
Abstract
The study on poverty dynamics has become more critical during the COVID-19 pandemic. This study gives insights into the scale of poverty and vulnerability transitions for 2019–2020 and the characteristics associated with each transition. Since panel data are unavailable for Indonesia, this study uses cross-sectional data and demonstrates the synthetic panels approach. The finding shows that the COVID-19 has induced poverty persistence in Indonesia as the economic shutdown took place. However, the pandemic impact is not uniformly distributed among Indonesian households. Those who fell into poverty during the pandemic most likely came from the vulnerable group, especially those living in rural areas, illiterate or with less education. The findings of this study, therefore, underlines the importance of literacy and education in poverty alleviation. This paper also highlights the urgency for redesigned poverty interventions as the economic shock has created new vulnerable groups. Higher probability of becoming vulnerable to poverty during the pandemic is associated with living in urban areas, having females as the household head, being a university graduate, and working in service sectors. Lastly, this study found that the synthetic panel estimates are sensitive to the assumptions made and how the key parameters are estimated.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The COVID-19 pandemic has disrupted the global economy since early 2020 and rapidly threatened the progress in poverty reduction. According to the World Bank (2021a), 97 million more people slipped into poverty in 2020, and the increase in poverty persisted in 2021. The new poor were estimated to concentrate in the poorest countries, including Sub-Saharan Africa and South Asia (Sumner et al. 2020).
Indonesia is one of the countries severely hit by the pandemic since March 2020. As of July 11, 2022, Indonesia has reported 6.11 million confirmed cases, with 156,798 deaths. As the fourth most populous country and the largest archipelago globally, Indonesia faces health challenges, including the lack of healthcare personnel and resource distribution in remote areas (Tenda et al. 2021). Besides the health challenges, as of July 2021, Indonesia has fallen back into the lower-middle-income classification after a short period of being in the upper-middle-income group (World Bank 2021b). Indonesia's progress in poverty reduction was also reversed. After a sustained decline in poverty rate since the 1998 crisis, the poverty headcount ratio rose from 9.41% in 2019 to 10.14% in 2021, implying 2.4 more million people have fallen into poverty due to the pandemic (BPS-Statistics Indonesia 2021).
Previous studies have attempted to estimate the consequences of COVID-19 on poverty in Indonesia. However, since the recent household data were unavailable, the analyses used data collected before the pandemic. Using simulation models, Suryahadi et al. (2020) forecasted the pandemic effect on poverty using data collected in previous economic crises (1997/1998 and 2005/2006). In the worst-case scenario, the poverty rate was expected to increase to 16.6%, which constitute the level in 2004. The existing studies have also assessed the regional consequences of COVID-19 on poverty by combining 2018 survey data and Google Mobility Reports (Gibson and Olivia 2020) and using published statistics from 2015 to 2020 (Brata et al. 2021). The two studies found a spatially heterogeneous effect of COVID-19 on poverty in Indonesia.
In times of uncertainty, poverty studies should have been reoriented to people's vulnerability and poverty dynamics (Lanjouw and Tarp 2021). There are two reasons why tracking people’s movement in and out of poverty has become more critical during the pandemic. First, a significant threat is likely to come from those who had previously escaped poverty but fell back into it due to the pandemic (Lanjouw and Tarp 2021). Secondly, the pandemic has created the existence of new poor and those who are not poor but are in danger of becoming poor (CSO, MOPFI, and UNDP, 2020; Bidisha, Hossain, and Mahmood, 2021). Therefore, identifying those groups is vital for effective poverty reduction strategies.
Most recent literature assessed the poverty transitions during a "normal" period to give an understanding of the impact of COVID-19 but did not take the pandemic directly into account (Aikaeli et al. 2021; Dang et al. 2021; Ferreira et al. 2021; Mekasha & Tarp 2021; Salvucci, & Tarp 2021). Aikaeli et al. (2021) found that having less education and a large number of dependants in a household were associated with persistent poverty or downward mobility in 2018 and these groups are most likely to have suffered the economic consequences caused by COVID-19. The pandemic were initially predicted to affect the less poor population in urban areas (Dang et al. 2021) and might have a domino effect on the rural poverty (Salvucci, & Tarp 2021). The likelihood of falling into poverty during normal times was also lower than the likelihood of becoming upwardly mobile to the non-vulnerable groups. However, the condition might have changed during the pandemic (Ferreira et al. 2021).
In the absence of panel data in Indonesia, this paper will fill the gaps by using the most recent cross-sectional data and implement a synthetic panel approach developed by Dang, Lanjouw, Luoto, and McKenzie (2014) and Dang and Lanjouw (2013). This paper aims to understand how poverty and vulnerability changed during the pandemic in Indonesia. This paper results in the bound and point estimates for poverty and vulnerability transitions in Indonesia in 2019/2020 and identifies population characteristics that are associated with those transitions.
This study offers substantive and methodological contributions to the scientific literature. First, this study is the first attempt to document the actual effect of the economic shock on poverty in Indonesia. Using the most recent survey data, this study assesses the pandemic effects on poverty mobility. This study also highlights the impact of COVID-19 on the risk of falling into poverty among vulnerable groups. Methodologically, this study contributes to the literature on synthetic panels and discuss its performance in the absence of panel data.
The remainder of this article is organised as follows. In Sect. 2, this paper reviews poverty and vulnerability concept as well as measurement and describes the poverty condition before and during COVID-19. Section 3 describes the measures used in this study and the steps of synthetic panels. In Sect. 4, this study presents the estimates of poverty and vulnerability transitions by different approaches and household characteristics. In Sect. 5, this paper discusses the transitions and the performance of synthetic panels. We conclude the article in Sect. 6 with a final discussion and future research directions.
2 Literature review
2.1 Poverty and vulnerability
Monetary poverty is measured as the shortage in material resources or the inability to acquire sufficient food and other essentials. Practices in measuring monetary poverty vary widely by country. According to the 2004–5 survey by The United Nations Statistical Division (UNSD), of the 84 nations, over half estimate poverty using expenditure/consumption data, around 30% use income data alone, and 13% use both (Morduch 2008). Indonesia uses the consumption-based approach and measures poverty as the inability to maintain a minimum level of household consumption. Poverty as a shortfall in consumption considers coping strategies and households' capacity to smooth consumption over time (Wemmerus and Porter 1996).
Poverty measurement consists of determining who is poor (identification) and constructing an index that reflects the degree of poverty (aggregation) (Sen 1976). The first step for identification is determining a poverty line, which is a threshold to identify who and how many are poor. The poverty line is the "cost of basic needs", measured by the amount of money required to purchase food containing a minimum amount of calories (2,100 kcal per day) and minimum non-food expenditures for a decent living standard. Those who are poor have average monthly consumption below the national poverty line. For the aggregation, the most used indicator is the poverty headcount ratio or the percentage of the population whose consumption is below the poverty line.
In designing forward-looking poverty interventions, poverty assessment should be extended beyond an identification of the poor to include an evaluation of who is likely to be poor and how likely they are to be poor (Chaudhuri 2003). Uncertainty about the future and exposure to risk distinguishes vulnerability from poverty (Alwang, Siegel and Jorgensen, 2001; Chaudhuri 2003). The core distinction is that poverty is an ex-post measure of a household's well-being reflecting the current level of deprivation, while the vulnerability is broadly interpreted as an ex-ante measure, reflecting potential deprivation in the future (Chaudhuri 2003; Calvo & Dercon 2005). Vulnerability as the probability of having a decline in well-being occurs due to the adverse shocks to welfare, including market-related shocks or changes in socioeconomic conditions (Glewwe and Hall 1998).
The existing studies define vulnerability as the probability of falling into poverty in the next period (Pritchett et al. 2000; Chaudhuri, Jalan, and Suryahadi, 2002; and Chaudhuri 2003). Dercon (1999) defines vulnerability as measurable loss below a particular minimum consumption level and that a threshold is needed for practical measurement. The threshold is used to identify vulnerable households. Most studies (e.g. Chaudhuri 2003) arbitrarily fix the vulnerability index (probability of falling into poverty) at 50% and then classify families as vulnerable if their vulnerability index is larger than 50%. Meanwhile, Dutta et al. (2011) proposed a threshold as the combination of the poverty line and indicators of the current living standard, such as income, which varies by individual. On the other hand, the latest work of Dang and Lanjouw (2017) focuses on the simplicity in measuring vulnerability and avoids setting the vulnerability line arbitrarily by linking it to the risk of sliding into poverty (measured by a particular vulnerability index/level). The method determines the index based on multiple considerations such as welfare objectives, national financial planning, or simply the level a country might accept for non-poor households to slide into poverty. Vulnerability is, thus, defined at the macro or aggregate level.
