
Abstract
Dental periapical X-ray image (DXRI) segmentation is an important process to examine dental images towards diagnosing medical systems is an essential operation within practical dentistry for periodontitis recognition. However, traditional clustering algorithms in image processing frequently accept deficiencies in finding teeth sample boundaries and parameters. The presentation related to clustering is improved while further data produced with the user. In DXRI segmentation, semi supervised fuzzy clustering which is a new collective scheme. Initially, pre-processing is done for the input X-Ray image in order to minimize error. Specifically, Otsu’s method divide the dental X-Ray image into background and foreground regions. Here, the chosen FCM to separate the teeth regions commencing on the preceding steps. A Semi-supervised Hyperbolic Tangent Gaussian kernel Fuzzy C-Means algorithm (HTGkFCM) is preferred so as to increase an outcome that is optimum than compared to the traditional methods. So, current method is less sensitive to noise with robustness. Real datasets for the implementation on the proposed framework with cluster validity computation such as, Davies–Bouldin (DB), Segmentation Accuracy (SA), Simplified Silhouete Width Criterion (SSWC), processing time, PBM and Mean Absolute Error (MAE). So the proposed work has been enhanced in terms of 7%, 2%, 5%, 6%, 3% and 30% than the state-of-the-art works. Simulation outcome shows the quality of clustering in the framework have higher accuracy and more reliable than other clustering methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
For any computer vision application [2], image segmentation is an important preliminary processing operation. To determine the dental problems like tooth fester, tooth pimple and periodontal bone loss or gum diseases, dental medical techniques radiography (X-ray images) [1] are used. To recognize the spoil images proper segmentation [14, 27, 36] is required. In case of fire victims, biometrics in dental area helps to identify the victim. Such system needs additional steps to execute. Nowadays, in biometrics, radiograph images are used. Cone beam computed Tomography (CBCT), Tuned vent computed tomography, charge-coupled tool establish images acquire through the use of a Trophy RVG-UI sensor [19, 20] and periapical radiographs are the important techniques in dental treatment [30]. Useful diagnostic images [16] are produced by the current generations of CBCT systems. Tuned aperture computed radiography [7] produces digital images that find the implants position related to the pretended and that yielded a series of tomographic slices viewed interactively. From ear to ear in an isolated radiography, it is used to analyse various oral problems e.g. affected teeth and shows extensive scanning of dental X-ray of two-dimensional view of the jaws with complete teeth in both upper and lower jaws, tissue and helping structure around it, which is known as orthopantomogram [6]. Also, recent medical articles have evaluated automatic and semiautomatic segmentation methods performed by thresholding algorithms, which could expedite the diagnostic procedure [4]. The threshold evaluation to discover the main dental image portion basically with image noises is the main disadvantage in the thresholding group. Thresholding the image into two segments and reserving label to each segment that is for “main part” and for “background is the main objective in segmentation.
In Segmentation process, an image separated from its location or objects that have same attribute or behaviours. The image segmentation methods are categorized based on two properties i.e. Discontinuity and similarity. The typical image segmentation methods are edge detection method, region growing method and threshold method. The final method is uncomplicated, that is extensively castoff in segmentation of image, simple to accomplish, and its presentation is even. In Otsu method, the basic principle has the extreme amongst-class variation amid the target and background that gains the reliable segmentation product is choose for an optimal threshold and (Otsu algorithm) [35, 37] is commonly used for image segmentation. Also, this segmentation concentrated on an image regions as teeth-parts removing and lesion-region localization [18]. For many applications, fresh sets are used to obtain a complete segmentation and the main drawback is the correct segmentation is nominated because edges are not always available [23]. Segmentation of dental radiograph is not an easy process. The fields in which segregation are used frequently are: medicinal applications (fuzzy algorithm based segmentation for navigation DXRI segmentation, resonance images, and angiographic images ventricular segmentation), segmentation of satellite image, segmentation of face image etc., [9]. The results are needed to recognise with few data which is more than fuzzy logic system [13, 32, 33]. Many problems arise in the radiograph images such as low variance, noise and uneven illumination. Region segmentation is processed on pixels, Boundaries and regions. Radiographs in dental image are necessary in oral analytical methods. For an oral diagnostic mechanism dental radiographs are essential. The main aim of radiograph segmentation is to constrain each tooth region in a dental X-ray image.
X-ray penetration across teeth and helping arrangements, dental radiograph photographic images are produced. Poor quality and low contrast, and uneven subjection are the core problems that difficult the task of segmentations. Periodontal diseases which are the most general teeth problems and thus radiographic segmentation thus for example help the dentist to detect/identify dental caries. To analyse teeth images for getting valuable data towards the diagnosis of medical support systems with another tools, it has been suggested that DXRI segmentation is one of the most important. Proper photograph locating, suitable X-ray showing and correct photograph processing technique are the main features for the production of diagnostic standard radiographs. Non-diagnostic and below optimal radiographic image are produced if the error in any of these factors. Thus many conditions can be recognized by the dentist otherwise might remain undetected by the diagnostic standard image through segmentation. Enhancing the presentation of the clustering algorithm the users provide new information to attach an input of the algorithm. To obtain maximum segmentation accuracy, specialized data mining methods for DXRI segmentation have been analysed. Challenges in finding factors or general limits of teeth samples are the major issues in existing clustering and image processing algorithms. Determining the real spectral grouping existing in a data set. There are numerous clustering algorithms that can be used.
