
Abstract
Assessing and evaluating the academic impact and its results produced by researchers is necessary to promote the academic progress. A diverse and varied set of parameters have been proposed by the scientific community to find the most influential researchers, including citation count, the total number of publications, hybrid approaches, h-index, extensions and variants of h-index. Current state-of-the-art depicts that there is no standard benchmark available to determine the optimum parameter to find the most influential author of a specific domain. Furthermore, it has been observed that such indices are assessed on a small dataset and ingenious scenarios. The small dataset can never truly help to analyze the nature of these indices and it is very difficult to determine the significance and influence of every index over the others. Hence, it’s necessary to assess them on a large dataset. The following research would help in scrutinizing the h-index along with its citation intensity based variants to rank the authors by using a large dataset of Mathematics domain that consist of 57,533 authors and 62,033 total numbers of publications. These indices make use of the total published papers, citation count, along with the h-index and the five of its citation intensity based variants. The esteemed awards that are won nationally and internationally in the field of mathematics serve as a benchmark. This study would deal and help to recognize the most influential authors by concluding the results gained after evaluation of these indices. For this purpose, firstly, we calculated the correlation among different indices. The strong correlation was found between the h-index and its five citation intensity based variants. The occurrence of the award winners is examined according to the rank lists. H-index brought around 30.88% awardees in the top 10% of the ranked list. In a bird’s eye view, no index could succeed in elevating a 50% of award winners in the top-ranking. Our benchmark dataset is composed of 68 awardees. In the ranking lists, the maximum number of awardees belongs to American Mathematics Society (AMS) which are 29.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Measuring the scientific production of an individual from the present day scientific society is a task that is not only critical but also extremely tedious (Jiang et al. 2013). According to Dorta-Gonzalez and Dorta-González (2013) authors, the ranking is very helpful when picking up the great scientists from any field and also in identifying the deserving ones for getting tenure, some funding or even a project. It can also be very helpful when rating academic output etc. Raheel et al. (2018) stated that if authors were ranked in a fair way which encapsulated their educational ability, then it would have been very easy for conference organizers to pick someone for a keynote address. It could also allow students to make a calculated and informed decision regarding which professor to choose as a supervisor for their research.
In today’s time, the process of assessing any research work greatly depends on the standards and merits created by the concerned researchers of the scientific community (Wilsdon et al. 2015), Dorta-Gonzalez and Dorta-González (2013) stated that a comprehensive ranking system will also answer questions like which author is the most deserving of scholarship and promotion. It would also help in identifying which researcher has the most innovative or impactful work. To acknowledge the contributions of authors in the scientific community, different metrics or indices have been proposed (Bornmann et al. 2008). According to James (2014) the concerned or related content puts forward a variety of parameters that may be used as indicators to evaluate the significance of any researcher. The pertinent literature benevolences number of parameters as a gauge to evaluate the worth of a scientist. Until now, many techniques have been designed on how to rank the authors according to their educational abilities. According to Harzing and Van der Wal (2008) each technique follows its own criteria on which it judges the authors. No matter what the technique, its method can both be qualitative and quantitative.
In the past, some approaches used to consider certain standards including the published papers or the articles that cite those published papers (Cameron et al. 2007; Bogers and Van den Bosch 2008). Later, the attention transitioned to introducing the indices that would calculate the influence of the researcher’s research work or assist to provide a ranking system for the authors (Moreira and Wichert 2013). These indicators were designed to calculate and quantify not just the production of researchers but also the impact of the publications, published by them (Balog et al. 2006).
One of the indicators that gained a lot of success was proposed by Hirsch (2005). Hirsch’s index (h-index) which aims to gauge the sustainability and the standard of the research work under consideration. The reason behind why the h-index is internationally made use of because of its handiness that helps in computing (Alonso et al. 2009; Bui et al. 2014). Hirsh revolutionized the h index and subsidized in making h index the most frequently used standard to gauge the competence of the researcher in the scientific community. His idea and work received a lot of attention and was appreciated by the masses. Hirsch (2005) stated that the h-index takes into consideration not only the current productivity but also the future impact of a piece of research work. It acquires the basis of the most commonly quoted research papers and the total citations received by a paper. Originally that was proposed to serve as a relative marker to judge the quality of any research paper published by theoretical physicists. Hirsch expresses that the h-index is extremely predictive when it comes to determining whether an author has received Nobel Prize or a National Academy Membership. After calculating the h-index for 10 renowned and well-cited biomedical scientists, he concluded that indeed the most-cited authors have a higher h-index. According to Dienes (2015), h-index has certain restrictions. Some of its specifications include that h-index doesn’t take into account the citations of top publications. Their h-index will always remain constant even if the citation is different for two separate authors. This is because h-index never copes with the high-level values of publications and citations, so it only shows one measure or citation in such cases. This confirms the lacking and inability of h-index since it not only depicts but also treats citation and publication as two different dimensions. It represents that in order to address two opposite dimensional values there always is an element of conversion variable which balances out the effect of those two opposite dimensional values (Dienes 2015). The author asserts that the delineation of h-index doesn’t explain the conversion value. It is also expressed that lacks the ability to accommodate the community factor, which is considered as one of the most important factors when it comes to the identification of potential experts or the best-ranked authors from any area or field (Ayaz and Afzal 2016; Dienes 2015). In order to eradicate the specifications put forward by h-index a list of variants and different extensions have to be seen, including: g-index (Egghe 2006), a-index (Jin 2006), r-index (Jin et al. 2007), q2-index (Cabrerizo et al. 2010), and hg-index (Alonso et al. 2010) etc.
According to Wilsdon et al. (2015) publications impact decides the ranking of the scholars. There are different ways that can be adopted for ranking the researchers based on the impact of their works. Each way has its own standard for ranking. According to Sidiropoulos et al. (2007), there are three most used techniques for it. The first technique is to ask an expert to rank the authors. Second is by analyzing the citation count. A combination of both the methods can also be used, but it would appear more like the second method. First technique works by gathering the views of various experts in a specific field. It is more like an impromptu method which does not work on preplanning. Also, by adopting this technique the experts have the leverage to rank the researchers however they like (Sidiropoulos et al. 2007). This method is quite intriguing considering it involves the opinions of the authors that they form by examining all the works and that this type of ranking is not based on the citation count. But the fact that this method is manual makes it prone to objectivity.
Sidiropoulos et al. (2007) stated that another method that can be used for examining the research works is by forming a tool that would compute the scores gained for the objects being examined, considering the graphic representation defined by the total number of citations. Harzing (2010) stated that marking any publication according to its quality and other metrics is an arduous task to perform. The common methods that are mostly adopted for this purpose are based on the basic arithmetic functions. For example, the total amount of the publications authored or the number of citations etc. Sidiropoulos did a comprehensive study on them in 2005. Sidiropoulos and Manolopoulos (2006) proposed the idea of combining both the approaches. The rankings acquired from them can be obtained by taking out the average of both techniques. No one method between them can be deemed as the best but the technique involving the citation count is mostly preferred. This is because it is automated and mechanical and is free of the human errors and because it makes use of the digital libraries by observing the given information related to citation count. The third approach is to assess the researchers by using national and international prestigious awards as the standard benchmark.
