
Abstract
Scientific cooperation is gaining importance as worldwide trends in co-authorship indicate. While clustering is an established method in this field and several have studied scientific-cooperation dynamics within a single discipline, little literature exists on its interdisciplinary facet. This paper analyses the evolution of co-authorship amongst social scientists in Slovenia over the three decades between 1991 and 2020 using bibliographic databases. The identification of groups (clusters) of authors based on patterns in their co-authorship ties both within and across decades is carried out using network-analytical method called stochastic blockmodeling (SBM). Meanwhile, previous research used generalised blockmodeling accounting only for within-period ties. Additionally, a topic model is developed to tentatively assess whether co-authorship is driven by research interests, organisational or disciplinary affiliation. Notably, while focusing on the result of the SBM for generalised multipartite networks, the paper draw compares with other SBMs. Generally, the paper identifies clusters of authors that are larger and less cohesive than those found in previous works. Specifically, there are three main findings. First, disciplines appear to become less important over time. Second, institutions remain central, corroborating the suggestion that Slovenian R&D policy reinforces parochial research practices. Yet, whether organisational segregation is an issue remains unclear. Third, interdisciplinarity’s emergence has been slow and partial, thus supporting the idea of a ‘covert interdisciplinarity.’ Importantly, it seems that members of different clusters lack fluency in a meta-language enabling effective communication across cognate paradigms. And this may hinder the implementation of long-term, up-to-date research policies in the country.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In its historically given form, the dominant mode of production of scientific knowledge between the middle of the seventeenth and twentieth centuries involved individuals carrying out research within well-defined disciplinary fences. However, a significant paradigm shift has been occurring since the second half of the twentieth century, with a visible acceleration in the first two decades of the twenty-first century. In essence, that shift marks the transition towards a collaborative mode of scientific-knowledge production and may encourage scientists to transcend disciplinary boundaries (Mali, 2010a; Wuchty et al., 2007). On the one hand, the coproduction of scientific knowledge is becoming increasingly prevalent across fields and around the globe. Partly, the growth in scientific collaboration stems from the challenges that individual researchers face in mobilising material and immaterial resources (equipment, workload, expertise). Moreover, advancements in information and communication technology (ICT) have significantly reduced distances between scientists accelerating and made collective efforts more affordable (Nowotny et al., 2003, p. 187). Furthermore, recent studies have shown that scientists engaging in collaboration produce a higher number of significant publications and receive more citations than those working alone (De Miranda Grochocki & Cabello, 2023; Henriksen, 2016; Rodrigues et al., 2016). Thus, empirical evidence corroborates the idea that collaborative research leads to more impactful and valuable scientific outcomes than individual endeavours (Adams, 2013; Gazni & Didegah, 2011). Consistently, various forms of scientific collaboration are now recognised as key drivers of productivity and quality enhancers in research (Beaver & Rosen, 2005). On the other hand, inter- and trans-disciplinary collaborations have not completely supplanted the traditional disciplinary and monographic structure of modern science. On the contrary, present-day science is still predominantly confined within the ‘chaos of disciplines’ (to borrow a successful phrase from Abbott, 2010; see also Rafols et al., 2012).
To some extent, the persistence of disciplinary fences follows also from epistemological reasons such as the commonplace emphasis on the incommensurability of scientific lexicons (Kuhn, 1991–1996/2022). Yet, interdisciplinary research is increasingly the focus of research and development (R&D) policy although it lacks disciplinary research’s track record. Currently, R&D policies increasingly invest in interdisciplinary collaboration as way to address pressing global issues and as a counterbalance to the dominant trend towards (hyper-)specialisation. This support manifests in new funding mechanisms, peer-review platforms, interdisciplinary research centres, fellowships, and grants (Abramo et al., 2018; D’Este & Robinson-García, 2023; Fontana et al., 2022). This trend is ushering in a new phase of scientific collaboration that allows for at least three way of transcending disciplines through different types of collaboration (Mali, 2010b; OECD, 1998): (1) multidisciplinary, characterised by coordinated work from the standpoint of each discipline; (2) interdisciplinary, involving the integration and linkage of disciplines; and (3) transdisciplinary, whereby disciplines are essentially transcended, transgressed, or transformed. Due to its strong orientation towards solving complex practical issues, the ongoing affirmation of scientific transdisciplinarity is deepening the ties between scientific and non-scientific sectors, such as corporations (Gibbons et al., 1994; Leydesdorff & Etzkowitz, 2001).
In light of this scientific and R&D policy context, our main objective is to explore the realm of interdisciplinary scientific collaboration in Slovenia over the last 30 years. Our approach consists in examining the temporal clustering of the co-authorship network amongst Slovenian social scientists. Innovatively, we propose dynamic-network blockmodeling as an effective method for charting the evolution of these co-authorship structures. As shown below (para. 2. Literature review), capturing their dynamic aspects more directly than other methods previously employed in the literature. Evidently, there are several choices underpinning this approach that ought to be clarified beforehand.
Why is our study of interdisciplinary collaboration grounded in analysis of co-authorship publications? The answer is simple. Detecting various forms of scientific collaboration, ranging from formal to informal, can be challenging (Laudel, 2002). Nevertheless, co-authored publications are recognized as an established and efficient tool for measuring the intensity of collaboration in science (Glänzel & Schubert, 2005; Katz & Martin, 1997). Co-authoring researchers contribute not only their individual expertise to a joint output but also engage in information exchange and mutual learning.
The choice of the social sciences warrants some arguing, too. In fact, significant differences in the rate of co-authorship publications between social sciences and science, technology, engineering, and math (STEM) are observed (see Fig. 1). And these gaps reflect the historical reality that co-authorship has long been predominant in STEM (Dahlander & McFarland, 2013; De Miranda Grochocki & Cabello, 2023). However, this study looks at the social sciences because the crossing of disciplinary boundaries to foster innovation through diverse knowledge and actors has become essential in this field, too. Our hypothesis is that the trend towards interdisciplinarity in the social sciences is tangible also in Slovenia.

Co-authorship rates and average number of co-authors in six scientific fields (top) and within the social sciences (bottom) in Slovenia from 1991 to 2021. Due to data-limitation issues, these counts only include authors registered as researchers in Slovenia (this includes mainly researchers working in academia and research institution, but excludes people employed in non-research institutions and those employed abroad, potentially underestimating the real figures
Finally, the selection of the period between 1991 and 2020 periodised into three decades is significant as well. By examining these three periods, we aim at identifying key milestones that shaped the cognitive and institutional characteristics of social sciences in Slovenia; at least indirectly. These milestones pertain to the evolution of national R&D policy mechanisms. As a small, Central-Eastern post-communist country, Slovenia went through transitions corresponding to these three decades.
In the first decade (1991–2000), Slovenia seceded from Yugoslavia and the political system democratised. Under real socialism, the imperatives of autarky and parochialism heavily shaped the social sciences, which were subject to strict political control (Adam & Makarovic, 2002; Kronegger et al., 2011). Thus, these years were marked by efforts to establish scientific autonomy and align national R&D-policy mechanisms with international standards, primarily those of European Union (EU) and the Organisation for Economic Co-operation and Development (OECD). The decade witnessed successful stories of collaboration between academic science and the business-enterprise sector (Mali, 1998), recruitment of PhDs in both sectors through the government-funded ‘Young Research Programme’ (Lešer et al., 2018), and the adoption of new ICT tools.
The second decade (2001–2010) marked the end of Slovenia's ‘learning period,’ as it strove to develop new R&D policy mechanisms to bridge the gap with the most advanced countries in Western Europe. Joining the EU in 2004 and the OECD in 2010, Slovenia benefited from the harmonisation process that facilitated its participation in EU research networks and informed R&D-policy reforms. In 2004, the establishment of an independent research agency currently named Agency for Research and Innovation in Slovenia (ARIS) was a key achievement of this policy convergence.Footnote 1 However, Slovenia did not capitalise on the opportunities presented by EU membership as much as other Eastern European countries.
The third decade (2011–2020) was characterizable as a period of maturity for Slovenia’s knowledge-production system. As a full member of the EU, the OECD, and other prestigious international organisations, Slovenia’s R&D policy has largely aligned with the knowledge-production standards of affluent countries. However, this period also witnessed tensions between ambition and operability in R&D-policy decisions. Obstacles still hinder the full realization of a modern R&D policy concept in Slovenia, with a significant gap persisting between aspirations and reality. During this period, Slovenia also faced major global challenges, including the Great Recession, which led to political instability and a banking crisis (Piroska & Podvršič, 2020). Although the recession did not cripple the country, it caused fluctuations in science funding. R&D expenditures dropped from 1.8% of government expenditure in 2011 to less than 1.3% in 2015 but have since been on the rise and hovering around 2% (Novak, 2023).
Our article is structured as follows: The first section includes a literature review, providing an overview of past bibliometric studies using co-authorship network and justifying our design choices. The second section offers a systematic description of the data and methods used for network creation and analysis. The third section discusses key findings from a dynamic-blockmodel analysis of the co-authorship network, both substantively and methodologically. Finally, the conclusions summarise the results, highlight potential limitations, and suggest directions for future research.
Literature review
Over the past two decades, there has been some interest among Slovenian scientists in exploring co-authorship networks. However, analyses of scientific interdisciplinarity, as an important research practice, have been absent or, at the very least, quite limited. Consequently, certain significant areas of interdisciplinary research have frequently been overlooked in social network, bibliometric, and sociological analyses. Past network-centred analyses based on data from national bibliographic databases primarily aimed to offer an integrated representation of scientific collaboration within specific disciplinary boundaries or related fields (Abbasi et al., 2011; Cugmas et al., 2016; Ferligoj & Kronegger, 2009; Ferligoj et al., 2015; Melin & Persson, 2005). In the case of Slovenian academia, the existing literature has mostly applied quantitative methods to longitudinal data such as surveys and the bibliometric analysis of co-authorship within disciplinary boundaries.
As a result, co-authorship practices have been assumed to exhibit a degree of homogeneity. In this regard, these network analyses followed the methodology of the highly influential study conducted by Moody (Moody, 2004) on the co-authorship among sociologists in 1963–1999. Moody concluded that both the average number of authors per co-authored paper and co-authorship rates grew exponentially over time.Footnote 2 However, contrary to Moody's findings, the growth in the Slovenian case was not exceptionally rapid, with an annual growth rate of 0.55% across all disciplines, near-linear preferential attachment,Footnote 3 and a strong (albeit decreasing) clustering coefficientFootnote 4 (Perc, 2010, pp. 477, 480). Similarly, analyses conducted on the case of Türkiye, another country outside the core of the European knowledge-production system, employed a similar approach and yielded comparable results, with an annual growth rate of 0.32% (cf, Çavuşoğlu & Türker, 2013).
Some of the previous studies focusing on Slovenia and based on the empirical analysis of bibliographic databases have focused on the differences in co-authorship practices among some disciplines (Ferligoj et al., 2015, p. 987; Groboljsek et al., 2014; Kronegger et al., 2011; Mali et al., 2010). For quite some time, these analyses were confined to comparing four disciplines: two natural sciences (physics and mathematics), a social science (sociology), and a biological science (biotechnology). Subsequently, the scope of these analyses was expanded to encompass all six fields recognised by the ARIS, each with its own network. (Cugmas et al., 2016; Ferligoj et al., 2015). Interestingly, these studies address questions about the continuity of collaboration over time by identifying cohesive groups of authors, known as clusters, and examining their stability. The focus is particularly on the dynamic nature of cooperation and its enduring, or at the very least, recurring features (Kronegger et al., 2011; Mali et al., 2010, 2012).