2.2 Poverty and vulnerability pre and during COVID-19
Poverty dynamics in Indonesia were first identified by Widyanti, Sumarto, & Suryahadi (2001), who mainly focused on rural areas in Indonesia. Using panel data from the 100 Village Survey in 1998/1999, the study revealed that 18% of households were always poor in the four survey rounds, and 25% were transiently poor. Using the latest panel data from SUSENAS 2008/2010, Purwono et al. (2021) found that the chronic poverty rate was 6.7%. Wardana and Sari (2020) used the same datasets and found spatial heterogeneity of chronic poverty, where rural areas and Eastern Indonesia had a higher chronic poverty rate. The most recent papers on poverty dynamics used different data source, which is not nationally representative. Using the 2007/2014 Indonesia Family Life Survey (IFLS), Sugiharti, Purwono, Esquivias, & Jayanti (2022) found that being older, female, low-educated, and living in a large household is associated with a higher possibility of experiencing chronic poverty. Due to panel data limitations, poverty studies in Indonesia thus lack the analysis of poverty dynamics.
Studying poverty and vulnerability transition has become more critical in times of COVID-19. The pandemic has created new sources of vulnerability and, more importantly, groups of newly vulnerable individuals (Lanjouw and Tarp 2021). The study on vulnerability in Indonesia was limited to the exploration of its measurement. The most recent paper refers to Bah (2013) who found that using the maximum vulnerability index (100%), 80% of the vulnerable households became poor in 2007.
The study on poverty transition was limited to the situation before the pandemic. However, the estimation on poverty and vulnerability transitions during COVID-19 was made based on the data in the pre-COVID period. Aikaeli, Garcés-Urzainqui, & Mdadila (2021) found that around 30% of Tanzanians moved in or out of poverty between 2012 and 2018 and large households with many dependents were most likely to have suffered its first-order economic consequences from COVID-19. Using pre-COVID data in India where rapid economic growth and declining poverty took place, populations in rural areas were already at risk of transitioning into poverty and they might experience chronic poverty once the economy stagnated (Dang et al. 2021). Mekasha & Tarp (2021) found that some populations in the poor and vulnerable group are also the ones relatively more affected by the pandemic. The number of households at risk of falling into poverty might increase and include households observed as less vulnerable in the pre-COVID era (Ferreira et al. 2021).
2.3 Synthetic panels
The assessment of poverty dynamics ideally relies on panel data that track income or consumption at the household level. However, panel data are not available in most developing countries like Indonesia. Even when panel data exist, the sample sizes are relatively small, with short or infrequent duration, and potentially suffer high attrition (Dang et al. 2014). Several studies, beginning with Deaton (1985), have developed a pseudo-panels method to overcome the data limitation issue by using multiple rounds of cross-sectional data and tracking income and consumption based on cohorts (Pencavel 2007; Antman and McKenzie 2007). However, using cohort means makes it challenging to measure mobility at a lower level than the cohort (Dang et al. 2014). Two studies have also constructed pseudo panels on household or individual levels to measure vulnerability to poverty (Bourguignon, Goh, Kim, 2004) and the probability of leaving unemployment (Güell and Hu, 2006). However, the approaches are heavily dependent on the occurrence of at least three rounds of cross-sections, and the assumption is not easily satisfied due to the first-order autoregression (AR (1)) process in which the current income is based on the past income (Dang and Lanjouw 2013).
Dang and Lanjouw (2013) and Dang et al. (2014) proposed a synthetic panels method to provide point and bound estimates of poverty mobility. Unlike the pseudo-panel method, synthetic panels can be employed using only two cross-sectional survey rounds and permit poverty assessment at a lower disaggregated level. The poverty dynamics resulted from the method are the joint probabilities of households’ poverty status in the first and second round. In pre-pandemic, the method has been applied in various settings where genuine panel data exist so that the results can be compared to the true estimates (Cruces et al., 2015; Perez 2015; Garcés-Urzainqui 2017; Hérault and Jenkins 2019) and also where no validation is provided (Ferreira et al. 2013; Rama et al. 2014; Dang and Lanjouw, 2015; Dang and Dabalen 2019; Dang and Ianchovichina, 2018). When a comparison can be made, the true estimates are sandwiched between the bound estimates from synthetic panels. However, with additional parametric assumptions or under some specifications where the bound estimates are narrow, the true estimates are not always positioned between the upper and lower bound, yet the differences are relatively low (0.7–0.8 percentage points) (Dang et al. 2014).
Bound estimates in Dang et al. (2014) left room for greater precision as wider bound estimates are more likely to contain the true estimates but have lower precision and vice versa. Dang and Lanjouw (2013) then proposed a method to derive point estimates by estimating the autocorrelation for the error terms (ρ). The method relies on cohort construction, which can be formed from age or a combination of age and other time-invariant characteristics. The ρ is then computed using the cohort-level correlation coefficient. Hérault and Jenkins (2019) found that point estimates are sensitive to specific cohort definitions. Garcés-Urzainqui (2017) further argues that the cohort approach can only be effective if the unobservable predictors of income at the cohort level do not change over time as those at the household level. As the parametric approach requires stronger assumptions that significantly affect the estimates, one is suggested to not rely solely on the point estimate and that the parametric bound estimates almost always encompass the true rates (Hérault and Jenkins 2019; Rongen et al., 2021). Moreover, using high-quality panel data from Australia and the UK, Hérault and Jenkins (2019) demonstrate that the point estimates are less accurate than estimates from earlier studies, which all concentrate on low- and middle-income nations. In essence, the finding emphasises what Dang and Lanjouw (2013) pointed out that the method has potential in settings where panel data do not exist or suffer from questionable quality.
The limited information on the actual impact of COVID-19 on poverty highlights the needs of using synthetic panels, especially with the data limitation issue in Indonesia. This study therefore demonstrates the synthetic panels to measure poverty and vulnerability transitions in Indonesia in 2019/2020 and identify whether an ex-ante vulnerability is translated into ex-post poverty during the pandemic. This study also presents the profile of each transition, highlighting which population segments are directly hit by the pandemic.
3 Methodology
3.1 Data sources
This study uses secondary household survey data from the Indonesian 2019–2020 National Social and Economic Survey (SUSENAS). It is a cross-sectional survey conducted twice a year, in March and September, by Indonesian National Statistical Office (BPS-Statistics). This study uses March SUSENAS, which has a larger sample size than September SUSENAS. The March SUSENAS is used to produce official statistics at the district level.
The survey collects information on demographics and social welfare at the household level. A household is defined as an individual or a group of individuals, whether related or unrelated, who reside in the same dwelling unit and share food and other basics for living. The survey administers two face-to-face questionnaires for all household members. The first is the core questionnaire, which covers social, health, and demographic questions, while the second is the consumption module, which is used for poverty estimation. The consumption module includes questions on food, beverages, and cigarette consumption within the past week from all possible sources, including purchases, home production, and gifts. The second module also includes expenditures on non-food items with one month and one year prior to the survey as the time reference, depending on the commodity types. The total sample size for March SUSENAS is slightly different each year. The response rate in 2019 was 98.6%. Of 320,000 target households in 2019, 315,672 households were successfully interviewed. In 2020, 334,229 of 345,000 households were interviewed, meaning the response rate declined to 96.9%.
SUSENAS employs a complex survey design. The target population comprises all Indonesian households. For practical reasons, the survey population consists only of occupants of private dwellings or general census blocks (Blok Sensus Biasa). It eliminates special or difficult-to-reach groups such as armed forces, people living in institutions, and communal establishments. SUSENAS uses two-stage stratified sampling. For a logistical reason, 40% of the census block is first selected using Proportional to Size (PPS) based on the number of households in each stratum (urban/rural) across all districts. The sampling frame for the first stage is derived from the list of census blocks in the 2010 Population Census. At the same stage, the census block is systematically selected based on Wealth Index. In the second stage, ten households were chosen from each selected census block using systematic sampling or implicit stratification based on the household head's education level and the presence of infants and pregnant women. The second stage frame is derived from a list of updated households within each selected census block. Design, non-response, and calibration weights are used in the analysis.