Raheel et al. (2018) stated that there is no specific standard that exists when it comes to ranking the authors. Most of the rankings are based on a certain index. Traditionally, when a new technique is put forth, it is developed on an imaginary scenario or on the basis of various datasets. Moreover, since these techniques are based and assessed on several types of datasets, which makes it arduous to catch and realize the cruciality of each technique separately. Hence there is an extreme obligation to measure and assess the h-index along with its variants on an extensive and large dataset. There is no situational benchmark present to identify the ultimate standard for ranking the authors. Most such rankings are based on single indices which raised a great concern. The concern regarding the current methods, move the scientific communities to find new ways and it is natural that the research on evaluation indices resulting in and a rapid increase of their pros, cons, and limitations (Raheel et al. 2018).
In a recent study, Ghani et al. (2019) evaluated H-Index and its extensions on the same dataset of Mathematics used in this research. The evaluated indices were M-quotient, hw-index, hm-Index, hi-index, hc-index, m-quotient, ht-index, fraction-count-on-citation and fraction-count-on-paper. The objective of the study was to identify the best performing index from these indices on the comprehensive dataset of mathematics (Ghani et al. 2019). However, the current study evaluates the citation intensity based variants such as: H-Index, g-index, q2-index, Hg-index, R-index, A-index. Furthermore, the current study evaluates the ranking obtained by the citation intensity based parameters and its contribution to identify prestigious award winners in mathematics for following years.
According to Sangwal (2012) in order to know the technique for ranking the authors that provides the best result, a detailed evaluation of these techniques should be done based on the datasets from one domain. This calls for the high need to evaluate the roles performed by these indices including “h-index, g-index, a-index, r-index, q2-index, and hg-index” (Raheel et al. 2018). This paper would interrogate the roles that these indices perform. The roles performed by these indices are based on a large dataset which has a belonging to the mathematics’ domain. The primary objective of this research is to extricate the indices that provide the best performance. For the sake of evaluation, the awards provided by the well-renowned societies in the field of mathematics are observed as a parameter or as a benchmark. We have used the most prestigious awards societies in mathematics as a benchmark. These societies include AMS (American Mathematical Society), IMU (International Mathematical Union), LMS (London Mathematical Society), Norwegian Academy of Science and Letters. It is noteworthy that in this research we are not forecasting the awards however we are evaluating the performance of the h-index and its citation intensity based variants.
The correlations are ciphered between the h-index and all its citation intensity based variants. Moreover, we observe: Are there any variants of h-index that have a weak correlation with the h-index? Then we determine that what level of correlation exists between the h-index and its variants. By taking the help of a proposed methodology, we will answer the following research questions
-
1.
Find the correlation among h-index and its citation intensity based indices and also determine that any citation intensity based variant of h-index exist to extend a non-repetitive hand to h-index?
-
2.
Are all the esteemed awards won, gained from h-index and its citation intensity based variants?
-
3.
Which h-index or h-index citation intensity based variant helps the most in elevating the national and international award winners to be ranked among the best 100, 500, 1000 authors?
-
4.
Does the performance of the h-indices differ between the different awarding societies?
Literature review
The parameters of ranking the authors have been originally used to help the students looking for the right supervisor to supervise their Ph.D.’s research work (James 2014). According to Liang and Jiang (2016) ranking of researchers is helpful in making judgments about certain decisions such as to elevate an individual, to accepts the research opportunities, to nominate the different awards won in the scientific community, to allocate the service period to skilled persons, to distinguish peer-reviewers, and to allocate the contracts to the professionals. According to Jiang et al. (2013) ranking the researchers has appeared as a crucial issue in the whole scientific society. There are different standards that form the basis for an individual to be ranked. For example, publication count, citation count, co-author, hybrid approaches, h-index, etc. have been used to rank researchers (Liang and Jiang 2016; Ayaz and Afzal 2016; Raheel et al. 2018). The common methods that are mostly adopted for this purpose are based on the basic arithmetic functions. For example, the total amount of the publications authored or the number of citations etc. Sidiropoulos did a comprehensive study on them in 2005 (Sidiropoulos and Manolopoulos 2005).
These parameters cannot be globally applied to individuals. Also, the challenge arises when it comes to developing a comparison between two types of researchers. One who annually published dozens of research papers or the one who obtained a rather selective approach and focus on to generate a few big shots (Aoun et al. 2013). The indices that are widely recognized include the total published research papers, or how many times they’ve been cited matters too (Hirsch 2005). According to Katsaros et al. (2009), the bibliometric indicators are used to statically and mathematically analyze the quality of publications, influence, and productivity of a researcher, connection between universities and organizations. Bogers and Van den Bosch (2008) stated that these indices have been subjected to strong criticism. Each of them carries certain specifications and shows some lacking. However, Panaretos and Malesios (2009) stated that the number of publications is measured by production. It does not depict the significance or the scientific influence of the publication. It only depicts the quantity of research work. Therefore, according to Cameron et al. (2007) researcher with the greater number of publications can be considered as a high-performance researcher. But, only the publication count is not sufficient for the researcher because many researchers publish their paper in low-quality journals and conferences.
On the contrary, a number of citations may not depict a perpetual and an efficacious occupation and may be effortlessly oscillated by two or three exceedingly applauded review papers or publications (Mingers 2009). However, sometimes authors cite their own paper and sometimes the other authors cite the research paper in order to give a criticism. Jin et al. (2007) stated that the total number of citation count has been a controversial subject. In addition, it has been subjected to an impact of self-citation. Moreover, Depending on the type of field citation counts and citation rates are different for different fields. Smolinsky and Lercher (2012) examined citation counts of various scholars who hold a great value in the field of mathematics and its subcategories or subfield. They reached the conclusion that citation counts differ because of the way publications are internally cited or the way they are published. There are subcategories of mathematics that can attain better citation count because of their bonding with the fields that are highly cited. Behrens and Luksch (2011) stated that in the field of mathematics citation count does not pick out all the subfields but only a few of them and is most of the times ignorant of the others.
