
Abstract
This study explores the curvilinear (inverted U-shaped) association of three classical dimension of co-authorship network centrality, degree, closeness and betweenness and the research performance in terms of g-index, of authors embedded in a co-authorship network, considering formal rank of the authors as a moderator between network centrality and research performance. We use publication data from ISI Web of Science (from years 2002–2009), citation data using Publish or Perish software for years 2010–2013 and CV’s of faculty members. Using social network analysis techniques and Poisson regression, we explore our research questions in a domestic co-authorship network of 203 faculty members publishing in Chemistry and it’s sub-fields within a developing country, Pakistan. Our results reveal the curvilinear (inverted U-shaped) association of direct and distant co-authorship ties (degree centrality) with research performance with formal rank having a positive moderating role for lower ranked faculty.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
A social network approach coupled with bibliometrics is often used to study co-authorship networks (Otte and Rousseau 2002), with authors being nodes/actors in the network and ties/relationships between them established when they co-author together (Newman 2004). Because of the intellectual nature of such social relationships, knowledge is expected to flow in such networks. Therefore, co-authorship networks can also be termed as knowledge networks (Oh et al. 2005). The authors embedded in these knowledge networks can benefit from the knowledge flowing within the network by acquiring structurally advantageous positions in the network (Badar et al. 2013, 2014) to derive favorable outcomes such as enhanced research performance.
In social network literature, network centrality is an application measuring the structurally advantageous positions of actors in the social network. A central actor in a co-authorship network can benefit from the knowledge flowing within the network to derive enhanced research performance outcomes. Thinking on these lines, prior research has investigated and identified the positive influence of centrality on research performance outcomes in co-authorship networks (Abbasi et al. 2011; Badar et al. 2013, 2014; Eaton et al. 1999; Fischbach et al. 2011; Lee et al. 2012; Liao 2011); yet leaving some important research questions largely un-answered. First, is the relationship between network centrality and research performance strictly linear or curvilinear (inverted U-shaped)? We argue that too much or too low network centrality might be constraining. There might be an intermediate level of network centrality which reaps the highest rewards for authors. These arguments stem from emerging empirical evidence concerning the diminishing returns of social network ties (Rotolo and Petruzzelli 2013; McFayden and Cannella 2004).
We contribute to this line of inquiry by investigating a curvilinear (inverted U-shaped) relationship (Virick et al. 2010) between the three classical dimensions of network centrality (degree, closeness and betweenness) and research performance (g-index) of individual authors.
Secondly, do individual characteristics interact with network centrality such that the benefits associated with network centrality are more/less apparent to authors with certain individual characteristics? Emerging empirical advancements have shown the value of examining the characteristics of individuals together with the social network structures in which they are embedded (Badar et al. 2013, 2014; Bhardwaj et al. 2008; Burt 1998; Lee and Bozeman 2005; Zhou et al. 2009). We contribute to these advancements by theorizing that an individual characteristic, formal rank, will moderate the curvilinear relationship between centrality and research performance.
We investigate these issues in a domestic co-authorship network of faculty members publishing in Chemistry and its sub-fields from a developing country, Pakistan. We argue that literature on co-authorship networks lacks contribution from a developing country perspective—a perspective which might provide critical insights due to underdeveloped research infrastructure leading to lackluster formal mechanisms for knowledge flow in higher education sector of these countries (Gossart and Özman 2009).
Literature review
Research performance
Assessment of research performance of researchers in universities and/or research institutes is inevitable for decision making regarding promotions, recruitments, award of grants and/or funds (Pike 2010). To assess the research performance of researchers, many quantitative bibiliometric indicators have been proposed in scientometrics. The basic idea is that both the quantity in terms of number of publications and quality in terms of number of citations of a researcher get accounted for. Following same lines, Hirsch (2005) introduced the h-index as a measure that combines both the quantity and quality of publications of a researcher, “A scientist has an h-index of h, if h of his/her Np papers have at least h citations each, and the other (Np−h) papers have at most h citations each.” (Hirsch 2005). In other words, a researcher with an index of h has published h papers, which have been cited at least h times. The h-index has gained popularity amongst the academic community and is implemented in popular academic databases such as ISI web of Science and Scopus. On the other hand, it has also been criticized for several disadvantages such as such as the influence of the length of the scientific career on the h-index, which puts newcomers at a disadvantage (Kelly and Jennions 2006), the need to take into account the number of co-authors signing the documents (Batista et al. 2006), the inadequateness of comparing scientists from different scientific fields (Hirsch 2005), its inability to differentiate clearly between active and inactive scientists (Sidiropoulos et al. 2007), its insensitivity to highly cited papers (Egghe 2006), or the fact that other bibliometric dimensions, such as journal quality or international performance—as a reference, are completely ignored in the calculation of the h-index (Van-Raan 2006; Costas and Bordons 2007). Therefore, various variants and extension of the h-index have been proposed. One such extension is the g-index introduced by Egghe (2006) to overcome one of the main disadvantages of h-index, i.e. its insensitivity to highly cited papers (Egghe 2006). The g-index takes into account the weight of the citations received by the top articles of a scientist (his/her most frequently cited papers) and the total number of documents does not limit the value of the index, as it is in the case of the h-index. Therefore, given a set of articles ranked in decreasing order of the number of citations that they received, the g-index is the (unique) largest number such that the top g articles received (together) at least g 2 citations (Egghe 2006).
We use the g-index to measure the research performance of authors in our network. We chose this particular indicator in the country context of our study. The policy makers in Pakistan, to date, have not used such an indicator to assess the research performance of researchers. Moreover, the g-index has been used as a measure of research performance (dependent variable) in prior studies on co-authorship networks testing similar research models (Abbasi et al. 2011; Bordons et al. 2015).
