
Abstract
Main path analysis (MPA) is a method for efficiently analyzing technological trends, which change rapidly in competitive environments. In general, MPA is based on citation networks, and it is used to derive the most key path in a complex network. However, the existing studies using MPA do not use important textual information of patents, except for citation data. In this paper, we suggest a new MPA based on patent documents to identify the main path of technological evolution. For this purpose, first, we used the subject-action-object structure to derive core keywords based on causal relationships in patent claims. Second, the DEcision-MAking Trial and Evaluation Laboratory (DEMATEL) technique was applied to draw link weights between patents where causal relationships of keywords were reflected. Finally, a main path in a patent network was identified using the global main path and key-route main path analysis methods. In this paper, we collected and analyzed patent data related to self-driving car technologies, and we verified the technical changes in the main path obtained based on the proposed approach. We found that the generic technologies of the self-driving operation had the strongest influence on the other self-driving car technologies in the sensing-planning-acting steps.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In recent years, systematic technology trend analysis has emerged as an essential technique to identify the core topics in the technology development field and predict the direction of future developments (Joung & Kim, 2017, Yang et al., 2018). Main path analysis (MPA), one of the most widely used methods to analyze technology trends, can help us to observe technological progress over time and extract core information from epic-scale data (Henrique et al., 2018). The MPA method is based on the citation network, which explores networks based on link weights, unlike the existing network analysis methods that focus on node centrality (Hummon & Dereian, 1989). In the existing studies, links are interpreted as technological development flows between network nodes and are used for analysis. Kumar et al. (2020) used MPA to identify the path of technology innovation and evolution, and Lai et al. (2020) used MPA to explore technological core competence, knowledge flow, and technology development. Chen et al. (2022) conducted an MPA analysis to identify multiple technology development trajectories, and Liao et al. (2022) used the MPA analysis method to revisit these development trajectories.
The main analysis process, which constitutes the MPA, involves establishing a citation network, calculating link weights, and exploring the main path. The existing MPA method has a few limitations in the phases of link-weight calculation and main path exploration. First, the existing MPA process, which is based on the citation network of patent bibliographic information, determines link weights by calculating the number of citations received by patents. Various methods are available for calculating link weights, but in all cases, the information related to research results or technologies in the relevant academic papers or patents has not been considered when deriving the path analysis results (Hummon & Dereian, 1989, Kumar et al., 2020, Lai et al., 2020, Yu & Sheng, 2021, Chen et al., 2022, Liao et al., 2022). Second, in several studies, keyword analysis has been used to overcome the aforementioned first limitation, but these studies are based on the simple similarity or appearance frequency of keywords. With the concept of similarity, it is possible to analyze the technological similarity between documents in cases where it is impossible to obtain analysis results related to the actual influence of the said documents or determine their technical impacts on the entire network. In addition, in most existing MPA studies, link weight calculation has been based on the number of patent citations, and text-based technical contents have not been considered. Third, a considerable amount of information is lost. Moreover, in the existing studies, link weights have been computed on the basis of citation frequency, and they do not include important content information; consequently, they do not represent an analysis of the network from various perspectives. Yu and Sheng (2021) attempted to propose a more intelligent patent node weight calculation method by applying an algorithm called PageRank. Even though a few methods for exploring the main path have been suggested, the literature on methods for exploring the main path of the desired characteristics depending on the analyst’s purpose is scarce (Hummon & Dereian, 1989).
To overcome these limitations, in this study, we propose an MPA method based on keyword causality. The research questions that we attempt to answer in this study are as follows. First, how can one develop an MPA that considers the content of the technology? Given that previous studies have performed MPA on the basis of simple citation information or keywords, it is impossible to consider the content of technology when using the existing methods. Therefore, in this study, we propose an MPA methodology that reflects the content of technology by constructing a network based on the subject-action-object (SAO) structure, which well expresses the function of technology. Second, how can one reflect information pertaining to technological causality? Thus far, previous studies have mainly used citation-frequency-based weighting to analyze the strength of the connection between two techniques or patents. However, in fact, information about the manner in which the technical contents or elements of two documents are connected is more useful than the number of citations between the two technologies. To reflect this information, herein, we propose the MPA methodology on the basis of the DEcision-MAking Trial and Evaluation Laboratory (DEMATEL) method. The remainder of the paper is organized as follows. In Section "Background", we discuss the theoretical backgrounds of MPA, the SAO structure, and the DEMATEL method, which are used in the proposed method. In Section "Research Framework", we propose a method for calculating link weights based on keyword causality, which is the core of this study. In Section "Illustration", we apply the proposed method to analyze documents related to self-driving car technologies and present the analysis results. In Section "Discussion", we interpret and discuss the analysis results. In Section "Conclusion", we summarize and organize the general research content and conclude this paper by mentioning the limitations of the proposed method.
Background
Main path analysis
MPA is a link-based network analysis method proposed by Hummon and Dereian (1989). The traditional MPA process consists of (1) building a cited network, (2) calculating link weights between nodes on the basis of citation frequency, and (3) searching for a main path. (1) In most studies, a node is defined as a patent or a set of patents, and an arc is defined as a patent citation. We utilize a patent database (DB) because it is a representative DB for technology R&D and MPA sources. Because patent database is a representative DB for technology R&D and MPA sources. (2) Hummon and Dereian (1989) proposed three link-weight calculation methods: Node pair projection count (NPPC), search path link count (SPLC), and search path node pair (SPNP). (3) The main path search method uses priority-first search. Subsequently, many researchers have proposed novel methods for link-weight calculation and main path search. The Table 1 summarizes the methodologies used in each step in various studies.
In brief, a comparison between the traditional MPA and the MPA process proposed herein is as follows. In this study, we propose a link-weight calculation method that can be used to derive the main path from various perspectives and text information. We propose a novel method for calculating the weight of a main path by considering the content-oriented importance of a cited link, thus going beyond the number of times the link is cited, which is the second step in the traditional MPA process. The calculated link weights reflect the technical influences of the cited patents on subsequent patents by acting as technology triggers. That is, the proposed approach can analyze the importance of cited links by reflecting the underlying technical causal information.
SAO structure
Subject-Action-Object (SAO) represents a keyword bundle with the structure “Subject (S)—Verb (A)—Object (O),” and it has been derived from the grammar rules for sentence formation in the English language (Hu et al., 2015). This grammatical structure was suggested based on a functional analysis of the Theory of Inventive Problem Solving (Teoriya Resheniya Izobretatelskikh Zadatch, TRIZ), which can be used to derive problems arising from the interactions between the components of a technical system (Altshuller & Altov, 1996). In many studies, the Verb (V) has been interpreted as functions and actions, for example, actions that occur between the Subject (S) and the Object (O), because structured technical information can be derived from atypical text data by using this concept (Guo et al., 2016; Kim et al., 2020; Wang et al., 2017a). The relationship between S and O, as defined by V, can represent means & objectives and problems & solutions (Hu et al., 2015; Kim et al., 2020; Wang et al., 2017a, b).
