
Abstract
Altmetrics are often praised as an alternative or complement to classic bibliometric metrics, especially in the social sciences discipline. However, empirical investigations of altmetrics concerning the social sciences are scarce. This study investigates the extent to which economic research is shared on social media platforms with an emphasis on mentions in policy documents in addition to other mentions such as Twitter or Facebook. Moreover, this study explores machine learning models to predict the likelihood of a research article being classified into the top-quality tier of a journal ranking based on the altmetric mentions. The included journal rankings are the academic journal guide (AJG), source normalized impact per paper (SNIP) and journal citation reports (JCR). The investigated journals have been selected based on the AJG list and extracted from Altmetric.com data. After applying extensive data cleaning on the extracted data, a final set of 55,560 journal article records is obtained. The results indicate that the average number of policy mentions of the publications of economics journals is higher than the other subject areas included in the AJG list. Moreover, the publications in top-ranking economic journals are more likely to have a higher average number of policy mentions. Policy and Twitter mentions are presented as the most significant and informative social media mentions in demonstrating the broader impact and dissemination of Economics discipline followed by Blogs, Facebook, Wikipedia, and News. The results show that Support Vector Machine and Logistic Regression performed best in classifying the journal ranking tiers i.e. SNIP-based with 77% accuracy, JCR-based with 71% accuracy, and AJG-based with 66% accuracy. The models classified the ranking tier AJG18 with lower accuracy than SNIP and JCR. This might be because the AJG18 rankings are based on expert opinion, whereas SNIP and JCR are based on citations.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The intention of research publications is not just to communicate with one’s peers and make a mark in the research community, but also to influence society. The classic (or bibliometric) way of measuring this influence has typically been through citation metrics. But these metrics have several limitations since they often only include research communication in peer-reviewed publications and thereby do not cover the full extent of a research publication’s usage. The introduction of social media platforms has highlighted that research is not just discussed in formal scholarly communication channels, but instead, it is often communicated and debated by a research community before being given a citation (Hassan et al. 2020a, b). By including social media data, invisible informal debate and usage can become visible (and measurable).
As a result, new possibilities of measuring the impact or broader usage of scientific publications in social media have emerged (Costas et al. 2015). These alternative metrics are often referred to as altmetrics. They refer to mentions of scientific outputs on Facebook, Twitter, blogs, news media, or reference management tools (Said et al. 2019), and since 2014, policy documents (Tattersall and Carroll 2018). In comparison with classic metrics, altmetrics often measure the immediate research attention and include a wider range of non-academic audiences, as well as cover more diverse research sources and outputs (Aung et al. 2019; Hassan et al. 2020a). For example, with the inclusion of policy mentions, it is possible to follow how research influences decision-makers in society.
Multiple studies have investigated the relationship between citation counts and altmetric mentions (Costas et al. 2015; Haustein et al. 2014; Thelwall et al. 2013; Hassan et al. 2019), but the findings do not agree whether altmetric mentions are associated with citation counts; instead, the relationship largely depends on the discipline (Hassan et al. 2020). Costas et al. (2015) found that publications from the Social Sciences and Humanities (SSH) exhibit a higher altmetrics activity compared to the other research branches, thus indicating a lot of potential for research evaluation.
The possibility of measuring the broader usage is essential to perform better evaluations of SSH research since it targets a broad array of audiences and has a more heterogeneous publishing approach (Nederhof 2006; Hammarfelt 2014). But, empirical investigations of the SSH are few, and especially in-depth studies of a single SSH discipline is lacking. This study seeks to address the following research questions (RQ):
RQ 1
What is the coverage of Economics on Altmetric.com?
RQ 2
What is the extent of economic research mentions in the policy documents?
RQ 3
Which social media mentions show the broader impact of economic research publications?
RQ 4
Which social media mentions relates to the journal indicators?
RQ 5
Can altmetrics serve as an authentic and reliable medium to classify the quality tiers of AJG, JCR, and SNIP?
Thus, this study investigates the extent to which economic research is mentioned on social media platforms with an emphasis on mentions in policy documents, and how these mentions relate to journal rankings. We explore the likelihood of an economic article being classified into the journal ranked outlet based on their altmetric mentions. Following this introduction, “Literature review” section presents the literature review, “Data and methodology” section describes the data and methodology, and “Results and discussion” section shows the results and findings. Moreover, “Concluding remarks” section provides the conclusion.
