
Abstract
This paper aims to employ and compare four methods of neural network (NN), support vector regression (SVR), least squares support vector regression (LSSVR) and adaptive neuro-fuzzy inference system (ANFIS) for modeling the time series behavior of the meteorological and the remotely sensed (RS) drought indices of the eastern district of Isfahan during 2000–2014. The data used in the paper are the normalized difference vegetation index (NDVI) and the land surface temperature time series of MODIS satellite and the rainfall time series of TRMM satellite. Then, three RS drought indices namely vegetation condition index, NDVI deviation index and temperature vegetation index and three meteorological drought indices namely 3-month SPI, 6-month SPI and 12-month SPI are generated by the data. Afterward, based on the correlation coefficient between the RS and the meteorological drought indices, three indices are chosen as candidate indices for monitoring the drought severity of the study area. After modeling the time series behavior of these indices by the aforementioned methods, the results indicate that the SVR has the highest and the NN has the lowest efficiency among all the methods. In addition, the performance speed of the LSSVR and then the ANFIS is the highest. At the end of the paper, a fuzzy inference system (FIS) is presented based on the candidate indices to monitor the drought severity at spring and summer of 2000–2014. According to the results of the designed FIS, the spring status is normal in all years except 2000 and 2011 (moderate drought) and the summer status is severe drought in all years except 2000, 2010, 2011 and 2014 (moderate drought).
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Drought as a complex and unavoidable natural disaster has frequently occurred in the different countries, especially in hot and dry regions and also in Iran (Rojas et al. 2011; Shahabfar et al. 2014). Timely detection of drought can be effective at managing and using the existing resources and reducing the devastating impacts of this natural hazard. However, detecting and constantly monitoring the drought is the one of the main problems of the organizations associated with this phenomenon. Since it develops slowly unlike the other natural disasters (such as earthquake, flood and storm) and lacks a universal definition (Jalili et al. 2014). An overview of drought definitions and concepts can be found in (Mishra and Singh 2010; Zargar et al. 2011; Agwata 2014).
Drought can be classified into three types: meteorological, agricultural and hydrological (Zargar et al. 2011). The most important type which is also considered in our research, i.e., the meteorological drought is a period of abnormal dryness mainly due to precipitation deficiency (Zargar et al. 2011; Jalili et al. 2014). To determine the severity of this drought type, various drought indices have already been developed. Based on the data and technology used, they can be categorized into two general groups: meteorological indices and remotely sensed (RS) indices (Sharma 2006; Rulinda 2007; Zargar et al. 2011).
The most widely used meteorological index is the standardized precipitation index (SPI) (Zargar et al. 2011). The RS indices are those derived from the normalized vegetation difference index (NDVI) and the land surface temperature (LST) or the combination of both (Orhan et al. 2014; Jalili et al. 2014).
There are a few studies using only meteorological indices for monitoring drought severity (Sahoo et al. 2015). In some studies, only RS indices such as NDVI, vegetation condition index (VCI), vegetation health index (VHI) and temperature vegetation index (TVX) have been used (e.g., Liu and Kogan 1996; Song et al. 2004; Rojas et al. 2011; Muthumanickam et al. 2011; Rulinda et al. 2012; Orhan et al. 2014). Some studies have employed the combination of the RS and the meteorological indices (e.g., Bhuiyan et al. 2006; Rahimzadeh-Bajgiran et al. 2009; Quiring and Ganesh 2010; Jain et al. 2010; Berhan et al. 2011; Shamsipour et al. 2011; Rahimzadeh-Bajgiran et al. 2012; Shahabfar et al. 2012; Zhou et al. 2012; Zhang and Jia 2013; Du et al. 2013; Shahabfar et al. 2014; Sur et al. 2015). The above-mentioned studies have demonstrated that the combination of the RS data and the ground data can have a strong potential and efficiency at monitoring the drought severity.
