
Abstract
Recently, the generative adversarial networks(GAN) has been widely used in various fields of machine learning. It avoids the complicated solving process of the original generation model while ensuring the generation effect. However, since the inputs of GAN are random initialized, it takes a long time to train the data generated by the model to fit the original data distribution. Therefore, in this paper, we propose a principal component analysis optimized generative adversarial networks (PCA-GAN). The original data is compressed and reduced by principal component analysis to generate the input of the confrontation network, so that the input data retains the characteristics of the original data to some extent, thereby improving the data generation performance and reducing the training time cost. We applied our PCA-GAN to image classification, and the experimental results show that the model effectively improve the accuracy of image classification and enhance the stability of the model.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recently, due to the good performance of machine learning algorithm [16,17,18,19], several image classification methods have been proposed.The generative adversarial networks(GAN) [5] is a novel machine learning structural model proposed by Professor Ian Goodfellow of the University of Montreal in 2014, which has achieved good results in data generation. Since GAN could generate random samples which are similar to the real data distribution through model training and learning, More and more scholars are engaged in the research of GAN [16]. Arjovsky proposed an improvement to GAN in the measurement of data similarity, namely Wasserstein GAN [2]. He used Wasserstein distance to replace the distance measurement formula of the probability distribution in the original GAN, and optimized the instability and model collapse of the original GAN training process. EBGAN [20] improved GAN from the perspective of energy model, which gives GAN a definition of an energy model that is different from other models in defining loss functions by distance metrics, training the GAN model with a broader structure and a wider variety of loss function types. DCGAN (Deep Convolutional Generative Adversarial Networks) [11] replaced the generation network and discriminant network in GAN with an improved CNN (Convolutional Neural Networks). The algorithm combines CNN (supervised learning) and GAN (unsupervised learning), provides a good network structure for GAN training, improves the stability of the training process and the quality of the generated results.The article “Adversarial Autoencoders” (AAE) [8] proposed an idea of using Autoencoder for confrontation learning, which, to some extent, provided some new ideas for the previous problems, and included three types of formulation: Unsupervised, semi-supervised and Supervised.
In recent years, GAN has been widely used in various fields of machine learning because of its many advantages, such as (1) using Laplacian pyramids for image refinement [3], and changing the previous single input into a pyramid-type multi-layer sequence input. The latter layer is upsampled on the basis of the previous layer, so that the fineness of the picture is getting higher and higher; (2) A generative antagonistic network based on loss sensitivity-Loss-Sensitive generative adversarial networks on lipschitz densities [9]. (3) using GANs to convert the description text into a picture, input a piece of text in the model to represent a picture, and the model generates a corresponding picture according to the description [12].
The application of GAN in classification is mainly about unsupervised learning and semi-supervised learning. The early GAN model is mainly applied to unsupervised learning tasks, the generated and trained samples have the same distribution of data, which can be 1D signals or 2D images. When applying GAN to a semi-supervised classification task, only a slight modification to the structure of the original GAN is required, replacing the output layer of the discriminator model with a softmax classifier. Assuming that the training data can be divided into c categories, then when training the GAN model, the sample simulated by the generator can be classified as the c + 1 class, and the softmax classifier also adds an output neuron to indicate the probability that the input of the discriminator model is “fake data”, “false data” here refers to the sample generated by the generator. Because the model can not only use tagged training samples, it can also learn from unlabeled generated data, so it is called “semi-supervised” classification. The work done in this paper is mainly to improve the original network structure based on the unsupervised classification using DCGAN. Using principal component analysis (PCA) [1] to compress and reduce the original data], and the resulting reduced-dimensional vector replaces the random noise as the input of the generator, so that the generated confrontation network can generate higher quality pictures.
In this paper, we propose a generative adversarial network improved based on principal component analysis. Combining principal component analysis with generative adversarial networks to improve the generative model, through experiments on handwritten characters and face data sets, the model’s generative effects were verified, then the second classifier of the discriminant model is changed to multi-classification, which is applied to semi-supervised image classification. In Section 2, we review the Generative Adversarial Networks and principal component Analysis. Then we present the Image Classification Based on Principal Component Analysis Optimized Generative Adversarial Networks in Section 3. In Section 4, extensive experiments are conducted to demonstrate the effectiveness of the proposed algorithm. Finally, we draw a conclusion in Section 5.
2 Related work
2.1 Principal component analysis (PCA)
PCA (principal Component Analysis), the principal component analysis method, is one of the most widely used data compression algorithms. In PCA, data is converted from the original coordinate system to the new one, which is determined by the data itself. When converting the coordinate system, the direction with the largest variance is taken as the direction of the coordinate axis, because the maximum variance of the data provides the most important information of the data. The first new axis selects the direction with the largest variance in the original data, and the second new axis selects the direction orthogonal to the first new coordinate axis and the second largest variance. This process is repeated and the number of repetitions is the feature dimension of the original data. Principal component analysis is often used to reduce the dimensionality of a data set while maintaining the feature that maximizes the contribution of the data set. This is done by preserving the low-order principal components and ignoring the higher-order principal components so that the low-order components tend to retain the most important aspects of the data.
Figure 1 is a schematic diagram of principal component analysis. The original data is three-dimensional data (left). After being compressed by principal component analysis, the data is marked as two-dimensional data (right).It can be seen from the above figure that the reduced data retains the characteristics of the original data to a large extent, and reducing the dimensionality of the data is also beneficial to reduce the complexity of subsequent experiments.

