
Abstract
The processing of morphologically complex words has been studied in many languages, leading to a variety of theoretical accounts. Prime type, individual differences, and cross-linguistic effects have emerged as potential factors in morphological processing, but the findings so far have been inconclusive, especially for young children. This study investigated the early stages of morphological processing in Turkish-speaking children using the visual masked priming paradigm. We used different prime conditions (truly suffixed, pseudo-suffixed, non-suffixed, and semantic) and measured reading proficiency skills (vocabulary, spelling, reading speed, and comprehension) to investigate whether prime types or individual differences modulate early word processing. Our sample of children showed priming effects for truly suffixed words, without sound differences between derived and inflected primes in their reaction times. The reaction times of the participants decreased with increasing reading proficiency in the experimental conditions. The results suggest a sensitivity for suffixes in the early word processing of Turkish primary school children rather than sensitivities for pseudo-suffixes, orthographic overlap, or semantic similarity.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Skilled adult readers are known to rapidly analyze the morphemic structure of morphologically complex words (e.g., gardener -> garden + -er) during word recognition (e.g., Amenta & Crepaldi, 2012). In contrast, comparatively little is known about the mechanisms and processes at work when young, developing readers read morphologically complex words (Dawson et al., 2021). Importantly, though, a better understanding of potential age-related changes in word-processing patterns can provide vital information regarding the onset, development, and characteristics of such mechanisms and help identify possible modulating factors (Barouch et al., 2022). This, in turn, may assist educators, administrators, and researchers in gaining a better understanding of reading-related mechanisms and in designing better-informed reading instruction processes. Two of the major questions that have yet to be answered within this scope are whether developing readers make use of processing mechanisms comparable to those employed by adults during word recognition and when in the developmental process they start to automatically process morphologically complex words (Fleischhauer et al., 2021). In the present study, we seek answers to these questions for second and fourth-grade developing readers of Turkish and try to understand whether individual differences between child readers lead to variability in visual word processing.
A large body of research on adult readers has suggested that during a very early phase of visual word recognition, skilled readers decompose not only morphologically structured (e.g., garden + er) but also monomorphemic pseudo-morphological items, which only appear morphologically complex but are actually not related in meaning to the embedded pseudo-stem (corn vs. corner). This process of blind decomposition, which is known as morpho-orthographic segmentation (Rastle et al., 2004), has been attested through visual masked priming studies with adult speakers conducted across typologically distinct languages like French (Longtin et al., 2003), English (Rastle et al., 2004), Russian (Kazanina et al., 2008), Dutch (Diependaele et al., 2009) and Turkish (Kırkıcı & Clahsen, 2013), among others. In the typical visual masked morphological priming paradigm, a morphologically complex prime word is presented for a brief duration (usually 30–70 ms) to exclude the involvement of conscious awareness and strategies (e.g., Feldman et al., 2012; Forster & Davis, 1984; Rastle et al., 2004). The prime is preceded by a series of unrelated symbols (e.g., hash symbols), which act as the forward mask, to ensure that participants are unaware of the prime.
Following the prime, a target (a word or a pseudoword) is presented for participants to respond to, typically by making a lexical decision. The relationships between the prime-target pairs are manipulated to examine which of the manipulation(s) facilitate(s) the response latencies and accuracies to targets relative to an unrelated baseline. With adult participants, it has commonly been reported that morpho-semantically related (gardener-garden) and morpho-orthographically related (corner-corn) prime-target pairs facilitate lexical decision latencies whereas prime-target pairs like dragon-drag, whose relationship is purely orthographical in nature, do not (Rastle et al., 2000).
On the other hand, examinations of the mechanism(s) employed by developing readers in the processing of morphologically complex words have been rather limited in number. This is rather unfortunate, as an understanding of how morphological knowledge is built by children and how this knowledge is employed during reading may shed light on the developmental process in learning to read and on the factors that help children become ‘skilled readers’ (Castles et al., 2018; Dawson et al., 2021). One factor that is known to play a vital role in the development of reading skills is morphological knowledge. Children have been found to be aware of morphological structure in spoken input as early as their preschool years and it has been shown that children at the age of 8 to 9 years display clear manifestations of morphological awareness in reading, which is the ability to understand sound-meaning relationships in a language and knowledge of the word formation rules behind possible morpheme combinations (Kuo & Anderson, 2006). Developing readers can and do use their morphological knowledge to learn and employ a number of literacy-related skills like spelling, word learning, word reading, and reading comprehension (Carlisle, 2000; Dawson et al., 2021; Hasenäcker et al., 2021). This impact of morphological knowledge on the development of reading skills has received cross-linguistic support, predominantly following research into Indo-European languages like Italian, French, English, and German (Fleischhauer et al., 2021).
Empirical research on morphological processing in child readers in general, and morpho-orthographic segmentation in particular, has arrived at largely inconsistent results. The development of morpho-semantic processing seems to start in the early grades of primary school. Using truly suffixed complex words as primes with short prime durations, studies using the masked priming paradigm with child participants have found facilitative priming effects as early as the second or third grade in French, German, and English (Beyersmann et al., 2012, 2015a, 2015b; Fleischhauer et al., 2021; Hasenäcker et al., 2015; Quémart et al., 2011). However, Oliveira and Justi (2017) failed to replicate these findings with second, third, and fourth graders in Brazilian-Portuguese, as in their study only the fifth-grade participants showed significant facilitative priming with truly suffixed complex word primes used with short prime durations. Most of the studies hence suggest that true affixes are salient units in early word processing of children.
Despite the abundance of evidence for the facilitatory effect of truly suffixed primes on visual target word recognition (e.g., gardener-garden), seemingly complex monomorphemic (henceforth, pseudo-suffixed) word primes (e.g., corner-corn) often cannot induce such effects in young readers, suggesting that the automatization of morpho-semantic processing develops faster than the automatization of morpho-orthographic processing in developing readers. A number of studies with young readers have reported facilitative priming effects for truly suffixed but not for pseudo-suffixed primes (e.g., Beyersmann et al., 2012; Quémart et al., 2011). In a recent study, Fleischhauer et al. (2021) observed such sensitivity only for truly suffixed words in third-grade children using a masked-priming experiment, while fourth graders in the same study showed priming effects for both true suffixes and pseudo-suffixes, like the adults. These findings suggest a developmental pattern in which the sensitivity for pseudo-suffixes, and morpho-orthographic processing, develops after the sensitivity for true suffixes in word processing.
One factor that might play a mediating role in this observed lack of prime facilitation for pseudo-suffixed words is a possible competition between a pseudo-suffixed word and its pseudo stem (e.g., corner vs. corn) (Beyersmann et al., 2015a, 2015b). This idea has been supported by findings from the experiments that include pseudo-suffixed nonword primes, which are created using legitimate stems and legitimate suffixes (e.g., read + ize = readize). Young readers with high levels of reading proficiency showed significant priming effects for such primes (Beyersmann et al., 2015a, 2015b; Hasenäcker et al., 2015), which could be attributed to the lack of the aforementioned competition since such nonword primes include only one potential real stem (only read for readize, unlike pseudo-suffixed primes like corner, which include two potential stems: corn and corner). It should be noted, however, that this competition account would not be able to fully explain the difference between morpho-orthographic and morpho-semantic processing in young readers as truly suffixed primes still yield a facilitation advantage over pseudo-suffixed primes even when nonwords are used. Beyersmann et al., (2015a, 2015b), for example, reported greater priming effects in the truly suffixed condition, and Hasenäcker et al. (2015) found the most pronounced numerical priming effect in the truly suffixed condition with readers who obtained relatively low scores on a reading proficiency test. Taken all together, the automatization of morpho-orthographic decomposition appears to develop fully only after primary school years (Beyersmann et al., 2012), and individual differences may play a crucial role in morphological processing since young readers with high reading proficiency skills display different processing patterns compared to less proficient readers.
