
Abstract
In the field of agriculture science, the presence of disease in fruits affects the quantity and quality of production. To sort the fruits based on quality is a challenging task. Human grades the fruit but this process is inconsistent, stagnant, expensive and get influenced by the surrounding. Thus an effective system for grading fruit is desired. In this paper, an automated fruit grading system has been developed for mono and bi-colored apples. An automated fruit grading system involves three steps, namely, segmentation, feature extraction, and classification. In this work, segmentation of defected area has been carried out using fuzzy c-means and for feature extraction, the various combination of Statistical/ Textural, Geometrical, Gabor Wavelet and, Discrete Cosine Transform feature have been considered. For classification three different classifiers i.e. k-NN (k- Nearest Neighbor)), SRC (Sparse Representation Classifier), SVM (Support Vector Machine) have been applied. The proposed system has been validated for four different databases of apples one having 1120 samples of which 984 were defective, the second having 333 samples of which 247 were defective, the third having 100 samples with 26 defective and the fourth with 56 defectives. The maximum accuracy of 95.21%, 93.41%, 92.64% and 87.91% for four datasets respectively, achieved by the system is encouraging and is comparable with the state of art techniques. The system performance has been validated using the k-fold cross-validation technique by considering k = 10. Results showed that a combination of features provides improved performance and the SVM classifier has the highest performance among k-NN, SRC. As compared to the state of art, our proposed solution yields better accuracy. Hence, the proposed algorithm showed great potential for the classification of apple and the possibility of its uses for further different fruit.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Among several species of fruits grown worldwide, there are 7500 known cultivations of an apple tree. Worldwide production of apples in 2017 was 77.3 million tones, with India accounting for 2.3 million tons of the total. Apple grading is done mainly by human investigators which leads to misclassifications. For many years, the food industry has been incorporating manual inspection which is inconsistent, laborious, and expensive. The assurance of properties like sweetness and firmness is done by scientific techniques generally used for agricultural products which are destructive and time-taking [1, 2]. Thus, intelligent, rapid and non-destructive techniques are required to grade apple [3]. Jackman et al. [4] provide an alternative solution for Computer vision systems in agriculture food quality evaluation and control, which replaces manual inspection. Hyperspectral imaging commonly used in food technology and science needs spatial and chemical information simultaneously [5, 6]. However, using a small number of wavelength [7], multispectral imaging is inexpensive, simple and rapid. Yu et al. [8] presented a novel edge-based active contour model for medical image segmentation which guarantees the stability of the evolution curve and the accuracy of the numerical computation. Chen et al. [9] proposed a novel matting method based on full feature coverage sampling and accelerated traveling strategy to get good samples for robust sample-pair selection. Zhang et al. [10] presented a new deep learning-based method for removing haze from a single input image by estimating a transmission map via a joint estimation of clear image detail. Singh and Singh [11] presented a novel technique to grade apples by using different features like the histogram of oriented gradients, Law’s Texture Energy, Gray level co-occurrence matrix and Tamura features.
Apple variety is classified as bi-colored (e.g. Fuji, Jonagold) and mono-colored skin (e.g. Granny Smith, Golden Delicious). For grading of mono-colored skin apples, work that utilized ordinary machine vision, Leemans et al. [12] proposed a color model-based to segment the defects on pixels locally of ‘Golden Delicious’ apples. Rennick et al. [13] use color information to extract intensity statistics features from enhanced monochrome images of ‘Granny Smith’ apples for defect detection. Blasco et al. [14] presented a system to sort apples by applying threshold segmentation on the defected area and attains an 85.00% recognition rate. Xing et al. [15] used second and third principal components with moment thresholding to identify the presence of noises and achieve 86.00% accuracy. Suresha et al. [16] used a red and green color component for classification and found 100% accuracy. Dubey and Jalal [17] proposed to use k-means clustering with a multi-class support vector machine to accurately detect the apple fruit diseases and achieve 95.94% accuracy. Ashok and Vinod [18] used a probabilistic neural network approach for detecting the healthy and defected apple and achieved 86.52% accuracy. Raihana and Sudha [19] presented a modified watershed segmentation method to detect the defected apple fruit using gray level covariance matrix based feature extraction and achieve 91.33% accuracy. Ali and Thai [20] proposed a prototype of an automated fruit grading system to detect the defect of apple fruit. Moallem et al. [21] proposed a computer vision algorithm to grade the ‘Golden Delicious’ apple using a multilayer perceptron neural network and found 92.50% accuracy. Jawale and Deshmukh [22] proposed an automatic evaluation of apple fruit disease using thermal camera and image processing bruises detection system.
