
Abstract
Massive inter predictive modes are adopted in latest High Efficiency Video Coding (HEVC) standard to eliminate temporal redundancies, which results in stronger inter-frame dependency among neighboring frames than previous standards like H.264. The inter-frame dependency makes currently independent rate-distortion optimization (RDO) non-optimal any more. Quantization parameter (QP) selection algorithm taking inter-frame dependency into consideration is supposed to optimize RDO based rate control greatly. According to our research, the inter-frame dependency is reflected by the linear relationship between QP change (ΔQP) and the resulting change of distortion (ΔD). An adaptive QP selection algorithm for global RDO is proposed based on the modeling function between ΔD and ΔQP in this paper. Firstly, based on intensive statistic analysis, three parameters (initial QP (\(\overline {QP}\)), the length of pictures of group (GOP), and the average of SATD of one frame) are used to formulate the relationship between ΔD and ΔQP. Secondly, the resulting rate change ΔR relative to ΔQP is also formulated similarly. Thirdly, optimized Lagrangian multiplier (λ) is calculated with these two mathematic models. Finally, we refine QP values based on the optimized λ in terms of dependent RDO. The experimental results show that the proposed frame-level QP selection algorithm can decrease Bj⊘tegaard Delta BitRate (BD-BR) by about 1.62% at the random-access (RA) configuration and 1.13% at the low-delay (LD) configuration, respectively. At the same time, it doesn’t increase complexity significantly.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
HEVC [20] the latest video coding standard, which nearly doubles the rate-distortion (RD) performance compared to previous video coding standard H.264 [24]. The use of more intra and inter predictive coding techniques [11] enhances the correlation of RD performance among temporal and spatial adjacent coding units, making it necessary to quantitatively measure the affect of reference coding units.
In video coding, RDO [21] is often used for frame QP selection, which can be formulated as
where N is the total number of encoded frames, RA is the target bitrate, Ri and Di represent the bitrate and distortion of the i-th frame, respectively, and \(Q^{\ast }=(Q^{\ast }_{1},Q^{\ast }_{2},\ldots ,Q^{\ast }_{N})\) denotes the set of optimal QP values. It can be observed from (1) that the generation of the optimal QP values is based on two conditions: one is the minimum distortion of each frame; and the other is the total number of coding bits cannot exceed the target bitrate. An effective method of solving the constrained optimization problem is the Lagrangian Multiplier Method [10], by which (1) can be converted into the following unconstrained formulation:
where J denotes the RD cost. It can be observed from (2) that the optimal QP value corresponds to the minimum RD cost.
However, the stronger dependency involved in HEVC makes currently independent RDO non-optimal any more. For the purpose of global algorithm optimization, some traditional works have been implemented for RDO. Work [13] and [12] proposed a QP refinement algorithm based on the relationship between λ and QP. From the view of perceptual sensitivity of human visual system (HVS), work [29] and [23] proposed adaptive λ calculation algorithms, by which the corresponding QP values were refined. However, these algorithms are usually applied for the units at different levels individually without considering the dependency among adjacent coding units at different levels to alleviate the high complexity. A typical method for optimizing the independent RDO is to substitute dependent RD models for independent ones. Work [3,4,5,6,7, 9, 14,15,16, 19, 22, 28, 30] proposed various algorithms, i.e., QP refinement, bit allocation, in terms of dependent RDO by using dependent RD models. Work [16] proposed a dependent RDO scheme for H.264 based on frame-level D − QP and R − QP models. Work [5] proposed two QPC algorithms based on dependent RDO for the RA configuration in HEVC. In work [6], inter-frame dependency is formulated by the importance of frame. Then a metric of just-noticeable temporal pumping artifact (JNTPA) based on characteristics of the human visual system was proposed to refine frame-level QP. Work [30] proposed an adaptive quantization parameter cascading (QPC) scheme for HEVC hierarchical coding by considering the inter-layer dependency, which is a constant value for the video sequence. Based on a self-domain (S-domain) observations, work [4] proposed empirical dependent R/D models, which was applied in a joint temporal-quality layer bit allocation algorithm formulated as a Lagrange optimization problem. Work [7] proposed an adaptive QP selection algorithm for RA coding in HEVC by involving the distortion dependency among different coding levels, where the inter-frame dependency is measured by an energy of prediction residuals based model. Work [4,5,6,7, 16, 30] all exhibited that there was a linear relationship between the predictive residual of coding units (frame-level and hierarchical coding-level) and