
Abstract
Machine Learning (ML) and Deep Learning (DL) have achieved high success in many textual, auditory, medical imaging, and visual recognition patterns. Concerning the importance of ML/DL in recognizing patterns due to its high accuracy, many researchers argued for many solutions for improving pattern recognition performance using ML/DL methods. Due to the importance of the required intelligent pattern recognition of machines needed in image processing and the outstanding role of big data in generating state-of-the-art modern and classical approaches to pattern recognition, we conducted a thorough Systematic Literature Review (SLR) about DL approaches for big data pattern recognition. Therefore, we have discussed different research issues and possible paths in which the abovementioned techniques might help materialize the pattern recognition notion. Similarly, we have classified 60 of the most cutting-edge articles put forward pattern recognition issues into ten categories based on the DL/ML method used: Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), Generative Adversarial Network (GAN), Autoencoder (AE), Ensemble Learning (EL), Reinforcement Learning (RL), Random Forest (RF), Multilayer Perception (MLP), Long-Short Term Memory (LSTM), and hybrid methods. SLR method has been used to investigate each one in terms of influential properties such as the main idea, advantages, disadvantages, strategies, simulation environment, datasets, and security issues. The results indicate most of the articles were published in 2021. Moreover, some important parameters such as accuracy, adaptability, fault tolerance, security, scalability, and flexibility were involved in these investigations.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Presently, researchers are captivated by big data, which poses a formidable challenge due to the amalgamation of four primary parameters (velocity, diversity, volume, and quality) that delineate the data flow for pattern detection [58, 113, 128]. Numerous sources of data, both homogeneous and heterogeneous, strive to embody these criteria [22, 23, 56]. Additionally, big data encompasses a repertoire of techniques and tools employed to scrutinize vast amounts of unstructured data, including videos and images [2, 54, 61]. Processing unstructured data presents a formidable task as it lacks the comprehensive structure characteristic of regular data formats, owing to its frequent alterations [24, 102, 105]. One prominent tool that addresses potential challenges and effectively handles large data sets is Hadoop [17, 45, 126]. The progressive advancement in pattern recognition approaches for both structured and unstructured data processing continually expands [44, 114, 117]. This capacity necessitates greater attention to data analysis methodologies that effectively manage these immense and diverse volumes of information [5, 57]. Several analytical techniques have been developed to fulfill the need for high-quality data analysis functions. These encompass visualization, pattern recognition, statistical analysis, Machine Learning (ML), and Deep Learning (DL), all of which contribute to extracting meaningful patterns from extensive data sets [59, 60].
Pattern recognition and other diverse computational methods have proven to be valuable assets in leveraging the potential of big data [25, 132]. Big data fusion with DL and ML has further enhanced computational pattern recognition, leading to insightful predictive findings from acquired data [82, 137]. However, it is important to acknowledge the inherent challenge of dealing with all attributes within vast and similar datasets found in big data [139, 140]. Therefore, new approaches for data certification and conformity must be explored. Advancements in computing technology have opened up possibilities for uncovering hidden values in massive datasets by utilizing various pattern recognition algorithms, which were previously cost-prohibitive [43, 65]. The emergence of pattern recognition has prompted the development of technologies that facilitate real-time accessibility, storage, and analysis of enormous data volumes [40, 87]. Notably, big data methods for visual pattern recognition differ in two key aspects [123, 125]. Firstly, big data refers to data sets that are too large to be stored on a single device [143, 144]. Secondly, the absence of structure in traditional data necessitates the replication of the big data concept, requiring specific tools and approaches [16, 121]. Innovations like Hadoop, Bigtable, and MapReduce have revolutionized visual pattern recognition, addressing significant challenges associated with efficiently handling vast data volumes [103, 129]. Various applications, such as simple Database (DB), NoSQL, Data Stream Management System (DSMS), and Memcached, can be employed for big data, with Hadoop standing out as the most popular and suitable choice [86, 116].
In our study, this paper contributes by conducting a comprehensive Systematic Literature Review (SLR) to evaluate the utilization of DL/ML methods in pattern recognition, addressing previous gaps in the literature. It focuses on practical approaches and categorizes them into ten distinct groups, providing a detailed analysis of each group's advantages, disadvantages, and applications. The paper consolidates findings, considers various factors, and offers a wide range of techniques, contributing to advancements in the field of pattern recognition. We undertook an integrated SLR to comprehensively examine the utilization of DL/ML methods in pattern recognition. Previous SLRs have failed to comprehensively evaluate all aspects of DL/ML approaches in this domain, prompting our research to fill this gap. Consequently, our paper primarily focuses on practical DL/ML approaches within the context of pattern recognition. The significance of our research lies in its exploration of diverse and efficient DL/ML methodologies employed to tackle pattern recognition challenges. We thoroughly analyzed, consolidated, and reported findings from similar publications through the SLR. Additionally, we categorized DL/ML approaches for pattern recognition into ten distinct groups, encompassing Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), Generative Adversarial Network (GAN), Autoencoder (AE), Ensemble Learning (EL), Reinforcement Learning (RL), Random Forest (RF), Multilayer Perception (MLP), Long-Short Term Memory (LSTM), and hybrid models. Each group was meticulously examined, considering various factors such as advantages, disadvantages, security implications, simulation environment, dataset, and the DL/ML approach employed in pattern recognition. The paper emphasizes the techniques and applications of DL/ML methods in pattern recognition, presenting a wide range of techniques that contribute to advancements in this field. Furthermore, we delved deeply into future work that must be implemented in future studies. Overall, this paper's contributions are:
-
Reviewing the present issues pertinent to DL/ML methods for pattern recognition;
-
Presenting a systematic overview of previous works on pattern recognition;
-
Evaluating each approach that emphasized DL/ML methods with diverse aspects;
-
Planning the key aspects that will allow the researchers to develop future works;
-
Explaining the definitions of pattern recognition methods used in various studies.
The subsequent compilation constitutes the framework of this article. The subsequent section elucidates the principal viewpoints and suitable terminology of DL/ML approaches employed in pattern recognition. Section 3 scrutinizes the relevant review papers. Section 4 encompasses the research methodology and tools employed for paper selection. Section 5 encompasses the chosen papers subjected to study and evaluation. The following section presents a comprehensive comparison and discussion of the outcomes, as expounded in Section 6. Section 7 deliberates on future endeavors, while Section 8 elucidates the ramifications. Furthermore, Table 1 provides a catalog of the abbreviations employed in the research.
2 Basic concepts and corresponding terminologies
In this part, we have provided a quick definition of important terms such as DL, ML, big data, and pattern recognition.
2.1 ML and DL
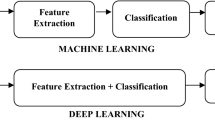
ML is a subset of Artificial Intelligence (AI) that enables computer programs to learn and adapt without human intervention [80, 142]. ML algorithms analyze vast amounts of data to detect patterns and make predictions in various fields such as advertising, finance, fraud detection, and more [62, 133]. It can process diverse data types like words, images, and clicks, making it applicable to digital storage. DL, a branch of ML, uses Artificial Neural Networks (ANN) to simulate the human brain's functioning [31, 141]. DL extracts feature from data by employing multiple hidden layers and progressively abstracts information. With increasing data analysis, DL can identify hidden patterns [67, 90]. It learns from processed data, autonomously extracting features without human involvement [68, 119]. DL techniques have revolutionized language modeling, exemplified by Google Tran slate’s contextual translations facilitated by DL-based Natural Language Processing (NLP). DL's ability to handle complex data and perform advanced tasks positions it at the forefront of AI technologies [3, 75].
2.2 What are big data and its usage?
Big data refers to a vast amount of ever-increasing data sets in a variety of formats, including structured, semi-structured, and unstructured information [74, 92]. Because of the complicated nature of big data, which necessitates powerful algorithms and robust technology, it is defined by the three primary criteria listed below.
-
I.
Volume: A huge amount of digital data is produced continuously from millions of applications and devices. More than several exabytes of data are increasingly produced each year.
-
II.
Diversity: Big data is generated in a variety of formats by several distant sources. Great data series include unstructured and structured data and local, private, completed, or uncompleted data.
-
III.
Distribution: Big data is being used as a successful solution in many fields, including smart grid, E-earth, the Internet of Things (IoT), public utilities, transportation and logistics, political services and government surveillance, and so on. DL/ML, on the other hand, objectively contributes to acquiring knowledge and making judgments for a variety of vital purposes, such as pattern recognition, recommendation engines, informatics, data mining, and autonomous control systems.
2.3 What is pattern recognition?
The detection of the features or data deployment that offer information about a specific system or data set is referred to as pattern recognition [50, 63]. In the professional context, a pattern may be a continuously repeating sequence of data over time that can be used to predict trends, specific configurations of image characteristics that recognize objects, frequent combinations of words and phrases for NLP, or particular groups of behavior on a network that can demonstrate an attack through virtually infinite other likelihoods [81, 89]. Pattern recognition, in essence, crosses several areas of IT, including biometric identity, security and AI, and big data analytics [76, 93]. Pattern recognition is distinct from ML, in which the pattern recognizer, unsupervised, and supervised learning methodologies are widely used during training [34, 94]. In supervised ML, the human contributor gives a representative set of configurable data to characterize the patterns [85, 98]. Unsupervised ML minimizes the use of a human element and pre-existing knowledge [35, 97]. In this approach, the algorithms are trained to discover new patterns without using existing labels simply by being familiar with a large data set. On the other hand, DL can be used to train pattern recognizers alongside machines regarding networks [10].
3 Relevant reviews
In this paper, we have presented a detailed assessment of independent ML/DL algorithms for large data pattern identification in cyber-physical systems and a discussion of the research contributions of these various approaches. Several related survey studies and journal articles based on ML/DL approaches in big data were studied in this regard. Even though we attempt to categorize articles, some of them may not correspond to one category. By the same token, Bai, et al. [11], to make pattern recognition robust and efficient, reviewed several articles accepted on explainable ML/DL. Their broad review of representative studies and current improvements in explainable ML/DL for effective and robust pattern recognition is of high quality, presenting the latest development of interpretability of DL strategies, well-organized and compacted network architectures in particular pattern recognition and new adversarial attacks, and stability preparation is investigated. Moreover, Paolanti and Frontoni [83] put forward new trends and methods of pattern recognition used in various fields, and different pattern recognition techniques have been reviewed. By putting special regard to ML, DL, and statistics, the authors investigated possible solutions for systems development. They mentioned elements like intelligent systems, devices, and end-to-end analytics. Then they examined multiple various fields of pattern recognition applications with particular attention to biology and biomedical, surveillance, social media intelligence, Direct Connect Hub (DCH), and retail.
Also, Zerdoumi, et al. [130] talked about large data, visual pattern recognition, and categorization. They discussed the potential advantages of ML algorithms for pattern recognition in huge data. They emphasized unresolved research difficulties related to the use of pattern recognition in big data. They performed a thorough literature review to demonstrate the applicability of multi-criteria decision approaches and DL algorithms to big data concerns. Moreover, Bhamare and Suryawanshi [13] offered an overview and analysis of several well-known tactics used at various levels of the pattern recognition system and research subjects' recognition and applications that are at the forefront of this intriguing difficult field. They presented pattern recognition frameworks based on several ML algorithms. On this basis, they examined 33 similar experiments from 2014 to 2017.
Smart city development is only one of several domains where common technology has significantly impacted it. As Atitallah, et al. [7] demonstrated this by reviewing several current studies. The primary goal of their research is to look into the use of IoT big data and DL analytics in the enhancement and development of smart cities. Following that, they identified IoT technology and demonstrated the computing foundation and ML/DL applications used by IoT data analytics, which includes fog, cloud, and edge computing. As a result, they investigated well-known DL architectures and their applications, disadvantages, and benefits. Furthermore, as ML and big data analytics have demanded progressive leaps and bounds in information systems and boundaries, Zhang, et al. [135] promised bibliometric research to examine the primary writers' contributions, countries, and organizations/universities in terms of citations, yield, and bibliographic coupling. As a result, they provided valuable information for potential participants and audiences regarding new research topics.
Similarly, the epidemic of chronic illnesses such as CoronaVirus Disease (COVID-19) gave healthcare facilities to populations all over the world [96, 108, 110]. With the advancement of the IoT, these wearables were able to collect context-specific data pertinent to behavioral, physical, and psychological health. By taking this issue into mind, Li, et al. [53] gave an in-depth evaluation of big data analytics in IoT healthcare by evaluating chosen relevant surveys to identify a research gap. Also, they provided cutting-edge smart health. Also, a detailed analysis of related reviews' weaknesses and strengths is shown in Table 2.
4 Methodology of research
The SLR approach was used in this section to understand better Autonomous ML/DL strategies for big data pattern recognition. The SLR is a critical examination of all research on a specific scope. This section will provide an in-depth discussion of ML approaches to pattern identification. Following that, we seek verification of the research selection technique. Subsequent subsections outline the search technique and include Research Questions (RQ) and selection criteria.
4.1 Question formulation
The primary purpose of this study is to categorize, recognize, survey, and assess certain specific existing articles in ML/DL techniques for pattern recognition applications. To achieve the discussed purpose, the aspects and characteristics of the techniques can be thoroughly researched using an SLR. Understanding the main concerns and challenges encountered thus far is the next goal of SLR in this phase. We proposed several RQs that had been pre-specified:
-
RQ 1: How can we identify the paper and select the ML/DL techniques in pattern recognition?
This is covered in Section 4.
-
RQ 2 What are the most important potential solutions and unanswered questions in this field?
Section 7 will present the outstanding issues.
-
RQ 3: How can the ML/DL methods in pattern recognition be categorized in big data? What are some of their instances?
The answer to this question can be found in Section 5.
-
RQ 4: What methods do the researchers use to conduct their investigation?
4.2 The paper selection procedure
The following four stages design the paper selection and search procedure for this research. This procedure is depicted in Fig. 1. Table 3 displays the terms and keywords for searching the articles at the first level. The articles in this set are the outcome of a typical electronic database query. Electronic databases used include Springer Link, ACM, Scopus, Elsevier, IEEE Explore, Emerald Insight, Taylor and Francis, Peerj, Dblp, ProQuest, and DOAJ. Books, chapters, journals, technical studies, conference papers, and special issues are also established. Stage 1 has 612 items allocated to it. Figure 2 displays the distribution of articles by publication.

The stages of the paper searching and selection procedure

The distribution of selected papers by publishers in the first stage
Stage 2 consists of two processes for determining the total number of articles to be researched. Figure 3 depicts the publisher's distribution of articles at this point. The papers are initially judged based on the criteria shown in Fig. 4. 305 articles are still present. In stage 2, the survey papers are extracted.; out of the 305 papers that remained in the previous stage, 35 (11.47%) were survey papers. There are presently 188 papers available. In step 3, the titles and abstracts of the articles were examined. Finally, 95 publications that met the stringent conditions were chosen to analyze and investigate the other papers. The distribution of the selected papers by their publishers is shown in Fig. 5. There were 60 manuscripts left for the final round, and Fig. 6 displays the journals that published the studies at that point.

