
Abstract
Young children, who are exposed to Latin script letters, experience difficulties in distinguishing between the reversible letters b and d and may therefore transform b into d (and vice versa). When children begin to write, in cultures with left-to-right writing/reading systems, they also often turn Arabic digits in the direction of writing/reading, thus, for example, producing ε instead of 3. However, two different terms or processes, namely, confusion and reversal, are used in the literature to label these apparent transformations. This study aimed to provide empirical evidence that the two processes are indeed very different. The sample consisted of 529 first graders (Mage = 6.21 years) who participated in the French National Assessment at the beginning of the school year. Simple linear, Bayesian, and logistic regression modeling of the left–right reversal rate in writing digits as a function of the confusion rate in children’s recognition of the letters b and d showed a negative relationship between the two rates, and a nonparametric test yielded a significant negative correlation (rS(318) = –0.373, p < .001). These results seem to rule out the possibility that the same process leads to reversing characters (letters or digits) in writing and misrecognizing b as d (or vice versa). This is the first study reporting strong empirical evidence that the processes of reversal and confusion are very different. Consequently, it would be a mistake to treat confusion between b and d as the reversal of b into d (and vice versa).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The reading and, to a lesser degree, the writing of the reversible letters b and d are well-studied paradigms in the literature, whether psychological, educational or neuroscientific (e.g., Ahr et al., 2016; Brault-Foisy et al., 2017; Fernandes & Leite, 2017; Fernandes et al., 2021; Pegado et al., 2011; Perea et al., 2011; Sidman & Kirk, 1974; Smith & Lovitt, 1973; Soares et al., 2019; Torres et al., 2021). However, traditionally, authors use two terms or processes to describe the apparent transformation of b into d (and vice versa): reversal (e.g., Frith, 1971), confusion (e.g., Davidson, 1935), and sometimes both (e.g., Liberman et al., 1971). This nondistinction of these two very different terms and processes is currently communicated and has been considerably expanded by numerous internet sites that aim to help parents who are often concerned with their child potentially having developmental dyslexia. For example, when searching the internet with the Google search engine during the preparation of the article, we found, using the key words “confusion versus reversal of b and d”, the following three articles: 1. “Is flipping ‘b’ and ‘d’ a sign of dyslexia?”; 2. “When b and d letter reversal is a problem”; and 3. “'b' and 'd'—Stop the confusion!”. However, in the vernacular, the difference between confusion and reversal is quite clearly delimited. Confusion leads to a state of bewilderment, misunderstanding or chaos; thus, confusion has a negative connotation even though it can accompany a state of cognitive disequilibrium that can be beneficial to learning (D’Mello et al., 2014). In contrast, reversal has a rather positive connotation. In adults, it is an understatement to say that the right-to-left reversed annotations added to Leonardo da Vinci’s drawings have not devalued them (Pevsner, 2002). In children, reversals are often precise and not blurred, as shown by the reversal writings reproduced in the literature (e.g., Fischer & Tazouti, 2012). In addition, they even reflect a form of creativity because children write symbols (letters, digits, words, and numbers) as they have generally never seen them before.
The distinction of b and d has become so important that it was chosen to illustrate the brain pathways for mirror discrimination learning during reading acquisition by Pegado et al. (2014) and Torres et al. (2021). In the twenty-first century, and particularly since the publication of Dehaene’s book (2009; see also Corballis & Beale, 1976), it is generally assumed that the process of symmetrization or generalization counteracts the encoding of character (letters or digits) orientation in memory. This important finding rapidly led researchers to suggest that reversals in word reading are related to “an inadequate suppression of symmetry generalized information” (Brendler & Lachmann, 2001, p. 313). Somewhat paradoxically, Lachmann and Van Leeuwen (2007) even showed that children with developmental dyslexia could benefit from nonsuppression in a same-different task involving pairs of letters, in which two symmetrical letters must be rated as the “same” (for further demonstrations, see Fernandes & Leite, 2017; Fernandes et al., 2016). It is possible that this generalization process was developed by our ancestors, who, to survive, had to recognize a tiger (or other dangerous animal) from its left profile when they had only seen it from its right profile (Rollenhagen & Olson, 2000). Because of this process, children beginning to read and write are not expected to distinguish b and d, two reversible letters; that is, letters whose left–right reversal is also legible, with p and q being the only other reversible letters in the Roman alphabet (Perea et al., 2011).
The cerebral process of generalization can lead children to read/write b instead of d or d instead of b, and p instead of q or q instead of p. For example, the 10 children (Mage = 9.3 years) with reading disabilities studied by Terepocki et al. (2002) produced 12 printings of b as d and 2 printings of p as q for the target words of a controlled writing task. However, they also produced 3 printings of b as p and 1 printing of p as d. Moreover, such writing errors should not be limited to the letters b/d and p/q. In fact, the generalization process should also lead children to replace, when writing, any other letter with its reversal, for example, ɑ with ɒ and h with ⑁. To test whether this is the case, we used data from Table 1 of the Lewis and Lewis study (1965). This table reports the reversal errors made by 354 first-grade pupils copying the manuscript forms of all lowercase letters. Our calculation yielded a larger median number of reversal errors for the reversible letters (b, d, p, q) than for the nonreversible (and asymmetric) letters (33 versus 7, respectively), a difference that was significant with the bilateral two-sample Wilcoxon test (p < 0.05). Similarly, we analyzed the two reversal datasets constructed by Fischer and Luxembourger (2021) with data from Torres et al. (2021) on Brazilian first-graders writing in a particular condition (without visual control: participants observed a letter for 3 s and then had to write the letter immediately afterwards while blindfolded). Again, the median percentage of reversal errors in the {b, d, p, q} subset was much larger than that in the other letter subset (both p < 0.05). Why does the reversal frequency in the subsets of reversible letters and other nonreversible (but asymmetric) letters quantitatively differ?
