
Abstract
Continuous household travel surveys have been identified as a potential replacement for traditional one-off cross-sectional surveys. Many regions around the world have either replaced their traditional cross-sectional survey with its continuous counterpart, or are weighing the option of doing so. The main claimed advantage of continuous surveys is the availability of data over a continuous spectrum of time, thus allowing for the investigation of the temporal variation in trip behavior. The objective of this paper is to put this claim to the test: Can continuous household travel surveys capture the temporal variation in trip behavior? This claim can be put to the test by estimating mixed effects models on the individual, household, spatial and modal level using date stemming from the Montreal Continuous Survey (2009–2012). A mixed effects model (also know as a hierarchical or multilevel model) respects the hierarchical design of a household survey by nesting or crossing entities where necessary. The use of a mixed effects econometric framework allows for partitioning the variance of the dependent variable to a set of grouping factors, strengthening the understanding of the underlying causes of variation in travel behavior. The findings of the paper conclude that the temporal variability in trip behavior is only observed when modelling on the regional level. Further, the study suggests that a large proportion of the variance of trip behavior is attributed to different grouping factors, such as region or municipal sector for regional trip behavior models.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Household travel surveys are fundamental for the understanding of the socio-economic factors underlying travel behavior. In many regions around the world, travel survey data are used almost entirely for their richness, depicting fluctuations in travel patterns and household socio-demographics (Ampt and Ortuzar 2011). Other regions collect such data for the training and development of sophisticated policy-oriented travel demand models. Many of these surveys are cross-sectional in nature. A cross-sectional survey is defined as a survey executed at a point in time and conducted on a one-off basis. Large regional household travel surveys, while typically conducted over weeks or months, are still considered cross-sectional, as the data are pooled to represent a “typical day” (Verreault and Morency 2011). The Transportation Tomorrow Survey (TTS), conducted in the Greater Toronto and Hamilton Area (GTHA) and repeated every 5 years, also falls under this category.
The Montreal metropolitan agency has been conducting large cross-sectional household travel surveys every 5 years since the 1970s (Habib and El-Assi 2015). The surveys are relatively large with a sampling rate of approximately 5%. In 2009, right after Montreal’s most recent origin–destination (OD) survey, the agency launched an experimental continuous/repeated cross-sectional survey (Tremblay 2014). In other words, households were sampled every day with each household only to be surveyed once. No repeated observations were recorded for any of the households. This is important to highlight as it strikes in contrast to panel surveys where repeated observations on the individual or household level are recorded over time. It is also very different from cross-sectional surveys as data is continuously sampled over an extended period of time (usually years) and is not pooled to represent a ‘typical day’. The Montreal survey ended at the end of 2012, a few months before the start of Montreal’s next major OD survey in 2013.
Montreal has been facing increasing challenges with its standard household travel survey such as declining response rates, incompleteness of its sampling frame, inability to monitor changes, etc. (Tremblay 2014). Montreal relies on its large-scale household travel surveys to support decision making regarding transportation investments, and to be able to measure fluctuations in transportation behavior after important changes in transportation supply. The launch of the experimental continuous household travel survey by Montreal comes with the aim to build on lessons learned from previous surveys, and to answer previously neglected questions such as seasonality of behavior.
However, a continuous survey is more useful than a traditional cross-sectional survey only if it can affirmatively answer the following question: Does a continuous survey over a 5-year time period capture the temporal variations of travel behavior? And if so, can such a survey capture the temporal variability on a disaggregate scale such as individuals and/or households, or on a more aggregate scale such as modes and/or regions? This study aims to answer these questions by estimating a set of mixed effects models on the individual, household, modal and spatial level using the Montreal Continuous OD survey, and by conducting a variance partition coefficient (VPC) analysis on the ensuing results. A VPC allows for investigating the importance of various levels in the mixed effects models hierarchy on the variance of the dependent variable (Goldstein et al. 2002). The study concludes that seasonality, or more generally the temporal variability, of travel behavior can only be captured on the more aggregate spatial (e.g. regional) and modal levels if using continuous survey data. It is also imperative to note that the design of the Montreal continuous survey is not of focus in this study; the focus is rather on the potential implications of continuous surveys on planner’s abilities to depict temporal variations in travel behavior.
The paper is organized as follows: A literature review is first presented. The literature review aims to put forward the motivation behind the use of continuous surveys. It will also highlight the lack of empirical evidence in regards to the ability of continuous surveys to capture travel behavior over time. The literature review also motivates the use of mixed effects models for modelling hierarchical data. After that, the data and its source (the Montreal Continuous OD survey) are briefly described, and the data preparation steps preceding the modelling exercise are listed. Next, the methodology behind the modelling exercise is explained, followed by the results. Finally, the paper objectives and results are reiterated and summarized in the conclusion along with the paper’s limitations and potential for future research.