For modeling the time series behavior of drought indices, most studies have employed univariate or multivariate simple linear regression. However, there are some studies which use the neural network (NN) method (e.g., Mishra and Desai 2006; Barua et al. 2010; Qiu et al. 2011; Dastorani et al. 2011; Keskin et al. 2011; Fatehi Marj and Meijerink 2011). At some studies, the support vector regression (SVR) has been used (e.g., Collier and McGovern 2008; Nikhbakht Shahbazi and Heidarnejhad 2012; Qing et al. 2012). In a recent study, both of SVR and NN have been employed to model the drought condition in Iran (Jalili et al. 2014). Another method for analyzing and predicting the drought is the adaptive neuro-fuzzy inference system (ANFIS) method (e.g., Keskin et al. 2009; Shirmohammadi et al. 2013). A comparative analysis has been accomplished between NN and ANFIS methods in another paper for the prediction of rainfall in the central region of Yazd (Dastorani et al. 2010). In another paper, the least squares support vector regression (LSSVR) and NN have been compared to estimate the drought severity (Sadri and Burn 2012). These studies have implied the high efficiency of four methods of NN, SVR, LSSVR and ANFIS at modeling the nonlinear time series behavior of drought indices.
So far, there are no studies which have compared four above-mentioned methods together. Therefore, one of the main objectives of this paper is to compare these methods for modeling the time series behavior of both meteorological and RS drought indices. The data used in this paper are the NDVI and LST time series of moderate-resolution imaging spectroradiometer (MODIS) and also the rainfall data of Tropical Rainfall Measuring Mission (TRMM) satellites during 2000–2014, and the study area is the eastern district of Isfahan. At first, three RS drought indices namely NDVI deviation (DEV), VCI and TVX are generated by the NDVI and LST time series data and three meteorological drought indices namely 3-month SPI, 6-month SPI and 12-month SPI are generated by the rainfall time series data. Then, the correlation coefficients between two these types are computed and the candidate indices are chosen among all indices for monitoring the drought severity for the study area. After modeling the candidate indices by four methods and comparing their results, another main objective of the paper is to design a fuzzy inference system (FIS) using the candidate indices in order to determine the drought severity of the study area during 2000–2014.
The reminder of the paper is organized as follows: Sect. 2 introduces the study area and the data used in the paper. The methodology of the paper is presented in Sect. 3. Section 4 provides the implementations and the results. Section 5 discusses on the obtained results. Section 6 presents the FIS system and its results. Finally, Sect. 7 gives the conclusions of the paper.
2 Study area and data
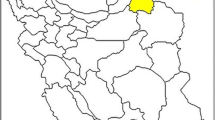
The study area is the eastern district of Isfahan, Iran (Fig. 1), which contains saline land and sand mountains and it has a hot desert climate (BWh) according to Köppen climate classification scheme (https://en.wikipedia.org/wiki/Koppen_climate_classification). Its latitude is between 51°42′30″E and 51°59′52″E, and its longitude is between 32°29′40″N and 32°45′47″N.

Study area (eastern district of Isfahan)
The data used in this study are the products of MODIS satellite namely MOD11 and MOD13 and also the rainfall data provided by TRMM satellite. MOD11 contains the day and night LST times, quality assessment, observation time, angles and emission factor estimated by the bands 31 and 32 of MODIS (Momeni and Saradjian 2007). MOD13 contains NDVI data. MOD11 and MOD13 are downloaded at scale of 0.01°, and the rainfall data are downloaded at scale of 0.25° during 2000–2014 month by month from NASA Web site (http://neo.sci.gsfc.nasa.gov/).
3 Methodology
The methodology presented in the paper has three main steps: At first, the RS and the meteorological drought indices are generated by the data introduced in the previous section. Then the correlation between two these types is surveyed and some are chosen as candidate indices for monitoring the drought severity of the study area. Finally, four machine learning methods namely NN, SVR, LSSVR and ANFIS are employed for modeling their time series behavior.
3.1 Generating drought indices
This section aims to explain how to generate the RS and meteorological drought indices using the NDVI, LST and rainfall data.