 , or B, and [de] written as d,
, or B, and [de] written as d,  , or D, for the 527 children
, or D, for the 527 childrenAn obvious reason is that reversed, nonreversible letters, which do not exist in the alphabet, are not reinforced through reading. This suggests a general difference between the reversals of characters based on whether their reversed version is reinforced. Therefore, the reversal process of Arabic digits, which do not have legible reversals, should differ from that of b and d. To differentiate the cognitive processes supporting this difference, we will discuss confusion if the reversal process concerns characters whose reversal is reinforced through reading. The choice of the term “confusion” for the reversal of reversible letters is also motivated by the similarities in the shapes and sounds of the letters b and d, each consisting of a vertical line and a loop at the bottom (the same holds for p and q, but the loop is at the top). This distinction between confusion and reversal is at the heart of the following analysis of a selection of items from the French 2020 National Assessment of first-grade students (MENJ, 2020).
Several priming experiments have highlighted the particularity of reversible letters. Ahr et al. (2016) found negative priming in elementary school students: when two animals were presented, one simply a mirror image of the other, children took longer to judge them as identical when the image was preceded by the reversible letters b/d than when it was preceded by the nonreversible letters f/t. Consistent with the prominent role of writing direction in explaining reversal (Fischer, 2017; Portex et al., 2018), Soares et al. (2019) found that d-words (i.e., words containing left-facing letters), but not b-words, showed interference effects for reversible letters in their masked lexical decision priming experiments. More directly related to our current distinction between reversed reversible characters and reversed nonreversible characters, Perea et al. (2011) showed a difference between the reversal of a reversible letter (e.g., d and b) and the reversal of a nonreversible letter (e.g., r and  ). For example, priming “idea” with “ibea” has a greater effect than priming “arena” with “a
). For example, priming “idea” with “ibea” has a greater effect than priming “arena” with “a ena”.
ena”.
Another limitation of the explanatory power of the symmetrization process comes from its restriction to left–right reversal. It cannot therefore account for other forms of transformations, such as upside-down inversion (e.g., b transformed in p) or 180° rotation on the plane (e.g., q transformed into b, 9 into 6). For example, the symmetrization process cannot explain why Liberman et al. (1971) found, in a word context, that their second-graders (with low reading proficiency) confused b with p on 13.7% of the occasions, but confused it with d only on 10.2% of the occasions. In contrast, the graphic and phonetic similarities between b and p can easily explain why they are confused.
The idea of the distinction between confusion and reversal is not entirely new. For example, Terepocki et al. (2002) suggested that nonreversible letter orientation errors “may reflect processes different from those related to orientation errors of reversible letters” (p. 218). However, Terepocki et al. did not explicitly distinguish confusion and reversal, speaking only of “orientation errors” in both cases. Moreover, the context—reversal is now considered a consequence of the process of cerebral symmetrization—has changed. This change may be partly responsible for the unsystematic use of the word and notion of confusion with respect to the reversible letters b, d, p, and q, although these letters were referred to as confusing in an early paper by Davidson (1935). This change also has methodological consequences. For example, the digits 6 and 9 are not reversible digits, contrary to their description by Terepocki et al. (p. 220), because one is not the left–right reversal of the other (it is the 180° rotation of the other). Finally, our demonstration, mainly based on the study of the correlation between confusion (of b with d) and reversal (of digits, when writing from memory), is quite original in the literature. Indeed, to the best of our knowledge, the only a priori relevant research—by McIntosh et al. (2018)—on the correlation between mirror writing and recognition errors excluded the reversible letters b/d and p.
If confusion and reversal are two different and somewhat independent processes, as the preceding analyses (and their different names) suggest, a child who confuses b and d has no compelling reason to reverse the digits more than a child who does not confuse them. Thus, the main hypothesis of the present research was that b/d confusion should not predict the digit reversal rate (or vice versa). With the nonparametric Spearman test, we simply predicted that the confusion rate would not positively correlate with the digit reversal rate.
The data also allowed for the testing of two secondary hypotheses. First, the rate of orientation errors for the letters b and d should be higher than that for asymmetric digits, even though the latter rate concerns a writing-from-memory task, which is more complex than a recognition task (a specific demonstration can be found in Fischer & Thierry, 2021). The reason that orientation errors might be more common for the letters b and d than for digits is that they can result from both reversal and confusion, and confusion should primarily affect reversible letters (no digit is reversible). Second, distinguishing the left-oriented digits (1, 2, 3, 7, 9: see Fischer, 2013) from the other digits (4, 5, 6) should allow for the testing of the right-orientation rule (Fischer & Luxembourger, 2018). This rule predicts that unsure children who orient the characters in the direction of their culture’s writing will mainly reverse the left-oriented characters.Footnote 1
Methods
Participants
The students were tested at the beginning of the school year (September–October) in the framework of the French National Assessment upon entry to elementary school. Access to the data from this assessment was possible as part of a more general project (LINUMEN: see http://linumen.univ-lorraine.fr/) and approved by the academic authorities. The 529 participants’ ages ranged from 5 years 8 months to 6 years 8 months (Mage = 6.21, SD = 0.28; 257 girls). They were recruited from 32 different schools in a medium-sized French city and its greater suburbs. According to the inspectors of the districts where the schools are located, these students approximately represent the characteristics of the French population. In addition, all of these students attended the upper section of the école maternelle.Footnote 2 Thus, according to the French curriculum, they had already been introduced to Arabic digit writing and different letter writing: uppercase, script and cursive (MENJS, 2020).
Materials and procedures
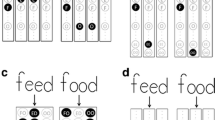
As part of the French National Assessment, students were asked to answer test items involving the recognition of different correct writings of several letters. Among these, we were particularly interested in the writings of [be] ([biː] in GB English phonetics) and [de] ([diː] in GB English phonetics). The different forms of writing were printed lowercase (b, d), cursive ( ,
,
 )
and uppercase (B, D). Children were asked to circle the writings of [be] in the sample of writings shown in Fig. 1. This allowed us to identify students who did not differentiate between b and d in Line 1. These students could either circle d only or both d and b, without circling any other writing. The same was applied for the letter d.