Researchers proposed a new parameter to overcome the weaknesses of publication count and citation count called h-Index. Hirsch (2005) proposed h-index. H-index simplicity and handiness attracted a great interest of the scientific world. This index has the ability to portray the influence and productivity of a researcher’s publication just through one figure or value. It takes into account not just the total publications but also the total citations that access the importance of a researcher. Along with the immense advantages, h-index tends to have some disadvantages too. Such as, in some cases they blend the number of publications and citation rate. This can sometimes experience criticism. If a research work gets nominated within the core publications of the h-index and experiences an upsurge in its citations then that would also affect the value of h-index (Alonso et al. 2009). The h-index cannot distinguish between the researchers who share the similar h-index (Panaretos and Malesios 2009). The issue arises because of the assumption made by Hirsch that this similarity can be differentiated by self-citing the publication. Gathering the required data for determining the h-index is not an easy task. At times, a complete list of the total publications of an author is essential to create a differentiation between the scientists who share a common name. Another thing about h-index is that it doesn’t go in the favor of new researchers because not only their publication rate but also the citation rate is comparatively less too.
According to Teixeira and Mota (2012) the h-index provides the scientists a breather to depend on their previously earned laurels and awards through an increase in the number of citations even when they aren’t publishing any new works. It is used to draw a comparison between some of the best scientists only. It doesn’t work to compare average scientists. To get rid of the various short-comings of h-index many formulas have been proposed to completely access a person’s scientific productivity (Bornmann et al. 2011).
It is stated by Sidiropoulos et al. (2007) that, the conventional system followed by h-index has numerous inefficiencies. This is the reason why Sidiropoulos et al. (2007) proposed two further extensions of h-index. Hence the researchers have introduced the two generalizations of h-index. They purposed three versions of h-index containing the standardized version of h-index, commonly regarded as the Standardized h-index, Trend h-index, and Contemporary h-index. These versions have the ability to unravel the concealed facts in different citation networks. They also help a great deal when it comes to ranking the publications in a journal or even in a conference. Hence, for evaluating the success of each conference/journal separately, indices can be used. It is concluded that these extensions such as Trend and Contemporary h-index give better performance over the h-index that is original (Sidiropoulos et al. 2007).
Bornmann et al. (2011) put forth a discussion regarding h-index and it’s all thirty-seven variants. They calculated the connection found between them. All those variants have already been talked over. However, h-index has also some limitations as it relies on long-term observation.
In another study, it was stated by Wu (2010) that an average value of h-index quadruples the total of w-index. We introduced a new index, i.e. w-index. It was proposed as a meaningful way to measure or determine the influence of an authors’ research, mainly the impressive ones. It is concluded that the papers assessed by using w-index had prominent differences when compared with h-index since w-index pays more attention to the well-cited works. W-index can be used to gauge the researchers, research cells, organizations, and scientists etc. (Wu 2010).
Aoun et al. (2013) analyzed and assessed the indices that help to calculate the scientific productivity of authors. According to the author, one of the indices that are known for its rigidity against the effects of self-citation is h-index. Additionally, an increase in h-index is observed which shows that it has been influenced by the time period of an individual’s educational life. This is the reason why h-index is known for putting junior researchers at a risk and hence it is an immense hindrance when judging the authors at different levels in their profession.
Mazloumian et al. (2013) proposed an index based on a specific network. It assesses and measures the scientific productivity that is used to conduct a detailed worldwide dissection of erudite knowledge. It also helps in pervasion depending on the geography.
Fukuzawa (2014) analyzes the distributions of research publications and citations that have been patented. He also estimated the relationship that existed between them. His work was made on the basis of a sample of above 4000 published works. The correspondents of this sample were considered among the top authors in Japan. They came across that the connection between them is U-shaped.
H-index and it’s some other variants like g-index, and complete-h etc. was measured by Ayaz and Afzal (2016), which was based on a set of data gathered by using the mathematical techniques. In order to draw a comparison between gained from all these indices, award winners who have won nationally and internationally are standardized as a merit in the field of mathematics. This work states that the index, complete-h completes the h-index. It not only completes it, but it also adds an effect of community or community factor to it. The performance of Complete-h is better than g-index and h-index when adding the awardees in the top-ranking lists (Ayaz and Afzal 2016).
It has been observed in the literature review that researchers used the same dataset with different parameters. For instance, three papers by Schreiber (2008a, b, 2010) and two papers by Liu and Rousseau (2007) and Liu et al. (2009) have used the same dataset. While in the literature review, the research work has been observed where the dataset is different but the parameters are same e.g. the work by Bornmann et al. (2008, 2009). Above mentioned paragraphs state various indices that are used to calculate the productivity of publications or to determine the most influential researchers. All the above-mentioned indices are applied on data sets that are not too comprehensive. Also, no standardized merit or benchmark exists when it comes to assessing and applying these indices (Raheel et al. 2018).
Methodology
Scientific Community has been proposing the variety of approaches to rank researchers’ in different domains (James 2014). After the critical analysis of these parameters, it has been identified that researchers are mostly ranked using publication based parameters, citations or h-index (Jiang et al. 2013). In order to make the evaluation perform, the esteemed awards that are won nationally and internationally in the field of mathematics serve as a benchmark. We have evaluated whether the awardees from traditional ranking indices also rank on the top by using h-index and its citation intensity based variants.
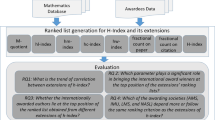
The methodology is discussed in this section and the diagram of suggested elucidation methodology is given in Fig. 1.

Block diagram of proposed methodology
Domain selection
In order to make use of the technique, data from a specific academic department is required. So selecting the field by making sure that it’s diverse we chose mathematics to evaluate the h-index and its citation intensity based variants. The filed that has been selected for the sake of this study is mathematics. There are various reasons behind the selection of this specific domain. The foremost reason that serves is the fact that mathematics is a field that is well linked to all the other branches of science i.e. physics, computer science or chemistry. Hence, it proves that the domain that has been chosen is diversified and ranking the authors according to this would be an immense execution. According to Moreira et al. (2015) it is important to assess the ranking parameters in other areas too because by doing so we would be assisting in promoting the academic growth and development. It would also assist in examining the h-index and its variants which would further help in ranking the researchers.
In order to gather the dataset, Ayaz and Afzal (2016) have devised the crawler. Crawler spawned the Google Scholar for the assortment of all the sets of data that have already been published in the field of mathematics. Some main key words were incorporated into the crawler by the MSC i.e. Mathematics Subject Classification. According to Harzing (2013), Google Scholar serves as a highly effective medium when it comes to educational purposes necessarily because of citation and bibliometric statistics. Neuhaus et al. (2006) stressed that one of the assets that Google Scholar holds is the scientific coverage that it provides. It has been found by Harzing (2010) that in comparison to Scopus and ISI, Google Scholar has the best ability to offer the citation count. One another perk that Google Scholar offers is the fact that it has the access to everyone which makes it way easier and reliable to use. According to De Winter et al. (2014), Google scholar is known for its precision and accuracy and it was found out when it got to be compared with the other eleven data sources that were taken into account. According to Harzing (2013) Google Scholar lets an open outlet for the accession of data, while other resources aren’t readily available. One other advantage of using Google Scholar is that it not only cites the data but also indexes it. According to De Winter et al. (2014), many research works are present that agrees on an immense highlight provided by Google Scholar and they honor Google Scholar more than any other resource The inclusiveness and diversity that Google Scholar offers for citation and bibliometric analysis make it unique and reliable (Harzing and Alakangas 2016). Hence, we have chosen Google Scholar as the source of our data.