Network centrality
Network centrality can be defined as an extent to which an actor is connected to other actors in the network (Wasserman and Faust 1994). Centrality analysis in sociological literature dates back to decades (Yan and Ding 2009). Freeman (1979) can be considered a pioneer when he proposed dimensions of centrality in a social network, which have been developed into degree centrality, closeness centrality and betweenness centrality. These dimensions are often correlated to some extent, specifying a conceptual overlap. But a conceptual distinction, on the other hand, is also observable in various network configurations (Valente et al. 2008). For example, a node in the center of a star or wheel is the most central node in the network by all centrality measures (Freeman 1979). In other network configurations, however, nodes with high degree centrality are not necessarily the most strategically located (Badar et al. 2013). A way to look at the distinctions among these concepts is in terms of how actors occupying positions high on each dimension of centrality i.e. degree, closeness and betweenness might derive differential benefits from these positions (degree centrality providing benefits of knowledge sharing via direct ties, closeness providing benefits of quick flow of knowledge by virtue of having low average distance to rest of the actors in the network and betweenness providing benefits of brokerage and control of knowledge by virtue of having ties that span social divides) that can facilitate instrumental outcomes (Badar et al. 2013, 2014). However, the outcomes from these structurally central positions might have diminishing returns (Rotolo and Petruzzelli 2013; Mcfadyen and Cannella 2004) due to the costs, stress and conflict, and random drift associated with these central positions (Ahuja and Katila 2004; Fleming and Sorenson 2001; Mcfadyen and Cannella 2004; Podolny and Baron 1997; Rotolo and Petruzzelli 2013). Therefore the, relationship between network centrality and its outcomes might not be strictly linear.
Individual characteristics
Emerging empirical evidence has recognized the contingencies associated with individual characteristics while studying the impact of social network structures on individual performance outcomes (Gargiulo et al. 2009). For example, in context of social networks, Badar et al. (2013) reported that female authors derived more benefits from direct and distinct co-authorship ties i.e. degree centrality and quick flow of knowledge i.e. closeness centrality as compared to male authors. Subsequently, Badar et al. (2014) also reported a positive moderating relationship of both academic age and institutional sector on the relationship between degree centrality and research performance for junior faculty members and faculty members employed in private sector universities/research institutes. We look to extend previous research by proposing the important contingency of formal rank on the effect of co-authorship network centrality on research performance.
Hypotheses
Degree centrality and research performance
Degree centrality is the number of the direct ties an actor in the network has with other actors (Freeman 1979). In the context of co-authorship networks, authors having more co-authors will have high degree centrality bringing benefits of knowledge sharing to these central authors who can use this knowledge to enhance their research performance (Badar et al. 2013, 2014). However, establishing co-authorship relationships requires time, energy and attention (McFadyen and Cannella 2004). Certain costs are associated with establishing these relationships, including start-up costs (Boissevain 1974). Therefore, a limit exists to the number of productive co-authorships in terms of degree centrality, that any given author can maintain, and no guarantee exists that any particular set of co-authors will be optimal for enhancement of research performance (Zucker et al. 1995). Hence, having too many co-authors i.e. high degree centrality might stifle an author’s pursuit for enhancement of research performance but having a moderate number of co-authors i.e. moderate degree centrality may facilitate an increase in research performance.
Therefore, we can propose the following hypothesis:
H 1a
The relationship between degree centrality and research performance (g-index) will be curvilinear (inverted U-shaped) in nature.
Closeness centrality and research performance
Closeness centrality defines how close an actor in the network is to the rest of the actors (Newman 2010). High closeness centrality for an author in the co-authorship network specifies that he has access to large portion of the knowledge flowing in the network (Perry-Smith and Shalley 2003). Hence, knowledge is likely to flow quickly and early to that author (Borgatti 1995). This knowledge can be used by the author for the enhancement of research performance. However, an author who is too close to many other actors in the network can be pulled in too many directions. This structural position would result in that individual’s being aware of too many conflicting view points within the network which, in turn, might result in stress and conflict (Podolny and Baron 1997). Too much stress and conflict might stifle an author’s pursuit for enhancement of research performance (Perry-Smith and Shalley 2003), but a lower, more manageable amount of stress and conflict, such as resulting from moderate closeness centrality, may facilitate an increase in research performance (Amabile et al. 1996).
Therefore we can propose the following hypothesis:
H 1b
The relationship between closeness centrality and research performance (g-index) will be curvilinear (inverted U-shaped) in nature.
Betweenness centrality and research performance
Betweenness centrality defines the extent to which an actor lies in-between other actors i.e. actors who are connected to others who are not themselves connected (Burt 2005). High betweenness centrality in a co-authorship network specifies that that an author having ties that span social divides is likely to have greater access to high volume of non-redundant and diverse knowledge which can be utilized for the enhancement of research performance (Badar et al. 2013). However, the first consequence of having a high volume of more diverse or non-redundant knowledge access is that these relationship consume time and resources that then cannot be allocated for absorbing and integrating the obtained knowledge (Gilsing et al. 2008). Second, non-redundant ties may result in a random drift so that an author’s knowledge base changes continuously in different and unrelated directions, making the accessed diverse knowledge difficult to absorb and integrate (Fleming and Sorenson 2001; Ahuja and Katila 2004). Thus, too many non-redundant ties; high betweenness centrality might stifle an author’s pursuit for enhancement of research performance while having a moderate number of non-redundant ties; not too high betweenness might facilitate an increment in research performance.
Therefore we can propose the following hypothesis:
H 1c
The relationship between betweenness centrality and research performance (g-index) will be curvilinear (inverted U-shaped) in nature.