Further support for the role of individual differences in early word processing comes from Hasenäcker et al. (2020), who ran a longitudinal study in which they investigated the masked priming patterns of the same group of developing readers of German repeatedly in second, third, and fourth grades. It was found that a subset of the participants they tested displayed priming from suffixed words, suffixed nonwords, and non-suffixed nonwords as early as second grade. Similar to the studies reported earlier, this subset of the participants consisted of ‘good readers’, who were labeled as such because of their high scores on a reading skills test. With the increasing grade level (and, hence, increasing reading instruction), the magnitudes of both suffixed word priming and suffixed nonword priming increased. Overall, the results showed that not only grade level but also reading skills modulated the priming effects, highlighting the importance of individual differences in morphological processing even in early developmental stages. Earlier studies with adult participants (e.g., Andrews & Lo, 2013; Beyersmann et al., 2015a, 2015b) showed that individual differences in reading-related skills also modulate priming effects in adult readers. The results reported in Hasenäcker et al. (2020) indicate that individual differences in morphological processing possibly have their roots in early reading development.
Although the studies so far have used reading proficiency measures as the sole source of individual differences, defining individual differences might be difficult even in a specific research area like word processing. Additional factors such as cognitive maturation or short-term memory (e.g., Martin & Gupta, 2004) can also influence word processing patterns and development. The likely possibility of more individual difference-related factors increases the complexity of investigating the word processing patterns of developing readers. On the one hand, dividing the pool of participants according to their ages or grade levels might help consider factors like cognitive maturation. On the other hand, most studies on word processing of developing readers have had limited numbers of participants per grade level and this division makes the results less reliable (Beyersmann et al., 2015a, 2015b; see “the present study” section below).
Another important factor in morphological processing is cross-linguistic differences. Morphological processing patterns might display some differences among languages due to language orthography, morphological productivity, or both, and may affect children’s sensitivity to morphological structures (Beyersmann et al., 2021; Casalis et al., 2015; Duncan et al., 2009). Infants start decomposing morphological units at around one year of age (Marquis & Shi, 2012; Mintz, 2013), and this process is even more advanced in Hungarian, an agglutinative language with a rich morphology (Ladányi et al., 2020). These enhanced processing skills were attributed to the difficulty of storing an innumerable number of suffixed words in Hungarian as a result of its morphological productivity. Similarly, Durrant (2013) argues that speakers of agglutinating languages might store fewer complex words holistically than speakers of languages with less morphological richness and rather depend on decomposition more. In reading, children acquiring agglutinating languages seem to store inflectional morphemes along with simple word representations and use those for decoding complex words rapidly as early as 7 years old (Acha et al., 2010). Fleischhauer et al. (2021) highlight the possibility that the observed discrepancies in the findings obtained with developing readers (see the discussion above) may stem from differences between the languages tested in morphological productivity and the morphological systems, which the authors claim to affect the efficiency with which readers carry out morphological decomposition. Such impact may explain the contradictory findings of Hasenäcker et al. (2015) in German and Quémart et al. (2011) in French regarding the necessity of suffixes and the findings of Oliveira and Justi (2017) in Brazilian-Portuguese regarding the absence of facilitative priming effects even for fourth graders. Fleischhauer et al. (2021) suggest that it may be comparatively easier for young readers of morphologically rich and productive languages like German and French to detect the morphological structure of complex words and to use automatic morphological decomposition. For developing readers of morphologically poorer languages like English, in contrast, the onset of automatic morphological decomposition may be delayed. Language orthography is another potential factor behind the cross-linguistic effects in morphological decomposition. Beyersmann et al. (2021) found suggestive results for the effect of orthography in their longitudinal masked priming study including German and French third and fourth-grade children. Young readers of a shallow orthography, German, showed no signs of morpho-orthographic and morpho-semantic priming while young readers of French, a language with deep orthography, showed both of them (morpho-orthographic priming only with prefixes). Therefore, the nature of cross-linguistic effects in morphological processing is largely unknown although such patterns are well-acknowledged in the literature.
Against this background, the present study reports the results from a masked morphological priming experiment examining the processing of morphologically complex Turkish words by second-grade and fourth-grade primary school children. The purpose of the study is to investigate whether developing readers of Turkish make use of morphological structure while processing inflected and derived words and whether semantic transparency, grade level, and individual differences modulate the early stages of word processing in reading.
The present study
As outlined above, a number of studies have investigated the nature of early word processing in developing readers; however, there are still considerable gaps in the literature, particularly when it comes to testing non-Indo-European languages like Turkish. Linguistic diversity should not be ignored in psycholinguistic research (Lahaussois & Vuillermet, 2019), and language processing patterns display apparent differences among different languages (Majid et al., 2004). In addition to the evidence presented above regarding the cross-linguistic effects in morphological decomposition, the reading literature suggests that characteristics like affix saliency and productivity have effects on the nature of language processing (e.g. Marcolini et al., 2011; Quémart et al., 2011; Schreuder & Baayen, 1995; Ziegler & Goswami, 2005), and the orthography of a language has effects on the acquisition order and nature of its salient units in reading (e.g. Marcolini et al., 2011; Ziegler & Goswami, 2005).
Turkish is an agglutinative language with a large number of iterative loops, which results in an extremely productive morphology that is potentially able to produce words of infinite length (Durgunoğlu, 2003). It is estimated that it is possible to obtain over 10 million words from a single nominal root in Turkish (Kibaroğlu, 1991) and that an educated Turkish speaker would need to store 200 billion lexeme entries if all words in Turkish were to be stored in the mental lexicon (Hankamer, 1989). A morphologically complex word in Turkish contains, on average, 4.8 morphemes (Hankamer, 1989) and can encode linguistic content that would typically be expressed with full sentences in other languages as illustrated in (1).
-
(1)
Bak-ma-yacak-tı-m.
look-NEGATIVE-FUTURE-PAST-1Sg
“I was not going to look.”
The agglutinating nature of Turkish and its vast morphological complexity may necessitate a set of morphological awareness components that differ from those typically assumed for non-agglutinative languages. Durgunoğlu (2006) states that these components need to include probabilistic information regarding the order of suffixes since the range of possible suffixes becomes smaller as words get more morphologically complex. Furthermore, although affixation in Turkish does usually not lead to major changes in a stem’s phonology or orthography (see Göksel & Kerslake, 2004), another necessary component of morphological awareness in Turkish relates to the ability to understand how morphological and phonological information interact in Turkish suffixes. Suffixes in Turkish undergo phonological changes in line with the rules of Turkish vowel and consonant harmony, which are operative in almost all suffixes. This adds a further layer of complexity to the already very complex morphological nature of the language and requires the speaker to choose the correct surface form of a suffix (e.g., -dı, -di, -du, -dü, -tı, -ti, -tu or -tü to mark perfectivity) depending on the phonological properties of the preceding morphological element, as illustrated in (2). As a final point, Turkish has a very shallow orthography; it is well-documented that reading acquisition in Turkish is mostly achieved within one school year (Babayiğit & Stainthorp, 2007; Durgunoğlu & Öney, 1999; Öney & Durgunoğlu, 1997). This process is known to be slower for languages with a deeper orthography (Seymour et al., 2003). Considering all these, Turkish is a good candidate to investigate potential cross-linguistic differences in the development of word processing with its morphological complexity, morpheme productivity, phonologically and orthographically consistent word derivation, and shallow orthography.
-
(2)
ara-dı-m “I called”
yen-di-m “I won”
dur-du-m “I stopped”
gör-dü-m “I saw”
Besides seeking clarification for the contradicting findings and claims summarized above, a further aim of the present study was to investigate whether there would be differences in the processing patterns of inflected versus derived Turkish words by developing readers. Realization-based morphological theories suggest that the difference between derivation and inflection is crucial: While canonical inflection changes the form features of a word (thus representing the same lexeme with form modifications), canonical derivation changes semantic, syntactic, and form features, and creates a new uninflected lexeme entry (Spencer, 2016). Experimental findings on the derivation-inflection distinction are quite contradictory. Overt priming studies (Feldman, 1994), fragment completion studies (Deacon et al., 2010; Rabin & Deacon, 2008) cross-modal priming studies (Clahsen & Fleischhauer, 2014), and masked (Raveh, 2002) and unmasked (Feldman et al., 2002) priming studies testing adult participants have yielded contradictory results for the derivation vs. inflection distinction. While there is, to date, no conclusive evidence regarding a derivation vs. inflection distinction morphological processing, to our knowledge, no masked priming studies have investigated the differences between the processing of derived and inflected words in developing readers.