the coding distortion of its reference units. Based on this detection, work [3] proposed a distortion propagation model and the corresponding RD model [22]. Using indirect RD modelling, work [28] proposes a temporal dependent RDO by establishing a source distortion temporal propagation model based on macroblocks, which takes inter-frame dependency into account. This model was further applied in adapting the Lagrange multiplier [19]. Work [15] proposed an adaptive QPC scheme, where the dependency between different layers was modeled by a linear factor. The optimal QPs were dynamically obtained for different layers based on the formulated RD curve. Work [14] proposed an improved model based on their previous work [15]. By using this model, a global analytical QP refinement scheme was presented, which minimized the GOP distortion under a subjective average bitrate of all frames in the GOP. The above researches are all performed in frame-level or hierarchical coding-level, which only sustain for a short time, to avoid high modeling complexity. However, the effect of inter-frame dependency will be obvious when propagated distortion is accumulated in a long temporal period. Therefore, to explore the characteristics of inter-frame dependency, more frames ought to be considered. As a state-of-art research zone, deep-learning is an useful method in building models. Work [9] proposed a linear quality dependency model between a picture and its references, which is used in bit allocation for scalable video coding (SVC). In work [25, 27], background modeling and image understanding methods are proposed based on deep-learning respectively. They provide novel methods for evaluating video content complexity. In work [26], a spatial-temporal attention mechanism for video captioning is proposed based on deep-learning. The mechanism shows superior accuracy in calculating spatial-temporal dependency, which will be helpful in exploring inter-frame dependency.
As inter predictive coding is isolated between different GOPs by I frame, inter-frame distortion propagation can only occur inside the GOP. Therefore, this paper adopts GOP as the basic unit to analyze the characteristics of inter-frame dependency. Firstly, based on intensive statistic analysis, three parameters (initial QP (\(\overline {QP}\)), the length of pictures of group, and the average of sum of absolute transformed difference (SATD) [18] of one frame, which represents the video content of the GOP) are used to formulate the relationship between ΔD and ΔQP. Secondly, the resulting rate change ΔR relative to ΔQP is also formulated similarly. Thirdly, optimized Lagrangian multiplier (λ) is calculated with these two mathematic models. Finally, we refine QP values based on the optimized λ in terms of dependent RDO. The experimental results show that the proposed frame-level QP selection algorithm can decrease BD-BR [1] by about 1.62% at the random-access (RA) configuration and 1.13% at the low-delay (LD) configuration, respectively. And it doesn’t increase complexity significantly.
The rest of this paper is organized as follows. Section 2 analyzes the causes and characteristics of inter-frame dependency in HEVC; Section 3 establishes the distortion and rate fluctuation prediction models; Section 4 proposes the QP selection algorithm based on inter-frame dependency; Section 5 presents the experimental results; and Section 6 concludes this paper.
2 Inter-frame dependency modeling
2.1 Analysis the cause of inter-frame dependency
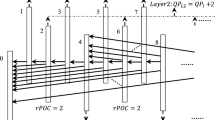
Massive inter predictive modes are adopted in latest HEVC video coding standard to eliminate temporal redundancies [17], where Fig. 1 shows an example. In inter-prediction, current frame can reference multiple adjacent decoded frames, and a block may be referenced multiple times. These characteristics result in a discontinuous inter-frame reference chain, leading to the difficulty of analyzing and modeling inter-frame dependency accurately.

Inter-predictive Coding
To explain the cause of inter-frame dependency better, frame P1 and P2 are used in the following analysis, where P1 is the starting frame of the GOP with intra-frame coding only, and P2 is P frame which only references the reconstructed frame of P1. The mean square error (MSE) of reference error is adopted to represent temporal residual energy, and formulated as (3).
where org2 denotes the original pixel of P2, rec1 is the pixel of the reconstructed frame of P1 and org1 is the original pixel of P1. From (3), we have
From (4), it can be observed that the predictive residual of P2 is composed of two parts. The first part is \(\delta _{org(1,2)}^{2}\) which represents the intrinsic difference between the original pictures P1 and P2 and is unrelated to inter-frame dependency. The second part is D1ref which denotes the coding distortion of P1 and propagates to P2 through inter-prediction. It is shown that the coding quality of P1 directly determines the coding quality of P2, thereby ultimately affects the RD performance of P2. From above analysis, we can conclude that inter-frame dependency is from inter-frame distortion propagation.