3.1.1 RS drought indices
At First, three important RS drought indices namely VCI, DEV and TVX are generated using the NDVI and LST data as follows (Jalili et al. 2014; Orhan et al. 2014; Patel and Yadav 2015):
where NDVImin and NDVImax are the absolute minimum and maximum NDVI, respectively, and NDVI i is the NDVI value at the current month. In addition, NDVImean is average of long-term NDVI for a period of time. Here, the period of 1 month (30 days) is considered for VCI and DEV. Figure 2 shows the seasonal time series of the three RS indices of the study area.

Seasonal time series plots of remote sensing indices a DEV, b VCI and c TVX
3.1.2 Meteorological drought indices
Using the rainfall data, the SPI for the study area can be generated as (Jalili et al. 2014):
where P is precipitation value and μ(P) and σ(P) are the average and the standard deviation of the precipitation at a specific time period. Here, we consider three periods, i.e., 3-month (short term), 6-month (middle term) and 12-month (long term). Figure 3 shows the seasonal time series of the three meteorological indices of the study area.

Seasonal time series plots of meteorological indices a 3-month SPI, b 6-month SPI and c 12-month SPI
3.2 Correlation between RS and meteorological drought indices
Although all of above-mentioned indices can use for drought monitoring, we aim to employ the most relevant indices based on the study area in this paper. For this purpose, we compute the correlation coefficients between the RS indices (DEV, VCI and TVX) and the meteorological indices (3-month SPI, 6-month SPI and 12-month SPI). Correlation coefficient (r) can be defined as follows:
where x is an RS index and y is a meteorological index, Cov(x, y) is the covariance between two indices and Var(x) and Var(y) are their variance. Table 1 presents the r value between the aforementioned indices.
According to the r values of Table 1, it can be concluded that the two first RS indices, i.e., DEV and VCI (related to the vegetation index) are positively more correlated with the 12-month SPI than the two other SPI, whereas TVX (related to LST and NDVI) is negatively more correlated with the 12-month SPI than the other SPI. It implies that the precipitation impacts directly on the vegetation indices. In other words, as precipitation increases, the vegetation indices values can increase. By contrast, TVX has an inverse relationship with precipitation so that as precipitation increases, the TVX value may decrease and vice versa. Another conclusion can be drawn from Table 1 is that among all vegetation-related indices, the VCI has a higher correlation with the SPI. Therefore, in this paper, VCI, TVX and 12-month SPI are employed as the candidate indices to determine the drought severity of the study area.
3.3 Modeling methods
The time series of the candidate drought indices can be modeled as (Zhang 2003):
where F is a function which can be determined by a modeling method, (y t−1, y t−2,…, y t−p) (as inputs) are the values/observations of p previous steps of the drought index and y t (as output) is its value at step t predicted by the method. In addition, w is a vector of all parameters. The methods used in this paper are the single-hidden layer feed-forward NN, the SVR with a radial basis function (RBF) kernel, the LSSVR with an RBF kernel and the ANFIS methods.
The NN has usually three layers including of input, hidden and output layers. Single-hidden layer feed-forward NN is the most widely used form of NN for modeling and predicting the time series (Zhang 2003). In addition, the back-propagation (BP) algorithm is more common than the other algorithms to train the NN method (Samsudin et al. 2010). Although NN can be employed by any number of layers, according to Kolmogorov theorem, a three-layer NN can be used to solve any regression problem in any space (Kurkova 1992).
The basic idea of SVR for a regression problem is to map the data into a high-dimensional feature space by a nonlinear mapping and then to employ a linear regression in that feature space. It is executable using the kernel trick. The most widely used kernels in remote sensing are the linear, polynomial, RBF and sigmoid functions (Khosravi and Mohammad-Beigi 2014). It is notable that the SVR results are sensitive to the used kernel and its tuning parameters.
The main idea of LSSVR for the regression problem is similar to the SVR. However, LSSVR employed the idea of least squares for solving the objective function problem (Shabri and Suhartono 2012). Like SVR, the LSSVR results are sensitive to the used kernel and its parameters. Usually, RBF kernel is used in LSSVR (Wang and Hu 2005).