)
and uppercase (B, D). Children were asked to circle the writings of [be] in the sample of writings shown in Fig. 1. This allowed us to identify students who did not differentiate between b and d in Line 1. These students could either circle d only or both d and b, without circling any other writing. The same was applied for the letter d.

The sample of different letter writings from which students had to recognize all writings of [be] or [de] (the lines are indicated in our text but were not indicated in the children’s test booklet; the children were encouraged to work line-by-line through a pretest example using a nontested letter)
In another test, the children had to write, under dictation, the ten Arabic digits and the number 10, always in the same order: 3, 5, 1, 4, 2, 6, 9, 0, 8, 10, 7. Figure 2 shows the writings of two children (note that the writing of 7 is taught with a second horizontal bar in French schools).

The digit writing subtest, as completed by two children
Because one may wonder why we do not compare reversal in the writing of b and d with reversal in the writing of digits, we must point out that the French National Assessment 2020 did not include a letter writing subtest. However, the assessment included a digit recognition subtest. In this subtest, children had to recognize an orally indicated Arabic digit among 6 printed digits (i.e., challenged with 5 distractors). Because the result of the digit recognition subtest was at the ceiling—all 10 digits were correctly recognized by 93.5% or more of the children—any statistical comparison of b/d reversal and digit reversal in similar recognition tasks seemed superfluous, and the data did not lend themselves to calculation of the correlation between the two tasks (cf., Levin, 1985).
Data and statistical processing
The students’ productions were first evaluated by advanced students and then reviewed (and corrected, if necessary) by one of the coauthors of this article. For the letter recognition items, the children’s choices were examined line by line.
In Table 1, for the letter recognition subtest of [be] and [de], the children’s choices analyzed line-by-line were classified as follows: (1) correct; (2) mirror, when the child circled only d for [be] or only b for [de] in Line 1 (in Line 2, only D for [be] or only  for [de]; in Line 3, only
for [de]; in Line 3, only  for [be] or B for [de]: see Fig. 1); (3) both, when the child circled the correct letter and the mirror of [be] or [de]; (4) other, when the child circled any other letter; and (5) no answer, when the child did not circle any letter.
for [be] or B for [de]: see Fig. 1); (3) both, when the child circled the correct letter and the mirror of [be] or [de]; (4) other, when the child circled any other letter; and (5) no answer, when the child did not circle any letter.
In Table 2, for the digit writing subtest, the children’s writings were categorized as follows: (1) correct (readable); (2) reflected (left–right reversal); (3) rotated 180°; (4) reflected, then rotated 180° (upside-down inversion); and (5) other (omission, other digit, unreadable, intermediate writing). For the composed transformation (4), the order was not determined because the four transformations (knowing that correct writing = identity) form a commutative group. For the digits, a 9 rotated by 180° looks like a 6, and vice versa.
An orientation error rate was computed, both for the letters b and d and the digits. The individual letter (b or d) orientation error rate was the number of mirrors the child circled divided by 2 (minus his or her nonrelevant productions). The individual digit orientation error rate was the number of mirror reversals the child produced, divided by 8 (minus his or her nonrelevant productions). The number 8 resulted from the 8 asymmetric digits that a child could reverse given that the symmetric 0 and 8 were excluded from the analysis. Both orientation error rates could vary from 0 to 1, but 0.5 was the only possible intermediate value for the letter orientation error rate. For example, a 6-year-old girl selected b for [de] and both b and d for [be]; she correctly wrote all the digits (including 10) except 6, which was reversed. The orientation error rate would be 2/2 (2 errors out of 2 occasions) = 1.000 for the letters, 1/8 (1 mirror error out of 8 occasions) = 0.125 for the written digits, or 1/9 = 0.111 for a computation including 10 in the reversal rate.
In part because of the very small number of possible values for the letter orientation error rate, a confusion index was defined, only for b and d (in Line 1), by adding the following points: 0 points for a (1) choice, 2 points for a (2) choice, and 1 point for a (3) choice (see the above defined classes of choices). Thus, the confusion index score can vary from 0 to 4; it determined a confusion rate τc = index/4 and five categories of confusion, from the lowest, 0 (i.e., no confusion), to the highest, 4 (i.e., only choosing the mirrored letter). This somewhat arbitrary index attempts to enhance the choice of the only mirrored letter because the confusion seems to be maximal with such a choice: in Category 4, the child behaves as if he or she thinks that b is a writing of [de] or that d is a writing of [be], whereas in Category 3, the child seems to think that both writings can be used indistinctly. This index increases the quantitative character of the preceding orientation error rate, an increase that is advantageous even for rank tests because it avoids massive ties. However, because of its arbitrariness, we also used the previous simpler orientation error rate to verify that the results did not fundamentally depend on this confusion index. As an example, the girl described above, with an orientation error rate of 1.000 for letters, would have a confusion index of (2 + 1)/4 = 0.750. Let us clarify that the numerator (2 + 1) comes from 2 pts (because the girl chose b instead of d) plus 1 point (because she chose both b and d instead of d), and the denominator from the maximum points that could be obtained (= 4 pts), which are attributed to a participant who selects both b instead of d and d instead of b.
The writing of 10 was not included in the calculation of the digit orientation errors. However, it provides a double indication of a child’s reversal tendency, as the child can reverse the order of the digits, writing 01, and can also reverse the 1 of 10. Therefore, the writing of 10 was included in the calculation of the reversal rate τr. The latter is the number mirror reversals a child produced, divided by 9 (minus his or her nonrelevant productions). The number 9 results from the addition of 8 asymmetric digits, which a child could reverse, and the possible mirror errors in writing 10, with each partial mirror being given 0.5 and a complete mirror writing (see Fig. 2, left-part) being given 1.
We first investigated the relationship between reversal in digit writing and confusion in b and d recognition with a classical linear regression, using the function lm of the statistical software R (R Core Team, 2020). However, because of both the partially unexpected and theoretical importance of the result, we also tested the relationship through three very different complementary statistical approaches. Such a reporting of multiple statistical models seems to be in line with the recent recommendations by Wagenmakers et al. (2021).
