
Abstract
A quantum particle evolving by Schrödinger’s equation contains, from the kinetic energy of the particle, a term in its Hamiltonian proportional to Laplace’s operator. In discrete space, this is replaced by the discrete or graph Laplacian, which gives rise to a continuous-time quantum walk. Besides this natural definition, some quantum walk algorithms instead use the adjacency matrix to effect the walk. While this is equivalent to the Laplacian for regular graphs, it is different for non-regular graphs and is thus an inequivalent quantum walk. We algorithmically explore this distinction by analyzing search on the complete bipartite graph with multiple marked vertices, using both the Laplacian and adjacency matrix. The two walks differ qualitatively and quantitatively in their required jumping rate, runtime, sampling of marked vertices, and in what constitutes a natural initial state. Thus the choice of the Laplacian or adjacency matrix to effect the walk has important algorithmic consequences.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Schrödinger’s equation [1]
is the fundamental equation in quantum mechanics [2], describing the time evolution of a quantum state \(\psi \) generated by Hamiltonian H. Note we have set \(\hbar = 1\). The Hamiltonian characterizes the total energy of the system, and for a particle of mass m, it includes a kinetic energy term
where \(\nabla ^2 = \partial ^2/\partial x^2 + \partial ^2/\partial y^2 + \partial ^2/\partial z^2\) is Laplace’s operator (in three-dimensional Euclidean space).
If the particle is confined to discrete spatial locations, such as when a particle trapped in an optical lattice [3], then \(\nabla ^2\) is replaced by the discrete or graph Laplacian \(L = A - D\), where A is the adjacency matrix (\(A_{ij} = 1\) if i and j are connected, and 0 otherwise), and D is the diagonal degree matrix (\(D_{ii} = \mathrm{deg}(i)\)). For example, for a one-dimensional grid with lattice spacing h, note the similarities between the continuous-space Laplacian
and the discrete-space analogue
Now letting \(\gamma = 1/2m\), the kinetic energy operator becomes
This defines a continuous-time quantum walk [4, 5], and it is the natural movement of a quantum particle with kinetic energy when confined to a lattice. The real parameter \(\gamma > 0\) corresponds to the jumping rate, or amplitude per time, of the walk. A higher jumping rate corresponds to a particle with less mass, since a less massive particle scatters more readily.
Besides this natural definition, any Hermitian operator (so that the time-evolution operator \(e^{-iHt}\) is unitary) that respects the locality of the graph defines a continuous-time quantum walk. Another commonly used definition is the adjacency matrix A [6, 7], which differs from the Laplacian by dropping the degree matrix D. That is, the term in the Hamiltonian effecting the walk is
These two common generators of the quantum walk, the Laplacian and adjacency matrix, can also arise in interacting spin models in statistical physics. In particular, a single excitation in a network of spins can be expressed as a particular spin being spin-up, while the others are spin-down. With \(XYZ\) interactions between nearest-neighbor spins (i.e., the Heisenberg model), the Hamiltonian reduces to the Laplacian of the graph, and with XY interactions alone, the adjacency matrix arises instead [8].
If the graph is regular, then the degree matrix D is a multiple of the identity matrix, so it only constitutes an unobservable, global phase or a rezeroing of energy and can be dropped [5]. Thus for regular graphs, the Laplacian and adjacency matrix are equivalent definitions of the quantum walk. If the graph is non-regular, however, then the two walks are inequivalent, and their differences have been explored for state transfer [9, 10].

Complete bipartite graph with \(N_1 = 4\) and \(N_2 = 3\) vertices in each vertex set, \(k_1 = 2\) and \(k_2 = 1\) of which are marked (denoted by double circles) in the respective sets. Identically evolving vertices are identically colored and labeled
In this paper, we investigate the algorithmic consequences of choosing the Laplacian or the adjacency matrix to effect the quantum walk by examining spatial search on the complete bipartite graph with multiple marked vertices, an example of which is shown in Fig. 1. We take the number of vertices in each vertex set \(V_1\) and \(V_2\) to be \(N_1\) and \(N_2\) (so that the total number of vertices is \(N = N_1 + N_2\)), and since they are allowed to differ, the graph is, in general, non-regular. Thus the Laplacian and adjacency matrix effect different walks, and we expect the search algorithms to also behave differently. For simplicity, we assume that the size of each vertex set scales with the number of vertices (i.e., \(N_1 = \Theta (N)\) and \(N_2 = \Theta (N)\)), and the number of marked vertices \(k_1\) and \(k_2\) in each set scales smaller (i.e., \(k_1 = o(N)\) and \(k_2 = o(N)\)). This assumption avoids scenarios where a vertex set is small and can be classically brute-force searched in little time, or where the number of marked vertices in one set is larger than the number of vertices in the other set, thereby simplifying the analysis.