Literature review
In September 2010, Jason Priem composed the term “altmetrics” in one of his tweets. Altmetrics stands for “alternative metrics.” As mentioned in the introduction, classic measures use bibliometric indicators, such as citation counts and journal rankings. Altmetrics were introduced to complement bibliometric measures, not to replace them. According to Kelly (2017), “altmetrics will give a complete picture of how to research and scholarly output is used.” The development of the concept of altmetrics has occurred simultaneously with the growth in web-tools, and it is a constantly expanding area.
Social usage data
There are three major altmetrics data providers: Altmetric.com, ImpactStory, and Plum Analytics. In this study, we use Altmetric.com, which captures the data from 17 different online platforms such as Policy Documents, Twitter, Facebook, Google + , Reddit, Blogs, Weibo, Stack Overflow, and CiteULike. Altmetric.com accumulates all the social media attention gathered by a scientific publication in an altmetric score. The altmetric score reflects both the quantity (higher attention, higher score) and quality (weighting according to different sources) of attention received by each item (Costas et al. 2015). In this paper, we will refer to the company as Altmetric as capitalized, and altmetrics as the process without a capital letter.
Altmetric measures the research impact through online interactions and provides additional demographics information such as user categories and geographical locations. Altmetric started tracking social media attention in 2011 and has since captured 2.8 million records, which contain at least one associated online activity. Altmetric is constantly expanding the coverage and is becoming increasingly popular among scholars, publishers, universities, and funders with the increased usage of social media for scholarly communications.
Still, despite the increasing usage, the characteristics and properties of altmetrics are not well understood. Previous studies find that the mentions and usage of research publications on social media platforms differ depending on the disciplines (Hassan et al. 2017; Holmberg and Thelwall 2014). Nuredini and Peters (2015, 2016) show that Mendeley, Twitter, and News are the top 3 altmetric sources that are used extensively for the Economic and Business Studies (EBS), whereas Zahedi et al. (2014) find Facebook, Twitter, and Blogs to be the most used altmetric sources for the health sciences and biomedical publications. Policy mentions are much less frequent for all disciplines; however, studies have found a greater trend in economics compared to other disciplines (Haunschild and Bornmann 2017; Tattersall and Carroll 2018).
The inclusion of policy documents on the Altmetric platform happened in 2014. Before Altmetric started tracking policy mentions, it was almost impossible to discover whether a piece of research had been cited in a policy document. You had to manually examine relevant documents, communicate with policymakers, or find the citations by pure chance (Tattersall and Carroll 2018). By gaining access to policy documents citations, it becomes possible to better track the societal impact of research. Policy document citations can be used to expose the interaction between science and politics and be considered a critical indicator for measuring the societal impact and the significance of a research article (Bornmann et al. 2016; Liu 2014).
Nevertheless, there are many coverage limitations, especially since Altmetric mainly covers English-language organizations and agencies.
Altmetrics and citations
Multiple studies have investigated the relationship between altmetric and bibliometric indicators. Tweets seem to have a positive relationship with early citation counts (Eysenbach 2011; Shuai et al. 2012), but most of the examined disciplines do already have a high and early citation rate. Thelwall et al. (2013) found that a positive correlation exists between 11 different altmetric indicators and Web of Science (WoS) citations based on 208,739 PubMed publications. Their results imply that for indicators like Twitter, Facebook posts, blogs, online media & forums, there is a positive relationship between the altmetric score and citation count. Nevertheless, Costas et al. (2015) find a weak correlation between citations and altmetric scores, and they conclude that altmetrics should be used to complement bibliometric citation analysis. Likewise, Nuredini and Peters (2015) find a moderate correlation between Mendeley readership and the journal impact factor in Economics and Business Studies Journals, and they also propose that reader counts can complement the bibliometric indicators. Bailey et al. (2017) investigate the relationship between altmetric indicators, bibliometric citations, and policy citations of research papers and explore methods to predict whether a research paper is cited in a policy document. They find a weak correlation between the altmetric indicators, bibliometric indices, and policy citations.
Most altmetrics studies focus on the medical sciences or natural sciences. There are few studies focusing solely on altmetrics evaluations in SSH. In this study, we address this lack of knowledge by exploring social media usage in economics with an emphasis on policy documents, and how journal rankings associate with economic research’s altmetric score. Furthermore, we explore classification models to predict the likelihood that an article is classified into the top quality tier of a journal ranking based on the altmetric mentions.
