
Abstract
This paper presents two robust hybrid watermarking techniques for securing the Three-Dimensional High Efficiency Video Coding (3D-HEVC). The first watermarking technique is the homomorphic-transform-based Singular Value Decomposition (SVD) in Discrete Wavelet Transform (DWT) domain. The second watermarking technique is the three-level Discrete Stationary Wavelet Transform (DSWT) in Discrete Cosine Transform (DCT) domain. The objective of the two proposed hybrid watermarking techniques is to increase the immunity of the watermarked 3D-HEVC streams to attacks. Also, we propose a wavelet-based fusion technique to combine two depth watermark frames into one fused depth watermark frame. Then, the resultant fused depth watermark is encrypted using chaotic Baker map to increase the level of security. After that, the resultant chaotic encrypted fused depth watermark is embedded in the 3D-HEVC color frames using the proposed hybrid watermarking techniques to produce the watermarked 3D-HEVC streams. In addition to achieving multi-level security in the transmitted 3D-HEVC streams, the proposed hybrid techniques reduce the required bit rate for transmitting the color-plus-depth 3D-HEVC data over limited-bandwidth networks. The performance of the proposed hybrid techniques is compared with those of the state-of-the-art techniques. Extensive simulation results on standard 3D video sequences have been conducted in the presence of attacks. The obtained results confirm that the proposed hybrid fusion-encryption-watermarking techniques achieve not only a good perceptual quality with high Peak Signal-to-Noise Ratio (PSNR) values and less bit rate, but also high correlation coefficient values between the original and extracted watermarks in the presence of attacks. Furthermore, the proposed hybrid techniques improve the capacity of information embedding and the robustness without affecting the perceptual quality of the original 3D-HEVC frames. Indeed, the extraction of the encrypted, fused, primary, and secondary depth watermark frames is possible in the presence of attacks.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The Three-Dimensional Video-plus-Depth (3DV + D) comprises diverse video streams captured by different cameras around an object. Therefore, it is an imperative assignment to perform efficient compression to transmit and store the 3DV + D content to meet the future requirements, whilst preserving a decisive reception quality. Also, the security of the transmitted 3DV + D is a critical issue for protecting its copyright content. Due to the fast progress in multimedia data communication network developments and applications [5, 6, 12, 42,43,44,45], users can easily and arbitrarily distribute or access digital multimedia data from networks. The ownership security has become an important issue for individuals, and it requires more interest. Thus, there is a significant threat to copyright owners and digital multimedia producers to conserve their multimedia from intruder prospection to avert loss in transmitted data [2, 15, 37]. Steganography can be employed to secure the multimedia data. It is a methodology of hiding information by embedding data into given media (called cover media) without making any visible changes in these media [1, 3, 4, 13, 14, 20, 30]. Also, watermarking is one of the most preferred methods to secure digital multimedia files in the domains of copyright protection and data authentication, where a watermark secret code is inserted into the transmitted digital multimedia, and it contains information about the creator of the media, the copyright owner, or the authorized user.
The utilization of digital watermarks for efficient video transmission can be beneficial to ensure copyright protection. A digital watermark can be embedded either in a compressed video or an uncompressed video [16]. Video information are always transported and stored in the form of compressed data. The uncompressed video watermarking techniques can also be utilized for the compressed video bit streams, however, they require complete video re-encoding and decoding for the watermark insertion or extraction. In different cases, the complete video stream decoding process is not recommended. So, the compressed video watermarking has recently acquired more attentiveness. Furthermore, the watermark insertion and extraction in compressed data has less computations, because the complete re-encoding and decoding of the transmitted stream is not required for embedding and extracting the watermark bits.
Recently, several video encoding standards have emerged. The objective of thes encoding standards is to achieve high data compression, while maintaining an acceptable quality. The 3D-HEVC is the most recently used encoding standard in different applications [8, 40, 41]. It has received a broad attentiveness, and it is expected to rapidly take the place of the traditional 2D video coding in numerous applications. The predictive 3D H.265/HEVC framework is used to compress the transmitted 3DV sequences. In the 3D-HEVC system, the original 3D Video (3DV) consisting of multiple video streams is captured for the same object by various cameras. Thus, to transport the 3DV over limited-resources networks, a highly efficient compression standard is needed, whilst preserving a high reception quality. The 3D-HEVC exploits the advantage of the time and space matching between frames in the same stream in addition to the inter-view matching within the different 3DV streams to enhance the encoding process.
The 3DV + D is a common format of 3D video representation that has recently been discussed intensively [31]. In this format, data about scene-per-pixel geometry is available. Depth data is very essential in 3D applications. It is beneficial for adaptable depth conception to harmonize various 3D displays. Moreover, it optimizes the 3DV stored bits compared to the traditional 2D videos. Because all object pixels have identical depth values, the depth information can be utilized to recognize the object boundaries. Due to the importance of the depth data corresponding to the texture color data of the transmitted 3DV, it must be utilized to represent the transmission of 3DV + D content over wireless networks. Unfortunately, the utilization of depth data increases the transmission bit rate due to the need of an additional transmission bandwidth to transmit the color data of the 3DV + D content.