This investigation differs from previous work on spatial search by continuous-time quantum walk. For example, much of the existing literature focuses on search on regular graphs, for which the Laplacian and adjacency matrix are equivalent. This includes the complete graph [5, 11], strongly regular graphs [12], the hypercube [5], arbitrary-dimensional periodic square lattices [5], and the simplex of complete graphs [13–16]. Even though the joined complete graphs in [13] form a non-regular graph, it is approximately regular, and so difference between the Laplacian and adjacency matrix is negligible. For spatial search on a truly non-regular graph, the work of [17] is of note, where they investigate search on the complete bipartite graph with one marked vertex. They only considered the adjacency matrix, however, whereas our analysis includes multiple marked vertices and the Laplacian as well. Furthermore, their algorithm reaches a success probability of 1 / 2 because, as we will show, a subideal initial state is used; with the ideal initial state, the algorithm searches with certainty. Finally, previous work on search on Erdös-Renyi random graphs [18] was also restricted to quantum walks effected by the adjacency matrix alone. Our work here seems to be the first direct comparison between the Laplacian and adjacency matrix in spatial search by continuous-time quantum walk.
In the next section, we analyze search on the complete bipartite graph with multiple marked vertices (e.g., Fig. 1) when the quantum walk is effected by the Laplacian. Depending on the choice of the jumping rate \(\gamma \), the algorithm either finds the marked vertices in one vertex set or the other and with different runtimes. Following this, we solve the search problem when the walk is governed by the adjacency matrix. What constitutes a natural initial state differs from the usual equal superposition, and with a particular choice of \(\gamma \), the system evolves to a combination of all marked vertices, regardless of which vertex set they are in. Qualitatively, this is a different behavior, and the runtime is also quantitatively different.
2 Laplacian walk
We begin with the quantum walk being generated by the Laplacian. In the standard spatial search algorithm by continuous-time quantum walk [5], the system \({\left| \psi (t) \right\rangle }\) starts in an equal superposition \({\left| s \right\rangle }\) over the vertices:
This state expresses our initial lack of knowledge of where the marked vertices are, so it guesses each vertex with equal probability. Moreover, since it is an eigenvector of the Laplacian L with eigenvalue 0, evolving by the quantum walk alone (\(H = -\gamma L\)) causes the system to stay in \({\left| s \right\rangle }\), expressing our continued lack of information as to where the marked vertices might be.
With an oracle that identifies the marked vertices, however, our information does change, and the system evolves from \({\left| s \right\rangle }\). In particular, the search Hamiltonian is

With this initial state and evolution, the system evolves in a four-dimensional (4D) subspace as shown in Fig. 1. Grouping identically evolving vertices together, we get a basis for the 4D subspace:
In this \(\{ {\left| a \right\rangle }, {\left| b \right\rangle }, {\left| c \right\rangle }, {\left| d \right\rangle } \}\) basis, the initial equal superposition state is
Additionally, the adjacency matrix in this basis is
where \(N_{ki} = N_i - k_i\), and the degree matrix is
The Laplacian is simply \(L = A - D\), so the search Hamiltonian is

Probability overlaps of \({\left| s \right\rangle }\), \({\left| a \right\rangle }\), and \({\left| b \right\rangle }\) with eigenstates of H for search on the complete bipartite graph with \(N_1 = 512\), \(N_2 = 256\), \(k_1 = 3\), and \(k_2 = 5\), where the walk is effected by the Laplacian
In Fig. 2, we plot the probability overlaps of the eigenstates of H with \({\left| s \right\rangle }\), \({\left| a \right\rangle }\), and \({\left| b \right\rangle }\), where \({\left| \psi _0 \right\rangle }\) denotes the eigenvector of H with the smallest eigenvalue, \({\left| \psi _1 \right\rangle }\) denotes the eigenvector with the next smallest eigenvalue, and so forth. Since these eigenvalues correspond to the energy levels of the system [2], \({\left| \psi _0 \right\rangle }\) is called the ground state, and \({\left| \psi _{i > 0} \right\rangle }\) is called the ith excited state. This reveals that the behavior of the algorithm strongly depends on the value of \(\gamma \). In particular, when \(\gamma \) is small, the initial equal superposition state \({\left| s \right\rangle }\) is approximately the second excited state \({\left| \psi _2 \right\rangle }\) of H, meaning the system starts in an eigenstate and fails to evolve apart from an unobservable, global phase. Similarly, when \(\gamma \) takes intermediate or large values, \({\left| s \right\rangle }\) is approximately the first excited state \({\left| \psi _1 \right\rangle }\) or ground state \({\left| \psi _0 \right\rangle }\) of H, so again the system fails to evolve apart from an unobservable, global phase. It is only when \(\gamma \) is near one of its two “critical values” [5], where \({\left| s \right\rangle }\) exhibits a “phase transition” in which eigenstates of H support it, that the system evolves substantially. In Fig. 2, the critical \(\gamma \)’s correspond to the crossings near \(\gamma = 0.004\) and \(\gamma = 0.002\). Let us, respectively, call these \(\gamma _a\) and \(\gamma _b\). When \(\gamma = \gamma _a = 0.004\), both \({\left| \psi _0 \right\rangle }\) and \({\left| \psi _1 \right\rangle }\) are half \({\left| s \right\rangle }\) and half \({\left| a \right\rangle }\). This causes the system to evolve from \({\left| s \right\rangle }\) to \({\left| a \right\rangle }\) in time \(\pi /\Delta E\), where \(\Delta E\) is the energy gap between \({\left| \psi _1 \right\rangle }\) and \({\left| \psi _0 \right\rangle }\) [5, 11]. Similarly, when \(\gamma = \gamma _b = 0.002\), both \({\left| s \right\rangle }\) and \({\left| b \right\rangle }\) are roughly half in \({\left| \psi _1 \right\rangle }\) and half in \({\left| \psi _2 \right\rangle }\), so the system evolves from \({\left| s \right\rangle }\) to \({\left| b \right\rangle }\) in time \(\pi /\Delta E\), where \(\Delta E\) is the energy gap between \({\left| \psi _2 \right\rangle }\) and \({\left| \psi _1 \right\rangle }\).