Literature review
Many travel survey researchers recommend a combination of data sources to replace large cross-sectional travel surveys (Ortúzar et al. 2011). These data sources include small sample panel surveys with the application of GPS/smartphone, or continuous surveys as opposed to simple cross-sectional surveys, etc. In a panel or longitudinal survey, households (or individuals) are repeatedly sampled, preferably over a long period of time. On the other hand, a continuous survey is an ongoing repeated cross-sectional survey where sampling time intervals are in very close proximity (usually a day). In other words, new households are sampled every day with no household sampled twice (Kish 1965).
A continuous survey has many advantages over its cross-sectional counterpart. In a full on-going continuous survey, data are collected for an entire weekday, every day of the week, 52 weeks a year (Ortúzar et al. 2011). Such effort should ideally be kept going for several years. This data, collected over a large period of time, can potentially be used to observe temporal trends in travel behavior in the survey area (Peachman and Battellino 2007). However, the specific time period where the survey is undertaken may be subject to unpredictable events (Stopher and Greaves 2007). For example, it is expected that a regional continuous survey should be capable of depicting the 2008 recession by observing a decline in the number of freight deliveries (potentially captured by a separate specialized survey) over that time period. Furthermore, a similar survey should also be able to capture the effect of a sustained increase in fuel prices on mode choice. Indeed, the correlation between travel behavior and socio-economic variables is a more complex one then what was just described. But, given sufficient useful data, the global evolution of mobility behavior over time can be captured via continuous feeds of data.
Several countries and metropolitan regions around the world have conducted continuous household travel surveys. Examples of such surveys include the National Travel Survey in Britain, the eldest ongoing continuous household travel survey since 1988, and the famous Sydney Household Travel Survey (Ampt and Ortuzar 2011). Continuous household travel surveys have sometimes shown promising results over their cross-sectional counterparts, such as improved reporting of travel behavior (Stopher et al. 2007). One of the key arguments for replacing large household cross-sectional surveys by continuous surveys is the dynamic nature of the data. In essence, the continuous element of an ongoing survey may be leveraged for time series analysis and depicting the temporal nature of travel behavior. Nevertheless, no empirical evidence can be found in the transportation literature using continuous survey data to support this claim. Detailed reviews were provided by Ortúzar et al. (2011) on the state of practice of continuous surveys, and by Stopher and Greaves (2007) on household travel surveys in general. Therefore, the remainder of this review will focus on modelling techniques using longitudinal or panel travel data.
It is very difficult to find literature on the statistical modelling tools and techniques used with continuous data to depict transportation behavior. However, in the case of (repeated) cross-sectional and panel datasets, the statistical model of choice was a mixed effects model.Footnote 1 A mixed effects model is a natural choice for investigating travel behavior using survey data as it accommodates the nested structure of household travel surveys (DiPrete and Grusky 1990), regardless of survey type. In essence, the modelling structure takes into consideration that individuals are nested within households, which in turn are nested within zones. The temporal dimension can also be taken into consideration as a higher level grouping factor.
Examples of using mixed effects models with survey data, with the exception of continuous data, are plenty. DiPrete and Grusky (1990) developed a multilevel model for the analysis of trends within repeated cross-sectional samples. The proposed model is first-order auto regressive at the macro-level equation (highest level in the multilevel model), defined to be a time variable such as a year. Such a custom model allows for time series analysis by serially correlating the errors of the upper-level equation (DiPrete and Grusky 1990).
A less programming intensive approach was presented by Lipps and Kunert (2005), where they used four cross-sectional data sets of the National Travel Survey (NTS) conducted in (West) Germany in 1976, 1982, 1989 and 2002 to build a hierarchical linear model (Lipps and Kunert 2005). The dependent variable of the model was the logarithmic transformation of the daily travel distance covered by survey respondents. Travel distance was regressed against a series of socio-demographic variables such as employment, number of cars available, population size and household size. The structure of the model was setup to have individuals nested within households nested within zones. The study showed that, by estimating a sequentially pooled (over the various time periods) mixed effects model, the total variance of daily travel distance decreased. This may indicate that at least the population surveyed is slowly developing increasingly homogeneous behavior over time. The study, although unique, does not correct for the differences in sampling frame and methods adopted across the four surveys, which may incur biased estimates over time (Ampt and Stopher 2006). That is not the case in a continuous survey, where the sampling frame and survey methods adopted are more or less uniform across.
Another great piece of work was completed by Goulias (2002). Goulias used a panel dataset, the Puget Sound Transportation Panel (PTSP), conducted in Washington to estimate a set of four correlated activity based multilevel models (Goulias 2002). The four multilevel models investigated individual choices in time allocation to maintenance, subsistence, leisure and travel time. A three-level nested hierarchy was exploited with occasions of measurements as the lowest level, individuals as the second and households as the third. The joint and multivariate correlation structure of the dependent variables, along with the flexibility offered via the use of mixed effects models, allowed for the investigation of three key factors: the behavioral context of individuals, heterogeneity of behavior and longitudinal variation of time allocation. The author’s key finding is that household level variance was more than one-third of that of the individual level and thus was considered of significance. Further, the author also concluded that clear evidence exists of non-linear dynamic behavior in time-allocation. None of the above have combined the flexibility of mixed effects models with continuous travel survey data. Our aim in this paper is to leverage mixed effects models to investigate whether continuous surveys capture transportation behavior over time.