2.2 Analysis of inter-frame dependency
From above analysis, the inter-frame distortion propagation is proven to be the root cause of inter-frame dependency. However, the characteristics of fragmented and multi-layered in inter-prediction make it difficult to track and analyze the inter-frame distortion propagation accurately. In this section, we will provide a holistic analysis of distortion propagation. The inter-frame dependency is isolated by the first frame of GOP which is encoded with intra-prediction only. When the initial QP of a certain reference frame (\(\overline {QP_{i}}\)) is added with the offset ΔQP, there shows distortion propagations within the GOP. To reflect the overall distortion propagation, we average the distortion offset of all frames in the GOP,
where ΔDT represents the average of all frame distortion offsets of the GOP, and define it as inter-frame distortion fluctuation.
To explore the relationship between ΔDT and ΔQP, this paper statistically delineates the scatter plot and fitted curve of ΔDT and ΔQP for different sequences as shown in Figs. 2 and 3. In the experiment, the interval of instantaneous decoding refresh (IDR) frame namely GOP size is fixed at 80, each mini-GOP contains four frames by default, rate control is closed to avoid skipping some encoding models by the limited bitrate, and other parameters are set as default in the encoder_randomaccess_main configuration. The \(\overline {QP}\) of i-th frame is set to 22, 27, 32, 37 where i is set to 1 here. From work [8], it is known that the clip of ΔQP has obvious influence on coding quality and bitrate smoothness. The clip of ΔQP is limited between -5 and 5 to limit unexpected large QP fluctuation among adjacent frames for smoothing coding quality and temporal bitrate. We use the fitting tool – cftool in MatLab to fit the acquired scatter plot between ΔQP and ΔDT. It shows that compared to the nonlinear model like exponential function, the linear model performs better at a higher correlation coefficient (R) and a lower root mean square error (RMSE), which are 0.964, 0.036 and 0.994, 0.010 on average for the nonlinear and linear fitting models. It can be observed that there exists a positive linear correlation for different \(\overline {QP}\) values, and can be formulated as

The Scatter plot and fitted line between ΔDT and ΔQP of Bqsquare. a Scatter plot and fitted line of QP equals to 22. b Scatter plot and fitted line of QP equals to 27. c Scatter plot and fitted line of QP equals to 32. d Scatter plot and fitted line of QP equals to 37
where K is the slope of the linear correlation between ΔDT and ΔQP. The bias of this linear correlation is zero because there is no inter-frame distortion fluctuation when ΔQP is zero. When the lager K is, the faster ΔDT changes with the ΔQP value meaning stronger inter-frame dependency between them. When the smaller K is, the slower ΔDT changes with the ΔQP indicating weaker inter-frame dependency between them. Therefore, K directly reflects the inter-frame dependency within a GOP in HEVC.
3 Establishing the distortion and rate fluctuation models
3.1 Factors affecting inter-frame distortion propagation
From above analysis, the cause of inter-frame dependency is from inter-frame distortion propagation. In Figs. 2 and 3, K varies with \(\overline {QP}\). Hence \(\overline {QP}\) is one factor that affects inter-frame distortion propagation. The video content is another factor that affects inter-frame distortion propagation during inter-predictive coding. The video content changes with the length of the sequence, so we use the average SATD of all frames in the GOP to represent the video content complexity,
where N is the length of the GOP, ε represents the average SATD of all frames in the GOP. A comprehensive analysis of the factors affecting inter-frame distortion propagation can be represented by modeling K based on \(\overline {QP}\) and ε, namely,

The Scatter plot and fitted line between ΔDT and ΔQP of Racehorses. a Scatter plot and fitted line of QP equals to 22. b Scatter plot and fitted line of QP equals to 27. c Scatter plot and fitted line of QP equals to 32. d Scatter plot and fitted line of QP equals to 37
3.2 Inter-frame distortion fluctuation modeling
This paper investigates the relationship (8) for different video sequences. The test flow is listed as follows:
- 1)
Set the initial number of coding frames to N (N is less than 80), and set the \(\overline {QP}\) of the first frame in the GOP to 18;
- 2)
Add ΔQP to \(\overline {QP}\), the initial value of ΔQP being -5;
- 3)
Start video coding to obtain the ΔDi and SATDi values of each frame, increasing the ΔQP value by 0.1;
- 4)
If the ΔQP isn’t larger than 5, return to the third step;
- 5)
Increase the value of N by 2. And if the number of frames is greater than 80, end the coding; if not, return to the first step.