The techniques using bicolored skin apples for grading are outlined here. Wen and Tao [23] proposed a rule-based decision for a single spectral system to sort ‘Red-Delicious’ apples with 85–90% accuracy. Leemans et al. [24] proposed a method based on Bayesian classification process for defect detection. Leemans et al. [25] presented multi-layer perceptron and quadratic-discriminant analysis for classification with 72.00% and 78.00% recognition rate for bi and mono-colored apples. Kleynen et al. [26] proposed a filter using quadratic discriminant analysis for detecting a wide range of defects using a multispectral vision system and achieve 90.80% accuracy. Leemans and Destian [27] proposed a quadratic discriminant classifier to detect defects in apples and achieved a 73.00% recognition rate. Unay and Gosselin [28] proposed an artificial neural network to eliminate false segmentation and achieved a 75.00% recognition rate. Kleynen et al. [29] incorporated Bayes Theorem using a multispectral vision for the detection of defects in apple and achieve 90.00% accuracy. Kavdir and Guyer [30] proposed back-propagation to grade apples and achieve 84.00–89.00% accuracy. Kleynen et al. [31] presented a multi-spectral vision system to sort apple by the linear discriminant classifier and attains 90.00% accuracy. Unay and Gosselin [32] introduced pixel-wise processing to grade apple by an artificial neural network with 90.00% accuracy. Xiaobo and Jiewen [33] use an electronic nose system and near-infrared machine vision system. Zou et al. [34] introduced multiple color cameras for scanning the apple surface by thresholding with 96.0% accuracy. Unay et al. [35] used minimal confusion matrix to extract features for classification with 93.50% accuracy. Bhargava and Bansal [36] reviewed various techniques for fruits and vegetables quality evaluation.
In the present work, the authors presented distinct methods that differ at quality categories taken, apple varieties tested, particular equipment used, and imaging technique employed. As a result of this review, finding a commonly relevant basis to the bi-colored and mono-colored group, the used grading algorithm compare these works and concludes as followed: “Quality grading of apple fruit by machine vision is a burdensome task due to the variance of the problem. Thus, the research for a robust, generic and accurate grading system that works for all apple variations while respecting all forms of standards is still in progress” [35]. This paper introduces a fruit grading system that segments the defected part by fuzzy c-means segmentation, then using defect segmentation several features from the defective skin are selected/extracted and lastly, statistical classifiers are incorporated for classifying apples into a corresponding quality category (healthy or defective).
2 Methodology
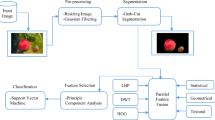
In this work, firstly segmentation is done rigorously on the defected part of the apple and then apple is sorted based on quality (healthy or defected). The defected segmentation area comprises specific discrimination of defects corresponding to image space. Figure 1. shows the proposed methodology.

The basic workflow for grading of apple fruit
2.1 Image acquisition
Our proposed algorithm uses four databases. The first database consists of ‘Jonagold’ apples with bandwidths of 80, 40, 80 and 50 nm centered at 450, 500, 750 and 800 nm respectively from a high-resolution camera with 8 bit per pixel resolution (created by Unay and Gosselin [32]). 1120 of the fruits were normal while 984 of them include various defects like a bruise, russet, hail damage, scald, rot, etc. as shown in Fig. 2. The second database consists of 247 defective apples like blotch, rot, scab and 86 normal images that are downloaded from google images [37] by entering the keywords “healthy apple” and “apple + disease name” for defective apple. The third database is ‘Golden Delicious’ apples (created by Blasco et al. [14]) which contain 100 images (74 healthy and 26 defective) acquired by EOS 550D digital camera with a resolution of .03 mm per pixel The fourth dataset consist of 112 images (56 healthy and 56 defectives) of 40 apples taken at different angles with 4000 × 3000 pixels from Redmi note 5 mobile (created by author). Dataset used by our algorithm consists of the following characteristics as shown in Table 1. Figure 3 shows some samples of dataset images used.