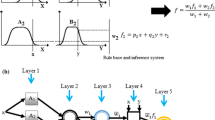
ANFIS employs the linguistic concept of the fuzzy systems and the training power of the NN to solve a regression problem. It has five layers and often uses a Takagi–Sugeno–Kang (TSK) fuzzy system as the feed-forward network structure. In addition, a hybrid learning method is used to train the ANFIS. It employed the BP algorithm at the first layer and the least squares estimation at the fourth layer (Srinivasan and Malliga 2014).
4 Results
Two preprocessing steps are needed before modeling indices: First, their time series should be detrended (their trend line should be removed), and then, their values are normalized (reducing their target values from their mean and then dividing by their standard deviation). In addition, each datum is divided into three categories: training samples (for building the model), validation samples (for optimizing model) and test samples (for evaluating model). In this paper, we consider the first 70% of the data for training, the second 15% for validation and the remaining 15% for test samples. Furthermore, to evaluate the modeling methods, the most widely used metrics such as mean absolute error (MAE), mean bias error (MBE) and root mean square error (RMSE) are employed. They are defined as follows (Chen and Lin 2010; Zhang et al. 2014):
where t i is the target or actual value, y i is the estimated value of the method for each index and m is the number of observations.
Since all the time series have seasonally been sorted (winter, spring, summer and autumn), we consider p = 4 at Eq. 6 for modeling all them, i.e., y t = F(y t−1, y t−2, y t−3, y t−4, w) + ε t . In other words, according to Eq. 6, each point can be related to its previous four points. Table 2 presents the evaluation results of four modeling methods for three candidate indices. Moreover, Fig. 4 illustrates the actual (blue) and the predicted (red) time series of the indices by four methods.

Actual (blue) and predicted (red) time series plots of VCI (left), TVX (mid) and SPI (right) obtained by a NN, b SVR, c LSSVR and d ANFIS methods
In addition to quantitative metrics, a visual comparative evaluation of the methods is accomplished based on the point errors of each method for each index at 60 seasons. The point error is the difference between target or actual (t i ) and estimated or predicted (y i ) values, i.e., t i − y i , i = 1,…, 60. Figure 5a–c shows the point errors plots obtained by four methods in modeling VCI, TVX and SPI, respectively. The blue, orange, gray and yellow plots correspond to the point errors plots obtained by NN, SVR, LSSVR and ANFIS, respectively.

Point error plots obtained by NN (blue), SVR (orange), LSSVR (gray) and ANFIS (yellow) in modeling a VCI, b TVX and c 12-month SPI
5 Discussion
From Table 2, among four methods, the SVR with the lowest all-RMSE for all the indices and the lowest all-MAE for VCI and SPI has the most efficiency and the NN with the highest all-RMSE and all-MAE for all the indices has the lowest efficiency at modeling. In addition, the test-RMSE and test-MAE values for three indices obtained by the SVR are lower than those of the other methods. It implies the higher absolute accuracy of the SVR compared with the other methods.
It is noteworthy that one of the characteristics of NN is to produce the non-unique results. In this paper, the NN model is trained several times and finally, the model with the lowest RMSE for the validation samples is chosen. However, its results have yet the lowest accuracy among four methods.
As previously mentioned, SVR is sensitive to the kernel type and its tuning parameters. In this paper, four common kernels namely linear, polynomial, sigmoid and RBF are employed. Based on the obtained results, the linear and polynomial kernels have the less flexibility and capability at modeling all the indices (with the highest RMSE). Moreover, the processing takes very long time by polynomial kernel compared to the other kernels and its results are not very favorable. By contrast, the performance speed of sigmoid kernel is the highest among all the kernels. However, the flexibility, capability and accuracy of the RBF kernel are the highest and it can produce the more desired results. Therefore, the RBF is used as the optimum kernel for all the indices. RBF kernel has two tuning parameters namely control parameter (C) and Gaussian width parameter (γ) (Khosravi and Mohammad-Beigi 2014). For obtaining their optimum values, a grid search algorithm is used with the intervals of [10−3, 10+3] and [2−3, 2+3] for C and γ, respectively. By focusing on the lowest RMSE for the validation samples, the values of 10, 100 and 1000 for C and the values of 1, 0.5 and 1 for γ are obtained for VCI, TVX and SPI, respectively.