Data and methodology
This section presents the detail of compiled datasets along with the bibliometric indices. We aim to find those factors or mentions of altmetrics that are positively correlated with the publications of highly ranked journals in economics. Furthermore, using altmetric mentions, we also employ machine learning models to predict the ranking of journals in economics.
Data acquisition
The data was collected from Altmetric.com in October 2019, and it consists of 8158,029 JavaScript Object Notation (JSON) files, which span the period from 1890 to 2017. Each file represents a single publication. The total 55,574 records have been extracted from the altmetrics data for the 332 journals in economics indexed by Academic Journal Guide (AJG). The extracted dataset is comprised of several features, including Altmetric id, Journal title, Publication year, Blogs mentions, Policy mentions, Facebook mentions, Twitter mentions, Google + mentions, News mentions, Wikipedia mentions, Total mentions, Altmetric score, Author count, etc. We used the ranked outlets of the indicators AJG, JCR, and SNIP. Before explaining the details of the data compilation process, we will briefly present the details of these indicators.
AJG: The Academic Journal Guide (AJG), created by the Chartered Association of Business Schools (CABS) (2018), is updated every third year. First, by a review board of editors and methodologists followed by a review by the scientific committee of subject experts along with, where applicable, supporting metrics (SNIP and JCR). The AJG 2018 list of journals (AJG18) is divided into 22 subject areas. These journals are ranked in five groups from higher to lower quality tier: 4*, 4, 3, 2, and 1.
JCR: To obtain the source data, Journal Citation Reports (JCR) uses approximately 11,000 journals indexed in the Web of Science database. The journal impact factor (JIF) formula uses publications citation counts from the previous 2 years but also offers a five-year JIF (Jacso 2009).
SNIP: Source Normalized Impact per Paper (SNIP) measures the impact of source titles by normalizing the citation potential in the field (Moed 2010; Waltman et al. 2013). SNIP’s main advantage is that it normalizes citations across the subject areas, and in contrast to JIF’s 2 years’ citation window, SNIP is calculated using 3 years of citation data.
Methodology
This section presents the overall approach of this research study, which takes account of all the steps from data collection, data processing, and statistical analysis to feature extraction and classify the ranked journals into the respective quartile. Figure 1 illustrates the overall workflow of the designed technique.

The workflow of the proposed study from data collection to analytical results
The raw data was collected in the JSON file format from Altmetric.com. We scripted the data to extract the publications of the economics journals, then we processed and cleaned the data. Prior to applying the machine learning models on the dataset, we examined the coverage of altmetric mentions and did statistical analysis (correlation and distribution of the altmetrics data) across the journal rankings using SPSS.
Then the data was divided into training and testing datasets for the machine learning models. These models were then trained using the training set and then evaluated based on the results of the testing dataset. We show the accuracy of the machine learning models by using altmetrics data in classifying the ranked journals into the respective quartile.
Smart data processing
For the extraction of the publications of the economics journals, an extensive data scripting was performed on MongoDB, a cross-platform document-oriented database program, by applying SQL queries on the raw data. From a total of 8,158,029 records in altmetrics, 55,574 records of the economic journals were extracted by cross matching the AJG list provided by the Association of Business Schools (ABS), based on journal´s International Standard Serial Number (ISSN) and/or journal’s title. ISSN number was used for extracting such publications where the journal’s title has been changed or missing. Prior to performing any data analysis, we applied substantial data cleaning and data processing on the datasets, including format corrections for the publication year and anomalies with the records, where publications were mapped with the years 2037, 2030, 2028, etc. We found 14 such instances in the data (0.03% records), and they were removed before further analysis. Thus, the final dataset file for economics journals consists of 55,560 publications.
Furthermore, the rankings of AJG18, JCR, and SNIP were divided into quartiles (Q1, Q2, Q3, or Q4) for data analysis. The Q1 indicates that the journal is in the top 25% of its subject category, while Q4 indicates that it belongs to the bottom 25% of the journals in that category. To divide the rankings into quartiles, ranges were defined for AJG18, JCR, and SNIP ranks. Note that of the total 332 journals obtained from AJG, we found only 213 which had been assigned a JCR and 292 which had been assigned a SNIP. This shows that AJG has more extensive coverage of economics journals in relation to Web of Science (WoS) and the Scopus since JCR is computed from WoS, and SNIP is computed from the Scopus database.