Principal component analysis
Figure 2 is a flow chart of principal component analysis. First, the original data needs to be normalized so that the mean value is 0 and the variance is 1. Then the covariance matrix is established to figure out the eigenvalues and eigenvectors, and the eigenvectors corresponding to the largest zdim eigenvalues are selected. Finally, the data is mapped into the new space constructed by zdim eigenvectors to obtain the compressed data.

Flow chart of principal component analysis
2.2 Generative adversarial networks(GAN)
Generative adversarial networks (GAN) is a deep learning model and one of the most promising methods for unsupervised learning in complex distribution in recent years. The model produces fairly good output through mutual game learning of two modules in the framework, the Generative Model and the Discriminative Model. G is a network that generates pictures, it receives a random noise z, which is used to generate a picture, recorded as G(z). D is a discriminating network that discriminates whether a picture is “real”. Its input parameter is x, which represents a picture, and the output D(x) represents the probability that x is a real picture. The output D(x) represents the probability that x is a real picture. If D(x) = 1, If D(x) = 1, it means that 100% of it is a real picture, and D(x) = 0 means it cannot be a real picture. In the training process, the goal of the generative network G is to generate a real picture as much as possible to deceive the discriminative network D. The goal of D is to separate the G-generated image from the real image. Thus, G and D constitute a dynamic process of “game”.
Since the generator of the original GAN uses random noise as an input, which causes instability in the training process and the quality of the generated picture is poor, so the original network structure needs to be improved. Paper Improved Techniques for Training [13] shows a good example to use semi-supervised to solve the problem and improve accuracy.
The model training of GAN can be divided into two parts: forward propagation and backward propagation. In the forward propagation phase, a random vector is randomly generated as the data of the generated model, and then a new vector is generated by the generative model, it is a Fake Image, recorded as xfake; Randomly select an image from the dataset, convert the image into a vector, and use it as a Real Image, recorded as xreal. D(z) or X is used as the input of the discriminant network. After the processing of discriminant network, the output is a number between 0 and 1, which is used to indicate the probability that the input picture is Real Image, real is 1, and fake is 0.According to the type of input , Fake Image or Real Image marks the label of the input data of the model as 0 or 1. That is, the input type of the discriminant model is (xfake,0) or (xreal,1). The backpropagation phase is based on the loss function of the generated model and the discriminant model obtained above, adjusts the relevant parameters continuously according to the needs of the problem until the model tends to be stable.
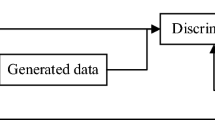
Unlike conventional deep learning models (such as CNN, DBN, RNN), the GAN model uses two independent neural networks called “generator” and “discriminator”. The generator is used to generate high-dimensional samples that look similar to real samples based on the input noise signal. The discriminator is used to distinguish between the samples produced by the generator and the actual training samples (belonging to a two-class problem). The model structure framework is as follows (Fig. 3).