Like SVR, an RBF kernel is used for LSSVR. In addition, the optimum values of its parameters are obtained using a grid search method focusing on the lowest RMSE for the validation samples. Although the LSSVR has a higher all-RMSE and all-MAE than the SVR at modeling all the indices, the all-MBE and test-MBE values for TVX obtained by the LSSVR are lower than those obtained by the SVR. It implies that the difference between TVX values predicted by the LSSVR and its actual values is lower than that of the SVR.
The last method, i.e., the ANFIS has obtained a unique result unlike the NN and its efficiency and accuracy has been higher than the NN at modeling three indices. In addition, the all-RMSE and test-RMSE for VCI and the all-RMSE for TVX obtained by the ANFIS have been lower than those of the LSSVR and vice versa at modeling SPI. In addition, the all-MAE and all-MBE for TVX obtained by the ANFIS has been lower than those of the SVR. It means that the difference between TVX values predicted by the ANFIS and its actual values is lower than that of the SVR.
In general, the LSSVR is the fastest method, and after that, the ANFIS has been faster than the SVR and the NN methods at modeling three indices. The performance speeds of the SVR and the NN are almost identical at modeling three indices.
As shown in Fig. 5a, the point errors of the NN (blue plot) and then, the LSSVR (gray plot) are higher than the other methods at almost all the lags of VCI. The maximum error at modeling VCI belongs to the NN method (around 70 and −80) that has occurred in the last steps related to the test samples. By contrast, the point errors of the SVR (orange plot) and then, the ANFIS (yellow plot) are much lower than two other methods. Even, the SVR has almost the lowest point errors. At Fig. 5b, i.e., the point errors plots related to TVX, the behavior of the NN errors plot (blue) is almost close to the LSSVR errors plots (gray). However, at some steps, the maximum error belongs to the NN errors plot (with a maximum value of 60) and at some steps, it belongs to the LSSVR errors plot (maximum values of 45 and 60). In addition, the behaviors of the SVR (orange) and the ANFIS (yellow) errors plots are almost close each other. However, the stability of the SVR plot is higher than that of the ANFIS plot. Figure 5c clearly illustrates that the SPI point errors of the NN are very higher than those of three other methods at almost all the lags. After that, the point errors of the ANFIS are the highest, whereas the ones of the SVR and the LSSVR are almost the lowest among all the methods.
By comparing Fig. 5a–c, it can be generally concluded that the SVR is the most successful method and by contrast, the NN is the most unsuccessful method among all the methods used in the paper at pointwise modeling all the indices. Meanwhile, the ANFIS method is more successful than the LSSVR at pointwise modeling VCI and TVX and vice versa at pointwise modeling SPI.
6 Monitoring drought severity by an FIS procedure
After modeling VCI, TVX and SPI, an FIS is presented to monitor the drought severity of the study area during the 15 recent years. The inputs of the FIS are these indices and its output is the drought severity (DS). Then, the FIS makes the decisions by designing a rule base for linguistic values of the indices. For the SPI, the linguistic values of very low (VL), low (L), medium (M), high (H) and very high (VH) and for the VCI and TVX, the linguistic values of L, M and H are definable. In addition, the linguistic values of severe drought (SD), moderate drought (MD), normal (N), moderate wet (MW) and severe wet (SW) can be defined for the DS.
The trapezoidal function is considered for the membership function of the input indices. Figure 6a–c shows their membership function and universe of discourse. Based on previous studies, their universe of discourse is determined (Lambin and Ehrlich 1996; Kogan 1997; Sharma 2006; Rulinda 2007; Agwata 2014). Two trapezoidal and three triangular functions are considered for the membership of the output of the FIS. Figure 6d shows its membership function and related universe of discourse. Arbitrarily, we consider [−1, +1] for its universe of discourse.