1.1 Contribution of the work
In the proposed work, the HTGkFCM-Otsu has benefits over FCM in terms of low computational time and simplicity. Likewise, HTGkFCM is castoff towards improving outcomes being attained through the FCM with pre-defined membership matrix. A new collective framework to the present of this work is that collaborate Otsu gateway method, FCM and semi-supervised Hyperbolic Tangent Gaussian kernel fuzzy C-Means clustering (HTGkFCM). For segmenting the Dental X-ray images, a novel HTGkFCM-Otsu method is proposed. In k-means algorithm data point must exclusively belong to one cluster centre and in case of FCM, Data point allocated in the membership of each cluster centre as a product of which more than one cluster centre the data point is belonged. The hyperbolic tangent Gaussian kernel method associates the input data space nonlinearly into attribute space having high dimensional and less sensitive to noise with robustness. The disadvantage of the FCM algorithm is overcome by the kFCM algorithm and adds kernel information to the standard fuzzy c-means algorithm.
Subsequently the remainder of this paper is organized. Reviews of the process associated to the segmentation of the dental radiographs are described in section 2. The methodologies proposed for improving the exactness of segmentation are reported in section 3. The experimental setup of our calculation is presented, strategies for combining relative criteria are examined and the obtained products are reviewed in section 4. The Final conclusion of our paper is addressed in section 5.
2 Related works
The segmented fats were termed as stand isolated from each other by the pericardium, mediastinal and epicedial. For minimal user involvement much effort was devoted. Rodrigues et al. [25] have proposed a quantification of two kinds of unified methods and cardiac fats for an independent processing. To perform proper segmentation, the methodology proposed contains classification and registration algorithms. They associate the presentation of various algorithms with classification and processing, containing decision tree algorithms and probabilistic models neural networks. Regarding Mean accuracy, in both visceral pericardium and if the features are normalized and its mediastinal fats is 99.5%, by showing an experimental results of a mean true positive rate of 98.0%. It attains 97.6% dice similarity index. By using three sequential and three rotational calculations, the effective medical plan was contrasted with the differentiate result and with the postsurgical expansion acquired an oblique surgical expansion. Analysing of both inferior and superior maxillary repositioning process in the impact of maxillary segmentation. Following to virtual surgical planning in 30 patients, K. Stokbro et al. [28] have calculated the positional and precision accuracy of various orthographic procedures. Till the segmentation effect on transverse expansion and positional accuracy there was no research of three-dimensional virtual surgical planning. With a large standard deviation, an enhanced degree of sequential exactness among arranged and postsurgical outcomes was found. Rotational difference showed an effect on the maxilla while improving the pitch. On maxillary placement, the segmentation had no important influence. In inferior maxillary repositioning a posterior movement was observed. The observation of a shortage of crosswise expansion in the segmentation is free from the degree of expansion. In the event of long-bone DXRI an integrated approach for the identification and calculation of orthopaedic fractures is proposed in Bandyopadhyay et al. [21].
An automated fragmentation is an important tool in the computer-aided tele-medicine system. For the using of paramedics or specialist doctors, a software tool has been developed by them that could be conveniently used. From a digital geometry many idea such as concavity index and comfortable straightness are used to observe fracture locations and type and also utilized to correct outline imperfections. So the DXRI show suitable product on the experiments of different databases. This proposed methodology, the bone region of a DXRI is segmented from its nearby flesh region and then using an adaptive thresholding approach called the bone-contour is developed. Because of the segmentation errors, alteration of bone-contour discontinuities are performed in unsupervised approach that might have been developed and finally, in the bone the presence of fracture is recognized. For an easy visualization of the fracture, the method could also condition on the line-of-break, the extent of damage is assess and its orientation is found. By the physiological confusion of granulation and endoxeros is the Oranges and lemons can be forced this leads to reducing their financial value. The disorders can be discerned by produce images of the internal construction of citrus on the X-ray radio graph. Dael et al. [10] have proposed to classify specimen as being mannered or not and to find these issues on the projected X-ray images.
A set of image attribute has been evaluated and using a naïve Bayes or kNN classifier, classification is done and this approach automatically segments healthy and forced tissue. For all fruits, non-destructive inspection the elaborated method permits while check failures due to negative sampling and avoids the need for destructive labour demanding sampling. The proposed algorithm classifies 93.6% of lemons and 95.7% of oranges correctly. To any existing inline X-ray radiograph equipment the classification method can be applied and it is fast and strong to noise. The subsequent evaluation are covers in TILT. By a fracture-dilation method first, tradition masks are developed for local thresholding which particularly intensifies the fracture signal on the power histogram. In the rock matrix to determine the fractures from vent the multi-scale Hessian fracture (MHF) filter has been incorporated and therefore for fracture behaviour in granular rocks the second TILT was particularly is well suited.
Hang Deng et al. [12] for quantification and visualization of rock fractures and for managing 3D X-ray computed tomography (xCT) images.
Presented a new method the Technique of Iterative Local Thresholding (TILT) to minimise the involvement of humans and facilitating automated processing of large 3D datasets, the thresholding and fracture separation steps are wrapped by the third TILT for binary segmentation in an optimized frequentative routine.