Overall, the results reveal a similar trend in the development of all scientific fields in Slovenia, albeit more pronounced than in previous studies. Specifically, three distinct types of author clusters emerged, in the analysis of co-authorship among Slovenian sociologists: core, semi-periphery, and periphery (Mali et al., 2010, pp. 42–43). The core is stable, exhibits a cohesive structure and comprises well-connected authors who collaborate extensively with each other. Incidentally, core authors are more likely tend to publish chapters in collective works, which may suggest that they systematically participate in large-scale research ARIS-financed projects (Mali et al., 2010, p. 43). The notion of semi-periphery describes differentiated clusters of researchers who co-author with the core less often than authors belonging to the core, and, to some extent, with each other. Finally, peripheral authors do not co-author with other Slovenian researchers. But often they publish works with foreign-based academics and non-academic researchers. Diachronically, the cores appear to remain stable in most disciplines, suggesting that this is a feature of the scientific system rather than of a specific discipline (Cugmas et al., 2016, p. 180ff). These analyses showed that the Slovenian co-authorship networks manifest high degrees of homophily,Footnote 5 strong parochial tendencies (at the disciplinary and institutional level) and a sizeable number of redundant contacts.Footnote 6 Moreover, core membership in the structure of Slovenian scientific co-authorship does not always serve as an indicator of scientific excellence. As noted by prominent social network theorists and sociologists of science, parochial cohesions among scientists can hinder the generation of new scientific ideas at the intersections of disciplines and in the international scientific arena. In fact, the entry of scholars who are not part of the established network provides more non-redundant connections. Moreover, these outsiders play a role in enhancing the effectiveness of information diffusion within otherwise parochial environments, where it is common for many scholars to share the same contacts (Burt, 2004; Granovetter, 1983; Ziman, 2001).
Due to the state of development of blockmodeling methods at the time of their publication, previous network-bases analyses of the Slovenian case relied on independent observations of co-authorship ties split into periods of five or ten years. In contrast, recent advancements enable the co-clustering of networks captured at successive points in time under more or less stringent assumptions. Leveraging such developments, this paper explores the first dynamic blockmodel of the co-authorship network among Slovenian social scientists spanning three decades, from 1991 to 2020. In doing so, it contributes to the existing literature by utilizing new methods to investigate longitudinal co-authorship data.
Building upon the previous literature, focusing on a set of related disciplines (such as the social sciences) serves a double purpose. First, it strikes a balance between precise yet relatively narrow studies of individual disciplines and overly complex but comprehensive analyses of cross-disciplinary networks. Moreover, the inherent similarity in scientific-collaboration and co-authorship patterns across the social sciences arguably make it better suited to offer practical guidance to policymakers. Moreover, in the specific case of Slovenia, there are visible differences in the way co-authorship takes place across disciplines. Namely, expanding on previous findings with new data for the period 2011–2021, the large gap existing between the average co-authorship ratesFootnote 7 in the ‘hard sciences’ (natural, medical, bio-technical sciences and engineering), on the one hand, and the humanities and social sciences, on the other, has been shrinking (Fig. 1, panel a). However, convergence on similar outcomes should not mislead into believing that trajectories and real-world practices are identical. On the contrary, there was considerable instability in the trajectory of all fields, with noteworthy differences in cross-field variability. Furthermore, the practices of co-authorship remain vastly different, with the average number of co-authors in the social sciences and humanities hover around two while in most fields that number is larger than four and even larger than six for the natural sciences and mathematics (Fig. 1, panel B). Concerning the differences in collaboration among disciplines measured by co-authorship, a lot of studies made in other national contexts converged to the equivalent results (Endersby, 1996; Fortunato et al., 2018; González Brambila & Olivares-Vázquez, 2021).
In light of these differences, attempts at analysing networks that span ‘hard’ and ‘soft’ sciences is much more complex, carries a heightened risk of producing modest results and may lead to ill-targeted policy advice. Meanwhile, the focus has been mostly on individual sets of disciplines and/or comparisons between co-authorship networks of different disciplines. Albeit there is no defined consensus on the issue, it seems reasonable to argue that transdisciplinary networks better capture system-wide changes. Vice versa, considering disciplinary boundaries may provide more fine-grained descriptions and suggestions.
Data and Methods
This section begins by presenting (1) the data sources and the guiding criteria for preliminary data selection, and (2) the data-processing operations that led to the final co-authorship network. The remainder of the section presents the methods using in the four parts of the analyses. First, it presents the generalised multipartite stochastic blockmodeling (MBM) the results of which are presented in the ‘Results’ section. Subsequently, a Bayesian topic model (fit using latent Dirichlet allocation) is presented as a tool to obtain further insights on the blockmodeling results’ meaning. Finally, other approaches to stochastic blockmodeling (SBM) applicable to dynamic networks are presented as they are instrumental for cross validating the salient features of the MBM’s results.
Data sources and selection
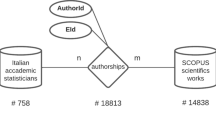
The co-authorship network used for this paper is built on data drawn from two main sources: the Co-operative Online Bibliographic System and Services (COBISS) (IZUM, 2023) and the Slovenian Current Research Information System (SICRIS) (ARRS, 2023). The SICRIS provides comprehensive information about researchers (incl. their education level and employment status), research groups, projects, and organisational affiliation. Meanwhile, COBISS functions as a national bibliographic database, allowing to associate individual researchers to their published works. So, linking SICRIS and COBISS while retaining only information on works in the social sciences, yields a database including over 81,000 works of the selected types published by more than 3,000 unique social scientists during the period 1991–2020.
Time-period selection
Indeed, the available data are well suited for the aforementioned periodisation. In fact, most of the records in these two databases belong to the period 1991–2020 (95% of the authors and 87% of the works). Thus, this choice allows to accommodate methodological as weel as substantive needs in the study of scientific cooperation and R&D policy in Slovenia.Footnote 8 For both substantive and methodological reasons, this period is split into three decades: 1991–2000, 2001–2010, 2011–2020.
Work-type selection
The COBISS lists a broad set of bibliographic entries including not just journal articles and monographs, but also many other types of material held by libraries and research still in progress. To give a faithful representation of Slovenian researchers’ scientific collaboration, the co-authorship network was built on the basis only of collaboration for works that the ARIS considers ‘scientific’ according to its internal criteria (as suggested in Kronegger, 2011, pp. 112–113).
Hence, the types of works underlying the network are: journal papers (original, reviews, short forms), papers published in conference proceedings, (chapters in) monographies, multimedia (audio or video recordings), databases/corpora, and patents.Footnote 9 Arguably, Slovenian researchers have substantive incentives to publish in these categories because the Slovenian research agency classifies them as relevant scientific contributions. Moreover, there is an established literature considering these types of work in the aggregate and yielding consistent results (see, amongst others, Mali et al., 2010, 2012; Ferligoj et al., 2015; Kronegger et al., 2015; Cugmas et al., 2020).
Other information
The SICRIS database provides detailed information on most of the authors whose works appear in the COBISS bibliography such as name, surname, sex, discipline, and organisation. In particular, the latter two variables are employed to help ‘make sense of’ the SBM partition. In fact, they are traits of the authors that could theoretically drive their patterns of scientific cooperation (on disciplines, see: Stephan & Levin, 1992, p. 110ff; Hudson, 1996; on organisations cf. the arguments in Cugmas et al., 2020, pp. 2471–2475) which do not inform the model directly. Thus, analyses of the clusters’ disciplinary and organisational composition are presented as a lens through which the partition can be interpreted.
Network creation procedure
The existing literature describes several ways of measuring co-authorship. So much so that the network-creation method presented here is a key innovation compared on previous studies on co-authorship in Slovenia. In fact, most of the existing literature focused on extremely cohesive and, logically small, groups in which almost everyone is tied to almost everyone else—what is sometimes called a clique. Instead, this research focuses on larger groups that are much more cohesive that the rest of the network, but comparatively less cohesive than those previously analysed.
Even with this clear objective in mind, the practical implementation is still far from predetermined. The most straightforward methods consist in creating simple binary ties that indicate whether any two authors have co-authored at least one eligible work within a specific period. Another, still relatively uncomplicated option consists in counting the number of works co-authored by each couple of individuals during each period and assigning this value to the weighted tie between them. However, both approaches have limitations that may warrant against their use. First, just counting the number of works that lists two researchers as co-authors does not account for the inverse relation between the number of co-authors and the average intensity of cooperation. In fact, publishing a work with a lot of authors does not necessarily mean knowing them all personally or have collaborated extensively with each and every of them. Yet, using these count weighted ties or simple binary ties lets works with a high number of co-authors create large cliques and, thus, may misrepresentation the reality of scientific collaboration. Furthermore, cliques are problematic for the SBMs used to analyse this network as they assume that within-group ties occur randomly with a given probability.
Therefore, considering the limitations of treating all co-authored works equally and the complications arising from large cliques, alternative approaches should be explored to capture meaningful collaboration patterns in co-authorship networks. One way to do so, which is also supported in the literature, is assign to the ties so-called Newman weights (Newman, 2001; cf. also Batagelj, 2020). In this way, each work cannot increase the total weight of all ties in the network by more than one. So, implicitly, co-authorship ties based on works with more co-authors are penalised compared to the opposite case. Namely, each work \(w\) contributes to the value (\(v\)) of tie between each pair of co-authors \(i, j\) in reverse proportion to the total number of authors (\({n}_{w}\); see Eq. 1). Then, the choice of a specific binarization value ought to took stake of two competing needs: reducing the network size, which pushed for lower thresholds; and keeping all meaningful co-operations, which imposes a floor on the threshold itself. Given that the average number of co-authors per work in the social sciences is around two, the network was binarized by setting the threshold at \(1/12\). So, all the ties with values indicating a cooperation less intense than co-authoring a paper with four total authors were zeroed (see Eq. 1).
Intuitively, despite using a formula that is well-argued for, the ties’ exact value is still somewhat arbitrary and, thus, not necessarily optimal. Even if the values are sufficiently precise, most blockmodeling approaches were originally designed for binary networks and perform the best in such applications. Indeed, there are blockmodeling approaches designed for valued networks (Nordlund & Žiberna, 2019) while some of the SBMs applicable to dynamic networks also support weighted ties. However, their performance on non-binary networks is still uncertain. From a practical point of view, one must consider that a network including several thousands of units is not just difficult to interpret, but of intractable size for most of the SBMs discussed in this paper. In fact, even the best performing SBMs (as identified in Cugmas & Žiberna, 2023) can only blockmodel networks with up to a few hundred units in each period in a reasonable time. Hence, to deal with both these issues, the network’s boundaries were restricted using a binarization threshold and the technique called \(k\)-core decomposition. In the way, the attention is focused on the most connected units in the network. After all, these procedures remove the authors that are entertain weak and/or sporadic ties with the other. Thus, their influence on the general structure of the network would be limited to the addition of a large, unconnected cluster. Notably, the selection of the exact binarization threshold and the minimum number of co-authors \(k\) for each author exposes to some degree of arbitrariness. Essentially, the specific value must consider the desired network size (around 600 units combining all time periods) while avoiding to arbitrarily omit valuable information. In addition, the value of \(k\) can justifiably be different for each period given that the network’s size varies with time. Eventually, the network was binarized to include all ties equivalent to having co-authored one work with four co-authors (\(1/12\)) and \(k\) was set, respectively, to four, five, and six for the three decades. Notably, each decade also includes nodes that would have been omitted only due to the \(k\)-core decomposition but qualified in at least one period. This yielded a co-authorship network in three time periods comprising 145 unique authors in the first decade, 275 in the second, and 316 in the third.
The distribution of works, authors, and disciplines over time is represented in Fig. 2. Summarily, it shows that authors from different disciplines benefitted to different extents from the near-exponential growth in co-authorship that ended in the late 2010s. In fact, about 40% of all works that contribute to ties in the final co-authorship network are always in economics. Moreover, pedagogy was similarly dominant during the decade starting in 1991. However, its relative presence in the network declined over time following a downward trajectory like, but speedier than, that of sociology. In contrast, management (encompassing both business studies and public administration) gained much traction over the years. Indeed, the thesis that the growth in scientific cooperation, and thus the final network, was unevenly distributed amongst disciplines is corroborated by an analysis of the authors that were not taken into account because they co-authored only sporadically and/or with just a few other researchers. In fact, these thresholds affected some disciplines (such as sociology, political science, and law) much more than others. Practically, in 1991–2000, most disciplines saw about half of their authors making it into the final network (on average, approx. 57%, excl. economics, sociology, psychology, and sports). Meanwhile, economists, psychologist, sociologists, and experts in sports fared much better: on average, just 25% of these disciplines’ authors was removed from the network due to insufficient co-authorship ties. In contrast, disciplines like library science, law, criminology, and social work, saw 70% of their authors or more failing to make it into the network in 2001–2010, whereas the figure is much lower for other disciplines. Meanwhile, once well-represented fields like sociology and political science, saw the share of removed authors almost double. Finally, this trend accentuates in the third period (2011–2020), when only four disciplines managed to get at least 30% of their authors in the network: economics, sports, management, and pedagogy.

