
Abstract
Multi-focus image fusion merges multiple source images of the same scene with different focus values to obtain a single image that is more informative. A novel approach is proposed to create this single image in this paper. The method’s primary stages include creating initial decision maps, applying morphological operations, and obtaining the fused image with the created fusion rule. Initial decision maps consist of label values represented as focused or non-focused. While determining these values, the first decision is made by feeding the image patches obtained from each source image to the modified CNN architecture. If the modified CNN architecture is unstable in determining label values, a new improvement mechanism designed based on focus measurements is applied for unstable regions where each image patch is labelled as non-focused. Then, the initial decision maps obtained for each source image are improved by morphological operations. Finally, the dynamic decision mechanism (DDM) fusion rule, designed considering the label values in the decision maps, is applied to minimize the disinformation resulting from classification errors in the fused image. At the end of all these steps, the final fused image is obtained. Also, in the article, a rich dataset containing two or more than two source images for each scene is created based on the COCO dataset. As a result, the method’s success is measured with the help of objective and subjective metrics. When the visual and quantitative results are examined, it is proven that the proposed method successfully creates a perfect fused image.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image fusion is an enhancement technique that aims to combine images acquired by different sensors to create an informative image that can facilitate operations on the image and aid in decision making. A good fusion technique should transfer important information from the source images to the fused image and provide a perfectly combined image. Advanced applications need a lot of information about images. However, sensors of the same type can only receive information from one direction and cannot provide the necessary information for such applications. Different sensor information is fused using image fusion techniques, and more detailed images are obtained for applications. For this reason, fusion techniques are frequently preferred in modern applications and computer vision applications.
Image fusion techniques are used in different fields such as remote sensing, merging satellite images, merging medical images to facilitate diagnosis, and merging multi-focus images [27]. This paper prefers to combine multi-focus images for a problem that has increased with the widespread use of imaging devices. Multi-focus image fusion methods aim to improve images taken with cameras with a limited depth of field. This feature of the cameras makes it impossible to obtain a perfect image with all the objects in focus unless expensive specialists and optical sensors are available. Multi-focus image fusion methods eliminate these problems and create a single, all-in-focus image by combining objects with a different focus.
The spatial domain and transform domain methods are two main categories for multi-focus image fusion [12]. The spatial domain methods use the pixel intensity values directly. In literature, several methods use the spatial domain. Averaging intensities of corresponding pixels in source images and selecting the maximum intensity of corresponding pixels in source images are traditional ways to fuse images in the spatial domain. In addition to the methods above, guided filter-based methods, methods with scale-invariant features, etc., are implemented to create all-in-focus images with great detail in the spatial domain. These methods have advantages like speed, ease of implementation, etc., but the pixel intensity values are not enough to create high detailed fused images [35]. Transform domain methods allow images to be examined in detail compared to spatial domain methods. These methods use the frequency components of source images for merging images. The frequency components give detailed information like edges, corners, smooth areas, etc. More detailed fused images can be obtained by using this information separately. Wavelet methods, pyramid-based methods, Fourier-based methods are mostly used in the transform domain [52]. In addition to the methods in these categories, deep learning-based methods have been preferred mainly by researchers in recent years. These methods are selected because the images created using these methods have more information and details about the source images compared to the images created by traditional methods. Convolutional Neural Networks and Generative Adversarial Networks are two types of deep learning methods, and they are applied in multi-focus image fusion.
This article proposes a new approach with a dynamic decision mechanism in multi-focus image fusion. The proposed method consists of three main steps. The first step is to generate initial decision maps for each source image. A new approach with an improved mechanism is used at this step while creating the initial decision maps. In this approach, the first decision is made with the modified CNN. Removing the pooling layer in the modified CNN architecture prevents the loss of important image features. This process is the main contribution to the proposed network, and all components of the network (number of layers, number of filters, layers, etc.) are designed specifically for the article. In cases where the network is unstable, instabilities are eliminated using the improvement mechanism based on focus metrics. This improvement makes the study unique. The second step is the improvement of decision maps with morphological operations. Morphological operations are used to correct distortions in the initial decision maps. The final step is the implementation of the fusion rule with the dynamic decision mechanism (DDM). Due to the designed dynamic fusion rule, the classification errors experienced, especially in the transition from the focused to the non-focused regions, are minimized, and more explicit all-in-focus images are created. Successful fusion can be performed even on images with low classification success of the network using this innovative approach. In addition, a rich dataset containing two or more source images of the same scene is created based on the COCO (https://cocodataset.org/) dataset in this article. This new data set enables image fusion for more than two source images and is expected to guide future studies. It is proved by visual and numerical results that the proposed method successfully combines images for two or more source images. The contributions of this article to the literature can be summarized as follows:
-
Creation of decision map for each source image.
-
Modified CNN architecture.
-
A new improvement mechanism designed based on focus metrics.
-
Fusion rule with dynamic decision mechanism (DDM).
-
Creating a new dataset with rich content.
2 Related works
Image fusion methods are frequently preferred today because modern applications can work more efficiently with images with detailed information. These methods are divided into two basic classes according to the algorithms they use. These are spatial domain methods and transform domain methods. In addition to these methods, practices based on deep learning have emerged as hot methods in recent years. With the emergence of these techniques, multi-focus image fusion methods, which are classically examined in two classes, are divided into three main categories today. Studies in the literature for each class will be presented in this section.
2.1 Spatial domain methods
In spatial domain methods, images are combined using some spatial properties. The distinctive feature of spatial domain methods is that the reconstruction process is not used when creating the fused image. Image transformation techniques such as wavelet transform and sparse representation for activity level measurement can be applied to some spatial domain methods, but these methods do not require inverse transformation. The primary purpose of spatial domain methods is to find the weights of the corresponding pixel values in the source images for the fused image. By using these weight values, detailed combined images are obtained. Spatial domain methods can be applied as block-based, region-based, and pixel-based [38].
The first block-based spatial domain method in multi-focus image fusion is introduced by Li et al. [24]. In this study, source images are initially divided into fixed-size blocks. Finally, the fusion process is done with a threshold-based fusion rule using spatial frequency information for each block. After this method, block-based methods are starting to become widespread. Huang et al. [19] perform a block-based fusion process based on focus metrics. They use Energy of Laplacian (EOL), Sum-modified laplacian (SML), and spatial frequency (SF), which are frequently preferred in this field, as focus metrics. In this study, multi-focus image fusion is performed with a hybrid approach using these metrics and PCNN. In addition to block-based, they propose a region-based approach using the PCNN method for segmenting images [25]. They use the salience and visibility properties of images as the fusion rule. In this way, they obtain a successful fused image. In addition to this work, Hao et al. [16] implement a multi-focus image fusion method based on mean shift segmentation, and they use the SML metric for activity measurement. This method also works on colour images.
Pixel-based spatial domain methods try to find the importance of each pixel for the fused image. These type of methods have been preferred more than other types in recent years because successfully fused images are created with the right decision being made for each pixel. In these methods, pixel-based weights are calculated for each source image and weight maps of the same size as the images are obtained. The resulting weights represent the importance of pixels for the fused image. In addition, several pixel-based methods use transform-based methods such as QWT [32, 33], NSCT [47], ND filtering [28], ICA [6] etc.
2.2 Transform domain methods
Transform domain methods consist of three stages. It is the separation of the source images into frequency components, combining the frequency components with the fusion rule and obtaining the fused image from the frequency components using inverse transform. According to the applied image transformation, transform field methods can be classified as multi-scale decomposition (MSD) based methods, sparse representation (SR) based methods and gradient-based (GD) methods [38]. The first transform domain-based approach was proposed by Burt et al. [7]. In this approach, a transformation based on the Laplacian pyramid is applied. After the transformation, the maximum selection fusion rule is implemented to combine the frequency components, and the all-in-focus image is obtained. After this study, methods using transform domain increase. Another technique in this domain is applied by Bogoni et al. [5]. In this study, the filter-subtract-decimate (FSD) pyramid is used, and it is a more efficient method than the Laplacian pyramid. Also, applying this method in the YUV colour space makes it workable for colour image fusion. In addition to pyramid-based approaches, wavelet-based approaches are frequently used in the literature. The method based on the discrete wavelet transform was firstly proposed by Li et al. [23]. With the help of the proposed method, the images are separated into frequency components, and these components are combined with the choose-maximum fusion rule. As a final step, inverse wavelet transform is applied to reconstruct the fused image. Due to this method, it turns out that wavelet transforms can be used for successful fusion. Gradient-based methods are helpful in the analysis of images. The larger the gradient value, the more valuable that part of the image is. Petrovic et al. [45]. proposes a gradient pyramid-based method for multi-focus image fusion. This method, unlike other methods, uses the “merge-then-separate” technique in the fusion phase. It is emphasized that this technique is successful in creating more detailed fused images.
SR-based methods have been rapidly gained popularity in the field of image fusion in recent years. This approach was first applied by Yang et al. [49] in multi-focus image fusion. In this study, operations are performed by dividing the source images into overlapping patches. With the help of the OMP algorithm, sparse parsing is performed independently on each patch. In the fusion stage, patches with high L1 norm from sparse coefficient vectors are transferred to the fused image. In addition to this study, another SR-based method was developed by Chen et al. [9]. This method is considered region-based. The source images are divided into overlapping regions, and the sharpness information obtained from the sparse vectors is calculated for each region. The sharpness information of the corresponding regions in the source images is averaged and transferred to the fused image.
2.3 Deep learning-based methods
Deep learning-based methods have been preferred more than spatial domain-based and transformation domain-based methods in recent years. These methods are selected because the images created using these methods have more information and detail about source images compared to images created using traditional methods. Convolution Neural Networks and Generative Adverbial Networks are the main two types of deep learning methods implemented in multi-focus image fusion. The deep learning-based methods used in this area are grouped into two categories: classification-based and regression-based [38]. The first method based on classification is implemented by Liu et al. [36]. The researchers used CNN with Siamese architecture to classify focused and non-focused areas in source images. They created a training set including 50.000 blurred and clear images using ImageNet. Blurred images made using a Gaussian filter represent non-focused areas and have a classification label as 0. In contrast to blurred ones, the clear images represent focused areas and have a classification label as 1. Lastly, Liu et al. used the sliding window technique to create a decision map. After this paper, the methods using deep learning started to increase. Another one is implemented by Tang et al. [46] They have an innovation different from the Liu et al.’s method. In addition to focused and non-focused regions, researchers added uncertain areas to the training set. Twelve blurred masks and four different filter sizes are used to create non-focused images in the training set. This set is trained using Pixel-wise Convolutional Neural Network (PCNN) in this paper. GAN (general adversarial network), a type of deep learning architecture, is mainly preferred by researchers in multi-focus image fusion topic. Guo et al. [15] implemented a method using this network. The GAN model has two parts; generator and discriminator. The generator’s output gives a focus map of images. In addition to the generator, the discriminator increases the similarity between the production and the ground-truth decision map. As the last step of the Guo et al.’s method, the focused map is created and converted to a binary image used to create the all-in-focus image.
The other category for the deep learning is regression-based methods. Researchers prefer this type of method and classification-based ones. Li et al. [29] implemented a regression-based method that combines CNN and wavelets. The high frequency and low-frequency components are fused using two end-to-end convolution networks. The methods which are cited above use supervised learning. Besides them, the methods that utilize unsupervised learning is implemented by a few researchers. Jung et al.’s [21] method is one of them. They designed a loss function created using structural tensor representations to specify similarity between fused images and source images in the gradient domain. Thus, they successfully merge the source images.
3 Proposed method
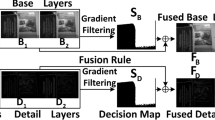
In this paper, a new approach based on deep learning, including innovations that can eliminate the shortcomings of the methods in the literature, is proposed. The flow chart of the proposed system is represented in Fig. 1. While the proposed method easily combines two or more source images, the figure shows the flow of the fusion for two source images. Firstly, a new dataset for multi-focus image fusion is created using Photoshop and used in this study. The datasets used in the literature have only two source images to fuse. In these datasets, the source images are opposite to each other. Namely, the object is focused in one of the source images, and in another source image, the object focused in the first image is defocused, and the rest is focused. This situation may be suitable to reality for some kind of digital photography like portrait photos. Still, in reality, more than two objects may be focused or non-focused in images. The new dataset created by us includes two or more than two images with different focused and non-focused parts. The differences of the new dataset from datasets used in the literature are expected to be important for the methods implemented in the future. Secondly, a modified CNN architecture is designed specifically to classify 8 × 8 patches as focused or non-focused. The most important feature of the proposed architecture is the protection of detail information in the source images by removing the pooling layer. This architecture is described in detail in the next sections. Samples from traditional datasets and new dataset are divided into overlapping patches and given as input to the network. At this stage, different from the methods in the literature, patches taken from each image are given to the network separately. In this case, a decision map is created for each image. Creating a decision map for each source image provides flexibility in the fusion phase and reduces the dependency on the classification success of the network. After this process, the network predictions for each image patch, which are labelled 0 for non-focused patches and 1 for focused patches are recorded in the initial decision maps of the source images. The whole patches for each source image are classified, and decision maps which are binary images, are created. Unlike the literature, an improvement mechanism is designed while making the first decision maps in the proposed method. The proposed mechanism comes into play when all corresponding image patches in the source images are labelled non-focused. Such situations usually occur at the border points between the focused and non-focused regions and may be called unstable. These situations should be minimized as they will negatively affect the success in obtaining a fused image. For this purpose, an intermediate mechanism based on focus measurement metrics is used as a decision mechanism in unstable situations. In this mechanism, three metrics that are found in the literature and which are frequently used to distinguish focused and non-focused are selected: variance of wavelet (WAVV), the sum of modified laplacian (SML), and spatial frequency (SF). These metrics are chosen because they help to find correct decisions for both smooth and detailed patches. A score map containing the scores for each image patch in the source images is created separately for each source image using these metrics. After this processing, the scores of corresponding patches are compared, and the patches of the bigger score are labelled as focused, and the other patches are labelled as non-focused, namely 0. The initial maps created after these steps may include some deficiencies such as black holes, staring effects, etc., so morphological operators are implemented to overcome these lacks. Due to the improvement mechanism applied in the proposed method, there is less need for morphological operations and thus the problem of softening or loss of edges caused by over-applying morphological operations is reduced. The close operations are applied to undesirable gaps, defects, etc., in initial maps. In addition, a thresholding-based method is applied to initial maps with close operation. In this method, the maps for each image are first blurred using a convolution kernel, so pixels that take values 0 and 1 will take values between 0 and 1. The threshold values are calculated using these pixel values, and smooth binary decision images are created by discarding unnecessary parts smaller than the threshold value. The maps which are obtained after morphological operations are named as final decision maps.
After creating final decision maps for each source image, the next step is specifying which pixel values will be transferred into the all-in-focus image. At this stage, the DDM fusion rule, which uses the corresponding values in the final decision maps, is designed to move the most appropriate pixel values in the source images to the fused image. DDM fusion rule offers two different options according to the label values found in the decision maps. If the corresponding values in the maps are the same, the gradient-based fusion rule, which is the first option, is applied. If the corresponding values in the maps are different, as a second option, the product of the corresponding values in the final decision maps and the source images is directly transferred to the all-in-focus image. In the literature, deep learning-based methods combine two source images into a single decision map, but a single decision map is often insufficient to obtain the best result. In the proposed method, when both separate decision maps are created for all source images and a scalable system that can combine two or more images is designed, intersection points in decision maps (the corresponding label values from the decision maps are the same) can be formed. In such cases, in accordance with the first option of the proposed DDM fusion rule, the gradient-based fusion rule is applied to transfer the correct pixel values to the fused image at these intersections. This fusion rule specifies the importance ratios of the corresponding pixels in the source images for the fused image and contributes to better-fused images. Since such a mechanism is not used in the literature, it can be accepted as one of the proposed method’s innovations to this field. And the disadvantages of classification errors that may arise from combinations using only a decision map can be minimized thanks to this innovation. Finally, the all-in-focus image is created and is ready for quality measurements. Evaluations are carried out for the new data set and the data sets used in the literature, and performance measurement is made with both objective and subjective metrics.