Furthermore, the ranges for AJG18, JCR, and SNIP, along with the quartiles, are shown in Table 1. For AJG18, Q1 consist of all level 4* and four journals, Q2 contains all level 3 journals, Q3 contains level 2 and Q1 consist of all top-level journals. The JCR and SNIP were sorted based on the individual journal values in descending order, then the top 25% journals were assigned to Q1 ranks, the next quartiles were assigned to respective outlets in Q2, Q3, and Q4. The information regarding the number of journals and the number of publications falls in each quartile against AJG18, JCR, and SNIP is also presented in Table 1.
Statistical analysis
We investigate the relationship between the altmetric mentions and the journal rankings using Spearman’s Rho correlation; Eq. 1 presents the mathematical formulation of the Spearman’s Rho correlation.
Here D indicates the difference between a pair of respective features, and N denotes the number of records.
Machine learning models
In order to classify the journal ranked outlets into the respective journal quartiles, we deployed four machine learning models (Random Forest, SVM, Naïve Bayes, and Logistic Regression) on our data feature file. The feature file comprises of the following six features: Blog mentions (the number of times a publication has been discussed in blogs), Facebook mentions (the number of times a publication has been mentioned on a Facebook wall), News mentions (the number of times a publication has been discussed in news outlets and magazines), Policy mentions and Twitter mentions (the number of times a publication is tweeted or retweeted. We used 10-fold cross-validation with 70% training data and 30% testing data for multi- and binary-class classification. Following are brief descriptions of deployed machine learning models:
Logistic Regression (LR) is a very basic and useful supervised classification algorithm that predicts a value that belongs to a discrete class (Wright 1995). The predicted value always lies between negative infinity to positive infinity by using a linear equation with independent predictors. But as the algorithm works for binary classification, therefore, the output of the linear equation is squashed into a range of [0, 1] by using a sigmoid function. Logistic regression is based on the logit or sigmoid function, as shown in Eq. 2.
where y indicates a class label, x indicates a data sample, and θ indicates a weight matrix.
Support Vector Machines (SVM) is a supervised machine learning algorithm that can be used for both classification and regression challenges (Suykens and Vandewalle 1999). SVM is a discriminative classifier that results in an optimal hyper-plane in N-dimensional space where N is the number of features. In this study, we used C- Support Vector Machine with the Radial Basis Function (RBF) kernel. Equation 3 presents the basic function of an SVM classifier.
Here W is the weight matrix, x is a data sample, b is bias value, and y is the class label.
Random Forest (RF) is a supervised learning algorithm (Segal 2004), also called a random decision forest, which is an ensemble learning method for classification, regression, and outlier detection. It works just like a meta estimator that fits a number of decision tree classifiers on various sub-samples of the dataset during training and results in a class that is the mean prediction of the individual trees or the mode of the classes to control over-fitting and to improve the predictive accuracy of the classifier.
Naive Bayes (NB) is the fastest and most robust supervised classification algorithm, which is suitable for a large chunk of data and works on an assumption of independence among predictors and is based on Bayes’ Theorem (Lewis 1998). Equation 4 presents the mathematical formulation for Bayes’ Theorem:
Here P (c|x) indicates the posterior probability of target class given observation, P(c) indicates the prior probability of the class, P (x|c) is the likelihood which is the probability of the observation given class and P(x) is the prior probability of the observation.
Extra tree classifier for feature importance
Extremely Randomized Trees Classifier, also known as ExtraTreesClassifier (EC), is a type of ensemble learning technique that implements a meta estimator that fits a number of randomized decision trees on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting. For the construction of each Decision Tree (DT), an original training sample along a random sample of k features from the feature-set is used, from which the best feature to split the data is selected using a mathematical criterion known as Gini Index. This random sample of features leads to the creation of multiple de-correlated decision trees. To perform feature selection, the Gini Importance for each feature is computed. Then each feature is ordered in descending order according to the Gini Importance, and the user selects the top k features according to his/her choice.
Results and discussion
In this section, we present the results of the statistical and machine learning models to answer the study’s five research questions.
Coverage of economics in Altmetric.com
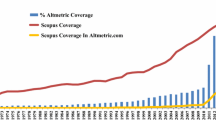
In response to the RQ 1 i.e., “What is the coverage of Economics in Altmetric.com?”, we extracted 55,560 publications records from 332 economics journals from the data indexed in Altmetric.com, i.e., 0.68% of the total publications in the entire altmetrics dataset. Figure 2 presents the publication trends of economics-related scientific literature in altmetrics. It shows how publications of recent years are more likely to be mentioned in Altmetric.com data than the publications of the previous years as altmetrics came into being in 2011. Additionally, it demonstrates a greater tendency to debate economic-related research on social media.