3.2 Measures
The unit of analysis in this study is household. The consumption in SUSENAS data constitutes the quantity and value of consumption of foods, beverages and cigarettes and expenditures on non-food items. Consumption of foods and beverages is distinguished between foods and beverages prepared at home, food and beverages directly consumed or not prepared by households, and cigarettes. It comprises 188 commodities that are divided into 14 groups. Meanwhile, expenditures on non-food items are divided into six groups-housing, goods and services (education and health), clothing and footwear, durable goods, tax and insurance, and party and religious ceremonies. The consumption is measured in IDR (Indonesian Rupiah). For poverty measurement, consumption refers to the average consumption per month. The consumption variable is then divided by household size, resulting in consumption per capita. For poverty identification, this study uses the official poverty line constructed by BPS-Statistics. Its construction steps are transparent and follow international guidelines (see BPS-Statistics, 2021). The national poverty lines are IDR425,250 per capita per month in 2019 and IDR454,652 in 2020.
This study documents vulnerability using a method established by Dang and Lanjouw (2017). Similar to earlier studies, vulnerability is measured as the likelihood of slipping into poverty over the following period. The method classifies households as poor, vulnerable, and middle-class. Households who are neither poor nor at risk of sliding into poverty are categorised as "middle-class" or "secure". When households' consumption falls between the poverty and vulnerability lines, the households are classified as vulnerable. Unlike poverty estimates, there is no official vulnerability line. The vulnerability line is derived from a specified vulnerability index/level, which can be defined in two ways. First, it can be defined as the probability of becoming poor in round 2 if one is in the middle-class in round 1 (the “insecurity index”, P1). Secondly, it can be defined as the probability of becoming poor in round 2 if one is vulnerable in round 1 (the “vulnerability index”, P2). One just needs to choose one method based on the purpose of the measurement. The second approach is more relevant for poverty measurement, while the first is more appropriate in measuring prosperities (Dang and Lanjouw 2017). Thus, this paper uses the vulnerability index/level (P2), given by.
where y1 and y2 stand for per capita expenditure in round 1 and round 2, Z1 and Z2 stand for poverty line for rounds 1 and 2, respectively and V1 and V2 stand for vulnerability line for round 1 and round 2.
The method starts by converting the cross-sectional data into synthetic panel data. Afterwards, this study defines a particular vulnerability index (P2) one is willing to accept for non-poor households to slide into poverty. In setting the vulnerability index, this study refers to the target recipients of the Family Hope Program, Indonesian prominent social safety net program managed by the Ministry of Social Affairs. The vulnerability index is set at a specified level so that with the target or available budget, all vulnerable households can be made secure. Besides specifying the vulnerability index, one also needs to specify the start, end, and step values in the iteration. The iteration starts from a value of IDR600,000, which is above the poverty line and has at least 500 observations, as suggested by Dang and Lanjouw (2017). The iteration ends in a sufficiently high value that covers a substantial portion of the consumption distribution (IDR2,000,000). The incremental (step) values for the iteration are set at IDR10,000, approximately 2% of the poverty line in 2019. The decision to use small incremental value is driven by the possibility of obtaining a full range of solutions, though it requires more computer processing time (Dang and Lanjouw 2017). The analysis iterates upwards until the value for vulnerability line for the desirable vulnerability index is reached.
It is worth noting that the iteration results in a vulnerability line for round 1. Thus the vulnerability line for round 2 equals the value for round 1 adjusted for inflation in round 2 (Dang and Lanjouw 2017). However, unlike in the application with true panel data, the use of synthetic panels for vulnerability analysis requires the poverty line to not differ across rounds (Rongen 2021). The method will have the same vulnerability line for the two survey rounds. Therefore, all expenditures data in 2020 needs to be adjusted first to 2019 prices using poverty lines in the two years as deflators.
3.3 Synthetic panels
This study uses the synthetic panels developed by Dang et al. (2014) and Dang and Lanjouw (2013). The idea is to do a multiple imputation procedure so that the values of consumption for households surveyed in round 2 are estimated using household characteristics surveyed in round 1 (Dang & Lanjouw 2013; Dang et al. 2014). This study estimates consumptions in 2019 for households observed in 2020 (round 2) using household characteristics observed in 2019 (round 1). Therefore, the poverty transition analysis uses the estimated consumption in round 1 and the observed/real consumption in round 2. The estimates will be equivalent if the prediction is made the other way around, i.e., predicting round 2 consumption for round 1 households (Rongen 2021). The synthetic panels were conducted using STATA 17 software. The first stage involved data cleaning and preparation. This study combined the household and individual data in each year's dataset by using a unique identifier available in the datasets. The monthly consumption per household used in this study was already available in the datasets. Combining the datasets enabled me to use the consumption data and the explanatory variables for the consumption model. A variable identifying the different survey rounds was made in the dataset. Afterwards, the datasets for rounds 1 and 2 were combined. This study declared the complex survey design features using the svyset command to account for clustering, stratification and survey weights, as well as to avoid analytical error (Heeringa et al., 2017). Finally, I did the synthetic panels to generate poverty and vulnerability transitions using the STATA do-file built by Rongen (2021). The analysis results in a new dataset containing each household's transition probabilities.
The first assumption of this method is that the employed data are comparable so that the analysis can utilise time-invariant household variables to estimate household consumption in a prior period. It means that the underlying population is the same throughout all survey rounds or that the sampling methodology has not changed throughout time (Dang and Lanjouw 2013). In addition, the method is inapplicable when there are substantial demographic shocks to the population composition, such as massive migration into or out of the country. Since no change was made in the sampling methodology for SUSENAS 2019 to 2020 and there is no evidence on how COVID-19 changes the population structure in Indonesia, the first assumption is fulfilled. The second assumption is that the correlation between the error terms of the consumption model must be non-negative across all survey rounds. The non-negative autocorrelation is the most likely outcome in building consumption model as there is a tendency for consumption to remain in the same state from one observation to the next. Dang et al. (2014) claimed that the two assumptions are met if the sample is limited to households whose heads are within a certain age range. This range is also selected to minimise the establishment of new families and the dissolution of existing ones (Garcés-Urzainqui et al. 2021). Following the previous applications on synthetic panels, this study limits the age from 25 to 55. Limiting the lower age to 25 is appropriate as heads of households generally have completed their maximum level of education. The age restriction is made in the first survey round and limited correspondingly in the following rounds.
The method starts by building a consumption model to predict the total consumption households in round 2 would have had in round 1. The consumption model includes variables available in the datasets and used in the existing literature on synthetic panels and poverty in Indonesia. The variables used to build the consumption projection are available in all two rounds and have no missing data. To deal with the skewness of consumption data, the response variable, consumption per capita, is log-transformed. There are two prediction models which progressively employ more time-invariant variables. The poverty and vulnerability transitions will be carried out using all models but only model 1, presented in the primary results.
This study begins with a basic model, which includes only regressors that this study confidently assumes to be time-invariant (Table 1). The first model includes the household's head's gender, age (defined in round 1 year), years of schooling, birth province, and literacy. Age and years of schooling are continuous variables, while the others are categorical variables. These variables are significantly associated with poverty or economic mobility in Indonesia (Sumarto, Suryadarma, & Suryahadi, 2007; Sugiharti et al. 2022).
Subsequently, the study adds variables which are forced to be time-invariant. In the second model, this study adds the head's marital status and a locational dummy of urban/rural. Rahayu et al. (2019) found that geographic locations strongly correlate with poverty in Indonesia. Marital status is also a significant predictor of chronic poverty in Indonesia (Sugiharti et al. 2022). In applying synthetic panels, Mekasha and Tarp (2021) included marital status in the study on Mozambique, and Dang et al. (2014) used an urban/rural dummy in the Indonesian case.
The consumption model is as follows.
where \({y}_{ij}\) is consumption for household i in round j; \(\beta ^\prime _{j}\) is the coefficient for all the regressors in the consumption model for round j; \({x}_{ij}\) is the value of predictors for household i in round j; and \({\varepsilon }_{ij}\) is residuals for households i in round j.
3.3.1 Non-parametric approach
The non-parametric approach makes no assumption on the error distribution and results in bound estimates. The non-parametric lower bound and upper bound estimates assume the correlation coefficient between error terms \({\varepsilon }_{i1}\) and \({\varepsilon }_{i2}\) (ρ) equals its highest value (1) and minimum value (0), respectively (Dang et al. 2014). When ρ equals 0, the two error terms are completely independent. Meanwhile, the two error terms are perfectly correlated in another extreme case (ρ equals 1). Intuitively, mobility will be greater if \({\varepsilon }_{i1}\) and \({\varepsilon }_{i1}\) are less correlated. Therefore, the upper-bound for poverty mobility and lower-bound for poverty immobility are based on the assumption that ρ equals 0. On the other hand, the lower-bound estimates for poverty mobility and upper-bound estimates for poverty immobility assume ρ to be equal to 1.
