
Abstract
In this paper we develop a syntax-semantics of negative concord in Romanian within a constraint-based lexicalist framework. We show that n-words in Romanian are best treated as negative quantifiers which may combine by resumption to form polyadic negative quantifiers. Optionality of resumption explains the existence of simple sentential negation readings alongside double negation readings. We solve the well-known problem of defining general semantic composition rules for translations of natural language expressions in a logical language with polyadic quantifiers by integrating our higher-order logical object language in Lexical Resource Semantics (LRS), whose constraint-based composition mechanisms directly support a systematic syntax-semantics for negative concord with polyadic quantification in Head-driven Phrase Structure Grammar (HPSG).
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Negative concord (NC) languages like Romanian pose a formidable challenge to common practices of composing meaning in most current theories of formal semantics. In NC constructions we observe the use of what prima facie seem to be several negative expressions in one clause with the overall effect of a single interpreted negation. The negative sentence (1a) with one negative expression (nobody) in a non-NC language like standard English thus has the Romanian counterpart in (1b), a sentence with two negative expressions, the n-word nimeni ‘nobody’ and the obligatory negative marker (NM) nu ‘not’. The co-occurrence of the corresponding expressions nobody and not in (standard) English results in an affirmative interpretation in (1c), which is unavailable in the Romanian sentence (1b).Footnote 1
-
(1)


The initial assumption that both nimeni and nu have negative semantics is preliminarily confirmed by (2a) and (2b), where each of the two words alone is responsible for the negative interpretation, just like their counterparts in the corresponding English translations.
-
(2)


Two kinds of solutions have been proposed for NC: (1) mechanisms to compose negative meanings by which the apparently gratuitous negations are factored out under certain conditions (Zanuttini, 1991; Haegeman, 1995; de Swart and Sag, 2002; Richter and Sailer, 2004) (“the negative quantifier [NQ] approaches”), and (2) treatments of n-words as negative polarity items, indefinites or existential quantifiers that carry no negative semantics of their own, the negation being contributed by a (possibly covert) negative operator (Ladusaw, 1992; Giannakidou, 1998; Zeijlstra, 2004; Penka, 2011) (“the negative polarity item [NPI] approaches”). The former analyses argue for a cross-linguistically uniform semantics of n-words on the basis of their negative contribution in contexts like (2). The latter use the obligatoriness of the NM in contexts like (1b) (and, possibly, other language-specific characteristics) to relate the difference between NC languages and non-NC languages to a cross-linguistic variation in the semantics of n-words.
The two principal ways of answering to the NC challenge both have their characteristic shortcomings. Unless it is embedded in a systematic and general theory of semantic composition, negation factorization in NQ approaches easily assumes the air of an ad hoc mechanism and raises serious questions about the nature of the syntax-semantics interface. These techniques tend to be at odds with straightforward renderings of a compositional Montagovian semantics. As for the second school of thinking about NC, a covert negative operator in NPI approaches is hard to take for granted considering the overwhelming cross-linguistic evidence that n-words overtly contribute negative semantics (see most recently de Swart, 2010). In light of the semantic properties of n-words in Romanian, we will follow the NQ approach and present an analysis of the syntax and semantics of Romanian NC constructions as polyadic quantification in Lexical Resource Semantics (LRS, Richter and Sailer, 2004). Polyadic quantifiers are higher-order functions that receive a mathematically rigorous formulation in Generalized Quantifier Theory (Keenan and Westerståhl, 1997; Peters and Westerståhl, 2006) and express relations between more than two sets; the flexible constraint-based composition mechanisms of LRS permit a direct formalization of our theory within HPSG (Pollard and Sag, 1994). Using polyadic quantifiers in our analysis defeats the ad-hoc character of older NQ approaches, while constraint-based composition mechanisms allow a coherent and systematic syntax-semantics interface for negative concord.
Following a proposal by de Swart and Sag (2002) for French, we express the truth conditions associated with Romanian NC constructions by means of negative polyadic quantifiers. Going beyond de Swart and Sag’s largely informal treatment of the logical representations for polyadic quantification in HPSG, we define a higher-order logic with polyadic quantification and modify the interface principles of LRS to accommodate the newly added quantifiers. This way we arrive at a fully explicit composition theory of Romanian NC using resumptive polyadic quantification. The fact that this is possible at all is of particular interest since resumptive polyadic quantifiers are a notorious problem for frameworks which use the lambda calculus in combination with a functional theory of types to define a syntax-semantics interface for natural languages. Our proposal of implementing them with LRS overcomes these fundamental formal limitations. With a combination of lexical underspecification and constraint-based semantic composition principles, we can express a precise systematic relationship between a surface-oriented syntax and semantic representations with polyadic quantifiers in a constraint-based semantic theory which acknowledges the pre-theoretical intuitive notion that all n-words are semantically negative.
The remainder of the paper is structured as follows: First we discuss the data that lead us to conclude that Romanian n-words are indeed negative quantifiers and multiple n-words in NC configurations form a polyadic quantifier (Sect. 2). Then we move on to the tools that we need to formulate our theory, and extend the logical object language and the principles of LRS to include resumptive polyadic quantifiers (Sect. 3). The core of our theory of Romanian NC is presented in Sect. 4, where we formulate a language-specific principle that captures the properties of simple Romanian NC constructions. A brief excursion into languages with different NC systems confirms that our theory can be seen as a language-specific instance of a typological theory of NC. In Sect. 5 we show that our analysis can be extended in a straightforward way to more complex cases which involve scope properties of negative quantifiers in embedded subjunctive clauses. In the final section we briefly summarize the results and speculate about possible future developments.
2 Data
In this section we discuss evidence for the negative semantics of n-words and for their quantificational behavior. Initially we focus on the properties of individual n-words in Romanian and on evidence against their treatment as NPIs. Then we shift our attention to their (polyadic) quantificational properties in NC constructions.
Sentential negation in Romanian is commonly expressed by the verbal prefix nu (Barbu, 2004). In the absence of other negative elements, nu contributes semantic negation, as in (3a). If in addition an n-word such as niciun is present, as in (3b), only a negative concord (NC) reading is available, a double negation (DN) interpretation is not. In constructions with two n-words, both a NC reading and a DN reading are available (see (3c)).
-
(3)


The DN reading in (3c) is dependent on a denial context in which speaker A formulates a negative proposition using the n-constituent nicio carte and speaker B denies that proposition by means of the n-constituent niciun student, as in (4) below.Footnote 2 In this context, an NC reading is excluded.Footnote 3
-
(4)


As (3b) indicates, the negative marker (NM) nu is always obligatory in finite sentences with n-words. Romanian thus qualifies as a strict negative concord language according to Giannakidou (2007), unlike most of the other Romance languages, which are non-strict NC, as illustrated by the Italian example in (5), where a preverbal n-word occurs without a negative marker. It is only outside the domain of finite verb constructions that Romanian displays what at first seems like a similar behavior: A preverbal n-word is the single exponent of negation with a past participle in (6). In Sect. 4.3 we will see that this is not a characteristic property of Romanian NC with non-finite verbs but rather due to the adjectival nature of the participle in this particular construction.
-
(5)

-
(6)



To solve the problem that NC poses, NPI approaches postulate that n-words like the ones in (3b) and (3c) are in fact negative polarity items without inherent semantic negation (Ladusaw, 1992). Such theories, however, cannot account for the DN reading in (3c). The data set in (3) suggests that (a) the negative marker nu contributes negation in the absence of n-words (3a), (b) the negative marker does not contribute negation in the presence of n-words (see the NC reading in (3b), (3c)), and (c) n-words are exponents of semantic negation (see the DN reading in (3c)). As one of its main features, our syntax-semantics interface for Romanian NC acknowledges the lexically negative semantics of n-words and of the NM, and it captures under what circumstances the inherent negativity of the NM can be observed.
2.1 Negative semantics for n-words
Besides the DN reading in (3c), evidence for the inherent negativity of n-words comes from fragmentary answers such as (7) and the past participial constructions illustrated in (6), where in the absence of a verb that would normally carry the NM, n-words contribute negation alone.
-
(7)


In addition, a fragmentary answer to a negative question triggers DN in (8). This makes the ellipsis explanation of NPI approaches (as in Giannakidou, 2007) invalid for (7). If the NM nu is elided, it triggers DN in a fragmentary answer with an n-word as in (8). By contrast, what is elided in (7) must be a semantically positive segment (see also Watanabe, 2004). Note that neither one of the putative elided structures would form a grammatical overt structure in Romanian, either because it would be syntactically ill-formed (7) or because it would receive a reading incompatible with the question (8).
-
(8)


Moreover, we can show that in these contexts n-words exhibit anti-additivity (9), and they can consequently license NPIs in their scope:Footnote 4 The NPI vreo is licensed by the anti-additive n-word nimeni but not by the universal quantifier toată in the same position (10).Footnote 5
-
(9)


-
(10)


2.2 No semantic licenser for n-words
NPI approaches to NC rest on two claims: (a) n-words lack negation, and (b) they are semantically licensed by an anti-additive operator. This operator assumes the central role of contributing the single negation to the utterance. Ladusaw (1992) argues that the semantic licenser of NPIs may be covert. This proposal has been widely exploited in the Minimalist tradition (see, for instance, Zeijlstra, 2004). Like many proponents of surface-oriented syntactic frameworks, we find it conceptually highly dubious to ascribe an essential aspect of the semantics of an entire class of utterances to invisible objects whose presence is intrinsically almost impossible to falsify. Rejecting the option of postulating an empty syntactic operator, the only remaining plausible licenser of n-words in an NC construction like (3b) is the NM. In Romanian the NM is usually obligatory with n-words, which has been interpreted as a consequence of its function as a semantic licenser. Analyses that adopt this view were formulated for Polish in Przepiórkowski and Kupść (1999) and Richter and Sailer (1999), and for Romanian in Ionescu (1999) (see also Isac, 2004 for a generative NPI approach). We do not think that this idea is correct and show instead that although the Romanian NM is obligatory with n-words, it does not behave like a semantic licenser, mainly because n-words, as carriers of negation, do not need one. Evidence for this view is brought from the lack of anti-additivity of the NM in combination with n-words, and from the syntactic independence of n-words from the NM.
First, according to Ladusaw, the semantic licenser of n-words must be at least anti-additive. In the absence of n-constituents, the NM nu receives an anti-additive interpretation as in (11).
-
(11)


If the disjunction that nu takes as argument contains n-words, anti-additivity disappears, and the two n-words are interpreted independently under the scope of negation as in (12). The only reading that survives is one that presupposes ellipsis, which is also available in (11) (but is not relevant for our discussion).
-
(12)


If the n-words in (12) are replaced with weak or strong NPIs, the anti-additivity test succeeds. The contrast between (12), on the one hand, and (13)–(14), on the other, shows that nu acts as a semantic licenser for NPIs, but not for n-words.Footnote 6
-
(13)


-
(14)


Second, it is a well-known fact since at least Ladusaw (1980) that the semantic licensing of NPIs usually also presupposes syntactic licensing: semantic licensing can only take place if the NPI is in the syntactic scope of its negative licenser. This condition holds even for the weakest forms of NPIs like any in English and vreun in Romanian. They are licensed at long distance, but cannot precede their licenser:

Moreover, the stronger the licensee the closer it tends to be to the licenser. NPIs like Romanian prea ‘too’ or English a bit, really must be in the same clause as their licenser (see also van der Wouden, 1997 for English and Dutch):
-
(16)


If n-words were to be semantically licensed by the NM, they would obviously violate the syntactic condition of semantic licensing as they may precede the NM (see (1b), (3b), (3c)), unlike any other kind of licensees of negation.
In the next section we will see that the locality conditions for the (syntactic) licensing of n-words by the NM are identical to the scope locality conditions of bona fide quantifiers. This will provide evidence that n-words behave like true quantifiers, supporting the view that they are indeed negative quantifiers.
2.3 Locality conditions on n-words
Besides their inherent negative semantics and their lack of semantic licensers, n-words display scope properties that are similar to those of universal quantifiers and contrast with the locality conditions of NPI licensing, as first observed in Giannakidou (1998) for Greek. We observe that n-words can enter NC with an NM across a subjunctive clause boundary (19a), but not across a ‘that’ complementizer, which is a constellation in which an NPI can be licensed (19b). This behavior finds its counterpart in universal quantifiers, which can take wide scope over an operator in the matrix clause from an embedded subjunctive clause (20a), but not from an embedded ‘that’-clause (20b).Footnote 7
-
(19)


-
(20)


In addition, adjunct clauses and relative clauses block NC formation (21) and wide scope of embedded universal quantifiers (22), but not NPI licensing (21):
-
(21)


-
(22)


Isac (2004) argues against the quantificational status of Romanian n-words. In a syntactic analysis she claims that only preverbal n-words are quantificational (due to their assumed focus position), while the postverbal ones are non-quantificational. This is intended to be shown by the ability of the preverbal n-word to take wide scope over the quantifier mai mult de doi ‘more than two’ in (23a), and the inability of the postverbal n-word to take wide scope over the quantifier cel puţin doi ‘at least two’ in (23b). Isac assumes that (23b) only has one interpretation, but remains silent about whether a wide scope reading for mai mult de doi is available in (23a).
-
(23)
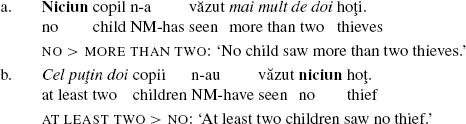

