
We do our best, but we cannot exclude errors.
RePEc
Abstract
This paper provides an overview of RePEc a digital platform for the dissemination of research in economics. Specifically, the focus is on RePEc’s main author ranking, which aggregates 36 different rankings based on a range of criteria. I first describe the logic behind the ranking and then presents some key descriptive statistics on the top 5% of authors. Notably, the ranking is dominated by English-speaking authors, particularly those affiliated with institutions in the USA. Moreover, less than 9% of authors are female, while around 6% are deceased. Among the living authors, the estimated average age is 60, with over 21% of them aged 70 or above. Next, I discuss the aggregation of the 36 rankings using the harmonic mean—RePEc’s preferred method. Some counterintuitive properties are highlighted. Finally, I propose a simpler ranking system based on two criteria—number of journal pages and number of citations—that weight journals and citations according to their qualities and also correct for the number of authors.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Research Papers in Economics or RePEc, in short, is a fabulous resource for economists around the world, see http://repec.org/.Footnote 1 It is a complex collaborative work with several imbricated webpages and services, all brought to us by a team of dedicated volunteers working on the project on their free time.
In this paper, I describe the various rankings of authors provided by RePEc, and I give descriptive statistics on the top 5% of the ranked population. Next, I discuss the pros and mostly the cons of aggregating ranks through the harmonic mean. I propose—using already available criteria—a more simple ranking of the most productive economists based on two criteria only. Finally, I discuss briefly in the conclusion about how to enhance the existing system.
A few words about RePEc Among various projects developed in RePEc’s universe, prominent ones are IDEAS, see https://ideas.repec.org/, which allows to search the RePEc database through keywords, thanks to Christian Zimmermann.Footnote 2 NEP, New Economics Papers, see http://nep.repec.org/, a free notification service –thematic newsletters informing subscribers about the last papers.Footnote 3 CiTEc, see http://citec.repec.org/, which provides citation analysis from items in the RePEc database, thanks to José Manuel Barrueco. As well as, a page dedicated to Co-Authorship Network in Economics, see https://collec.repec.org, where beautiful graphs are displayed on demand, thanks to Christian Düben. Overall, RePEc accomodates more than 1.3 million of visitors each month. Last and not least, it is free of charge and free of advertising.
Basically, RePEc is a document (articles and working papers) archive.Footnote 4 More precisely, it is an aggregation of archives produced in a decentralized fashion. For example, after the publication of a new issue of a journal, someone from the journal staff, fills a file describing the published articles. This metadata file is then put on a secret server where it is harvested by RePEc. Then in a day or two the articles appear on RePEc. Once on RePEc, the registered authors have to claim it to confirm that they are indeed one of the authors, a wise precaution given the many researchers named John Smith.Footnote 5
A (very) short history It was 1997 when the adventure began—a time when the internet was still in its infancy. Google was yet to be born, and a browser war raged on between Netscape and Internet Explorer. Amazon was being sued by Barnes & Noble for daring to call itself “the world’s largest bookstore”.Footnote 6 It was in this world that RePEc, or Research Papers in Economics, came into being. And now, twenty-five years later, it stands as a venerable institution of the web.
As the archive grew, the idea of using its content to produce rankings naturally emerged. In 1998, a first ranking appeared based on page hits, followed by an author ranking in 2000. The first institution ranking was published in 2001, and by then there were already over 600 authors affiliated with 329 institutions. The motto at the time was clear: “So encourage your colleagues to register!”
Citation counts were added to the rankings in 2004, just as FaceMash was changing its name to TheFacebook. By then, the number of registered authors had swelled to around 4000. An aggregate score was also introduced based on the harmonic mean of the various ranks (only four in 2004).
By 2009, the number of registered authors had climbed to an impressive 20,000. Nowadays, RePEc boasts a whopping 66,000 registered authors and nearly 8700 institutions located all over the world. It’s an astonishing success story, and one that makes it undoubtedly the world’s largest database of economists.
The truth is there are a lot of things to rank according to a lot of criteria and RePEc has kept an open minded approach, so a lot of rankings are available, see https://ideas.repec.org/top/. Roughly there are four types of items to be ranked: (i) Articles and working papers, (ii) (working paper) Series and Journals, (iii) Authors, and (iv) Institutions. They are mainly ranked according to quantity (number of works and number of pages), citations, downloads, and abstract views. The reference period is a key parameter: a ranking can be done for all the items or only for the recent (less than 10 years) items. For authors and institutions, geography is also a key parameter and rankings are provided for different geographic perspectives (region, countries). Finally, rankings by fields are also provided.
Articles using RePEc’s data RePEc is undoubtedly a tremendous and multifaced resource for economists. It can be used to search the literature, to find the impact of a journal (or a working paper series), to assess the impact of one’s own work, to browse rankings, to look at coauthor network, and much more. It is also a (relatively) new resource to study the academic production of scholars in the (broadly defined) field of economics. Thus, it is great news that more and more economists are noticing the usefulness of RePEc in that dimension. Zimmermann (2013) is an early description of the making of the RePEc author rankings. Seiler and Wohlrabe (2012) also discusses the author rankings. They propose an original new ranking based on principal component analysis. In a sense the current paper can be seen as an update of these two pieces. Hausken (2016) compares several citation indexes using RePEc’s data on 54 top researchers. Hamermesh (2018) relies more on the Web of Science or Google Scholar for his sources of citations but he makes some use of RePEc’s data. Konig et al. (2020) studies the impact of collaboration on research output by analyzing the coauthorship network of economists registered in the RePEc Author Service. Zacchia (2021) relies on RePEc’s data to measure women’s visibility in rankings of top economists and argues that women are penalised in their academic progresses. Baumann and Wohlrabe (2020) use RePEc to study four major working paper series in economics. They show that 66.5% of the working papers are ultimately published in a journal and 8% as a book chapter. Wohlrabe and Bürgi (2021) expand this analysis and show that the publication in a journal results in around twice the number of yearly citations relative to working papers that never get published in a journal. Finally, Jelnov and Weiss (2022) study the relationship between age and influence—defined as the rank in RePEc’s main ranking. For that purpose they built a panel of top authors present during 100 months (from March 2012 to June 2020) in the top 5% of RePEc’s main ranking. They find that the rank of an author peaks at age 60 or 30 years after Ph.D. graduation.
Plan of the paper RePEc’s success notwithstanding, a casual look at one of the monthly rankings leaves most of us with an impression of mystery. There is however a simple logic in how the criteria have been created and how they are aggregated, which I explain in "RePEc’s kitchen" section. Next, in "The proof of the pudding: descriptive statistics" section, I take a closer look at the population of ranked authors who are among the best (most productive, and/or most cited, and/or most looked for, and/or with the best network) economists in the world.Footnote 7 As Hamermesh (2018), I am able to study differences of citations by affiliation and gender. His focus, however, is only on the top U.S. Universities whereas RePEc allows to look at all top economists wherever they are located.Footnote 8 In "Questions about aggregation" section, I discuss how the aggregation of the various criteria is done and what types of problems it creates. In "A simpler customization" section, I present a simpler (two-criteria) ranking (easily available on RePEc). Finally, in "Discussion" section, I discuss various extensions of RePEc.
RePEc’s kitchen
Although it’s commonly advised that we shouldn’t be too curious about what goes on in a restaurant’s kitchen, as economists, we can’t help but be intrigued by the inner workings of things. Understanding the production process, even the less glamorous aspects, is essential to our appreciation of the final product. Without such knowledge, we cannot fully enjoy the finished result.
Through the years, RePEc has built as many as 39 criteria each summarizing, in a particular dimension, RePEc’s data. Among them 36 are used to compile monthly rankings of Authors as well as Centers.Footnote 9 A Center is treated like the aggregation of all its affiliated authors—taking into account the percentage of affiliation chosen by the authors in their RePEc profiles. The three excluded criteria are Number of Works –instead Number of Distinct Works is used—Number of Twitter followers, and Wu index.Footnote 10 The criteria are described—using RePEc’s own words—in Table 1.