Membership functions of the FIS inputs and outputs. a SPI, b TVX, c VCI and d DS. Notes VL very low, L low, M medium, H high, VH very high/SD severe drought, MD moderate drought, N normal, MW moderate wet, SW sever drought/DS drought severity
The next step is to define fuzzy rules for the FIS according to Table 3. This work has not been accomplished for drought monitoring in the previous studies, at all. The SPI is the basic index for monitoring the drought. Therefore, whenever its value is VL, the DS is SD (rule 1) and whenever its value is VH, the DS is SW (rule 29) without considering TVX and VCI values. For three other linguistic values of SPI with three linguistic values of TVX and VCI, 3 × 3 × 3 = 27 other fuzzy rules can be defined, i.e., altogether 29 rules. All rules have the same weights in the FIS. Finally, Table 4 presents the DS reported by the designed FIS for the study area during 2000–2014.
From Table 4, during the 15 recent years from 2000 to 2014 except of 2000 and 2011, spring has a normal status and it has been confronted with the medium drought in two these years. Summer of all years except of 4 years (2000, 2010, 2011 and 2014) has been confronted with the severe drought and it has the moderate drought status in the four aforementioned years.
7 Conclusion
This paper studied the drought severity in the eastern district of Isfahan during 2000–2014 based on a fuzzy inference system and the VCI, TVX and 12-month SPI time series. Four machine learning methods namely NN, SVR, LSSVR and ANFIS were used to model their time series behavior. The results indicated that the SVR had the highest and the NN had the lowest efficiency at modeling all the indices. In addition, the LSSVR and then, the ANFIS were faster than the other methods at modeling them. In the end of the paper based on 29 fuzzy rules for the indices, an FIS was designed to determine the drought severity of the study area at the spring and summer seasons of 15 recent years. It is shown that spring of all years except 2000 and 2011 were in normal state and the two mentioned years had a moderate drought condition. By contrast, the summer of 4 years, 2000, 2010, 2011 and 2014 were confronted with the moderate drought state and the remaining years with the severe drought.
In fact, this study aims to provide a strategy for monitoring drought severity using machine learning methods and the RS and the meteorological time series data and fusing them in a fuzzy inference system.
References
Agwata JF (2014) A review of some indices used for drought studies. Civ Environ Res 6(2):14–21
Barua S, Perera BJC, Ng AWM, Tran D (2010) Drought forecasting using an aggregated drought index and artificial neural networks. J Water Clim Change 1:193–206
Berhan G, Hill S, Tadesse T, Atnafu S (2011) Using satellite images for drought monitoring: a knowledge discovery approach. J Strateg Innov Sustain 7(1):135–153
Bhuiyan C, Singh RP, Kogan FN (2006) Monitoring drought dynamics in the Aravalli Region (India) using different indices based on ground and remote sensing data. Int J Appl Earth Obs Geoinf 8:289–302
Chen CC, Lin CJ (2010) LIBSVM: A library for support vector regressions. http://www.csie.ntu.edu.tw/~cjlin/libsvm
Collier MW, McGovern A (2008) Kernels for the investigation of localized spatiotemporal transitions of drought with support vector regressions. In: IEEE international conference on data mining workshops, pp 359–368
Dastorani MT, Afkhami H, Sharifidarani H, Dastorani M (2010) Application of ANN and ANFIS models on dryland precipitation prediction (case study: Yazd in central Iran). J Appl Sci 10(20):2387–2394
Dastorani MT, Afkhami H, Borroni B (2011) Application of artificial neural networks on drought prediction in Yazd (Central Iran). Desert 16:39–48
Du L, Tian Q, Yu T, Meng Q, Jansco T, Udavrdy P, Huang Y (2013) A comprehensive drought monitoring method integrating MODIS and TRMM data. Int J Applied Earth Obs Geoinf 23:245–253