Because SAO can structurally derive the necessary information, many studies have used it for content analysis to establish technological development strategies or future corporate management strategies (Yang et al., 2018). As aforementioned, many studies have extracted significant technical information by defining the relationships between keywords as means & purpose and problems & solutions for various actions. In these studies, the SAO itself was considered as a problem, a solution, a function, and an effect, and technological evolution was observed by mapping the SAO structure defined as a solution (Hu et al., 2015). In one such study, a keyword-based morphological matrix was established by interpreting the S and O information in the SAO structure as the relationship between problems and components and, subsequently, exploring technological opportunities by combining the component keywords (Wang et al., 2017a). As such, there are many studies that have used the SAO structure to solve technology management problems such as identifying R&D partners, predicting technology, analyzing technology development trends, and discovering promising patents (Wang et al., 2017b; Guo et al., 2016; Yang et al. 2016, 2018; Park et al., 2013).
In this paper, we derive keyword pairs coupled by causality by using these structural concepts of SAO. Specifically, we define the causalities between two keywords by interpreting the S as causes, O as results, and V as the action that links the causalities between the two keywords.
DEMATEL
DEcision-MAking Trial and Evaluation Laboratory (DEMATEL) is a technique suggested by the Battelle Geneva Institute in 1971 to solve complex planet-wide problems, such as race, environmental protection, and energy conservation. This method can be used to identify important factors that have a significant effect on a specific event or task or to support decision-making to solve problems (Tsai et al., 2017). DEMATEL analysis can largely be divided into four phases. First, all the factors to be analyzed are defined and listed in rows and columns. Second, the matrix is filled with values of 0–3 or 0–4 depending on the degree of effects of the factors in the rows on the factors in the columns. The higher the number, the stronger is the influence. The matrix completed up to this point is called the direct-relation matrix (DRM). Third, all the sums of the rows in the matrix are calculated; all matrix values are divided by the largest value among them, and the calculation formula can be expressed as following Eq. 1:
Fourth, the total relation matrix (TRM) is established. When the normalized DRM is set as “M,” the formula can be expressed as following Eq. 2, where “I” is a unit matrix.
With the TRM acquired in this manner, the indexes of D, R, D + R, and D-R are obtained. The index \(D = \left[ {\mathop \sum \nolimits_{j = 1}^{n} m_{ij} } \right]_{nx 1}\) is calculated by summing the row values of the factors; index \(R = \left[ {\mathop \sum \nolimits_{i = 1}^{n} m_{ij} } \right]_{1 xn}\) by adding the column values of the factors; index D + R by summing the values of indexes D and R; and index D-R by calculating the difference between values of indexes D and R. D, R, and D + R are used as indexes to represent the influence of factors; D-R is mainly used as a type-discrimination index to distinguish the tendency of factors. Thus, the DEMATEL method may digitalize the influence of factors into four indexes, and it can be used to analyze the causal relationships between technological elements (Shieh et al., 2010; Zhou et al., 2011; Yoon & Jeong, 2013; Namjoo & Keramati, 2018; Kim & Kim, 2012; Dalvi-Esfahani, et al., 2019; Zhang & Deng, 2019).
In this paper, we describe how to calculate link weights from the D, R, and D + R perspectives by applying the DEMATEL technique to the keywords derived from the SAO structure. Starting from Section "Research Framework", the proposed method is described in detail.
Research framework
Overall process
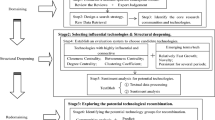
We propose a framework to analyze the main paths of technological development focusing on the textual contents of patent documents. The general processes of main path analysis are configured in the same way as the traditional approach discussed in Section "Background": (1) building a citation network, (2) calculating link weights, and (3) searching for a main path. The suggested framework reflects on technical contents, especially textual information describing a causal relationship between citation patents. Building a citation network, SAO structures, where A is a verb word related to causal meaning, are extracted in citing and cited patent documents. The link weight is calculated by the DEMATEL approach. The Keyword link weight causality-based SAO structures are used to calculate the link weight of the patent document. At last, we make a group of the global main paths to interpret the trajectory of technological developments. Overall processes consist of six detailed steps as Fig. 1.

Overall process
Detailed process
Collecting and preprocessing data
This section describes the data collection and preprocessing methods used in this study. We select technologies for analysis and collect patent data. First, a technology field to be analyzed is selected. Patent data are collected using a search formula and composing the technical vocabulary related to the selected field. Then, a citation network is created for MPA. Citation networks can be built using citation information. In the aforementioned network, one node represents one patent document, and the arrows indicate citation links. A patent with an arrow pointing outward represents a cited patent. A patent with an inward arrow represents a citing patent.
Extracting SAO structures based on causality
We analyze SAOs whose actions correspond to causative verbs in patent claims. Specifically, we consider V as an action that connects S with O. We also derive the S and O keywords linked by V. Kim et al. (2007) analyzed recorded aviation accident reports and found a constant regularity in the expressions representing causality; moreover, they derived the primary expressions representing causality, as summarized in Table 2. The list of causative verbs includes cause, lead, and bring about. In the present study, among the SAOs that can be abstracted from patent claims, we derive only the SAO whose causative verb is V. For example, the corresponding SAO structure of “system (S)—activate (A)—camera (O)” derived from a patent claim document can be interpreted as a technical entity in which “system” affects “camera” because the action word “activate” is included in the list of causative verbs. However, if A does not belong to the list of causative verb, it cannot be interpreted as causal information. For example, the word “include,” the most frequently used verb in patent documents, cannot appropriately be interpreted as causal information but as an inclusive relation. We pre-process the S and O keywords, connect them with the causative verbs obtained from the derived SAO, and use them as factors of the TRM. Pre-processing unifies all the grammatical expressions of the S and O keywords into their original forms and then removes duplicate keywords.
Structuring the total relation matrix
In this step, the TRM is established. All the S and O keywords derived as SAOs are placed as factors in the rows and columns. For example, if a total of “m” units of the S and O keywords are obtained, the matrix becomes an m × m matrix. Then, among the SAOs containing the causative verbs, the matrix value should be filled with the frequency of the SAOs that have the row factor as S and the column factor as O. For instance, among the SAOs containing causative verbs, if \(\theta\) SAO units have the keyword \(w_{1}\) as the S and the keyword \(w_{2}\) as the O, the value of matrix (1,2) is \(\theta\), as depicted in Fig. 2.