Therefore, one of the main contributions of this paper is to present robust and reliable hybrid compressed video watermarking techniques for efficient transmission of 3D-HEVC compressed bit streams. These techniques have the following characteristics:
-
1.
Quality. The quality of the watermarked 3D-HEVC frames resulting from the embedding process is maintained as high as possible by efficiently choosing the most suitable domain for watermark embedding.
-
2.
Robustness and Security. The proposed watermark embedding and extraction procedures are robust. The embedded watermarks can survive different types of attacks.
-
3.
Transmission Bit Rate. The proposed watermarking techniques reduce the transmission bit rate through hiding and embedding multiple depth frames into the corresponding color frames of the transmitted 3D-HEVC data.
-
4.
Complexity. The computational cost due to watermark embedding is kept minimum.
The rest of this paper is organized as follows. Section 2 introduces the existing hybrid watermarking related works. Section 3 gives an explanation of the proposed hybrid fusion-encryption-watermarking techniques. Simulation results and the comparative study are presented in Section 4. The conclusions are presented in Section 5.
2 Related works
With the emerging evolution of 3D-HEVC applications, the security and copyright protection have become important aspects for the 3DV content storage and transmission. Multimedia watermarking techniques are employed for protecting the 3DV + D data copyright. These techniques are classified into two main categories; spatial- and transform-domain techniques. The spatial-domain techniques hide the watermark in the given video frames by directly adjusting their pixel values. They are simple to carry out and need less computations. Unfortunately, they are not robust enough to attacks. The transform-domain watermarking techniques adjust the video frames coefficients in a certain transform domain based on the adopted watermark embedding method. Thus, the transform-domain watermarking techniques achieve more robustness than those of the spatial-domain watermarking techniques.
There are few research works on 3DV data watermarking, and most of them deal with Depth-Based Image Rendering (DBIR) [8]. Thus, 3DV watermarking is still in its rudimentary phase. A watermarking method in the wavelet domain for stereo images was introduced in [7]. It depends on extracting the depth map from the stereo-pairs for watermark embedding. In [25], a visual model for watermarking of High Definition (HD) stereo images in DCT domain was presented. It is based on the visual sensitivity of the human eye to identify the perceptual modifications in the watermark embedding process. A blind diverse watermarking method was suggested in [23] based on DBIR method performed on the center image and the depth image generated by the content provider. Kim et al. [21] introduced a watermarking method for 3D images through the quantization of the Dual-Tree Complex Wavelet Transform (DT-CWT) coefficients. To improve the watermark robustness. Two features of the DT-CWT have been utilized; the approximate shift invariance and the directional selectivity. In [19], some efficient and robust hybrid watermarking schemes for different color image systems have been presented.
An efficient watermarking method for 3D images based on DBIR scheme was presented in [38] by utilizing the Scale-Invariant Feature Transform (SIFT) to choose some suitable regions for watermarking and the spread spectrum technique to insert the watermark data in the DCT coefficients of the selected regions. A 3DV blind watermarking technique based on a virtual view invariant domain was introduced in [11]. The average luminance values of the 3DV frames are chosen for watermark embedding. Swati et al. [36] suggested a fragile watermarking method, in which the watermark is inserted in the Least Significant Bit (LSB) of the non-zero quantized coefficients in the HEVC compressed video. Ogawa et al. [29] proposed an efficient watermarking scheme for HEVC bit streams that inserts the watermark information in the video compression phase. Also, there are several traditional works for watermarking of the 2D H.264/AVC compressed bit streams. Zhang et al. [46] suggested a video watermarking technique, where the security information is represented in a pre-processed binary data sequence and embedded into the middle frequency coefficients in the I frame. To enhance the watermark verification, the signs of the coefficients are altered depending on the watermark. The work introduced in [46] has been enhanced in [47] by concentrating on gray-scale characteristics and patterns. Qiu et al. [32] suggested a robust intra-frame watermark embedding scheme in quantized DCT coefficients and a fragile inter-frame watermark embedding method in motion vectors.
Kuo and Lo [22] enhanced the video watermark embedding scheme that was suggested in [32] by selecting more appropriate regions for both robust and fragile watermark embedding within the H.264 compressed video through the video encoding process. In [26], the process of watermark embedding is executed through the direct change of some data bits within the bit stream, however the pre-embedding process has complex computations. In [27], the same authors of [26] suggested a non-blind and robust watermarking method by utilizing the Watson Visual Model for watermark embedding in the I frame. Their proposed non-blind method [27] was extended for the P frame in [28], where the watermark bits are embedded in all non-zero coefficients of the P frame. An information hiding model was implemented in [10] to choose the watermark embedding area based on the forbidden-zone-data-hiding concepts. The sign parity of the coefficients and the values of the middle-frequency coefficients are altered for watermark embedding in the I frame [39]. In [9], the watermark is embedded in the non-zero coefficients of the P frame in the compressed domain to achieve better perceptual quality of the watermarked video frames and a minimal increase in video bit rate. In [34], a structure preserving non-blind H.264 watermarking technique was suggested to insert the watermark through substituting secret bits in the motion vector differences of the non-reference images. Su et al. [35] suggested another non-blind watermark embedding algorithm for the I frames and P frames. The watermark embedding is implemented based on the spread spectrum technique and the Watson Visual Model [27].