Travel survey and data description
Travel survey description
At the end of the Montreal 2008 cross-sectional OD survey, the metropolitan agency decided to test an experimental on-going survey—a continuous household travel survey for Montreal. Already at that time, partners were looking for ways to monitor the temporal evolution of travel behavior. The objective of the continuous survey was to gather temporal data, and to investigate the impact of changes in transportation infrastructure or travel conditions on behavior and decision-making.
Data were collected over 4 years on a continuous basis using non-repeated sampling from January 2009 to December 2012. Interviews were conducted using the same CATI tool that was used during the previous large-scale survey. This experiment was also the test-bed for new questions, and was used as preparation for the 2013 cross-sectional survey.
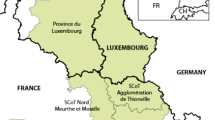
On a typical week, some 250 to 400 households were surveyed, amounting to 14,400 households in the first year of the survey (2009), and between 16,000 and 16,700 households for each of the other 3 years (2010–2012, inclusive). The data were collected from 8 regions and 107 municipal sectors in the Montreal Metropolitan Area. On average, approximately 257 individuals (or 112 households) were surveyed every year from each municipal sector. No official results were published after the conduct of the survey. Some information in regards to survey design and the data collection process can be found online (Tremblay 2014), but there was no systematic modelling of travel behavior using the data. A map for the 107 municipal sectors is shown below.
Data cleaning
After completion of the survey, the data was validated to limit the presence of erroneous records. The resulting dataset contains all trips, their related attributes as well as data on individuals and households. While some variables were readily available for modelling, others required pre-processing, such as trip chain identification and duration estimation. Other databases were fused with the survey dataset; namely data from Environment Canada on daily weather conditions from the international airport sensor (snow, rain, average temperature), and fuel price from the Régie de l’énergie du Québec. Land use data was not available for modelling.
Overall, the total number of individuals surveyed was 152,157. The dataset was then prepared for modelling. Holidays were removed from the dataset so as to capture trip distance variation on an “average” workday. The total number of records removed was 958. After that, records with missing values were deleted, bringing down the total number of surveyed individuals to 148,992. Respondents who answered a survey question by “I refuse to answer” or by “I don’t know”, or records with missing values were also removed.
A description of the available variables in the dataset may be seen in Table 1 below. Table 2 provides summary statistics.
Methodology
Linear mixed effects models
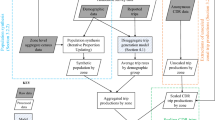
Respondents from the Montreal continuous survey were interviewed within households randomly sampled from regions at different time points. Therefore, it is logical to assume that the collected data has an inherent nested structure. The appropriate methodology to analyze hierarchically nested data is by using a mixed effects model (Rabe-Hesketh and Skrondal 2012). A mixed effects model attempts to describe the contextual effect of the data while accounting for the variation in the dependent variable originating from multiple levels (Goulias 2002). Further, a mixed effects model handles random effects. That includes the grouping of observations under higher levels (or clusters) such as the grouping of individuals under households. The act of clustering observations within groups leads to correlated error terms. Treating clustering as a nuisance, as in simple regression, causes biased estimates of parameter standard errors (Garson 2013). This can lead to mistakes in interpreting the significance of coefficients. Figure 1 shows the nested hierarchy of the survey data.

Map of Montreal Metropolitan Area broken by municipal sectors
The figure shows individual respondents nested in households and households nested in their respective regions, as expected. Usually, individuals belong to a single household and households can only be located in one spatial area. On the other hand, the figure shows regions crossed with time periods. This is because data were collected from all regions at continuous time points. In other words, no region belongs to a single time point only; rather the survey design ensured a distributed sampling effort. It is important to recognize the cross-classified structure of the model, for applying a model with nested regions in time points can seriously bias standard errors of parameters and variance component estimates—an important factor in this paper (Garson 2013). The three time periods in Fig. 2 refer to the three time periods used in this study: Year, Season, and Month.

Nested hierarchy of mixed effects model
To understand a mixed effects model with a structure similar to that displayed in Fig. 1, it is convenient to first start with a simple two-level hierarchy. A two level mixed effects model maybe expressed in the following form (Scott et al. 2013):
where \(y_{ij}\) is an n × 1 vector of random variables representing the observed value for individual i nested in household (group) j. The term \(u_{j}\) is called the group random effects. It is an independent error term (or group effect) assumed to follow a normal distribution of mean 0 and variance \(\sigma^{2}\). The individual residuals \(e_{ij}\) also represents an independent error term assumed to follow a normal distribution of mean 0 and variance \(\sigma^{2}\). Adding explanatory variables is fairly simple:
where \(\beta\) is an n x q matrix of regressors; it represents the coefficient for \(x_{ij}\).Footnote 2 The two-level notation can be expanded to form a three level model, where individuals i are nested in household j and region k:
Here, \(u_{jk}\) is the effect of household j nested in region k. It is also an independent error term assumed to follow a normal distribution of mean 0 and variance \(\sigma^{2}\). To represent the crossed effects, the model maybe denoted as follows (Scott et al. 2013):
The above notation adds another random effect \(u_{jt}\). The subscript of the effect implies the nesting of household j in time periods t. Moreover, the individual level residual error term is now denoted as \(e_{{ij\left( {kt} \right)}}\) to indicate the crossed effects between regions and time periods (Leckie 2013; Scott et al. 2013). It is important to note that effects \(u_{jk}\) and \(u_{jt}\) are no longer independent of each other, rather they have a bivariate normal distribution with zero means and an unstructured 2 × 2 covariance matrix (Rabe-Hesketh and Skrondal 2012).