Taxonomy building
Mathematics domain is versatile and associated with all other fields of studies. To retrieve the dataset, a crawler was designed that makes Google Scholar crawl to retrieve the dataset for publication to be applied in mathematics. MSC (Mathematics Subject Classification) was used as the basis and some keywords were introduced to be entered in the crawler (Ayaz and Afzal 2016). Those key terms were to act as an input for the crawler. Editorial departments from two well-renowned foundations i.e. the database of bibliographic records invented MSC. The present version of MSC i.e. MSC2010 has 64 sections that have been divided into 2 digits and further furnished into more than 5000 three-five-digit divisions. Many of these classifications use a certain list of words that provide unrelated and unnecessary search results when searched in Google Scholar.
The MSC categories are given to Google scholar to obtain papers related to them. The results that appear upon searching for a topic are usually in connection with the term that was searched. Or it can either be dependent on the received number of citations. Hence, for the sake of this study papers that were ranked on the top or the results that appeared from searching were included. The top 600 records that appeared in the results were selected. This is because the top 600 results are usually the most relevant and the answers start to become more extraneous after it crosses the top 600. After obtaining the results, the Meta data of the research paper was identified by the module, which includes the authors name, the title of paper, and year of publication, total citations and URL of the paper. After that all the data is stored in a database before performing the further processing. MSC2010 is the name of the version that has been recently produced. Total number of top best categories that forms this set of classification is 64, which is further divided into two sets i.e. 45 pertaining to pure mathematics and 19 related to applied mathematics. This gave rise to a taxonomy that has 45 top levels and 239 sub levels. It is available at http://cdsc-cust.org/research/scientometrics/.
Some fundamental steps were observed to authenticate the data including: (1) Elimination of search results that had irrelevant titles. A total of 69,527 results were gathered and 169 of them had the irrelevant material which was no way related to publications. After the elimination of all those invalid characters, 69,367 results that had appeared were left. So, all those remaining publications were examined and for this sake their places of publications were filtered and observed. By checking their places of publication, we came to know that some of them belonged to the mathematics journals and others that did not. A total of 9368 publications never even made it to mathematics journals. All those publications that had no connection with mathematics were rejected. So, 69,197 publications were left. Another subject that often comes up is the ambiguity that arises when one name is shared by various authors at the same time or when various varieties of the name of one author happen to be existing in the database. To eliminate these confusions in the dataset, all names are confirmed and filtered.
The total amount of authors whose works existed in the database was 57,533, out of which 29,263 had the similar name issues. This created a huge ambiguity. Among those 29,263 almost 7744 shared the names that were not so common. It was found out that 100 s of authors shared the same name sometimes and sometimes it was shared by only 2. Now in this situation two different types of conditions can be observed. One is various authors sharing the full name with each other i.e. first and last name both, and second can be only last or only first names are shared. After a detailed examination it was found out that no two authors shared the same full names. But a total of 4945 authors out of 7744 had different first names but similar surnames. A final glimpse of the statistics is shared in Table 1. Data that was gathered was precise as a lot of citations had to be acquired but it cannot be said that all the works of every author was collected. All of the different indices were compared and applied on the collected data therefore results can be computed for all indices.
Dataset description
In order to gather the data about the researchers, published and cited works against the classification system of MSC, Google Scholar is used for that matter. This dataset has been retrieved in December 2014 by Ayaz and Afzal (2016). There are many alternatives that are available to obtain the right data such as the web of science and Zentralblatt MATH but these resources are based on subscription (Bosman et al. 2006). They aren’t explicitly available for everyone. Also, the resources like Web of Science encounter certain specifications. For instance, it offers a reserved highlight of the domains in mathematics when drawn a comparison with Google Scholar.
The crawler provides the Google Scholar with the list of classification systems. It gathers the title names of the published research works, of the authors or the researchers, location or place where it was published. It also keeps in track the total number of citation count, the date, and time of the publication and the URL of the published research work. It has been discussed by Beel and Gipp (2009) the way Google Scholar digs out the stored data when searched for any query. They deciphered that the best relevant results shown by Google Scholar are the ones that appear on the top and are frequently occurred in the title of the paper. To ensure the correctness of data, all 64 categories were compiled and verified by the domain experts. The dataset of mathematics consists of 57,533 and found 57,515 authors after removal of ambiguities by former researchers but there remains the problem of duplication and ambiguous author names which have been corrected manually.
Pre-processing
On this dataset of mathematics, pre-processing has been done to filter this dataset in two dimensions. One dimension is to check that is the data really from the domain of mathematics or not? The other dimension includes removal and eradication of the duplications and correction of ambiguous last and initial names of authors. In this section, the methodology is summarized in a way that the ranking list from h-indices is evaluated in order to identify and find a presence in the awardees on the top who are given prestigious awards in exchange of their remarkable contribution in the scientific community.
Benchmark Dataset
This specific research domain has no merited standard based on a dataset that could be used to evaluate and assessed (Ayaz and Afzal 2016). A comprehensive and extensive benchmark dataset is required to assess the h-indices. Hence, in this study, the highly esteemed awards are used as a standard merit or benchmark. Adler et al. (2009) stated that many people achieve awards for their relentless efforts in different fields. Likewise, people and individuals are given many prestigious awards and honors in the field of mathematics too.
This study encounters the data of different awardees who won the 25 most esteemed laurels. These laurels are usually bestowed by different mathematical societies working in different parts of the world. These societies include AMS (American Mathematical Society), IMU (International Mathematical Union), LMS (London Mathematical Society), Norwegian Academy of Science and Letters. This benchmark dataset has been retrieved in October 2018. The benchmark dataset consist of the data of awardees from 2015 to 2018. All the awards are included by the four major award societies of mathematics. These all societies are supervised by international scientific unions for mathematics representing mathematics at world stage, members of the international council for science (ICUS)Footnote 1 (Adler et al. 2009). According to Yan et al. (2011) the researchers ranking is often limited to homogeneous dataset which is unable to account for the different factors that organize the scholarly communication and reward system. In this study we are ranking the researchers and evaluating the ranking parameters by using heterogeneous dataset in a nuanced and comprehensive way. We retrieved this benchmark dataset in November 2018. The actual numbers of considered awardees are 104. Out of which, the unique awardees have counted to be 102 and we have found 68 awardees in our dataset.