Generative adversarial networks
The generated confrontation network is composed of two parts, a generator G and a discriminator D. G is a network for generating pictures, which receives a random noise and generates a picture through this noise. D is a discriminating network that discriminates whether a picture is “real”, and then feeds the result to G and D to adjust the parameters. In the training process, the goal of generating the network G is to generate a picture that is as realistic as possible to deceive the discriminant network D, and the goal of D is to separate the picture generated by G from the real picture as much as possible. Thus, G and D constitute a dynamic “game process.”
Since the generator of the original GAN uses random noise as an input, which causes instability in the training process and the quality of the generated picture is poor, so the original network structure needs to be improved. This paper proposes an improved generative adversarial networks based on principal component analysis to solve the above problems and apply it to semi-supervised classification.
3 Semi-supervised classification based on principal component analysis improved generative adversarial networks
3.1 Semi-supervised classification
Semi-Supervised Learning (SSL) is an important issue in the field of pattern recognition and machine learning, which is a combination of supervised learning and unsupervised learning. Semi-supervised learning uses a large amount of unlabeled data as well as tagged data for pattern recognition. In semi-supervised learning, as few people as possible will be required to work, and at the same time, higher accuracy can be guaranteed.Therefore, semi-supervised learning is receiving more and more attention. Semi-Supervised Classification (Semi-SupervisedClassification) is to train samples of classification labels with the help of samples without classification labels to obtain a classifier with better performance than samples with only classification labels. The process uses category tags to make up for sample defects. Although unlabeled samples do not directly contain tag information, if they are sampled separately from the same data source as the tagged information samples, the information they contain about the data distribution is useful for modeling. Semi-supervised learning, which lets the learner improve the learning performance without relying on external interactions and automatically use unlabeled samples. In the real task, the number of unlabeled samples is far more than that of the labeled samples is a common phenomenon, and how to use the unlabeled samples to improve the generalization ability of the model is the focus of semi-supervised learning research.
In paper “Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks” [15] gives us a typical cases about combine unsupervised and semi-supervised learning with GAN. “Semi-Supervised Learning with Context-Conditional Generative Adversarial Networks” [4] show us a practical application that we can use semi-Supervised learning and GAN to finish word processing and even consider the context. “Improved Semi-supervised Learning with GANs using Manifold Invariance” [6] also show us a excellent result about using Manifold Invariance to transform GAN.The result of the above paper can make us infer there still have huge potential in combine GAN with Semi-supervised learning.
3.2 Building a model
In the original generative adversarial networks, the input of the generator is a random noise that conforms to a normal distribution or a uniform distribution, and the data has a huge randomness, which results in a long training time, and the effect of generating an image is general. The principal component analysis can preserve some image features while reducing the dimension of the image, therefore, we use principal component cnalysis to reduce the original image, and replace the random vector with the reduced vector as the input of the generator in GAN. Since the improved input preserves some of the features of the image, it is possible to generate a picture closer to the real picture,and greatly reducing the training time. The algorithm flow chart is as follows (Fig. 4).