Quantifier scope in Romanian is determined by an interplay between linear order and the c-command relations between the quantifiers (see Iordăchioaia, 2010, Sect. 3.5, for details). On that basis the scope preference in (23) is expected, given that niciun copil and cel puţin doi copii are in the subject position and also precede mai mult de doi hoţi and niciun hoţ, respectively.
According to Isac’s line of reasoning, mai mult de doi is a true quantifier. Under the right contextual conditions it should thus take wide scope over the preverbal subject n-word from its object position. According to our native speaker informants, a wide scope reading is slightly easier to obtain for mai mult de doi in (23a) than for the postverbal n-word niciun in (23b). But this preference does not prove that the n-word in postverbal position is less quantificational than a non-negative quantifier as Isac’s analysis predicts. The same scope preference can be observed in English, a DN language where it is standardly assumed, even in Isac (2004), that n-words are always negative quantifiers:
-
(24)


More corroborating evidence for the quantificational nature of Romanian n-words comes from the scope blocking effect of English ‘that’-clauses and the lack of this effect in ‘to’-infinitives. While a wide scope reading of the embedded negative quantifier is impossible in (25b), it is available in (25a). Considering that the infinitival construction corresponds to a subjunctive clause in Romanian, the scope properties of Romanian n-words, illustrated in (19), are similar to those we observe here for negative quantifiers in English.
-
(25)


We conclude that n-words in Romanian are negative quantifiers. Following Ionescu (1999, 2004), we take their dependence on the presence of an NM to indicate that their sentential scope must be marked on the main verb. This is a purely syntactic licensing condition, unlike the semantic licensing of NPIs in the scope of an appropriate semantic operator. A detailed discussion of embedded subjunctive clauses with NC in Sect. 5.1 will provide further support for this analysis. Unlike the proposal that we develop here, Ionescu (1999, 2004) argues that n-words are existential, not negative quantifiers. Under the existential quantifier hypothesis, however, it is unclear why the scope properties of n-words illustrated in (19a) should differ from those of existential NPIs (typical existential quantifiers whose scope is marked by sentential negation) exemplified in (19b). It is equally unclear how one would derive the DN reading in (3c).
Syntactic licensing of negative quantifiers by a scope marker might be considered an odd phenomenon by some. But note that negative quantifiers are the only quantifiers for which there is a truth-conditionally equivalent operator that appears on the verb. It might then be not entirely unexpected that a language enlists the available operator to disambiguate difficult scope facts in complex sentences by apparent syntactic-semantic redundancy.Footnote 8 We speculate that the potential perceptive advantage of such a strategy might even be one of the factors that drive a grammatical system with an independent negative interpretation of negative markers on the verb toward an NC system of the type that Romanian represents.
The negative semantics and the quantificational properties of n-words that we have argued for explain the possibility of a DN reading with two n-words: it is the interpretation we expect with two negative quantifiers. In this respect there is no difference between the semantic status of n-words in Romanian and in DN languages like standard English or German, where DN is the only interpretation for two co-occurring n-constituents. What remains to be explained is the availability of the NC reading.
2.4 Scope properties of negative polyadic quantifiers in NC
Following de Swart and Sag (2002), we analyze determiner n-words and negative NP constituents as quantifiers of Lindström type 〈1,1〉 and 〈1〉, respectively (see Lindström, 1966). They may combine by resumption to form a polyadic quantifier of type 〈1n,n〉 or 〈n〉 (van Benthem, 1989; Keenan, 1992; Keenan and Westerståhl, 1997; Peters and Westerståhl, 2006) and thus give rise to an NC interpretation. The negative marker nu is analyzed as a negative quantifier of type 〈0〉 that is absorbed under resumption with other polyadic quantifiers.
Before we turn to the specific details of a constraint-based implementation of this general approach in Sect. 3, we gather additional evidence by considering related quantificational structures in Romanian. Comparing the scope interaction of Romanian NC constructions with adverbial quantifiers to the scope interaction of a cumulative quantifier with adverbial quantifiers, we observe a remarkable parallelism in the formation of polyadic quantifiers.
The strongest evidence for the presence of polyadic quantification in natural languages comes from examples with peculiar semantic properties. Keenan (1992) focuses on a range of phenomena in natural languages that are known to lie ‘beyond the Frege boundary’, i.e. beyond the expressive power of (iterated) monadic quantifiers. He lists many examples of polyadic quantification which survive a critical review of the older literature on the topic. The sentences (27a) and (27b) from Keenan are transparent examples in which the most natural reading involves an interpretation in which the second quantificational expression (different questions and the same questions, respectively) is not independent of the first. For (27a) this can be seen by considering that the sentence not only asserts that several pupils are in the answering relation with several questions. Crucially, each pupil is in the answering relation with a question that no other pupil chose to answer, making the elements in the second argument slot of the answer relation dependent on the totality of pupils in its first argument, and on the questions they worked on: For each pupil, the set of chosen questions is distinct from the questions answered by any other pupil. If the noun phrases are seen as generalized quantifiers, we can conclude that the formation of a polyadic quantifier is necessary, since no two independent quantifiers can have the intended meaning.Footnote 9
-
(27)


In our comparison of clear cases of polyadic quantification with NC we will draw on the Romanian counterpart of (27c), which is ambiguous between three readings, paraphrased in (27c-i)–(27c-iii). The first two readings can be derived by successive application of the two cardinal quantifiers forty contributors and thirty-two papers in different order, and they may involve up to 1280 authors or papers. In the present context, we are especially interested in the third reading, (27c-iii), the so-called cumulative reading, which is also the most prominent interpretation in a neutral context. This last reading shares the property of requiring complex polyadic quantification with (27a) and (27b): Informally, it is again only the totality of all contributors in the first argument slot of the binary write relation that determines the possible members of the second argument slot for each contributor, in this case the total number of papers that occur with the set of paper-writing contributors.
The simple symbolization of (27a)–(27c) in a logic with polyadic quantification, (28), illustrates the underlying structure from a representational perspective. In all three cases ((27a), (27b), (27c-iii)), a polyadic quantifier of type 〈12,2〉 first takes two one-place predicates as restrictors (forming a quantifier of type 〈2〉) and then reduces a binary relation to a truth value. The observed dependency between the two arguments in the relation can be formulated because the semantics of the polyadic quantifier affords the expressive power to specify them simultaneously, which cannot be done through the successive application of two monadic quantifiers.
-
(28)
-
a.
(different, different)(pupil, question)(answer)
-
b.
(every, the same)(student, question)(answer)
-
c.
(40, 32)(contributor, paper)(write)
-
a.
For the investigation of the quantificational structure of NC we will exploit the Romanian counterpart of (27c), shown in (29), which exhibits the same ambiguity as in English: The notation (40, 32) designates the cumulative reading, while 40>32 and 32>40 depict the scope interaction from successive applications of two monadic quantifiers. 40>32 indicates that forty contributors outscopes thirty-two papers.
-
(29)


Adding the quantificational adverb frequently to a sentence with two cardinals reveals interpretational restrictions, as only a subset of the logically possible scope interactions occur. A connection of the possible readings to NC constructions can be established by replacing the two cardinals with n-constituents and by comparing the putative formation of a negative polyadic quantifier to the configurations in which we observe a cumulative polyadic quantifier with cardinals. The conditions under which we will see cumulation with cardinals will correspond to those in which we assume a polyadic quantifier expressing NC.
In addition to the notational devices introduced above, we use the ampersand when we do not want to commit to a particular reading. 40 & 32 means that the two cardinals either form a polyadic quantifier, (40, 32), or they take individual scope, i.e. 40>32 or 32>40. With three quantificational expressions we have to investigate three scenarios: The adverb may take narrowest scope (30a), the adverb may take widest scope (30b), or the adverb is in an intermediate position (30c).
-
(30)


The interpretation pair (30b-i) and (30b-ii), in which the cardinals are adjacent, and the pair (30c-i) and (30c-ii), in which we test the availability of an intermediate position of the adverb, reveal a remarkable pattern. The first of the two pairs shows that adjacent cardinals receive a cumulative reading (30b-i). This contrasts with the second pair, in which the three quantifiers can only be interpreted with scope interaction, showing that they are monadic quantifiers (30c-ii). A reading in which the cardinals form a polyadic quantifier together with the adverbial is not available (30c-i). Thus it seems that in complex quantificational environments speakers follow a clear strategy of resolving the available interpretation choices: In case the cardinals receive an adjacent interpretation, the polyadic reading prevails. If a third quantifier intervenes, the individual monadic interpretation of all three survives. The readings with reversed scope of the two cardinals in (30b-iii) follows the same pattern.
A slight complication arises with the remaining readings. (30c-iii), in which the adverbial is outscoped by 32 papers, is excluded for the same reason for which no readings with narrow scope of the adverbial are available (30a): To obtain a plausible reading, a different lexical choice of the verb is necessary, re-scrie ‘to re-write’ instead of scrie. With this small modification, (30c-iii) seems possible, as well as the cumulative reading with (40,32) outscoping the adverbial in (30a). This is consistent with the pattern above.
In (31) we replicate the tests for available readings, with two n-constituents replacing the cardinals. If NC behaves the same way as the cumulative interpretation of two cardinals, we expect an obligatory NC reading when the negative quantifiers are adjacent, and a double negation reading when an adverbial quantifier intervenes. This is in fact what we find:Footnote 10
-
(31)


The differences that we see in a pairwise comparison to the corresponding interpretation choices in (30) are independent of the pattern concerning the adjacency of the two negative and the two cardinal quantifiers and their interpretation as two monadic or a single polyadic quantifier. Unlike in (30), there is a preference of the negative quantifiers to take wide scope over the adverb. For that reason, (31a-i) is preferred over (31b-i). Given this orthogonal difference, the comparison between (31a-i) and (31c-i) shows that the NC reading is only possible if the two negative quantifiers are adjacent. The pair of (31a-ii) and (31c-ii) indicates that DN arises when the adverb intervenes.
We should stress that the NC character of Romanian causes the DN reading (31c-ii) of sentence (31) to be highly context dependent. It is only really legitimate in a denial context like the one we construct in (32).Footnote 11 The focus intonation of (32a) ensures that frequently takes wide scope over no book. Example (32b) denies this reading, yielding the DN interpretation of (31c-ii).
-
(32)


We conclude that apart from different scope preferences between monadic quantifiers and different preferences in the relative scope of the polyadic quantifier with respect to the adverbial, the pattern underlying NC and cumulative readings of two cardinals in the presence of the adverbial quantifier frequently is the same. The adjacent interpretation of two potentially polyadic quantifiers is polyadic. If a third quantifier intervenes, their interpretation is monadic.
3 Tools: polyadic quantifiers and lexical resource semantics
Previous analyses of NC with polyadic quantifiers were proposed in a generative framework by May (1989) and in HPSG by de Swart and Sag (2002). These treatments are implemented by means of an additional layer of syntactic structure (May) or construct resumptive quantifiers with a quantifier retrieval mechanism (de Swart and Sag); they do not address the properties of their syntax-semantics interfaces from the perspective of an elaborate notion of semantic compositionality. The main challenge for a technically precise implementation is that resumption of quantifiers, for example the formation of a binary quantifier out of two monadic quantifiers, cannot in general be expressed by a compositional semantic operation in a functional type theory. However, the observations on Romanian NC in the previous section suggest that this type of logical analysis is what we need for an adequate description of the data. Whenever we can test their semantic import, single n-words have the properties of negative quantifiers. Multiple n-words in a sentence behave like a single negative polyadic quantifier (unless they are interpreted as individual negative quantifiers). Standard semantic theories for natural language with composition mechanisms such as function application of the logical translation of one syntactic daughter to the translation of the other cannot do justice to both observations at the same time. Indeed, they cannot construct polyadic quantifiers at all.Footnote 12
This is where we turn to an alternative, systematic theory of the syntax-semantics interface that can give us exactly what we need, viz. a standard logical interpretation of natural language expressions, a translation of Romanian nimeni ‘nobody’ and corresponding quantificational expressions as negative quantifiers, and the potential formation of a polyadic negative quantifier from several lexical negative quantifiers in clearly specified syntactic environments. A constraint-based theory of semantic composition from the family of semantic underspecification formalisms can do this for us. We choose a member of this family of representation and composition formalisms that is very precise about its logical object languages, and supports the construction of a polyadic quantifier in the presence of lexical negative quantifiers directly by underspecification, without the necessity of integrating a resumption operator in the logical language. As a result, we will obtain elegant general specifications, and transparent logical translations of Romanian sentences.
To sum up our shopping list, for our analysis of Romanian NC with polyadic quantifiers we need two ingredients: A higher-order logical object language for expressing the truth conditions of sentences with NC constructions, and a semantic composition theory which derives the intended expressions from lexical semantic specifications and the syntactic structure of our sentences. As logical object language we use a straightforward extension of two-sorted type theory (Ty2, Gallin, 1975) by negative polyadic quantification (Sect. 3.1); the theory of semantic composition is taken from LRS (Richter and Sailer, 2004; Richter and Kallmeyer, 2009), which gives us a system of constraints for semantic composition and a format for lexical specifications, as well as an interface to syntactic structures in HPSG (Sect. 3.2). Only minimal adjustments are necessary to accommodate polyadic quantification in this system. For convenience we briefly restate all relevant LRS principles from the literature, and conclude with a simple example of semantic composition in Sect. 3.3.
3.1 The logical object language
We assume a simple theory of types with types e (for entities), s (for world indices) and t (truth values). Functional types are formed in the usual way. The syntax of the logical language provides function application, lambda abstraction, equality and negative polyadic quantifiers, as given in this order in Definition 1 below. By standard results this is enough to express the usual logical connectives and monadic quantifiers. In reference to the simple type theory and the close relationship to Gallin (1975), we call our family of languages Ty2. For simplicity, polyadic negative quantification is introduced syncategorematically.Footnote 13 Var and Const are a countably infinite supply of variables and constants of each type:
Definition 1
Ty2 Terms: Ty2 is the smallest set such that:
Var⊂Ty2, Const⊂Ty2,
-
for each τ,τ′∈Type, for each α ττ′,β τ ∈Ty2:
$$(\alpha_{\tau\tau'}\beta_{\tau})_{\tau'}\in \mathit{Ty}2, $$ -
for each τ,τ′∈Type, for each \(i\in\mathbb{N}^{+}\), for each v i,τ ∈Var, for each α τ′∈Ty2:
$$(\lambda v_{i,\tau}.\alpha_{\tau'})_{(\tau\tau')} \in \mathit{Ty}2, $$ -
for each τ∈Type, and for each α τ ,β τ ∈Ty2:
$$(\alpha_{\tau}=\beta_{\tau})_t\in \mathit{Ty}2, $$ -
for each τ∈Type, for each \(n \in \mathbb{N}^{0}\), for each \(i_{1}, i_{2}, \ldots, i_{n} \in \mathbb{N}^{+}\), for each \(v_{i_{1},\tau}, v_{i_{2},\tau}, \ldots, v_{i_{n},\tau}\in \mathit{Var}\), for each α t1,α t2,…,α tn ,β t ∈Ty2:
$$\bigl(\mathit{NO}(v_{i_1,\tau},\ldots,v_{i_n,\tau})(\alpha_{t1}, \ldots \alpha_{tn})(\beta_{t})\bigr)_t\in \mathit{Ty}2. $$
Our syntactic notation for the family of negative polyadic quantifiers (which bind n variables of arbitrary but identical type τ) is motivated by the function of variables in LRS as handles for syntactic arguments of natural language predicates. For convenience we assume that the number of variables (\(v_{i_{n},\tau}\)) corresponds to the number of restrictors (α tn ) of each quantifier, with β t the nuclear scope of the quantifier. In our fragment of Romanian, the restrictors will come from the head nouns of generalized quantifiers in syntactic argument positions of verbs, and the nuclear scope will essentially be the translation of the verbal predicate itself.
The standard constructs (function application, lambda abstraction, and equality) receive their usual interpretation. Here we only state the interpretation of negative polyadic quantifiers:
Definition 2
The Semantics of Ty2 Terms (clause for negative polyadic quantifiers only). For each model M and for each variable assignment a∈Ass, for each τ∈Type, for each \(n \in \mathbb{N}^{0}\), for each \(i_{1}, i_{2}, \ldots, i_{n} \in \mathbb{N}^{+}\), for each \(v_{i_{1},\tau}, v_{i_{2},\tau}, \ldots, v_{i_{n},\tau}\in \mathit{Var}\), for each α t1,α t2,…,α tn ,β t ∈Ty2:

Intuitively speaking, this says that an expression with a negative quantifier with n restrictors can only be true in a model M with respect to a variable assignment a if for each n tuple of objects d i of the appropriate type, either (1) at least one of the restrictors α ti does not hold of its corresponding object d i , or (2) the nuclear scope β t does not hold of the n tuple of objects. In other words, either it is not an n tuple of the kind we are interested in, or the main predicate of the sentence does not hold of it (or both).
Example (33) illustrates how the definitions are put to use for sentences with NC and sentential negation by stating the truth conditions we obtain for the intended logical specifications of the Romanian literal counterparts of John didn’t come (33a) and No teacher didn’t give no book to no student, where all NPs are n-constituents and form a ternary negative quantifier by resumption (33b):Footnote 14
-
(33)


(33a) is an example of a quantifier of Lindström type 〈0〉, which corresponds to classical negation. The negative polyadic quantifier in (33b) corresponds to a quantifier of Lindström type 〈13,3〉, i.e. it can be read in the given context as reducing three unary relations (the restrictors) and a ternary relation (the predicate give′), and returning a truth value. Note that in the Lindström classification, a determiner quantifier such as most is of type 〈1,1〉 (reducing two relations, restrictor and nuclear scope, by one argument), and a generalized quantifier such as every student is of type 〈1〉 (reducing a relation, the nuclear scope, by one argument).
3.2 Basics of lexical resource semantics
LRS is a constraint-based semantic composition theory built around the leading intuition that a system of constraints governs the combinability of lexical semantic contributions depending on the syntactic structure in which they participate. Approaching the LRS architecture by way of an introductory simile, semantic composition can be thought of as solving a jigsaw puzzle: All words in an utterance contribute their semantics in terms of (potentially several pieces of) typed logical expressions to an unstructured repository of expressions from which the semantics of the utterance must be composed. The words thus provide all the semantic resources of an utterance, or the pieces of the puzzle. Just as with a jigsaw puzzle, the task is to determine in which way the pieces in the bag fit together to form a coherent whole. The logical types of the formal expressions are a first layer of restrictions that correspond to the tabs and blanks of puzzle pieces. But in addition to the type-determined shapes of the contributed pieces, an additional set of restrictions on permissible combinations enters the scene: the constraint system of the semantic theory (which could be conceived of as the picture printed on the pieces). Fundamental constraints are triggered by the syntactic structure that is responsible for the ways in which words and phrases are combined. These constraints are reminiscent of a classical semantic translation function that works in tandem with syntactic rules. Its constraint-based counterparts decree, depending on the kind of syntactic configuration of signs, which restrictions the combination of their semantic translation must obey. For example, when a determiner such as three syntactically combines with a noun such as students, the logical translation of the noun must occur in the restrictor of the logical translation of the determiner. The set of all combinatoric constraints (triggered by phrase structure and other criteria) together with the shapes of logical expressions that were collected in the bag of resources contributed by the lexical elements in the utterance, determine how the pieces may be combined to yield a well-formed logical translation of the utterance. Note that, in contrast to simple traditional jigsaw puzzles, more than one legitimate well-formed picture may emerge: utterances may be semantically ambiguous, even for a single syntactic analysis.
Finally, for NC one more property of LRS plays a major role, which does not have a counterpart in jigsaw puzzles: If two words contribute semantic expressions of the same shape, it might turn out (by means of the constraint system) that these expressions are not only of the same shape, they are one and the same expression. This means that the semantic contribution of two negative polyadic quantifiers by two n-words can potentially be resolved to a single negative polyadic quantifier of the appropriate arity. However, since the relevant constraints of Romanian are not always deterministic, semantic underspecification may permit more than one solution for NC constructions. Two lexically underspecified negative polyadic quantifiers, contributed by two n-words, may legitimately form a binary negative quantifier; or they may be conceived of as two distinct monadic negative quantifiers, one outscoping the other. By contrast, Romanian is strict about the behavior of finite verbs in the presence of an n-word. The presence of an underspecified polyadic quantifier contributed by an n-word leads to the requirement that the finite verb be negated and the contingent negative quantifier at the verb enter NC with a polyadic quantifier.
Summarizing our high-level characterization of the present approach, what is at work in the LRS account of Romanian NC are by and large three components of the semantic composition theory: underspecified semantic contributions of words (the lexical resources); a very general strategy of indiscriminately collecting all these contributions in a sentence, generating a large space of possible readings (a bag of lexical resources for a given utterance); and a set of constraints whose job it is to filter the space of possible readings in order to narrow it down to the actual readings of the sentence (the set of semantic constraints applied to a given syntactic structure).
Let us now take a closer look at how the above program is carried out. In order to feed the constraint system, LRS distinguishes several aspects of the semantics of a sign, of which we single out five that are immediately relevant for our purposes: (1) its semantic contribution, expressed through a list-valued feature parts, which records which components of the semantic term of an utterance are contributed by that sign, (2) the internal content of a sign (value of the attribute incont), which distinguishes the part of the term that will be outscoped by any other operator with which the sign combines within its syntactic projection, (3) the external content of a sign (value of the attribute excont), which is the term formed at the maximal syntactic projection of the sign, (4) the var value of local semantics, by which semantic functors gain access to logical variables provided by their arguments, and (5) the main value of the local semantics, which contains the main semantic contribution of lexical signs, e.g. the lexical semantic predicate of verbs or nouns.
The two descriptions in (34a) and (34b) illustrate these distinctions with two syntactic categories relevant to our discussion, the head noun of an NP, studenţi ‘students’, and the corresponding NP node, trei studenţi ‘three students’.
-
(34)


The local content of the noun studenţi (under the loc(al) attribute, and therefore available for syntactic-semantic selection by valence features in HPSG) consists of its main content, the nonlogical constant student′ and a variable, designated by the tag  .Footnote 15 The tag notation indicates that the variable originates from the syntactic determiner the noun selects by means of one of its val(ence) features, (\(\mbox{\textsc{DetP}}_{\scriptsize\fbox{4a}}\)). The fact that the variable does not come from the noun can be confirmed by investigating the noun’s combinatoric semantics, contained in the lrs structure under the sem(antics) attribute: The parts list enumerates the semantic lexical resources contributed by the noun. These are two objects, the nonlogical constant student′, indicated by tag
.Footnote 15 The tag notation indicates that the variable originates from the syntactic determiner the noun selects by means of one of its val(ence) features, (\(\mbox{\textsc{DetP}}_{\scriptsize\fbox{4a}}\)). The fact that the variable does not come from the noun can be confirmed by investigating the noun’s combinatoric semantics, contained in the lrs structure under the sem(antics) attribute: The parts list enumerates the semantic lexical resources contributed by the noun. These are two objects, the nonlogical constant student′, indicated by tag  , and the application of student′ to an argument,
, and the application of student′ to an argument,  . The variable,
. The variable,  , is not an element on the list of contributed resources, given that it is contributed by the determiner. The internal content of the noun consists of the nonlogical constant applied to its argument (which will be outscoped by any scope taking element in the noun’s syntactic projection), and the external content must be a generalized quantifier. By this specification, the nominal head already determines that its maximal projection must denote a quantifier.
, is not an element on the list of contributed resources, given that it is contributed by the determiner. The internal content of the noun consists of the nonlogical constant applied to its argument (which will be outscoped by any scope taking element in the noun’s syntactic projection), and the external content must be a generalized quantifier. By this specification, the nominal head already determines that its maximal projection must denote a quantifier.
Example (34b) shows a nominal phrase that is the maximal syntactic projection of the previous noun. As will be explained below, a syntactic projection shares the local semantic values with its head as well as the incont and excont values. As to the semantic resources, the nominal phrase trei studenţi comprises the previously discussed resources of studenţi plus the resources contributed by the generalized quantifier. The quantifier contributes the variable (x), the quantifier symbol three, and applications to its arguments, all designated by tags starting with the integer 4. Finally, the AVM in (34b) is conjoined with a subterm constraint, \(\scriptsize\fbox{3} \triangleleft \gamma\). This constraint says that the expression student′(x), designated by  , must be a (possibly improper) subterm of the restrictor, γ, of the generalized quantifier. A stronger statement to the effect that student′(x) equals the restrictor of the quantifier is potentially false, because further syntactic material (such as an extraposed relative clause) might introduce additional semantic restrictions on the set of students inside the restrictor.
, must be a (possibly improper) subterm of the restrictor, γ, of the generalized quantifier. A stronger statement to the effect that student′(x) equals the restrictor of the quantifier is potentially false, because further syntactic material (such as an extraposed relative clause) might introduce additional semantic restrictions on the set of students inside the restrictor.
Contributions to the semantics of utterances are exclusively and exhaustively made by the lexical items in the utterance. Phrases do not contribute meaning components, they only trigger restrictions, expressed in the Semantics Principle, which constrain how the semantics of their immediate syntactic daughters can be put together.Footnote 16 Two such clauses of the Semantics Principle that we introduce below in (38) and (39) will dictate that when a determiner quantifier together with a nominal projection forms a nominal phrase, the semantics of the noun projection must be in the restrictor of the quantifier that comes from the determiner; and when a generalized NP quantifier combines as a syntactic argument with a verb projection, the semantics of the verbal head of the VP must be in the nuclear scope of the generalized quantifier. The internal and external contents of the phrase and of its daughters are instrumental in stating constraints like these, together with the subterm relation (α◁β). Later we will see a generalization of the subterm relation to the form \(\alpha \triangleleft_{\in} \vec{\nu}\), where α is a term, \(\vec{\nu}\) is a vector of terms, and α must be a (possibly improper) subterm of one of the terms in \(\vec{\nu}\).
LRS principles express restrictions on terms of a logical object language (in our case: terms of Ty2), i.e. they are written in a meta-language whose expressions denote terms of Ty2. For reasons of convenience and readability, the expressions of the meta-language partially look like the object language itself, adding meta-variables and additional syntactic constructs such as the notation for subterm constraints. To avoid confusing different levels of denotation, it is important to keep in mind that LRS meta-language expressions such as come′(john′) are descriptions of object language terms, in this case of the Ty2 expression of the same form.Footnote 17
Before discussing a simple example of deriving the semantics of a phrase, let us briefly review three standard LRS principles that underlie the present version of our constraint-based semantic framework.Footnote 18 These are the LRS Projection Principle, the Incont Principle and the Excont Principle. The LRS Projection Principle governs the relationship of the attribute values of excont, incont and parts at phrases relative to their syntactic daughters. It is responsible for the excont and the incont identity along syntactic head projections, and for the inheritance of the elements of parts lists by phrases from their daughters:
-
(35)


The Incont Principle and the Excont Principle constrain the admissible values of the incont and the excont attribute in syntactic structures. The Incont Principle is the simpler one of them. It guarantees two things: First, the internal content of a sign (the part of its semantics that is outscoped by any operator the sign combines with along its syntactic projection) is always semantically contributed by the sign, i.e. it is a member of its parts list. And second, the internal content is in the external content of a sign. In a first approximation (which is precise enough for our purposes) this means that the internal content contributes its semantics within the maximal syntactic projection of a sign.
-
(36)