It is noticed that several authors introduced a lot of work on 3D image watermarking in the spatial domain. Most recent 3D image and video watermarking techniques have been implemented in transform domains. Generally, there are few contributions in the literature on 3D compressed video watermarking techniques. Some of these introduced techniques have critical problems with watermark verification and extraction. The traditional video watermarking techniques have not achieved adequate watermarked and extracted watermark subjective and objective qualities in the presence of multimedia attacks. Thus, they have low robustness and imperceptibility. Moreover, most of the traditional video watermarking techniques work on uncompressed images. So, they require more computations in the watermark insertion and extraction processes, where a complete encoding and decoding of the transmitted stream are needed for embedding and extracting the watermark data. Thus, they increase the computational overhead. Furthermore, the traditional video watermarking techniques failed in selecting the most suitable regions inside the host frames for watermark embedding. Thus, they have an effect on the imperceptibility and quality of the watermarked frames, and they also increase the computations.
Taking into account the limitations of the state-of-the-art video watermarking techniques, the main contribution of this paper is to present an efficient hybrid framework for secure 3DV communication. This framework consists of transform-domain watermarking, wavelet-based fusion, and chaotic encryption techniques to efficiently protect the copyright of the 3DV + D HEVC streams to preserve both robustness and imperceptibility. Moreover, the proposed hybrid framework saves the 3D-HEVC transmission bit rates. Therefore, they have good imperceptibility, high quality, high robustness, acceptable bit rate, low computational complexity, and adequate immunity to different types of multimedia attacks compared to the traditional watermarking techniques.
3 The proposed hybrid fusion-encryption-watermarking techniques
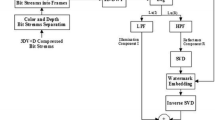
In this section, the proposed hybrid fusion-encryption-watermarking techniques are introduced. We present the homomorphic transform based SVD watermarking in the DWT domain and the three-level DSWT watermarking in the DCT domain. They are suggested for 3DV data hiding taking into account increasing the embedding capacity without affecting the quality of the watermarked 3DV streams. In the proposed hybrid techniques, two depth watermark frames are firstly fused using the proposed wavelet based fusion technique. Then, the resultant fused depth watermark is encrypted utilizing the chaotic Baker map encryption technique. After that, the resultant encrypted fused depth watermark is embedded into the original 3DV color frames using the proposed hybrid watermarking techniques to produce the watermarked 3D-HEVC streams. So, the proposed hybrid fusion-encryption-watermarking framework consists of three different phases as shown in Fig. 1. In the first phase, the primary depth watermark frame is fused with the secondary depth watermark frame using the proposed wavelet-based fusion technique to produce the fused depth watermark frame. In the second phase, the fused depth watermark frame is encrypted using the chaotic Baker map encryption technique. In the third phase, the encrypted fused depth watermark frame is embedded into the original 3D-HEVC color frames using the proposed hybrid watermarking techniques. The watermark extraction process is performed in three reverse steps; the extraction of the fused depth watermark frame, the decryption process, and the anti-fusion process to extract the primary and secondary depth watermark frames.

The proposed hybrid fusion-encryption-watermarking framework
In the first phase, we exploit the proposed wavelet-based fusion technique, which is effective for combining perceptually important image features. It is used for many applications such as medical applications and remote sensing applications. The basic idea of the proposed wavelet-based fusion technique is that the two depth watermark frames are firstly transformed using the DWT transform. Then, the fusion process is executed and after that the Inverse DWT (IDWT) is employed to construct the fused depth watermark frame. The proposed wavelet-based fusion process is shown in Fig. 2.

The proposed wavelet-based fusion process of the two primary and secondary depth watermark frames
In the second phase, the resultant fused depth watermark frame is encrypted with the proposed 2D chaotic Baker map encryption technique to increase the level of security of the transmitted 3D-HEVC data. Then, the encrypted fused depth watermark frame is embedded to the 3D-HEVC color frames as will be discussed in more details in Sections 3.1 and 3.2. The discretized chaotic Baker map randomizes a square matrix by assigning each pixel to another location in a bijective manner. The discretized chaotic Baker map will be denoted by \( {B}_{\left({n}_1,\dots, {n}_l\right)} \), where the sequence of l integers, n1, n2,. .., nl, is selected such that each integer ni divides N, and Ni = n1 + …. + ni. The pixel at (r, s) with Ni ≤ r < Ni + ni and 0 ≤ s < N is mapped to:
The steps of chaotic Baker map randomization can be summarized as follows:
-
1.
An N × N square matrix is divided into l vertical rectangles of height N and width ni with n1 + n2 +. .. +nl = N.
-
2.
Each vertical rectangle is divided into ni blocks, and each block contains N points.
-
3.
Each of these blocks is mapped to a row of pixels.