Algorithm flowchart of PCA-GAN
In the semi-supervised learning based on principal component analysis improved generative adversarial networks, The input z of the generator in the original confrontation network is improved, and the vector obtained by compressing the dimensionality reduction of the picture by the PCA is used instead of the originally randomly distributed noise z input to the generator of GAN for training the generator to generate the picture G(z). The generated picture G(z) and the real picture x are used as inputs of the discriminator (classifier) D for training the discriminator (classifier), and the discriminator determines which type the picture belongs to (The original picture x has a k class, and the k + 1 class indicates that there is a “fake picture” generated by the generator G). According to the result of the discriminator (classifier), the parameters of the generator and the discriminator are adjusted by backpropagation to minimize the loss function L.
In the semi-supervised learning based on principal component analysis improved generative adversarial networks, the loss function of generator G should be minimized as much as possible, which is denoted as follows.
The loss function of discriminator D is:
Since the dataset contains both labeled data and unlabeled data, the The loss function of discriminator D consists of Supervised loss Lsupervised and Unsupervised loss Lunsupervised. Where
So the The loss function of discriminator D is calculated through followed formulation.
Where pmodel(y|x, y < k + 1) denotes the probability of x, y belongs to one of the K classes.
For unsupervised learning, it only need to output true or false, and do not need to determine which category it is, so we assume that:
Where P represents the probability that the picture is judged to be a fake image, then D represents the probability that the output is a real image, so the loss function of unsupervised learning can be expressed as
4 Experimental results and analysis
4.1 Experiment setting
Hardware: HP Z4 G4 workstation (NVIDIA TAITAV XP), Linux operating system.
Software: In the experiment, the program is written in Python language and Tensorflow framework. TensorFlow is a symbolic mathematics system based on data flow programming. It is widely used in the programming implementation of various machine learning algorithms. It uses data flow graphs to represent the dependencies between computational instructions, and then creates sessions and runs various parts of the graph according to the graph.
4.2 The experimental process
This experiment is divided into two steps: the first step is to improve the model. Principal Component Analysis (PCA) is combined with the Generated Confrontation Network (GAN) to improve the original generation against the network, the MNIST and celebA data sets were used to verify the generation of the raw model; the second step is to apply the model. The improved network model was used for semi-supervised classification, and two data sets Cifar-10 and SVHN were added to verify the classification effect of the model.
We establish the generator of GAN along the following steps. (1) Input: Randomly generated uniform distribution noise (shape = 64,100) combined with class labels y (shape = 64,10) is considered as input data for the generator; (2) Layer G1: Linear transformation transforms the dimension of the input data to 1024. Then normalization and ReLU transformation is followed to obtain a nonlinear output h0 (shape = 64,1024), which is finally combined with class labels to obtain the final output h0 of the G1 layer (shape = 64,1034); (3) Layer G2: Linear transformation is performed on the output h0 of G1 layer, making the dimension of the data becomes 128 ∗ 7 ∗ 7 = 6272. Then normalized and ReLU transformation is followed to get a nonlinear output h1(shape = 64, 7, 7, 128). Finally, h1 is combined with class labels to get final output h1 of the G2 layer (shape = 64,7,7,139); (4) Layer G3: Deconvolution of the output h1 of the G2 layer transforms the dimension of the data to 64 ∗ 14 ∗ 14 ∗ 128. Then normalized and ReLU transformation is followed to obtain a nonlinear output h2(shape = 64, 14, 14, 128). Finally, the final output h2 of the G3 layer is obtained (shape = 64, 7, 7, 139); (5) Layer G4: Deconvolution of the output h2 of the G3 layer transforms the dimension of the data to 64 ∗ 28 ∗ 28. Then normalized and ReLU transformation is followed to get the output of the generator, which is generatedexample(shape = 64, 28, 28, 1).
Then we establish the Discriminator of the GAN along the following steps. (1)Input: Real picture or generated picture combined with class labels is considered as input of the discriminator. Data dimension is shape = 64,28,28,11; (2)D1 layer: Convolution operation is performed on input data, where convolution kernel size is 5 ∗ 5/11. Then nonlinear transformation is carried out to obtain a nonlinear output h0(shape = 64,14,11). Finally, the final output h0 of the D1 layer is obtained by combining with the class labels (shape = 64, 14, 14, 21); (3) Layer D2: Convolution operation is performed on the output h0 of the D1 layer, where convolution kernel size is 5 ∗ 5 ∗ 21. then row normalization and nonlinear transformation is performed to get a nonlinear output h1(shape = 64,7,7,74). After that, the final output h1 of the D2 layer (shape = 64, 64, 7 ∗ 7 ∗ 74 + 10 = 3636) is obtained by reshape and combination with the class labels; (4) D3 layer: The output h1 of the D2 layer is linearly transformed to transform the dimension of the data to 1024. Then row normalization and nonlinear transformation are carried out to obtain a nonlinear output h2 (shape = 64, 1024). Finally, the final output h2 of the D2 layer is obtained (shape = 64, 1034); (5) D4 layer: The output h2 of the D2 layer is linearly transformed, yielding the dimension of the data becomes to 11. Then the class value h3 of the output picture is obtained after the Softmax function transformation (shape = 64, 11) (Figs. 5 and 6).