Flow diagram of the proposed method
3.1 Preparation of training components
3.1.1 Training dataset
The preparation of the training set has a vital role in the training accuracy of the network. It may be said that the better your training set, the better your training results will be, so a comprehensive training set is prepared in this study. A classification-based deep learning method is implemented in this paper. Because of this, the training set includes images for two classes with label 0 and label 1. Label 0 represents non-focused image patches, and label 1 illustrates focused image patches. Namely, the method in this paper aims to find classes of patches in source images. The CIFAR-100 [22] dataset, which includes 100 classes containing 600 images each, is used to create a training dataset. There are 60.000 images with the size of 32 × 32. Each image in the CIFAR-100 dataset is divided into patches with the size of 8 × 8 that is proposed network input size and obtained 800.000 focused patches with label one after this processing. Also, the modifications such as rotation, shearing, translations, contrast enhancement are implemented to patches and obtained 1.600.00 extra patches, so 2.400.000 image patches with the size of 8 × 8 are created for label 1. For the non-focused patches, the Gaussian filter with six different sizes used to blur patches is implemented to focused patches, and 2.400.00 non-focused patches are obtained. The sizes of the Gaussian filter are selected as 3, 5, 7, 9, 11, 13, separately. In this paper, a total of 4.800.000 image patches are used to train. 70% of these images are used for training and 30% for validation. In this paper, different from the other methods in the literature, modifications such as translation, shearing, rotation, contrast changes, etc., are applied to image patches while creating the training set, so the training set is enriched. Some images from the Cifar-100 dataset are given in Fig. 2.