Sample of defected image as a Bruise b Russet c Scald d Rot

2.2 Pre-processing and automatic defect segmentation
Image acquired by camera contains various noise which degrades the appearance of the image, hence it cannot provide sufficient data for the processing of the image. The enhancement of the image is therefore done by adjusting the image intensity value or color map. European commission marketing standard [38] for apples defines a category for quality which also requires defect information. Therefore, it is necessary to specifically segment the defect which is ambiguous because of size, type, texture, and color variations. In this work, images are taken on a black background and observations acknowledge that defected parts can be segregated from the background easily by thresholding, Fuzzy c-means clustering. Figure 4 depicts three samples from the database along with segmentation. The first four columns present images from different filters (Jonagold Apple) while the last one shows corresponding manual segmentation, row displays apples damaged by different defect types. Fuzzy c-means (FCM) [39] with different membership grades employs fuzzy partitioning such that a data point can belong to all groups. The aim is to minimize dissimilarity function for cluster centroids.

Examples of apple images and their segmentation
According to the membership matrix (U) initialized for fuzzy partitioning [39],
The dissimilarity function is given by,
where uijis the membership (either 0 or 1) of jth neighbor to the ith class.
ci is the centroid of cluster i.
c is a number of clusters.
dij is Euclidean distance between data point j and centroid i.
The conditions to reach minimum dissimilarity function are [39].
2.3 Feature extraction
Segmentation results in definite unconnected objects with different sizes and shapes. Each object handles separately or together for the correct decision of fruit. These segmented areas are further used for feature extraction summarized in Table 2.
2.3.1 Statistical and textural features
The statistical features are the probability of the first-order measure observing the random gray pixels values that include mean, standard deviation, variance, smoothness, inverse difference moment, RMS, skewness, and kurtosis. Table 3 list the corresponding indexes and formulae. These features do not take contingent relations of gray values into account. The textural features are the probability of second-order measure as pixel pairs that include energy, contrast, entropy, correlation, and homogeneity.
Pattern recognition widely uses geometric moment’s textural features. Another prominent group of textural features includes gray-level co-occurrence matrices (GLCM) [40, 41] which shows a number of occurrences for gray level pairs as a square matrix. The GLCM features, inverse difference moment (IDM) is related to smoothness while variance and contrast are an assessment of local variations. A GLCM is defined as a matrix (M X N) gray level image I, parameterized by an offset [42], defined as:
where I(p, q), the gray level of the image I at pixel (p, q).
In this work, Unser’s texture features are chosen because the addition (a) and subtraction (s) of two variables with the same variances are not related. Hence a and s histograms for texture [43] are used. The addition and subtraction with relative displacement for the non-normalized image I is defined as:
The addition and subtraction histograms for domain N are defined as:
2.3.2 Geometrical features
Also, features can be extracted for recognition depending on the geometry of the object. Nonetheless, defects of apple cannot have peculiar characteristics. Hence, we inked the geometric features that include solidity, area, and a maximum length of the area, eccentricity, and perimeter listed in Table 4.
The extraction of geometrical features can be done using the following steps:
Step 1: Extract “area” feature precisely in the object.
Step 2: Form a convex hull by the “Graham Scan method” [44].
Step 3: Form an ellipse to extract “minor length”, “major length” and “eccentricity” features (the second moment for both must be same)
2.3.3 Gabor wavelet feature
Gabor wavelet is invented by Dennis Gabor using the complex function to minimize the product of its standard deviation in time and frequency domain [45]. Mathematically,
The Fourier transform of Gabor Wavelet is also a Gabor Wavelet given by:
2.3.4 Discrete cosine transform (DCT)
DCT is a powerful transform to extract proper features. After applying DCT to the entire image, some of the coefficients are selected to construct feature vectors. Most of the conventional approaches select coefficients in a zigzag manner or by zonal masking. The low-frequency coefficients are discarded in order to compensate illumination variations [46].
This work uses several combinations of these features. An overview of the approach used in the present work is outlined in Fig. 5.