For search on the complete bipartite graph with \(N_1 = 512\), \(N_2 = 256\), \(k_1 = 3\), and \(k_2 = 5\), where the walk is effected by the Laplacian: the success probability in (a) \({\left| a \right\rangle }\) when \(\gamma = \gamma _a\) and (b) \({\left| b \right\rangle }\) when \(\gamma = \gamma _b\)
Proving this simply involves finding the eigenvectors and eigenvalues of the search Hamiltonian (2) when \(\gamma \) takes its critical values of \(\gamma _a\) and \(\gamma _b\). We find these eigenvectors and eigenvalues in Appendix 1 using degenerate perturbation theory [12], showing that when \(\gamma \) is within \(o(1/N^{3/2})\) of
then two of the (unnormalized) eigenvectors and corresponding eigenvalues of the search Hamiltonian (2), for large N, are
Thus for large N, the system evolves from \({\left| s \right\rangle }\) to \({\left| a \right\rangle }\) in time
As a check, in Fig. 3a, we plot the probability in \({\left| a \right\rangle }\) as the system evolves with \(\gamma = \gamma _a = 1/256 \approx 0.004\) . As expected, the success probability nears 1 (with the slight deficiency from 1 remedied by increasing N) at time \(t_a = (\pi /2) \sqrt{(512 + 256)/3} = 8\pi \approx 25.133\).
Also shown in Appendix 1, when \(\gamma \) is within \(o(1/N^{3/2})\) of the critical value of
the search Hamiltonian (2) for large N has (unnormalized) eigenvectors and corresponding eigenvalues
Thus for large N, the system evolves from \({\left| s \right\rangle }\) to \({\left| b \right\rangle }\) in time
As a check, in Fig. 3b, we plot the probability in \({\left| b \right\rangle }\) as the system evolves with \(\gamma = \gamma _b = 1/512 \approx 0.002\). As expected, the success probability nears 1 at time \(t_b = (\pi /2) \sqrt{(512 + 256)/5} \approx 19.468\).
Thus depending on whether \(\gamma \) equals \(\gamma _a\) or \(\gamma _b\), the system evolves to one of \({\left| a \right\rangle }\) or \({\left| b \right\rangle }\), not a combination of \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\). That is, the final state samples entirely from the marked vertices in one vertex set or the other. As we will see in the next section, this differs from search with the adjacency matrix, which samples from both vertex sets simultaneously. Of course, this excludes the special case when \(N_1 = N_2 = N/2\), which causes the graph to be regular. Then the Laplacian and adjacency matrix are equivalent, and the algorithm will sample from both \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\) simultaneously. It also excludes when \(N_1\) and \(N_2\) are within \(o(\sqrt{N})\) of each other, which causes \(\gamma _a\) and \(\gamma _b\) to be within \(o(1/N^{3/2})\) of each other. In this regime, we also have that the Laplacian and adjacency matrix are asymptotically equivalent, and we can use the analysis from the adjacency matrix in the next section.
We also note that \(\gamma _a\) and \(\gamma _b\) only depend on \(N_1\) and \(N_2\), which are presumed to be known since the spatial search problem assumes that the graph structure is known. That is, \(\gamma _a\) and \(\gamma _b\) do not depend on \(k_1\) and \(k_2\), which may be unknown. For example, say there are \(k = 10\) marked vertices. Then the critical \(\gamma \)’s do not depend on their arrangement, on whether \(k_1 = 3\) and \(k_2 = 7\), or \(k_1 = 6\) and \(k_2 = 4\), for instance. This differs from the more complicated “simplex of complete graphs” in [14], where different arrangements of marked vertices can yield different critical \(\gamma \)’s.
Finally, although the runtimes \(t_a\) and \(t_b\) do depend on the number of marked vertices \(k_1\) and \(k_2\) in each vertex set, one can use the same sampling or counting techniques as for Grover’s algorithm with an unknown number of marked vertices [19].