Examples from the Cifar-100 dataset
3.1.2 Designed modified convolutional neural network (CNN)
Convolutional Neural Networks (CNN or ConvNet), a type of Deep neural network, facilitate image analysis by taking advantage of extracting important features of images such as edges, corners, etc. There are three main layers in CNN architectures: Convolution Layer, Pooling Layer, and Fully-Connected Layer. The convolution layer is used to extract features of image patches with filters in different sizes and amounts. This layer has input parameters which are filter size, filter amounts, etc. The output of the convolution layer is given to the pooling layer as input. The pooling layer is used to downsample the input signal, so the computational load is reduced. Lastly, the fully connected layer (FC) operates on an input where each input is connected to all neurons. FC layers are often found towards the end of the CNN architecture and can optimize goals such as class scores. Generally, the softmax function is located after the fully-connected layer. This function provides probability and label of classification output. In addition to these layers, the leaky ReLU layers and normalization layers may be used to refine the success of the training. While the normalization layer reduces the sensitivity to network initialization, the leaky ReLu layer is located after the normalization layer and converted linearity to nonlinearity. Also, the leaky ReLU layer allows us to learn nonlinearity in addition to linearity.
In this paper, a new network based on CNN architecture is designed. This network has a total of 21 layers. First of all, it is the image input layer that accepts 8 × 8 image patches as input. It is aimed to increase the predictability of small details and the success of the method by selecting small input sizes. Also, since grey images are preferred as network input, RGB images must be converted to grey images to be input into the network. Other layers used for the modified CNN architecture are convolution, nonlinear activation, and fully-connected layers. These layers are combined to learn all the characteristic features of the image in the best way.
A layer with a 3 × 3 filter size and number of variable filters starting with eight and increasing in each block was created in the convolution layer. This layer is used to extract essential features of images and has a significant role in the network’s success. Initial convolution filters in the designed network start with small sizes to better extract local features. These values are gradually increased in the following blocks to learn more general features. In addition, stride size is set as one due to the small size of the image patches, and the padding size is determined in a way that does not change the size of the input patches as there may be important information at the edge points of the patches. Data in real life are not linear, so nonlinear activation functions are essential in proposed networks. The Leaky ReLU function is used as an activation layer in the designed network. In addition, since mini-batch stochastic gradient descent is used as the optimization method, the range represented by the derivative of the selected activation function is also essential. Most activation functions allow learning values in a limited range. While the derivative of the Leaky ReLU function goes to infinity for positive values, it also provides learning for negative values. Therefore, it is frequently preferred in the literature as an activation function. The pooling layer used to decrease input size is not used in the designed network because the image patches in the training set are already small. Also, the down sampling operation used by the pooling layer may cause the elimination of essential features, which may decrease the training success of the designed network. The whole network layers are shown in Fig. 3. Finally, the output layer calculates both the label values, and the probability values of these labels are determined for two classes.
The most crucial part of deep learning methods is the selection of hyper parameters. Selected hyper parameters are given in this section.
Optimization method
In the designed network, mini-batch stochastic gradient descent is chosen. This method has the same logic as classical gradient descent. The difference here is that while the parameter is updated for each sample from the gradient descent, in this algorithm, the parameters are updated after training data as much as the selected batch size in this algorithm. Mini-batch SGD is used in this study because of its advantages, such as easily fitting into computer memory, being computationally efficient, removing local minimization problems, and producing stable error and convergence results.
Batch size
Batch size is one of the crucial parameters for the training phase. This concept refers to the number of samples fed into the network at one time. Generally, the larger the batch size, the faster the training will be, but in this case, the quality of the model may decrease, and the model cannot generalize. Smaller sizes cause the training to slow down and the network to oscillate too much. The batch size is chosen as 256 because the size of the training set is enormous, and the memory of the environment is limited.
Learning rate
The learning rate determines how fast the parameters of the network will be updated. Low learning rates reduce the learning speed but converge successfully. Significant learning rates accelerate learning but make it difficult to reach the global minimum. Generally, a decreasing learning rate is preferred in networks. Initially, the learning coefficient is large, and it is reduced after a specific epoch. In this study, the learning rate is determined as 0.001, and it is reduced by 10% in every ten epochs.
Loss functions
The selection of the loss function, which is a part of the optimization process, is significant. Loss functions are used to detect the loss of the model, update the weights, and reduce the loss. Generally, two different loss functions are used in the proposed networks, namely MSE and Cross-entropy. MSE is usually preferred in regression-based methods, and since it makes updates linearly, it has disadvantages such as local minimization and early termination of training. Cross-entropy is a logarithmic function and is generally preferred in classification-based applications. Since it is logarithmic, the training slows down, but it provides more accurate results. In this study, the cross-entropy loss function is chosen because it is suitable for the proposed network classification purpose and increases the network’s success.
Epoch size
An epoch is the time interval in which the entire dataset passes through the proposed network as back and forth. It is not enough to give the whole dataset through the network once. Since the gradient descent method works on a vast dataset, it is not possible to generate accurate weight updates all at once. Therefore, the number of epochs is essential. A single epoch can cause underfitting, but too large epoch number can also cause overfitting. For this reason, as a result of the trials, the number of epochs is determined as 30 for the proposed network.
The images are trained using these parameters. Training and validation accuracy are obtained as %99,50, %98,34, respectively. The experimental results show that the designed network is suitable for multi-focus image fusion.

Proposed CNN architecture for training
The proposed CNN architecture is designed to separate the two classes. The classes in this paper are focused and non-focused parts, as can be seen from the output layer of the network. The 8 × 8 image patches taken from the source images are given to the trained network to determine which class they belong to. As a result, the network’s decisions are improved with different mechanisms, and an entirely focused image is obtained.
3.2 Preparation of new dataset
The datasets used in the literature generally have the same logic. These datasets have only two source images to fuse. The source images used in these datasets include one object with focus, and the rest of the source image is non-focused. This situation is opposed to reality because the images captured by devices may consist of more than two objects with randomly focused or non-focused. Because of this, a new dataset will be used in this area, which is needed. The dataset created by us is prepared by considering these needs.
The new dataset prepared using Photoshop contains a total of 715 colour images with 155 sets. These sets have source images to be fused between 2 and 6. The original images are taken from the COCO dataset [22] and modified in Photoshop. The source images in these datasets have different sizes and different focused areas. The features of this dataset may be named as a novel because the datasets in the literature include only two source images to fuse, and the images are limited. Considering these situations, it can be said that the new data set (https://drive.google.com/file/d/1t28bbxOxO2m7l9p-Kbq-jrjZxt1CPBpf/view?usp=sharing) will fill a significant gap in this area and will also guide further studies.
3.3 Feeding source images to the trained network
The training network is designed to classify image patches as focused or non-focused. This network combines the image input layer, convolution layer, nonlinearity layer, and fully connected layer. The pooling layer, which is generally used in CNN architecture, is used to downsample input signals. The down sampling operation may result in eliminating important features and reducing the size of inputs. Besides these, the size of image patches in this paper is already tiny, so the pooling layer is not preferred in the proposed network design. The image patches are small because large ones may cause details such as edges, corners, etc., in images to be ignored. The experimental results prove that the images fused using the proposed method have more information than the combined images created by methods in the literature.
In this paper, we fused both images in traditional datasets and images in the new dataset created by us. They are divided into small overlapping patches with 8 × 8, and these patches are fed into the trained network separately. After this process, the predictions for related patches are saved to the decision maps of source images. These predictions are represented as label 1 for focused areas and label 0 for non-focused areas. After each prediction, an improvement mechanism is applied in the proposed method. Such a mechanism is a new refinement method for predictions that have not been previously used in the literature. It is only activated when the predictions of corresponding image patches in the source images are labeled 0. In such cases, which may be named instability, unwanted pixels may be transferred to the fused image. In the proposed method, the mechanism based on focus measure metrics is applied to image patches that the trained network can not decide. Three different focus measure metrics that are Variance of Wavelet (WAVV), Sum Modified Laplacian(SML), and Spatial Frequency (SF), are selected to make the correct prediction for these patches. The refining method details are given in the next section.
3.4 Refining initial maps using designed improvement mechanism
Focused areas have more explicit and more detailed components than non-focused areas. Therefore, focus measurement metrics are expected to give maximum value in focused regions. This feature helps to separate focused and non-focused areas with these metrics easily. In literature, different metrics which measure the focus degree of image or image patches are proposed. These metrics are very successful in deciding focused areas, so in the proposed method, these metrics are used to increase success in situations where the deep learning network is unstable. Focus measure metrics are generally divided into five different groups. These are laplacian-based, gradient-based, statistical-based, wavelet-based, and dct-based metrics. In this paper, three different metrics, which are Variance of Wavelet (WAVV), Sum Modified Laplacian (SML), and Spatial Frequency (SF), from three groups are used. The metrics which are selected in this paper are given in the following sections. These metrics are chosen because they can better represent edges, corners, etc., in source images. When creating score maps, calculations are made using selected metrics for image patches extracted from source images. The score maps and source images are the same size. When finding the score of an image patch, metrics are calculated separately for the corresponding patches in each source image. The results for these patches are compared, and the score of the patch with the higher value is increased by one. Thus, a score map ranging from 0 to 3 is created for each source image. This score map is used where the proposed modified CNN architecture is unstable (labelling each image patch as out of focus). In these cases, the scores for corresponding patches are obtained, and then these scores are compared with each other. As a result of this comparison, the image patch with the higher score is labelled as focused, while the others are labelled as non-focused. With this mechanism, which was not used in the literature before, unstable situations became stable, and better quality fused images are created. The algorithm of the improvement mechanism is given in Algorithm 1. The main contribution of this algorithm is to minimize the cases where the proposed network fails to classify. This situation reduces the need for morphological operations. Thus, the problems of softening of the edges and loss of important information in source images that can be caused by morphological operations are eliminated.
Algorithm 1. Improvement mechanism for unstable network situations

In the equation, the first image patch of source image one is represented with img_pat_1, and the score map is represented with sc1. As seen in the equation, comparisons are made for each metric separately. In the comparison, the score of the image patch with a high metric value is increased by one. This process is repeated for all three metrics while calculating the score. That is, the score takes a value between 0 and 3 for any image patch. For example, the first comparison in Eq. 1 gives the measurement for the SML metric of each source image’s corresponding first image patches. The number of measured values is equal to the number of source images (SIC). The SML metric is calculated for the first patches extracted from all source images separately, and the maximum one is taken. The score of the image patch to which the maximum value belongs is increased by one. These processes are repeated for all image patches.
This algorithm is valid for two source images, and the same logic can be used for multiple source images. Each image patch is classified using this algorithm in unstable network conditions. The network output gives the classification label of the respective image patch. If both labels are zero, the table where the scores of the relevant patch are kept is checked to avoid this situation. In this situation, the image patch with the higher score is labeled as focused and transmitted to the decision map. The decision map obtained after this mechanism contains the initial classification labels for the source images and is created separately for each image.
This section gives the step-by-step visual expression of creating a combined image with the proposed method. From these figures, the positive effect of the innovations in the study is clearly seen. In the first stage, the images taken from the new dataset are divided into overlapping patches separately. Samples taken from the new data set are given in Fig. 4.