As an explanatory sample, to the 3D xCT images the TILT was applied of unreacted and proceed fractured limestone cores. Other segmentation methods in image processing were also pertained to offer perceptions regarding to variability. In automation the result outperformed the existing methods, and was completely effective in segregating fractures from the porous rock matrix and TILT significantly separate isolation of gray scale intensities. Because the other methods possess constrained ability in differentiating fractures from pores, larger fracture volumes (up to 80%) are measured by those methods, roughness (up to a factor of 2) and surface areas (up to 60%) since the new approaches have the possibility to misclassify fracture edges as void.
In fracture geometry as determined by 2D flow simulations these differentiation could possibly lead to great differences in hydraulic permeability predictions.
Problem statement
Mostly, segmentation of dental X-Ray imaging process used a Fuzzy C-Means (FCM) algorithm. FCM is based on the Fuzzy set theory and in which it uses soft clustering methodology. Here the major problem related to this FCM is it has the complexity in segmentation time and noises. In order to overcome these type of challenges, here we introduce HTGkFCM-Otsu method.
3 Proposed Otsu THRESHOLDING based hyperbolic tangent GAUSSIAN kernel FCM
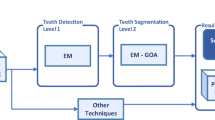
Here, we present a novel approach named as HTGkFCM-Otsu. In this approach, a semi-supervised fuzzy clustering algorithms is applied to DXRI segmentation and its process flow is represented in Fig. 1.

Process flow of the proposed method
In this approach fuzzy clustering of DXRI segmentation is being focussed. Background area and the main part from a DXRI are attributed by the Otsu method. After the previous steps results, the FCM algorithm is selected to cluster the domain of Dental Structure. The output is improved by the clustering methods and with robustness Semi-supervised Hyperbolic Tangent Gaussian Kernel Fuzzy Clustering algorithm (kFCM) is determined to illuminate less sensitive to noise. The final results of segmentation is calculated by the semi-supervised fuzzy clustering algorithm in a functional way. The integration of the Fuzzy C-Means (FCM), Otsu approach along with the HTGkFCM processes is applied to deal with the constraints of independent approaches.
The objective function of Otsu based Hyperbolic Tangent Gaussian Kernel FCM as,
In this work the foremost goal is to enhance the precision of segmentation because it decide the success or failure of the final exploration process. In order to make our objective true we have to take the following methods.
To obtain an accurate segmentation results, the two clustering methods are combined in the proposed approach.
The process flow of our method is represented in Fig. 1, that demonstrates pre-processing, FCM, and semi-supervised clustering (HTGkFCM). To avoid the uncertainties at first, from the input image the background is detached then next segmentation is done for the three remaining regions. The FCM has some constrains i.e. sensitivity to noise and random initialization to deal with these median filter is employed for noise reduction before subtractive approach is being applied which is applied to identify the appropriate values of cluster centre. The FCM comes under the unsupervised clustering type and performance degradation occurs because of the unlabelled data’s. This trouble of FCM could be avoided by a semi-supervised clustering approach based on hyperbolic tangent to segregate the brain images into tissues. The proposed approach’s detailed description is given below.
3.1 Pre-processing stage (De-noising)
This phase targets to improve the quality of image through eliminating noise then standardizing the image pixels intensity. The guided filter that conserves edges though eliminating artefacts. This changes every neighbourhood window centre pixel of an m × m through guided image filtering. Here a guided filter with the window size of 3 × 3 is cast-off towards computing the rate of output pixels. With the guidance I a local linear pattern besides the filtering results X is the important hypothesis of the guided filter [15]. Consider, a right change of I in a window wK positioned at the pixel K is represented as X:
Here (AK, BK) are few linear coefficients thought chosen to be consistent in wK. A square window is utilized with radius r. Since ∇X = A ∇ I, q has an edge while I has an edge and is guaranteed by local linear pattern. The linear coefficients (AK, BK) are determined using the limits from the filter input P. The input P is subtracted from undesirable factors N such as, noise or textures to form the output X:
A solution is needed to reduces the variations between X and P but the linear pattern should be preserved at the same time. In particular, we reduce the associated cost function in the window wK:
Where, a regularization factor is represented as ∈ which penalize expansive AK. Equation (4) presents the linear ridge regression model with its clarification.
In which, μK and \( {\sigma}_K^2 \) represents the mean and variance of I in wK, |w| denotes the amount of pixels in wK, and \( \overline{P_K}=\frac{1}{\left|w\right|}{\sum}_{i\in {w}_K}{P}_i \) is the mean of P in wK. The acquired linear coefficients (AK, BK) are used to calculate the filtering result Xi by (2). In any case, a pixel i is associated in every one of the overlying windows wK which covers i. Thus, when the estimation Xi provided in (2) calculated for various windows, it does not give the identical results. Hence, all the feasible estimations of Qi are simply averaged. Then, the filtering output is computed after the calculation of (AK, BK). wK is the image for all windows and is given by.
By seeing, \( {\sum}_{\left.K\right|i\in {w}_K}{A}_K={\sum}_{K\in {w}_i}{A}_K \) because of the symmetry of the square window, we change (7) by
The mean coefficients of every windows overlapping i is stated as \( \overline{A_i}=\frac{1}{\left|w\right|}{\sum}_{K\in {W}_i}{A}_K \) and \( \overline{B_i}=\frac{1}{\left|w\right|}{\sum}_{K\in {W}_i}{B}_K \).
