
Abstract
The title of the journal article as a genre has been extensively investigated for variations across disciplines (e.g., titles in sciences vs. social sciences or in linguistics vs. medicine), genres (e.g., research article titles vs. review article titles), and cultures (e.g., titles composed by native vs. non-native authors). However, little is known about how title language is manipulated at “a highly specific sub-disciplinary” level to make articles stand out (Pearson, Scientometrics 123:997–1019, 2020). Our analysis is based on an investigation of a corpus of 1458 titles of original contributions to TESOL Quarterly over a 55-year period. The results show a considerable increase in the average title length in running words, content words, and syllables. The rate of occurrence of compound constructions (CC) increased by 5.7-fold from 1967 to 2022, accompanied by a 3.7-fold decline in the use of nominal constructions (NC). In addition, CC titles featuring a quotation and a V-ing phrase are increasing, while nominal segments are steadily declining in number. The results support some of the previous findings from research at the disciplinary level of linguistics and sub-disciplinary level of applied linguistics but vary from others, indicating there is value in research into the field- and journal-specific titling practices. In general, the article titles in the journal are becoming increasingly diversified and complex, both stylistically and syntactically, but more flexible by allowing writers to create a balance between informativeness and allure.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Research article titles present authors and journal editors with a rhetorical challenge that any other section of an article seldom does. In the newly revised edition of the Publication Manual of the American Psychological Association (2020, p. 46), the recommendation of a 12-word maximum title length is changed to “there is no prescribed limit for title length,” while authors are encouraged to keep their titles simple and concise. The revision was conducted in response to a study showing that the average title length in APA journals has increased to the point that more than half exceed the suggested limit (Hallock & Dillner, 2016). Longitudinal studies on journal articles in economics (Guo et al., 2015), biology (Lewison & Hartley, 2005), medicine (Cameron & Robertson, 1997; Salager-Meyer & Alcaraz-Ariza, 2013), mathematics (Milojević, 2017), applied linguistics (Sahragard & Meihami, 2016), and literature (Xiang & Li, 2020) have also reported varying increases in the length of article titles. At the same time, contradictory findings are reported in the literature. For example, a study on titles of research articles in economics published between 1890 and 2012 showed that authors used increasingly lengthier titles (Guo et al., 2015); however, in another study on titles of research articles published between 1961 and 2010 in journals in five disciplines, the same discipline, economics, stood out as the only one in which the titles have not increased in size (Milojević, 2017). The apparent contradiction between the results of the two studies might be methodological, but their data and journal sources are more likely to be responsible. While the former investigated a corpus of 338,866 article titles in 576 journals from the EconLit and the Web of Knowledge, the latter examined 21,602 article titles in 12 economics journals in Liner’s (2002) Core Journals in Economics.
Journal editorial policies disagree, too. For example, research shows that editors at the BMJ preferred the compound construction (CC), a structure comprising two segments separated by a colon or other punctuation, much more than their colleagues at the England Journal of Medicine and Lancet (Cameron & Robertson, 1997). Richard Smith (2000), one of the BMJ editors, explained how his journal located itself between academia and journalism, attempting to cater to both researchers and practitioners. Eventually, since 2003, the BMJ has required the titles of original research articles to include the research question and the study design (https://www.bmj.com/about-bmj/resources-authors/article-types), which are often, although not always, structured in the form of a CC structure. In contrast, editors of the Journal of Bacteriology suggest that the numbered series title and the main title/subtitle arrangement be avoided (https://journals.asm.org/journal/jb/article-types), which can be interpreted as discouragement from the CC structure. Unlike the BMJ and Journal of Bacteriology, many other journals provide have no specific guidelines regarding what information to include in article titles. However, as Nature states (https://www.nature.com/nature/for-authors/formatting-guide), “editors often suggest revised titles” for the final version of the manuscript to improve their readability.
These conflicting research findings and differing editorial policies suggest the need to re-consider the hypothesis of (sub-)disciplinary homogeneity in titling practice, on which much of the titleological research in the literature is based, by examining the extent to which titular attributes identified at the broad, (sub-)disciplinary level apply to research concerns at “a highly specific sub-disciplinary” level (Pearson, 2020, p. 997) or at the individual level of journals. A few studies have focused on the title writing practices in small academic discourse communities (Pearson, 2020; Whissell et al., 2013) or single journals (Becker, 2003; Li & Xu, 2019; Whissell, 2004, 2012), expecting to “offer some magic solution to the problem of the increasingly formulaic character of journal articles” (Becker, 2003, p. v). For example, Pearson (2020) investigated titles of research articles on written feedback on English-as-a-second-language writing published in a variety of academic journals and discovered significant variations from previous findings at the disciplinary level of linguistics. While his research is synchronic, he suggests future temporal analyses, which may trace the evolution of the identified attributes. The present study aims to investigate a corpus of titles of research articles published over a 55-year period in TESOL Quarterly, a leading journal in teaching English to speakers of other languages (TESOL).
Literature review
Issues concerning the titling of research papers have long been the subject of much debate, sometimes intense or even emotional, on the pages of scientific journals such as Science (Baskerville, 1904; Shull, 1931), Nature (Branner, 1905; Munroe, 1967), BMJ (Billings, 1881), and The Lancet (Taylor, 1965). A 1924 letter to Science even suggested that it be a crime against science for authors to use “faulty and misleading titles” and, as such, the editors who publish them be participrs crimilzis (Gudger, 1924, p. 14). However, it was not until the second half of the twentieth century that more severe research into article titles began to be undertaken in several fields, opening up a research field called “titology” (Levin, 1977) or “titleology” (Pearson, 2020; Salager-Meyer & Alcaraz-Ariza, 2013).
The first approach to the article title was developed in the 1960s when the computer began to be used for automatic indexing and information retrieval. Among the “permuted-title indexes” created was the KWIC (Keyword-in-Context). Its underlying principle is that, as the title of a document represents its contents, keywords can be extracted from it for effective indexing. While the fundamental techniques of the KWIC system were widely welcomed, “the need for better titles” was frequently discussed in studies improving the index (Fischer, 1966, p. 65). This need soon generated an increasing research interest in “title efficiency” (Sedano, 1964) and “author participation” (Kennedy, 1963). These studies mainly focused on variations in the descriptiveness or informativeness of titles across disciplines (Balog, 1981; Bottle, 1970; Buxton & Meadows, 1977; Diener, 1984; Garfield, 1970; Ghosh, 1977) and measures to help authors write better titles (Fischer, 1966; Herner, 1963).
The informativeness of titles is usually measured by the substantive or lexical words (nouns, adjectives, verbs, and adverbs, as opposed to function words such as determiners and prepositions) that they contain. As Lane (1964) showed, titles in science and engineering are more informative than those in non-technical fields, describing the contents of the articles that they entitle. Similarly, Buxton and Meadows (1977) discovered that physical science titles are more informative than social science titles. Diachronic studies in this tradition were also conducted to reveal how titular informativeness has changed over time. Tocatlian (1970), for instance, measured the informational value of titles in the chemical literature and discovered that uninformative titles were being eliminated since the advent of the KWIC index. Yitzhaki (1997) demonstrated that, while considerable differences were found in the number of substantive words in article titles between the humanities journals, they followed a general trend of increase in informativity, although at a slower pace than titles in the natural and social sciences.