First, we used Bayesian regression instead of the ordinary least square regression involved in lm. Bayesian regression has the advantage of yielding stable estimates (Gelman et al., 2021, p. 16). In particular, the median and SD of the median absolute deviation (MAD_SD) outputs of the Bayesian general linear regression function stan_glm (from the package rstanarm for R) are more stable summaries for low sample sizes or skewed distributions (Gelman et al., p. 73). As the Bayesian approach requires defining a prior distribution, we used the default weak priors of the stan_glm function. Note that the default priors specified, N(0.13, 2.5) for intercept, N(0, 2.5) for coefficients, and exponential (rate = 1) for sigma, were automatically adjusted (scaled) in the stan_glm function.
Second, given the result of the classic linear regression model, which clearly contrasts the low confounders (children in Categories 0 or 1 for their b/d confusion index) to high confounders (children in Categories 2 to 4), a logistic linear regression model assigning Yi = 0 to children in the former group and Yi = 1 to those in the latter group seemed appropriate. This modeling, with the glm (binomial family) function of R, should allow probabilistic individual predictions of confusion as a function of the child’s rate of digit reversal.
Third, because some conditions for adjusting a linear regression model could not be perfectly verified (e.g., the normality of the regression residuals was not guaranteed by a graphical check), we also computed Spearman’s rho. This statistic gives taxonomic value, by reference to Cohen (1988), of the strength of the relationship between reversal and confusion and allows for nonparametric tests of the strength.
Results
Test of the main hypothesis
For comparison purposes, the calculation of the left–right orientation error rate was first limited to the 527 students who were present for both the letter recognition and digit writing subtests. Moreover, for the following fit of a linear regression model and computation of the correlation coefficient between τc and τr, the respective rates of confusion and reversal in the letter recognition and digit writing tasks, the sample was restricted to the subsample of children for whom (τc, τr) ≠ (0, 0). The obvious reason was that studying the relationship between confusion errors and reversal errors in children who make neither type of error appears to be nonsense. Figure 3 suggests a negative correlation between τc and τr. However, such a correlation would be better analyzed by treating the confusion rate as a categorical variable.

A jittered scatterplot of the reversal rate (τr) as a function of the confusion rate (τc), with the regression line (in red) and the 95% confidence interval (in gray)
Before fitting a linear regression model to reversal in writing the digits as a function of the five categories of confusion, we also included the sex and centered age of the children in a model. However, we finally did not retain the latter two variables because their regression coefficients suggested little (nonsignificant) influence. The fit of the regression model, with the five categorized confusions as predictors, was significant (F(4, 314) = 6.84, p < 0.001), and the model explained approximately 8% of the variance (multiple R2 = 0.080). The complete results are given in Table 3.
Table 3 shows that, except for the intercept, all regression coefficient estimates were negative. Therefore, we could estimate that, compared to the group of children who did not confuse b and d, the children in Cat. 2, Cat. 3, and Cat. 4 produced, on average, 10.1%, 9.1%, and 8.8% fewer reversals in writing the digits, respectively. Although the nonsignificant estimate of the Cat. 3 coefficient could reflect instability, it is the same magnitude as that for Cat. 2 and Cat. 4, and the SEs clearly showed that the nonsignificance resulted from the higher SE due to the small number of children in this category (n = 8 vs. 55 in Cat. 4, or 102 in Cat. 2).
The Bayesian linear regression fit resulted in very similar coefficients. Precisely, the coefficient estimates were 18.8%, –2.4%, –10.1%, –9.0%, and –8.8%. They are almost identical to those in Column 2 of Table 3.
The modeling through logistic linear regression (see the Methods section) led to a coefficient of τr that was also negative and highly significant (z = –4.684, p < 0.001). The probability of being a high confounder was calculated as Pr(Yi = 1) = logit−1(τr) = (e0.584 – 3.991*τr))/(1 + e0.584 – 3.991*τr). Table 4 gives some predicted probabilities as a function of τr.
Finally, the rank correlation between τc and τr was negative (rS(316) = –0.373), and significant (p < 0.001). It could be estimated as medium to large according to Cohen’s (1988, p. 79ff) classification scheme. This seems consistent with our hypothesis of a nonpositive correlation. However, it must be acknowledged that the substantial size of the negative correlation is somewhat surprising. We will comment at length on this negative correlation in the following discussion.
Tests of the secondary hypotheses
The comparison of Tables 1 and 2 suggests that the recognitions of the letters b and d yielded a greater left–right orientation error rate than the writings of the digits. The computation yielded 0.21 and 0.38 for the b and d rates, respectively, and 0.10 for the digit reversal rate, the mean of the 8 asymmetrical digits (no individual digit orientation error rate exceeding 0.16). Even the most reversed digit (i.e., 9) was significantly less reversed than the letters b or d, which were falsely (mirrored) recognized (both p < 0.001 with the chi-square test, McNemar’s method). This result was consistent with our hypothesis.
Table 5 was developed to examine whether the left-oriented digits (left part, bottom row) were more reversed than the right-oriented digits (4, 5, 6: right part, bottom row) in the present research. To better reveal the left–right reversal as a function of digits and to study its evolution between the upper section of the French école maternelle and the first quarter in first grade, we calculated the percentage reversal as the number of reversals divided by the number of theoretically relevant writings (i.e., correct writings plus reversed writings) and compared it to Fischer and Luxembourger’s (2018, Table 1) calculation in Table 5. The calculation confirms that the mean reversal rate of 0.176 for the left-oriented digits was higher than that for the right-oriented digits (0.129, p = 0.037) (Wilcoxon paired test). In addition, the present data on digit reversal as a function of digit orientation correlated with those in Fischer and Luxembourger’s Table 1, which were obtained from somewhat younger children (rS(6) = 0.714, p = 0.029 with a one-tailed test).