Calculation of indices
After we were done gathering the data, 6 indices were encountered in the data. “Appendix” depicts the evaluation of those total 6 indices. When we were done calculating we ranked each author relative to each index. In the end, we are able to get 6 different standards in which we ranked the authors.
Definitions of the h index variants
H-index
Jorge Hirsch, a researcher famous for inventing h-index in the year 2005, introduced the h-index to measure the productivity of the researchers and their research works. It involves different scientific measures that can be computed by taking the total number of an author’s publications as the number of citations. Many scientists are working on in bringing out as many uses of h-index as possible for example in physics Michael has endeavored to discover new areas of study and components. The researchers who were chosen for higher research had higher h-index than the ones who didn’t get selected (Bornmann and Daniel 2005). One of the most radical steps of h-index was it becoming the most modern approach in the area of indices. It can be used to dig out the odds between new researches and old ones. Not only has this but it also assisted the new scholars in helping them finding the works that have already been done in a certain field of study. It has the ability to calculate the value of a given paper and also measure its impact factor. Another one of the strongest aspects of h-index is the fact that it helps in positioning the researchers according to their contributions. One of its other advantages is that it is broad and offers fewer limitations when compared with other indices. One limitation that h-index is known for is that it doesn’t credit any paper that has low number of citations.
G-index
According to Egghe (2006), g-index is an index that was projected as a continuation of h-index. G-index is similar to h-index in a sense that it is also used for bibliometric purposes. Egghe (2006) defines the g index “as the highest number g of papers that together received g2 or more citations. From this definition, it is already clear that g > h.” In contrast to the h-index, the g-index gives more weight to highly cited papers. One of the perks of g-index over h-index is that it actually credits the paper with high citation. It even assists in crediting the papers that are ranked low in terms of citation. It proves that g-index provides variety and contributes a lot when it comes to ranking the researchers.
A-index
Burrell (2007) stated that the h-index hunts to discover the most useful core of a researcher’s work in accordance with the received number of total citations. Rousseau (2006) proposed a term for that core known as Hirsch core. According to Jin et al. (2007) Hirsch core is a collection that consists of the highly rated and best publications. The a-index only consists of the works that are a part of Hirsch core. Therefore, it is defined as a maximum number of cited papers. Jin (2006) proposed that since it contains the maximum number of citations it should be considered as variant of h-index. Later Rousseau (2006) termed this index as a-index and defined it as:
R-index
Jin et al. (2007) concluded that a-index punishes the scientists with higher h-index for h gets divided by a-index. Hence, researchers have argued that by taking the square root of the total sum of citations instead of dividing by h. Jin et al. (2007) referred to this new index as r-index. R-index calculates the number of citations just like a-index therefore it can be very prone to even a few papers that have been highly cited. The r-index can be defined as:
Q 2-index
Q2-index is formed by taking the geometric mean of h-index and m-index. Here h-index serves as the quantitative measure whereas m-index as the qualitative. The quantitative measure i.e. h-index is applied because of its vigorous nature and also because it gives a description about the total number of papers and the qualitative measure i.e. m-index is applied because it gives an idea into the impact that papers produce and also because it shrewdly deals with the distribution pertaining to the number of citations. This index observes both the quantitative and qualitative aspects of the researcher’s publications hence it attains a more universal outlook when compared with dealing both the aspects distinctly. Geometric mean has been applied in this index because of the fact that it makes it easier to calculate, it is easy and is not easily dominated by the other values that are high. Hence, it provides the information in a more stable and composed form. The q2-index of a researcher is computed as the geometric mean of his h-index and m-index, Cabrerizo et al. (2010) defined it as:
Hg-index
Rousseau (2006) stated that h-index and g-index compute various aspects of the researcher’s publication. However, the problem with that is h-index never covers the whole floor and even though g-index is considered to be more intense than h-index even it lacks in it. Alonso et al. (2010) presented that both calculate different characteristics of the research publications and should be considered to compute the scientific results. Hence, researchers provided another index known as hg-index which combines the best qualities of both the indices and also mitigates the weaknesses of each of the indices. The hg-index of an author is calculated by taking the geometric mean h and g indices, that is:
Evaluation
After getting done with calculating the lists in which we ranked the authors, the analysis of four different research questions has been discussed.
Calculated indices correlation
The first question is to determine whether there is actually a correlation exist between the h-indices? The motive to find the correlation that indices have is to have a look at the similarities that they share. The other question that arises is to find such h-indices that extend a non-repetitive role to the index. According to Corder and Foreman (2009), Spearman’s rank correlation coefficient can be used to determine the correlation between these indices.
Determine the trend of awardees
After evaluating the top-ranked authors, we will determine that whether in the top 10% of the list the global award winners of the mathematics domain are present or not? We will also extrapolate that which index actually helps the most in elevating the award winners in the top list of authors. To answer these two questions we determine how many authors are present in the top 10% of the list then also find out the occurrence of awardees in 1–10%, 11–20% up to 90–100%. Also, the manifestation of award winners has analyzed among the best 100, 500, and 1000 authors. In order to dig out the total statistics of award winners from the list, first of all, we evaluate the total number of indices. Then, we rank all the researchers individually. Then, we highlight the position of awardees in the list. After which we calculated the awardees in the top 10% and similarly for the whole ranked list we will find out the occurrence of awardees.
Finally, we assess the percentage of awardees in the top 10% of the whole list of awardees which occurred in the dataset of mathematics. In the same manner, we will determine the percentage of the awardees occurrence for 1–10%, 11–20% up to 90–100%. For instance, we have a list of 100 authors in a specific dataset and 20 from that list are the awardees. Now, there we will organize the names of the authors in a descending way. So, we extrapolate 10% of the data from our data set. This states that 10% of the data consist of the record of 10 authors that were on top. Let’s say among those top 10% of the awardees we have 4 occurrences. Therefore, in this scenario 20% awardees would be considered in the top 10% of the researchers, which would obviously be based on their index values.
Performance of mathematical awards societies between different h-index indices
Here, in this area, the main attention would be on the fifth and the last question. The question is to evaluate that how the performance of the h-indices differs between the different awarding societies that are responsible for bestowing the awards such as IMU, AMS, LMS, and NASL. In order to get this done, first, we determine the frequently appeared awardees in the top 10% of the ranking list of the best authors.
Previously, we had determined the percentage of awardees appearing in the 10% of the ranking list. Now, we have calculated that from a total number of awardees from one society, how many appear in the top 10%. For instance, suppose that we have a total of 350 names of the awardees from IMU and they were found in the mathematics dataset. Now, let’s say that from those 350 names, 151 names were the 10% names of the ranked list from the g-index value. So, in this scenario, in the top 10% of the generated list, 42% of award holders are from IMU on the basis of their g-index value.