An example of the chaotic Baker map randomization of an 8 × 8 matrix is shown in Fig. 3. The secret key is (2, 4, 2). Hence, N = 8, n1 = 2, n2 = 4, and n3 = 2. The N is defined as the total number of rows of the square matrix, while Ni is the total number of columns in each vertical division. In the introduced example of chaotic Baker map randomization presented in Fig. 3, we assumed that N = 8, and Ni = (2,4,2).

Chaotic Baker map randomization example using a secret key of (2, 4, 2): (a) Discretized Baker map, (b) The 8 × 8 randomized output
3.1 Homomorphic-transform-based SVD watermarking in the DWT domain
In this section, the proposed homomorphic-transform-based SVD watermarking in the DWT domain is introduced. The proposed framework for encrypted fused depth watermark embedding is shown in Fig. 4, and that for encrypted fused depth watermark extraction is shown in Fig. 5. In this technique, the encrypted fused depth watermark frames are inserted in the chosen wavelet transform coefficients of the 3DV luminance (Y) components of the color frames. The first step of this technique is the transformation of the RGB color space to the YUV color space. The 2D DWT is used to split each Y frame into four sub-bands, which are the approximation sub-band (low frequency LL), the horizontal detail sub-band (high frequency LH), the vertical detail sub-band (high frequency HL), and the diagonal detail sub-band (high frequency HH). So, the wavelet transform is performed on the luminance (Y) component of every color frame within the 3DV stream. The reflectance components of the LL sub-bands are extracted through the homomorphic transform. The encrypted fused depth watermark frame is embedded by employing the SVD algorithm on the extracted reflectance components of the LL sub-bands.

Watermark embedding in the proposed technique of homomorphic-transform-based SVD watermarking in the DWT domain

Watermark extraction in the proposed technique of homomorphic transform based SVD watermarking in the DWT domain
The main contribution of the proposed homomorphic-transform-based SVD watermarking in the DWT domain is the utilization of the homomorphic transform jointly with the DWT and SVD transforms. So, the homomorphic transform improves the performance of the watermarking process through choosing the most suitable regions inside the host color frames for watermark embedding to maintain the imperceptibility and robustness of the watermarked frames. The homomorphic transform is performed based on the fact that the frame intensity is represented by the multiplication of light illumination and reflectance of objects inside images. Because the illumination is approximately constant and the reflectance is variable from an image to another, the image reflectance represents the most important component of the transmitted images. Thus, the image reflectance can be extracted through the homomorphic transform, and then it is used for watermark embedding. Therefore, the homomorphic transform is utilized to efficiently choose the most suitable frequency regions inside the host color frames for watermark embedding.
The low-frequency LL sub-band intensity can be formulated by (2), where I(n1, n2) is the illumination and R(n1, n2) is the reflectance of the selected color frame, whose values at the spatial coordinates (n1, n2) are positive scalar quantities. The homomorphic transform is executed as given in (3). A High Pass Filter (HPF) and a Low Pass Filter (LPF) are applied to the ln [FLL(n1, n2)] to separate the illumination from the reflectance. We can represent ln [R(n1, n2)] and ln [I(n1, n2)] in matrix form as R and I matrices. After that, the SVD is applied on the reflectance R matrix as in (4), where U and V are orthogonal matrices and S is a diagonal matrix. The Singular Values (SVs) of the matrix R are the entries of the S matrix. Then, the encrypted fused depth watermark (W matrix) is combined with the SVs of the reflectance R matrix as in (5). After that, the SVD is employed on the modified matrix (D matrix) as given by (6), and then the frame (Rw matrix) is obtained by utilizing the modified matrix (Sw matrix) as in (7). The inverse homomorphic transform is applied on the I and Rw to get a matrix Xw as in (8), and then the low-frequency sub-band of the watermarked frame (FLLw) can be obtained by (9). The inverse DWT is implemented to get the 3DV watermarked frame Fw.
For the extraction of the possibly distorted encrypted fused depth watermark from the possibly corrupted watermarked 3D-HEVC frames, given the Uw, Sw, Vw matrices and the possibly distorted frame Fw, the above-mentioned steps are reversely executed. The homomorphic transform is applied on the LL sub-band of the watermarked frame FLLw. A HPF is utilized to obtain the possibly distorted reflectance component R*w, and then the SVD is employed on the R*w matrix as given by (10). The matrix that includes the watermark is computed by (11), and so the possibly corrupted encrypted fused depth watermark is obtained by (12).
3.2 Three-level DSWT watermarking in the DCT domain
In this technique, the transformation from the RGB color space to the YUV color space is the first step, and then the DCT is applied on each Y-frame. The three-level DSWT is utilized to divide the DCT domain into four sub-bands, which are the approximation sub-band (A), the horizontal sub-band (H), the vertical sub-band (V), and the diagonal sub-band (D). These A, H, V, and D sub-band matrices have identical sizes. The encrypted fused depth watermark frame is embedded on the matrix A.
The encrypted fused depth watermark frame embedding steps are shown in Fig. 6 and summarized below:
-
Step 1: The original compressed 3DV stream is transformed from the RGB to the YUV color space, and then the luminance Y values of the 3DV frames are further utilized.
-
Step 2: The converted 3DV stream is partitioned into groups of k frames.