Publication trends of Economics related scientific literature in altmetrics
Furthermore, we show the coverage of aggregated altmetric mentions across the quartiles for AJG, JCR, and SNIP. Figure 3 shows that the publications with higher-than-average altmetric mentions are also more likely to fall in the Q1. This demonstrated that if the altmetric mentions of a particular publication are high, then it is more likely to be published in a highly ranked journal that falls in Q1.

Average total mentions across the journal ranked outlets
Trend of policy mentions for economics
In this section, we address RQ 2 i.e., “What is the extent of Economic research mentions in the policy documents?” At first, we illustrated the coverage of policy mentions across selected quartiles (see Fig. 4). We found that the publications with high average policy mentions are more likely to fall in the first quartile (Q1) of the journal ranking,s which clearly indicates that the policy mentions hold significance in predicting the quartiles for the journal rankings.

Average policy mentions across the journal outlets
In addition, a separate dataset of 204,053 records was extracted from the altmetrics database against all the subject areas mentioned in the CABS (2018); this dataset was used to study how many publications against all the ABS fields indexed in altmetrics are mentioned in policy-related documents. Table 2 shows that policy mentions are more frequent in Economics, Econometrics and Statistics (43%) compared to the other fields in the AJG list (7–39%), as well as being more frequently mentioned in policies. Consequently, our results correspond to the trend found by Tattersall and Carroll (2018) and Haunschild and Bornmann (2017) with policy mentions showing promise in measuring the broader impact of economics. Thus, the highest percentage of policy mentions for economics journals across all the other ABS fields demonstrates the significance and importance of policy mentions for the publications of economics journals.
Coverage of altmetrics factors across the economics journal publications
In order to answer RQ 3 i.e. “Which social media mentions show the broader impact of economic research publications?”, we explore the overall coverage of the altmetric mentions over the economics domain using the dataset extracted from Altmetric.com. This coverage along with the percentage of all the altmetric mentions, is shown in Table 3. The results demonstrated that Twitter mentions are most prevalent with 51.4% followed by Policy mentions with 42.8%. It shows which altmetrics factors occur in more than 5% of the mapped economics journal publications. These altmetric factors: Blogs, Facebook, News, Policy, Twitter and Wikipedia, are further presented in Table 4, which shows their mean, median, standard deviation, and coverage. These six factors are used in the further analysis. It is apparent that both Twitter and Policy mentions are critical to demonstrating the broader impact and dissemination of economics followed by Blogs, Facebook, Wikipedia, and News.
Social media mentions in relation to bibliometric journal indicators
We use the Spearman’s Rho Correlation results to answer RQ 4 “Which social media mentions relates to the journal indicators?”. Table 5 shows the correlation between the ranked outlets of the journal and all the social mentions. Interestingly, Facebook mentions have a weak negative correlation with the journal rankings for economics, which demonstrates that it rarely happens that publications from the top journals are being shared on Facebook. On the other hand, Facebook mentions have a correlation at 0.22–0.35 with Blogs, News, and Twitter mentions. This weak positive correlation indicates that the publications getting attention on Facebook may get mentions on other social media platforms as well.
Predictive power of altmetric mentions for the quality tiers of AJG, JCR and SNIP
To answer RQ 5, “Can altmetrics serve as an authentic and reliable medium to classify the quality tiers of AJG, JCR, and SNIP?”, we ran a set of experiments as follows:
Machine learning model for multiclass classification
We performed multiclass experiments to classify a publication into the ranked outlets: Q1, Q2, Q3, and Q4 using the altmetric mentions displayed in Table 4, which exist in over 5% of the dataset. The models were trained using a 10-fold cross-validation technique and were evaluated on the basis of accuracy, precision, recall, and F1-measure metrics. Note that for each ranked outlet, we ran a separate ML model. Table 6 shows the evaluation results of our employed ML models for four classes from Q1 to Q4. In the case of AJG18, it was observed that SVM and LR had performed the best with 40% accuracy. However, for JCR, SVM scored 51% accuracy. For SNIP quality metric, RF, SVM and LR achieved 59% accuracy scores.
The achieved accuracy results were not satisfying, so to improve the accuracy, we converted the multiclass classification problem into a binary-class classification problem.