This study starts by predicting the round 1 consumption for round 2 households using the model in Eq. 2. The residual for households in round 2 is then added to the predicted round 1 consumption to obtain the lower-bound estimates. It takes more steps to get the upper-bound estimates for poverty mobility (ρ = 0), where the errors are drawn randomly from round 1 household and added to the predicted round 1 consumption of round 2 households. Based on the estimated consumption, this study then identifies households’ poverty status and calculates the transition probabilities for each transition state. Finally, this study aggregates the transition probabilities at national level. Since the estimation process for the upper bound is random, one additional step is needed. The estimation procedure is repeated multiple times, and the upper bound is the average over all draws. The transition probabilities for each category are as follows (Tables 2, 3).
Tables 2, 3 shows the estimates for joint probabilities or the fraction of households in each transition category considering all survey rounds together. As poverty dynamics are initially a conditional concept (Fields & Viollaz 2013), this study also estimates conditional probabilities, derived from the joint probabilities from each bound estimate (Table 4). Conditional probabilities represent households’ probabilities of being in a particular poverty status given their status in previous period. Conditional probabilities also reflect the poverty exit and entry probabilities.
3.3.2 Parametric approach
The parametric approach requires a stronger assumption: the error terms of the two survey rounds have a bivariate normal distribution with a non-negative correlation coefficient ρ at the household level. For a given poverty line and predicted round 1 and round 2 income, the transition probabilities can be derived using the correlation coefficient ρ estimates. A lower value of ρ indicates a greater likelihood of entering/exiting poverty or a greater degree of mobility, while a higher value of ρ means a greater degree of immobility. This approach yields a point estimate and narrower bounds on poverty mobility (Dang and Lanjouw 2013; Dang et al. 2014). The correlation coefficient ρ in Dang and Lanjouw (2013) is estimated using information on the intertemporal correlation of consumption (\({\rho }_{{y}_{1}{y}_{2}}\) or ρy). The ρy can be obtained in two ways: i) import ρy from the true panel data in previous periods or ii) estimate from a cohort-level correlation of consumption \({\rho }_{{y}_{c1}{y}_{c2}}\), which proxies for the unobserved household-level correlation of consumption (ρy) (Dang and Lanjouw 2013). The latter method proposes constructing cohorts based on age or combinations of age and other variables strongly correlated with household consumption. After the cohort construction, one needs to compute cohort-level mean consumption correlation coefficient \({\rho }_{{y}_{c1}{y}_{c2}}\), where c indexes the cohorts constructed. Afterwards, the correlation coefficient of errors, ρ, for the point estimation can be computed as follows.
The upper value of the estimated correlation coefficient of errors is equal to the cohort-level simple correlation coefficient \({\rho }_{{y}_{1}{y}_{2}}\), and the lower value is \(\frac{{{\beta }_{1}}{\prime}var({x}_{i}){\beta }_{2}}{\sqrt{var\left({y}_{i1}\right)var({y}_{i2})}}\).
This study uses the two methods and contrasts the estimates in the next section. For the first method, this study uses the value of ρ for Indonesia, which is available from the reference paper on synthetic panels (Dang et al. 2014). This study also estimates the cohort-level correlation coefficient using cohorts built from a combination of age and gender. The steps to obtain the point estimate are similar to the non-parametric approach. The joint probabilities for each poverty and vulnerability transition category can be obtained as follows (Tables 5, 6).
4 Results
4.1 Poverty transitions
This section shows the estimates of poverty dynamics over 2019–2020. The main results are only generated from Model 1. Table 7 displays the joint and conditional probabilities derived from the non-parametric and parametric techniques. The two sets of estimates are essential in understanding poverty transitions. Panel A represents the joint probabilities or the proportion of households in each state. For instance, "poor, poor" represents the share of households that remained poor in 2019/2020. Panel B shows the conditional probabilities of each transition category. For instance, "poor to poor" reflects the conditional probability of becoming poor in 2020, given that the households were poor in 2019. This study also generates the estimates using Model 2. The consumption model 2 led to a slightly increased adjusted-R2. The estimates using Model 2 are presented in Appendix 2. Model 2 has a slightly narrower interval and made little difference to the bound estimates.
It is worth noting that the interval of the bound estimates, especially in Panel A, is narrower than the estimates in previous studies (i.e. Ferreira et al. 2021; Mekasha & Tarp 2021; Aikaeli, Garcés-Urzainqui, & Mdadila, 2021), especially the study for Indonesia in the reference paper (Dang et al. 2014). The non-parametric estimates show that 0.7–5.1% of Indonesian households remained poor in 2019/2020. In contrast, up to 6% of the households escaped poverty in 2020. In the greatest mobility scenario in Panel B, the poverty transitions indicate that households that were poor in 2019 were more likely to move out of poverty (89%) than to stay poor by 2020 (11%). In the least mobility scenario, the conditional probability of falling into poverty in 2020 given the households were non-poor in 2019 was 3.9%. It is slightly higher than the probability of transitioning out of poverty in 2020, given that being poor in 2019 (3%). The estimates in Panel A further show that up to 8% of non-poor households in 2019 fell into poverty in 2020, higher than the fraction of poor households who became non-poor (5.8%). It might indicate the effects of the economic shock caused by the pandemic.
Following the application in Dang et al. (2014), this study also shows the parametric bound estimates under three specifications. Specification 3 with a narrower range of ρ is suggested for Indonesia as ρ for Indonesia and other developing countries derived from the true panel data ranges from 0.3 to 0.7 (Dang et al. 2014). The results in Table 7 show that the bound estimates are sequentially tighter the narrower the range of correlation used. While the narrower bounds might not encompass the true rates, previous studies, including Dang et al. (2014) and Hérault & Jenkins (2019), have shown that the estimated parametric bounds from all specifications virtually always encompass the true rates, which strengthens the validity of the bound estimates given the assumptions are met. The result of the Doornik-Hansen normality test rejects the assumption of bivariate normality distribution for the error terms. However, according to the Central Limit Theorem, it does not cause a problem when dealing with a large sample size.
This study focuses on the parametric bound estimates from Specification 3 for interpretation. The poverty exit probability or the conditional probability of moving out of poverty in 2020 given households were poor in 2019 is relatively high, ranging from 46 to 75%. In contrast, the probability of non-poor households sliding into poverty in 2020 was relatively low, between 6.8% and 8.8%. The fraction of households found to be poor in both survey rounds ranges from 1.7% to 3.6%. Meanwhile, 85% to 87% of the households stayed out of poverty in 2019 and 2020. The conditional probability of remaining non-poor in 2020, given non-poor in 2019, is extremely high, between 91 and 93%.
This study also derives the point estimates from Dang and Lanjouw's (2013) parametric approach. The method relies on information about the intertemporal correlation of consumption, ρy. Since no real panel data is available for the same periods, this study first generates the point estimates using all possible values of ρy. The estimates use a value of ρy from 0.1 to 0.9. The range of possible values for ρy also results in the estimated ρ for Indonesia and other countries mentioned in Table 3, Dang et al. (2014). The parametric point estimation cannot be executed using ρy = 0 and also at the other extreme, ρy = 1. It occurs due to the unmet assumptions in Dang and Lanjouw (2013), where the ρ must be non-negative, and the upper value of ρ is ρy. When ρy = 0 is used, ρ has a negative value, while ρy = 1 results in a ρ that is higher than ρy.
Figure 1 shows how the point estimates of joint and conditional probabilities change as the ρy changes. In Panel A, the joint probability estimates show that the poverty immobility categories or the fraction of households that remained poor or non-poor in both periods increases as ρy increases. On the other hand, the estimated share of households that experienced poverty mobility (either moving in or out of poverty) decreases as ρy increases. In addition, Panel B shows that the conditional probabilities for categories “poor to poor” and “poor to non-poor” experiences a sharp increase or decrease as ρy increases. It indicates that the change in ρ affects the conditional probabilities more significantly for transition categories that include being poor in the first period. This finding highlights the importance of the decision on ρ since the poverty programs usually focus more in helping people escape poverty, and policymakers more often use point estimates for easy interpretation and communication.