In the present study, factors like affix saliency, affix productivity, frequency, and orthographic similarity, which are known to influence morphological processing, were taken into consideration to minimize any distinguishing processing effects. As the participants in the present study were developing readers, the morphemes to be used in the experimental task needed to be high in frequency. Furthermore, the same targets were used for both inflected and derived primes to prevent potential confounds stemming from between-items effects. It was also necessary to identify a derivational and an inflectional morpheme that could be added to a good number of target words with similar frequency and length properties. With these criteria and constraints present, the Turkish suffixes -lI and –lAFootnote 1 were selected since, in addition to meeting the criteria listed above, they display a high orthographic similarity.
Due to rapid reading acquisition in Turkish, primary school children are expected to show efficient word processing patterns even at early ages. To our knowledge, no study has to date investigated the morphological processing of Turkish complex words by developing readers using the visual masked priming paradigm. Although there have been a few masked priming studies with adult native speakers, second language learners and heritage speakers of Turkish (e.g., Jacob & Kırkıcı, 2016; Jacob et al., 2019; Kırkıcı & Clahsen, 2013; Uygun & Clahsen, 2021), no study has experimentally investigated the morphological processing patterns of developing readers of Turkish.
Despite its effect on morphological processing, the role of individual reading proficiency in the development of morphological processing is unclear due to the limited number of studies and small sample sizes per age group in earlier studies (Beyersmann et al., 2015a, 2015b). The prevailing method has been to divide participants by their grade levels and analyze how reading proficiency affects word processing across grades. Beyersmann et al., (2015a, 2015b) argue that these grade-level comparisons decrease the statistical power of analyses and suggest that researchers should rather investigate the word processing patterns of developing readers by their reading proficiency scores without considering grade levels. While this holistic approach can help ensure the statistical power needed for reliable results, measurements of reading proficiency might fail to capture all the differences between the word processing patterns of developing readers. Cognitive maturation, for example, might not be reflected in a reading proficiency test while influencing word processing patterns in reading. For this reason, studies with enough participants for each age group should investigate individual differences by considering grade level as a separate factor. Since we have a modest number of participants in the present study, we will investigate the potential effects of individual differences without dividing our developing readers according to their grade level. While this potential limitation might result in only suggestive findings regarding the issue, the main goal of this study is to investigate the morphological processing patterns of developing readers in an agglutinative language with a highly complex morphology. After revealing the general pattern of morphological processing in such language, further studies can create more complex designs to manipulate individual differences and investigate their role in the word processing of developing readers in more detail.
In line with earlier studies, we expected primary school students to show priming effects with truly suffixed complex primes (the truly suffixed condition) in the present study. As for seemingly complex pseudo-suffixed primes, it was expected that lexical competition between the prime and the pseudo stem (corner-corn) might prevent facilitative priming effects since words rather than nonwords were used in this condition. We also investigated whether embedded pseudo-stems would facilitate the recognition of real target words by including a non-suffixed condition. This condition consisted of primes that were monomorphemic real words with pseudo stems and without suffix-like endings (e.g., carrot-car). If these primes led to significant facilitative priming effects, we could assume that our sample group detached embedded pseudo stems even without the presence of suffixes or pseudo-suffixes. We did not predict any facilitative priming in the semantic condition, in which primes and targets had only semantic relationships without orthographic or morphological similarity (e.g., inek-süt, cow-milk). The most obvious expectation was faster reaction times for fourth graders compared to second graders, but if our fourth graders manifested facilitative priming effects in one or multiple conditions while second graders did not, the findings would indicate a developmental pattern in child word processing. Similarly, any significant effects of individual measures on the reaction times were going to support the role of individual differences in word processing at early ages, although these suggestive findings might require further confirmation. Finally, the comparison of derived and inflected primes in the truly suffixed condition was expected to provide valuable information regarding the potential differences between derivational and inflectional suffixes; processing differences for these suffixes were going to support Realization-Based Morphological Theories (Spencer, 2016).
Method
Participants
The participants of the main experiment were 76 primary school children. While 39 of the participants were second-grade students (mean age: 7.45, SD: 0.36; 19 females), the remaining 37 participants were fourth-grade students (mean age: 9.36, SD: 0.41; 20 females). All participants were selected from two state primary schools in Erzurum, Türkiye. None of the participants reported being bilingual. All participants had a normal or corrected-to-normal vision, and no language/learning disorders were reported.
Two separate groups of 107 second-grade and 146 fourth-grade students completed a Vocabulary Test and a Spelling Test, respectively. A Word Association task and a Word Recognition task were completed by an independent group of 40 second-grade children who did not take part in the main experiment. Also, 20 Turkish adults, all native speakers of the language, completed the Prime-Target Relatedness Test.
Measures
Word association task
A word association task with 61 frequent words was used to find possible semantically-related target words for children. Words were selected from the Turkish National Corpus (Aksan et al., 2012). Forty second-grade participants (different from the participants in the main experiment) were asked to write down the first word that came to their minds after reading each stimulus word in a paper/pencil format. We chose 24 target words that received the most common responses and used the responses as experimental primes in the semantic condition. For example, süt-milk was chosen as a target word since the majority of our participants agreed that the most related word association was inek-cow for this item. This common answer, inek-cow, was then used as the experimental prime for the word süt-milk.
Word recognition task
A word recognition task was administered to check whether Turkish-speaking second-grade students were familiar with the words used in the main experiment. The task included all the potential target words and prime words to be later used in the main experiment. In this test, participants were asked to cross out unfamiliar words on their papers. The words that were crossed out by more than 3 students were not included in the final experimental lists.
Prime-target relatedness test
A 7-point Likert scale was created to test the relatedness of prime-target pairs in the related and unrelated conditions before the experiment. Twenty native speakers of Turkish completed this test in a paper/pencil format. An independent samples t-test showed that there was a significant difference between the ratings for the related primes (M = 5.59, SD = 0.41) and the ratings for the unrelated primes (M = 1.39, SD = 0.25), t (298) = 85.79, p < 0.0001).
Reading proficiency tests
Vocabulary test
A multiple-choice vocabulary test was created for each grade. The difficulty of the items was manipulated through word frequency: We created 9 difficulty levels, and as levels got higher, the frequency of the words to be used as options decreased. We used the difficulty levels 1–6 for second graders and 4–9 for fourth graders to create 60 questions per test. The reason for using different difficulty levels was to create a similar challenge for both grades. The two tests were examined with the help of a teacher of Turkish (with a teaching experience of over 8 years), and items that were evaluated as extremely difficult or vague were removed. The final versions of the two tests contained 54 items each. The Cronbach's Alpha test showed high-reliability values for the second-grade and fourth-grade vocabulary tests (α = 0.86 and α = 0.84, respectively).
Spelling test
In the creation of spelling tests, the same procedures as with the Vocabulary Test were followed. 60 questions were created per test based on the difficulty levels, and with the help of the same teacher, this number is reduced to 54 questions per each test. The Cronbach's Alpha tests showed high-reliability values for the second-grade and the fourth-grade spelling tests (α = 0.87 and α = 0.85, respectively).
Reading task and comprehension test
For the reading tasks, short passages (214 words for second graders, 265 words for fourth graders) were used from the Turkish translations of The Little Black Fish (Küçük Kara Balık; Behrang, 1968) and Jayden's Rescue (Kraliçeyi Kurtarmak; Tumanov, 2002) for second and fourth graders, respectively. A class teacher (with 10+ years of experience) suggested the books for the intended grade levels. With the help of the same class teacher, 10 comprehension questions were created for each reading sample.
Experimental items
The target and prime words were divided into 4 different word sets: the semantic condition word set, the pseudo-suffixed condition word set, the non-suffixed condition word set, and the truly suffixed condition word set. Each word set included experimental primes and unrelated primes.