3 Adjacency walk
In this section, we now use the adjacency matrix to effect the quantum walk, so the search Hamiltonian is

Before analyzing the algorithm, however, we must first define the initial state of the system. Before, when the walk was governed by the Laplacian, the initial state was the equal superposition \({\left| s \right\rangle }\) over all the vertices. With this initial state, the quantum walk alone (\(H = -\gamma L\)) caused the system to stay in \({\left| s \right\rangle }\), which is expected because without the oracle, no new information is acquired as to where the marked vertices may be.
The equal superposition \({\left| s \right\rangle }\), however, is not an eigenvector of A. Then the quantum walk governed by the adjacency matrix alone (i.e., \(H = -\gamma A\)), will cause \({\left| s \right\rangle }\) to evolve, even though no oracle is being queried and our information is unchanged.
So instead of using \({\left| s \right\rangle }\), we choose the initial state of the system to be
which is an eigenstate of A with eigenvalue \(\sqrt{N_1N_2}\). With this state, vertices in the left vertex set start with probability \(1/2N_1\), and vertices in the right vertex set start with probability \(1/2N_2\). Although this is a non-uniform probability distribution over all the vertices, the benefit of starting in \({\left| \sigma \right\rangle }\) is that evolving it by the quantum walk alone (i.e., \(H = -\gamma A\)) only contributes a global, unobservable phase, so our initial probability distribution is unchanged, as expected since no new information is garnered. Perhaps the most compelling reason to start in \({\left| \sigma \right\rangle }\), however, is that it is the state that naturally evolves by the search algorithm to the marked vertices with certainty; starting in \({\left| s \right\rangle }\), by comparison, yields a worse success probability.
With this initial state and search Hamiltonian, the system evolves in the same 4D subspace shown in Fig. 1 with orthonormal basis \(\{ {\left| a \right\rangle }, {\left| b \right\rangle }, {\left| c \right\rangle }, {\left| d \right\rangle } \}\) as before. In this basis, the initial state is
Using (1), the search Hamiltonian is
where we again denote \(N_{ki} = N_i - k_i\).

Probability overlaps of \({\left| \sigma \right\rangle }\), \({\left| a \right\rangle }\), and \({\left| b \right\rangle }\) with eigenstates of H for search on the complete bipartite graph with \(N_1 = 512\), \(N_2 = 256\), \(k_1 = 3\), and \(k_2 = 5\), where the walk is effected by the adjacency matrix
As before, we can determine how the algorithm depends on \(\gamma \) by plotting the probability overlaps of the eigenstates of H with the starting state \({\left| \sigma \right\rangle }\) and the marked vertices \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\), as shown in Fig. 4. When \(\gamma \) is small or large, the initial state \({\left| \sigma \right\rangle }\) is approximately the second excited state \({\left| \psi _2 \right\rangle }\) or the ground state \({\left| \psi _0 \right\rangle }\) of H, meaning the system starts in an eigenstate and fails to evolve apart from an unobservable, global phase. But when \(\gamma \) takes its critical value of roughly 0.0028, both \({\left| \psi _0 \right\rangle }\) and \({\left| \psi _2 \right\rangle }\) are half \({\left| \sigma \right\rangle }\) and half some combination of \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\). Then the system evolves from \({\left| \sigma \right\rangle }\) to that combination of \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\) in time \(\pi /\Delta E\), where \(\Delta E\) is the energy gap between \({\left| \psi _2 \right\rangle }\) and \({\left| \psi _0 \right\rangle }\).
Again, proving this simply involves finding the eigenvectors and eigenvalues of the search Hamiltonian (3) when \(\gamma \) takes its critical value. As shown in Appendix 2 using degenerate perturbation theory [12], when \(\gamma \) takes its critical value of
then two of the (unnormalized) eigenvectors of the search Hamiltonian (3), for large N, are
with corresponding eigenvalues
So for large N, the system evolves from \({\left| \sigma \right\rangle }\) to
in time
As a check, in Fig. 5, we plot the probability in \({\left| a \right\rangle }\), \({\left| b \right\rangle }\), and their sum (i.e., the success probability) as the system evolves with \(\gamma = \gamma _* = 1/\sqrt{512 \cdot 256} \approx 0.0028\). As expected, at time \(t_* = \pi \sqrt{512 \cdot 256} / \sqrt{2(5 \cdot 512 + 3 \cdot 256)} \approx 13.941\), the probability in \({\left| a \right\rangle }\) reaches \(3 \cdot 256 / (5 \cdot 512 + 3 \cdot 256) \approx 0.231\), and the probability in \({\left| b \right\rangle }\) reaches \(5 \cdot 512 / (5 \cdot 512 + 3 \cdot 256) \approx 0.769\), for a total success probability of 1.