Poverty dynamics 2019–2020, point estimates of joint and conditional transition probabilities using all possible values for intertemporal correlation of consumption ρy
As mentioned in the Methodology, ρy for the point estimates can be imported from ancillary panel data or estimated from the cohort-level correlation coefficient method. This study uses both methods. However, since there is no information on ρy from true panel data for Indonesia, this study imports the value for the correlation coefficient between the error terms (ρ) from IFLS 1997–2000 in Dang et al. (2014) and works backwards to obtain ρy. The imported ρ is 0.5, which implies that ρy equals 0.55. In addition, this study builds cohorts based on age and gender and found that ρy is 0.938, implying ρ equals 0.938. Even though it satisfies the synthetic panel assumption on the value of ρ bounded by [1, 0], the estimates appear to be higher than the estimated ρ in other settings (details in Garcés-Urzainqui, Lanjouw, & Rongen, 2022). This study failed to estimate the consumption correlation using different cohort definitions due to the unmet assumptions. Defining age and other time-invariant characteristics, including education and literacy, results in a small size for some cohorts, which violates the standard of cohort size in pseudo-panel literature (Verbeek 2008). Secondly, this study also tried to estimate the poverty transition using cohort-level correlation defined by age only and age combined with the head’s birth province. The analysis results in a ρ higher than ρy, thus violating the assumption of bounds for ρ (Dang and Lanjouw 2013).
Tables 8 and 9 show that how ρy is estimated strongly influences the poverty transition estimates. All the point estimates using imported ρ fall inside the estimated bounds. However, not all the point estimates from the cohort approach fall inside the non-parametric bounds, but when this is the case, the gaps between the point estimate and the closest bound are inconsiderable. Besides, the estimates from the cohort approach fall only between the parametric bounds under Specification 1. The relatively high value of ρy resulting from the cohort approach indicates a strong correlation between household consumption in both survey rounds. Thus, the estimates are higher than the estimates from ancillary panel data for poverty immobility categories. It also explains why the estimates from the cohort approach are close to the lower bounds for poverty mobility (or upper bounds for poverty immobility).
For interpretation, this study focuses on the point estimates using ρ from ancillary panel data. There is a relatively high poverty exit probability, 62%. In contrast, the likelihood of becoming poor in 2020, given households were non-poor in 2019, is relatively low, about 8%. Concerning poverty immobility, only 2.6% of the households were poor in both years, whereas 86% were non-poor in 2019 and 2020. Lastly, the fraction of poor households in 2019 who became the new poor in 2020 is higher than the fraction who remained in poverty (7.4% versus 2.6%).
As the results from both methods show contrasting estimates, this study continues the analysis using the imported ρ. The first reason is that the estimated cohort-level correlation (ρ) is sensitive to the definition of the cohort used (Garcés-Urzainqui 2017; Hérault & Jenkins 2019). Even though this study cannot prove how sensitive it is, the estimated ρ for Indonesia is still way higher than countries with similar settings. Besides, Hérault and Jenkins (2019) found that even using the cohort definition that generates the best estimates of ρ, sometimes the corresponding estimates might depart considerably from their true estimates. Secondly, Hérault & Jenkins (2019) and Garcés-Urzainqui, D., Lanjouw, P., & Rongen, G. (2021) suggested emphasising the findings that are consistent with patterns captured by the bound estimates, especially when validation on the point estimates cannot be made. Lastly, since ρ is rather stable, proven by the range of ρ over the entire study period for countries in Dang et al. (2014), ρ from the ancillary panel data might still be relevant or that the true ρ might not depart significantly from it (Garcés-Urzainqui et al. 2021).
4.2 Vulnerability transitions
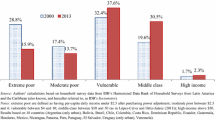
Following the method proposed in Dang and Lanjouw (2017), the analysis starts by determining the vulnerability index (P2) and then deriving the vulnerability line using the specified P2. As the desired vulnerability index can be tied to welfare goals, this study refers to the household target in Family Hope Programme, which is a cash transfer programme. The Family Hope Program targeted 10 million households as the beneficiary recipients in 2020. This study assumes an equal cash transfer distribution for all the recipients to make the analysis easier. Based on Population Projection in 2019, there are 68.7 million households in Indonesia, and the estimates in Table 8 show that 6.7% (or 4.6 million households) were poor in 2019. If the aid targets 4.6 million households, the remaining budget could cover 5.4 million households. Table 8 also shows that 93.3% of households in Indonesia were non-poor in 2019, corresponding to 64.1 million households. Thus the vulnerability index is set at 9% (obtained by dividing 5.4 million aid-eligible households that would have fallen into poverty without this assistance by 64.1 million non-poor households). The specified index is also appropriate since the index should be higher than the conditional probability of “nonpoor to poor” (7.9%) (Dang and Lanjouw 2017). By specifying the vulnerability index at 9%, this study obtains a vulnerability line of IDR1,820,000 per month.
Based on the estimated vulnerability line, this study computes the conditional and unconditional transition probabilities using synthetic panels (ρ is set to 0.5). As observed in Tables 10, 3% of the households remained poor in 2019/2020. The proportion of households who were vulnerable in 2019 and then slipped into poverty in 2020 was 6.7%, and 12.1% of households were middle-class in 2019 and became vulnerable in 2020. Based on Panel B, vulnerable households in 2019 were more likely to stay vulnerable than fall into poverty (77.7% versus 9.5%). It seems likely for poor households in 2019 to transition upward to the vulnerable group in 2020 (62.3%). Besides, the probability of becoming vulnerable in 2020, conditional on being secure in 2019, was also relatively high (58%). In contrast, it appears extremely unlikely have an upward mobility from the poor group to the middle class (1.4%) and downward mobility from the middle-class to the poor group (1.1%).
4.3 Profiles of poverty and vulnerability transitions
As the synthetic panels result in the transition probabilities for each household, it is possible to aggregate the probabilities by particular characteristics. This study analyses the association between poverty and vulnerability transitions with household characteristics used in the consumption model and other variables found to be associated with poverty in the existing literature. It is worth noting that the purpose is just to document statistical associations, not to report the causes of poverty and vulnerability transitions. The analysis focuses on both poverty immobility and upward/downward mobility.
4.3.1 Geographic differences
The differences between each category of poverty immobility are less pronounced. Based on Fig. 2, the probability for a household to stay poor in 2020, given being poor in 2019, is 38% for urban areas and 40% for rural areas. The probabilities are also higher for households living outside Java island (Fig. 2). However, the probabilities of remaining vulnerable in both periods are the same for all the geographic categories (Fig. 5, Panel B).

Joint and conditional probabilities of the state “poor, poor” by geographical and household characteristics, 2019–2020

Joint and conditional probabilities of the state “non-poor, poor” by geographical and household characteristics, 2019–2020

Joint and conditional probabilities of the state “poor, non-poor” by geographical and household characteristics, 2019–2020


Joint probabilities (Panel A) and conditional probabilities (Panel B) of poverty immobility by geographical/household characteristics, 2019–2020
î
The joint and conditional probabilities for downward mobility are very low and range from 7 to 9% (Fig. 3). The most significant differences are found in the likelihood of sliding into poverty in 2020, conditional on being non-poor in 2019 for households living in urban versus rural areas (7.7% versus 8.6%). The differences between conditional and joint probabilities for urban vs rural areas and Java vs non-Java islands are also insignificant for vulnerability transitions (Fig. 6). Regardless of the geographic characteristics, the highest conditional probabilities of experiencing downward transitions belong to the “middle-class, vulnerable” state, with the conditional probabilities of 58%. Meanwhile, the “middle class, poor” state has the lowest conditional probabilities, around 1.1%.


Joint probabilities (Panel A) and conditional probabilities (Panel B) of downward mobility by geographical/household characteristics, 2019–2020
The upward transitions can be seen in Figs. 4 and 7. The conditional probability of moving to the non-poor group in 2020, conditional on being poor in 2019, reaches about 62% for urban and 60% for rural areas (Fig. 4, Panel B). The conditional probability of becoming non-poor in 2020 given the households were poor in 2019 appears to be higher for Java than outside Java (62% versus 59%). Figure 7 shows that regardless of the transition category, the conditional probabilities of experiencing upward transition are higher for households living in urban area and Java island than those living in rural area and outside Java.


Joint probabilities (Panel A) and conditional probabilities (Panel B) of upward mobility by geographical/household characteristics, 2019–2020
4.3.2 Household characteristics
The highest likelihood to remain poor in 2020 if they were poor in 2019 belongs to households whose heads are illiterate (62%). The conditional probabilities for staying poor in both periods are higher for households whose heads are female, widowed, less educated, and work in the agricultural sector. The conditional probabilities are the same regardless of the household size. As seen in Fig. 5, the significant differences for conditional probabilities of “vulnerable, vulnerable” only belong to the head’s literacy.