Variance partition coefficient analysis
In mixed effects models, the residual variation in the response variable is partitioned into components that are attributed to the different levels or groups (Goldstein et al. 2002). The proportion of the total variance of each level can be a reflection of the “importance” of each of these groups. This is referred to as variance partition coefficient (VPC) analysis (Goldstein et al. 2002). Following specification and model estimation, the VPCs of each grouping level were calculated using the following formula (Rabe-Hesketh and Skrondal 2012):
The VPC ranges from 0 to 1. If the VPC of a level is 0, no between group differences exist. If the VPC is equal to 1, no within group differences exist (Fiona 2008). The VPC measures the proportion of total variance in the dependent variable that is due to the differences between groups. For a simple mixed effects model, the VPC is equal to the intra-class correlation (Fiona 2008). To illustrate with an arbitrary example, a VPC of 0.2 for time periods implies that 20% of the variation in the dependent variable is between time periods and 80% is within. The intra-class correlation is also equal to 20%.
In this investigation, different time periods (months, seasons, and years) will be tested for significance, and their VPC, along with that of other groups, will be calculated accordingly. This exercise is essential to understand the reasons behind the variation in trip behavior in general. A log likelihood ratio test will be used to identify the significance of the grouping factors (Rabe-Hesketh and Skrondal 2012).
Model estimation
The mixed effects modelling approach attempts to answer the main research question investigated in this paper. That is, are continuous household travel surveys capable of capturing temporal patterns in travel behavior? It is possible that a continuous survey may capture temporal trends in regional travel behavior, but not in household travel behavior or vice versa. The VPC analysis helps to identify how much of the dependent variable variance can be attributed to the temporal component of the survey. Therefore, in order to investigate the full range of possibilities presented in a traditional household travel survey structure (individual, household and spatial), five groups of models were estimated:
-
A group of mixed effects models with individual level observations; the chosen dependent variable was the logarithmic transformation of travel distance
-
A group of mixed effects models with household level observations; the chosen dependent variable was the logarithmic transformation of travel distance
-
A group of mixed effects models with regional level observations; the chosen dependent variable was numbers of trips generated per region per temporal variable
-
A group of mixed effects models with aggregated modal level observations; the chosen dependent variable was the logarithmic transformation of travel distance
-
A group of mixed effects models for aggregated walking and cycling trips; the chosen dependent variable was the logarithmic transformation of travel distance for one set of models, and the logarithmic transformation of trip counts for another set of models
Within every group, various temporal variables were tested as random effects to investigate their contribution to the total variance of the dependent variable. If only one group of models were fitted on the individual level, the VPC analysis will solely enable the investigation of multiple factors on the trip behavior of individuals. Nevertheless, by aggregating on different levels of the traditional survey hierarchy and repeating the modelling exercise accordingly, the question of whether continuous surveys capture the temporal rhythm of transportation behavior can be answered, alongside at what level of the traditional survey hierarchy can the temporal rhythms be observed.
All models were estimated in R using the lme4 package.
Data preparation for model estimation
Data preparation for individual level modelling
It was noticed that approximately 17% of the remaining respondents reported zero trips on the day they were surveyed. Therefore, to avoid floored residuals, individuals who didn’t conduct any trip, or conducted a trip of less than 0.5 km in distance, were removed. This provides for a more homogeneous group for analysis. The final dataset has 88,156 individual records. Every row in the resulting dataset represents the total trip distance of an individual.
Data preparation for household level modelling
The total trip distance per household was calculated from the survey dataset. Household level attributes were also aggregated accordingly. Further, households with a total of zero trips were not included in the analysis. Every row in the resulting dataset constituted a household. The final dataset has 42,895 household records.
Data preparation for spatial level modelling
The total number of trips per spatial unit (region or municipal sector) per time period were aggregated. No individuals were excluded. Every row in the resulting dataset represents the total number of trips per region and time period.
Data preparation for modal level modelling
Trip level data were aggregated by mode. Modal, spatial and temporal grouping factors were included. A separate model was estimated for each combination of grouping factors. Every row in the resulting dataset represents the logarithm of the total trip distiance per mode, region and time period.