Results
In this section, our four research questions are discussed in detail.
Correlation among the indices ranked lists
This assessment has been done in order to discover the similarity among the ranked lists. In other words, we have to calculate the correlation among all the indices, which is the answer to our first research question. To achieve this task, it has been computed that how each ranked list is correlated with itself as well as the other ranked lists. Three possibilities have been seen regarding the correlation values.
-
The positive correlation value indicates that the considering ranked lists are directly related to each other (increase in one ranked list’s value also causes an increase in the other and vice versa).
-
The negative correlation value indicates that considering ranked lists are inversely related (increase in one ranked list’s value causes a decrease in the other and vice versa).
-
There is no correlation exist when the value is zero between the considering ranked lists (the values of both ranked lists are independent of each other).
The magnitude depicts the intensity of correlated values from one and other. The meticulous set of correlation values of ranked lists generated from the 6 indices is represented in Table 2. The correlation values among these indices have been represented graphically in Fig. 2. Table 2 represented the complete range of values. The strong values have been highlighted using the red color. The correlation of the index with itself is 1. The weak correlation has been represented by the blue color line. The negative correlation has been highlighted using the purple color. All the indices that have the value below 0.4, equal to 0.4 or having value greater than 0.6 are exhibited. Here indexes are represented by the rectangle and the edges represent the correlation strength.

High, low and negative correlation
The h-index has a strong correlation with 4 indices and with 1 index it has a weak correlation. As a whole, the strong correlation between indices is greater than the weak correlation. It has been evident from this correlation output that as whole the strong correlation values overcome the weak correlation. The outcome of our first research question stimulates us to examine the next questions.
The significance of correlation is at level 0.01.
Awardees trend in the author ranked lists
Here we have assessed the next two research questions. We have determined the indices role in fetching the awardees at the top of the rank list and to determine the occurrence of awardees in the top ranking merits. To get the answer to these two questions, we first scanned the awardees’ occurrence for each parameter in the top 10% of the generated ranked list which is shown in Fig. 3. Secondly, we checked that how many awardees occurred in 1–10%, 10–20%, 20–30% and up to 90–100% of the whole ranked list generated by calculating each index which is shown by Fig. 4. From Fig. 3 It can be perceived that maximum occurrences of award winners (around 30.86%) lie in the top 10% authors, acquired by the h-index. The g-index, hg-index q2-index and r-index show the same performance (29.4%). The lowest performance is seen in the case of a-index (14.7%).

Awardees percentage in the top 10% of ranked lists

The occurrence of award winners in partial 10% part of each ranked list
The prestigious award societies decencies on indices’ results
The last question of our research is to determine which award giving society predominantly relies on which index. For tackling this, we scrutinized the occurrence of award winners in the top 10% of the list. As we have already mentioned that our benchmark dataset is composed of 68 awardees. Out of these, 29 were from AMS, 6 from IMU, 23 from LMS and 12 award winners from NASL. Generally, it is anticipated for the award winners that their total number of citations and the total number of publications must be high i.e. they must have a strong and sound research background. But, this assumption has seemed to be invalid for some cases. We also evaluated the performance of each awarding society individually for retrieving the award winners in the ranking lists.
From Fig. 5, it has been evident that the AMS brought out 29 awardees (42.6%). Whereas 6 awardees (8.82%) are fetched by the IMU, 23 (33.8%) by the LMS and NASL retrieve the 8 awardees (11.76%) (Fig. 6).

Total number of awardees retrieved from awarding societies

Awardees percentage retrieved from awarding society in the ranked lists
From the Fig. 7, it has been clear that which awarding society is well-suited to which index. Besides evaluation of each index individually, we have also evaluated the performance of each awarding society individually for retrieving the award winners in the top 10% ranking list. Given below observations are concluded as a result of our research:

Trend of indices on awardees societies
-
1.
AMS
-
(a)
The h-index, g-index, hg-index and the q2-index performance remain equally well (almost 37.93%).
-
(b)
The r-index performed up to 34.38%.
-
(c)
The a-index, however, shows the poor performance (13.79%).
-
(a)
-
2.
IMU
-
(a)
The performance of the h-index, g-index, hg-index, r-index, and the q2-index remains equal (almost 33.33%).
-
(b)
The performance of a-index remained lowered (almost 16.66%) as compared to the other indices.
-
(a)
-
3.
LMS
-
(a)
The h-index performs the best (almost 21.73%).
-
(b)
The performance of q2-index, g-index and the hg-index is same (almost 17.39%).
-
(c)
The performance of the r-index and the a-index remain low (13.04%).
-
(a)
-
4.
NASL
-
(a)
The h-index, g-index, hg-index, r-index and the q2-index performance is the same (almost 37.5%).
-
(b)
The performance of the a-index is low (25%).
-
(a)
Award winners’ evaluation in top-ranked authors
We have examined the occurrence of awardees in the top 100, 500 and 1000 ranked authors. Figure 8 represented the percentage of all awardees’ occurrence in top-ranked authors. As regards the top 100, the q2-index performs the best in retrieving the awardees it retrieves 2.94% awardees. The performance of g-index, h-index, a-index, r-index, and the hg-index is equal (1.47%). Hg-index shows the best performance in the case of the top 500, it retrieves 8.82%. H-index and q2-index perform equally well (both 7.35%). The performance of g-index is 5.88%. When considered the top 1000 ranked authors, the maximum performance is seen by the q2-index, it retrieves 11.76%. The hg-index got the second highest performance (10.29%) as followed by the h-index, g-index and r-index (8.82%). A-index retrieved almost 1.47%.

Awardees winners’ occurrence in top-ranked authors
It is worth mentioned here that the above-mentioned results are evaluated on the complete dataset of mathematics which we have retrieved. It means that almost all the awardees have been retrieved by all the considered indices. The difference only lies related to the efficiency of each index. Here efficiency refers that how maximum numbers of awardees have been retrieved by the top-ranked authors. Regarding this, the A-index has shown the least performance.
Conclusion
We have evaluated the h-index and its citation intensity based variants in this research. We have considered the role of h-index, g-index, hg-index, r-index, q2-index, and a-index on the large dataset of mathematics fields. We have used the national and international award winners of the prestigious mathematics societies as a standard benchmark for comparing the results of various considered indices as previously used by Raheel et al. (2018).
Our first research question has been addressed by calculating the Spearman Rank correlation among the indices. The results discovered that the high correlation exists among most of the indices. The negative correlation is found in the case of h-index, g-index, and hg-index with the a-index. Among these mentioned indices, the a-index has the negative correlation with h-index, g-index and hg-index and low correlation with q2-index and r-index. Actually, the positive correlation value and the negative correlation value reflect the extent to which the ranked lists are similar and dissimilar respectively (Raheel et al. 2018). By considering all the aspects of research, it has been concluded that the high correlation exists among most of the indices.