Number of unique authors and number of works (total and count by discipline) in the network (1991–2020)
What is (stochastic) blockmodeling
Most studies on co-authorship use either non-network techniques (e.g., regression such as in Adams et al., 2005) or descriptive network statistics and basic clustering techniques (Abbasi et al., 2011; Çavuşoğlu & Türker, 2014; Ferligoj et al., 2015; Moody, 2004; Perc, 2010). Nevertheless, past analyses of Slovenian academia have already used successful a more refined clustering technique called blockmodeling (see, e.g., Mali et al., 2010, 2012; Cugmas et al., 2016, 2020). Indeed, this approach has been deemed especially useful for co-authorship networks since it is apt to identify the sort of (multi-)core/semi-periphery/periphery structure theoretically hypothesised for them (Cugmas et al., 2016; Kronegger et al., 2011).
Briefly, blockmodeling provides a comprehensive understanding of co-authorship networks and their overall structure. More extendedly, blockmodeling is a set of procedures that simplify large and potentially incoherent networks and reduce them to a smaller, comprehensible, and interpretable structure by identifying ‘clusters of equivalent units based on a selected definition of equivalence’ (Žiberna, 2007, p. 105). Basically, the most common types of equivalence sought after in blockmodeling are (Doreian et al., 1994): structural equivalence linking others in the same exact way) and regular equivalence (i.e., linking in equivalent ways equivalent units). In addition, stochastic blockmodeling (SBM) looks for an approximation of structural equivalence such that swapping two equivalent nodes does not affect the tie probability distribution (Lambiotte & Schaub, 2021, pp. 31–32).
In the SBM’s case, the local-optimisation procedure entails some degree of randomness due to the adoption of smooth stochastic optimisation procedures such as Markov chains (usually Monte Carlo-based, MCMC), the Newton–Raphson method, or some version of the expectation-maximisation (EM) algorithm (e.g., Bar-Hen et al., 2022; Chabert-Liddell et al., 2021; Škulj & Žiberna, 2022).. In most SBMs, the objective function is some likelihood-based formula that penalises for the number of clusters (Biernacki et al., 2000). However, there is also another major difference. In fact, generalised blockmodeling according to structural equivalence as employed in most previous studies searches for subgroups (blocs) of authors with either no or all possible ties amongst them. Formally, the density of such bloc should be as close as possible to zero in the former case (null block) or one in the latter (complete block). In practice, any block with density greater than one half is treated as complete vice versa for null blocks. But usually, co-authorship networks’ mean densities are below 0.1. Thus, such a threshold sets a high bar for a complete block and ends up favouring small, very dens complete blocks (indicating ties within or among groups). On the other hand, SBMs search for subgroups with that differ in their patter of ties (and, thus, blocks with different densities) without setting a fixed threshold, which leads to more diverse partitions with potentially larger and less cohesive clusters.
In dealing with networks’ evolution over time, the existing literature’s default method has long been to consider each period separately (even while not using blockmodeling, such as in Kronegger et al., 2015) and optimise distinct blockmodels for each time point (Cugmas et al., 2016; Kronegger et al., 2011). In contrast, this paper employs and presents SBM approaches able to leverage information from other time points to enhance the partition. Additionally, a dynamic model allows for an understanding of how the network's structure and partition by establishing a connection between different time points through time-dependent parameters (cf. the organic review in Lee & Wilkinson, 2019, esp. pp. 31–35). In this paper, based on previous simulation studies (Cugmas & Žiberna, 2023), five SBMs were selected: (1) the generalised multipartite blockmodeling (MBM, Bar-Hen et al., 2022), which produced the results presented in the main analysis; (2) the SBM for linked networks proposed by Škulj and Žiberna (2022); (3) Chabert-Liddell et al. (2021) SBM for multilevel networks; (4) Matias and Miele’s (2017) dynamic blockmodeling; and (5) Peixoto’s (2020) Bayesian SBM.Footnote 10
Generalised multipartite blockmodeling
The SBM called generalised multipartite blockmodeling (MBM) was initially proposed to study the intertwined sets of ties between distinct species within and ecosystem. It conceptualises these sets of relations as the juxtaposition of networks representing interaction between shared sets of individuals (Bar-Hen et al., 2022). By extension, it is adaptable to temporal networks conceived as a collection of (at least two) networks representing within-time relation and others (at least one) indicating cross-time relations between the same units in subsequent periods (Fig. 3a).

Comparison of the representations of dynamic networks for A MBM, B linked network SBM, and C dynamic SBM
The model and its implementation in the R package ‘GREMLINS’Footnote 11 pose extraordinarily little constraints, allows for units not present at all time periods, and supports partitions with a different number of clusters in each period. Furthermore, the implemented variational EM (VEM) algorithm automatically selects the optimal of cluster for each period within-time network based on its ICL criteria.
SBM for linked networks
The SBM for linked networks provides a different representation of dynamic networks, albeit the two interpretations are exchangeable and therefore equivalent. Instead of looking at a collection of distinct but interconnected networks, it considers a large-scale network comprising multiple sets of units (Fig. 3b). So, the purpose becomes to optimise a partition for each set of units that somehow takes into account the presence of (some) common units across different networks. In this case, the within- and cross-time networks are conceptualised as an organic whole, rather than the juxtaposition of several networks (Škulj & Žiberna, 2022).
The model and its implementation in the R package ‘StochBlock’ allow for units to be absent in some periods as well as for different numbers of clusters in each period. However, the implemented classification EM (CEM) algorithm cannot suggest an optimal number of clusters. Still, different partitions can be compared using ICL.Footnote 12
SBM for multilevel networks
The SBM for multilevel networks was originally proposed to deal with the sociology of organisations and the interdependence between individuals’ professional interactions and the ties between the organisations they are affiliated to (Chabert-Liddell et al., 2021). Essentially, these sets of ties are conceptualised as ‘layers’ rendered interdependent by the knowledge of people’s affiliation to one or another organisation.
The implementation offered in the R package MLVSBM provides a generalisation of this model to networks with an arbitrary number of such layers.Footnote 13 The choice of the best partition is automatic based on ICL, but it is heavily dependent on the initialisation, so multiple independent runs should employed and the one with the best ICL is to be chosen Here, the method was initialised starting from each of the’best’ partitions from the other approaches as well as allowing it to initialise with its preferred method (i.e., spectral clustering). Practically, the conceptualisation of these generalised multilevel networks can be compared to that of a generalised multipartite network. Hence, it is possible to consider each within-time network as a ‘layer’ and let the cross-time networks’ indication that the same authors are present across layer induce some temporal dependence. Namely, authors’ membership in a cluster at any given time is affected by the same author’s cluster membership in the previous period. Theoretically speaking, this method is especially suitable to identify consistent groups across layers/time.
Dynamic blockmodeling
The approach simply termed ‘dynamic stochastic blockmodeling’ proposed by Matias and Miele (2017) aims at ensuring that the groups’ evolution of over time can be easily tracked. In technical terms, since the overall social structure is supposedly stable, most units (in this case: authors) should not change group membership over time. However, due to computational limitations, it is not possible to impose this constraint directly in the mathematical modelling (i.e., operating on the transition matrix \([P]\)). So, the implementation offered in the R package ‘dynsbm’ forces within-group connectivity behaviour to be stable across time.Footnote 14 Notably, the model requires that the number of groups be constant for all time periods, too. A formula to compute ICL is provided and the results can be used to compare solutions with different number if clusters and to select the appropriate number of clusters. Thus, these assumptions are stronger than those required by the approaches and seem to indicate that this SBM works best when the network’s structure does not change much over time (see Cugmas & Žiberna, 2023).
Practically, inference on within-time clusters relies on a VEM algorithm whereas the dynamic (cross-time) part is modelled using MCMC. The network’s conceptualisation is close to that of generalised multipartite network with the difference that there are not cross-time networks and that all units/authors are noted down at all times in the same order regardless of whether they are present or not. In this way, the temporal network ends up being a \(T\)-dimensional array (where \(T\) is the number of periods) in which each row and column corresponds to a unit active in at least one period. The presence/absence of the units is reported in a dedicated matrix where rows are units and columns are periods. However, that matrix is not part of the network in the strictest sense of the term, rather it is a support to aid the necessary calculations. Meanwhile, the mathematical model is remarkably similar to the multilevel model with the main difference being the restriction on the stable within-group connectivity parameters and constant number of clusters.
Bayesian SBM
The SBMs described until now rely on a frequentist interpretation of randomness. Yet, Bayesian approaches to SBM are not only possible, but quite common (e.g., Mørup & Schmidt, 2012; Peixoto, 2013, 2020; Schmidt & Morup, 2013). In the case of the Bayesian SBM implemented, the model strives to be agnostic in laying out assumptions about the data (i.e., it uses uninformative prior probability distributions) according to the principle of maximum indifference. Thus, it infers the number of groups and their size—as well as units’ membership in them—from the network itself. By using this combination of priors and hyper-priors, the approach is robust to overfitting (i.e., finding more groups than there actually are). In addition, the model supports degree correction to fit highly heterogeneous degree distributions better as well as traditional SBM.Footnote 15 The implementation provided in the python module ‘graph-tool’ (Peixoto, 2020) automatically identifies the best partition using a minimum descriptor length based on entropy.
Albeit not thought for linked or dynamic networks, this approach can be adapted to them using one or another workaround. Adhering to the conceptualisation of linked network, a dynamic network can be represented as a large graph in which the units are authors in each period. So, each unit can have ties within-time, to other authors active in the same period, and cross-time, to itself in contiguous periods (see Fig. 3b). Essentially, partition-constraint labels allow to blockmodel a network by preventing units with different labels from being clustered together (as shown in Gerlach et al., 2018).
Bayesian topic model
Topic modelling is employed to understand how research interests relate to the patterns of scientific cooperation identified using SBM. It is a powerful unsupervised-machine-learning technique that uncovers latent patterns in large collections of text data. At its core, topic modelling identifies clusters of words that frequently co-occur together across ‘topics’ that compose (or are dealt with in) the texts under analysis (each called a ‘document’). Incidentally, this means assuming that cooccurrence is a valid indicator of semantic relatedness. So, topic modelling requires pre-processing: breaking the text into words (tokenisation), removing meaningless and overly frequently-used words (called stop-words), and reduce the remaining terms to their basic form. In the current application, the documents are the titles of the works determining the ties between the authors in the network, translated in English (if in a different language) aggregated over authors.
After having cleaned the texts,Footnote 16 the topics were identified using Latent Dirichlet Allocation (LDA), a Bayesian model.Footnote 17 LDA assumes that each topic is a probability distribution over words and each document is a probability distribution over topics. Through an iterative process, LDA estimates the topic-word distribution and the document-topic distribution, enabling the identification of the most relevant topics for each document and the most representative words for each topic. So, in this case, the LDA allowed to assign each author/document to the topic that contributes the most to the collection of the titles of its works. Practically, a document represents the titles of an author’s works published during one of the periods during which they were included in the network. So, each author can be associated with one, two, or three documents, but the number of documents in each period is the same as that of the units in the network at that time. But, given that the documents from all time periods were modelled jointly, the topics represent affiliations of which the SBM is unaware in the same way as organisations and disciplines are. Thus, they have been used to assess the meaningfulness of and provide an interpretation for the partitions. Finally, the number of topics was selected based on the measures for exclusivity and coherence (as proposed by Roberts et al., 2014).Footnote 18
Results
This section starts presenting the partition of the dynamic network of social scientists built from the COBISS-SICRIS database obtained using generalised multipartite blockmodeling (MBM). The clusters are first presented using basic descriptive statistics and then tentatively explained considering the authors’ organisational, disciplinary, and topic affiliations. Then, the partitions drawn using the other approaches described above are compared to the MBM’s results in terms of the key features emerging from the analysis for each type of affiliation.