Fact 1
(RePEc’s main ranking) The main ranking is based on the harmonic mean of 32 ranks out of the 36—the best two and worst two ranks of each author are deleted. This ranking is updated monthly and available for the top 5% at: https://ideas.repec.org/top/top.person.all.html.
All 65,674 registered authors are ranked for all criteria and then in RePEc’s main ranking but detailed rankings are available only for the top 5% –or 3284—authors by the end of November 2022. From now on, I use the acronym RMR5 to refer to the top 5% of RePEc’s Main Ranking.Footnote 11
The logic of RePEc’s criteria recipe The primary material is all the works of all registered authors. RePEc stores six types of works: working papers, articles (i.e. journal articles), chapters, books, and programs (e.g. Stata packages). These works have several characteristics that can be used to build a production measure. Among them the following ones have been used in the literature:Footnote 12 (i) the number of authors, (ii) the number of pages, (iii) the quality of the journal (or working paper series), and (iv) the number (and quality) of citations.
Fact 2
(RePEc’s quality-weights) One of RePEc’s fundamental contributions is the computation of two sets of quality-weights for journals (and working paper series). Simple Impact Factors, SIF (where each citation counts the same) and Recursive Impact Factor, RIF, (where each citation counts more if it comes from a more cited journal).
SIF and RIF are (potentially) updated every day. For journals, they can be viewed at
https://ideas.repec.org/top/top.journals.simple.html and https://ideas.repec.org/top/top.journals.recurse.html.Footnote 13
These weights are computed either by using all years (for publications and citations) or only the last ten years.Footnote 14 They are essential for distinguishing quality from quantity of works.Footnote 15 SIF is fairly simple to compute. A journal (or a working paper series) has received c citations over the relevant time period for a number n of articles (or working papers), then its SIF is c/n.Footnote 16 RIF is computed recursively. At the first iteration, a citation from journal j counts SIF\(_j\) instead of 1, then the total of (weighted) citations \(c_1\) is divided by the number of articles to give the first round RIF which are used to weight the citations in the second iteration of the process. Hopefully it converges after a number of iterations. The weights themselves have a misleading numerical precision. See Stern (2013), Stern (2017), and Konig et al. (2022) for an assessment along this line of thought.Footnote 17
The resulting lists are rather convincing (the difference between SIF and RIF is by itself instructive) but of course it cannot please every editors nor authors. Compared to the journal rankings of the Journal Citation Reports (Web of Science) or of the SCImago Journal Rank (Scopus), RePEc’s contribution is primarily to rank (and give a weight to) more than two thousand journals and four thousand series. My personal bias would push me to argue that Microeconomics or Theory journals tend to have (at equal status in the profession) lower weights than Finance/Economic Policy/Geography/Macroeconomics journals. But people in other fields probably have similar complaints.Footnote 18
It is now possible to describe how RePEc’s criteria are structured.
Fact 3
(RePEc’s 36 criteria) The 36 criteria are organized as follows.
A) Combining three weighting schemes with/out a correction for the number of authors, leads to
-
six measures of the Nb of Distinct Works (1 to 6 in Table 1),
-
six measures the Nb of Journal Pages (7 to 12 in Table 1),
-
six measures of Nb of Citations (13 to 18 in Table 1),
-
six measures of Nb of Citations Discounted by Citation Age (19 to 24 in Table 1).
B) Four additional measures of citations (25 to 28 in Table 1). C) Four visibility measures on RePEc’s website (29 to 32 in Table 1). D) Four measures of network quality (33 to 36 in Table 1).
These various criteria highlight different aspects of the work done by the authors registered on RePEc. They are not exactly different dimensions and certainly not independent dimensions. In order to have a large score in terms of Recursive Impact Factor one also needs a large enough number of works. But one can have a large number of works in journals (or working paper series) with low Recursive Impact Factors and therefore ends with a modest score.
RePEc only displays the scores of the top 5% authors of each criterion. But it still allows for interesting descriptive statistics. Table 2 shows for each criterion the number of authors in the top 5% (usually 3284 but it can be larger for criteria with tied authors), the mean of the score, the minimum, Q1, Q2, Q3, and the maximum value. The table also shows for each criterion the percentile ratio p90/p10 which gives an idea of the inequality among top researchers. For example, in terms of Nb of Citations the ratio is 5.34. The third column of Table 2 “% in RMR5” gives the percentage of authors who are both in RMR5 and in the top 5% of the ranking according to the line criterion. Less than half the authors who are in the top 5% according to Students, Closeness, and Betweenness make it in RMR5. Slightly more than half the authors in the top 5% according to Nb of Distinct Works and Nb of Distinct Works, Weighted by Nb of Authors are also in RMR5. On the contrary, the percentages of those in the top 5% of a citation criterion (i.e. 13 to 28 and 36) and in RMR5 is usually large (about 80%).
Few criteria have a directly comprehensible score. The first one—Nb of Distinct Works—is transparent, however. On average, the top 5% authors with the largest number of distinct works have 135 of them. To enter this specific top 5% group, an author needs at least 80 distinct works. At a rate of four distinct works per year, a new author would have to wait 20 years to reach this pinnacle.Footnote 19 At the very top of this criterion, 14 authors have more than 500 distinct works.Footnote 20 Some of them might suffer from publicaholism!
To understand the score of the second criterion—Nb of Distinct Works, Weighted by Simple Impact Factor—requires to be familiar with the SIF themselves. As an arbitrary reference, let’s take the SIF of a top field journal like the RAND J. of Economics. As as of early January 2023, its SIF is 52.263,Footnote 21 The mean of Score 2 is 3714. Therefore, these top 5% authors have on average the equivalent of 71 articles in the RAND. Something quite amazing. To enter the top 5% an author needs (at least) the equivalent of 32 articles in the RAND. For example, someone publishing twice a year in the RAND would have to wait 16 years to join the 5% club.Footnote 22 The bar is fairly high but 32 is less than 80, so a focus on quality instead of quantity matters.
Imagine an author waking up with an additional publication in the Quarterly J. of Economics (resp. in Econometrica). How many ranks would this author gain in the ranking for Nb of Distinct Works, Weighted by Simple Impact Factor? Would this author start with a score of 1678 (the minimum to be in the top 5% for this criterion) s/he would move to \(1678+154.92=1832.92\) (resp. \(1678+118.78=1796.78\)) and this new score would allow the author to gain 365 (resp. 285) ranks. In terms of Nb of Distinct Works, and starting with 80 of them publishing in the QJE would move the score to 81 and to a rank of 3139 (tied with 87 other authors) or a gain of 87 ranks.
Criterion 13 in Table 1 is Nb of Citations, a fairly comprehensible measure. On average, authors in the top 5% for this criterion have received 3678 citations according to CiTEc. The minimum number of citations required to enter this group is 1217. Again the bar is high (usually the number of citations found by CiTEc is lower than the one found by Google Scholar.). For example, an author with 80 distinct works would need slightly more than 15 citations per work to reach that bar.
To conclude these examples with another well known criterion: criterion 25 is the h-index. Here the average among the top 5% authors for this criterion is 24 (i.e. 24 works cited at least 24 times) and the minimum needed to be in this club is 16. The top author has 101 works cited more than 101 times each.
Belonging to the top 5% group of authors for one specific criterion is not a guarantee to belong to another such group. However, an author with enough citations to be at the top in terms of Nb of Citations (say in the top 1%) has a good chance to also be in the other 15 citations-based-criteria top 5%. Table 3 shows for all 11,535 authors who are in at least one top 5% group in exactly how many of them they belong. These 11,535 authors represent 17.56% of the 65,674 authors. Among them 1415—or 12.3%—are female. Table 3 also shows the distribution of authors in terms of the number of top 1% group they belong to. The 3093 authors being in at least one such group represent 4.71% of the 65,674 authors. Among them 251—or 8.1%—are female.
Fact 4
(Number of tops) Half of the 11,535 authors who are in at least one top 5% are in 5 top 5% groups or less. Half of the 3093 authors who are in at least one top 1% are in 3 top 1% groups or less. The intersection of all 36 top 5% sets contains 317 (12—or 3.8%—of them female) authors, that is 0.48% of the 65,674 authors. The intersection of all 36 top 1% groups contains 29 (0 of them female) authors, that is 0.044% of the 65,674 authors.