Formal rank and network centrality
The formal rank of an author, being an important individual-level contingency, is proposed to moderate the curvilinear relationship between co-authorship network centrality and research performance. An author’s rank in the hierarchy of a university/research institute can affect their ability to seek co-authorship with their colleagues (Gargiulo et al. 2009). Although co-authorship relations might be established outside the formal hierarchy of universities/research institutes, and/or across universities/research institutes, the authors usually are aware of each other’s ranks. This awareness might be beneficial to junior ranked authors who can look forward to establishing co-authorship ties with much powerful and resourceful senior ranked authors, thereby gaining access to a large pool of knowledge resources. The benefits of network centrality, therefore, should be more apparent for lower ranked authors and less apparent for higher ranked authors who can substitute the power and resources (for e.g. knowledge capital, funding/grants, research assistants, etc.) conferred by their rank as an alternative lever to enhance their research performance. In other words, senior faculty might not depend solely on co-authorship ties given the potential consequent centrality to produce research (Badar et al. 2013, 2014). We should expect, therefore, that the benefits of network centrality in terms of degree, closeness and betweenness decrease systematically with their rank, with the highest benefits accruing to the lowest ranks.
Therefore we can propose the following hypothesis:
H 2a
Formal rank will moderate the curvilinear (inverted U-shaped) relation between degree centrality and research performance: lower rank faculty will exhibit greater research performance at intermediate levels of degree centrality than when rank is high.
H 2b
Formal rank will moderate the curvilinear (inverted U-shaped) relation between closeness centrality and research performance: lower rank faculty will exhibit greater research performance at intermediate levels of closeness centrality than when rank is high.
H 2c
Formal rank will moderate the curvilinear (inverted U-shaped) relation between betweenness centrality and research performance: lower rank faculty will exhibit greater research performance at intermediate levels of betweenness centrality than when rank is high.
Data and methods
We utilized a previous dataset used by Badar et al. (2013). The original bibliometric data set was downloaded from ISI Web of Science (from years 2002–2009) and consisted of 1699 articles published in Chemistry and its sub-fields from Pakistani authors only. Social network analysis (SNA) techniques using Sci2 (Sci2 Team 2009) and UCINET VI (Borgatti et al. 2002) revealed a domestic co-authorship network which had 1782 authors in the giant interconnected component out of which 203 were identified as faculty members at Pakistani universities/institutes. This identification was accomplished firstly by cleaning the raw bibliometric dataset for author name disambiguation problem by converting the names that were in last-name-plus-initial form to last-name-plus-full-first-name form; and secondly the cleaned dataset was matched with the Higher Education Commissions’ (HEC) database of faculty and the university/research institutes’ web pages.
Based on recommendations for future research by Badar et al. (2013) we extracted the co-authorship network existing only among the faculty members. This process was achieved using UCINET VI’s filter/extract command (Borgatti et al. 2002) and the extract sub-matrix subcommand, including only the identified faculty members. Figure 1 depicts the visualization of the co-authorship network existing among the faculty members from years 2002–2009.

Visualization of co-authorship network among faculty members (2002–2009)
We further extended the original dataset by downloading the citation data for each faculty member using the Publish or Perish software (Harzing 2007) from years 2010 to 2013. This data served the important purpose of controlling for reverse causality. It can be argued that high network centrality causes high research performance; however, it can also be argued that high research performance causes authors to be central. Therefore, to clearly assess the role of centrality on research performance, we studied the relationship of network centrality in terms of degree, closeness and betweenness in an early time window (t1: 2002–2009) with research performance in terms of g-index in a later time window (t2: 2010–2013).
We also downloaded CVs of faculty members from university/research institutes’ web pages, their personal webpages and/or HEC’s database of faculty members. The CVs provided data about the formal rank of faculty members as well as data about control variables.
Measures
Dependent variable: research performance (g-index)
The g-index of 203 faculty members from years 2010 to 2013 was calculated using the Publish or Perish software (Harzing 2007). The g-index is a count variable with mean 5.25 and the values ranging from 0 to 18. It followed poisson distribution, as it was not over-dispersed and the percentage of zeros was not excessive.
Independent construct: centrality (degree, closeness, betweenness)
Degree centrality
Degree centrality of a node n i is mathematically measured as follows (Scott 1991):
where g is the total number of nodes in the network and a(n i , n j ) is a function which is equal to 1 if and only if node n i and n j are connected and zero otherwise. Normalized version of degree centrality has been proposed (Freeman 1979) which can be defined as the proportion of nodes adjacent to n i :
Closeness centrality
Closeness centrality is measured as a function of mean geodesic/shortest distances. If d(n i , n j ) is the length of geodesic path from n i to n j , meaning the shortest number of edges along the path, then the mean geodesic distance from n i to n j averaged over all vertices g in the network (Newman 2010) is:
This quantity takes low values for vertices that are separated from others by only a short geodesic distance on average. The mean distance ℓ(n i ) is not a centrality measure since it gives low values for more central vertices. Therefore, closeness centrality is calculated as an inverse of ℓ(n i ) and can be defined as inverse average distance between node n i and all other nodes (Newman 2010).
Betweenness centrality
Betweenness centrality measures the extent to which an actor lies on the geodesic paths between other actors. Suppose that a node n j and n k are connected in a network via several geodesic paths. Hence, each geodesic is equally likely to be used. Let ğ jk be the number of geodesics linking the two nodes. If a distinct node n i lies on any of the geodesics linking n j and n k , we can label ğ jk (n i ) as the number of geodesics linking the two nodes that contain node n i . Hence, ğ jk (n i )/ğ jk is the probability of node n i lying “between” nodes n j and n k .
Therefore, betweenness centrality for node n i is simply the sum of these estimated probabilities over all pairs of actors excluding n i (Wasserman and Faust 1994).
Just like other measures, this measure of betweenness centrality also depends on g so it is also standardized like other centrality measures. Because we consider pairs of actors in this measure, we standardize it using (g − 1)(g − 2)/2 which is the maximum number of pairs of actors in a undirected network excluding n i (Wasserman and Faust 1994). Hence:
UCINET VI uses all the above routines to calculate the classic dimensions of centrality.Footnote 1 The co-authorship network of faculty members was represented by a binary un-directed (203 × 203) matrix. This matrix was loaded in UCINET VI and normalized versions of the degree, closeness and betweenness were calculated.