Different combination of extracted features
2.4 Grading
The essential feature for fruit grading is classification. By using a sufficient number of training samples, the grading is done, by using the following classifiers.
Nearest Neighbor Classifier (k-NN) - k-NN measures the closeness of samples using a distant metric and assign a value to the more appropriate category within its closest k-neighbors. KNN is a statistical classifier that focus on the proximity of samples measured by Euclidean distance to measure the distance between points in input data and trained data [47]. It assigns data to the most represented category within its closest k-neighbors.
Algorithm
- 1.
Firstly select k number of neighbors.
- 2.
Apply Euclidean distance and select k nearest neighbor of the new point.
where q = (q1,q2…….,qn) and p = (p1,p2…….,pn) are the points in Euclidean space.
- 3.
In each category, a number of data points are calculated.
- 4.
Finally, to find more points, a new point is chosen.
Figure 6 demonstrates the working of k-NN

kNN institution for k = 5 [49]
Support Vector Machine (SVM) - SVM is used for grading purpose which is formerly proposed for 2-class problems. SVM is a supervised learning method that is based on the minimization procedure of structural risk [48]. It calculates the hyperplane which separates the classes with a maximum margin for binary values. To prevent biasing of sample order before being introduced to the classifier, samples are randomly ordered. Assuming two training of hollow and solid dots, H is hyperplane optimized, H1 & H2 (support vectors) are samples whose distance is minimum as shown in Fig. 7.

Linearly separable 2D hyperplane
The linear regression is defined by
where ai is Lagrange multipler, b∗ is the threshold, yi is either 1 or − 1, which indicates the class to which point belongs.
Sparse Representation Classifier (SRC) - SRC is a non-parametric and prediction based learning method that allocates a label to a test sample using the SRC dictionary (training samples). The basic block diagram of SRC is as shown in Fig. 8. Unlike k-NN, SRC does not require training in its classification process. SRC is first introduced [50] in which a dictionary is constructed from training samples for signal classification purpose represented by
where y is input signal, D is a dictionary and x is a sparse representation.

Basic block diagram of SRC
The SRC uses sparse representation to solve the minimization problem as follows:
Above equation is also known as non-deterministic polynomial hard problem [50].
The above classifiers are selected based on architectural complexity. k-NN is a popular classifier that made its decision based on the closeness of training samples using a distant matric. SVM is a very popular classifier that has proven its efficacy in various classification problems. SRC is a non-parametric and prediction based learning method that allocates a label to a test sample using the SRC dictionary (training samples). In this work, MathWorks Inc., LIB-SVM [51] and adaptation of Quinlan’s [52] works are employed for k-NN, SVM classifiers whereas SRC is implemented by authors. After several trials, optimum parameters for each classifier were formed as k = 5 for k-NN, a kernel with γ = 10 and C = 80 for SVM.
2.5 Evaluation
The classification is evaluated by k-fold (k = 10) cross-validation process. Here, K complementary subsets are partitioned from the dataset from which training is done for k-1 subset and validation is done by one subset. The whole process repeats K times by using every subset once for validation. The mean value of the results is computed for the final estimation. Figure 9 shows the simplified diagram of a 10 –fold cross-validation process.

A tenfold cross-validation
The prediction performances of the classifier use the following measures tested in this study: accuracy, sensitivity, and specificity. Accuracy is calculated as all correct overall (true positive & negative) classifications. Sensitivity is also known as recall or true positive rate and is the probability of detection of undesirable objects which is correctly classified. Specificity is known as the true negative rate and is the probability of detecting the sound kernel correctly.
3 Experimental results
European commission marketing standard [38] for apples defines one reject and three acceptable quality category. Nonetheless, wide literature consists of healthy/defective grading due to the adversity of the collection of databases and sorting processes. Hence, to compare with the reviewed literature, two-category sorting was introduced. It is observed from several trials that two-category grading Haralick features from GLCM matrices degrade the accuracy. The fruit grading is performed with each classifier (k-NN, SRC and SVM) first using Statistical/ Textural with Gabor Wavelet & DCT (15 features) and Geometrical features with Gabor wavelet & DCT (16 features) separately and then all features (31 features) combined together. A total dataset of apples is 2104 (1120 healthy, 984 defectives) for Set 1, 333(86 healthy, 247 defectives) for Set 2, 100 (74 healthy, 26 defectives) for Set 3 and 112 (56 healthy, 56 defective) for Set 4. Note that, each feature set selected, consist of a combination of Statistical/ Textural, Geometrical, Gabor wavelet, and DCT features.