The reason for focusing on this partition is multifaceted. On the one hand, this result represents a good summary of the salient features highlighted by several approaches. For instance, the limited extent to which clusters can be explained by their members’ affiliations and the many temporal continuities. On the other, it is much simpler than some other partitions, hosting just 21 clusters across three decades years. And this simplicity does not delete the fine-grained core-semiperiphery-periphery relations identified by other approaches (chiefly the SBM for linked networks). Rather, such structures are still present, but subsumed within a smaller number of clusters.
Generalised multipartite blockmodeling
The MBM implemented in the R package ‘GREMLINS’ automatically selected the number of clusters per period settling for three groups in 1991–2000, five in 2001–2010, and nine in 2011–2020. Arguably, the number of clusters increases with time mainly because each period includes more authors than in the past (see para. 3.2 above). However, this selection reflects a growing specialisation and differentiation of Slovenian academia, too (see 5.1 below).
Descriptive statistics
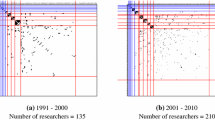
Descriptive statistics on the MBM partition are summarised in Fig. 4 below,Footnote 19 which shows a high variability in both density and size as well as, albeit less visibly so, average degree across clusters in all time periods.

Descriptive statistics of the partition produced by the MBM
Also, it is worth mentioning that the authors removed during the network-construction procedure would not have altered the blockmodel visibly. In fact, their pattern of ties is quite different from that of the authors included in the final network, as the network-construction procedure was intended to eliminate the least cooperative researchers. Namely, considering all co-authorship ties regardless of their strength and the number of unique co-authors, the average removed node had much less unique co-authors than the average researcher in the network.Footnote 20 Moreover, considering only the removed authors, they entertain little to no relation with each other and were mostly tied sporadically to authors in the network. Generally, those that do entertain relations with other removed authors do so on a small scale: couples or triples of authors co-authoring with each other more or less strongly, but with ties outside their dyad/triangle.
Blockmodeling analysis: static view and continuities
An accessible way to get a sense of this partition consists in plotting as a graph (see Fig. 5 or the Online Resources for the linked-network matrix drawn in line with the blockmodeling solutions).

Diagnostics of the LDA topic model for a model with between five and 34 topics
Since the VEM algorithm opted for just three clusters (labelled 1 through 3 in the figure) in the first period, the lack of a clear structure should be unsurprising. The clusters are mostly disconnected, except for some sporadic ties between clusters 1 and 2. Even though the latter is a denser cluster,Footnote 21 the difference is small and there are really a few ties between these two clusters. Thus, one cannot hypothesise a proper core-periphery relation between them. Meanwhile, cluster 3 seems to remain a community because of both its separateness and its higher density.
Summarily, it seems that the absence of a well-defined structure that marked the previous period persists in the second one, at least to some extent. Possibly, the lack of clear structural features is due to the splitting of pre-existing groups and their dilution due to the high number of newcomers. Yet, one can still notice that cluster 7 is a clique made up of units from cluster 3, that cluster 6 gathers many of the units previously in cluster 2, and that cluster 1 split in several groups.
A process of slow merging and remixing differentiates the third time period’s partition from the second period’s clustering, albeit only slightly. Interestingly, there seems to be a structure articulated around: multiple cores: cluster 12, 13, and 14 plus some sparser, but still well-connected groups (clusters 15, 10, and 9). Indeed, there are other dense clusters such as 11, 16, and 17, but they seem more self-contained and relatively isolated. In addition, the authors that were excluded from the network using binarization thresholds and \(k\)-core decomposition would have made up a large, unconnected cluster in each period (see 3.2 above). In fact, they are mostly authors that had extremely limited connections to those in the network or who co-authored only in very restricted groups (mostly pairs or triads, see 4.1.1 above). Given the circumstances, these findings are in line with what would have been expected given the findings in the literature: multiple core groups of highly connected authors and a sparser collection of authors who co-author little if at all (see Kronegger et al., 2011; Mali et al., 2012). Yet, there is a caveat due to the unique way in which the networks were constructed and analysed in previous studies. In fact, past works looked for extremely dense clusters, hence called ‘cores’ that almost resemble cliques. By contrast, the denser clusters found in this research are sparser and much larger, albeit still relatively dense.
In terms of temporal continuities, one cannot miss to underline that most clusters inherit compact groups of authors from the second period (e.g., cluster 12 from cluster 6; cluster 15 from 5, 10 from 8, and 11 from cluster 7). Moreover, there are chains of clusters spanning all three decades, with several authors remaining in the same cluster since 1991–2000: 2-6-10, and 3-7-11. Furthermore, newcomers flow chiefly towards comparatively less dense clusters, albeit not exclusively to them. Relatedly, authors belonging to lower-density clusters represent most outgoing authors in each of the two transitions. Thus, it seems that a marginal position in the co-authorship network makes it more likely to drop out of the network in the future. Conversely, core clusters are more stable across time (in line with previous findings, see 2.3 above).
Possible drivers of cooperation patterns: disciplines, organisational, and topical affiliation
In order to operationalise these results, it is necessary to try and make sense of the structure, albeit an arguably incomplete one, that emerged from the MBM. Based on both data availability and the literature, three criteria seem the most useful to carry out this analysis: scientific disciplines, organisational affiliation, and topics (see also 3.1.3 and 3.4 above). Each of these three variables provides a summary description of the authors/nodes and, thus, a potential explanation for both the clusters’ composition and the pattern of ties between them. These analyses are carried out and presented using mesoscopic graphs (Fig. 5). For reference, the intensity of the ties’ colour represents the density of the bloc between the two clusters while the line type indicates whether the ties is cross-time (dashed) or within-time (solid). In addition, the clusters are drawn as pies of size directly proportional to the number of authors assigned to that group, whose slices represent their members’ affiliation in terms of discipline, organisations, or topics, and whose border’s colour reflects the cluster’s density using the same greyscale as the ties.
Starting with organisations, the authors’ workplace help clarifying the reasons for the main diachronic continuities in the MBM. Specifically, clusters 3, 7, and 11 are comprised exclusively of authors employed at the Faculty of Social Sciences of the University of Ljubljana (indicated as UL FDV in Fig. 5, panel a). Similarly, the intense cross-time ties (i.e., share of common authors) between clusters 2, 6, and 10 is imputable to the fact that most of these authors work at the Faculty of Sports at the University of Ljubljana (UL FS): 95%, 89%, 89%. Meanwhile, a discontinuity emerged in the third period when looking at the faculties of management and economist at the two largest public universities in the country (the University of Ljubljana, UL, and the University of Maribor UM). In fact, authors from the two faculties of management (aliased as ‘UL Mngmnt’ and ‘UM Mngmnt’ in the figure) belong to separate clusters. Analogously, authors working in the two universities’ economics faculties (UL EF and UM EPF) are largely separated (see 4.2.4 below). However, this is about it regarding the explanatory power of an analysis of the pattern of inter-cluster ties based solely on major organisations. After all, despite the small size of Slovenian academia, many of the second and third period’s clusters include large shares of authors from minor institutions. Hence, the interpretation of the pattern of ties within those periods based on organisations rather tedious.
Moving to disciplines (Fig. 5, panel b), this piece of information helps clarifying the result to some degree both corroborating and supplementing the findings related to organisational affiliations. In particular, the almost uninterrupted continuity between clusters 3, 7, and 11 appears related to the fact that all their members are all sociologists (besides working at the same institution). Moreover, it is possible to make some sense of the pattern of ties in 2001–2010. In fact, these three groups include at least relative majorities of economists and scholars of management (96%, 89%, and 30%).
Finally, disciplinary affiliation gives some insights into the structure composed of multiple denser groups (clusters 12, 13, 14, and 17) and some sparser ones (15 and 9) in the third period. In fact, ties amongst economists and between them and experts in management drive the connectivity amongst these clusters and may help explain it. Specifically, authors in these disciplines represent absolute majorities of these clusters’ members apart from cluster 17. Meanwhile, cluster 17 (made up of psychologists and some pedagogues) includes a relative majority of authors from the UL’s Faculty of Arts (UL FF) and mostly researchers from minor institutions.
Interestingly, these findings find further confirmation in the comparison of the MBM partition with a LDA topic model with 10 topics (see 3.4 above). Arguably, the choice of this number of topics is contingent on a degree of arbitrariness. Yet, the use of diagnostic measures offers a sound justification for this choice (Fig. 5). Namely, the marginal gain in coherence of adding any number of topics would by insufficient to outperform the model with 10 topics. Moreover, as marginal exclusivity decreases with a more than proportional trend as the number of topics increases, the gain in exclusivity of models with more topics is not worth the loss in coherence. Finally, the analysis aggregated some of these ten topics that are closely related to each other. In particular, the topics team sports, kinematics, and children sports were aggregated under the heading ‘Sports’. Similarly, business management and corporate social responsibility compose the topic ‘Business’.
From this vantage point, it is easily possible to corroborate findings from the disciplinary and organisational analysis. For instance, cluster 3, 7, and 11 (which include only sociologists from the UL FDV) are also engaged exclusively in one topic (labelled in Fig. 6, panel c as ‘Surveys’). Similarly, clusters 2, 6, and 10 (corresponding mostly to authors from the UL FS) engage for the most part in the study of sports (91%, 97%, 84%) and, minimally, of pedagogy (0, 2.6%, 14%). Moreover, the sparser cluster in all periods (1, 4, 9) are mixed in terms of topics, containing authors relatable to almost all topics. Conversely the denser clusters in each period are much more homogenous. For instance, most of the authors in clusters 8, 12, and 13 belong to the topic Business; respectively: 59%, 48%, and 69%. And these findings strengthen the results obtained by looking at organisations or disciplines. In fact, similar percentages of these clusters’ authors work in the field of management, such as in the case of cluster 12, or are employed at related faculties: the UM EPF for cluster 8, the faculty of management at the UL for cluster 12, and the faculty of management at the UM for cluster 14. Meanwhile, the two of the three remaining groups are mostly devoted to minor topics (Security studies for cluster 5 and Logistics for cluster 16). Finally, cluster 17 (psychologists and pedagogues from various organisations), which appeared descriptively similar to the denser clusters. But it is only weakly related to the sparser clusters, and it is even more homogenous than the other most dense clusters: 92% of its members worked on the topic of ‘School and Education’. Thus, the topic model provides insights regarding the reason for its peculiar pattern of ties: it is a mostly mono-thematic cluster that relates only to those amongst the densest clusters which addressed its members’ topic of interest. Indeed, albeit its internal structure is different, cluster 16 seems to be amenable to a similar explanation, being mostly oriented towards the topic of ‘Logistics and transport’, it links to the core clusters 12 and 14, but not to the sparser clusters.

Mesoscopic graphs of the MBM’s partition representing the clusters’ composition in terms of their members’ affiliations (disciplines, organisations, and topics). For the sake of simplicity some strictly related topics have been aggregated. The number of aggregated topics is indicated right after the aggregates’ name: two for business and three for sports
Comparison
Comparing the MBM partition with those obtained using other SBMs for temporal networks generates two types of information. First, it strengthens (or disproves) the results obtained by analysing the MBM considering the authors’ affiliations. Second, it allows a ground to ‘test’ different approaches on empirical data on which extended theoretical knowledge is available to discern acceptable from heavily sub-optimal results. Specifically, the MBM’s partition with three, five, and nine clusters for each of the three decades (formally: \(Q=\{3, 5, 9\}\)) is compared to the results that each other SBM considered the ‘best’ according to its own criterion:
-
The SBM for linked networks as implemented in the R package ‘StochBlock’ does not explore partitions or suggest an optimal number of clusters automatically. So, each within-time network was modelled separately for several clusters \(2\le {k}_{t}\le 10 \forall t\in \left[1, 3\right]\). Then, the number of clusters with the best ICL was selected for each period and a linked-network SBM optimised on the resulting partition (\(Q=\{6, 6, 9\}\)).