Data preparation for active modes modelling
A subset of the dataset that included trips conducted by walking or biking was used for modelling. A mixed effects model was then estimated with the log of trip distance as the dependent variable for a set of models, and the log of number of trips by mode for another set of models. The grouping factors considered were mode, region and different time periods. Only region was considered for spatial units due to the small sample size of trips conducted by active modes of transport. Every row in the resulting dataset represents the logarithm of the total trip distance or the total number of trips per active mode, region and time period.
Empirical results
In this section, a high level summary of the VPC analysis results will first be displayed to help deliver the main findings of the paper. After that, the results of each and every modeling exercise across all time periods will be presented in detailed.
Summary of VPC analysis results
Table 3 presents a summary of the variance partition coefficients for each modeling group and across the 3 main time periods only: season, month and year. Empty cells indicate that a cluster or grouping effect was not applied to one of the models (i.e. there was no mode grouping effect in the regional individual level models). For continuous household travel surveys to capture the temporal variation in travel behavior across all levels of a travel survey hierarchy (individual, household, spatial unit, etc.), the VPCs of time periods should be magnitudinally large.
Three key observations can be made from Table 3. First, the time period VPCs for individual and household level models are very small (less than 1%). This is an indication that continuous surveys can’t capture the variation in travel behavior on the individual and household level, thus limiting their advantage over traditional cross-sectional surveys. On the other hand, the second main observation is that the time period VPCs for the spatial and active mode level models are fairly large, ranging from 1.11 to 35.37%. In other words, the time period VPCs for the spatial and active mode models explain a sizeable portion of the total variance in travel behavior. This indicates that, while the temporal rhythms may not be captured by continuous surveys on the individual or household level, it clearly captures changes in travel behavior on more aggregate levels of the survey hierarchy. This may primarily be because repeated observations are observed on the spatial and modal level over time in a continuous survey (e.g. households will be sampled from region 1 in month 1, then again in month 2, and then again..), inducing a panel like structure on such levels in the survey hierarchy.
The third main observation to be made from Table 3 is that the time period VPCs for the municipal sector spatial models are larger than the time period VPCs for the region spatial models. That is, a larger proportion of trip behavior can be explained when modelling on a more disaggregate spatial scale. This may be due to land use and built environment differences, influencing the mode of trips selected and the number of trips generated by residing populations. A more in depth discussion of the results is carried on in the sections below.
Individual level mixed effects model
For the individual level mixed effects model, individuals were nested in households and households were nested in regions. Regions were crossed with various time periods.
Table 4 lists the parameter estimates, t-statistics and confidence intervals. A likelihood ratio test showed that the season model was the best. Thus, only the fixed effects of the season model are presented. For the income variable, income category 1 (0–$20,000) was used as a base. Similarly, the “other” work category was set as the base for the variable occupation status.
Almost all parameters were estimated with the expected signs and were statistically significant at the 95% confidence interval, with the exception of household size. Interestingly, household size was a significant variable until the addition of the region random effect. Thus, it may be that the effect of household size is region dependent, with individuals living further away from the downtown core travelling longer distances on a daily basis and vice versa.Footnote 3
The income variable, as in all income categories compared to the base category, was statistically significant and positively correlated with total trip distance travelled. This is in line with transportation literature (Meyer and Miller 2001). Further, women seem to prefer travelling shorter travel distances as the women variable proved to have a negative correlation (taking men travellers as a base) with travel distance. This may be because women tend to work closer to home (Hanson and Johnston 2013). An interaction variable consisting of gender and occupation status was tested to determine if this behavior varies across different employment conditions. Nevertheless, the results proved insignificant and the interaction term was removed from the model.
A significant positive relationship between age and total trip distance was also identified. This is a reasonable conclusion as with age comes more household responsibility, resulting in longer distance travel. Further, full time and part time workers showed a positive correlation with total trip distance as compared to the “other” work category. The survey did not ask whether the individual was unemployed, rather it included an “other” category. Thus, full and part time workers may well travel more than other non-workers for commuting and other activities. On the other hand, Individuals who work at home alongside retirees and students may choose to travel on shorter trips for leisure, maintenance and subsistence activities (Goulias 2002). Overall, a working individual (or even a retired person) may have a larger spending capacity and thus justifying the feasibility of longer trip making.
Variance partition coefficient analysis
Five mixed effects models were estimated using the same previously described variables, but while varying the time period component (Table 5). That is, mixed model 1 was assigned “Season” as its time variable, mixed model 2 was assigned “Season by Year”, mixed model 3 was assigned “Month”, etc. Adding time periods as a grouping factor enables the investigation of its importance on the total variation in the dependent variable—total trip distance travelled. If the random effect is significant, and the VPC is substantive, then it is safe to say that continuous surveys are more effective than cross-sectional surveys in the sense that the variation of trip behavior over time may be observed.
Interestingly, all time period random effects were proven to be statistically significant via a Chi squared test. Nevertheless, the VPC of every single time period is below 1%. This means that only a small fraction (< 1%) of the variance of the total trip distance travelled may be explained by varying time periods. Most of the variation in the total trip distance covered was explained by the differences between individuals (~ 67%), followed by the variation between households (~ 23%), and that between regions (~ 9.5%). The relatively large VPC for households and regions gives support for active research areas in transportation planning that tackle household interactions (e.g. who gets the car?) (Roorda et al. 2009). Further, the fact that more than 30% of the variation in trip behavior is explained by the different random effects implies that the data exhibit some degree of clustering (Rabe-Hesketh and Skrondal 2012).