For search on the complete bipartite graph with \(N_1 = 512\), \(N_2 = 256\), \(k_1 = 3\), and \(k_2 = 5\), where the walk is effected by the adjacency matrix: the probability in \({\left| a \right\rangle }\) (solid black), the probability in \({\left| b \right\rangle }\) (dashed red), and their sum (dot-dashed blue) when \(\gamma = \gamma _*\) (Color figure online)

Runtimes for search on the complete bipartite graph with (a) \(N_1 = 512\), \(N_2 = 256\), \(k_1\) varying, and \(k_2 = 5\), and (b) \(N_1 = 512\), \(N_2 = 1024\), \(k_1 = 3\), and \(k_2\) varying
We stress that this is a qualitatively different behavior from search with the Laplacian. Here the final state is a combination of \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\), so it samples from all the marked vertices, albeit unequally. With the Laplacian in the last section, the system evolved to either \({\left| a \right\rangle }\) or \({\left| b \right\rangle }\) exclusively, depending on the choice of \(\gamma \). These behaviors are summarized in Table 1.
Except for the special case when \(N_1 \approx N_2\), which causes the graph to be approximately regular and the Laplacian and adjacency matrix to generate asymptotically equivalent walks, the search algorithms generally yield different runtimes. By comparing \(t_a\), \(t_b\), and \(t_*\), we find that when \(N_1 > N_2\), the adjacency walk’s runtime \(t_*\) is always faster than the Laplacian’s \(t_b\), and it is also faster than the Laplacian’s \(t_a\) when
For example, with \(N_1 = 512\), \(N_2 = 256\), and \(k_2 = 5\), we find that \(t_*\) is faster than \(t_a\) when \(k_1 < 30\), as verified in Fig. 6a. Similarly, when \(N_1 < N_2\), then \(t_*\) is always faster than \(t_a\), and it is also faster than \(t_b\) when
For example, with \(N_1 = 512\), \(N_2 = 1024\), and \(k_1 = 3\), we find that \(t_*\) is faster than \(t_b\) when \(k_2 < 18\), as verified in Fig. 6b. These results indicating when the Laplacian or adjacency matrix searches faster are summarized in Table 2.
Another way to compare the two quantum walk search algorithms is by considering a slightly different problem. Rather than searching for one of k marked vertices, say we instead want to find all k marked vertices. With the graph Laplacian, we can choose \(\gamma = \gamma _a = 1/N_2\) so that the system evolves to \({\left| a \right\rangle }\), which is a uniform superposition over the \(k_1\) marked vertices in the left vertex set. Classically, sampling all \(k_1\) of these marked vertices is simply the “coupon collector’s problem” from classical probability theory [20], and the expected number of repetitions is \(k_1 H_{k_1}\), where \(H_n = 1 + 1/2 + 1/3 + \dots + 1/n = \Theta (\ln (n))\) denotes the n-th harmonic number. Similarly, with the graph Laplacian and \(\gamma = \gamma _b = 1/N_1\), the system evolves to \({\left| b \right\rangle }\), and we expect to make \(k_2 H_{k_2}\) repetitions of the algorithm to find all \(k_2\) marked vertices in the right vertex set. Thus with the Laplacian, we expect to run the algorithm \(k_1 H_{k_1} + k_2 H_{k_2}\) times to find all k marked vertices. As an example, if \(k_1 = 3\) and \(k_2 = 5\), this yields \(3H_3 + 5H_5 = 203/12 \approx 16.917\) repetitions.
By contrast, searching with the adjacency matrix results in a non-uniform final state (4). To sample all marked vertices from this final state, we intuitively need more repetitions than the Laplacian case because there are now a greater number of vertices from which we might repeatedly sample. Mathematically, this is the coupon collector’s problem generalized to non-uniform probabilities [21–23], which has expected value
For example, with \(N_1 = 512\), \(N_2 = 256\), \(k_1 = 3\), and \(k_2 = 5\), this numerically integrates to 26.368, which is greater than the Laplacian’s 16.917. Thus to find all marked vertices, the Laplacian is expected to be faster.
We end by commenting on the success of the algorithm if the initial state is the equal superposition \({\left| s \right\rangle }\) over the vertices, rather than the state \({\left| \sigma \right\rangle }\) that evolves fully to \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\). Consider the state
which is orthonormal to \({\left| \sigma \right\rangle }\). The equal superposition \({\left| s \right\rangle }\) can be expressed as a linear combination of \({\left| \sigma \right\rangle }\) and \({\left| \delta \right\rangle }\):
As shown in Appendix 2, \({\left| \delta \right\rangle }\) is approximately an eigenstate of the search Hamiltonian (3), and so it does not evolve apart from a global, unobservable phase. Thus if we start in \({\left| s \right\rangle }\), the part in \({\left| \sigma \right\rangle }\) evolves to a combination of \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\). Meanwhile, the part in \({\left| \delta \right\rangle }\) only acquires a phase, but since it has negligible projections onto \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\) compared to its components in \({\left| c \right\rangle }\) and \({\left| d \right\rangle }\), it has negligible effect on the success probability. Thus at the runtime of \(t_*\), the system will reach a success probability of roughly
from the \({\left| \sigma \right\rangle }\) piece. Since this is lower-bounded by 1 / 2, if we start in \({\left| s \right\rangle }\), up to two repetitions of the algorithm are expected, on average, to find a marked vertex. To emphasize again, this contrasts with starting in \({\left| \sigma \right\rangle }\), which naturally evolves to the marked vertices with certainty.