-
The SBM for generalised multilevel networks implemented in the R package ‘MLVSBM’ automatically selects the ‘best’ number of clusters based on ICL and an internal heuristic algorithm. In this case it settled for the partition (\(Q=\{4, 8, 15\}\));
-
The SBM for dynamic networks implemented in the R package ‘dynsbm’ does not select automatically the ‘best’ solution. However, it can only optimise partitions with the same number of clusters in all time periods, so it is not prohibitive test all the possible combinations on a network of this size. In this case, the ICL identifies two results as almost equally ‘good’ fitting: \(Q=\{5, 5, 5\}\) and \(Q=\{6, 6, 6\}\). At a close inspection, the former is much sparser in terms of inter-cluster ties and there is barely any identifiable structure. By contrast, the latter shows a more easily identifiable structure and is also more in line with other approaches and, thus, was chosen for this analysis.
-
The Bayesian SBM implemented in the python module ‘graph-tool’ automatically selects the ‘best’ partition based on a measure of entropy and considering the partition-constraint labels (i.e., authors from different time periods cannot belong to the same group). Eventually, comparing both the degree-corrected and traditional versions of the hierarchical and simple versions of this SBM led to select the following simple, degree-corrected blockmodel \(Q=\{3, 8, 10\}\).
Overall, the main structural difference between these partitions lies in that the SBM for linked network is the only approach expressly identifying core-periphery relations. However, the same structures are present in the MBM, too. But the reduced size of the partition means that core-periphery structures exist within the clusters rather than between them. That being said, to avoid an excessively lengthy analysis, this section does not analyse each partition in turn. Rather, it first presents the result of some summary agreement indices for comparing partitions. Then, it goes over the difference and similarities between these partitions in terms of disciplinary, organisational, and topic affiliation.
Agreement indices
The most widely used summary indices to compare partitions are the symmetric Rand Index (RI)Footnote 22 and the asymmetrical Wallace indices (\({\text{WI}}_{1}\) and \({\text{WI}}_{2}\)).Footnote 23 The latter tends ‘to reflect how much object pairs have been assigned to different clusters in both partitions’ rather than to the same (Warrens & van der Hoef, 2022, p. 503). Thus, even when the partitions would be considered quite different by at an attentive observer, the RI tends to be quite large. To mitigate this issue, the literature suggests the Adjusted Rand Index (ARI), which corrects for the possibility that two units can end up in different clusters by mere chance. Overall, comparing each pair of partitions using these measures leads to the conclusion that the MBM partition is most like that produced by the Bayesian and multilevel SBMs. Meanwhile, the SBM for linked networks and that for dynamic networks produce different results. Yet, the similarity is still appreciably strong across different measures. Thus, a more qualitative analysis is warranted to appreciate the subtlety of these differences (Fig. 7).

Selected agreement indices amongst various SBMs
Disciplinary affiliation: the clusters of sociologists
Two SBMs fail to identify a cluster of sociologists in all time periods, but in diverse ways. The Bayesian SBM misses on this feature of the network almost completely. In fact, it fails to identify any cluster that is mostly associate with a single discipline. However, its clusters tend to be homogeneous in terms of topics (see 4.2.5 below). The linked-network SBM identifies the cluster of FDV sociologists in 1991–2000 (cluster 5), but this cluster is completely different from those put together by the MBM, the multilevel SBM, and the dynamic SBM. Most notably, it hosts only a handful of the authors clustered together by the other approaches. Furthermore, its members have no connections to each other, instead they are tied to almost all other sociologists and other social scientists at the UL FDV (in cluster 2). Finally, these authors will be out-goers in 2001–2010, which explains why this approach fails to identify the cluster of sociologists so in subsequent years. Instead, it clusters UL FDV sociologists chiefly with other UL FDV authors or, more sporadically, researchers at other UL faculties.
Besides the MBM, also the dynamic SBM and the multilevel SBM find three clusters of sociologists. The dynamic SBM identifies the cluster sociologists in all time periods (clusters 2, 8, 14). Unlike in the MBM, there is a moderate tendency to welcome authors from other disciplines, but it is barely noticeable: 92.9% of the authors belonging to cluster 14 are still sociologist working at the UL FDV. The multilevel SBM also identifies a cluster of FDV sociologists in all time periods (2, 7, 17). However, it dilutes faster and more intensely than according to the dynamic SBM. Namely, only 57.1% of its members (in 2011–2020) are sociologists employed at the UL FDV, whereas the remaining 42.9% works at the UL FS.
Organisational affiliation: the clusters of the UL FS
Likewise, the Bayesian SBM and the linked-network SBM do not identify the cluster of the Faculty of Sports at the University of Ljubljana as clearly as the others. The Bayesian SBM picks up the UL FS’s cluster only in 1991–2000 (cluster 2, 100% of its members are employed at the faculty). Mostly, this is due to the larger number of clusters this approach’s favoured solution has way more clusters in the second and third time periods than any other. Consequently, UL FS authors split along topical cleavages. Similarly, the linked-network SBM identifies the UL FS’s cluster most visibly in 1991–2000 (cluster 4, 90.9% of the members). However, due to the larger number of clusters in 2001–2010 and 2011–2020, this faculty’s large group of authors tends to scatter across several clusters that are more topically homogeneous.
Meanwhile, the dynamic SBM and the multilevel SBM always find the UL FS’s clusters. The dynamic SBM picks up the UL FS’s cluster at all time periods (6, 12, 18). And it remains fairly singular in its evolution (89.4% of its members still belong to the UL FS in 2011–2020). Also, the multilevel SBM pick up the UL FS’ cluster at all times (1, 11, 18), but less clearly so in 2001–2010. To be more precise, the second period has a cluster that is mostly comprised of UL FS authors, but their dominance falls short of an absolute majority (stopping at exactly 50%). Partly, it looks like UL FS pedagogues manage to drag other experts in education into the cluster, diluting it more than in other approaches’ partitions.
Organisational affiliation: economics and management at the two main public universities
As mentioned above in passing, in the third period the MBM develops a tendency to keep authors in from the faculties of economics of the two largest Slovenian public universities (the one in Ljubljana, UL EF, and that in Maribor, UM EPF) separate. Similarly, also authors working at the respective faculties of management are not clustered together, but they do mix with economists across universities and cities.
Indeed, the multilevel SBM and the Bayesian SBM do not seem to notice any specific difference in the pattern of ties of economists working at the UL EF and the UM EPF. As a result, authors from these two institutions are almost always grouped together in clusters characterised mostly by their topical composition. Moreover, these two SBMs do not identify any cluster as mostly composed by scholars working at the UM; whereas authors at the UM (either the EPF or the faculty of management) are the majority in at least one cluster according to all other approaches.
Meanwhile, he linked-network SBM keeps UM EPF authors out of the UL EF’s cluster only in 1991–2000 (cluster 1). Then, it allows these two organisation’s authors to mix freely. However, this approach does not identify any cluster as dominated by the UL EF in 2001–2010. In contrast, this faculty regularly gets to dominate a cluster according to the MBM, the multilevel SBM, and the dynamic SBM.
The dynamic SBM allocates economists working at the UL EF (clusters by period: 4/5, 10/11, 17/18) and the UM EPF (3, 9, 15) almost invariably in separate clusters that entertain closer relations (in 2001–2010, cluster 11 is a denser cluster linked to the sparser cluster 9; in 2011–2020, the denser cluster 17 and the sparser group 15). The only exception are the peripheral clusters 4 (where 22.2% works at the UL EF and 5.6% at the UM EPF) and 10 (UL EF: 22.4%, UM EPF: 6.9%).
Topical affiliation
Across all approaches, clusters tend to be homogeneous in terms of topic. However, topical coherence is even greater for the multilevel SBM and the Bayesian SBM, which do not pick up mono-organisation clusters.
Interpretation
The observed network structure exhibits evident similarities with previous research’s findings. Authors tend to form distinct clusters that are well separated, indicating a lack of collaboration between researchers from different clusters. However, both this and previous studies highlight the presence of exceptions in the form of core-periphery structures and core-core ties. Moreover, the presence of researchers who engage in less systematic collaboration and are not part of linked clusters—the (semi-)periphery—is confirmed by this study. And this is noteworthy given that this paper analyses scientific collaboration across a set of related disciplines rather than within disciplinary fences as done in the past. Furthermore, considering the authors’ organisational and disciplinary affiliations does not provide an all-encompassing understanding of the drivers of scientific cooperation. Thus, albeit researchers’ organisational affiliation significantly influences scientific collaboration, there is a substantial level of interdisciplinary co-authorship driven almost exclusively by research themes.
In terms of substantive insights into the patterns of scientific cooperation and co-authorship in Slovenia, two conclusions can be drawn. First, the emergence of interdisciplinarity is slow and its, influence over Slovenian social sciences covert. Second, the structure of higher education and R&D founding in Slovenia favours to a large extent organisational segregation in the social sciences despite the small size of this academic community (Mali et al., 2010).
Interdisciplinarity: Stagnant progress or covert bridgeheads?
Disciplines’ role as a driver of co-authorship seems to have weakened in the social sciences. Even when several SBMs identify the same tightly connected, disciplinarily homogenous clusters (e.g., the sociologists employed at the UL FDV), these groups develop ties to heterogenous clusters and either show decreasing density (in the MBM) or dilute (dynamic and multilevel SBMs) over time.
Indeed, theoretical predictions postulated a weakening of disciplinary boundaries (Dogan & Pahre, 1990/2019), but not their overnight demise (Klein, 1990, 2000) coherently with the trends identified in this paper. Instability and ambiguous boundaries are intrinsic to very definition of a scientific discipline (Aram, 2004, p. 380) as is the fragmentation of its scholars in sub-groups (Dogan & Pahre, 1990/2019, p. 58 ff). Furthermore, interdisciplinarity did carry for long time a ‘bad name’ in some academic circles due to its too close association with ‘radically political, feminist, or postmodern’ worldviews (Payne, 1999, p. 177).Footnote 24 And yet, new empirical evidence consistently demonstrates the sensible and positive impact of interdisciplinarity on scientific research (Li et al., 2023; Zhang et al., 2021).
Thus, social scientists often find themselves in a conundrum. Either they accept willingly the ‘incorporation into the prevailing framework of thinking’ (Becher & Trowler, 2001, p. 59), which requires them to keep their academic practice, ‘by and large, introverted and self referential affairs’ (Rosamond, 2006, p. 517). Or they willingly take the risk that a ‘systematic questioning of the accepted disciplinary ideology will be seen as heresy and may be punished by expulsion’ (Becher & Trowler, 2001, p. 59).
And this tension is manifest in the discussion of the ARIS’s decision not to fully recognize ‘interdisciplinary research’ as a distinct area within the social sciences (Kronegger et al., 2015, pp. 323–24). Practically, one gets the impression that within the formal classification structure of fields and disciplines at ARIS, ‘interdisciplinary research’ is merely an aesthetic addition. In fact, the agency’s classification identifies 68 disciplines across seven sciences or fields. And, although one of these seven aggregates is called ‘Interdisciplinary research’, it does not hold equal weight as traditional filed like the engineering, medical sciences, and the social sciences. Thus, ‘interdisciplinary research’ should complement or enhance traditional research fields in principle. But it has not received full recognition in the ARIS’s funding allocation. Consequently, Slovenia’s R&D funding policies maintain a conservative stance toward supporting proposals from explicitly interdisciplinary research groups.
As a result, ‘overt interdisciplinarity’ has not made much progress in the Slovenian social sciences. However, the current results suggest that ‘the concealed reality of interdisciplinarity’ has built some bridgeheads (Clayton, 1985, pp. 195–196). Though, these forward bases’ establishment took time because the Slovenian social-science community has achieved a high degree of institutionalisation only recently.Footnote 25 Thus, in the 1990s and, arguably, early 2000s the three preconditions for either overt or covert interdisciplinarity could not have been attained: weaking disciplinary fences, sprawling methodological innovations, and a suitably large demand for new researchers (Stephan & Levin, 1992, p. 110; Hudson, 1996). In contrast, Slovenian academia has been growing both larger (Perc, 2010) and better financed, despite the lows reached during the Great Recession, since the mid-to-late 2000s (touched upon in 3.1.1 above). Thus, despite interdisciplinarity’s lacklustre growth trajectory, a few solid bridgeheads have finally been established in Slovenia.