Machine learning model for binary-class classification
Studies have shown that the accuracy of the system is not always notable while solving a multiclass classification problem. Conversion of the multiclass problem into a binary-class problem is one of the solutions recommended by researchers (Hassan et al. 2018). For this conversion, Q1 and Q2 were set under a single class label named class 1, i.e., a set of high-ranking journals. Whereas class 0 is used for representing the instances of Q3 and Q4, i.e., set of lower-ranking journals. After this conversion, the machine learning models were applied on the dataset and were trained with respect to the altmetric mentions displayed in Table 4, which include Blogs mentions, Facebook mentions, News mentions, Policy mentions, Twitter mentions, and Wikipedia mentions. Table 7 shows improved results computed for binary-class classification. We observed quite significant improvements in precision, recall, F-measure, and accuracy scores. In the case of AJG18, SVM and LR had performed with 66% accuracy. Similarly, for JCR and SNIP indicators SVM and shows 71% and 77% accuracy scores, respectively. Thus, the results have shown that altmetrics is an authentic and reliable medium to classify quality tiers (AJG, JCR, and SNIP).
Feature importance through ExtraTreeClassifier
Finally, to test the effectiveness of each feature in the classification of quartiles, we used ExtraTreeClassifier (EC), which computes the feature importance also known as Gini importance. The entire sample was used in training and random splits were drawn for each of the randomly selected features, after which the best split among those was chosen. For each tree, the importance is computed from the impurity of the splits, with higher value corresponding to more important features. Table 8 shows the performance of the individual features. Our results indicate that the following features are most informative and are also aligned with the classic bibliography for the classification of quartiles against AJG, JCR, and SNIP: Policy mentions—F4, Twitter mentions—F5, Total mentions—F7, Blogs mentions.
Discussion and policy implications
To predict the likelihood of a research article being classified into the respective ranked outlet based on altmetric score and to check the authenticity and reliability of altmetrics in classifying the quality tiers, this study implements four classifiers namely: Multinomial Naïve Bayes classifier, Random Forest classifier, Logistic Regression Classifier and Support Vector Machine classifier. SVM and Logistic Regression gives the best results in classifying the quantitative tier SNIP with 77% accuracy using altmetrics data. With 71% accuracy, SVM and Logistic regression also perform well on classifying the quantitative tier JCR using the altmetrics data. The AJG18 is classified with an accuracy of up to 66% which demonstrates that the ML models have performed much better in classifying the citation-based quantitative ranked outlets than the expert-based qualitative outlet. The altmetrics is based on crowdsourcing while AJG ranks depend upon expert opinion, and the results indicate that the ML models have classified the AJG ranks with less accuracy than the quantitative outlets (JCR and SNIP) which reveals that the expert opinion is not aligned with the crowdsourcing. Thus, the results shown in Table 7 demonstrate that altmetrics is an authentic and reliable medium to classify the quality tiers of AJG, JCR and SNIP.
Policy mentions and Twitter mentions are extracted as the most significant features for the classification of quartiles as both exists in over 5% of the data, as shown in Table 4. Moreover, Table 8 also demonstrates that policy mentions and Twitter mentions, along with the total mentions and blog mentions, are the most informative and significant features. The research being used in policy mentions is less likely to be tweeted. This demonstrates that policy documents are an important outlet to investigate the broader impact of many research areas. These findings might be helpful for the community, which aims to discover the relationship between the altmetric mentions and the classic bibliometric indices and to recognize the usability and significance of altmetrics features for the prediction of future citations.
This study is limited by the data coverage of altmetric. We have used JCR and SNIP for the classification of the quantitative outlets in this study since citation information is not available on Altmetric.com. Thus, the next step could be to combine the data with citation data, so this study can be extended to improve the accuracy of the proposed system by training the dataset on other machine learning classifiers with different feature sets. Besides, there could be a language issue, since, in this study, we focus on policy documents, which often are written in other languages than English. This limits the data coverage since altmetrics mainly includes English records. Finally, it is difficult to track policy citations since the reference praxis of policy documents not as standardized as academic references and, therefore, harder to track.
Concluding remarks
This study examined 332 economics journals’ publications usage on social media. In this study, a specific set of features are used to track the online attention of scholarly publications and to build classifiers. The results show that altmetrics is an authentic and reliable medium to classify quality tiers (AJG, JCR, and SNIP). The first part of this study demonstrates how policy mentions can help in showing the broader impact of economics, where a large share of the mapped publications has at least one policy mention. These results correspond to the findings by previous research on policy mentions (Haunschild and Bornmann 2017; Tattersall and Carroll 2018). This study also confirms that research publications from economics compared to other business associated social science fields have a greater tendency to be applied in policies. The publications published in higher-ranking economic journals have a greater tendency to be used in policies than publications from lower-ranking journals.