We implement fruit sorting using different classifiers (k-NN, SRC, SVM) to analyze different classification capacity and to confirm which kind of classifier is better for the apple fruit classification using the different feature set taken one at a time. Highest recognition rate achieved with SVM for Statistical/ Textural with Gabor wavelet & DCT (15 features) is 78.37% (Jonagold Apple), 84.00% (Google Dataset), 88.54% (Golden Apple) and 82.57% (Self-Created). As the accuracy is unacceptable, so different combination of feature (Geometrical features with Gabor Wavelet & DCT (16 features)) are considered which results in 74.15% (Jonagold Apple), 83.91% (Google Dataset), 83.76% (Golden Apple) and 79.64% (self-created). These recognition rates are still unsatisfactory. Statistically, as examined, when all the features are taken together (Statistical/ Textural, Geometrical, Gabor Wavelet, DCT (31 features)) highest recognition rate achieved is 95.21% (Jonagold Apple), 93.41% (Google Dataset), 92.64% (Golden Apple) and 87.91% (Self-Created) respectively with accuracy as shown in Table 5. Note that, feature set selected with each classifier are presented in Table 2. It can be found that the SVM classifier is superior to all other classifiers and is best for apple recognition. It can also be observed that by increasing the number of features accuracy is also increasing which is comparable with the literature survey.
An attempt has been made to study the impact of segmentation and it has been found that the segmentation technique employed in the proposed system accurately segments 93.24% images. Further, if we consider only correctly segmented images for training and testing the accuracy of the proposed system to determine defect increase to 96.02% from 95.21%. However, there is a marginal increase but it indicates with improved segmentation techniques the accuracy of the proposed system may increase further.
Moreover, not only increasing the number of features but also the selection for the combination of several features is necessary to identify the deficiency efficiently. Taking an increasing number of combinations of features above 30, the accuracy rate is observed to be decreasing. Therefore, the proposed combination of features is effective for two-category apple grading.
Figure 10 displays the results obtained. In each plot, k-NN, SRC and SVM are taken along the x-axis and the recognition rate obtained using the test images is represented on the y-axis. In each plot, it can be observed that the performance of all the combined features is far better than the performance of a small set of features. Sensitivity and specificity give an indication of how well the sound kernels were classified. As classification accuracy only indicates the presence of errors, one may prefer to describe the model in terms of sensitivity and specificity to better describe the model. The lower sensitivity and specificity indicate the classification errors and the higher values indicate the perfectly classified classes. The False Positive Rate (FPR) and False Negative Rate (FNR) were used to measure the errors done by the method. The minimum and maximum values of FPR are 8.01% and 41.67% and of FNR are 11.51% and 44.34% respectively.

The accuracy rate for a different database with different classifiers
A significant contribution to fruit sorting was done by Unay et al. [34] and Moallem et al. [21]. The fruit database employed in said work was identical as used by authors and summarized in Table 6. In Unay’s and Moallem’s work, Jonagold apple [32] and golden delicious apple [14] database were used which predicts results with an accuracy of 85.60% and 92.50% respectively. The obtained accuracy in the present work of the proposed system is comparable with Moallem et al. [21]. However, our results show an increase of 3% from 92.50% to 95.21% is encouraging and satisfactory. Comparative analysis of the proposed system with other existing techniques show improved and better results with four different datasets. Hence, our approach contributes to improved recognition with cascaded features and a suitable classifier. The accuracy obtained by the proposed system is better as compared to the available system. Nevertheless, the system performance can be improved by taking more combinations of features.