The Excont Principle is slightly more complex. Its first clause requires that the external content of a non-head daughter be semantically contributed from within the non-head-daughter. The second clause is a closure principle and says that the semantic representation of an utterance comprises all and only those pieces of semantic representations that are contributed by the lexical items in the utterance.
-
(37)


As stated above, we follow the usual notational conventions and write descriptions of expressions of the semantic representation language as (partial) logical expressions. For describing polyadic quantifiers we use the notation \(Q(\vec{v},\vec{\phi},\psi)\). Here \(\vec{v}\) and \(\vec{\phi}\) are shorthand for a (possibly empty) vector of variables and a (possibly empty) vector of expressions; ψ is a single expression. In the analysis of Romanian below we will assume that there is an appropriate subsort of gen-quantifier in our grammar which is interpreted as negative polyadic quantifier. In our notation this family of quantifiers will be denoted by \(\mathit{no}(\vec{v},\vec{\phi},\psi)\).
In addition to the core principles of the attributes excont, incont and parts, LRS offers a set of constraints that are collected in the clauses of the Semantics Principle. The clauses of the semantics principle concern phrasal syntactic structures and make statements about the relationship between (subterms of) the excont and the incont values of phrases of a particular syntactic type and their daughters. These are the restrictions of how the semantic contributions of the daughters fit together and may be combined at the mother node. If the restrictions are not very specific, they might allow different ways of putting the pieces together: The readings we obtain at the mother node are underspecified.
The clause of the Semantics Principle governing the combination of quantificational determiners with nominal heads has to be adjusted to polyadic quantifiers. The relevant clause is shown in (38). Except for the generalization from monadic quantifiers to polyadic quantifiers, it is identical to the corresponding clause in Richter and Kallmeyer (2009:65).
-
(38)


One more clause of the Semantics Principle will become relevant in Sect. 4 when we combine noun phrase quantifiers with the verb phrase which subcategorizes them. Here is the semantic constraint which must hold for these syntactic structures, generalized from standard formulations to the case of polyadic quantification:
-
(39)


With the integration of polyadic quantifiers and the modified clauses of the Semantics Principle we have completed the adjustments in LRS needed to formulate our theory of NC. Resumption will be implemented in LRS as identity of quantifiers contributed by lexical elements, and there is no need to add a resumption operator to the logical language. For that reason no special technical apparatus for the resumption operation has to be introduced in preparation of our analysis of negative concord in Romanian. We conclude the discussion of LRS with a simple example in Sect. 3.3.
Among the most salient properties of LRS is its capability to provide underspecified descriptions of sets of meanings, and its use of subterm constraints. In this respect it is very similar to other frameworks of underspecified semantics, including Minimal Recursion Semantics (MRS, Copestake et al., 2005) and the Constraint Language for Lambda Structures (CLLS, Egg et al., 2001). While MRS is also typically used in a feature logic encoding in HPSG and serves as a widely used meta-language framework for semantic representations in computational environments, LRS emphasizes the specification of concrete higher-order logical object languages for the investigation of semantic distinctions for which the exact truth conditions of linguistic expressions matter. CLLS shares the idea of embedding standard logical languages of linguistic semantics with LRS. At the same time there is one crucial feature that distinguishes LRS from MRS, CLLS, and all other underspecification frameworks we are aware of, which is the strategy of permitting multiple lexical sources of one and the same meaning contribution to an utterance. We will see that this property plays an indispensable role in our polyadic analysis of NC.
3.3 An example
With the principles in the previous section everything is in place to explain the LRS analysis of the semantic composition in a simple clause with a generalized quantifier in subject position (Fig. 1). As elsewhere in this paper, we ignore tense.

LRS analysis of Trei studenţi au venit ‘Three students came’
The words at the leaves of the syntactic tree reveal the lexical semantic specifications of determiners, count nouns and verbs. The noun studenţi ‘students’ expects a generalized quantifier in its maximal projection (excont value). Its internal content is student′(x), the application of the constant student′ of type 〈e,t〉 to a variable of type e. The variable is known to the word studenţi because as a noun it selects its determiner via its spr list, where it has local access to the variable.Footnote 19 The parts list shows that the word studenţi contributes the constant student′ and its application to x to the semantics of the utterance. The determiner trei ‘three’ contributes the monadic quantifier three (of type 〈1,1〉), the variable x, and the applications of the quantifier to its restrictor and scope. The internal and the external content of trei is the generalized quantifier, whose restrictor and scope are not known in the lexicon. They are given in terms of two meta-variables, γ and δ. The verb au venit ‘came’ looks similar to a count noun, except that it imposes no restriction on the external content at the lexical level: The verb contributes the constant come′ of type 〈e,t〉 and its application to an argument of type e. Parallel to the situation in nominal projections, the verb has access to that argument through the syntactic selection of the subject by a valence feature. In the present example, the var value of the subject is the variable x (see (34b)).
The lexical semantic resources of the quantifier, the noun and the verb (typed terms plus some information on which functor applies to which argument) are the material that the LRS constraints work on to determine the possible excont values of the sentence. In our simple example they will lead to a single reading. The LRS principles determine the semantics of the NP based on the lexical semantic contributions of the determiner and the noun, and on the syntactic fact that a determiner is syntactically combined with a nominal head: The semantic contributions of the two daughters are collected in the parts list of the NP mother, and internal and external content are inherited from the syntactic head daughter, which is the noun (LRS Projection Principle). Clause 1 of the Semantics Principle demands that the incont of the determiner be equal to the excont of studenţi and that the incont of the head daughter, student′(x), be a subterm of the restrictor of the generalized quantifier. The semantics of the NP is thus given by the constraints on the excont of the NP: It is the generalized quantifier three binding the variable x, with student′(x) in the restrictor and as yet unknown nuclear scope. The scope of the quantifier is determined when the NP combines with the verb to form the sentence: The verb is the syntactic head of the construction, which is why the incont and excont of the verb and the sentence node are identical; all elements from all parts lists are collected on the parts list of the sentence (LRS Projection Principle). The semantics of a syntactic combination of a nominal generalized quantifier with a verbal projection is restricted by Clause 2 of the Semantics Principle, which demands that the incont of the verb, come′(x), be a subterm of the nuclear scope, δ, of the quantifier. This is indicated in Fig. 1 by the subterm constraint ( ◁ δ, notated next to the AVM at the S node.
◁ δ, notated next to the AVM at the S node.
Finally, the Excont Principle decrees that the external content of the NP must be contributed from within the NP (which it is, as it comes from trei), and that the excont value of the complete utterance must be constructed from all contributions of all the words in it. Of course, that value must respect all constraints that are imposed on the possible combinations of all terms. In particular, student′(x) must be in the restrictor and come′(x) must be in the scope of the quantifier. The only term which respects these conditions (and is a well-formed term) is the one shown as excont value of the sentence in Fig. 1.
4 The analysis of Romanian NC
We will proceed in several steps, with the main plot developing in the first two sections: In Sect. 4.1 we lay out the analysis of sentential negation with the verbal prefix nu using a lexical rule, and in Sect. 4.2 we turn to NC in simple clauses. As we will only analyze simple clauses in this part of the paper, the logical specifications will be stated in an extensional higher-order logic, i.e. we will only use types e and t of the type theory of Ty2. When we investigate complex clauses with propositional attitude verbs in Sect. 5, we will revise these initial specifications to take care of possible worlds by means of the type s.
Sections 4.3 and 4.4 outline the broader context of our analysis by taking a look at related constructions in Romanian (Sect. 4.3) and by indicating how our theory of NC in Romanian finite constructions fits into the well-studied typological variation of NC in different languages (Sect. 4.4). For reasons of space, these two sections do not provide a comprehensive and fully worked-out theory. Instead they present the central strategies and concepts we imagine to be employed in a full-scale analysis.
4.1 Sentential negation
The analysis of simple negated clauses without n-constituents like (3a) follows immediately from the lexical analysis of verbs with the NM prefix nu. The affixal nature of nu is extensively argued for in Barbu (2004). Following assumptions similar to ours in Ionescu (1999) and the parallel analysis of the Polish negative marker in Przepiórkowski and Kupść (1997), we formulate the lexical rule in (40), which relates each verb form of the appropriate kind to a corresponding negated form.
-
(40)


The NM attaches to finite and infinitival verb forms as indicated by the vform value in (40). The feature nu has three values (unmarked, NM, and expletive), and ensures that nu is attached to a verb only once. All verb forms in the (base) lexicon are specified as [nu unmarked] and may have a [nu NM] counterpart only if they undergo this lexical rule. The value [nu expletive] is reserved for expletive negation, on which we briefly comment below. The function f neg in the phon value description of the output encodes a phonological rule and is responsible for the correct phonological forms with the verbal prefix. It permits reduction of nu to n- depending on the first phoneme in the input’s verb form.
The semantic counterpart to the negative prefixation by nu in the phonological form is a negative quantifier  on the parts list of the originally positive verb (note that the input must lack a negative quantifier). The interpretation of the verb form as negated is a consequence of the requirement that the internal content of the verb
on the parts list of the originally positive verb (note that the input must lack a negative quantifier). The interpretation of the verb form as negated is a consequence of the requirement that the internal content of the verb  be a subterm of the nuclear scope δ of this quantifier (
be a subterm of the nuclear scope δ of this quantifier ( ◁ δ in the output description of the lexical rule). The negative quantifier
◁ δ in the output description of the lexical rule). The negative quantifier  is also a subterm of the external content
is also a subterm of the external content  of the verb (\(\scriptsize\fbox{3} \triangleleft \scriptsize\fbox{0}\)). This condition will become important in the analysis of embedded clauses in Sect. 5 and will be responsible for the inability of the negation on an embedded verb form to outscope a matrix verb. As discussed below, negative quantifiers contributed by embedded clause n-words in argument position will, under certain conditions, have the additional option of taking a scope that includes the matrix clause.
of the verb (\(\scriptsize\fbox{3} \triangleleft \scriptsize\fbox{0}\)). This condition will become important in the analysis of embedded clauses in Sect. 5 and will be responsible for the inability of the negation on an embedded verb form to outscope a matrix verb. As discussed below, negative quantifiers contributed by embedded clause n-words in argument position will, under certain conditions, have the additional option of taking a scope that includes the matrix clause.
The negative verb form nu a venit in our sentence (3a) is licensed as output of the NM Lexical Rule and is shown below:
-
(41)


With standard LRS mechanisms we obtain the two readings available for the ambiguous sentence in (3a): three(x,student′(x), no((),(),come′(x))), where three takes scope over no, and no((),(),three(x,student′(x),come′(x))), where the NM outscopes the cardinal quantifier. The variable and restrictor lists of the negative quantifier are empty (Lindström type 〈0〉) because the negative verb does not introduce a variable, and the sentence does not provide a restrictor.
4.2 NC constructions
Determiner n-words contribute negative quantifiers of underspecified Lindström type 〈1n,n〉. In their LRS representation they lexically contribute exactly one new variable, which means that they contribute a Lindström quantifier 〈1n,n〉 with n≥1. The (relevant part of the) lexical entry of the determiner niciun exemplifies this pattern (42a). Unlike the negated verb in (41), niciun introduces a variable (x), and the negative quantifier \(\mathit{no}(\vec{v},\vec{\alpha},\beta)\) binds x (\(x\in\vec{v}\)). In addition, the variable is a subterm of the nuclear scope (x◁β) and a subterm of a member in the restrictor list of the quantifier (\(x\triangleleft_{\in}\vec{\alpha}\)). These conditions guarantee the existence of a restrictor and prevent vacuous quantification.
-
(42)


With the lexical entries of the determiner and the noun we have all necessary ingredients to investigate simple NC constructions with one n-word like sentence (3b). The relevant parts of the structure are shown in Fig. 2.

LRS analysis of (3b) Niciun student nu a venit
According to the LRS Projection Principle, the NP inherits the incont value  of its nominal head. Due to the first clause of the Semantics Principle the internal content must be a subterm of a member of the restrictor list of the quantifier (\(\scriptsize\fbox{2}\triangleleft_{\in}\vec{\alpha}\)). The excont value is identified with the incont value
of its nominal head. Due to the first clause of the Semantics Principle the internal content must be a subterm of a member of the restrictor list of the quantifier (\(\scriptsize\fbox{2}\triangleleft_{\in}\vec{\alpha}\)). The excont value is identified with the incont value  of the determiner due to the interaction of the first clause of the Excont Principle with the other restrictions on the excont of the NP. At the S node of the sentence two more restrictions become relevant. All lexically introduced pieces of semantic representation must be realized in the excont of the sentence, including the excont of the NP and the negative polyadic quantifier from the parts list of the verb (\(\scriptsize\fbox{1} \triangleleft \scriptsize\fbox{0}, \scriptsize\fbox{7} \triangleleft \scriptsize\fbox{0}\)). Moreover, the standard clause of the LRS Semantics Principle for combining NP-quantifiers in argument position with verbal projections requires that the polyadic quantifier of the NP take scope over the verb (\(\scriptsize{\fbox{3}} \triangleleft\beta\)).
of the determiner due to the interaction of the first clause of the Excont Principle with the other restrictions on the excont of the NP. At the S node of the sentence two more restrictions become relevant. All lexically introduced pieces of semantic representation must be realized in the excont of the sentence, including the excont of the NP and the negative polyadic quantifier from the parts list of the verb (\(\scriptsize\fbox{1} \triangleleft \scriptsize\fbox{0}, \scriptsize\fbox{7} \triangleleft \scriptsize\fbox{0}\)). Moreover, the standard clause of the LRS Semantics Principle for combining NP-quantifiers in argument position with verbal projections requires that the polyadic quantifier of the NP take scope over the verb (\(\scriptsize{\fbox{3}} \triangleleft\beta\)).
All these restrictions together license three distinct expressions in the excont of the sentence. Only one of them, shown in (43a), corresponds to the linguistic facts, the other two result from possible scope interactions of the negative quantifier of the verb and the NP-quantifier. The NC reading (43a) obtains if the two negative quantifiers get identified, meaning that \(\scriptsize\fbox{1} = \scriptsize\fbox{7}\), \(\vec{v}=\vec{u}= x\), \(\vec{\alpha}=\vec{\gamma}= \mathit{student}'(x)\), and β=δ=come′(x).
-
(43)


Examples (43b) and (43c) are impossible DN readings of (3b) and have to be excluded by the theory of Romanian NC. At the same time we have to take care that an n-word in a sentence obligatorily triggers the NM on the finite verb. We achieve both goals in one step by adapting the Neg Criterion for Polish of Richter and Sailer (2004) to Romanian and the polyadic quantifier approach.