Household level mixed effects model
Similar to the individual-level model, the effect of clustering was taken into account by nesting households in regions. The regions were also crossed with time periods to assess the temporal variability of travel distance on the household level.
Table 6 lists the fixed effects chosen along with their parameter estimates, t-statistics and confidence intervals. All variables were shown to be significant with the expected signs. The results show that travel distance is positively correlated with increasing income, car ownership, and household size.
Five temporal variables were assessed for significance: month, season, year, month by year and season by year. All temporal variables were shown to be significant via a likelihood ratio test. Contrary to the individual level analysis, the VPCs were calculated for both region and municipal sector spatial units.
Similar to the individual level models, the contribution of temporal variables to the total variance in the dependent variable was less than 1%. Thus, although statistically, a temporal variation exists, the magnitude of that significance is negligible. Table 7 provides a summary of the variance contribution of the different temporal variables on the dependent variable, alongside the other random effects. It is evident from the table that approximately 90% of the trip variation in the dependent variable is due to variation within regions/municipal sectors and between households, with the remaining 9%-to-10% is attributed to differences between regions/municipal sectors. Minor differences in VPCs were reported between the group of models estimated with a region grouping variable versus municipal sector.
Spatial level mixed effects model
Unlike individuals and households, a continuous survey dataset is likely to exhibit repeated observations at a spatial unit recorded over time. This is especially true if the spatial unit is large (such as a region). In other words, the continuous dataset on the region level exhibits a panel like structure.
A series of random-intercept only models (with the exception of including the logarithm of population for all municipal sector models) were estimated on the region and municipal sector level, with data aggregated temporally over five different time periods: year, month, month by year, season and season by year. All of the temporal random effects mentioned were found to be significant at the 95% confidence interval. Table 8 provides a summary of the VPC results.
Summarizing the region level modelling results, approximately 90% to 98% of regional level trip generation variance may be attributed to between region differences. Nevertheless, the VPC analysis for the region level model provided unique insights on the effect of various temporal variables, and between and within region differences, on trip generation. The VPC analysis with year as the temporal variable in the model remained at approximately 1%. On the other hand, it can be observed that the variation in trip generation on the region level is increasingly explained by more disaggregate time units. For example, the time period VPCs of trips generated across season and even months are quite significant. That is, seasons and months may differ significantly from one another affecting travel behavior (potential reasons: weather changes, school year, vacations calendar, etc.) as opposed to a homogeneous set of years.
On the other hand, the VPC analysis for the municipal sector model yielded much larger time period coefficients with 7% for between year, 25.7% for between season and 35.4% for between month variation. The results indicate that a larger proportion of trip generation behavior can be explained when modelling on a more disaggregate spatial scale. One potential reason may be due to the land use and built environment differences that can be observed when comparing smaller geographic units as opposed to larger ones, influencing the mode of trips selected and the number of trips generated by residing populations.
Moreover, a significant proportion of the variance in trip generation is explained by the within municipal sector differences (differences in the trip generation between households and individuals for example) with the VPC ranging from 26% to approximately 46%. This is much larger than what can be observed on the region level. This could be a direct effect of the land use and built environment pronounced in each municipal sector, while that effect may be diluted when grouping trips by region. Nevertheless, to properly explain this observation, a further study is needed incorporating land use and built environment variables as random coefficients in these models.
Modal level mixed effects model
Contrary to individual trips, but similar to trips aggregated on the spatial level, a continuous survey dataset is likely to exhibit repeated observations on the modal level. Therefore, in an attempt to investigate the temporal variation in travel behavior, a series of random-intercept only models were estimated at the modal level. That is, data were aggregated by mode, alongside the commonly used spatial and temporal variables. The modelling exercise was carried out for both regions and municipal sectors, with data aggregated temporally over five different time periods: season, season by year, month, month by year, and year. The dependent variable was chosen to be the logarithm of trip distance.
All of the temporal random effects mentioned were found to be significant at the 95% confidence interval, with the exception of the year random effect in the regional modelling exercise. Table 9 provides a summary of the variance partition coefficient results.
The hypothesis in this paper has been that if a particular variable, such as mode or region/municipal sector, exhibited repeated observations, then the magnitude of the temporal VPC is likely to be significant. That is, a sizable proportion of the total variance of the dependent variable is explained by the temporal random effect. Nevertheless, the results for this modelling section seem, at first sight, counter intuitive. That is, the temporal random effect explains very little (less than 1%) of the total trip distance variance.