A different approach to research article titles originated in the 1990s in the field of genre analysis, which focuses on how the rhetorical functions of sub-genres, such as academic introductions, literature reviews, results, and discussions, are realized by lexico-syntactic means. Research article titles, therefore, began to be investigated as “serious stuff” (Swales, 1990, p. 224). In this tradition, article titles are usually classified into various syntactic categories (e.g., nominal construction, verbal construction, and propositional construction) and compared for variations across disciplines (Ball, 2009; Diao, 2021; Haggan, 2004; Moattarian & Alibabaee, 2015; Moslehi & Kafipour, 2022), genres (Cianflone, 2013; Gesuato, 2008; Méndez & Ángeles Alcaraz, 2017; Soler, 2007), and cultures (Busch-Lauer, 2000; Soler, 2011; Xie, 2020). Haggan (2004), for example, analyzed article titles in linguistics, literature, and science, and results show that compound titles dominate literature research articles, while approximately two-thirds of the titles in science and linguistics are in the form of a nominal construction. Diao (2021) examined the lexical density and syntactic structure of 690 research article titles chosen from library science and scientometrics journals and found that the former demonstrates more punctuation complexity, while the latter shows more involvement of words related to research methods.
Cross-generic studies have compared titles of original research articles with other academic titles, such as review articles (Kerans et al., 2016; Soler, 2007), popular science articles (Ángeles Alcaraz & Méndez, 2016), scientific letters (Méndez & Ángeles Alcaraz, 2017), case reports (Salager-Meyer & Alcaraz-Ariza, 2013; Salager-Meyer et al., 2013), conference papers (Gesuato, 2008), and theses and dissertations (Jalilifar, 2010). Soler (2007), for instance, examined article titles in two sub-genres—research papers (RP) and review papers (RVP)—in biological sciences and the social sciences and found that the compound construction occurs more frequently in RP titles than in RVP titles. In addition, the full-sentence construction, a common title form in biology, medicine, and biochemistry, has not been found in RVP titles. Additionally, in a cross-cultural and cross-disciplinary study, Xie (2020) has demonstrated striking differences between English-language research article titles by Chinese and international authors. For example, nearly all titles in natural science in the former are nominal (92%), in sharp contrast to 60.67% in the latter. Full-sentence titles, which account for only 3.66% of the Chinese corpus, constitute 15.67% of the samples by their international colleagues.
The third approach is pedagogically focused, investigating the effectiveness of research article titles. Article titles are categorized according to what information they contain. For example, Goodman et al. (2001) classified a corpus of titles from four peer-reviewed medical journals into Topic Only, Methods/Design, Dataset, Results, and Conclusions. They found that most of them lacked information about study design, methods, and results, recommending that discussions be conducted for consensus on the purposes of titles and that editorial policies be developed to better serve the needs of editors, authors, and readers. A much-studied title type is the compound construction, which is classified into various categories. Swales and Feak (2004) distinguished four types of compound titles according to the relationship between the two constituent parts: problem: solution; general: specific; topic: method; and major: minor. The classification was designed for use in classroom instruction of academic writing, and it has been applied to analyzing article titles across disciplines and cultures (Busch-Lauer, 2000; Pearson, 2020). Anthony (2001) identified five types of what he called “hanging titles” in computer science: name: description, topic: scope, topic: method, description: name, and topic: description. His analysis of a corpus of 600 research articles from six journals showed that the name: description relationship was the most popular title structure in computer science, followed by the topic: scope. This finding, along with his results in terms of title length, punctuation usage, word frequency, and preposition usage, shows that some of the observations made in the literature about title writing are either unjustified or misleading, ignoring the effects of discipline and field variation. Cheng et al. (2012) modified Anthony’s (2001) classification to develop a typology consisting of eleven types of informational combinations, and the results of their study on titles in linguistics journals show that six combinations—topic: scope; topic-method; topic: description; topic: source; metaphor: topic; and topic: question—account for more than 96% of the occurrences of the compound construction.
A growing body of informetric and bibliometric title studies has investigated how certain structural, functional, or rhetorical characteristics correlate with scholarly impact. Some studies have explored the effects of title length and type on the impact of research (Habibzadeh & Yadollahie, 2010; Heard et al., 2023; Jacques & Sebire, 2009). Rhetorical features of titles, such as those featuring a question (Ball, 2009; Dietz, 2001; Fiala et al., 2021), a quotation (Pearson, 2021; Pułaczewska, 2009), a full sentence (Cheng et al., 2012; Haggan, 2004; Soler, 2007), an allusion (Goodman, 2005), a cliché (Goodman, 2012), and a sense of humor (Sagi & Yechiam, 2008; Subotic & Mukherjee, 2014), have also been investigated for their effects on the quality of research. These studies reached opposing conclusions, showing marked variations in titular traditions across fields and disciplines. For example, positive relations between title length and citation rate are found in general and specialist medicine (Falagas et al., 2013; Jacques & Sebire, 2009; van Wesel et al., 2014), multidisciplinary sciences (Habibzadeh & Yadollahie, 2010), humanities (Yitzhaki, 2002), and ecology and astronomy (Milojević, 2017), but negative relations are discovered in article titles in biology (Didegah & Thelwall, 2013), economics (Bramoullé & Ductor, 2018), management science (Nair & Gibbert, 2016), psychology (Subotic & Mukherjee, 2014), sociology (van Wesel et al., 2014), scientometrics (Fumani et al., 2015), social sciences (Didegah & Thelwall, 2013), and Public Library of Science (PLoS) dataset (Jamali & Nikzad, 2011; Paiva et al., 2012). Guo et al. (2018) found that the correlation between title length and the number of citations in economics turned from negative to positive in 2000, when online datasets became the predominant source for literature retrieval, echoing White and Hernandez (1991), who posit that time is the most important factor related to title length.
Finally, a non-comparative perspective has been adopted across the four traditions reviewed. The focus of such research is often on research article titles in single disciplinary or sub-disciplinary fields. These studies, be they synchronic or diachronic, are based on the hypothesis that titling practices are discipline-constrained and that the titles of research articles in a discipline are generically similar. As Pearson (2021) notes, several sub-disciplines of linguistics, such as applied linguistics (Cheng et al., 2012; Jalilifar et al., 2010; Sahragard & Meihami, 2016; Yang, 2019) and pragmatics (Dietz, 2001; Li & Xu, 2019; Pułaczewska, 2009), have been targeted for such descriptive studies. Another focused area includes medicine (Cameron & Robertson, 1997; Falagas et al., 2013; Goodman, 2010, 2011, 2012; Goodman et al., 2001) and sub-strands such as clinical medicine (Goodman, 2000; Kerans et al., 2020), veterinary medicine (Cianflone, 2010, 2012), alternative medicine (Lewin et al., 2015; Salager-Meyer et al., 2017), and community medicine (Wadde & Domple, 2021).