Example of matrix creation
Then, the matrix value is replaced with 0–3 according to the DEMATEL technique. The frequency with which SAOs fill the matrix can be considered the influence that keywords exchange with each other. The \(\theta\) value in Fig. 2 shows the extent to which the keyword \(w_{1}\) affects \(w_{2}\). In other words, the higher the matrix value, the higher is the extent of exchanged influence. A matrix value that is among the top 25% of the matrix values is to be replaced by 3; a matrix value that is among the next 25% (75%–50%) is to be replaced by 2; a matrix value that is among the next 25% (50%–25%) is to be replaced by 1; and a matrix value that is among the bottom 25% (25% to minimum) is to be replaced by 0. The reason for changing the frequency of SAOs to values of 0–3 without using it intact is to mitigate the fluctuation of values because the SAO frequency may deviate excessively. Then the TRM is obtained according to the formula mentioned in Section "Background".
Calculating link weight via DEMATEL
The process of calculating link weights by using the TRM is divided into three steps. First, the weight of each keyword is calculated. Second, the document weight is computed based on the keyword weight. Third, the link weight is calculated based on the document weight.
First, the weight of each keyword is computed using the existing DEMATEL technique. We calculate the keyword weights for the indexes D, R, and D + R, while excluding the index D − R. Figure 3 shows the process of deriving keyword weights from the TRM as an example. The index D refers to the sum of the keyword rows. In other words, D refers to the total influence that the relevant keyword has on other keywords. The index R represents the sum of the keyword columns; that is, it represents the total influence of other keywords on the relevant keyword. The index D + R is the sum of the indexes D and R. Because this index sums the influences that the relevant keyword has on and receives from other keywords, the index D + R highlights the importance of the effect that the relevant keyword has on all the keywords.

Process of deriving keyword weights
Second, by using the keyword weights computed for the indexes D, R, and D + R, the patent document weight is calculated. As shown in Fig. 3, supposing that the weight of a specific keyword is \(V_{{\ell \in \left\{ {D, R, D + R} \right\}}} \left( {w_{m} } \right)\) and that the frequency of appearance of the relevant keyword in the first patent document claims is \(f_{{w_{m} }} \left( {P_{1} } \right)\), the weight \(\theta_{{\ell { } \in \left\{ {D, R, D + R} \right\}}} \left( {P_{1} } \right)\) of the first patent document is calculated as following Eq. 3, 4, and 5. Index D is the causative factor of technology, and it refers to the degree of influence that a preceding patent has on subsequent patents. Index R is a consequent factor, and it refers to the degree of influence that subsequent patents have received from preceding patents. Index D + R shows the total importance of a patent by considering all the give and take effects between technologies. In this case, the keyword indicating the cause and effect of the patent is used as an analysis unit. Each index is calculated by considering the frequency between keywords. Therefore, it is possible to calculate the weights of links through causal content analysis based on DEMATEL indicators to overcome the limitation of existing research, in which link weights are calculated based on citation frequencies.
Finally, the weight of a link is calculated based on the weight of each patent document that has a citation relation. Assuming that patent document \(P_{1}\) is cited in patent document \(P_{2}\); If the two document weights are \(\theta_{{\ell { } \in \left\{ {D, R, D + R} \right\}}} \left( {P_{1} } \right)\) and \(\theta_{{\ell { } \in \left\{ {D, R, D + R} \right\}}} \left( {P_{2} } \right)\), respectively, the link weight can be calculated as following Eq. 6. Citation flow refers to the process of absorbing preceding information and technologies to create new information or advanced technologies (Jiang & Zhuge, 2019). Accordingly, we define link weights as the product of the weights of the two patent documents, where, if the patent document value is 0, it should be increased to 1 before computing the product. The link weight determined from the perspective of index D represents the influence that the relevant link has on other link flows. The link weight determined from the perspective of index R refers to the influence of other links on the relevant link. The link weight determined from the perspective of index D + R indicates the importance of the link.
Searching the main path
In this step, the main path is derived using the link weights calculated thus far. There are various approaches to searching for the main path. In this study, we use the global main path and key-route main path analysis methods to derive the main paths when the D-based, R-based, and D + R-based link weights are reflected.
The global main path method derives the path with the largest link weight sum as the main path. The key-route main path search method is used to observe two or more key paths in a network. For example, assuming that there are 100 patent development paths that could be derived from a patent citation network, the global main path method can derive only one path that has the largest link-weight sum among all the paths, whereas the key-route main path search method can identify the top “k” units of the paths with the highest link-weight sums as the main path, where the value of “k” can be assigned directly by the analyst, and the size of the main path is determined by the “k” value.
Detecting groups using Girvan-Newman clustering
The content information contained in a patent document represents a product or system. Accordingly, it is impossible to review the extent of the development flow in a technical field by conducting a search for only the keyword causality-based weight values or main paths. Our purpose here is to suggest a search method for main paths based on keyword causalities, but to use the main path search results in practice, it is essential to review not only the development path of patents but also the development trends in the relevant technical field. To this end, in this step, clustering analysis can be performed to detect a technology group that forms a network. When performing clustering analysis, nodes with high similarity can be grouped into one cluster, and nodes with low similarity can be placed in another cluster (Krishna et al., 2018). Clustering analysis can be performed using multiple methods, and the method used in this study is Girvan–Newman clustering (G–N clustering). By using G–N clustering to detect the internal technology structure of the network, we can identify whether the patents derived as the main path belong to different technology clusters or a same technology cluster.
Illustration
Data
We selected “self-driving car” technology as the technology to be analyzed. In modern times, the development of a self-driving car, which does not require a driver’s intervention, is underway. However, social awareness about self-driving cars is remarkably low, and such cars are not popular yet, because the self-driving technology requires one to hand over control to the system instead performing the driving activity themselves; consequently, the resulting dangers are being mentioned constantly (Dixon et al., 2020). According to the literature on self-driving car technology, some technologies are being investigated actively and in detail to increase the stability of cars, rather all automotive systems (Dabral et al., 2014; Duraisamy et al., 2013; Kaempchen et al., 2004; Tian et al., 2018; Xia et al., 2016). Accordingly, to develop a technology with higher safety, it is necessary to first review the technical information pertaining to the relevant technology and examine the associated detailed trends in terms of time.
We collected patents published between 1976 and 2019 from the USPTO. To collect the related patent documents, a search formula for “recognition,” “judgment,” and “control,” which are the three key phases of autonomous driving, was considered along with the universal search formula. Second, the search terms for “judgment” were “driving judgment,” “driving decision,” “on-board diagnosis” and “monitor.” Finally, the patent documents related to “control” were retrieved by using terms such as “steering,” “speed,” “touch,” “adapt,” and “power.” The search formulas for the three key phrases are presented in Appendix 1. By using these search formulas, we collected 20,068 patent documents to analyze the main path of self-driving cars.