-
Step 3: The DCT components of each Y-frame are obtained using the 2D-DCT transform.
-
Step 4: The determined DCT components of each Y-frame are decomposed into four sub-ands (A, H, V, and D) using the 3-level DSWT.
-
Step 5: The encrypted fused depth watermark frame is embedded into the matrix A of each Y-frame by multiplying the watermark by a key K and adding it to the matrix A, where 0 < K < 1.
-
Step 6: The inverse DSWT is implemented, and then the inverse DCT to obtain the watermarked Y-frame, and thus the watermarked 3DV stream.

Watermark embedding in the proposed technique of three-level DSWT watermarking in the DCT domain
The encrypted fused depth watermark frame extraction steps are shown in Fig. 7, and summarized below:
-
Step 1: The watermarked 3DV is transformed from the RGB to the YUV color space, and just the luminance Y values of the frames are further processed.
-
Step 2: The converted watermarked 3DV stream is partitioned into groups of k frames.
-
Step 3: The DCT components are extracted from each watermarked Y-frame using the 2D-DCT transform.
-
Step 4: The determined DCT components of each Y-frame are decomposed into four frequency sub-bands (Aw, H, V, D) utilizing the 3-level DSWT.
-
Step 5: The possibly-distorted encrypted fused depth watermark frame is extracted from the matrix Aw of each watermarked Y-frame by subtracting the matrix A of the original frame from the matrix Aw of the watermarked frame and dividing the result by K.

Watermark extraction in the proposed technique of three-level DSWT watermarking in the DCT domain
4 Simulation results and discussions
To assess the performance of the proposed hybrid fusion-encryption-watermarking techniques, several simulation tests on the standard well-known 3DV + D (Shark and PoznanStreet) 1920 × 1088 sequences [24] have been carried out. For each sequence, the coded 3D H.265/HEVC bit streams are produced by employing the reference HM codec [17]. All simulation tests have been performed using an Intel® Core™i7-4500 U CPU @1.80GHz and 2.40GHz with 8GB RAM, working with Windows 10 64-bit operating system, and using MATLAB 2017a. The visual results ensure watermark invisibility and no degradation in the watermarked frames quality compared to the original frames. The PSNRs of the watermarked frames and the Normalized Correlation (NC) values of the extracted possibly-corrupted encrypted fused, decrypted fused, primary, and secondary depth watermarks are estimated. The PSNR is calculated by (13) and (14) [8], where MSE is the Mean Square Error between the original host and watermarked color frames, A is the original color frame, Aw is the watermarked color frame, and M × N is the size of the host and the watermarked color frames. The NC is estimated by (15), where W is the original depth watermark and W* is the extracted corrupted depth watermark. In our simulations, we apply different types of attacks on the watermarked frames, and then we extract the encrypted fused, decrypted fused, primary, and secondary depth watermarks to test the robustness of the proposed techniques. We have run two experiments for each proposed watermarking technique. The first one uses the 3DV + D Shark sequence by selecting color frame 50 as a test host Y-frame, depth frame 50 as a primary depth watermark frame, and depth frame 100 as a secondary depth watermark frame. The other experiment uses the 3DV + D PoznanStreet sequence by selecting color frame 100 as a test host Y-frame, depth frame 100 as a primary depth watermark frame, and depth frame 200 as a secondary depth watermark frame as shown in Fig. 8, which also shows their fused and encrypted fused depth watermark frames.

The 3D-HEVC Shark and PoznanStreet host color frame and primary, secondary, fused, and encrypted fused depth watermark frames
To clarify the efficiency of the proposed hybrid fusion-encryption-watermarking techniques in protecting and securing the transmitted 3DV + D HEVC bit streams in the presence of attacks, we have compared their performance with those of the state-of-the-art hybrid watermarking techniques such as the DCT + DWT, DWT + SVD, and DCT + SVD [18, 19, 33]. The comparisons depend on both subjective visual results and objective results; the PSNRs of the watermarked frames and the NC of the extracted watermark frames. In the introduced simulation results, the DWT + Homomorphic + SVD refers to the first proposal of the homomorphic transform based SVD watermarking in the DWT domain, and the DCT + DSWT refers to the second proposal of the three-level DSWT watermarking in the DCT domain. Figures 9 and 10 show the visual results with the PSNR and NC values of the color watermarked and extracted encrypted fused, decrypted fused, primary, and secondary depth watermark frames for the Shark and PoznanStreet 3DV streams without attacks compared to those of the state-of-the-art techniques. It is clear from Figs. 9 and 10 that there is a high similarity between the original and watermarked frames in the proposed techniques compared to the state-of-the-art techniques. Moreover, the proposed DWT + Homomorphic + SVD technique introduces better watermarked and extracted watermark frames than those of the proposed DCT + DSWT technique. The proposed techniques achieve high PSNR and NC values for all tested 3DV frames compared to those of the related works.