The semantic condition word set included 24 prime-target pairs that had strong semantic relations without any morphological relations and with little to no orthographic similarities between them (e.g., çatı-ev, house-roof; tavuk-yumurta, chicken-egg; inek-süt, cow-milk). The pseudo-suffixed condition word set included 24 existing Turkish simple words that looked like complex words with pseudo-stems and pseudo suffixes (e.g., elma-el, apple-hand; kapı-kap, door-container; kira-kir, rent-dirt). The non-suffixed condition word set included 24 existing Turkish simple words that were not morphologically complex but seemed to have an embedded stem (e.g., hapis-hap, prison-pill; pilav-pil, pilaf-battery; külah-kül, cone-ash). What distinguished this set from the words in the pseudo-suffixed condition was the words in the non-suffixed condition did not have pseudo-suffixes after their seemingly embedded pseudo stems (e.g., word-final is in hapis ‘prison’ is not an existing suffix in Turkish, while hap ‘pill’ is a legitimate word). The truly suffixed condition word set contained two experimental prime conditions: the derived prime condition and the inflected prime condition (merak-meraklı-merakla, curiosity-curious-with curiosity; güven-güvenli-güvenle, trust-safety-safely; ses-sesli-sesle, sound-noisy-with sound). The derivational suffix -lI and the inflectional suffix –lA were attached to the same targets to create the derived prime and the inflected prime conditions, thus these two conditions had identical targets: merak-lı (‘curious’, derived prime)—merak-la (‘with curiosity’, inflected prime)—merak (‘curiosity’, target). Each experimental prime list had 28 primes with the common target words across experimental prime groups in the truly suffixed condition.
Orthographic overlap between the prime-target sets in the five prime conditions was matched using the Match Calculator (Davis, 2010). Overall, the prime-target sets, with the exception of the semantic condition, showed very high orthographic overlap with each other. Other possible factors like prime frequency, prime length, target frequency, and target length were also checked. The mean values for each factor and each condition are presented in Table 1.
Bonferroni posthoc tests showed that the targets of the pseudo-suffixed condition and the non-suffixed condition were significantly shorter than the targets in the other conditions (p < 0.0001 for all comparisons), while they did not significantly differ from each other. The reasons behind these differences were two-fold: Second graders chose the primes for the target words in the semantic condition, and words that seem to have a pseudo-suffix or a pseudo-stem are scarce in Turkish. In addition to these, finding derived and inflected words with a common target was another challenge for the truly suffixed condition. Therefore, the pseudo conditions (pseudo-suffixed and non-suffixed) and the truly suffixed condition could not be matched in terms of target length and prime length.
We used simple words for unrelated primes that had little or no orthographic similarity and no apparent semantic similarity to the targets in the semantic, pseudo-suffixed, and non-suffixed conditions (e.g., maske-yumurta, mask-egg). For the truly suffixed condition, we chose complex words as unrelated primes (since the experimental primes were also complex) that again had no apparent orthographic or semantic similarity with the relevant target words (e.g., bilge-hız, wise-speed). The lack of orthographic similarity for the unrelated primes was easy to determine, but the lack of semantic similarity was more subjective to evaluate. Therefore, we conducted a Target-Prime Relatedness test (see above) to ensure the lack of semantic similarity between unrelated primes and targets.
In addition to the experimental items, 100 filler words and 200 filler non-words were added to the design. We used highly frequent simple Turkish words as fillers considering our participants’ age range. These fillers were similar in length to our experimental items. The Turkish module of Wuggy (Keuleers & Brysbaert, 2010), a multilingual pseudoword generator, was used to create non-words. Our primes for fillers and nonwords had little or no orthographic and semantic similarity with their targets, thus they were all unrelated primes. A Latin-square design was used to create 4 different lists and 4 reversed versions of the same lists to avoid fatigue and task familiarity effects; therefore, each participant saw each target only once (in the truly suffixed condition, an experimental prime for a specific target was either an inflected or derived prime in the same list to ensure the single appearance of target words, and we balanced the number of derived and inflected primes among lists).
Procedure
The vocabulary tests and the spelling tests were administered on consecutive days in group settings with paper and pencil. Before the main masked priming experiment, a pilot study was conducted with 4 second-grade participants, using each list. The same procedures below were followed in the pilot, and as no problems were encountered, no changes were made to the materials and procedures in the main experiment.
Each participant completed the main experiment individually on an assigned day. The masked priming experiment was created using DMDX (Forster & Forster, 2003). For the presentation of the stimuli, an ASUS laptop with a screen size of 15.6 inches was used. The participants responded to the stimuli using a Logitech F510 wired gamepad. Items were presented in white Times New Roman 24 fonts on a black background. Trials began with a fixation cross remaining in the middle of the screen for 500 ms (ms). Just before the primes showed up, a mask having the same number of hashtags (#) with the upcoming prime was presented for 500 ms. This was followed by the presentation of the prime for a duration of 50 ms and the presentation of the target for 5000 ms or until participants responded. All primes were presented in lower case letters while the targets were presented in upper case letters to prevent visual continuity. If no answer was given within 5000 ms, the trial was classified as an incorrect answer. The masked priming experiment took approximately 40 minutes. The participants were told to respond to the words as quickly and accurately as they could by using their dominant hand. For nonwords, the non-dominant hand was used. Each participant completed a practice part with 10 trials before the real experiment. After the practice, we gave our participants a small word list including all the primes and targets used in the practice run and asked them to mark the words they had seen. None of the participants reported to have seen the prime words, and we concluded that our participants did not consciously see our 50 ms primes. All participants took a compulsory break after every 100 words in the main experiment (3 breaks were provided in total).
After the masked priming experiment, the participants read the text selected for their grade level and answered the comprehension questions, which were recorded using a Sony ICD-PX440 voice recorder. If a participant misread a word and did not correct it, this word was not counted. The researcher and the class teacher (with 20+ years of teaching experience) evaluated the answers to the comprehension questions. The average score for the comprehension test was 5.65 out of 10 (6.13 for second graders and 5.19 for fourth graders).
Responses with reaction times below 400 ms were taken as accidental key presses and were removed. Two second-grade and one fourth-grade participants had to be excluded due to high error rates in either word or non-word responses (> 70%). Thus, the eventual number of participants was 73 (37 second graders and 36 fourth graders).
Results
The final data was analyzed with R version 4.02. (R Core Team, 2021 ) and RStudio 1.3.1073 (Rstudio Team, 2020). We also used the R-packages ggplot2 (Version 3.3.5; Hadley Wickham, 2016), glmulti (Version 1.0.8; Vincent Calcagno, 2020), and lme4 (Version 1.1.27.1; Bates et al., 2014).
Table 2 displays the descriptive statistics for the main experiment and the individual tests by grade levels. The participants gave 1592 wrong answers for words (10.9%) and 1818 wrong answers for nonwords (12.4%) in a total of 29,200 trials (88.3% total accuracy); therefore, our final data points to analyze was 25,790. A Welch two-samples t-test was run to investigate the potential difference between words and nonwords in reaction times. The difference was significant t (139.99) = 6.23, p < 0.001, d = 1.53; the participants reacted faster to words than to nonwords.
Four separate Linear Mixed Models were run for the four different conditions (semantic, pseudo-suffixed, non-suffixed, and truly suffixed) using the lme4 package (Bates et al., 2014). We included reaction times to target words as the dependent variable. Fixed effects were Prime Type (Experimental, Unrelated), Grade (Second, Fourth), and Reading Proficiency. The last fixed effect, Reading Proficiency, was based on the reading proficiency measures in the study: We calculated the z-scores of each test (Vocabulary test, Spelling test, Reading speed measure, and Comprehension Test) per grade separately, and after this standardization process, we summed up those scores to create a composite proficiency score for each participant (see Chignell et al., 2015). The reaction times for the targets were transformed through reverse data transformation (-1000/RT). The full model formula for the Linear Mixed Models was as follows:
We used the glmulti package (Version 1.0.8; Vincent Calcagno, 2020) to find the best model fitting the data. If the suggested best model had interactions in the formula, we also checked the significance of the variables in these interactions. This package evaluates all the potential models including the full model and finds the best one based on the selected method. We chose the AIC (Akaike information criterion) method as it is advised when the true model is thought to be complex (Vrieze, 2012). In investigating the highly complex phenomenon of word processing, candidate models in studies are likely to be oversimplifications. In line with our model selection, the final models were the ones with the lowest AIC values (Lower scores indicate better fit).