Extracting SAO structures based on causality
The SAO was derived for the patent claims. The total number of derived SAOs was 1,017,765 units. Among them, 26,424 SAOs were bound by 18 causative verbs. Table 3 shows the collected results for each verb. After the derivation, the verb “provide” appeared the most by a wide margin, and any SAO structure containing the verb “relax” was not found.
Structuring total relation matrix and calculating link weight
The derived number of S and O keywords constituting the 26,424 SAOs was 2,036; these keywords were arranged in the rows and columns of the matrix, which completed the TRM. Next, we calculated the weight of each keyword from the perspectives of the three indexes, namely D, R, and D + R. Table 4 lists some of the results of keyword weight derivation.
The index D refers to the magnitude of influence of a keyword on other keywords, the index R refers to the magnitude of influence of other keywords on the given keyword, and the index D + R indicates the importance of the given keyword. For the keyword “engine,” because the value of D was higher than that of R, its tendency to influence other keywords was stronger. By contrast, for the keyword “location,” there was no significant difference between the D and R values. Subsequently, we calculated the patent document weights according to the suggested process based on the derived keyword weights. Table 5 lists a few of the derived document weights. In addition, the calculation procedure was implemented for link weights in accordance with the suggested process. We used link weights to search for the main path in the next step.
Searching for a main path
This step describes a way to search for the main path based on the three link weights derived in the preceding section. Before searching for the main path, to extract the patent documents with high importance from all the data, we used the Pareto principle, which assumes that 20% of the total causes and efforts could account for 80% of the overall results and performance (Yang & Shieh, 2019). The Italian economist Vilfredo Pareto first discovered that 20% of the Italian nation owned 80% of the total wealth. Since then, this law has been applied and used in diverse research areas, including quality control, project management, and systems (Mesbahi et al., 2017; Reh, 2017). In this study, we assumed that the technological change process represented by all the data could be explained by the top 20% of the patents, in accordance with the Pareto principle. The upper 20% percentile of the value of D + R, an integrated index of importance, was set as the threshold based on the Pareto principle. For each patent, only the cases in which the D + R values were greater than or equal to the corresponding thresholds were selected. In this manner, 2625 patents were selected for the MPA.
Self-driving cars move by following a three-step process: “Sensing” to recognize the driving environment, “Planning” to formulate a driving plan, and “Acting” to move and control the vehicle according to the driving plan (Surden and Williams 2016). In all the derived main paths, we mostly observed patents related to the above three-step basic process. Tables 6 and 7 list the search results for the global main paths. Based on the link weight values of the indexes D, R, and D + R, we derived one path with the highest sum of weights. The same results were obtained for the indexes R and D + R, which indicates that the importance of the patent depends on the degree to which it is affected by other patents, rather than the degree to which it affects other patents, in terms of the patent documents related to “self-driving car” technologies.
Figures 4 and 5 show the search results of the key-route main paths. Based on the link weight values of the indexes D, R, and D + R, we derived the top 30 paths with the highest sum of weights. Similar to the search results of the global main paths, the same results were obtained for the indexes R and D + R. The path highlighted in blue indicates the global main path, and the large arrow on the left represents the flow direction of the key-route main path.

Key-route main-path based on link weight of Index D

Key-route main-path based on the link weights of indexes R and D + R
Based on an intense review of the patents related to index D on the global main path with the highest index value, we found that patents related to public interest were developed in the past. US4069888 (1976) presents the general transport system technology for unmanned public transportation. US4361202 (1979) describes an automatic transport technology for transporting goods. Additionally, it includes a control system to select speeds and routes, guardrail devices for unmanned transport, and radar technologies for recognizing the driving environment. Particularly, in US4361202 (1979), which described the technology of the Freight Shuttle System and was initially studied in 1999 by the Texas Transportation Institute (TTI) in the United States, can be considered as an example. The device described in this patent can move without oil fuel or a driver, and it was proposed to address environmental contamination and traffic safety problems caused by the use of medium-sized diesel trucks (Levien, 2011). Since the relevant technology can be used to efficiently transport large-capacity freight, such as containers, on an elevated single-purpose road, it can be operated safely in the unmanned state (Roop, Ragab et al. 2010). Since US4361202 (1979), three patents related to self-driving technologies, all of which could be applied to general vehicles, have been published. US9043016 (2006), US7894951 (2006), and US8126642 (2008) are the patents that represent vehicle control technologies for automatic driving. US10451425 (2015) and US10077056 (2015) pertain to a system for collecting and learning from data for autonomous driving. US10451425 (2015) enables autonomous driving by learning vehicle route data. US10077056 (2015) can collect data on a driver’s vehicle-driving methods to ensure that autonomous driving matches the driver's preferences. Because it is difficult to consider all environmental variables that may occur on the road, learning-based driving system is one of the technical fields that is being studied actively (Xia et al., 2016). The need for the development of learning-based driving has been growing because it can help to minimize resource consumption and prevent potential threats with high occurrence probabilities (Xia et al., 2016, Tian et al., 2018). US8781669 (2012) and US9715711 (2015) are associated with a system for recognizing the autonomous driving mode of a self-driving vehicle and detecting surrounding hazards. US10471829 (2017) describes a system that can automatically recognize defects and respond to them appropriately when a problem occurs in a vehicle. US10282625 (2018), a patent similar to US10471829 (2017), can detect smoke when a fire occurs in the vehicle, send a danger signal, and drive the vehicle automatically driven depending on the disaster situation. As an example of the patents related to learning-based driving system technologies and risk-perception technologies, self-driving cars could be equipped with an AI-based Advanced Driver Assistance System (ADAS), which is being developed collaboratively by the companies Volvo, Autoliv, and NVIDIA. The three companies emphasized the development of a deep-learning-based system to perceive the surrounding environment and predict potential threats; their goal was to commercialize the system and sell the finished products by 2021, as communicated by Volvo (Volvo, 2017). US10481606 (D) is a patent indicating a system that can perceive other vehicles to facilitate movement of a vehicle. Vehicle-To-Vehicle (V2V) is the network technology for exchanging signals between vehicles. In the United States, with governmental support, the US Department of Transportation (USDOT) and University of Michigan Transportation Research Institute (UMTRI) tested approximately 3,000 vehicles equipped with V2V on real roads between August 2012 and August 2013 (Narla, 2013) because V2V is required to reduce possible collisions between vehicles (Sahin et al., 2018).