Since the linear coefficients \( \left(\overline{A_i},\overline{B_i}\right) \) shift spatially, ∇X never again scaling of ∇I with the alteration in (8). In any case, the gradients of the mean filter can be predictable to be very smaller than that of I closer to solid edges similar to the output \( \left(\overline{A_i},\overline{B_i}\right) \). Herein this circumstance still we could maintain, \( \nabla X\approx \overline{A}\nabla I \) which describes that sudden intensity variations in I can be regularly conserved in X.
3.2 Otsu method
The Otsu approach efficiently decides the background/main parts among the image processing depends on pixel [24] and for fast processing the Background domain is eliminated from a DXRI. An image can be separated into background and main parts of two regions for Otsu method. Teeth’s density is similar to the bone that’s why soft area as the background and the main parts are the bone and teeth. Usually, dental X-Ray image can be separated into bone and teeth depend upon its distributing density with low, medium and high density and the area into the soft domain. The black and white pixels inner class changes should be minimised for this an image based on a global threshold (T) can be partitioned into two regions. For this classification a label should be assigned to every pixel as the background areas and the main part as,
In Otsu, every pixel is labelled relied on its grey value g(x) as background area bo and image area Io. In dental image, black is background area and white is the object area. Here the range of pixel intensities are 0 and 255. So, in this work we selected the threshold value T as 127. If the g(x) value is greater than T means it selected F(x) as image area Io and if the g(x) value is less than T means it selected F(x) as back ground area bo.
The additional information in a semi-supervised fuzzy clustering is exploited to lead, control and supervise the clustering process.
Semi-supervised learning approaches generally use pairwise constraints or partial labelling to transfer expert knowledge into process of clustering. It has alternative and consensus clustering collect data from some partitions of data to a single common assessment. Here in this methodology, we have focussed on the stated issues: Exactly how, we have to evaluate the clustering model that has to conserve a fixed amount of data about existing categories. In addition to that, focusing on defining clusters that are very probable towards belonging to only one class. Alternatively, more number of algorithms related to clustering usually use Euclidean distance for reflecting the link among occurrences, Such a Euclidean distance executes badly in fact while every features of the case is reliant on others. In our work, we using Euclidean distance for dental image segmentation with spatial information to provide less noise, in our proposed approach uses Gaussian kernel and Hyperbolic Tangent function. This is the semi supervised function and since it provides best partition into clusters. In addition to that, fuzzy number (each fuzzy memberships weighted exponent), that deals with the fuzziness of clustering algorithm and controls the competition between clusters. In addition to that, it has the gentle control on an image’s edge increase and decrease level on the sides of the centre decreasing the width of the edge to strengthen edge and this can be done by hyperbolic tangent function.
3.3 FCM
Any data about spatial background is not concerned by the standard FCM algorithm therefore its effort fit on the images that are noise-free, it is much knowledgeable to some of the imaging procedures and noise. A dental images foremost part is divided by FCM into dental and teeth structure domain. Algorithm for the FCM is given in Table 1.
Extensive analysed and effective application in image segmentation and clustering uses Fuzzy clustering because it is the soft segmentation technique. The FCM algorithm due to its strong attributes is popular technique in general which is applied in the segmentation task. One the familiar and best method for clustering is the FCM algorithm. Bezdek [8] proposed integration point of a data element Xk to cluster jth represented by the term ukj was appended to the goal function in Eq. (10) is the fuzzy clustering problem. Dependent on the membership degree, a data element could belong to some clusters. A Standard of the partitioning is measured by the goal function to segregate a dataset into c clusters. The objective function is Fm(U, V) when the weight in the set of squared error is minimised, the algorithm produces an optimal c partition which is an iterative clustering approach.
Wherever m is fuzzy number (each fuzzy memberships weighted exponent), that deals with the fuzziness of clustering algorithm and controls the competition between clusters. Where, r denotes the dimensions, the no of data elements are denoted by N and the no of clusters are denoted by C, ukj is the elements membership degree Xk in cluster j, Xk ∈ Rr is the main part of data k of X = X1, X2, ⋯, Xn and Vj is the cluster centre.
The constraints of the objective function is defined as,
The cluster centre and the pixel distance is calculated using the Euclidean distance formula given below:
A confined optimization problem is described in Function (10), employing the Lagrange multiplier techniques this problem can be switched to an unobstructed optimization problem the calculation is as follows.
3.4 Hyperbolic tangent Gaussian kernel based FCM (HTGkFCM)
High dimensional attribute distance for direct computation take less time.
The Fuzzy kernel c-means algorithm (kFCM) role is report below. The kernel procedure maps high dimensional feature distance from nonlinear input data space. It fundamentally makes the essential sensitive to the noise constrains because Gaussian kernel is expropriate for clustering. The disadvantages of the FCM algorithm is overcome by the KFCM algorithm and in this section a kernel information is included by the KFCM algorithm to the traditional FCM algorithm. Plain as well as linearly independent after the nonlinear transform of FCM datain the feature space product from the difficult and non-linear result. From the pre-defined membership matrix to simplify and upgrade the product the kFCM algorithm [34] is used. Across a non-linear transform, the input data is nonlinearly mapped by this method into a vast data space and then performs FCM in that attribute space.
