
Abstract
The majority of the volume in a plant cell is water. Therefore, the growth and metabolism of plants are highly dependent on the changes in plant water content. To optimize plant growth in water limited and drought stress conditions, many mechanisms have been considered. The aim of this study was to design and develop an intelligent system, based on an Artificial Neural Network (ANN) and machine vision that would optimize plant growth in limited water situations. To this end, color, morphological and textural features were extracted from a set of turfgrass plant images under drought stress conditions and were analyzed to determine plant water requirement. To maximize classification accuracy, an optimum set of features [h (hsl color space), L (Lab color space), H (HSV color space) and PDF1 (Probability Density Functions)] were selected using a genetic algorithm. Then a data classification operation was conducted using an ANN. The classifier accuracy for three plant situations (fresh, at the edge of wilting and wilted) as well as its total accuracy were 91.3, 77.8, 97.9 and 90.7%, respectively. The automated irrigation system could measure and determine the plant wilting condition by investigation of four extracted features and then determine and apply the correct amount of water required for optimum plant growth in water limited situations.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Irrigated agriculture is a major consumer of water globally and a significant force in the global economy. Improvements in water use efficiency would significantly reduce water consumption. A precise estimation of required water for a plant is one of the important methods to improve water management in agriculture (Ahmadzadeh Gharah Gwiz et al. 2010). To this end, various parameters, e.g. water stress, should be considered in order to retain plant growth in drought conditions (Berger et al. 2010).
Salehi et al. (2008a) stated that the turfgrass industry is growing rapidly, so that the cultivated area under grassland is twice that under crops. Turfgrasses are composed of individual herbaceous plants, which have distinct features such as prostrate creeping tendency, high shoot density, coarse-to-fine leaf texture and low growth habit. Planting and maintaining turfgrass in green spaces is therefore an important and costly problem. The use of turfgrass is important for: the disposal of toxic substances caused by the use of fossil fuels, in preventing soil erosion and intense evaporation of water from the ground, carbon sequestration and oxygen production. Thus, planting turfgrass under controlled conditions and using proper irrigation management can contribute significantly to refining the air as well as human health by producing oxygen and absorbing harmful gases (Salehi et al. 2008b).
The wilting of plants can be determined by measuring plant parameters such as pigment concentration and biochemical indices, leaf water and temperature, photosynthetic and transpiration rates (Nakahara and Inoue 1997; Jones and Leinonen 2003). There are various non-destructive methods to measure plant parameters (Liang et al. 2013; Lin et al. 2013) available when using image processing to assess plant water status (Foucher et al. 2004). Combinations of color, morphology and texture features have been used successfully in many studies to detect different types of stress in plants (Leemans et al. 2002; Chen et al. 2010). Using image processing as a non-invasive tool to obtain plant information (color, morphological, temporal and spectral) plays an important role in the precise analysis and management of plants and has attracted a great deal of attention from researchers (Noda et al. 2006; Jones et al. 2009). Machine vision has broadened its range of applications in the field of agriculture in which there is a high degree of quality achieved as compared to human vision inspection. So far, various studies aimed at measuring crop conditions have been conducted by monitoring a single plant (Hetzroni et al. 1994; Kacira et al. 2002) or a single leaf (Seginer et al. 1992; Revollon et al. 1998). The crop canopy region has also been considered for sampling (Leinonen and Jones 2004; Ushada et al. 2007).
Font and Farkas (2007) developed an algorithm to analyse the lateral images of tomato plants in a greenhouse. In this study, the canopy direction was determined using their algorithm in each image by comparison to a predefined vertical direction. Plants with canopy direction closer to the predefined vertical were defined as fresh, otherwise the plant was considered to be withered. Hendrawan and Murase (2011) used machine vision as a non-destructive method to determine the water content and wilting of Sunagok moss and hence achieve automatic and accurate irrigation. Different optimization algorithms were investigated to find the features best correlated predicting the water requirements of Sunagok moss. Ant colony optimization (Dorigo and Stutzle 2009) had the best performance as a method of feature selection among all models; the minimum average prediction mean square error (MSE) obtained was 1.75 × 10−3.
Garcia-Mateos et al. (2015) compared different color models for automatic image analysis for irrigation control. Lab was selected as the most suitable color space as it led to 99.2% correct classification. Noda et al. (2006) designed a system to irrigate withered plants using image processing. In this research, three indicators (the area of circumscribed quadrangle of the leaf region, the leaf degrees from center line of processing region to both sides, and the degrees of each leaf) were proposed to detect wilting of the plants. Sun et al. (2016) constructed inversion models for machine vision analysis of cucumbers. The coefficients of determination (R2) between the measured values and inversion values of stem height, stem diameter, leaf number and fruit number were 0.921, 0.899, 0.95 and 0.908, respectively.