The distribution of selected papers by publishers in the second stage

Standard for selecting papers proces

The distribution of selected papers by publishers in the third stage

The distribution of selected papers by publishers in the fourth stage
5 Techniques for autonomous ML for big data pattern recognition
This section investigates autonomous ML/DL algorithms for large data pattern detection in a variety of applications. We are going to touch on distinct articles in the following paragraphs. 10 categories of ML/DL techniques, including CNNs, RNNs, GANs, AEs, ELs, RLs, RFs, MLPs, LSTMs, and hybrid emphasis studied articles, are appropriately organized into them. Figure 7 depicts the proposed assortment of ML/DL Techniques used in pattern recognition.

The introduced taxonomy of DL/ML methods for pattern recognition
5.1 CNN mechanisms for pattern recognition
CNN is one of the most important ML/DL techniques because it can take an input image, assign importance (learnable biases and weights) to distinct objects/facets in the image, and compare them. In comparison, CNN requires less pre-processing than other techniques. CNN can learn these features/filters the same way trained filters in primary mechanisms are hand-engineered. CNN's architecture is inspired by the connection between the pattern of the human brain's neurons and the structure of the visual cortex. Individual neurons respond to spurs in a restricted visual field area known as the receptive field. Such fields congregate to overlap adequately to cover the entire visual region. In this regard, Awan, et al. [8] used a Deep Transfer Learning (DTL) method known as the Apache Spark system, which is a large data framework that uses a 100%-accuracy CNN. ResNet50, VGG19—on COVID-19 chest X-ray images—and Inception V3 are three architectures used to quickly identify and isolate positive COVID-19 patients [111, 112]. However, COVID-19/pneumonia/normal detection accuracy was 98.55% for the ResNet50 and VGG19 models and 97% for the inceptionV3 design. The authors investigated weighted recall, weighted precision, and accuracy as DTL operation metrics. The results of ResNet50, VGG19, and InceptionV3 were excellent, and these three models for binary-class assortment provided 100% detection accuracy. While categorizing the three classes, VGG19, ResNet50, and Inception V3 achieved 98.55%, 98.55%, and 97% accuracy, respectively.
Furthermore, one of the most important financial markets is the stock market, which generates a lot of money, but the most difficult challenge that has not been solved is deciding which stocks to buy and when to buy or sell shares. With this issue in mind, Sohangir, et al. [101] provided the idea of using DL systems to construct the sentiment analysis feature for StockTwits. CNN, doc2vec, and LSTM were among the models used to analyze stock market ideas submitted on StockTwits. The authors used n-grams, bi-grams, unigrams, and the CNN method to extract document sentiment efficiently. Then, they used logistic regression based on a set of terms. They concluded that the CNN method effectively extracts stock emotion from their utterances.
Also, Hossain and Muhammad [39] proposed an emotion recognition system based on big emotional data and a DL method big data comprises video and voice, in which a speech signal is processed in the beginning to obtain a Mel-spectrogram in the frequency domain, and can be considered an image. As a result, a CNN employed the Mel-spectrogram. The authors employed 2D and 3D CNN for the voice and video signals, respectively, and their results showed that the ELM-based fusion performed better than the categorizer's composition because ELMs add a significant degree of non-linearity to the feature fusion.
Also, Ni [79] evaluated CNN to generate many visual attributes, then lowered the number of calculations, followed by a dimension reduction by the pooling layer. The increased ReLU performance, ReLU employed, and the effect of less performance of the model were investigated for the network structure based on LeNet-5 to be more helpful for face image processing. The authors used CelebA as a training set for the model and LEW as a testing set for performance testing. As a result, the produced LeNet-5 model with A-softmax loss had a shorter training time when using A-software and softmax loss between LeNet-5, implying a faster convergence speed in this model. Following that, A-softmax loss was employed throughout an LFW testing set, and as a result, the recognition accuracy of the produced LeNet-5 was significantly greater than that of LeNet-5With increased size, the recognition rate of the two models increased, and the difference between the two models widened.
By the same token, Xu, et al. [122] created an emotion-sensitive learning framework that analyzes the cognitive state and approximates the learners' focus and mood based on head posture and facial expression in a non-invasive manner. As a result, the learners' emotions are assessed based on their facial expressions. They concluded that their suggested method can approximate learner attention and sentiment with 88.6% and 79.5% accuracy rates, demonstrating the system's strength for evaluating sentiment-sensitive learning cognitive circumstances.
Additionally, Li, et al. [55] presented a deep CNN model to reach the hierarchical properties of huge data by extending the CNN from vector space to tensor space using the tensor representation paradigm. To avoid overfitting and improve training efficiency, a tensor convolutional procedure is provided to fully use the local properties and topologies present in the huge data. Furthermore, they applied a high-order back promotion algorithm for teaching the deep convolutional computational model's parameters in the high-order space. Finally, tests on three datasets, SNAE2, CUAVE, and STL-10, demonstrated their model's capacity to learn big data and traditional data features.
Finally, Sevik, et al. [95] created a deep network capable of recognizing both letters and fonts in Turkish. A pre-trained network has been taught using around 13 thousand images to accomplish this goal. The letter and font identification training accuracies are 100% and 73.44%, respectively. Because the type of faces is similar, they used a possibility calculation after determining the network output to improve the font recognition percentage. Although the first test image font's accuracy is 14/26% because the probability is greater than 0.5%, they recognized it as Arial, and the function was slightly improved as a result. Following then, 12 images containing letters were addressed to the network test. As a result, letter identification accuracy with this network was roughly 100%, but font accuracy recognition was low. Table 4 discusses the CNN methods used in pattern recognition and their properties.
5.2 RNN mechanisms for pattern recognition
An RNN is a type of ANN in which node connections form either an undirected or directed graph based on a transitory sequence. As a result, it exhibits a transient dynamic style. RNNs, which are derived from feedforward neural networks, can process varying length sequences of inputs by utilizing their interior state (memory). As a result, they can be employed for tasks such as unsegmented, connected speech recognition, or handwriting recognition. "RNN" refers to a network's class with an infinite impulse response, whereas "CNN" refers to a class with a finite impulse response. Both classes of networks show a transient dynamic manner. In this regard, Jun, et al. [47] presented a mechanism for character extraction based on RNN AEs. The RNN AEs range the initial skeleton information more discriminatively and decrease unrelated data, which is especially significant with the LSTM AE, which performed better than the Generic Encapsulation (GRE AE). As a result, the characteristics shape the recognition operation of RNN DMs (Direct Messages) and other DMs. Through the DMs, the GRE DM outperforms the GRE AE, and the GRE DM outperforms the LSTM DM in terms of accuracy. The RNN AE-DM hybrid structures that are nourished with the characteristics perform better than the separate RNN SMs nourished with the initial skeleton information. They do so with less training time and fewer learning elements. Furthermore, the RNN AE-two-pace DM's training is more efficient than the End-to-End model's single training with a similar input stream.
Chancán and Milford [15] suggested an RNN + CNN model that can learn meaningful transient connections from a single image sequence in a large drawing dataset.; when standard sequence-based techniques surpass in terms of runtime, computing requirements, and accuracy. The authors used a minor two-layer CNN to examine DeepSeqSLAM's end-to-end training method, but their basic results showed that the CNN element does not generalize well to dramatic visual differences, which was estimated given that these models require a large amount of data for efficient generalizing and training. They tested their method on two large benchmark datasets: Oxford RobotCar and Nordland, which logged over 10 km and 728 km tracks, respectively, over a year with varying seasons, lighting conditions, and weather. On Nordland, they compared their model with two sequence-based mechanisms along the entire road under seasonal fluctuations, using a sequence length of 2, and showed that their model could attain above 2% AUC for SEQSLAM and 72% AUC in compared with 27% AUC for Delta Descriptors.; when the arrangement time is reduced from roughly 1 h to 1 min.
As well, Gao, et al. [30] proposed an effective RNN transducer-based Chinese Sign Language Recognition (CSLR) method. They used RNN-Transducer in CSLR for the first time. To begin, they created a multi-level visual hierarchy transcription network using phrase-level BiLSTM, gloss-level BiLSTM, and frame-level BiLSTM to examine multi-scale visual semantic properties. Following that, a lexical anticipating network was used to model the contextual data from sentence labels. Finally, a collaborative network seeks to learn language representations as well as video properties. It was then fed into an RNN-Transducer to optimize adjustment learning between sentence-level labels and sign language video. Extensive examinations of the CSL dataset confirmed that the provided H2SNet can achieve higher authenticity and faster velocity.
Besides, Hasan and Mustafa [36] suggested an effective mechanism for robust gait recognition using an RNN that is related to Gated Recurrent Units (GRU) architecture and is exceptionally powerful in capturing the transient dynamics of the human body gesture sequence and executing recognition. They created a low-dimensional gait characteristic descriptor derived from 2D that mixes human gesture data, is unaffected by diverse covariate factors, and is efficient in describing the dynamics of various gait paradigms. According to their findings, the experiment using the CASIA A and CASIA B gait datasets demonstrated that the given methodology surpasses the current approaches.
As offline Persian handwriting recognition is an issue task due to the Persian scripts' cursive essence and sameness through the Persian alphabet letters, Safarzadeh and Jafarzadeh [91] proposed a Persian handwritten word identifier based on a continuous labeling mechanism with RNN. A Connectionist Temporal Classification (CTC) loss operation is also exploited to remove the segmentation pace required in convolutional systems. Following that, the layers are used to exploit the sequence of features from a word picture. Overall, the RNN layer with CTC performance was used for labeling the input succession. As a result, they demonstrated that this composition is an appropriate robust recognizer for the Persian language. Consequently, they tested the approach on IFN/ENIT, Arabic, and Persian datasets.
Furthermore, Zhao and Jin [138] enhanced a "doubly deep" approach in temporal and spatial layers of recurrent and convolutional networks for performance recognition. To begin, they presented a developed p-non-local performance as a common efficient element for capturing long-distance relationships. Second, they proposed Fusion KeyLess Attention in the class forecast level merging with the backward and forward bidirectional LSTM to learn the sequential essence of the information more effectively and elegantly, which employs a multi-epoch model fusion based on the confusion matrix. The authors tested the proposed model on two heterogeneous datasets, Hollywoods and HMDB51, which resulted in the model outperforming standard models and thus just using Rotating Graphics Base (RGB) features for performance action recognition based on RNN. Table 5 discusses the RNN methods used in pattern recognition and their properties.
5.3 GAN mechanisms for pattern recognition
A GAN is a type of ML/DL framework that learns to produce new information with the same statistics as the training set in a given set. A GAN educated on images, for example, can produce new images that appear to human observers to be at least allegedly genuine, with multiple realistic qualities. Despite being primarily proposed as a type of generative model for unsupervised learning. GANs have also been shown to aid reinforcement learning, semi-supervised learning, and entirely supervised learning. The main principle behind a GAN is "indirect" training among the separator, a further neural network that can determine how much input is common-sense and constantly updated. This indicates that the producer is not educated to reduce the distance to a certain image but rather to deceive the separator. This allows the model to learn an unsupervised behavior. In this regard, Luo, et al. [66] presented a Face Augmentation GAN (FA-GAN) to reduce the impact of uneven property distributions. The authors used a hierarchical disentanglement module to decouple these attributes from the identity representation. Graph Convolutional Networks (GCNs) are also employed for geometric data recovery by exploring the interrelationships between local zones to provide identity protection in face information augmentation. Broad examinations of face reconstruction, identification, and manipulation revealed the efficacy of their proposed approach.
Additionally, Gammulle, et al. [28] addressed the problem of fine-grained action fragmentation in sequences in which various performances are proposed in an unsegmented video stream. The authors introduced a semi-supervised frequent GAN model for fine-grained human activity segmentation. A Gated Context Extractor (GCE) module, a combination of gated attention units, seizes transient context data and leads it among the generator model for increased functionality segmentation. GAN is created to enable the model to satisfy the action taxonomy accompanying the unsupervised, normal GAN learning process due to learning features in a semi-supervised behavior. Finally, the result showed that it could outperform the current state-of-the-art on three major datasets: MERL shopping and Tech egocentric performances dataset and 50 salads.
Also, Fang, et al. [27] presented a face-aging approach called Triple-GAN for organizing age-processed faces. Triple-GAN has adjusted increased adversarial loss to emphasize the synthesized faces’ realism and learn efficient mapping along age margins. Rather than resolving ages as independent clusters, triple translation loss has been coupled to an additional model to the intricate solidarity of multiple age ranges and simulates more realistic age enhancement, another enhancing the generator's predominance. Multiple qualitative and quantitative examinations performed on CACD, MORPH, AND CALFW showed the efficiency of their proposed mechanism.
Chen, et al. [21] presented the NM-GAN anomaly distinction model, which incorporates the discrimination network D in the GAN-like architecture as well as the reconstructing network R. Their work provided a significant contribution by regulating the generalization capability of detection capabilities of networks D and R by embedding the noise map into an end-to-end adversarial learning technique at the same time. The authors provided the model to improve the discriminator's detection capability and the generative model's generalization capability in an integrated architecture. According to the results of the studies, their model outperforms most competing models in terms of stability and accuracy, demonstrating that the offered noise-modulated adversarial learning is efficient and trustworthy.
Finally, Men, et al. [72] developed an attribute-Decomposed GAN, a new generative model for controllable person image combination capable of producing realistic person images with desired human attributes derived from various source inputs. The authors fundamentally integrated human traits as distinct codes in the hidden space and subsequently obtained flexible and sequential management of attributes through combination and interpolation performances in vivid style representations. They specifically presented a design that incorporates two encoding routes connected by style block connections for the aim of principal hard mapping deconstruction into multiple accessible subtasks. They then used an off-the-shelf human decomposer to exploit component layouts and feed them into a shared global texture encoder for decomposed hidden codes. As a result, they concluded that their proposed approach is more effective than the existing ones. Table 6 summarizes the GAN approaches and their properties in pattern recognition.
5.4 AE mechanisms for pattern recognition
An AE is a type of ANN that is used to learn effective coding of unlabeled data. An attempt to recreate the input from the encoding authenticates and purifies the encoding. The AE learns to serve a data set, typically for dimensionality reduction, by training the network to ignore irrelevant information. The variant present addresses the need to force known representations to assume useful properties. AEs are used for a variety of tasks, including feature detection, anomaly detection, facial recognition, and determining the meaning of words. Furthermore, AEs are generative models: they are capable of producing new information that appears to be input information by accident. By this token, Simpson, et al. [100] presented a reduced sequenced modeling mechanism based on the availability of output and input data for developing a representation that can mimic the reaction of nonlinear infrastructure systems under "unseen" compelling time histories. They demonstrated the modeling approach and its efficacy on various nonlinear systems of variable size and complexity.