Intuitively, the Neg Criterion says that the presence of an n-word in a sentence requires the presence of a (possibly different) n-word that undergoes resumption with the NM on the verb. More precisely, the Neg Criterion is sensitive to the presence of a negative quantifier of a type higher than 〈0〉 in the excont of a finite verb (contributed by at least one n-word). In that constellation a negative quantifier of type higher than 〈0〉 must also be on the parts list of the verb. Since those verbs that are licensed by lexical entries do not carry negative quantifiers in their parts lists, this means that only verbs licensed by the NM Lexical Rule are eligible. But since the quantifier contributed by a negative verb originally has an empty variable list, it would be of the excluded type 〈0〉 if it were not identified with a quantifier contributed by an n-word. It is due to the fact that the Neg Criterion requires a quantifier of a type higher than 〈0〉 on the verb’s parts list that identification with a quantifier from at least one n-word is necessary.
If we apply this reasoning to our example in Fig. 2 we see that the negative quantifier contributed by the n-word and the negative quantifier on the parts list of the verb must be identical. We obtain an obligatory NC reading, and the other two readings in (43) are correctly ruled out.
In sentences with more than one n-word such as (3c), the negative quantifier contributed by the verb must undergo resumption with at least one of the two quantifiers contributed by the n-words for the reasons just described. If one n-word does not undergo resumption with the NM and the other n-word, we obtain the DN reading in (45a). However, there is also the possibility that all the negative quantifier contributions in the sentence are identified. The number of variables contributed by the individual n-words determines the type of the resumptive quantifier. For (3c) with two n-words, each contributing one variable, the second available alternative is resumption of all three negative quantifiers, which leads to a quantifier of type 〈12,2〉 for the NC reading, shown in (45b).
-
(44)


Ionescu (2004) raises concerns regarding an analysis of nu as participating in resumption, because he believes that this would assimilate nu, as a contributor of a type 〈0〉 negative quantifier, to expletive negation in NC contexts. Expletive negation (abbreviated as nu expl below) is known to appear with some matrix verbs like a se teme ‘fear’ without contributing negative meaning. Since semantic negation is not present in utterances with nu expl , and since all lexical semantic contributions must be overtly visible in utterances according to one of the central principles of LRS, nu expl cannot possibly be associated with a type 〈0〉 negative quantifier. For that reason Ionescu’s apprehensions do not apply to the present proposal, where expletive negation does not contribute a type 〈0〉 negative quantifier. The assumption of semantic vacuity of expletive negation is supported by its inability to license strong NPIs like prea and by its inability to undergo resumption with negative quantifiers in (46a). By contrast, the NM nu always coincides with semantic negation. Consequently, it licenses strong NPIs and takes part in negative concord, as illustrated in (46b).
-
(45)


A description of the exact distribution of expletive negation requires a separate careful study, but we may note here that its occurrence is in complementary distribution with its NM function (see (47)). It can be accounted for by assuming that there is a lexical rule corresponding to the NM lexical rule in (40) that derives verbs marked by expletive negation, nu expl . The input to this second rule is similar to the one for the NM lexical rule, but the output has the feature specification [nu expletive] and does not contain a negative quantifier in the word’s semantics.

4.3 Beyond Romanian core constructions
In this paper we focus on core constructions of negative concord in Romanian (finite verbs and their arguments) and their semantic description in terms of negative polyadic quantification. In the preceding sections we presented an analysis that covered simple clauses. In the present section, we outline how related constructions in Romanian fit into our approach, followed by typological considerations in languages with different NC systems in Sect. 4.4.
We begin with a sketch of how we envisage the analysis of further Romanian NC constructions. These are (1) adverbial n-words, (2) fără ‘without’-NC constructions, (3) NC in non-finite clauses with the prefix ne- ‘non-’ on verbs, and (4) the combination of past participles with preverbal n-words.
Although we have left out adverbial NC constructions from our considerations above, it is well-known that adverbials participate in NC cross-linguistically (see (48) for Romanian). Our analysis predicts this behavior of adverbial negative quantifiers in case they are treated as (polyadic) generalized quantifiers, because NC is triggered by each configuration in which a negative quantifier of a type higher than 〈0〉 outscopes the verb. An analysis which follows the proposal for quantificational adverbs like always in de Swart (1993) and can be extended to also cover negative adverbs of manner (e.g., nici(de)cum ‘nohow’) and location (e.g., nicăieri ‘nowhere’) would thus be compatible with our Neg Criterion. The best way to spell out the analysis depends mostly on issues that are orthogonal to our present investigation, such as the exact choice of a tense semantics or an appropriate adaptation of a semantics of events. Once these are fixed, any lexical entry of an adverbial whose semantics comprises an underspecified negative quantifier automatically obeys the NC principles of Romanian.
-
(48)


NC constructions involving fără ‘without’, as illustrated in (49), can be considered another hallmark of NC, as their counterparts are typically found in NC languages. In order to capture them, we have to extend the syntactic and semantic analysis to minor categories like the negative preposition at hand. In accordance with the standard treatment of prepositions in HPSG, let us assume that fără is the head of the phrase and may have either a verbal or a nominal complement. More specifically, the verbal complement is a subjunctive or non-finite verb phrase without an NM at the verb, i.e. [nu unmarked], or a nominal phrase.
-
(49)


The LRS analysis of the resulting prepositional phrases extends the Semantics Principle by a new clause that classifies these constructions as content raisers (Richter and Sailer, 2004), which raise the incont of the syntactic non-head to the head (the preposition). In addition, we assume that prepositions of the relevant type also raise the excont of the complement. The lexical semantics of fără suggests that it contributes an underspecified negative polyadic quantifier to the semantics, while its main predicate expresses a relation of accompaniment. Consequently, de Swart and Sag (2002) assume in their analysis that it is translated with a negative quantifier of type 〈0〉 that undergoes resumption with the negative quantifiers of its complements. In our architecture, fără requires identity of its negation with the negation of nominal complements that are negative quantifiers (49b). For non-finite verbal complements, fără is subject to the same constraint as finite verbs in Romanian are with the Neg Criterion. Due to the incont and excont identities at the syntax-semantics interface, an NC reading of (49a) is guaranteed.Footnote 20
A third interesting area for NC are different types of non-finite constructions. The easiest case concerns NC in non-finite contexts in which the role of the NM is taken over by the prefix ne- ‘un-/non-’ as shown in (50).
-
(50)


The data in (50) can be captured by our analysis if we assume a variant of the NM Lexical Rule that is specialized for non-finite verb forms (with the exception of the infinitive). The output of the rule will essentially mirror the NM Lexical Rule for finite verbs in (40), except that the phonological function will have to be adjusted. With the lexical rule in place, we extend the applicability of the Neg Criterion in (44) to the new lexically negative non-finite verb forms. In effect this means that the licensing conditions of NC in those non-finite clauses are the same as for finite clauses.
This leaves an interesting residue of rather atypical cases of non-strict negative concord in Romanian. The preliminary exposition of Romanian data in Sect. 2 already showed an instance of a past participial construction in which a preverbal n-word contributes negation in the absence of an NM (see (6) and Ionescu, 1999, for details). Teodorescu (2005) interprets these data in terms of a general contrast between NC in finite and non-finite constructions. According to her analysis, non-finite constructions involve a silent NM which is structurally situated above the overt NM ne- and below the preverbal n-word, and licenses the latter. However, the data are not as uniform as this analysis suggests. In particular, present participles behave just like finite verbs with respect to preceding n-words. Example (51) shows that a non-finite construction with a preverbal n-word is ungrammatical in the absence of the NM ne- on the present participle verb.
-
(51)


With our interpretation of the data we follow the argumentation of Iordăchioaia (2004), who argues that the absence of a negation prefix in the presence of a preceding n-word in (6) is due to the adjectival nature of the relevant past participial constructions. This is supported by the fact that pre-adjectival n-words can also negate bona fide adjectives as in (52a). The present participle is usually verbal in Romanian, which explains the pattern in (51), although Teodorescu documents an instance of an adjectivized present participle where the preposed n-word behaves just like in (6) (see (52b)).
-
(52)


In conclusion, the contrast between past participles and finite verbs with preposed n-words correlates with a contrast between adjectives and verbs. A complete theory of NC outside the domain of finite verbs must be sensitive to this categorical distinction.
The distinction between adjectival and verbal NC contexts seems to be a peculiar property of Romanian; Penka (2011:Chap. 2) shows that it is not present in strict NC languages such as Russian. In our account of Romanian, adjectival constructions differ from instances of NC in that the adjectival head is not subject to an NC constraint, which means that an n-word contributes its negation without triggering NC with a lexical head. This view of the matter is also supported by an observation of Ionescu (1999) and Teodorescu (2005), who report that in these constructions NC does not occur in combination with other n-words (see (53)).Footnote 21

4.4 Remarks on the typology of negative concord
A test of any new analysis of NC is how well it captures the varied landscape of NC across different languages.Footnote 22 The present focus on putting forth, and technically spelling out, polyadic negative quantification as the appropriate tool for an empirically adequate description of the NC facts of Romanian prohibits an in-depth discussion of typological data. In this section we briefly review the most salient properties of cross-linguistic variation in Romanian, Polish, French, Italian and German in order to indicate which parts of our theory will serve as pivot for variation, and which features of the analysis remain fixed.
The first formulation of a Neg Criterion in HPSG was presented by Richter and Sailer (2004:125) in an LRS analysis of NC in Polish. This analysis was based on an interpretation of n-words as (negative) monadic quantifiers and used the idea of identifying negative quantifiers originating from different lexical contributors at the syntax-semantics interface. The authors deliberately called their central principle of Polish Neg Criterion after a constraint that Haegeman and Zanuttini (1991) had formulated much earlier in a different grammar framework, because the function of the HPSG principle was designed to express similar insights into the mechanisms behind NC. In Haegeman and Zanuttini’s formulation the Neg Criterion essentially requires that n-words and sentential negation enter a Spec-Head relation; variation between languages is a consequence of whether the rule applies at S-structure or at LF in combination with further conditions on n-words and sentential negation in a particular language.
Still following the spirit of the proposal by Haegeman and Zanuttini in the disguise of its translation into HPSG and LRS by Richter and Sailer, we take n-words and (non-expletive) sentential negation to express semantic negation across languages. We model linguistic variation by the interaction of language specific variants of the Neg Criterion with lexical variation of key lexical elements in the negation systems of the respective languages. This means that the syntactic (or morphological) nature of the negation particle or negation adverb or negation argument or negation suffix of a verb may vary, and single words participating in negation contexts or entire classes of (n-)words may carry additional restrictions that might have to do with the overall linguistic system in which they are embedded.Footnote 23 Although this interaction can result in initially quite puzzling data configurations, the underlying categorical theory is rather simple: We adopt the typological theory of NC in Polish, French and German of Richter and Sailer (2006), adding Romanian and Italian, and generalizing the interpretation of sentential negation and n-words from classical negation and monadic negative quantifiers to n-ary polyadic quantification. It follows that the different NC systems in the five languages under consideration must be due to variation in (a) the Neg Criterion, and (b) additional constraints that can be lexical or syntactic in nature.
For Polish, French and German, we adapt Richter and Sailer’s account to negative polyadic quantification.Footnote 24 Restricting our attention to simple finite clauses, Polish and (standard) German mark the two ends of the NC continuum: Polish is a strict NC language in which no double negation readings are possible, and German is a non-NC language. The occurrence of an n-word in a Polish finite clause necessitates the presence of the verbal negation prefix nie, and the interpretation is always NC, independent of the number of n-words (54a). In German, the sentential negation adverb nicht ‘not’ and any n-word in a clause require the independent realization of their negative semantic contribution to the clause (54b). In addition, German does not require a sentential adverb in order to express sentential negation (54c).
-
(54)


The Polish Neg Criterion is stricter than the Romanian Neg Criterion: Whenever a negative quantifier of type higher than type 〈0〉 outscopes a finite verb in its excont, its variable must be in the variable vector of a negation on the parts list of the verb. Verbs with negation prefix are formed with a NM Lexical Rule like in Romanian. The strengthened Neg Criterion for Polish enforces the negation prefix on the verb in the presence of an n-word, and it guarantees that each n-word enters NC. While the Neg Criterion for Polish does not permit DN readings at all, its Romanian counterpart only excludes DN triggered by the negative marker, a negative quantifier of type 〈0〉.
In German NC is impossible: According to the analysis of Richter and Sailer (2006), the German Neg Criterion takes the form of a Negation Faithfulness Constraint, which requires that each negation be expressed independently. This amounts to saying that each lexically introduced negation must be uniquely visible in the interpretation of a clause. If there are two negations, no matter whether they come from two n-words or an n-word and the sentential negation adverbial, they will be perceived as double negation.Footnote 25 Moreover, the occurrence of an n-word is not contingent on the occurrence of the negation adverbial.
French occupies an intermediate position, with n-words generally permitting but not enforcing NC. At the same time, the lexeme for sentential negation, pas ‘not’, exhibits lexically idiosyncratic distributional behavior.Footnote 26 We follow Rowlett (1998) in assuming that the preverbal particle ne is an expletive that does not express negation in European French.
First of all, we observe that an n-word (personne ‘nobody’) is sufficient to express sentential negation (55a).Footnote 27 However, if there are two n-words as in (55b), there is a contextually determined choice between an NC reading and a double negation reading. The examples in (55c) and (55d) show that this choice is not available with pas: A preverbal subject n-word and a postverbal object n-word both lead to a double negation reading.
-
(55)