More recently, studies have investigated intelligent irrigation systems. Osroosh et al. (2016) compared different irrigation automation algorithms for drip-irrigated apple trees; Lozoya et al. (2016) developed a sensor-based model-driven control strategy for precision irrigation; Goodchild et al. (2015) used a method based on a modified PIDFootnote 1 control algorithm for precision closed-loop irrigation; Chikankar et al. (2015) designed an automatic irrigation system using ZigBee wireless sensor network; Gao et al. (2013) manufactured an intelligent irrigation system based on wireless sensor network and fuzzy control; and Romero et al. (2012) researched automatic irrigation control. However, most of the irrigation systems available on the market need a large number of sensors across the farm or greenhouse area to represent different sections of the cultivation area. This is not economically desirable nor practical. Therefore, the use of intelligent irrigation systems based on image processing techniques could help to retain water resources under such conditions (situation of water crisis).
Water management in low water conditions is critical for optimum plant growth therefore, an efficient method for water stress detection in plants is very importance. Machine vision provides an excellent solution to this problem because it does not require a sensor array and can be applied across the entire crop. Thus, an automated irrigation system based on machine vision is proposed in this paper. This system would measure morphological, color and textural parameters of plant to determine plant wilting condition and hence apply the optimum amount of water.
Materials and methods
In this study, the experiments were carried out in a greenhouse located at Agriculture and Natural Resources University of Khuzestan (Mollasani, 31°N, 48°E, 35 km north east of Ahvaz, Iran). To train the intelligent machine vision system using ANN, this research was conducted in two stages: (1) design and implementation of hardware equipment for automated control irrigation system, and (2) development of software for extracting color, morphological and texture features to detect wilting of the plants and control an irrigation system.
Experiments and plant growth conditions
The samples were chosen from a turfgrass cultivar with the scientific name of cynodon dactylon. Thirty-two samples of cultured turfgrass plants were used; each sample was placed in a 0.3 m × 0.5 m plastic container. In these experiments, plants were grown in a soil with field capacity of 21%. The samples were kept under controlled conditions in a greenhouse (at temperature between 23 and 27 °C and relative humidity of 80 ± 15%).
The plants were divided into two groups (16 plants per group). In the water-stressed group, all samples were watered to field capacity one day before the experiment and no water was applied for 20 consecutive days. The other group were the control plants, which were irrigated every three days to hold the volume of water at field capacity. This control group was used to test the system.
Determination of the plant moisture
Immediately after taking images, all plants were sampled to determine plant moisture for the duration of the experiments (20 days). Different plant moisture indices were calculated using the relationships given by Eqs. (1)–(9) (Barrs 1968; Clarke and McCaig 1982; Manette et al. 1988; Xing et al. 2004). These data were used to develop an ANN classifier based on the image processing parameters.
where WF is the weight of fresh plant (0.5 g during the experiments); WD is the dry weight (obtained by placing the plant in an oven at 80 °C for 24 h); WT is turgescence weight (plant placed in distilled water for 18–20 h); and W1, W2 and W3 are plant weight after 2, 4 and 6 h, respectively, in distilled water at 25 °C.
Image acquisition system and imaging system
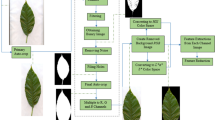
Images were captured at a certain time of the day (8–9 AM) every second day. The image acquisition system was a digital camera with resolution of 1280 × 1024 pixels and frame rate of 30 frames per second (TP-LINK/TL-SC3230N H.264, Sydney, Australia). The captured images were wirelessly transferred to a computer equipped with R2016a (Version 9.0) Matlab software using audio-video receiver and transmitter devices (Boscam/SC2000, New York, USA). The camera was installed vertically 0.75 m above the subject and light was held constant (3320 lux) during image capture. In order to reduce noise caused by camera jitter or unadjusted focus, three images were taken from each sample and the average of these three images was used for further analysis. A Gaussian filter had the ability to remove some of this noise, but there was the possibility of eliminating image information using this filter. Therefore, the averaging technique was used in preference to a Gaussian filter. After transferring the images through wireless to the computer, image processing was carried out using Matlab software release 2016a (Version 9.0) platform (MathWorks, Natick, MA, USA) (Fig. 1).

Schematic of automatic irrigation control system
The use of a wireless data transfer link was important in the system. Image capture needs to move around the greenhouse to capture the entire crop and this would require a prohibitively large amount of cable without wireless data transfer. Minimising cabling in the greenhouse is desirable because of the humid environment of the greenhouse.
Image processing
The image histograms were first equalized to eliminate the effects of fluctuations in light sources. Then, pre-processing operations were conducted to reduce noise and to improve contrast of the images. Next, image segmentation was carried out to differentiate background (plant container and soil) from foreground object (turfgrass) using an adaptive thresholding method (Abdolahzare and Abdanan Mehdizadeh 2014; Abdanan Mehdizadeh and Banhazi 2015). To find the image edges, a Laplacian operator was applied on segmented images (Gonzalez et al. 2004).