Discussion and conclusion
Left–right mirror errors were the material of interest for the present analysis. A necessary condition for their statistical study is that children produce them sufficiently. Tables 1 and 2 show that this was the case. Furthermore, Table 1 justifies our focus on the recognition of b and d in their usual print. For the letters [be] and [de], indicated orally, 112 and 199 children (of the 527 children included in this table) produced reversal errors for b and d, respectively, whereas only 30, 32, 59, and 24 produced such errors for  ,
,  , B, and D, respectively. In addition, Table 2 justifies our focus on the reflected digits because the other errors were negligible. Indeed, all the asymmetrical digits were transformed (other than those reflected by less than 1% of the children), except the digit 9 (2.3% of the children).
, B, and D, respectively. In addition, Table 2 justifies our focus on the reflected digits because the other errors were negligible. Indeed, all the asymmetrical digits were transformed (other than those reflected by less than 1% of the children), except the digit 9 (2.3% of the children).
Main result
The far most important result of this analysis of partial data from the French National Assessment was the negative correlation between the rate of confusion in the recognition of b and d and the rate of digit reversal in writing from memory (rS = –0.37): Children who confused b and d the least were generally those who reversed digits the most. A fitted linear regression model, whether an ordinary, a Bayesian, or a logistic model, shows that high confounding was associated with a decrease in the average percentage of reversals. In the linear (nonlogistic) regression model, the decrease was approximately 10% in Categories 2 to 4 (see the Methods section). The logistic regression modeling showed that the probability of being a strong confounder decreased from 0.642 to 0.398 when the rate of digit reversal increased from 0 to 25% (see Table 3). Although the negative correlation may be favored by the difference in tasks, it strongly suggested that the two processes leading to orientation errors in digit writing and confusion in b and d recognition were at least partly independent and, in any case, not identical.
This result also leads to the exclusion of the fact that an individual child has a greater or lesser propensity to reverse any written symbolic material, called strephosymbolia with Orton’s (1925) naming (the root strepho is ancient Greek for “twisted” or “reversed”). This is especially interesting because for a long time—almost the whole twentieth century—mirror writing was attributed to certain subgroups of children, notably those who wrote with their left hand (e.g., Lebrun et al., 1989) or intellectually disabled children (e.g., Gordon, 1921).
How to interpret the results
Since children primarily confuse letters whose mirror reversals are also legible letters (see the Introduction section), the confusion process is easy to imagine when children have to recognize b or d. Due to the process of symmetrization, both writings are strongly represented in children’s declarative memory; due to their phonological and graphical analogies, both representations are also strongly activated. Thus, children are confused about choosing one of them until the correct writing is consolidated into the declarative memory system (Menon & Chang, 2021; Squire, 1994). Following our result, we think that the reversal process in writing digits from memory should be different from this recognition process. What could this process be?
One theory proposes that children have a representation of both a character and its reversal, possibly in each cerebral hemisphere, due to reversal during hemispheric transfer (Corballis, 2018). A child then selects the more active of these two representations, one of the two at random, or if possible, both. This theory results in similar reversal processes in writing digits and in recognizing the letters b and d and thus does not account for our negative correlation. Another theory assumes that 5-year-old children have a nonoriented representation of characters. Thus, when they write digits from memory, they must improvise an orientation. They often “reasonably” choose the direction of writing/reading in their culture (Fischer, 2017; Portex et al., 2018). This is clearly a different process from that which is at work in choosing the writing on the basis of its representation in memory. This theoretical proposal is consistent with the nonpositive correlation obtained in this study.
Since orientation in the direction of writing (to the right) results in the reversal of only the left-oriented digits (1, 2, 3, 7, 9), the present data provide also some support for the second theory. In addition, these data help to refine the developmental aspect of the digit reversal process. Because our first-graders were older than the children in the last year of the French école maternelle in Fischer and Luxembourger’s study (2018, Table 1), some developmental changes are apparent and are presented Table 5. First, 9, not 3, was the most reversed digit; second, the right-oriented 6, which was behind the five left-oriented digits in the frequency reversal ranking, ranked 3rd and higher than the left-oriented digits 1, 2, and 7 (see Table 5). These changes may reflect a developmental trend of the reversal process toward a confusion process, particularly because of (1) the graphical similarity of 6 and 9, (2) the 180°-rotation of 6 into 9 (and vice versa), and (3) the considerable resemblance of the mirror image of 9 to the lowercase letter e, which is the most frequently used letter of the alphabet. Thus, we can assume that the mirror reversal of 9 is well represented in memory (cf., Frith, 1971). As a test of these particularities of 6 and 9, we excluded the digits 6 and 9 from the calculation of τr and reanalyzed the correlation between τc and τr. As expected, the negative correlation increased in strength (rS (285) = –0. 384), albeit slightly.
Why a negative correlation?
How can we understand the negative correlation, which shows that the children who reverse the digits the most when writing are generally those who confuse b and d the least? The developmental change described above suggests an explanation. Since lowercase letters are taught about one year after digits are taught in the French curriculum (MENJS, 2020), some children who have already mastered the writing of the digits may still have difficulty differentiating b and d. Typically, they then make errors in recognizing the letters b and d, but not in writing the digits, and thus contribute to the negative correlation. The data provide some support for this interpretation, as 130 children (out of 345) made 1 (n = 52) or 2 (n = 78) orientation errors in their choices of b or d, but made no reversal errors in writing the digits. An opposite pattern—reversing some digits, but not confusing b and d—is also possible when a less developmentally advanced child reverses digits but randomly selects the correct target on the letter recognition subtest. Although the latter pattern is less frequent (n = 81), it also contributes to the negative correlation.
Specific interpretation of the confusion between b and d
Once we admit that the two processes leading to the reversal of digits in writing and to the confusion of reversible letters in a recognition task differ, many theories that try to explain the latter issue can be put forward to explain our observation of the recognition errors of b and d. In particular, in Lachmann’s (2018) opposition between holistic and analytical processes, strategies of the latter type are required for letter recognition in the more general reading-specific procedure. An analytical processing preference for the letters effect has been effectively demonstrated in adults by Lachmann and colleagues (Lachmann & Van Leeuwen, 2008; Lachmann et al., 2014). However, young children, up to the 3rd or 4th grade (Lachmann & Van Leeuwen, 2007), or even older (Froysen et al., 2009), are not biased against the use of holistic strategies. Thus, our hypothesis is simply that many of our 6-year-old participants used such holistic strategies, which allowed them to recognize nonreversible letters but led them to confuse the letters b and d, which are difficult to distinguish holistically.