The French NC system will be obtained by a liberal Neg Criterion which leaves the occurrence of negation identities unregulated. Negative polyadic quantifiers contributed by n-words that outscope the finite verb may either scope independently (double negation readings) or enter into a joint n-ary negative polyadic quantifier (NC readings). Without anything else being said, any combination of this is possible for more than two n-words, although we expect that information structural restrictions and restrictions on scope will play an important role in determining the actual interpretation possibilities. The negative adverb pas is a lexical exception from this liberal behavior. According to Richter and Sailer, it has a lexical collocation restriction reminiscent of the German Negation Faithfulness Constraint to the effect that the negation contributed by pas may not enter into NC with other negative quantifiers.
Let us finally consider finite clauses in Italian, another non-strict NC language that behaves differently from both Romanian and French, and is well-suited to illustrate the effect of more subtle variants of the Neg Criterion and its interaction with the NM Lexical Rule. The initial two examples suggest a familiar picture: A NM contributes sentential negation alone (56a), and a postverbal n-word requires the presence of the NM on the verb (56b), leading to a single negation reading.
-
(56)


However, the next set of data deviates from the Romanian pattern we saw earlier. A preverbal n-word contributes negation alone and licenses NC with other postverbal n-words (57a). The special status of a preverbal n-word is further confirmed by its interaction with the NM on the verb, and with other postverbal n-words. A preverbal n-word co-occurring with an NM can only be interpreted as DN (57b), and adding another postverbal n-word does not change the DN reading (57c).Footnote 28
-
(57)


In order to capture this pattern in our present NC architecture, we need to extend the notion of negation marking at the verb. Evidently, it is not only the preverbal NM that plays this role in Italian, a preverbal n-word can do so as well. The first step to express this in the grammar would be a modification of the NM Lexical Rule on verbs. Its Italian counterpart distinguishes two cases. In the first one, which is similar to Romanian, a negation prefix is attached to the verb, but this time with the additional restriction that the subject’s variable may not be included in the variable vector of the polyadic negative quantifier. This excludes NC with the subject in sentences (57b) and (57c), while it provides the observed interpretation of (56a) and (56b). The second possibility for the rule output is a verb without NM prefix that introduces a negative polyadic quantifier which contains the subject variable on its variable vector. This is the situation in which a negative subject licenses the morphologically invisible negation on the verb. It is realized in simple negation readings with an n-word as subject and in NC constructions like (57a).
Since Italian subjects can act as negation markers, the Italian Neg Criterion has to take note of them. Its condition on Italian finite verbs says that if a non-subject negative quantifier outscopes the finite verb in the verb’s excont, then the non-subject’s variable must be on the variable vector of the verb’s negative quantifier. In other words, non-subject n-words are in NC with negated verbs. In combination with the NM Lexical Rule, this makes the NM or a subject n-word obligatory in (56b) and (57a). The interaction of the NM Lexical Rule and the Neg Criterion also determines that a preverbal n-word in combination with a morphological NM on the verb entails a double negation reading ((57b)–(57c)), as their negative semantics must be independent.
5 N-words in embedded subjunctive clauses
To complete our analysis of Romanian, we investigate the function of the NM in NC constructions and show that our theory can be extended to account for locality conditions on the scope of negative quantifiers in NC constructions in complex sentences.
5.1 The NM as a scope marker
We argued that the NM cannot be a semantic licenser of n-words, as it does not maintain anti-additivity in the relevant contexts (12). We also saw that in NC constructions the negation contributed by the NM must always undergo resumption with at least one n-word, as decreed by the Neg Criterion for Romanian (44). But if the NM is neither a semantic licenser nor a real negation contributor in NC, what is its role in these constructions and why is it obligatory with n-words?
We think that an answer to these questions can be found in complex sentences like (58) where an n-word is contained in an argument phrase in an embedded subjunctive clause. In this kind of construction the negative quantifier may take wide scope over the matrix verb (58a) or narrow scope within the subjunctive clause (58b). Parallel observations hold for English n-words embedded in infinitival clauses (59). But unlike in the ambiguous English construction, in Romanian the scope of the quantifier is resolved by the (obligatory) NM: The scope of the negative quantifier is associated with the verb that carries the NM ((58a) vs. (58b)). We see that the NM functions as a syntactic licenser for n-words; the NM marks the sentential scope of the negative quantifier (cf. also Ionescu, 1999, 2004).Footnote 29
-
(58)


-
(59)
I will force you to marry no one. (Klima 1964:285)


Assume that we modify the lexical semantic specifications of Sect. 4 by adding world arguments of type s to the non-logical constants for predicates and noun phrases in the usual way, i.e. we will now use the full type theory of Ty2 in our specifications.Footnote 30 Moreover, assume for the moment that the excont of matrix and embedded clause are distinct. With these modifications and assumptions, which we will explain in more detail in Sect. 5.2, our theory captures (58a) and (58b).
In both sentences, independent LRS principles for quantifiers in argument position dictate that the negative quantifier associated with nicio carte must outscope the verb in the embedded clause. Let us look at (58a). Suppose nicio carte takes scope in the embedded clause. Then the Neg Criterion is violated since the non-negated verb cannot have a negative quantifier on its parts list. Suppose it takes scope in the matrix clause. Then the Neg Criterion is satisfied by resumption of the negative quantifier from nicio carte with the quantifier of the negated verb. We obtain the truth conditions \(\mathit{no}(y,\mathit{book}'_{s_{0}}(y),\mathit{ask}'_{s_{0}}(\mathit{john}',\mathit{mary}',\lambda w.\mathit{read}'_{w}(\mathit{mary}', y)))\). The converse holds in (58b). The embedded verb has a negative marker and a negative quantifier on its parts list, which means that nicio carte can take scope within the verb’s excont by resumption (\(\mathit{ask}'_{s_{0}}(\mathit{john}',\mathit{mary}',\lambda w.\mathit{no}(y,\mathit{book}'_{w}(y),\mathit{read}'_{w}(\mathit{mary}', y)))\)). It cannot take scope in the matrix clause, because the matrix verb lacks a negative quantifier on its parts list.
5.2 An intensional fragment of Romanian
In order to formulate truth conditions for sentences that are embedded under propositional attitude predicates, we add appropriate possible world arguments to our non-logical constants and modify the lexical entries of finite verbs: As can be seen in (60) below, verbs now contribute a world variable and lambda abstraction over that world variable, where the lambda abstraction is lexically constrained to take place in the external content of the verb.
For simplicity, we adopt the standard textbook analysis of propositional attitude verbs and finite sentences of Gamut (1991:Chap. 6), which closely follows the design of Montague’s PTQ fragment. The only substantial new technique in our Romanian grammar fragment compared to Sect. 4 concerns the treatment of embedded sentences as propositions and the way we ensure that root clauses still denote truth values in spite of the fact that every finite verb has a lambda abstraction over its contributed world variable. In effect, finite verbs introduce restrictions on the distribution of world variables which, as a consequence of routinely applying the combinatoric semantic principles of LRS, will force matrix clauses to be of logical type t, while embedded sentences are analyzed as propositions. Propositions denote sets of worlds and are of type 〈s,t〉. We assume that a grammar principle demands that unembedded signs (in our fragment: declarative sentences) be of type t, and their external content has the form (λw.ϕ)(w).Footnote 31 Apart from the types of (most) non-logical constants, nothing else will change in our grammar fragment, not even the representations for polyadic quantifiers and their types.
To illustrate and explain the changes, we extend the specification of the negative verb form nu a venit from Sect. 4. The reader might recall that it describes a verb form that is licensed in the grammar as the output of the NM Lexical Rule.

The logical constant come′ (see the main value) is now of type 〈s,〈e,t〉〉. We notate the additional argument, a world variable, as a subscript (as shown in the incont) to clearly distinguish it from the argument of type e, which will typically be a constant in our example sentences below. The parts list reveals that finite verbs now introduce a lambda abstraction with respect to a world variable w over a sentence ( ), and they contribute the world variable themselves to the semantic specification (second element of the parts list). In additional restrictions we require that the lambda abstraction be inside the external content of the verb, the negation be in the scope of the lambda abstraction, and the constant come′ be in the restrictor of the negation (the latter as before). The last restriction in (60) says that the world variable, w, is the argument of a proposition, ϕ′. In a simple clause, this restriction will ensure that the semantic type of the truth conditions is a logical sentence. This is the type of expression that an HPSG grammar with semantic specifications in Ty2 requires of the logical specification of unembedded utterances. For embedded clauses, the constraint \(\phi'_{\langle s,t\rangle}(w)\) will not be satisfied by the embedded proposition; it will be satisfied at the level of the matrix clause.
), and they contribute the world variable themselves to the semantic specification (second element of the parts list). In additional restrictions we require that the lambda abstraction be inside the external content of the verb, the negation be in the scope of the lambda abstraction, and the constant come′ be in the restrictor of the negation (the latter as before). The last restriction in (60) says that the world variable, w, is the argument of a proposition, ϕ′. In a simple clause, this restriction will ensure that the semantic type of the truth conditions is a logical sentence. This is the type of expression that an HPSG grammar with semantic specifications in Ty2 requires of the logical specification of unembedded utterances. For embedded clauses, the constraint \(\phi'_{\langle s,t\rangle}(w)\) will not be satisfied by the embedded proposition; it will be satisfied at the level of the matrix clause.
With these adjustments in place, we can explain the form of the new excont values of finite sentences.
-
(61)


The familiar example Ion nu a venit (‘John didn’t come’) receives the excont value shown in (61a). We will simplify this type of logical expressions to formulas such as the one shown in (61b), which results from beta-converting (61a) and following the linguistic naming convention of designating the world in which an expression is evaluated with the first variable of type s, s 0.
The interaction of the lexical restrictions on the truth conditions of finite verbs with other semantic composition principles is hardly more intricate in complex sentences with propositional attitude verbs as matrix predicates. In this section, we are ignoring the interaction with other grammar principles, and restrict attention to the distribution of the newly introduced lambda abstraction and world variable.
For the sentence in (58b), in which the negative quantifier contributed by the nominal phrase nicio carte scopes in the embedded clause, we obtain the truth conditions in (62a) as excont value.
-
(62)
Ion i-a cerut Mariei [să nu citească nicio carte].
-
a.
\(\lambda w.\mathit{ask}'_{w}(\mathit{john}',\mathit{mary}',\lambda w.\mathit{no}(y,\mathit{book}'_{w}(y),\mathit{read}'_{w}(\mathit{mary}',y)))(w)\)
-
b.
\(\mathit{ask}'_{s_{0}}(\mathit{john}',\mathit{mary}',\lambda w.\mathit{no}(y,\mathit{book}'_{w}(y),\mathit{read}'_{w}(\mathit{mary}', y)))\)
-
a.
The argument of ask′ that contains the truth conditions of the sentential complement is a proposition (type 〈s,t〉), as required by the typing of the constant ask′, 〈s,〈〈s,t〉,〈e,〈e,t〉〉〉〉. The world variable w that originates from the predicate să nu citească in the embedded clause thus cannot be realized as an argument of the proposition in the third argument slot of ask′, as this would lead to a type mismatch. The constraint \(\phi'_{\langle s,t\rangle}(w)\), which is introduced twice, once by the matrix verb and once by the embedded verb, can only be satisfied by applying the representation of the proposition constructed in the matrix clause to w. Note that each finite verb introduces the same world variable. This will lead to the correct result, as each occurrence of w is bound by a particular lambda operator.
Example (62b) repeats the notational conventions for excont values of root clauses which we already introduced for the simple clause in (61), and which we will use for readability in the following discussion: By beta-conversion and naming the world variable of the matrix clause s 0, we arrive at a simpler form of the actual excont value (62a), which is the form of the expression as it is actually specified in the grammar principles.
5.3 Complex sentences with two NMs
The situation becomes more complex—and also more interesting—when both the matrix and the embedded verb in a complex clause carry an NM:
-
(63)




The sentence (63) has two readings as indicated in the two translations. The negative quantifier nicio carte may enter NC with the matrix verb (63a) or with the embedded verb (63b). In either case, the other verb contributes a type 〈0〉 negative quantifier to the interpretation. This means that one negation outscopes the other.
In preparation of our analysis of (63), we start our discussion with the simpler case of a complex sentence without n-words but with an NM at the matrix verb and the embedded verb (64). The relevant parts of its analysis tree are shown in Fig. 3.
-
(64)