Multi-focus LAPTOP Image in the new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Source Image 3(512 × 512), (d) Source Image 4(512 × 512)
In the second stage, overlapping patches extracted from each source image are given to the modified CNN network separately, and binary decision maps are created for each image.
In the third stage, a mechanism is implemented to improve decision maps based on focus metrics, one of the proposed method’s innovations to this field. This mechanism works for patches where the proposed network cannot classify (classifying all corresponding patches as unfocused) and minimizes these situations. Another feature of this stage is that it reduces the need for morphological. Due to this innovation, undesirable problems in decision maps are eliminated, and the need for morphological operations is reduced. Less morphological operations will prevent the softening of the edge regions of the decision maps so that sharp-edged fused images will be obtained.
The images obtained as a result of the second and third stages are given in Fig. 5. These images consist of two parts. While the right part of the images shows the result of the second stage, the left part gives the result of the third stage, which includes the improvement mechanism. As can be seen from these parts, the proposed improvement mechanism positively affects the decision maps.

Multi-focus LAPTOP Image in the new dataset: (a) Decision maps before and after the improvement mechanism for Source Image 1(512 × 512), (b) Decision maps before and after the improvement mechanism for Source Image 2(512 × 512), (c) Decision maps before and after the improvement mechanism for Source Image 3(512 × 512), (d) Decision maps before and after the improvement mechanism for Source Image 4(512 × 512)
In the Fourth Stage, some errors remaining in the decision maps created in the first three stages are corrected. Due to the low number of mistakes at these stages, errors can be corrected with small morphological operations. This situation allows the creation of a detailed fused image in which edge information is preserved. Final decision maps created after the fourth stage are given in Fig. 6.

Multi-focus LAPTOP Image in the new dataset: (a) Final decision map for Source Image 1 (512 × 512), (b) Final decision map for Source Image 2 (512 × 512), (c) Final decision for Source Image 3 (512 × 512), (d) Final decision map for Source Image 4 (512 × 512), (k) All-in-focus Image (512 × 512)
Decision maps created in step four are combined with the proposed dynamic fusion rule. The most important feature of this rule is that it can eliminate situations that cannot be resolved in the other four stages. No matter how good the proposed network is, it is challenging to make the right decision to transition from focused to non-focused regions. These regions usually include edges and are very important for the combined image. With the proposed fusion rule, the cases where the network can decide are transferred directly to the merged image. However, in cases where the network can not decide, a gradient-based fusion rule is applied, resulting in a perfect image with detailed and sharp edges. The fused image is given in Fig. 7.

(a) All-in-focus Image(512 × 512)
3.4.1 Focus metrics used for improvement of the proposed method
The variance of Wavelet (WAVV)
Focus measurements using wavelet transforms are preferred because they can represent the spatial and frequency contents in the source images. The wavelets separate source images into detailed and approximation coefficients. Detail coefficients reveal essential components such as edges, corners, etc., while approximation coefficients reveal smooth areas like background. In this way, focus level measurements can be made for both detail and smooth regions. The WAVV metric produces higher results in focused areas.
In the proposed method, the variance of wavelet coefficients is calculated to measure focus level for corresponding image patches in source images. Then, the calculation results are compared, and the score is increased by one for the image patch whose value is higher.
Sum Modified Laplacian (SML)
Sum Modified Laplacian metric [19] was proposed by Nayar and Nakagawa in 1994. The researchers stated that the second derivatives in the x and y direction could be the opposite sign and neutralize each other, so they designed ML metric to eliminate this issue. The SML metric is calculated using Eq. 2.
In this equation, T is the discrimination value, and N is the window size for image patches. This metric successfully finds detailed parts of the image such as edges, corners, etc. Focused areas have sharper edges than non-focused areas, so this metric that works well at edges can be suitable for multi-focus image fusion. While the metric result is higher in focused areas that have more details than non-focused, the result is lower in non-focused areas. In the proposed method, this metric is calculated for the corresponding image patches in source images, and the score of the image patch with the higher metric result is increased by one.
Spatial frequency (SF)
Spatial frequency [57] is a metric used to measure overall activity in images. This metric gives high results in detailed regions so that it can separate focused and non-focused areas. The calculation of these metrics is shown in Eq. 3.
Spatial frequency is represented with SF in Eq. 3. RF and CF represent row frequency and column frequency, respectively.
The row and column numbers are shown with M and N, respectively, and the I is the fused image.
3.5 Creating fused image with the designed fusion rule
The fusion rule, the most important and last step of the multi-focus image fusion methods, determines the importance of the pixel values in the source images for the fused image. Namely, the fusion rules are the essential components that directly affect the success of the method. The methods used in the literature usually combine the two source images, and the decision maps are opposite to each other in these methods. In this case, the corresponding values of the decision maps and source images are multiplied and transferred to the fused image. However, an error in the decision map found with these methods (labelling the focused region as non-focused) causes irreversible results in fused images.
In the proposed method, a fusion rule with a dynamic decision mechanism (DDM) is designed. This rule dynamically selects the fusion rule according to the corresponding label values in the decision maps. This dynamic decision mechanism fusion rule has two options; rules that work when the corresponding values in decision maps are different and the corresponding values in decision maps are the same. If the corresponding values in the decision maps are different, it means that the proposed network can make the right decision for image patches. Thus, label values and the corresponding pixel intensities in the source images are multiplied and transferred to the fused image. If the corresponding values in the decision maps are the same, it means that the proposed network has difficulty deciding for image patches. A gradient-based fusion rule is applied in these situations, and the relevant pixels are transferred to the fused image using this rule. The gradient-based fusion rule is told in Section 3.5.1. In this fusion rule, the gradient value is calculated for the relevant pixels. Using these values, the importance ratios of the pixel values in the source images for the fused image are determined. While gradient values are high in detailed areas such as slope, edges, and corners, these values appear close to zero in smooth regions. Due to this feature of the gradient, it can be said that the combined image will have more details. The algorithm of the DDM fusion rule is given in Algorithm 2. In this algorithm, it is explained how to reach the fused image pixel using decision maps.
Algorithm 2. DDM fusion rule