As is shown in the above review, previous studies on title attributes in various traditions have helped reach the consensus that titling practice varies across disciplines, genres, and cultures. Studies have also confirmed that article titles in many fields have increased in length over time, though to varying degrees (Cameron & Robertson, 1997; Lewin et al., 2015; Li & Xu, 2019). The compound construction has become a favorite choice among writers in a majority of disciplines (Haggan, 2004; Soler, 2007). However, as Nair and Gibbert (2016, p. 1332) state, the results of many titular studies “do not add up, and even appear contradictory.” For example, while some studies (e.g., Falagas et al., 2013; Jacques & Sebire, 2009; van Wesel et al., 2014) found that title length is positively related to citation rate in general and specialist medicine, Paiva et al. (2012) and Jamali and Nikzad (2011) discovered that the two factors are negatively correlated in their analyses of titles from PLoS journals, which includes the journal of PLoS Medicine. The contradictory results raise the question of to what extent “good practices” identified at the (sub-)disciplinary level apply at a “highly specific sub-disciplinary” level (Pearson, 2020, p. 997) or an individual level of journals. Whissell (2013), for example, investigated the titles from 65 volumes of American Psychologist, which, unlike other research journals, has emphasized the importance of broad appeal and an accessible writing style in articles, and discovered that titles in the journal are shorter than the norm in the discipline (8 words as opposed to 10). Similarly, Anthony (2001, p. 193) reported that the lengths of the titles of research articles from the six journals of the IEEE Computer Society varied substantially, claiming that “an adequate description depends more on the type of study or problem being investigated than the discipline itself.” These observations highlight the value of studies on title writing practices of smaller discourse communities.
Study aims
To address the gap, in this paper, we analyze a corpus of 1,458 titles of research articles published in TESOL Quarterly, a leading professional journal for TESOL teachers, educators, and researchers worldwide. Specifically, we address the following research questions:
-
(1)
How have the titles in the journal changed in terms of length and syntax between 1967 and 2022?
-
(2)
How do evolutionary changes in the titles in the journal affect their lexical density, diversity, and complexity?
-
(3)
How do changes in the compound construction affect the relationship between its two segments?
-
(4)
Do the changes identified in the study vary from related findings in the literature, especially studies in linguistics?
Data and method
Data selection
The corpus for the present study consists of the titles of research articles in the 220 issues of TESOL Quarterly published from 1967, the year of its establishment, to 2021. The journal is published on behalf of the TESOL International Association. With its focus on English language teaching and learning as a second language, it includes articles on a wide range of topics, especially in the psychology and sociology of language teaching and learning, research and teaching issues, professional training, curriculum design, research methodology, instructional methods, and testing and assessment. The journal does not have a stated policy regarding the writing of titles.
The journal has a number of columns, each with its own editor. The policies for these sections differ (https://onlinelibrary.wiley.com/page/journal/15457249/homepage/ForAuthors.html). For example, submissions to the “Articles” section are supposed to be 7,000 to 8,500 words and about recent research on a topic in a more general area, and those to the “Brief Reports” section are expected to be empirical research reports of no more than 3400 words that highlight innovative methodologies, new approaches to data interpretation, or novel theoretical frameworks. “Articles” and “Brief Reports” columns accept unsolicited manuscripts, but contributions to other sections are either pre-approved or solicited by section editors. The following is intended for a brief glimpse of the columns in the journal.
Restricting our study to articles that could be considered original contributions, we only selected articles labeled “Articles,” “Original Articles,” and “Full-length Articles” in each issue, which are shown in bold type in Table 1. Articles in other sections, including “Brief Reports,” “Review Articles,” “Special Issue Articles,” and “Forum,” were excluded. The choice was made on the basis of two considerations. On the one hand, titles of various academic genres, such as research articles, review articles, and technical reports, which target at different audiences, exhibit significant cross-generic variations. For example, significant syntactic differences are found between the titles of research articles and review articles (Soler, 2007); titles of medical case reports are reported to show a different line of evolution from that of original research articles (Salager-Meyer & Alcaraz-Ariza, 2013). On the other hand, the original contributions, though with different column titles in various issues, are the only “regular” column in the journal, while other columns appear irregularly, and some have been renamed or even removed.
In issues before June 1983, as shown in Table 1, the section containing research articles was untitled and placed before “Reviews,” “Research Notes,” or “Forum” as the main part of each issue. These articles were regarded as original contributions and, as such, selected.
As a result, a total of 1,458 article titles were yielded for the study. The details of the corpus are given in Table 2.
Method
Our analysis of the titles in the corpus yielded five categories in terms of syntactic structures. It is a classification similar to Cheng et al. (2012), but the term “sentential construction,” instead of “full-sentence construction,” was chosen, as incomplete sentences frequently appear in our corpus as segments of compound titles. The five categories are:
-
Nominal construction (NC) in the form of one or more noun phrases, e.g., School teachers’ perceptions of similarities and differences between teaching English and a non-language subject
-
Verbal construction (VC) in the form of a V-ing phrase structure, e.g., Exploring the positioning of teacher expertise in TESOL-related curriculum standards
-
Compound construction (CC) a two-part construction separated by a colon or other punctuation. Theoretically, CC titles can be divided into 20 groups according to syntactic relationships between the pre-colon and post-colon constituents. However, our analysis recorded 18 types, of which five occurred more than 35 times over the 55-year period. It is, therefore, classified into six groups: NC: NC; VC: NC; SC: NC; NC: VC; NC: SC; and others. The titles below exemplify some of them:
Teacher cognition of pronunciation teaching: Teachers’ concerns and issues
Measuring L1 and L2 productive derivational knowledge: How many derivatives can L1 and L2 learners with differing vocabulary levels produce? [VC: SC]
Beyond good teaching practices: Language teacher leadership from the learners’ perspective [PC: NC]
-
Prepositional construction (PC) in the form of a prepositional phrase, e.g., From teaching points to learning opportunities and beyond
-
Sentential construction (SC) in the form of a sentence, complete or incomplete, which is further divided into three categories: statement, question, and negation:
Interaction goes international [statement]
Is text written for children useful for l2 extensive reading? [question]
Cohesion is not coherence [negation]
The two of us independently coded the titles in the corpus. While the majority of article titles were syntactically unambiguous, disagreements did occur on several occasions in the coding process when for example, a title involved a language other than English (e.g., Kan yu ret an rayt en Ingles: Children become literate in English as a second language and “Nosotras no empezamos a hacer eso”: A social semiotic view of a sheltered science investigation) or an incomplete sentence (e.g., “Like everybody else”: Equalizing educational opportunity for English language learners and “Technically an EL”: The production of raciolinguistic categories in a dual language school). Discussions were then held, the related articles reviewed, and language experts consulted, when necessary, to reach an agreement for coder reliability.
Results and discussion
Title length
Changes in average title length in our corpus were measured by (running) words, syllables, and content words (shown in Fig. 1), in addition to measurements of words with three or more syllables and words with more than six characters. Overall, as shown in Fig. 1, the average title length experienced steady growth over time in all three aspects. The average title length of articles in the journal increased from 8.03 words in 1967 to 14.18 words in 2022, resulting in a significant growth of 77%. With the greatest annual averages appearing in the past decade—2018 (14.6 words), 2014 (14.47 words), and 2020 (14.44 words), it can be reasonably argued that the article titles in the journal are increasing rapidly. The year 2022 witnessed a couple of the most extended individual titles in the corpus:
“It may also be our own fault to think so, to limit them before even trying”: Assuming learner limitations during materials design in English language teacher education [27 words, Dec. 2022 issue]
Examining the interaction between two process-based L2 listening instruction methods and listener level: Which form of instruction most benefits which learners? [22 words, Mar. 2022 issue]
English medium instruction, English-enhanced instruction, or English without instruction: The affordances and constraints of linguistically responsive practices in the higher education classroom [22 words, Dec, 2021 issue]

Frequency distributions of title length over time
Our result corroborates the findings of previous studies on article titles. Guo et al. (2015), for example, reported a substantial increase of 50.45% in the average number of titles in economics from the 1890s to the 2000s; Goodman (2011) revealed an approximate doubling in the length of articles in medicine since the 1970s. It seems that, as Li and Xu (2019), who examined titles of research articles published between 1978 and 2018 in Journal of Pragmatics, assert, writing longer article titles has become a prevailing trend in a variety of disciplines. However, it should be noted that the titles in TESOL Quarterly (77%) increased much more steeply over time, compared with the findings in Li and Xu’s (2019) study of the titles from Journal of Pragmatics (50%) and Xiang and Li’s (2020) from seven linguistics journals (70%). Additionally, the average title length in our corpus (10.28 words) contrasts rather strongly with the results in Li and Xu (2019) (9.7 words) and Xiang and Li (2020) (8.45 words), given the different time frames that the three studies involved: 1967–2022, 1978–2018, and 1988–2018, respectively. Neither TESOL Quarterly nor Journal of Pragmatics was included in Xiang and Li’s (2020) corpus. Our finding, therefore, poses a challenge to the conclusion that “linguistics titles tend to be short (7.9–8.8 words) compared to other fields” (Pearson, 2021, p. 3423), indicating that titling practices may vary considerably at a sub-disciplinary level.