3DV watermarked and extracted encrypted fused, decrypted fused, primary, and secondary depth watermark Shark frames without attacks

3DV watermarked and extracted encrypted fused, decrypted fused, primary, and secondary depth watermark PoznanStreet frames without attacks
In Tables 1, 2, 3, 4, and 5, we compare the objective PSNR values of the watermarked color frames and the NC values of the extracted encrypted fused, decrypted fused, primary, and secondary depth watermark frames of the Shark and PoznanStreet 3D-HEVC sequences for the proposed watermarking techniques and the state-of-the-art watermarking techniques at different types of attacks. From all presented simulation results, we deduce that the suggested techniques always achieve superior PSNR and NC values. It can be realized that the proposed techniques have a meaningful average gain in objective PSNR and NC for all tested 3D-HEVC sequences for different types of attacks.
From Table 1 presenting the simulation results in the case of different rotation attacks, it is noticed that both the DWT + Homomorphic + SVD and the DCT + DSWT watermarking techniques give the highest PSNR values between the original and watermarked frames. Also, it is clear that the DWT + Homomorphic + SVD technique achieves the best results in the case of the rotation attack. From Table 2 presenting the simulation results in the case of different Gaussian noise attacks, it is noticed that the proposed hybrid watermarking techniques give not only the highest PSNR values between the original and watermarked frames, but also the best correlation values between the original and the primary, and secondary depth watermark frames. In addition, it is clear that the DWT + Homomorphic + SVD technique achieves the best results in the case of the Gaussian noise attack. From Table 3 including the simulation results in the case of different (Motion, Disk, and Average) blurring attacks, it is noticed that both the DWT + Homomorphic + SVD and the DCT + DSWT watermarking techniques give not only the highest PSNR values between the original and watermarked frames, but also the best correlation values between the original and the extracted primary, and secondary depth watermark frames. Moreover, it is clear that the DWT + Homomorphic + SVD technique achieves the best results with different types of blurring attacks.
From Table 4 including the simulation results with different JPEG compression attacks, it is noticed that the proposed hybrid watermarking techniques give not only the highest PSNR values between the original and watermarked frames, but also the best correlation values between the original and extracted watermarks. In addition, it is clear that the DWT + Homomorphic + SVD technique achieves the best results with the JPEG compression attack. From Table 5 including the simulation results with resizing and crop attacks, it is noticed that all the presented watermarking techniques in this paper present good results of high PSNR values between the original and watermarked frames, and also high correlation values between the original and extracted primary, and secondary depth watermark frames. It is also clear that the proposed hybrid watermarking techniques still achieve the best results. It is clear that the DWT + Homomorphic + SVD technique achieves the best results in the case of resizing and crop attacks. From all presented simulation results, we deduce that the suggested hybrid techniques always achieve superior PSNR and NC values. It can be realized that the proposed techniques have a meaningful average gain in objective PSNR and NC for all tested 3DV + D HEVC frames with different types of attacks.
Table 6 presents the average CPU time results of the proposed embedding techniques compared to the state-of-the-art embedding techniques for the Shark and PoznanStreet 3DV + D HEVC streams without attacks. It is noticed that the proposed hybrid techniques introduce acceptable embedding CPU processing times, and hence they can be recommended for online and real-time video transmission applications. The DCT + DWT technique has the shortest CPU processing time, and the DCT + SVD technique has the longest CPU processing times in the watermark embedding process.
It is known that the color and depth frames of the transmitted 3DV + D HEVC sequences need two separate channels for their transmission over networks. In order to further confirm the performance efficiency of the proposed hybrid fusion-watermarking techniques in minimizing the required bandwidth for transmitting the 3DV + D data over limited-resources wireless networks, we run more simulation tests. The results prove that the proposed hybrid fusion-watermarking techniques can jointly transmit the color and depth frames on the same channel through embedding multiple fused depth frames within the color frames of the 3DV + D. Table 7 shows the size in bytes of the original host color frame, original primary, secondary, and fused watermark depth frames, and watermarked color frames for the Shark and PoznanStreet 3DV streams. From this table, it is noticed that the size of the fused watermark depth frame is smaller than the summation of the sizes of the primary and secondary watermark depth frames. Also, it is noticed that the size of the watermarked color frame is smaller than the summation of the sizes of the host color frame and the fused watermark depth frame. Therefore, it is clear that the proposed techniques and all presented techniques give good results in minimizing the required channel bandwidth for transmitting the color and depth frames of the transmitted 3DV + D data. Thus, instead of the transmission of the color and depth frames separately needing more transmission bandwidth, we transmit both the color and depth frames on the same channel that has a bandwidth less than that required for transmitting color and depth frames, separately. This is achieved through hiding multiple fused depth frames inside the color frames of the transmitted 3DV + D data. So, the proposed fusion and watermarking techniques improve the capacity of the embedded information, save the transmission bit rate, and subsequently enhance the channel bandwidth-efficiency.
Therefore, it is noticed from all presented objective and subjective results that the proposed hybrid fusion-encryption-watermarking techniques are good candidates for securing the transmission of 3DV + D HEVC data and they can survive different types of multimedia attacks. Moreover, the proposed hybrid techniques save the transmission bit rate by using multiple depth frames within the color frames. So, they minimize the required transmission bandwidth for streaming the 3DV + D HEVC data over the limited-resources networks, and thus they enhance bandwidth-efficiency of the communication channel. The subjective and objective results also prove that there is no remarkable difference between the original and the watermarked frames, which reveals the fidelity of the proposed hybrid fusion-encryption-watermarking techniques.