As seen in Fig. 3, the probabilities of entering poverty given being non-poor differ significantly by household head’s literacy. It is more likely for households with low-educated heads to fall into poverty. The probability of being poor in 2020 given the households were non-poor in 2019 is the highest for those working in agriculture, about 9%. As seen in Fig. 6 Panel B, the conditional probabilities of becoming poor in 2020, given that being vulnerable in 2019 for households with an illiterate head, almost tripled the probabilities for households with literate heads (24.6% versus 9.5%). The lower conditional probabilities of downward transitions are associated with higher education level of the heads. The probability of becoming vulnerable in 2020, given that being middle-class in 2019, is the highest for households with illiterate heads (73%). Based on Panel A, the share of households that became the new vulnerable group is higher among households whose heads are female, widowed, university graduates, and work in other sectors (mainly service sectors).
With regard to the upward transitions in Figs. 4 and 7, the probabilities of becoming non-poor in 2020, given that the household poor in 2019 are around 62% for all categories, except for households whose heads are illiterate (38%), female (58%), widowed (57%), and work in agriculture (59%). In particular, the conditional probabilities of moving to the vulnerable group conditional on being poor are around 60% for most of the characteristics, except for households with illiterate heads (40%). In addition, the likelihoods of becoming middle-class given being poor are always the lowest regardless of the characteristics.
4.3.3 Ownership of durable goods
The joint and conditional probabilities of remaining poor in 2020 if households were poor in 2019 are lower for households that own durable goods (television and motor vehicle). Besides, households who did not own a TV have a probability of 8.3% sliding into poverty. In contrast, those who owned a TV have a probability of 7.3%. Lastly, possessing durable goods is associated with higher conditional probabilities of having upward transition.
5 Discussion
Evaluating the impact of COVID-19 on poverty is hindered by the lack of evidence in the period preceding the shock. This study demonstrates synthetic panels to identify the consequences of COVID-19 on poverty dynamics in Indonesia. A success in poverty reduction before the pandemic is reflected by the narrower bound estimates. The poverty persistence rate in 2019/2020 ranges between 0.7 and 5.1%, narrower than the estimates in 1997/2000 in Dang et al. (2014) (3.5 to 15.1%). Besides, the fraction of households who fell into poverty ranges from 3.7 to 8.1%, lower than the true estimates in Dang et al. (2014), 8.3%. Based on the point estimates, the poverty exit probabilities are higher than the poverty entry. The results also show that the fraction of households that transitioned from vulnerable to the poor is 6.7%, higher than the poverty persistence rate. It indicates that the pandemic has more significantly created the new poor than brought the risks of being trapped in poverty.
The impact of COVID-19 and the measures to curb its spread are not uniformly distributed among Indonesian households. The probabilities of poverty persistence differ by area of residence, household head’s gender, literacy, education level, marital status, working sector, and possession of durable goods. The significant differences between those categories also occur in the probabilities of downward mobility, except for marital status. The different probabilities of poverty transitions between each geographic characteristic align with Gibson and Olivia (2020) and Brata et al. (2021), which found that the effects of COVID-19 on poverty in Indonesia in the aggregate are spatially heterogeneous. The highest probability of transitioning from being non-poor to poverty for agricultural households confirms the findings of Morgan and Trinh (2021), which found that, unlike other ASEAN countries, the most significant income decline during the pandemic in Indonesia belongs in agricultural households. In the pre-pandemic situation, people who worked in service sectors were also found to have a lower poverty risk than those in agriculture (Faharuddin & Endrawati, 2022). Households headed by high school or university graduates also had a lower likelihood of experiencing income decline in COVID-19 times (Morgan and Trinh 2021). In addition, asset possession is significantly associated with lower poverty risk before the pandemic (Sumarto et al. 2007).
This study highlights literacy as the structural cause of poverty. Illiteracy also became the most significant factor that caused poverty persistence and created the new poor group in the pandemic. Middle-class households were less likely to slide into poverty, but the likelihood is the greatest for households with illiterate heads. In addition, the probability of moving from being secure to the vulnerable group was pretty high. The high fractions of new vulnerable were associated with living in the urban area, having heads who were female, illiterate, university graduate, widowed, worked in other sectors (mainly services sectors), and households that owned a TV. Regardless of the socioeconomic characteristics, it is less feasible for households already poor or vulnerable before the pandemic to move into middle-class groups.
The analysis only covers the early situation of the shock. Thus, it cannot account for a specific policy response that would have lessened the impact of COVID-19. Moreover, this study also cannot consider migration from one region/province to the other due to the nature of synthetic panels. Warr and Yusuf (2021) found that the pandemic loss of urban jobs in Indonesia has induced a large urban to rural migration, called de-urbanisation. These unaccounted dynamics would affect the transition probabilities, which are not captured in this study. However, this phenomenon might explain why the poverty persistence and the new poor groups are greater in rural areas than in urban areas, which have more COVID-19 restrictions. Warr and Yusuf (2021) found that de-urbanisation has exacerbated rural poverty by expanding the agricultural workforce in rural areas by 7.8%. The rural households were also more affected by the pandemic due to the reliance on the internal migrants’ remittances. Before the pandemic, 85% of rural–urban labour migrants in Indonesia regularly transferred almost 50% of their income to their families who lived elsewhere (Lu 2010).
The findings of this study are relevant for designing poverty alleviation strategies in various ways. First, while keeping the existing poverty programs is essential, the governments should specifically renew the interventions that directly consider those affected by the pandemic. Secondly, the new vulnerable group from the service or non-essential sectors explains how poverty and vulnerability have changed during the shock. While this group might not be the target before the pandemic, the social safety net policies during the crisis should also include those who are vulnerable and those who have moved out of poverty so that they will remain out of poverty. Lastly, the post-pandemic recovery might be more challenging for particular segments. Hence, it is recommended that the governments should sharpen the focus on poverty reduction on those severely hit by the pandemic.
6 Conclusion
After years of sustained economic growth and persistent poverty reduction, Indonesia faces an unprecedented challenge induced by the COVID-19 pandemic. The results show that the poverty persistence rate in Indonesia is 2.6%, highlighting the needs of policy targeted specifically at the structural causes of poverty. The pandemic impact can be seen in the 6.7% of households who were vulnerable before the pandemic and became the new poor in 2020. In addition, it is more likely for the households who were in the middle-class group to become vulnerable than to fall into poverty during the pandemic. This study also highlights that not all households were affected in the same way by the pandemic. Area of residence, demographics, literacy, education level, and possession of durable goods are correlated with different poverty transitions, highlighting the needs for different policy responses based on the households’ circumstances.
This paper exhibits great potential in developing measurement for poverty dynamics during an economic crisis when panel data is scarce. The empirical findings of this study add evidence to the needs of redesigning poverty reduction strategies. This study highlights the urgency of helping not only those who are already poor, but those who are vulnerable of falling into poverty. The policy designs also need to take into account the household characteristics that are associated with each poverty transition. Following previous studies on the application of synthetic panels, this study also found that the method is sensitive to the assumptions made (parametric/non-parametric) and the way key parameters (ρ) are estimated.
The limitation of this study relates to the methodological parts. Due to data limitations, this study only uses a small number of time-invariant variables. As a result, the consumption model has low R2 and produces less precise estimates. The scarcity of recent panel data in Indonesia led this study to generate point estimates using ρ from outdated datasets, which might not capture the change in households’ consumption patterns during the pandemic. Recent studies have documented the change in people’s consumption behaviour during the pandemic. For example, some households might reduce their consumption in 2020 due to lower income (Piyapromdee & Spittal 2020; Xiong et al. 2021). Thus, it could result in a lower correlation coefficient. Conversely, the change in consumption might not be about the total consumption but more about what people consume. For instance, consumption of travel, recreation, clothes, and education was shifted to more spending on healthcare among people in China (Xiong et al. 2021). It would, therefore, results in a higher correlation coefficient. It is also worth noting that Dang and Lanjouw (2013) pointed out the possibility of different ρ for different household welfare outcomes (food / non-food consumption). A separate estimation for ρ might be more recommended during the pandemic since the ρ for non-food consumption may be lower than for food due to social restrictions and changes in non-food consumption behaviour. In essence, the change induced by the pandemic might strongly be significant in the choice of critical parameters in synthetic panels.
Further research can incorporate longer periods in the analysis so that the scale of the poverty dynamics during COVID-19 can be documented. Hérault & Jenkins (2019) found that the estimates are also sensitive to age restrictions. Future studies can expand the sample coverage to households whose heads are aged 25–75 years old, considering that the poverty rates among the elderly in Indonesia were significantly higher than those of the rest of the population (Priebe & Howell 2014; Priebe 2017). However, due to the prevalence of household dissolution among the elderly in Indonesia, one has to be cautious concerning the assumptions about stable households in synthetic panels. Finally, since Indonesia is the only data the author can access, this study can also be applied in other settings where panel data during COVID-19 is unavailable.