Algorithm for the HTGkFCM is given in Table 2. In our attitude from the updated cluster centre of the FCM having the large membership value, the cluster centres (prototypes) are evaluated and the clustering process is convert into the kernel space. The FCM algorithms Kernel version has the objective function as,
The fuzzy number is denoted as ‘m’. In the segmentation process by without considering spatial information, conventional kernel FCM algorithm is highly unprotected to noise. In terms of Euclidean distance for dental image segmentation with spatial information to provide less noise, in our proposed approach uses Gaussian kernel and Hyperbolic Tangent function. So that this method provides more efficiency and robustness.
By using the Lagranian method, the centres and membership degrees are calculated as follows.
For minimalizing Fm(U, V) in Eq. (15) identified are revised in Eqs. (16) and (18) only if a Gaussian function is used by means of a kernel function K [31] with K(Xk, Vj) as,
Where, φ(XK) is the massive feature space, the user defined function is σ2 and φ(⋅) is non-linear associate function. By varying the σ2 values there is a variation in the segmentation algorithms presentation. To fix the suitable value for σ2 this method is need. To smoothen the images, Gaussian function will reduce the noise influence. Gentle control of the images edges increasing and decreasing grey level of both sides of the centre minimising the edge width to reinforce the edge and this can be done by hyperbolic tangent function.
The hyperbolic tangent function [5] used is mentioned below.
Here the value of σ2 is we considered with the adjacent P neighbours variation of radius R form the centre pixel Xk.
Where, the total image variation is denoted as σ2 and \( \overline{X}=\frac{\sum \limits_{K=1}^P{X}_k}{P} \) is the neighbouring pixels mean. The kFCM algorithm associates high dimensional attribute space from the input data space. In image segmentation it is established that the presentation of HTGkFCM algorithm is better than FCM algorithm that is specified with augmented robustness and efficiency. Unlike FCM, it can adaptively determine the no of clusters in the data under some criteria.
The mentioned flow chart (Fig. 2) explains the entire process flow of the proposed work. In this method the segmentation of DXRI using core attitude of FCM is concentrated. Background area and the main part from a DXRI are attitude by the Otsu thresholding. After the previous steps results, the FCM method is selected to cluster the Dental Structure domain and this will used to separate dental structure area. The results could be improved depending on the former clustering methods optimum result with robustness Semi-supervised Hyperbolic Tangent Gaussian Kernel Fuzzy Clustering algorithm (kFCM) is selected to elucidate less sensitive to noise. From the paradigm the FCM in a sensible processing manner computes the final segmentation results. The incorporation of the Fuzzy C-Means (FCM), Otsu method and the HTGkFCM processes are used to improve the limits of independent approaches.

Flow chart for semi-supervised Otsu based HTGkFCM
4 Results and discussion
The proposed technique HTGkFCM-Otsu will be executed in Matlab 2014a and the presentation will be calculated along with the Otsu and FCM methods. The proposed methods performance is compared with the eSFCM [29] that use various semi-supervised fuzzy clustering algorithm. Original set of hypothetical dental X-ray image dataset from IIT Roorkee hospital containing 152 images is used for our execution. The parameter used in the algorithm can be denoted as m = 2 and threshold (ε = o. oo2). The experimental product for the proposed dental image segmentation are illustrated in Figs. 3, 4, 5, 6.

Dental X-ray image’s experimental results. a Original image; b Image after the applying Otsu

Experimental results with three cluster on Otsu applied image. a FCM clustering results; b clustering by HTGkFCM-Otsu

Experimental results with five cluster on Otsu applied image. a results of clustering by FCM; b clustering by HTGkFCM-Otsu

Experimental results with seven cluster on Otsu applied image. a FCM clustering results; b clustering by HTGkFCM-Otsu
For the dental analysis radiographs, seven structures of the tooth were involved: caries, enamel, dentin, pulp, crown, cementum, and root canal. The dental substance is made of soft tissue (pulp) and the hard tissues (Enamel, dentin, and cementum). On the anatomic crownsouter surface, the enamel is formed. The main portion of the tooth is formed by Dentin in which root is the part delighted in cementum and crown is the part wrapped in enamel. Cementum covers the root and there are various junctions such as, dentine enamel junction, cement enamel junction and cement dentinal junction. In the centre of a tooth the dental pulp is the part which is made up of concavity, dental caries, also known as tooth decay. In the below Fig. 7, the segmentation results for the five images are given. Thus, the result for the dental image segmentation is illustrated based upon the seven tooth structures.

Experimental segmentation results for the proposed HTGkFCM-Otsu method with clusters c = 3, c = 5 and c = 7. (a)-(c) represents results for image 1after segmentation, (d)-(f) represents the segmentation results for image 2, (g)-(i) represents the segmentation results for image 3, (j)-(l) represents the segmentation results for image 4, (m)-(o) represents the segmentation results for image 5
While comparing to the existing methodologies, our proposed work have following advantages:
- a)
The proposed work offerings an initial effort towards modelling the segmentation result of DXRI with semi supervised fuzzy clustering. With new hyperbolic tangent function in Eq. (20) combines neighbourhood information and the dental features of a pixel, an outcome of the semi-supervised fuzzy clustering model comprising membership matrix and cluster centres which are focused by a dental X-ray images structure. It carries more significance for practical dentistry towards receiving segmented images which are nearest to an optimum outcomes.
- b)
Further information is presented at the membership matrix in the FCM algorithm through which combines threshold based segmentation. Compared to the traditional FCM, our HTGkFCM-otsu gives proposer methods for specifying the further information in addition tothat incorporate the objective function into the model.