Lachmann’s (2018) elaborations also allow us to clarify, albeit very speculatively, a point of understanding concerning developmental dyslexia. Our results certainly argue against the possibility that reversible letter confusion in recognition and letter reversal in writing are associated in children aged 5 or 6 years. However, they do not exclude that at a later age, children who have not automatized an analytical strategy are still affected by their suboptimal holistic letter recognition strategy. The confusion of reversible letters over several years can then lead to what is seen and interpreted by teachers or any other observer as writing reversals. We could thus find an association in some dyslexic students in the 3rd or 4th year of school, that we could not find in students at an earlier age (the beginning of first grade).
Limitations of the study
Many limitations, mainly due to the rather observational nature of the data, affected our study. The data do not have all the qualities of well-controlled experimental data; for example, an overindulgent teacher may not have sufficiently prevented some children from copying (leading to nonindependent observations). However, we emphasized the importance of such analysis in the schools, with teachers administering the test themselves. There is the general reason for the need to balance rigor and reality in scientific research, as Cantlon (2020) has argued for developmental neuroscience. There is the additional specific reason for poor agreement between a teacher’s assessment of reversal and a formal left–right reversal test (e.g., Cotter et al., 1987, who used the test of Jordan & Jordan, 1974).
Another weakness of the study that emerged in our interpretation of the negative correlation was the difference between the tasks being compared, namely, recognition and production. However, because of the difference in difficulty (reinforced by teaching), it is also not appropriate to correlate the result of a lowercase letter writing task with that of a digit writing task (writing always from memory) in French children and certainly not in other children (e.g., the Scottish children in the study of McIntosh et al., 2018). In addition, for the recognition of both digits and letters (b and d), the comparison was unsuccessful due to the ceiling effect in the recognition of digits. More generally, it may be noted that a very different approach, such as Lyle’s (1969) factorial study, “has thrown no light on the exact nature of reversal tendencies in reading and writing” (p. 842).
Our comparison between a recognition task (reading) and a writing task also raises the general question of the relationship between reading and writing. For students who are sufficiently advanced in their learning process, a key question is not the reality of the relationship but rather whether it is unidirectional (reading to writing) or bidirectional. With a longitudinal study of 3- to 6-year-olds, Kim et al. (2018) stated that it is rather unidirectional. However, it is not certain, a priori, that a relationship is established in the early years of learning. In their model of the developmental relationship between reading and writing, Fitzgerald and Shanahan (2000) distinguished an emerging literacy stage (birth to age 6). For this stage, they indicated that research has documented that literate knowledge “develops concomitantly in reading, writing, listening, and speaking” (p. 46). Thus, a posteriori, we can think that a relationship between reading and writing should already be present in our students beginning first grade.
The partially unexpected nature of the negative correlation may also be seen as a weakness of our study. Nevertheless, it is similar to the recent observation by Fischer and Luxembourger (2021) that good discrimination of mirrored letters by 6-year-olds does not predict a lower frequency of letter reversal during writing, whereas the discrimination of other (other than letters) mirrored images does. Taken together, these observations provide compelling support for the hypothesis that reversal during writing is an essentially different process than visual confusion. The importance of confirming this hypothesis comes from the fact that visual confusion is typically at work in the reading process, of which the major role in our cultures it is unnecessary to stress.
Conclusion
Despite these limitations, our conclusion is that character reversal should be differentiated from character confusion, even though the former may be the cause of the latter in some cases. Specifically, the confusion of the reversible letters b and d and similar characters such as p and q, and the nonreversible but graphically similar characters b and p, p and d, and 6 and 9, does not, in general, appear to be the consequence of a reversal process. This may in fact explain why children also confuse b and p, p and d, and 6 and 9, that is, characters that are not reflected by each other and whose confusion cannot therefore be attributed to the process of cerebral symmetrization. Although the problem may appear to be one of vocabulary—speaking in terms of confusion rather than reversal—we believe it may also express a misunderstanding by many research studies.
Data Availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Code availability
(Software application or custom code): The program used R is free.
Notes
The rule applies only to the writing of characters and thus makes no assumption about a more frequent recognition of b as d than of d as b (see the distinguishing of d-type letters from b-type letters by Treiman and Kessler, 2011).
In France, écoles maternelles (preschools) are open to all children aged at least 3 years. Almost all children attend at least the second year (middle section, 4- to 5 years of age) and the final year (upper section, 5 to 6.5 years of age).
References
Ahr, E., Houdé, O., & Borst, G. (2016). Inhibition of the mirror generalization process in reading in school-aged children. Journal of Experimental Child Psychology, 145, 157–165. https://doi.org/10.1016/j.jecp.2015.12.009
Brault-Foisy, L. M., Ahr, E., Masson, S., Houdé, O., & Borst, G. (2017). Is inhibitory control involved in discriminating pseudowords that contain the reversible letters b and d? Journal of Experimental Child Psychology, 162, 259–267. https://doi.org/10.1016/j.jecp.2017.05.011
Brendler, K., & Lachmann, T. (2001). Letter reversals in the context of the Functional Coordination Deficit Model of developmental dyslexia. In E. Sommerfeld, R. Kompass, & T. Lachmann (Eds.), Proceedings of the International Society for Psychophysics (pp. 308–313). Pabst Science Publishers
Cantlon, J. F. (2020). The balance of rigor and reality in developmental neuroscience. NeuroImage, 216, 116464. https://doi.org/10.1016/j.neuroimage.2019.116464
Cohen, J. (1988). Statistical power analysis for the behavioral sciences. Taylor & Francis.
Corballis, M. C. (2018). Mirror-image equivalence and interhemispheric mirror-image reversal. Frontiers in Human Neuroscience, 12, 140. https://doi.org/10.3389/fnhum.2018.00140
Corballis, M. C., & Beale, I. L. (1976). The psychology of left and right. Erlbaum.