For the second research question, we have determined the award winner’s occurrence in the ranked lists. We have compared the awardees with the top 10% ranked authors. Our results show that none of the indices prospered in fetching even 50% awardees, which is much astonishing. The h-index brought around 30.88% awardees, followed by the hg-index and the g-index (29.4%). Our benchmark dataset consist of 68 awardees of AMS, IMU, LMS and NASL awarding societies. AMS brought out 29 awardees (42.6%), whereas, 6 awardees (8.82%) are fetched by the IMU, 23 awardees (33.8%) by the LMS and NASL retrieve the 8 awardees (11.76%) in the ranking list. The maximum number of awardees retrieved by the considered six indices in the top 100 is only 2%. In the top 500, this figure grows to 4.6%. Ultimately, 33% enhancement is seen in case of the top 1000 ranked authors. As regards the top 100, the q2-index performs the best in retrieving the awardees. Hg-index shows the best performance in the case of the top 500 and q2-index performs the best in the case of top 1000.
To scrutinize the fourth research question, we have checked out the difference of the h-indices between the different awarding societies. The maximum occurrences of fetched award winners, who lie in the top 10% of ranked lists of h-index, belong to the AMS (almost 37.93%) as followed by the NASL (almost 37.5%) and the IMU (almost 33.33%). The least number of awardees has been brought out by LMS (almost 21.73%). It has been evident from the result that AMS society brought the maximum number of awardees at the top.
Future work
The ranking community of researchers has also proposed the numerous other indices besides these. They all also required to be assessed on the large datasets, to reveal their capacity. We aim to assess the other indices on the comprehensive dataset from different fields, in the future. Moreover a homogenous dataset can be constructed and define winners on basis of similar criteria e.g. two homogenous benchmarks can be constructed: one based on junior researchers, and one based on senior researcher and compare the performance of these parameters on these two groups respectively.
References
Adler, R., Ewing, J., & Taylor, P. (2009). Citation statistics: A report from the International Mathematical Union (IMU) in cooperation with the International Council of Industrial and Applied Mathematics (ICIAM) and the Institute of Mathematical Statistics (IMS). Statistical Science, 24(1), 1–14.
Alonso, S., Cabrerizo, F. J., Herrera-Viedma, E., & Herrera, F. (2009). h-index: A review focused on its variants, computation, and standardization for different scientific fields. Journal of Informetrics, 3(4), 273–289.
Alonso, S., Cabrerizo, F. J., Herrera-Viedma, E., & Herrera, F. (2010). hg-index: A new index to characterize the scientific output of researchers based on the h-and g-indices. Scientometrics, 82(2), 391–400.
Aoun, S. G., Bendok, B. R., Rahme, R. J., Dacey, R. G., & Batjer, H. H. (2013). Standardizing the evaluation of scientific and academic performance in neurosurgery—Critical review of the “h” index and its variants. World Neurosurgery, 80(5), e85–e90.
Ayaz, S., & Afzal, M. T. (2016). Identification of conversion factor for completing-h index for the field of mathematics. Scientometrics, 109(3), 1511–1524.
Balog, K., Azzopardi, L., & De Rijke, M. (2006, August). Formal models for expert finding in enterprise corpora. In Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval (pp. 43–50). ACM.
Beel, J., & Gipp, B. (2009, April). Google Scholar’s ranking algorithm: The impact of citation counts (an empirical study). In Third international conference on research challenges in information science, 2009. RCIS 2009 (pp. 439–446). IEEE.
Behrens, H., & Luksch, P. (2011). Mathematics 1868–2008: A bibliometric analysis. Scientometrics, 86(1), 179–194.
Bogers, T., & Van den Bosch, A. (2008, October). Recommending scientific articles using CiteULike. In Proceedings of the 2008 ACM conference on recommender systems (pp. 287–290). ACM.
Bornmann, L., & Daniel, H. D. (2005). Committee peer review at an international research foundation: Predictive validity and fairness of selection decisions on post-graduate fellowship applications. Research Evaluation, 14(1), 15–20.
Bornmann, L., Mutz, R., & Daniel, H. D. (2008). Are there better indices for evaluation purposes than the h index? A comparison of nine different variants of the h index using data from biomedicine. Journal of the Association for Information Science and Technology, 59(5), 830–837.
Bornmann, L., Mutz, R., Daniel, H. D., Wallon, G., & Ledin, A. (2009). Are there really two types of h index variants? A validation study by using molecular life sciences data. Research Evaluation, 18(3), 185–190.
Bornmann, L., Mutz, R., Hug, S. E., & Daniel, H. D. (2011). A multilevel meta-analysis of studies reporting correlations between the h index and 37 different h index variants. Journal of Informetrics, 5(3), 346–359.
Bosman, J., Mourik, I. V., Rasch, M., Sieverts, E., &Verhoeff, H. (2006). Scopus reviewed and compared: The coverage and functionality of the citation database Scopus, including comparisons with Web of Science and Google Scholar. Report, Utrecht University Library.
Bui, D. L., Nguyen, T. T., & Ha, Q. T. (2014). Measuring the influence of bloggers in their community based on the H-index family. In T. van Do, H. Thi, & N. Nguyen (Eds.), Advanced computational methods for knowledge engineering (pp. 313–324). Cham: Springer.
Burrell, Q. (2007). Hirsch index or Hirsch rate? Some thoughts arising from Liang’s data. Scientometrics, 73(1), 19–28.
Cabrerizo, F. J., Alonso, S., Herrera-Viedma, E., & Herrera, F. (2010). q2-Index: Quantitative and qualitative evaluation based on the number and impact of papers in the Hirsch core. Journal of Informetrics, 4(1), 23–28.
Cameron, D. H. L., Aleman-Meza, B., Decker, S., &Arpinar, I. B. (2007). SEMEF: A taxonomy-based discovery of experts, expertise and collaboration networks. Doctoral dissertation, University of Georgia.
Corder, G. W., & Foreman, D. I. (2009). Comparing variables of ordinal or dichotomous scales: Spearman rank‐order, point‐biserial, and biserial correlations. In Nonparametric statistics for non-statisticians: A step-by-step approach (pp. 122–154). Wiley.
De Winter, J. C., Zadpoor, A. A., & Dodou, D. (2014). The expansion of Google Scholar versus Web of Science: A longitudinal study. Scientometrics, 98(2), 1547–1565.
Dienes, K. R. (2015). Completing h. Journal of Informetrics, 9(2), 385–397.
Dorta-Gonzalez, P., & Dorta-González, M. I. (2013). Impact maturity times and citation time windows: The 2-year maximum journal impact factor. Journal of Informetrics, 7(3), 593–602.
Egghe, L. (2006). An improvement of the h-index: The g-index. ISSI.