In terms of correlation, as many as \(36\times 35/2=630\) of them can be computed. Moreover either the Spearman coefficients or the Kendall \(\tau\) can be used (both are useful for rankings).Footnote 23 In addition, the coefficient of correlation between two rankings can only be computed on the intersection of their top 5% populations, and the size of this intersection should also be an interested parameter to look at. This would be a lot to process.
To illustrate, consider two intuitively different criteria. Nb of Distinct Works (criterion 1 of Tables 1 and 2) and Nb of Journal Pages, Weighted by Nb of Authors and Recursive Impact Factors (criterion 12 of Tables 1 and 2). The first counts all distinct works (including unpublished working papers) while the second focuses on published articles and takes into account the number of pages, the number of authors, and uses RIF weights. The intersection of these two top 5% populations is 1168 (35.6% of 3284 the maximum possible size of the intersection). So indeed, the two criteria are very different. The Spearman coefficient of correlation is 0.1724 and the Kendall \(\tau\) is 0.1169. The coefficient of correlation between the two scores is 0.1980.
On the other hand, one can expect the criteria Nb of Citations, Weighted by Nb of Authors and Simple Impact Factors (criterion 17 of Table 2) and Nb of Citations, Weighted by Nb of Authors and Recursive Impact Factors (criterion 18 of Table 2) to provide relatively similar rankings. Indeed, the intersection of these two top 5% populations is 3035 (92.4% of 3284). The Spearman coefficient of correlation is 0.9563 and the Kendall \(\tau\) is 0.8353. The coefficient of correlation between the two scores is 0.9861.
Table 4 splits the population of authors who are in at least on top 5% group into two groups: those who are and those who are not in RMR5.
Fact 5
(Top of the tops) Authors who are in only one, two, or three individual top 5% groups do not belong to RMR5.Footnote 24 They represent a large proportion of those not in the overall ranking: 4945 authors out of 8253—or 59.92%.
Authors belonging to a number of individual top 5% groups between 4 and 15 are more likely not to be including in RMR5. The reverse is true for a number between 16 and 21.
As many as 91% of the 3284 authors in RMR5 belong to 16 or more individual top groups. Authors who are in 22 or more individual top 5% groups are all in RMR5. These rather consistent authors account for 2322—or 70.7%—of the 3284 who are in RMR5.
Table 4 is a good transition with the next section which focuses on the 3284 who are in RMR5.
The proof of the pudding: descriptive statistics
The top of the top—RMR5—is available at https://ideas.repec.org/top/top.person.all.html. As of the end of November 2022, the top ten is: Andrei Shleifer, James J. Heckman, Daron Acemoglu, Joseph E. Stiglitz, Robert J. Barro, John List, Jean Tirole, Peter C. B. Phillips, David E. Card, and Eugene F. Fama Sr. All well known and renown economists—5 of them Nobel Prize Winners.Footnote 25 Their coauthors-networks are presented in Fig. 4, in the Appendix.Footnote 26 Roughly, the larger the graph the better the rank in terms of Closeness and Betweenness. John List is first for both criteria, Joseph E. Stiglitz second and fifth, whereas Robert J. Barro is ranked above 1000 for both of them. Would you click on the link above to see the updated ranking, chance is that it would still be familiar. In 2012, the top nine authors were (in that order) Andrei Shleifer, Joseph E. Stiglitz, Robert J. Barro, James J. Heckman, Robert E. Lucas, Jr., Peter C. B. Phillips, Martin S. Feldstein, Daron Acemoglu, and Jean Tirole.Footnote 27
Few variables describe RePEc registered authors. Affiliations give information, besides their university, about the country (even the city) where they work. RePEc also provides a gender (male or female) and (sometimes) the year of terminal degree, which give information about their age.
Location
Among the best 10 RMR5 authors, 80% of them are affiliated in the USA.Footnote 28 This is not chance. Using the affiliation(s) listed in the RePEc ranking, it transpires that many of these top 5% authors are affiliated in one center only. Indeed, 2698 authors—or 82.16%—have exactly one, and 303—or 9.23%—have two affiliations or more (but only the two most important are listed).Footnote 29 Otherwise, 283 authors have no affiliation among them all the 199 deceased authors.Footnote 30 Consequently, in the following I only use the first affiliation.Footnote 31
Fact 6
(English speaking authors) RMR5 is dominated by authors affiliated in English speaking countries: 2080 out of 3001 (or 69.3%).Footnote 32 In the top 1% they account for 83.3% of the authors with an affiliation.
Table 5 lists the 17 countries (in total 223 countries are listed in RePEc) with more than 25 registered authors in RMR5. Together these countries house 2809 authors—or 93.6%—of the 3001 for whom a location is known. In the first two columns, countries are sorted by decreasing numbers of authors. In the following two columns countries are sorted by increasing average ranks. In the next three columns, countries are sorted according to the number of authors in the top 5% divided by the number of authors registered in RePEc. In the final three columns, countries are sorted according to the number of authors in the top 5% divided by the total population of the country.
Fact 7
(US dominance) RMR5 is dominated by authors affiliated in the USA. This is true in absolute numbers: 1633 out of 3001 (54.4%). This is true in terms of average rank: 1483.7, which is the lowest among all countries with more than 25 authors. This is true in terms of numbers relative to registered authors: 12.98% of the 12,582 registered US located authors are in RMR5. Finally, this is true in terms of numbers relative to the country population—USA is second behind Switzerland.
The UK is second in size with 275 affiliated authors compared to 159 in Germany, which is third. In terms of average rank, the UK is 4th as authors affiliated in Canada (2nd) and Switzerland (3rd) are on average ranked better.
In terms of Nb5/Nb ratios, the USA lead with almost 13% of their registered authors in RMR5 (1633 authors in RMR5 for a total of 12,582 authors). If the distributions of authors were the same in all countries, this ratio would be 5% everywhere. The ratio for the UK is also high given its large population of registered authors. Of course a greater ratio might reflect self-selection of authors, with the less productive ones not registering in some countries. For example, Israel is a small country (less than ten millions of people) yet the pool of registered authors—255—is quite small.
In the last three columns, countries with less inhabitants are more likely to show up at the top. Switzerland is first and is, indeed, the country with the smallest population. The USA are, however, second while their population is one of the largest. The Netherlands with a population of 17.53 millions perform better than smaller countries like Sweden or Belgium.
Table 6 confirms the prominent position of the USA affiliated authors. In the top 1% (i.e. \(r<658\)) they weight even more: 69.6% versus 54.4% in the top 5%. In the range \(2628<r<3284\) (i.e. between p4 and p5), there is only 42.2% of USA affiliated authors. The distribution of UK authors is more uniform, with a (small) peak at the end.
In the working paper, Linnemer (2023), the USA are split into their States (see Table 21 and comments page 14). It emphasizes even more the USA dominance as US States have a smaller population than several European countries. California then has the most affiliated authors, 291. Still in the working paper, Table 22 lists the cities where most top authors work. The two largest cities are Cambridge (USA) and Washington. The two could not be more different. Cambridge (USA) hosts three institutions: Harvard U., the Massachusetts Institute of Technology (MIT), and the National Bureau of Economic Research (NBER).Footnote 33 On the other hand, no less than 17 institutions located in Washington have at least one author in RMR5. Among them the World Bank Group, the International Monetary Fund (IMF), Georgetown U., the Federal Reserve Board, and the Brookings Institution.
Finally, Table 7 lists all 37 Universities/Institutions with at least 20 affiliated authors in RMR5. Together they account for 40.7% of the authors in RMR5. Among them, 29 are located in the USA, 3 in the UK, 2 in Canada, and then one in France, Italy, and Spain. Table 7 is quite different from the ranking of institutions given by RePEc—see https://ideas.repec.org/top/top.inst.all.html. Indeed, for its ranking, RePEc counts the production of all authors whether or not they are in the top 5%. In RePEc’s ranking, the NBER is first and Harvard second. Chicago is no longer second but sixth. The London School of Economics moved up from sixth to third. Also RePEc’s ranking is slightly less dominated by the USA: only 26 centers are located in the USA among the top 37.