The mnist comparison of the PCA-GAN and the original GAN

The face image comparison of the PCA-GAN and the original GAN
4.2.1 Principal component analysis improved generation against networks (PCA-GAN)
In this paper, the MNIST handwritten character dataset and the celebA face dataset are used to train and test the PCA-GAN’s image generation function. The following is a comparison of the PCA-GAN and the original GAN generated image effects.
Comparing the above two pictures, it can be found that the picture generated by PCA-GAN is obviously clearer than the picture generated by GAN. The characters in the left picture are vague and unrecognizable, while the generative pictures in the right are close to the real image. It shows that the generation effect of PCA-GAN is better than GAN.
Comparing the experimental results, we can see that the image generated by GAN is blurred and the facial features are not clear or even distorted compared with the face image generated by PCA-GAN, while the picture generated by PCA-GAN on the right is closer to the real face, and only a few of them are not well generated.
4.2.2 Apply PCA-GAN to semi-supervised classification
Semi-supervised learning based on PCA-GAN is a classification method that applies the improved generative adversarial networks using principal component analysis to semi-supervised learning. It mainly improves the input and output of the original generation against the network, changes the original random input into the image data compressed by PCA, and the output is changed from the original two-category output (true/false) to multi-category. Images that are applied to semi-supervised classifications contain labeled data and unlabeled data as well as fake images generated by the generator. There is the experimental effect of the model on the three data sets MNIST, Cifar10, and SVNH.
The first is the semi-supervised classification of the MNIST handwritten character set operated by PCA-GAN. The following is a graph of the classification accuracy and loss function changing with the number of iterations (Figs. 7 and 8).

The classification accuracy of MNIST

The loss function of MNIST
Since the MNIST data set is a two-dimensional grayscale image, its processing is not complicated and the program can achieve convergence in a short time. It can be seen from the above two figures that the classification accuracy of the two models is relatively high for MNIST, and finally stabilizes at about 99%, but the loss function of PCA-GAN converges to a stable value more quickly, indicating that the stability of the PCA-GAN model is better.
Cifar-10 is a 32*32 color dataset with a total of 60,000 images divided into 10 categories, including 50,000 training sets and 10,000 test sets. There is the result about the semi-supervised classification of Cifar10 classified by PCA-GAN and GAN (Figs. 9 and 10).

The classification accuracy of cifar10

The loss function of cifar-10
From the experimental results, it can be seen that PCA-GAN has a better semi-supervised classification effect on Cifar10 than GAN. In the PCA-GAN model, the classification accuracy of Cifar10 is finally stabilized at about 99%, and the classification accuracy of GAN for Cifar10 is finally around 92%. The loss function graph also shows that after the number of iterations reaches 10,000, the PCA-GAN model has reached equilibrium, and the GAN model is still not stable enough.
SVHN is a house number data set. Each picture contains more than one number. and the picture becomes a 32*32 image with only one number after preprocessed. The following is a comparison of semi-supervised classification results for the SVHN data set (Figs. 11 and 12).