In the above procedure, the \(\overline {QP}\) value and frame number are altered in order to simulate the actual distortion propagation process. The scatter plot of K with \(\overline {QP}\) and ε is shown in subplot (a), (c) of Fig. 4, where the horizontal axis represents \(\overline {QP}\), and the vertical axis is ε. The fitted results are presented below in subplot (b), (d) of Fig. 4. From (7) and (9), the ΔDT model based on K built by data fitting is
where p1, p2, p3, p4, p5, p6, and p7 are all modeling parameters. The experimental results show that these model parameters vary with the video content complexity, which is reflected by ε. And we find that all the video complexity can be divided into three stages by two ε thresholds. Parameters for different video content complexity as shown in Table 1.

The scatter plot of K and fitted surface. a Scatter plot of Bqsquare. b Fitted surface of Bqsquare. c Scatter plot of Racehorses. (d) Fitted surface of Racehorses
3.3 Rate fluctuation prediction modeling
Following similar procedure in previous Section, we make an off-line and statistical description of the correlation between the bitrate fluctuation ΔRT and ΔQP. The results are shown in Figs. 5 and 6. There exists a negative linear correlation between ΔRT and ΔQP, which can be formulated as
where H is the slope of the linear correlation. The results shown in subplot (a), (c) of Fig. 7 are obtained by using the same test procedure as the K modeling in Section 3. It is shown from Fig. 7 that

The Scatter plot and fitted line between ΔRT and ΔQP of Bqsquare. a Scatter plot and fitted line of QP equals to 22. b Scatter plot and fitted line of QP equals to 27. c Scatter plot and fitted line of QP equals to 32. d Scatter plot and fitted line of QP equals to 37

The Scatter plot and fitted line between ΔRT and ΔQP of Racehorses. a Scatter plot and fitted line of QP equals to 22. b Scatter plot and fitted line of QP equals to 27. c Scatter plot and fitted line of QP equals to 32. d Scatter plot and fitted line of QP equals to 37

The scatter plot of H and fitted surface. a Scatter plot of Bqsquare. b Fitted surface of Bqsquare. c Scatter plot of Racehorses. d Fitted surface of Racehorses
In this paper, the model of ΔRT based on H built by data fitting is
where H0, A, w1, w2, b1, b2 are all modeling parameters. The subplot (b), (d) of Fig. 7 show the fitted surface. Like the model parameters in formula (9), the parameters in (12) also vary with the video content which is classified by ε. The fitted model parameters for different video contents are tabulated in Table 2.
4 Proposed method
In HEVC video coding, the relationship between QP and λ is:
where qfactor denotes the parameter related to the encoder structure, and its default value is 0.85. From (13), we can derive QPi by:
It is shown that the QPi is determined by λi = −∂Di/∂Ri. In previous sections, both the distortion and the bitrate fluctuation are based on inter-frame independence. From (6), (10) and (13), we can have:
Substituting (15) into (14), we obtain the following QP value:
Here \(\widehat {QP}_{i}\) represents the frame QP value calculated by inter-frame dependency. In order to avoid the large fluctuation of video coding quality, this paper adopts the weighted sum of \(\overline {QP}\) and \(\widehat {QP}\) to obtain new frame QP value,
where w ∈ [0,1].
The weight coefficient w, affects the final frame QP value as in (17). This paper statistically analyzes the BD-BR performance according to different w values. The results are shown in Fig. 8, where the BD-BR shows best when w is around 0.53. Therefore, we set the value of w to 0.53.

BD-BR under different w. a The fitted curve of Bqsquare. b The fitted curve of Racehorses
5 Experimental results
The platform used in this paper is HM-16.0. To evaluate the accuracy of proposed K and H prediction model, we statistically analysis the predictive error of these two models in Fig. 9. It is shown that more than 95% of prediction errors are concentrated in the range of zero-centered [-0.04, 0.04]. The error statistics of the rest sequences are shown in Table 3, which demonstrates that the proposed models can make an accurate prediction of K and H.

Predictive error statistics histogram. a Predictive error of Bqsquare. b Predictive error of Racehorses
Two other related approaches are also tested for the coding efficiency comparisons, which are Li’s [14] and the QP cascading (QPC) algorithm [30]. The rate-distortion performance is evaluated by BD-BR and Bj⊘tegaard Delta PSNR(BD-PSNR), where negative value of BD-BR or positive value of BD-PSNR represent performance gains. The coding results of the three algorithms are shown in Table 4, where the default RA configurations [2] in HM is used as the benchmark. It can be seen from Table 4 that Li’s algorithm increases BD-BR by 5.86%, QPC reduces BD-BR by 1.09%, and the proposed algorithm reduces BD-BR by 1.62% on average, which indicates that the proposed algorithm can effectively reduce the number of coding bits, with the video coding quality being the same.