In the literature, deep learning-based multi-focus image fusion methods focus on combining two source images, thus these methods transfer the product of decision maps and corresponding pixels directly to the fused image. The disadvantage of these fusion rules is that the classification error in the proposed network directly affects the method’s success. Learning-based methods often give erroneous results in transition pixels from focused regions to non-focused regions in images. This situation causes distortions on the edges of the fused images. The proposed fusion rule considers this situation and takes a dynamic approach. In cases where the proposed network can decide right (when it is clear that the image patches are focused or unfocused), the fusion rule used in the literature is applied. This fusion rule is to directly transfer the product of the label value in the decision maps and the pixel intensity values corresponding to this value in the source images to the fused image. In cases where the network is unstable, unable to decide whether the image patches are focused or non-focused, a gradient-based fusion rule is applied. This rule generally works at the transition points from the focused regions to the defocused regions in images and makes the edges of the fused image more prominent. The gradient operator takes high values in the essential parts of the image (edge, corner, etc.), while it takes low values in the soft regions. Due to this feature, it is very successful in preserving essential parts in the source images for the fused image. For these reasons, thanks to the proposed fusion rule, the proposed method creates a more detailed fused image than other literature methods.
3.5.1 Gradient-based fusion rule
A gradient is a crucial tool in images that suppresses unimportant components that highlight essential features. This situation is similar to multi-focus image fusion purposes since these methods aim to transfer vital elements in the source images to the fused image. In the proposed method, a gradient-based fusion rule is used to improve the DDM fusion rule. The gradient magnitude is calculated for each pixel in the source images. The corresponding gradient magnitudes are proportioned using Eq. 11, and the significance of pixels for the combined image is determined. Each pixel is transferred to the fused image according to its importance ratio.
This rule was first used by Aymaz et al. [3]. In the proposed method, this rule, which is Sobel-based, is recommended as an improvement mechanism during the merging phase. A 3 × 3 mask is preferred as the Sobel operator. The larger the mask, the harder it is to capture details, so a large mask size is not chosen [37]. Maps of gradient magnitudes are created using this operator for each source image. The equations for creating these maps are like in the following;
Firstly, the whole image is scanned with the help of Sobel operators, and the gradient image is obtained.
\({S}_{x}\) and \({S}_{y}\) represent the Sobel operator in the x and y-direction, respectively. The gradient images are created using Eqs. 8–10.
And finally, gradient magnitudes for each image are calculated using Eq. 11.
After these steps, each source image creates a gradient magnitude matrix of the same size as the images. The importance of these magnitude matrices for the fused image is determined by proportioning the corresponding values. The equation used to determine the significance ratios is as follows.
\({Imp}_{k}\) is the matrix that stores the importance ratios of the source image pixels for the fused image. \({Mag}_{k}\) matrix is the matrix that stores the gradient magnitudes of the source images. While k is the number of images to be calculated, n is the total number of source images. This optimization mechanism works in cases where the method is unstable. For the pixels where the system is unstable, obtaining the fused values is calculated by the following formula.
The fused image is represented by Fused. In addition, Img represents the source images, while Imp represents the importance ratios of that source image for the combined image.
Typically, this kind of improvement is not included in the literature because the methods found in the literature combine source images with a single decision map and do not contain intersection points in decision maps. In other words, the techniques in the literature transfer the outputs of the network directly to the combined image. However, the proposed networks cannot always make the correct classification. Usually, this situation occurs in the transition from focused regions to non-focused regions. This situation can be expressed as an aperture in the literature because the decision map cannot always represent the image perfectly. This situation causes irreparable problems. For these reasons, this mechanism used in the proposed method makes the method general and reduces the negative effect of mislabeling.
4 Measuring performance of the proposed method
The method is dependent on mathematical modeling, and it is named an objective analysis. The quality of the fused image is the spectral and spatial similarities between the combined image and raw input images. With reference image and without reference image are two primary approaches of measuring performance [43].
4.1 With reference image
This type of metrics is used when a reference image is available. These metrics are used to measure the similarity between the reference image and the fused image. Metrics such as Root Mean Square Error (RMSE), Spectral Angular Mapper (SAM), Relative Dimensionless Global Error (ERGAS), Mean Bias (MB), Percentage Fit Error (PFE), Signal to Noise Ratio (SNR), Peak Signal to Noise Ratio (PSNR), Correlation Coefficient (CC), Universal Quality Index (UQI), Structural Similarity Index Measure (SSIM), etc. are subjective metrics frequently encountered in the literature.
4.2 Without reference image
When there is no reference image, evaluations are made using objective metrics. These metrics measure how successful the transfers are made from the source images to the fused image.
Metrics such as Standard Deviation (σ), Entropy (He), Cross-Entropy (CE), Spatial Frequency (SF), Edge Preservation (\({Q}^{\frac{AB}{F}}\) ), Mutual Information (MI), Fusion Quality Index (FQI), Fusion Similarity Metric (FSM), etc., are objective metrics frequently encountered in the literature.
4.3 Quality metrics for performance measuring
4.3.1 Average gradient (AG)
The contrast and texture alteration properties in the image are extracted using AG. And also, the image clarity is defined using this metric. It is calculated by Eq. (14) [14].
ΔIx and ΔIy represent the first order of the pixel (x,y) in the x and y-direction, respectively. The height and width of images are shown with M and N. The larger the result of this metric, the more successful the method is.
4.3.2 Petrovics Metric (\({Q}^{\frac{AB}{F}}\))
\({Q}^{\frac{AB}{F}}\) metric is used to measure the detailed information (edge, corner, etc.) transferred from the source images to the fused image. It is calculated using Eq. 15 [53].
Where \({Q}^{AF}\left(i,j\right)={Q}_{a}^{AF}\left(i,j\right){Q}_{b}^{AF}\left(i,j\right)\) and 0≤\({Q}^{AF}\left(i,j\right)\)≤1.
\({Q}_{a}^{AF}\left(i,j\right)\) and \({Q}_{b}^{AF}\left(i,j\right)\) represent the loss of information in the F image. \({w}^{A}\)(i,j) \({w}^{B}\)(i,j) are the weights for \({Q}_{a}^{AF}\left(i,j\right)\) and \({Q}_{b}^{AF}\left(i,j\right)\), respectively. The amount of detailed information on transmission between A and F images is shown by\({Q}^{AF}\). And edge strength of the source image is shown with\({w}^{A}\). The larger the result of this metric, the more successful the method will be.
4.3.3 Mutual information (MI)
Mutual Information is an important metric that shows how much information is transferred from the source images to the fused image. MI is calculated by Eqs. (16) and (17) [53].
In these equations, A and B represent the source images while F represents the fused image. \({P}_{AF}\)and \({P}_{BF}\) represent the joint histograms of source images between fused images The histogram of A, B, F images are shown with \({P}_{A}\),\({P}_{B}\),\({P}_{F}\) respectively. Consequently, the expression is as in Eq. (18).
The larger the results of this metric, the more successful the method will be.
4.3.4 Chen-Blum Metric(\({Q}_{CB}\))
\({Q}_{CB}\) [8] which is based on the human vision system is a quality assessment method for image fusion.
5 Evaluation results
In this paper, a new method for multi-focus image fusion is proposed. This method is distinguished from other methods in the literature by using a new dataset, offering a new network for training, and the improvement mechanisms it applies in the fusion phase. Generally, methods in the literature use the Lytro dataset with a limited number of source images. The methods using this dataset focus on combining the two source images, and the focused regions in these images are opposite each other. In other words, source images can be combined with a single decision map. Contrary to this situation, images taken with real-life imaging devices can be more than two, and the focused regions in these images are random. For these reasons, a new large data set suitable for real-life was prepared and used in this paper. This dataset contains two or more source images with random focus regions suitable for real life. Since the methods in the literature only focus on combining two source images, the fusion rules used in these methods are also created for this purpose. These methods generate only one decision map for the two source images. This decision map consists of classification labels detected for a source image. The decision map created for the other source image is the inverse of the first decision map. For this reason, the approaches proposed in the literature are not sufficient to combine the dataset created for this study. Due to overcoming these shortcomings, the proposed method is designed to fuse traditional datasets and new datasets containing more than two source images to be combined. At the same time, a new network for training was organized. This network consists of 21 layers; the feature that distinguishes this network from others is protecting detailed information by removing the max-pooling layer. Another difference compared to the methods in the literature is the procedures applied for image patches to be trained. While other methods use transformations such as rotation and translation, the proposed method also applies contrast changes in addition to these. Thus, both training success and test success are increased.
Other vital points in the proposed method are the refinement based on the focus measurement metrics applied while finding the final decision maps and the gradient-based fusion rule used at the intersection of the final decision maps in the final stage of the proposed method. These two improvement methods significantly contribute to the fusion of datasets containing more than two source images and eliminating a literature gap. After all these stages, the performance of the proposed method is measured using objective metrics and compared with other techniques in the literature.
In this paper, objective metrics are used for metric measurement purposes. These metrics are such as \({Q}^{\raisebox{1ex}{$AB$}\!\left/ \!\raisebox{-1ex}{$F$}\right.}\)MI, etc., are frequently used metrics in the literature. These metrics measure how much the source images are represented in the fused image. In other words, by looking at these metrics, it can be said how many essential parts such as edges and vertices in the source images can be preserved in the proposed method. Due to these properties, objective metrics are preferred more frequently in the literature. The results are given for three different data sets. These are the Lytro data set, the new data set created by us, and the traditional data set consisting of images used in most of the methods in the literature. The visual and quantitative results for each dataset are given in the following sections.
5.1 Evaluations using new dataset
In this study, a new dataset consisting of 155 sets of 715 colour images is designed. This dataset contains two or more source images to be combined, unlike the literature. Since it is used for the first time in this study, only visual and quantitative results are given, and no comparison is made. Figures 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23 and 24 shows the visual impacts of the proposed method using the new dataset. The effects of combining both for two images and for more than two source images are given in the figures. It is seen that there are only two source image fusion results, so this method differs from other methods in the literature. While creating the figures for the samples with four source images in the data set, an image was designed to represent the fused image, the b-e images to represent the source images, and the f-I images to represent the final decision map. In addition, in figures with two source images, an image is designed to represent the combined image, b-c images to represent the source images, and d-e images to represent the final decision maps. The figures given below are randomly selected images from the data set.

Multi-focus Image with number of GOODS in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Source Image 3(512 × 512), (d) Source Image 4(512 × 512), (e) Final decision for Source Image 1(512 × 512), (f) Final decision for Source Image 2(512 × 512), (g) Final decision for Source Image 3(512 × 512), (h) Final decision for Source Image 4(512 × 512), (i) All-in-focus Image(512 × 512)
Figure 8 contains the results for image GOODS in the new dataset. a-d give source images with different focus areas for fusion e-h images provide the final decision maps created after the proposed method. The last one (ı) image shows the all-in-focus image after the proposed method. As seen from the images, the method generates a decision map for each source image and combines them to create a fused image with more detail than the source images.

Multi-focus Image with number of HORSEANDCOW in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Source Image 3(512 × 512), (d) Source Image 4(512 × 512), (e) Final decision for Source Image 1(512 × 512), (f) Final decision for Source Image 2(512 × 512), (g) Final decision for Source Image 3(512 × 512), (h) Final decision for Source Image 4(512 × 512), (ı) All-in-focus Image(512 × 512)
Figure 9 contains the results for image HORSEANDCOW in the new dataset. a-d images give source images with different focus areas for fusion e-h images provide the final decision maps created after the proposed method. The last one (ı) image shows the all-in-focus image after the proposed method. This figure provides the results of combining four different source images. The image created using the proposed method is more precise and more detailed than the source images.

Multi-focus Image with number of DOG in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Final Decision for Source Image 1(512 × 512), (d) Final Decision for Source Image 2 (512 × 512), (e) All-in-focus Image(512 × 512)
Figure 10 contains the results for image DOG in the new dataset. a-b images give source images with different focus areas to be used for fusion. The c-d images show the final decision maps for source images after the proposed method, and (e) image gives the fused image. This figure shows the results of the proposed method for two different source images. Decision maps and combined images show how well the method saves details.

Multi-focus Image with number of JETS in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Source Image 3(512 × 512), (d) Source Image 4(512 × 512), (e) Final decision for Source Image 1(512 × 512), (f) Final decision for Source Image 2(512 × 512), (g) Final decision for Source Image 3(512 × 512), (h) Final decision for Source Image 4(512 × 512), (ı) All-in-focus Image(512 × 512)
Figure 11 contains the results for image JETS in the new dataset. a-d images give source images with different focus areas to be used for fusion e-h images provide the final decision maps created after the proposed method, and the last one (ı) image gives the all-in-focus image after the proposed method. There are four source images in this figure, where each object in the images has a different focus point. The proposed method creates a fused image by successfully detecting focused and non-focused objects.