Moderating variable: formal rank
Formal rank is the title of the faculty member at the time that the co-authorship network was identified for the study, i.e., 2002. The faculty members in the co-authorship network were comprised of the assistant professors, associate professors and professors. We represented these ranks with two dummy variables with the lowest rank (assistant professor) being the omitted category (Gargiulo et al. 2009).
Control variables
Our model controlled for a number of variables that could affect the research performance of faculty members. These variables capture the attributes of faculty members: gender, academic age and institutional sector.
Past research suggests that gender has a strong impact on the development of co-authorship networks (Arensbergen et al. 2012; Badar et al. 2013; Barrios et al. 2013; Borrego et al. 2010; Sotudeh and Khoshian 2014) and their effect on research performance. Yet, the literature demonstrates contradictory findings with one stream reporting higher research performance for male researchers (Ledin et al. 2007; Prpic 2002; Tower et al. 2007; Stack 2004) while another stream reports higher research performance for female researchers (Arensbergen et al. 2012; Barrios et al. 2013; Borrego et al. 2010). We therefore controlled for gender by using a dummy variable coded as male = 1 and female = 0.
Academic age is the time elapsed since the researcher formally started research. It can be interpreted as proxy of experience and knowledge (Gargiulo et al. 2009) gained through seniority. It is reasonable to expect that senior researchers have had more time to develop their scientific and technical human capital, their professional networks and have more resources (funding/grants, research assistants, etc.) at their disposal (Lee and Bozeman 2005; Oh et al. 2005) which in turn can affect their research performance. Prior research suggests senior researchers have higher research performance (Lavie and Drori 2012; Lee and Bozeman 2005; Oh et al. 2005), whereas contradictory research evidence suggests junior researchers derive more research performance benefits from co-authorship within their networks (Badar et al. 2014). We measured the academic age for each faculty member by the number of years since earning a Ph.D. degree (at the time the studied co-authorship network had been identified, i.e. 2002) (Lee and Bozeman 2005). This variable was introduced in the model as a continuous variable starting from zero. A career age of zero specified that the faculty member has either completed his Ph.D. in 2002 or later (after the time window of the studied co-authorship network, i.e. 2002–2009).
Institutional sector of a researcher specifies differential availability of resources to researchers employed in public and private sector universities/research institutes (James and Benjamin 1988; Wilkinson and Yussof 2005) which in turn can affect their research performance. Prior research has reported higher performance for researchers employed in public sector universities/institutes (De-Cohen 2003) whereas contradictory evidence suggests researchers employed in private sector universities/institutes derive more research performance benefits from co-authorship within their networks (Badar et al. 2014). We therefore controlled for institutional sector of a faculty member (at the time the studied co-authorship network had been established—2002) by using a dummy variable coded as public = 1, private = 0.
Data analysis techniques
Correlation and regression analysis
Due to the expected non-parametric nature of centrality measures (Yan and Ding 2009), we used Spearman’s correlation between centrality measures to test correlation amongst variables.
The indicator of research performance, g-index, was a count variable that was not over-dispersed (Min: 0; Max: 18; Mean: 5.25; SD: 4.15; Skewness: 1.019; Kurtosis: 0.523) and the percentage of zeros (6.4 %) was not excessive. Therefore, we used Poisson regression to test the hypotheses using the squared terms for each measure of centrality to test the curvilinear (inverted u shaped) effects and interaction terms to test for the moderating impact of formal rank.
Results
The 203 faculty members are involved in 1086 publications (Min: 1; Max: 59; Mean: 7.23; SD: 9.145; Skewness: 2.945; Kurtosis: 10.330). Figure 2 depicts the publication count/g-index of four different groups of faculty authors with faculty authors in publication group of 11–20 publications having a higher g-index, on average as compared to faculty authors in other groups (ANOVA: F = 2.290, p < 0.10).

Box plot of publication count by research performance (g-index)
Table 1 presents means/percentages, standard deviations and Spearman correlations for all variables in the analysis. Findings indicate 77.8 % of the faculty members are males, 44.1 % have a career ageFootnote 2 of zero specifying that they were new entrants to the research field, 73.4 % are employed in public sector universities/research institutes, 40.6 % are assistant professors, 17.3 % are associate professors and 42 % are professors. Correlation among variables is generally low except for the centrality measures. The potential problem of multicollinearity is addressed using the maximum likelihood method in Poisson regression (Abbasi et al. 2011).
Table 2 presents the results of the Poisson regression analysis to explain the research performance (in terms of g-index) of the faculty members in their co-authorship network. We present six models with prime focus on the full model (model 6). Model 1 is the base model containing only control variables. Models 2–4 contains only one independent variable and model 5 contains all three independent variables but without interactions terms. The coefficients are quite robust over the models indicating no potential multicollinearity problem. The deviance for all the models is insignificant which specifies that the Poisson model is an ideal fit for the data. The likelihood ratio Chi square test is significant for all the models specifying the statistical significance of all the models.
The findings related to control variables reveal some consistencies and contradictions with previous research. Male faculty members have higher research performance (β = 0.245, p < 0.01) than female faculty members. Figure 3 reveals that male faculty members, on average, have higher research performance than female faculty members (Mean g-index for Males = 5.54 and females = 4.22). This finding is consistent (Ledin et al. 2007; Prpic 2002; Tower et al. 2007; Stack 2004) as well as contradictory (Arensbergen et al. 2012; Barrios et al. 2013; Borrego et al. 2010) with the findings of previous research on co-authorship networks. Academic age of the faculty members didn’t have a significant impact on research performance (β = −0.004, p > 0.10) which contradicted findings of previous research (Lavie and Drori 2012; Oh et al. 2005). Faculty members employed in public sector universities/research institutes have higher research performance (β = 0.240, p < 0.01) than faculty members employed in private sector universities/research institutes. Figure 4 reveals that faculty members employed in public sector universities/research institutes, on average have higher research performance than faculty members employed in private sector universities/research institutes (Mean g-index for public sector faculty = 5.66 and private sector faculty = 4.11). This finding is consistent with the findings of previous research (De-Cohen 2003).

