weighted principal component analysis. International Journal of Geographical Information Science, 25(10), 1717–1739.
Hashimoto, A., & Ishikawa, H. (1993). Using DEA to evaluate the state of society as measured by multiple social indicators. Socio-Economic Planning Sciences, 27, 257–268.
Hermans, E., Brijs, T., Wets, G., & Vanhoof, K. (2009). Benchmarking road safety: Lessons to learn from a data envelopment analysis. Accident Analysis & Prevention, 41(1), 174–182.
Hope, A. C. A. (1968). A simplified Monte Carlo significance test procedure. Jounal of the Royal Statistical Society B, 30(3), 582–598.
Insch, A., & Florek, M. (2008). A great place to live, work and play: Conceptualising place satisfaction in the case of a city’s residents. Journal of Place Management and Development, 1(2), 138–149.
Istat. (2015). Il Benessere Equo e Sostenibile nelle città (in Italian). Technical report, ISTAT, Rome.
Larraz Iribas, B., & Pavia, J. M. (2010). Classifying regions for European development funding. European Urban and Regional Studies, 17(1), 99–106.
Lloyd, C. D. (2010). Analysis population characteristics using geographically weighted principal component analysis: A case study of Northern Ireland in 2001. Computers, Environment and Urban Systems, 34, 389–399.
Lovell, C. A. K., Pastor, J. T., & Turner, J. A. (1995). Measuring macroeconomic performance in the OECD: A comparison of European and non-European countries. European Journal of Operational Research, 87(3), 507–518.
Lu, B., Harris, P., Charlton, M., & Brunsdon, C. (2014). The GWmodel R package: Further topics for exploring spatial heterogeneity using geographically weighted models. Geo-spatial Information Science, 17(12), 85–101.
Mariano, E. B., Sobreiro, V. A., & Rebelatto, D. A. (2015). Human development and dataenvelopment analysis: A structured literature review. Omega, 54, 33–49.
Mazziotta, M., & Pareto, A. (2016). On a generalized non-compensatory composite index for measuring socio-economic phenomena. Social Indicators Research, 127, 983–1003.
Melyn, W., & Moesen, W. (1991). Towards a synthetic indicator of macroeconomic performance: Unequal weighting when limited information is available. Public economics research paper, CES 17, KU Leuven, KU Leuven
Michalos, A. C. (2008). Education, happiness and wellbeing. Social Indicators Research, 87(3), 347–366.
Munda, G., & Nardo, M. (2009). Non-compensatory/non-linear composite indicators for ranking countries: A defensible setting. Applied Economics, 41, 1513–1523.
Murias, P., Martínez, F., & Miguel, C. (2006). An economic wellbeing index for the spanish Provinces: A data envelopment analysis approach. Social Indicators Research, 77(3), 395–417.
Nardo, M., Saisana, M., Saltelli, A., Tarantola, S., Hoffman, A., & Giovannini, E. (2008). Handbook on constructing composite indicators: Methodology and user guide. Working papers 2005/3, OECD Statistics, OECD Publishing
Nicoletti, G., Scarpetta, S., & Boylaud, O. (2000). Summary indicators of product market regulation with an extension to employment protection legislation. Working Papers no. 226, ECO/WKP(99)18, Economics Department
Nissi, E., & Sarra, A. (2018). A measure of well-being across the Italian urban-areas: An integrated DEA-entropy approach. Social Indicators Research, 136(3), 1183–1029.
OECD. (2008). Handbook on constructing composite indicators. Paris: OECD Publishing.
OECD. (2011). How’s life? Measuring well-being. Paris: OECD Publishing.
Ramanathan, R. (2006). Evaluating the comparative performance of countries of the Middle East and North Africa: A DEA application. Socio-Economic Planning Sciences, 40(2), 156–167.
Rousseeuw, P. J. (1985). Multivariate estimation with high breakdown point. In W. Grossmann, G. Pflug, I. Vincze, & W. Wertz (Eds.), Mathematical statistics and applications (Vol. B, pp. 283–297). Dordrecht: Reidel.
Saaty, T. L. (1980). The analytic hierarchy process. Planning, priority setting, resource allocation. New York: McGraw-Hill.
Saaty, T. L. (2001). Decision making for leaders. The analytic hierarchy process for decisions in a complex world. Pittsburgh: RWS Publications.
Saltelli, S. (2007). Composite indicators between analysis and advocacy. Social Indicators Research, 81(1), 65–77.
Shen, Y., Hermans, E., Ruan, D., Wets, G., Brijs, T., & Vanhoof, K. (2010). Evaluating trauma management performance in Europe: A multiple-layer data envelopment analysis model. Transportation Research Record: Journal of the Transportation Research Board, 2148, 69–75.
Stiglitz, J., Sen, A., & Fitoussi, J.-P. (2009). Report by the commission on the measurement of economic performance and social progress. Technical report, French Commission on the Measurement of Economic Performance and Social Progress
Tabachnick, B. G., & Fidell, L. S. (2007). Using Multivariate Statistics. Boston: Pearson Education.
Tran, L. T., O’Neill, R. V., & Smith, E. R. (2010). Spatial pattern of environmental vulnerability in the Mid-Atlantic region, USA. Applied Geography, 30(2), 191–202.
Trogu, D., & Campagna, M. (2018). Towards spatial composite indicators: A case study on Sardinian landscape. Sustainability, 10(5), 1369.
UNDP. (2010). Human Development Report 2010: The Real Wealth of Nations: Pathways to Human Development. Technical report, United Nations, New York: Palgrave Macmillan.
United Nations. (2014). World Urbanization Prospects: The 2014 Revision, CD ROM Edition. Technical report, United Nations, Department of Economic and Social Affairs, Population Division, New York), NY USA .
Zhou, P., Ang, B. W., & Poh, K. L. (2007). A mathematical programming approach to constructing composite indicators. Ecological Economics, 62, 291–297.
Zhou, P., Ang, B. W., & Zhou, D. Q. (2010). Weighting and aggregation in composite indicator construction: A multiplicative optimization approach. Social Indicators Research, 96(1), 169–181.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Tables 2, 3 and 4 and Fig. 3.


Spatial distribution of first component. (Blue points positive values-red points negative values)
Rights and permissions
About this article

Cite this article
Sarra, A., Nissi, E. A Spatial Composite Indicator for Human and Ecosystem Well-Being in the Italian Urban Areas. Soc Indic Res 148, 353–377 (2020). https://doi.org/10.1007/s11205-019-02203-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11205-019-02203-y