Organisational patterns: the clusters’ separateness and organisational segregation
Despite the relatively small size of the Slovenian social science academia, our investigation revealed that the co-authors in our network are affiliated with 25 different organisations.Footnote 26 This fact indicates the strong institutional fragmentation within social sciences in Slovenia, partly stemming from its historical legacy. Throughout its recent history, Slovenia has been part of two distinct political entities (the Austro-Hungarian Empire and the Socialist Republic of Yugoslavia) both of which exhibited strong centrifugal tendencies in the structuring of higher education. During the Austro-Hungarian Empire, scholars played an instrumental role in formulating academic regulations and policies. As a result, ‘faculties functioned more like federated universities with their deans’ rather than being subdivisions of a single larger institution’ (Surman, 2019, p. 51). The political tendencies to fragment higher education were even more pronounced in socialist Yugoslavia. The communist party, keen on maintaining political control over intellectuals and universities, prevented the emergence of strong, politically independent academic centres and perpetuated institutional separateness in the higher education landscape (Uvalić-Trumbić, 1990; Zgaga, 2023).
In addition to the historical roots of a fragmented R&D institutional structure, Slovenia faces the challenge of a lack of trans-organisational cooperation. Consider the collaboration between the University of Ljubljana and the University of Maribor as an example. The Slovenian social sciences seem characterized by an unequal duopoly between UL and UM, where numerous functions and subject areas are allocated to equivalent faculties,Footnote 27 with economics being a case in point. Notably, our analysis revealed differences in the grouping of authors at UM EPF and UL EF by various SBMs, as discussed earlier (see 4.2.4) and it is insightful to delve into the co-authorship patterns among authors from these two organisations. And, specifically, to explore whether economists tend to co-author more with colleagues from the same university or across this divide.Footnote 28
To this end, Fig. 8 describes the percentages of co-authored works with at least two authors form the UM EPF/UL EF or at least one from each faculty. The percentage reported in it are calculated on the total number of works co-authored in each decade that satisfy these criteria and give the shares of publications that authored with or without cross-faculty cooperation.

Patterns of co-authorship amongst authors employed at the faculties of economics of the universities of Ljubljana (UL EF) and Maribor (UM EPF) in the co-authorship network over time. The colour of the tiles represents the share of all co-authored works in that contributed to the within-time ties
The analysis indicates that co-authorship across organisational boundaries has been infrequent over the last thirty years. For instance, between 1991 and 2000, UL EF and UM EPF were entirely isolated, with minimal cross-institutional cooperation. Subsequently, from 2001 to 2010, cross-institutional co-authorship remained minimal and below 1% of all works. Then, in 2011–2020, inter-organisational cooperation regressed, despite the stable number of publications within both faculties.
The significant lack of cross-institutional cooperation in Slovenian R&D, prevalent both in the past and present, can be partially attributed to post-1991 policymaking as well as historical legacies. And the ARIS’s funding policies are especially relevant in this regard. Over the last twenty years, the ARIS has been the primary public financer of R&D since the Ministry of Science stopped handling such funding directly. Both the ARIS and the ministerial bureaucracy employed research programs as the main instrument for funding R&D. These programs were designed to cover research areas expected to remain relevant for extended periods, often spanning 7 to 10 years (Demšar & Južnič, 2014). While these research programs ensured long-term stability for research groups within the academic science sector,Footnote 29 they did not significantly foster cross-institutional scientific cooperation in Slovenia. Practically, the evaluation and financing of research programs favoured grant holders composed of scientific groups recruited from individual academic institutions (faculties, departments) and, often, specific disciplines. These relatively small scientific groups, drawn from domestic memberships, were more concerned with meeting requirements set by specific faculties or departments than with addressing broader inter- or trans-disciplinary research issues. Consequently, in the past three decades, they have not played a pivotal role in encouraging trans-institutional or interdisciplinary scientific collaborations.
This situation has numerous negative consequences for interdisciplinary scientific excellence which have been documented as a ‘parochial’ tendency in scientific cooperation (e.g., Wagner & Leydesdorff, 2005). This parochial focus can perpetuate outdated knowledge and weaken healthy competition (Lambiotte & Panzarasa, 2009). Organisational segregation and limited interdisciplinarity may spawn ‘intellectual idols’ hindering the disciplines’ renewal (Lichnermicz, 1972) and lead to overcrowding academia with researchers pursuing more of the same (Dogan & Pahre, 1990/2019). In this sense, our analysis provides a dynamic-network corroboration of previous studies indicating that the structure of Slovenian R&D funding tends to reward such a ‘parochial’ publishing behaviour. In fact, previous studies have already argued convincingly that some of the more ‘book-publishing disciplines’ in the field of social sciences and humanities used to show higher rates of publication in the local language (Ferligoj et al., 2015). And publications in Slovene often include mostly authors affiliated with the same academic institutions (Mali et al., 2010). Furthermore, several studies maintained that authors partaking in such parochial co-authorship practices manifested less interests in international and multi-institutional publications (Cugmas et al., 2020). Such self-segregating tendencies in the social sciences and humanities stem, at least partly, from external factors and policy choices. For instance, the linkage of long-term financial support to the establishment of research groups and the lack of incentives for internal competition amongst the participants to such programmes.
Moreover, there’s a growing lack of integration and concentration of R&D human resources. Contemporary scientific achievements in Europe are less reliant on individual links between scientists and more on collaboration within R&D teams (Graf & Kalthaus, 2018; Gusmão, 2001). To become an equal partner or coordinator in significant EU R&D consortia, integration and concentration of national R&D capacities are crucial—especially in smaller EU countries like Slovenia where human capital is rather limited. Thus, more efficient R&D policy instruments are needed to mitigate these limitations (Cuschieri, 2022; Hadjimanolis & Dickson, 2001; Horta et al., 2011). Unfortunately, the results of our study based on analysis of co-authorship publications supports the thesis that current R&D policy mechanisms in Slovenia cannot be deemed apt to encourage nation-wide such integration of with the aim of increasing competitiveness in the context of the EU R&D research networks.
Conclusion
From a methodological point of view, this paper shows that existing SBMs for dynamic networks can yield diverse results, thus corroborating the results of previous simulation studies (Cugmas & Žiberna, 2023). In some cases, the variation in outcomes can be largely predicted based on the underlying assumptions and mathematical structure of the models, as seen with the dynamic SBM. However, there are instances where the heterogeneity of results cannot be easily explained. Interestingly, approaches specifically designed for dynamic networks (like dynamic SBM) and those theoretically expected to perform well in such applications (such as the multilevel SBM) do not necessarily outperform ‘generalist’ approaches (i.e., the SBMs for linked or generalised-multipartite networks and the Bayesian SBM). Furthermore, similar ways of intending and modelling the network’s dynamic properties do not translate directly into similar partitions (cf. MBM, Bayesian SBM, and SBM for linked networks).
Nevertheless, in substantive terms, there are notable similarities amongst these approaches. At least, as far as the partitions of the co-authorship network of social scientists in Slovenia over the three decades since 1991 are concerned. First, the importance of disciplinary boundaries in co-author selection appears to diminish over time, in line with theoretical expectations, but less markedly than expected by some theorists. Meanwhile, institutional affiliation remains a solid driver of scientific cooperation. Despite the small size of the Slovenian social-science academia, a certain level of organisational distinctness consistently emerges from most blockmodels. Indeed, the existing literature does suggest that R&D policy may contribute to the perpetuation of parochial research practices, but the extent to which organisational segregation is an issue remains unclear. Still, the specific relationship between the University of Ljubljana’s Faculty of Economics and the University of Maribor’s Faculty of Business and Economics suggests that there might be an isolationist tendency. Finally, focusing on the topic of co-authored works seems to provide a better understanding of authors’ genuine interests and explains their cooperation patterns better besides strengthening the previous findings.
The emergence of interdisciplinarity has been slow and partial. Arguably, the fact that the topics identified for this paper tend to sit squarely in the fences of one or another discipline but attract scholars across them supports the idea of a ‘covert interdisciplinarity’. And this feature is highlighted by the low structural cohesion observed across different blockmodeling approaches, which suggests that authors with specific methodological and/or substantive expertise rarely cooperate with each other systematically (White & Harary, 2001). Considering the findings related to topics and organisations, it becomes apparent that interpreting these results may require identifying ‘interpretive communities’ (Kuhn, 1962), referring to groups of researchers who share texts, interpretations, and beliefs within a specific ontological domain that shapes their research interests. Importantly, members of these communities lack fluency in a meta-language that would enable effective communication across related paradigms. And, in the long term, this may hinder the implementation of up-to-date research policies in the country.
Notes
At the time of establishment, the agency was named Slovenian Research Agency (ARRS in Slovenian). In 2023, it took its current name shortened as ARIS.
Still, the authors’ institutional (and, thus, geographical) heterogeneity is unclear in Moody’s analysis, but given the time frame and the data source the network is likely to include mostly authors from Anglo-Saxon and West European countries. In these analyses of co-authorship networks, the focus is usually on the formation of co-authorship ties and so-called ‘network effects’ (Abbasi et al., 2011; Moody, 2004).
Preferential attachment indicates that a network’s nodes are more likely to be connected to well-connected nodes than to comparatively isolate ones. When the connections (degree) at time t and t + 1 are directly proportional, then there is linear preferential attachment.
The clustering coefficient expresses the extent to which nodes in a network tend to form clusters (groups). Namely, taken three nodes (A, B, C), it measures the likelihood that A and B are connected when they are both tied to C.
Homophily refers to the tendency of individuals to associate or connect with others who are similar to them in some way, such as sharing common characteristics, interests, beliefs, or attributes.
Redundant contacts are ties between actors in a network that are essentially duplicative.
The co-authorship rate defined at the share of co-authored works on the total gives a rough measure of the extent to which co-authoring is (not) prevalent in a scientific field, institution, or other relatively homogeneous group of authors.
The corresponding codes in the COBISS database are: 1.01,1.02,1.03,1.06,1.08,1.16, 2.01,2.18,2.20, and 2.24.
A tabular comparison between these SBMs is available in the second part of the ESM.
Available as: Donnet and Barbillon (2023). GREMLINS: Generalized Multipartite Networks (0.2.1). https://CRAN.R-project.org/package=GREMLINS.
Žiberna & Telarico (2023). StochBlock: Stochastic Blockmodeling of One-Mode and Linked Networks (0.1.2). https://cran.r-project.org/web/packages/StochBlock/.
Chabert-Liddell (2022). MLVSBM: A Stochastic Block Model for Multilevel Networks (0.2.4). https://cran.r-project.org/web/packages/MLVSBM/.
Matias & Miele (2020). dynsbm: Dynamic Stochastic Block Models (0.7). https://cran.r-project.org/web/packages/dynsbm/.
The implementation allows for both a ‘simple’ and a ‘hierarchical’ or ‘nested’ version (cf. Peixoto, 2014). Both were tried, but the former returned a result that was easier to explain and, thus, made more sense to include in this analysis.
As implemented in the R package ‘topicmodels’ (Grün et al., 2023).
Exclusivity measures whether each topic’s most common words (usually the top 10) are also common in other topics. Consistency measures whether each topic’s most common words (usually the top 10) well represent the entire topic.
Implemented in Friedman, D. (2022). topicdoc: Topic-Specific Diagnostics for LDA and CTM Topic Models (0.1.1). https://CRAN.R-project.org/package=topicdoc/.
See Online Resource for a tabular representation.
By period, the average degree for the removed nodes was 1.87, 3.17, and 4.73; against 7.45, 10.7, and 14.6 for the authors in the network.
They are affected by the order in which the partitions (say, \(\mathcal{U}\) and \(\mathcal{V}\)) are considered in the same way in which the difference between two number changes depending on which is the minuend and which the subtrahend. Namely, the WIs are such that the \(W{I}_{1}\left(\mathcal{U}, \mathcal{V}\right)=W{I}_{2}\left(\mathcal{V}, \mathcal{U}\right)\) and \(W{I}_{1}\left(\mathcal{V}, \mathcal{U}\right)=W{I}_{2}\left(\mathcal{U}, \mathcal{V}\right)\).
It is indifferent to the order in which the partitions (say, \(\mathcal{U}\) and \(\mathcal{V}\)) are considered, like the sum is indifferent to the order of the addenda. So \(RI\left(\mathcal{U}, \mathcal{V}\right)=RI\left(\mathcal{V}, \mathcal{U}\right)\).