LRS analysis of (64) Ion nu i-a cerut Mariei să nu citească Nostalgia
The excont of the non-head daughter VP on the right, which is the embedded subjunctive clause, must be an element of the parts list of that VP (Excont Principle). Let us first consider the options for this excont value from the perspective of the embedded clause alone, ignoring possible requirements of its matrix environment. The smallest piece of semantic representation which is eligible without violating any other LRS principles is the incont value  . The largest piece of semantic representation that the excont
. The largest piece of semantic representation that the excont
 of the embedded subjunctive clause can be identified with is the lambda term λw.ψ. A third option seems to be the negative quantifier
of the embedded subjunctive clause can be identified with is the lambda term λw.ψ. A third option seems to be the negative quantifier  , which is contributed by the verb să nu citească and is licensed by the NM Lexical Rule. However, since the output of the lexical rule guarantees that this negative quantifier is a subterm of the scope of the lambda abstraction which in turn is a subterm of the external content of the verb, we are forced to conclude that
, which is contributed by the verb să nu citească and is licensed by the NM Lexical Rule. However, since the output of the lexical rule guarantees that this negative quantifier is a subterm of the scope of the lambda abstraction which in turn is a subterm of the external content of the verb, we are forced to conclude that  equals
equals  , the largest possible candidate for the excont value, which we already considered before.
, the largest possible candidate for the excont value, which we already considered before.
Next, we have to consider the matrix environment of the embedded VP. It may be surprising that the conditions discussed so far do not prevent the negative quantifier of the embedded verb in Fig. 3 from taking scope in the matrix sentence. The reason is that nothing forces the quantifier  to take immediate scope over the predicate
to take immediate scope over the predicate  ; other functors or operators can intervene. As a consequence,
; other functors or operators can intervene. As a consequence,  may be identified with the matrix negation or trigger DN within the matrix clause. Neither of the resulting semantic representations expresses possible truth conditions for the sentence in (64). If our reasoning so far were complete, an NM at an embedded verb could even outscope an affirmative matrix verb, giving the sentence in (65) the reading in (65b).
may be identified with the matrix negation or trigger DN within the matrix clause. Neither of the resulting semantic representations expresses possible truth conditions for the sentence in (64). If our reasoning so far were complete, an NM at an embedded verb could even outscope an affirmative matrix verb, giving the sentence in (65) the reading in (65b).
-
(65)


However, we also have to take the typing restrictions of the matrix predicate into account. They require that the sentential argument be represented by an expression of type 〈s,t〉. This can only be the case if the lambda abstraction originating with the verb in the complement clause is realized in the argument slot of the matrix predicate. Since the negation of the embedded verb is constrained to be in the scope of the lambda abstraction, it can not take scope outside of the embedded clause.
Moreover, we independently want to restrict the external content of embedded sentences more tightly in order to confine scope projection conditions of finite verbs to their syntactic projection. To this end, a new clause of the Semantics Principle ensures that the external content of the complement clause of a propositional attitude verb remains within the scope of the matrix verb:
-
(66)


In our example in Fig. 3 the new clause of the Semantics Principle makes the excont of the subjunctive clause  a subterm of the scope η of the verb ask′. The negative quantifier
a subterm of the scope η of the verb ask′. The negative quantifier  contributed by the NM on the embedded verb is a subterm of the lambda abstraction
contributed by the NM on the embedded verb is a subterm of the lambda abstraction  , which in turn is a subterm of η. The only reading we obtain for (64) is the one in which both verbs are negated (67), as desired.
, which in turn is a subterm of η. The only reading we obtain for (64) is the one in which both verbs are negated (67), as desired.
-
(67)
\(\mathit{no}((),(),\mathit{ask}'_{s_{0}}(\mathit{john}',\mathit{mary}',\lambda w.\mathit{no}((),(),\mathit{read}'_{w}(\mathit{mary}',\mathit{nostalgia}'))))\)
Now everything is in place for the analysis of the two readings of the ambiguous sentence (63). A description of the tree structure is given in Fig. 4. The only difference from Fig. 3 is the negative quantifier in the embedded VP which takes the position of the proper name Nostalgia. For reasons of space, information carried by identical tags as in Fig. 3 is not repeated in Fig. 4.

LRS analysis of (63) Ion nu i-a cerut Mariei să nu citească nicio carte
There are three negative quantifiers whose scope interaction must be determined. The restriction \(\scriptsize\fbox{0}\in\scriptsize\fbox{13}\) (known from the previous example) and the identity of η with the exc of the embedded clause (\(\eta = \scriptsize\fbox{0}\)) leave two possibilities: the scope ψ of the lambda abstraction  λw.ψ could be identical with
λw.ψ could be identical with  or with
or with  . If \(\psi = \scriptsize\fbox{6}\) we are in the situation in which the negative quantifier
. If \(\psi = \scriptsize\fbox{6}\) we are in the situation in which the negative quantifier  of nicio carte is interpreted in the embedded clause. Being identical with ψ it is a subterm of η and cannot take scope in the matrix clause. On top of this, the Neg Criterion forces resumption between
of nicio carte is interpreted in the embedded clause. Being identical with ψ it is a subterm of η and cannot take scope in the matrix clause. On top of this, the Neg Criterion forces resumption between  and
and  . We obtain an NC reading in the subjunctive clause and the interpretation (68a) for (63). If we start with the possibility of \(\psi = \scriptsize\fbox{11}\) without making initial commitments about the nature of
. We obtain an NC reading in the subjunctive clause and the interpretation (68a) for (63). If we start with the possibility of \(\psi = \scriptsize\fbox{11}\) without making initial commitments about the nature of  , the negative quantifier
, the negative quantifier  could also take scope in the matrix clause where it would then undergo resumption with
could also take scope in the matrix clause where it would then undergo resumption with  to satisfy the Neg Criterion. The result is an NC reading in the matrix clause and the interpretation (68b) for (63):
to satisfy the Neg Criterion. The result is an NC reading in the matrix clause and the interpretation (68b) for (63):
-
(68)


In this section we showed that our theory of NC in Romanian contains all the ingredients required to account for the properties of negative quantifiers and NC in complex clauses, and we integrated our theory of polyadic quantifiers with two-sorted type theory. The analysis is still incomplete in at least one important respect: We did not carefully consider the full range of data that is relevant for a comprehensive theory of NC in complex sentences. The empirical questions are quite challenging. What interpretations are available for negative quantifiers in complex sentences with two or more n-words? An unconstrained theory predicts scope interactions that native speakers most likely will not perceive given the usual difficulties with multiple negations. It will be important for future extensions of our theory to find out which readings are available and preferred, and which grammatical or processing constraints are at play. We expect that only carefully controlled experimental studies can provide reliable answers to these empirical questions.
6 Conclusion and further issues
The present analysis of NC in Romanian elaborates the approach that was pioneered by an analysis of French in de Swart and Sag (2002). Our theory considerably extends de Swart and Sag’s proposal by explicitly integrating a higher-order logic with polyadic quantification in HPSG and making all semantic composition principles for polyadic quantification entirely explicit. We believe that the formulation of the polyadic quantifier approach to NC in LRS is fully compatible with and can in fact subsume the typological theory of NC in Polish, French and German presented in Richter and Sailer (2006), even though that theory was formulated on the basis of monadic quantification. To the extent that we were able to explore the compatibility of our analysis with their much broader typological considerations (Sect. 4.4), we do not see any obstacles to expressing obligatory NC in Polish, optional NC in French, and absence of NC in German in terms of restrictions on possible resumption of negative quantifiers. Future work should still spell out the necessary semantic composition constraints with more formal rigor and in a more systematic way, testing out the robustness and plausibility of the general framework in capturing fine-grained typological variation by gradually varying constraints on semantic composition and their interaction with the idiosyncratic behavior of lexical items that play a prominent role in the negation systems of different languages. For these future developments we would like to attach particular interest to the behavior of languages like Italian, which require additional refinements of the NC conditions concerning preverbal n-constituents.
With negative concord we addressed a rather special case of applying the tool of polyadic quantification to the analysis of a family of data in natural languages: The negative polyadic quantifiers we defined are decomposable into iterations of monadic quantifiers. To argue for our analysis, we had to show that it involved the most parsimonious set of assumptions which could describe the full range of data of Romanian NC and could do justice to the observable meaning of n-words and the verbal negation prefix in isolation as well as in various syntactic constellations. We were not in a position to argue that polyadic quantifiers are an absolute technical necessity to derive the readings of the Romanian NC sentences that we investigated. The fact that the description of NC is in principle possible under traditional assumptions about semantic compositionality with a higher-order logical language based on a functional theory of types is perhaps the main reason why researchers have been hesitant to step outside these well-established boundaries to obtain what we consider a much simpler picture of the landscape of negative concord. Recall that we did not appeal to the usual host of unobservable empty categories that easily complicate assumptions about syntactic structure (let alone the machinery required for efficiently parsing these structures), and we did not introduce at least equally problematic but analytically essential empty semantic operators that are only justified by complex nonlocal syntactic licensing conditions whose exact inner workings are rarely pursued to full formal explicitness.
The real potential of a fully explicit integration of polyadic quantification with precise syntactic and semantic assumptions only comes alive when we turn to expressions whose interpretation is no longer amenable to the decomposition of polyadic quantifiers into monadic quantifiers. These are cases of so-called unreducible polyadic quantifiers, which we already referred to in passing and for comparison with NC in Sect. 2.4: Our examples there included cumulative quantifiers and readings obtained with same/different (27). If one accepts that these constructions are genuine cases of quantification and that the assumed readings correctly reflect their semantics (rather than being a consequence of additional repairs at some post-semantic or pragmatic level), one is also forced to tell a story about their integration in a mathematically exact grammar framework.Footnote 32 Adding polyadic quantification to LRS answers to this need and opens the door to exploring a whole range of new semantic phenomena that have not been explored in model-theoretic grammar frameworks like HPSG, including the aforementioned cumulative and same/different (unreducible) polyadic quantifiers, and other similar constructions well-known in the semantic literature on quantification (Keenan, 1992; Keenan and Westerståhl, 1997). Since the present constraint-based syntax-semantics interface supports polyadic quantifiers, HPSG theories can start to investigate them in the context of concrete syntactic analyses. This brings within reach a hitherto impossible explicit specification of the syntax and semantics of constructions that require unreducible polyadic quantifiers for an adequate rendering of their truth conditions and have, for that reason, eluded a comprehensive treatment in other grammar frameworks.
Notes
List of abbreviations: ACC ‘accusative case marker’, CL ‘clitic’, DN ‘double negation’, NC ‘negative concord’, NM ‘negative marker’, NQ ‘negative quantifier’, NPI ‘negative polarity item’, SJ ‘subjunctive marker’.
An NLLT reviewer correctly points out that if the denial of speaker B targets the object position of speaker A’s utterance (e.g., A: No student read this book; B: No student read no book), the DN reading is not available anymore in Romanian. This is most likely due to the different information structural status of subjects and objects in Romanian, an issue that needs further investigation independently of negation.
A function f is anti-additive iff for each pair of sets X and Y, f(X∪Y)=f(X)∩f(Y).
We thank an anonymous NLLT reviewer for bringing the strong NPI data in (14) to our attention.
Following an NLLT reviewer’s comment, we note that in Neg raising contexts, n-words may sometimes be licensed across a that-complementizer as below:
-
(17)

Although we will not investigate them further, such examples are not fundamentally at odds with our observations, since we assume with Sailer (2006) that in Neg raising constructions the negation only outscopes the embedded verb. By contrast, the presence of an n-word in the matrix clause forces the negative operator to outscope the matrix verb with the result that the embedded predicate lacks the negation that is locally required by its own n-word argument, which leads to the ungrammaticality of (18):