Also, Kim, et al. [49] introduced a parallel end-to-end Text-To-Speech (TTS) system that generates more natural-sounding audio than the previous two-step approaches. Their technique modified variable assumptions raised using normalizing streams and an adversarial training procedure, which developed generative modeling's stunning strength. The authors also proposed a stochastic duration predictor to unify speech with different rhythms from input text. Their model asserted the natural one-to-many link in which text input can be spoken in numerous directions with diverse rhythms and pitches using the unpredictable modeling over hidden variables, the stochastic duration predictor. A subjective human evaluation of the LJ speech, a unique speaker dataset, showed that their method surpassed the best publicly available TTS systems and achieved a Metal Oxide Semiconductor (MOS) comparable to trustworthiness.
Furthermore, Utkin, et al. [107] developed a mechanism for modeling an anticipating DL model that combines the variational AE and the conventional AE. The variational AE provided a series of vectors based on the previously described picture embedding at the testing or describing level. Following that, the conventional AE's directed decoder section rebuilt a succession of images that configured a heatmap explaining the original explained image. Finally, they tested their model on two well-known datasets, CIFAR10 and MNIST.
Additionally, et al. [84] developed a generative AE model with dual contradistinctive losses to produce a generative AE that simultaneously acts on both reconstruction and sampling. The suggested model, known as the dual contradistinctive generative AE (DC-VAE), combined an instance-stage discriminative loss with a set-level adversarial loss, both of which are contradistinctive. They analyzed extensive experimental conclusions by DC-VAE over various resolutions consisting of 32 × 32, 64 × 64, 128 × 128, and 512 × 512 are recorded. The two contradistinctive losses in VAE function concord in DC-VAE resulted in specific quantitative and qualitative operations gained across the baseline VAEs missing architectural variances.
Moreover, Bhamare and Suryawanshi [13] proposed an end-to-end algorithm, VGELDA, that complemented diverse deduction and graph AEs for IncRNA-disease contributions forecasting. VGAELDA included two types of graph AEs. The association of both the VGAE for substitute training and graph representation learning by various assumptions intensified the ability of VGAEDA to grasp effective low-dimensional representations from high-dimensional characteristics and therefore allowed the accuracy and robustness for forecasting IncRNA-disease contributions. Their analyses highlighted the solvation of the designed co-training framework of IncRNA for VGAELDA, a geometric matrix issue for grasping effective low-dimensional representations by a DL method.
Besides, Atitallah, et al. [7] developed a 5-layer AE-based model for detecting unusual network traffic. The primary architecture and parts of the suggested model were developed as a result of a thorough investigation into the influence of an AE model's major function indicators and recognition accuracy. According to their results, their model achieved the maximum accuracy using the proposed two-sigma outlier availability method and Metropolitan Area Exchange (MAE) as the rebuild loss criterion. The authors used MAE based on rebuild loss performance to achieve the maximum accuracy for the AE model used in network anomaly recognition. In comparison to alternative model architectures, the suggested model with the optimal number of neurons exploited at each latent space layer delivers the best function. Finally, they tested the model using the widely used NSL-KDD dataset. Compared to similar models, the performance attained 90.61% accuracy, 98.43% recall, 86.83% precision, and 92.26% F1 score.
On the other hand, Zhang, et al. [135] introduced an attack architecture, Anti-Intrusion Detection AE (AIDAE), to create features to disable the IDE. An encoder in the framework sends parts into a hidden space, while many decoders reconstruct the sequence and distinct properties accordingly. The authors tested the framework using datasets from UNSW-NB15, NSL-KDD, and CICIDS2017, which resulted in the system degrading the detection function of existing Intrusion Detection Systems (IDSs) by producing features. Table 7 discusses the AE methods used in pattern recognition and their properties.
5.5 EL mechanisms for pattern recognition
EL mechanisms in ML/ DL and statistics use many learning algorithms to provide higher predictive functions than each component learning algorithm solidarity. In contrast to a statistical ensemble in statistical mechanics, an ML ensemble, which is often unlimited, includes just a limited specific sequence of alternative models but normally seeks a more flexible structure to exist amongst those substitutes. With this in mind, Abbasi, et al. [1] presented an EL called ElStream uses seven various artificial and real datasets for assortment. Various ensemble and ML algorithms based on majority voting are used. The ELStream technique employed elegant ML algorithms that are evaluated using f-scores and accuracy criteria. The baseline approach achieved the highest accuracy of 92.35%, but the ElStream mechanism achieved the highest accuracy of 99.99%, displaying a skilled utility of 7.64%. According to their findings, the proposed Elstream method can identify idea drifts and categorize data more accurately than earlier research.
By this token, Zhang, et al. [134] suggested an EL model that directly forecasted Vickers hardness, which consists of anomalous load-dependent hardness, with quantitative accuracy. Their approach was confirmed by developing a unique hold-out test set of hard materials and analyzing eight metal disilicides. Both provided excellent assurance in achieving hardness at all loads for both materials. The model used to anticipate the hardness of 66,440 is part of Pearson's crystal dataset, which contains probable hard characteristics in just 68 previously unexplored materials. The proposed approach of direction finding is set to update the search for innovative hard material by leveraging ML's effectiveness, transferability, and scalability.
Additionally, Lee, et al. [52] proposed a unified ensemble technique called SUNRISE, which is compatible with different off-policy RL algorithms. Two important components that have been integrated are (a) an interference technique that selected functions for effective inspection by using the highest upper-confidence limits and (b) Weighted Bellman backups relied on ambiguity approximates from a Q-ensemble to re-weight marked q-values. The authors implemented the method among agents using Bootstrap with random initialization to show that these various ideas are highly orthogonal and can be beneficially integrated, as well as the subsequent development of the performance of existing off-policy RL algorithms, such as Rainbow DQN and a Soft Actor-Critic, for both separate and continuous control tasks on both high-scale and low-scale ecosystems.
Onward, Mohammed, et al. [73] contributed to the critical improvement of an entirely digital COVID-19 test [109] using ML mechanisms to analyze cough recordings. They developed a way for creating crowdsourced cough sound examples by breaking/insulating the cough sound into non-overlapping coughs and utilizing six different representations from each cough sound. It was assumed that there was unnoticeable data loss or frequency deformation. They did not attain more than 90% accuracy due to a large degree of overlap among the class of characteristics. However, this unbiased selection criterion ensures that the predictive model is as independent kinds of the pattern and categorizer as possible.
On the other hand, Khairy, et al. [48] presented a voting prepositioning and boosting ensemble model for banknote recognition. A mixture of ten algorithms and nine different pairings were sampled, yielding an exact accuracy rate. Experiments on Swiss franc banknote and banknote authentication datasets showed that ensemble algorithmic models could create accurate identification of exclusive methods. With the banknote authentication dataset, voting and AdaBoost served for a maximum of 100% and 99.90%, respectively, while the Swiss franc dataset served for a maximum of 99.50 percent. As a result, testing and analyzing the offered models confirmed their adequacy and applicability for detecting counterfeit banknotes.
Zhang, et al. [136] advocated employing ML technologies to solve the PPH predictive detection problem. Two principal contributions were (1) the well-organized EL approaches and (2) the amassing of a big clinical dataset. Their DIC and PPH datasets each have 212 and 3842 records. The trained prediction detection model produced accurate findings. As a result, the accuracy of real PPH detection would increase to 96.7%; The overall accuracy of anticipating Disseminated Intravascular Coagulation (DIC) can surpass 90%. Table 8 displays the EL methods used in pattern recognition and their properties.
5.6 RL mechanisms for pattern recognition
RL is a branch of ML concerned with how intelligent agents should be enforced in an ecosystem to increase the concept of crowded awards. RL is one of the three main ML patterns found in supervised and unsupervised learning. RL differs from supervised learning because it does not require labeled output/input pairs to be presented, and it does not require sub-optimal performance to be adjusted. Because dynamic programming approaches are utilized in the context of RL algorithms, the environment typically begins in the shape of a Markov decision process. Automatic surgical gesture recognition, such as competence appraisal and conducting sophisticated surgical inspection tasks, is a fundamental advancement in robot-assisted surgery. In this regard, Gao, et al. [29] suggested a framework for simultaneous surgical gesture assortment and segmentation based on RL and tree search. An agent was instructed whose direct actions were appropriately reviewed via tree search to collect and segment the surgical video in a human-like behavior. The proposed tree search algorithm unified the outputs from two designed value networks and neural networks policy. Overall, the proposed method consistently outperformed existing strategies on the suturing task of the JIGSAWS dataset in terms of edit, accuracy, and F1 score. Finally, they discussed the usage of tree search in the RL framework for robotic surgical applications.
Benhamou and Saltiel [85] also handled the difficult task of modifying and determining portfolio commitment to the crisis ecology. The authors exploited contextual data with the help of a second deep RL sub-network. The model considered portfolio approaches standard disparity, such as contextual data, and portfolio methods over multiple rolling periods, such as the Citigroup economic surprise index, risk aversion, and bond-equity correlation. The additional contextual data made the dynamic property manager agent's learning more resilient to crises. Furthermore, using the standard deviation of portfolio strategies generated a significant indication for future crises. Their model outperformed typical financial models in terms of functionality.
Besides, Wang and Deng [114] provided an adoptive border to learn balanced operation for many races that rely on large border losses. The proposed RL is based on a Race Balanced Network (RL-RBN), which formulated the procedure of discovering the optimal borders for non-caucasian as a Markov decision procedure and used deep Q-learning to learn rules for an agent to choose the proper border by estimating the Q-value operation. Agents reduced the skewness of attributes distributed between races. They also created two ethnicity-aware education databases. The datasets BUPT-Balancedfaced and BUPT-Global face were used to analyze racial prejudice from both algorithm facets and data. Several large-scale analyses of the RFW database showed that RL-RBN successfully lowers racial prejudice and learns a fairer operation.
In addition, Wang, et al. [115] modeled an online key decision process in dynamic video segmentation as a deep RL issue and learned an impressive scheduling rule from special data about the history and the procedure of maximizing global return. They also looked into dynamic video segmentation on face videos, which has never been done previously. They demonstrated that the operation of their reinforcement key scheduler surpasses that of alternative baselines in terms of running velocity and efficient key selections by analyzing the 300VW dataset. According to their findings, their provided method was generalizable to various modes, and they introduced an online key-frame decision in dynamic video segmentation for the first time.
Further, Ma, et al. [69] proposed a DL solution for robust action identification with WiFi that exploits an RL agent to recognize the original neural architecture for the identification algorithm. They evaluated the provided design using real-world tracks of 5 activities carried out by seven people. The introduced concept achieved 97% average identification accuracy for unidentified receiver directions/places and unseen people. When the neural architecture was manually examined, the RL agent exhibited a 15% improvement in accuracy. In collaboration with the RL agent, the state machine improved the additional 20% accuracy by learning transient dependencies from previous assortment outcomes. Two public datasets assess the presented design and reach 80% and 83respectively.
Moreover, Gowda, et al. [32] proposed a centroid-based model that clustered semantic and visual models, considered full training instances at once, and generalized precision to samples from previously undiscovered classes. They optimized the clustering using RL, which is serious for their model to work. They discovered that it consistently outperformed the proposed model in the most standard datasets, including HMDB51, Olympic Sports, and UCF101, by calling the presented method CLUSTER, which was both in generalized zero-shot learning and zero-shot assessment. They also outperformed their model in the image-board competition. Table 9 lists the RL methods and their attributes utilized in this topic.
5.7 RF mechanisms for pattern recognition
RF decision is an aggregate learning technique for assortment, regression, and other tasks that involves constructing many decision trees during training. For assorting tasks, the RF yield is the class picked by the majority of trees. The average forecast or mean of exclusive trees is returned for regression tasks. RFs are ideal for decision trees since they have a habit of overfitting to the training series. RFs outperform decision trees on average, but their accuracy is lower than that of gradient-increased trees. In this regard, Awan, et al. [9] proposed a solution to a security problem that resulted in a secure platform for social media users. The solution used facial recognition and Spark ML lib to train 70% of the profile data on ML and then investigated the remaining 30% of data to investigate prediction and accuracy. Their prediction model was based on words such as reading datasets from CSV characteristic engineering training data using RF, displaying learning curves, plotting confusion matrix, and plotting ROC cure. They achieved 94% accuracy. The limitation of this plan consisted of multiple false positive outcomes that can alter the result operation by up to 6%.
Also, Moussa, et al. [77] applied the fractional coefficients method for facial recognition scope. In addition, they applied RF and SVM in face recognition over the Euclidean distance. They then compared and examined the functions of RF and SVM to categorize the characteristic vectors, and the results of the assortment issued from various characteristics created the model's outstanding benefit, followed by selecting the Discrete Cosine Transform (DCT) coefficients. The authors demonstrated efficient results of applying the RF in terms of accuracy when compared to SVM and Euclidean distance while the face recognition algorithm is investigated. As a result, despite SVM, unique decision trees in the RF instructive performances were automatically used more frequently in the training phase, resulting in separate predictions blended to generate an accurate RF.
Besides, Marins, et al. [71] established an approach for identifying and categorizing problematic events across the operational performance of O&G generation lines and wells. They considered seven types of faults with normal performance status. The enhanced system used a categorizer based on the RF algorithm and a Bayesian non-convex optimization technique to optimize the system hyperparameters. Three tests were included to evaluate the system's capability and robustness in diverse fault recognition/taxonomy settings: tests 1and 2 regarded the binary normal × faulty situations, that the flaws were standing altogether and exclusively, respectively; test 3 draws the multiclass scenario, that the system operated simultaneous fault recognition and assortment and is the best for functional utilization. Besides the high accuracy, the system also reached a short recognition latency, detecting the fault before finishing 88% of its temporal period, so it generated more time for the conductor to decrease associated destructions.
Moreover, Jiao, et al. [46] focused on a computational TTCA recognizer called iTTCA-RF, utilizing the hybrid characteristics of Global Positioning System Data (GPSD), PAAC, and GAAPC. Using the MRMD-successful characteristic selection approach and IFS theory, the top 263 relevant characteristics were chosen to construct the best operation predictor. In this manner, the imbalance problem was addressed by utilizing the SMOTE-Tomek resampling process. ITTCA-RF reaches the best CV appraising BACC value of 83.71% which is 4.9% higher than the related valuing of the prior stated best predictor. The independent experiment BACC point was 73.14% development of 2.4%, and joint Sp and Matthews Correlation Coefficient (MCC) values enhanced by 4.0% and 4.6% accuracy respectively as well.