For an early attempt at disentangling the nexus between interdisciplinarity and poststructuralism, see Newell (1992).
As a matter of fact, the University of Ljubljana did not have a faculty of social sciences bearing this name until the country’s independence in 1991. More than thirty years later, there is only one other public research institution whose name alludes to the social sciences, a private university’s relatively small Faculty of Applied Business and Social Studies, which was only established in 2003.
Of the 25 organisations comprising the social-science institutional landscape in Slovenia, the great majority of them (20) are faculties and research centres at the two largest Slovenian public universities (the University of Ljubljana and the University of Maribor). Of the remaining organisations, two are belong to the University of Primorska, two are think tanks (the Institute for Social Studies and the Institute for Economic Research), and the last one is the Faculty of Applied Business and Social Studies at the private university Doba.
Of course, the University of Ljubljana and the University of Maribor do not function as a perfect duopoly. Namely, not all UL faculties are mirrored in the UM and those duplicates are usually only tangentially relevant to the social sciences proper (e.g., management, pedagogy, and philosophy).
Note that diagonal values quantify co-authorship and should not added up twice. So, the total of 100% is obtained summing the percentage of works authored without cross-faculty cooperation and those with authors from both faculties taken once: e.g., \(61.76\%+37.53\%+0.71\%\) and not \(61.76\%+37.53\%+0.71\%+0.71\%\) for the second period.
For example, in Article 17 of the new Scientific research and innovation activity act which have been accepted on November 18. 2021, there are defined the following funds to ensure the stable funding of scientific research activities in Slovenia: funds for the institutional funding pillar, funds for the programme funding pillar and funds for the developmental funding pillar (ZZrID) (2021) Scientific Research and Innovation Activity Act, available: http://www.aris-rs.si/en/akti/).
References
Abbasi, A., Altmann, J., & Hossain, L. (2011). Identifying the effects of co-authorship networks on the performance of scholars: A correlation and regression analysis of performance measures and social network analysis measures. Journal of Informetrics, 5(4), 594–607. https://doi.org/10.1016/j.joi.2011.05.007
Abbott, A. (2010). Chaos of disciplines. University of Chicago Press.
Abramo, G., D’Angelo, C. A., & Di Costa, F. (2018). The effect of multidisciplinary collaborations on research diversification. Scientometrics, 116(1), 423–433. https://doi.org/10.1007/s11192-018-2746-2
Adam, F., & Makarovic, M. (2002). Postcommunist transition and social sciences: The case of Slovenia. East European Quarterly, 36(3), 365.
Adams, J. (2013). The fourth age of research. Nature, 497(7451), 557–560.
Adams, J. D., Black, G. C., Clemmons, J. R., & Stephan, P. E. (2005). Scientific teams and institutional collaborations: Evidence from U.S. universities, 1981–1999. Research Policy, 34(3), 259–285. https://doi.org/10.1016/j.respol.2005.01.014
Aram, J. D. (2004). Concepts of interdisciplinarity: Configurations of knowledge and action. Human Relations, 57(4), 379–412. https://doi.org/10.1177/0018726704043893
Bar-Hen, A., Barbillon, P., & Donnet, S. (2022). Block models for generalized multipartite networks: Applications in ecology and ethnobiology. Statistical Modelling, 22(4), 273–296. https://doi.org/10.1177/1471082X20963254
Batagelj, V. (2020). On fractional approach to analysis of linked networks. Scientometrics, 123(2), 621–633. https://doi.org/10.1007/s11192-020-03383-y
Beaver, D., & Rosen, R. (2005). Studies in scientific collaboration: Part I. The professional origins of scientific co-authorship. Scientometrics, 1(1), 65–84. https://doi.org/10.1007/bf02016840
Becher, T., & Trowler, P. (2001). Academic tribes and territories: Intellectual enquiry and the culture of disciplines. Society for Research into Higher Education & Open University Press.
Biernacki, C., Celeux, G., & Govaert, G. (2000). Assessing a mixture model for clustering with the integrated completed likelihood. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(7), 719–725. https://doi.org/10.1109/34.865189
Burt, R. S. (2004). Structural holes and good ideas. American Journal of Sociology, 110(2), 349–399. https://doi.org/10.1086/421787
Çavuşoğlu, A., & Türker, İ. (2013). Scientific collaboration network of Turkey. Chaos, Solitons & Fractals, 57, 9–18. https://doi.org/10.1016/j.chaos.2013.07.022
Çavuşoğlu, A., & Türker, İ. (2014). Patterns of collaboration in four scientific disciplines of the Turkish collaboration network. Physica a: Statistical Mechanics and Its Applications, 413, 220–229. https://doi.org/10.1016/j.physa.2014.06.069
Chabert-Liddell, S.-C., Barbillon, P., Donnet, S., & Lazega, E. (2021). A stochastic block model approach for the analysis of multilevel networks: An application to the sociology of organizations. Computational Statistics & Data Analysis, 158, 107179. https://doi.org/10.1016/j.csda.2021.107179
Clayton, K. (1985). Inter disciplinarity revisited: Re-assessing the concept in the light of institutional experience. The University of East Anglia.
Cugmas, M., Ferligoj, A., & Kronegger, L. (2016). The stability of co-authorship structures. Scientometrics, 106(1), 163–186. https://doi.org/10.1007/s11192-015-1790-4
Cugmas, M., Mali, F., & Žiberna, A. (2020). Scientific collaboration of researchers and organizations: A two-level blockmodeling approach. Scientometrics, 125(3), 2471–2489.
Cugmas, M., & Žiberna, A. (2023). Approaches to blockmodeling dynamic networks: A Monte Carlo simulation study. Social Networks, 73, 7–19. https://doi.org/10.1016/j.socnet.2022.12.003
Cuschieri, S. (2022). Are medical students interested in conducting research? A case study on the recruitment outcome of an elective research summer opportunity. Medical Science Educator, 32(6), 1279–1283. https://doi.org/10.1007/s40670-022-01645-3
D’Este, P., & Robinson-García, N. (2023). Interdisciplinary research and the societal visibility of science: The advantages of spanning multiple and distant scientific fields. Research Policy, 52(2), 104609. https://doi.org/10.1016/j.respol.2022.104609
Dahlander, L., & McFarland, D. A. (2013). Ties that last: Tie formation and persistence in research collaborations over time. Administrative Science Quarterly, 58(1), 69–110. https://doi.org/10.1177/0001839212474272
Donnet, S., & Barbillon, P. (2023). GREMLINS: Generalized Multipartite Networks (0.2.1) [Computer software]. https://CRAN.R-project.org/package=GREMLINS
De Miranda Grochocki, L. F., & Cabello, A. F. (2023). Research collaboration networks in maturing academic environments. Scientometrics, 128(4), 2535–2556. https://doi.org/10.1007/s11192-023-04671-z
Demšar, F., & Južnič, P. (2014). Transparency of research policy and the role of librarians. Journal of Librarianship and Information Science, 46(2), 139–147. https://doi.org/10.1177/0961000613503002
Doreian, P., Batagelj, V., & Ferligoj, A. (1994). Partitioning networks based on generalized concepts of equivalence. The Journal of Mathematical Sociology, 19(1), 1–27. https://doi.org/10.1080/0022250X.1994.9990133
Endersby, J. W. (1996). Collaborative research in the social sciences: Multiple authorship and publication credit. Social Science Quarterly, 77(2), 375–392.
Ferligoj, A., & Kronegger, L. (2009). Clustering of attribute and/or relational data. Metodološki Zvezki (advances in Methodology and Statistics), 6, 135–153. https://doi.org/10.51936/gvzj6999
Ferligoj, A., Kronegger, L., Mali, F., Snijders, T. A. B., & Doreian, P. (2015). Scientific collaboration dynamics in a national scientific system. Scientometrics, 104(3), 985–1012. https://doi.org/10.1007/s11192-015-1585-7
Fontana, M., Iori, M., Sciabolazza, V. L., & Souza, D. (2022). The interdisciplinarity dilemma: Public versus private interests. Research Policy, 51(7), 104553.
Fortunato, S., Bergstrom, C. T., Börner, K., Evans, J. A., Helbing, D., Milojević, S., Petersen, A. M., Radicchi, F., Sinatra, R., Uzzi, B., Vespignani, A., Waltman, L., Wang, D., & Barabási, A.-L. (2018). Science of science. Science, 359(6379), eaao0185. https://doi.org/10.1126/science.aao0185
Gazni, A., & Didegah, F. (2011). Investigating different types of research collaboration and citation impact: A case study of Harvard University’s publications. Scientometrics, 87(2), 251–265.
Gerlach, M., Peixoto, T. P., & Altmann, E. G. (2018). A network approach to topic models. Science Advances, 4(7), eaaq1360. https://doi.org/10.1126/sciadv.aaq1360
Gibbons, M., Limoges, C., Nowotny, H., Schwartzman, S., Scott, P., & Trow, M. (1994). The new production of knowledge: The dynamics of science and research in contemporary societies (1st ed.). SAGE Publications Ltd.
Glänzel, W., & Schubert, A. (2005). Domesticity and internationality in co-authorship, references and citations. Scientometrics, 65(3), 323–342. https://doi.org/10.1007/s11192-005-0277-0
González Brambila, C. N., & Olivares-Vázquez, J. L. (2021). Patterns and evolution of publication and co-authorship in social sciences in Mexico. Scientometrics, 126(3), 2595–2626. https://doi.org/10.1007/s11192-020-03644-w
Graf, H., & Kalthaus, M. (2018). International research networks: Determinants of country embeddedness. Research Policy, 47(7), 1198–1214. https://doi.org/10.1016/j.respol.2018.04.001
Granovetter, M. (1983). The strength of weak ties: A network theory revisited. Sociological Theory, 1, 201–233. https://doi.org/10.2307/202051
Groboljsek, B., Ferligoj, A., Mali, F., & Kroneggeriglič, L. H. (2014). The role and significance of scientific collaboration for the new emerging sciences: The case of Slovenia. Teorija in Praksa, 50, 866–885.
Gusmão, R. (2001). Research networks as a means of European integration. Technology in Society, 23(3), 383–393. https://doi.org/10.1016/S0160-791X(01)00021-5
Hadjimanolis, A., & Dickson, K. (2001). Development of national innovation policy in small developing countries: The case of Cyprus. Research Policy, 30(5), 805–817. https://doi.org/10.1016/S0048-7333(00)00123-2
Henriksen, D. (2016). The rise in co-authorship in the social sciences (1980–2013). Scientometrics, 107(2), 455–476. https://doi.org/10.1007/s11192-016-1849-x
Horta, H., Sato, M., & Yonezawa, A. (2011). Academic inbreeding: Exploring its characteristics and rationale in Japanese universities using a qualitative perspective. Asia Pacific Education Review, 12(1), 35–44. https://doi.org/10.1007/s12564-010-9126-9
Hudson, J. (1996). Trends in multi-authored papers in economics. Journal of Economic Perspectives, 10(3), 153–158. https://doi.org/10.1257/jep.10.3.153
Katz, J. S., & Martin, B. R. (1997). What is research collaboration? Research Policy, 26(1), 1–18. https://doi.org/10.1016/S0048-7333(96)00917-1
Klein, J. T. (1990). Interdisciplinarity: History, theory, and practice. Wayne State University Press.
Klein, J. T. (2000). A conceptual vocabulary of interdisciplinary science. In P. Weingart & N. Stehr (Eds.), Practising interdisciplinarity (pp. 3–24). University of Toronto Press. https://doi.org/10.3138/9781442678729.6
Kronegger, L., Mali, F., Ferligoj, A., & Doreian, P. (2011). Collaboration structures in Slovenian scientific communities. Scientometrics, 90(2), 631–647. https://doi.org/10.1007/s11192-011-0493-8
Kronegger, L., Mali, F., Ferligoj, A., & Doreian, P. (2015). Classifying scientific disciplines in Slovenia: A study of the evolution of collaboration structures. Journal of the Association for Information Science and Technology, 66(2), 321–339. https://doi.org/10.1002/asi.23171
Kuhn, T. S. (1962). The structure of scientific revolutions. The University of Chicago Press.