From Table 6, in which the patent after US4361202 (1979) is US7894951 (2006), a large time gap between patents was found. This result was ascribed to our selection of the analysis dataset. First, in the data-acquisition stage, a search formula was proposed based on the keywords that describe the technical field. But this formula did not reflect the network structure due to connections resulting from citations of patents. For this reason, the patents that are actually cited may be omitted during the process of data collection using the proposed search formula. In addition, in this study, the main path was derived by sampling the patents belonging to the upper group, which are important from the viewpoint of causal information, to ensure analysis efficiency. Even if a patent with a weak causal connection was actually linked to the cited patent, it was excluded. The purpose of analyzing the main path is to concisely express the development path of the patent based on the main patents with high levels of technical influence. Therefore, a temporal gap between patents in the path may have been obtained, but this gap can possibly be interpreted as a period of stagnation in terms of technologically important developments.
Next, we intensively reviewed the patents of indexes R and D + R for the global main path with the highest index value. US5081667 (1990) and US4887064 (1987) represent an interface system technology for integrating an automotive assistance system and mobile terminals. US6542076 (2000) and USRE43891 (2011) indicate the overall control system of vehicles. The derived main path result contains only four patents. This number is extremely small compared to the entire dataset, but as shown in Fig. 5, the analysis results can be expanded and interpreted in relation to the key patents in the subsequent rankings. The technology in which automotive assistance systems and mobile terminals are integrated is a service that is actually being offered by the carmaker BMW, which has developed a driver-assistance system equipped with sensor functions, including GPS and cameras, by using smartphones, which are portable. Upon downloading the BMW-exclusive application to a smartphone, information related to vehicles and road conditions can be obtained to prevent car accidents in advance (Dean, 2011). However, in the relevant technology, the application date of the patent is 1990, but it was commercialized relatively recently, probably because of the emergence of smartphones, which represent an excellent technology that provides diverse functions, including information management services, such as news, e-mail, and entertainment services, other than basic functions of phone calls and text messages. Smartphones were first released in 2007, and their use has grown rapidly in the modern era, such that more than most of the populations in Korea and the United States use smartphones, which is probably the reason for the differences in the times of patent application, technology development, and technology commercialization (Jung et al., 2015).
Detecting groups using Girvan–Newman clustering
In this analysis step, we test whether the derived results of the main paths, index D, R, and D + R, represent the technology flow suitable for the definition and direction of each index. To this end, we previously performed a G–N clustering analysis of 2,625 patents to investigate the internal structure of the network; the results indicated that the top 20% of these patents had high D + R index values. We found that the 2,625 patents were composed of 315 clusters. From the cluster with the largest number of nodes to the cluster with the fewest nodes, we assigned numbers from 0 to 314 to classify the nodes of the key-route main paths by cluster and visualize the classification results. Figure 6 shows the cluster structure of the key-route main path derived based on index D. Figure 7 shows the key-route main path derived based on the indexes R and D + R.

Cluster structure of index D-based key-route main path

Cluster structure of key-route main path based on the indexes R & D + R
We validate the technology main path derived by the proposed study by reviewing technology reports in practical fields. The technology flow that constitutes the key-route main path derived based on the index D value can largely be ascribed to Cluster 2, Cluster 0, and Cluster 3 in that order. Cluster 2 represented the generic technologies required for self-driving technologies and the initial technology related to self-driving proposed for the public interest (Levien, 2011). Although not drawn as the global main path, the other two patents belonging to Cluster 2 on the key-route main path were automated control systems and driving environment recognition technology, which could be the basis of self-driving systems. Cluster 0, connected from Cluster 2, represented the technology for assessing the risks associated with self-driving and the degrees of these risks. This risk-detection technology belongs to the sensing step in the three-step self-driving process. This technology is required to prepare for and prevent potential threats, and it goes beyond simply recognizing the road on which the vehicle is to be driven before the vehicle moves. Accordingly, the technology that is the most basic should be developed on a priority basis for self-driving and research has been steadily conducted on how to more accurately identify and collect driving environment information (Kaempchen et al., 2004; Duraisamy et al., 2013, Dabral et al., 2014). Cluster 3 indicates the driving-route analysis and guidance system for self-driving. In terms of the steps of the self-driving system, this technology pertains to the planning and action steps. When the driving environment and risk data collected in the sensing step are transmitted, the next step involves making a decision and performing self-driving. US10282625 (2018), which was derived as a global main path, is a representative patent that comprehensively proposes technologies for all the steps of the self-driving system, starting from the sensing step to the action step.
The key-route main path derived based on the values of R and D + R was composed of a relatively greater number of technology clusters than the path derived based on the index D. The technical flow of the analysis results based on R and D + R was largely directed from Clusters 1 and 4 to Cluster 2 and then to Cluster 6. Cluster 1 consisted of patents pertaining to the signal-processing of driving environment data. This technology is used immediately after the sensing step, and it is used to identify roads or objects and convert them into signals to provide driving commands. Signal processing technology has multiple purposes, including preventing collisions with objects and setting the travel path. Cluster 4 was the technology cluster that was the most similar to Cluster 1, which represented a technology in the sensing step that processes the data signals collected from the driving environment; Cluster 4 represented a system or device for transmitting and receiving the driving command signals issued in the planning step, which are generated on the basis of driving environment data. The technologies belonging to both Cluster 1 and Cluster 4 exhibited a form that converged in Cluster 2. As mentioned in the result of index D, Cluster 2 represents generic technologies for self-driving. Even in Cluster 2, the patent selected as the key-route main path of the indexes R and D + R was a technology representing the general applications of the technologies belonging to Clusters 1 and 4. US6226389 (1999), continued from Cluster 1, describes the overall methods for identifying obstacles, outputting signals, and using them as control signals for driving a vehicle. US6141620 (1996), continued from Cluster 4, demonstrates how to use signals to check the vehicle condition by periodically receiving signals related to its movements. Cluster 6, following Cluster 4, described the technology of a phased control system or device for controlling a self-driving vehicle.
Discussion
Discussion of MPA results
In this study, a new methodology for calculating the link weight by considering the causal relationship at the keyword level was proposed to derive the main path of a patent. Figure 8 shows the top 30 main paths derived using the existing approach based on SPC weights, which calculates the link weights based on the number of citations. The seven nodes marked in color are the parts in which results identical to those obtained using the existing methodology were obtained. The yellow nodes are the patents that represent the top 20% of index D + R. The blue nodes are patents that represent the top 30 paths of index D. The red patents represent the top 30 paths of the indexes R and D + R. The results obtained using the existing methodology generally included several patents with high D + R index values. When a company attempts to create a new technology, it can reduce technological threats by utilizing the key technology development paths that can be derived through index D. Any technology that has reached a mature stage of development can be identified, along with its risks, by reviewing not only information on the theory of the technology but also examples of it gaining a stable market position through actual development. However, in the case of a new technology that is in the development stage, there is little information on success references, which increases the risk level. For this reason, it is necessary to collect information that influences technological ideas within the technology market and examine whether a company is a viable option. Nevertheless, the existing approach does not consider the results obtained by identifying important patents in terms of technical ideas and development performance. The proposed methodology considers both when information about a technology idea is needed, when information pertaining to technology development performance is needed, or when important technical information that is of high value from both perspectives is needed.