- c)
This study initially deliberates an outcomes of the problem with the optimization under the fuzzy concept. Distinct from traditional approaches with normal FCM, the current work distinguishes inaccessible difficulties and resolves that within an identical context. The effectiveness of the proposed work is to be ideally authenticated in which the quality of clustering with hyperbolic tangent function is better than the traditional FCM.
- d)
This novel algorithm is to be prepared through theoretical studies. Most of algorithms and suggestions has to be explained, but such an evaluation are given below in order to show the proposed work performance.
The Cluster validity computation such as, Davies–Bouldin (DB), Segmentation Accuracy (SA), Simplified Silhouete Width Criterion (SSWC) and Mean Absolute Error (MAE). A novel algorithm named as kFCM-Otsu will possibly acquire higher accuracy and more reliable than the existing clustering approaches.
Segmentation Accuracy (SA): It is the correctly segmented pixels ratio to the overall no of pixels. Based on the SA value the performance of clustering becomes better.
Mean Absolute Error (MAE): The MAE is an amount measure of closeness to the segmented algorithm to the accurate segmentation, for an image segmentation, it given by,
Where the result is represented as fi and yi is the correct value.
Davies-Bouldin: The Davies-Bouldin index [11] bases are the clusters separation measure and the cluster variation measure and are depends on similarity measure of clusters. The similarity mean among each cluster and its great equivalent one is calculated in Davies – Boludin index. For better cluster configuration, clusters have to be compress and isolated the lower Davies – Bouldin index.
Where \( {D}_j=\underset{\begin{array}{l}j=1,\cdots, {n}_c,\\ {}i\ne j\end{array}}{\max}\left({D}_{ij}\right),i=1,\cdots, C \) and \( {D}_{ijj}=\frac{\left({\overline{d}}_j+{\overline{d}}_i\right)}{d_{i,j}} \).
In which, the mean distances of clusters i and j are signified as \( {\overline{d}}_i \) and \( {\overline{d}}_j \). These clusters distance is denoted as di, j.
The DB criterions low value is optimum.
Simplified Silhouette Width Criterion (SSWC):The Silhouette Width Criterion (SWC) is for compactness and partition of clusters [17, 26], a different eminent index is depends on geometrical concerns. Then, an individual object the silhouette is termed as:
This stops the SWC, well-defined as the mean of Sxk over j = 1, 2, ⋯, N as,
The variance of object k to its cluster p is defined as ap, k. To elect the trivial solution as the best one k = N (with the datasets each object forming its own cluster). The better value partition presents new effective algorithm and are estimated to be differentiated through higher values of SWC Using SSWC.
PBM: The hierarchy produce the best partitioning [22], by highest value of this index, called the PBM – index. PBM is depends on clusters distance and using the formula the distance amongst the cluster is calculated.
Where, \( {E}_1=\sum \limits_{k=1}^N\left\Vert {x}_i-{\overline{x}}_k\right\Vert \), \( {E}_k=\sum \limits_{i=1}^c\sum \limits_{x_i\in C}\left\Vert {x}_i-{\overline{x}}_k\right\Vert \) and \( {D}_k=\max \sum \limits_{k=1}^N\left\Vert {x}_i-{\overline{x}}_k\right\Vert \).
Where, the sum of distances among the grand means of the data and the objects is calculated as E1 the maximum distance between group centroids is represented as DK and the sum of within-group distances is denoted by EK. PBM is maximized when the best partition should be indicated, which implies EK value is minimized while maximizing the DK.
The best values are calculated from the power indices. The experimental results for the five benchmark images from the dataset (Image 1–Image 5) consist of different values which are categorized in the Table 3. Compared to other algorithms, the proposed frameworks accuracy is improved than the eSFCM-Otsu. The table undoubtedly identify that HTGkFCM-Otsu attained additional number of validation indices (SSWC and PBM) where its product are improved compared with the existing algorithms. An effective tool for DXIS is collective framework HTGkFCM-Otsu with proper adaptation.
HTGkFCM-Otsu creates further details together from the optimum consequences of hyperbolic tangent function and FCM.
- 1.
The proposed work has improved value compared with the fuzzy clustering and semi-supervised algorithms namely eSFCM and FCM respectively. Rather than arbitrarily establishment of further details in the eSFCM algorithm, HTGkFCM-Otsu acquires from the FCMs optimal results and by spatial restrictions its modified which have the following outcomes could congregate in order to getting more exact results of an issue.
- 2.
HTGkFCM-Otsu is not intensifying the bunch of data. Here the parameters of the algorithm are similar to the Otsu and it not able to take maximum time for processing. Whatever this concept is a combination of more identical concepts, this is running efficiently for the set of images. So this is reliable that with the time for processing of proposed algorithm. This algorithm is much more efficient than FCM, but it is not too much success concept than FCM.
- 3.
HTGkFCM-Otsu is reliable for implementing.
- 4.
HTGkFCM-Otsu takes an important way to cooperate much more parameters for a problems related to medical diagnosis and which is important for the growth of health-care schemes in dental science.
4.1 Non-background dataset based experimental results
Table 3 shows the outcome of every algorithm through further values of parameters on real time data. An outcomes are assessed through the validity measurements in which the best values are given from the Table 3, the performances such as SA, PBM, SSWC and MAE are better than the existing algorithms. In terms of short performance, Table 4 presents the mean and the variance of every measures.