The title length in content words follows a similar pattern, but to a greater degree, with an increase of nearly 90% over the same period. The difference may be explained by the observation that, as titles grow in length, more content words, instead of functional ones, are used (Abuxton & Meadows, 1977; Yitzhaki, 1997).
The number of syllables in the titles changed most dramatically, almost doubled, from 15.89 per title in 1967 to 31 per title in 2022. This supports the results of Guo et al. (2015), who found in their study of economics titles that the increase rate of the average syllable number is much larger than that of the average word number. They suggested that authors were using more multisyllabic words than disyllabic and monosyllabic words with no more than two syllables. A recent study shows that the prevalence of quoted speech in the CC construction, the most significant contributor to the increased title length in many disciplines, has risen significantly since 2004 (Pearson, 2021). As many words in quotations are monosyllabic (e.g., it, we, more, think, say, who) or dissyllabic (e.g., maybe, even, before, which), their increasing use might lower the rate of multisyllabic words in a text as short as about ten words.
It seems that 1999 served as a turning point in our corpus for a period of substantial increase in average title length. For example, in the three years between 2001 and 2003, title lengths in words, content words, and syllables increased by alarming rates of 33%, 35%, and 27%, respectively. The change may be attributed to “the second stage of development in information retrieval” in the 1980s (Yitzhaki, 1997, p. 226), stimulated by the advent of online search services. The increasing competition for being read and cited has resulted in the need for both the author and the editor to be aware of the importance of informative titles. It took about a decade for the technological influence to accumulate until it could be measured in terms of title length. According to Yitzhaki (1997), the first development stage in retrieval systems and services came along with the introduction of title indexes in the 1960s. Its impact on article title length in many disciplines became noticeable from 1970 onward.
Lexical density, diversity, and complexity
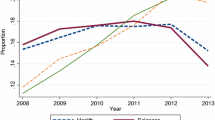
The titles in the corpus were measured for rates of diachronic changes in lexical density, diversity, and complexity. Lexical density is the ratio of content words (nouns, adjectives, verbs, and adverbs) to the total number of running words. Lexical diversity is measured by type/token ratio (TTR). Types are defined as the number of unique words in a text, and tokens are the total number of words. Words with three or more syllables and words with more than six characters were calculated to examine how complicated multisyllabic words are distributed in the corpus. The details are shown in Fig. 2.

Lexical features of the titles over time
As anticipated, the average lexical density in the journal experienced a slight, long-term tendency towards using more content words for the titles over the time span of 55 years. In the 24 years from 1967 to 1991, it moved well below the 0.7 line, but fluctuated rather wildly for the next two decades around the line. However, the past decade witnessed a tendency for a slight increase, with 0.7247 and 0.7213 in 2015 and 2021, respectively. The result is consistent with Li and Xu’s (2019) study on titles in pragmatics. However, it varies from some earlier studies (Bird & Knight, 1975; Abuxton & Meadows, 1977; Yitzhaki, 1997; Diener (1984). For example, Bird and Knight (1975) measured the information content of titles in Nature magazine and found rapid growth in the number of words per title between 1954 and 1964, followed by a slight increase between 1964 and 1974. Similarly, Yitzhaki (1997) reported that titles of papers in humanities journals followed a gradual increase in informativity from 1940 to 1990. The contrasts between our results and these studies, many of which dated before the turn of the century, are probably due to the development of information retrieval systems, which was discussed earlier. As shown in Fig. 2, throughout the years before 1991, the average number of content words per title moved in a relatively linear pattern. However, it fluctuated around the 0.7 line, rather wildly, in the following decade. The change may be explained by increasing awareness among authors of the need for more informative titles.
Fluctuating widely around 0.6, the lexical diversity, as measured by the type/token ratio, showed a tendency to neither increase nor decrease. As an author rarely repeats a content word in a construction as brief as an article, the type/token ratio of the title words in an issue or a volume actually indicates how often a research topic, scientific research method, theoretical perspective, or subject of study is revisited in a different articles.
Regarding the distribution of complicated words in the titles, neither the average number of words with three or more syllables nor those with more than six characters displayed any discernible trend of increase or decrease. The former moved well below 0.3 throughout much of the period, averaging 0.2674, and the latter fluctuated around 0.5, averaging 0.4967. This confirms our earlier speculation that the frequency rate of multisyllabic words in titles may not have increased as significantly as those of title length in words and in syllables. This may be attributed to the increasing use of spoken language in titles that feature quoted speech or questions, which contain more monosyllabic and dissyllabic words than other types of titles, as the following examples show.
“I'm very not about the law part”: Nonnative speakers of English and the Miranda warnings
Teacher language background, codeswitching, and English-only iInstruction: Does age make a difference to learners' attitudes?
Title structures
The titles in the corpus are classified syntactically into five categories: nominal construction (NC), verbal construction (VC), compound construction (CC), prepositional construction (PC), and sentential construction (SC), and the details are given in Table 1 and Fig. 3.

Frequency distribution of title types over time
As shown in Table 1, NC and CC titles constitute more than 42% and 45% of the titles in the corpus, respectively, nearly 88% of all titles throughout the period checked. They are followed by the VC title, which accounts for 8.44%. PC and SC titles were only occasionally used in the journal, each with less than 2% occurrence. This result confirms the finding in Cheng et al. (2012) that NC (39.20%) and CC (53.89%) constructions predominated their corpus of titles of research articles published between 1999 and 2008 in four journals in applied linguistics. It also corroborates the finding about the two title constructions (29.3% and 68.7%, respectively) in Xiang and Li’s (2020) study of the titles of research article published between 1978 and 2018 in seven journals in linguistics. However, differences of statistical significance arose when we consider the distributions of the two title types in the corpora in the three studies in the same period (1999–2008): the finding in Xiang and Li (56% vs. 33%) is virtually the reverse of ours (35.83% vs. 57.68%) and Cheng et al.’s (39.20% vs. 53.89%). In addition, as TESOL Quarterly is included in Cheng et al.’s corpus, the two title constructions in the other three applied linguistics journals that they checked must have shared even smaller percentages, compared with our result. Given that none of the journals selected in Xiang and Li (2020) and Cheng et al. (2012) overlap, the contrast between their results indicates that titular attributes identified at the disciplinary level of linguistics may vary significantly from those uncovered at the sub-disciplinary level of applied linguistics, which, in turn, may differ from those in TESOL Quarterly.