Box plot of gender and research performance (g-index)

Box plot of affiliation and research performance (g-index)
Model 2, 3 and 4 introduce respectively degree, closeness and betweenness as independent variables. In model 2, the coefficient for degree centrality is positive and significant (β = 0.126, p < 0.01), and the coefficient for degree centrality squared is negative and significant (β = −0.005, p < 0.01). These finding provide support to Hypothesis 1a. In model 3, coefficient for closeness centrality is insignificant (β = 0.025, p > 0.10), and the coefficient for closeness centrality squared is insignificant as well (β = 9.101, p > 0.01). These findings provide no support for Hypothesis 1b. In model 4, coefficient for betweenness centrality is positive and significant (β = 0.075, p < 0.01), but the coefficient for betweenness centrality squared is insignificant (β = −0.002, p > 0.01). These findings provide no support for Hypothesis 1c. These results also hold for Model 5 and Model 6 when three independent variables were introduced simultaneously and with interaction terms in Models 5 and 6 respectively.
Model 6 introduces the linear and squared interaction terms to test Hypotheses 2a, 2b and 2c. The coefficients for interaction terms of degree centrality squared with associate professor dummy is positive and significant (β = 0.563, p < 0.01) but the coefficients for interaction terms of degree centrality squared with professor dummy is insignificant (β = 0.282, p > 0.10). This finding shows that the curvilinear effect of degree centrality on research performance diminishes, systematically with rank, thus furnishing support for Hypothesis 2a. Hypotheses 2b and 2c are not supported because the coefficients for closeness centrality squared with associate professor and professor dummy variables and coefficients for betweenness centrality squared with associate professor and professor dummy variables, respectively, are insignificant (β = 0.893, p > 0.10, β = 0.927, p > 0.10; β = −2.555, p > 0.10, β = −0.927, p > 0.10).
Discussion
The results implied that co-authorship ties may come with an opportunity cost. Although increasing direct and distinct co-authorship ties measured by degree centrality, can offer authors several benefits to facilitate research productivity, namely knowledge sharing (Ahuja 2000), joining of complementary skills (Ahuja 2000), deepening of research discussion, enjoying each other’s economies of specialization (Ahuja 2000) and learning each other’s research and domain of expertise (Avkiran 1997), an excessive number of direct and distinct co-authorship ties might have an overwhelming effect on the author given a limited time available to the author to manage these ties and the knowledge associated with these ties (Rotolo and Petruzzelli 2013).
Findings related to closeness centrality was consistent across all models—insignificant. Faculty members in the co-authorship network did not seem to rely on the quick flow of knowledge that may be obtained by having low average distance to other authors. Provided that the co-authorship network is a faculty-only co-authorship network, higher closeness centrality implied that the faculty members might be aware of too many conflicting view points within the network (Perry-Smith and Shalley 2003). It seems that faculty members may avoid such conflicts with in the network by not utilizing the quick flow of knowledge and relying just on their direct and distinct co-authorship ties.
Findings related to betweenness centrality revealed an inconsistency. In Model 4, the coefficient of betweenness centrality was significant which implied that faculty members in the co-authorship network may benefit to some extent from the brokerage of non-redundant and diverse knowledge by virtue of being in-between disconnected others. However, a look across Models 4 and Models 5 revealed the insignificance of the coefficient of betweenness centrality. Therefore, the benefits associated with direct and distinct co-authorship ties seem to outweigh the benefits of non-redundant and diverse knowledge brokerage. This again might be due to the costs associated with non-redundant and diverse knowledge. Given the limited time and resources available to the faculty members, it may be difficult for the faculty members to absorb and integrate the obtained diverse and non-redundant knowledge (Gilsing et al. 2008).
Findings related to moderating impact of formal rank indicated a positive moderating impact for lower-ranked faculty within the curvilinear relationship between degree centrality and research performance. This finding suggests that lower-ranked faculty members are the ones deriving maximum benefits at intermediate level of their direct and distinct co-authorship ties. This finding strengthens the proposed argument that higher ranked faculty members do not depend solely on co-authorship ties to produce highly quality research and that lower-ranked faculty derive greater benefits from their co-authorship network ties to facilitate research performance.
Implications for theory
A rich stream of literature exists when it comes to studying the concept of centrality and its impact on innovation and performance in organizational social networks (Andrews 2010; Tsai 2001; Sparrowe et al. 2001). These studies reported positive association of centrality with innovation and performance. Our research saw the need to conduct social network research in the academic context because of the different and contrasting nature of academic organizations. Although few studies have explored the concept of centrality in academic co-authorship networks (Zurián et al. 2007; Gossart and Özman 2009; Newman 2004; Nagpaul 2002), they studied centrality as a tool to reveal the structural properties (such as identification of influential nodes) of the network and lack an insight about the outcomes of centrality for nodes in the network. In addition, while a few studies have investigated and identified the positive influence of centrality on performance outcomes in co-authorship networks (Abbasi et al. 2011; Eaton et al. 1999; Liao 2011), they lack an insight about the diminishing returns of different dimensions of centrality and the potential moderating effects of individual characteristics.
In addition, literature on co-authorship networks lacks contribution from a developing country perspective. While some research has studied co-authorship networks in Iran (Yousefi-Nooraie et al. 2008), Turkey (Gossart and Özman 2009) and India (Nagpaul 2002), all of these studies were conducted at the organizational level of analysis which ignored individuals, their centrality and their characteristics that might play an important role within the actual network of individual coauthors.