For the semantic condition, there were significant main effects of grade level (beta = −0.27, t = −7.45, p < .001), and reading proficiency (beta = −0.02, t = −2.35, p = .022). The fourth graders responded faster than the second graders, and no priming effects were observed. Although experimental primes and grade levels seemed to interact with each other as the second-grade participants responded numerically faster to experimental items (Fig. 1), this interaction was not statistically significant (beta = −0.06, t = 1.96, p = .051).

Priming effects for the experimental primes in the semantic condition for different grade levels
For the pseudo-suffixed condition, there was a significant main effect of grade level (beta = -0.18, t = -4.96, p < .001). The fourth graders again responded faster than the second-grade participants; the experimental primes did not induce significant facilitative priming effects.
For the non-suffixed condition, there was a significant main effect of grade level (beta = −0.17, t = −4.83, p < .001). The fourth graders reacted faster to trials compared to their second-grade counterparts, without any priming effects for the experimental primes.
For the truly suffixed condition, there were significant main effects inflected primes (beta = −0.62, t = −2.96, p < .01), derived primes (beta = −0.61, t = −2.79, p = .01), grade level (beta = −0.25, t = −6.87, p < .001), and reading proficiency (beta = -0.02, t = −2.55, p = .013). In addition to the common finding of faster response latencies for the fourth graders, both prime types also led to significant facilitative priming effects (Fig. 2, Table 3).

Facilitative priming effects for the experimental primes in the truly suffixed condition
In summary, the fourth graders reacted faster than the second graders across all conditions (Table 3), and the truly suffixed condition resulted in the largest priming magnitudes as well as the only significant facilitative priming effects for the experimental primes (Table 4). The participants with higher reading proficiency scores gave faster responses to experimental primes (Fig. 3) and thus had faster reaction times across all conditions. These lower reaction times resulted in numerically lower numerical priming values in most conditions. However, the participants with higher proficiency scores also showed greater numerical priming effects in the pseudo-suffixed and non-suffixed conditions compared to their peers with relatively lower reading proficiency, contrary to the pattern in all other conditions (Fig. 4). This might indicate a developmental change in which increased proficiency might allow recognizing pseudo-suffixes and pseudo-stems while lower proficiency levels cannot use morpho-orthographic processing. In addition, the second graders reacted faster to the experimental primes in the pseudo-suffixed condition while the same primes were the most challenging for the fourth graders (Fig. 5), suggesting extra processing cost that might be due to a developing morpho-orthographic processing system for the older children in our sample. All significant findings are listed in Table 5.

Reaction times for experimental primes across different reading proficiency scores.

Numerical priming effect sizes for all experimental conditions across reading proficiency scores

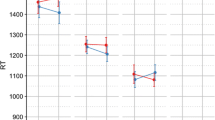
Reaction times for experimental primes in second graders (a) and fourth graders (b) (PS: Pseudo-suffixed primes, Non-S: Non-suffixed primes, Sem: Semantic primes, Der.: Derived primes, Inf.:Inflected primes)
Discussion
The aim of the present study was to investigate the little-known processes and mechanisms involved in complex word reading by developing readers. To this end, we ran a masked priming experiment to take a closer look at the early word recognition stages of primary school children in Turkish by examining the effects of suffixation, pseudo-suffixation, pseudo-stems, semantic similarity, and reading proficiency through different experimental conditions. The findings revealed a salient role for true suffixes in early word processing for developing readers, while pseudo morphemes (suffixes and stems) and semantic similarity failed to induce significant effects in our sample group. The role of proficiency was apparent in the responses and priming effect sizes, as the participants with higher reading proficiency responded faster to targets in the experimental conditions and showed more numerical priming effects in the pseudo-morpheme conditions (the pseudo-suffixed and non-suffixed conditions).
While the error rate percentages in the responses were similar for different types of primes and targets, the reaction times for the responses revealed significant differences. The sensitivity shown for suffixed words (the truly suffixed condition) was the most prominent finding, as only the primes with true suffixes led to significant facilitation effects while pseudo-suffixed primes failed to do so, in line with the earlier findings on morphological processing in young readers (Beyersmann et al., 2012; Beyersmann et al., 2015a, 2015b; Hasenäcker et al., 2015; Quémart et al., 2011). Just like adult readers (Amenta & Crepaldi, 2012), developing readers showed patterns indicating that morphemes in truly suffixed complex words are recognized and processed immediately during early word recognition. Besides showing morphological awareness in reading (Kuo & Anderson, 2006), the results suggest that young readers recognize the morphemes in complex words preconsciously in the very early stages of word recognition.
A further investigation of the current study regarding true suffixes was the potential difference between derivation and inflection in word processing. The primary school students showed comparable priming effects for the inflected and derived primes in the current study. The derivational suffix -lI is highly transparent, productive, and frequent in Turkish, just like the inflectional suffix -lA. Since varying morphological productivity and morphological systems might result in divergent word processing patterns for the developing readers of different languages (Fleischhauer et al., 2021), complex words derived with the suffix -lI might be decomposed like inflected words in Turkish because of these inflection-like characteristics. Such an assumption is further supported by the Dual-Route Model of Grainger and Ziegler (2011); this model accepts the possibility that the effective use of the fine-grained processing route, which is attributed to detaching common letter clusters like affixes, could hinder the development of the coarse-grained route that processes words as a whole. This hindrance might not block the use of the coarse-grained route completely; rather, it may lead to varying efficiency for this route in different languages. Other studies highlight that cross-linguistic differences, in general, were likely to affect word processing (e.g., Marcolini et al., 2011; Ziegler & Goswami, 2005). In a neuropsychological investigation, Raman and Weekes examined a Turkish-English bilingual with impaired language capabilities (Raman & Weekes, 2005a, 2005b; Weekes & Raman, 2008). The participant performed significantly worse in spelling derived nouns as opposed to simple nouns, suggesting that the representations of derived nouns are likely to differ from simple nouns in Turkish; organizing and adding suffixes to simple words to create complex ones is a characteristic of Turkish (Raman & Weekes, 2005b), and this behavior might eliminate the necessity of storing derived Turkish words as separate entries. Thus, the derived and inflected primes in the current study might have been processed similarly because of the characteristics of word processing in the Turkish language as well as their similar characteristics (transparency, productivity, and high frequency).
Contrary to the facilitation priming observed for the true suffixes, a numeric delay effect (−59.14 ms) was observed for the pseudo-suffixed primes. As predicted at the outset of the study, the presence of two semantically unrelated words in each prime (e.g., corner and corn in corner) might have caused competition and resulted in this delay effect (Beyersmann et al., 2015a, 2015b). One reason behind the lack of a similar delay effect in the non-suffixed condition might be the absence of pseudo-suffixes; the pseudo-stems in the non-suffixed condition was possibly not recognized without the presence of a suffix or a suffix-like ending (e.g., while car is a pseudo-stem in carrot, rot is not a suffix in English). Therefore, young readers of Turkish might require both stems and suffixes to apply morphological segmentation, just as the young readers of French reported in Quémart et al. (2011)
The lack of priming effects in the pseudo-suffixed condition might also be indicative of a developmental pattern. The development of morpho-semantic processing appears to be completed in our sample, but the development of the morpho-orthographic processing mechanisms is possibly still ongoing. Remember that Beyersmann et al. (2021) observed priming effects for both truly suffixed and pseudo-suffixed primes in French third graders while the readers of a shallower orthography, German, showed no signs of morphological processing in either prime type. It may take readers of shallow orthographies longer to develop their morpho-semantic and morpho-semantic processing mechanisms. This might also explain the absence of priming effects for the fourth and lower grades in Oliveira and Justi (2017), a study conducted in another shallow-orthography language. Suffix-stripping behavior in Turkish has its roots in infancy as infants produce root words, which are rare in Turkish (Raman & Yildiz, 2022). Organizing and using suffixes to create complex words brings additional load to the cognitive system (Raman & Weekes, 2005b), and similarly, stripping off suffixes or pseudo-suffixes from words might require extra processing effort. Our second graders reacted fastest with the pseudo-suffixed primes and slowest with the truly suffixed primes (Fig. 5). While using morphological decomposition for the truly suffixed words and reflecting the extra cost in their reaction times, the second graders in our sample might not have recognized the pseudo-suffixes and perceived the pseudo-suffixed primes as simple words due to their underdeveloped morpho-orthographic processing system, resulting in a processing advantage for shorter target words in this condition. On the contrary, our fourth graders gave their slowest responses for the pseudo-suffixed and non-suffixed conditions. Recognizing and decomposing pseudo-suffixes and pseudo-stems might have increased the cognitive effort in morphological processing, which might be an indicator of a developing morpho-orthographic processing system. Turkish young readers, who seem to achieve automatized morpho-semantic processing rather early, then might develop a fully automatized morpho-orthographic processing system subsequently. Accordingly, Turkish readers might show significant priming effects for pseudo-suffixes and pseudo-stems in grades later than the fourth grade, similar to the findings of Fleischhauer et al. (2021), in which a developmental pattern was suggested as the younger readers in the study showed only morpho-semantic priming while the participants in a later grade level showed both morpho-semantic and morpho-orthographic priming.