In addition, it is shown that the performance of the proposed algorithm varies with the video content. The average BD-BR performance of Class A and D is better than the other sequences by using the proposed algorithm, like Traffic, PeopleOnStreet and BlowingBubbles sequences. This is because there is less motion in Class A and D. The coding blocks can easily get optimal reference blocks from adjacent frames instead of multi frames in the list of reference frames. Therefore, the reference frames of Class A and D are referenced at a higher frequency, which means higher inter-frame dependency. Conversely, there is dramatic foreground and background motion in the sequences of Class B, C and F. The reference frames are more dispersive, resulting in weaker inter-frame dependency with unnoticeable performance improvement. Since the parameters used in the proposed models can be obtained from off-line preprocessing, the proposed algorithm increases the computational complexity insignificantly. During the evaluation of the proposed algorithm, we find that the additional time incurred by the proposed algorithm is less than 0.5s, which can be ignored in practice.
Compared to [14, 30], the proposed algorithm performs better. From Table 4, it can be seen that Li’s algorithm only works well for sequences with slow motion. That is because the parameters updating in Li’s algorithm is depending on the parameters of the latest former GOP, which can’t reflect inter-frame dependency of the current GOP for those sequences with fast motion. In the QPC, the inter-frame dependency is only illustrated by a static parameter δ for all video sequences, which makes the algorithm non-adaptive for different video content and limits the algorithm performance. In the proposed algorithm, the model parameters are divided into three stages depending on the average video content complexity, which makes the model become universal for various video content. When the proposed algorithm is employed in LD configuration, the performance decrease at about 0.5% with BD-BR. The root reason is that LD is a forward-reference encoding structure, which means that encoding error can only propagate to the current frame from one single direction. However, RA is a bi-directional reference encoding structure, the encoding of the current frame is related to more frames, which means the inter-frame dependency in RA is stronger than that in LD. It also reflects that the proposed algorithm can exploit the inter-frame dependency better and get a better performance.
6 Conclusion
In this paper, we have proposed a frame-level QP selection algorithm based on inter-frame dependency. Firstly, the distortion fluctuation model between ΔD and ΔQP is established to illustrate the inter-frame distortion propagation. Then, the rate fluctuation model between ΔR and ΔQP is also formulated in a similar way. With these two mathematic models, we determine the Lagrangian multiplier (λ) in terms of dependent RDO. Finally, with the optimized λ, we optimally refine the QP in the sense of dependent RDO. The experimental results show that the proposed frame-level QP selection algorithm can decrease BD-BR by about 1.62% at the RA configuration and 1.13% at the LD configuration respectively. And it doesn’t increase complexity significantly.
References
Bjontegaard G (2001) Calculation of average psnr differences between rd-curves. ITU-T SG16/Q.6 Doc. VCEG-M33
Bossen F (2013) Common test conditions and software reference configurations. JCTVC-L1100, 12th Meeting
Chao P, Au OC, Feng Z, Dai J, Zhang X, Wei D (2013) An analytic framework for frame-level dependent bit allocation in hybrid video coding. IEEE Trans Circ Sys Video Technol 23(6):990–1002
Cho Y, Kwon DK, Liu J, Kuo CCJ (2013) Dependent r/d modeling techniques and joint t-q layer bit allocation for h.264/svc. IEEE Trans Circ Sys Video Technol 23(6):1003–1015
Gong Y, Shuai W, Yang K, Yuan Y, Bo L (2016) Rate-distortion-optimization-based quantization parameter cascading technique for random-access configuration in h.265/hevc. IEEE Trans Circ Sys Video Technol 27 (6):1–1
Gong Y, Wan S, Yang K, Wu HR, Yang F, Li B (2016) Reduction of temporal distortion in video coding based on detection of just-noticeable temporal pumping artifact. Image Commun 42(C):1–18