Our results were consistent with findings reported by prior studies in similar context. Mcfadyen and Cannella (2004), in their study of a co-authorship network sample of biomedical research scientists, tested the relationship between social capital in terms of number and strength of ties and knowledge creation in terms number of publications of scientists weighted by the ISI impact factor. They reported that with increasing number of relations, the returns to knowledge creation diminished. More recently Rotolo and Petruzzelli (2013), in their study of co-authorship networks of Italian academics, tested the relationship between centrality measured in terms of Bonacich’s power and academic productivity in terms of number of publications weighted by number of citations and reported an inverted U-shaped relationship. Our results were also consistent with findings reported by a prior social network study in a different national context. Zhou et al. (2009), with a network sample of employees and their supervisors in a high-tech company in China, theorized and found a curvilinear relationship between number of weak ties and creativity, based on supervisors’ rating such that employees exhibited greater creativity when their number of weak ties was at intermediate levels rather than at lower or higher levels.
Findings related to the moderating impact of formal rank in this study contradicted with the findings of Lee and Bozeman’s (2005) study, who found the relationship between degree centrality and productivity to be stronger for senior researchers due to the fact that they have had time to acquire greater knowledge and scientific and technical human capital, but they also have more experience with the collaboration process itself.
Coming to the overall structure of the co-authorship network (Fig. 1—Visualization of co-authorship network among faculty members) we see a densely connected large interconnected structure which is consistent with the findings of previous studies on co-authorship networks in various contexts (Eaton et al. 1999; Fischbach et al. 2011; Nascimento et al. 2003; Newman 2004). Thus generalizability about the network structure can be claimed. Moreover the presence of a large and densely interconnected component might have implications in other developed country settings. Due to the underdeveloped research infrastructure and lackluster formal mechanisms for knowledge flow in higher education sector of developing countries, we might expect denser domestic co-authorship networks facilitating knowledge flow.
Implications for practice
Our study offers several implications for science managers, education policy makers and university administrators and researchers. Our findings revealed that researchers can utilize the knowledge flowing in the co-authorship network by utilizing the benefits of their direct and distinct co-authorship ties; degree centrality and improve their research performance. However, these ties are beneficial for research performance only up-to a certain level after which the returns begin to diminish. Science managers, education policy makers and university administrators and researchers, therefore, must be aware of this double-edged sword effect (Rotolo and Petruzzelli 2013) and must make efforts to invest time and resources toward managing and maintaining potentially productive and valuable co-authorship ties. In addition, our findings related to moderating impact of formal rank on the curvilinear relationship between centrality and research performance can be heartening and motivating for junior ranked faculty in suggesting opportunities to surpass barriers of domination imposed by high ranked faculty and poor resource access through co-authorship ties.
Limitations and conclusions
As is usually the case, some potential limitations of this research open the door to many new research questions. First, from the methodological standpoint, although we controlled for reverse causality using temporal analysis, a further exploration is needed of how all pieces in the potential causal chain come together (Zaheer and Soda 2009). Our research explored the impact of three classical dimensions of network centrality; degree, closeness, betweenness on research performance in terms of g-index without considering the antecedents of network centrality. We did not focus on an important research question “what factors (in an earlier time period) make an author central (in a later time period) in the co-authorship network?” Secondly, we considered only network centrality causing research performance, whereas impact of other network measure such as network closure, structural holes, tie strength, and differentiating between weak and strong ties, as well as differing types of relational embeddedness (Hite 2003, 2008) on research performance needs to be explored. Third, due to the fact that our level of analysis were individual authors, a further insight is needed regarding multi-level analysis; for example exploring the joint influence of individual level and team level network measures on research performance might be explored (Wei et al. 2011). Fourth, we used only formal rank as a contingency. Future research might look to test moderating impact of more individual and work related characteristics by getting additional data from authors in the network with the help of questionnaires. Fifth, we used only g-index as a measure of research performance. Understanding the fact that research performance is a multidimensional and multifaceted construct, future research might look to test ours or similar research models with a composite measure of research performance (Nagpaul and Roy 2003). Sixth, our study focused on a domestic co-authorship network of a specific field (Chemistry) of a specific country (Pakistan) only. Future research could replicate these analyses in other academic domains and in other developing countries.
Notes
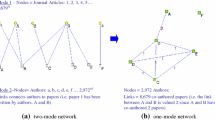
We didn’t just rely on the values returned by the software, UCINET VI. In order to validate our results, we manually calculated degree, closeness and betweenness for a very small sub-sample of our data set (Fig. 5). The results were then verified by UCINET VI to reveal exactly the same values as our manual calculations. Appendix Tables 3, 4, and 5 depict these manual calculations (See for Example Chapter 2. McCulloh et al. 2013).
Frequency analysis indicated a career age mode of “0” with a valid percentage of 44.1 %.
References
Abbasi, A., Altmann, J., & Hossain, L. (2011). Identifying the effects of co-authorship networks on the performance of scholars: A correlation and regression analysis of performance measures and social network analysis measures. Journal of Informetrics, 5(4), 594–607.
Ahuja, G. (2000). Collaboration networks, structural holes, and innovation: A longitudinal study. Administrative Science Quarterly, 45(3), 425–455.
Ahuja, G., & Katila, R. (2004). Where do resources come from? The role of idiosyncratic situations. Strategic Management Journal, 25(8/9), 887–907.
Amabile, T. M., Conti, R., Coon, H., Lazenby, J., & Herron, M. (1996). Assessing the work environment for creativity. Academy of Management Journal, 39(5), 1154–1184.
Andrews, R. (2010). Organizational social capital, structure and performance. Human Relations, 63(5), 583–608.
Arensbergen, P., Weijden, I., & Besselaar, P. (2012). Gender differences in scientific productivity: A persisting phenomenon? Scientometrics, 93(3), 857–868.
Avkiran, N. K. (1997). Models of retail performance for bank branches: Predicting the level of key business drivers. International Journal of Bank Marketing, 15(6), 224–237.