Reading proficiency was a significant factor in the reaction times and priming effect sizes in our results. The participants with higher reading proficiency scores responded faster in the experimental conditions (Fig. 3), and this finding supports previous research that links reading proficiency and word recognition (e.g., Yap et al., 2012). When it comes to priming effects, higher proficiency predicted higher numeric values for the priming in the pseudo-morpheme conditions, despite faster overall responses that generally result in lower numerical priming values (Fig. 4). This finding seems to be consistent with the findings of Hasenäcker et al. (2020), in which a subset of young developing readers with high reading proficiency repeatedly showed priming effects with suffixed and non-suffixed nonwords, showing that skilled young readers benefit from pseudo-suffixes or orthographic similarity. Similarly, Beyersmann et al., (2015a, 2015b) found priming effects with pseudo-suffixed nonword primes with highly proficient readers, but this effect size was smaller than the priming effect obtained for truly suffixed primes. The highly proficient readers in our study also showed significant priming effects in the truly suffixed condition, whereas the priming effects for the pseudo-morpheme conditions were not significant but still higher than those of other participants. The lack of significant priming of such units in good readers despite greater priming sizes in our study might be related to the competition between two real word stems in pseudo-suffixed word primes (Beyersmann et al., 2015a, 2015b), as mentioned above. Similar studies including pseudo-suffixed nonword primes in Turkish will help shed light on this issue. Taken all together, developing readers of Turkish with high reading proficiency seem to start recognizing pseudo-morphemic units, as well as morphemic units, even in the early stages of word processing. Developing readers might depend solely on morpho-semantic processing at beginning levels (Hasenäcker et al., 2015), and this might also explain why only the younger participants in our sample showed more numerical priming effects in the semantic condition (Fig. 1). As reading proficiency and grade level increase, the efficiency of morpho-orthographic processing might also increase and introduce the emergence of pseudo-morphemic priming. Alternatively, the increased efficiency of morpho-semantic processing might allow both the development of morpho-orthographic processing and increased reading proficiency.
This study has shown that developing readers as young as 7 years old can rapidly recognize real morphemes in complex words, and they are likely to recognize pseudo-morphemes in monomorphemic structures as their morpho-orthographic processing develops with increasing grade level, reading proficiency, or efficiency of morpho-semantic processing. The crucial importance of learning more about the developmental path to skilled reading (Castles et al., 2018; Dawson et al., 2021) is underlined at the beginning of our study. As the current results indicate faster developing morpho-semantic processing compared to morpho-orthographic processing, this rapid initial development should further be supported by explicit instruction on semantically meaningful morphemes, like suffixes. Fast-developed morpho-semantic processing mechanism(s) might also allow a faster development of morpho-orthographic mechanism(s) and a higher reading proficiency. The next section explores this potentially beneficial teaching practice.
Implications for reading instruction
The findings of the present study suggest that real suffixes are salient units in early word processing even in the second grade if the patterns of word processing observed in the current task are like the patterns in natural reading. It is therefore plausible to support the development of these units. Although there have been some objections to the explicit instruction of morphemes in the early grades, the extensive literature review of Bowers et al. (2010) on morphological instruction suggests that such instruction is as effective in the early grades as it is for the later grades. Similarly, the meta-analysis of Goodwin and Ahn (2010) shows that morphological instruction improves spelling, vocabulary knowledge, morphological awareness, and phonological awareness. Morphological instruction is then likely to increase the efficiency of the development of morpho-semantic processing, which in turn contributes to reading proficiency (or vice versa) and the development of morpho-orthographic processing. Remember that higher reading proficiency emerged as the indicator of faster word recognition and of more priming effects in pseudo-morphemic conditions in the current study. Taken together, explicit morpheme instruction in Turkish primary schools will have positive effects on the reading proficiency and word processing of Turkish primary school children.
Limitations
Some pseudo-suffixes in the pseudo-suffixed condition did not comply with the rules of Turkish Vowel Harmony (e.g. the pseudo-suffix –a in the Turkish word bina). This is a potential confounding factor that future studies should investigate. Also, four derived word primes in the truly suffixed condition had ambiguous suffixation, which could indicate both derived and inflected word interpretations. However, removing these four words did not change the significance of the results in a separate analysis. We had a limited number of participants in each grade, which prevented us from analyzing individual differences separately for each grade level. Finally, we only considered the surface frequency values of our items, but base and ngram frequencies are also argued to have an influence on morphological processing (see Bilgin, 2016). Since the corpus we used at the time lacked such features, future studies should consider these measurements as well.
Data and code availability
The data and the R-script used for analyses are available on https://osf.io/dyb9w/?view_only=d027a43432984f29a19ca3c0b1662598. The files will be made public after the publication.
Notes
We follow the standard conventions of Turkish linguistics by using capital letters in morphemes to indicate underspecified vowels which undergo vowel harmony. –lA stands for the two surface-level variations of the suffix: -le and -la. In the case of –lI, these are –lı, -li, –lu, and –lü.
References
Acha, J., Laka, I., & Perea, M. (2010). Reading development in agglutinative languages: Evidence from beginning, intermediate, and adult Basque readers. Journal of Experimental Child Psychology, 105(4), 359–375. https://doi.org/10.1016/j.jecp.2009.10.008
Aksan, Y., Aksan, M., Koltuksuz, A., Sezer, T., Mersinli, Ü., Demirhan, U. U., Yilmazer, H., Atasoy, G., Öz, S., Yildiz, I., & Kurtoğlu, Ö. (2012). Construction of the Turkish National Corpus (TNC). LREC, pp. 3223–3227.
Amenta, S., & Crepaldi, D. (2012). Morphological processing as we know it: An analytical review of morphological effects in visual word identification. Frontiers in Psychology, 3, 232. https://doi.org/10.3389/fpsyg.2012.00232
Andrews, S., & Lo, S. (2013). Is morphological priming stronger for transparent than opaque words? It depends on individual differences in spelling and vocabulary. Journal of Memory and Language, 68(3), 279–296. https://doi.org/10.1016/j.jml.2012.12.001
Babayiğit, S., & Stainthorp, R. (2007). Preliterate phonological awareness and early literacy skills in Turkish. Journal of Research in Reading, 30(4), 394–413. https://doi.org/10.1111/j.1467-9817.2007.00350.x
Barouch, B., Weiss, Y., Katzir, T., & Bitan, T. (2022). Neural processing of morphology during reading in children. Neuroscience, 485, 37–52. https://doi.org/10.1016/j.neuroscience.2021.12.025
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2014). Fitting linear mixed-effects models using lme4. arXiv preprint arXiv:1406.5823. https://doi.org/10.18637/jss.v067.i01
Behrang, S. (1968). The little black fish. Institute for the Intellectual Development of Children and Young Adults.