Interestingly, 22 of the 29 SC titles are interrogative, leaving only 5 in the confirmative and 2 in the negative forms, which all appeared before 1982 (Table 3).
However, a diachronic examination reveals a different picture. As illustrated in Fig. 3, while the rates of change in SC and PC patterns remain low enough throughout the whole period to be negligible, CC and NC titles stand in marked contrast. The former has been constantly on the increase, from the lowest point of 0.118 in 1970 to the highest point of 0.794 in 2020, showing a 5.7-fold increase in the period checked. In contrast, the latter has declined, from the highest point of 0.735 in 1970 to the new low of 0.158 in 2022, experiencing a 3.7-fold decrease.
Interestingly, the two constructions developed to a considerable extent in a complementary relationship, which means that one increases in the same way that the other decreases. In the first 16 years, from 1967 to 1983, the NC structure, while showing a gradual downward trend, maintained overwhelming dominance. The CC outnumbered the NC for the first time in 1984, which marked the beginning of a period of competition between them, in which it seemed that they were evenly matched. Still, both fluctuated dramatically until the turning point came in 2002, when the CC structure began to dominate. The CC type was becoming increasingly popular among authors, so much so that six issues in the decade between 2012 and 2022 contained all-CC titles. These constructions accounted for over 70% of all titles in six individual volumes in the same period.
Prior to 1980, the VC title accounted for nearly 15% on average, being preferred to the CC construction for a couple of years. It was most popular in 1976, with a frequency of 21%, while the NC and CC structures were about 46% and 32%, respectively. However, it was used much less frequently during the remainder of the period, occasionally reaching the 10% mark but also remaining absent for a total of 14 years. Nevertheless, it is too early to conclude here that the VC construction has already fallen out of favor in academia before we investigate the functions that it may serve in compound constructions.
Generally speaking, our results corroborate previous findings about varying diachronic increase in the usage of the CC construction, along with a decrease in the NC construction, in the social sciences and the humanities in general (Soler, 2011; Nagano, 2015) and in linguistics in particular (Li & Xu, 2019; Xiang & Li, 2020). Our findings also support the observations in Li and Xu (2019) that the first few years served as the turning point where CC titles outnumbered NC titles and predominated the titling practice in linguistics journals. However, in Xiang and Li’s (2020) corpus, CC titles (51%) were still strongly preferred, as late as 2008, to NC titles (39%) in the community of linguistics writers. In addition, while Li and Xu (2019) identified a slight upward tendency in the usage of NC titles in the decade between 1978 and 1988 before it increased more dramatically in the following periods, our research shows, as is seen in Fig. 3, a general downward trend in the popularity of the title type in the decade. It could be argued, therefore, that research article titles in individual journals, though generically discipline-constrained, may have followed different lines of evolution. It might be attributed to traditional editorial policies, field-specific research methodologies, or even problems being investigated (Anthony, 2001).
Compound constructions
All possible combinations of pre-colon and post-colon segments of the CC titles were examined (Table 4). Two of them—PC: PC and SC: PC—were not found in the corpus, leaving a total of 18 categories. With a frequency of more than 54%, the NC: NC relationship dominates the sub-corpus. It is followed by VC: NC (11.48%) and SC: NC (9.97%). Still less frequently used are the NC: VC and NC: SC relationships. The remaining types can be said to be rare combinations. Accordingly, CC titles are divided into six categories in the following section for a diachronic analysis. These are: NC: NC; VC: NC; SC: NC; NC: VC; NC: SC; and others. The details are displayed in Table 4.
As illustrated in the table, the NC: NC construction was used in an overwhelming proportion (85.2%) in the three years checked in the 1960s, suggesting that other forms of combination were only occasionally used. However, it made a downward movement all the way to 43% in the 1990s, dwindling by 98% in approximately three decades. In the following decade, it increased to 54% before resuming the previous downward trend in the 2020s to about the level in the 1990s. We speculate that the brief period of increase had to do with the second stage of development in information retrieval, when, as we have shown earlier, titles started to grow more rapidly in numbers of words, syllables, and content words as the importance of informative titles was being increasingly recognized. Nevertheless, it can well be predicted that the frequency of NC: NC construction will continue to decrease in the coming years (Fig. 4).

Frequency distribution of CC construction over time
For the other four syntactic types except the NC: SC relationship, it seems that the 1990s served as the point of no return, before which they increased at varying rates. In the following two decades, the growth rates of the VC: NC, SC: NC, and NC: VC titles almost leveled off at 13%, 10%, and 6%, respectively. However, as the NC: NC titles continue to dwindle, it seems that all three have gained fresh impetus to increase. It was rather unexpected that the SC: NC relationship developed from 10.5% in the 2010s to 23.6% in the 2020s.
We also conducted a closer examination of the individual segments of the CC titles, and the data show that a majority of them are NC phrases (72.89%), suggesting that, on average, each CC title contained nearly one and a half nominal phrases. Looking back at the competition between the NC and CC titles, as discussed earlier, we can well speculate that it was not a trade-off game. In other words, it was not that NC titles were no longer preferred and replaced by CC titles, but that they were used in the CC construction either as the pre- or post-colon segment or both.
In the same vein, V-ing phrases constituted more than 14% of the number of CC segments, which means that one in three of CC titles contain a V-ing phrase, either as the pre-colon or the post-colon segment. Previously, we reported that, as the CC construction continued to rise after 1980, the frequency of the VC construction fell precipitously. As a matter of fact, more VC phrases were used as segments in CC titles.
It is the same with SC titles, which appeared only 29 times throughout the period. In contrast, they averaged more than 10% as the segments of CC titles, making their presence felt with 139 instances in the period (Table 5).
Questions and quotations in CC construction
With 22 individual titles structured as questions, our result supports the finding in previous studies that article titles featuring a question account for a tiny proportion of the titles in a various disciplines (Anthony, 2001; Cook & Plourde, 2016; Milojević, 2017). While Ball (2009) reported marked increase of article titles with question marks in physics, life sciences, and medicine, our data show no indications that questions as individual article titles would increase.
However, nearly three times more interrogative segments were found in CC titles, with more post-colon segments (45) than pre-colon segments (17). Question titles constituted 4.68% of the CC constituents. In other words, 9 out of every 100 CC titles were so structured. As the NC: NC relationship is continually declining, it is likely that CC titles featuring questions and quotations will increase. In addition, nearly 73% of the question segments in our corpus occur as post-colon information. As such, they are often intended to provoke contemplation or intrigue from readers rather than create an information gap, as quotation titles do. The titles below serve as illustrations:
Critical literacy, whole language, and the teaching of writing to deaf students: Who should dictate to whom?
Transforming talk and phonics practice: Or, how do crabs clap?
Our data (Table 6) show that quotation titles were non-existent in the journal before the 1970s and were occasionally used in the next three decades. The 2010s witnessed a sudden increase in usage, with 15 instances, a sharp contrast to the four in the previous decade. Given that 14 quotation titles appear in the first three volumes of the journal in the 2020s, a surge is expected in the coming years. In addition, our result confirms Pearson’s (2021) observation that quoted lines occur mainly as the pre-colon segment of a compound, which accounts for over 95% of all occurrences in our corpus. As a cataphoric reference, quotations create an information gap to interest would-be readers.