Additionally, Hafeez, et al. [33] developed a model to identify the action; each action derived based on the character derived from a method of directional angle, time-domain, and depth motion map, for the Huthe man Action Recognition (HAR) system. They used multiple RF algorithms as a categorizer with a benchmark UTD-MHAD dataset and achieved an accuracy of 90%. As a result, they demonstrated that the identification handled by their method is much improved in terms of imprecision and efficiency.
Besides, Langroodi, et al. [51] provided a fractional RF algorithm to develop an accurate activity detection model. They tested the generalizability of the suggested technique by applying it to three case studies in which several scenarios were constructed. Consequently, they reached these results: (1) The current Frame Relay Forum (FRF) can give equivalent operation to contemporary DL-based activity detection systems with only a fraction of the training dataset used in earlier techniques, with an accuracy of up to 94% for articulated equipment and 99% for rigid body equipment. (2) Compared to other baseline superficial learners, FRF performs better in accuracy, recall, and precision.; (3) With an accuracy of 86.2%, the FRF approach can forecast activities of an actual piece of equipment in varied shapes/sizes. In a repeated scenario of testing the technique on scaled RC equipment, FRF achieved an accuracy of 72.9%, which is equivalent to the results reported in existing machine-learning-based techniques.
Moreover, Akinyelu and Adewumi [4] developed a content-based phishing recognition system that bridged a recent gap discovered in their research. The authors employed and documented the use of RF ML in categorizing phishing strikes. The primary goal is to upgrade created phishing email categorizers with greater forecasting accuracy and fewer features. Afterward, they examined the proposed method on a dataset including 2000 ham and phishing emails, a series of eminent phishing email features extracted and exploited by the ML algorithm with a consequence categorizing accuracy of 99.7% with a trivial false positive rate of about 0.06%. Table 10 deliberates the RNN approaches used in pattern recognition and their properties.
5.8 MLP learning mechanisms for pattern recognition
A class of feedforward ANN called multilayer perceptron, which is utilized vaguely, sometimes means any feedforward ANN, usually severely points to networks combined of several layers of perceptron, terminology, and see. The multilayer perceptron is commonly referred to as a "vanilla" neural network, especially when they comprise a single hidden layer. An MLP includes as many as three-node layers: a concealed layer, an input layer, and an output layer. Each node is a neuron with nonlinear activation performance except for the input nodes. For training, MLP employs a supervised learning method known as backpropagation. MLP is distinguished from a linear perceptron by its several layers and non-linear activation. It is capable of distinguishing information that is not linearly divisible. By the same token, de Arruda, et al. [6] focused on improving a systematic method of recognition-among concepts from feature selection, pattern recognition, and network science-the features that are especially particular to prose and poetry. The authors drew on the Gutenberg database for poetry and prose. They summarized the texts in terms of total recognition of the phones and rhymes. Their contour was characterized in terms of some supplied criteria, which included the coefficient of the diversity of time intervals and the mean, which is then used to choose amongst data property selectors. They expressed the connection of patterns as a complex network of instances.
Also, Chen, et al. [18] introduced an LPR-MLP hybrid pattern that utilizes ReliefF, PCA, and Local Binary Pattern (LBP) due to process image information and meteorological mechanics information, and thus exploited MLP to forecast its health stage, then solved the issue of forecasting the health state of transmitting lines below multimode, high-dimension, heterogeneous, nonlinear, information. According to their findings, the LPR-MLP pattern outperformed the other classic patterns in terms of forecasting accuracy and function. Their provided model generated a fresh notion and effective transmission line health forecasting methodologies, but the rough character of the feature identified from data photos is a disadvantage.
Also, Zhang, et al. [131] presented a new MorphMLP architecture that focused on collecting local information at low-stage layers while gradually shifting to focus on long-term modeling at high-stage layers. They specifically designed a fully-connected-Like layer, understood as MorphFC, of two morphable filters that enhanced their receptive field progressively over the width and height dimensions. They also offered to modify the MorphFC layer in the video spectrum freely. They created an MLP-like backbone for learning video outlines for the first time. Finally, they looked at large-scale tests on picture assortments, semantic fragmentation, and video assortment.
Similarly, Chen, et al. [20] presented a typical MLP-like architecture, CycleMLP, that was an adaptable backbone for dense forecasting and visual recognition. Compared to recent MLP architectures such as Gmlp, ResMLP, and MLP-Mixer, whose architectures complement picture size and are hence unachievable in object detection and fragmentation, CycleMLP offers two advantages. (1) it achieved linear computing complexity to image size by employing local windows. (2) It could handle a variety of image sizes. Mutually, prior MLPs had O(N2) computations owing to fully spatial relations. The authors constructed a family of patterns that exceed present MLPs and even state-of-the-art Transformer-based patterns. CycleMLP-Tiny outperformed Swin-Tiny by 1.3% mIoU on ADE20K dataset with lower FLOPs. Additionally, CycleMLP displayed great zero-shot robustness on the ImageNet-C dataset as well.
Moreover, Hou, et al. [41] proposed an MLP-like network architecture for visual detection called Vision Permutator. They showed that individually encoding the width and height data can greatly develop the pattern action compared to current MLP-like patterns that consider the two spatial sizes as one. Despite the significant advancement over concurrently famous MLP-like patterns, a significant downside of the given Permutator is the scaling issue in spatial sizes, which is prevalent in other MLP-like patterns. Because the characteristics' forms in the fully-connected layer are designed, processing input photos with arbitrary forms is impossible, making MLP-like patterns difficult to exploit in downstream tasks with different-sized input images. Table 11 discusses the MLP methods used in pattern recognition and their properties.
5.9 LSTM mechanisms for pattern recognition
LSTM is a type of artificial RNN architecture used in DL. Unlike traditional feedforward neural networks, LSTM contains a feedback loop that can process individual data points and entire data sequences. A standard LSTM module consists of an input gate, a cell, a forget gate, and an output gate. The cell refers to values at arbitrary time intervals, and the three gates control the current of data in and out of the cell. LSTM networks are designed to categorize, analyze, and forecast data based on time-series information, which is a challenge when training typical RNNs. Associated invulnerability to gap length is a benefit of LSTM over RNNs, hidden Markov models, and other continuous learning strategies in several applications. In this regard, Xia, et al. [120] proposed a DNN that composed convolutional layers with LSTM for human activity detection. The CNN weight attributes concentrated mostly on the fully-connected layer. In response to this characteristic, a GAP layer was used to change the fully-connected layer beneath the convolutional layer, significantly reducing model features while maintaining a high recognition rate. In addition, after the GAP layer, a BN layer was added to enhance the pattern's convergence and apparent effect. Ultimately, the F1 score achieved 92.63%, 95.78%, and 95.85% accuracy on the OPPORTUNITY, UCI-HAR, and WISDM datasets. Also, they investigated the effect of some hyper-parameters on model actions like the filter amount, the kind of optimizers, and batch size.
Also, Ullah, et al. [106] suggested an effective framework for real-world anomaly recognition in supervision ecosystems with high accuracy on present anomaly recognition datasets. Their framework's generic pipeline used the LSTM model from continuous frames, which were traced by a unique multi-layer BD-LSTM for ordinary and anomalous class classification. The examined results showed an enhanced accuracy of 3.14% for the UCF-Crime dataset and 8.09% for the UCFCrime2Local dataset. Recently, the accuracy of their framework is insufficient for low difference and requires development, especially as the UCF-Crime dataset consists of very challenging classifications.
Besides, Rao, et al. [88] presented a generic unsupervised technique called AS-CAL to learn efficient performance agents from unlabeled skeleton information for performance recognition. They presented a method for learning essential performance patterns by comparing the similarity of increased skeleton sequences altered by various novel increase methodologies, allowing their technology to realize the fixed pattern and discriminative performance features from unlabeled skeleton sequences. They also proposed using a queue to build a more stable, memory-effective dictionary with variable management of preceding encoded keys to simplify contrastive learning. Computer-Aided Engineering (CAE) was established as the ultimate function representation for performing action detection. Their technique beats existing hand-crafted and unsupervised learning mechanisms, and its function is comparable to or even better than some supervised learning mechanisms.
Moreover, Huang, et al. [42] presented an LSTM technique for the recognition of 3D objects in a sequence of LiDAR point cloud observations. Their method conceals status variables linked to 3D points from previous object recognitions and relies on memory, which varies depending on vehicle ego-motion at each time step. A sparse 3D convolution network that co-voxelized the input point cloud and concealed state at each frame and memory is the foundation of their LSTM. Tests on Waymo Open Dataset displayed that their algorithm reached the outperformed results and acted with a single initial baseline of 7.5%, a multi-frame object baseline of 6.8%, and a multi-frame object recognition baseline of 1.2% of accuracy.
In addition, Liu, et al. [64] proposed a new spatiotemporal saliency-based multi-stream ResNet and a new spatiotemporal saliency-based multi-stream ResNet with attention-conscious LSTM for function recognition; these two techniques included three supplementary currents: a spatial current fed by RGB frameworks, a transient current fed by optical flood frameworks, and a spatiotemporal saliency current fed by spatiotemporal saliency graphs. Compared to convolutional two-stream-based and LSTM-based patterns, the presented techniques Synchronous Transport Signal (STS) can produce spatiotemporal object background data while reducing foreground intrusion, confirming efficiency for human performance recognition and the STS-ALSTM multi-stream pattern achieved the highest accuracy when compared to input with individual modalities. Table 12 shows the LSTM methods used in pattern recognition and their properties.
5.10 Hybrid methods for pattern recognition
Contrary to the other systems that are simple enough to solve the detection issues, dynamic environments have to synthesize some approaches to tackle the sophistication of pattern recognition. Such a situation necessitates the use of hybrid techniques that combine two or more DL techniques. So, Mao, et al. [70] proposed a System Activity Report (SAR) image provision mechanism relying on Cognitive Network-Generative Adversarial Network (CN-GAN), which mixes LSGAN and Pix2Pix. A limit of regression performance was added to the producer's loss performance to reduce the mean square path between the produced and the actual instances. By considering Pix2Pix, random noise is exchanged by the noise images inputted to LSGAN. Based on the convolutional CNN technique, a light network architecture designed to avoid the issue of high model sophistication and overfitting resulted in the addition of a deep network structure, allowing the detection operation to be developed. MSTAR data regulation was used in the productive pattern training and goal detection tests. These results demonstrated that CN-GAN can resolve SAR image difficulties with a small instance suitably and powerful speckle noise.
Also, Wang, et al. [118] presented a new mechanism relying on the utilization of a GAN and CNN for Public Domain (PD) pattern recognition categorization in Geographic Information System (GIS) on unbalanced instances. The unbalanced instances equalized using this mechanism. A WD2CGAN is designed to offer fault instances for an unbalanced instance caused by a faulty signal. Furthermore, the deconstructed hierarchical investigation space automatically constructs an ideal CNN for PD in the GIS. Finally, the PD pattern identification in GIS under imbalanced cases is recognized using the trained ASCNN and WD2CGAN. When compared to traditional GAN, the WD2CGAN instance equalization processing developed by about 1% shows clear advantages. Simultaneously, in comparison with traditional CNN, the recognition accuracy of ASCNN is enhanced by a minimum of 0.4%, and its parameter amount and space of storage are particularly decreased. Consequently, the results validated the superiority of the presented WD2CGAN and ASCNN models.
Besides, Nandhini Abirami, et al. [78] presented an effective assortment framework for the account of retinal fundus image recognition to prevail over these obstacles. They began by preprocessing the input image from the publicly accessible STARE database in three stages: (a) specular reflection elimination and smoothing, (b) contrast increase, and (c) retinal region extension. The features recovered from the preprocessing image using Multi-Scale Discriminative Robust Local Binary Pattern (MS-DRLBP), based on RGB element selection, LBP descriptor, and Gradient operation. Finally, the images were classified using a hybrid CNN and RBF model that divided the retinal fundus images into four categories: Copy Number Variation (CNV), Designated Router (DR), New Radio (NR), and Advanced Micro Devices (AMD). Examined results of the presented mechanism gave an accuracy of 97.22% in comparison with the other present methodologies. Table 13 shows the hybrid methods used in pattern recognition and their properties.
In addition, Butt, et al. [14] introduced DL considering method over an RNN that gained successful consequences over Arabic text datasets like Alif and Activ. RNN’s operation in sequence learning methods has been significant in previous works, particularly in text transcription and speech recognition. The attention layer allowed people to obtain a concentrated scope of the input sequence, resulting in faster and easier learning. The authors developed the lowering inline error rate in preprocessing by creating a new dataset of one word on an image from Alif and Activ. They interpreted it with an accuracy of 85% to 87%. This model reached better results than those based on a typical CNN, RNN, and hybrid CNN-RNN.
Furthermore, Subhashini, et al. [104] used the DNN-Radial Basis Function (DNN-RBF) for performing. To remove noise from the input signal, accessible speech samples are preprocessed using a Wiener filter, and the Mel Frequency Cepstral Coefficients (MFCC) features of this preprocessed signal are retrieved. The Gaussian Mixture Model (GMM) super vector estimated an i-vector with reduced dimensionality. The Texas Instruments/ Massachusetts Institute of Technology (TIMIT) dataset is used to evaluate the function of this speaker detection algorithm. The efficiency of the provided algorithm is then evaluated using multiple functions such as recall, precision, and accuracy. Through AHHO-based DNN-RFB, accuracy, precision, and recall values are achieved at 94.92%, 89.87%, and 94.67%, respectively. The performance of DNN-RBF developed in the presence of an adaptive optimization method in speaker recognition. Table 13 discusses the Hybrid techniques used in pattern recognition and their properties.
6 Results and comparisons
The previous section investigated several papers that used DL/ML approaches in pattern recognition issues. DL techniques are being used to train computers for various tasks, such as face recognition, image classification, object identification, and computer vision. In this approach, computer vision seeks to mimic human perception, its many performances, and DL behavior by providing computers with the necessary data. This section involves five subsections that evaluate various aspects of DL/ML methods: DL methods applications, DL method for pattern recognition, datasets of DL methods, criteria of DL/ML methods, and result and analysis. Pattern recognition practices utilize various methods to extract meaningful information from data. One commonly employed method is the use of machine learning algorithms, such as SVMs, Random Forests, and MLP neural networks. SVMs are effective in binary classification tasks, finding an optimal hyperplane to separate data points. Random Forests combine multiple decision trees to improve accuracy and handle complex datasets. MLP neural networks consist of interconnected layers of artificial neurons and are effective in learning complex patterns. Another popular method is deep learning, which involves the use of deep neural networks, such as CNNs and LSTM networks. CNNs excel in image and video analysis, capturing spatial hierarchies, while LSTMs are suitable for sequential data analysis, preserving temporal dependencies. Ensemble learning methods, including AdaBoost and Bagging, combine multiple models to enhance prediction accuracy. Reinforcement learning techniques, such as Q-learning and Policy Gradient, enable machines to learn optimal decisions through interactions with an environment. These methods provide a diverse toolbox for practitioners in pattern recognition, allowing them to tackle various tasks and achieve accurate results.