Badar, K., Hite, J. M., & Badir, Y. F. (2013). Examining the relationship of co-authorship network centrality and gender on academic research performance: The case of chemistry researchers in Pakistan. Scientometrics, 94(2), 755–775.
Badar, K., Hite, J. M., & Badir, Y. F. (2014). The moderating role of academic age and insitutional sector on the relationship between co-authorship network centrality and academic research performance. Aslib Journal of Information Management, 66(1), 38–53.
Barrios, M., Villarroya, A., & Borrego, A. (2013). Scientific production in psychology: A gender analysis. Scientometrics, 95(1), 15–23.
Batista, P. D., Campiteli, M. G., Kinouchi, O., & Martinez, A. S. (2006). It is possible to compare researchers with different scientific interests? Scientometrics, 68(1), 179–189.
Bhardwaj, A., Qureshi, I., & Lee S. H. (2008). A study of race/ethnicity as a moderator of the relationship between social capital and satisfaction. Paper presented at the academy of management annual meeting, Anaheim, CA.
Boissevain, J. (1974). Friends of friends: Networks, manipulators and coalitions. New York: St. Martin’s Press.
Bordons, M., Aparicio, J., González-Albo, B., & Díaz-Faes, A. A. (2015). The relationship between the research performance of scientists and their position in co-authorship networks in three fields. Journal of Informetrics, 9, 135–144.
Borgatti, S. P. (1995). Centrality and AIDS. Connections, 18(1), 112–114.
Borgatti, S. P., Everett, M. G., & Freeman, L. C. (2002). UCINET for windows: Software for social network analysis. Harvard, MA: Analytic Technologies.
Borrego, A., Barrios, M., Villarroya, A., & Olle, C. (2010). Scientific output and impact of postdoctoral scientists: A gender perspective. Scientometrics, 83(1), 93–101.
Burt, R. S. (1998). The gender of social capital. Rationality and Society, 10(1), 5–46.
Burt, R. S. (2005). Brokerage and closure: The social capital of structural holes. Oxford: Oxford University Press.
Costas, R., & Bordons, M. (2007). The h-index: Advantages, limitations and its relation with other bibliometric indicators at the micro-level. Journal of Informetrics, 1(3), 193–203.
De-Cohen, D. C. (2003). Diversification in Argentine higher education: Dimensions and impact of private sector growth. Higher Education, 46(1), 1–35.
Eaton, J. P., Ward, J. C., Kumar, A., & Peter, H. R. (1999). Structural analysis of co-author relationships and author productivity in selected outlets for consumer behavior research. Journal of Consumer Psychology, 8(1), 39–59.
Egghe, L. (2006). Theory and practise of the g-index. Scientometrics, 69(1), 131–152.
Fischbach, K., Putzke, J., & Schoder, D. (2011). Co-authorship networks in electronic markets research. Electronic Markets, 21(1), 19–40.
Fleming, L., & Sorenson, O. (2001). Technology as a complex adaptive system: Evidence from patent data. Research Policy, 30(7), 1019–1039.
Freeman, L. C. (1979). Centrality in social networks. Conceptual clarification. Social Networks, 1, 215–239.
Gargiulo, M., Ertug, G., & Galunic, C. (2009). The two faces on control: Network closure and individual performance among knowledge workers. Administrative Science Quarterly, 54(2), 299–333.
Gilsing, V., Nooteboomb, B., Vanhaverbekec, W., Duystersd, G., & Oorda, A. V. (2008). Network embeddedness and the exploration of novel technologies: Technological distance, betweenness centrality and density. Research Policy, 37(10), 1717–1731.
Gossart, C., & Özman, M. (2009). Co-authorship networks in social sciences: The case of Turkey. Scientometrics, 78(2), 323–345.
Harzing, A. W. (2007). Publish or perish. http://www.harzing.com/pop.htm.
Hirsch, J. E. (2005). An index to quantify an individual’s scientific research output. Proceedings of the National Academy of Sciences, 102(46), 16569–16572.
Hite, J. M. (2003). Patterns of multidimentionality among embedded network ties: A typology of relational embeddedness in emerging enterpreneurial firms. Strategic Organization, 1(1), 9–49.
Hite, J. M. (2008). The role of dyadic multi-dimensionality in the evolution of strategic network ties. In J. A. C. Baum & T. J. Rowley (Eds.), Network Strategy (pp. 133–170). Bradford: Emerald Group Publishing Limited.
James, E., & Benjamin, G. (1988). Public policy and private education in Japan. London: Macmillan.
Kelly, C. D., & Jennions, M. D. (2006). The h-index and career assessment by numbers. Trends in Ecology and Evolution, 21(4), 167–170.
Lavie, D., & Drori, I. (2012). Collaborating for knowledge creation and application. Organization Science, 23(3), 704–724.
Ledin, A., Bornmann, L., Gannon, F., & Wallon, G. (2007). A persistent problem. EMBO Reports, 8(11), 982–987.
Lee, S., & Bozeman, B. (2005). The impact of research collaboration on scientific productivity. Social Studies of Science, 35(5), 673–702.
Lee, D. H., Seo, I. W., Choe, H. C., & Kim, H. D. (2012). Collaboration network patterns and research performance: The case of Korean public research institutions. Scientometrics, 91(3), 925–942.
Liao, C. H. (2011). How to improve research quality? Examining the impacts of collaboration intensity and member diversity in collaboration networks. Scientometrics, 86(3), 741–761.
McCulloh, I., Armstrong, H., & Johnson, A. (2013). Social network analysis with applications. Hoboken: Wiley.
Mcfadyen, A. M., & Cannella, J. A. (2004). Social capital and knowledge creation: Diminishing returns of the number and strength of exchange relationships. Academy of Management Journal, 47(5), 735–746.