Feature extraction (color, morphological and textural features)
Color, morphological and textural features have been used in numerous research studies to evaluate and determine the quality of agricultural products (Abdanan Mehdizadeh et al. 2014; Abdanan Mehdizadeh et al. 2017). In this research, 12 color features, 4 morphological features and 30 textural features were extracted from the images of samples. These extracted features were used to train the ANN classifier. Furthermore, Duncan’s multiple-range tests were performed during the 20 days of experiment to determine whether there was a statistically significant difference among the 46 features extracted from the samples images (color, morphological and textural features) as well as among the measured moisture parameters.
Color features
In this study, four color spaces were used: RGB, Lab, HSV and hsl. Figure 2 shows the results of color transformation of these color spaces.

Four color spaces used in an image of plant sample, these color spaces are: a RGB, b Lab, c HSV and d hsl (Color figure online)
In the RGB color model, the color is a combination of the three primary colors: red, green and blue (Luzuriaga and Balaban 2002). In the Lab color model, L is defined as luminance of sample, a is a green–red axis, and b is a blue–yellow axis (HunterLab 2012). HSV and hsl spaces closely resemble human perception of color. The HSV model consists of the hue (H), color saturation (S), and color value (V). The hsl model consists of hue (h) which is the same as HSV, saturation or color purity, s, and brightness, l (Gonzalez et al. 2004). After taking the images, color co-ordinates of R, G, B, H, S, V, L, a, b, h, s and l were extracted from each sample.
Morphological features
After image segmentation, green coverage index, perimeter index and browning index were extracted as morphological features. Green coverage index is the green area of turfgrass which has direct relationship with the water content of plants (Fig. 3a). Perimeter index is the edge of green coverage area (Fig. 3b). Browning index is yellow-brown area of turfgrass which can be seen in the plant under water stress conditions (Fig. 3c). To measure these features, first, green and yellow-brown areas of turfgrass were separated by intensity-based thresholding and then boundaries of green coverage area were found. Finally, the number of non-zero pixels in each segmented sub-image were counted to calculate each feature (Igathinathane et al. 2006).

Morphological features from a part of the plant: a green coverage, b perimeter index and c brown coverage (Color figure online)
Textural features
Numerous studies show that the textural features can be used as a suitable criterion for the detection and classification of many agricultural products in machine vision (Chandraratne et al. 2007; Dutta et al. 2016). In this research, the numerous textural features such as mean, standard deviation, smoothness, third moment, uniformity, entropy, skewness and kurtosis were calculated (Gonzalez et al 2004). Other textural features were extracted from turfgrass images using the following methods:
Neighborhood gray-tone difference matrix (NGTDM)
The NGTDM was presented by Amadasun and King (1989). Each image is assumed as a matrix, so that f(k,l) is gray intensity of any pixel at the co-ordinates (k,l). The average gray-tone in the center of the neighborhood is calculated according to Eq. (10):
where d is the neighborhood size and W = (2d + 1)2.
Then the ith term in the NGTDM is obtained using Eq. (11):
where {Ni} is the set of all pixels with the identical amount of gray tone i.
After determining the NGTDM, five features, coarseness (fcos), contrast (fcon), busyness (fbus), complexity (fcom) and strength (fstr) were extracted by the following relationships (Eqs. 12–16) (Amadasun and King 1989):
where Gh is the highest gray-tone value in the image and, ε is an essential small number to avoid fcos from becoming infinite. For an N × N image, p is the probability of occurrence of gray-tone value i, and is obtained by
where Ng is the total number of different gray levels in the image, and is obtained by
Grey level co-occurrence matrix (GLCM)
Among all texture analysis methods, the GLCM (Haralick et al. 1973) is one of the most commonly used. Moreover, the GLCM is a second-order statistical approach which is formed on the basis of estimation of second-order joint conditional probability density functions P(i, j:d, θ). The function P(i, j:d, θ) is the probability that two pixels, which are neighbouring and have the grey levels i and j, occur in a predefined distance and direction (d, θ). The dimensions of this matrix are equal to the grey levels in the image. Thus, four co-occurrence matrices obtained in four main directions (θ = 0°, 45°, 90° and 135°) and at given distance d = 1, and finally the summation matrix P(i, j) was calculated by adding these four matrices. Furthermore, P (i, j:d, θ) and P(i, j) are normalized by dividing each entry of the co-occurrence matrix with the total number of paired occurrences in the image (Chandraratne et al. 2006). Some of the texture features can be estimated from these normalized matrices. In this research, six texture parameters were calculated from the GLCM: contrast, correlation, energy, homogeneity, entropy and prominence (Haralick et al. 1973; Gonzalez et al. 2004; Chandraratne et al. 2006).
Grey level difference method (GLDM)
The GLDM is the one of the calculation methods to determine the first-order statistics. The occurrence of absolute difference, in the GLDM (Weszka et al. 1976), between pairs of separated grey levels by a certain distance in a certain direction was computed. Therefore, the set of single variable probability distributions obtained and four features (PDF1, PDF2, PDF3 and PDF4) were calculated from the GLDM, as explained in Kim and Park (1999), by replacing unit displacement (d = 1) and four principal directions (θ = 0°, 45°, 90° and 135°) in the function p(i, j|d, θ). It is necessary to mention that i and j are the grey levels of two pixels which are located with an inter-sample distance d and a direction θ.