3.1 Proposed methods comparison
The sorting of apple fruit results manifests that by direct and cascading features high recognition rate can be achieved. Table 7 presents a specified contrast to these methods. We perceive that cascaded features mainly out-perform individual features in terms of user’s and producer’s predictions of each category, overall accuracy, and actual error. Kappa statistics are cogent with marketing standard for apples [38] defined by three quality categories: Extra, Class I and Class II with corresponding tolerances of 5%, 10% and 10% as observed on user’s accuracy. It also reveals that the author method will not fit in these tolerance ranges because the statistics ignore the up-graded fruits and downgraded-ones, whereas the user’s accuracy considers both.
Concerning the computational complexities, individual features as geometrical or statistical are a relatively simple while, cascading features are more efficient. In conclusion, the individual features are less reliable while the combination of features is more accurate and reliable. Therefore, the decision depends on how powerful the user wants a computer vision-based apple inspection system.
3.2 Practical implementation
In order to cope up with the industry, the inspection system has to process at least 10 apples/s. Moreover, to inspect the whole surface of the fruit, different images must be obtained. The proposed method requires an Intel Pentium IV Processor (1.5GHz) with 256 M memory with a computation time of the order 3 s/view. However, the computational time can be mitigated using optimized software, efficient hardware and various inspection systems simultaneously. Currently, statistical and geometrical features are used. Employing more feasible features e.g. local binary patterns can also be tested in terms of inspection accuracy and computational cost.
In the present work, experimental assessment is done on single-view images but can be extended for multiple-view images as per the needs of the industry.
4 Conclusion
In this paper, a fully automatic sorting system for mono and bi-colored apples is proposed. The area of fruit is extracted from the background and is segmented by the Fuzzy c-means clustering algorithm. After segmentation, multiple features are extracted which are fed to the binary (healthy or defective) classifier. The apple fruit sorting results show that the combination of statistical, geometrical, Gabor and Fourier features are more accurate than individual features. The maximum accuracy of 95.21% with 31 features and the SVM classifier is encouraging and provides a reliable estimation. Results showed that the proposed system with the SVM classifier has better performance as compared to SRC, k-NN classifier.
Further, the system performance can be further improved by considering a large number of apple images, different segmentation techniques, more significant features and a combination of classifiers techniques. In the future, a more generalized and robust system with improved performance may be worked upon. The idea of the proposed system may be extended to other multimedia data such as social media [55], video data [56, 57] and graphics data [58, 59].
References
Valous N, Zheng L, Sun D-W, Tan J (2016) Quality evaluation of meat cuts. In: Computer vision technology for food quality evaluation, 2nd edn. Elsevier, pp 175–193
Magwaza LS, Opara UL (2015) Analytical methods for determination of sugars and sweetness of horticultural products? A review. Sci Hortic 184:179–192
Wu D, Sun D-W (2013) Color measurements by computer vision for food quality control–a review. Trends Food Sci Technol 29:5–20
Jackman P, Sun D-W, ElMasry G (2012) Robust color calibration of an imaging system using a color space transform and advanced regression modeling. Meat Sci 91:402–407
Dissing BS, Clemmesen LH, Løje H, Ersbøll BK, Adler-Nissen J (2009) Temporal reflectance changes in vegetables. Paper presented at the IEEE 12th international conference, Vancouver, Canada.
Ariana D, Guyer DE, Shrestha B (2006) Integrating multispectral reflectance and fluorescence imaging for defect detection on apples. Comput Electron Agric 50(2):148–161
Gowen AA, O'Donnell CP, Cullen PJ, Downey G, Frias JM (2007) Hyperspectral imaging–an emerging process analytical tool for food quality and safety control. Trends Food Sci Technol 18(12):590–598
Yu H, He F, Pan Y (2019) A novel segmentation model for medical images with intensity inhomogeneity based on adaptive perturbation. Multimed Tools Appl 78(9):11779–11798
Chen X, He F, Yu H (2019) A matting method based on full feature coverage. Multimed Tools Appl 78(9):11173–11201
Zhang S, He F, Ren W, Yao J (2018) Joint learning of image detail and transmission map for single image dehazing. Vis Comput. https://doi.org/10.1007/s00371-018-1612-9
Singh S, Singh NP (2019) Machine learning based classification of good and rotten apple. Recent trends in Communication, Computing and Electronics, 377–386.