Beyersmann, E., Casalis, S., Ziegler, J. C., & Grainger, J. (2015a). Language proficiency and morpho-orthographic segmentation. Psychonomic Bulletin & Review, 22(4), 1054–1061. https://doi.org/10.3758/s13423-014-0752-9
Beyersmann, E., Castles, A., & Coltheart, M. (2012). Morphological processing during visual word recognition in developing readers: Evidence from masked priming. Quarterly Journal of Experimental Psychology, 65(7), 1306–1326. https://doi.org/10.1080/17470218.2012.656661
Beyersmann, E., Grainger, J., Casalis, S., & Ziegler, J. C. (2015b). Effects of reading proficiency on embedded stem priming in primary school children. Journal of Experimental Child Psychology, 139, 115–126. https://doi.org/10.1016/j.jecp.2015.06.001
Beyersmann, E., Mousikou, P., Schroeder, S., Javourey-Drevet, L., Ziegler, J. C., & Grainger, J. (2021). The dynamics of morphological processing in developing readers: A cross-linguistic masked priming study. Journal of Experimental Child Psychology, 208, 105140. https://doi.org/10.1016/j.jecp.2021.105140
Bilgin, O. (2016). Frequency effects in the processing of morphologically complex Turkish words. [Unpublished Master’s Thesis]. Bogazici University.
Bowers, P. N., Kirby, J. R., & Deacon, S. H. (2010). The effects of morphological instruction on literacy skills: A systematic review of the literature. Review of Educational Research, 80(2), 144–179. https://doi.org/10.3102/0034654309359353
Carlisle, J. F. (2000). Awareness of the structure and meaning of morphologically complex words: Impact on reading. Reading and Writing, 12(3), 169–190. https://doi.org/10.1023/A:1008131926604
Casalis, S., Quémart, P., & Duncan, L. G. (2015). How language affects children’s use of derivational morphology in visual word and pseudoword processing: Evidence from a cross-language study. Frontiers in Psychology, 6, 452. https://doi.org/10.3389/fpsyg.2015.00452
Castles, A., Rastle, K., & Nation, K. (2018). Ending the reading wars: Reading acquisition from novice to expert. Psychological Science in the Public Interest, 19(1), 5–51. https://doi.org/10.1177/1529100618772271
Chignell, M., Tong, T., Mizobuchi, S., Delange, T., Ho, W., & Walmsley, W. (2015). Combining multiple measures into a single figure of merit. Procedia Computer Science, 69, 36–43. https://doi.org/10.1016/j.procs.2015.10.004
Clahsen, H., & Fleischhauer, E. (2014). Morphological priming in child German. Journal of Child Language, 41(6), 1305–1333. https://doi.org/10.1017/S0305000913000494
Davis, C. J. (2010). Match calculator. Computer Software. Available at http://www.pc.rhul.ac.uk/staff/c.davis/. Accessed, 21.
Dawson, N., Rastle, K., & Ricketts, J. (2021). Finding the man amongst many: A developmental perspective on mechanisms of morphological decomposition. Cognition, 211, 104605. https://doi.org/10.1016/j.cognition.2021.104605
Deacon, S. H., Campbell, E., Tamminga, M., & Kirby, J. (2010). Seeing the harm in harmed and harmful: Morphological processing by children in Grades 4, 6, and 8. Applied Psycholinguistics, 31(4), 759. https://doi.org/10.1017/S0142716410000238
Diependaele, K., Sandra, D., & Grainger, J. (2009). Semantic transparency and masked morphological priming: The case of prefixed words. Memory & Cognition, 37(6), 895–908. https://doi.org/10.3758/MC.37.6.895
Duncan, L. G., Casalis, S., & Colé, P. (2009). Early metalinguistic awareness of derivational morphology: Observations from a comparison of English and French. Applied Psycholinguistics, 30(3), 405–440. https://doi.org/10.1017/S0142716409090213
Durgunoğlu, A. Y. (2003). Recognizing morphologically complex words in Turkish. In Reading complex words (pp. 81–92). Springer. https://doi.org/10.1007/978-1-4757-3720-2_4
Durgunoğlu, A. Y. (2006). Learning to read in Turkish. Developmental Science, 9(5), 437–439. https://doi.org/10.1111/j.1467-7687.2006.00522.x
Durgunoğlu, A. Y., & Öney, B. (1999). A cross-linguistic comparison of phonological awareness and word recognition. Reading and Writing, 11(4), 281–299. https://doi.org/10.1023/A:1008093232622
Durrant, P. (2013). Formulaicity in an agglutinating language: The case of Turkish. Corpus Linguistics and Linguistic Theory, 9(1), 1–38. https://doi.org/10.1515/cllt-2013-0009
Feldman, L. B. (1994). Beyond orthography and phonology: Differences between inflections and derivations. Journal of Memory and Language, 33(4), 442–470. https://doi.org/10.1006/jmla.1994.1021
Feldman, L. B., Rueckl, J., Diliberto, K., Pastizzo, M., & Vellutino, F. R. (2002). Morphological analysis by child readers as revealed by the fragment completion task. Psychonomic Bulletin & Review, 9(3), 529–535. https://doi.org/10.3758/BF03196309
Feldman, L. B., Kostić, A., Gvozdenović, V., O’Connor, P. A., del Prado, M., & Martín, F. (2012). Semantic similarity influences early morphological priming in Serbian: A challenge to form-then-meaning accounts of word recognition. Psychonomic Bulletin & Review, 19(4), 668–676. https://doi.org/10.3758/s13423-012-0250-x
Fleischhauer, E., Bruns, G., & Grosche, M. (2021). Morphological decomposition supports word recognition in primary school children learning to read: Evidence from masked priming of German derived words. Journal of Research in Reading, 44(1), 90–109. https://doi.org/10.1111/1467-9817.12340
Forster, K. I., & Davis, C. (1984). Repetition priming and frequency attenuation in lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10(4), 680. https://doi.org/10.1037/0278-7393.10.4.680
Forster, K. I., & Forster, J. C. (2003). DMDX: A Windows display program with millisecond accuracy. Behavior Research Methods, Instruments, & Computers, 35(1), 116–124. https://doi.org/10.3758/BF03195503
Göksel, A., & Kerslake, C. (2004). Turkish: A comprehensive grammar. Routledge. https://doi.org/10.4324/9780203340769
Goodwin, A. P., & Ahn, S. (2010). A meta-analysis of morphological interventions: Effects on literacy achievement of children with literacy difficulties. Annals of Dyslexia, 60(2), 183–208. https://doi.org/10.1007/s11881-010-0041-x
Grainger, J., & Ziegler, J. (2011). A dual-route approach to orthographic processing. Frontiers in Psychology, 2, 54. https://doi.org/10.3389/fpsyg.2011.00054
Hankamer, J. (1989). Morphological parsing and the lexicon. In Lexical representation and process (pp. 392–408).
Hasenäcker, J., Beyersmann, E., & Schroeder, S. (2020). Morphological priming in children: Disentangling the effects of school-grade and reading skill. Scientific Studies of Reading, 24(6), 484–499. https://doi.org/10.1080/10888438.2020.1729768
Hasenäcker, J., Beyersmann, E., & Schroeder, S. (2015). Language proficiency moderates morphological priming in children and adults. NetWordS, 132–135.
Hasenäcker, J., Solaja, O., & Crepaldi, D. (2021). Does morphological structure modulate access to embedded word meaning in child readers? Memory & Cognition. https://doi.org/10.3758/s13421-021-01164-3
Jacob, G., & Kırkıcı, B. (2016). The processing of morphologically complex words in a specific speaker group: A masked-priming study with Turkish heritage speakers. The Mental Lexicon, 11(2), 308–328. https://doi.org/10.1075/ml.11.2.06jac
Jacob, G., Şafak, D. F., Demir, O., & Kırkıcı, B. (2019). Preserved morphological processing in heritage speakers: A masked priming study on Turkish. Second Language Research, 35(2), 173–194. https://doi.org/10.1177/0267658318764535
Kazanina, N., Dukova-Zheleva, G., Geber, D., Kharlamov, V., & Tonciulescu, K. (2008). Decomposition into multiple morphemes during lexical access: A masked priming study of Russian nouns. Language and Cognitive Processes, 23(6), 800–823. https://doi.org/10.1080/01690960701799635
Keuleers, E., & Brysbaert, M. (2010). Wuggy: A multilingual pseudoword generator. Behavior Research Methods, 42(3), 627–633. https://doi.org/10.3758/BRM.42.3.627
Kibaroğlu, O. (1991). Spell Checking in Agglutinative Languages and an Implementation for Turkish. [Unpublished master's thesis]. Boğaziçi University.