Comparison of MPA results between the traditional and proposed methods
The MPA derived in this study contains results that seem unreasonable. For example, the MPA derived using index D includes a patent link with a time gap of more than 20 years in Table 6. The result was that US9098080 was a sink node, even though a number of patents have cited it since then. In addition, only four patents were included in the MPA result derived using the D + R index. This analysis result can be interpreted as the result of selection and concentration in the dataset. That is, in this study, the causality of the preceding and following patents was analyzed, and the contents that were actually written in the patent document were emphasized. Therefore, even if there were many cited patents, they were likely to be excluded from the path if technical causality was inadequate. However, there was a high possibility that the cited patent was excluded during this process because it was collected by creating a search formula based on the keywords of the technology to be analyzed in the data-collection stage. This limitation related to missing data can be overcome by supplementing the data collection process. In this study, we considered only 18 causative verbs for analyzing causality. The list of verbs for examining causality can be broadened, or a causal content-linking phrase that is not expressed as a verb can be included. We compared the MPA results obtained using the proposed and the existing methods. Among the core patents derived using the existing methodology, only three blue patents had high value as technology ideas. In addition, only four red patents were particularly valuable in terms of technological development. However, a large number of yellow patents with high value, which can be interpreted as having a high level of technological importance, were included as both technological ideas and technological development results.
Theoretical and managerial implications
In this section, we discuss the theoretical and managerial implications of the proposed method. The framework proposed herein draws the main path of technology development by using SAO structures and the DEMATEL method. We compared the proposed method with the methods described in existing MPA studies with a focus on the calculation of link weights and technical influence. The existing methodologies have limitations in terms of deriving patents from various viewpoints and delivering as much information as the proposed methodology. From the academic perspective pertaining to the suggested keyword causal relationship-based link weights, our greatest contribution is that the proposed method uses the keyword information of the patent document directly to compute the weights. We derived keyword information from the claims describing the technical functions in the patent documents, and we used this information to determine a new link weight for MPA. The second contribution is that we minimized information loss by deriving the main paths separately by considering the indexes D, R, and D + R and then suggested them. For the purpose of our analysis, the proposed method can derive the main path of the patents that have a strong degree of influence on other patents, the patents that are affected to a strong degree by other patents, and the patents that have high importance. The contribution from a managerial point of view is that the proposed method could help to identify important technology flows that are difficult to grasp by using only citation information because it considers the influence of a patent document. The proposed method can identify the latest technological development trends by efficiently analyzing big data, and it can provide useful information for foreseeing the direction of technological development in the future.
Moreover, the results can be utilized to manage the R&D on self-driving cars. When reviewing the main path and technological cluster structure based on index D, we found that the driving environment recognition, risk detection, driving route analysis, and guidance technologies for self-driving cars represent the most important technology flow. These technologies are related to the most basic processes required for the operation of self-driving cars, in the order of sensing to collect vehicle location and surrounding information by using sensor devices, such as Radar, Lidar, GPS, and cameras; planning to detect speed, direction, and destination by analyzing sensing data; and acting to move the vehicle according to the driving plan. This is the basic process for moving the vehicle, and it is also a type of learning process that is repeated several times to quickly adapt and respond, even if the driving environment changes suddenly (Surden and Williams, 2016). Because this is the most basic technology that was used before other technologies or services based on self-driving technologies were developed, it has the greatest influence on the development of other technologies related to self-driving. Therefore, the index D, which represents the extent of influence, shows that the actual technological development flow can be derived and it is suitable for the definition and direction of indexes.
Next, by analyzing the indexes R and D + R, we identified the data-signal transmission and reception technology for self-driving cars as the most important technology flow. Because the index R refers to the degree to which a patent is influenced by other patents, the technology that is the most strongly affected by other technologies is data-signal transmission & reception. It is the most strongly affected by the technologies for sensing, planning, and acting, which were obtained as the results of index D, because signal transmission & reception technology is important, especially in the sensing step. Since the sensing step is the pre-step for not only collecting information about roads and objects but also for detecting and preventing potential risks, the key is to quickly process and transmit the collected data. Furthermore, even when the planning and action steps receive and process data, signal transmission & reception technology is required. Accordingly, research to improve the performance of signal processing functions, including signal range, speed, and direction, is being conducted together with research on self-driving technologies. For this reason, we believe that signal transmission & reception technology is greatly affected by the underlying technology in the self-driving field (Jo & Sunwoo, 2013; Patole et al., 2017). The analysis of the index D + R, which indicates importance, yielded the same results as those obtained using index R. This implies that the indexes R and D + R have a strong correlation for self-driving car technologies. In other words, the technological importance of self-driving car technologies depends on the technology used to process the data signals for self-driving. The relationship between the importance index D + R and the other indexes D and R may differ if the technology to be analyzed is not meant for self-driving cars.
Conclusion
In this study, a data-based quantitative methodology was proposed to analyze technology development paths and identify competitive relationships between the development paths to explore technological opportunities. A keyword causality-based MPA methodology for technology development path analysis was proposed. Patents were selected based on the main path obtained using the proposed methodology, and cases developed as actual technologies or services were analyzed. In addition, the proposed methodology was verified through comparison with the existing methodologies.
The contributions of this study are as follows. We researched and suggested the MPA method based on the keyword causal relationships by deriving information from the body of patent claims. We collected and analyzed patent data on the technology of self-driving cars. By means of the index D, which represents the extent of influence of a patent, we derived the core technology flow that forms the basis of the self-driving car process. By using the indexes R and D + R, we drew the core technology flow related to signal processing that was most affected by the generic technology of self-driving cars. By using the proposed method and actual analysis results, we outlined our contributions to the MPA research field from the academic and managerial perspectives. Finally, we concluded by proposing future research projects to overcome the limitations of the proposed method and other limitations.