Fatehi Marj A, Meijerink AMJ (2011) Agricultural drought forecasting using satellite images, climate indices and artificial neural network. Int J Remote Sens 32(24):9707–9719
http://neo.sci.gsfc.nasa.gov/. Accessed Dec 2014
Jain SK, Keshri R, Goswami A, Sarkar A (2010) Application of meteorological and vegetation indices for evaluation of drought impact: a case study for Rajasthan, India. Nat Hazards 54:643–656
Jalili M, Gharibshah J, Ghavami SM, Beheshtifar MR, Farshi R (2014) Nationwide prediction of drought conditions in iran based on remote sensing data. IEEE Trans Comput 63(1):90–101
Keskin ME, Terzi O, Taylan ED, Kucukyaman D (2009) Meteorological drought analysis using data-driven models for the Lakes District, Turkey. Hydrol Sci J Sci Hydrol 54(6):1114–1124
Keskin ME, Terzi O, Taylan ED, Kucukyaman D (2011) Meteorological drought analysis using artificial neural networks. Sci Res Essays 6:4469–4477
Khosravi I, Mohammad-Beigi M (2014) Multiple classifier systems for hyperspectral remote sensing data classification. J Indian Soc Remote Sens 42(2):423–428
Kogan FN (1997) Global drought watch from space. Bull Am Meteorol Soc 78:621–636
Kurkova V (1992) Kolmogorov’s theorem and multilayer neural networks. Neural Netw 5(3):501–506
Lambin EF, Ehrlich D (1996) The surface temperature-vegetation index space for land cover and land-cover change analysis. Int J Remote Sens 17(3):463–487
Liu WT, Kogan FN (1996) Monitoring regional drought using the vegetation index. Int J Remote Sens 17(14):2761–2782
Mishra AK, Desai VR (2006) Drought forecasting using feed-forward recursive neural network. Ecol Model 198:127–138
Mishra AK, Singh VP (2010) A review of drought concepts. J Hydrol 391:202–216
Momeni M, Saradjian MR (2007) Evaluating NDVI-based emissivities of MODIS bands 31 and 32 using emissivities derived by day/night LST algorithm. Remote Sens Environ 106:190–198
Muthumanickam D, Kannan P, Kumaraperumal R, Natarajan S, Sivasamy R, Poongodi C (2011) Drought assessment and monitoring through remote sensing and GIS in western tracts of Tamil Nadu, India. Int J Remote Sens 32(18):5157–5176
Nikhbakht Shahbazi A, Heidarnejhad M (2012) Meteorological drought prediction in Karoon watershed using meteorological variables. Int Res J Appl Basic Sci 3(9):1760–1768
Orhan O, Ekercin S, Dadaser-Celik F (2014) Use of landsat land surface temperature and vegetation indices for monitoring drought in the Salt Lake Basin Area, Turkey. Sci World J 2014:1–11
Patel NR, Yadav K (2015) Monitoring spatio-temporal pattern of drought stress using integrated drought index over Bundelkhand region, India. Nat Hazards 2015(77):663–677
Qing C, Xiaoli Z, Kun Z (2012) Research on precipitation prediction based on time series model. In: 2012 International conference on computer distributed control and intelligent environmental monitoring, pp 568–571
Qiu L, Zhao M, Wei M (2011) Center approach grey BP neural network prediction model for years of drought occurrence in Xinzhou District of Wuhan City. In: 2011 5th International conference on bioinformatics and biomedical engineering, (iCBBE), pp 1–4
Quiring SM, Ganesh S (2010) Evaluating the utility of the vegetation condition index (VCI) for monitoring meteorological drought in Texas. Agric For Meteorol 150:330–339
Rahimzadeh-Bajgiran P, Shimizu Y, Hosoi F, Omasa K (2009) MODIS vegetation and water indices for drought assessment in semi-arid ecosystems of Iran. J Agric Meteorol 65(4):349–355
Rahimzadeh-Bajgiran P, Omasa K, Shimizu Y (2012) Comparative evaluation of the vegetation dryness index (VDI), the temperature vegetation dryness index (TVDI) and the improved TVDI (iTVDI) for water stress detection in semi-arid regions of Iran. ISPRS J Photogramm Remote Sens 68:1–12
Rojas O, Vrieling A, Rembold F (2011) Assessing drought probability for agricultural areas in africa with coarse resolution remote sensing imagery. Remote Sens Environ 115:343–352