Multi-focus Image with number of KNIFEANDBANANA in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Source Image 3(512 × 512), (d) Source Image 4(512 × 512), (e) Final decision for Source Image 1(512 × 512), (f) Final decision for Source Image 2(512 × 512), (g) Final decision for Source Image 3(512 × 512), (h) Final decision for Source Image 4(512 × 512) All-in-focus Image(512 × 512)

Multi-focus Image with number of APPLE in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Source Image 3(512 × 512), (d) Source Image 4(512 × 512), (e) Final decision for Source Image 1(512 × 512), (f) Final decision for Source Image 2(512 × 512), (g) Final decision for Source Image 3(512 × 512), (h) Final decision for Source Image 4(512 × 512), (ı) All-in-focus Image(512 × 512)
Figures 12 and 13 contain the results for images KNIFEANDBANANA and APPLE in the new dataset, respectively. In these images, a-d images give source images with different focus areas for fusion, e-h images provide the final decision maps created after the proposed method, and the last (ı) image gives the all-in-focus image after the proposed method. When the figures are examined, it is seen that the proposed method is successful in detecting different objects in source images. It is seen that the fused images created using the proposed method are much more detailed than the source images.

Multi-focus Image with number of ELEPHANT in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Final Decision for Source Image 1(512 × 512), (d) Final Decision for Source Image 2 (512 × 512), (e) All-in-focus Image(512 × 512)

Multi-focus Image with number of BIKER in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Final Decision for Source Image 1(512 × 512), (d) Final Decision for Source Image 2 (512 × 512), (e) All-in-focus Image(512 × 512)

Multi-focus Image with number of ROSE in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Final Decision for Source Image 1(512 × 512), (d) Final Decision for Source Image 2 (512 × 512), (e) All-in-focus Image(512 × 512)

Multi-focus Image with number of MOTORCYCLE in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Final Decision for Source Image 1(512 × 512), (d) Final Decision for Source Image 2 (512 × 512), (e) All-in-focus Image(512 × 512)

Multi-focus Image with number of MINICAT in new dataset: (a) Source Image 1(512 × 512), (b) Source Image 2(512 × 512), (c) Final Decision for Source Image 1(512 × 512), (d) Final Decision for Source Image 2 (512 × 512), (e) All-in-focus Image(512 × 512)
Figures 14, 15, 16, 17 and 18 gives the visual results of the proposed method for sets with two source images in the new dataset. In these figures, a-b images give source images with different focus areas to be used for fusion. The c-d images show the final decision maps for source images after the proposed method, and (e) image gives the fused image. When examined, these figures, decision maps, and combined images show how well the proposed method saves details. These figures consist of a few examples selected from the new dataset. This dataset has many samples with different characteristics like these images. Therefore, it will be important in future studies to measure the success of the methods.
As seen in all figures, the proposed method for both two source images and more than two source images produces successful results. Unlike the literature, this paper creates a decision map for each image given in figures. In addition, quantitative results for twelve images in the new data set are shown in Table 1. Results are obtained using metrics that are \({Q}^{\raisebox{1ex}{$AB$}\!\left/ \!\raisebox{-1ex}{$F$}\right.}\), Standard Deviation (STD), Structural Similarity (SSIM), and Average Gradient (AG). Each image is numbered in the new data set, so these numbers are shown in the image section of Table 1. The images given in the table are obtained by fusing the source images whose number varies between 2 and 4.
Table 1 shows the objective and subjective evaluation results for the new data set. SSIM is a subjective metric that gives the similarity ratio between the combined image and the reference image. The remaining metrics are objective and measure the accuracy of the data transferred from the source images to the fused image. SSIM and \({Q}^{\raisebox{1ex}{$AB$}\!\left/ \!\raisebox{-1ex}{$F$}\right. }\)take values between 0 and 1. The larger the results of these metrics, the more successful the proposed method will be. When looking at the metric results, it is seen that the proposed method is very successful in representing the source images in the fused image. Since the data set is used for the first time in this publication, no comparison is given using this dataset.
5.2 Evaluations for traditional datasets
This dataset is frequently used in methods in the literature. Usually, the image sets consist of two images to be combined and are grey level. In addition to other datasets, this traditional dataset is also used in this paper. Visual results are given for Flower, Leopard, Leaf, Hoed, and Cameraman images in this dataset. Also, comparisons are made with sixteen different methods in the literature according to objective evaluation results using this dataset. For comparison, new techniques in the literature are selected, and the comparison results are given in Table 2.

Multi-focus Flower Image: (a) Source Image 1(480 × 640), (b) Source Image 2(480 × 640), (c) Final Decision for Source Image 1(480 × 640), (d) Final Decision for Source Image 2 (480 × 640), (e) All-in-focus Image(480 × 640)

Multi-focus Leopard Image: (a) Source Image 1(360 × 480), (b) Source Image 2(360 × 480), (c) Final Decision for Source Image 1(360 × 480), (d) Final Decision for Source Image 2 (360 × 480), (e) All-in-focus Image(360 × 480)

Multi-focus Leaf Image: (a) Source Image 1(204 × 268), (b) Source Image 2(204 × 268), (c) Final Decision for Source Image 1(204 × 268), (d) Final Decision for Source Image 2 (204 × 268), (e) All-in-focus Image(204 × 268)

Multi-focus Cameraman Image: (a) Source Image 1(256 × 256), (b) Source Image 2(256 × 256), (c) Final Decision for Source Image 1(256 × 256), (d) Final Decision for Source Image 2 (256 × 256), (e) All-in-focus Image(256 × 256)

Multi-focus Hoed Image: (a) Source Image 1(256 × 256), (b) Source Image 2(256 × 256), (c) Final Decision for Source Image 1(256 × 256), (d) Final Decision for Source Image 2 (256 × 256), (e) All-in-focus Image(256 × 256)
Figures 19, 20, 21, 22 and 23 consist of images frequently used in the literature. The results of the proposed method are also given for this dataset. In these figures, a and b images give the source images to be used for fusion, c-d images show the final decision maps for source images after the proposed method. Lastly, the e image gives the all-in-focus image. As can be seen in the figures, the combined images have more details than the source images. In addition, measurements are made based on objective metrics and compared with sixteen different methods found in the literature. While making comparisons, methods found in the literature are tried to be selected in recent years. The source images, Book, Clock, Pepsi, Lab, Disk, Leaf, and Flower, are chosen to compare the proposed method with methods in the literature. Table 2 gives the objective comparison results for the proposed method and the compared methods for these images. The best results are shown with bold.
Objective metrics measure the amount of information transferred from the source images to the fused image and how well the methods preserve the detail components of the source images, so they are often used in multi-focus image fusion methods. Mutual Information (MI) shows how important data is transferred from the source images to the combined image. \({Q}^{\frac{AB}{F}}\)shows how much the edge information in the source images is represented in the fused image. The quantitative results show that the proposed method objectively is more successful than other methods in the literature. Indirectly, it is proved that the information and details such as edge, corners, etc., in the source images, are more protected than other methods in the literature. The methods are given in the table generally transfer the focus information to the fused image with a certain coefficient. The disadvantages of these methods are that they do not take into account the transition from focused regions to non-focus regions and it is difficult to find the correct coefficient for focus information. Unlike the compared methods, the proposed method transfers the correct focus information to the fused image with its successful classification and improvement mechanisms. It also determines the points where the classification may be wrong and ensures that these points are transferred to the fused image with maximum accuracy. For these reasons, the proposed method is quite superior to other studies in the literature.
In addition, subjective evaluations are also made for some traditional images frequently used in the literature. Since it is difficult to find reference image datasets in the literature, finding results for these metrics is challenging. In this paper, a comparison is given with the methods proposed by Moushmi et al. [41] and Li et al. [26] used in the literature using the Root Mean Square Error (RMSE) subjective metric. This metric measures how similar the fused image and the reference image are taken from the dataset. In other words, it indirectly gives the success of the proposed method in transferring important information from source images to the fused image. Book, Clock, Saras, Flower, and Lab images are used for comparison. Moushmi et al. used Book, Clock, and Saras images while giving the results of the method, and the RMSE values for these images were 7.04, 4.51, and 2.85, respectively, while the values obtained as a result of the proposed method were 0.36, 1.50 and 0.94, respectively. Also, Li et al. used Lab and Flower images while giving the results of the method, and the RMSE values for these images are 4.65 and 7.84, respectively, while the values obtained as a result of the proposed method are 1.11 and 1.24, respectively. When the results are examined, it can be said that the proposed method is subjectively more successful than the compared methods, and it is more successful in transferring important information from the source images to the fused image.
5.3 Evaluations using Lytro dataset
The Lytro dataset (https://mansournejati.ece.iut.ac.ir/content/lytro-multi-focus-dataset) is one of the rare colour datasets used in this field. Generally, it is frequently used in other methods in the literature. This data set contains 20 pairs of different images in 520 × 520 sizes. Like the images in other datasets, these images are opposite to each other and can be represented with a single decision map. Visual results for the proposed method are given in figures [3, 8, 14, 19, 21, 22, 37, 43, 53, 57]. And also proposed method is compared with six different methods [26, 27, 36, 40, 41; https://mansournejati.ece.iut.ac.ir/content/lytro-multi-focus-dataset] in the literature using this dataset. Objective metrics are chosen for comparison since the reference image is not provided in the Lytro data set. These metrics measure the success of the method without using a reference image. The objective quality metrics, which are \({Q}_{CB}\), \({Q}^{\raisebox{1ex}{$AB$}\!\left/ \!\raisebox{-1ex}{$F$}\right.}\), Standard Deviation(STD), and Mutual Information(MI), are selected to compare proposed methods with methods in the literature. These metrics are frequently preferred in the literature as they can better determine the amount of transfer from the source images to the fused image. \({Q}_{CB}\)is a contrast sensitivity based metric proposed by Chen et al. [8] \({Q}^{\raisebox{1ex}{$AB$}\!\left/ \!\raisebox{-1ex}{$F$}\right.}\)measures the number of edges transferred from the source images to the fused image, the pixel distribution is calculated using STD, and the correct data transfer between the source images and the fused image is calculated using MI. The primary purpose of all these metrics is to measure the representation success of the source images in the fused image.