Gender
Gender is not chosen by the authors when they register, RePEc uses an algorithm based on their first names to identify female authors. As RePEc also gives ranking(s) for female authors only, it is possible to retrieve a long list of female authors and then to find the ones in RMR5.
Fact 8
(Gender) Among the 3284 authors in RMR5, only 291, or 8.90%, are female. Among the 657 top 1% authors, only 35, or 5.33%, are female.
The average rank for male authors is 1622.5 while it is 1848.3 for female authors. Table 8 details how many female authors are in each percentile between 1 and 5. In the fifth percentile, the percentage of female authors reaches 11.11% (Tables 9, 10).
Female authors are not equally distributed geographically either. Table 17, in the Appendix, lists their numbers for each country of Table 5. In percentage, Spain who has 63 authors in the top 5% and 9 of them—or 14.29%—are female, has the greatest percentage of the table. China is second with 13.33% the U.K. third with 11.64 percent. Other countries with more than 9% of female authors are the USA, France, and Australia. Somehow the Netherlands and Israel have no female authors in RMR5.
Table 2 also shows how many female authors are in the top 5% of each criterion. The lowest point is for Nb of Journal Pages, Weighted by Nb of Authors with only 218 female authors—or 6.64%. The highest point is for the criterion Closeness measure in co-authorship network, with 424 female authors—or 12.91%.
Nobel Laureates
A way to look at the quality present in RMR5 is to focus on the Nobel Prize Laureates. All the 92 Nobel Prize winners are registered on RePEc.Footnote 34 About half of them are deceased (45 out of 92). But alive or not most of them are still in RMR5. The 1969 laureates Ragnar Frisch (1895–1973) and Jan Tinbergen (1903–1994) are not but the 1970 laureate Paul A. Samuelson (1915–2009) is ranked 113.
Fact 9
(Nobel Laureates) Among the 92 Nobel Prize Laureates in Economics, 75 are in RMR5, and 53 in the top 1%. Their average rank is 506, the median rank is 234, the best rank is 2 and the worst is 2466.
Table 20, in the Appendix, lists all the Nobel Prize Laureates in Economics, in chronological order, with their ranks (for those in the top 5%). Among them, 26 are in the top 100 Authors.
Among the Nobel laureates, an instructive example is John F. Nash Jr.Footnote 35 It gives an idea of the order of magnitude of the needed citations to reach an excellent rank (with a rank of 2424, Nash is in the top 3.7%). RePEc lists eight works for Nash. Among them: one working paper, four articles, one chapter, and two books. With so few works, Nash is ranked 35,387 for Number of Distinct Works and 40,607 for Number of Article Pages. Not a good start to enter the top 5% of authors! Nash’s forte is his citations. He is ranked 1466 for Number of Cites and 327 for the Euclidian criterion. Among Nash’s eight referenced works, however, only two have a non negligible number of citations: Nash (1950a) and Nash (1953) with respectively 1811 and 750 citations.Footnote 36 Thanks to these 2561 citations, Nash is in the top 5% for 16 of the 17 citation based criteria (he misses the h-index criterion).Footnote 37
Age
In addition to the gender issue, it is striking that authors in RMR5 are not young (even when focusing only on those alive). In a sense this should not be that surprising as an older author had more time to accumulate more works and citations. Yet, at the top, authors are visibly quite senior. To explore seniority in more details, I have followed two complementary strategies. First, I looked on the internet for the year of birth of the 657 authors in the top 1%. Among them 43 are deceased and I could collect their year of birth and of death. Among the 614 living authors, the year of birth was available for 510 of them—or 83%
Fact 10
(Age in the top 1%) Living authors in the top 1% with an available year of birth are 66-year-old on average and the median age is also 66. The youngest is 42 year old and the oldest is 98 year old. Female authors are, on average, five years younger than men.
Figure 1 shows the histogram of the age distribution of the top 1% living authors.

Histogram of age among the top 1% living authors

Histogram of age at Ph.D. year
As it is time consuming to find the age of authors on the internet. I turned to a second strategy using the year of the terminal degree of authors. Indeed, RePEc Genealogy,Footnote 38 has collected the year of terminal degree for many authors. In particular, this information is available for 2085 out of the 3284 authors in RMR5. I have manually collected either the year of birth or the PhD year (both when available) for all the other authors in the top 5%. At the end, the information for both the year of birth and the PhD year is available for 842 authors. Figure 2 shows the histogram of the age at Ph.D. year for these authors for whom both the year of birth and the Ph.D. year are available. The three most frequent ages are 26, 27, and 28. One can suspect that ages below 25 do not correspond to a Ph.D. (some authors don’t have one). Some authors apparently received their Ph.D. at a rather old age but less than 9 percent received it when older than 33. I used the empirical distribution of PhD year of the 726 authors whose age at PhD year was between 25 and 32 to input a year of birth when it was missing but a terminal degree year was available.Footnote 39
Fact 11
(Estimated Age in the top 5%) Age is known or inferred for 2987 authors—or 96.8%—out of 3085 living authors in the top 5%. On average, they are 60-year-old and the median age is 59. The youngest is 30 year old and the oldest is 98 year old. Female authors are, on average, four years younger than men.
Table 11 illustrates Fact 12. I have also run t-tests to check if the means between two subsequent percentiles were equal or not. The differences are significantly different from zero except between p3 and p4.
Fact 12
(Age and Rank) On average, age decreases with Rank. From 64 years old in p1 down to 56 years old in p5.
The best ranks are mostly filled with older authors. In particular, Table 11 emphasizes the large number of emeritus professors among the top 5%. Assuming that any author 70 years old or older has the emeritus status, then 21% of the 2987 living authors, with a known or estimated age, are emeritus scholars. The percentage is even 31 in the top 1% of RePEc’s main ranking.
Wrap up
To summarize the descriptive statistics, I regressed the authors’ ranks on the few available variables describing the authors. The coefficient of age (measured in years) is negative and significantly different from zero. This captures the finding that highly ranked authors are older. The coefficient of age square is positive indicating that this relationship is reversed for large values of age. Indeed, starting from 82 (resp. 75, 75, 74, 73) years in column I (resp. II, III, IV, V) being one year older makes the rank increase. Yet, this reversal occurs for authors who are already emeritus professors. Being female increase the rank which is also coherent with the previous findings. The coefficient of the dummy variable for deceased authors is not significant while the coefficient of the dummy variable for being a Nobel Laureate is negative and significantly different from zero (Table 12).
In column III, I introduced dummy variables to describe the type of authors’ affiliation: Academic, Bank (mostly Central Banks and Federal Reserves), Governmental Body, and (international or national) Organizations (which are non academic). Deceased authors have no affiliation and some living authors also have no affiliation. Only the coefficient for Academic is significantly different from zero. It is negative indicating a lower (and thus better) rank for authors affiliated to an academic institution (mostly universities).
In column IV, I introduced dummy variables for country of affiliation. As expected, the coefficients for USA and UK are negative and significantly different from zero. Switzerland is the only other country with a significant coefficient. It is also negative. As seen before, authors in Switzerland tend to perform well in the ranking.
Column V includes all variables. Academic is no longer significantly different from zero and Bank is now significantly positive. The other coefficient are quantitatively very similar to the ones in the previous columns.
Questions about aggregation
Looking at a ranking such as RePEc’s main ranking, one has many questions. Among them two stand out. First, the selection question: Which criteria should be taken into account? Second, the aggregation question: Which summary statistics should be use? I have discussed the 36 criteria in "RePEc’s kitchen" and I will come back to selection in "A simpler customization" section. In "Ways and means" and "Issues with the harmonic mean" sections I discuss the aggregation methods.
Ways and means
As explained before RePEc’s main ranking aggregates 32 ranks (as from the 36 eligible rankings the the best two and the worst two ranks of each authors are discarded) through the harmonic mean. True to its philosophy, RePEc provides other ways, however. It allows the curious user to aggregate the ranks using either the arithmetic or the geometric mean.Footnote 40 RePEc also proposes three other ways: a lexicographic, a graphicolexic, and a percent method.Footnote 41 So six aggregation ways are possible.