Grey level run length matrix (GLRLM)
The GLRLM is a higher-order statistical approach to the determination of textural features (Galloway 1975). The length of grey level runs are estimated by this method. A grey level run is defined as the connected set of collinear pixels having the same gray level value, is defined as a grey level run. The spatial variation of pixel values in an image can be characterized using the grey level runs: the length of the run, direction of the run and grey level of the run.
In the run-length matrix, the p(i, r|θ) is the probability of runs of length r, in some direction θ, of gray level i. In this research, run length matrices of θ equal to 0°, 45°, 90° and 135° were obtained. Then, seven texture features were computed from the GLRLM according to Dutta et al. (2016): short runs emphasis (SRE); long runs emphasis (LRE); grey level non uniformity (GLN); run length non-uniformity (RLN); run percentage (RP); low gray level run emphasis (LGRE) and high gray level run emphasis (HGRE) were computed from the GLRLM.
Feature selection
Proper feature selection can increase the performance of an inference model. For optimal scheduling of activities, a Genetic Algorithm (GA) was applied to select the features. The GA can find optimal numbers for several diverse features and improve the classification accuracy by selecting appropriate features and removing less important ones. In this research, crossover with mutation was utilized and operated on a population of binary-encoded chromosomes, each chromosome representing n candidate features. Parameter settings for the GA included the crossover probability, mutation probability and population sizes were 0.8, 0.01 and 500, respectively (Abdanan Mehdizadeh et al. 2014). A rank-based scheme was used for selection of parent chromosomes for the next generation. The fitness function in this research was obtained through Eq. (17) (Babatunde et al. 2014).
where \(\alpha\) is the classification error of ANN, and Nf is the cardinality of the selected features.
By applying the fitness function, the primary population (initial subset) was valued. If the selected subset estimates the predefined criterion, this is reported as the optimal feature subset; otherwise, a new feature subset is selected using two important genetic operators called the crossover and mutation operators, and again this new subset is evaluated using the fitness function. These steps will continue while the final response is obtained. The implementation of genetic algorithm was conducted in R2016a (Version 9.0) Matlab software (Babatunde et al. 2014).
Data classification
The Artificial Neural Network was used for separation and classification of the feature dataset. In order to train the network, a multi-layer perceptron (MLP) classifier was applied by the back propagation learning method with Levenberg-Marquardt training algorithms (Sapna et al. 2012). Various models were evaluated in the back propagation network and different states were investigated in each model to obtain the best result (Kurtulmus et al. 2016). The neuron numbers in the input layer was equal to the number of selected features. The output layer had three binary neurons representing the plant condition (fresh, at the edge of wilting and wilted). Different neuron numbers, ranging from 3 to 20 in the hidden layer were used. However, no significant difference in classification accuracy was observed using more than 10-hidden neurons. Therefore, 10 neurons were used in the hidden layer. Since, the large number of epochs could increase the problem of overfitting (Maier and Dandy 2000), therefore, for each training the epoch size was set at 30000. Furthermore, the training was repeated twenty times to find the best ANN according to the classification accuracy. During the training phase, backward error propagation was used to adjust the weights. The error term for a given pattern was the difference between the predicted output and the real output (Beyaz et al. 2017). For training and testing ANN classifier, data was first randomly split into two parts, so that two-thirds (number of 213 data) and one-thirds (number of 107 data) of the data were selected for training, and testing the network, respectively. Various evaluation characteristics can be computed from a confusion matrix to evaluate a classifier. In this paper, the total accuracy of the classifier was used for ANN evaluation.
Automatic irrigation control system
After data classification and getting the appropriate decision based on plant condition through the ANN classifier, a command signal was sent to activate irrigation control circuit which interfaces between the computer and eight 12-volt solenoid valves (EMC/E247, Shenzhen, Guangdong, China).
Results and discussion
Changing of water content of turfgrass under drought stress conditions
Many parameters of the plant moisture change gradually under drought stress conditions. One of the most important of these parameters is the relative water content (RWC) of the plant. Figure 4 shows that average RWC values decreased gradually from 85.89% (second day) to 17.80% (twentieth day) under drought stress conditions. Physiological status of the plant, as well as the color and morphological parameters of the image changed with reduction of the water content of the plant.

Changes in relative water content under drought stress conditions during experiment
Figure 5 shows the RGB histograms at 2th, 8th, 14th and 20th day of the drought stressed turfgrasses under drought stress. These histograms showa flatter distribution compared to the RGB histogram derived from the fresh turfgrass.

Changes in plant physiological status under drought stress conditions during experiment (20 days)
Statistical analysis results of the measured parameters and grouping data
Under water stress situations, the plant temperature rise and consequently, its transpiration status is also changed. These conditions lead to increased water requirement of the plant, which is followed by increased wilting. Furthermore, features extracted from images varied nearly proportionally to plant moisture changes. Results of the statistical analysis are shown in Tables 1, 2, 3, and 4.