Moreover, there is a positive relationship between most of the altmetrics indicators and the journal ranking. Thus, only Facebook has a negative correlation with the journal rankings. The positive relationship could be because of the greater visibility of the higher-ranking journals among government officials and other researchers, but it could also be due to other characteristics of the publications such as research focus and methods, the number of authors or author’s affiliation. Policy mentions and Twitter mentions are presented as the most significant and informative social media mentions along with Blogs mentions, Facebook mentions, Wikipedia mentions, and News mentions.
The next step is to further explore whether some article characteristics could be related to greater social media visibility. What are the dominant topics in policy documents, and do they differ from other altmetrics sources? In addition, the relationship between altmetric indicators and other bibliometric indicators for economics should also be further explored.
References
Aung, H. H., Zheng, H., Erdt, M., Aw, A. S., Sin, S. C. J., & Theng, Y. L. (2019). Investigating familiarity and usage of traditional metrics and counts. Journal of the Association for Information Science and Technology, 70(8), 872–887.
Bailey, C., Kale, B., Walker, J., Siravuri, H. V., Alhoori, H., & Papka, M. E. (2017). Exploring features for predicting policy citations. In 2017 ACM/IEEE Joint Conference on Digital Libraries (JCDL) (pp. 1–2). IEEE.
Bornmann, L., Haunschild, R., & Marx, W. (2016). Policy documents as sources for measuring societal impact: How often is climate change research mentioned in policy-related documents? Scientometrics, 109, 1477–1495.
CABS. (2018). AJG academic journal guide—methodology. Retrieved from Chartered Association of Business Schools. Retrieved from https://charteredabs.org/academic-journal-guide-2018/.
Costas, R., Zahedi, Z., & Wouters, P. (2015). Do “altmetrics” correlate with citations? Extensive comparison of altmetric indicators with citations from a multidisciplinary perspective. Journal of the Association for Information Science and Technology, 66(10), 2003–2019.
Drongstrup, D., Malik, S., & Hassan, S.U. (2019). Altmetrics study of economics. In Paper Presented at the 17th International Conference on Scientometrics and Informetrics, Rome, Italy.
Eysenbach, G. (2011). Can tweets predict citations? Metrics of social impact based on Twitter and correlation with traditional metrics of scientific impact. Journal of Medical Internet Research, 13(4), e123. https://doi.org/10.2196/jmir.2012.
Hammarfelt, B. (2014). Using altmetrics for assessing research impact in the humanities. Scientometrics, 101(2), 1419–1430.
Hassan, S. U., Aljohani, N. R., Idrees, N., Sarwar, R., Nawaz, R., Martínez-Cámara, E., et al. (2020a). Predicting literature’s early impact with sentiment analysis in Twitter. Knowledge-Based Systems, 192, 105383. https://doi.org/10.1016/j.knosys.2019.105383.
Hassan, S. U., Aljohani, N. R., Shabbir, M., Ali, U., Iqbal, S., Sarwar, R., et al. (2020b). Tweet coupling: A social media methodology for clustering scientific publications. Scientometrics. https://doi.org/10.1007/s11192-020-03499-1.
Hassan, S. U., Bowman, T. D., Shabbir, M., Akhtar, A., Imran, M., & Aljohani, N. R. (2019). Influential tweeters in relation to highly cited articles in altmetric big data. Scientometrics, 119(1), 481–493.
Hassan, S.-U., Imran, M., Gillani, U., Aljohani, N. R., Bowman, T. D., & Didegah, F. (2017). Measuring social media activity of scientific literature: An exhaustive comparison of scopus and novel altmetrics big data. Scientometrics, 113(2), 1037–1057.
Hassan, S. U., Imran, M., Iqbal, S., Aljohani, N. R., & Nawaz, R. (2018). Deep context of citations using machine-learning models in scholarly full-text articles. Scientometrics, 117(3), 1645–1662.
Hassan, S. U., Iqbal, S., Aljohani, N. R., Alelyani, S., & Zuccala, A. (2020c). Introducing the ‘alt-index’for measuring the social visibility of scientific research. Scientometrics, 123(3), 1407–1419.