References
Aikaeli, J., Garcés- Urzainqui, D., Mdadila, K.: Understanding poverty dynamics and vulnerability in Tanzania: 2012–2018. Rev. Dev. Econ. 25, 1869–1894 (2021). https://doi.org/10.1111/rode.12829
Antman, F., McKenzie, D.: Earnings mobility and measurement error: a synthetic panel approach. Econ. Dev. Cult. Change 56(1), 125–162 (2007)
Bah, A.: Estimating vulnerability to poverty using panel data: evidence from Indonesia, (2013) https://doi.org/10.2139/ssrn.2411921
Bane MJ, Ellwood D (2000) Slipping into and out of poverty: the dynamics of spells. J Human Resour 21(1): l–23
Bourguignon, F., Goh, C., and Kim, D.I.: Estimating individual vulnerability to poverty with pseudo-panel data (World Bank Policy Research Working Paper No. 3375). https://openknowledge.worldbank.org/handle/10986/14150
BPS-Statistics Indonesia. Penghitungan dan analisis kemiskinan makro Indonesia 2021 (The Calculation and Analysis of 2021 National Poverty Estimates in Indonesia) (2021). Retrieved from https://bps.go.id/publication.html
Brata, A.G., Pramudya, E.P., Astuti, E.S., Rahayu, H.C; Heron, H.: COVID-19 and socio-economic inequalities in Indonesia: a subnational-level analysis (ERIA Discussion Paper Series No.371). https://www.eria.org/publications/covid-19-and-socio-economic-inequalities-in-indonesia-a-subnational-level-analysis/ (2021)
Calvo, C., & Dercon, S.: Measuring individual vulnerability (Economic Series Working Papers No. 229). https://ora.ox.ac.uk/objects/uuid:aec11fc8-51d7-414e-b0ce-9bd274e9417f(2005)
Central Statistical Organization (CSO), Ministry of Planning, Finance and Industry (MOPFI), and United Nations Development Programme (UNDP). (2020). Household Vulnerability Survey (HVS) key findings: Rapid assessment of the economic impact of COVID-19 restrictions on vulnerable households. Retrieved from https://www.csostat.gov.mm/AvailableBookshop/Availablenow
Chaudhuri, S., Jalan J., Suryahadi, A.: Assessing household vulnerability to poverty from cross-sectional data: a methodology and estimates from Indonesia (Columbia University Department of Economics Working Paper 0102–52). https://academiccommons.columbia.edu/doi/https://doi.org/10.7916/D85149GF(2002)
Chaudhuri, S.: Assessing vulnerability to poverty: concepts, empirical methods and illustrative examples. http://www.econdse.org/wp-content/uploads/2012/02/vulnerability-assessment.pdf(2003)
Cruces, G., Lanjouw, P., Lucchetti, L., Perova, E., Vakis, R., Viollaz, M.: Estimating poverty transitions repeated cross-sections: a three-country validation exercise. J. Econ. Inequal. 13, 161–179 (2015)
Dang, H.H., Dabalen, A.L.: Is poverty in Africa mostly chronic or transient? Evidence from synthetic panel data. J. Dev. Stud. 55(7), 1527–1547 (2019). https://doi.org/10.1080/00220388.2017.1417585
Dang, H.A., Lanjouw, P.F.: Welfare dynamics measurement: two definitions of a vulnerability line and their empirical application. Rev. Income Wealth 63, 633–660 (2017). https://doi.org/10.1111/roiw.12237
Dang, H.A., Lanjouw, P.F.: Poverty dynamics in India between 2004 and 2012: insights from longitudinal analysis using synthetic panel data. Econ. Dev. Cult. Change 67(1), 131–170 (2018). https://doi.org/10.1086/697555
Dang, H.A., Lanjouw, P., Luoto, J., McKenzie, D.: Using repeated cross-sections to explore movements into and out of poverty. J. Dev. Econ. 107, 112–128 (2014). https://doi.org/10.1016/j.jdeveco.2013.10.008
Dang, H.A., Lanjouw, P., Vrijburg, E.: Poverty in India in the face of Covid-19: diagnosis and prospects. Rev. Dev. Econ. 25, 1816–1837 (2021). https://doi.org/10.1111/rode.12833
Dang, H.A., & Lanjouw, P.: Measuring poverty dynamics with synthetic panels based on cross-sections (World Bank Policy Research Working Paper No.6504). https://openknowledge.worldbank.org/handle/10986/15863 (2013)
Deaton, A.: Panel data from time series of cross-sections. J. Econ. 30, 109–216 (1985)
Duncan, G.J., Gustafsson, B., Hauser, R., et al.: Poverty dynamics in eight countries. J Popul Econ 6, 215–234 (1993). https://doi.org/10.1007/BF00163068
Duncan, G. J., Richard D.C., & Martha S. H. (1984). The Dynamics of Poverty. In Greg J. Duncan (ed.), Years of Poverty. Years of Plenty (pp. 33–70). Ann Arbor: Institute for Social Research.
Dutta, I., Foster, J., Mishra, A.: On measuring vulnerability to poverty. Soc. Choice Welfare 37(4), 743–761 (2011). https://doi.org/10.1007/s00355-011-0570-1
Faharuddin, F., Endrawati, D.: Determinants of working poverty in Indonesia. J. Econ. Dev. (2022). https://doi.org/10.1108/JED-09-2021-0151
Ferreira, F.H.G., Messina, J., Rigolini, J., López-Calva, L.-F., Lugo, M.A., Vakis, R.: Economic mobility and the rise of the latin american middle class. The World Bank, Washington, DC (2013)
Ferreira, I.A., Salvucci, V., Tarp, F.: Poverty and vulnerability transitions in Myanmar: an analysis using synthetic panels. Rev. Dev. Econ. 25, 1919–1944 (2021). https://doi.org/10.1111/rode.12836
Fields, G. & Viollaz, M. (2013). Can the limitations of panel datasets be overcome by using pseudo-panels to estimate income mobility?. In: Paper Presented at the ECINEQ Conference, Bari, Italy.
Fields, G.S., Ok, E.A.: The measurement of income mobility: an introduction to the literature. In: Silber, J. (ed.) Handbook on income inequality measurement, pp. 557–596. Kluwer Academic Publishers, Norwell, MA (1999)
Garcés-Urzainqui, D., Lanjouw, P., Rongen, G.: Constructing synthetic panels for the purpose of studying poverty dynamics: a primer. Rev. Dev. Econ. 25, 1803–1815 (2021). https://doi.org/10.1111/rode.12832
Garcés-Urzainqui, D. (2017). Poverty transitions without panel data? an appraisal of synthetic panel methods. In; Paper presented at the ECINEQ Conference, New York City.
Gibson, J., Olivia, S.: Direct and indirect effects of Covid-19 on life expectancy and poverty in Indonesia. Bull. Indones. Econ. Stud. 56(3), 325–344 (2020). https://doi.org/10.1080/00074918.2020.1847244
Glewwe, P., Hall, G.: Are some groups more vulnerable to macroeconomic shocks than others? Hypothesis tests based on panel data from Peru. J. Dev. Econ. 56, 181–206 (1998). https://doi.org/10.1016/S0304-3878(98)00058-3
Gottschalk, P.: Earnings mobility: permanent change or transitory fluctuations? Rev. Econ. Stat. 64(3), 450–456 (1982). https://doi.org/10.2307/1925943
Güell, M., Luojia, H.: Estimating the probability of leaving unemployment using uncompleted spells from repeated cross-section data. J. Econ 133, 307–341 (2006)
Heeringa, S.G., West, B.T., & Berglund, P.A. (2017). Applied Survey Data Analysis (2nd ed.). New York, NY: Chapman and Hall/CRC. https://doi.org/10.1201/9781315153278
Hérault, N., Jenkins, S.: How valid are synthetic panel estimates of poverty dynamics? J. Econ. Inequal. 17, 51–76 (2019). https://doi.org/10.1007/s10888-019-09408-8
Hoddinott, J. and Quisumbing. A. (2010). Methods for microeconometric risk and vulnerability assessment. In R. F.-N. and P. A. Seck, ed., Risk, Vulnerability and Human Development: On the Brink. London: Palgrave Macmillan-United Nations Development Programme,.
Jalan, J., Ravallion, M.: Transient poverty in postreform rural China. J. Comp. Econ. 26, 338–357 (1998)
Lanjouw, P.F., Tarp, F.: Poverty, vulnerability and Covid-19: introduction and overview. Rev. Dev. Econ. 25(4), 1797–1802 (2021). https://doi.org/10.1111/rode.12844
Levy, F. (1977). How big is the american underclass?. Working paper 0090–1. Washington, D.C.: The Urban Institute.