Table 1 shows that the values of some moisture parameters RWC, RWL, IWC, LWC, ELWL and LWC gradually reduced under water stress conditions while other parameters WSD, ELWR and RWP increased steadily. On the basis of a statistical significance test, there was no significant difference in most moisture parameters between days 2, 4 and 6 of the experiment. The data obtained in these days was significantly different to the other days of the experiment. Thus, the data obtained in these days were placed in a group (Group I: fresh). The data obtained on day 8 was not significantly different from the 6th day and was significantly different to the 10th day. Thus, the 8th day was considered as a distinct group (Group II: at the edge of wilting). There were significant differences between the data values on days 10, 12, 14, 16, 18 and 20 compared to the early days of the experiment. This indicated that the plants had wilted in these days; accordingly the entire data of these days were also placed in another group (Group III: wilted).
Thus, based on the results of the statistical analysis of moisture data, the extracted parameters from images were categorized into three groups according to the plant conditions (fresh, at the edge of wilting and wilted): (1) Group I: all the data of days 2, 4 and 6, (2) Group II: all the data of the 8th day of experiment, and (3) Group III: all the data of days 10, 12, 14, 16, 18 and 20. This grouping was used to select the appropriate features, which is explained in the next section.
Tables 2, 3, and 4, which present the color, morphological and textural features extracted features from images, show no clear statistical pattern. For this reason, feature selection was used for classification.
Feature selection and classification results
The technique described by Witten et al. (2011) was used to find the optimum set of features. Based on grouping of extracted parameters described above, the GA was used in 500 iterations to select the most appropriate features. The GA selected the different combinations with almost identical accuracies.
Figure 6 shows the frequency of occurrence for each feature after 500 iterations of the GA arranged from largest amount to smallest. The parameters that had the most number of occurrences (h, L, H and PDF1) were considered as the most appropriate features. The same statistical trend was noted between these selected features and moisture data (Tables 1, 2, 4).

Resulting plot of Genetic Algorithm
Figure 7 shows the results of the accuracy of the trained network. According to this figure (Fig. 7), it was observed that the best accuracy of classifier for each group as well as total accuracy (the average values of three groups: fresh, at the edge of wilting and wilted) were achieved when four features h, L, H and PDF1 were used in the input layer of the network.

Performance of classification based on number of features (1–46)
Figure 8 shows the change in these features during the experiment days. Parameters h and H decreased gradually as drought stress increased while the parameter L increased. According to the results of statistical analysis obtained from the completely randomized design (Table 2), these values, (h, L and H) were significantly different (p < 0.05) between the days of experiment. Despite the fluctuations, the parameter PDF1 remained in the same range for Group I: fresh (the first day until the day 6 of experiment) indicating that the plant’s freshness status remained unchanged during this period. PDF1 was significantly different on day 8 compared to days 6 and 10, which corresponds to Group II: edge of wilting. The value of PDF1 on day 8 was higher than other days of the experiment; according to the results of the statistical analysis section and classification, this shows that the plant is at the edge of wilting on day 8. According to Fig. 8, the value of PDF1 was almost constant from day 10 to the end of day 20, which corresponds with Group III: wilted.

Behavior changes for the features of h, L, H and PDF1 during experiment days
For the proper functioning of the irrigation system (performance of timely irrigation), three plant conditions—fresh, at the edge of wilting and wilted—were considered. Four features were extracted from the images and used as neurons in the input layer. The result of the tested network accuracy for each group is shown in Table 5. The classifier accuracy for Groups I, II, III and the total accuracy were 91.3, 77.8, 97.9 and 90.7%, respectively.
Figure 9a shows that for a plant at the edge of wilting (group II) prior to irrigation, the computer vision system discriminated a plant as being fresh 48 h after irrigation. However, if the plant was in group III (wilted), it needed at least 96 h and two irrigations to return to freshness (Fig. 9b). This can be perceived by comparing extracted features before (L = 114.97, H = 0.26, h = 118.16 and PDF1 = 828 363) and after 96 h and two irrigations (L = 110.98, H = 0.34, h = 134.60 and PDF1 = 833 791). The number of irrigations and the time required for the plant to regain freshness was higher for plants with more severe wilting.

Performance of intelligent irrigation system: a for plant at the edge of wilting (group II) and b for wilted plant (group III)
Thus, it can be concluded that the automated irrigation system is able to measure and evaluate wilting plant conditions and provide required water for the plant using only four extracted features from the plant image (h, L, H and PDF1). These results of this research are almost the same as obtained by Moshou et al. (2014), who used the Support Vector Machine (SVM) algorithm to classify the healthy and water stressed wheat plants with a classification accuracy equal to 98%; the reason for this high accuracy is that in this research only two states (the presence or absence of water stress) were detected. Also, Kacira et al. (2002) developed a machine vision system for early detection of water stress of New Guinea Impatiens. In this method, the coefficient of relative variation of Top–projected canopy area (TPCA) as an indicator of water stress was defined for investigation of water stress condition. Researchers showed that the success rate of the classification algorithm under water stress condition at 139.0 ± 2.89 light level (lux) and 30.0 ± 5.89 relative humidity (%) was 89%. According to the result of Hendrawan and Murase (2011), the Back-Propagation Neural Network (BPNN) was able to establish a non-linear relationship between the water content of Sunagoke moss and the extracted features from a plant image (color, morphological and textural features).