4 Conclusion
The continuous-time quantum walk can be defined in a variety of ways, so long as it is generated by a Hermitian operator that respects the locality of the graph. The two most common definitions utilize the graph Laplacian L and adjacency matrix A. Although these are equivalent for regular graphs, they differ for non-regular graphs.
In this paper, we investigated how each type of walk differs when solving the spatial search problem on the complete bipartite graph with multiple marked vertices, which in general is non-regular. This leads to qualitative and quantitative differences between the two walks. For the Laplacian walk, two critical jumping rates \(\gamma _a\) and \(\gamma _b\) exist, which, respectively, cause the system to evolve from the equal superposition over the vertices \({\left| s \right\rangle }\) to either \({\left| a \right\rangle }\) or \({\left| b \right\rangle }\), the marked vertices in each vertex set. This contrasts with the adjacency walk, which utilizes a different starting state \({\left| \sigma \right\rangle }\), and a single critical jumping rate \(\gamma _*\) causes the system to evolve to a combination of \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\). Besides these qualitative differences, the runtimes of the respective algorithms are, in general, different, and depending on the number of marked and unmarked vertices in each vertex set, one walk can outperform the other. Thus the choice of the Laplacian or adjacency matrix to effect the walk has important algorithmic consequences.
References
Schrödinger, E.: An undulatory theory of the mechanics of atoms and molecules. Phys. Rev. 28, 1049–1070 (1926)
Griffiths, D.J.: Introduction to Quantum Mechanics. Prentice Hall, New Jersey (2005)
Bloch, I.: Ultracold quantum gases in optical lattices. Nat. Phys. 1, 23–30 (2005)
Farhi, E., Gutmann, S.: Quantum computation and decision trees. Phys. Rev. A 58, 915–928 (1998)
Childs, A.M., Goldstone, J.: Spatial search by quantum walk. Phys. Rev. A 70, 022314 (2004)
Childs, A.M., Cleve, R., Deotto, E., Farhi, E., Gutmann, S., Spielman, D.A.: Exponential algorithmic speedup by a quantum walk. Proceedings of the Thirty-fifth Annual ACM Symposium on Theory of Computing. STOC ’03, pp. 59–68. ACM, New York, NY, USA (2003)
Farhi, E., Goldstone, J., Gutmann, S.: A quantum algorithm for the Hamiltonian NAND tree. Theory Comput. 4(8), 169–190 (2008)
Bose, S., Casaccino, A., Mancini, S., Severini, S.: Communication in XYZ all-to-all quantum networks with a missing link. Int. J. Quantum Inf. 07(04), 713–723 (2009)
Alvir, R., Dever, S., Lovitz, B., Myer, J., Tamon, C., Xu, Y., Zhan, H.: Perfect state transfer in Laplacian quantum walk. J. Algebraic Combin. 43, 801–826 (2016)
Ackelsberg, E., Brehm, Z., Chan, A., Mundinger, J., Tamon, C.: Laplacian state transfer in coronas. Linear Algebra Appl. 506, 154–167 (2016)
Wong, T.G.: Grover search with lackadaisical quantum walks. J. Phys. A: Math. Theor. 48(43), 435304 (2015)
Janmark, J., Meyer, D.A., Wong, T.G.: Global symmetry is unnecessary for fast quantum search. Phys. Rev. Lett. 112, 210502 (2014)
Meyer, D.A., Wong, T.G.: Connectivity is a poor indicator of fast quantum search. Phys. Rev. Lett. 114, 110503 (2015)
Wong, T.G.: Spatial search by continuous-time quantum walk with multiple marked vertices. Quantum Inf. Process. 15(4), 1411–1443 (2016)
Wong, T.G., Ambainis, A.: Quantum search with multiple walk steps per oracle query. Phys. Rev. A 92, 022338 (2015)
Wong, T.G.: Faster quantum walk search on a weighted graph. Phys. Rev. A 92, 032320 (2016) arXiv:1508.01327v3
Novo, L., Chakraborty, S., Mohseni, M., Neven, H., Omar, Y.: Systematic dimensionality reduction for quantum walks: optimal spatial search and transport on non-regular graphs. Sci. Rep. 5, 13304 (2015)
Chakraborty, S., Novo, L., Ambainis, A., Omar, Y.: Spatial search by quantum walk is optimal for almost all graphs. Phys. Rev. Lett. 116, 100501 (2016)
Boyer, M., Brassard, G., Høyer, P., Tapp, A.: Tight bounds on quantum searching. Fortsch. Phys. 46(4–5), 493–505 (1998)
Motwani, R., Raghavan, P.: Randomized algorithms. Cambridge University Press, New York (1995)
von Schelling, H.: Auf der spur des zufalls. Deutsches Statistisches Zentralblatt 26, 137–146 (1934)
von Schelling, H.: Coupon collecting for unequal probabilities. Amer. Math. Mon. 61(5), 306–311 (1954)
Flajolet, P., Gardy, D., Thimonier, L.: Birthday paradox, coupon collectors, caching algorithms and self-organizing search. Discrete Appl. Math. 39, 207–229 (1992)
Wong, T.G.: Diagrammatic approach to quantum search. Quantum Inf. Process. 14(6), 1767–1775 (2015)
Acknowledgments
TW and NN were supported by the European Union Seventh Framework Programme (FP7/2007-2013) under the QALGO (Grant Agreement No. 600700) project, and the ERC Advanced Grant MQC. LT was supported by CNPq CSF/BJT grant reference 301181/2014-4.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Eigensystem for Laplacian walk
The search Hamiltonian, when walking with the Laplacian, is given in (2). Finding the exact eigenvectors and eigenvalues of H is intractable, but they can be approximated for large N using degenerate perturbation theory, which also gives a way to find the critical \(\gamma \)’s [12]. To do this, we separate the Hamiltonian (2) into its leading- and higher-order terms, i.e., \(H = H^{(0)} + H^{(1)} + \dots \), where
The idea is to first find the eigenvectors and eigenvalues of the leading-order Hamiltonian \(H^{(0)}\), which is a much simpler matrix. Then we add the next-order corrections \(H^{(1)}\) and see how this perturbation modifies them. This gives an approximation for the eigenvectors and eigenvalues of H.