Table 5 provides all algorithms performance comparison regarding quantitative measures.
Table 5 is taken from Table 4 through evaluating the optimal value and allocating the identical value in Table 3. Further values in the similar row are intended through isolating an equivalent values in Table 4 through the best value for seeing the presented optimum algorithm is reliable than other algorithm. From Table 5, we obviously identify that more no of validation indices (SSWC, PBM and DB) were attained by eSFCM-Otsu through which has the reliable algorithm. Further comparative methods namely (eSFCM-Otsu and FCM) is to be attained maximum results; this is unbalanced though analysing through further methods. It is evidently confirms that the supportive agenda HTGkFCM-Otsu using a suitable processing is a tool applicable for the segmentation of DXRI.
4.2 State of the art comparison
The proposed segmentation results are indicated in Fig. 8 compared with other methods on different dental images of the different patients. From the state of the art comparison, we can notice that the results related to the segmentation in the proposed HTGkFCM-Otsu has more performance than other techniques. From the Fig. 8(a) shows that Davies Bouldin (DB) has minimum value (0.625) than other techniques like FCM, Otsu, eSFCM and CANOM (Clustering Algorithm based on Neutrosophic Orthogonal Matrices) [3] techniques. Since the proposed work has better performance than other techniques. In case of Fig. 8 (b), Simplified Silhouette Width Criterion (SSWC) has maximum value (0.982) than other techniques and hence the proposed system has higher performance than other techniques. Finally, In case of Fig. 8 (c) processing time it consumes less time than other method and it processed at the 8.523 s and the other methods FCM, Otsu, eSFCM and CANOM processed at 12.883, 10.132, 13.190 and 13.771 respectively. Compared with the existing algorithm the results are found better because the table evidently identify that HTGkFCM-Otsu attained additional number of validation indices (SSWC and DB). While testing with other indices, yet they are volatile while testing with other indices.

Box plot comparison for (a) Davies & Bouldin, (b) SSWC and (c) Time
5 Conclusion
In this article, we condensed on the DXRI segmentation with the primary attitude being fuzzy clustering activity. This work’s contribution provide a novel semi-supervised collective structure that combine Ostu thresholding with the Hyperbolic Tangent Gaussian kernel Fuzzy C-Means algorithm method (HTGkFCM). In this FCM, the dental images main part is classified into Teeth and Dental areas. The attained result from the FCM are then rectified by means of HTGkFCM. It reveals that the semi-supervised fuzzy clustering algorithm was capable to establish segmentation products at final from the paradigm in a reasonable processing manner. The exploration of the further works of this research as follows (i) Gaussian kernel could not manipulate entire structure of the data, so upgrade the possible function to determine the cluster centre instead of the Gaussian kernel function. (ii) In simulation, it is detect that the data segmentation approach for enamel, dentin and pulp creates a logical additional training sample, but the new classes transmits, crown, cementum and root canal, seem somewhat dissimilar conversing with their comparative location, so the segmentation need to be improved, and (iii) concentrate on Computer-Automated Detection of Caries in Bitewing Radiography.
References
Ahmad AS (2010) The effect of sharp contrast-limited adaptive histogram equalization (SCLAHE) on intra-oral dental radiograph images. Biomedical Engineering and Sciences (IECBES), IEEE EMBS Conference on, IEEE 400-405
Ahmad, Bt SA, Taib MN, Elaiza AN, Khalid, Taib H (2015) Variations of Adaptive Histogram Equalization (AHE) analysis on intra-oral dental radiograph. IEEE 6th Control and System Graduate Research Colloquium (ICSGRC) IEEE 87-92
Ali M, Khan M, Tung NT (2018) Segmentation of dental X-ray images in medical imaging using neutrosophic orthogonal matrices. Expert Syst Appl 91:434–441
Aoki EM, Abdala-Júnior R, Oliveira JXD, Arita ES, Cortes AR (2015) Reliability and reproducibility of manual and automated volumetric measurements of Periapical lesions. J Endod 41(9):1555–1559
Baldwin D, Göktaş Ü, Hereman W (2004) Symbolic computation of hyperbolic tangent solutions for nonlinear differential–difference equations. Comput Phys Commun 162(3):203–217
Barone S, Paoli A, Razionale AV (2015) Geometrical modeling of complete dental shapes by using panoramic X-ray, digital mouth data and anatomical templates. Comput Med Imaging Graph 43:112–121
Barton DJ, Clark SJ, Eleazer PD, Scheetz JP, Farman AG (2003) Tuned-aperture computed tomography versus parallax analogy and digital radiographic images in detecting second mesiobuccal canals in maxillary first molars. Oral Surg Oral Med Oral Pathol Oral Radiol Endod 96(2):223–238
Bezdek JC, Ehrlich R (1984) Full W the fuzzy c-means clustering algorithm. Comput Geosci 10(2):191–203
Bhatia A, Mago V, Singh R (2014) Use of soft computing techniques in medical decision making: A survey, Advances in Computing, Communications and Informatics (ICACCI, 2014 International Conference on, IEEE