He J, Yang EH, Yang F, Yang K (2017) Adaptive quantization parameter selection for h.265/hevc by employing inter-frame dependency. IEEE Trans Circ Sys Video Technol 28(12):3424– 3436
Hu S, Wang H, Kwong S (2012) Adaptive quantization-parameter clip scheme for smooth quality in h.264/avc. IEEE Trans Image Process 21(4):1911–1919
Hu S, Wang H, Kwong S, Zhao T, Kuo CCJ (2011) Rate control optimization for temporal-layer scalable video coding. IEEE Trans Circ Sys Video Technol 21(8):1152–1162
Everett H (1963) Generalized lagrange multiplier method for solving problems of optimum allocation of resources. Operations Res 11(3):399–417
Lainema J, Bossen F, Min J, Ugur K (2013) Intra coding of the hevc standard. IEEE Trans Circ Sys Video Technol 22(12):1792–1801
Li B, Xu J, Zhang D, Li H (2013) Qp refinement according to lagrange multiplier for high efficiency video coding. In: 2013 IEEE international symposium on circuits and systems (ISCAS2013). IEEE, pp 477–480
Li B, Zhang D, Li H, Xu J (2012) Qp determination by lambda value. In: JCTVC-I0426
Li X, Amon P, Hutter A, Kaup A (2010) Adaptive quantization parameter cascading for hierarchical video coding. In: IEEE international symposium on circuits and systems, pp 4197–4200
Li X, Peter A, Andreas H, Andre K (2009) Model based analysis for quantization parameter cascading in hierarchical video coding. In: 2009 16th IEEE international conference on image processing (ICIP), pp 3765–3768
Liu J, Cho Y, Guo Z, Kuo CCJ (2010) Bit allocation for spatial scalability coding of h.264/svc with dependent rate-distortion analysis. IEEE Trans Circ Sys Video Technol 20(7):967–981
Ohm J, Sullivan GJ, Schwarz H, Tan TK, Wiegand T (2012) Comparison of the coding efficiency of video coding standards–including high efficiency video coding (hevc). IEEE Trans Circ Sys Video Technol 22(12):1669–1684
Seidel I, Brscher AB, Güntzel JLA, Agostini LV (2016) Energy-efficient satd for beyond hevc. In: 2016 IEEE international symposium on circuits and systems (ISCAS), pp 802–805
Shuai L, Zhu C, Gao Y, Zhou Y, Dufaux F, Sun MT (2016) Lagrangian multiplier adaptation for rate-distortion optimization with inter-frame dependency. IEEE Trans Circ Sys Video Technol 26(1):117–129
Sullivan GJ, Ohm J, Han WJ, Wiegand T (2013) Overview of the high efficiency video coding (hevc) standard. IEEE Trans Circ Sys Video Technol 22 (12):1649–1668
Sullivan GJ, Wiegand T (1998) Rate-distortion optimization for video compression. IEEE Signal Processing Magazine 15(6):74–90
Wang S, Ma S, Wang S, Zhao D, Wen G (2013) Rate-gop based rate control for high efficiency video coding. IEEE Journal of Selected Topics in Signal Processing 7(6):1101–1111
Wang S, Ma S, Zhao D, Gao W (2014) Lagrange multiplier based perceptual optimization for high efficiency video coding. In: Signal and information processing association annual summit and conference (APSIPA), 2014 Asia-Pacific, pp 1–4
Wiegand T, Sullivan GJ, Bjontegaard G, Luthra A (2003) Overview of the h.264/avc video coding standard. IEEE Trans Circ Sys Video Technol 13(7):560–576
Yan C, Li L, Zhang C, Liu B, Zhang Y, Dai Q (2019) Cross-modality bridging and knowledge transferring for image understanding. IEEE Trans Multimed 21(10):2675–2685
Yan C, Tu Y, Wang X, Zhang Y, Hao X, Zhang Y, Dai Q (2019) Stat: spatial-temporal attention mechanism for video captioning. IEEE Trans Multimed. 1–1
Yan C, Xie H, Chen J, Zha Z, Hao X, Zhang Y, Dai Q (2018) A fast uyghur text detector for complex background images. IEEE Tran Multimed 20 (12):3389–3398
Yang T, Zhu C, Fan X, Peng Q (2012) Source distortion temporal propagation model for motion compensated video coding optimization. In: IEEE international conference on multimedia and expo, pp 85–90
Zeng H, Ngan KN, Wang M (2013) Perceptual adaptive lagrangian multiplier for high efficiency video coding. 2013 Picture Coding Symposium (PCS). 69–72
Zhao T, Wang Z, Chen CW (2016) Adaptive quantization parameter cascading in hevc hierarchical coding. IEEE Trans Image Process 25(7):2997–3009
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Huang, X., Li, D. & Yin, H. HEVC quantization parameter selection algorithm based on inter-frame dependency. Multimed Tools Appl 79, 13951–13966 (2020). https://doi.org/10.1007/s11042-020-08612-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-020-08612-3