Nagpaul, P. S. (2002). Visualizing cooperation networks of elite institutions in India. Scientometrics, 54(2), 213–228.
Nagpaul, P. S., & Roy, S. (2003). Constructing a multi-objective measure of research performance. Scientometrics, 56(3), 383–402.
Nascimento, M. A., Sander, J., & Pound, J. (2003). Analysis of SIGMOD’s co-authorship graph. SIGMOD Record, 32(3), 8–10.
Newman, M. E. (2004). Who is the best connected scientist? A study of scientific coauthorship networks. Complex Networks, 650, 337–370.
Newman, M. E. (2010). Networks: An introduction. Oxford: Oxford University Press.
Oh, W., Choi, J. N., & Kim, K. (2005). Co-authorship dynamics and knowledge capital: The patterns of cross-disciplinary collaboration in information systems research. Journal of Management Information Systems, 22(3), 265–292.
Otte, E., & Rousseau, R. (2002). Social network analysis: A powerful strategy, also for the information sciences. Journal of Information Science, 28(6), 441–453.
Perry-Smith, J. E., & Shalley, C. E. (2003). The social side of creativity: A static and dynamic social network perspective. The Academy of Management Review, 28(1), 89–106.
Pike, T. W. (2010). Collaboration networks and scientific impact among behavioral ecologists. Behavioral Ecology, 21(2), 431–435.
Podolny, J. M., & Baron, J. N. (1997). Relationships and resources: Social networks and mobility in the workplace. American Sociological Review, 62, 673–693.
Prpic, K. (2002). Gender and productivity differentials in science. Scientometrics, 55(1), 27–58.
Rotolo, D., & Petruzzelli, M. (2013). When does centrality matter? Scientific productivity and the moderating role of research specialization and cross-community ties. Journal of Organizational Behavior, 34(5), 648–670.
Scott, J. (1991). Social network analysis: A handbook. Boston: Sage.
Sci2 Team. (2009). Science of science (Sci2) tool. Indiana University and SciTech Strategies. http://sci2.cns.iu.edu. Accessed May 5, 2011.
Sidiropoulos, A., Katsaros, D., & Manolopoulos, Y. (2007). Generalized h-index for disclosing latent facts in citation networks. Scientometrics, 72(2), 253–280.
Sotudeh, H., & Khoshian, N. (2014). Gender differences in science: The case of scientific productivity in nano science and technology during 2005–2007. Scientometrics, 98(1), 457–472.
Sparrowe, T., Liden, R., Robert, G. J., Wayne, S., & Kraimer, M. L. (2001). Social networks and the performance of individuals and groups. Academy of Management Journal, 44(2), 316–325.
Stack, S. (2004). Gender, children and research productivity. Research in Higher Education, 45(8), 891–920.
Tower, G., Plummer, J., & Ridgewell, B. (2007). A multidisciplinary study of gender-based research productivity in the world’s best journals. Journal of Diversity Management, 2(4), 23–32.
Tsai, W. (2001). Knowledge transfer in intraorganizational networks: Effects of network position and absorptive capacity on business unit innovation and performance. Academy of Management Journal, 44(5), 996–1004.
Valente, T. W., Loronges, K., Lakon, C., & Costenbader, E. (2008). How correlated are network centrality measures? Connections, 28(1), 16–26.
Van Raan, A. F. J. (2006). Comparisons of the Hirsch-index with standard bibliometric indicators and with peer judgment for 147 chemistry research groups. Scientometrics, 67(3), 491–502.
Virick, M., DaSilva, N., & Arrington, K. (2010). Moderators of the curvilinear relation between extent of telecommuting and job and life satisfaction: The role of performance outcome orientation and worker type. Human Relations, 63(1), 137–154.
Wasserman, S., & Faust, K. (1994). Social networks analysis: Methods and applications. Cambridge: Cambridge University Press.
Wei, J., Zheng, W., & Zhang, M. (2011). Social capital and knowledge transfer: A multi-level analysis. Human Relations, 64(11), 1401–1423.
Wilkinson, R., & Yussof, I. (2005). Public and private provision of higher education in Malaysia: A comparative analysis. Higher Education, 50(3), 361–386.
Yan, E., & Ding, Y. (2009). Applying centrality measures to impact analysis: A coauthorship network analysis. Journal of the American Society for Information Science and Technology, 60(10), 2107–2118.
Yousefi-Nooraie, R., Akbari-Kamrani, M., Hanneman, R. A., & Etemadi, A. (2008). Association between co-authorship network and scientific productivity and impact indicators in academic medical research centers: A case study in Iran. Health Research Policy and Systems,. doi:10.1186/1478-4505-6-9.
Zaheer, A., & Soda, G. (2009). Network evolution: The origins of structural holes. Administrative Science Quarterly, 54(1), 1–31.
Zhou, J., Shin, S. J., Brass, D. J., Choi, J., & Zhang, Z. X. (2009). Social networks, personal values and creativity: Evidence for curvilinear and interaction effects. The Journal of Applied Psychology, 94(6), 1544–1552.
Zucker, L. G., Darby, M. R., Brewer, M. B., & Peng, Y. (1995). Collaboration structure and information dilemmas in biotechnology. In R. M. Kramer & T. R. Tyler (Eds.), Trust in organizations. Thousand Oaks, CA: Sage.
Zurián, J., Alcaide, G. G., Zurián, J., Benavent, F. J. B., & Miguel-Dasit, A. (2007). Coauthorship networks and institutional collaboration in Revista Española de CardiologÍa Publications. Revista Espanola de Cardiologia, 60(2), 117–130.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix

Subsample of authors in the network
Rights and permissions
About this article

Cite this article
Badar, K., Hite, J.M. & Ashraf, N. Knowledge network centrality, formal rank and research performance: evidence for curvilinear and interaction effects. Scientometrics 105, 1553–1576 (2015). https://doi.org/10.1007/s11192-015-1652-0
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-015-1652-0