6.1 DL applications for big data pattern recognition
In this section, we will discuss a variety of applications of DL techniques in pattern recognition.: (a) Virtual assistants such as Google Assistant, Amazon Echo, Siri, and Alexa all use DL to provide you with a personalized user experience. They are trained to recognize the user's voice and accent and provide you with a secondary human experience amid machines by utilizing deep neural networks that replicate speech and human tone. (b) DL is used in the iPhone's Facial Recognition to detect data points from the user's face to unlock the phone in photos. DL used a large number of data points to create a precise map of a user's face, which the built-in algorithm then uses for detection. (c) NLP: Some well-known applications gaining traction include document summarization, language modeling, sentiment analysis, question answering, and text classification. (d) Healthcare: Primitive illness and condition recognition, quantitative imaging, and the availability of decision support tools for experts are all having a significant impact on life science, medicine, and healthcare. (e) Data from geo-mapping, GPS, and sensors are merged in DL to develop models that specify recognized directions, street signs, and dynamic components like congestion, traffic, and pedestrians. (f) DL models for text generation perfect spelling, style, punctuation, grammar, and tone are required to replicate human behavior. (g) CNN enables digital image processing, which can later be separated into handwriting, object recognition, facial recognition, etc. Figure 8 shows the frequency of parameters used in evaluations of papers, and based on the evaluation, accuracy (29.6%), delay (15.8%), and availability (11.3%), respectively, are the most frequent parameters studied in the investigated papers. Also, Fig. 9 demonstrates the frequency of different DL methods for pattern recognition. As is shown in this figure, visual recognition (26.7%), image recognition (20.0%), and speech recognition (5.0%), respectively, are the most frequent pattern recognition applications which use DL methods.

Frequency of parameters used in evaluations of papers

Distribution of pattern recognition approaches using the DL method in studied papers
6.2 DL methods for big data pattern recognition
DL mechanisms are representation-learning methods with numerous degrees of representation, achieved by combining plain but non-linear modules which each exchange the representation at one stage (beginning with the raw input) in a representation at a higher, somewhat abstract stage.
6.2.1 CNN methods
CNN takes various techniques for arranging data. They benefit from the hierarchical pattern in data and collect patterns of enhancing sophistication by utilizing easier and smaller patterns highlighted in their filters. Some utilities of CNN in pattern recognition are image classification, facial recognition software, speech recognition programs, evaluating documents, environmental and historical collections, predicting climate, grey zones, advertising, etc. The benefits of using CNNs over other standard neural networks in computer vision environments are listed below: (a) the primary reason for using CNN is the weight-sharing feature, which decreases the number of learnable network components and aids the network in increasing generalization and preventing overfitting. (b) Learning the assortment and feature extraction layers concurrently leads to the model's highly reliable and well-organized output on the extracted features. (c) Implementing a large-scale network with CNN is significantly easier than with other neural networks. Also, some disadvantages: (a) CNN is particularly slower owing to performance as the max pool. (b) if the CNN has multiple layers, thus the training process takes a great deal of time if the computer does not involve a suitable GPU. (c) a CNN needs a big dataset to process and learn the neural network. Overall, all papers investigated the CNN method and highlighted the diverse applications of deep learning in various domains, including healthcare, finance, emotion recognition, education, IoT, and image recognition. They demonstrated the potential of deep learning approaches and the utilization of big data for improved analysis and decision-making in different fields. The papers mentioned likely used the CNN method due to its exceptional capability in processing and analyzing visual data. CNNs have been widely recognized for their effectiveness in tasks such as image classification, object detection, and segmentation, making them a natural choice for visual pattern recognition applications. The CNN architecture is specifically designed to capture spatial and hierarchical features from images, allowing it to learn and detect intricate visual patterns automatically. Moreover, CNNs are well-suited for big data analysis as they can efficiently handle large volumes of image data by leveraging parameter sharing and local receptive fields. With a proven track record of success in deep learning tasks and their adaptability to specific applications, CNNs offer a powerful framework for extracting meaningful information from visual data, making them an ideal choice for these papers.
6.2.2 RNN methods
The logic of employing RNN is based on input sequencing. RNNs can use their internal state to process variable lengths of inputs that make them applicable to pattern recognition tasks such as handwriting recognition, speech recognition, and so on. To forecast the next word in the sequence, we must recall what word appeared in the previous time level. Because this level is performed for each input, these neural networks are referred to as recurrent. Here we have listed some of its advantages. (a) the RNN is a dynamic neural network that is computationally strong and can be utilized in multiple transient processing applications and models. (b) using RNN, we can approximate arbitrary nonlinear dynamical systems with arbitrary accuracy by perceiving complicated mappings from input to output sequences. Also, some of its disadvantages include (a)exploding issues and gradient vanishing. (b) learning an RNN is a complex task. All papers that studied RNN methods covered a diverse range of topics in big data analysis. They included an overview of the applications of rough sets, an analysis of research and technology trends in smart livestock technology, a survey on data-efficient algorithms, research on vessel behavior pattern recognition, a systematic review of automatic segmentation of brain MRI images, and the authentication of commercial kinds of honey using pattern recognition analysis. Each paper contributed valuable insights and advancements in their respective areas of study within the field of big data analysis. Briefly, all papers investigated the RNN method often use the Recurrent Neural Network (RNN) method due to its ability to handle sequential and temporal data effectively. RNNs are particularly suitable for tasks where the order and context of data are crucial for accurate predictions or classifications. In pattern recognition, RNNs can capture the data's sequential dependencies and temporal relationships, making them well-suited for tasks such as speech recognition, natural language processing, and time series analysis. The recurrent nature of RNNs allows them to retain information from previous inputs and utilize it in the current prediction, enabling them to model complex patterns and dependencies in the data. Therefore, researchers in pattern recognition often leverage RNNs to achieve better performance and accuracy in analyzing and recognizing patterns in sequential data.
6.2.3 GAN methods
The application of GANs has seen rapid growth in recent years. The main idea of GAN lies behind the indirect training among the discriminator, which can predict and recognize patterns in which how much input is credentialed. The technique has been used for high-reliability natural image combination, data accompaniment, producing image condensations, and other applications. Several advantages of the GAN method are: (a) GANs produce the same data as original data. Similarly, it can produce various text, video, and audio versions. (b) GANs go into in-depth details of data so they can interpret it into various versions simply and is suitable for doing ML work. To name mention but a few disadvantages of GANs: (a) difficult training: we have to produce various kinds of data continuously to monitor if it corks precisely or not. (b) it isn't very easy to produce results from speech or text. The papers that studied the GAN method covered a range of topics related to big data analysis. These papers contributed to understanding different aspects of big data analysis in areas such as heterogeneity, healthcare, agriculture, classification, and medical applications. They used the GAN method because it generates new and realistic data samples. GANs are particularly useful for image generation, data augmentation, and anomaly detection tasks. GANs consist of two components: a generator and a discriminator. The generator generates synthetic data samples, while the discriminator tries to distinguish between real and generated samples. Through an adversarial training process, GANs learn to generate data that closely resembles real data distribution. This makes GANs a valuable tool in pattern recognition for tasks such as image synthesis, data generation, and data representation learning. By using GANs, researchers can explore new possibilities in data analysis, improve the quality of generated samples, and enhance the overall performance of pattern recognition systems.
6.2.4 AE methods
AEs are neural network models that are used to train complex nonlinear connections between data points. Given an AEs are efficient in learning representations for classification patterns and employ several issues from anomaly recognition, facial recognition, and feature recognition to attaining the meaning of words. The primary applications of AEs are dimensionality reduction and data retrieval; however, novel variations have been used in various tasks. Due to the state, we have to refer to some advantages of the AE method: (a) the benefit of the AE is that it eliminates noise from the input signal, leaving a high-value representation of the input. By the way, ML algorithms can operate better owing to the algorithms can learn patterns in the data from a smaller series of valuable input. And some disadvantages, such as (a) the AE may conduct a better job on the messy data, but it may be performing better yet to data cleaning. (b) another drawback is that we may remove the significant data in the input data. The AE algorithm needs a purposeful performance for assessing the precision of decoded/encoded input data. Papers that studied AE methods in pattern recognition have been utilizing the autoencoder method for several reasons. First, autoencoders are effective in unsupervised learning tasks, where labeled training data may be scarce or unavailable. They can learn useful representations and extract meaningful features from the input data without the need for explicit class labels. Second, autoencoders can reduce dimensionality, which is beneficial for handling high-dimensional data and reducing computational complexity. By compressing the input data into a lower-dimensional latent space, autoencoders can capture the most salient information and discard irrelevant or noisy features. Third, autoencoders are used for data reconstruction and denoising. By training the model to reconstruct the original input from a corrupted or incomplete version, autoencoders can effectively denoise and recover missing or distorted patterns in the data. This makes them particularly useful in applications where data quality and integrity are crucial. Finally, autoencoders can also be employed for anomaly detection. By learning the normal patterns in the data, they can identify deviations or anomalies that do not conform to the learned representations. This ability to detect anomalies is valuable in various domains, including fraud detection, cybersecurity, and fault diagnosis. Overall, the autoencoder method offers a versatile framework for pattern recognition tasks, providing capabilities such as unsupervised learning, dimensionality reduction, data reconstruction, and anomaly detection.
6.2.5 EL methods
The number of applications for massive EL in a logical time framework has recently increased due to progressive computational capacity facilitating learning massive EL in a logical time framework. It facilitates the use of EL for recognizing the common pattern. Change detection, Malware detection, intrusion detection, face recognition, and emotion recognition are some of the benefits of this technology. Two primary reasons for utilizing an ensemble over a signal model are (a) robustness: an ensemble decreases the dispersion or spread of the forecasting and model operation. (b) performance: an ensemble can make better forecasting and reach better operation than any individual associating model. There are some drawbacks too. For instance, (a) interpreting an ensemble can be difficult. Usually, even the best ideas cannot be sold to decision-makers, and the final users do not confirm the best idea. (b) creating, training, and deploying ensembles are costly. Ensemble learning is a powerful technique that combines multiple individual models to improve overall predictive performance and robustness. The specific reasons why the mentioned papers used ensemble learning may vary, but some common motivations include its ability to reduce bias and variance, enhance generalization, handle complex and high-dimensional data, and mitigate overfitting. By leveraging the diversity of multiple models or algorithms, ensemble learning can capture different aspects of the data and make more accurate predictions. Additionally, ensemble methods are known for their flexibility and applicability to various domains and problem types.
6.2.6 RL methods
RL has made quick progress on action recognition in the video, which depends on a large-scale training set. The RL analysis aims to construct a mathematical framework to answer the problems. Various applications include resource management in computer clusters, traffic light monitoring, robotics, web system configuration, chemistry, and games. The main advantage of RL is (a) maximizing performance and (b) bearing change for a long period. And the disadvantages are: (a) overload of states results from too much reinforcement learning. (b) RL is not beneficial for solving simple issues. RL requires many data and many computations. All considered papers in pattern recognition have utilized reinforcement learning as a powerful approach to improve the performance of pattern recognition systems. Reinforcement learning enables the development of intelligent agents that can learn optimal decision-making policies by interacting with an environment. In the context of pattern recognition, reinforcement learning algorithms can learn to make sequential decisions based on observed patterns or features, optimizing their actions to maximize performance metrics such as accuracy or recognition rates. By employing reinforcement learning, these papers aim to enhance pattern recognition systems' adaptability, flexibility, and robustness, allowing them to learn and improve from experience, adapt to changing environments, and make optimal decisions in complex and dynamic scenarios. The utilization of reinforcement learning techniques in pattern recognition research contributes to the advancement of intelligent systems capable of autonomously learning and improving their pattern recognition capabilities.
6.2.7 RF methods
In ML, the RF algorithm is commonly used as the RF classifier. The ensemble classifier that relies on RF was presented to tackle the complex issue. The appropriateness of RF in both regression learning and classifications, handling missing values, and the capacity to operate on a big data set with increased dimensionality are some of the advantages and major aspects of RF application. Some advantages of RF are: (a) providing high accuracy and (b) managing big data with multiple variables running into thousands. Mention some disadvantages of RF there are: (a) an RF is less interpretable than an individual decision tree, and (b) a learned RF might need particular memory for storage. All studied papers that applied the RF method in pattern recognition topics have employed the random forest method due to its ability to handle complex and high-dimensional data, robustness against noise and missing values, and efficient processing of large datasets. Random forest is an ensemble learning technique that combines multiple decision trees to make predictions. It leverages the diversity of the ensemble to capture intricate patterns and relationships in the data, providing accurate and reliable classification or prediction results. Additionally, the random forest offers feature importance measures, allowing researchers to identify the most relevant features for pattern recognition. Its popularity in recent research reflects its effectiveness in addressing pattern recognition challenges and achieving high-performance outcomes.
6.2.8 MLP methods
MLP classical neural networks are utilized for prime performances like encryption, data visualization, and data compression. MLP is a holistic means of coping with a wide range of complex tasks in pattern recognition and regression owing to its highly adjustable non-linear structure. Some advantages of MLP are (a) aiding probability-based forecasting or categorizing of items in numerous labels. (b) ability to learn non-linear models. Also, some disadvantages such as (a) MLP with latent layers have a non-convex loss performance that there is more than one local one. (b) MLP needs tuning several hyperparameters, such as the number of latent layers, neurons, and iterations. All in all, all papers that used the MLP method in studying pattern recognition have utilized the MLP method due to its capability to handle complex and nonlinear relationships within data. MLP is an artificial neural network consisting of multiple layers of interconnected nodes, allowing it to learn intricate patterns and make accurate predictions. It is widely used in pattern recognition tasks because it captures high-level abstractions and extracts features from input data. MLPs are flexible and can be trained on various data types, making them suitable for diverse pattern recognition applications. The popularity of MLPs in recent research signifies their effectiveness in modeling complex patterns and achieving superior recognition performance in various domains.
6.2.9 LSTM methods
LSTM is an artificial RNN architecture used in DL that addresses the issue of human activity recognition and classifying sequences of patterns. LSTM applications include robot control, time series prediction, handwriting recognition, protein homology detection, and human action recognition. From a beneficial standpoint, (a) LSTM generates various parameters like learning rates and input and output biases. Therefore, no need for fine regulations. (b) the complexity of updating every weight is decreased to O (1), the same as Back Propagation Through Time (BPTT). We have to mention a few drawbacks of LSTM: (a) LSTM takes longer to learn and needs more memory to learn. (b) LSTM has a harder process for dropout implementation. By the way, all papers that used the LSTM method studying pattern recognition have employed the LSTM method due to its ability to model sequential and temporal dependencies in data effectively. LSTM is a type of RNN that addresses the vanishing gradient problem by introducing memory cells and gates that regulate the flow of information. This enables LSTMs to capture long-term dependencies and retain important context information over extended sequences. In pattern recognition tasks, such as speech recognition, natural language processing, and gesture recognition, where sequential patterns play a crucial role, LSTM has shown remarkable performance. Its ability to learn and remember information over extended time steps makes it suitable for capturing intricate patterns and making accurate predictions. The utilization of LSTM in recent research underscores its effectiveness in handling sequential data and its impact on advancing pattern recognition techniques.