Quotations as the first segments are eye-catching on journal title pages, leaving the function of informing the reader to the second segments. In contrast, question titles often inform them before attempting to stimulate their interest. Unlike any function word used as a linking device, the colons allow authors to place the two segments in an order that best serves their purposes without considering whether they are grammatically parallel. In other words, the CC construction gives them the freedom to take maximum advantage of all other title types. Compared with other title types, the two-segment CC titles better serve the function of the article title to inform and attract the audience, helping writers and editors enhance the visibility of their articles in an increasingly competitive world.
Conclusion
In this study, we analyzed a corpus of titles of original contributions to TESOL Quarterly over 55 years since 1967. Our results support some significant findings from previous research (Cheng et al., 2012; Haggan, 2004; Soler, 2007; Xiang & Li, 2020). The period witnessed a considerable increase in the average length of titles in words, syllables, and content words, which can be primarily attributed to the increasing popularity of the more complicated but flexible CC titles. While the rate of occurrences of CC titles increased by 5.7-fold from 1967 to 2022, NC titles experienced a 3.7-fold decline. Our structural analysis of CC segments revealed that CC titles have not been replacing NC titles, as NC segments accounted for nearly 73% of all segments of CC titles. In addition, our results show a precipitate decline in usage of the NC: NC structure throughout the period, which parallels the decline of NC titles in general, while CC segments featuring a quotation, question, or V-ing phrase are gaining in popularity.
By examining the titles in terms of lexical density, lexical diversity, and lexical complexity, we discovered that the average lexical density in the journal experienced a slight, long-term tendency towards using more running words and content words. However, the lexical diversity in the titles, as measured by the type/token ratio, showed no clear tendency to significant diachronic change. Contrary to Guo et al. (2015), our analysis of words with three or more syllables shows that the rate of multisyllabic words in the titles remained relatively constant.
Our results also vary from previous findings in the literature, especially studies of research article titles in the broad field of linguistics. For example, the average title length of research articles in TESOL Quarterly (10.28 words) challenges the conclusion that linguistics titles tend to be short compared to other fields, measuring between 7.9 and 8.8 words (Haggan, 2004; Soler, 2007). The figure, however, parallels the result in Pearson (2021), 12.2 words, given that his data covered a shorter and later period, from the 1980s to the 2010s. In addition, the CC titles in the journal accounted for a more significant percentage of all title types than in other journals in linguistics in general (Xiang & Li, 2020) and in applied linguistics in particular (Cheng et al., 2012). These variations demonstrate that field-specific discourse conventions and journal-specific editorial policies may have a role to play in titling practice, indicating there is value in future research into article titles at a highly specific sub-disciplinary level in different academic fields.
It should be noted that this study investigated title samples from a single journal. Our findings need to be validated using data from other journals or specific sub-disciplines. In future research, each title type could also be further classified according to their internal structure for more detailed analyses of titular evolution in the journal. In addition, space limitations have made it necessary for us to leave out an analysis of the informational aspects of the titles in the corpus. Such a study would be valuable in providing insight into how title language is manipulated to better inform the reader about research topics, methods, results, and perspectives.
References
American Psychological Association. (2020). Publication manual of American Psychological Association (7th ed.). American Psychological Association.
Ángeles Alcaraz, M., & Méndez, D. I. (2016). When astrophysics meets lay and specialized audiences: Titles in popular and scientific papers. Journal of Language and Communication, 3(2), 109–120.
Anthony, L. (2001). Characteristic features of research article titles in computer science. IEEE Transactions on Professional Communication, 44(3), 187–194. https://doi.org/10.1109/47.946464
Ball, R. (2009). Scholarly communication in transition: The use of question marks in the titles of scientific articles in medicine, life sciences and physics 1966–2005. Scientometrics, 79(3), 667–679. https://doi.org/10.1007/s11192-007-1984-5
Balog, C. (1981). Information content of titles of papers in an agricultural journal. Journal of Research Communication Studies, 2(4), 263–270.
Baskerville, C. (1904). The titles of papers. Science, 19(487), 702–703. https://doi.org/10.1126/science.19.487.702
Becker, H. S. (2003). Long-term changes in the character of the sociological discipline: A short note on the length of titles of articles submitted to the American Sociological Review during the year 2000. American Sociological Review, 68(3), iii–v. https://doi.org/10.2307/1519726
Billings, J. S. (1881). An address on our medical literature. BMJ, 2(1076), 262–268. https://doi.org/10.1136/bmj.2.1076.262
Bird, P. R., & Knight, M. A. (1975). Word count statistics of the titles of scientific papers. Information Scientist, 9(2), 67–69.
Bottle, R. T. (1970). The information content of titles in engineering literature. IEEE Transactions on Engineering Writing and Speech, 13(2), 41–45. https://doi.org/10.1109/tews.1970.4322437
Bramoullé, Y., & Ductor, L. (2018). Title length. Journal of Economic Behavior & Organization, 150, 311–324. https://doi.org/10.1016/j.jebo.2018.01.014
Branner, J. C. (1905). The omission of titles of addresses on scientific subjects. Nature, 72(1874), 534–534. https://doi.org/10.1038/072534b0
Busch-Lauer, I. (2000). Titles in English and German research papers in medicine and linguistics. In A. Trosborg (Ed.), Analysing professional genres (pp. 77–97). John Benjamins. https://doi.org/10.1075/pbns.74.08bus
Buxton, A. B., & Meadows, J. (1977). The variation in the information content of titles of research papers with time and discipline. Journal of Documentation, 33(1), 46–52. https://doi.org/10.1108/eb026633
Cameron, H., & Robertson, A. (1997). The colon in medicine: Nothing to do with the intestinal tract. BMJ, 315, 1657–1658. https://doi.org/10.1136/bmj.315.7123.1657
Cheng, S. W., Kuo, C., & Kuo, C. (2012). Research article titles in applied linguistics. Journal of Academic Language & Learning, 6(1), A1–A14. https://doi.org/10.4236/jsea.2009.25050
Cianflone, E. (2010). Scientific titles in veterinary medicine research papers. English for Specific Purposes World, 30(9), 1–8.
Cianflone, E. (2012). Titles in veterinary medicine research articles. Círculo De Lingüística Aplicada a La Comunicación, 52, 3–20. https://doi.org/10.5209/rev_CLAC.2012.v52.41091
Cianflone, E. (2013). Framing research in food science: The state of the art on research article, short communication and poster presentation titles. Revista De Lenguas Para Fines Específicos, 19, 269–286.
Cook, J. M., & Plourde, D. (2016). Do scholars follow Betteridge’s Law? The use of questions in journal article titles. Scientometrics, 108(3), 1119–1128. https://doi.org/10.1007/s11192-016-2030-2
Diao, J. (2021). A lexical and syntactic study of research article titles in Library Science and Scientometrics. Scientometrics, 126, 6041–6058. https://doi.org/10.1007/s11192-021-04018-6
Didegah, F., & Thelwall, M. (2013). Which factors help authors produce the highest impact research? Collaboration, journal and document properties. Journal of Informetrics, 7(4), 861–873. https://doi.org/10.1016/j.joi.2013.08.006
Diener, R. A. V. (1984). Informational dynamics of journal article titles. Journal of the American Society for Information Science, 35(4), 222–227. https://doi.org/10.1002/asi.4630350405
Dietz, G. (2001). The pragmatics of scientific titles formulated as questions. In A. Kertész (Ed.), Approaches to the pragmatics of scientific discourse (pp. 19–33). Peter Lang.