Conclusions
Precise estimation of plant water requirements is important in agricultural management. Providing a suitable solution for the control of plant irrigation is needed. In this study, machine vision and image processing techniques were used to detect plant water requirements. Then, according to the results of Duncan’s multiple range test (p<0.05), and based on the changes of moisture parameters during the plant wilting process, the extracted features from the image (color, morphological and textural features) were categorized into three groups (fresh, at the edge of wilting and wilted). Finally, based on the classification results, the most suitable features were selected using a GA, and then the classification operation was conducted using ANN with an overall accuracy of 90.7%. Thus, this study demonstrated that the sensing system was able to measure and evaluate wilting plant conditions based on four extracted features from the plant image (h, L, H and PDF1). It can be concluded that plant wilting conditions can be reliably determined using machine vision techniques to extract only four parameters—h, L, H and PDF1—from plant images. This system, having reliably determined wilting condition, can be used to apply an optimum amount of water to maximize plant growth.
Notes
Proportional, Integral and Derivative (PID) parameters.
References
Abdanan Mehdizadeh, S., & Banhazi, T. M. (2015). Evaluating droplet distribution of spray-nozzles for dust reduction in livestock buildings using machine vision. International Journal of Agricultural and Biological Engineering, 8(5), 58–64.
Abdanan Mehdizadeh, S., Minaei, S., Hancock, N. H., & Torshizi, M. A. K. (2014). An intelligent system for egg quality classification based on visible-infrared transmittance spectroscopy. Information Processing in Agriculture, 1(2), 105–114.
Abdanan Mehdizadeh, S., Nouri, M., Soltani Kazemi, M., & Amraei, S. (2017). Non-destructive investigation of the quality factors in citrus juice during storage using digital image processing. Iranian Food Science and Technology Research Journal, 2(42), 262–272 (In Persian).
Abdolahzare, Z., & Abdanan Mehdizadeh, S. (2014). Study of seed spacing uniformity and seed falling dynamics of a pneumatic planter under laboratory conditions using machine vision. Journal of Researches in Mechanics of Agricultural Machinery, 3(2), 19–28 (In Persian).
Ahmadzadeh Gharah Gwiz, K., Mirlatifi, S. M., & Mohammadi, K. (2010). Comparison of artificial intelligence systems (ANN & ANFIS) for reference evapotranspiration estimation in the extreme arid regions of Iran. Journal of Water and Soil, 24(4), 679–689 (In Persian).
Amadasun, M., & King, R. (1989). Textural features corresponding to textural properties. IEEE Transactions on systems, man, and Cybernetics, 19(5), 1264–1274.
Babatunde, O., Armstrong, L., Leng, J., & Diepeveen, D. (2014). A genetic algorithm-based feature selection. British Journal of Mathematics & Computer Science, 4(21), 889–905.
Barrs, H. D. (1968). Determination of water deficits in plant tissues. In T. T. Kozolvski (Ed.), Water deficits and plant growth (pp. 235–368). New York, USA: Academic Press.
Berger, B., Parent, B., & Tester, M. (2010). High throughput shoot imaging to study drought responses. Journal of Experimental Botany, 61(13), 3519–3528.
Beyaz, A., Ozkaya, M. T., & icen, D. (2017). Identification of some spanish olive cultivars using image processing techniques. Scientia Horticulturae, 225, 286–292.
Chandraratne, M. R., Kulasiri, D., & Samarasinghe, S. (2007). Classification of lamb carcass using machine vision: Comparison of statistical and neural network analyses. Journal of Food Engineering, 82(1), 26–34.
Chandraratne, M. R., Samarasinghe, S., Kulasiri, D., & Bickerstaffe, R. (2006). Prediction of lamb tenderness using image surface texture features. Journal of Food Engineering, 77(3), 492–499.
Chen, X., Xun, Y., Li, W., & Zhang, J. (2010). Combining discriminant analysis and neural networks for corn variety identification. Computer and Electronics in Agriculture, 71, 48–53.
Chikankar, P. B., Mehetre, D., & Das, S. (2015). An automatic irrigation system using ZigBee in wireless sensor network. In S. O. Rajankar, V. V. Dixit (Eds.), 2015 International conference on pervasive computing (pp. 1–5). Institute of Electrical and Electronics Engineers.
Clarke, J. M., & McCaig, T. N. (1982). Excised- leaf water retention capability as an indicator of drought resistance of Triticum genotypes. Canadian Journal of Plant Science, 62, 571–578.