There may be two main reasons for such a conclusion. The first is that the variance contribution of the temporal variables is overshadowed by the between-mode differences. Indeed, the between-mode differences are attributed between 58 and 65% of the overall variation in the trip distance by mode. The other reason may be that travel behavior over the selected time periods is homogeneous. That is, individuals travel the same distance by mode every month, season or year. Intuitively, this explanation may stand for auto and transit users but is rather difficult to justify for active modes such as walking and cycling. The next section is devoted to investigating whether temporal variation in trip behavior may be observed for active modes. Here, active modes are defined as either walking or cycling trips (Mahmoud et al. 2015).
Aside from the between-mode differences, the within mode differences were attributed between 13 and 26% of the total variation in modal travel distance. In addition, the between region/municipal sector differences were attributed anywhere between 10 and 25% of the total variation.
It is important to note that the analysis in this section was repeated for (the logarithm of) trip counts by mode as a dependent variable to validate the results. However, the aforementioned conclusions were largely similar.
Active mode level mixed effects model
After aggregating trips by mode, a subset of the dataset that includes trips conducted by walking or biking was taken out and used for modelling. A random effects model was then estimated with the log of trip distance as the dependent variable for a set of models, and the log of trip counts by mode for another set of models. The grouping factors (random effects) considered were mode, region and different time periods (season, year, month, season by year, month by year). Only the region grouping factor was considered as the number of trips, or total trip distance covered, by active modes would have been too thinly distributed across different municipal sectors for analysis purposes. Table 10 summarizes the obtained VPC results.
Interestingly, the VPCs of the different temporal variables were significant at the 95% confidence interval (with the exception of the year variable for the trip counts model) and ranged from 1 to 25%. That is, approximately 1% to 25% of the variation in travel behavior, whether it is trip distance or a number of trips, is attributed to between time period differences. This means that, in the case of active modes, the temporal nature of the data are heteroscedastic. This is in contrast to the conclusion of the previous section, where the temporal component of the estimated models proved negligible in explaining the variation in travel behavior, but is inline with the overall hypothesis of the paper. Here lies the advantage of continuous surveys, as their continuous data elements can be leveraged to conduct time series analysis and identify temporal trends for various policy purposes, but only on grouping levels that exhibit repeated observations such as spatial units and modes.
In the case of total travel distance covered, anywhere from 25 to 71% of the total variance may be attributed to between-region differences. Further, modal differences still played a role in explaining the variance (10% to 18%). On the other hand, in the case of trip rates, or count of trips by mode, between mode differences played a bigger role in explaining the variance of the dependent variable. That may be because, while the trip distances covered by walking and cycling can likely be very similar, the number of trips by each mode can vary significantly. It is also possible that such trips are under-reported in the Montreal Continuous Survey. The same set of models were estimated for the remaining dataset that included all other modes with the exception of walking and biking. The variance component in travel behavior attributed to the temporal component of the model was below 1%.
Conclusion
The VPC analysis conducted suggests that only a very small percentage of the total variation in trip distance travelled by individuals and/or households in a typical weekday can be attributed to between time period differences, whether its year, season, month, etc. This begs the question of whether continuous surveys are any more advantageous than large one-off cross-sectional surveys, the dominant practice in most major Canadian cities (Habib and El-Assi 2015), for investigating temporal differences in trip behavior on the household or individual level. However, the continuous nature of the data may allow for time series analysis of trip behavior at a more aggregate level such as zones/municipal sectors, modes or regions due to the presence of repeated observations. This has been shown multiple times in this paper, where the between time period differences explained up to 35% of the total variance of the dependent variable. As for capturing the temporality of individual or household travel behavior, panel surveys have been and remain the method of choice. Another main conclusion presented in this paper is that the difference between time periods can be more profound when grouping trips on a more disaggregated level such as municipal sectors versus regions, or active modes versus non-active modes.
The study, however, is not without its limitations. For instance, to develop a more elaborate understanding of trip behavior in the Montreal metropolitan area, it is imperative to also investigate the subset of the population that did not conduct any trips on the day of the survey. A zero inflation analysis can be implemented to compare respondents who reported immobility with the remaining respondents that conducted at least one trip. Moreover, additional transportation dimensions such as activity type or departure time could have also exhibited significant temporal behavior. However, such data was not available. Further, random coefficients were not introduced as part of the modelling structure. Random coefficients pertained to built environment and land use can help explain trip behavior across various spatial units. That said, such variables could alter the variance of the dependent variable, thus affecting the calculated VPCs. In addition, it is imperative to investigate the confidence intervals around the variance calculations. The confidence intervals can be calculated via bootstrap, and will reflect the range that the VPC analysis can take. The analysis of confidence intervals was beyond the scope of this study. There is also potential to study and compare the change in fixed effects estimates when using mixed effects models as opposed to linear regression models. The limitations present futile ground for further research on the potential of continuous household travel surveys.
Notes
A mixed effect model is also known in literature as a multilevel model, hierarchical linear model, and random intercept/coefficient model (Rabe-Hesketh and Skrondal 2012).
The fixed effects factor was removed from subsequent notation as the focus is more on the correct representation of the random effects.
The model was re-estimated while eliminating the hhsize variable. All parameter estimates were more or less identical. A likelihood ratio test was conducted to determine whether the model is better off without hhsize. Nevertheless, the null hypothesis could not be rejected and it was decided to keep the variable.