Falagas, M. E., Zarkali, A., Karageorgopoulos, D. E., Bardakas, V., & Mavros, M. N. (2013). The impact of article length on the number of future citations: A bibliometric analysis of general medicine journals. PLoS ONE, 8(2), e49476. https://doi.org/10.1371/journal.pone.0049476
Fiala, D., Král, P., & Dostál, M. (2021). Are papers asking questions cited more frequently in computer science? Computers, 10, 96. https://doi.org/10.3390/computers10080096
Fischer, M. (1966). The KWIC index concept: A retrospective view. American Documentation, 17(2), 57–70. https://doi.org/10.1002/asi.5090170203
Fumani, M. R. F. Q., Goltaji, M., & Parto, P. (2015). The impact of title length and punctuation marks on article citations. Annals of Library and Information Studies, 62, 126–132. https://doi.org/10.56042/alis.v62i3.8137
Garfield, E. (1970). Methods and objectives in judging the information content of document titles. Journal of Chemical Documentation, 10(4), 260–260. https://doi.org/10.1021/c160039a009
Gesuato, S. (2008). Encoding of information in titles: Practices across four genres in linguistics. In C. Taylor (Ed.), Ecolingua: The role of E-corpora in translation and language learning (pp. 127–157). Edizioni Università di Trieste.
Ghosh, J. S. (1977). The information content of titles in contraception literature. Journal of Chemical Information and Modeling, 17(1), 36–40. https://doi.org/10.1021/ci60009a009
Goodman, N. W. (2000). Survey of active verbs in the titles of clinical trial reports. BMJ, 320(7239), 914–915. https://doi.org/10.1136/bmj.320.7239.914
Goodman, N. W. (2005). From Shakespeare to Star Trek and beyond: A medline search for literary and other allusions in biomedical titles. BMJ, 331(7531), 1540–1542. https://doi.org/10.1136/bmj.331.7531.1540
Goodman, N. W. (2010). Novel tool constitutes a paradigm: How title words in medical journal titles have changed since 1970. The Write Stuff, 19(4), 265–267.
Goodman, N. W. (2011). Fashion in medicine and language: Inferences from titles and abstracts of articles listed in PubMed. The Write Stuff, 20(1), 39–42.
Goodman, N. W. (2012). Familiarity breeds: Clichés in article titles. British Journal of General Practice, 62(605), 656–657. https://doi.org/10.3399/bjgp12x659420
Goodman, N. W., Thacker, S. B., & Siegel, P. Z. (2001). What’s in a title? A descriptive study of article titles in peer-reviewed medical journals. Science Editor, 24(3), 75–78.
Gudger, E. W. (1924). On the proper wording of the titles of scientific papers. Science, 60(1540), 13–15. https://doi.org/10.1126/science.60.1540.13
Guo, S., Zhang, G., Ju, Q., Chen, Y., Chen, Q., & Li, L. (2015). The evolution of conceptual diversity in economics titles from 1890 to 2012. Scientometrics, 102, 2073–2088. https://doi.org/10.1007/s11192-014-1501-6
Habibzadeh, F., & Yadollahie, M. (2010). Are shorter article titles more attractive for citations? Cross-sectional study of 22 scientific journals. Croatian Medical Journal, 51(2), 165–170. https://doi.org/10.3325/cmj.2010.51.165
Haggan, M. (2004). Research paper titles in literature, linguistics and science: Dimensions of attractions. Journal of Pragmatics, 36, 293–317. https://doi.org/10.1016/S0378-2166(03)00090-0
Hallock, R. M., & Dillner, K. M. (2016). Should title lengths really adhere to the American Psychological Association’s twelve word limit? American Psychologist, 71(3), 240–242. https://doi.org/10.1037/a0040226
Heard, S. B., Cull, C. A., & White, E. R. (2023). If this title is funny, will you cite me? Citation impacts of humour and other features of article titles in ecology and evolution. FACETS, 8, 1–15. https://doi.org/10.1139/facets-2022-0079
Herner, S. (1963). Effect of automated information retrieval systems on authors. In Automation and scientific communication (pp. 101-102), American Documentation Institute, Washington, D. C.
Jacques, T. S., & Sebire, N. J. (2009). The impact of article titles on citation hits: An analysis of general and specialist medical journals. Journal of the Royal Society of Medicine Short Reports, 1(2), 1–5. https://doi.org/10.1258/shorts.2009.100020
Jalilifar, A. (2010). Writing titles in applied linguistics: A comparative study of theses and research articles. Taiwan International ESP Journal, 2(1), 29–54.
Jalilifar, A., Hayati, A., & Mayahi, N. (2010). An exploration of generic tendencies in applied linguistics titles. Journal of Faculty of Letters and Humanities, 5(16), 35–57.
Jamali, H. R., & Nikzad, M. (2011). Article title type and its relation with the number of downloads and citations. Scientometrics, 88, 653–661. https://doi.org/10.1007/s11192-011-0412-z
Kennedy, R. A. (1963). Writing informative titles for technical papers: A guide to authors. In Automation and scientific communication (pp. 133–134), American Documentation Institute, Washington, D. C.
Kerans, M. E., Marshall, J., Murray, A., & Sabaté, S. (2020). Research article title content and form in high-ranked international clinical medicine journals. English for Specific Purposes, 60, 127–139. https://doi.org/10.1016/j.esp.2020.06.001
Kerans, M. E., Murray, A., & Sabatè, S. (2016). Content and phrasing in titles of original research and review articles in 2015: Range of practice in four clinical journals. Publications, 4(2), 11.
Lane, B. B. (1964). Key words in–and out of–context. Special Libraries, 55, 46–40.