Does the choice of aggregation matter? In an ideal scenario, the aggregate ranks of some authors would vary but for most of them they would not change in a significant way. This optimistic view is presented by Zimmermann (2013). In particular, his Table 5 (p. 275) shows rank correlations between the six aggregation methods. He uses the full sample of authors (at the time only 32,731 authors were registered compared to 65,674 in December 2022) and finds very high Spearman correlation coefficients—larger than 0.99—) between the first three means.Footnote 42 Using only the freely available RePEc data—i.e. rankings for the top 5%—I find Spearman coefficients of correlations lower than 0.99 but still larger than 0.9, see Table 18, in the Appendix, for details. Table 19—also in the Appendix—lists the Kendall rank correlation coefficients. It shows lower values than those of Table 18. This emphasizes that the number of discordant pairs—authors A and A’ form a discordant pair if A is better ranked than A’ in the first measure but the reverse is true for the second measure. All correlations remain positive and significantly different from zero.
Table 13 summarizes the distribution of the rank changes expressed in percentageFootnote 43 between the Arithmetic (resp. Geometric) mean and the Harmonic mean.
Fact 13
(A.G.H.) When the arithmetic (resp. geometric) mean is used for aggregating the 32 ranks, the final rank of an author change (up or down) by 30% (resp. 17%) compared to the harmonic mean. The change is larger than 27% (resp. 14%) for a quarter of the authors.
Tables 21 and 22, in the Appendix, zoom on the first one hundred authors for the three means. They display both small and large movements either up or down. In column 5 and 8 the authors name are in Bold (resp. black, italic) when their rank has improved (resp. remained the same, deteriorated). The exact change of rank is indicated in parenthesis next to the new rank. For example, Joseph E. Stiglitz is ranked first according to arithmetic mean. He is up 3 ranks. Stiglitz switched ranks with Andrei Shleifer who is down 3 ranks. Among the first ten harmonic-mean authors, Eugene F. Fama is the most penalized by the use of the arithmetic mean. His rank drops from 10 to 257.Footnote 44 The geometric mean induces movements somehow similar to the arithmetic mean but usually less pronounced. In particular, Fama is still down but only by 29 ranks.
Issues with the harmonic mean
In this section, I expand on a more fundamental issue with the harmonic mean, which I have not found discussed elsewhere.Footnote 45
Zimmermann (2013) writes (bottom of page 263): “In such a mean, very good rankings have a lot of weight; for example, the first rank counts twice as much as the second one. This aggregation method therefore rewards those who are particularly good in some category, but perhaps rewards too much. For this reason, the harmonic mean is dampened somewhat by adding a constant (currently one) to each rank and then subtracting it from the mean.”
To get an intuition on the behavior of the harmonic mean, one can begin by looking at its level curves. The following fact highlights a crucial property of such level curves.
Fact 14
(Level curves for the Harmonic mean) Let \(n\ge 2\) be the number of rankings, let \(\textbf{r}=(r_1, \ldots , r_n)\) denote the list of ranks, and for all i let \(\textbf{r}_{-i}\) denote the list of \(n-1\) ranks where \(r_i\) has been removed, then,
In particular, for \(n=2\),
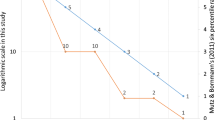
To illustrate graphically, Fig. 3 plots, for \(n=2\), the level curves of the harmonic, arithmetic, and geometric means. The three means are all equal to \(h_0\) when \(r_1=r_2=h_0\), and they are very much alike around this point. Pairs \((r_1,r_2)\) above (resp. below) the straight line \(r_2=2h_0-r_1\) have an arithmetic mean larger (resp. smaller) than \(h_0\). Similarly pairs above the blue (resp. maroon) curve have a harmonic (resp. geometric) mean larger than \(h_0\).Footnote 46

Level curves for the three means
As a consequence,
To insist, even if \(r_2\rightarrow +\infty\) the harmonic mean \(H(r_1,r_2)\) remains lower than \(h_0\). A rank lower than \(h_0/2\) for one ranking infinitely protects the mean from a bad outcome in the other ranking. A phenomenon which does not happen with the arithmetic nor the geometric means.
The problem does not disappear when more rankings are aggregated. It seems attenuated as the condition becomes \(r_1<\frac{h_0}{n}\) but with more ranks a group of them can serve to build an infinite protection. Adding 1 to the ranks and subtracting 1 to the mean, as it is currently done by RePEc, is a clever attempt but it does not really change this issue (see the examples below). Another way to look at the same issue is presented in Fact 15.
Fact 15
(Upper bounds for the Harmonic mean) Let \(n\ge 2\) be the number of rankings, let \(\textbf{r}=(r_1, \ldots , r_n)\) denote the list of ranks, and let \(\textbf{b}\) denote the bottom of the list—i.e. the k lowest ranks, and let \(\textbf{t}\) denote the top of the list—i.e. the complementary list of the \(n-k\) highest ranks, then,
In particular, for \(k=1\),
Examples Some examples are in order. First, let me illustrate Fact 15 with a rather shocking example. Any author with a rank of 1—among his remaining 32 ranks—cannot have an harmonic mean larger than 32 (or 63 the \(+1/-1\) correction). Indeed,
Currently, in RePEc main ranking a score of 63 corresponds to a rank of 49. This not as good as first but it is still in the top 0.1%. When all ranks are 66,000 and one is 1, the outlier is 1 not 66,000. At least, that would be my intuition. Can someone who is last 31 times out of 32 be ranked 49?Footnote 47 What is even more shocking is that 66,000 could be replaced by 66 billions.
Back to real life, Andrei Shleifer is first in RePEc’s main ranking. How well is he protected against (imaginary) bad shocks in some rankings? His 32 ranks (once the best 2 and the worst 2 have been removed from the 36 rankings) are:
Shleifer is seven times first (i.e. nine times out of 36). These seven ranks alone already secure him an excellent position even if he were to (unrealistically) fall in all the other rankings:
This time, a score of 8.14 corresponds to a rank of 5 in the current RePEc ranking. Again such an imaginary author would be ranked first seven times and last 25 times.Footnote 48 Keeping more ranks would of course limit even more the fall. Replacing Shleifer’s worst rank of 380 by 66,000 barely changes the harmonic mean and he would remain first. But even if he were to be ranked last 9 times he would remain first by keeping his first 23 ranks. This lack of sensitivity to numerous huge negative shocks is a property which can be found counterintuitive.
The arithmetic mean can also lead to counterintuitive results. An author ranked 31 times first and one time last would have a score of 1876, and a rank of 1169. It certainly looks unfair, and this one bad outcome (three given that two are removed) might be a measurement error. If not it might question the pertinence of including all these rankings. But in any case, a rank of 1169 means that the author is in the top 2% (top 1.77 to be precise).
As shown in Table 21 Joseph E. Stiglitz is first when the arithmetic mean is used to aggregate the 32 ranks. Stiglitz’s profile is:
Compared to Shleifer’s profile, these ranks are more homogenous and Stiglitz’s arithmetic mean is 8.69 whereas Shleifer’s is 26.57 (making him fourth in the ranking). From the top ten, the most dramatic change when using the arithmetic mean instead of the harmonic is for Eugene F. Fama Sr. who moves from 10 down to 257. This is explained by his third worst rank which is 5362.Footnote 49 But, although disappointing for someone of Fama’s caliber, I don’t think the arithmetic mean is the culprit here. First, a rank of 257 is still outstanding—i.e. top 0.4%. Second, the problem comes from the inclusion of what I could call (interesting but) noisy criteria.