The loss function of cifar-10

The loss function svhn
The experimental results show that the classification accuracy of PCA-GAN for SVHN dataset is always higher than GAN, and the average is about 97%, while GAN is only 90%. It can be seen from the change of the loss function that the loss function of GAN still has strong fluctuations until the end, while which has stabilized in PCA-GAN.
We also compared PCA-GAN method with several GAN-based methods [7, 10, 19] on CIFAR-10 and SVHN. The error rate is shown in Table 1. In the compared GAN-based methods, the generator and the discriminator used Adam optimizer. Spectral normalization is used in the generator. For the CIFAR-10 dataset, the initial learning rate was set to 0.0003, and the batch size was set to 25. For the SVHN dataset, the initial learning rate was set to 0.0003, and the batch size was set to 50. Our method shows good performance on CIFAR-10, but the superiority on SVHN is not very obvious. The application of PCA helps to retain the image characteristic to some extent, leading to better input for GAN to generate better images.
5 Conclusions
Aiming at the poor performance of the original generated model and the low accuracy of semi-supervised classification and the instability of the model, this paper proposes a generation against networks improved by principal component analysis (PCA-GAN) and applies it to semi-supervised. In order to verify the image generation effect of PCA-GAN, two data sets of MNIST and celebA are used. The experimental results show that the picture generated by PCA-GAN is closer to the original picture, and the generated effect is better. In the experiment of PCA-GAN for semi-supervised classification, there are three data sets, MNIST, Cifar10 and SVHN, were trained and tested. The experimental results show that PCA-GAN has a certain improvement on the classification accuracy of the data and the stability of the model.
References
Abdi H, Williams L J (2010) Principal component analysis. Wiley Interdiscip Rev Comput Stat 2(4): 433–459
Arjovsky M, Chintala S, Bottou L (2017) Wasserstein GAN
Denton E, Chintala S, Szlam A et al (2015) Deep generative image models using a Laplacian pyramid of adversarial networks. NIPS 47:56–72
Denton E, Gross S, Fergus R (2016) Semi-supervised learning with context-conditional generative adversarial networks. Comput Sci 25:89–105
Goodfellow I J, Pouget-Abadie J, Mirza M, et al. (2014) Generative adversarial networks. In: Advances in neural information processing systems, vol 3, pp 2672–2680
Kumar A, Sattigeri P, Fletcher PT (2017) Improved semi-supervised learning with GANs using manifold invariances. NIPS 12:64–88
Li C, Xu T, Zhu J, Zhang B (2017) Triple generative adversarial nets Guyon I, Luxburg U V, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds), vol 30, Curran Associates, Inc.
Makhzani A, Shlens J, Jaitly N, et al. (2015) Adversarial autoencoders. Comput Sci 12:93–101
Qi G J (2017) Loss-sensitive generative adversarial networks on Lipschitz densities. International journal of computer vision. https://doi.org/10.1007/s11263-019-01265-2
Qi GJ, Zhang L, Hu H, Edraki M, Wang J, Hua XS (2018) Global versus localized generative adversarial nets. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1517–1525
Radford A, Metz L, Chintala S (2015) Unsupervised representation learning with deep convolutional generative adversarial networks computer science. NIPS 32:345–362
Rosca M, Lakshminarayanan B, Warde-Farley D et al (2017) Variational approaches for auto-encoding generative adversarial networks. NIPS 79–92
Salimans T, Goodfellow I, Zaremba W et al (2016) Improved techniques for training GANs. In: Proceedings of NIPS
Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X, Chen X (2016) Improved techniques for training gans. In: Lee D D, Sugiyama M, Luxburg U V, Guyon I, Garnett R (eds) Advances in neural information processing systems, vol 29. Curran Associates Inc., pp 2234–2242
Springenberg J T (2015) Unsupervised and semi-supervised learning with categorical generative adversarial networks computer science. Comput Sci 9:34–50
Song L, Wang C, Zhang L, Du B, Zhang Q, Huang C, Wang X (2020) Unsupervised domain adaptive re-identification: Theory and Practice. Pattern Recognit 102:1–11
Wang N, Ma S, Li J, Zhang Y, Zhang L (2020) Multistage attention network for image inpainting. Pattern Recognit 106:1–12
Zhang S, He F (2020) DRCDN: learning deep residual convolutional dehazing networks. Vis Comput online. https://doi.org/10.1007/s00371-019-01774-8
Zhang S, He F, Ren W (2020) NLDN: non-local dehazing network for dense haze removal. Neurocomputing 410:363–373
Zhao J, Mathieu M, Lecun Y (2016) Energy-based generative adversarial network. Neurocomputing 20:246–256
Acknowledgements
This work is funded by the National Natural Science Foundation of China under Grant No.61772180, Technological innovation project of Hubei Province 2019(2019AAA047), Green Industry Science and Technology Leadership Program of Hubei University of Technology(No.CPYF2018005) and Hubei province graduate education innovation plan.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, C., Wu, P., Yan, L. et al. Image classification based on principal component analysis optimized generative adversarial networks. Multimed Tools Appl 80, 9687–9701 (2021). https://doi.org/10.1007/s11042-020-10137-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-10137-8