To begin, the eigenvectors and eigenvalues of \(H^{(0)}\) are
Note that the third eigenvector, which we call \({\left| r \right\rangle }\), is approximately \({\left| s \right\rangle }\) for large N since the \(k_1\) and \(k_2\) terms in \({\left| s \right\rangle }\) are dominated by \(N_1\) and \(N_2\) for large N.
Now we include the perturbation \(H^{(1)}\) to see how these leading-order eigenvectors and eigenvalues change. If they are non-degenerate, then \(H^{(1)}\) can only contribute higher-order terms to the eigenvectors and eigenvalues, so the starting state \({\left| s \right\rangle } \approx {\left| r \right\rangle }\) is still an approximate eigenvector of the perturbed system for large N [2]. If the leading-order eigenvectors are degenerate, however, the behavior is vastly different. For example, say
so that \({\left| a \right\rangle }\) and \({\left| r \right\rangle }\) are degenerate to leading-order. Then the addition of \(H^{(1)}\) causes two linear combinations of them
become eigenstates of the perturbed system [2]. To find the coefficients, we solve the eigenvalue problem
where \(H_{ar} = \langle a | H^{(0)} + H^{(1)} | r \rangle \), etc. Evaluating the matrix elements,
This has solutions
Since \({\left| r \right\rangle } \approx {\left| s \right\rangle }\), for large N, the (unnormalized) eigenvectors and eigenvalues of H when \(\gamma = \gamma _a\) are
as stated in the main text of the paper.
Note that \({\left| s \right\rangle } + {\left| a \right\rangle }\) and \({\left| s \right\rangle } - {\left| a \right\rangle }\) are non-degenerate eigenstates of the perturbed system, so the first-order correction \(H^{(1)}\) has lifted the degeneracy. Then any higher-order corrections (\(H^{(2)}\), \(H^{(3)}\), etc.) will not significantly change these eigenstates and eigenvalues, meaning any contributions from them will go to zero more quickly than the terms we have derived [2], and hence we can safely ignore them.
Using the method of Sect. IV of [16], we can find how close \(\gamma \) must be to its critical value. Say \(\gamma \) is within \(\epsilon \) of its critical value, i.e., \(\gamma = \gamma _a + \epsilon = 1/N_2 + \epsilon \). If \(\epsilon \) is small such that \({\left| a \right\rangle }\) and \({\left| r \right\rangle }\) are near-degenerate to leading-order, then the perturbation still causes \(\alpha _a {\left| a \right\rangle } + \alpha _r {\left| r \right\rangle }\) to be eigenvectors of the perturbed system. To find the coefficients, one solves an eigenvalue problem, which has a leading-order term in \(\epsilon \) scaling as \(\epsilon N_2\) due to the component \(H_{aa} = \langle a | H^{(0)} + H^{(1)} | a \rangle \). Thus for the system to retain the error-free energy gap of \(\Theta (1/\sqrt{N})\), we need \(\epsilon N_2 = o(1/\sqrt{N})\). That is, \(\epsilon = o(1/N^{3/2})\), which is the precision stated in the main text of the paper.
Similarly, if
so that \({\left| b \right\rangle }\) and \({\left| r \right\rangle }\) are degenerate to leading-order, then the perturbation \(H^{(1)}\) causes two linear combinations \(\alpha _b {\left| b \right\rangle } + \alpha _r {\left| r \right\rangle }\) to be eigenvectors of the perturbed system. Solving a similar eigenvalue problem for the coefficients \(\alpha _b\) and \(\alpha _r\), we find that the perturbed eigenstates are
Since \({\left| r \right\rangle } \approx {\left| s \right\rangle }\), for large N, the (unnormalized) eigenvectors and eigenvalues of H when \(\gamma = \gamma _b\) are
as stated in the main text of the paper.