Lillard, L.A., Willis, R.J.: Dynamic aspects of earning mobility. Econometrica 46(5), 985–1012 (1978). https://doi.org/10.2307/1911432
Lu, Y.: Mental health and risk behaviours of rural-urban migrants: Longitudinal evidence from Indonesia. Popul. Stud. 64(2), 147–163 (2010). https://doi.org/10.1080/00324721003734100
Martin, A., Markhvida, M., Hallegatte, S., Walsh, B.: Socio-economic impacts of COVID-19 on household consumption and poverty. Econ Disasters Clim Change 4, 453–479 (2020). https://doi.org/10.1007/s41885-020-00070-3
Mekasha, T.J., Tarp, F.: Understanding poverty dynamics in Ethiopia: implications for the likely impact of COVID-19. Rev. Dev. Econ. 25, 1838–1868 (2021). https://doi.org/10.1111/rode.12841
Morduch, J.: Chapter 2: concepts of poverty. In: United nations handbook of poverty statistics, pp. 23–51. United Nations, New York (2008)
Morgan, J.N.: Five thousand american families, vol. I. Institute for Social Research, Ann Arbor (1974)
Morgan, P. J. and Trinh, L.Q.: Impacts of COVID-19 on households in ASEAN countries and their implications for human capital development (ADBI Working Paper 1226) (2021). https://www.adb.org/publications/impacts-covid-19-households-asean-countries
OECD: Employment outlook. OECD, Paris (2001)
Pencavel, J.: A life cycle perspective on changes in earnings inequality among married men and women. Rev. Econ. Stat. 88(2), 232–242 (2007)
Perez, V.: Moving in and out of poverty in Mexico: what can we learn from pseudo-panel methods? (ISER Working Paper 2015–16, University of Essex) (2015)
Piyapromdee, S., Spittal, P.: The income and consumption effects of covid-19 and the role of public policy. Fisc. Stud. 41(4), 805–827 (2020). https://doi.org/10.1111/1475-5890.12252
Priebe, J.: Old-age poverty in indonesia: measurement issues and living arrangements. J. Dev. Change 4(6), 1362–1385 (2017)
Priebe, J., & Howell, F.: Old-age poverty in Indonesia: Empirical evidence and policy options a role for social pensions (TNP2K Working Paper 07) (2014). https://www.tnp2k.go.id/images/uploads/downloads/Old%20Age%20Poverty%20April%201%20Approved%20for%20Publication_EV-2.pdf
Pritchett, L., Suryahadi, A., and Sumarto, S.: Quantifying vulnerability to poverty: a proposed measure, applied to Indonesia (World Bank Policy Research Working Paper No. 2437) (2000). https://openknowledge.worldbank.org/handle/10986/21355
Purwono, R., Wardana, W.W., Haryanto, T., Khoerul Mubin, M.: Poverty dynamics in Indonesia: empirical evidence from three main approaches. World Dev. Perspect. (2021). https://doi.org/10.1016/j.wdp.2021.100346
Rahayu, H.C., et al.: Dynamic panel data analysis of poverty in Indonesia. In: Advances in economics, business and management research, volume 143 of 2nd ISBEST, (2019)
Rainwater, L., Center for Urban Studies, J.: Persistent and transitory poverty: a new look. Joint Center for Urban Studies of MIT and Harvard University, Cambridge, MA (1981)
Rama, M., Be ́teille, T., Li, Y., Mitra, P.K., Newman, J.L.: Addressing inequality in South Asia. The World Bank, Washington, DC (2014)
Rongen, G.: Manual for the estimation of a synthetic Panel and vulnerability analysis. DEEP Methods and Tools Note 01 (2021) https://doi.org/10.55158/DEEPMTN1
Salvucci, V., Tarp, F.: Poverty and vulnerability in Mozambique: an analysis of dynamics and correlates in light of the Covid-19 crisis using synthetic panels. Rev. Dev. Econ. 25, 1895–1918 (2021). https://doi.org/10.1111/rode.12835
Sen, A.: Poverty: an ordinal approach to measurement. Econometrica 44(2), 219–231 (1976). https://doi.org/10.2307/1912718
Sugiharti. L., Purwono, R., Esquivias, M.A., and Jayanti, A.D.: Poverty dynamics in Indonesia: The prevalence and causes of chronic poverty. Journal of Population and Social Studies, 30 (2022). Retrieved from https://so03.tci-thaijo.org/index.php/jpss/article/view/258737
Sumarto, S., Suryadarma, D., Suryahadi, A.: Predicting consumption poverty using non-consumption indicators: experiments using Indonesian. Soc. Indicators Res. 81(3), 543–578 (2007)
Sumner, A., Hoy, C., Ortiz-Juarez, E.: Estimates of the impact of COVID-19 on global poverty (UNU-WIDER Working Paper No. 2020/43). https://doi.org/10.35188/UNU-WIDER/2020/800-9 (2020)
Suryahadi, A., Sumarto, S.: Poverty and vulnerability in Indonesia before and after the economic crisis. Asian Econ. J. 17(1), 45–64 (2003)
Suryahadi, A., Izzati, R.A., Suryadarma, D.: Estimating the impact of COVID-19 outbreak on poverty. Bull. Indones. Econ. Stud. 25, 1–33 (2020). https://doi.org/10.1080/00074918.2020.1779390
Tenda, E.D., Asaf, M.M., Pradipta, A., Kumaheri, M.A., Susanto, A.P.: The COVID-19 surge in Indonesia: what we learned and what to expect. Breathe (sheff.) 17(4), 210146 (2021). https://doi.org/10.1183/20734735.0146-2021
Verbeek, M.: Synthetic panels and repeated cross-sections. In: Matyas, L., Sevestre, P. (eds.) The econometrics of panel data, pp. 369–383. Springer-Verlag, Berlin (2008)
Wardana, W.W., Sari, D.W.: Dynamic poverty study: chronic and transient poverty in Indonesia. Int. J. Innov. Creat. Change 11(9), 600–622 (2020)
Warr, P., & Yusuf, A.A.: Pandemic-induced de-urbanisation in Indonesia (Working Papers in Trade and Development No. 2020/08) (2021). https://acde.crawford.anu.edu.au/sites/default/files/publication/acde_crawford_anu_edu_au/2021-03/acde_td_warr_yusuf_2021_08.pdf
Wemmerus, N., & Porter, K.: An ethnographic analysis of zero-income households in the survey of income and program participation. Mathematica Policy Research Reports fb85852141294588ad7dd0a27 (1996)
Widyanty, W., Sumarto. S., and Suryahadi, A.: Short-term poverty dynamics: evidence from rural Indonesia (SMERU Working Paper) (2001). https://smeru.or.id/sites/default/files/publication/povertydynamics.pdf
Wisor, S.: Monetary approaches. In: Measuring Global Poverty, pp. 59–76. Palgrave Macmillan, London (2012). https://doi.org/10.1057/9780230357471_4
World Bank: Poverty and shared prosperity 2020: reversals of fortune. The World Bank, Washington, DC (2020)
World Bank. (2005). Introduction to poverty analysis. Retrieved from https://web.worldbank.org/archive/website01407/WEB/IMAGES/POVER-26.PDF
World Bank.: Updated estimates of the impact of COVID-19 on global poverty: turning the corner on the pandemic in 2021? [Blog post] (2021a). Retrieved from https://blogs.worldbank.org/opendata/updated-estimates-impact-covid-19-global-poverty-turning-corner-pandemic-2021
World Bank.: New World Bank country classifications by income level: 2021–2022 [Blog post] (2021a). Retrieved from https://blogs.worldbank.org/opendata/new-world-bank-country-classifications-income-level-2021-2022
Xiong, J., Tang, Z., Zhu, Y., Xu, K., Yin, Y., Xi, Y.: Change of consumption behaviours in the pandemic of COVID-19: examining residents’ consumption expenditure and driving determinants. Int. J. Environ. Res. Public Health 18(17), 9209 (2021). https://doi.org/10.3390/ijerph18179209
Acknowledgements
The author gratefully acknowledges the guidance of Professor Jouni Kuha from the London School of Economics (LSE). The author is also grateful for the constructive comments given by the reviewers.
Funding
The author declares that no funds were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
The author performed the entire process of manuscript procession.
Corresponding author
Ethics declarations
Conflict of interest
The author declares that she has no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tantriana, A. Poverty and vulnerability transitions in Indonesia before and during the COVID-19: insights from synthetic panels. Qual Quant 58, 3215–3249 (2024). https://doi.org/10.1007/s11135-023-01785-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11135-023-01785-7