-
(17)
The scope disambiguating function of the verbal prefix is reminiscent of the domain restriction effect of modal adverbs that Huitink (2012) describes for modal concord of adverbs and modal verbs in Dutch. However, as Huitink emphasizes, it is unclear if modal concord and NC can be treated analogously under the perspective of polyadic quantification.
See Barker (2007) for a compositional continuation semantic analysis of same and different as adjectives. Another compelling instance of polyadic quantification is discussed by Moltmann (1995:260), who argues that the denotation of the exception sentence in (26) involves subtracting the pair (John, Mary) from the set of pairs of men and women.
-
(26)
Every man danced with every woman except John with Mary.
-
(26)
We ignore the negative marker nu, because we already know that it is not interpreted independently in the presence of an n-word but always enters into a concord relation.
Example adapted from Iordăchioaia (2010:102).
For an argument why this fails even for the simplest mode of polyadic composition, iteration, which corresponds semantically to function application, see Iordăchioaia (2010:142–146). The reason that compositionality fails for iteration is that the syntax of natural language does not appropriately map onto the syntax of a logical language with iteration.
The syntax underlying our LRS implementation will treat it as a family of constants. For that reason, we refer to our logical languages as Ty2, although strictly speaking the present definition presents Ty2 augmented by syncategorematic polyadic quantifiers.
Initially we will not employ the type s of possible worlds in our representations. Possible worlds will be added in Sect. 5.
We follow the notational convention in the LRS literature of grouping related resources by tags with the same integer: In the present examples, the contributions of studenţi are designated by 3, the contributions of trei by 4, followed by lower case letters.
As a reviewer remarks, this strategy of purely lexicalized semantic resources seems at odds with work in Construction Grammar that assumes semantic effects of constructions in addition to the words that occur in them. The apparent incompatibility of these assumptions is weaker than it appears: Work in LRS also assumes phrasal lexical entries, which license phrases that contribute semantic resources because they are conceived of as complex lexical items. The theory of idiomatic phrases and phraseological clauses of Richter and Sailer (2009) develops central aspects of this approach and compares it to Sign-based Construction Grammar. A detailed discussion is beyond the scope of the present paper.
For mathematical details of how object languages such as Ty2 can be specified in a feature logic for HPSG, see Sailer (2003); Penn and Richter (2004, pp. 426–429) present a feature logical signature and a set of axioms of LRS that can easily be extended to capture the version of Ty2 with polyadic quantification we use here.
We follow the most recent version of LRS presented in Richter and Kallmeyer (2009).
For simplicity, the var attribute is not shown in Fig. 1; (34a) above contains the complete LRS specification with determiner selection and local var and main values of the word.
The lack of a negation prefix at the non-finite verb is presumably due to the presence of fără, which could be syntactically marked ([marking marked]), thus assimilating fără to HPSG’s marker category. One might argue that this lends additional support to the idea that Romanian n-words need a syntactic scope marker in verbal projections. As fără is a good scope marker in this context, no second scope marker is necessary. Its function as a scope marker is also a unifying property with negated finite verbs, which makes it plausible that the Neg Criterion applies to both, as the two elements serve the same syntactic purpose with respect to negation.
See Zeijlstra (2004) for a recent overview.
For example, negative polar indefinites are in distributional competition with n-words in strict NC languages and in weaker competition in non-strict NC languages, with non-NC languages providing yet another set of restrictions on the distribution of both types of elements, n-words and corresponding negative polarity items. See Hoeksema (2010, 2012) for thrilling cross-linguistic observations on different kinds of contextual effects on the diachronic development of fine-grained lexical distribution patterns in connection with negation.
See Richter and Sailer (2006) for a comprehensive discussion of data for all three languages, which we do not replicate here. The French data are all from European French. Especially with respect to the NC behavior of pas ‘not’, European French differs from other varieties of French.
Negation faithfulness only applies to standard German. There is a certain amount of dialectal variation with respect to the availability of NC.
Richter and Sailer (2006) discuss the diachronic reasons for the peculiar distribution properties of pas and relate them to dialectal synchronic data that suggest an analysis in terms of lexical distribution restrictions. HPSG supports a precise formulation of these constraints.
All French examples are from Richter and Sailer (2006).
For this quick overview of Italian core data, we ignore left dislocation, which we assume to be correlated with additional information-structural effects. We should also note that DN readings in Italian are reportedly highly marked and context-dependent like in Romanian.
Like English and other languages, Romanian also has Neg raising predicates, which may sometimes interact with the licensing of n-words, as illustrated in (17) and (18). Neg raising in Romanian deserves a separate study, as it occurs both with subjunctive and ‘that’-clauses and thus requires a more complex fragment of grammar. The technical insight, however, would follow the analysis of strict NPI licensing with Neg raising verbs in Sailer (2006), which is compatible with our present account of negative concord.
We will assume that proper names are rigid designators.
Unembedded signs in HPSG are the type of signs which occur as independent utterances; they also play a crucial role in the model theory of grammars. See Richter (2007) for details. An extension of our present fragment would of course allow other unembedded signs beyond declarative sentences.
A symptomatic example for the conceptually unsatisfactory situation in the framework of compositional LF-semantics is provided by the analysis of exception sentences in Moltmann (1995:275–276). As the desired integration of polyadic quantification is impossible, the theory must be formulated on a post-semantic level of implications which need to repair the semantics. Major architectural design decisions should not be forced upon linguists by limitations of their framework but rather by empirical evidence.


References
Barbu, Ana-Maria. 2004. The negation NU: lexical or affixal item. In Understanding Romanian negation. Syntactic and semantic approaches in a declarative perspective, ed. Emil Ionescu, 68–82. Bucharest: Bucharest University Press.
Barker, Chris. 2007. Parasitic scope. Linguistics and Philosophy 30 (4): 407–444.
Copestake, Ann, Dan Flickinger, Carl Pollard, and Ivan A. Sag. 2005. Minimal Recursion Semantics: an introduction. Research on Language and Computation 3: 281–332.
Corblin, Francis, and Lucia M. Tovena. 2001. On the multiple expression of negation in Romance. In Romance Languages and Linguistic Theory 1999, eds. Yves D’Hulst, Johan Rooryck, and Jan Schroten, 87–115. Amsterdam: Benjamins.
de Swart, Henriëtte. 1993. Adverbs of quantification: a generalized quantifier approach. New York: Garland.
de Swart, Henriëtte. 2010. Expression and interpretation of negation. An OT typology. Berlin: Springer.
de Swart, Henriëtte, and Ivan A. Sag. 2002. Negation and negative concord in Romance. Linguistics and Philosophy 25: 373–417.
Egg, Markus, Alexander Koller, and Joachim Niehren. 2001. The constraint language for lambda structures. Journal of Logic, Language and Information 10 (4): 457–485.
Farkas, Donka. 2002. Extreme non-specificity in Romanian. In Romance Languages and Linguistic Theory 2000, eds. Claire Beyssade, Reineke Bok-Bennema, Frank Drijkoningen, and Paola Monachesi, 127–151. Amsterdam: Benjamins.
Fălăuş, Anamaria. 2007. Le paradoxe de la double négation dans une langue à concordance négative stricte. In La négation dans les langues romanes, ed. Franck Floricic, 75–97. Amsterdam: Benjamins.
Fălăuş, Anamaria. 2010. Alternatives as sources of semantic dependency. In Proceedings of SALT 20, eds. Nan Li and David Lutz, 406–427.
Gallin, Daniel. 1975. Intensional and higher-order modal logic. Amsterdam: North-Holland.
Gamut, L. T. F. 1991. Logic, language and meaning. Intensional logic and logical grammar, Vol. 2. Chicago: The University of Chicago Press.
Giannakidou, Anastasia. 1998. Polarity sensitivity as (non)veridical dependency. Vol. 23 of Linguistik aktuell. Amsterdam: Benjamins.
Giannakidou, Anastasia. 2007. N-words and negative concord. In The Blackwell companion to syntax, eds. Martin Everaert and Henk van Riemsdijk, Vol. III. Malden: Blackwell.
Haegeman, Liliane. 1995. The syntax of negation. Cambridge: Cambridge University Press.
Haegeman, Liliane, and Raffaella Zanuttini. 1991. Negative heads and the Neg criterion. The Linguistic Review 8: 233–251.
Hoeksema, Jack. 2010. Dutch ENIG: from nonveridicality to downward entailment. Natural Language and Linguistic Theory 28: 837–859.
Hoeksema, Jack. 2012. On the natural history of negative polarity items. Linguistic Analysis 38 (1–2): 3–33.
Huitink, Janneke. 2012. Modal concord: a case study of Dutch. Journal of Semantics 29 (3): 403–437.
Ionescu, Emil. 1999. A quantification-based approach to negative concord in Romanian. In Proceedings of Formal Grammar 1999, eds. Geert-Jan M. Kruijff and Richard T. Oehrle, 25–35. Utrecht.
Ionescu, Emil. 2004. The semantic status of Romanian n-words in negative concord constructions. In Understanding Romanian negation. Syntactic and semantic approaches in a declarative perspective, ed. Emil Ionescu, 83–118. Bucharest: Bucharest University Press.
Iordăchioaia, Gianina. 2004. N-words as negative quantifiers in Romanian. In Understanding Romanian negation. Syntactic and semantic approaches in a declarative perspective, ed. Emil Ionescu, 119–150. Bucharest: Bucharest University Press.
Iordăchioaia, Gianina. 2010. Negative concord with negative quantifiers: a polyadic quantifier approach to Romanian negative concord. PhD diss., University of Tübingen. http://nbn-resolving.de/urn:nbn:de:bsz:21-opus-48224.
Isac, Daniela. 2004. Focus on negative concord. In Romance Languages and Linguistic Theory 2002: selected papers from ‘going romance’, Groningen, 28–30 November 2002, eds. R. Bok-Bennema, et al., 119–140.
Keenan, Edward L. 1992. Beyond the Frege boundary. Linguistics and Philosophy 15: 199–221.
Keenan, Edward L., and Dag Westerståhl. 1997. Generalized quantifiers in linguistics and logic. In Handbook of language and logic, eds. Johan van Benthem and Alice ter Meulen, 837–893. Amsterdam: Elsevier Science.
Klima, Edward. 1964. Negation in English. In The structure of language, eds. Jerry A. Fodor and Jerrold J. Katz, 246–323. Englewood Cliffs: Prentice Hall.
Ladusaw, William A. 1980. Polarity sensitivity as inherent scope relations. New York: Garland.
Ladusaw, William A. 1992. Expressing negation. In Proceedings of SALT 2, 237–259. Columbus: The Ohio State University.
Lindström, Per. 1966. First order predicate logic with generalized quantifiers. Theoria 32: 186–195.
May, Robert. 1989. Interpreting logical form. Linguistics and Philosophy 12: 387–435.
Moltmann, Friederike. 1995. Exception sentences and polyadic quantification. Linguistics and Philosophy 18: 223–280.
Penka, Doris. 2011. Negative indefinites. Oxford: Oxford University Press.
Penn, Gerald, and Frank Richter. 2004. Lexical Resource Semantics: from theory to implementation. In Proceedings of the 11th international conference on Head-driven Phrase Structure Grammar, ed. Stefan Müller, 423–443. Stanford: CSLI Publications.
Peters, Stanley, and Dag Westerståhl. 2006. Quantifiers in language and logic. Oxford: Oxford University Press.
Pollard, Carl, and Ivan A. Sag. 1994. Head-driven Phrase Structure Grammar. Chicago: University of Chicago Press.
Przepiórkowski, Adam, and Anna Kupść. 1997. Negative concord in Polish. Technical report, Institute of Computer Science, Polish Academy of Sciences.
Przepiórkowski, Adam, and Anna Kupść. 1999. Eventuality negation and negative concord in Polish and Italian. In Slavic in HPSG, eds. Robert Borsley and Adam Przepiórkowski, 211–246. Stanford: CSLI Publications.
Richter, Frank. 2007. Closer to the truth: a new model theory for HPSG. In Model-theoretic syntax at 10. Proceedings of the ESSLLI’07 workshop MTS@10, eds. James Rogers and Stephan Kepser, 101–110. Dublin: Trinity College.
Richter, Frank, and Laura Kallmeyer. 2009. Feature logic-based semantic composition: a comparison between LRS and LTAG. In Typed feature structure grammars, eds. Anders Søgaard and Petter Haugereid, 32–92. Frankfurt a.M.: Peter Lang.
Richter, Frank, and Manfred Sailer. 1999. LF conditions on expressions of Ty2: an HPSG analysis of negative concord in Polish. In Slavic in HPSG, eds. Robert Borsley and Adam Przepiórkowski, 247–282. Stanford: CSLI Publications.
Richter, Frank, and Manfred Sailer. 2004. Basic concepts of Lexical Resource Semantics. In ESSLLI 2003—Course material I. Vol. 5 of Collegium logicum. Wien: Kurt Gödel Society Wien. ISBN 3-901546-00-6.
Richter, Frank, and Manfred Sailer. 2006. Modeling typological markedness in semantics: the case of negative concord. In Proceedings of the 13th international conference on Head-driven Phrase Structure Grammar, ed. Stefan Müller, 305–325. Stanford: CSLI Publications.
Richter, Frank, and Manfred Sailer. 2009. Phraseological clauses in constructional HPSG. In Proceedings of the 16th international conference on Head-driven Phrase Structure Grammar, ed. Stefan Müller, 297–317. Stanford: CSLI Publications.
Rowlett, Paul. 1998. A non-overt negative operator in French. PROBUS International Journal of Latin and Romance Linguistics 10 (2): 185–206.
Sailer, Manfred. 2003. Combinatorial semantics and idiomatic expressions in Head-driven Phrase Structure Grammar. Phil. diss. (2000). Arbeitspapiere des SFB 340. 161, Eberhard-Karls-Universität Tübingen.
Sailer, Manfred. 2006. Don’t believe in underspecified semantics: Neg raising in Lexical Resource Semantics. In Empirical issues in syntax and semantics 6, eds. Olivier Bonami and Patricia Cabredo Hofherr, 375–403. http://www.cssp.cnrs.fr/eiss6.
Teodorescu, Alexandra. 2005. Romanian n-words and the finite/non-finite distinction. In Theoretical and experimental approaches to Romance linguistics, eds. Randall S. Gess and Edward J. Rubin, 273–290.
van Benthem, Johan. 1989. Polyadic quantifiers. Linguistics and Philosophy 12: 437–464.
van der Wouden, Ton. 1997. Negative contexts. Collocation, polarity and multiple negation. London: Routledge.
Watanabe, Akira. 2004. The genesis of negative concord: syntax and morphology of negative doubling. Linguistic Inquiry 35: 559–612.
Zanuttini, Raffaella. 1991. Syntactic properties of sentential negation. A comparative study of Romance languages. PhD diss., University of Pennsylvania.
Zanuttini, Raffaella. 1994. Re-examining negative clauses. In Paths towards universal grammar. Studies in honor of Richard S. Kayne, eds. G. Cinque, J. Koster, J. Y. Pollock, L. Rizzi, and R. Zanuttini, 427–451. Georgetown: Georgetown University Press.
Zeijlstra, Hedde H. 2004. Sentential negation and negative concord. Utrecht: LOT Publications.
Acknowledgements
We would like to thank five anonymous reviewers and our NLLT editor, Louise McNally, for insightful criticism and numerous suggestions for improvements. It is only due to their persistent requests that the presentation of LRS became as self-contained as it is. Students at Universität Tübingen and the audience of the 2009 International HPSG Conference in Göttingen asked for clarifications that informed subsequent modifications. Christopher Piñón and Ivan Sag went to great lengths to provide extensive comments that led to substantive revisions and what we hope is a much more lucid line of argumentation than in earlier drafts. Janina Radó did the proofreading, bringing our thoughts into readable shape. Without Manfred Sailer we would not have written this paper. Barbara Partee has much more to do with it than meets the eye: Thank you!
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Iordăchioaia, G., Richter, F. Negative concord with polyadic quantifiers. Nat Lang Linguist Theory 33, 607–658 (2015). https://doi.org/10.1007/s11049-014-9261-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11049-014-9261-9