6.3 Dataset for big data pattern recognition
Datasets are used for ML research and have been discussed in peer-reviewed academic journals since they are an essential component of the area of ML. Progress in learning algorithms, the availability of high-quality learning datasets, and, less logically, computer hardware datasets were the primary drivers of development in this sector. With this in mind, a large number of examples, such as 10,000, are characterized as being more than sufficient to learn the topic. This serves as an upper bound on the number of training instances and takes advantage of the various samples in the test set. The proposed models were tested by fitting them to various-sized learning datasets and evaluating their ability to operate on the test set. Too few samples will result in poor experiment accuracy because the chosen model overfits the learning set or the learning set is insufficiently representative of the issue. On the other side, too many samples will result in outstanding but less-than-perfect accuracy; this could be because the chosen model can train the nuance of such a large learning dataset, or the dataset is over-representative of the issue. A line plot of learning dataset size versus experiment accuracy must show a growing tendency to decline returns and possibly even a small drop in operation. In the case of a fixed model and learning dataset, we must determine how much data is required to achieve a precise approximate model operation. This subject can be investigated by fitting an MLP with a fixed-sized training set and evaluating the model with variable-sized experiment sets. We can employ a mechanism similar to that used in the previous section's study.
A dataset is a data collection based on the capacity of a single database table or a single statistical data matrix. Each table column represents a significant variable, and rows relate to a specific dataset member. For ML projects, the real dataset used to create the training model for operating distinct performances is referred to as the training dataset.
6.3.1 Importance of dataset
The reliance on a dataset for ML is not only unavoidable since AI cannot learn without it, but it is also the most important aspect that facilitates algorithm training. The significance of the dataset stems from the observation that the size of the AI team is not as significant as the appropriate size of the dataset. Data is required at every stage of AI growth, from training, tuning, and model selection to testing. We look at three different datasets: the training set, the authenticated set, and the testing set. Keep in mind that simply gathering data is not enough; datasets must also be categorized and labeled, which takes a significant amount of effort. Two main datasets used for various purposes during AI projects are dataset and test sets. (a) Some concepts, such as neural networks, are necessary to train and generate results when using a training dataset to train an algorithm. It includes both input and expected output data. Nearly 60% of the total data is made up of training sets. (b) The test data set is used since the training algorithm is being evaluated with the training dataset. The training dataset cannot be used during testing because the algorithm already knows the expected output. Twenty percent of the total data is made up of testing sets. It must be verified that input data is grouped with properly validated outputs, often through human authentication. Data processing entails selecting the correct data from the ideal dataset and generating a training set. Feature transportation refers to the process of assembling data in the best possible format. Long-term and goal-oriented ML initiatives rely on dynamic, continuously updated datasets. In other words, a method for continuous development of the considered dataset is as accurate a model as it can be.
6.3.2 The best public datasets for big data pattern recognition
Here we are going to list some of the common datasets used for DL projects in different categories. To begin with, we mention some dataset finders, including Google Dataset Search, Kaggle, UGI ML Repository, VisualData, GMU Libraries, Big Bad NLP database, and so on. Some general databases include Housing datasets, such as the Boston Housing dataset, and geographic datasets, such as Google-Landmarks-v2. The Mall Gustomers, IRIS, MNIST, and Boston Housing datasets are just a few examples of machine learning datasets.
6.4 Criteria of DL/ML methods
The quality of functions is defined by mathematical metrics that show profitable feedback and analysis of an ML/DL pattern's performance. To name but a few critical parameters, we have to name accuracy, MCC, Confusion Matrix, recall, precision, and F1 score. As a result, as previously stated, accuracy is the most significant indicator for demonstrating the fraction of accurately recognized observed to satisfy the predicted observation demand. In the time of combining total values in a confusion matrix, the True Negative to True Positive rate is exploited. The total quantity of patterns successfully detected is demonstrated by n, and the entire pattern number is given by t in this equation [37].
The given number of exact predictions has indicated by P and the rate of True Positive forecasted in comparison with the total positively forecasted as well. Moreover, \({S}_{TP}\) is the representation of the sum of total true positives, when \({A}_{FP}\) is the representation of total false positives.
A criterion of the amount of real positive observations is demonstrated by \({Re}_{Call}\) named recall which can precisely forecast. Besides, \({A}_{FN}\) specifies total false negatives in Eq.
In addition, the F1 score is a total functionality criterion determination of Recall and Precision and representation of Harmonic achieved by Precision and Recall.
Additionally, functionality matrix measurement which weighs forecasted and real observations is a confusion matrix that utilizes True Negatives, True positives, False Positives labels, and False Negatives. All true predictions are the total number of Positives and Negatives, so all wrong predictions are the aggregated False Negatives and False Positives [38].
Furthermore, in binary classification, a true positive refers to the correct prediction of a positive class instance, while a true negative represents the correct prediction of a negative class instance. On the other hand, false negatives are incorrect predictions of negative class instances, while false positives are incorrect predictions of positive class instances. The MCC is an individual value function that encapsulates the entire confusion matrix. It provides a more informative and accurate evaluation metric than the F1 score and accuracy in assessing classification challenges. A high MCC score indicates advantageous prediction outcomes across all four quadrants of the confusion matrix.
6.5 Result and analysis
After everything was said and done, we evaluated 60 publications in 10 categories about using DL/ML techniques in pattern recognition in previous portions. The more prominent flaws in these articles have missed the impact of security as well as a lack of adaptive capacity in these strategies. We thoroughly examine the mechanisms under discussion in diverse contexts with all of this in mind. Figure 10 displays DL methods and their frequency in selected papers. Python is the most well-known programming language for this kind of job in the case of implementation, simulation, and theatrical about the presented mechanisms, which is such an appealing section for investigators to utilize in future work, as shown in Fig. 11. Depending on the application of each method for every specific use, they applied these ways. Moreover, Fig. 12 shows a geographical distribution map of countries that contributed to the investigated papers in which China, with 23 papers, the USA, with 7 papers, and Pakistan, with five papers is the most frequently studied article. Also, Table 14 depicts the considered parameters in studies articles.

DL methods used and their frequency in selected papers

The distribution of the utilization of various simulation environments in DL-pattern recognition

The geo-chart about the studied countries by the studied articles
7 Open issues
Despite all of the breakthrough development in pattern recognition algorithms in DL, some bottlenecks and drawbacks need to be addressed in additional research. Many investigators have reached promising consequences by employing a broad range of algorithms, but there is some overlap through studies, as well as the joint use of several efficient tools, is slow to advent. The lack of common consensus regarding the most precious characteristics and the optimal neural network architecture might hinder reaching better practical consequences. Recognition of continuous patterns remains a remarkable issue; even the best-automated systems struggle with fine pattern distinction. This might be partially a result of the fact that many available datasets consist of only limited vocabularies and typical sentences. At the same time, training models for progressed patterns need far more expansive libraries consisting of various samples. The realization of pattern connection stands as a tough issue for automated systems. From a closer point of view, the reasons for the continued inability of machines to accurately and continuously interpret patterns to weigh sequences are not as puzzling as they appear. Any natural-language characteristics are a complicated interaction of multiple policies and connections, which are problematical to summarize in a mathematical layout that can be programmed into computers. So, these drawbacks will virtually stay in the future, as this field is a significant topic from the perspective of many world research teams. Several other major reasonable challenges which would expect to be considered for future work in this area include the following:
-
Dataset
To begin with, Normally, all DL techniques necessitate large datasets. Using DL techniques on moderate-sized datasets is not worthwhile, although increased computer power and speed reduce computing costs. Nonetheless, while there are casual or intricate communications between data to be learned by geometric transformations, DL techniques underperform and fail when the dataset size is taken into account. Furthermore, the scarcity of huge datasets limits deep model training. Large datasets in practical applications limit the ability to train dependable supervised techniques. As a result, establishing large, reliable, available, and homogeneous datasets is fundamentally gathered either by (1) providing synthetic datasets by current algorithms or (2) scanning multiple bags with various objects and directions in a lab environment manually.
-
Input type
The main reviewed methods make use of depth modeling, even though some are concentrated on the RGB images in detail to simplify effective recognition. Sequential data has been beneficial as well, most generally for tracking things and sites, along with data about the joint positions. There is a difference between dynamic and static signs on the phase of signs, with the next category having a subclass utilized in sequence SLR. With this in mind, it can be presumed that complex patterns and continuous video will become a critical focus in further studies. It is crystal clear that the total precondition is in the position for this focus move.
-
Synthesizing various features
Several researchers have addressed this problem, but some of them yet require to be studied. Mixing features to describe numerous parts of the human body is desirable. But this challenge is generally complicated by the variation in the type of formats which consist of images, depth and skeleton data, textual elements, etc., merging several of these data can result in developed feature engineering and a more accurate model. The torso, hands, and facial area are three major body parts where such characteristics are focused. Imperfect models are the result of limiting the focus to hands. Particular parts related to successful modeling consist of hand position recognition, hand shapes, and gesture recognition. It is worth mentioning that quick motion of the neck and face during language use presents problems.
-
Sequence patterns
While remarkable success has been achieved in the field of isolated patterns, the algorithms must recognize the sole word or alphabetic sign; the likeness cannot be considered for sequence patterns, which consists of the interpretation of lingering speech segments. Contextual connections between signs have a powerful influence on the meaning of the sentences; as a result, this task cannot be decreased to the recognition of the gestures of the individual. Finding an appropriate configuration can tackle the difficulties. We believe that investigation in this subject will dwell on more complex neural network methods that apply more layers and mix multiple types of layer compositions to gain more processing power.
-
Developing recognition accuracy
To ensure commercial utilization and gain credibility among an expanding user base, technologies must exhibit high levels of security (> 99%) and stability. As the size of the vocabulary and task complexity increases, there is a higher likelihood of incorrectly detecting patterns, resulting in false positives or false negatives. Consequently, it becomes imperative to proceed with the next step, which involves summoning extensive support and gathering sufficient resources to achieve optimal accuracy levels. Undoubtedly, the systems should undergo thorough analysis across different settings and yield valuable results, even in less-than-ideal external conditions.
-
Developing the efficiency of pattern recognition solutions
Previously, scientific studies have been limited to improving the principal ability of meaningful connect observed body gestures and hands and fixed units of sign language. Since it is comprehendible for the early level of scientific investigation, it is critical to enhance attention on the dimension's applicability in future work. Several pattern recognition solutions needed part-worn sensors and other equipped tools, but modern systems are notably less reliant upon them and might involve only a few cameras. Also, the interaction between users and the system can be considered seriously as a future topic with the notion of generating the user with the stage of management over the software utilized by a system. In addition, feedback methods are being developed to swiftly discover broad faults while ensuring that user suggestions are honored.
-
Poor quality of information
Detection for ML will be impossible if the trained data has many flaws, noise, and outliers. So, for a machine to recognize a pattern correctly, data scientists must pay extra attention to cleaning the data. one of the main overarching issues in pattern recognition research is the chronic deficiency of high-quality inputs. This is gradually altering as the volume of study into pattern recognition increases. On the other hand, some regional changes in languages, signs, and words have occurred due to an exclusive mix of facial and hand gestures to express meaning. Also, there is a lack of enough labeled sets which enable the evaluation of pattern tools under normal situations; hopefully, developed datasets will finally simplify the improvement of the applicable pattern recognition method.
-
Well-organized reports
The ability to reap the full benefits of open access data repositories in terms of reusability and data transmission is frequently hampered by a lack of standards for consolidated reporting data and nonconsolidated data reported.
-
Enough well-trained data
Despite all attempts, ML is not up to date, even though most algorithms require a large quantity of data to perform properly. Huge samples are required to create a new case for enforcing a common duty. For example, completing an advanced task like picture or speech identification may necessitate millions of samples.
-
Nonrepresentative training data
Making sure training data is representative of new cases for generalization aims the model for more accurate prediction, which is almost a gap in this area that should be covered by more investigation.
-
Overfitted training data
Overfitting occurs when the model is overly clever, resulting in overgeneralization and, as a result, ML models mimicking it. As a result, the overfitted model performs well but fails to generalize, and for an organized system to be successfully used, this issue has to be solved.
-
Underfitted training data
it is the opposite of overfitting and occurs when the model is too simple and learns the behavior from the data. A linear model on a series with multi-collinearity is used for confident underfit, and the predictions will be inaccurate. It also needs the same attitude toward a well-organized system.
-
Useless features
The outputs of the ML system will be unexpected if the data learned contains unrelated features. As a result, one of the most important aspects of a successful ML project is selecting the necessary characteristics.
-
Model arrangement and offline Learning
The deficiency of skilled deployment of data is one of the biggest issues for ML practitioners. Developers need an online source like Kaggle to collect data, train the model, and put offline learning under question, which may not be useful for variable data types.
-
Sensing
The issues arise in input, like sensitivity, latency, bandwidth, distortion, resolution, signal-to-noise ratio, etc.
-
Grouping and Segmentation
The most crucial issue in pattern recognition is recognizing or incorporating each other in the different parts of an object.
-
Different Issues
Furthermore, DL approaches employ crucial aspects for a variety of applications such as NLP, Service Edge Router (SER), and sequential information processing. Using supervised algorithms during its implementation increases the learning of actual data without the need for manual human labeling. The incorporation of various categorization models like GMMs and HMMs needs a larger dataset to gain more accuracy. It is worth noting that sensitivity to gradient eclipse is a major issue that affects the overall performance of the RNN. As a result, a customizable SER system based on the DL method known as Diagonal Recurrent Neural Network (DRNN) is used for SER. Furthermore, using CNN and RNN as a hybrid DL modality allows the model to detect patterns with both transient and frequent dependencies. The RNN model is used for pattern prediction and constructing AEs for features. It can also be used to gain greater insight into the operation of LSTM-based RNNs by utilizing regression models such as Software Verification Results (SVR). Last but not least, various fundamental flaws have not been addressed. There are two key issues: (1) a lack of generalization potential. The supervised learning process cannot adapt to a circumstance that has not been cleared in the training set.; (2) Deploying on mobile devices is tricky. CNN's sophisticated and amazing operation is frequently accompanied by many parameters, which is a problem for real-time calculation on mobile devices. Additionally, multiple directions might be the next study in the future. To begin, semantic segmentation is a computationally intensive approach for embedding layout. More efficient architectures must be investigated. Second, supervised learning requires a large amount of annotated data, and labeling data is a time and expensive money operation. Making accurate predictions in a changeable environment is also critical.