Fukuzawa, N. (2014). An empirical analysis of the relationship between individual characteristics and research productivity. Scientometrics, 99(3), 785–809.
Ghani, R., Qayyum, F., Afzal, M. T., & Maurer, H. (2019). Comprehensive evaluation of h-index and its extensions in the domain of mathematics. Scientometrics. https://doi.org/10.1007/s11192-019-03007-0.
Harzing, A. W. (2010). Citation analysis across disciplines: The impact of different data sources and citation metrics. https://harzing.com/publications/white-papers/citation-analysis-across-disciplines. Accessed 13 Jan 2019.
Harzing, A. W. (2013). A preliminary test of Google Scholar as a source for citation data: A longitudinal study of Nobel prize winners. Scientometrics, 94(3), 1057–1075.
Harzing, A. W., & Alakangas, S. (2016). Google Scholar, Scopus and the Web of Science: A longitudinal and cross-disciplinary comparison. Scientometrics, 106(2), 787–804.
Harzing, A. W. K., & Van der Wal, R. (2008). Google Scholar as a new source for citation analysis. Ethics in Science and Environmental Politics, 8(1), 61–73.
Hirsch, J. E. (2005). An index to quantify an individual’s scientific research output. Proceedings of the National Academy of Sciences of the United States of America, 102(46), 16569.
James, D. W. (2014). Completing Hirsch’s h-index measuring scholarly impact. In Scholardox E4.
Jiang, X., Sun, X., & Zhuge, H. (2013). Graph-based algorithms for ranking researchers: Not all swans are white! Scientometrics, 96(3), 743–759.
Jin, B. (2006). H-index: An evaluation indicator proposed by the scientist. Science Focus, 1(1), 8–9.
Jin, B., Liang, L., Rousseau, R., & Egghe, L. (2007). The R-and AR-indices: Complementing the h-index. Chinese Science Bulletin, 52(6), 855–863.
Katsaros, D., Akritidis, L., & Bozanis, P. (2009). The f index: Quantifying the impact of coterminal citations on scientists’ ranking. Journal of the Association for Information Science and Technology, 60(5), 1051–1056.
Liang, R., & Jiang, X. (2016, February).Scientific ranking over heterogeneous academic hypernetwork. In AAAI (pp. 20–26).
Liu, Y., Rao, I. R., & Rousseau, R. (2009). Empirical series of journal h-indices: The JCR category Horticulture as a case study. Scientometrics, 80(1), 59–74.
Liu, Y., & Rousseau, R. (2007). Hirsch-type indices and library management: The case of Tongji University Library. In 11th International conference of the International Society for Scientrometrics and Informetrics, June 25–27, 2007, Madrid, Spain (pp. 514–522).
Mazloumian, A., Helbing, D., Lozano, S., Light, R. P., & Börner, K. (2013). Global multi-level analysis of the ‘Scientific Food Web’. Scientific reports, 3, 1167.
Mingers, J. (2009). Measuring the research contribution of management academics using the Hirsch-index. Journal of the Operational Research Society, 60(9), 1143–1153.
Moreira, C., Calado, P., & Martins, B. (2015). Learning to rank academic experts in the DBLP dataset. Expert Systems, 32(4), 477–493.
Moreira, C., & Wichert, A. (2013). Finding academic experts on a multisensor approach using Shannon’s entropy. Expert Systems with Applications, 40(14), 5740–5754.
Neuhaus, C., Neuhaus, E., Asher, A., & Wrede, C. (2006). The depth and breadth of Google Scholar: An empirical study. Portal Libraries and the Academy, 6(2), 127–141.
Panaretos, J., & Malesios, C. (2009). Assessing scientific research performance and impact with single indices. Scientometrics, 81(3), 635.
Raheel, M., Ayaz, S., & Afzal, M. T. (2018). Evaluation of h-index, its variants, and extensions based on publication age & citation intensity in civil engineering. Scientometrics, 114, 1107–1127.
Rousseau, R. (2006). New developments related to the Hirsch index. Preprint, http://eprints.rclis.org/7616/. Accessed 13 Jan 2019.
Sangwal, K. (2012). On the age-independent publication index. Scientometrics, 91(3), 1053–1058.
Schreiber, M. (2008a). An empirical investigation of the g-index for 26 physicists in comparison with the h-index, the A-index, and the R-index. Journal of the American Society for Information Science and Technology, 59(9), 1513–1522.
Schreiber, M. (2008b). To share the fame in a fair way, hm modifies h for multi-authored manuscripts. New Journal of Physics, 10(4), 040201.
Schreiber, M. (2010). Twenty Hirsch index variants and other indicators giving more or less preference to highly cited papers. Annalen der Physik, 522(8), 536–554.
Sidiropoulos, A., Katsaros, D., & Manolopoulos, Y. (2007). Generalized Hirsch h-index for disclosing latent facts in citation networks. Scientometrics, 72(2), 253–280.
Sidiropoulos, A., & Manolopoulos, Y. (2005). A citation-based system to assist prize awarding. ACM SIGMOD Record, 34(4), 54–60.
Sidiropoulos, A., & Manolopoulos, Y. (2006). Generalized comparison of graph-based ranking algorithms for publications and authors. Journal of Systems and Software, 79(12), 1679–1700.
Smolinsky, L., & Lercher, A. (2012). Citation rates in mathematics: A study of variation by subdiscipline. Scientometrics, 91(3), 911–924.
Teixeira, A. A., & Mota, L. (2012). A bibliometric portrait of the evolution, scientific roots and influence of the literature on university-industry links. Scientometrics, 93(3), 719–743.
Wells, J. D. (2014). Scholardox E4 (2014) Completing Hirsch’s h-index measuring scholarly impact By James D. Wells (University of Michigan, Ann Arbor) April 13, 2014.
Wilsdon, J., Allen, L., Belfiore, E., Campbell, P., Curry, S. H., Jones, R., et al. (2015). The metric tide: Report of the independent review of the role of metrics in research assessment and management. Technical report.
Wu, Q. (2010). The w-index: A measure to assess scientific impact by focusing on widely cited papers. Journal of the Association for Information Science and Technology, 61(3), 609–614.
Yan, E., Ding, Y., & Sugimoto, C. R. (2011). P-Rank: An indicator measuring prestige in heterogeneous scholarly networks. Journal of the American Society for Information Science and Technology, 62(3), 467–477.
Funding
Funding was provided by Capital University of Science and Technology.
Author information
Authors and Affiliations
Corresponding author
Appendix
Rights and permissions
About this article

Cite this article
Ain, Qu., Riaz, H. & Afzal, M.T. Evaluation of h-index and its citation intensity based variants in the field of mathematics. Scientometrics 119, 187–211 (2019). https://doi.org/10.1007/s11192-019-03009-y
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-019-03009-y