Rulinda CM (2007) Mining drought from remote sensing images. M.Sc. Thesis, Geo-information Science and Earth Observation
Rulinda CM, Dilo A, Bijker W, Stein A (2012) Characterizing and quantifying vegetative drought in East Africa using fuzzy modelling and NDVI data. J Arid Environ 78:169–178
Sadri S, Burn DH (2012) Nonparametric methods for drought severity estimation at ungauged sites. Water Resour Res 48:1–10
Sahoo AK, Sheffield J, Pan M, Wood EF (2015) Evaluation of the tropical rainfall measuring mission multi-satellite precipitation analysis (TMPA) for assessment of large-scale meteorological drought. Remote Sens Environ 159:181–193
Samsudin R, Shabri A, Saad P (2010) A comparison of time series forecasting using support vector regression and artificial neural network model. J Appl Sci 10(11):950–958
Shabri A, Suhartono (2012) Streamflow forecasting using least-squares support vector machines. Hydrol Sci J 57(7):1275–1293
Shahabfar A, Ghulam A, Eitzinger J (2012) Drought monitoring in Iran using the perpendicular drought indices. Int J Appl Earth Obs Geoinf 18:119–127
Shahabfar A, Ghulam A, Conrad C (2014) Understanding hydrological repartitioning and shifts in drought regimes in Central and South-West Asia using MODIS derived perpendicular drought index and TRMM data. IEEE J Sel Top Appl Earth Obs Remote Sens 7(3):983–993
Shamsipour AA, Zewar-Reza P, Alavi Panah SK, Azizi G (2011) Analysis of drought events for the semi-arid central pains of Iran with satellite and meteorological based indicators. Int J Remote Sens 32(24):9559–9569
Sharma A (2006) Spatial data mining for drought monitoring: an approach using temporal NDVI and rainfall relationship. M.Sc. Thesis, Geo-information Science and Earth Observation
Shirmohammadi B, Moradi H, Moosavi V, Taei Semiromi M, Zeinali A (2013) Forecasting of meteorological drought using wavelet-ANFIS hybrid model for different time steps (case study: Southeastern Part of East Azerbaijan Province, Iran). Nat Hazards 2013(69):389–402
Song X, Saito G, Kodama M, Sawada H (2004) Early detection system of drought in East Asia using NDVI from NOAA AVHRR data. Int J Remote Sens 25(16):3105–3111
Srinivasan SP, Malliga P (2014) A conceptual framework for Jatropha seed yield estimation using adaptive neuro-fuzzy inference system (ANFIS) modelling. Int J Sustain Eng 4(2):183–191
Sur C, Hur J, Kim K, Choi W, Choi M (2015) An evaluation of satellite-based drought indices on a regional scale. Int J Remote Sens 36(22):5593–5612
Wang H, Hu D (2005) Comparison of SVM and LS–SVM for regression. In: International conference on neural networks and brain 2005. ICNN&B ‘05’, pp 279–283
Zargar A, Sadiq R, Naser B, Khan FI (2011) A review of drought indices. Environ Rev 19:333–349
Zhang P (2003) Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 50:159–175
Zhang A, Jia G (2013) Monitoring meteorological drought in semiarid regions using multi-sensor microwave remote sensing data. Remote Sens Environ 138:12–23
Zhang X, Zhang T, Young AA, Li X (2014) Applications and comparisons of four time series models in epidemiological surveillance data. PLoS ONE 9(2):1–16
Zhou L, Zhang J, Wu J, Zhao L, Liu M, Lu A, Wu Z (2012) Comparison of remotely sensed and meteorological data-derived drought indices in Mid-Eastern China. Int J Remote Sens 33(6):1755–1779
Author information
Authors and Affiliations
Corresponding author
Additional information
The original version of this article was revised: A hyphen needed to be inserted in the last name of author Yaser Jouybari-Moghaddam.
An erratum to this article is available at http://dx.doi.org/10.1007/s11069-017-2879-2.
Rights and permissions
About this article

Cite this article
Khosravi, I., Jouybari-Moghaddam, Y. & Sarajian, M.R. The comparison of NN, SVR, LSSVR and ANFIS at modeling meteorological and remotely sensed drought indices over the eastern district of Isfahan, Iran. Nat Hazards 87, 1507–1522 (2017). https://doi.org/10.1007/s11069-017-2827-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-017-2827-1