Leemans V, Magein H, Destain M-F (1998) Defect segmentation on 'golden delicious' apples by using color machine vision. Comput Electron Agric 20(2):117–130
Rennick G, Attikiouzel Y, Zaknich A (1999) Machine grading and blemish detection in apples. Int Symp Signal Processing and Appl 567(570)
Blasco J, Aleixos N, Molto E (2003) A machine vision system for automatic quality grading of fruit. Biosyst Eng 85(4):415–423
Xing J, Bravo C, Jancsok PT, Ramon H, Baerdemacker JD (2005) Detecting bruises on Golden delicious apples using hyperspectral imaging with multiple wavebands. Biosyst Eng 90(1):27–36
Suresha M, Shilp NA, Sommy B (2012). Apple grading based on SVM Classifier. International Journal of Computer Applications 0975–8878
Dubey SR, Jalal AS (2015) Apple disease classification using color, texture and shape features from images. Springer, London
Ashok V, Vinod DS (2014), Automatic Quality Evaluation of Fruits Using Probabilistic Neural Network Approach. International Conference on Contemporary Computing and Informatics (IC3I), 308–31.
Raihana A, Sudha R (2016) AFDGA: defect detection and classification of apple fruit images using the modified watershed segmentation method. Int J Sci Technol Eng 3(6):75–85
Ali MAH, Thai KW (2017) Automatic fruit grading system. International Symposium on Robotics and Manufacturing Automation
Moallem P, Serajoddin A, Pourghassem H (2017) Computer vision based apple grading for golden delicious apples based on surface features. Inform Proces Agric 4:33–40
Jawale D, Deshmukh M (2017) Real-time bruise detection in apple fruits using thermal. In: International conference on communication and signal processing, pp 1080–1085
Wen Z, Tao Y (1999) Building a rule-based machine-vision system for defect inspection on apple sorting and packing lines. Expert Syst Appl 16:307–313
Leemans V, Magein H, Destain M-F (1999) Defect segmentation on 'Jonagold' apples using color vision and a Bayesian classification method. Comput Electron Agric 23(1):43.53
Leemans V, Magein H, Destain MF (2002) On-line fruit grading according to their external quality using machine vision. Biosyst Eng 83:397–404
Kleynen O, Leemans V, Destain M, F. (2003) Selection of the most efficient wavelength bands for ‘Jonagold’ apple sorting. Postharvest Biol Technol 30(3):221.232
Leemans V, Destain M (2004) A real-time grading method of apples based on features extracted from defects. J Food Eng 61(1):83–89
Unay D, Gosselin B (2004) A quality sorting method for 'Jonagold' apples. Int Conf of Agricultural Engineering.
Kleynen O, Leemans V, Destain M, F. (2004) Development of a multi-spectral vision system for the detection of defects on apples. J Food Eng 69(1):41–49
Kavdir I, Guyer DE (2004) Comparison of artificial neural networks and statistical classifiers in apple sorting using textural features. Biosyst Eng 89:331–344
Kleynen O, Leemans V, Destain MF (2005) Development of multi-spectral vision system for the detection of defects on apples. J Food Eng 69:41–49
Unay & Gosselin (2005). Artificial neural network-based segmentation and apple grading by machine vision. International Conference on Image processing.
Xiaobo Z, Jiewen Z (2005) Apple quality assessment by fusion three sensors. Sensors IEEE:389–392
Zou XB, Zhao JW, Li Y, Mel H (2010) In-line detection of apple defects using three color cameras system. Comp Electron Agric 70(1):129–134
Unay D, Gosselin B, Keenan D, Leemans V, Destain M, Debeir O (2011) Automatic grading of bi-colored apples by multispectral machine vision. Comput Electron Agric 75:204–212
Bhargava, A., Bansal., A. (2018), “Fruits and vegetable quality evaluation using computer vision: A review” J King Saud Univ Comp Infor Sci, https://doi.org/10.1016/j.jksuci.2018.06.002
Apples Image. Retrieved January 15, 2018, from https://www.google.com/search?biw=1366&bih=657&tbm=isch&sa=1&ei=2T4wXaz0HNO5rQHbnpewBA&q=healthy+apples+images&oq=healthy+apples+images&gs_l=img.3...9438.13173..13989...0.0..0.1981240.0j8......0....1..gws-wiz-img.......0i8i7i30.1bojhB1Q xk&ved=0ahUKEwjsxIfYlr7jAhXTXCsKHVvPBUYQ4dUDCAY&uact=5
Anonymous (2004). Commission regulation (EC) no 85/2004 of 15 January 2004 on marketing standards for apples. Off. J. Eur. Union L 13, 3–18.