Kırkıcı, B., & Clahsen, H. (2013). Inflection and derivation in native and non-native language processing: Masked priming experiments on Turkish. Bilingualism: Language and Cognition, 16(4), 776. https://doi.org/10.1017/S1366728912000648
Kuo, L., & Anderson, R. C. (2006). Morphological awareness and learning to read: A cross-language perspective. Educational Psychologist, 41(3), 161–180. https://doi.org/10.1207/s15326985ep4103_3
Ladányi, E., Kovács, Á. M., & Gervain, J. (2020). How 15-month-old infants process morphologically complex forms in an agglutinative language? Infancy, 25(2), 190–204. https://doi.org/10.1111/infa.12324
Lahaussois, A., & Vuillermet, M. (2019). Methodological tools for linguistic description and typology. University of Hawai’i Press.
Longtin, C.-M., Segui, J., & Hallé, P. A. (2003). Morphological priming without morphological relationship. Language and Cognitive Processes, 18(3), 313–334. https://doi.org/10.1080/01690960244000036
Majid, A., Bowerman, M., Kita, S., Haun, D. B. M., & Levinson, S. C. (2004). Can language restructure cognition? The case for space. Trends in Cognitive Sciences, 8(3), 108–114. https://doi.org/10.1016/j.tics.2004.01.003
Marcolini, S., Traficante, D., Zoccolotti, P., & Burani, C. (2011). Word frequency modulates morpheme-based reading in poor and skilled Italian readers. Applied Psycholinguistics, 32(3), 513. https://doi.org/10.1017/S0142716411000191
Marquis, A., & Shi, R. (2012). Initial morphological learning in preverbal infants. Cognition, 122(1), 61–66. https://doi.org/10.1016/j.cognition.2011.07.004
Martin, N., & Gupta, P. (2004). Exploring the relationship between word processing and verbal short-term memory: Evidence from associations and dissociations. Cognitive Neuropsychology, 21(2–4), 213–228. https://doi.org/10.1080/02643290342000447
Mintz, T. H. (2013). The segmentation of sub-lexical morphemes in English-learning 15-month-olds. Frontiers in Psychology, 4, 24. https://doi.org/10.3389/fpsyg.2013.00024
Oliveira, B. S. F. D., & Justi, F. R. D. R. (2017). Morphological priming development in Brazilian Portuguese-speaking children. Psicologia: Reflexão e Crítica, 30. https://doi.org/10.1186/s41155-017-0058-8
Öney, B., & Durgunoğlu, A. Y. (1997). Beginning to read in Turkish: A phonologically transparent orthography. Applied Psycholinguistics, 18(1), 1–15. https://doi.org/10.1017/S014271640000984X
Quémart, P., Casalis, S., & Colé, P. (2011). The role of form and meaning in the processing of written morphology: A priming study in French developing readers. Journal of Experimental Child Psychology, 109(4), 478–496. https://doi.org/10.1016/j.jecp.2011.02.008
R Core Team. (2021). R: A Language and environment for statistical computing. https://www.R-project.org/
Rabin, J., & Deacon, H. (2008). The representation of morphologically complex words in the developing lexicon. Journal of Child Language, 35(2), 453. https://doi.org/10.1017/S0305000907008525
Raman, I., & Weekes, B. (2008). Cognitive neuropsychology of acquired language disorders in a Turkish-English bilingual case. In Proceedings of the 10th international conference on cognitive neuroscience. https://doi.org/10.3389/conf.neuro.09.2009.01.228
Raman, I., & Weekes, B. S. (2005a). Acquired dyslexia in a Turkish-English speaker. Annals of Dyslexia, 55(1), 79–104. https://doi.org/10.1007/s11881-005-0005-8
Raman, I., & Weekes, B. S. (2005b). Deep dysgraphia in Turkish. Behavioural Neurology, 16(2–3), 59–69. https://doi.org/10.1155/2005/568540
Raman, I., & Yildiz, Y. (2022). Orthographical, phonological, and morphological challenges in language processing: The case of Bilingual Turkish-English Speakers. In I. R. Management Association (Ed.), Research anthology on bilingual and multilingual education (pp. 304–326). IGI Global. https://doi.org/10.4018/978-1-6684-3690-5.ch017
Rastle, K., Davis, M. H., Marslen-Wilson, W. D., & Tyler, L. K. (2000). Morphological and semantic effects in visual word recognition: A time-course study. Language and Cognitive Processes, 15(4–5), 507–537. https://doi.org/10.1080/01690960050119689
Rastle, K., Davis, M. H., & New, B. (2004). The broth in my brother’s brothel: Morpho-orthographic segmentation in visual word recognition. Psychonomic Bulletin & Review, 11(6), 1090–1098. https://doi.org/10.3758/BF03196742
Raveh, M. (2002). The contribution of frequency and semantic similarity to morphological processing. Brain and Language, 81(1–3), 312–325. https://doi.org/10.3758/BF03196742
RStudio Team. (2020). RStudio: Integrated development environment for R. RStudio, PBC. http://www.rstudio.com/
Schreuder, R., & Baayen, R. H. (1995). Modeling morphological processing. Morphological Aspects of Language Processing, 2, 257–294.
Seymour, P. H. K., Aro, M., Erskine, J. M., & Collaboration with COST Action A8 Network. (2003). Foundation literacy acquisition in European orthographies. British Journal of Psychology, 94(2), 143–174. https://doi.org/10.1348/000712603321661859
Spencer, A. (2016). Two Morphologies or One?: Inflection versus Word-formation. In A. Hippisley & G. Stump (Eds.), The Cambridge Handbook of Morphology (pp. 27–49). Cambridge University Press. https://doi.org/10.1017/9781139814720.002
Tumanov, V. A. (2002). Jayden’s rescue. Scholastic Canada Toronto, ON.
Uygun, S., & Clahsen, H. (2021). Morphological processing in heritage speakers: A masked priming study on the Turkish aorist. Bilingualism: Language and Cognition, 24(3), 415–426. https://doi.org/10.1017/S1366728920000577
Vincent Calcagno. (2020). glmulti: Model Selection and Multimodel Inference Made Easy. https://CRAN.R-project.org/package=glmulti
Vrieze, S. I. (2012). Model selection and psychological theory: A discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychological Methods, 17(2), 228. https://doi.org/10.1037/a0027127
Wickham, H. (2016). ggplot2: Elegant Graphics for Data Analysis. Springer, New York. https://ggplot2.tidyverse.org. https://doi.org/10.1007/978-3-319-24277-4
Yap, M. J., Balota, D. A., Sibley, D. E., & Ratcliff, R. (2012). Individual differences in visual word recognition: Insights from the English Lexicon Project. Journal of Experimental Psychology: Human Perception and Performance, 38(1), 53. https://doi.org/10.1037/a0024177
Ziegler, J. C., & Goswami, U. (2005). Reading acquisition, developmental dyslexia, and skilled reading across languages: A psycholinguistic grain size theory. Psychological Bulletin, 131(1), 3. https://doi.org/10.1037/0033-2909.131.1.3
Acknowledgements
The authors wish to thank Hasibe Kahraman for her contribution to the R-script, Ozan Çağlar and Esra Ataman for their suggestions on the analyses, and Martina Gračanin Yüksek and Özgür Aydın for their suggestions on the study design.
Funding
The authors did not receive support from any organization for the submitted work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors certify that they have no relevant financial or non-financial interests to disclose.
Consent
Participation in the study was voluntary with the requirement of getting written consent from the parents.
Ethics approval
In addition to the approval of the University Ethics Committee, the authors also got permissions from the Ministry of Education, school principals, and teachers.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Oğuz, E., Kırkıcı, B. The processing of morphologically complex words by developing readers of Turkish: a masked priming study. Read Writ 36, 2053–2080 (2023). https://doi.org/10.1007/s11145-022-10377-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11145-022-10377-0