Lambiotte, R., & Panzarasa, P. (2009). Communities, knowledge creation, and information diffusion. Journal of Informetrics, 3(3), 180–190. https://doi.org/10.1016/j.joi.2009.03.007
Lambiotte, R., & Schaub, M. T. (2021). Modularity and dynamics on complex networks. Cambridge University Press.
Laudel, G. (2002). What do we measure by co-authorships? Research Evaluation, 11(1), 3–15. https://doi.org/10.3152/147154402781776961
Lee, C., & Wilkinson, D. J. (2019). A review of stochastic block models and extensions for graph clustering. Applied Network Science, 4(1), 122. https://doi.org/10.1007/s41109-019-0232-2
Lešer, V. J., Širca, N. T., Dermol, V., & Trunk, A. (2018). Career opportunities for PhD graduates in the knowledge-based economy: Case of Slovenia. Procedia-Social and Behavioral Sciences, 238, 104–113. https://doi.org/10.1016/j.sbspro.2018.03.013
Li, B., Chen, S., & Larivière, V. (2023). Interdisciplinarity affects the technological impact of scientific research. Scientometrics, 128(12), 6527–6559. https://doi.org/10.1007/s11192-023-04846-8
Lichnermicz, A. (1972). Mathematic and transdiciplinarity. In L. Apostel, G. Berger, A. Briggs, & G. Michaud (Eds.), Interdisciplinarity: Problems of teaching and research in universities (pp. 121–127). Organisation for Economic Co-operation and Development.
Mali, F. (1998). The eastern European transition: Barriers to cooperation between university and industry in post-communist countries. Industry and Higher Education, 12(6), 347–356. https://doi.org/10.1177/095042229801200604
Mali, F. (2010a). Policy issues of the international productivity and visibility of the social sciences in Central and Eastern European Countries. Sociologija i Prostor, 48(3), 415–435.
Mali, F. (2010b). Turning science transdisciplinary: Is it possible for the new concept of cross-disciplinary cooperations to enter slovenian science and policy? In L. Kajfež-Bogataj, K. H. Müller, I. Svetlik, & N. Toš (Eds.), Modern RISC-societies: Towards a new paradigm for societal evolution. Edition Echoraum.
Mali, F., Kronegger, L., Doreian, P., & Ferligoj, A. (2012). Dynamic scientific co-authorship networks. In A. Scharnhorst, K. Börner, & P. van den Besselaar (Eds.), Models of science dynamics: Encounters between complexity theory and information sciences (pp. 213–254). Springer. https://doi.org/10.1007/978-3-642-23068-4_6
Mali, F., Kronegger, L., & Ferligoj, A. (2010). Co-authorship trends and collaboration patterns in the Slovenian sociological community. Corvinus Journal of Sociology and Social Policy. https://doi.org/10.14267/cjssp.2010.02.02
Matias, C., & Miele, V. (2017). Statistical clustering of temporal networks through a dynamic stochastic block model. Journal of the Royal Statistical Society. Series B (statistical Methodology), 79(4), 1119–1141.
Matias, C., & Miele, V. (2020). dynsbm: Dynamic Stochastic Block Models (0.7) [Computer software]. https://cran.r-project.org/web/packages/dynsbm/
Melin, G., & Persson, O. (2005). Studying research collaboration using co-authorships. Scientometrics, 36(3), 363–377. https://doi.org/10.1007/bf02129600
Moody, J. (2004). The structure of a social science collaboration network: Disciplinary cohesion from 1963 to 1999. American Sociological Review, 69(2), 213–238. https://doi.org/10.1177/000312240406900204
Mørup, M., & Schmidt, M. N. (2012). Bayesian community detection. Neural Computation, 24(9), 2434–2456. https://doi.org/10.1162/NECO_a_00314
Newell, W. H. (1992). Academic disciplines and undergraduate interdisciplinary education: Lessons from the School of Interdisciplinary studies at Miami University Ohio. European Journal of Education, 27(3), 211–221. https://doi.org/10.2307/1503450
Newman, M. E. J. (2001). The structure of scientific collaboration networks. Proceedings of the National Academy of Sciences, 98(2), 404–409. https://doi.org/10.1073/pnas.98.2.404
Nordlund, C., & Žiberna, A. (2019). Blockmodeling of valued networks. Advances in Network Clustering and Blockmodeling. https://doi.org/10.1002/9781119483298.ch6
Novak, P. (2023). The scope and structure of funding. ARRS.
Nowotny, H., Scott, P., & Gibbons, M. (2003). INTRODUCTION: ‘Mode 2’ revisited: The new production of knowledge. Minerva, 41(3), 179–194.
Payne, S. L. (1999). Interdisciplinarity: Potentials and challenges. Systemic Practice and Action Research, 12(2), 173–182. https://doi.org/10.1023/A:1022473913711
Peixoto, T. P. (2013). Parsimonious module inference in large networks. Physical Review Letters, 110(14), 148701. https://doi.org/10.1103/PhysRevLett.110.148701
Peixoto, T. P. (2014). Hierarchical block structures and high-resolution model selection in large networks. Physical Review X, 4(1), 011047. https://doi.org/10.1103/PhysRevX.4.011047
Peixoto, T. P. (2020). Bayesian stochastic blockmodeling. Advances in Network Clustering and Blockmodeling. https://doi.org/10.1002/9781119483298.ch11
Perc, M. (2010). Growth and structure of Slovenia’s scientific collaboration network. Journal of Informetrics, 4(4), 475–482. https://doi.org/10.1016/j.joi.2010.04.003
Piroska, D., & Podvršič, A. (2020). New European banking governance and crisis of democracy: Bank restructuring and privatization in Slovenia. New Political Economy, 25(6), 992–1006. https://doi.org/10.1080/13563467.2019.1669548
Rafols, I., Leydesdorff, L., O’Hare, A., Nightingale, P., & Stirling, A. (2012). How journal rankings can suppress interdisciplinary research: A comparison between innovation studies and business & management. Research Policy, 41(7), 1262–1282.
Roberts, M. E., Stewart, B. M., Tingley, D., Lucas, C., Leder-Luis, J., Gadarian, S. K., Albertson, B., & Rand, D. G. (2014). Structural topic models for open-ended survey responses. American Journal of Political Science, 58(4), 1064–1082. https://doi.org/10.1111/ajps.12103
Rodrigues, M. L., Nimrichter, L., & Cordero, R. J. (2016). The benefits of scientific mobility and international collaboration. FEMS Microbiology Letters, 363(21), fnw247.
Rosamond, B. (2006). Disciplinarity and the political economy of transformation: The epistemological politics of globalization studies. Review of International Political Economy, 13(3), 516–532. https://doi.org/10.1080/09692290600769419
Schmidt, M. N., & Morup, M. (2013). Nonparametric Bayesian modeling of complex networks: An introduction. IEEE Signal Processing Magazine, 30(3), 110–128. https://doi.org/10.1109/MSP.2012.2235191
Škulj, D., & Žiberna, A. (2022). Stochastic blockmodeling of linked networks. Social Networks, 70, 240–252. https://doi.org/10.1016/j.socnet.2022.02.001
Stephan, P. F., & Levin, S. G. (1992). Striking the mother lode in science: The importance of age, place, and time. Oxford University Press.
Surman, J. (2019). Universities in imperial Austria, 1848–1918: A social history of a multilingual space. Purdue University Press.
Uvalić-Trumbić, S. (1990). New trends in higher education in Yugoslavia? European Journal of Education, 25(4), 399–407. https://doi.org/10.2307/1502626
Wagner, C. S., & Leydesdorff, L. (2005). Network structure, self-organization, and the growth of international collaboration in science. Research Policy, 34(10), 1608–1618. https://doi.org/10.1016/j.respol.2005.08.002
Warrens, M. J., & van der Hoef, H. (2022). Understanding the adjusted rand index and other partition comparison indices based on counting object Pairs. Journal of Classification, 39(3), 487–509. https://doi.org/10.1007/s00357-022-09413-z
White, D. R., & Harary, F. (2001). The cohesiveness of blocks in social networks: Node connectivity and conditional density. Sociological Methodology, 31(1), 305–359. https://doi.org/10.1111/0081-1750.00098
Wuchty, S., Jones, B. F., & Uzzi, B. (2007). The increasing dominance of teams in production of knowledge. Science, 316(5827), 1036–1039. https://doi.org/10.1126/science.1136099
Zgaga, P. (2023). The Saga of academic autonomy in Slovenia (1919–1999). Center for Educational Policy Studies Journal. https://doi.org/10.26529/cepsj.1475
Zhang, L., Sun, B., Jiang, L., & Huang, Y. (2021). On the relationship between interdisciplinarity and impact: Distinct effects on academic and broader impact. Research Evaluation, 30(3), 256–268. https://doi.org/10.1093/reseval/rvab007
Žiberna, A. (2007). Generalized blockmodeling of valued networks. Social Networks, 29(1), 105–126. https://doi.org/10.1016/j.socnet.2006.04.002
Ziman, J. (2001). Real science: What it is, and what it means. Public Understanding of Science, 10(1), 145. https://doi.org/10.1088/0963-6625/10/1/701
ARRS. (2023). Slovenian current research information system (SICRIS) . https://cris.cobiss.net/ecris/si/en
Bird, S., Klein, E., & Loper, E. (2022). Natural language processing with python: Analyzing text with the natural language Toolkit (3.8) [Python]. O’Reilly Media, Inc. https://github.com/nltk/nltk (Original Work Published 2009)
Dogan, M., Pahre, R. (2019). Creative marginality: Innovation at the intersections of social sciences. Routledge. (Original Work Published 1990)
Grün, B., Hornik, K., CTM), D. M. B. (VEM estimation of L. and, CTM), J. D. L. (VEM estimation of, LDA), X.-H. P. (MCMC estimation of, RNG), M. M. (Mersenne T., RNG), T. N. (Mersenne T., & RNG), S. C. (Mersenne T. (2023). topicmodels: Topic Models (0.2–14) [Computer software]. https://CRAN.R-project.org/package=topicmodels
IZUM. (2023). Co-operative online bibliographic system and services (COBISS) . https://www.cobiss.net/cobiss-platform.htm
Kronegger, L. (2011). Dinamika omrežij soavtorstev slovenskih raziskovalcev [Dynamics of Slovenian co-authorship networks] [PhD dissertation, University of Ljubljana, Faculty of Social Sciences]. https://repozitorij.uni-lj.si/IzpisGradiva.php?id=17928
Kuhn, T. S. (2022). The last writings of Thomas S. Kuhn: Incommensurability in science (B. Mladenović, Ed.). University of Chicago Press. (Original work published 1991–1996)
Leydesdorff, L., Etzkowitz, H. (2001). The transformation of university-industry-government relations. Electronic Journal of Sociology, 5(4).
Németh, L. (2022). hunspell: The most popular spellchecking library (1.7.2) [C++]. Free Software Foundation Hungary (FSFH). https://CRAN.R-project.org/package=hunspell (Original Work Published 2003)
OECD. (1998). Interdisciplinarity in science and technology. In Directorate for science, technology and industry. OECD Paris.
Telarico, F. A., & Watanabe, K. (2023). morestopwords: All stop words in one place (0.2.0) [Computer software]. https://CRAN.R-project.org/package=morestopwords/
Žiberna, A., & Telarico, F. A. (2023). StochBlock: Stochastic blockmodeling of one-mode and linked networks (0.1.2) [Computer software]. https://cran.r-project.org/web/packages/StochBlock/
Funding
This study was supported by the First Author’s Young Researcher fellowship, co-funded by the Slovenian Research and Innovation Agency (www.aris-rs.si/) through the national budget as well as funded by the Slovenian Research and Innovation Agency with grants P5-0168 and J5-2557.
Author information
Authors and Affiliations
Contributions
The study was conceptualized AŽ and designed by AŽ and FAT. Material preparation and data collection was the work of FAT. Formal analyses were conducted by FAT and AŽ. The first draft of the manuscript was written by FAT and all authors commented on previous versions of the manuscript. The manuscript was edited by all authors after the first review. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Telarico, F.A., Mali, F. & Žiberna, A. Revealing dynamic co-authorship structure in the social sciences through blockmodeling: the Slovenian case (1991–2020). Scientometrics (2024). https://doi.org/10.1007/s11192-024-05130-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11192-024-05130-z