Multi-focus Lytro-14 Image from Lytro Dataset: (a) Source Image 1 (520 × 520), (b) Source Image 2 (520 × 520), (c) Final Decision for Source Image 1(520 × 520), (d) Final Decision for Source Image 2(520 × 520), (e) All-in-focus Image (520 × 520)
Figure 24 contains the results for the Lytro-14 image in the Lytro dataset. a-b images give the source images with different focus values to be used for fusion. The c-d images provide the final decision maps created after the proposed method, and lastly, the e image gives the fused images created using the proposed method. In this paper, it is tried to increase the success by making a decision map for each source image.

Multi-focus Lytro-13 Image from Lytro Dataset: (a) Source Image 1 (520 × 520), (b) Source Image 2 (520 × 520), (c) Final Decision for Source Image 1(520 × 520), (d) Final Decision for Source Image 2(520 × 520), (e) All-in-focus Image (520 × 520)
Figure 25 contains the results for the Lytro-13 image in the Lytro dataset. a-b images give the source images with different focus values to be used for fusion. The c-d images provide the final decision maps created after the proposed method, and lastly, the e image gives the fused images created using the proposed method.

Multi-focus Lytro-12 Image from Lytro Dataset: (a) Source Image 1 (520 × 520), (b) Source Image 2 (520 × 520), (c) Final Decision for Source Image 1(520 × 520), (d) Final Decision for Source Image 2(520 × 520), (e) All-in-focus Image (520 × 520)
Figure 26 contains the results for the Lytro-12 image in the Lytro dataset. a-b images give the source images with different focus values to be used for fusion. The c-d images provide the final decision maps created after the proposed method, and lastly, the e image gives the fused images created using the proposed method.

Multi-focus Lytro-11 Image from Lytro Dataset: (a) Source Image 1 (520 × 520), (b) Source Image 2 (520 × 520), (c) Final Decision for Source Image 1(520 × 520), (d) Final Decision for Source Image 2(520 × 520), (e) All-in-focus Image (520 × 520)
Figure 27 contains the results for the Lytro-11 image in the Lytro dataset. a-b images give the source images with different focus values to be used for fusion. The c-d images provide the final decision maps created after the proposed method, and lastly, the e image gives the fused images created using the proposed method.

Multi-focus Lytro-10 Image from Lytro Dataset: (a) Source Image 1 (520 × 520), (b) Source Image 2 (520 × 520), (c) Final Decision for Source Image 1(520 × 520), (d) Final Decision for Source Image 2(520 × 520), (e) All-in-focus Image (520 × 520)
Figure 28 contains the results for the Lytro-10 image in the Lytro dataset. a-b images give the source images with different focus values to be used for fusion. The c-d images provide the final decision maps created after the proposed method, and lastly, the e image gives the fused images created using the proposed method.

Multi-focus Lytro-03 Image from Lytro Dataset: (a) Source Image 1 (520 × 520), (b) Source Image 2 (520 × 520), (c) Final Decision for Source Image 1(520 × 520), (d) Final Decision for Source Image 2(520 × 520), (e) All-in-focus Image (520 × 520)
Figure 29 contains the results for the Lytro-03 image in the Lytro dataset. a-b images give the source images with different focus values to be used for fusion. The c-d images give the final decision maps created after the proposed method, and lastly the e image shows the fused images created using the proposed method.

Multi-focus Lytro-01 Image from Lytro Dataset: (a) Source Image 1 (520 × 520), (b) Source Image 2 (520 × 520), (c) Final Decision for Source Image 1(520 × 520), (d) Final Decision for Source Image 2(520 × 520), (e) All-in-focus Image (520 × 520)
Figure 30 contains the results for the Lytro-01 image in the Lytro dataset. a-b images give the source images with different focus values to be used for fusion. The c-d images give the final decision maps created after the proposed method, and lastly the e image shows the fused images created using the proposed method.