Is it much different for authors ranked out of the top ten? At rank 142 of RePEc’s main ranking is Edward LazearFootnote 50 with an harmonic mean of 142.268. Already at these ranks the \(+1/-1\) correction has no bite it would move his mean to 142.936. Is Lazear’s position in danger if he were to fall in a couple of rankings? Putting his last 16 ranks at 66,000 increases his harmonic mean to 184.213 (or 185.779 with the \(+1/-1\) correction). The change is larger than at the very top but Lazear would only loose about 42 ranks moving him in the company of other legendary economists: Sherwin Rosen, Kenneth J. Arrow, William J. Baumol, and Rudiger Dornbusch. Again, one could argue that such a position is barely compatible with having half of the ranks at 66,000.
Authors registered on RePEc can have very different profiles. A striking one (even more extreme than Nash) is Mark Carhart. Mark is a quant hedge fund manager. He is currently not affiliated to any academic center (he has a 1995 PhD from Chicago Booth). He has one working paper and two articles referenced on RePEc. However, Mark belongs to RMR5, even the top 2% as his rank is about 900. In fact, he is in 16 of the 36 possible top 5% of Table 1. This is because his 1997 J. of Finance article received more than 4500 citations. This allows him to perform excellently in all citations-based criteria (except the h-index). In particular he is ranked 72 according to the Euclidian criteria. This case illustrates the issue with aggregating many correlated criteria with a harmonic mean—i.e. Facts 14 and 15. Here the citation dimension is strong enough to discard completely the poor rankings in terms of quantity of publication as well as visibility and network. Using the arithmetic mean of the 32 ranks (removing from the 36 ranks the best two and the worst two) would put him at a rank closer to 12,000 than 900.
A simpler customization
To reiterate, there is nothing inherently flawed about the various measures offered by RePEc, and exploring through different lenses authors’ scholarly impact can be a fascinating albeit time-consuming endeavor. However, the challenge of how to consolidate these disparate dimensions into a single, definitive ranking is a daunting one. RePEc’s approach involves calculating the harmonic mean of 32 ranks (after excluding from their 36 ranks the top two and bottom two for each author). In this section, I offer my own perspective on this issue and propose a simpler and more straightforward alternative—using only already available RePEc data. In "Discussion" section, I discuss the introduction of normalized criteria which would provide another perspective and possibly a more nuanced ranking.
Although the 36 criteria have a strong underlying logic, computing their mean (regardless of the type of mean used) ultimately reflects a particular choice and is neither agnostic nor neutral. To illustrate, consider two journals, J1 and J2, and two weighting schemes, E and R. In E, both journals have a weight of 1, while in R, J1 has a weight of 1 and J2 has a weight \(w > 1\). Now suppose there are two authors, A and B. A has \(n_A\) articles in J1, while B has \(n_B\) articles in J1 and \(m_B\) articles in J2. If \(n_A = n_B + m_B\), E would assign both authors the same rank, while R would rank B higher. Computing an average of these two rankings would effectively diminish the impact of the weight w.Footnote 51
Fact 16
(Simple ranking) Conditional on the currently available RePEc information, I propose a straightforward approach that combines only two dimensions. The simple ranking is obtained by taking the mean of the ranks of AWScPages—Nb of Journal Pages, Weighted by Nb of Authors and Recursive Impact Factors—and AWScCites—Nb of Citations, Weighted by Nb of Authors and Recursive Impact Factors.
This method values the quality and size of each publication, as well as its impact, while correcting for the number of authors. The motivations for this proposition are: (i) It is not advisable to combine rankings based on different weighting schemes, as this obscures the underlying methodology. Hence the focus on the recursive weights.Footnote 52 (ii) Given that the primary goal of research is to publish in high-quality journals, I believe that journal articles should be the only type of publication taken into account for ranking purposes. Working papers are undoubtedly important for economists, but they should be excluded from rankings.Footnote 53 (iii) Additionally, focusing solely on journal articles allows to take into account the number of pages—not available for working papers. Again this is an imperfect signal but longer articles are generally considered to be more significant contributions than shorter notes. As discussed in "Discussion" section, I think that normalized pages and normalized citations should be used but this is not currently available in RePEc.
To compute the ranking, I could use RePEc’s sandbox.Footnote 54 The sandbox lists the 3284 best-ranked authors—the top 5% of all registered authors. Depending on the preference for the type of mean used, three final rankings are possible: arithmetic (which is my preferred choice), geometric, or harmonic. The intersection of this new set of authors with the ones in RMR5 contains 2547 authors. The Spearman correlation coefficient between the simple ranking and RMR5 is 0.75, and the Kendall tau is 0.57.Footnote 55
Table 14 details some of the differences between the two rankings by looking at the first 1000 authors for each ranking. Each author is allocated, for each ranking, to a bin of width 100 ranks. For example, among the 100 authors ranked from 1 to 100 in RePEc’s main ranking (column [1, 100] in the Table) only 69 are still ranked below 100 in the simple ranking, 13 are ranked between 101 and 200, etc. Finally, 8 have a rank larger than 1000.
In terms of statistics descriptive, the population of authors in the top 5% of the simple ranking is not completely similar to the one in the top 5% of RePEc’s main ranking. In particular, authors are slightly more affiliated in an English speaking country (76% vs 69%), they are more located in the USA (1821 authors vs 1633), and more authors are female (324 vs 291). The Nobel Laureates are also differently ranked. John F. Nash is no longer in the top 5%. Among the recent laureates (after 2000), Robert J. Aumann gains 546 ranks moving from 911 to 365. Both 1996 Laureates William S. Vickrey (+614 ranks) and James A. Mirrlees (+379 ranks) benefit from my choice of ranking. Roger B. Myerson moves from 299 to 79, almost switching ranks with Esther Duflo who moves from 79 to 224. The number of deceased authors increased from 199 to 211. The distributions of the age of living authors are fairly similar.
Tables 15 and 16 display three rankings all based on a different aggregation of the two chosen criteria AWScPages and AWScCites. The arithmetic mean ranking is presented in the first three columns, followed by the geometric mean, and finally the harmonic mean. The names are in Bold (resp. black, italic) when their rank has improved (resp. remained the same, deteriorated). The exact change of rank is indicated in parenthesis next to the new rank. The (estimated) year of birth (and sadly the year of death for some) is shown in parentheses after the name of the author. For example, Daron Acemoglu is first in the arithmetic-mean ranking. He moves to second in the geometric-mean ranking and to third in the harmonic-mean ranking.
Discussion
RePEc is a valuable source of information on researchers in economics, collecting data on their publications (from working papers to journal articles) and citations. However, the current data collection process could be improved to provide a better description of the registered authors. For instance, RePEc could ask for additional information such as the author’s city and year of birth, citizenship,Footnote 56 gender, and Ph.D. university and year of completion. RePEc Genealogy provides information on the author’s terminal degree, but it is incomplete, with only about 15,000 authors listed out of the 66,000 registered authors. Moreover, the distinction between Ph.D. and M.A. degrees is often not made.
To incentivize authors to provide their data, RePEc could offer a new service called “RePEc C.V.”, which would allow registered authors to generate a beautifully formatted curriculum vitae automatically. To make this service possible, RePEc would need to keep a record of past affiliations, which would also benefit researchers who want to disentangle the effect of an author from that of their center. With RePEc’s creativity and expertise, the options for this service could be endless!
RePEc collected information about Twitter (I don’t know how). They could (try to) collect information about Google Scholar profiles. Indeed, it would be most interesting to compare them with CiTEc data.
Given the current data collection, more analyses could be provided. One important improvement would be to compute SIF and RIF by period of time. Ideally, SIF\(_y\), the simple impact factor of year y, would be computed using data from \(y-5\), ..., y, ...\(y+5\) (adapting the moving window for years close to the current year). That would capture better the “importance”, the “value” of a given journal at year y. An article published in year y would be weighted by SIF\(_y\).
Counting pages of the published articles is important. However, journals have various layouts and this is a source of noise. One way to deal with this problem is to normalize, as in Combes and Linnemer (2003), by the average number of pages in the same journal and year. That way, an article would be longer or shorter relative to its peers. This solution also captures the fact that the length of an article can change through time. Similarly, citation counts vary from one field to the other. In Linnemer and Visser (2016) the number of citations received by an article are normalized. See also, along these lines, Bornmann and Wohlrabe (2019). Normalizing citations by fields would be an improvement.Footnote 57
Currently, the sandbox can only be used to rank authors (or institutions) worldwide but not at a country level. For example, I could easily ask RePEc for the rankings of Tables 15 and 16 but it is impossible to have the same rankings for France only.