5 Conclusions
This paper introduced efficient and robust hybrid fusion-encryption-watermarking techniques for 3D-HEVC streams. It also presented a comparative study between these proposed hybrid techniques and the existing state-of-the-art techniques. The evaluation metrics for the comparisons on standard 3D-HEVC streams include the stability, reliability, and robustness. Experimental results revealed the superiority of the proposed techniques in maintaining high robustness and fidelity in the presence of different types of attacks compared to the existing hybrid techniques. Also, the proposed techniques achieve high degree of capacity, security, and robustness without affecting on the 3DV perceptual quality in the presence of attacks. They can extract the encrypted, fused, primary, and secondary depth watermark frames with high probability of detection and good quality. Furthermore, the proposed techniques show that the proposed wavelet-based fusion technique can be used as a new way to embed more watermark frames into the watermarking system. Thence, the proposed techniques can be utilized for minimizing the transmission bit rate of the streamed color-plus-depth 3D-HEVC data.
References
Abu-Marie W, Gutub A, Abu-Mansour H (2010) Image based steganography using truth table based and determinate array on rgb indicator. Int J Signal Image Process 1(3):196–204
Al-Otaibi A, Gutub A (2014) 2-leyer security system for hiding sensitive text data on personal computers. Lect Notes Inform Theory 2:151–157
Al-Otaibi A, Gutub A (2014) Flexible stego-system for hiding text in images of personal computers based on user security priority. In: International Conference on Advanced Engineering Technologies (AET) pp 250–256
Alotaibi N, Gutub A, Khan E (2015) Stego-system for hiding text in images of personal computers. In: The 12th learning and technology conference: wearable tech/wearable learning
Bhimani J, Mi N, Leeser M, Yang Z (2017) FiM: performance prediction for parallel computation in iterative data processing applications. In: IEEE 10th International Conference on Cloud Computing (CLOUD) pp 359–366
Bhimani J, Yang Z, Leeser M, Mi N (2017) Accelerating big data applications using lightweight virtualization framework on enterprise cloud. In: IEEE High Performance Extreme Computing Conference (HPEC) pp 1–7
Campisi P (2008) Object-oriented stereo-image digital watermarking. J Electron Imaging 17(4):043024
Dutta T, Gupta P (2016) A robust watermarking framework for high efficiency video coding (HEVC)–encoded video with blind extraction process. J Vis Commun Image Represent 38:29–44
Dutta T, Sur A, Nandi S (2013) A robust compressed domain video watermarking in P-frames with controlled bit rate increase. In: National Conference on Communications (NCC) pp 1–5
Esen E, Alatan A (2011) Robust video data hiding using forbidden zone data hiding and selective embedding. IEEE Trans Circuits Syst Video Technol 21(8):1130–1138
Franco-Contreras J, Baudry S, Doërr G (2011) Virtual view invariant domain for 3D video blind watermarking. In: IEEE 18th International Conference on Image Processing (ICIP) pp 2761–2764
Gao H, Yang Z, Bhimani J, Wang T, Wang J, Sheng B, Mi N (2017) AutoPath: harnessing parallel execution paths for efficient resource allocation in multi-stage big data frameworks. In: IEEE 26th International Conference on Computer Communication and Networks (ICCCN) pp 1–9
Gutub A (2010) Pixel indicator technique for RGB image steganography. J Emerg Technol Web Intell 2(1):56–64
Gutub A, Ankeer M, Abu-Ghalioun M, Shaheen A, Alvi A (2008) Pixel indicator high capacity technique for RGB image based Steganography. In: IEEE 5th International Workshop on Signal Processing and its Applications (WoSPA)
Gutub A, Al-Juaid N, Khan E (2017) Counting-based secret sharing technique for multimedia applications. Multimed Tools Appl 1–29. https://doi.org/10.1007/s11042-017-5293-6
Hartung F, Girod B (1998) Watermarking of uncompressed and compressed video. Signal Process 66(3):283–301
HEVC Reference Software (2014) http://hevc.kw.bbc.co.uk/trac/browser/jctvc-hm/tags
Joshi M, Gupta S, Girdhar M, Agarwal P, Sarker R (2017) Combined DWT–DCT-based video watermarking algorithm using Arnold transform technique. In: International conference on data engineering and communication technology. Singapore: Springer pp 455–463
Khalid A (2017) Utilization of watermarking schemes for securing digital images. Master Thesis, Department of Computer Science and Engineering, Faculty of Electronic Engineering, Menoufia University
Khan F, Gutub A (2007) Message concealment techniques using image based steganography. In: IEEEGCC
Kim D, Lee W, Oh W, Lee K (2012) Robust DT-CWT watermarking for DIBR 3D images. IEEE Trans Broadcast 58(4):533–543