Nonetheless, the present study has several limitations. The first limitation of the proposed method is that because the weights are suggested based on the appearance frequency of keyword pairs of S and O in the SAO structure, if the frequency of a keyword is low, even though the keyword has a core meaning, the corresponding weight value is low. Next, when predicting the main route, the timing of emergence of new technologies cannot be predicted. The proposed methodology identifies only the technical prospects and the competitive situation based on the current data. However, the possibility of changes in the competitive situation due to the emergence of new influential patents is not considered. This study focused on patent data to derive the MPA. Therefore, it is necessary to extend the results to papers and other technical information to apply the results.
References
Altshuller, G., & Altov, H. (1996). And suddenly the inventor appeared: TRIZ, the theory of inventive problem solving. Technical Innovation Center Inc.
Chen, L., Xu, S., Zhu, L., Zhang, J., Xu, H., & Yang, G. (2022). A semantic main path analysis method to identify multiple developmental trajectories. Journal of Informetrics, 16(2), 101281.
Dabral, S., Kamath, S., Appia, V., Mody, M., Zhang, B., & Batur, U. (2014). Trends in camera based automotive driver assistance systems (adas). In 2014 IEEE 57th International Midwest Symposium on Circuits and Systems (MWSCAS), IEEE.
Dalvi-Esfahani, M., Niknafs, A., Kuss, D. J., Nilashi, M., & Afrough, S. (2019). Social media addiction: Applying the DEMATEL approach. Telematics and Informatics, 43, 101250.
Dean, J. (2011). Extremely mobile devices. Popular Science., 35, 2011–2008.
Dixon, G., Hart, P. S., Clarke, C., O’Donnell, N. H., & Hmielowski, J. (2020). What drives support for self-driving car technology in the United States? Journal of Risk Research, 23(3), 275–287.
Duraisamy, B., Schwarz, T., & Wöhler, C. (2013). Track level fusion algorithms for automotive safety applications. In 2013 International Conference on Signal Processing, Image Processing & Pattern Recognition, IEEE.
Surden, H., & Williams, M.- A. (2016). Self-driving cars predictability and law. Working Draft.
Guo, J., Wang, X., Li, Q., & Zhu, D. (2016). Subject–action–object-based morphology analysis for determining the direction of technological change. Technological Forecasting and Social Change, 105, 27–40.
Henrique, B. M., Sobreiro, V. A., & Kimura, H. (2018). Building direct citation networks. Scientometrics, 115(2), 817–832.
Hu, Z., Fang, S., Wei, L., Wen, Y., Zhang, X., & Wang, M. (2015). An SAO-based approach to technology evolution analysis using patent information: Case study—Graphene sensors. Journal of Data and Information Science, 7(3), 62.
Hummon, N. P., & Dereian, P. (1989). Connectivity in a citation network: The development of DNA theory. Social Networks, 11(1), 39–63.
Hwang, S., & Shin, J. (2019). Extending technological trajectories to latest technological changes by overcoming time lags. Technological Forecasting and Social Change, 143, 142–153.
Jiang, X., & Zhuge, H. (2019). Forward search path count as an alternative indirect citation impact indicator. Journal of Informetrics, 13(4), 100977.
Jo, K., & Sunwoo, M. (2013). Generation of a precise roadway map for autonomous cars. IEEE Transactions on Intelligent Transportation Systems, 15(3), 925–937.
Joung, J., & Kim, K. (2017). Monitoring emerging technologies for technology planning using technical keyword based analysis from patent data. Technological Forecasting and Social Change, 114, 281–292.
Jung, C. M., Hur, W.-M., & Kim, Y. (2015). A comparison study of smartphone acceptance between Korea and the USA. International Journal of Mobile Communications, 13(4), 433–453.
Kaempchen, N., K. C. Fuerstenberg, A. G. Skibicki and K. C. Dietmayer (2004). Sensor fusion for multiple automotive active safety and comfort applications. In Advanced Microsystems for Automotive Applications (pp. 137–163). Springer.
Kim, S., Bracewell, R. H., & Wallace, K. M. (2007). A framework for automatic causality extraction using semantic similarity. In International Design Engineering Technical Conferences and Computers and Information in Engineering Conference.
Kim, H., & Kim, K. (2012). Causality-based function network for identifying technological analogy. Expert Systems with Applications, 39(12), 10607–10619.
Kim, S., Park, I., & Yoon, B. (2020). SAO2Vec: Development of an algorithm for embedding the subject–action–object (SAO) structure using Doc2Vec. PLoS ONE, 15(2), e0227930.
Kim, Y. G., Suh, J. H., & Park, S. C. (2008). Visualization of patent analysis for emerging technology. Expert Systems with Applications, 34(3), 1804–1812.
Krishna, R. J., Chaudhry, Y., & Sharma, D. P. (2018). Analysis of community detection algorithms. In 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), IEEE.
Kumar, V., Lai, K. K., Chang, Y. H., Bhatt, P. C., & Su, F. P. (2020). A structural analysis approach to identify technology innovation and evolution path: A case of M-payment technology ecosystem. Journal of Knowledge Management, 25(2), 477–499.
Lai, K. K., Chen, H. C., Chang, Y. H., Kumar, V., & Bhatt, P. C. (2020). A structured MPA approach to explore technological core competence, knowledge flow, and technology development through social network patentometrics. Journal of Knowledge Management, 25(2), 402–432.
Lathabai, H. H., Prabhakaran, T., & Changat, M. (2017). Contextual productivity assessment of authors and journals: A network scientometric approach. Scientometrics, 110(2), 711–737.
Levien, M. (2011). Freight shuttle system: Cross-border movement of goods. Texas A & M Research Foundation.
Liao, S. C., Chou, T. C., & Huang, C. H. (2022). Revisiting the development trajectory of the digital divide: A main path analysis approach. Technological Forecasting and Social Change, 179, 121607.
Liu, X., Yu, Y., Guo, C., Sun, Y., & Gao, L. (2014). Full-text based context-rich heterogeneous network mining approach for citation recommendation. In IEEE/ACM Joint Conference on Digital Libraries, IEEE.
Mesbahi, M. R., Rahmani, A. M., & Hosseinzadeh, M. (2017). Highly reliable architecture using the 80/20 rule in cloud computing datacenters. Future Generation Computer Systems, 77, 77–86.
Namjoo, M. R., & Keramati, A. (2018). Analysing Causal dependencies of composite service resilience in cloud manufacturing using resource-based theory and DEMATEL method. International Journal of Computer Integrated Manufacturing, 31(10), 942–960.
Narla, S. R. (2013). The evolution of connected vehicle technology: From smart drivers to smart cars to... self-driving cars. Ite Journal, 83(7), 22–26.
Park, H., Ree, J. J., & Kim, K. (2013). Identification of promising patents for technology transfers using TRIZ evolution trends. Expert Systems with Applications, 40(2), 736–743.