Cotter, S. A., Rouse, M. W., & DeLand, P. N. (1987). Comparative study of the Jordan left-right reversal test, the reversals frequency test, and teachers’ observations. American Journal of Optometry and Physiological Optics, 64(3), 195–203.
D’Mello, S., Lehman, B., Pekrun, R., & Graesser, A. (2014). Confusion can be beneficial for learning. Learning and Instruction, 29, 153–170. https://doi.org/10.1016/j.learninstruc.2012.05.003
Davidson, H. P. (1935). A study of the confusing letters b, d, p, and q. The Pedagogical Seminary and Journal of Genetic Psychology, 47(2), 458–468. https://doi.org/10.1080/08856559.1935.10534056
Dehaene, S. (2009). Reading in the brain: The new science of how we read. Penguin Books.
Fernandes, T., Arunkumar, M., & Huettig, F. (2021). The role of the written script in shaping mirror-image discrimination: Evidence from illiterate, Tamil literate, and Tamil-Latin-alphabet bi-literate adults. Cognition, 206, 104493. https://doi.org/10.1016/j.cognition.2020.104493
Fernandes, T., & Leite, I. (2017). Mirrors are hard to break: A critical review and behavioral evidence on mirror-image processing in developmental dyslexia. Journal of Experimental Child Psychology, 159, 66–82. https://doi.org/10.1016/j.jecp.2017.02.003
Fernandes, T., Leite, I., & Kolinsky, R. (2016). Into the looking glass: Literacy acquisition and mirror invariance in preschool and first-grade children. Child Development, 87(6), 2008–2025. https://doi.org/10.1111/cdev.12550
Fischer, J. P. (2013). Digit reversal in children’s writing: A simple theory and its empirical validation. Journal of Experimental Child Psychology, 115, 356–370. https://doi.org/10.1016/j.jecp.2013.02.003
Fischer, J. P. (2017). Character reversal in children: The prominent role of writing direction. Reading and Writing, 30(3), 523–542. https://doi.org/10.1007/s11145-016-9688-y
Fischer, J. P., & Luxembourger, C. (2018). A synoptic and theoretical account of character (digits and capital letters) reversal in writings by typically developing children. Education Sciences, 8(3), 137. https://doi.org/10.3390/educsci8030137
Fischer, J. P., & Luxembourger, C. (2021). A test of three models of character reversal in typically developing children’s writing. Frontiers in Communication, 6, 719652. https://doi.org/10.3389/fcomm.2021.719652
Fischer, J. P., & Tazouti, Y. (2012). Unraveling the mystery of mirror writing in typically developing children. Journal of Educational Psychology, 104(1), 193–205. https://doi.org/10.1037/a0025735
Fischer, J. P., & Thierry, X. (2021). Miswriting (especially mirror writing) of the digits: An ecological assessment using ELFE data. Journal of Cognitive Education and Psychology, 20(1), 3–17. https://doi.org/10.1891/JCEP-D-19-00053
Fitzgerald, J., & Shanahan, T. (2000). Reading and writing relations and their development. Educational Psychologist, 35(1), 39–50. https://doi.org/10.1207/S15326985EP3501_5
Frith, U. (1971). Why do children reverse letters? British Journal of Psychology, 62(4), 459–468. https://doi.org/10.1111/j.2044-8295.1971.tb02059.x
Froyen, D. J. W., Bonte, M. L., van Atteveldt, N., & Blomert, L. (2009). The long road to automation: Neurocognitive development of letter–speech sound processing. Journal of Cognitive Neuroscience, 21(3), 567–580. https://doi.org/10.1162/jocn.2009.21061
Gelman, A., Hill, J., & Vehtari, A. (2021). Regression and other stories. Cambridge University Press. https://doi.org/10.1017/9781139161879
Gordon, H. (1921). Left-handedness and mirror writing, especially among defective children. Brain, 43(4), 313–368. https://doi.org/10.1093/brain/43.4.313
Jordan, B. T., & Jordan, S. G. (1974). Jordan left-right reversal test: A study of visual reversals in children. Child Psychiatry and Human Development, 4(3), 178–187. https://doi.org/10.1007/BF01436026
Kim, Y. S. G., Petscher, Y., Wanzek, J., & Al Otaiba, S. (2018). Relations between reading and writing: A longitudinal examination from grades 3 to 6. Reading and Writing, 31(7), 1591–1618. https://doi.org/10.1007/s11145-018-9855-4
Lachmann, T. (2018). Reading and dyslexia: The functional coordination framework. In T. Lachmann, T. Weis (Eds.), Reading and dyslexia: from basic functions to higher order cognition (pp. 271–296). Literacy Studies, vol. 16. Springer. https://doi.org/10.1007/978-3-319-90805-2_13
Lachmann, T., Schmitt, A., Braet, W., & van Leeuwen, C. (2014). Letters in the forest: Global precedence effect disappears for letters but not for non-letters under reading-like conditions. Frontiers in Psychology, 5, 705. https://doi.org/10.3389/fpsyg.2014.00705
Lachmann, T., & Van Leeuwen, C. (2007). Paradoxical enhancement of letter recognition in developmental dyslexia. Developmental Neuropsychology, 31, 61–77. https://doi.org/10.1207/s15326942dn3101_4
Lachmann, T., & Van Leeuwen, C. (2008). Differentiation of holistic processing in the time course of letter recognition. Acta Psychologica, 129(1), 121–129. https://doi.org/10.1016/j.actpsy.2008.05.003
Lebrun, Y., Devreux, F., & Leleux, C. (1989). Mirror-writing. In P. G. Aaron & R. M. Joshi (Eds.), Reading and writing disorders in different orthographic systems (pp. 355–378). Kluver Academic Publishers.
Levin, J. R. (1985). Some methodological and statistical “bugs” in research on children’s learning. In M. Pressley & C. J. Brainerd (Eds.), Cognitive learning and memory in children (pp. 205–233). Springer.