RePEc’s main ranking is built on publication and citation stocks. For this reason, older researchers tend to have larger stocks and better ranks. To emphasize more recent publications, RePEc provides rankings (either directly or through the sandbox) on the last ten years. It is clearly useful to identify highly productive young(er) authors. Analyzing these last ten years rankings would be a task for a future paper. Putting more emphasis on the last ten years might be a way to attract young scholars to register. I noticed that some prestigious young economists are not yet on RePEc. “So encourage your colleagues to register!”
Notes
In a sense, the paper is in a read and click format. I provide many links to RePEc’s webpages to encourage exploration, without forgetting to come back to the text!.
See also https://ideas.repec.org/credits.html.
The director of NEP is Marco Novarese.
To be complete, it also archives “Software Components”, “Chapters”, and “Books”.
A corollary is that if you once registered to RePEc and never connected again since, no new publication has been added to your profile. Also when you change affiliations you need to connect and enter the new one.
See https://www.nytimes.com/1997/10/22/business/two-booksellers-settle-lawsuits.html. Soon Amazon would sue Barnes & Noble for infringing its “one click” checkout patent.
The definition of “economist” is loose. Authors registered with RePEc do not necessarily belong to an economics department. Many Business, Finance, and Statistics folks are included. Many of them (economists or not) are affiliated to an inter/national non academic organization, e.g. a central bank.
A type of study that cannot be done with RePEc’s data is the study of the influence of economic publication on other scientific fields, see Angrist et al. (2020).
RePEc also compiles rankings and weights for journals and working papers series. These weights are very important for the author and center rankings.
An author with a Wu index of w has w articles cited 10w times or more.
For RePEc’s main ranking, Authors in the top 6% (but not top 5%) are listed in alphabetical order, and so on until the top 10%. But the exact rank and affiliation details are known only for the top 5%. Otherwise each author receives privately a monthly email with a link to his/her 39 ranks (and scores).
See Combes and Linnemer (2003) for a survey of the early literature.
See https://ideas.repec.org/top/top.journals.simple10.html and https://ideas.repec.org/top/top.journals.recurse10.html. One reason to look at the last ten years is that the length of the history of journals is not the same. Econometrica issues are listed from 1969 (yet the journal exists since 1933). On the contrary all issues of the Quarterly J. of Economics (from 1886) seem to be listed. RePEc also ranks journals (and working paper series) by four additional criteria: Discounted impact factors, Recursive discounted impact factors, h-index, Euclidian citation score. Finally, RePEc computes an Aggregate ranking based on the harmonic mean of the individual ranks \(+1\), leaving aside the best and the worst ranks. Also notice that Citation counts are adjusted to exclude citations from the same series.
Nothing really prevents authors to upload working papers (so working paper series accept all papers). The only limit is physical: how many different working papers can an author (pretend to) write? In equilibrium, however, undiscriminatory working paper series (or journals) should receive few citations and should have low SIF and RIF.
Notice that these SIF are quite different from the IF provided by the Journal Citation Reports (Clarivate). For a given journal, the JCR counts the number of citations c received during year t by the n articles published in years \(t-1\) and \(t-2\), then IF is c/n. The idea of RePEc is similar but the considered time periods are different. The pool of journals is also different and a unique characteristic of RePEc is that they provide SIF for both journals and working paper series.
So, one could argue in favor of grouping journals by class instead of using precise weights. That would be in the spirit of Principle 8 of the Leiden Manifesto “Avoid misplaced concreteness and false precision”, see Hicks et al. (2015).
For example, the J. of the Royal Statistical Society Series B and the J. of the American Statistical Association, two influential journals in Statistics, have a rank of 128 and 131 respectively in the all years RIF ranking. As a comparison, the Canadian J. of Economics/Revue canadienne d’économique is ranked 132. This is probably due to the fact that not all Statistics journals are included in RePEc, depriving these two journals of more sources of citations.
Wrongly assuming that the entry threshold would remain the same. On the one hand the threshold increases through time as authors mechanically accumulate more works. On the other hand, the number of registered authors also increases which makes the top 5% group larger and might lower the entry threshold.
See https://ideas.repec.org/top/top.person.dnbworks.html, for the current list.
Similar numbers are obtained with the SIF of the following journals: J. of Monetary Economics American Economic J.: Macroeconomics, J. of Labor Economic, J. of Accounting and Economics, or American Economic J.: Applied Economics.
A more successful author publishing twice a year in the QJE instead of the RAND would have to wait only 5 years and a half. Indeed, (as of early January 2023) QJE’s SIF is 154.92.
One could be also interested in the correlation of the scores not the ranks.
This is almost mechanical given the removal of the two best ranks.
By chronological order: James J. Heckman shared the 2000 Nobel prize with Daniel L. McFadden (who is 254th in the ranking). Joseph E. Stiglitz shared the 2001 Nobel prize with George A. Akerlof (who is 81st in the ranking) and A. Michael Spence (who is 393rd in the ranking). Eugene F. Fama shared the 2013 Nobel prize with Lars Peter Hansen (who is 67th in the ranking) and Robert J. Shiller (who is 76th in the ranking). Jean Tirole received the prize in 2014. David E. Card received half the prize in 2021 the other half was shared between Joshua D. Angrist (who is 41st in the ranking) and Guido W. Imbens (who is 46th in the ranking).
These beautiful graphs are obtained at https://collec.repec.org/app/collec_app: just type a name and wait. The graphs are interactive. The graph of Eugene Fama is not available.
Only Tirole and Peter C.B. Phillips are not.
Recall that authors choose the percentage they spend at each affiliation. As the example of Peter C. B. Phillips shows some information might be lost for a few authors.
On average, they passed away at the age of 73.7 with a median at 75. The minimum age was 37 and the maximum 103. As many as 25% of them died past 84 but 25% died before 64.
Among the 303 authors with two shown affiliations, these are in the same country 231 times -\(-\)76.2%– e.g. 132 of them are in the USA for both, 21 in the UK for both.
These countries are (by decreasing number of authors): USA, UK, Canada, Australia, New Zealand, Ireland, and South Africa. Adding India to the list would increase the percentage to 69.5%.
About the NBER: the authors counted here as affiliated at the NBER have the NBER as their first, and sometimes only, affiliation. There might be some sloppiness involved.
Among the oldest, most of them have been registered by Christian Zimmermann.
Nash’s RePEc profile is: https://ideas.repec.org/e/pna13.html.
His third famous article (Nash, 1950b) is not included in the RePEc database.
What is striking is the relative small number of citations found by CiTEc. By comparison, his bargaining piece (Nash, 1950a) is cited 11,458 in Google Scholar and 3992 in the Web of Science, which only counts citations in a (short) list of journals. Nash (1953) is cited 4626 in Google Scholar and 1492 in the Web of Science. The missing article (Nash, 1950b) is cited 9866 in Google Scholar and 3581 in the Web of Science. RePEc is not responsible for the missing article. It is the responsibility of the journals to reference their articles.
See https://genealogy.repec.org/, this is probably inspired by The Mathematics Genealogy Project, see https://www.genealogy.math.ndsu.nodak.edu/. See Dubois et al. (2014) for an analysis of the productivity and mobility of mathematicians using the Mathematical Reviews database.
More precisely, with probability 7.84 (resp. 16.78, 19.81, 18.57, 13.07, 11.42, 7.70, and 4.81) the inputted age is 25 (resp. 26, 27, 28, 29, 30, 31, and 32).
These three means are called the Pythagorean means. See https://en.wikipedia.org/wiki/Mean.
For formal definitions see Zimmermann (2013) and https://ideas.repec.org/t/rankcodes.html
The other coefficients are in general also high, above 0.9. The percent method gave strange correlations, however.
That is \(100\left| r_1-r_0\right| /r_0\).
Of course 257 is still an excellent rank (top 0.4% of all authors) but it is not a negligible change. I explain below what causes Fama’s drop (more a question of criterion selection than of aggregation method).