Patole, S. M., Torlak, M., Wang, D., & Ali, M. (2017). Automotive radars: A review of signal processing techniques. IEEE Signal Processing Magazine, 34(2), 22–35.
Reh, F. J. (2017). Understanding Pareto’s principle-the 80-20 rule, The Balance.
Roop, S. S., Ragab, A. H., Olson, L. E., Protopapa, A. A., Yager, M. A., Morgan, C. A., Warner, J. E., Mander, J., Parkar, A., & Roy, S. L. (2010). The freight shuttle system: advancing commercial readiness. Texas Transportation Institute.
Sahin, T., Klugel, M., Zhou, C., & Kellerer, W. (2018). Virtual cells for 5G V2X communications. IEEE Communications Standards Magazine, 2(1), 22–28.
Shieh, J.-I., Wu, H.-H., & Huang, K.-K. (2010). A DEMATEL method in identifying key success factors of hospital service quality. Knowledge-Based Systems, 23(3), 277–282.
Tian, Y., Pei, K., Jana, S., & Ray, B. (2018). Deeptest: Automated testing of deep-neural-network-driven autonomous cars. In Proceedings of the 40th International Conference On Software Engineering.
Tsai, S.-B., Zhou, J., Gao, Y., Wang, J., Li, G., Zheng, Y., Ren, P., & Xu, W. (2017). Combining FMEA with DEMATEL models to solve production process problems. PLoS ONE, 12(8), e0183634.
Tseng, Y.-H., Wang, Y.-M., Lin, Y.-I., Lin, C.-J., & Juang, D.-W. (2007). Patent surrogate extraction and evaluation in the context of patent mapping. Journal of Information Science, 33(6), 718–736.
Volvo. (2017, Jun 27, 2017). "Volvo Cars and Autoliv team up with NVIDIA to develop advanced systems for self-driving cars." from https://www.media.volvocars.com/global/en-gb/media/pressreleases/209929/volvo-cars-and-autoliv-team-up-with-nvidia-to-develop-advanced-systems-for-self-driving-cars.
Wang, X., Ma, P., Huang, Y., Guo, J., Zhu, D., Porter, A. L., & Wang, Z. (2017a). Combining SAO semantic analysis and morphology analysis to identify technology opportunities. Scientometrics, 111(1), 3–24.
Wang, X., Wang, Z., Huang, Y., Liu, Y., Zhang, J., Heng, X., & Zhu, D. (2017b). Identifying R&D partners through Subject-Action-Object semantic analysis in a problem & solution pattern. Technology Analysis & Strategic Management, 29(10), 1167–1180.
Xia, W., Li, H., & Li, B. (2016). A control strategy of autonomous vehicles based on deep reinforcement learning. In 2016 9th International Symposium on Computational Intelligence and Design (ISCID), IEEE.
Yang, C., Huang, C., & Su, J. (2018). An improved SAO network-based method for technology trend analysis: A case study of graphene. Journal of Informetrics, 12(1), 271–286.
Yang, Y.-T., & Shieh, J.-C. (2019). Is there the Pareto principle in public library circulation? A case study of one public library in Taiwan. Malaysian Journal of Library & Information Science, 24(2), 97–113.
Yoon, B., & Jeong, S. (2013). Impact analysis of biological technology: Application of network analysis and decision making trial and evaluation laboratory. Advanced Science Letters, 19(12), 3610–3614.
Yoon, B., & Park, Y. (2004). A text-mining-based patent network: Analytical tool for high-technology trend. The Journal of High Technology Management Research, 15(1), 37–50.
Yu, D., & Sheng, L. (2021). Influence difference main path analysis: Evidence from DNA and blockchain domain citation networks. Journal of Informetrics, 15(4), 101186.
Zhang, W., & Deng, Y. (2019). Combining conflicting evidence using the DEMATEL method. Soft Computing, 23(17), 8207–8216.
Zhou, Q., Huang, W., & Zhang, Y. (2011). Identifying critical success factors in emergency management using a fuzzy DEMATEL method. Safety Science, 49(2), 243–252.
Funding
This work was supported by the National Research Foundation of Korea under Grant NRF-2021R1I1A2045721.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no financial or non-financial interests to disclose.
Appendix: Searching formulas
Appendix: Searching formulas
-
(a)
recognition: “TAC = ((("RADAR" OR "radio detection and ranging" OR "radio waves" OR "millimeter wave" OR "SRR" OR "Short Range Radar" OR "LRR" OR "Long Range Radar" OR "Laser radar") OR ("ultraviolet" OR "near infrared" OR "LASER" OR "Light Amplification by the Stimulated Emission of Radiation" OR "LIDAR" OR "Lager Imaging Detection And Ranging") OR "Ultrasonic") AND ((auto* OR robotic OR driverless OR "self drivinig") W/5 (vehicle OR car)))”, “TAC = ("camera" AND ((auto* OR robotic OR driverless OR "self drivinig") W/5 (vehicle OR car)))”, and “TAC = (("telematics" OR "V2X" OR "V2V" OR "vehicle-to-vehicle" OR "vehicle-to-infrastructure" OR "Vehicular communication" OR "connected car" OR "connected vehicle" OR "wireless communication" OR "bluetooth" OR "Wi Fi" OR "short range communication" OR "internet of things" OR "in-car networking" OR "connectivity") AND ((auto* OR robotic OR driverless OR "self driving") W/5 (vehicle OR car)))”.
-
(b)
judgment: “TAC = ((((self OR vehicle OR driving) AND (plan* OR diagnos* OR monitor*)) OR "On board diagnos*" OR "OBD") AND ((auto* OR robotic OR driverless OR "self drivinig") W/5 (vehicle OR car)))”, and “TAC = (((adaptive OR super OR smart) AND (cruise OR decision OR act*)) AND ((auto* OR robotic OR driverless OR "self drivinig") W/5 (vehicle OR car)))”.
-
(c)
control: “TAC = ((((touch OR active front OR active independent front OR car) AND steering) OR steering) AND ((auto*OR robotic OR driverless OR "self drivinig") W/5 (vehicle OR car)))”, “TAC = ((speed AND (control OR adapt* OR advice OR device)) AND ((auto* OR robotic OR driverless OR "self drivinig") W/5 (vehicle OR car)))”, and “TAC = (((("automotive power" OR "vehicle stability" OR engine) AND control) OR "active safety") AND ((auto* OR robotic OR driverless OR "self drivinig") W/5 (vehicle OR car)))”.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Oh, M., Jang, H., Kim, S. et al. Main path analysis for technological development using SAO structure and DEMATEL based on keyword causality. Scientometrics 128, 2079–2104 (2023). https://doi.org/10.1007/s11192-023-04652-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-023-04652-2