References
Ampt, E., Ortuzar, J.: On best practice in continuous large-scale mobility surveys. Transp. Rev. 24(3), 337–363 (2011)
Ampt, E., Stopher, P.: Mixed methods data collection in travel surveys: challenges and opportunities. In: Presented at the 28th Australian Transport Research Forum (2006)
Data Management Group.: Transportation tomorrow survey (2013) http://www.dmg.utoronto.ca/transportationtomorrowsurvey/. Accessed 2015
DiPrete, T., Grusky, D.: The multilevel analysis of trends with repeated cross-sectional data. Am Sociol Assoc 20, 337–368 (1990)
Fiona, S.: Module 5: introduction to multilevel modelling concepts. In: Learning Environment for Multilevel Methodology and Applications. University of Bristol, Centre for Multilevel Modelling (2008)
Garson, G.: Hierarchical Linear Modelling—Guide and Applications, 1st edn. SAGE Publications Inc., Thousands Oak (2013)
Goldstein, H., Browne, W., Rasbash, J.: Partitioning variation in multilevel models. Underst. Stat.: Stat. Issues Psychol., Educ. Soc. Sci. 1(4), 223–231 (2002)
Goulias, K.: Multilevel analysis of daily time use and time allocation to activity types accounting for complex covariance structures using correlated random effects. Transportation 29, 31–48 (2002)
Habib, K., El-Assi, W.: How large is too large? the issue of sample size requirements of regional household travel surveys, the case of the transportation tomorrow survey in the greater Toronto and Hamilton area. In: Presented at the 95th Annual Meeting of the Transportation Research Board (2015)
Hanson, S., Johnston, I.: Gender differences in work trip length: explanations and implications. Urban Geogr. 6(3), 193–219 (2013)
Kish, L.: Survey Sampling. John Wiley & Sons Inc, New York (1965)
Leckie, G.: Module 12: cross-classified multilevel models. In: Learning Environment for Multilevel Methodology and Applications. University of Bristol, Centre for Multilevel Modelling (2013)
Lipps, O., Kunert, U.: Measuring and explaining the increase in travel distance: a multilevel analysis using repeated cross-sectional travel surveys. In: DIW-Diskussionspapiere, vol 492 (2005)
Mahmoud, M., El-Assi, W., Habib, K., Shalaby, A.: How active modes compete with motorized modes in high density areas: a case study of downtown Toronto. In: Canadian Transportation Research Forum (2015)
Meyer, M., Miller, E.: Urban Transportation Planning, 2nd edn. McGraw Hill, New York (2001)
Ortúzar, J.D.D., Armoogum, J., Madre J.-L., Potier, F.: Continuous mobility surveys: the state of practice. Transp. Rev. 31(3), 293–312 (2011)
Peachman, J., Battellino, H.: The joys and tribulations of a continuous survey. In: International Conference on Transportation Survey Quality and Innovation (2007)
Rabe-Hesketh, S., Skrondal, A.: Multilevel and Longitudinal Modelling Using Stata. Stata Press, Texas (2012)
Roorda, M., Carrasco, J., Miller, E.: An integrated model of vehicle transactions, activity scheduling and mode choice. Transp. Res. Part B: Methodol. 43(2), 217–229 (2009)
Scott, M.A., Shrout, P.E., Weinberg, S.L.: Multilevel modelling notation-establishing commonalities. In: Scott, M.A., Simonoff, J.S., Marx, B.D. (eds.) The SAGE Handbook of Multilevel Modelling. SAGE Publications Inc. (2013)
Stopher, P., Greaves, S.: Household travel surveys: where are we going? Transp. Res. Part A 41, 367–381 (2007)
Stopher, P., FitzGerald, C., Xu, M.: Assessing the accuracy of the sydney household travel survey with GPS. Transportation 34, 723–741 (2007)
Tremblay, P.: An overview of OD-surveys in quebec (2014). http://uttri.utoronto.ca/files/2014/10/5-Tremblay-An-Overview-of-OD-Surveys-in-Quebec.pdf. Accessed 2015
Verreault, H., Morency, C.: Transcending the typical weekday with large-scale single-day survey samples. Transp. Res. Rec. J. Transp. Res. Board 2230, 38–47 (2011)
Acknowledgements
The study was partially funded by an NSERC Discovery grant. The authors would like to thank the AMT (Metropolitan Transportation Agency) for providing access to the data (continuous survey) for research purposes, as well as to Hubert Verreault (Polytechnique Montreal) for his contributions in data processing. An earlier version of the paper was presented at the 2017 International Conference on Travel Survey Methods in Montreal, Canada, and the paper has benefited from the comments and suggestions of the conference attendees.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
El-Assi, W., Morency, C., Miller, E.J. et al. Investigating the capacity of continuous household travel surveys in capturing the temporal rhythms of travel demand. Transportation 47, 1787–1808 (2020). https://doi.org/10.1007/s11116-019-09981-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11116-019-09981-x