Kuo Y, Lo C (2010) A hybrid scheme of robust and fragile watermarking for H.264/AVC video. In: IEEE international symposium on Broadband Multimedia Systems and Broadcasting (BMSB) pp 1–6
Lin H, Wu L (2011) A digital blind watermarking for depth-image-based rendering 3D images. IEEE Trans Broadcast 57(2):602–611
Mueller K, Vetro A (2014) Common test conditions of 3D-MVV core experiments. Joint Collaborative Team on 3D Video Coding Extensions JCT3V-G1100, 7th Meeting: San Jose, USA
Niu Y, Souidene W, Beghdadi A (2011) A visual sensitivity model based stereo image watermarking scheme. In: IEEE 3rd European Workshop on Visual Information Processing (EUVIP) pp 211–215
Noorkami M, Mersereau M (2005) Compressed-domain video watermarking for H.264. In: IEEE International Conference on Image Processing (ICIP) pp II–890
Noorkami M, Mersereau M (2007) A framework for robust watermarking of H.264-encoded video with controllable detection performance. IEEE Trans Inf Forensics Secur 2(1):14–23
Noorkami M, Mersereau M (2008) Digital video watermarking in P-frames with controlled video bit-rate increase. IEEE Trans Inf Forensics Secur 3(3):441–455
Ogawa K, Ohtake G (2015) Watermarking for HEVC/H.265 stream. In: IEEE International Conference on Consumer Electronics (ICCE) pp 102–103
Parvez T, Gutub A (2011) Vibrant color image steganography using channel differences and secret data distribution. Kuwait J Science Eng 38(1):127–142
Purica I, Mora G, Pesquet-Popescu B, Cagnazzo M, Ionescu B (2016) Multiview plus depth video coding with temporal prediction view synthesis. IEEE Trans Circuits Syst Video Technol 26(2):360–374
Qiu G, Marziliano P, Ho T, He D, Sun Q (2004) A hybrid watermarking scheme for H. 264/AVC video. In: 17th International Conference on Pattern Recognition (ICPR) pp 865–868
Singh D, Singh K (2017) DWT-SVD and DCT based robust and blind watermarking scheme for copyright protection. Multimed Tools Appl 76(11):13001–13024
Stütz T, Autrusseau F, Uhl A (2014) Non-blind structure-preserving substitution watermarking of H.264/CAVLC inter-frames. IEEE Trans Multimed 16(5):1337–1349
Su C, Wu S, Chen F, Wu Y, Wu C (2011) A practical design of digital video watermarking in H.264/AVC for content authentication. Signal Process Image Commun 26(8):413–426
Swati S, Hayat K, Shahid Z (2014) A watermarking scheme for high efficiency video coding (HEVC). PLoS One 9(8):e105613
Tew Y, Wong K (2014) An overview of information hiding in H.264/AVC compressed video. IEEE Trans Circuits Syst Video Technol 24(2):305–319
Wang S, Cui C, Niu X (2014) Watermarking for DIBR 3D images based on SIFT feature points. Measurement 48:54–62
Xu D, Wang R, Wang J (2011) A novel watermarking scheme for H.264/AVC video authentication. Signal Process Image Commun 26(6):267–279
Yan C, Zhang Y, Xu J, Dai F, Li L, Dai Q, Wu F (2014) A highly parallel framework for HEVC coding unit partitioning tree decision on many-core processors. IEEE Signal Process Lett 21(5):573–576
Yan C, Zhang Y, Xu J, Dai F, Zhang J, Dai Q, Wu F (2014) Efficient parallel framework for HEVC motion estimation on many-core processors. IEEE Trans Circuits Syst Video Technol 24(12):2077–2089
Yan C, Xie H, Liu S, Yin J, Zhang Y, Dai Q (2018) Effective Uyghur language text detection in complex background images for traffic prompt identification. IEEE Trans Intell Transp Syst 19(1):220–229
Yan C, Xie H, Yang D, Yin J, Zhang Y, Dai Q (2018) Supervised hash coding with deep neural network for environment perception of intelligent vehicles. IEEE Trans Intell Transp Syst 19(1):284–295
Yang Z, Wang J, Evans D, Mi N (2016) AutoReplica: automatic data replica manager in distributed caching and data processing systems. In: IEEE 35th International Performance Computing and Communications Conference (IPCCC) pp 1-6
Yang Z, Hoseinzadeh M, Andrews A, Mayers C, Evans T, Bolt T, Swanson S (2017) AutoTiering: automatic data placement manager in multi-tier all-flash datacenter. In: IEEE 36th International Performance Computing and Communications Conference (IPCCC)
Zhang J, Ho T (2006) Efficient video authentication for H.264/AVC. In: first International Conference on Innovative Computing, Information and Control (ICICIC) pp 46–49
Zhang J, Ho T, Qiu G, Marziliano P (2007) Robust video watermarking of H.264/AVC. IEEE Trans Circuits Syst II: Express Briefs 54(2):205–209
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
El-Shafai, W., El-Rabaie, ES.M., El-Halawany, M. et al. Efficient multi-level security for robust 3D color-plus-depth HEVC. Multimed Tools Appl 77, 30911–30937 (2018). https://doi.org/10.1007/s11042-018-6036-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-6036-z