Lewis, E. R., & Lewis, H. P. (1965). An analysis of errors in the formation of manuscript letters by first-grade children. American Educational Research Journal, 2(1), 25–35. https://doi.org/10.3102/00028312002001025
Liberman, I. Y., Shankweiler, D., Orlando, C., Harris, K. S., & Berti, F. B. (1971). Letter confusions and reversals of sequence in the beginning reader: Implications for Orton’s theory of developmental dyslexia. Cortex, 7, 127–142. https://doi.org/10.1016/S0010-9452(71)80009-6
Lyle, J. G. (1969). Reading retardation and reversal tendency: A factorial study. Child Development, 40(3), 833–843. https://doi.org/10.2307/1127192
McIntosh, R. D., Hillary, K., Brennan, A., & Lechowicz, M. (2018). Developmental mirror-writing is paralleled by orientation recognition errors. Laterality Asymmetries of Body, Brain and Cognition, 23(6), 664–683. https://doi.org/10.1080/1357650X.2018.1445748
MENJ (2020). Repère CP 2020: Guide du professeur. Ministère de l’Education Nationale et de la Jeunesse. https://cache.media.eduscol.education.fr/file/CP/84/6/20CPP_guide_1318846.pdf
MENJS (2020). Programme du cycle 1. Ministère de l’Education Nationale, de la Jeunesse et des Sports. https://cache.media.eduscol.education.fr/file/A-Scolarite_obligatoire/24/3/Programme2020_cycle_1_comparatif_1313243.pdf
Menon, V., & Chang, H. (2021). Emerging neurodevelopmental perspectives on mathematical learning. Developmental Review, 60, 100964. https://doi.org/10.1016/j.dr.2021.100964
Orton, S. T. (1925). “Word-blindness” in school children. Archives of Neurology and Psychiatry, 14(5), 581–615. https://doi.org/10.1001/archneurpsyc.1925.02200170002001
Pegado, F., Nakamura, K., Cohen, L., & Dehaene, S. (2011). Breaking the symmetry: Mirror discrimination for single letters but not for pictures in the visual word form area. NeuroImage, 55(2), 742–749. https://doi.org/10.1016/j.neuroimage.2010.11.043
Pegado, F., Nakamura, K., & Hannagan, T. (2014). How does literacy break mirror invariance in the visual system? Frontiers in Psychology, 5, 703. https://doi.org/10.3389/fpsyg.2014.00703
Perea, M., Moret-Tatay, C., & Panadero, V. (2011). Suppression of mirror generalization for reversible letters: Evidence from masked priming. Journal of Memory and Language, 65, 237–246. https://doi.org/10.1016/j.jml.2011.04.005
Pevsner, J. (2002). Leonardo da Vinci’s contributions to neuroscience. Trends in Neurosciences, 25(4), 217–220. https://doi.org/10.1016/s0166-2236(00)02121-4
Portex, M., Carolane, H., Ponce, C., & Foulin, J. N. (2018). Dynamics of mirror writing compared to conventional writing in typical preliterate children. Reading and Writing, 31(6), 1435–1448. https://doi.org/10.1007/s11145-018-9838-5
R Core Team (2020). R: A language and environment for statistical computing. R Foundation for Statistical Computing, https://www.R-project.org/.
Rollenhagen, J. E., & Olson, C. R. (2000). Mirror-image confusion in single neurons of the macaque inferotemporal cortex. Science, 287, 1506–1508. https://doi.org/10.1126/science.287.5457.1506
Sidman, M., & Kirk, B. (1974). Letters reversals in naming, writing, and matching to sample. Child Development, 45, 616–625. https://doi.org/10.2307/1127827
Smith, D. D., & Lovitt, T. C. (1973). The educational diagnosis and remediation of written b and d reversal problems: A case study. Journal of Learning Disabilities, 6(6), 356–363. https://doi.org/10.1177/002221947300600604
Soares, A. P., Lages, A., Oliveira, H., & Hernández, J. (2019). The mirror reflects more for d than for b: Right asymmetry bias on the visual recognition of words containing reversal letters. Journal of Experimental Child Psychology, 182, 18–37. https://doi.org/10.1016/j.jecp.2019.01.008
Squire, L. R. (1994). Declarative and nondeclarative memory: Multiple brain systems supporting learning and memory. In D. L. Schacter & E. Tulving (Eds.), Memory systems 1994 (pp. 203–231). MIT Press.
Terepocki, M., Kruk, R. S., & Willows, D. M. (2002). The incidence and nature of letter orientation errors in reading disability. Journal of Learning Disabilities, 35(3), 214–233. https://doi.org/10.1177/002221940203500304
Torres, A. R., Mota, N. B., Neto, N. A., Adamy, N., Naschold, A., Lima, T. Z., Copelli, M., Weissheimer, J., Pegado, F., & Ribeiro, S. (2021). Selective inhibition of mirror invariance for letters consolidated by sleep doubles reading fluency. Current Biology, 31, 1–11. https://doi.org/10.1016/j.cub.2020.11.031
Treiman, R., & Kessler, B. (2011). Similarities among the shapes of writing and their effects on learning. Written Language and Literacy, 14(1), 39–57. https://doi.org/10.1075/wll.14.1.03tre
Wagenmakers, E. J., Sarafoglou, A., Aarts, S., Albers, C., Algermissen, J., Bahník, Š, van Dongen, N., Hoekstra, R., Moreau, D., van Ravenzwaaij, D., Sluga, A., Stanke, F., Tendeiro, J., & Aczel, B. (2021). Seven steps toward more transparency in statistical practice. Nature Human Behaviour, 5, 1473–1480. https://doi.org/10.1038/s41562-021-01211-8
Acknowledgements
We thank all the children and teachers who participated in the assessment. We are also grateful to the colleagues and administrators who have facilitated our work.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
The two authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by CL. The first draft of the manuscript (including statistical processing) was written by JPF. The two authors commented on previous versions of the manuscript and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Fischer, JP., Luxembourger, C. Typical 6-year-old children’s confusion between “b” and “d” in reading cannot be assimilated to reversal. Read Writ 35, 2433–2451 (2022). https://doi.org/10.1007/s11145-022-10290-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11145-022-10290-6