For the precision with which \(\gamma \) must be chosen to its critical value, we can again use the argument of [16] to show that \(\gamma \) must be within \(o(1/N^{3/2})\) of \(\gamma _b\), as stated in the main text of the paper.

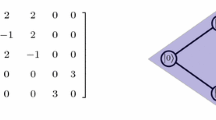
Apart from a factor of \(-\gamma \), the a Hamiltonian for search on the complete bipartite graph, where the walk is effected by the Laplacian, and b the leading-order terms. Note \(N_{ki} = N_i - k_i\)
This calculation using degenerate perturbation theory can also be understood diagrammatically [24]. The search Hamiltonian (2) can be depicted as shown in Fig. 7a. Keeping only the leading-order terms, \(H^{(0)}\) is shown in Fig. 7b, and the diagram reveals its four eigenvectors: \({\left| a \right\rangle }\), \({\left| b \right\rangle }\), and two linear combinations of \({\left| c \right\rangle }\) and \({\left| d \right\rangle }\) (one of which we called \({\left| r \right\rangle }\)). By choosing \({\left| a \right\rangle }\) to be degenerate with \({\left| r \right\rangle }\), the perturbation, which restores the missing edges, causes \({\left| a \right\rangle }\) and \({\left| r \right\rangle }\) to mix. Similarly, if \({\left| b \right\rangle }\) is degenerate with \({\left| r \right\rangle }\), the perturbation causes them to mix.
Appendix 2: Eigensystem for adjacency walk
Similar to the last section, we approximate the eigenvectors and eigenvalues of the search Hamiltonian (3) using degenerate perturbation theory [12]. Breaking H into its leading- and higher-order terms,
\(H^{(0)}\) has eigenvectors and eigenvalues
Note that the third eigenvector, which we call \({\left| u \right\rangle }\), is approximately \({\left| \sigma \right\rangle }\) for large N. Also, the fourth eigenvector, which we call \({\left| v \right\rangle }\), is approximately \({\left| \delta \right\rangle }\) for large N.
Now we include the perturbation \(H^{(1)}\). If \({\left| u \right\rangle }\) is non-degenerate to leading-order, then the starting state \({\left| \sigma \right\rangle } \approx {\left| u \right\rangle }\) approximately remains an eigenstate of the perturbed system. On the other hand, if
then \({\left| a \right\rangle }\), \({\left| b \right\rangle }\), and \({\left| u \right\rangle }\) are degenerate to leading-order, and the three linear combinations of them
will be eigenvectors of the perturbed system. To find the coefficients, we solve the eigenvalue problem
where \(H_{ab} = \langle a | H^{(0)} + H^{(1)} | b \rangle \), etc. Evaluating the matrix components, we get
Solving this yields (unnormalized) eigenstates
with corresponding eigenvalues
Note that \(\psi _\mp \) and its corresponding eigenvalues \(E_\mp \) were stated in the main text of the paper, with \({\left| u \right\rangle }\) replaced by \({\left| \sigma \right\rangle }\), assuming large N.

Apart from a factor of \(-\gamma \), the a Hamiltonian for search on the complete bipartite graph, where the walk is effected by the adjacency matrix, and b the leading-order terms. Note \(N_{ki} = N_i - k_i\)
As before, we can use the argument of [16] to find the precision with which \(\gamma \) must be chosen to its critical value. If \(\gamma \) is within \(\epsilon \) of \(\gamma _*\), then there is a term scaling as \(\epsilon \sqrt{N_1N_2}\) that appears in the perturbative calculation, which is leading-order in \(\epsilon \). For this to be small enough to not interfere with the energy gap of \(\Theta (1/\sqrt{N})\), we get \(\epsilon = o(1/N^{3/2})\), which is the precision stated in the main text of the paper.
The Hamiltonian (3) can be represented diagrammatically [24], as depicted in Fig. 8a. Keeping only the leading-order terms, \(H^{(0)}\) is shown in Fig. 8b, and we see that \({\left| a \right\rangle }\) and \({\left| b \right\rangle }\) are always degenerate since they have the same self-loop. Making these degenerate with \({\left| u \right\rangle }\), which is a combination of \({\left| c \right\rangle }\) and \({\left| d \right\rangle }\), the perturbation restores the missing edges and mixes \({\left| a \right\rangle }\), \({\left| b \right\rangle }\), and \({\left| u \right\rangle }\).
Finally, since \(\gamma > 0\), the leading-order eigenvector \({\left| v \right\rangle }\) is never degenerate with the others. So it remains an approximate eigenstate of the perturbed system. Since \({\left| v \right\rangle } \approx {\left| \delta \right\rangle }\), we get that \({\left| \delta \right\rangle }\) is approximately an eigenvector of H for large N, as stated in the main text of the paper.
Rights and permissions
About this article

Cite this article
Wong, T.G., Tarrataca, L. & Nahimov, N. Laplacian versus adjacency matrix in quantum walk search. Quantum Inf Process 15, 4029–4048 (2016). https://doi.org/10.1007/s11128-016-1373-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11128-016-1373-1