Levin, H. (1977). The title as a literary genre. The Modern Language Review, 72(4), 23–36. https://doi.org/10.2307/3724776
Lewin, B. A., Salager-Meyer, F., & Briceño, M. L. (2015). The colon title in complementary and alternative medicine articles (1995–2016). Journal of Applied Linguistics and Professional Practice, 12(3), 313–335. https://doi.org/10.1558/jalpp.34990
Lewison, G., & Hartley, J. (2005). What’s in a title? Numbers of words and the presence of colons. Scientometrics, 63(2), 341–356. https://doi.org/10.1007/s11192-005-0216-0
Li, Z., & Xu, J. (2019). The evolution of research article titles: The case of Journal of Pragmatics 1978–2018. Scientometrics, 121, 1619–1634. https://doi.org/10.1007/s11192-019-03244-3
Liner, G. H. (2002). Core journals in economics. Economic Inquiry, 40, 138–145. https://doi.org/10.1093/ei/40.1.138
Méndez, D. I., & Ángeles Alcaraz, M. (2017). Titles of scientific letters and research papers in astrophysics: A comparative study of some linguistic aspects and their relationship with collaboration issues. Advances in Language and Literary Studies, 8(5), 128–139. https://doi.org/10.7575/aiac.alls.v.8n.5p.128
Milojević, S. (2017). The length and semantic structure of article titles: Evolving disciplinary practices and correlations with impact. Frontiers in Research Metrics and Analytics. https://doi.org/10.3389/frma.2017.00002
Moattarian, A., & Alibabaee, A. (2015). Syntactic structures in research article titles from three different disciplines: Applied linguistics, civil engineering, and dentistry. The Journal of Teaching Language Skills, 7(1), 27–50. https://doi.org/10.22099/JTLS.2015.3530
Moslehi, S., & Kafipour, R. (2022). Syntactic structure and rhetorical combinations of Iranian English research article titles in medicine and applied linguistics: A cross-disciplinary study. Frontiers in Education., 7, 935274. https://doi.org/10.3389/feduc.2022.935274
Munroe, E. (1967). Titles. Nature, 214(5092), 1064. https://doi.org/10.1038/2141064e0
Nagano, R. L. (2015). Research article titles and disciplinary conventions: A corpus study of eight disciplines. Journal of Academic Writing, 5, 133–144. https://doi.org/10.18552/joaw.v5i1.168
Nair, L. B., & Gibbert, M. (2016). What makes a “good” title and (how) does it matter for citations? A review and general model of article title attributes in management science. Scientometrics, 107(3), 1331–1359. https://doi.org/10.1007/s11192-016-1937-y
Paiva, C., Lima, J., & Paiva, B. (2012). Articles with short titles describing the results are cited more often. Clinics, 67(5), 509–513. https://doi.org/10.6061/clinics/2012(05)17
Pearson, W. S. (2020). Research article titles in written feedback on English as a second language writing. Scientometrics, 123, 997–1019. https://doi.org/10.1007/s11192-020-03388-7
Pearson, W. S. (2021). Quoted speech in linguistics research article titles: Patterns of use and effects on citations. Scientometrics, 126, 3421–3442. https://doi.org/10.1007/s11192-020-03827-5
Pułaczewska, H. (2009). “I bet they are going to read it”: Reported direct speech in titles of research papers in linguistic pragmatics. Lodz Papers in Pragmatics, 5(2), 271–291. https://doi.org/10.2478/v10016-009-0010-1
Sagi, I., & Yechiam, E. (2008). Amusing titles in scientific journals and article citation. Journal of Information Science, 34(5), 680–687. https://doi.org/10.1177/0165551507086261
Sahragard, R., & Meihami, H. (2016). A diachronic study on the information provided by the research titles of applied linguistics journals. Scientometrics, 108, 1315–1331. https://doi.org/10.1007/s11192-016-2049-4
Salager-Meyer, F., & Alcaraz-Ariza, M. Á. (2013). Medical case reports and titleology: A diachronic perspective (1840–2009). Revista De Lenguas Para Fines Específicos, 19, 397–413.
Salager-Meyer, F., Alcaraz-Ariza, M. A., & Briceño, M. L. (2013). Titling and authorship practices in medical case reports: A diachronic study (1840–2009). Communication & Medicine, 10(1), 63–80. https://doi.org/10.1558/cam.v10i1.63
Salager-Meyer, F., Lewin, B. A., & Briceño, M. L. (2017). Neutral, risky or provocative? Trends in titling practices in complementary and alternative medicine articles (1995–2016). Revista De Lenguas Para Fines Específicos, 23(2), 263–289. https://doi.org/10.20420/rlfe.2017.182
Sedano, J. M. (1964). Keyword-in-Context (KWIC) indexing: Background, statistical evaluation, pros and cons, and applications [Unpublished master’s thesis], The University of Pittsburgh
Shull, C. A. (1931). Erroneous citations and titles of scientific papers. Science, 73(1892), 363–364. https://doi.org/10.1126/science.73.1892.363
Smith, R. (2000). Informative titles in the BMJ. BMJ, 320, 91. https://doi.org/10.1136/bmj.320.7239.914
Soler, V. (2007). Writing titles in science: An exploratory study. English for Specific Purposes, 26(1), 90–102. https://doi.org/10.1016/j.esp.2006.08.001
Soler, V. (2011). Comparative and contrastive observations on scientific titles written in English and Spanish. English for Specific Purposes, 30(2), 124–137. https://doi.org/10.1016/j.esp.2010.09.002
Subotic, S., & Mukherjee, B. (2014). Short and amusing: The relationship between title characteristics, downloads, and citations in psychology articles. Journal of Information Science, 40(1), 115–124. https://doi.org/10.1177/0165551513511393
Swales, J. M. (1990). Genre analysis: English in academic and research settings. Cambridge University Press.
Swales, J., & Feak, C. B. (2004). Academic writing for graduate students (2nd ed.). University of Michigan Press.
Taylor, C. E. D. (1965). Titles of articles in medical periodicals. The Lancet, 285(7382), 437. https://doi.org/10.1016/s0140-6736(65)90044-9
Tocatlian, J. J. (1970). Are titles of chemical papers becoming more informative? Journal of the American Society for Information Science, 21(5), 345–350. https://doi.org/10.1002/asi.4630210506
van Wesel, M., Wyatt, S., & ten Haaf, J. (2014). What a difference a colon makes: How superficial factors influence subsequent citation. Scientometrics, 98(3), 1601–1615. https://doi.org/10.1007/s11192-013-1154-x
Wadde, S. K., & Domple, V. K. (2021). Assessment of titles of original research articles published in two peer-reviewed journals of community medicine and public health from India: A descriptive study. Journal of Datta Meghe Institute of Medical Sciences University, 16(1), 181–185. https://doi.org/10.4103/jdmimsu.jdmimsu_332_20
Whissell, C. (2004). Titles of articles published in the journal Psychological Reports: Changes in language, emotion, and imagery over time. Psychological Reports, 94, 807–813. https://doi.org/10.2466/pr0.94.3.807-813
Whissell, C. (2012). The trend toward more attractive and informative titles: American Psychologist 1946–2010. Psychological Reports, 110(2), 427–444. https://doi.org/10.2466/17.28.pr0.110.2.427-444
Whissell, C., Abramson, C., & Barber, K. (2013). The search for cognitive terminology: An analysis of comparative psychology journal titles. Behavioral Sciences, 3(1), 133–142. https://doi.org/10.3390/bs3010133
White, A., & Hernandez, N. R. (1991). Increasing field complexity revealed through article title analyses. Journal of the American Society for Information Science, 42, 731–734. https://doi.org/10.1002/(SICI)1097-4571(199112)42:10%3C731::AID-ASI6%3E3.0.CO;2-W
Xiang, X., & Li, J. (2020). A diachronic comparative study of research article titles in linguistics and literature journals. Scientometrics, 122, 847–866. https://doi.org/10.1007/s11192-019-03329-z
Xie, S. (2020). English research article titles: Cultural and disciplinary perspectives. SAGE Open, 10(2), 1–12. https://doi.org/10.1177/2158244020933614
Yang, W. (2019). A diachronic keyword analysis in research article titles and cited article titles in applied linguistics from 1990 to 2016. English Text Construction, 12(1), 84–102. https://doi.org/10.1075/etc.00019.yan
Yitzhaki, M. (1997). Variation in informativity of titles of research paper in selected humanities journals: A comparative study. Scientometrics, 38(2), 219–229. https://doi.org/10.1007/BF02457410
Yitzhaki, M. (2002). Relation of the title length of a journal article to the length of the article. Scientometrics, 54(3), 435–447. https://doi.org/10.1023/a:1016038617639
Acknowledgements
The authors would like to thank the handling editor and the anonymous reviewers for their constructive comments, which helped us to improve the manuscript.
Funding
This research was supported and funded by Project Fund for Research on and Reform of Education in New Humanities and Social Sciences of the Ministry of Education of China (2021090090).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jiang, G.K., Jiang, Y. More diversity, more complexity, but more flexibility: research article titles in TESOL Quarterly, 1967–2022. Scientometrics 128, 3959–3980 (2023). https://doi.org/10.1007/s11192-023-04738-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-023-04738-x