Dorigo, M., & Stutzle, T. (2009). Ant colony optimization (aco) technique in economic power dispatch problems. In I. Musirin, N. H. F Ismail, M. R. Kalil, M. K. Idris, T. K. A. Rahman & M. R. Adzman, (Eds.), Trends in communication technologies and engineering science (pp. 191–203). New York, USA: Springer.
Dutta, M. K., Sengar, N., Minhas, N., Sarkar, B., Goon, A., & Banerjee, K. (2016). Image processing based classification of grapes after pesticide exposure. LWT-Food Science and Technology, 72, 368–376.
Font, L., & Farkas, I. (2007). Wilting detection in greenhouse plants by image processing. In S. De Pascale, G. Scarascia Mugnozza, A. Maggio, & E. Schettini (Eds.), ISHS Acta Horticulturae 801: international symposium on high technology for greenhouse system management: Greensys 2007 (pp. 669–676).
Foucher, P., Revollon, P., Vigouroux, B., & Chasseriaux, G. (2004). Morphological image analysis for the detection of water stress in potted Forsythia. Biosystems Engineering, 89(2), 131–138.
Galloway, M. M. (1975). Texture analysis using grey level run lengths. Computer Graphics and Image Processing, 4, 172–179.
Gao, L., Zhang, M., & Chen, G. (2013). An intelligent irrigation system based on wireless sensor network and fuzzy control. Journal of Networks, 8(5), 1080–1087.
Garcia-Mateos, G., Hernandez-Hernandez, J. L., Escarabajal-Henarejos, D., Jaen-Terrones, S., & Molina-Martinez, J. M. (2015). Study and comparison of color models for automatic image analysis in irrigation management applications. Agricultural Water Management, 151, 158–166.
Gonzalez, R. C., Woods, R. E., & Eddins, S. L. (2004). Digital image processing using MATLAB (p. 624). Upper Saddle River, New Jersey, USA: Pearson Prentice Hall.
Goodchild, M. S., Kuhn, K. D., Jenkins, M. D., Burek, K. J., & Button, A. J. (2015). A method for precision closed-loop irrigation using a modified PID control algorithm. Sensors and Transducers, 188(5), 61–68.
Haralick, R. M., Shanmugan, K., & Dinstein, I. (1973). Texture features for image classification. IEEE Transactions on Systems, Man and Cybernetics, 3(1), 610–621.
Hendrawan, Y., & Murase, M. (2011). Bio inspired feature selection to select informative image features for determining water content of cultured Sunagoke moss. Expert Systems with Applications, 38(11), 14321–14335.
Hetzroni, A., Miles, G. E., Engel, B. A., Hammer, P. A., & Latin, R. X. (1994). Machine vision monitoring of plant health. Advances in Space Research, 14(11), 203–212.
HunterLab. (2012). Measuring Color using Hunter L, a, b versus CIE 1976 L*a*b* - AN-1005b. pp. 1–4. Retrieved January 28, 2015 from, https://support.hunterlab.com/hc/en-us/articles/204137825
Igathinathane, C., Prakash, V. S. S., Padma, U., Ravi Babu, G., & Womac, A. R. (2006). Interactive computer software development for leaf area measurement. Computers and Electronics in Agriculture, 51(1), 1–16.
Jones, H. G., & Leinonen, I. (2003). Thermal imaging for the study of plant water relations. Journal of Agricultural Meteorology, 59(3), 205–217.
Jones, H. G., Serraj, R., Loveys, B. R., Xiong, L. Z., Wheaton, A., & Price, A. H. (2009). Thermal infrared imaging of crop canopies for the remote diagnosis and quantification of plant responses to water stress in the field. Functional Plant Biology, 36, 978–989.
Kacira, M., Ling, P. P., & Short, T. H. (2002). Machine vision extracted plant movement for early detection of plant water stress. Transactions of the ASAE, 45(4), 1147–1153.
Kim, J. K., & Park, H. W. (1999). Statistical textural features for detection of micro calcifications in digitized mammograms. IEEE Transactions on Medical Imaging, 18(3), 231–238.
Kurtulmus, F., Alibas, I., & Kavdir, I. (2016). Classification of pepper seeds using machine vision based on neural network. International Journal of Agricultural and Biological Engineering, 9(1), 51–62.
Leemans, V., Magein, H., & Destain, M. F. (2002). On line fruit grading according to their external quality using machine vision. Biosystems Engineering, 83(4), 397–404.
Leinonen, I., & Jones, H. G. (2004). Combining thermal and visible imagery for estimating canopy temperature and identifying plant stress. Journal of Experimental Botany, 55(401), 1423–1431.
Liang, D., Guan, Q., Huang, W., Huang, L., & Yang, G. (2013). Remote sensing inversion of leaf area index based on support vector machine regression in winter wheat. Transactions of the CSAE, 29(7), 117–123.
Lin, H., Liang, L., Zhang, L., & Du, P. (2013). Wheat leaf area index inversion with hyperspectral remote sensing based on support vector regression algorithm. Transactions of the CSAE, 29(11), 139–146.