Haunschild, R., & Bornmann, L. (2017). How many scientific papers are mentioned in policy-related documents? An empirical investigation using web of science and altmetric data. Scientometrics, 110(3), 1209–1216.
Haustein, S., Peters, I., Sugimoto, C. R., Thelwall, M., & Larivière, V. (2014). Tweeting biomedicine: An analysis of tweets and citations in the biomedical literature. Journal of the Association for Information Science and Technology, 65(4), 656–669.
Holmberg, K., & Thelwall, M. (2014). Disciplinary differences in twitter scholarly communication. Scientometrics, 101(2), 1027–1042.
Jacso, P. (2009). Five-year impact factor data in the journal citation reports, online information review (pp. 603–614). Bingley: Emerald Group Publishing Limited.
Kelly, E. J. (2017). Altmetrics and archives. Journal of Contemporary Archival Studies, 4(1), 1.
Lewis, D. D. (1998). Naive (Bayes) at forty: The independence assumption in information retrieval. In European Conference on Machine Learning (pp. 4–15). Springer, Berlin, Heidelberg.
Liu, J. (2014). New source alert: Policy documents. Retrieved from https://www.Altmetric.com/blog/new-source-alert-policy-documents/Moed.
Moed, F. (2010). Measuring contextual citation impact of scientific journals. Journal of Informetrics, 4(3), 265–277.
Nederhof, A. J. (2006). Bibliometric monitoring of research performance in the social sciences and the humanities: A review. Scientometrics, 66(1), 81–100.
Nuredini, K. & Peters, I. (2015). Economic and business studies journals and readership information from Mendeley. Re: Inventing Information Science in the Networked Society. In Proceedings of the 14th International Symposium on Information Science, Zadar/Croatia, (ISI 2015) (pp. 380–392).
Nuredini, K. & Peters, I. (2016). Enriching the knowledge of altmetrics studies by exploring social media metrics for economic and business studies journals. In Proceedings of the 21st International Conference on Science and Technology Indicators (STI Conference 2016).
Said, A., Bowman, T. D., Abbasi, R. A., Aljohani, N. R., Hassan, S. U., & Nawaz, R. (2019). Mining network-level properties of Twitter altmetrics data. Scientometrics, 120(1), 217–235.
Segal, M. R. (2004). Machine learning benchmarks and random forest regression. Netherlands: Kluwer Academic Publishers.
Shuai, X., Pepe, A., & Bollen, J. (2012). How the scientific community reacts to newly submitted preprints: Article downloads, Twitter mentions, and citations. PLoS ONE, 7(11), e47523. https://doi.org/10.1371/journal.pone.0047523.
Suykens, J. A., & Vandewalle, J. (1999). Least squares support vector machine classifiers. Neural Processing Letters, 9(3), 293–300.
Tattersall, A., & Carroll, C. (2018). What can altmetric. com tell us about policy citations of research? An analysis of altmetric. com data for research articles from the University of sheffield. Frontiers in Research Metrics and Analytics. https://doi.org/10.3389/frma.2017.00009.
Thelwall, M., Haustein, S., Larivière, V., & Sugimoto, C. R. (2013). Do altmetrics work? Twitter and ten other social web services. PLoS ONE, 8(5), e64841.
Waltman, L., van Eck, N. J., van Leeuwen, T. N., & Visser, M. S. (2013). Some modifications to the snip journal impact indicator. Journal of Informetrics, 7(2), 272–285.
Wright, R. E. (1995). Logistic regression. Washington: American Psychological Association.
Zahedi, Z., Fenner, M., & Costas, R. (2014). How consistent are altmetrics providers? Study of 1000 PLOS ONE publications using the PLOS ALM, Mendeley and altmetric. com APIs. In Altmetrics 14. Workshop at the Web Science Conference, Bloomington, USA.
Acknowledgements
This article is an extended version of research in progress presented at the 17th International Conference on Scientometrics and Informetrics, Rome (Italy), 2–5 September 2019 (Drongstrup et al. 2019). The authors (Saeed-Ul Hassan and Salem Alelyani) are grateful for the financial support received from King Khalid University for this research under Grant No. 239, 2019.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Drongstrup, D., Malik, S., Aljohani, N.R. et al. Can social media usage of scientific literature predict journal indices of AJG, SNIP and JCR? An altmetric study of economics. Scientometrics 125, 1541–1558 (2020). https://doi.org/10.1007/s11192-020-03613-3
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-020-03613-3