Multi-focus Lytro-08 Image from Lytro Dataset: (a) Source Image 1 (520 × 520), (b) Source Image 2 (520 × 520), (c) Final Decision for Source Image 1(520 × 520), (d) Final Decision for Source Image 2(520 × 520), (e) All-in-focus Image (520 × 520)
Figure 31 contains the results for the Lytro-08 image in the Lytro dataset. a-b images give the source images with different focus values to be used for fusion. The c-d images give the final decision maps created after the proposed method, and lastly, the e image provides the fused images created using the proposed method.
As can be seen in the figures, the proposed method visually produces good results for this dataset. Since the method is general, it can produce results even if the number of images increases. Table 3 shows the comparison results for this dataset with six different approaches based on deep learning. These are the learning method with two-stage [11], the deep convolution neural network-based one [36], general adversarial network-based one [40], the ensemble of CNN based one [1], the sparse representation based one [31], convolutional neural network-based one [56], multi-scale decomposition and sparse representation-based one[34], quadtree-based one [4], and boundary finding based one[54]. The metrics used in this paper are frequently preferred metrics in calculating data transferred from source images to the fused image. These metrics, which are Mutual Information (MI), Chen-Blum Metric (\({Q}_{CB}\)), Petrovic’s Metric (\({Q}^{AB/F}\)), and Standard Deviation (STD), show how much of the vital information in the source images are transferred to the fused image. The bigger the metric results, the more successful the method will be.
The methods are given in Table 3 consist of recent studies in this field. Objective metric results for methods [1, 4, 31, 34, 36, 40, 54, 56] are taken from [11]. The metrics used show how successful the methods can be in multi-focus image fusion. These metrics measure the representational capabilities of the source images for the fused image. The better the correct information is represented in the source images, the greater the success of the methods. Results are obtained for the twenty pairs of images in the Lytro dataset, and the mean and variance calculations of these results are given in Table 3. The methods given in this table aim to create a fused image by classifying the focused and unfocused regions in source images. The compared methods generally use large-size image patches. The larger the image patches, the more unsuccessful the classifiers fail at transition points from focused regions to defocused regions. In addition, the fusion made with the compared methods are directly dependent on the success of the classifier. Classification errors highly affect the fused image because of this reason. In the proposed study, smaller-sized image patches are used, unlike the studies in the literature. Thus, fewer errors are made at the transition points from focused regions to non-focused regions. In addition, thanks to the improvement mechanism based on focus metrics, the classification success is increased. An important aspect of the proposed study, compared to the studies in the literature, is to identify the faulty pixels in the transitions from the focused regions to the defocused regions and transfer these pixels to the fused image with the gradient-based fusion rule. Thanks to this feature, the amount of correct information transferred from the source images to the fused image is maximized. When the results are examined, it is seen that the proposed method is superior to the methods in the literature.
This table shows that the proposed method is more successful than the methods in the literature for this dataset, so it can be said that the proposed method transfers the correct information in the source images to the fused image better than other methods. The correct information here is that the focused pixels from each source image are correctly classified by the network, and important information such as edges and corners in the source images are transferred to the combined image. The proposed method is compared with the important studies in this field. It is seen that the proposed method is suitable for multi-focus image fusion looking at these results.
6 Conclusions
In this paper, a new method including improvement mechanisms is proposed for multi-focus image fusion. In addition, unlike the datasets in the literature, a new dataset containing more than two source images to fuse is prepared. Since the methods in the literature focus on combining only two source images, they are not scalable, so this dataset is expected to guide new methods.
Firstly, a new network design that can classify patches extracted from source images as focused or non-focused is established for the study. The corresponding image patches in the source images are given to the trained network separately, and initial decision maps with a label of 0 or 1 are created for each image. The methods in the literature try to combine images using only one decision map, which causes irreversible negativity if the decision map is wrong. For these reasons, in this study, decision maps are found for each source image, and these decision maps are tried to be improved. Also, methods that use only a single decision map are unsuitable for real life as they merely fuse two images. The proposed method is designed in a suitable way for both real-life and to eliminate the shortcomings of the methods in the literature. This method uses an improvement mechanism while finding initial maps for each source image. This mechanism becomes active if the trained network is unstable in its predictions. When the predictions for the corresponding image patches have the 0 labels, this can be expressed as instability. In this case, unstable situations are eliminated using focus measurement metrics, and initial decision maps are created for each image. After this stage, decision maps, which are binary images, are improved with the help of morphological processes, and the final decision image is created for each source image. The final decision maps are then combined with the help of the DDM fusion rule. Due to the DDM fusion rule, which offers two different combining options, unlike the methods in the literature, the success of the proposed method is minimally affected by the wrong predictions of the network. In addition, contrary to the methods commonly used in the literature, maximum transfer of information from the source images to the fused image is ensured, especially at the transition points from the focused regions to the non-focused regions.
It is proved with visual and quantitative results that the fused image created after all the steps of the proposed method are applied has more important information than the images created by other methods in the literature and is more successful in fusing the source images than these methods. In addition, the proposed method can be expressed as a scalable method that can combine images regardless of the number of source images. As a result, it is clear that this study can be used to combine two or more source images with different focus points to create a single all-in-focus, easy-to-process, detailed image. In addition, it is expected that the innovative steps of the proposed method will guide future studies.
References
Amin-Naji M, Aghagolzadeh A, Ezoji M (2019) Ensemble of CNN for multi-focus image fusion. Inf Fusion 51:201–214
Amin-Naji M, Aghagolzadeh A, Ezoji M (2020) CNN’s hard voting for multi-focus image fusion. J Ambient Intell Humaniz Comput 11:1749–1769
Aymaz S, Köse C, Aymaz Ş (2020) Multi-focus image fusion for different datasets with super-resolution using gradient-based new fusion rule. Multimed Tools Appl 79:13311–13350
Bai X, Zhang Y, Zhou F (2015) Quadtree-based multi-focus image fusion using a weighted focus-measure[J]. Inf Fusion 22:105–118
Bogoni L, Hansen M (2001) Pattern-selective colour image fusion. Pattern Recognit 34:1515–1526
Bouzos O, Andreadis I, Mitianoudis N (2019) Conditional random field model for robust multi-focus image fusion. IEEE Trans Image Process 28(11):5636–5648
Burt P, Adelson E (1985) Merging images through pattern decomposition, in Applications of Digital Image Processing VIII. Int Soc Opt Photonics 575:173–181
Chen Y, Blum RS (2009) A new automated quality assessment algorithm for image fusion[J]. Image Vis Comput 27(10):1421–1432
Chen L, Li J, Chen C (2013) Regional multi-focus image fusion using sparse representation. Opt Express 21(4):5182–5197
Chen C, Gend P, Lu K (2015) Multi-focus image fusion based on multiwavelet and DFB. Chem Eng Trans 46:277–283
D.Gai X, Shen H, Chen P, Su (2020) Multi-focus image fusion method based on two-stage of convolutional neural network. Sig Process 176:107681
Du C, Gao S (2018) Multi-focus image fusion algorithm based on pulse coupled neural network modified decision map. Optik 157:1003–1015
Du C, Gao S, Liu Y, Gao B (2019) Multi-focus image fusion using deep support value convolutional neural network. Optik 176:567–578
Fu W, Huang S, Li Z, Shen H, Li J, Wang P (2016) The optimal algorithm for Multi-source RS image fusion. MethodsX 3:87–101
Guo X, Nie R, Cao J, Zhou D, Qian W (2018) Fully convolutional network-based multi-focus image fusion. Neural Comput 30(7):1775–1800
Hao X, Zhao H, Liu J (2015) Multi-focus colour image sequence fusion based on mean shift segmentation. Appl Opt 54(30):8982–8989
He K, Zhou D, Zhang X, Nie R (2018) Multi-focus: focused region finding and multi-scale transform for image fusion. Neurocomputing 320:157–170
Hua KL, Wang HC, Rusdi AH, Jiang SY (2014) A novel multi-focus image fusion based on random walks. J Vis Commun İmage R 25:951–962
Huang W, Jing Z (2007) Evaluation of focus measures in multi-focus image fusion. Pattern Recognit Lett 28(4):493–500
Jiang Q, Jin X, Lee S, Yao S (2016) A Novel Multi-Focus Image Fusion Method Based on Stationary Wavelet Transform and Local Features of Fuzzy Sets. Neurocomputing 174:733–748
Jung H, Kim Y, Jang H, Ha N, Sohn K (2020) Unsupervised deep image fusion with structure tensor representations. IEEE Trans Image Process 29:3845–3858
Krizhevsky A, Nair V, Hinton G. https://www.cs.toronto.edu/~kriz/cifar.html. Accessed 11 Oct 2020
Li H, Manjunath B, Mitra S (1995) Multisensor image fusion using the wavelet transform. Graph Models Image Process 57(3):235–245
Li S, Kwok J, Wang Y (2001) Combination of images with diverse focuses using the spatial frequency. Inform Fusion 2(3):169–176
Li M, Cai W, Tan Z (2006) A region-based multi-sensor image fusion scheme using pulse–coupled neural network. Pattern Recognit Lett 27(16):1948–1956
Li H, Chai Y, Yin H, Liu G (2012) Multi-focus image fusion and denoising scheme based on homogeneity similarity. Opt Commun 285(2012):91–100
Li S, Kang X, Fang L, Hu J, Yin H (2017) Pixel-level Image Fusion: A survey of the state of the art. Inform Fusion 33:100–112
Li H, Qiu H, Yu Z, Li B (2017) Multi-focus image fusion via fixed window technique of multiscale images and non-local means filtering. Sig Process 138:71–85
Li H, Nie R, Cao J, Guo X, Zhou D, He K (2019) Multi-focus image fusion using u-shaped networks with a hybrid objective. IEEE Sens J 19(21):9755–9765
Li L, Ma H, Jia Z, Si Y (2021) A novel multiscale transform decomposition-based multi-focus image fusion framework. Multimed Tools Appl 80:12389–12409
Liu Y, Wang Z (2014) Simultaneous image fusion and denoising with adaptive sparse representation[J]. IET Image Process 9(5):347–357
Liu Y, Jin J, Wang Q, Shen Y, Dong X (2013) Novel focus region detection method for multi-focus image fusion using quaternion wavelet. J Electron Imaging 22(2):23017
Liu Y, Jin J, Wang Q, Shen Y, Dong X (2014) Region level based multi-focus image fusion using quaternion wavelet and normalized cut. Sig Process 97:9–30
Liu Y, Liu S, Wang Z (2015) A general framework for image fusion based on multi-scale transform and sparse representation[J]. Inf Fusion 24:147–164
Liu C, Long Y, Mao J (2016) Energy efficient multi-focus image fusion based on neighbour distance and morphology. Optik 127:11354–11363
Liu Y, Chen X, Peng H, Wang Z (2017) Multi-focus image fusion with a deep convolutional neural network. Inform Fusion 36:191–207
Liu Y, Zheng C, Zheng Q, Yuan H (2018) Removing Monte Carlo noise using a Sobel operator and a guided image filter. Vis Comput 34:589–601
Liu Y, Wang L, Cheng J, Li C, Chen X (2020) Multi-focus image fusion: A survey of the state of the art. Inform Fusion 64:71–91
Liu S, Lu Y, Wang J, Hu S, Zhao J, Zhu Z (2020) A new focus evaluation operator based on max-min filter and its application in high-quality multi-focus image fusion. Multidimens Syst Signal Process 31:569–590
Ma J, Yu W, Liang P (2019) FusionGAN: a generative adversarial network for infrared and visible image fusion[J]. Inf Fusion 48:11–26
Moushmi S, Sowmya V, Soman KP (2016) Empirical wavelet transform for multi-focus image fusion. Proceedings of the international conference on soft computing systems. Advances in Intelligent Systems and Computing, India
Nejati M, Samavi S, Karimi N, Soroushmehr SMR, Shirani S, Roosta I, Najarian K (2017) Surface-area based focus criterion for multi-focus image fusion. Inform Fusion 36:284–295
Pa J, Hegde AV (2015) A review of quality metrics for fused image. International conference on water resources, coastal and ocean engineering (ICWRCOE (2015)) 4, pp 133–142
Panigrahy C, Seal A, Mahato NK (2020) Fractal dimension based parameter adaptive dual-channel PCNN for multi-focus image fusion. Opt Lasers Eng 133:106141
Petrovic V, Xydeas C (2004) Gradient-based multiresolution image fusion. IEEE Trans Image Process 13(2):228–237
Tang H, Xiao B, Li W, Wang G (2018) Pixel convolutional neural network for multi-focus image fusion. Inf Sci (Ny) 433:125–141
Wang H (2018) Multi-focus image fusion algorithm based on focus detection in spatial and nsct domain. PLoS ONE 13(9):e0204225
Wen Y, Yang X, Celik T, Sushkova O, Albertini MK (2020) Multi-focus image fusion using convolutional neural network. Multimed Tools Appl 76(4):34531–34543
Yang B, Li S (2012) Pixel-level image fusion with simultaneous orthogonal matching pursuit. Inform Fusion 13(1):10–19
Yang Y, Que Y, Huang S, Lin P (2017) Technique for multi-focus image fusion based on fuzzy-adaptive pulse-coupled neural network. SIVip 11:439–446
Yang Y, Zhang Y, Huang S, Wu J (2020) Multi-focus image fusion via NSST with non-fixed base dictionary learning. Int J Syst Assur Eng Manag 11:849–855
Yin H, Li Y, Chai Y, Liu Z, Zhu Z (2016) A novel sparse-representation-based multi-focus image fusion approach. Neurocomputing 216:216–229
Zhang X, Li X, Feng Y (2016) A new multi-focus image fusion based on spectrum comparison. Sig Process 123:127–142
Zhang Y, Bai X, Wang T (2017) Boundary finding based multi-focus image fusion through multi-scale morphological focus-measure[J]. Inf fusion 35:81–101
Zhang B, Lu X, Pei H, Liu H, Zhao Y, Zhou W (2016) Multi-focus Image fusion algorithm based on focused region extraction. Neurocomputing 174:733–748
Zhang Y, Liu Y, Sun P (2020) IFCNN: a general image fusion framework based on convolutional neural network[J]. Inf Fusion 54:99–118
Zheng Y, Essock EA, Hansen BC, Haun AM (2007) A new metric based on extended spatial frequency and its application to DWT based fusion algorithms. Inform Fusion 8:177–192
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Aymaz, S., Köse, C. & Aymaz, Ş. A novel approach with the dynamic decision mechanism (DDM) in multi-focus image fusion. Multimed Tools Appl 82, 1821–1871 (2023). https://doi.org/10.1007/s11042-022-13323-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-13323-y