I could not find much on the harmonic mean besides its definition and a couple of properties. A Google Scholar search, for example, leads to Ferger (1931) in the J. of the American Statistical Association where the author emphasizes which of the arithmetic or harmonic mean is better suited to average different ratios (like speed per hour) depending on the type of data. Wikipedia is not very informative, also.
The level curve of the geometric mean is, of course, the iso-utility curve for a Cobb-Douglas utility function \(U=\sqrt{x y}\). Keeping the analogy with utility functions, the arithmetic mean level curve is the analogous of perfect substitutes, and the harmonic mean of a Cobb-Douglas with minimum level of consumption.
Among the initial 36 ranks of this imaginary author 3 would have to be 1, and 33 would have to be 66,000.
More precisely, nine times first and 27 times last.
Fama does not have a lot of works although his articles are widely cited and very well published. He also does not have a lot of co-authors and he performs badly according the network criteria Closeness and Betweenness. These two bad ranks are eliminated but he keeps relatively bad ranks for Nb of Distinct Works and Nb of Distinct Works, Weighted by Nb of Authors.
Lazear (1948–2020) was a hugely influancial U.S. economist, see https://en.wikipedia.org/wiki/Edward_Lazear.
Let \(x=n_A = n_B + m_B\), then the score of A in both ranking is x and the score of B is x for E and \(x+(w-1)m_B\) for R. Taking the average score keeps A’s score at x while B’s score becomes \(x+(w-1)m_B/2\), which gives less weight to the more prestigious publications.
It is more difficult to publish in selective journals and Recursive Impact Factors weights tend to reward such journals. Although they are not perfect, they avoid rewarding authors with many articles in less prominent journals.
I understand that many authors have unpublished working papers that are highly valuable. They did not find a suitable journal or the authors had not enough time to tailor their work for a journal. Yet, there is no limit on the number of working papers and some authors with a high number of distinct works have over 500 working papers and only around 30 articles.
The comparison with the purely quantitative ranking, Number of Distinct Works, shows a Spearman correlation coefficient with my simple ranking of 0.16, a Kendall tau is 0.11, with an intersection of 1221 authors. Among the 14 authors with more than 500 distinct works, only Joseph E. Stiglitz remains in the top 100 of my simple ranking, actually Stiglitz is ranked 4th. Six of the remaining thirteen authors are not in the top 5% of my simple ranking while they were in RMR5.
Citizenship (past and present) and place of birth could be useful to know more about migration patterns among researchers, and in particular about how many migrants are working in the USA. Did they migrate to do their Ph.D. and then stayed, or did they arrived already with a doctorate?
Of course the first step would be to define fields. The JEL codes would be useful here but a careful approach would have to be followed.
References
Angrist, J., Azoulay, P., Ellison, G., Hill, R., & Lu, S. F. (2020). Inside job or deep impact? Extramural citations and the influence of economic scholarship. Journal of Economic Literature, 58(1), 3–52.
Baumann, A., & Wohlrabe, K. (2020). Where have all the working papers gone? Evidence from four major economics working paper series. Scientometrics, 124 (3): 2433–2441.
Bornmann, L., & Wohlrabe, K. (2019). Normalisation of citation impact in economics. Scientometrics, 120(2), 841–884.
Combes, P.-P., & Linnemer, L. (2003). Where are the economists who publish? Publication concentration and rankings in Europe based on cumulative publications. Journal of the European Economic Association, 1(6), 1250–1308.
Dubois, P., Rochet, J.-C., & Schlenker, J.-M. (2014). Productivity and mobility in academic research: Evidence from mathematicians. Scientometrics, 98, 1669–1701.
Ferger, W. F. (1931). The nature and use of the harmonic mean. Journal of the American Statistical Association, 26(173), 36–40.
Hamermesh, D. S. (2018). Citations in economics: Measurement, uses, and impacts. Journal of Economic Literature, 56(1), 115–156.
Hausken, K. (2016). The ranking of researchers by publications and citations: Using RePEc data. Journal of Economics Bibliography, 3(4), 530–558.
Hicks, D., Wouters, P., Waltman, L., De Rijcke, S., & Rafols, I. (2015). Bibliometrics: The Leiden manifesto for research metrics. Nature, 520(7548), 429–431.
Jelnov, P., & Weiss, Y. (2022). Influence in economics and aging. Labour Economics, 77, 101992.
Konig, J., Stern, D. I., & Tol, R. S. J. (2022). Confidence intervals for recursive journal impact factors. arXiv preprint https://arxiv.org/abs/2206.00004
Konig, M., Liu, X., Hsieh, C. -S., & Zimmermann, C. (2020). Collaboration in bipartite networks, with an application to coauthorship networks. Centre for Economic Policy Research (CEPR) discussion paper, (26907).
Linnemer, L. (2023). A menagerie of rankings: A look in RePEc’s factory. CESifo working paper no. 10343, CESifo.
Linnemer, L., & Visser, M.. (2016). The most cited articles from the top-5 journals (1991–2015). Working paper series 5999, CESifo.
Nash, J. F. (1950). The bargaining problem. Econometrica, 18(2), 155–162.
Nash, J. F. (1950). Equilibrium points in n-person games. Proceedings of the National Academy of Sciences, 36(1), 48–49.
Nash, J. F. (1953). Two-person cooperative games. Econometrica, 21(1), 128–140.
Perry, M., & Reny, P. J. (2016). How to count citations if you must. American Economic Review, 106(9), 2722–41.
Seiler, C., & Wohlrabe, K. (2012). Ranking economists on the basis of many indicators: An alternative approach using RePEc data. Journal of Informetrics, 6(3), 389–402.
Stern, D. I. (2013). Uncertainty measures for economics journal impact factors. Journal of Economic Literature, 51(1), 173–89.
Stern, D. I. (2017). Comment on Bornmann (2017): Confidence intervals for journal impact factors. Scientometrics, 113, 1811–1813.
Stern, D. I., & Tol, R. S. J. (2021). Depth and breadth relevance in citation metrics. Economic Inquiry, 59(3), 961–977.
Wohlrabe, K, & Bürgi, C. (2021). What is the benefit from publishing a working paper in a journal in terms of citations? Evidence from economics. Scientometrics, 126(6), 4701–4714.
Zacchia, G. (2021). What does it take to be top women economists? An analysis using rankings in RePEc. Review of Political Economy, 33(2), 170–193.
Zimmermann, C. (2013). Academic rankings with RePEc. Econometrics, 1(3), 249–280.
Acknowledgements
I am grateful to Christian Zimmermann for patiently answering my numerous questions. I also benefited of feedback from Daniel Hamermesh, David Stern, Michael Visser, and Klaus Wohlrabe, many thanks to all of them. A working paper first version of this article is Linnemer (2023).
Funding
This research is supported by a grant of the French National Research Agency (ANR), “Investissements d’Avenir” (LabEx Ecodec/ANR-11-LABX-0047).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author has no conflict of interest nor competing interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: A harmonic mean level curves
Appendix: A harmonic mean level curves
Assume for all i, \(r_i>0\). I show here that (i.e. that Fact 14 is true)
Indeed,
Now it is also true that
or
and therefore
which gives the result.
About Fact 15: Let \(n\ge 2\) be the number of rankings, let \(\textbf{r}=(r_1, \ldots , r_n)\) denote the list of ranks, and let \(\textbf{b}\) denote the bottom of the list –i.e. the k lowest ranks, and let \(\textbf{t}\) denote the top of the list—i.e. the complementary list of the \(n-k\) highest ranks, then,
which is the result.
The number of observations used corresponds to the number of authors in the intersection of the two top 5%. In any top 5% there are 3284 authors. But, for example, only 2971 authors (90% of 3284) are both in the top 5% of the ranking based on the harmonic mean and in the one based on the arithmetic mean.

Coauthorship networks of authors ranked 1 to 9 in RePEc’s main ranking
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Linnemer, L. A menagerie of rankings: a look in RePEc’s factory. Scientometrics 129, 321–372 (2024). https://doi.org/10.1007/s11192-023-04879-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-023-04879-z