8 Conclusion and limitation
This research comprehensively explores ML/DL approaches for pattern recognition. The study begins by discussing the benefits and drawbacks of survey papers, establishing a foundation for further investigation. Then, the reviewed research articles are evaluated based on their main ideas, strategies, simulation environments, and datasets, with a particular focus on assessing their accuracy, security, adaptability, robustness, availability, integrity, latency, flexibility, and scalability. The findings show that the majority of the publications were released in 2021. Python has the most simulation environments. Additionally, the most crucial factors in these studies include accuracy, flexibility, and fault tolerance. By highlighting the potential of DL in uncovering patterns and behaviors, this research provides valuable insights and serves as a comprehensive resource for future studies in DL approaches for pattern recognition. It offers a well-organized roadmap for researchers and practitioners interested in implementing established DL methods in real-world infrastructures, facilitating advancements in intelligent solutions, and driving innovation in pattern recognition.
Also, our literature review may be limited by the scope of the study and the selection criteria for including papers. It is challenging to cover the entire breadth of research in such a broad and interdisciplinary field, which may result in some relevant papers being excluded or overlooked. Besides, assessing the quality and validity of the included papers may be challenging. The review relies on the available information provided in the selected papers, and variations in research methodologies, experimental setups, and reporting standards can impact the overall quality and reliability of the findings. Finally, we discovered several limitations, such as the lack of use of book chapters and literary notes, which prevents us from benefiting from many studies that can be incorporated into future research. Another barrier was the inaccessibility of non-English articles, which prevented us from participating in various research papers. In addition, we found certain flaws in the clear explanations of their suggested frameworks and approaches in the publications we examined. Our last limitation was dissatisfaction with various papers released by specific publications.
References
Abbasi A, Javed AR, Chakraborty C, Nebhen J, Zehra W, Jalil Z (2021) ElStream: An ensemble learning approach for concept drift detection in dynamic social big data stream learning. IEEE Access 9:66408–66419
Aghakhani S, Larijani A, Sadeghi F, Martín D, Shahrakht AA (2023) A novel hybrid artificial bee colony-based deep convolutional neural network to improve the detection performance of backscatter communication systems. Electronics 12(10):2263
Akhavan J, Lyu J, Manoochehri S (2023) A deep learning solution for real-time quality assessment and control in additive manufacturing using point cloud data. J Intell Manuf. https://doi.org/10.1007/s10845-023-02121-4
Heidari A, Navimipour NJ, Jamali MAJ, Akbarpour S (2023) A hybrid approach for latency and battery lifetime optimization in IoT devices through offloading and CNN learning. Sustain Comput Inform Syst 39:100899. https://doi.org/10.1016/j.suscom.2023.100899
Amiri Z, Heidari A, Navimipour NJ et al (2023) Resilient and dependability management in distributed environments: a systematic and comprehensive literature review. Cluster Comput 26:1565–1600. https://doi.org/10.1007/s10586-022-03738-5
de Arruda HF, Reia SM, Silva FN, Amancio DR, Costa LdF (2021) A pattern recognition approach for distinguishing between prose and poetry. arXiv preprint arXiv:2107.08512
Atitallah SB, Driss M, Boulila W, Ghézala HB (2020) Leveraging Deep Learning and IoT big data analytics to support the smart cities development: Review and future directions. Comput Sci Rev 38:100303
Awan MJ, Bilal MH, Yasin A, Nobanee H, Khan NS, Zain AM (2021) Detection of COVID-19 in chest X-ray images: A big data enabled deep learning approach. Int J Environ Res Public Health 18(19):10147
Awan MJ, Khan MA, Ansari ZK, Yasin A, Shehzad HMF (2022) Fake profile recognition using big data analytics in social media platforms. Int J Comput Appl Technol 68(3):215–222
Bagheri M, Zhao H, Sun M, Huang L, Madasu S, Lindner P, Toti G (2020) Data conditioning and forecasting methodology using machine learning on production data for a well pad. In: Offshore technology conference. OTC, p D031S037R002
Bai X et al (2021) Explainable deep learning for efficient and robust pattern recognition: A survey of recent developments. Pattern Recogn 120:108102
Benhamou E, Saltiel D, Ohana J-J, Atif J (2021) Detecting and adapting to crisis pattern with context based Deep Reinforcement Learning, in 2020 25th International Conference on Pattern Recognition (ICPR), IEEE, pp. 10050–10057
Bhamare D, Suryawanshi P (2018) Review on reliable pattern recognition with machine learning techniques. Fuzzy Inf Eng 10(3):362–377
Butt H, Raza MR, Ramzan MJ, Ali MJ, Haris M (2021) Attention-Based CNN-RNN Arabic Text Recognition from Natural Scene Images. Forecasting 3(3):520–540
Chancán M and Milford M (2020) Deepseqslam: A trainable cnn+ rnn for joint global description and sequence-based place recognition, arXiv preprint arXiv:2011.08518
Chen P et al (2022) Effectively detecting operational anomalies in large-scale IoT data infrastructures by using a gan-based predictive model. Comput J 65(11):2909–2925
Chen Y, Chen Z, Guo D, Zhao Z, Lin T, Zhang C (2022) Underground space use of urban built-up areas in the central city of Nanjing: Insight based on a dynamic population distribution. Underground Space 7(5):748–766
Chen Y, Chen S, Zhang N, Liu H, Jing H, Min G (2021) LPR-MLP: a novel health prediction model for transmission lines in grid sensor networks. Complexity 2021:1–10
Chen J, Wu D, Zhao Y, Sharma N, Blumenstein M, Yu S (2021) Fooling intrusion detection systems using adversarially autoencoder. Digit Commun Netw 7(3):453–460
Chen S, Xie E, Ge C, Liang D, Luo P (2021) Cyclemlp: A mlp-like architecture for dense prediction, arXiv preprint arXiv:2107.10224
Chen D, Yue L, Chang X, Xu M, Jia T (2021) NM-GAN: Noise-modulated generative adversarial network for video anomaly detection. Pattern Recogn 116:107969
Cheng L, Yin F, Theodoridis S, Chatzis S, Chang T-H (2022) Rethinking Bayesian learning for data analysis: The art of prior and inference in sparsity-aware modeling. IEEE Signal Process Mag 39(6):18–52
Darbandi M (2017) Proposing new intelligent system for suggesting better service providers in cloud computing based on Kalman filtering. Published by HCTL Int J Technol Innov Res, (ISSN: 2321-1814) 24(1):1–9
Darbandi M (2017) Kalman filtering for estimation and prediction servers with lower traffic loads for transferring high-level processes in cloud computing. Published by HCTL Int J Technol Innov Res,(ISSN: 2321-1814) 23(1):10–20
Deng Y, Zhang W, Xu W, Shen Y, Lam W (2023) Nonfactoid question answering as query-focused summarization with graph-enhanced multihop inference. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2023.3258413
Du S, Krishnamurthy A, Jiang N, Agarwal A, Dudik M, Langford J (2019) Provably efficient RL with rich observations via latent state decoding, in International Conference on Machine Learning, PMLR, pp 1665–1674
Fang H, Deng W, Zhong Y, Hu J (2020) Triple-GAN: Progressive face aging with triple translation loss. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp 804–805
Gammulle H, Denman S, Sridharan S, Fookes C (2020) Fine-grained action segmentation using the semi-supervised action GAN. Pattern Recogn 98:107039
Gao X, Jin Y, Dou Q, Heng P-A (2020) Automatic gesture recognition in robot-assisted surgery with reinforcement learning and tree search, in 2020 IEEE International Conference on Robotics and Automation (ICRA), IEEE, pp 8440–8446
Gao L, Li H, Liu Z, Liu Z, Wan L, Feng W (2021) RNN-transducer based Chinese sign language recognition. Neurocomputing 434:45–54
Gong J, Rezaeipanah A (2023) A fuzzy delay-bandwidth guaranteed routing algorithm for video conferencing services over SDN networks. Multimed Tools Appl 82:25585–25614. https://doi.org/10.1007/s11042-023-14349-6
Gowda SN, Sevilla-Lara L, Keller F, Rohrbach M (2021) Claster: clustering with reinforcement learning for zero-shot action recognition. arXiv preprint arXiv:2101.07042
Hafeez S, Jalal A, Kamal S (2021) Multi-fusion sensors for action recognition based on discriminative motion cues and random forest, in 2021 International Conference on Communication Technologies (ComTech): IEEE, pp 91–96
Hajipour Khire Masjidi B, Bahmani S, Sharifi F, Peivandi M, Khosravani M, Hussein Mohammed A (2022) CT-ML: Diagnosis of breast cancer based on ultrasound images and time-dependent feature extraction methods using contourlet transformation and machine learning. Comput Intell Neurosci:2022
Han C, Fu X (2023) Challenge and opportunity: Deep learning-based stock price prediction by using bi-directional LSTM model. Front Bus Econ Manag 8(2):51–54
Hasan MM, Mustafa HA (2020) Multi-level feature fusion for robust pose-based gait recognition using RNN. Int J Comput Sci Inf Secur (IJCSIS) 18(1)
Heidari A, Javaheri D, Toumaj S, Navimipour NJ, Rezaei M, Unal M (2023) A new lung cancer detection method based on the chest CT images using Federated Learning and blockchain systems. Artif Intell Med 141:102572
Heidari A, Jafari Navimipour N, Unal M (2023) A secure intrusion detection platform using blockchain and radial basis function neural networks for internet of drones. IEEE Internet of Things Journal 10(10):8445–8454. https://doi.org/10.1109/JIOT.2023.3237661
Hossain MS, Muhammad G (2019) Emotion recognition using deep learning approach from audio–visual emotional big data. Inf Fusion 49:69–78
Hou X et al (2023) A space crawling robotic bio-paw (SCRBP) enabled by triboelectric sensors for surface identification. Nano Energy 105:108013
Hou Q, Jiang Z, Yuan L, Cheng M-M, Yan S, Feng J (2023) Vision permutator: A permutable MLP-like architecture for visual recognition. IEEE Trans Pattern Anal Mach Intell 45(1):1328–1334. https://doi.org/10.1109/TPAMI.2022.3145427
Huang R et al (2020) An lstm approach to temporal 3d object detection in lidar point clouds. European Conference on Computer Vision. Springer, pp 266–282
Huang C -Q, Jiang F, Huang Q -H, Wang X -Z, Han Z -M, Huang W -Y (2022) Dual-graph attention convolution network for 3-D point cloud classification. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2022.3162301
Jafari BM, Luo X, Jafari A (2023) Unsupervised keyword extraction for hashtag recommendation in social media. In: The International FLAIRS Conference Proceedings, vol 36
Jafari BM, Zhao M, Jafari A (2022) Rumi: An intelligent agent enhancing learning management systems using machine learning techniques. J Softw Eng Appl 15(9):325–343
Jiao S, Zou Q, Guo H, Shi L (2021) iTTCA-RF: a random forest predictor for tumor T cell antigens. J Transl Med 19(1):1–11
Jun K, Lee D-W, Lee K, Lee S, Kim MS (2020) Feature extraction using an RNN autoencoder for skeleton-based abnormal gait recognition. IEEE Access 8:19196–19207
Khairy RS, Hussein A, ALRikabi H (2021) The detection of counterfeit banknotes using ensemble learning techniques of AdaBoost and voting. Int J Intell Eng Syst 14(1):326–339
Kim J, Kong J, Son J (2021) Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. in International Conference on Machine Learning, PMLR, pp 5530–5540
Kosarirad H, Nejati MG, Saffari A, Khishe M, Mohammadi M (2022) Feature selection and training multilayer perceptron neural networks using grasshopper optimization algorithm for design optimal classifier of big data sonar. J Sens 2022
Langroodi AK, Vahdatikhaki F, Doree A (2021) Activity recognition of construction equipment using fractional random forest. Autom Constr 122:103465
Lee K, Laskin M, Srinivas A, Abbeel P (2021) Sunrise: A simple unified framework for ensemble learning in deep reinforcement learning, in International Conference on Machine Learning, PMLR, pp 6131–6141
Li W et al (2021) A comprehensive survey on machine learning-based big data analytics for IoT-enabled smart healthcare system. Mob Netw Appl 26(1):234–252
Li J, Chen M, Li Z (2022) Improved soil–structure interaction model considering time-lag effect. Comput Geotech 148:104835
Li P, Chen Z, Yang LT, Zhang Q, Deen MJ (2017) Deep convolutional computation model for feature learning on big data in internet of things. IEEE Trans Industr Inf 14(2):790–798
Li B, Li Q, Zeng Y, Rong Y, Zhang R (2021) 3D trajectory optimization for energy-efficient UAV communication: A control design perspective. IEEE Trans Wireless Commun 21(6):4579–4593
Li Q-K, Lin H, Tan X, Du S (2018) H∞ consensus for multiagent-based supply chain systems under switching topology and uncertain demands. IEEE Trans Syst Man Cybern: Syst 50(12):4905–4918
Li B, Lu Y, Pang W et al (2023) Image colorization using CycleGAN with semantic and spatial rationality. Multimed Tools Appl 82:21641–21655. https://doi.org/10.1007/s11042-023-14675-9
Li X, Sun Y (2020) Stock intelligent investment strategy based on support vector machine parameter optimization algorithm. Neural Comput Appl 32:1765–1775. https://doi.org/10.1007/s00521-019-04566-2
Li X, Sun Y (2021) Application of RBF neural network optimal segmentation algorithm in credit rating. Neural Comput Appl 33:8227–8235
Li B, Tan Y, Wu A-G, Duan G-R (2021) A distributionally robust optimization based method for stochastic model predictive control. IEEE Trans Autom Control 67(11):5762–5776
Lin J (2019) Backtracking search based hyper-heuristic for the flexible job-shop scheduling problem with fuzzy processing time. Eng Appl Artif Intell 77:186–196
Liu Q, Kosarirad H, Meisami S, Alnowibet KA, Hoshyar AN (2023) An optimal scheduling method in IoT-fog-cloud network using combination of aquila optimizer and african vultures optimization. Processes 11(4):1162
Liu Z, Li Z, Wang R, Zong M, Ji W (2020) Spatiotemporal saliency-based multi-stream networks with attention-aware LSTM for action recognition. Neural Comput Appl 32(18):14593–14602