Lozoya, C., Mendoza, C., Aguilar, A., Roman, A., & Castello, R. (2016). Sensor-based model driven control strategy for precision irrigation. Journal of Sensors 12.
Luzuriaga, D. A., & Balaban, M. O. (2002). Color machine vision system: An alternative for color measurement. In F. S. Zazueta, & J. Xin (Eds.), Proceedings of the 2002 conference on world congress of computers in agriculture and natural resources (pp. 93–100). St. Joseph, MI, USA: American Society of Agricultural and Biological Engineers.
Maier, H. R., & Dandy, G. C. (2000). Neural networks for the prediction and forecasting of water resources variables: a review of modelling issues and applications. Environmental Modelling and Software, 15(1), 101–124.
Manette, A. S., Richard, C. J., Carver, B. F., & Mornhinweg, D. W. (1988). Water relations in winter wheat as drought resistance indicators. Crop Science, 28, 526–531.
Moshou, D., Pantazi, X. E., Kateris, D., & Gravalos, I. (2014). Water stress detection based on optical multisensor fusion with a least squares support vector machine classifier. Biosystems Engineering, 117, 15–22.
Nakahara, M., & Inoue, Y. (1997). Detecting water stress in differentially-irrigated tomato plants with infrared thermometry for cultivation of high-brix fruits. Journal of Agricultural Meteorology, 53(3), 191–199.
Noda, K., Ezakil, N., Takizawa, H., Mizuno, S., & Yamamoto, S. (2006). Detection of plant saplessness with image processing. In S. Kim, & S. C. Kim (Eds.), 2006 SICE ICASE international joint (pp. 4856–4860). Institute of Electrical and Electronics Engineers.
Osroosh, Y., Peters, R. T., Campbell, C. S., & Zhang, Q. (2016). Comparison of irrigation automation algorithms for drip-irrigated apple trees. Computers and Electronics in Agriculture, 128, 87–99.
Revollon, P., Chasseriaux, G., Riviere, L. M., & Gardet, R. (1998). The use of image processing for tracking the morphological modification of Forsythia following an interruption of watering. In J. A. Mwakali, & G. Taban-Wani (Eds.), Proceedings of international conference on agricultural engineering 1998 (pp. 872–873).
Romero, R., Muriel, J. L., Garcia, I., & Munoz de la Pena, D. M. (2012). Research on automatic irrigation control: State of the art and recent results. Agricultural Water Management, 114, 59–66.
Salehi, M. R., Ashiri, F., & Salehi, H. (2008a). Effect of different ethanol concentrations on seed germination of three turfgrass genera. Advances in Natural and Applied Sciences, 2(1), 6–10.
Salehi, H., Salehi, M., & Sticklen, M. B. (2008b). Tissue culture and genetic transformation of some turfgrass genera. Floriculture and Ornamental Biotechnology, 2(2), 25–31.
Sapna, S., Tamilarasi, A., & Kumar, M. P. (2012). Back propagation learning algorithm based on Levenberg Marquardt Algorithm. Computer Science Information Technology, 2, 393–398.
Seginer, L., Elster, R. T., Goodrum, J. W., & Rieger, M. W. (1992). Plant wilt detection by computer vision tracking of leaf tips. Transactions of ASAE, 35(5), 1563–1567.
Sun, G., Li, Y., Zhang, Y., Wang, X., Chen, M., Li, X., et al. (2016). Non-destructive measurement method for greenhouse cucumber parameters based on machine vision. Engineering in Agriculture, Environment and Food, 9(1), 70–78.
Ushada, D., Murase, H., & Fukuda, H. (2007). Non-destructive sensing and its inverse model for canopy parameters using texture analysis and artificial neural network. Computers and Electronics in Agriculture, 57(2), 149–165.
Weszka, J. S., Dyer, C. R., & Rosenfeld, A. (1976). A comparative study of texture measures for terrain classification. IEEE Transactions on Systems, Man and Cybernetics, 6, 269–285.
Witten, I. H., Frank, E., & Hall, M. A. (2011). Data mining: Practical machine learning tools and techniques (3rd ed., p. 664). Massachusetts, USA: Morgan Kaufmann.
Xing, H., Tan, L., An, L., Zhao, Z., Wang, S., & Zhang, C. (2004). Evidence for the involvement of nitric oxide and reactive oxygen species in osmotic stress tolerance of wheat seedlings: Inverse correlation between leaf abscisic acid accumulation and leaf water loss. Plant Growth Regulation, 42, 61–68.
Acknowledgements
The authors express appreciation for the financial support provided by Agricultural Sciences and Natural Resources University of Khuzestan.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Nadafzadeh, M., Abdanan Mehdizadeh, S. Design and fabrication of an intelligent control system for determination of watering time for turfgrass plant using computer vision system and artificial neural network. Precision Agric 20, 857–879 (2019). https://doi.org/10.1007/s11119-018-9618-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11119-018-9618-x