Ashok V, Vinod DS (2014) Using K-means cluster and fuzzy C means for defect segmentation in fruits. Int J Comp Eng Technol:11–19
Ou X, Pan W, Xiao P (2014) Vivo skin capacitive imaging analysis by using grey level co-occurrence matrix (GLCM). Int J Pharm 460(2):28–32
Raheja JL, Kumar S, Chaudhary A (2013) Fabric defect detection based on GLCM and Gabor filter: a comparison. Opt – Int J Light Electron Opt 124(23):6469–6474
Haralick RM, Shanmugam K, Dinstein I (1973) Textural features for image classification. IEEE Trans Systems, Man Cybernetics 3(6):610–621
Unser M (1995) Texture classification and segmentation using wavelet frames. Image process. IEEE Trans 4(11):1549–1560
Lou S, Jiang X, Scott PJ (2012) Algorithms for morphological profile filters and their comparison. Precis Eng 36(3):414–423
Arivazhagan S, Ganesan L, Priyal SP (2006) Texture classification using Gabor wavelets based rotation invariant features. Pattern Recogn Lett 27(16):1976–1982
Dabbaghchian S, Aghagolzadeh A, Moin MS (2007) Feature extraction using discrete cosine transform for face recognition. In: International symposium on signal processing and its applications (ISSPA).
Naik S, Patel B (2014) CIELab based color feature extraction for maturity level grading of Mango (Mangifera indica L.). Nat J Syst Inform Technol 7(1):0974–3308
Burges, C.J.C. (1998). A tutorial on support vector machines for pattern recognition.
Udemy (2017). Machine Learning A-ZTM: Hands-On Python & R In Data Science
Wright J, Yang AY, Ganesh A, Sastry SS, Yi M (2009) Robust face recognition via sparse representation, Pattern Analysis, and Machine Intelligence. IEEE Transactions on 31:210–227
Chang CC, Lin CJ (2001) Libsvm: a library for support vector machines, via http://www.csie.ntu.edu.tw/cjlin/libsvm
Quinlan JR (1993) C4.5: programs for machine learning. Morgan Kaufmann, San Francisco.
Seng WC, Mirisaee SH (2009) A new method for fruits recognition system. In: International conference on electrical engineering and informatics, pp 130–134
Khan MA, MIU L, Sharif M, Javed K, Aurangzeb K, Haider SI, Altamrah AS, Akram AT (2019) An optimized method for segmentation and classification of apple diseases based on strong correlation and genetic algorithm based feature selection. IEEE Access 7:46261–46277
Pan Y, He F, Yu H (2019) A novel enhanced collaborative autoencoder with knowledge distillation for top-N recommender systems. Neuro computing 332:137–148
Li K, He F, Yu H, Chen X (2018) A parallel and robust object tracking approach synthesizing adaptive Bayesian learning and improved incremental subspace learning. Front Comp Sci 13:1116–1135. https://doi.org/10.1007/s11704-018-6442-4
Kang L, Fazhi H, Haiping Y, Xiao C (2017) A correlative classifiers approach based on particle filter and sample set for tracking occluded target. Appl Math A J Chinese Univ 32(3):294–312
Wu Y, He F, Zhang D, Li X (2018) Service-oriented feature-based data exchange for cloud-based design and manufacturing. IEEE Trans Serv Comput 11(2):341–353
Lv X, He F, Yan X, Wu Y, Cheng Y (2019) Integrating selective undo of feature-based modeling operations for real-time collaborative CAD systems Journal: Future Generation Computer Systems. https://doi.org/10.1016/j.future.2019.05.021.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Informed consent
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Bhargava, A., Bansal, A. Quality evaluation of Mono & bi-Colored Apples with computer vision and multispectral imaging. Multimed Tools Appl 79, 7857–7874 (2020). https://doi.org/10.1007/s11042-019-08564-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-08564-3