Lu S, Ding Y, Liu M, Yin Z, Yin L, Zheng W (2023) Multiscale feature extraction and fusion of image and text in VQA. Int J Comput Intell Syst 16(1):54
Luo M, Cao J, Ma X, Zhang X, He R (2021) FA-GAN: face augmentation GAN for deformation-invariant face recognition. IEEE Trans Inf Forensics Secur 16:2341–2355
Lv Z, Qiao L, Li J, Song H (2020) Deep-learning-enabled security issues in the internet of things. IEEE Internet Things J 8(12):9531–9538
Lv Z, Yu Z, Xie S, Alamri A (2022) Deep learning-based smart predictive evaluation for interactive multimedia-enabled smart healthcare. ACM Trans Multimed Comput Commun Appl (TOMM) 18(1s):1–20
Ma Y et al (2021) Location-and person-independent activity recognition with WiFi, deep neural networks, and reinforcement learning. ACM Trans Internet Things 2(1):1–25
Mao C, Huang L, Xiao Y, He F, Liu Y (2021) Target recognition of SAR image based on CN-GAN and CNN in complex environment. IEEE Access 9:39608–39617
Marins MA et al (2021) Fault detection and classification in oil wells and production/service lines using random forest. J Petrol Sci Eng 197:107879
Men Y, Mao Y, Jiang Y, Ma W-Y, Lian Z (2020) Controllable person image synthesis with attribute-decomposed gan. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5084–5093
Mohammed EA, Keyhani M, Sanati-Nezhad A, Hejazi SH, Far BH (2021) An ensemble learning approach to digital corona virus preliminary screening from cough sounds. Sci Rep 11(1):1–11
Morteza A, Sadipour M, Fard RS, Taheri S, Ahmadi A (2023) A dagging-based deep learning framework for transmission line flexibility assessment. IET Renew Power Gener 17(5):1092–1105
Morteza A, Yahyaeian AA, Mirzaeibonehkhater M, Sadeghi S, Mohaimeni A, Taheri S (2023) Deep learning hyperparameter optimization: Application to electricity and heat demand prediction for buildings. Energy Build 289:113036
Mousavi A, Sadeghi AH, Ghahfarokhi AM, Beheshtinejad F, Masouleh MM (2023) Improving the Recognition Percentage of the Identity Check System by Applying the SVM Method on the Face Image Using Special Faces. Int J Robot Control Syst 3(2):221–232
Moussa M, Hmila M, Douik A (2021) Face recognition using fractional coefficients and discrete cosine transform tool. Int J Electr Comput Eng 11(1):892
Nandhini Abirami R, Durai Raj Vincent PM, Srinivasan K, Tariq U, Chang CY (2021) Deep CNN and deep GAN in computational visual perception-driven image analysis. Complexity 2021:1–30
Ni H (2020) Face recognition based on deep learning under the background of big data. Informatica 44(4)
Ni Q, Guo J, Wu W, Wang H, Wu J (2021) Continuous influence-based community partition for social networks. IEEE Trans Netw Sci Eng 9(3):1187–1197
Niknam T, Bagheri B, Bonehkhater MM, Firouzi BB (2015) A new teaching-learning-based optimization algorithm for distribution system state estimation. J Intell Fuzzy Syst 29(2):791–801
Pan S, Lin M, Xu M, Zhu S, Bian L-A, Li G (2021) A low-profile programmable beam scanning holographic array antenna without phase shifters. IEEE Internet Things J 9(11):8838–8851
Paolanti M, Frontoni E (2020) Multidisciplinary pattern recognition applications: a review. Comput Sci Rev 37:100276
Parmar G, Li D, Lee K, Tu Z (2021) Dual contradistinctive generative autoencoder. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 823–832
Peivandizadeh A, Molavi B (2023) Compatible authentication and key agreement protocol for low power and lossy network in Iot environment. Available at SSRN 4454407
Peng Y, Zhao Y, Hu J (2023) On The Role of Community Structure in Evolution of Opinion Formation: A New Bounded Confidence Opinion Dynamics. Inf Sci 621:672–690
Qu Z, Liu X, Zheng M (2022) Temporal-spatial quantum graph convolutional neural network based on Schrödinger approach for traffic congestion prediction. IEEE Trans Intell Transp Syst. https://doi.org/10.1109/TITS.2022.3203791
Rao H, Xu S, Hu X, Cheng J, Hu B (2021) Augmented skeleton based contrastive action learning with momentum lstm for unsupervised action recognition. Inf Sci 569:90–109
Sadi M et al. (2022) Special session: On the reliability of conventional and quantum neural network hardware. in 2022 IEEE 40th VLSI Test Symposium (VTS), IEEE, pp 1–12
Saeed R, Feng H, Wang X, Zhang X, Fu Z (2022) Fish quality evaluation by sensor and machine learning: A mechanistic review. Food Control 137:108902
Safarzadeh VM and Jafarzadeh P (2020) Offline Persian handwriting recognition with CNN and RNN-CTC. in 2020 25th international computer conference, computer society of Iran (CSICC), IEEE, pp 1–10
Salehi S, Miremadi I, Ghasempour Nejati M, Ghafouri H (2023) Fostering the adoption and use of super app technology. IEEE Trans Eng Manag. https://doi.org/10.1109/TEM.2023.3235718
Sarbaz M, Manthouri M, Zamani I (2021) Rough neural network and adaptive feedback linearization control based on Lyapunov function. in 2021 7th International Conference on Control, Instrumentation and Automation (ICCIA), IEEE, pp 1–5
Sarbaz M, Soltanian M, Manthouri M, Zamani I (2022) Adaptive optimal control of chaotic system using backstepping neural network concept. in 2022 8th International Conference on Control, Instrumentation and Automation (ICCIA), IEEE, pp 1–5
Sevik A, Erdogmus P, Yalein E (2018) Font and Turkish letter recognition in images with deep learning. in 2018 International Congress on Big Data, Deep Learning and Fighting Cyber Terrorism (IBIGDELFT): IEEE, pp 61–64
Shahidi S, Vahdat S, Atapour A, Reisizadeh S, Soltaninejad F, Maghami-Mehr A (2022) The clinical course and risk factors in COVID-19 patients with acute kidney injury. J Fam Med Prim Care 11(10):6183–6189
Shen G, Han C, Chen B, Dong L, Cao P (2018) Fault analysis of machine tools based on grey relational analysis and main factor analysis. J Phys: Conf Ser 1069(1: IOP Publishing):012112
Shen G, Zeng W, Han C, Liu P, Zhang Y (2017) Determination of the average maintenance time of CNC machine tools based on type II failure correlation. Eksploatacja i Niezawodność 19(4)
Shi Z, Zhang H, Jin C, Quan X, Yin Y (2021) A representation learning model based on variational inference and graph autoencoder for predicting lncRNA-disease associations. BMC Bioinformatics 22(1):1–20
Simpson T, Dervilis N, Chatzi E (2021) Machine learning approach to model order reduction of nonlinear systems via autoencoder and lstm networks. J Eng Mech 147(10):04021061
Sohangir S, Wang D, Pomeranets A, Khoshgoftaar TM (2018) Big Data: Deep Learning for financial sentiment analysis. J Big Data 5(1):1–25
Song F, Liu Y, Shen D, Li L, Tan J (2022) Learning control for motion coordination in wafer scanners: Toward gain adaptation. IEEE Trans Industr Electron 69(12):13428–13438
Song Y, Xin R, Chen P, Zhang R, Chen J, Zhao Z (2023) Identifying performance anomalies in fluctuating cloud environments: a robust correlative-GNN-based explainable approach. Futur Gener Comput Syst 145:77–86
Subhashini PS, Ram MSS, Rao DS. DNN-RBF & AHHO for speaker recognition using MFCC
Tian J, Hou M, Bian H et al (2023) Variable surrogate model-based particle swarm optimization for high-dimensional expensive problems. Complex Intell Syst 9:3887–3935. https://doi.org/10.1007/s40747-022-00910-7
Ullah W, Ullah A, Haq IU, Muhammad K, Sajjad M, Baik SW (2021) CNN features with bi-directional LSTM for real-time anomaly detection in surveillance networks. Multimed Tools Appl 80(11):16979–16995
Utkin L, Drobintsev P, Kovalev M, Konstantinov A (2021) Combining an autoencoder and a variational autoencoder for explaining the machine learning model predictions. in 2021 28th Conference of Open Innovations Association (FRUCT), IEEE, pp 489–494
Vahdat S (2022) A review of pathophysiological mechanism, diagnosis, and treatment of thrombosis risk associated with COVID-19 infection. IJC Heart & Vasculature 41:101068
Vahdat S (2022) The effect of selenium on pathogenicity and mortality of COVID-19: focusing on the biological role of selenium. J Pharm Negat Results, pp 235–242
Vahdat S (2021) Association between the use of statins and mortality in COVID-19 patients: A meta-analysis. Tob Regul Sci 7(6):6764–6779
Vahdat S (2022) The role of IT-based technologies on the management of human resources in the COVID-19 era. Kybernetes 51(6):2065–2088
Vahdat S (2022) Clinical profile, outcome and management of kidney disease in COVID-19 patients—A narrative review. Eur Rev Med Pharmacol Sci 26(6):2188–2195
Wang H, Cui Z, Liu R, Fang L, Sha Y (2023) A multi-type transferable method for missing link prediction in heterogeneous social networks. IEEE Trans Knowl Data Eng. https://doi.org/10.1109/TKDE.2022.3233481
Wang M, Deng W (2020) Mitigating bias in face recognition using skewness-aware reinforcement learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 9322–9331
Wang Y, Dong M, Shen J, Wu Y, Cheng S, Pantic M (2020) Dynamic face video segmentation via reinforcement learning, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 6959–6969
Wang H, Gao Q, Li H, Wang H, Yan L, Liu G (2022) A structural evolution-based anomaly detection method for generalized evolving social networks. Comput J 65(5):1189–1199
Wang B, Shen Y, Li N, Zhang Y, Gao Z (2023) An adaptive sliding mode fault‐tolerant control of a quadrotor unmanned aerial vehicle with actuator faults and model uncertainties. Int J Robust Nonlinear Control
Wang Y, Yan J, Yang Z, Jing Q, Wang J, Geng Y (2022) GAN and CNN for imbalanced partial discharge pattern recognition in GIS. High Voltage 7(3):452–460
Wang B, Zhu D, Han L, Gao H, Gao Z, Zhang Y (2023) Adaptive fault-tolerant control of a hybrid canard rotor/wing UAV under transition flight subject to actuator faults and model uncertainties. In: IEEE Trans Aerosp Electron Syst. https://doi.org/10.1109/TAES.2023.3243580
Xia K, Huang J, Wang H (2020) LSTM-CNN architecture for human activity recognition. IEEE Access 8:56855–56866
Xiong Z, Li X, Zhang X et al (2023) A comprehensive confirmation-based selfish node detection algorithm for socially aware networks. J Sign Process Syst. https://doi.org/10.1007/s11265-023-01868-6
Xu R, Chen J, Han J, Tan L, Xu L (2020) Towards emotion-sensitive learning cognitive state analysis of big data in education: deep learning-based facial expression analysis using ordinal information. Computing 102(3):765–780
Xu J, Guo K, Sun PZ (2022) Driving performance under violations of traffic rules: novice vs. experienced drivers. IEEE Trans Intell Veh 7(4):908–917
Xu W, Jang-Jaccard J, Singh A, Wei Y, Sabrina F (2021) Improving performance of autoencoder-based network anomaly detection on nsl-kdd dataset. IEEE Access 9:140136–140146
Xu J, Pan S, Sun PZH, Hyeong Park S, Guo K (2023) Human-factors-in-driving-loop: driver identification and verification via a deep learning approach using psychological behavioral data. IEEE Trans Intell Transp Syst 24(3):3383-3394. https://doi.org/10.1109/TITS.2022.3225782
Yan A et al (2022) LDAVPM: a latch design and algorithm-based verification protected against multiple-node-upsets in harsh radiation environments. IEEE Trans Comput-Aided Des Integr Circ Syst
Yang M, Nazir S, Xu Q, Ali S (2020) Deep learning algorithms and multicriteria decision-making used in big data: a systematic literature review. Complexity:2020
Yumusak S, Layazali S, Oztoprak K, Hassanpour R (2021) Low-diameter topic-based pub/sub overlay network construction with minimum–maximum node degree. PeerJ Computer Science 7:e538
Zenggang X et al (2022) Social similarity routing algorithm based on socially aware networks in the big data environment. J Signal Process Syst 94(11):1253–1267
Zerdoumi S et al (2018) Image pattern recognition in big data: taxonomy and open challenges: survey. Multimed Tools Appl 77(8):10091–10121
Zhang DJ et al. (2021) MorphMLP: A self-attention free, MLP-like backbone for image and video. arXiv preprint arXiv:2111.12527
Zhang X, Huang D, Li H, Zhang Y, Xia Y, Liu J (2023) Self-training maximum classifier discrepancy for EEG emotion recognition. CAAI Transactions on Intelligence Technology
Zhang J, Liu Y, Li Z, Lu Y (2023) Forecast-assisted service function chain dynamic deployment for SDN/NFV-enabled cloud management systems. IEEE Syst J. https://doi.org/10.1109/JSYST.2023.3263865
Zhang Z, Mansouri Tehrani A, Oliynyk AO, Day B, Brgoch J (2021) Finding the next superhard material through ensemble learning. Adv Mater 33(5):2005112
Zhang JZ, Srivastava PR, Sharma D, Eachempati P (2021) Big data analytics and machine learning: A retrospective overview and bibliometric analysis. Expert Syst Appl 184:115561
Zhang Y, Wang X, Han N, Zhao R (2021) Ensemble learning based postpartum hemorrhage diagnosis for 5g remote healthcare. IEEE Access 9:18538–18548
Zhang X, Wen S, Yan L, Feng J, Xia Y (2022) A hybrid-convolution spatial–temporal recurrent network for traffic flow prediction. The Comput J:bxac171
Zhao H and Jin X (2020) Human action recognition based on improved fusion attention cnn and rnn. in 2020 5th International Conference on Computational Intelligence and Applications (ICCIA), 2020: IEEE, pp 108–112
Zheng W et al (2022) A few shot classification methods based on multiscale relational networks. Appl Sci 12(8):4059
Zheng W, Zhou Y, Liu S, Tian J, Yang B, Yin L (2022) A deep fusion matching network semantic reasoning model. Appl Sci 12(7):3416
Zhou L, Ye Y, Tang T, Nan K, Qin Y (2021) Robust matching for SAR and optical images using multiscale convolutional gradient features. IEEE Geosci Remote Sens Lett 19:1–5
Zhou G, Zhang R, Huang S (2021) Generalized buffering algorithm. IEEE Access 9:27140–27157
Zong C, Wan Z (2022) Container ship cell guide accuracy check technology based on improved 3D point cloud instance segmentation. Brodogradnja: Teorija i praksa brodogradnje i pomorske tehnike 73(1):23–35
Zong C, Wang H (2022) An improved 3D point cloud instance segmentation method for overhead catenary height detection. Comput Electr Eng 98:107685
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Amiri, Z., Heidari, A., Navimipour, N.J. et al. Adventures in data analysis: a systematic review of Deep Learning techniques for pattern recognition in cyber-physical-social systems. Multimed Tools Appl 83, 22909–22973 (2024). https://doi.org/10.1007/s11042-023-16382-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-16382-x