Dael M, Lebotsa S, Herremans E, Verboven P, Sijbers J, Opara UL, Cronje PJ, Nicolaï BM (2016) A segmentation and classification algorithm for online detection of internal disorders in citrus using X-ray radiographs. Elsevier. Postharvest Biol Technol 112:205–214
Davies DL, Bouldin DW (1979) A cluster separation measure. IEEE Trans Pattern Anal Mach Intell 1:224–227
Deng H, Fitts JP, Peters CA (2016) Quantifying fracture geometry with X-ray tomography: Technique of Iterative Local Thresholding (TILT) for 3D image segmentation, Springer. Computational Geosciences 1-14
Grira N, Crucianu M, Boujemaa N (2008) Active semi-supervised fuzzy clustering. Pattern Recogn 41(5):1834–1844
Gumus E (2016) Segmentation and root localization for analysis of dental radiographs, Signal, Image and Video Processing 1-7
He K, Sun J, Tang X (2013 Jun) Guided image filtering. IEEE Trans Pattern Anal Mach Intell 35(6):1397–1409
Huang CC, Lee BS (2015) Diagnosis of vertical root fracture in endodontically treated teeth using computed tomography. J Dental Sci 10(3):227–232
Kaufman L, Rousseeuw P (1990) Finding Groups in Data, Wiley
Lin PL, Huang PY, Huang PW (2012) An automatic lesion detection method for dental X-ray images by segmentation using variational level set. Int Conf Mach Learn Cybern 5:1821–1825
Ludlow J, Mol A (2011) Image-receptor performance, a comparison of trophy RVG UI sensor and Kodak Ekta speed plus film, Oral surgery, Oral medicine, Oral pathology. Oral Radiology and Endodontology 91(1):109–119
Matsuda Y, Hanazawa T, Seki K, Araki K, Okano T (2002) Comparison between RVG UI sensor and Kodak insight film for detection of incipient proximal caries. Oral Radiol 18(2):41–47
Oishila Bandyopadhyay BA, Bhattacharya BB (2016) Long-bone fracture detection in digital X-ray images based on digital-geometric techniques, Elsevier. Comput Methods Prog Biomed 123:2–14
Pakhira MK, Bandyopadhyay S, Maulik U (2004) Validity index for crisp and fuzzy clusters. Pattern Recogn 37:487–501
puram K, Raghu FH, Nasraoui O (2011) Fuzzy and possibilistic shell clustering algorithms and their application to boundary detection and surface approximation. IEEE Trans Fuzzy Syst 3(1):29–43
Rad AE, Rahim MS, Norouzi A (2014) Level set and morphological operation techniques in application of dental image segmentation, World Academy of Science, Engineering and Technology. Int J Medical, Health, Biomed, Bioeng Pharmaceu Eng 8(4):182–185
Rodrigues ÉO, Morais FFC, Morais NAOS, Conci LS, Neto LV, Conci A (2016) A novel approach for the automated segmentation and volume quantification of cardiac fats on computed tomography. Comput Methods Prog Biomed 123:109–128
Rousseeuw PJ Silhouettes (1987) a graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math 20:53–65
Shah S, Abaza A, Ross A, Ammar H (2006) Automatic tooth segmentation using active contour without edges, Biometrics Symposium: Special Session on Research at the Biometric Consortium Conference, IEEE 1-6
Stokbro K, Aagaard E, Torkov P, Bell RB, Thygesen T (2016) Surgical accuracy of three-dimensional virtual planning: a pilot study of bimaxillary orthognathic procedures including maxillary segmentation. Elsevier. Int J Oral Maxillofac Surg 45(1):8–18
Tuan TM (2016) A cooperative semi-supervised fuzzy clustering framework for dental X-ray image segmentation. Expert Syst Appl 46:380–393
Wang Y-M (2015) Evaluation of location and dimensions of mandibular lingual canals, a cone beam computed tomography study. Int J Oral Maxillofac Surg 9:1197–1203
Yang MS, Tsai HS (2008) A Gaussian kernel-based fuzzy c-means algorithm with a spatial bias correction. Pattern Recogn Lett 29(12):1713–1725
Yasunori E, Yukihiro H, Makito Y, Sadaaki M (2009) On semi-supervised fuzzy c-means clustering. IEEE, InFuzzy Systems, IEEE International Conference. 1119-1124
Yin X, Shu T, Huang Q (2012) Semi-supervised fuzzy clustering with metric learning and entropy regularization. Knowl-Based Syst 35:304–311
Zhang DQ, Chen SC (2004) A novel kernelized fuzzy c-means algorithm with application in medical image segmentation. Artif Intell Med 32(1):37–50
Zhang J, Hu J (2008) Image segmentation based on 2D Otsu method with histogram analysis, Computer Science and Software Engineering, IEEE 6
Zhao M, Ma L, Tan W, Nie D (2006) Interactive tooth segmentation of dental models. IEEE Engineering in Medicine and Biology 27th Annual Conference 654-657
Zhou C (2015) A method of two-dimensional Otsu image threshold segmentation based on improved firefly algorithm, Cyber Technology in Automation, Control, and Intelligent Systems (CYBER). International Conference on, IEEE
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Anuj Kumar, H. S. Bhadauria, Annapurna Singh, state that there are no conflicts of interest. Patients’ rights and animal protection statements: This research article does not contain any studies with human or animal subjects.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kumar, A., Bhadauria, H.S. & Singh, A. Semi-supervised OTSU based hyperbolic tangent Gaussian kernel fuzzy C-mean clustering for dental radiographs segmentation. Multimed Tools Appl 79, 2745–2768 (2020). https://doi.org/10.1007/s11042-019-08268-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-019-08268-8